Release 1 (9.0.1)
Part Number A88856-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Database Concepts Release 1 (9.0.1) Part Number A88856-02 |
|
![]()
![]()
This chapter provides an overview of some of the features of the Oracle server. The topics include:
This chapter contains information relating to both Oracle9i and the Oracle9i Enterprise Edition. Some of the features and options documented in this chapter are available only if you have purchased the Oracle9i Enterprise Edition. See Oracle9i Database New Features for information about the differences between Oracle9i and the Oracle9i Enterprise Edition.
Note:
As internet computing becomes more prevalent in today's computing environments, database management systems must be able to take advantage of distributed processing and storage capabilities. This section explains the architectural features of Oracle that meet these requirements.
|
See Also:
|
Distributed processing uses more than one processor to divide the processing for a set of related jobs. Distributed processing reduces the processing load on a single processor by allowing different processors to concentrate on a subset of related tasks, thus improving the performance and capabilities of the system as a whole.
An Oracle database system can easily take advantage of distributed processing by using its client/server architecture. In this architecture, the database system is divided into two parts: a front-end or a client and a back-end or a server.
The client is the front-end database application and is accessed by a user through the keyboard, display, and pointing device such as a mouse. The client has no data access responsibilities. It concentrates on requesting, processing, and presenting data managed by the server. The client workstation can be optimized for its job. For example, it may not need large disk capacity or it may benefit from graphic capabilities.
The server runs Oracle software and handles the functions required for concurrent, shared data access. The server receives and processes the SQL and PL/SQL statements that originate from client applications. The computer that manages the server can be optimized for its duties. For example, it can have large disk capacity and fast processors.
A multitier architecture has the following components:
This architecture enables use of an application server to:
The identity of the client is maintained throughout all tiers of the connection. The Oracle database server audits operations that the application server performs on behalf of the client separately from operations that the application server performs on its own behalf (such as a request for a connection to the database server). The application server's privileges are limited to prevent it from performing unneeded and unwanted operations during a client operation.
A distributed database is a network of databases managed by multiple database servers that appears to a user as a single logical database. The data of all databases in the distributed database can be simultaneously accessed and modified. The primary benefit of a distributed database is that the data of physically separate databases can be logically combined and potentially made accessible to all users on a network.
Each computer that manages a database in the distributed database is called a node. The database to which a user is directly connected is called the local database. Any additional databases accessed by this user are called remote databases. When a local database accesses a remote database for information, the local database is a client of the remote server. This is an example of client/server architecture.
While a distributed database enables increased access to a large amount of data across a network, it must also hide the location of the data and the complexity of accessing it across the network. The distributed database management system must also preserve the advantages of administrating each local database as though it were not distributed.
Location transparency occurs when the physical location of data is transparent to the applications and users of a database system. Several Oracle features, such as views, procedures, and synonyms, can provide location transparency. For example, a view that joins table data from several databases provides location transparency because the user of the view does not need to know from where the data originates.
Site autonomy means that each database participating in a distributed database is administered separately and independently from the other databases, as though each database were a non-networked database. Although each database can work with others, they are distinct, separate systems that are cared for individually.
The Oracle distributed database architecture supports all DML operations, including queries, inserts, updates, and deletes of remote table data. To access remote data, you make reference to the remote object's global object name. No coding or complex syntax is required to access remote data.
For example, to query a table named EMP in the remote database named SALES, reference the table's global object name:
SELECT * FROM emp@sales;
Oracle provides the same assurance of data consistency in a distributed environment as in a nondistributed environment. Oracle provides this assurance using the transaction model and a two-phase commit mechanism.
As in nondistributed systems, transactions should be carefully planned to include a logical set of SQL statements that should all succeed or fail as a unit. Oracle's two-phase commit mechanism guarantees that no matter what type of system or network failure occurs, a distributed transaction either commits on all involved nodes or rolls back on all involved nodes to maintain data consistency across the global distributed database.
Replication is the process of copying and maintaining database objects, such as tables, in multiple databases that make up a distributed database system. Changes applied at one site are captured and stored locally before being forwarded and applied at each of the remote locations. Oracle replication is a fully integrated feature of the Oracle server. It is not a separate server.
Replication uses distributed database technology to share data between multiple sites, but a replicated database and a distributed database are not the same. In a distributed database, data is available at many locations, but a particular table resides at only one location. For example, the EMP table can reside at only the db1 database in a distributed database system that also includes the db2 and db3 databases. Replication means that the same data is available at multiple locations. For example, the EMP table may be available at db1, db2, and db3.
Distributed database systems often locally replicate remote tables that are frequently queried by local users. By having copies of heavily accessed data on several nodes, the distributed database does not need to send information across a network repeatedly, thus helping to maximize the performance of the database application.
Data can be replicated using materialized views.
Oracle9i, Release 1 (9.0.1), supports materialized views that are hierarchical and updatable. Multitier replication provides increased flexibility of design for a distributed application. Using multitier materialized views, applications can manage multilevel data subsets where there is no direct connection between levels.
An updatable materialized view lets you insert, update, and delete rows in the materialized view and propagate the changes to the target master table. Synchronous and asynchronous replication is supported.
Figure 2-1 shows an example of multitier architecture, diagrammed as an inverted tree structure. Changes are propagated up and down along the branches connecting the outermost materialized views with the master (the root).
