Release 1 (9.0.1)
Part Number A90236-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Globalization Support Guide Release 1 (9.0.1) Part Number A90236-02 |
|
![]()
![]()
This chapter examines globalization support for individual Java components. It includes the following topics:
Java support is included in all tiers of a multitier computing environment so that you can develop and deploy Java programs. You can run Java classes as Java stored procedures, Java servlets, Java CORBA objects, and Enterprise Java Beans (EJB) on the Java Virtual Machine (Oracle JVM) of the Oracle9i database. You can develop a Java class, load it into the database, and package it as a stored procedure that can be called from SQL. You can develop a Java servlet, load it on the database, and publish it as a callable servlet from a web browser. You can also develop a standard Java CORBA object or EJB, load the related classes into the database and publish them as named objects that are callable from any CORBA or EJB client.
The JDBC driver and SQLJ translator are also provided as programmatic interfaces that enable Java programs to access the Oracle9i database. You can write a Java application using JDBC or SQLJ programs with embedded SQL statements to access the database. Globalization support is provided across all these Java components to ensure that they function properly across databases of different character sets and language environments, and that they enable the development and deployment of multilingual Java applications for Oracle9i.
This chapter examines globalization support for individual Java components. Typical database and client configurations for multilingual application deployment are discussed, including an explanation of how the Java components are used in the configurations. Finally, the design and implementation of a sample application are explored to demonstrate how Oracle's Java support is used to make the application run in a multilingual environment.
Java components provide globalization support and use Unicode as the multilingual character. The following are Oracle9i's Java components:
Oracle provides JDBC as the core programmatic interface for accessing Oracle9i databases. There are three JDBC drivers provided by Oracle: two for client access and one for server access.
SQLJ acts like a preprocessor that translates embedded SQL in the SQLJ program file into a Java source file with JDBC calls. It gives programmers a higher level of programmatic interface for accessing databases.
A Java VM based on that of the JDK is integrated into the database server that enables the running of Java classes. It comes with a set of supporting services such as the library manager, which manages Java classes stored in the database.
The Java Servlet API 2.2 has been implemented to support the deployment of Java servlets in the Oracle JVM. The Servlet API provides important internationalization support to build a multilingual Java servlet. A JavaServer Page (JSP) compiler is also provided to compile JSPs into Java servlets.
In addition to the Java runtime environment, Oracle integrates the CORBA Object Request Broker (ORB) into the database server, and makes the database a CORBA server. Any CORBA client can call the Java CORBA objects published to the ORB of the database server.
The Enterprise Java Bean version 1.1 container is built into the database server to provide a platform to develop and deploy EJBs.
This section describes the following:
Oracle JDBC drivers provide globalization support by allowing you to retrieve data from or insert data into columns of the SQL CHAR datatypes and the SQL NCHAR datatypes of an Oracle9i database. Because Java strings are UTF-16 encoded (16-bit Unicode) for JDBC programs, the target character set on the client is always UTF-16. For data stored in the CHAR, VARCHAR2, LONG, and CLOB datatypes, JDBC transparently converts the data from the database character set to UTF-16. For Unicode data stored in the NCHAR, NVARCHAR2, and NCLOB datatypes, JDBC transparently converts the data from the national character set to UTF-16.
Following are a few examples of commonly used Java methods for JDBC that rely heavily on NLS character set conversion:
java.sql.ResultSet's method getString() returns values from the database as Java strings.
java.sql.ResultSet's method getUnicodeStream() returns values as a stream of Unicode characters.
oracle.sql.CLOB's method getSubString() returns the contents of a CLOB as a Unicode stream.
oracle.sql.CHAR's methods getString(), toString(), and getStringWithReplacement().
At database connection time, the JDBC Class Library sets the server NLS_LANGUAGE and NLS_TERRITORY parameters to correspond to the locale of the Java VM that runs the JDBC driver. This operation is performed on the JDBC OCI and JDBC Thin drivers only, and ensures that the server and the Java client communicate in the same language. As a result, Oracle error messages returned from the server are in the same language as the client locale.
To insert a Java string to a database column of a SQL CHAR datatype, you may use the PreparedStatement.setString() method to specify the bind variable, and Oracle's JDBC drivers transparently convert the Java string to the database character set. An example for binding a Java string ename to a VARCHAR2 column ename is shown below.
int empno = 12345; String ename = "\uFF2A\uFF4F\uFF45"; PreparedStatement pstmt = conn.prepareStatement ("INSERT INTO emp (empno, ename) VALUES(?,?); pstmt.setInt(1. empno); pstmt.setString(2, ename); pstmt.execute(); pstmt.close();
For data stored in the SQL CHAR datatypes, the techniques that Oracle's drivers use to perform character set conversion for Java applications depend on the character set that the database uses. The simplest case is where the database uses a US7ASCII or WE8ISO8859P1 character set. In this case, the driver converts the data directly from the database character set to UTF-16,which is used in Java applications.
If you are working with databases that employ a non-US7ASCII or non-WE8ISO8859P1 character set (for example, Japanese or Korean), then the driver converts the data, first to UTF8, then to UTF-16. The following sections detail the conversion paths for different JDBC drivers.
Figure 9-1 presents a graphical view of how data is converted in JDBC drivers.
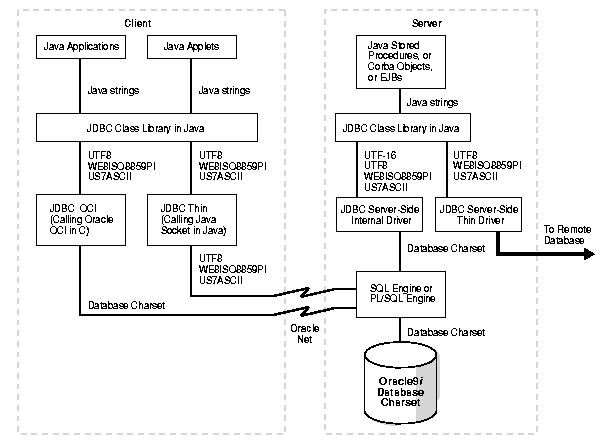
The JDBC Class Library is a Java layer that implements the JDBC interface. Java applications, applets, and stored procedures interact with this layer. The library always accepts US7ASCII, UTF8 or WE8ISO8859P1 encoded string data from the input stream of the JDBC drivers. It also accepts UTF-16 for the JDBC server-side driver. The JDBC Class Library converts the input stream to UTF-16 before passing it to the client applications. If the input stream is in UTF8, the JDBC Class Library converts the UTF8 encoded string to UTF-16 by using the bit-wise operation defined in the UTF8-to-UTF-16 conversion algorithm. If the input stream is in US7ASCII or WE8ISO8859P1, it converts the input string to UTF-16 by casting the bytes to Java characters. This is based on the first 128 and 256 characters of UTF-16 corresponding to the US7ASCII and WE8ISO8859P1 character sets, respectively. Treating WE8ISO8859P1 and US7ASCII separately improves the performance for commonly used single-byte clients by eliminating the bit-wise conversion to UTF8.
