Release 2 (v9.0.2)
Part Number A95949-01
Home |
Solution Area |
Contents |
Index |
| Oracle9i Warehouse Builder User's Guide Release 2 (v9.0.2) Part Number A95949-01 |
|
This appendix contains information about partition exchange loading, which is available during the physical configuration of the warehouse. This appendix includes:
There are many reasons for creating and maintaining data warehouses. One of them is the expected high performance that a data warehouse could bring to business applications, such as DSS, OLAP, and Data Mining. These applications share a salient characteristic: they often need to query a large amount of historical data organized along a time dimension. The horizontal data partitioning technology, available since Oracle8TM, can effectively help the queries cut down the amount of data that have to be processed by many levels of magnitude. This is done through an automatic mechanism in the Oracle SQL optimizer known as partition pruning. Data partitioning is also an enables the backup and/or removal of dormant data that has aged out over time.
The way data is partitioned is a key data warehouse design issue, which must be considered after the logical design of a data warehouse. Oracle9i Warehouse Builder provides assistance in partitioning various physical objects, including tables, dimensions, facts, materialized views, and indexes.
With Warehouse Builder, design for data partitioning has one added importance: it can also be leveraged within a certain context to achieve significant performance gains in the process of loading a data warehouse. This new Warehouse Builder runtime performance feature is known as Partition Exchange Loading (PEL).
PEL technique performs loading of new data by exchanging them into a target table as a partition. What actually get exchanged are merely identities, in the following manner. The table that holds the new data takes over the identity of one empty partition from the target table; at the same time, this empty partition assumes the identity of the source table. The whole exchange process is purely a DDL operation. No data movement is involved. The general idea of PEL is depicted in Figure D-1.
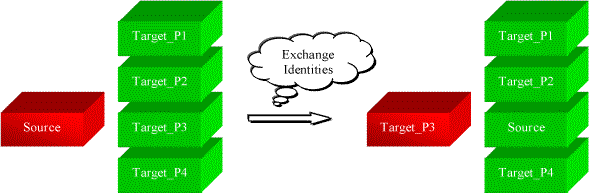
In Figure D-1, data from the Source table needs to be inserted into a target table consisting of four partitions: Target_P1, Target_P2, Target_P3, and Target_P4. Suppose that the new data needs to be loaded into Target_P3. The partition exchange operation will swap the names on the data objects. The actual data never moves. After the exchange, the Source table is renamed Target_P3, and the Target_P3 is renamed Source. Most importantly, the target table is still composed of four partitions named Target_P1, Target_P2, Target_P3, and Target_P4. The partition exchange operation provided by Oracle8TM completes the loading process without generating the need for data movement.
Figure D-1 shows a highly simplified case where only one table is presented as a source, and there is an implicit assumption that this source table is readily available for changing its identity. Being a general data warehouse design tool, Warehouse Builder operations are not this simple. Warehouse Builder must be prepared for the more general possibility, that the source may be the results from a join of multiple source tables. Some of these source tables may also be located in other databases.
In general, there may not be a single local table for partition exchange. The design decision in Warehouse Builder is to automatically create a temporary table which materializes results from source processing before the partition exchange actually happens.
Will the materialization of results from source processing hurt performance? Will it render the PEL useless since data movement (i.e., DML) has not been avoided? In the case that there is no single local table for partition exchange, it is quite obvious that avoiding DML entirely is not possible. As such, the PEL's performance potential can only be gauged by an examination of how it does DMLs, and specifically, the INSERTs. The remainder of this section presents a brief explanation of how PEL works. This should answer the above questions. Getting familiar with the technical background will be very important to you if you plan to use the Partition Exchange Loading feature.
When you use PEL, a new temporary or staging table is automatically created to hold results from source processing. Because this staging table is purely internal to the PEL process and invisible to general users, the PEL process does not create any indexes and constraints before the INSERT operation is completed. This measure can drastically reduce the amount of data that need to be processed due to index maintenance and foreign key lookups.
In contrast, using the normal non-PEL style processing requires data to be directly inserted into the target that often has to carry several huge indexes and many constraints. Of course, you could choose to drop all the indexes and disable all the constraints before loading, but when the target has accumulated enough historical data, recreating indexes and re-enabling constraints after loading may be a very costly decision.
After new data has been loaded into the temporary table, the PEL method creates all the indexes on the temporary table only. The index creations benefit from a parallel index creation mechanism provided by the Oracle database server. It also uses the NOLOGGING option to further speed up the index building process. Using the PARALLEL NOLOGGING options, index creations generate writes for only the index structures, and I/O conflicts are minimized. As the result, the index creation time is minimized.
After indexes have been created on the temporary table, primary and unique keys are instantly enabled and validated a by using the USING INDEX option of the ALTER TABLE ADD CONSTRAINT command.