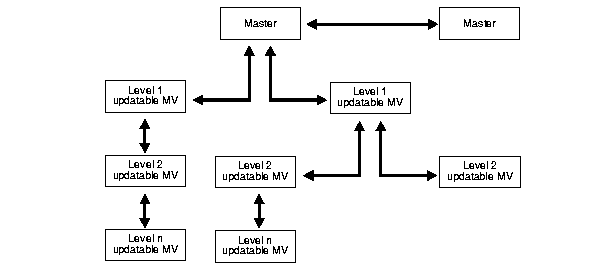
In Oracle9i, Release 1 (9.0.1), conflict resolution routines are defined at the topmost level, the master site, and are pulled into the updatable materialized view site when needed. This makes it possible to have multitier materialized views. Existing system-defined conflict resolution methods are supported.
In addition, users can write their own conflict resolution routines. A user-defined conflict resolution method is a PL/SQL function that returns either TRUE or FALSE. TRUE indicates that the method was able to successfully resolve all conflicting modifications for a column group.
|
See Also:
Oracle9i Replication and Oracle9i SQL Reference for more information about creating and managing multitier materialized views |
Oracle Net Services is Oracle's mechanism for interfacing with the communication protocols used by the networks that facilitate distributed processing and distributed databases. Communication protocols define the way that data is transmitted and received on a network. In a networked environment, an Oracle database server communicates with client workstations and other Oracle database servers using Oracle Oracle Net Services software.
Oracle Net Services supports communications on all major network protocols, ranging from those supported by PC LANs to those used by the largest of mainframe computer systems.
Using Oracle Net Services, the application developer does not have to be concerned with supporting network communications in a database application. If a new protocol is used, the database administrator makes some minor changes, while the application requires no modifications and continues to function.
Heterogeneous Services is a component within the Oracle9i database server that is necessary for accessing a non-Oracle database system.
The term "non-Oracle database system" refers to the following:
Heterogeneous Services makes it possible for Oracle9i database server users to do the following:
Heterogeneous Services is generally applied in one of two ways:
Oracle Advanced Queuing provides an infrastructure for distributed applications to communicate asynchronously using messages. Oracle Advanced Queuing stores messages in queues for deferred retrieval and processing by the Oracle server. This provides a reliable and efficient queuing system without additional software such as transaction processing monitors or message-oriented middleware.
Consider a typical online sales business. It includes an order entry application, an order processing application, a billing application, and a customer service application. Physical shipping departments are located at various regional warehouses. The billing department and customer service department can also be located in different places.
This scenario requires communication between multiple clients in a distributed computing environment. Messages pass between clients and servers as well as between processes on different servers. An effective messaging system implements content-based routing, content-based subscription, and content-based querying.
A messaging system can be classified into one of two types:
Synchronous communication is based on the request/reply paradigm--a program sends a request to another program and waits until the reply arrives.
This model of communication (also called online or connected) is suitable for programs that need to get the reply before they can proceed with their work. Traditional client/server architectures are based on this model.
The major drawback of the synchronous model of communication is that the programs to whom the request is sent must be available and running for the calling application to work.
In the disconnected or deferred model, programs communicate asynchronously, placing requests in a queue and then proceeding with their work.
For example, an application might require entry of data or execution of an operation after specific conditions are met. The recipient program retrieves the request from the queue and acts on it. This model is suitable for applications that can continue with their work after placing a request in the queue -- they are not blocked waiting for a reply.
For deferred execution to work correctly even in the presence of network, machine and application failures, the requests must be stored persistently, and processed exactly once. This can be achieved by combining persistent queuing with transaction protection.
Processing each client/server request exactly once is often important to preserve both the integrity and flow of a transaction. For example, if the request is an order for a number of shares of stock at a particular price, then execution of the request zero or two times is unacceptable even if a network or system failure occurs during transmission, receipt, or execution of the request.
Oracle Advanced Queuing supports the following:
Using Oracle Advanced Queuing, you can:
Because Oracle Advanced Queuing queues are implemented in database tables, all the operational benefits of high availability, scalability, and reliability apply to queue data. In addition, database development and management tools can be used with queues.
Applications can access the queuing functionality through the native interface for Oracle Advanced Queuing (defined in PL/SQL, C/C++, Java, and Visual Basic) or through the Java Messaging Service interface for Oracle Advanced Queuing (a Java API based on the Java Messaging Service standard).
|
See Also:
Oracle9i Application Developer's Guide - Advanced Queuing for detailed information about Oracle Advanced Queuing |
Oracle9i, Release 1 (9.0.1), provides many features that support the needs of data warehousing and business intelligence. These features are typically useful for other activities such as Online Transaction Processing (OLTP). Therefore, most features described in this manual are presented in general terms, rather than emphasizing their data warehousing use.
These are some of the Oracle features that are designed to support data warehousing and business intelligence:
Oracle9i Data Warehousing Guide for details about using these features for data warehousing
See Also:
This section introduces how Oracle meets the general requirements for a DBMS to:
SQL is a simple, powerful database access language that is the standard language for relational database management systems. For information about Oracle's compliance with ANSI/ISO standards, see Oracle9i SQL Reference.
All operations on the information in an Oracle database are performed using SQL statements. A SQL statement is a string of SQL text that is given to Oracle to execute. A statement must be the equivalent of a complete SQL sentence, as in:
SELECT ename, deptno FROM emp;
Only a complete SQL statement can be executed, whereas a sentence fragment, such as the following, generates an error indicating that more text is required before a SQL statement can run:
SELECT ename
A SQL statement can be thought of as a very simple, but powerful, computer program or instruction. SQL statements are divided into the following categories:
Data definition language statements define, maintain, and drop schema objects when they are no longer needed. DDL statements also include statements that permit a user to grant other users the privileges, or rights, to access the database and specific objects within the database.