In the case of a JDBC OCI driver installation, there is a client-side character set as well as a database character set. The client character set is determined at client installation by the value of the NLS_LANG environment variable. The database character set is determined at database creation. The character set used by the client can be different from the character set used by the database on the server. So, when performing character set conversion, the JDBC OCI driver has to take three factors into consideration:
The JDBC OCI driver transfers the data from the server to the client in the character set of the database. Depending on the value of the NLS_LANG environment variable, the driver handles character set conversions in one of two ways:
NLS_LANG is not specified, or if it is set to the US7ASCII or WE8ISO8859P1 character set, then the JDBC OCI driver uses Java to convert the character set from US7ASCII or WE8ISO8859P1 directly to UTF-16 in the JDBC class library.
NLS_LANG is set to a non-US7ASCII or non-WE8ISO8859P1 character set, then the driver changes the value of the NLS_LANG parameter on the client to UTF8. This happens automatically and does not require any user-intervention. OCI uses the value of NLS_LANG to convert the data from the database character set to UTF8; the OCI JDBC driver then passes the data to the JDBC class library where the UTF8 data is converted to UTF-16.
If your applications or applets use the JDBC Thin driver, then there is no Oracle client installation. Because of this, the OCI client conversion routines in C are not available. In this case, the client conversion routines are different from the JDBC OCI driver.
If the database character set is US7ASCII or WE8ISO8859P1, the data is transferred to the client without any conversion. The driver then converts the character set to UTF-16 in Java.
If the database character set is something other than US7ASCII or WE8ISO8859P1, then the server first translates the data to UTF8 before transferring it to the client. On the client, the JDBC Thin driver converts the data to UTF-16 in Java.
For Java classes running in the Java VM of the Oracle9i Server, the JDBC Server-side Internal driver is used to talk to the SQL engine or the PL/SQL engine for SQL processing. Because the JDBC Server-side Internal driver is running in the same address space as the Oracle server process, it makes a local function call to the SQL engine or the PL/SQL engine. Data sent to or returned from the SQL engine or the PL/SQL engine will be encoded in the database character set. If the database character set is US7ASCII, WE8ISO8859P1, or UTF8, no conversion is performed in the JDBC Server-side Internal driver, and the data is passed to or from the JDBC Class Library as is. Otherwise, the JDBC Server-side Internal driver converts the data from the database character set to UTF-16 before passing it to and from the class library. The class library does not need to do any conversion in this case.
JDBC allows Java programs to access columns of the SQL NCHAR datatypes in an Oracle9i database. The data conversion path for the SQL NCHAR datatypes is different from that of the SQL CHAR datatypes. All Oracle JDBC drivers convert data in the SQL NCHAR column from the national character set, which is either UTF8 or AL16UTF16, directly to UTF-16 encoded Java strings. In a Java program, you may bind a Java string ename to a NVARCHAR2 column ename as follows:
int empno = 12345; String ename = "\uFF2A\uFF4F\uFF45"; oracle.jdbc.OraclePreparedStatement pstmt = (oracle.jdbc.OraclePreparedStatement) conn.prepareStatement("INSERT INTO emp (empno, ename) VALUES (?, ?)"); pstmt.setFormOfUse(2, oracle.jdbc.OraclePreparedStatement.FORM_NCHAR); pstmt.setInt(1. empno); pstmt.setString(2, ename); pstmt.execute(); pstmt.close();
|
See Also:
Chapter 6, "Unicode Programming" for more information about programming against the SQL |
The oracle.sql.CHAR class has special functionality for NLS conversion of character data. A key attribute of the oracle.sql.CHAR class, and a parameter always passed in when an oracle.sql.CHAR object is constructed, is the NLS character set used in presenting the character data. Without a known character set, the bytes of data in the oracle.sql.CHAR object are meaningless.
When you call the OracleResultSet.getCHAR() method to get a bind variable as an oracle.sql.CHAR object, JDBC constructs and populates the oracle.sql.CHAR objects after character data has been read from the database.
The oracle.sql.CHAR class provides the following methods for converting character data to strings:
getString()
Converts the sequence of characters represented by the oracle.sql.CHAR object to a string, returning a Java String object. If the character set is not recognized (that is, if you entered an invalid OracleID), then getString() throws a SQLException.
toString()
Identical to getString(), but if the character set is not recognized (that is, if you entered an invalid OracleID), then toString() returns a hexadecimal representation of the oracle.sql.CHAR data and does not throw a SQLException.
getStringWithReplacement()
Identical to getString(), except a default replacement character replaces characters that have no Unicode representation in the character set of this oracle.sql.CHAR object. This default character varies from character set to character set, but is often a question mark.
In Oracle9i, JDBC drivers support Oracle object types. Oracle objects are always sent from database to client as an object represented in the database character set. That means the data conversion path in Figure 9-1, "JDBC Data Conversion", does not apply to Oracle object access. Instead, the oracle.sql.CHAR class is used for passing string data from the database to the client. The following is an example of an object type created using SQL:
CREATE TYPE PERSON_TYPE AS OBJECT (NAME VARCHAR2(30), AGE NUMBER); CREATE TABLE EMPLOYEES (ID NUMBER, PERSON PERSON_TYPE);
The Java class corresponding to this object type can be constructed as follows:
public class person implement SqlData { oracle.sql.CHAR name; oracle.sql.NUMBER age; // SqlData interfaces getSqlType() {...} writeSql(SqlOutput stream) {...} readSql(SqlInput stream, String sqltype) {...} }
The oracle.sql.CHAR class is used here to map to the NAME attributes of the Oracle object type, which is of VARCHAR type. JDBC populates this class with the byte representation of the VARCHAR data in the database and the character set object corresponding to the database character set. The following code retrieves a person object from the people table,
TypeMap map = ((OracleConnection)conn).getTypeMap(); map.put("PERSON_TYPE", Class.forName("person")); conn.setTypeMap(map); . . . . . . ResultSet rs = stmt.executeQuery("SELECT PERSON FROM EMPLOYEES"); rs.next(); person p = (person) rs.getObject(1); oracle.sql.CHAR sql_name = p.name; String java_name = sql_name.getString();
The getString() method of the oracle.sql.CHAR class converts the byte array from the database character set to UTF-16 by calling Oracle's Java data conversion classes and return a Java string. For the rs.getObject(1) call to work, the SqlData interface has to be implemented in the class person, and the Typemap map has to be set up to indicate the mapping of the object type PERSON_TYPE to the Java class.
