Release 1 (9.0.1)
Part Number A87503-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Database Performance Guide and Reference Release 1 (9.0.1) Part Number A87503-02 |
|
![]()
![]()
This chapter expands on the ideas introduced in Chapter 1 and explains optimizer actions in greater detail for specific cases. This chapter describes how the cost-based optimizer evaluates expressions and performs specific operations. It also explains how the CBO transforms some SQL statements into others to achieve the same goal more efficiently.
This chapter contains the following sections:
The optimizer fully evaluates expressions whenever possible and translates certain syntactic constructs into equivalent constructs. The reason for this is that either Oracle can more quickly evaluate the resulting expression than the original expression, or the original expression is merely a syntactic equivalent of the resulting expression. Sometimes, different SQL constructs can operate identically (for example, = ANY (subquery) and IN (subquery)); Oracle maps these to a single construct.
This section discusses how the optimizer evaluates expressions and conditions that contain the following:
This operator is used when there is an IN clause with values.
The execution plan is identical to what would result for a statement with an equality clause instead of IN. There is one additional step: the IN-list iterator that feeds the equality clause with unique values from the IN-list.
Both the statements below are equivalent and produce the same plan:
SELECT header_id, line_id, revenue_amount FROM so_lines_all WHERE header_id in (1011,1012,1013); SELECT header_id, line_id, revenue_amount FROM so_lines_all WHERE header_id = 1011 OR header_id = 1012 OR header_id = 1013; Plan ------------------------------------------------- SELECT STATEMENT INLIST ITERATOR TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N1
This is equivalent to the following statement, with :b1 being bound to the different unique values by the IN-list iterator:
SELECT header_id, line_id, revenue_amount FROM so_lines_all l WHERE header_id = :b1; Plan ------------------------------------------------- SELECT STATEMENT TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N1
The following example uses a unique index. Because there is a sort involved on the IN-list, even with complete keys of unique indexes, there is still a range scan.
SELECT header_id, line_id, revenue_amount FROM so_lines_all WHERE line_id IN (1011,1012,1013); Plan ------------------------------------------------- SELECT STATEMENT INLIST ITERATOR TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_U1
In the following example, this operator can be used when driving into a table with a nested loop operation.
SELECT h.header_id, l.line_id, l.revenue_amount FROM so_headers_all h, so_lines_all l WHERE l.inventory_item_id = :b1 AND h.order_number = l.header_id AND h.order_type_id IN (1,2,3); Plan ------------------------------------------------- SELECT STATEMENT NESTED LOOPS TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N5 INLIST ITERATOR TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_U2
In the example below, this operator is especially useful if there is an expensive first step that you do not want to repeat for every IN-list element. In the example below, even though there are three IN-list elements, the full scan on so_lines_all happens only once.
SELECT h.header_id, l.line_id, l.revenue_amount FROM so_headers_all h, so_lines_all l WHERE l.s7 = :b1 AND h.order_number = l.header_id AND h.order_type_id IN (1,2,3); Plan ------------------------------------------------- SELECT STATEMENT NESTED LOOPS TABLE ACCESS FULL SO_LINES_ALL INLIST ITERATOR TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_U2
The optimizer uses an IN-list iterator when an IN clause is specified with values, and the optimizer finds a selective index for that column. If there are multiple OR clauses using the same index, then the optimizer chooses this operation rather than CONCATENATION or UNION ALL, because it is more efficient.
There are no hints for this operation. You can provide a hint to use the index in question, which can cause this operation.
Example before using hint:
SELECT h.customer_id, l.line_id, l.revenue_amount FROM so_lines_all l, so_headers_all h WHERE l.s7 = 20 AND h.original_system_reference = l.attribute5 AND h.original_system_source_code IN (1013,1014); Plan -------------------------------------------------- SELECT STATEMENT NESTED LOOPS TABLE ACCESS FULL SO_LINES_ALL TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N5
Example after using hint:
SELECT /*+INDEX(h so_headers_n9 */ h.customer_id, l.line_id, l.revenue_amount FROM so_lines_all l, so_headers_all h WHERE l.s7 = 20 AND h.original_system_reference = l.attribute5 AND h.original_system_source_code IN (1013,1014); Plan -------------------------------------------------- SELECT STATEMENT NESTED LOOPS TABLE ACCESS FULL SO_LINES_ALL INLIST ITERATOR TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N9
Concatenation is useful for statements with different conditions combined with an OR clause.
Below, there are two plans, each accessing the table via the appropriate index, combined via concatenation.
SELECT l.header_id, l.line_id, l.revenue_amount FROM so_lines_all l WHERE l.parent_line_id = :b1 OR l.service_parent_line_id = :b1; Plan ------------------------------------------------- SELECT STATEMENT CONCATENATION TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N20 TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N17
The plan does not return duplicate rows, so for each component it appends a negation of the previous components. In this case, the components will be the following:
The example below shows that concatenation is particularly useful in optimizing queries with OR conditions. With concatenation, you get a good execution plan with appropriate indexes.
SELECT p.header_id, l.line_id, l.revenue_amount FROM so_lines_all p , so_lines_all l WHERE p.header_id = :b1 AND (l.parent_line_id = p.line_id OR l.service_parent_line_id = p.line_id); Plan ------------------------------------------------- SELECT STATEMENT CONCATENATION NESTED LOOPS TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N1 TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N20 NESTED LOOPS TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N1 TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N17
Trying to execute the statement in a single query (by using a hint to disable concatenation) produces a poor execution plan. Because the optimizer has two paths to follow and has been instructed not to decompose the query, it needs to access all the rows in the second table to see if any match one of the conditions. For example:
SELECT /*+NO_EXPAND */ p.header_id, l.line_id, l.revenue_amount FROM so_lines_all p, so_lines_all l WHERE p.header_id = :b1 AND (l.parent_line_id = p.line_id OR l.service_parent_line_id = p.line_id); Plan ------------------------------------------------- SELECT STATEMENT NESTED LOOPS TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N1 TABLE ACCESS FULL SO_LINES_ALL
Use the hint USE_CONCAT for this operation.
When not to use concatenation:
OR conditions are on same column can use the IN-list operator, which is a more efficient than concatenation.
In the example below, there is a full scan on so_lines_all as the first stage. The optimizer chooses to use a single column index for the second table, but we want it to use a two column index.
