Release 1 (9.0.1)
Part Number A88808-01
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Data Guard Concepts and Administration Release 1 (9.0.1) Part Number A88808-01 |
|
![]()
![]()
This chapter explains how to set up and use log transport services to control the automated archival of redo logs from the primary database to one or more standby sites. It includes the following topics:
The log transport services component of the Data Guard environment is responsible for the automatic archival of primary database online redo logs. Once archived, these logs are known as archived redo logs. Log transport services provide for the management of archived redo log permissions, destinations, transmission, reception, and transmission failure resolution. In a Data Guard environment, the log transport services component coordinates its activities with the log apply services component.
Log transport services and log apply services automate the process of copying online redo logs to a remote node and applying them so that data from a primary database can be made available on a standby database. Log transport services provide the capability to archive the primary databases's redo log files to a maximum of ten archiving locations called destinations.
Log transport services provide flexibility in defining destinations and archiving completion requirements. These services also provide I/O failure handling and transmission restart capability.
Figure 3-1 shows a simple Data Guard configuration with redo logs being archived from a primary database to a local destination and a remote standby database destination using log transport services.
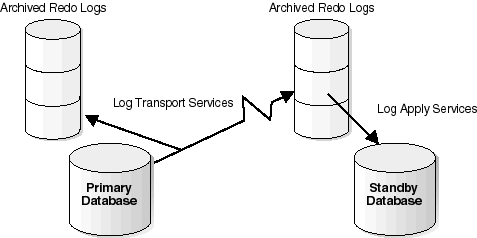
The archiver or log writer process (LGWR) can be configured to archive online redo logs to a maximum of ten destinations. These destinations are specified using database initialization parameters. One destination must be a local directory, but others can be in remote locations. A remote destination is identified by using an Oracle Net network service name, which is defined in the appropriate network services configuration files. It is the job of the archiver or log writer process to archive redo logs to the remote sites.
Archiving redo logs to a remote destination requires uninterrupted connectivity through Oracle Net. If the destination is a standby database, it must be mounted or open in read-only mode. If a network connection to a standby database is broken, it must be reestablished to continue log archiving.
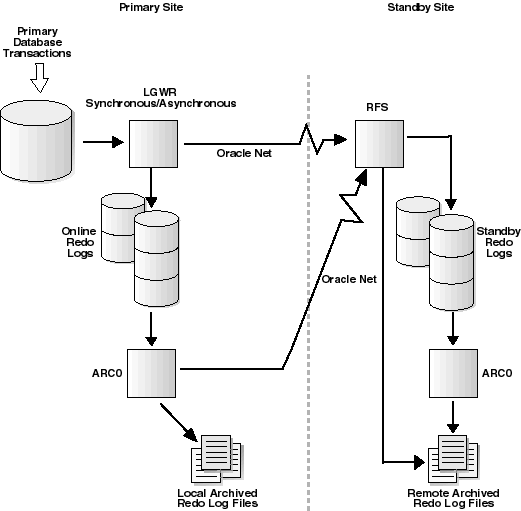
Log transport services use the following processes on the primary site:
The log writer process (LGWR) collects transaction redo and updates the online redo logs. The log writer process can also create local archived redo logs and transmit online redo to standby databases.
The archiver process (ARCn), or a SQL session performing an archival operation, creates a copy of the online redo logs, either locally or remotely, for standby databases.
This background Oracle database server process pulls archived redo log files from the primary site. The FAL client initiates and requests the automatic archiving of redo logs when it detects an archive gap on the standby database.
This background Oracle database server process runs on the primary database and services the fetch archive log (FAL) requests coming from the FAL client. For example, servicing a FAL request might include queuing requests (to send archived redo log files to one or more standby databases) to an Oracle database server that runs the FAL server. Multiple FAL servers can run on the same primary database at one time. A separate FAL server is created for each incoming FAL request.
Log transport services capabilities allow you to determine how the archival of online redo logs will be handled in a Data Guard configuration. These capabilities can be classified into five categories:
You control whether the primary database can archive redo logs to a standby site, and whether the standby database can receive them from a primary site. Permission is set using the REMOTE_ARCHIVE_ENABLE database initialization parameter.
Using log transport services, redo logs can be archived to any of the following destinations:
A local file system location.
A remote location accessed using an Oracle Net service name. There are several types of remote destinations, as shown in the following table:
|
See Also:
|
You can choose the method by which redo logs are archived from the primary database to each archive destination by specifying:
You can specify that the log writer process or that the archiver process performs the archival operation.
When using the log writer process for archival operations, you can specify synchronous or asynchronous network transmission of redo logs to remote destinations.
When using the archiver process for archival operations, only synchronous transmission of redo logs to remote destinations is available.
Using transmission options, you can configure log transport services availability modes. Availability modes give you the flexibility to specify various levels of protection for your data in the Data Guard environment.
You can specify whether log archiving disk write I/O operations are to be performed synchronously or asynchronously.
Reception gives you control over determining where redo logs will be placed at remote destinations. The redo data can be stored on the standby site using either standby redo logs or archived redo logs.
Oracle9i introduces the concept of standby redo logs. Standby redo logs form a separate pool of log file groups. Standby redo log file groups are only used when a database is operating in a physical standby role.
Failure resolution gives you control over determining what actions will occur on a primary database if log archiving from the primary database to the standby database fails. These actions include:
Log transport services options are entered and changed using the following interfaces:
You configure the primary database to perform remote archiving by setting destinations and associated states. You do this using LOG_ARCHIVE_DEST_n initialization parameters and corresponding LOG_ARCHIVE_DEST_STATE_n initialization parameters.
LOG_ARCHIVE_DEST_n (where n is an integer from 1 to 10) initialization parameters allow you to specify up to ten archival destinations, including one required local destination and up to nine additional local or remote destinations. These parameters also allow you to set a number of archival options for each destination. These options are set using the attributes described in Table 3-1 and in Chapter 8.