Data manipulation language statements manipulate the database's data. For example, querying, inserting, updating, and deleting rows of a table are all DML operations. Locking a table or view and examining the execution plan of an SQL statement are also DML operations.
Transaction control statements manage the changes made by DML statements. They enable the user or application developer to group changes into logical transactions. Examples include COMMIT, ROLLBACK, and SAVEPOINT.
Session control statements let a user control the properties of his current session, including enabling and disabling roles and changing language settings. The two session control statements are ALTER SESSION and SET ROLE.
System control statements change the properties of the Oracle server instance. The only system control statement is ALTER SYSTEM. It lets you change such settings as the minimum number of shared servers, to kill a session, and to perform other tasks.
Embedded SQL statements incorporate DDL, DML, and transaction control statements in a procedural language program (such as those used with the Oracle precompilers). Examples include OPEN, CLOSE, FETCH, and EXECUTE.
A transaction is a logical unit of work that comprises one or more SQL statements executed by a single user. According to the ANSI/ISO SQL standard, with which Oracle is compatible, a transaction begins with the user's first executable SQL statement. A transaction ends when it is explicitly committed or rolled back by that user.
Consider a banking database. When a bank customer transfers money from a savings account to a checking account, the transaction can consist of three separate operations: decrease the savings account, increase the checking account, and record the transaction in the transaction journal.
Oracle must guarantee that all three SQL statements are performed to maintain the accounts in proper balance. When something prevents one of the statements in the transaction from executing (such as a hardware failure), the other statements of the transaction must be undone; this is called rolling back. If an error occurs in making any of the updates, then no updates are made.
Figure 2-2 illustrates the banking transaction example.
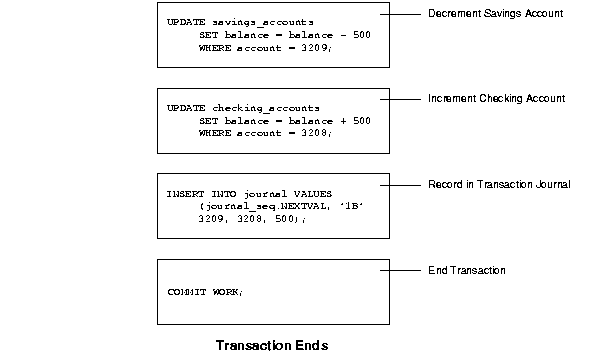
The changes made by the SQL statements that constitute a transaction can be either committed or rolled back. After a transaction is committed or rolled back, the next transaction begins with the next SQL statement.
Committing a transaction makes permanent the changes resulting from all SQL statements in the transaction. The changes made by the SQL statements of a transaction become visible to other user sessions' transactions that start only after the transaction is committed.
Rolling back a transaction retracts any of the changes resulting from the SQL statements in the transaction. After a transaction is rolled back, the affected data is left unchanged as if the SQL statements in the transaction were never executed.
For long transactions that contain many SQL statements, intermediate markers, or savepoints, can be declared. Savepoints can be used to divide a transaction into smaller parts.
By using savepoints, you can arbitrarily mark your work at any point within a long transaction. This gives you the option of later rolling back all work performed from the current point in the transaction to a declared savepoint within the transaction. For example, you can use savepoints throughout a long complex series of updates, so if you make an error, you do not need to resubmit every statement.
Transactions enable the database user or application developer to guarantee consistent changes to data, as long as the SQL statements within a transaction are grouped logically.
A transaction should consist of all of the necessary parts for one logical unit of work--no more and no less. Data in all referenced tables are in a consistent state before the transaction begins and after it ends. Transactions should consist of only the SQL statements that make one consistent change to the data.
For example, recall the banking example. A transfer of funds between two accounts (the transaction) should include increasing one account (one SQL statement), decreasing another account (one SQL statement), and the record in the transaction journal (one SQL statement). All actions should either fail or succeed together; the credit should not be committed without the debit. Other nonrelated actions, such as a new deposit to one account, should not be included in the transfer of funds transaction. Such statements should be in other transactions.
PL/SQL is Oracle's procedural language extension to SQL. PL/SQL combines the ease and flexibility of SQL with the procedural functionality of a structured programming language, such as IF ... THEN, WHILE, and LOOP.
When designing a database application, a developer should consider the advantages of using stored PL/SQL because:
Even when PL/SQL is not stored in the database, applications can send blocks of PL/SQL to the database rather than individual SQL statements, thereby again reducing network traffic.
The following sections describe the different program units that can be defined and stored centrally in a database.
Procedures and functions consist of a set of SQL and PL/SQL statements that are grouped together as a unit to solve a specific problem or perform a set of related tasks. A procedure is created and stored in compiled form in the database and can be run by a user or a database application.
Procedures and functions are identical except that functions always return a single value to the caller, while procedures do not return values to the caller.
Packages provide a method of encapsulating and storing related procedures, functions, variables, and other package constructs together as a unit in the database. Packages enable the administrator or application developer to organize such routines. They also offer increased functionality (for example, global package variables can be declared and used by any procedure in the package). They also improve performance (for example, all objects of the package are parsed, compiled, and loaded into memory once).