Hints can force concatenation, but this repeats the initial full scan, which is not desirable. Instead, if you provide a hint to use the two column index, then the optimizer switches to that with an IN-list operator. The initial scan is not repeated, and there is a better execution plan.
Initial Statement
SELECT h.customer_id, l.line_id, l.revenue_amount FROM so_lines_all l, so_headers_all h WHERE l.s7 = 20 AND h.original_system_reference = l.attribute5 AND h.original_system_source_code IN (1013,1014); Plan -------------------------------------------------- SELECT STATEMENT NESTED LOOPS TABLE ACCESS FULL SO_LINES_ALL TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N5
Example using concatenation hint:
SELECT h.customer_id, l.line_id, l.revenue_amount FROM so_lines_all l, so_headers_all h WHERE l.s7 = 20 AND h.original_system_reference = l.attribute5 AND h.original_system_source_code IN (1013,1014); Plan -------------------------------------------------- SELECT STATEMENT CONCATENATION NESTED LOOPS TABLE ACCESS FULL SO_LINES_ALL TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N9 NESTED LOOPS TABLE ACCESS FULL SO_LINES_ALL TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N9
Example using index hint:
SELECT h.customer_id, l.line_id, l.revenue_amount FROM so_lines_all l, so_headers_all h WHERE l.s7 = 20 AND h.original_system_reference = l.attribute5 AND h.original_system_source_code IN (1013,1014); Plan -------------------------------------------------- SELECT STATEMENT NESTED LOOPS TABLE ACCESS FULL SO_LINES_ALL INLIST ITERATOR TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N9
The remote operation indicates that there is a table from another database being accessed via a database link.
The following example has a remote driving table:
SELECT c.customer_name, count(*) FROM ra_customers c, so_headers_all@oe h WHERE c.customer_id = h.customer_id AND h.order_number = :b1 GROUP BY c.customer_name; Plan -------------------------------------------------- SELECT STATEMENT SORT GROUP BY NESTED LOOPS REMOTE TABLE ACCESS BY INDEX ROWID RA_CUSTOMERS INDEX UNIQUE SCAN RA_CUSTOMERS_U1
A remote database query obtained from the library cache:
SELECT "ORDER_NUMBER","CUSTOMER_ID" FROM "SO_HEADERS_ALL" "H" WHERE "ORDER_NUMBER"=:"SYS_B_0";
The example below has a local driving table. Several factors are influencing the execution plan:
In general, the optimizer chooses to access the remote tables first, before accessing the local tables. This works well for cases like the previous example, where the driving table was the remote table. However, if the driving table is the local table, then there might not be any selective way of accessing the remote table without first accessing the local tables. In such cases, you might need to provide appropriate hints to avoid performance problems.
Original Query:
SELECT c.customer_name, h.order_number FROM ra_customers c, so_headers_all@oe h WHERE c.customer_id = h.customer_id AND c.customer_name LIKE :b1; Plan -------------------------------------------------- SELECT STATEMENT MERGE JOIN REMOTE SORT JOIN TABLE ACCESS BY INDEX ROWID RA_CUSTOMERS INDEX RANGE SCAN RA_CUSTOMERS_N1
Remote database query obtained from the library cache:
SELECT "ORDER_NUMBER","CUSTOMER_ID" FROM "SO_HEADERS_ALL" "H" WHERE "CUSTOMER_ID" IS NOT NULL ORDER BY "CUSTOMER_ID";
After hints:
SELECT /*+USE_NL(c h) */ c.customer_name, h.order_number FROM ra_customers c, so_headers_all@oe h WHERE c.customer_id = h.customer_id AND c.customer_name LIKE :b1; Plan -------------------------------------------------- SELECT STATEMENT NESTED LOOPS TABLE ACCESS BY INDEX ROWID RA_CUSTOMERS INDEX RANGE SCAN RA_CUSTOMERS_N1 REMOTE
Remote database query obtained from the library cache:
SELECT /*+ USE_NL("H") */ "ORDER_NUMBER","CUSTOMER_ID" FROM "SO_HEADERS_ALL" "H" WHERE :1="CUSTOMER_ID" FILTER;
This indicates that the optimizer is applying a filter condition to filter out rows, which could not be applied when the table was accessed.
The example below uses no filter. Besides the conditions used in the access path, a table might have additional conditions to filter rows when the table is visited. Conditions that get applied when the table is accessed, like attribute1 IS NOT NULL, do not show up as FILTER.
SELECT h.order_number FROM so_headers_all h WHERE h.open_flag = 'Y' AND attribute1 IS NOT NULL; Plan -------------------------------------------------- SELECT STATEMENT TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N2
Example - filter due to GROUP BY condition:
SELECT h.order_number, count(*) FROM so_headers_all h WHERE h.open_flag = 'Y' AND attribute1 IS NOT NULL GROUP BY h.order_number HAVING COUNT(*) = 1 ß Filter condition; Plan -------------------------------------------------- SELECT STATEMENT FILTER SORT GROUP BY TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N2
Example - filter due to a subquery:
In the example below, for every row meeting the condition of the outer query, the correlated EXISTS subquery is executed. If a row meeting the condition is found in the so_lines_all table, then the row from so_headers_all is returned.
SELECT h.order_number FROM so_headers_all h WHERE h.open_flag = 'Y' AND EXISTS (SELECT null FROM so_lines_all l WHERE l.header_id = h.header_id AND l.revenue_amount > 10000); Plan -------------------------------------------------- SELECT STATEMENT FILTER TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N2 TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N1
The optimizer chooses execution plans for SQL statements that access data on remote databases in much the same way that it chooses executions for statements that access only local data:
When choosing a cost-based execution plan for a distributed statement, the optimizer considers the available indexes on remote databases just as it does indexes on the local database. The optimizer also considers statistics on remote databases for the CBO. Furthermore, the optimizer considers the location of data when estimating the cost of accessing it. For example, a full scan of a remote table has a greater estimated cost than a full scan of an identical local table.
For a rule-based execution plan, the optimizer does not consider indexes on remote tables.
Sort operations happen when users specify some operation that requires a sort. Commonly encountered operations include the following:
This operation occurs if a user specifies a DISTINCT clause, or if there is an operation requiring unique values for the next step.