| Attribute | Description | Capability | More Information |
|---|---|---|---|
|
|
Log transport services will ensure that redo logs are successfully archived to a destination and are immediately available for recovery operations |
Transmission |
See Section 3.6.3.3 and see AFFIRM and NOAFFIRM in Chapter 8 |
|
|
Specifies an alternate location that can be used as a destination for archival operations if archival to the associated destination fails |
Failure resolution |
See Section 3.4.2.5 and see ALTERNATE and NOALTERNATE in Chapter 8 |
|
|
The archiver process will archive online redo logs to local and remote destinations |
Transmission |
See Section 3.6.3.1 and see ARCH and LGWR in Chapter 8 |
|
|
Network I/O operations for log transport services are to be done asynchronously. Specifies the size of the SGA network buffer to be used. |
Transmission |
See Section 3.6.3.2 and see SYNC and ASYNC in Chapter 8 |
|
|
Specifies a time interval between archiving a redo log at a remote site and applying that archived redo log to the standby database |
Reception |
See Section 3.4.2.8 and see DELAY and NODELAY in Chapter 8 |
|
|
Archival operations to a destination are dependent upon the success or failure of archival operations to another local destination |
Transmission |
See Section 3.4.2.6 and see DEPENDENCY and NODEPENDENCY in Chapter 8 |
|
|
The log writer process will archive current online redo logs to local and remote destinations |
Transmission |
See Section 3.6.3.1 and see ARCH and LGWR in Chapter 8 |
|
|
Identifies a local disk directory location where archived redo logs will be stored |
Destination |
See Section 3.4.2.3 and see LOCATION and SERVICE in Chapter 8 |
|
|
Archiving to this location must succeed for log transport services operations to continue |
Failure resolution |
See Section 3.4.2.3 and see MANDATORY and OPTIONAL in Chapter 8 |
|
|
Sets a limit on the number of times log transport services will retry archival operations to a remote location after a communications failure |
Failure resolution |
See Section 3.4.2.5 and see MAX_FAILURE and NOMAX_FAILURE in Chapter 8 |
|
|
Successful archiving to this location is not necessary |
Failure resolution |
See Section 3.4.2.3 and see MANDATORY and OPTIONAL in Chapter 8 |
|
|
The maximum number of 512-byte blocks that can be archived on the specified destination |
Transmission |
See Section 3.4.2.9 and see QUOTA_SIZE and NOQUOTA_SIZE in Chapter 8 |
|
|
Identifies the size of all of the archived redo logs currently residing on the specified destination |
Transmission |
|
|
|
Specifies whether or not the archival location is to be recorded in the standby database control file |
Reception |
See REGISTER and NOREGISTER in Chapter 8 |
|
|
The remote archival location is to be recorded in the standby database control file |
Reception |
See Section 3.4.2.7 and see REGISTER=location_format in Chapter 8 |
|
|
Specifies the number of seconds that log transport services will wait before retrying an archival operation to a remote location after a communications failure |
Failure resolution |
See Section 3.4.2.5 and see REOPEN and NOREOPEN in Chapter 8 |
|
|
Specifies the net service name of a standby database where redo log files are to be archived |
Destination |
See Section 3.4.2.2 and see LOCATION and SERVICE in Chapter 8 |
|
|
Network I/O operations for log transport services are to be done synchronously |
Transmission |
See Section 3.6.3.2 and see SYNC and ASYNC in Chapter 8 |
The LOG_ARCHIVE_DEST_STATE_n (where n is an integer from 1 to 10) initialization parameters specify the state of the corresponding destination indicated by the LOG_ARCHIVE_DEST_n parameters (where n is the same integer). For example, the LOG_ARCHIVE_DEST_STATE_3 parameter specifies the state of the LOG_ARCHIVE_DEST_3 destination.
LOG_ARCHIVE_DEST_STATE_n parameters attributes are described in Table 3-2.
Setting up log transport services requires modification of the database initialization file. When you set up log transport services parameters, you can specify attributes as:
Example 3-1 shows how to specify a single attribute on one line.
LOG_ARCHIVE_DEST_1='LOCATION=/disk1/d1arch'
Example 3-2 shows how to set multiple attributes on a single line.
LOG_ARCHIVE_DEST_1='LOCATION=/disk1/d1arch OPTIONAL'
Example 3-3 shows how to set multiple attributes incrementally on separate lines. SERVICE or LOCATION attributes must be specified on the first line.
LOG_ARCHIVE_DEST_1='LOCATION=/disk1/d1arch' LOG_ARCHIVE_DEST_1='OPTIONAL' LOG_ARCHIVE_DEST_1='REOPEN=5'
Example 3-4 shows how to specify attributes for multiple destinations.
LOG_ARCHIVE_DEST_1='LOCATION=/disk1/d1arch OPTIONAL' LOG_ARCHIVE_DEST_2='SERVICE=stby REOPEN=60'
Attributes specified on multiple lines for a single destination must be entered sequentially. Example 3-5 shows an entry for the LOG_ARCHIVE_DEST_1 that is not allowed.
LOG_ARCHIVE_DEST_1='LOCATION=/disk1/d1arch' LOG_ARCHIVE_DEST_2='SERVICE=stby REOPEN=60' LOG_ARCHIVE_DEST_1='OPTIONAL'
A destination specification can be redefined after another destination has been specified if the new specification includes LOCATION or SERVICE attributes. Example 3-6 shows how to replace the initial specification of LOG_ARCHIVE_DEST_1.
LOG_ARCHIVE_DEST_1='LOCATION=/disk1/d1arch' LOG_ARCHIVE_DEST_2='SERVICE=stby REOPEN=60' LOG_ARCHIVE_DEST_1='LOCATION=/disk3/d3arch MANDATORY'
A string containing a null value for parameter attributes will clear a previously entered destination specification. Example 3-7 shows how to clear the definition of LOG_ARCHIVE_DEST_1.
LOG_ARCHIVE_DEST_1='LOCATION=/disk1/d1arch' LOG_ARCHIVE_DEST_2='SERVICE=stby REOPEN=60' LOG_ARCHIVE_DEST_1=''
To specify service names that use embedded characters, such as equal signs (=) and spaces, use double quotation marks (") around the service name. Example 3-8 shows the specification of a service name that includes a space.
LOG_ARCHIVE_DEST_6='SERVICE="stdby arch" MANDATORY'
SQL statements can be used to set up most initialization parameters for log transport services and to monitor the environment. You can use SQL statements for the following tasks:
You can use SQL to query fixed views such as V$ARCHIVE_DEST to see current LOG_ARCHIVE_DEST_n initialization parameters settings. For example, to view current destination settings on the primary database, enter the following statement:
SQL> SELECT DESTINATION FROM V$ARCHIVE_DEST;
At runtime, LOG_ARCHIVE_DEST_n initialization parameters can be changed using ALTER SYSTEM and ALTER SESSION statements. You can specify the attributes in one or more strings in one statement or incrementally in separate statements.
Example 3-9 shows how to modify archive destination parameters at the system and session level.
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_6='SERVICE=stby REOPEN=8'; SQL> ALTER SESSION SET LOG_ARCHIVE_DEST_6='SERVICE=stby2 REOPEN=10';
Unlike setting parameters in the database initialization file at startup, at runtime you can incrementally change the characteristics of a destination after modifying the settings of another destination. Example 3-10 shows how to make incremental changes to LOG_ARCHIVE_DEST_6 after LOG_ARCHIVE_DEST_7 has been defined.