If the database character set is neither ASCII (US7ASCII) nor ISO-LATIN-1 (WE8ISO8859P1), then the Thin driver must impose size restrictions for CHAR and VARCHAR2 bind parameters that are more restrictive than normal database size limitations. This is necessary to allow for data expansion during conversion.
The Thin driver checks CHAR or VARCHAR2 bind sizes when the setXXX() method is called. If the data size exceeds the size restriction, then the driver throws a SQL exception (ORA-17070 "Data size bigger than max size for this type") from the setXXX() call. This limitation is necessary to avoid the chance of data corruption whenever an NLS conversion occurs and increases the length of the data. This limitation is enforced when you are doing all the following:
CHAR or VARCHAR2 datatypes
When the database character set is neither US7ASCII nor WE8ISO8859P1, the Thin driver converts Java UTF-16 characters to UTF-8 encoding bytes for CHAR or VARCHAR2 binds. The UTF-8 encoding bytes are then transferred to the database, and the database converts the UTF-8 encoding bytes to the database character set encoding.
This conversion to the character set encoding might result in a size increase. The NLS ratio for a database character set indicates the maximum possible expansion in converting from UTF-8 to the character set:
NLS ratio = maximum character size in the database character set
Table 9-1 shows the database size limitations for CHAR and VARCHAR2 data, and the Thin driver size restriction formulas for CHAR and VARCHAR2 binds. Database limits are in bytes. Formulas determine the maximum size of the UTF-8 encoding, in bytes.
The formulas guarantee that after the data is converted from UTF-8 to the database character set, the size will not exceed the database maximum size.
The number of UTF-16 characters that can be supported is determined by the number of bytes per character in the data. All ASCII characters are one byte long in UTF-8 encoding. Other character types can be two or three bytes long.
Table 9-2 lists the NLS ratios of some common server character sets, then shows the Thin driver maximum bind sizes for CHAR and VARCHAR2 data for each character set, as determined by using the NLS ratio in the appropriate formula.
Maximum bind sizes are for UTF-8 encoding, in bytes.
| Server Character Set | NLS Ratio | Thin Driver Maximum VARCHAR2 Bind Size (UTF-8 Bytes) | Thin Driver Maximum CHAR Bind Size (UTF-8 Bytes) |
|---|---|---|---|
|
WE8DEC |
1 |
4000 |
2000 |
|
JA16SJIS |
2 |
2000 |
2000 |
|
JA16EUC |
3 |
1333 |
1333 |
Oracle JDBC drivers perform character set conversions as appropriate when character data is inserted into or retrieved from the database. In other words, the drivers convert Unicode characters used by Java clients to Oracle database character set characters, and vice versa. Character data making a round trip from the Java Unicode character set to the database character set and back to Java can suffer some loss of information. This happens when multiple Unicode characters are mapped to a single character in the database character set. An example would be the Unicode full-width tilde character (0xFF5E) and its mapping to Oracle's JA16SJIS character set. The round trip conversion for this Unicode character results in the Unicode character 0x301C, which is a wave dash (a character commonly used in Japan to indicate range), not a tilde.
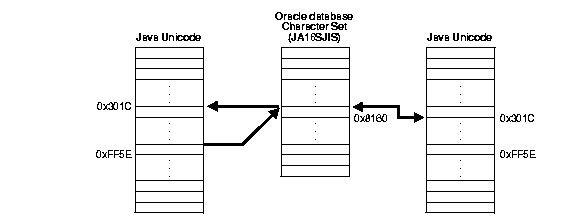
This issue is not a bug in Oracle's JDBC. It is an unfortunate side effect of the ambiguity in character mapping specification on different operating systems. Fortunately, this problem affects only a small number of characters in a small number of Oracle character sets such as JA16SJIS, JA16EUC, ZHT16BIG5, and KO16KS5601. The workaround is to avoid making a full round-trip with these characters.
SQLJ is a SQL-to-Java translator that translates embedded SQL statements in a Java program into the corresponding JDBC calls regardless of which JDBC driver is used. It also provides a callable interface that the Oracle9i database server uses to transparently translate the embedded SQL in server-side Java programs. SQLJ by itself is a Java application that reads the SQLJ programs (Java programs containing embedded SQL statements) and generates the corresponding Java program files with JDBC calls. There is an option to specify a checker to check the embedded SQL statements against the database at translation time. The javac compiler is then used to compile the generated Java program files to regular Java class files.
Figure 9-3 presents a graphical view of how the SQLJ translator works.
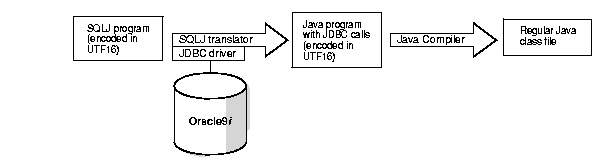
SQLJ enables multilingual Java application development by allowing SQLJ files encoded in different encoding schemes (those supported by the JDK). In the diagram above, a UTF-16 encoded SQLJ program is being passed to the SQLJ translator and the Java program output is also encoded in UTF-16. SQLJ preserves the encoding of the source in the target. To specify the encoding of the source, use the -encoding option as follows:
sqlj -encoding Unicode source_file
Unicode notation \uXXXX (which is referred to as a Unicode escape sequence) can be used in embedded SQL statements for characters that cannot be represented in the encoding of the SQLJ program file. This enables you to specify multilingual object names in the SQL statement without using a UTF-16 encoded SQLJ file. The following SQLJ code shows the usage of Unicode escape sequences in embedded SQL as well as in a string literal.
int empno = 12345; String name ename = "\uFF2A\uFF4F\uFF45"; double raise = 0.1; #sql {INSERT INTO E\u0063\u0064 (ename, empno) VALUES (:ename, :empno)}; #sql { update EMP set SAL = :(getNewSal(raise, ename)) WHERE ename = :ename;
|
See Also:
"Multilingual Demo Applications in SQLJ" for an example of SQLJ usage for a multilingual Java application |
In Oracle9i, the oracle.sql.NString class is introduced in SQLJ to support the NVARCHAR2, NCHAR, and NCLOB Unicode datatypes. You may declare a bind an NCHAR column using a Java object of the oracle.sql.NString type, and use it in the embedded SQL statements in your SQLJ programs.
int empno = 12345; oracle.sql.NString ename = new oracle.sql.NString ("\uFF2A\uFF4F\uFF45"); double raise = 0.1; # #sql {INSERT INTO E\u0063\u0064 (ENAME, EMPNO) VALUES (:ename, :empno)}; sql { UPDATE emp SET sal = :(getNewSal(raise, ename)) WHERE ename = :ename;
This example binds the ename object of the oracle.sql.NString datatype to the ename database NVARCHAR2 column.
|
See Also:
Chapter 6, "Unicode Programming" for more details on the SQL |
The Oracle9i Java VM base is integrated into the database server to enable the running of Java classes stored in the database. Oracle9i allows you to store Java class files, Java or SQLJ source files and Java resource files into the database, to publish the Java entry points to SQL so that it can be called from SQL or PL/SQL, and to run the Java byte code.