SELECT DISTINCT last_name, first_name FROM per_all_people_f WHERE full_name LIKE :b1; Plan -------------------------------------------------- SELECT STATEMENT SORT UNIQUE TABLE ACCESS BY INDEX ROWID PER_ALL_PEOPLE_F INDEX RANGE SCAN PER_PEOPLE_F_N54
Sort unique is happening to provide the outer query with a unique list of header_id. There is a view that indicates that the IN subquery has been un-nested by transforming into a view.
SELECT c.customer_name, h.order_number FROM ra_customers c, so_headers_all h WHERE c.customer_id = h.customer_id AND h.header_id in (SELECT l.header_id FROM so_lines_all l WHERE l.inventory_item_id = :b1 AND ordered_quantity > 10); Plan -------------------------------------------------- SELECT STATEMENT NESTED LOOPS NESTED LOOPS VIEW VW_NSO_1 SORT UNIQUE TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N5 TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX UNIQUE SCAN SO_HEADERS_U1 TABLE ACCESS BY INDEX ROWID RA_CUSTOMERS INDEX UNIQUE SCAN RA_CUSTOMERS_U1
If the optimizer can guarantee (with unique keys) that duplicate values will not be passed, then a sort can be avoided.
UPDATE so_lines_all l SET line_status = 'HOLD' WHERE l.header_id IN ( SELECT h.header_id FROM so_headers_all h WHERE h.customer_id = :b1); Plan -------------------------------------------------- UPDATE STATEMENT UPDATE SO_LINES_ALL NESTED LOOPS TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N1 INDEX RANGE SCAN SO_LINES_N1
This operation does not actually involve a sort. It is used when aggregates are being computed across the whole set of rows.
SELECT SUM(l.revenue_amount) FROM so_lines_all l WHERE l.header_id = :b1; Plan -------------------------------------------------- SELECT STATEMENT SORT AGGREGATE TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N1
This is used when aggregates are being computed for different groups in the data. The sort is required to separate the rows in different groups.
SELECT created_by, SUM(l.revenue_amount) FROM so_lines_all l WHERE header_id > :b1 GROUP BY created_by; Plan -------------------------------------------------- SELECT STATEMENT SORT GROUP BY TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N1
This happens during sort merge joins if the rows need to be sorted by the join key.
SELECT SUM(l.revenue_amount), l2.creation_date FROM so_lines_all l, so_lines_All l2 WHERE l.creation_date < l2.creation_date AND l.header_id <> l2.header_id GROUP BY l2.creation_date, l2.line_id; Plan -------------------------------------------------- SELECT STATEMENT SORT GROUP BY MERGE JOIN SORT JOIN TABLE ACCESS FULL SO_LINES_ALL FILTER SORT JOIN TABLE ACCESS FULL SO_LINES_ALL
This operation is required when the statement specifies an ORDER BY that cannot be satisfied by one of the indexes.
SELECT h.order_number FROM so_headers_all h WHERE h.customer_id = :b1 ORDER BY h.creation_date DESC; Plan -------------------------------------------------- SELECT STATEMENT SORT ORDER BY TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N1
Either of the following could cause the view:
Example - Using a view
SELECT order_number FROM orders WHERE customer_id = :b1 AND revenue > :b2; Plan -------------------------------------------------- SELECT STATEMENT VIEW ORDERS FILTER SORT GROUP BY NESTED LOOPS TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N1 TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N1
View Definition
There is a view due to the IN subquery requiring a sort unique on the values being selected. This view would be unnecessary if the columns being selected were unique, not requiring a sort.
SELECT c.customer_name, h.order_number FROM ra_customers c, so_headers_all h WHERE c.customer_id = h.customer_id AND h.header_id IN (SELECT l.header_id FROM so_lines_all l WHERE l.inventory_item_id = :b1 AND ordered_quantity > 10); Plan -------------------------------------------------- SELECT STATEMENT NESTED LOOPS NESTED LOOPS VIEW VW_NSO_1 SORT UNIQUE TABLE ACCESS BY INDEX ROWID SO_LINES_ALL INDEX RANGE SCAN SO_LINES_N5 TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX UNIQUE SCAN SO_HEADERS_U1 TABLE ACCESS BY INDEX ROWID RA_CUSTOMERS INDEX UNIQUE SCAN RA_CUSTOMERS_U1
In the example below, the distribution of orders and revenue by the number of lines/order is examined. In order to do the double grouping, temporary inline views are used.
SELECT COUNT(*) "Orders", cnt "Lines", sum(rev) "Revenue" FROM (SELECT header_id, COUNT(*) cnt, SUM(revenue_amount) rev FROM so_lines_all GROUP BY header_id) GROUP BY cnt; Plan -------------------------------------------------- SELECT STATEMENT SORT GROUP BY VIEW SORT GROUP BY TABLE ACCESS FULL SO_LINES_ALL
Computation of constants is performed only once, when the statement is optimized, rather than each time the statement is executed.
For example, the following conditions test for monthly salaries greater than 2000:
sal > 24000/12 sal > 2000 sal*12 > 24000
If a SQL statement contains the first condition, then the optimizer simplifies it into the second condition.
This operator is useful for combining OR clauses into one compound statement or for breaking up a complex statement into a compound statement containing simpler select statements that are easier to optimize and understand.
Like concatenation, you do not want to duplicate expensive operations by using UNION ALL.
The optimizer uses UNION/UNION ALL when the SQL statement contains UNION/UNION ALL clauses.
The following examples find customers who are new or have open orders.
Example without the UNION clause:
SELECT c.customer_name, c.creation_date FROM ra_customers c WHERE c.creation_date > SYSDATE - 30 OR customer_id IN (SELECT customer_id FROM so_headers_all h WHERE h.open_flag = 'Y'); Plan -------------------------------------------------- SELECT STATEMENT FILTER TABLE ACCESS FULL RA_CUSTOMERS TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N1
Because the driving conditions come from different tables, you cannot execute it effectively in a single statement.
With a UNION clause, you can break it up into two statements:
1. new customers
2. customers with open orders
These two statements can be optimized easily. Because you do not want duplicates (because some customers meet both criteria), use UNION rather than UNION ALL, which eliminates duplicates by using a sort. If you were using two disjoint sets, then you could have used UNION ALL, eliminating the sort.