Oracle lets you write procedures written in PL/SQL, Java, or C that run implicitly whenever a table or view is modified or when some user actions or database system actions occur. These procedures are called database triggers.
Database triggers can be used in a variety of ways for the information management of your database. For example, they can be used to automate data generation, audit data modifications, enforce complex integrity constraints, and customize complex security authorizations.
A method is a procedure or function that is part of the definition of a user-defined datatype (object type, nested table, or variable array).
Methods are different from stored procedures in two ways:
Every user-defined datatype has a system-defined constructor method; that is, a method that makes a new object according to the datatype's specification. The name of the constructor method is the name of the user-defined type. In the case of an object type, the constructor method's parameters have the names and types of the object type's attributes. The constructor method is a function that returns the new object as its value. Nested tables and arrays also have constructor methods.
Comparison methods define an order relationship among objects of a given object type. A map method uses Oracle's ability to compare built-in types. For example, Oracle can compare two rectangles by comparing their areas if an object type called RECTANGLE has attributes HEIGHT and WIDTH and you define a map method area that returns a number, namely the product of the rectangle's HEIGHT and WIDTH attributes. An order method uses its own internal logic to compare two objects of a given object type. It returns a value that encodes the order relationship. For example, it can return -1 if the first is smaller, 0 if they are equal, and 1 if the first is larger.
It is very important to guarantee that data adheres to certain business rules, as determined by the database administrator or application developer. For example, assume that a business rule says that no row in the INVENTORY table can contain a numeric value greater than 9 in the SALE_DISCOUNT column. If an INSERT or UPDATE statement attempts to violate this integrity rule, Oracle must roll back the invalid statement and return an error to the application. Oracle provides integrity constraints and database triggers to manage a database's data integrity rules.
An integrity constraint is a declarative way to define a business rule for a column of a table. An integrity constraint is a statement about a table's data that is always true and that follows these rules:
Integrity constraints are defined with a table and are stored as part of the table's definition, centrally in the database's data dictionary, so that all database applications must adhere to the same set of rules. If a rule changes, it need only be changed once at the database level and not many times for each application.
The following integrity constraints are supported by Oracle:
Key is used in the definitions of several types of integrity constraints. A key is the column or set of columns included in the definition of certain types of integrity constraints. Keys describe the relationships between the different tables and columns of a relational database. The different types of keys include:
Individual values in a key are called key values.
Database triggers let you define and enforce integrity rules, but a database trigger is not the same as an integrity constraint. Among other things, a database trigger defined to enforce an integrity rule does not check data already loaded into a table. Therefore, it is strongly recommended that you use database triggers only when the integrity rule cannot be enforced by integrity constraints.
Multiuser database systems, such as Oracle, include security features that control how a database is accessed and used. For example, security mechanisms:
Associated with each database user is a schema by the same name. By default, each database user creates and has access to all objects in the corresponding schema.
Database security can be classified into two categories: system security and data security.
System security includes the mechanisms that control the access and use of the database at the system level. For example, system security includes:
System security mechanisms check whether a user is authorized to connect to the database, whether database auditing is active, and which system operations a user can perform.
Data security includes the mechanisms that control the access and use of the database at the schema object level. For example, data security includes:
SCOTT can issue SELECT and INSERT statements but not DELETE statements using the EMP table)
The Oracle server provides discretionary access control, which is a means of restricting access to information based on privileges. The appropriate privilege must be assigned to a user in order for that user to access a schema object. Appropriately privileged users can grant other users privileges at their discretion. For this reason, this type of security is called discretionary.
Oracle manages database security using several different facilities:
Figure 2-3 illustrates the relationships of the different Oracle security facilities, and the following sections provide an overview of users, privileges, and roles.
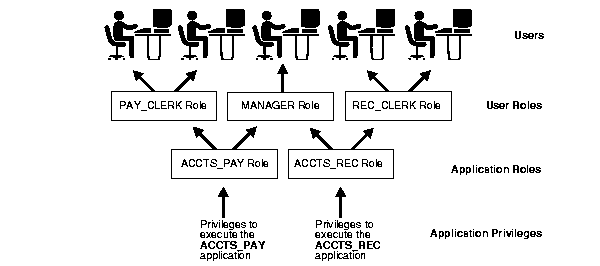
Each Oracle database has a list of usernames. To access a database, a user must use a database application and attempt a connection with a valid username of the database. Each username has an associated password to prevent unauthorized use.
Each user has a security domain--a set of properties that determine such things as:
Each property that contributes to a user's security domain is discussed in the following sections.
A privilege is a right to execute a particular type of SQL statement. Some examples of privileges include the right to:
The privileges of an Oracle database can be divided into two categories: system privileges and schema object privileges.
System privileges allow users to perform a particular systemwide action or a particular action on a particular type of schema object. For example, the privileges to create a tablespace or to delete the rows of any table in the database are system privileges. Many system privileges are available only to administrators and application developers because the privileges are very powerful.
Schema object privileges allow users to perform a particular action on a specific schema object. For example, the privilege to delete rows of a specific table is an object privilege. Object privileges are granted (assigned) to users so that they can use a database application to accomplish specific tasks.
Privileges are granted to users so that users can access and modify data in the database. A user can receive a privilege two different ways:
EMP table can be explicitly granted to the user SCOTT.
EMP table can be granted to the role named CLERK, which in turn can be granted to the users SCOTT and BRIAN.