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_6='SERVICE=stby1 REOPEN=8'; SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_7='SERVICE=stby2 NOREOPEN'; SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_6='MANDATORY LGWR DELAY';
You can enter a null value for a destination to clear a previous definition. Example 3-11 shows how to clear the definition of LOG_ARCHIVE_DEST_6.
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_6='SERVICE=stby1 REOPEN=8'; SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_7='SERVICE=stby2 NOREOPEN'; SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_6='';
To specify service names that use embedded equal signs (=) and spaces, use double quotation marks (") around the service name. Example 3-12 shows the specification of a service name that includes a space.
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_6='SERVICE="stdby arch" MANDATORY';
Table 3-3 lists the attributes that can be set for LOG_ARCHIVE_DEST_n initialization parameters and indicates whether the attribute can be changed using an ALTER SYSTEM or ALTER SESSION statement.
You can set specific options for log transport services using SQL statements. The following example sets PROTECTED mode.
SQL> ALTER DATABASE SET STANDBY DATABASE PROTECTED;
This section discusses what settings can be made on the primary database to use the various options of log transport services in a Data Guard environment. The following topics are included in this section:
Considerations when configuring log transport services on the primary database include:
To use log transport services, you must set the primary database to run in ARCHIVELOG mode. When you run a database in ARCHIVELOG mode, you enable the archiving of the online redo logs. The database control file indicates that a group of filled online redo logs cannot be reused by the log writer process until the group is archived. A filled group is immediately available for archiving after a redo log switch occurs.
Log transport services do not require filled online redo logs to be archived to disk if you run in NOARCHIVELOG mode. You can set this mode at database creation or by using the SQL ALTER DATABASE statement.
Both the size of the online redo logs and the frequency with which they switch affect the generation of archived redo logs at the primary site. In general, the most important factor when considering the size of an online redo log should be the amount of application data that needs to be applied to a standby database during a database failover operation. The larger the online redo log, the more data that needs to be applied to a standby database to make it consistent with the primary database.
Another important consideration should be the size of the archival media. Online redo logs should be sized so that a filled online redo log group can be archived to a single unit of offline storage media (such as a tape or disk), with the least amount of space on the medium left unused. For example, suppose only one filled online redo log group can fit on a tape, and 49% of the tape's storage capacity remains unused. In this case, it is better to decrease the size of the online redo log files slightly, so that two log groups can be archived per tape.
The best way to determine the appropriate number of online redo log files for a database instance is to test different configurations. The goal is to create the fewest groups possible without hampering the log writer process's ability to write redo log information.
In some cases, a database instance may require only two groups. In other situations, a database instance may require additional groups to guarantee that a recycled group is always available to the log writer process. During testing, the easiest way to determine if the current configuration is satisfactory is to examine the contents of the log writer process's trace file and the database's alert log. If messages indicate that the log writer process frequently must wait for a group because a checkpoint has not completed or a group has not been archived, add more groups.
Table 3-4 provides some guidelines to help in determining the number and sizes of primary database online redo logs.
Set the CONTROL_FILE_RECORD_KEEP_TIME initialization parameter to prevent reusing archived redo logs for a specified period of days. Setting this parameter prevents the ARCHIVELOG mechanism from overwriting information in the archived redo logs. Using this parameter helps to ensure that data is made available on the standby database. The range of values for this parameter is 0 to 365 days. The default value is 7 days. If you set the parameter to 0, the redo logs are reused and overwritten immediately.
|
See Also:
Oracle9i Database Reference for more details about the |
The Oracle database server will attempt a checkpoint at each log switch. Therefore, if the online redo log size is too small, frequent log switches will lead to frequent checkpointing and negatively affect system performance. Oracle Corporation recommends a checkpoint and log switch interval between 5 and 15 minutes during normal operations and at 5-minute intervals during peak load periods, such as during batch processing. To get started, examine the V$SYSSTAT view during a peak load period and then calculate 5 to 10 minutes of redo.
If you have remote hardware mirroring, you may want a minimum number of log groups, to ensure that no-data-loss failover can occur in case some logs are not archived. Furthermore, if some logs are not archived, they are not available to the standby database. This is another reason to avoid overly large online redo logs.
If you do not have remote hardware mirroring, the loss of a primary site will mean the loss of at least two logs of data. The sizing of the log files should factor in how much data loss your site can tolerate.
You should avoid situations where you cannot overwrite a redo log because you must wait for a checkpoint or archival of that log. In these cases, there is usually a combination of problems with redo log configuration and database tuning. Oracle Corporation recommends that you solve the tuning problem first but, if that fails to correct the problem, add more log groups or increase log sizes.
Oracle Corporation generally recommends:
Oracle9i Database Administrator's Guide for more details about configuring online redo logs and online redo log groups
See Also:
The log transport services component of the Data Guard environment is configured primarily through the setting of database initialization parameters and options. You set parameters by editing the database initialization parameter file or using SQL statements.
|
See Also:
Oracle9i Database Reference for details about creating and editing database initialization parameter files |
Permission for the archiving of online redo logs to remote destinations is specified using the REMOTE_ARCHIVE_ENABLE initialization file parameter. This parameter should be set to true on both the primary and standby databases in a Data Guard environment. Table 3-5 identifies the options of the REMOTE_ARCHIVE_ENABLE initialization parameter.
In addition to setting up the primary database to run in ARCHIVELOG mode, you must configure the primary database to archive online redo logs by setting destinations and associated states. You do this using the LOG_ARCHIVE_DEST_n initialization parameters and corresponding LOG_ARCHIVE_DEST_STATE_n parameters as discussed in Section 3.3.1.
This section describes the creation of a standby database named standby1 on a remote node named stbyhost based on the following assumptions:
prmyinit.ora is the initialization parameter file for the primary database.
stbyhost).
stbyhost.
stbyhost to use the TCP/IP protocol, and to statically register the standby1 database service using its SID, so that the standby1 standby database can be managed by the Data Guard broker.
standby1 that can be resolved to a connect descriptor that contains the same protocol, host address, port, and SID that were used to statically register the standby1 standby database with the listener on stbyhost.
stbyhost.
Oracle9i Net Services Administrator's Guide for details about using Oracle Net networking components
See Also:
To set up log transport services to archive redo logs to the standby database, make the following modifications to the primary database initialization parameter file. These modifications will take effect after the instance is restarted:
prmyinit.ora file:
LOG_ARCHIVE_DEST_2 = 'SERVICE=standby1 MANDATORY REOPEN=60'
prmyinit.ora file:
LOG_ARCHIVE_DEST_STATE_2 = ENABLE
To avoid having to restart the instance, you can issue the following statements to ensure that the initialization parameters you have set in this step take effect immediately:
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_2='SERVICE=standby1 MANDATORY REOPEN=60'; SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_2=ENABLE;
You can specify a policy for the reuse of online redo logs using the OPTIONAL or MANDATORY attributes of the LOG_ARCHIVE_DEST_n initialization parameters. The archival of log files to an OPTIONAL destination can fail, and the online redo log will be overwritten. If the archival of redo log files to a MANDATORY destination fails, online redo log files will not be overwritten.