Example with the UNION clause:
SELECT c.customer_name, c.creation_date FROM ra_customers c WHERE c.creation_date > SYSDATE - 30 UNION ALL SELECT c.customer_name, c.creation_date FROM ra_customers c WHERE customer_id IN (SELECT customer_id FROM so_headers_all h WHERE h.open_flag = 'Y'); Plan -------------------------------------------------- SELECT STATEMENT SORT UNIQUE UNION-ALL TABLE ACCESS BY INDEX ROWID RA_CUSTOMERS INDEX RANGE SCAN RA_CUSTOMERS_N2 NESTED LOOPS TABLE ACCESS BY INDEX ROWID SO_HEADERS_ALL INDEX RANGE SCAN SO_HEADERS_N2 TABLE ACCESS BY INDEX ROWID RA_CUSTOMERS INDEX UNIQUE SCAN RA_CUSTOMERS_U1
There are no hints for this operation.
The optimizer simplifies conditions that use the LIKE comparison operator to compare an expression with no wildcard characters into an equivalent condition that uses an equality operator instead. For example, the optimizer simplifies the first condition below into the second:
ename LIKE 'SMITH' ename = 'SMITH'
The optimizer can simplify these expressions only when the comparison involves variable-length datatypes. For example, if ename was of type CHAR(10), then the optimizer cannot transform the LIKE operation into an equality operation due to the equality operator following blank-padded semantics and LIKE not following blank-padded semantics.
The optimizer expands a condition that uses the IN comparison operator to an equivalent condition that uses equality comparison operators and OR logical operators. For example, the optimizer expands the first condition below into the second:
ename IN ('SMITH', 'KING', 'JONES') ename = 'SMITH' OR ename = 'KING' OR ename = 'JONES'
The optimizer expands a condition that uses the ANY or SOME comparison operator followed by a parenthesized list of values into an equivalent condition that uses equality comparison operators and OR logical operators. For example, the optimizer expands the first condition below into the second:
sal > ANY (:first_sal, :second_sal) sal > :first_sal OR sal > :second_sal
The optimizer transforms a condition that uses the ANY or SOME operator followed by a subquery into a condition containing the EXISTS operator and a correlated subquery. For example, the optimizer transforms the first condition below into the second:
x > ANY (SELECT sal FROM emp WHERE job = 'ANALYST') EXISTS (SELECT sal FROM emp WHERE job = 'ANALYST' AND x > sal)
The optimizer expands a condition that uses the ALL comparison operator followed by a parenthesized list of values into an equivalent condition that uses equality comparison operators and AND logical operators. For example, the optimizer expands the first condition below into the second:
sal > ALL (:first_sal, :second_sal) sal > :first_sal AND sal > :second_sal
The optimizer transforms a condition that uses the ALL comparison operator followed by a subquery into an equivalent condition that uses the ANY comparison operator and a complementary comparison operator. For example, the optimizer transforms the first condition below into the second:
x > ALL (SELECT sal FROM emp WHERE deptno = 10) NOT (x <= ANY (SELECT sal FROM emp WHERE deptno = 10) )
The optimizer then transforms the second query into the following query using the rule for transforming conditions with the ANY comparison operator followed by a correlated subquery:
NOT EXISTS (SELECT sal FROM emp WHERE deptno = 10 AND x <= sal)
The optimizer always replaces a condition that uses the BETWEEN comparison operator with an equivalent condition that uses the >= and <= comparison operators. For example, the optimizer replaces the first condition below with the second:
sal BETWEEN 2000 AND 3000 sal >= 2000 AND sal <= 3000
The optimizer simplifies a condition to eliminate the NOT logical operator. The simplification involves removing the NOT logical operator and replacing a comparison operator with its opposite comparison operator. For example, the optimizer simplifies the first condition below into the second one:
NOT deptno = (SELECT deptno FROM emp WHERE ename = 'TAYLOR') deptno <> (SELECT deptno FROM emp WHERE ename = 'TAYLOR')
Often, a condition containing the NOT logical operator can be written many different ways. The optimizer attempts to transform such a condition so that the subconditions negated by NOTs are as simple as possible, even if the resulting condition contains more NOTs. For example, the optimizer simplifies the first condition below into the second, and then into the third.
NOT (sal < 1000 OR comm IS NULL) NOT sal < 1000 AND comm IS NOT NULL sal >= 1000 AND comm IS NOT NULL
If two conditions in the WHERE clause involve a common column, then the optimizer sometimes can infer a third condition using the transitivity principle. The optimizer can then use the inferred condition to optimize the statement. The inferred condition potentially could make available an index access path that was not made available by the original conditions.
Imagine a WHERE clause containing two conditions of these forms:
WHERE column1 comp_oper constant AND column1 = column2
In this case, the optimizer infers the condition:
column2 comp_oper constant
where:
|
comp_oper |
Any of the comparison operators =, !=, ^=, <, <>, >, <=, or >=. |
|
constant |
Any constant expression involving operators, SQL functions, literals, bind variables, and correlation variables. |
For example:
In the following query, the WHERE clause contains two conditions, each of which uses the emp.deptno column:
SELECT * FROM emp, dept WHERE emp.deptno = 20 AND emp.deptno = dept.deptno;
Using transitivity, the optimizer infers this condition:
dept.deptno = 20
If an index exists on the dept.deptno column, then this condition makes available access paths using that index.
Common subexpression optimization is an optimization heuristic that identifies, removes, and collects common subexpression from disjunctive (OR) branches of a query. In most cases, it results in the reduction of the number of joins that would be performed.
Common subexpression optimization is enabled with the initialization parameter OPTIMIZER_FEATURES_ENABLE.
A query is considered valid for common subexpression optimization if its WHERE clause is in following form:
ORed logs.
ANDed logs.
AND or OR.)
The following query finds names of employees who work in a department located in L.A. and who make more than 40K or who are accountants.
SELECT emp.ename FROM emp E, dept D WHERE (D.deptno = E.deptno AND E.position = 'Accountant' AND D.location ='L.A.')OR E.deptno = D.deptno AND E.sal > 40000 AND D.location = 'L.A.');
The following query contains common subexpressions in its two disjunctive branches. The elimination of the common subexpressions transforms this query into the following query, thereby reducing the number of joins from two to one.