Because roles enable easier and better management of privileges, privileges are normally granted to roles and not to specific users. The following section explains more about roles and their use.
Oracle provides for easy and controlled privilege management through roles. Roles are named groups of related privileges that you grant to users or other roles.
Oracle provides a way to direct and limit the use of disk space allocated to the database for each user, including default and temporary tablespaces and tablespace quotas.
Each user is associated with a default tablespace. When a user creates a table, index, or cluster and no tablespace is specified to physically contain the schema object, the user's default tablespace is used if the user has the privilege to create the schema object and a quota in the specified default tablespace. The default tablespace feature provides Oracle with information to direct space usage in situations where schema object's location is not specified.
Each user has a temporary tablespace. When a user executes a SQL statement that requires the creation of temporary segments (such as the creation of an index), the user's temporary tablespace is used. By directing all users' temporary segments to a separate tablespace, the temporary tablespace feature can reduce I/O contention among temporary segments and other types of segments.
Oracle can limit the collective amount of disk space available to the objects in a schema. Quotas (space limits) can be set for each tablespace available to a user. The tablespace quota security feature permits selective control over the amount of disk space that can be consumed by the objects of specific schemas.
Each user is assigned a profile that specifies limitations on several system resources available to the user, including the following:
Different profiles can be created and assigned individually to each user of the database. A default profile is present for all users not explicitly assigned a profile. The resource limit feature prevents excessive consumption of global database system resources.
Oracle permits selective auditing (recorded monitoring) of user actions to aid in the investigation of suspicious database use. Auditing can be performed at three different levels: statement auditing, privilege auditing, and schema object auditing.
For all types of auditing, Oracle allows the selective auditing of successful statement executions, unsuccessful statement executions, or both. This enables monitoring of suspicious statements, regardless of whether the user issuing a statement has the appropriate privileges to issue the statement. The results of audited operations are recorded in a table called the audit trail. Predefined views of the audit trail are available so you can easily retrieve audit records.
This section covers the structures and software mechanisms used by Oracle to provide:
In every database system, the possibility of a system or hardware failure always exists. If a failure occurs and affects the database, the database must be recovered. The goals after a failure are to ensure that the effects of all committed transactions are reflected in the recovered database and to return to normal operation as quickly as possible while insulating users from problems caused by the failure.
Several circumstances can halt the operation of an Oracle database. The most common types of failure are described as follows:
Oracle provides for complete recovery from all possible types of hardware failures, including disk crashes. Options are provided so that a database can be completely recovered or partially recovered to a specific point in time.
If some datafiles are damaged in a disk failure but most of the database is intact and operational, the database can remain open while the required tablespaces are individually recovered. Therefore, undamaged portions of a database are available for normal use while damaged portions are being recovered.
Oracle uses several structures to provide complete recovery from an instance or disk failure: the redo log, undo records, a control file, and database backups. If compatibility is set to Oracle9i, Release 1 (9.0.1) or higher, undo records can be stored in either rollback segments or undo tablespaces.
The redo log is a set of files that protect altered database data in memory that has not been written to the datafiles. The redo log can consist of two parts: the online redo log and the archived redo log.
The online redo log is a set of two or more online redo log files that record all changes made to the database, including both uncommitted and committed changes. Redo entries are temporarily stored in redo log buffers of the system global area, and the background process LGWR writes the redo entries sequentially to an online redo log file. LGWR writes redo entries continually, and it also writes a commit record every time a user process commits a transaction.
The online redo log files are used in a cyclical fashion. For example, if two files constitute the online redo log, the first file is filled, the second file is filled, the first file is reused and filled, the second file is reused and filled, and so on. Each time a file is filled, it is assigned a log sequence number to identify the set of redo entries.
To avoid losing the database due to a single point of failure, Oracle can maintain multiple sets of online redo log files. A multiplexed online redo log consists of copies of online redo log files physically located on separate disks. Changes made to one member of the group are made to all members.
If a disk that contains an online redo log file fails, other copies are still intact and available to Oracle. System operation is not interrupted, and the lost online redo log files can be easily recovered using an intact copy.
Optionally, filled online redo files can be archived before being reused, creating an archived redo log. Archived (offline) redo log files constitute the archived redo log.
The presence or absence of an archived redo log is determined by the mode that the redo log is using:
|
ARCHIVELOG |
The filled online redo log files are archived before they are reused in the cycle. |
|
NOARCHIVELOG |
The filled online redo log files are not archived. |
In ARCHIVELOG mode, the database can be completely recovered from both instance and disk failure. The database can also be backed up while it is open and available for use. However, additional administrative operations are required to maintain the archived redo log.
If the database's redo log operates in NOARCHIVELOG mode, the database can be completely recovered from instance failure but not from disk failure. Also, the database can be backed up only while it is completely closed. Because no archived redo log is created, no extra work is required by the database administrator.
If compatibility is set to Oracle9i, Release 1 (9.0.1) or higher, undo records can be stored in either rollback segments or undo tablespaces.
Rollback segments have traditionally stored undo information used by several functions of Oracle. During database recovery, after all changes recorded in the redo log have been applied, Oracle uses rollback segment information to undo any uncommitted transactions. Because rollback segments are stored in the database buffers, this important recovery information is automatically protected by the redo log.