By default, one destination is mandatory even if all destinations are designated to be optional.
Example 3-13 shows how to set a mandatory local archiving destination and enable that destination.
LOG_ARCHIVE_DEST_3 = 'LOCATION=/arc_dest MANDATORY' LOG_ARCHIVE_DEST_STATE_3 = ENABLE
The LOG_ARCHIVE_MIN_SUCCEED_DEST=n parameter (where n is an integer from 1 to 10) specifies the number of destinations that must receive redo logs successfully before the log writer process can reuse the online redo logs. All MANDATORY destinations and non-standby OPTIONAL destinations contribute to satisfying the LOG_ARCHIVE_MIN_SUCCEED_DEST=n count. Example 3-14 shows how to specify that redo logs must be successfully archived to two destinations before the online redo logs can be reused.
LOG_ARCHIVE_MIN_SUCCEED_DEST=2
You use attributes of the LOG_ARCHIVE_DEST_n initialization parameters to specify what actions are to be taken when archiving to a destination fails. You can use LOG_ARCHIVE_DEST_n attributes to:
Use the REOPEN attribute of the LOG_ARCHIVE_DEST_n parameters to determine whether and when the archiver process or the log writer process attempts to archive redo logs again to a failed destination following an error.
The REOPEN=seconds attribute specifies the minimum number of seconds that must elapse following an error before the archiving process will try again to access a failed destination. The default value is 300 seconds. The value set for the REOPEN attribute applies to all errors, not just connection failures. You can turn off the option by specifying NOREOPEN.
You can use the REOPEN attribute in conjunction with the MAX_FAILURE attribute to limit the number of attempts that will be made to reestablish communication with a failed destination. Once the specified number of attempts has been exceeded, the destination is treated as if the NOREOPEN attribute had been specified.
If you specify REOPEN for an OPTIONAL destination, it is still possible for the Oracle database server to overwrite online redo logs even if there is an error. If you specify REOPEN for a MANDATORY destination, log transport services stalls the primary database when it cannot successfully archive redo logs. When this situation occurs, consider the following options:
When you use the REOPEN attribute, note that:
REOPEN attribute, the archiving process checks whether the time of the recorded error plus the REOPEN interval is less than the current time. If it is, the archival operation to that destination is retried.
You can control the number of times a destination will be retried after a log archiving failure by specifying a value for the MAX_FAILURE=count attribute of the LOG_ARCHIVE_DEST_n initialization parameters.
The MAX_FAILURE attribute specifies the maximum number of contiguous archival failures that will be allowed for the particular destination. This attribute is useful for archive destinations that you want to retry after a failure, but do not want to retry indefinitely. The REOPEN attribute is required when you use the MAX_FAILURE attribute. Example 3-15 shows how to set a retry time of 5 seconds and limit retries to 3 times.
LOG_ARCHIVE_DEST_1='LOCATION=/arc_dest REOPEN=5 MAX_FAILURE=3'
Using the ALTERNATE attribute of the LOG_ARCHIVE_DEST_n parameters, you can specify alternate archive destinations. An alternate archive destination can be used when the archiving of an online redo log to a standby site fails. If archiving fails and the NOREOPEN attribute has not been specified, or the MAX_FAILURE attribute threshold has been exceeded, log transport services will attempt to archive redo logs to the alternate destination on the next archival operation.
Use the NOALTERNATE attribute to prevent the original archive destination from automatically changing to an alternate archive destination when the original archive destination fails.
Example 3-16 shows how to set the initialization parameter file so that a single, mandatory, local destination will automatically fail over to a different destination if any error occurs.
LOG_ARCHIVE_DEST_1='LOCATION=/disk1 MANDATORY ALTERNATE=LOG_ARCHIVE_DEST_2' LOG_ARCHIVE_DEST_STATE_1=ENABLE LOG_ARCHIVE_DEST_2='LOCATION=/disk2 MANDATORY' LOG_ARCHIVE_DEST_STATE_2=ENABLE LOG_ARCHIVE_DEST_STATE_2=ALTERNATE
If the LOG_ARCHIVE_DEST_1 destination fails, the archiving process will automatically switch to the LOG_ARCHIVE_DEST_2 destination.
Archiving redo logs to a remote database can be defined as being dependent upon the success or failure of an archival operation for another destination. The dependent destination is known as the child destination. The destination on which the child depends is known as the parent destination.
Use the DEPENDENCY attribute of the LOG_ARCHIVE_DEST_n initialization parameters to define a child destination. This attribute indicates that this destination depends upon the successful completion of archival operations for the parent destination.
Specifying a destination dependency can be useful in the following situations:
In these situations, although a physical archival operation is not required, the standby database needs to know the location of the archived redo logs on the primary site. This allows the standby database to access the archived redo logs on the primary site when they become available for managed recovery. You must specify an archiving destination as being dependent on the success or failure of another (parent) destination. This is known as a destination dependency.
The REGISTER attribute indicates the fully qualified filename of the archived redo log at the remote destination. This information is recorded in the standby database control file. The fully qualified filename is derived from the values entered in the STANDBY_ARCHIVE_DEST and LOG_ARCHIVE_FORMAT initialization parameters. This is the implicit default setting.
For a standby destination database, this archived redo log registry serves as the manifest for the managed standby recovery operation.
The optional REGISTER=location_format attribute is used to specify a filename format different from the format defined by the STANDBY_ARCHIVE_DEST and LOG_ARCHIVE_FORMAT primary database initialization parameters. This is the filename that will be recorded in the corresponding remote destination control file. If this attribute value is not specified, then the setting is the same as REGISTER.
If you are using managed recovery, use the REGISTER=location_format attribute to specify the fully qualified filename of the archived redo log on the remote site.
By default, in managed recovery mode, the standby database automatically applies redo logs when they arrive from the primary database. But in some cases, you may want to create a time lag between the archiving of a redo log at the primary site and the applying of the redo log at the standby site. A time lag can protect against the transfer of corrupted or erroneous data from the primary site to the standby site.
Use the DELAY=minutes attribute of the LOG_ARCHIVE_DEST_n initialization parameters to specify a time lag for applying redo logs at the standby site. The default setting for this attribute is NODELAY. If the DELAY attribute is set with no value specified, then the value for this attribute is 30 minutes. Example 3-17 shows how to set up a destination with a time delay of 4 hours.