SELECT emp.ename FROM emp E, dept D WHERE (D.deptno = E.deptno AND D.location = 'L.A.')AND (E.position = 'Accountant' OR E.sal > 40000);
The following query contains common subexpression in its three disjunctive branches:
SELECT SUM (l_extendedprice* (1 - l_discount)) FROM PARTS, LINEITEM WHERE (p_partkey = l_partkeyAND p_brand = 'Brand#12' AND p_container IN ('SM CASE', 'SM BOX', 'SM PACK', 'SM PKG') AND l_quantity >= 1 AND l_quantity <= 1 + 10 AND p_size >= 1 AND p_size <= 5 AND l_shipmode IN ('AIR', 'REG AIR') AND l_shipinstruct = 'DELIVER IN PERSON')OR (l_partkey = p_partkey)AND p_brand = 'Brand#23' AND p_container IN ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK') AND l_quantity >= 10 AND l_quantity <= 10 + 10 AND p_size >= 1 AND p_size <= 10 AND p_size BETWEEN 1 AND 10 AND l_shipmode IN ('AIR', 'REG AIR') AND l_shipinstruct = 'DELIVER IN PERSON')OR (p_partkey = l_partkeyAND p_brand = 'Brand#34' AND p_container IN ('LG CASE', 'LG BOX', 'LG PACK', 'LG PKG') AND l_quantity >= 20 AND l_quantity <= 20 + 10 AND p_size >= 1 AND p_size <= 15 AND l_shipmode IN ('AIR', 'REG AIR') AND l_shipinstruct = 'DELIVER IN PERSON');
The previous query is transformed by common subexpression optimization to the following, thereby reducing the number joins from three down to one.
SELECT SUM (l_extendedprice* (1 - l_discount)) FROM PARTS, LINEITEM WHERE (p_partkey = l_partkey /* these are the four common subexpressions */AND p_size >= 1 AND l_shipmode IN ('AIR', 'REG AIR') AND l_shipinstruct = 'DELIVER IN PERSON') AND((p_brand = 'Brand#12' AND p_container IN ( 'SM CASE', 'SM BOX', 'SM PACK', 'SM PKG') AND l_quantity >= 1 AND l_quantity <= 1 + 10 AND p_size <= 5)OR (p_brand = 'Brand#23'AND p_container IN ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK') AND l_quantity >= 10 AND l_quantity <= 10 + 10 AND p_size <= 10)OR (p_brand = 'Brand#34'AND p_container IN ('LG CASE', 'LG BOX', 'LG PACK', 'LG PKG') AND l_quantity >= 20 AND l_quantity <= 20 + 10AND p_size <= 15));
In some cases, the optimizer can use a previously calculated value rather than executing a user-written function. This is only safe for functions that behave in a restricted manner. The function must return the same output return value for any given set of input argument values.
The function's result must not differ because of differences in the content of package variables or the database, or session parameters such as the globalization support parameters. Furthermore, if the function is redefined in the future, then its output return value must be the same as that calculated with the prior definition for any given set of input argument values. Finally, there must be no meaningful side effects to using a precalculated value instead of executing the function again.
The creator of a function can promise to the Oracle server that the function behaves according to these restrictions by using the keyword DETERMINISTIC when declaring the function with a CREATE FUNCTION statement or in a CREATE PACKAGE or CREATE TYPE statement. The server does not attempt to verify this declaration--even a function that obviously manipulates the database or package variables can be declared DETERMINISTIC. It is the programmer's responsibility to use this keyword only when appropriate.
Calls to a DETERMINISTIC function might be replaced by the use of an already calculated value when the function is called multiple times within the same query, or if there is a function-based index or a materialized view defined that includes a relevant call to the function.
|
See Also:
|
SQL is a very flexible query language; there are often many statements you could use to achieve the same goal. Sometimes, the optimizer (Query Transformer) transforms one such statement into another that achieves the same goal if the second statement can be executed more efficiently.
This section discusses the following topics:
"Understanding Joins" for additional information about optimizing statements that contain joins, semi-joins, or anti-joins
See Also:
If a query contains a WHERE clause with multiple conditions combined with OR operators, then the optimizer transforms it into an equivalent compound query that uses the UNION ALL set operator if this makes it execute more efficiently:
OR transformation for IN-lists or ORs on the same column; instead, it uses the INLIST iterator operator.
"Understanding Access Paths for the RBO" and "How the CBO Chooses an Access Path" for information on access paths and how indexes make them available
See Also:
For example:
In the following query, the WHERE clause contains two conditions combined with an OR operator:
SELECT * FROM emp WHERE job = 'CLERK' OR deptno = 10;
If there are indexes on both the job and deptno columns, then the optimizer might transform this query into the following equivalent query:
SELECT * FROM emp WHERE job = 'CLERK' UNION ALL SELECT * FROM emp WHERE deptno = 10 AND job <> 'CLERK';
When the CBO is deciding whether to make a transformation, the optimizer compares the cost of executing the original query using a full table scan with that of executing the resulting query.
The execution plan for the transformed statement might look like the illustration in Figure 2-1.
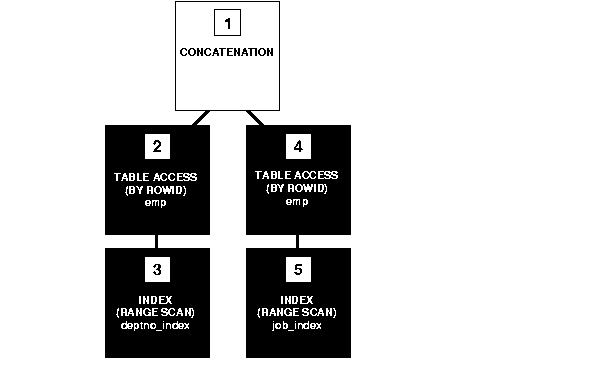
To execute the transformed query, Oracle performs the following steps:
job and deptno columns using the conditions of the component queries. These steps obtain rowids of the rows that satisfy the component queries.
If either of the job or deptno columns is not indexed, then the optimizer does not even consider the transformation, because the resulting compound query would require a full table scan to execute one of its component queries. Executing the compound query with a full table scan in addition to an index scan could not possibly be faster than executing the original query with a full table scan.