In addition to the engine that interprets Java byte code, the Oracle Java VM includes the core run-time classes of the JDK. The components of the Java VM are depicted in Figure 9-4.
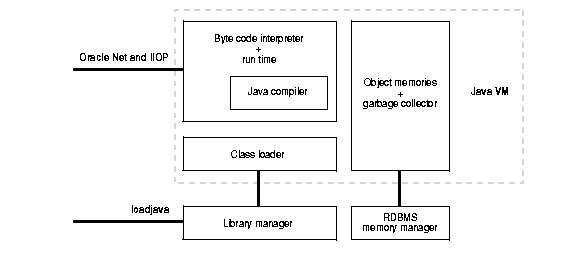
The Java VM provides an embedded Java class loader that locates, loads, and initializes locally stored Java classes in the database, and a byte code compiler which translates standard Java programs into standard Java .class binary representation. A library manager is also included to manage Java program, class, and resource files as schema objects known as library units. It not only loads and manages these Java files in the database, but also maps Java name space to library units. For example:
public class Greeting { public String Hello(String name) { return ("Hello" + name + "!"); } }
After the preceding Java code is compiled, it is loaded into the database as follows:
loadjava Greeting.class
As a result, a library unit called Greeting, is created as a schema object in the database. Class and method names containing characters that cannot be represented in the database character set are handled by generating a US7ASCII library unit name and mapping it to the real class name stored in a RAW column. This allows the class loader to find the library unit corresponding to the real class name when Java programs run in the server. In other words, the library manager and the class loader support class names or method names outside the namespace of the database character set.
A Java stored procedure or function requires that the library unit of the Java classes implementing it already be present in the database. Using the Greeting library unit example in the previous section, the following call specification DDL publishes the method Greeting.Hello() as a Java stored function:
CREATE FUNCTION MYHELLO(NAME VARCHAR2) RETURN VARCHAR2 AS LANGUAGE JAVA NAME 'Greeting.Hello(java.lang.String) return java.lang.String';
The DDL maps the Java methods, parameter types and return types to the SQL counterparts. To the users, the Java stored function has the same calling syntax as any other PL/SQL stored functions. Users can call the Java stored procedures the same way they call any PL/SQL stored procedures. Figure 9-5 depicts the runtime environment of a stored function.
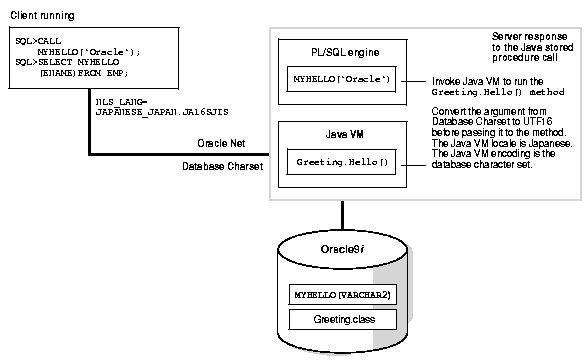
The Java entry point, Greeting.Hello(), is called by invoking the proxy PL/SQL MYHELLO() from the client. The server process serving the client runs as a normal PL/SQL stored function and uses the same syntax. The PL/SQL engine takes a call specification for a Java method and calls the Java VM. Next, it passes the method name of the Java stored function and the argument to the Java VM for execution. The Java VM takes control, calls the SQL to Java using code to convert the VARCHAR2 argument from the database character set to UTF-16, loads the class Greeting, and runs the method Hello() with the converted argument. The string returned by Hello() is then converted back to the database character set and returned as a VARCHAR2 string to the caller.
The globalization support that enables deployment and development of internationalized Java stored procedures includes:
NLS_LANGUAGE and NLS_TERRITORY database parameters) of the current database session propagated from the NLS_LANG environment variable of the client. A mapping of Oracle language and territory names to Java locale names is in place for this purpose. In additions, the default encoding of the Java VM follows the database character set.
You can write a Java servlet or a JavaServer Page (JSP) and deploy it on an Oracle9i database. Oracle9i provides a servlet engine and JSP compiler for the deployment of Java servlets and JSPs.
When a HTTP requests come to invoke a Java servlet in OSE, the Oracle HTTP Server directs the request to the database, the database invokes OSE in the context of a database session, OSE locates the requested Java servlet and dispatches to it with the HTTPServletRequest object and the HTTPServletResponse object.
To deploy a Java servlet or JSP to the database, follow the steps below:
loadjava utility
httppublish utility. You publish a Java servlet with a virtual path for the servlet.
Oracle9i Servlet Engine Developer's Guide for information about managing Java servlets in OSE
See Also:
A Java servlet or JSP receives HTTP requests from a browser, processes the request, and generates an HTTP response back to the browser.
The following sections describe the things you should consider when programming a Java servlet or JSP to support multiple languages.
To present the user interface in the user's desired language, applications need to detect his or her desired locale and construct HTML content in the desired language and use the correct cultural conventions. Both JSPs and Java servlets can use the HttpServletRequest.getLocale() method of the Servlet API to get the Java locale corresponding to the Accept-Language HTTP header and use it as the desired locale. Once the desired locale is found, set the Java locale as the default Java locale to direct all locale-sensitive Java objects functions to behave accordingly.
Locale.setDefault(userLocale);
The default Java locale is used for all Java threads. To ensure that different locales are used on different threads, specify the desired locale for each Java object.
The encoding of an HTML page is a very important piece of information to the browser and your applications. The browser needs to know so that it can use correct font and mapping tables for displaying pages, and applications need to know so they can safely assume the encoding of form input data and query strings.