Oracle9i, Release 1 (9.0.1), offers another method of storing undo records: using undo tablespaces. Automatic undo management has the following advantages over the traditional rollback segments:
Oracle recommends operating in automatic undo management mode. The database server can manage undo more efficiently, and automatic undo management mode is less complex to implement and manage.
|
See Also:
|
The control files of a database keep, among other things, information about the file structure of the database and the current log sequence number being written by LGWR. During normal recovery procedures, the information in a control file is used to guide the automated progression of the recovery operation.
Oracle can maintain a number of identical control files, updating all of them simultaneously.
Because one or more files can be physically damaged as the result of a disk failure, media recovery requires the restoration of the damaged files from the most recent operating system backup of a database. There are several ways to back up the files of a database.
A whole database backup is an operating system backup of all datafiles, online redo log files, and the control file of an Oracle database. A whole database backup is performed when the database is closed and unavailable for use.
A partial backup is an operating system backup of part of a database. The backup of an individual tablespace's datafiles or the backup of a control file are examples of partial backups. Partial backups are useful only when the database's redo log is operated in ARCHIVELOG mode.
A variety of partial backups can be taken to accommodate any backup strategy. For example, you can back up datafiles and control files when the database is open or closed, or when a specific tablespace is online or offline. Because the redo log is operated in ARCHIVELOG mode, additional backups of the redo log are not necessary. The archived redo log is a backup of filled online redo log files.
Because of the way DBWn writes database buffers to datafiles, at any given time a datafile might contain some tentative modifications by uncommitted transactions and might not contain some modifications by committed transactions. Therefore, two potential situations can result after a failure:
To solve this situation, two separate steps are always used by Oracle during recovery from an instance or media failure: rolling forward and rolling back.
The first step of recovery is to roll forward, which is to reapply to the datafiles all of the changes recorded in the redo log. Rolling forward proceeds through as many redo log files as necessary to bring the datafiles forward to the required time.
If all necessary redo information is online, Oracle rolls forward automatically when the database starts. After roll forward, the datafiles contain all committed changes as well as any uncommitted changes that were recorded in the redo log.
The roll forward is only half of recovery. After the roll forward, any changes that were not committed must be undone. After the redo log files have been applied, then the undo records are used to identify and undo transactions that were never committed yet were recorded in the redo log. This process is called rolling back. Oracle completes this step automatically.
Rapid recovery minimizes the time data is unavailable to users, but it does not address the disruption caused when user sessions fail. Users need to reestablish connections to the database, and work in progress can be lost. Transparent Application Failover (TAF) can mask many failures from users, restoring any session state and resuming queries that had been in progress at the time of the failure. Developers can further extend these capabilities by building applications that leverage TAF and make all failures, including those affecting transactions, transparent to users.
Recovery Manager (RMAN) is an Oracle utility that manages backup and recovery operations, creates backups of database files (datafiles, control files, and archived redo log files), and restores or recovers a database from backups.
Recovery Manager maintains a repository called the recovery catalog, which contains information about backup files and archived log files. Recovery Manager uses the recovery catalog to automate both restore operations and media recovery.
The recovery catalog contains:
There are several methods for improving performance of instance and crash recovery to keep the duration of recovery within user-specified bounds. For example:
Besides using checkpoints to tune instance recovery, you can also use a variety of parameters to control Oracle's behavior during the rolling forward and rolling back phases of instance recovery. In some cases, you can parallelize operations and thereby increase recovery efficiency.
The size of a redo log file directly influences checkpoint performance. The smaller the size of the smallest log, the more aggressively Oracle writes dirty buffers to disk to ensure that the position of the checkpoint has advanced to the current log before that log completely fills. Forcing the checkpoint to advance into the current log before it fills means that Oracle does not need to wait for the checkpoint to advance out of a redo log file before it can be reused. Oracle enforces this behavior by ensuring that the number of redo blocks between the checkpoint and the most recent redo record is less than 90% of the size of the smallest log.
If the redo logs are small compared to the number of changes made against the database, then Oracle must switch logs frequently. If the value of LOG_CHECKPOINT_INTERVAL is less than 90% of the size of the smallest log, then the size of the smallest log file does not influence checkpointing behavior.
Although you specify the number and sizes of online redo log files at database creation, you can alter the characteristics of the redo log files after startup. Use the ADD LOGFILE clause of the ALTER DATABASE statement to add a redo log file and specify its size, or the DROP LOGFILE clause to drop a redo log.
The size of the redo log appears in the LOG_FILE_SIZE_REDO_BLKS column of the V$INSTANCE_RECOVERY dynamic performance view. This value shows how the size of the smallest online redo log is affecting checkpointing. By increasing or decreasing the size of the online redo logs, you indirectly influence the frequency of checkpoint writes.
|
See Also:
Oracle9i Database Performance Guide and Reference for more information about tuning instance recovery |
Besides setting initialization parameters and sizing your redo log files, you can also influence checkpoints with SQL statements. ALTER SYSTEM CHECKPOINT directs Oracle to record a checkpoint for the node, and ALTER SYSTEM CHECKPOINT GLOBAL directs Oracle to record a checkpoint for every node in a cluster.
SQL-induced checkpoints are heavyweight. This means that Oracle records the checkpoint in a control file shared by all the redo threads. Oracle also updates the datafile headers. SQL-induced checkpoints move the checkpoint position to the point that corresponded to the end of the log when the statement was initiated. These checkpoints can adversely affect performance, because the additional writes to the datafiles increase system overhead.