For example, the following query assumes that there is an index on the ename column only:
SELECT * FROM emp WHERE ename = 'SMITH' OR sal > comm;
Transforming the previous query would result in the following compound query:
SELECT * FROM emp WHERE ename = 'SMITH' UNION ALL SELECT * FROM emp WHERE sal > comm;
Because the condition in the WHERE clause of the second component query (sal > comm) does not make an index available, the compound query requires a full table scan. For this reason, the optimizer does not make the transformation, and it chooses a full table scan to execute the original statement.
To optimize a complex statement, the optimizer chooses one of the following:
The optimizer transforms a complex statement into a join statement whenever the resulting join statement is guaranteed to return exactly the same rows as the complex statement. This transformation allows Oracle to execute the statement by taking advantage of join optimizer techniques described in "Understanding Joins".
The following complex statement selects all rows from the accounts table whose owners appear in the customers table:
SELECT * FROM accounts WHERE custno IN (SELECT custno FROM customers);
If the custno column of the customers table is a primary key or has a UNIQUE constraint, then the optimizer can transform the complex query into the following join statement that is guaranteed to return the same data:
SELECT accounts.* FROM accounts, customers WHERE accounts.custno = customers.custno;
The execution plan for this statement might look like Figure 2-2.
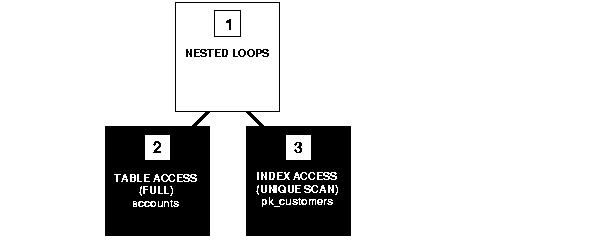
To execute this statement, Oracle performs a nested-loops join operation.
If the optimizer cannot transform a complex statement into a join statement, then the optimizer chooses execution plans for the parent statement and the subquery as though they were separate statements. Oracle then executes the subquery and uses the rows it returns to execute the parent query.
The following complex statement returns all rows from the accounts table that have balances greater than the average account balance:
SELECT * FROM accounts WHERE accounts.balance > (SELECT AVG(balance) FROM accounts);
No join statement can perform the function of this statement, so the optimizer does not transform the statement.
To merge the view's query into a referencing query block in the accessing statement, the optimizer replaces the name of the view with the names of its base tables in the query block and adds the condition of the view's query's WHERE clause to the accessing query block's WHERE clause.
This optimization applies to select-project-join views, which are views that contain only selections, projections, and joins--that is, views that do not contain set operators, aggregate functions, DISTINCT, GROUP BY, CONNECT BY, and so on (as described in "Mergeable and Nonmergeable Views").
For example:
The following view is of all employees who work in department 10:
CREATE VIEW emp_10 AS SELECT empno, ename, job, mgr, hiredate, sal, comm, deptno FROM emp WHERE deptno = 10;
The following query accesses the view. The query selects the IDs greater than 7800 of employees who work in department 10:
SELECT empno FROM emp_10 WHERE empno > 7800;
The optimizer transforms the query into the following query that accesses the view's base table:
SELECT empno FROM emp WHERE deptno = 10 AND empno > 7800;
If there are indexes on the deptno or empno columns, then the resulting WHERE clause makes them available.
The optimizer can merge a view into a referencing query block when the view has one or more base tables, provided the view does not contain the following:
UNION, UNION ALL, INTERSECT, MINUS)
CONNECT BY clause
ROWNUM pseudocolumn
AVG, COUNT, MAX, MIN, SUM) in the select list
When a view contains one of the following structures, it can be merged into a referencing query block only if complex view merging (described below) is enabled:
View merging is not possible for a view that has multiple base tables if it is on the right side of an outer join. However, if a view on the right side of an outer join has only one base table, then the optimizer can use complex view merging, even if an expression in the view can return a nonnull value for a NULL.
If a view's query contains a GROUP BY clause or DISTINCT operator in the select list, then the optimizer can merge the view's query into the accessing statement only if complex view merging is enabled. Complex merging can also be used to merge an IN subquery into the accessing statement if the subquery is uncorrelated (see "IN Subquery Example").
Complex merging is not cost-based--it must be enabled with the initialization parameter OPTIMIZER_FEATURES_ENABLE or the MERGE hint. Without this hint or parameter setting, the optimizer uses another approach (see "How the CBO Pushes Predicates").
The view avg_salary_view contains the average salaries for each department:
CREATE VIEW avg_salary_view AS SELECT deptno, AVG(sal) AS avg_sal_dept, FROM emp GROUP BY deptno;
If complex view merging is enabled, then the optimizer can transform the following query, which finds the average salaries of departments in London:
SELECT dept.loc, avg_sal_dept FROM dept, avg_salary_view WHERE dept.deptno = avg_salary_view.deptno AND dept.loc = 'London';
into the following query:
SELECT dept.loc, AVG(sal) FROM dept, emp WHERE dept.deptno = emp.deptno AND dept.loc = 'London' GROUP BY dept.rowid, dept.loc;
The transformed query accesses the view's base table, selecting only the rows of employees who work in London and grouping them by department.
Complex merging can be used for an IN clause with a noncorrelated subquery, as well as for views. The view min_salary_view contains the minimum salaries for each department:
SELECT deptno, MIN(sal) FROM emp GROUP BY deptno;
If complex merging is enabled, then the optimizer can transform the following query, which finds all employees who earn the minimum salary for their department in London:
SELECT emp.ename, emp.sal FROM emp, dept WHERE (emp.deptno, emp.sal) IN min_salary_view AND emp.deptno = dept.deptno AND dept.loc = 'London';
into the following query (where e1 and e2 represent the emp table as it is referenced in the accessing query block and the view's query block, respectively):
SELECT e1.ename, e1.sal FROM emp e1, dept, emp e2 WHERE e1.deptno = dept.deptno AND dept.loc = 'London' AND e1.deptno = e2.deptno GROUP BY e1.rowid, dept.rowid, e1.ename, e1.sal HAVING e1.sal = MIN(e2.sal);
The optimizer can transform a query block that accesses a nonmergeable view by pushing the query block's predicates inside the view's query.