You can tag the HTTP header by calling the setContentType() method of the Servlet API. The following doGet() function shows how this method should be called to specify UTF-8 as the encoding of the HTML output.
public void doGet(HttpServletRequest req, HttpServletResponse res)throws ServletException, IOException { // generate the MIME type and character set header res.setContentType("text/html; charset=utf-8"); // generate the HTML page Printwriter out = res.getWriter(); out.println("<HTML>"); .. .. .. out.println("</HTML>"); }
Note that the setContentType() method should be called before the getWriter() method because the getWriter() method initializes an output stream writer using the character set specified in the setContentType() method.
For JSPs, you can tag the encoding of an HTML page using the contentType page directive. An example is shown below.
<%@ page contentType="text/html; charset=utf-8" %>
The character set of the contentType page directive describes the encoding of the JSP page as well as the encoding of the HTML page sent to the browser.
In most JSP and servlets engines including OSE, the Servlet API implementation assumes that incoming form input is in ISO-8859-1 encoding. As a result, when the HttpServletRequest.getParameter() API is called, all data of the input text is decoded and the decoded input is converted from ISO-8859-1 to UTF-16 and returned as a Java string. The Java string returned is incorrect if the encoding of the HTML form is not in ISO-8859P-1. However, you can solve this. When the JSP or Java servlet receives form input or query strings, it needs to convert them back to the original form, and then convert the original form to a Java string based on the correct encoding.
String orig = request.getParameter("name"); String real = new String(orig.getBytes("ISO8859_1"),"UTF8");
In the above example, the Java string real will be initialized to store correct characters from a UTF-8 form input.
If a query string is constructed in a JSP or Java servlet, all 8-bit bytes must be encoded using their hexadecimal values prefixed by a percent sign as described above. The following code shows you how to encode a Java string into its hexadecimal representation in UTF-8.
byte[] htmlBytes = queryString.getBytes("UTF8"); for (int i= 0; i < htmlBytes.length; i++) { if ((htmlBytes[i] & 0xff) > 0x7f) queryString += "%" + Long.toHexString ((long)(htmlBytes[i] &0xff)); else queryString += new String(htmlBytes,i, 1,"ISO8859_1"); }
Visigenic's CORBA Object Request Broker (ORB) is integrated into the database server to make it a Java CORBA object and EJB server running the IIOP protocol. CORBA support also includes a set of supporting services that enables the deployment of CORBA objects to the database.
The CORBA ORB is written in Java and includes an IIOP interpreter and the object adapter. The IIOP interpreter processes the IIOP message by invoking the object adapter to look for the CORBA object being activated and load it into the memory, and running the object method specified in the message.
A couple of CORBA objects are predefined. The LoginServer object is used for explicit session log in, and the PublishContext object is to used to resolve a published CORBA object name to the corresponding PublishedObject.
CORBA objects implemented in Java in Oracle9i are required to be loaded and then published before the client can reference it. Publish is a Java written utility that publishes a CORBA object to the ORB by creating an instance of PublishedObject which represents and activates the CORBA object, and binding the input (CosNaming) name to the published object.
Oracle9i implements the CosNaming standard for specifying CORBA object names. CosNaming provides a directory-like structure that is a context for binding names to CORBA objects. A new JNDI URL, sess_iiop:, is created, and indicates a session-based IIOP connection for a CORBA object. A name for a CORBA object in the local database can be published as:
sess_iiop://local:2222:ORCL/Demo/MyGreeting
where 2222 is the port number for receiving IIOP requests, ORCL is the database instance identifier and /Demo/MyGreeting is the name of the published object. The namespace for CORBA objects in Oracle9i is limited to US7ASCII characters.
Figure 9-6 presents a graphical view of the components in a CORBA environment:
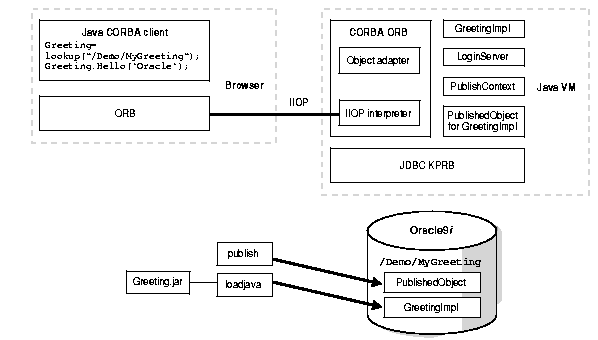
The CORBA objects for Oracle9i can only be written in Java and they run on the Java VM of the database. The CORBA client can be written in any language the standard supports. An interface definition language (IDL) file that identifies the CORBA objects and their interfaces will be compiled with the idl2java translator to generate the stub for the client and the skeleton code for the CORBA server objects. CORBA object programmers are required to program the implementation classes of the CORBA objects defined in the IDL in Java by extending the skeleton classes generated and load them to the database together with the skeleton code.
Module Demo { interface Greeting { wstring Hello(string str); }; }; >idl2java Greeting.IDL Creating: Demo/Greeting.java Demo/GreetingHolder.java Demo/GreetingHelper.java Demo/_GreetingImpBase.java
public class GreetingImpl extends _GreetingImplBase implements ActivatableObject { public GreetingImpl (String name) { super(name); } public GreetingImpl() { super(); } public org.omg.CORBA.Object _intializeAuroraObject() { return this } public String Hello(String str) { return "Hello" + str; } }
In the above code, the CORBA object Greeting has been implemented with a method called Hello(). The CORBA standard defines the wstring data type to pass multibyte strings via CORBA/IIOP, and the Visigenic ORB implements the wstring data type as a Unicode string. If the string datatype is specified instead, the parameter passed into the Hello() method is assumed to be a single byte. The wstring data type enables the development of multilingual CORBA objects. The implementation class for Greeting extends the skeleton class
_GreetingImplBase generated by idl2java.
Once the CORBA object has been implemented, the below example shows the steps involved in loading the Java object implementation classes into the database and publishing the Java CORBA object using the CosNaming convention.
loadjava -user scott/tiger -grant public Greeting.jar publish -user scott -password tiger -service sess_iiop://local:2222:orcl/Demo/MyGreeting Demo.GreetingImpl Demo.GreetingHelper
Assume that all Java classes (implementation and helper classes) required to implement the Greeting object are in the Greeting.jar file. They are loaded to the database as public, and the implementation class is published to the database. The name of the published object is /Demo/MyGreeting, and it is used in the client code to reference this CORBA object.