Oracle's Standby Database is the most frequently used and, for most environments, the most effective disaster recovery solution for Oracle databases. Oracle9i, Release 1 (9.0.1), provides enhancements that do much more than meet essential disaster recovery requirements. By automating complex tasks and providing dramatically enhanced monitoring, alert, and control mechanisms, Standby Database and a number of new modules now help you to survive mistakes, corruptions and other disasters that might otherwise destroy your database. Also, the downtime required for upgrades, such as hardware and operating system maintenance, can be significantly reduced using Oracle9i standby databases.
As well as enhancing Standby Database, several entirely new components have been added that provide further protection against user errors and corruptions. These new components, together with the enhanced Standby Database, are contained in a new Oracle9i database feature called Oracle9i Data Guard.
The Oracle8 Automated Standby Database feature provides the means to create and automatically maintain copies of a production database to protect against disasters.
Oracle8 Automated Standby Database configuration performs the following functions:
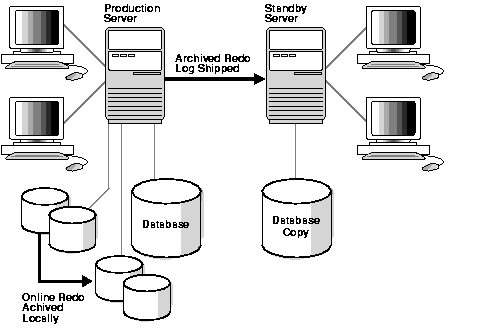
Figure 2-4 shows that as the online redo logs are archived locally, they are concurrently shipped to the standby database(s) through Oracle Net Services.
Most Oracle8-based disaster protection solutions include Automated Standby Database. Any application can use Automated Standby Database, because any Oracle database can be rebuilt with a backup and its logs using standard Oracle recovery. The performance impact of log shipping on primary-side performance is negligible.
Cluster technologies that are used for fast failover are often referred to as high availability solutions. But maintaining enterprise application continuity after a disaster or corruption is also a critical part of achieving high service levels. Fast failover cluster technologies, and the problems they solve, are quite different from those used for disaster protection. While these two areas are not mutually exclusive, from a practical perspective, the technologies used in one area often are not applied to solve problems in the other.
Cluster-based high availability solutions include more than one system or instance pointed at the same pool of disks. A high availability cluster can include multiple active and independent nodes working together on one database, or just one node that operates on the database at a time and then fails over to another single node on the same cluster. Fast failover solutions minimize downtime by detecting and identifying system faults or failures, and then failing over quickly. Any disaster that destroys or corrupts data does so for all potential failover target systems. Even with a fully hardware-mirrored disk configuration, any corruption written to one disk is immediately propagated to the mirror; there is no practical way to prevent this by checking at the hardware level.
Scalability is an additional advantage of multisystem clusters that operate on one database. Oracle9i Real Application Clusters is an example of this kind of a cluster solution that provides both scalability as well as enterprise-class availability.
There are no shared disks in typical disaster protection, or in DR (disaster recovery) configurations. The first priority is to ensure that copies of the data are elsewhere, usable, and correct when any data-destroying disaster strikes. Each site's peculiar risk profile determines the likelihood of disasters like floods, hurricanes, and earthquakes, and therefore the distance needed to ensure that one site's risks are independent of the other. That is, the standby database must be far enough away from the primary system's location so that the same events likely to disable the primary are unlikely to also cripple the standby. In hurricane or earthquake country, this can mean more than 250 miles. Hardware and cluster-based mirroring technologies currently provide solutions that either do not scale to meet these needs, or do so in configurations that are difficult to economically justify.
You can implement Automated Standby Database locally, that is, connected to the primary using a local area network (LAN). The standby database would be a failover option despite slower failover time compared to clusters. Such a standby configuration would provide greater protection against user errors, system problems, and corruptions. Errors can appear on the primary database without propagating to the standby. In these cases, the only database copy not impacted would be on the standby database's disks.
If your environment demands fast failover as well as data protection, you can implement cluster solutions along with Automated Standby Database. Oracle Fail Safe or Oracle9i Real Application Clusters can be used for quick failover to another instance for transient faults, with failover to a standby reserved for more serious problems.
|
See Also:
Oracle9i Real Application Clusters Concepts for more information about high availability strategy |
Oracle9i provides a number of new features that help to prevent or minimize losses due to human errors, disasters, and data corruption.
Physical standby database is the Oracle9i version of the Oracle8 Automated Standby Database feature, with one difference. The log transport services are now a separate component. The log transport services have been enhanced to support the new logical standby database feature and other features as well as physical standby database.
We call this "physical" standby because of this feature's roots in recovery. A physical standby is physically identical to the primary. Put another way, standby on-disk data structures are identical to the primary's on a block-for-block basis, because recovery applies changes block-for-block using the physical ROWID. The database schema, including indexes, must be the same, and the database cannot be opened read/write.
Logical standby database is a new feature that takes standard Oracle archive logs, transforms them back into SQL transactions, and then applies them to an open standby database. Because the database is open, it is physically different from the primary database. As the standby is logically the same as the primary, it can be used to take over processing if the primary database is mistakenly harmed by human error, a corruption, or a disaster. Because transactions are applied using SQL, the standby database can be used concurrently for other tasks. Decision support can be optimized by using different indexes and materialized views than those on the primary.
Logical standby database is first and foremost a data protection feature. Just like physical standby database, it uses archive logs shipped the moment they are created on the primary system, performing all related processing on the standby database, out of harm's way in the case of a primary database failure. Updates recorded in the log always include the previous values as well as the new, updated values. Logical standby database compares these previous values to the previous values in the logical standby database.