For example:
The two_emp_tables view is the union of two employee tables. The view is defined with a compound query that uses the UNION set operator:
CREATE VIEW two_emp_tables (empno, ename, job, mgr, hiredate, sal, comm, deptno) AS SELECT empno, ename, job, mgr, hiredate, sal, comm, deptno FROM emp1 UNION SELECT empno, ename, job, mgr, hiredate, sal, comm, deptno FROM emp2;
The following query accesses the view. The query selects the IDs and names of all employees in either table who work in department 20:
SELECT empno, ename FROM two_emp_tables WHERE deptno = 20;
Because the view is defined as a compound query, the optimizer cannot merge the view's query into the accessing query block. Instead, the optimizer can transform the accessing statement by pushing its predicate, the WHERE clause condition (deptno = 20), into the view's compound query.
The resulting statement looks like the following:
SELECT empno, ename FROM ( SELECT empno, ename, job, mgr, hiredate, sal, comm, deptno FROM emp1 WHERE deptno = 20 UNION SELECT empno, ename, job, mgr, hiredate, sal, comm, deptno FROM emp2 WHERE deptno = 20 );
If there is an index on the deptno column, then the resulting WHERE clauses make it available.
Figure 2-3 shows the execution plan of the resulting statement.
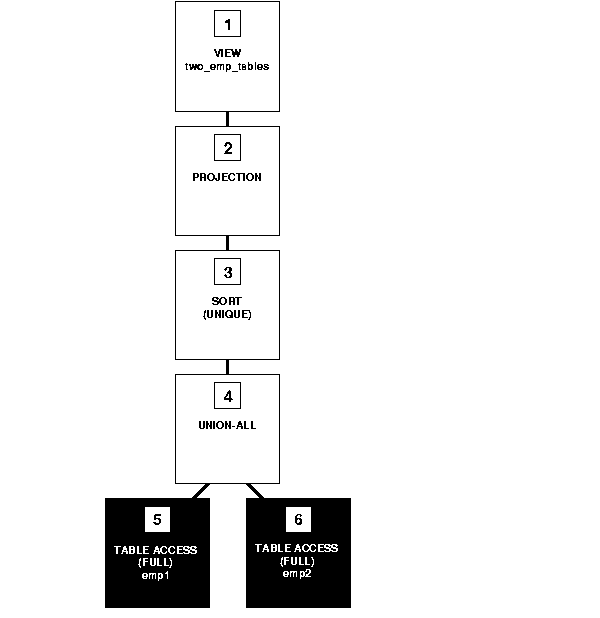
To execute this statement, Oracle performs the following steps:
emp1 and emp2 tables.
UNION-ALL operation returning all rows returned by either step 5 or step 6, including all copies of duplicates.
In the following example, the view emp_group_by_deptno contains the department number, average salary, minimum salary, and maximum salary of all departments that have employees:
CREATE VIEW emp_group_by_deptno AS SELECT deptno, AVG(sal) avg_sal, MIN(sal) min_sal, MAX(sal) max_sal FROM emp GROUP BY deptno;
The following query selects the average, minimum, and maximum salaries of department 10 from the emp_group_by_deptno view:
SELECT * FROM emp_group_by_deptno WHERE deptno = 10;
The optimizer transforms the statement by pushing its predicate (the WHERE clause condition) into the view's query. The resulting statement looks like the following:
SELECT deptno, AVG(sal) avg_sal, MIN(sal) min_sal, MAX(sal) max_sal, FROM emp WHERE deptno = 10 GROUP BY deptno;
If there is an index on the deptno column, then the resulting WHERE clause makes it available. Figure 2-4 shows the execution plan for the resulting statement. The execution plan uses an index on the deptno column.
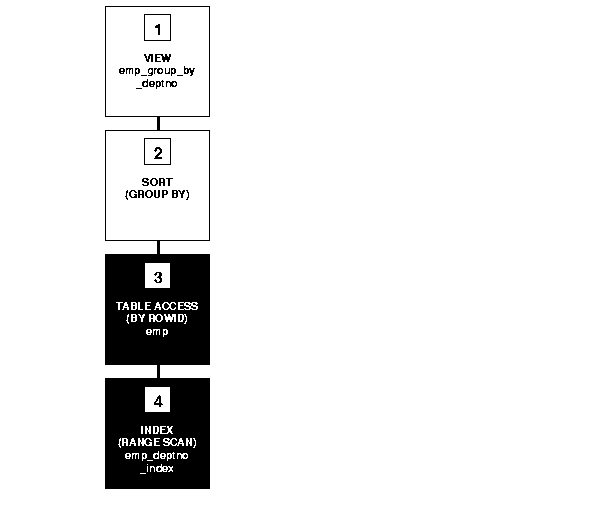
To execute this statement, Oracle performs the following operations:
emp_deptno_index (an index on the deptno column of the emp table) to retrieve the rowids of all rows in the emp table with a deptno value of 10.
emp table using the rowids retrieved by step 4.
sal values.
The optimizer can transform a query that contains an aggregate function (AVG, COUNT, MAX, MIN, SUM) by applying the function to the view's query.
For example:
The following query accesses the emp_group_by_deptno view defined in the previous example. This query derives the averages for the average department salary, the minimum department salary, and the maximum department salary from the employee table:
SELECT AVG(avg_sal), AVG(min_sal), AVG(max_sal) FROM emp_group_by_deptno;
The optimizer transforms this statement by applying the AVG aggregate function to the select list of the view's query:
SELECT AVG(AVG(sal)), AVG(MIN(sal)), AVG(MAX(sal)) FROM emp GROUP BY deptno;
Figure 2-5 shows the execution plan of the resulting statement.
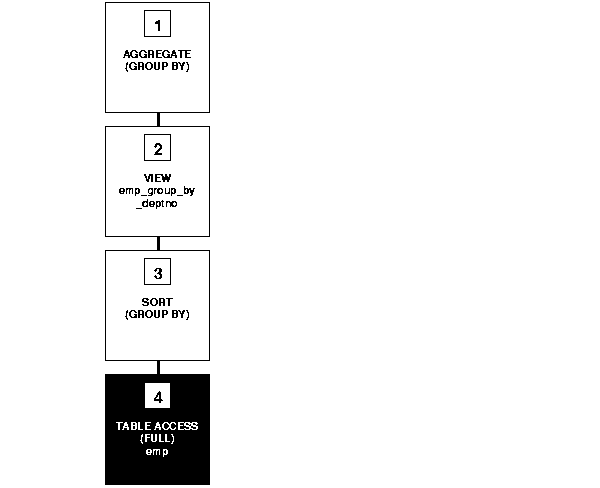
To execute this statement, Oracle performs the following operations:
emp table.
deptno values and calculates the average, minimum, and maximum sal value of each group.