Clients accessing a CORBA object in the database require an ORB and authentication from the database where the object is stored. The following is a excerpt of a client code in Java accessing the Greeting object. The ORB is initialized when the CORBA object is first activated by means of Oracle's implementation of the Java Native Directory Interface (JNDI).
import java.util.Hashtable; import javax.naming.*; import oracle.aurora.jndi.sess_iiop.ServiceCtx; public class Client { public static void main(String args[]) throws Exception { Hashtable environment = new Hashtable(); environment.put(javax.naming.Context.URL_PKG_PREFIXES, "oracle.aurora.jndi"); environment.put(Context.SECURITY_PRINCIPAL, "scott"); environment.put(Context.SECURITY_CREDENTIALS, "tiger"); environment.put(Context.SECURITY_AUTHENTICATION,
ServiceCtx.NON_SSL_CREDENTIAL); Context ic = new InitialContext(environment); Greeting greet = (Greeting) ic.lookup("sess_iiop://local:2222:ORCL/Demo/MyGreeting"); System.out.println(greet.Hello(arg[0])); } }
The database is a secure environment, so Java clients must be authenticated before they can access CORBA objects, and the locale of the Java VM running the CORBA object is initialized when the session running the object is authenticated. To access a CORBA object, you can use explicit or implicit authentication:
The client can initialize the service context object with its user name and password as shown in the above code. The default locale of the client Java VM is implicitly stored in the service context object and passed to the server ORB in the first IIOP request. The server Java VM locale is initialized with the same locale as the client.
The client can call the authenticate() method of the Login object to access the LoginServer CORBA object in the server. The LoginServer object can be accessed without being authenticated. The authenticate() method accepts user name, password, role and Java locale as arguments. If the Java locale argument is not provided, the default locale of the Java VM in the server will be initialized to the database language defined by the NLS_LANGUAGE and NLS_TERRITORY database parameters.
In addition to CORBA objects, Oracle provides tools and an environment for developing and deploying EJBs in the Oracle9i server. An EJB is called using the IIOP protocol provided for CORBA support, and hence shares a lot of similarities with the CORBA object. An EJB is defined in the EJB descriptor, which specifies the home interface, remote interface, home name and allowed identities of the EJB among other things.
The following shows the EJB descriptor for GreetingBean, which is functionally equivalent to the CORBA object Greeting described earlier.
SessionBean GreetingServer.GreetingBean { BeanHomeName = "Demo/MyGreeting"; RemoteInterfaceClassName = hello.Greeting; HomeInterfaceClassName = hello.GreetingHome; AllowedIdentities = { PUBLIC }; RunAsMode = CLIENT_IDENTITY; TransactionAttribute = TX_SUPPORTS; }
An EJB descriptor can be in any encoding supported by the JDK. However, only the AllowedIdentities field can be non-US7ASCII. There are two ways you can specify non-US7ASCII AllowedIdentities:
-encoding command line argument to tell ejbdeploy the encoding of the input file.
The implementation class for the EJB is in GreetingBean.java package GreetingServer;
import javax.ejb.SessionBean; import javax.ejb.CreateException; import javax.ejb.SessionContext; import java.rmi.RemoteException; public class GreetingBean implements SessionBean { // Methods of the Greeting interface public String Hello (String str) throws RemoteException { return "Hello" + str; } // Methods of the SessionBean public void ejbCreate () throws RemoteException, CreateException {} public void ejbRemove() {} public void setSessionContext (SessionContext ctx) {} public void ejbActivate () {} public void ejbPassivate () {} }
Note that all strings passed to the EJB as arguments and returned from the EJB as function values are UTF-16 encoded Java strings.
An EJB resembles a CORBA object in that it is required to be published before being referenced. The EJB Home name specified in the EJB descriptor will be used to publish. For example:
deployejb -republish -temp temp -u scott -p tiger -encoding Unicode -s sess_iiop://local:2222:ORCL -descriptor Greeting.ejb server.jar
Because deployejb uses IIOP to connect to Oracle, the service name for the IIOP service of the database server has to be specified. Also, server.jar should contain the class files for the home interface object, remote interface object, and the bean implementation object of the EJB Greeting. Note that the -encodingargument is required if the EJB descriptor file Greeting.ejb is in different encoding from the default encoding of the Java VM. In this example, the Greeting.ejb is a Unicode text file.
An EJB client is like a CORBA client in that it can be a Java program using Oracle's JNDI interface to authenticate a session and look for the EJB object in the database server. To look for the corresponding EJB object, the EJB client looks for the home interface object whose name is specified in the EJB descriptor and calls the create() method of this home interface object to create the EJB instance in the database server. After the instance of the EJB is created, you can call the methods within it.
The following code shows how the EJB client calls the Hello() method of the EJB called Demo.Greeting. It is functionally equivalent to the code of the CORBA Client in the previous section, but uses the explicit authentication mechanism.
import Demo.Greeting; //Remote interface object import Demo.GreetingHome; //Home interface object import javax.naming.*; import java.util.Hashtable; import oracle.aurora.jndi.sess_iiop.ServiceCtx; import oracle.aurora.client.*; public class Client { public static void main (String[] args) throws Exception { Hashtable environment = new Hashtable (); environment.put (Context.URL_PKG_PREFIXES, "oracle.aurora.jndi"); Context ic = new InitialContext (environment); // Login to the 9i server LoginServer lserver = (LoginServer) ic.lookup ("sess_iiop://local:2222:ORCL/etc/login"); Login li = new Login (lserver) li.authenticate (username, password, null); // Activate a Greeting instance in the 9i server // This creates a first session in the server GreetingHome greetingHome = (GreetingHome) ic.lookup ("sess_iiop://local:2222:ORCL/Demo/MyGreeting"); Greeting greet = greetingHome.create (); System.out.println (greet.Hello (arg[0])); } }
Similar to the implicit authentication mechanism, the explicit authentication protocol, li.authenticate(), will automatically pass the default Java locale of the client to the LoginServer object in the database server. This Java locale will be used to initialize the Java locale of the server Java VM on which the EJB runs. In addition, the NLS_LANGUAGE and NLS_TERRITORY session parameters will be set to reflect this Java VM locale. This is to preserve the locale settings from EJB client to EJB server so that server uses the same language as the client.
To develop and deploy multilingual Java applications for Oracle9i, the database configurations and client environments for the targeted systems have to be determined.
In order to store multilingual data into an Oracle9i database, you need to configure the database appropriately. There are two ways to store Unicode data into the database:
CHAR datatypes in a Unicode database
NCHAR datatypes in a non-Unicode database
Chapter 5, "Supporting Multilingual Databases with Unicode" for more information about choosing a Unicode solution and configuring the database for Unicode
See Also:
For each Oracle9i session, a separate Java VM instance is created in the server for running the Java object, and Oracle9i Java support ensures that the locale of the Java VM instance is the same as that of the client Java VM. Hence the Java objects always run on the same locale in the database as the client locale.