LOG_ARCHIVE_DEST_3='SERVICE=stby1 DELAY=240 REOPEN=300' LOG_ARCHIVE_DEST_STATE_3=ENABLE
You can specify the amount of physical storage on a disk device to be allocated for an archiving destination using the QUOTA_SIZE attribute of the LOG_ARCHIVE_DEST_n initialization parameters. The QUOTA_SIZE attribute indicates the maximum number of 512-byte blocks of physical storage on a disk device that may be consumed by a destination. The value is specified in 512-byte blocks even if the physical device uses a different block size. The optional suffix values K, M, and G represent thousand, million, and billion, respectively (the value "1K" means 1,000 512-byte blocks).
A destination can be designated as being able to occupy all or some portion of the physical disk represented by the destination. For example, in a Real Application Clusters environment, a physical archived redo log disk device may be shared by two or more separate nodes (through a clustered file system, such as is available with Sun Clusters). As there is no cross-instance initialization parameter knowledge, none of the Real Application Clusters nodes is aware that the archived redo log physical disk device is shared with other instances. This leads to substantial problems when the destination disk device becomes full; the error is not detected until every instance tries to archive to the already full device. This seriously affects database availability.
The QUOTA_SIZE value does not have to be the actual number of blocks on the disk device; the value represents the portion of the disk device that can be consumed by the archived redo log destination.
This section describes how to set up log transport services on the standby database in preparation for switchover. The following topics are presented:
Most initialization parameters at the primary and standby databases should be identical, although some initialization parameters such as CONTROL_FILES and DB_FILE_NAME_CONVERT must differ. Differences in initialization parameters other than those described in Table 3-6 can cause performance degradation at a standby database and, in some cases, halt database operations completely. Change parameter values only when it is required for the functionality of the standby database or for filename conversions.
The initialization parameters in Table 3-6 play a key role in the configuration of the standby database. For a complete list of database initialization parameters specific to the Data Guard environment, see Chapter 7.
| Parameter | Guideline | For More Information |
|---|---|---|
|
|
Always set this parameter to the same value at the primary and standby databases. If the values differ, you may not be able to archive the redo logs from your primary database to the standby database. |
|
|
|
Always set this parameter to a different value from the |
|
|
|
Set this parameter to distinguish standby database filenames from primary database filenames. Because the standby database control file is a copy of the primary database control file, you must convert the standby database filenames if the standby database is on the same site as the primary database or on a separate site with different path names. |
See Section 4.6 |
|
|
Specifies the maximum number of database files that can be open for this database. |
|
|
|
Always set to the same value as the |
|
|
|
This parameter, which is used solely by a standby database in managed recovery mode, specifies the Oracle Net service name that the FAL server should use to connect to the standby database. This parameter is set on the standby site. |
See Section 4.5 |
|
|
This parameter, which is used solely by a standby database in managed recovery mode, specifies the Oracle Net service name that the standby database should use to connect to the FAL server. This parameter is set on the standby site. |
See Section 4.5 |
|
|
This parameter specifies the name space that the distributed lock manager (DLM) uses to generate lock names. Set this value if the standby database has the same name on the same cluster as the primary database. |
|
|
|
The value set in this parameter is used by the standby database ARCn process as the storage location for standby redo logs. |
See Section 3.3.1 |
|
|
The value of this parameter is used in conjunction with the |
See Section 3.6.3.4 |
|
|
Always set this parameter to |
|
|
|
Optionally, set this parameter to an integer value to see the progression of the archiving of redo logs at the standby site. The Oracle database server writes an audit trail of the redo logs received from the primary database into a trace file. This parameter controls output generated by the archiver process (ARCn), and foreground processes on the primary database and the RFS and FAL server processes on the standby database. |
See Section 4.9.5 |
|
|
Set this parameter to make your standby redo log filenames distinguishable from primary database redo log filenames. This parameter value converts the filename of a new log file on the primary database to the filename of a log file on the standby database. Adding a log file to the primary database necessitates adding a corresponding file to the standby database. When the standby database is updated, this parameter is used to convert the log filename on the primary database to the log filename on the standby database. The file must exist and be writable on the standby database or the recovery process will halt with an error. |
See Section 4.6 |
|
|
Always set this parameter to |
See Section 3.4.2 |
|
|
Used solely by a standby database in managed recovery mode to determine the archive location of online redo logs received from the primary database. The RFS process uses this value along with the |
See Section 3.6.3.4 |
|
|
Using this parameter, the Oracle database server automates the creation and deletion of datafiles on the standby system.
The |
See Section 4.6 |
Once you have configured the primary database initialization parameter file, you can duplicate the file for use by the standby database. The procedure for creating the standby initialization parameter file is as follows:
Oracle Corporation suggests that you maintain two database initialization parameter files at both the primary and standby databases. This will allow you to easily change the databases from the primary role to the standby role or from the standby role to the primary role.
Example 3-18 and Example 3-19 show sections of initialization parameter files that you could maintain on the primary database. These examples show only parameters specific to log transport services. For complete examples of database initialization files, see Chapter 6, "Data Guard Scenarios".
Example 3-18 shows log transport services initialization parameters for a typical primary database. These log transport services parameter settings are used when the primary database is operating in the primary role.
DB_NAME=primary1 CONTROL_FILES=primary.ctl COMPATIBLE=9.0.1.0.0 LOG_ARCHIVE_START=true LOG_ARCHIVE_DEST="" LOG_ARCHIVE_DUPLEX_DEST="" LOG_ARCHIVE_DEST_1='LOCATION=/oracle/arc/ MANDATORY REOPEN=30' LOG_ARCHIVE_DEST_2='SERVICE=standby MANDATORY REOPEN=15' LOG_ARCHIVE_DEST_STATE_1=enable LOG_ARCHIVE_DEST_STATE_2=enable LOG_ARCHIVE_FORMAT=arc%t_%s.arc REMOTE_ARCHIVE_ENABLE=true . . .
Example 3-19 shows log transport services parameters for an initialization parameter file to be maintained on the primary database and used if the primary database's role is changed to the standby role.
DB_NAME=primary1 CONTROL_FILES=primary.ctl COMPATIBLE=9.0.1.0.0 LOG_ARCHIVE_START=true LOCK_NAME_SPACE=primary1 FAL_SERVER=standby1 FAL_CLIENT=primary1 DB_FILE_NAME_CONVERT=('/standby','/primary') LOG_FILE_NAME_CONVERT=('/standby','/primary') STANDBY_ARCHIVE_DEST=/oracle/arc/ LOG_ARCHIVE_DEST_1='LOCATION=/oracle/arc/' LOG_ARCHIVE_TRACE=127 LOG_ARCHIVE_FORMAT=arc%t_%s.arc STANDBY_FILE_MANAGEMENT=auto REMOTE_ARCHIVE_ENABLE=true . . .