Log transport services are used by both physical and logical standby database components. The functions it provides include control of different log shipping mechanisms, log shipping error handling and reporting, and retrieving "lost" logs after a system failure. Guaranteed data protection is now possible using one of the new log transport modes.
Data Guard broker provides monitoring, control, and automation of the log transport services and the logical and physical standby components. For instance, using only one command to initiate failover, Data Guard broker can be used to control the entire process as the primary role moves from the primary to either type of standby database. Users can choose one of two different interfaces to perform role changes such as failover, that is, having the standby take over production processing from the primary database. One option is to use the new Oracle Enterprise Manager Data Guard Manager. It provides a graphical user interface (GUI) for most configuration and set-up tasks, as well as operational functions. A command-line interface (CLI) is also available. It provides access to both basic monitoring and all commands needed to make role changes, as well as the ability to configure and set up a Oracle9i Data Guard environment.
Data Guard Manager is a part of Oracle Enterprise Manager. More than GUI-based access, the complete Oracle Enterprise Manager architecture is implemented while also fully integrated with Oracle9i Data Guard broker.
LogMiner has been significantly enhanced in Oracle9i. LogMiner is a relational tool that lets the administrator use SQL to read, analyze, and interpret log files. LogMiner can view any redo log file, online or archived.
LogMiner technology now provides much of the infrastructure used by logical standby database and other features that are not discussed here, as well as broader data type support and other enhancements to LogMiner itself. A new Oracle Enterprise Manager application, Oracle9i LogMinerTM Viewer, adds a GUI-based interface to the pre-existing command-line interface.
Figure 2-5 illustrates how these components fit together, as described in the text following the figure.
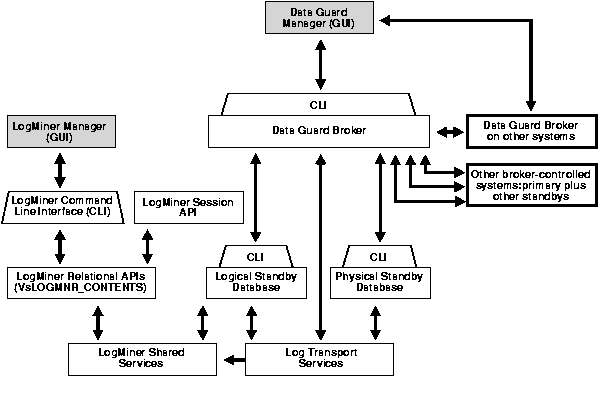
Figure 2-5 shows the various access options and user interface preferences.
There are a number of factors to consider when choosing whether to implement a physical standby database, a logical standby database, or both. These include:
In today's world of e-commerce, companies that do business on the Internet must have a strategy for recovering their applications and databases when, not if, things go wrong. The subject of disaster recovery and planned or unplanned failover should be considered by every database administrator who might oversee an unplanned outage from a real disaster such as a hurricane, or a planned outage such as when upgrading hardware.
The Disaster Recovery (DR) Server is part of a larger high availability strategy that helps the database administrator achieve this goal.
|
See Also:
|
The DR Server is a distributed computing system that delivers enhanced ability to recover from various disaster scenarios.
An Oracle DR Server fundamentally consists of a collection of loosely connected nodes that combines physical and logical standby solutions into a single, easily managed disaster recovery solution. DR Server nodes, or sites, may be dispersed geographically and, if so, are connected through the network. Each DR Server node may be a simple instance, or the node may be a more complex system such as a fail safe cluster. DR Server manages these nodes as a single distributed computing system that offers higher availability than one can get from the individual nodes alone.
DR Server implements a failover system with replicated data across the server nodes. The database administrator configures the server such that the database and applications are instantiated on each node. One node is designated a primary node. This is where the database is fully available to applications and from whence data is shipped primarily in the form of redo logs. The other server nodes serve as standby systems to the primary node. They accept redo logs shipped from the primary node and apply changes (logically or physically) to their copies of the database.
The standby nodes of the DR Server are ready to take over in the event that the primary node fails. Thus, the data and applications being served to users remain available in the face of a disaster that removes the primary node from operation.
The DR Server architecture provides two major functions for the database administrator:
Oracle9i Data Guard Concepts and Administration for more information about the disaster recovery server and DRMON
See Also:
In a primary/standby configuration, all noncurrent logs of the primary site are shipped to the standby site. This keeps the standby site up to date. However, if the primary database shuts down unexpectedly, records in a redo log that is still recording will be lost, because they have not yet been archived to the standby site. Open threads in a redo log file constitute a lag between the primary and standby databases.
Oracle9i, Release 1 (9.0.1), provides some ways to limit this lag and the data loss it can cause.
ARCHIVE_LAG_TARGET in the initialization file to the number of seconds that can elapse between the time a redo log is started and the time it is archived to standby. A recommended value is 1800 seconds (30 minutes).
Oracle9i Data Guard Concepts and Administration for details about choosing values for
See Also:
ARCHIVE_LAG_TARGET
LogMiner is a relational tool that lets you read, analyze, and interpret online and archived log files using SQL. You can also use LogMiner Viewer to access LogMiner functionality. LogMiner Viewer, which is available with Oracle Enterprise Manager, provides a graphical user interface to LogMiner.
Analysis of the log files with LogMiner can be used to:
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|