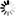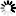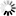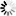
Obtaining the Server Pool ID Value
In the previous example, Section 2.6.6, “Creating a Server Pool”, we created a server pool and finally obtained the server pool ID as an object that we could reuse immediately when setting up clustering. However, let's presume that we didn't get that ID for some reason, and now need to find it so that we can configure clustering. Using the REST API, we can obtain the ID Value for the server pool that we have created based on the name that we assigned to it:
r=s.get(baseUri+'/ServerPool/id')
for id in r.json():
if id['name']=='MyServerPool':
sp_id=idSince this is the type of action that may need to be repeated for other objects in the environment, it may be useful to define a function for this type of action:
def get_id_from_name(s,baseUri,resource,obj_name):
uri=baseUri+'/'+resource+'/id'
r=s.get(uri)
for obj in r.json():
if 'name' in obj.keys():
if obj['name']==obj_name:
return obj
raise Exception('Failed to find id for {name}'.format(name=obj_name))In terms of the WS-API, an ID for an object contains a collection of information, including the object name, the model used by the API to define the object, the URI that can be used to query the object, and the unique ID value. ID Values are typically used in URI's to identify a particular object, while IDs are usually passed as XML objects within the body of a POST or PUT request. For this reason, we distinguish between an ID and ID Value throughout this document. In this case, we return the entire ID object as this contains the full collection of information that may be required.
Create the Cluster Object
Now to create the cluster, we submit a POST request to the URI that we construct using the server pool id:
...
data={'name':'MyServerPool_cluster'}
uri='{base}/ServerPool/{spid}/Cluster'.format(base=baseUri, spid=sp_id['value'])
r=s.post(uri,data=json.dumps(data))
job=r.json()
# wait for the job to complete
cluster_id=wait_for_job(job['id']['uri'],s)Note that in this piece of code, we assume that you have populated the sp_id with the dictionary returned for the server pool ID. In the URL that we are posting to, we specify the server pool ID Value, to attach the cluster to the correct server pool. Once again, we wait for the job to complete using the function that we defined previously, and expect the successful completion of the job to return the cluster ID. We need this, so that we can create a Cluster Heartbeat Device attached to this new cluster object.
Create the Cluster Heartbeat Device
Finally, to create a cluster heartbeat device you need to choose a shared storage repository that can be used for the heartbeat device. If you have not already set up a storage repository, you must do so before continuing. See Section 2.6.9, “Discovering a Network File Server” and Section 2.6.10, “Creating a Storage Repository” for more information. In our example, we use an NFS repository that is already available within Oracle VM Manager, and obtain the ID for a File System that we have already reserved for the purpose of acting as a server pool file system. For this, we use the get_id_from_name function that we defined previously:
... nfs_id=get_id_from_name(s,baseUri,'FileSystem','nfs:/mnt/vol1/poolfs01') data={ 'name':'MyServerPool_cluster_heartbeat', 'networkFileSystemId': nfs_id, 'storageType':'NFS', } uri='{base}/Cluster/{cluster_id}/ClusterHeartbeatDevice'.format( base=baseUri, cluster_id=cluster_id['value']) r=s.post(uri,data=json.dumps(data)) job=r.json() # wait for the job to complete cl_hb_id=wait_for_job(job['id']['uri'],s)