Example 3-20 and Example 3-21 show sections of initialization parameter files that you could maintain on the standby database. These examples show only parameters specific to log transport services. For complete examples of database initialization files, see Chapter 6, "Data Guard Scenarios".
Example 3-20 shows log transport services parameters for an initialization parameter file to be maintained on the standby database when it is operating in the standby role.
DB_NAME=primary1 CONTROL_FILES=standby.ctl COMPATIBLE=9.0.1.0.0 LOG_ARCHIVE_START=true LOCK_NAME_SPACE=standby1 FAL_SERVER=primary1 FAL_CLIENT=standby1 DB_FILE_NAME_CONVERT=("/primary","/standby") LOG_FILE_NAME_CONVERT=("/primary","/standby") STANDBY_ARCHIVE_DEST=/oracle/stby/arc LOG_ARCHIVE_DEST_1='LOCATION=/oracle/stby/arc/' LOG_ARCHIVE_TRACE=127 LOG_ARCHIVE_FORMAT=arc%t_%s.arc STANDBY_FILE_MANAGEMENT=auto REMOTE_ARCHIVE_ENABLE=true . . .
Example 3-21 shows transport services parameters for an initialization parameter file to be maintained on the standby database and used when it is to operate in the primary role.
DB_NAME=primary1 CONTROL_FILES=standby.ctl COMPATIBLE=9.0.1.0.0 LOG_ARCHIVE_START=true LOG_ARCHIVE_DEST="" LOG_ARCHIVE_DUPLEX_DEST="" LOG_ARCHIVE_DEST_1='LOCATION=/oracle/stby/arc/ MANDATORY REOPEN=30' LOG_ARCHIVE_DEST_2='SERVICE=primary1 MANDATORY REOPEN=15' LOG_ARCHIVE_DEST_STATE_1=enable LOG_ARCHIVE_DEST_STATE_2=enable LOG_ARCHIVE_FORMAT=arc%t_%s.arc REMOTE_ARCHIVE_ENABLE=true . . .
This section includes the following topics:
The primary and standby databases are synchronized by applying redo logs from the primary database to the standby database. Although the goal is to keep the databases identical, the transactions applied to the standby database can sometimes lag behind the primary database.
This lag may occur either because the data has not yet reached the standby site, or it may have reached the standby site, but has not yet been applied to the standby database.
If the data needed to keep the databases synchronized is not yet available on the standby site, and you must fail over, the contents of the databases will diverge, and some data will be lost. To protect against potential data loss, use Data Guard features such as log data availability modes and standby redo logs.
Varying degrees of potential data loss can be configured, from no data loss to minimal data loss; each degree of potential data loss has a varying effect on primary database performance. Choose the degree of potential data loss that suits the application requirements.
The definition of no data loss is deceptively simple and very subtle; log transport services will not acknowledge application modifications to the primary database until the modifications are also available on a standby database. No data loss does not imply that the data modifications have been applied to the standby database, but that the data is available for log apply services to apply to the standby database.
No data loss is achieved by using standby redo logs on the standby database and setting an appropriate data availability mode.
The definition of data divergence extends the concept of no data loss. Data divergence occurs when data modifications occur on the primary database when connectivity to the standby database is not available.
No data divergence prohibits primary database modifications when connectivity to at least one standby database is not available. In other words, the data on the primary database is protected against both loss and data divergence.
To prevent data divergence, Data Guard can be configured to automatically shut down the primary database instance when network connectivity to the last standby database is lost.
In some cases, the performance of the primary database is more important than the potential loss of some data. Minimal data loss and high database performance can be achieved using the ASYNC and NOAFFIRM attributes for an archive destination. For example, using a lower block count for the ASYNC attribute combined with the NOAFFIRM attribute minimizes the amount of potential data loss and increases performance.
Weigh your business requirements for data availability against user demands for response time and performance, to determine the appropriate data availability mode to use.
The following data availability modes can be configured in the Data Guard environment:
With guaranteed protection, the standby database cannot diverge from the primary database at all, and no data can be lost. If a standby database is unavailable, processing automatically halts on the primary database as well.
When operating in this mode, the log writer process transmits redo records from the primary database to the standby database, and a transaction is not committed on the primary database until it has been confirmed that the transaction data is available on at least one standby database. This has the potential to affect primary database performance, but provides the highest degree of data availability at the standby site. Stock exchanges, currency exchanges, and financial institutions are examples of businesses that require guaranteed protection.
With instant protection, the standby database may temporarily diverge from the primary database, but upon failover to the standby database, the databases can be synchronized, and no data will be lost. As with guaranteed protection, the log writer process transmits redo logs from the primary database to the standby database. The transaction is not committed on the primary database until it has been confirmed that the transaction data is either available on the standby database, or that the data could not be received by the standby database. An example of a business that can use instant protection is a manufacturing plant; the risks of having no standby database for a period of time and data divergence are acceptable as long as no data is lost if failover is necessary.
With rapid protection, the log writer process transmits redo logs to the standby sites. Use this mode when availability and performance on the primary database are more important than the risk of losing a small amount of data. During normal operations, processing on the primary database continues without regard to the data availability on any standby database. Rapid protection can be used if your business has some other form of backup or the loss of data would have a small impact on your business model.
With delayed protection, the archiver process transmits the redo logs to the standby sites. This lowest level of protection has been available in releases prior to Oracle9i. In a failover, it is possible to lose data from one or more logs that have not yet been transmitted.
Log transport services provide four data availability modes, as explained in Section 3.6.2. You configure data availability modes by:
Table 3-7 lists the availability modes and the settings required to implement each mode. You can set other variations of archive destination attributes and log transport services options; however, the following table identifies the most common settings.
Timely protection of application data requires use of the log writer process to propagate primary database modifications to one or more standby databases. This is achieved using the LGWR attribute of the LOG_ARCHIVE_DEST_n initialization parameters.
| Attribute | Example | Default |
|---|---|---|
|
{ |
|
|
Choosing the LGWR attribute indicates that the log writer process (LGWR) will concurrently create the archived redo logs as the online redo log is populated. Depending on the configuration, this may require the log writer process to also transmit redo log files to remote archival destinations.
Choosing the ARCH attribute indicates that the archiver process (ARCn) will create archived redo logs on the primary database and also transmit redo logs for archival at specified destinations. This is the default setting.
The LGWR and ARCH attributes are mutually exclusive. Therefore, you cannot specify the two attributes for the same destination.
The LGWR attribute can be specified for individual destinations. This allows you to specify that the log writer process writes to redo logs and archives for some destinations while the archiver process archives redo logs to other destinations.
It is possible to specify that the log writer process archive redo logs to all destinations; however, Oracle Corporation recommends that you use the log writer process for only one remote destination, due to the increased network I/O effect on the primary database.