For a view that is on the right side of an outer join, the optimizer can use one of two methods, depending on how many base tables the view accesses:
The optimizer cannot transform all statements that access views into equivalent statements that access base table(s). For example, if a query accesses a ROWNUM pseudocolumn in a view, then the view cannot be merged into the query, and the query's predicate cannot be pushed into the view.
To execute a statement that cannot be transformed into one that accesses base tables, Oracle issues the view's query, collects the resulting set of rows, and then accesses this set of rows with the original statement as though it were a table.
For example:
Consider the emp_group_by_deptno view defined in the previous section:
CREATE VIEW emp_group_by_deptno AS SELECT deptno, AVG(sal) avg_sal, MIN(sal) min_sal, MAX(sal) max_sal FROM emp GROUP BY deptno;
The following query accesses the view. The query joins the average, minimum, and maximum salaries from each department represented in this view to the name and location of the department in the dept table:
SELECT emp_group_by_deptno.deptno, avg_sal, min_sal, max_sal, dname, loc FROM emp_group_by_deptno, dept WHERE emp_group_by_deptno.deptno = dept.deptno;
Because there is no equivalent statement that accesses only base tables, the optimizer cannot transform this statement. Instead, the optimizer chooses an execution plan that issues the view's query and then uses the resulting set of rows as it would the rows resulting from a table access.
|
See Also:
"Understanding Joins" for more information on how Oracle performs a nested loops join operation |
Figure 2-6 shows the execution plan for this statement.
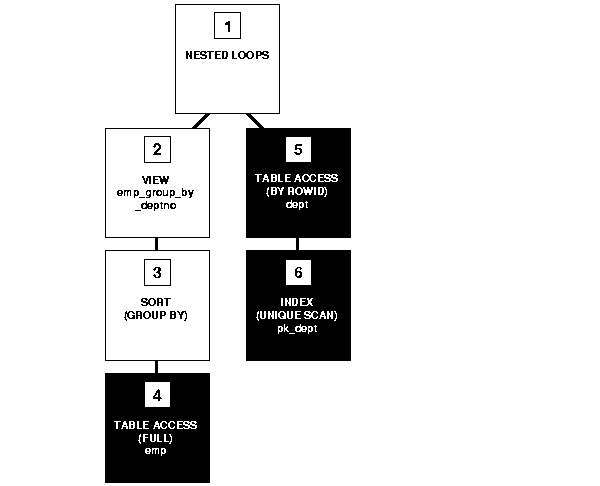
To execute this statement, Oracle performs the following operations:
emp table.
sal values selected by the query for the emp_group_by_deptno view.
deptno value to perform a unique scan of the pk_dept index.
deptno table with the matching deptno value.
To choose the execution plan for a compound query, the optimizer chooses an execution plan for each of its component queries, and then combines the resulting row sources with the union, intersection, or minus operation, depending on the set operator used in the compound query.
Figure 2-7 shows the execution plan for the following statement, which uses the UNION ALL operator to select all occurrences of all parts in either the orders1 table or the orders2 table:
SELECT part FROM orders1 UNION ALL SELECT part FROM orders2;
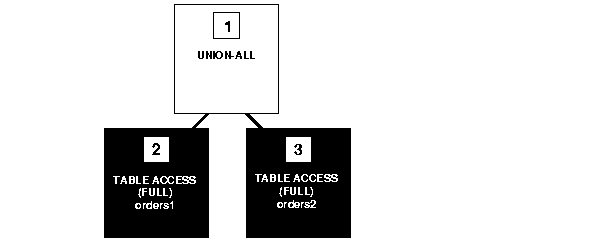
To execute this statement, Oracle performs the following steps:
orders1 and orders2 tables.
UNION-ALL operation returning all rows that are returned by either step 2 or step 3 including all copies of duplicates.
Figure 2-8 shows the execution plan for the following statement, which uses the UNION operator to select all parts that appear in either the orders1 or orders2 table:
SELECT part FROM orders1 UNION SELECT part FROM orders2;
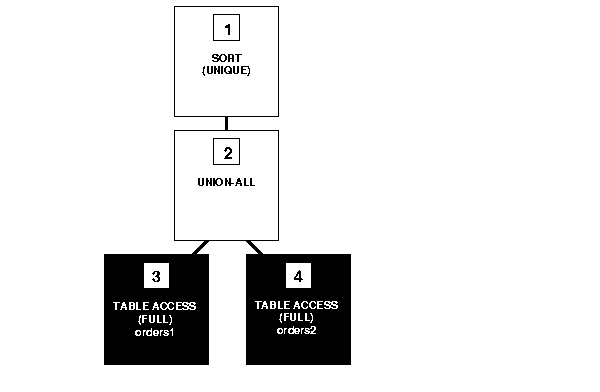
This execution plan is identical to the one for the UNION-ALL operator shown in Figure 2-7, except that in this case, Oracle uses the SORT operation to eliminate the duplicates returned by the UNION-ALL operation.
Figure 2-9 shows the execution plan for the following statement, which uses the INTERSECT operator to select only those parts that appear in both the orders1 and orders2 tables:
SELECT part FROM orders1 INTERSECT SELECT part FROM orders2;
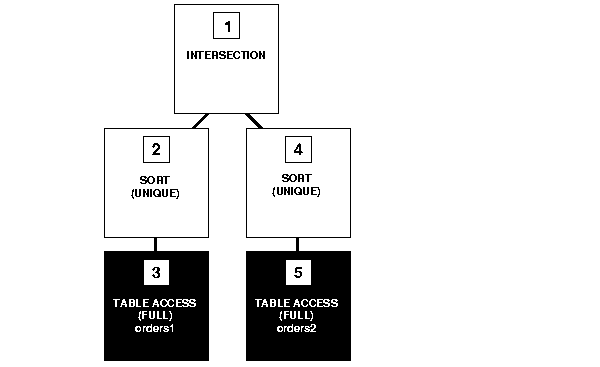
To execute this statement, Oracle performs the following steps:
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|