For non-Java clients, the default locale of the Java VM instance will be the best matched Java locale corresponding to the NLS_LANGUAGE and NLS_TERRITORY session parameters propagated from the client NLS_LANG environment variable. In case of JSP and Java servlets, there is no NLS_LANG environment, the Java servlet is responsible to determine the locale of the client and synchronize it with the default Java locale of the Java VM instance on which the Java servlet runs.
Java objects in the database such as Java stored procedures, Java servlets, Java CORBA, and EJB objects are server objects which are accessible from clients of different language preferences. They should be internationalized so that they are sensitive to the Java locale of the Java VM, which is initialized to the locale of the client.
With JDK internationalization support, you are able to specify a Java locale object to any locale-sensitive methods or use the default Java locale of the Java VM for those methods. Here are examples of how you may want to internationalize a Java stored procedure, Java servlet, Java CORBA object, or EJB:
DateFormat and NumberFormat to format your date, time, numbers and currencies with the assumption that they will reflect the locale of the calling client.
Character, Collator, and BreakIterator to check the classification of a character, compare two strings linguistically, and parse a string character by character.
All Java server objects access the database with the JDBC Server-side Internal driver and should use either a Java string or oracle.sql.CHAR to represent string data to and from the database. Java strings are always encoded in UTF-16, and the required conversion from the database character set to UTF-16 is transparently done as described previously. oracle.sql.CHAR stores the database data in byte array and tags it with a character set ID. It should be used when no string manipulation is required on the data. For example, oracle.sql.CHAR is the best choice for transferring string data from one table to another in the database.
When developing Java CORBA objects, the wstring data type should be used in the IDL as described in "Java CORBA Object" to ensure that Unicode data is being passed from client to server.
Clients (or middle tiers) can have different language preferences, database access mechanisms, and Java runtime environments. The following are several commonly used client configurations.
A CORBA client written in Java can access CORBA objects in the database server via IIOP. The client can be of different language environments. Upon log in, the locale of the Java VM running the CORBA client will be automatically sent to the database ORB, and is used to initialize the Java VM session running the server objects. The use of the wstring data type of the server objects ensures the client and server communicate in Unicode.
Java applets running in browsers can access the Oracle9i database via the JDBC Thin driver. No client-side Oracle library is required. The applets use the JDBC Thin driver to invoke SQL, PL/SQL as well as Java stored procedures. The JDBC Thin driver makes sure that Java stored procedures run in the same locale as the Java VM running the applets.
HTML pages invoke Java servlets via URLs over HTTP. The Java servlets running in the database construct dynamic HTML pages and deliver back to the browser. They should determine the locale of a user and construct the page according to the language and cultural convention preferences of the user.
Java applications running on the Java VM of the client machine can access the database via either JDBC OCI or JDBC Thin drivers. Java applications can also be a middle tier servlet running on a Web server. The applications use JDBC drivers to invoke SQL, PL/SQL as well as Java stored procedures. The JDBC Thin and JDBC OCI drivers make sure that Java stored procedures will be running in the same locale as that of the client Java VM.
Non-Java clients can call Java stored procedures the same way they call PL/SQL stored procedures. The Java VM locale is the best match of Oracle's language settings NLS_LANGUAGE and NLS_TERRITORY propagated from the NLS_LANG environment variable of the client. As a result, the client always gets messages from the server in the language specified by NLS_LANG. Data in the client are converted to and from the database character set by OCI.
This section contains a simple bookstore application written in SQLJ to demonstrate a database storing book information of different languages, and how SQLJ and JDBC are used to access the book information from the database. It also demonstrates the use of internationalized Java stored procedures to accomplish transactional tasks in the database server. The sample program consists of the following components:
UTF8 is used as the database character set to store book information, such as names and authors, in languages around the world. The following tables in Figure 9-7 are defined for storing the book and inventory information of the store.
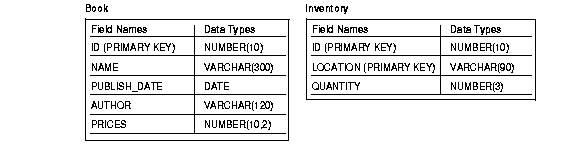
In addition, indexes are built with the NAME and AUTHOR columns of the BOOK table to speed up searching for books. A BOOKSEQ sequence will be created to generate a unique Book ID.
The Java class called Book is created to implement the methods Book.remove() and Book.add() that perform the tasks of removing books from and adding books to the inventory respectively. They are defined according to the following code. In this class, only the remove() method and the constructor are shown. The resource bundle BookRes.class is used to store localizable messages. The remove() method returns a message gotten from the resource bundle according to the current Java VM locale. There is no JDBC connection required to access the database because the stored procedure is already running in the context of a database session.