When using the log writer process to archive redo logs, the DBA can specify synchronous (SYNC) or asynchronous (ASYNC) network transmission of redo logs to archiving destinations using the SYNC or ASYNC=blocks attributes.
The SYNC attribute indicates that all network I/O operations are to be performed synchronously, in conjunction with each write operation to the online redo log. Control is not returned to the executing application or user until the redo information is received by the standby site. This attribute has the potential to affect primary database performance adversely, but provides the highest degree of data availability at the destination site. Synchronous transmission is required for no-data-loss environments.
The ASYNC=blocks keyword indicates that all network I/O operations are performed asynchronously, and control is returned to the executing application or user immediately. You can specify a block count to determine the size of the SGA network buffer to be used. Block counts from 0 to 20,480 are allowed. The attribute allows the optional suffix value K to represent 1,000 (the value "1K" indicates 1,000 512-byte blocks). In general, for slower network connections, use larger block counts.
When you use the ASYNC attribute, there are several events that cause the network I/O to be initiated:
| Attribute | Example | Default |
|---|---|---|
|
{ |
|
|
Table 3-8 identifies the attributes of the LOG_ARCHIVE_DEST_n initialization parameters that are used to specify the transmission mode.
The [NO]AFFIRM attribute of the LOG_ARCHIVE_DEST_n parameters is used to specify whether log archiving disk write I/O operations are to be performed synchronously or asynchronously. By default, disk write operations are performed asynchronously.
It is necessary for the primary database to receive acknowledgement of the availability of the modifications on the standby database in a no-data-loss environment. This is achieved using the SYNC and AFFIRM attributes of the LOG_ARCHIVE_DEST_n initialization parameters. The SYNC attribute indicates that synchronous network transmission is necessary, and the AFFIRM attribute indicates that synchronous archived redo log disk write I/O operations are necessary. Together, these attributes ensure that primary database modifications are available on the standby database.
This attribute applies to local and remote archive destination disk I/O operations and standby redo log disk write I/O operations.
| Attribute | Example | Default |
|---|---|---|
|
|
|
|
Online redo logs transferred from the primary database are received by the remote file server process (RFS) on the standby site and can be stored as either standby redo logs or archived online redo logs as shown in Figure 3-2.
Oracle9i Data Guard introduces the concept of standby redo logs. Standby redo logs form a separate pool of log file groups.
Standby redo logs provide the following advantages over archived online redo logs:
Standby redo logs are created using the ADD STANDBY LOGFILE clause of the ALTER DATABASE statement. Additional log group members can be added later to provide another level of reliability against disk failure on the standby site.
Once you have created the standby redo logs, they are automatically selected as the repository of redo data received from the primary site, if all of the following conditions apply:
For example, if the primary database uses two online redo log groups whose log size is 100K and 200K, respectively, then the standby database should have standby redo log groups with those same sizes. However, it may be necessary to create additional standby log groups on the standby database, so that the archival operation has time to complete before the standby redo log is used. If the primary database is operating in protected mode, and a standby redo log cannot be allocated, the primary database instance will be shut down immediately. Therefore, be sure you allocate an adequate number of standby redo logs.
When you use Real Application Clusters, the various standby redo logs are shared among the various primary database instances. Standby redo log groups are not dedicated to a particular primary database thread.
Standby redo logs must be archived before the data can be applied to the standby database. The standby archival operation occurs automatically, even if the standby database is not in ARCHIVELOG mode. However, the archiver process must be started on the standby database. Note that the use of the archiver process (ARCn) is a requirement for selection of a standby redo log.
Because of this additional archival operation, using standby redo logs may cause the standby database to lag further behind the primary database than when archiving directly from the primary database to standby destinations. However, the use of standby redo logs ultimately improves redo data availability on the standby database.
Standby redo logs created on a primary database are not used until the database assumes the standby role. However, Oracle Corporation recommends that you create standby redo logs so that the primary database can switch roles easily and quickly without additional DBA intervention.
The best way to determine the appropriate number of standby redo log groups for a database instance is to test different configurations. The minimum configuration has the same number of groups as the primary database. The optimum configuration has slightly more groups than the primary database.
In some cases, a standby database instance may require only two groups. In other situations, a database may require additional groups to guarantee that a recycled group is always available to receive redo information from the primary database. During testing, the easiest way to determine if the current standby log configuration is satisfactory is to examine the contents of the RFS process trace file and the database alert log. If messages indicate that the RFS process frequently has to wait for a group because an archival has not completed, add more standby groups.
Consider the parameters that can limit the number of standby redo log groups before setting up or altering the configuration of the standby redo log groups. The following parameters limit the number of standby redo log groups that you can add to a database:
MAXLOGFILES parameter of the CREATE DATABASE statement for the primary database determines the maximum number of groups of standby redo logs per standby database. The only way to override this limit is to re-create the primary database or control file.
LOG_FILES initialization parameter can temporarily decrease the maximum number of groups of standby redo logs for the duration of the current instance.
MAXLOGMEMBERS parameter of the CREATE DATABASE statement used for the primary database determines the maximum number of members per group. The only way to override this limit is to re-create the primary database or control file.
Plan the standby redo log configuration of a database and create all required groups and members of groups after you have instantiated the standby database. However, there are cases where you might want to create additional groups or members. For example, adding groups to a standby redo log configuration can correct redo log group availability problems. To create new standby redo groups and members, you must have ALTER DATABASE system privilege. A database can have as many groups as the value of MAXLOGFILES.
To create a new group of standby redo logs, use the ALTER DATABASE statement with the ADD STANDBY LOGFILE clause.
The following statement adds a new group of standby redo logs to the database:
SQL> ALTER DATABASE ADD STANDBY LOGFILE 2> ('/oracle/dbs/log1c.rdo','/oracle/dbs/log2c.rdo') SIZE 500K;
You can also specify a number that identifies the group using the GROUP option:
SQL> ALTER DATABASE ADD STANDBY LOGFILE GROUP 10 2> ('/oracle/dbs/log1c.rdo','/oracle/dbs/log2c.rdo') SIZE 500K;
Using group numbers can make administering standby redo log groups easier. However, the group number must be between 1 and the value of the MAXLOGFILES parameter. Do not skip redo log file group numbers (that is, do not number groups 10, 20, 30, and so on), or you will consume additional space in the standby database control file.
In some cases, it might not be necessary to create a complete group of standby redo logs. A group could already exist, but not be complete because one or more members were dropped (for example, because of disk failure). In this case, you can add new members to an existing group.
Use fully qualified filenames of new log members to indicate where the file should be created. Otherwise, files will be created in either the default or current directory of the database server, depending upon your operating system.
