Release 9.0.1
Part Number A90122-01
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle Text Application Developer's Guide Release 9.0.1 Part Number A90122-01 |
|
![]()
![]()
![]()
Indexing, 2 of 6
An Oracle Text index is an Oracle domain index.To build your query application, you can create an Oracle Text index of type CONTEXT and query it with the CONTAINS operator.
For better performance for mixed queries, you can create a CTXCAT index. Use this index type when your application relies heavily on mixed queries to search small documents or descriptive text fragments based on related criteria such as dates or prices. You query this index with the CATSEARCH operator.
To build a document classification application, you create an Oracle Text index of type CTXRULE. With such an index, you can classify plain text, HTML, or XML documents using the MATCHES operator.
You create an index from a populated text table. In a query application, the table must contain the text or pointers to where the text is stored. Text is usually a collection of documents, but can also be small text fragments. If you are building a document classification application, you store your defining query set in the text table.
You create a text index as a type of extensible index to Oracle using standard SQL. This means that an Oracle Text index operates like an Oracle index. It has a name by which it is referenced and can be manipulated with standard SQL statements.
The benefits of a creating an Oracle Text index include fast response time for text queries with the CONTAINS, CATSEARCH, and MATCHES Oracle Text operators. These operators query the CONTEXT, CTXCAT, and CTXRULE index types respectively.
Oracle Text indexes text by converting all words into tokens. The general structure of an Oracle Text CONTEXT index is an inverted index where each token contains the list of documents (rows) that contain that token.
For example, after a single initial indexing operation, the word DOG might have an entry as follows:
DOG DOC1 DOC3 DOC5
This means that the word DOG is contained in the rows that store documents one, three and five.
For more information, see optimizing the index in this chapter.
By default in English and French, Oracle Text indexes theme information with word information. You can query theme information with the ABOUT operator. You can optionally enable and disable theme indexing.
|
See Also:
To learn more about indexing theme information, see "Creating Preferences" in this chapter. |
You initiate the indexing process with the CREATE INDEX statement. The goal is to create an Oracle Text index of tokens according to the parameters and preferences you specify.
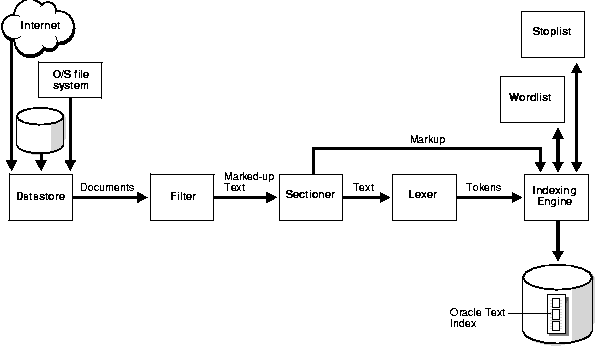
Figure 2-1 shows the indexing process. This process is a data stream that is acted upon by the different indexing objects. Each object corresponds to an indexing preference type or section group you can specify in the parameter string of CREATE INDEX or ALTER INDEX. The sections that follow describe these objects.
The stream starts with the datastore reading in the documents as they are stored in the system according to your datastore preference. For example, if you have defined your datastore as FILE_DATASTORE, the stream starts by reading the files from the operating system. You can also store you documents on the internet or in the Oracle database.
The stream then passes through the filter. What happens here is determined by your FILTER preference. The stream can be acted upon in one of the following ways:
After being filtered, the marked-up text passes through the sectioner that separates the stream into text and section information. Section information includes where sections begin and end in the text stream. The type of sections extracted is determined by your section group type.
The section information is passed directly to the indexing engine which uses it later. The text is passed to the lexer.
The lexer breaks the text into tokens according to your language. These tokens are usually words. To extract tokens, the lexer uses the parameters as defined in your lexer preference. These parameters include the definitions for the characters that separate tokens such as whitespace, and whether to convert the text to all uppercase or to leave it in mixed case.
When theme indexing is enabled, the lexer analyses your text to create theme tokens for indexing.
The indexing engine creates the inverted index that maps tokens to the documents that contain them. In this phase, Oracle uses the stoplist you specify to exclude stopwords or stopthemes from the index. Oracle also uses the parameters defined in your WORDLIST preference, which tell the system how to create a prefix index or substring index, if enabled.
You can create a partitioned CONTEXT index on a partitioned text table. The table must be partitioned by range. Hash, composite and list partitions are not supported.
You might create a partitioned text table to partition your data by date. For example, if your application maintains a large library of dated news articles, you can partition your information by month or year. Partitioning simplifies the manageability of large databases since querying, DML, and backup and recovery can act on single partitions.
To query a partitioned table, you use CONTAINS in the SELECT statement no differently as you query a regular table. You can query the entire table or a single partition. However, if you are using the ORDER BY SCORE clause, Oracle recommends that you query single partitions unless you include a range predicate that limits the query to a single partition.
Oracle Text supports parallel indexing with CREATE INDEX on a partitioned text table.
The parallel indexing operation creates multiple threads where each thread works on a partition. Since indexing is an I/O intensive operation, parallel indexing is most effective in decreasing your indexing time when you have distributed disk access and multiple CPUs.
Since parallel indexing decreases the initial indexing time, it is useful for
A column can have no more than a single domain index attached to it, which is in keeping with Oracle standards. However, a single Text index can contain theme information in addition to word information.
Oracle SQL standards does not support creating indexes on views. Therefore, if you need to index documents whose contents are in different tables, you can create a data storage preference using the USER_DATASTORE object. With this object, you can define a procedure that synthesizes documents from different tables at index time.
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|