import java.sql.*; import java.util.*; import sqlj.runtime.ref.DefaultContext; /* The book class implementation the transaction logics of the Java stored procedures.*/ public class Book { static ResourceBundle rb; static int q, id; static DefaultContext ctx; public Book() { try { DriverManager.registerDriver(new oracle.jdbc.driver.OracleDriver()); DefaultContext.setDefaultContext(ctx); rb = java.util.ResourceBundle.getBundle("BookRes"); } catch (Exception e) { System.out.println("Transaction failed: " + e.getMessage()); } } public static String Remove(int id, int quantity, String location) throws SQLException { rb = ResourceBundle.getBundle("BookRes"); try { #sql {SELECT QUANTITY INTO :q FROM INVENTORY WHERE ID = :id AND LOCATION = :location}; if (id == 1) return rb.getString ("NotEnough"); } catch (Exception e) { return rb.getString ("NotEnough"); } if ((q - quantity) == 0) { #sql {DELETE FROM INVENTORY WHERE ID = :id AND LOCATION = :location}; try { #sql {SELECT SUM(QUANTITY) INTO :q FROM INVENTORY WHERE ID = :id}; } catch (Exception e) { #sql { DELETE FROM BOOK WHERE ID = :id }; return rb.getString("RemoveBook"); } return rb.getString("RemoveInventory"); } else { if ((q-quantity) < 0) return rb.getString ("NotEnough"); #sql { UPDATE INVENTORY SET QUANTITY = :(q-quantity) WHERE ID = :id and LOCATION = :location }; return rb.getString("DecreaseInventory"); } } public static String Add( String bname, String author, String location, double price, int quantity, String publishdate ) throws SQLException { rb = ResourceBundle.getBundle("BookRes"); try { #sql { SELECT ID into :id FROM BOOK WHERE NAME = :bname AND AUTHOR = :author }; } catch (Exception e) { #sql { SELECT BOOKSEQ.NEXTVAL INTO :id FROM DUAL }; #sql { INSERT INTO BOOK VALUES (:id, :bname, TO_DATE(:publishdate,'YYYY-MM-DD'), :author, :price) }; #sql { INSERT INTO INVENTORY VALUES (:id, :location, :quantity) }; return rb.getString("AddBook"); } try { #sql { SELECT QUANTITY INTO :q FROM INVENTORY WHERE ID = :id AND LOCATION = :location }; } catch (Exception e) { #sql { INSERT INTO INVENTORY VALUES (:id, :location, :quantity) }; return rb.getString("AddInventory"); } #sql { UPDATE INVENTORY SET QUANTITY = :(q + quantity) WHERE ID = :id AND LOCATION = :location }; return rb.getString("IncreaseInventory"); } }
After the Book.remove() and Book.add() methods are defined, they are in turn published as Java stored functions in the database called REMOVEBOOK() and ADDBOOK() as follows:
CREATE FUNCTION REMOVEBOOK (ID NUMBER, QUANTITY NUMBER, LOCATION VARCHAR2) RETURN VARCHAR2 AS LANGUAGE JAVA NAME 'Book.remove(int, int, java.lang.String) return java.lang.String'; CREATE FUNCTION ADDBOOK (NAME VARCHAR2, AUTHOR VARCHAR2, LOCATION VARCHAR2, PRICE NUMBER, QUANTITY NUMBER, PUBLISH_DATE DATE) RETURN VARCHAR2 AS LANGUAGE JAVA NAME 'Book.add(java.lang.String, java.lang.String, java.lang.String, double, int, java.sql.Date) return java.lang.String';
Note that the Java string returned will first be converted to a VARCHAR2 string, which is encoded in the database character set, before they are passed back to the client. If the database character is not UTF8, any Unicode characters in the Java strings that cannot be represented in the database character set will be replaced by ?. Similarly, the VARCHAR2 strings, which are encoded in the database character set, are converted to Java strings before being passed to the Java methods.
The SQLJ client is a GUI Java application using either a JDBC Thin or JDBC OCI driver. It connects the client to a database, displays a list of books given a searching criterion, removes selected books from the inventory, and adds new books to the inventory. A class called BookDB is created to accomplish these tasks, and it is defined in the following code.
A BookDB object is created when the sample program starts up with the user name, password, and the location of the database. The methods are called from the GUI portion of the applications. The methods removeBook() and addBook() call the corresponding Java stored functions in the database and return the status of the transaction. The methods searchByName() and searchByAuthor() list books by name and author respectively, and store the results in the iterator books (the BookRecs class is generated by SQLJ) inside the BookDB object. The GUI code in turn calls the getNextBook() function to retrieve the list of books from the iterator object until a NULL is returned. The getNextBook() function simply fetches the next row from the iterator.
package sqlj.bookstore; import java.sql.*; import sqlj.bookstore.BookDescription; import sqlj.runtime.ref.DefaultContext; import java.util.Locale; /*The iterator used for a book description when communicating with the server*/ #sql iterator BooksRecs( int ID, String NAME, String AUTHOR, Date PUBLISH_DATE, String LOCATION, int QUANTITY, double PRICE); /*This is the class used for connection to the server.*/ class BookDb { static public final String DRIVER = "oracle.jdbc.driver.OracleDriver"; static public final String URL_PREFIX = "jdbc:oracle:thin:@"; private DefaultContext m_ctx = null; private String msg; private BooksRecs books; /*Constructor - registers the driver*/ BookDb() { try { DriverManager.registerDriver ((Driver) (Class.forName(DRIVER).newInstance())); } catch (Exception e) { System.exit(1); } } /*Connect to the database.*/ DefaultContext connect(String id, String pwd, String userUrl) throws SQLException { String url = new String(URL_PREFIX); url = url.concat(userUrl); Connection conn = null; if (m_ctx != null) return m_ctx; try { conn = DriverManager.getConnection(url, id, pwd); } catch (SQLException e) { throw(e); } if (m_ctx == null) { try { m_ctx = new DefaultContext(conn); } catch (SQLException e) { throw(e); } } return m_ctx; } /*Add a new book to the database.*/ public String addBook(BookDescription book) { String name = book.getTitle(); String author = book.getAuthor(); String date = book.getPublishDateString(); String location = book.getLocation(); int quantity = book.getQuantity(); double price = book.getPrice(); try { #sql [m_ctx] msg = {VALUE ( ADDBOOK ( :name, :author, :location, :price, :quantity, :date))}; #sql [m_ctx] {COMMIT}; } catch (SQLException e) { return (e.getMessage()); } return msg; } /*Remove a book.*/ public String removeBook(int id, int quantity, String location) { try { #sql [m_ctx] msg = {VALUE ( REMOVEBOOK ( :id, :quantity, :location))}; #sql [m_ctx] {COMMIT}; } catch (SQLException e) { return (e.getMessage()); } return msg; } /*Search books by the given author.*/ public void searchByAuthor(String author) { String key = "%" + author + "%"; books = null; System.gc(); try { #sql [m_ctx] books = { SELECT BOOK.ID, NAME, AUTHOR, PUBLISH_DATE, LOCATION, QUANTITY, PRICE FROM BOOK, INVENTORY WHERE BOOK.ID = INVENTORY.ID AND AUTHOR LIKE :key ORDER BY BOOK.ID}; } catch (SQLException e) {} } /*Search books with the given title.*/ public void searchByTitle(String title) { String key = "%" + title + "%"; books = null; System.gc(); try { #sql [m_ctx] books = { SELECT BOOK.ID, NAME, AUTHOR, PUBLISH_DATE, LOCATION, QUANTITY, PRICE FROM BOOK, INVENTORY WHERE BOOK.ID = INVENTORY.ID AND NAME LIKE :key ORDER BY BOOK.ID}; } catch (SQLException e) {} } /*Returns the next BookDescription from the last search, null if at the end of the result list.*/ public BookDescription getNextBook() { BookDescription book = null; try { if (books.next()) { book = new BookDescription(books.ID(), books.AUTHOR(), books.NAME(), books.PUBLISH_DATE(), books.PRICE(), books.LOCATION(), books.QUANTITY()); } } catch (SQLException e) {} return book; } }
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|