To add new standby redo log group members, use the ALTER DATABASE statement with the ADD STANDBY LOGFILE MEMBER parameter. The following statement adds a new member to redo log group number 2:
SQL> ALTER DATABASE ADD STANDBY LOGFILE MEMBER '/oracle/dbs/log2b.rdo' 2> TO GROUP 2;
When archived redo logs are used, the STANDBY_ARCHIVE_DEST initialization parameter is used to specify the directory in which to store the archived redo logs. Log transport services use this value in conjunction with the LOG_ARCHIVE_FORMAT parameter to generate the archived redo log filenames on the standby site.
Log transport services store the fully qualified filenames in the standby control file. Log apply services use this information to perform recovery operations on the standby database. You can access this information through the V$ARCHIVED_LOG view on the standby database:
SQL> SELECT name FROM v$archived_log; NAME -------------------------------------------------------------------------------- /arc_dest/log_1_771.arc /arc_dest/log_1_772.arc /arc_dest/log_1_773.arc /arc_dest/log_1_774.arc /arc_dest/log_1_775.arc
When standby redo logs are used, the LOG_ARCHIVE_DEST_1 initialization parameter on the standby database specifies the directory in which to store standby redo logs.
| Parameter | Indicates | Example |
|---|---|---|
|
|
The directory for storage of standby redo logs on the standby site |
|
A failure resolution policy determines what actions will occur on a primary database when the last standby destination fails to archive redo logs.
To set the highest level of data protection, guaranteed protection, place the primary database in PROTECTED mode using the SET STANDBY DATABASE clause of the ALTER DATABASE statement as shown in the following example:
SQL> ALTER DATABASE SET STANDBY DATABASE PROTECTED;
When this statement is used, the primary database is protected against data loss and divergence. If connectivity between the primary and standby database should now be lost, the primary database will shut down. When using this level of data protection, standby databases must have two or more standby redo log groups. Also, one or more primary database archive redo log destinations must have LGWR and SYNC attributes specified. The functionality of the AFFIRM attribute is implicitly set.
You can revert to a mode that allows data divergence by placing the primary database in UNPROTECTED mode using the following statement:
SQL> ALTER DATABASE SET STANDBY DATABASE UNPROTECTED;
The difference between the functionality of the destination disk write I/O attribute [NO]AFFIRM and the SYNC and ASYNC network transmission attributes is that the SYNC and ASYNC attributes apply only to network I/O performance when the log writer process is used. Table 3-9 shows a comparison of primary database performance to data availability on the standby database when various combinations of archive process, network I/O, and disk I/O attribute settings are used.
The process of archiving redo logs involves reading a buffer from the redo log and writing it to the archive log location. When the destination is remote, the buffer is written to the archive log location over the network using Oracle Net services.
The default archive log buffer size is 1 megabyte. The default transfer buffer size for Oracle Net is 2 kilobytes. Therefore, the archive log buffer is divided into units of approximately 2 kilobytes for transmission. These units could get further divided depending on the maximum transmission unit (MTU) of the underlying network interface.
The Oracle Net parameter that controls the transport size is session data unit (SDU). This parameter can be adjusted to reduce the number of network packets that are transmitted. This parameter allows a range of 512 bytes to 32 kilobytes.
For optimal performance, set the Oracle Net SDU parameter to 32 kilobytes for the associated SERVICE destination parameter.
The following example shows a database initialization parameter file segment that defines a remote destination netserv:
LOG_ARCHIVE_DEST_3='SERVICE=netserv' SERVICE_NAMES=srvc
The following example shows the definition of that service name in the tnsnames.ora file:
netserv=(DESCRIPTION=(SDU=32768)(ADDRESS=(PROTOCOL=tcp)(HOST=host) (PORT=1521)) (CONNECT_DATA=(SERVICE_NAME=srvc)(ORACLE_HOME=/oracle)))
The following example shows the definition in the listener.ora file:
LISTENER=(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=tcp) (HOST=host)(PORT=1521)))) SID_LIST_LISTENER=(SID_LIST=(SID_DESC=(SDU=32768)(SID_NAME=sid) (GLOBALDBNAME=srvc)(ORACLE_HOME=/oracle)))
If you archive to a remote site using high-latency/high-bandwidth connections, you can improve performance by increasing the TCP send and receive window sizes. Use caution, however, because this may adversely affect networked applications that do not exhibit the same characteristics as archiving. This method consumes a large amount of system resources.
This section describes manual methods of monitoring redo log archival activity for the primary database.
The Oracle9i Data Guard Manager graphical user interface automates many of the tasks involved in monitoring a Data Guard environment. See Oracle9i Data Guard Broker and the Data Guard Manager online help for more information.
Enter the following query on the primary database to determine the current redo log sequence numbers:
SQL> SELECT thread#, sequence#, archived, status FROM v$log; THREAD# SEQUENCE# ARC STATUS -------- --------- --- ------ 1 947 YES ACTIVE 1 948 NO CURRENT
Enter the following query at the primary database to determine the most recently archived redo log file:
SQL> SELECT MAX(sequence#) FROM v$archived_log; MAX(SEQUENCE#) -------------- 947
Enter the following query at the primary database to determine the most recently archived redo log file to each of the archive destinations:
SQL> SELECT destination, status, archived_thread#, archived_seq# 2> FROM v$archive_dest_status 3> WHERE status <> 'DEFERRED' AND status <> 'INACTIVE'; DESTINATION STATUS ARCHIVED_THREAD# ARCHIVED_SEQ# ------------------ ------ ---------------- ------------- /private1/prmy/lad VALID 1 947 standby1 VALID 1 947
The most recently archived redo log file should be the same for each archive destination listed. If it is not, a status other than VALID may identify an error encountered during the archival operation to that destination.
You can issue a query at the primary database to find out if a log has not been sent to a particular site. Each archive destination has an ID number associated with it. You can query the DEST_ID column of the V$ARCHIVE_DEST fixed view on the primary database to identify archive destination IDs.
Assume the current local archive destination is 1, and one of the remote standby archive destination IDs is 2. To identify which logs have not been received by this standby destination, issue the following query:
SQL> SELECT local.thread#, local.sequence# FROM 2> (SELECT thread#, sequence# FROM v$archived_log WHERE dest_id=1) 3> local WHERE 4> local.sequence# NOT IN 5> (SELECT sequence# FROM v$archived_log WHERE dest_id=2 AND 6> thread# = local.thread#); THREAD# SEQUENCE# --------- --------- 1 12 1 13 1 14
|
See Also:
Appendix A, "Troubleshooting the Standby Database" to learn more about monitoring the archiving status of the primary database |
To see the progression of the archiving of redo logs to the standby site, set the LOG_ARCHIVE_TRACE parameter in the primary and standby initialization parameter files. See Section 4.9.5 for complete details and examples.
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|