Foreign key constraints are maintained by making use of a new parallel validation feature in Oracle8i. This is done by first adding a foreign key constraint in ENABLED NOVALIDATE state. Then, a subsequent command does the real foreign key validation in parallel. Adding a foreign key with ENABLED NOVALIDATE status does not hinder performance. The subsequent parallel constraint validation can fully utilize system resources. The overall design is an optimal constraint maintenance mechanism.
In contrast, if the PEL is not used, it can be an almost impossible task to disable and re-enable existing constraints. Suppose, for example, 500,000 rows of new data generated from one-day activities have been inserted into a target table already containing 500 million rows of data; and one primary constraint and one foreign key constraint were disabled before loading and they must now be re-enabled. This whole process amounts to scanning more than 500 million rows of data twice, plus building a unique index. It could be hundreds of times slower than if only the new data was manipulated as in PEL.
Whenever an error is encountered during inserting into the temporary table, building indexes, or enabling constraints, the temporary table is dropped and the error logged. The target is not altered. Data in the target is still in its previous state.
During the entire PEL loading process, except for the final partition exchange step (which normally takes almost no time because it is a pure DDL operation), the target table is always available for any database operations, including any DML operations.
In PEL, insertion into the temporary table is always done using parallel direct-path INSERT. On a multiprocessor machine with a correctly striped tablespace, more than 90% utilization on each CPU can be consistently achieved. The insertion completes in the shortest possible time.
In contrast, if the PEL method is not used, several factors can hinder the loading process from fully utilizing the CPU resource. First, index maintenance can generate more I/O requests and reduce CPU utilization. (The PEL technique would have no index maintenance during insert.) Second, when loading into a partitioned table, a more serious issue results from the fact that Oracle8i assigns only one server process to each partition. If all data must go into same partition as is true for incremental loading of daily or monthly data, the loading process runs serially, as shown in Figure D-2.
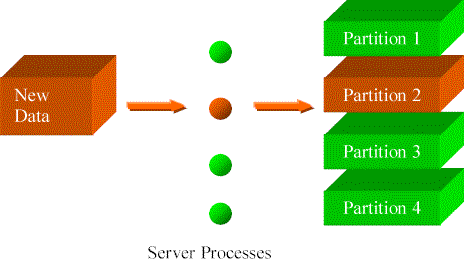
A concrete measurement can help understand the performance impact of incremental loading into only one partition of a partitioned table. On a Sun Ultra 450 server with four 400Mhz CPUs, 6 million rows from one daily collection are inserted into a target table that is partitioned by day. The completion time is 3 minutes 9 seconds. But when the same amount of data is inserted into a non-partitioned table using parallel direct-path INSERT, it completes in 1 minute 48 seconds. So the serial insert in the partitioned case lost roughly two times of performance on the 4-processor machine. The PEL method solves this problem by always performing parallel direct-path INSERT into a non-partitioned table.
Like all performance features, the PEL technique is advantageous only in a certain context, and can be deemed not useful in some other situations. The foremost condition required by the PEL is that the target table must be partitioned. Another condition under which the PEL could provide greatest performance benefit is if target table has already accumulated a huge amount of historical data. An example is an application where the warehouse collects data from an OLTP database or Web log files daily. Each row of source data is about one mouse click from a Web user. Depending on the popularity of the site, as much as several million rows per day could be generated. These data then need to be transformed and loaded into a data warehouse holding a lot more historical data, e.g., from the past five years. For this type of situations, the PEL will be the key to scalable loading performance that makes the loading time correlated only to the amount of new data.
A third condition under which the PEL can help greatly is when all the new data must be loaded into the same partition in a target table, as shown in Figure D-2. If the data warehouse collection is scheduled on a regular basis, this condition can normally be satisfied.
Again, take the clickstream warehouse as an example. If the target table is partitioned by day, then all the daily data will have to be loaded into one partition. The non-PEL loading will go serially, but the PEL will be able to run parallel direct-path INSERT.
In case the target table is partitioned by month and the collection of new clickstream data is still scheduled daily, new data may have to be inserted into a nonempty partition. In case the target partition is not empty, the PEL process will not actually perform partition exchange. It will directly insert new data into one explicitly specified partition, still using parallel direct-path INSERT. The drawback on performance is that the insertion is accompanied by simultaneous index and constraint maintenance. Therefore, using the PEL method to load data into a nonempty partition will go slower than if the target partition is empty.
Still a third case in our clickstream example: assume the target table is partitioned by hour and new data is still collected daily. New data collected from one day will be able to go into separate partitions in parallel. In this case, the PEL is not useful anymore. In fact, in Warehouse Builder, the PEL does not work for such a case. Table D-1 summarizes these three possibilities.
As Table D-1 shows, the PEL method can be used in the case that the loading size is less than or equal to the partition granularity of the target. In Warehouse Builder, you can specify the target partition granularity. But there is currently no validation to check if the loading size is not larger than the partition granularity.
This section presents a step-by-step example showing how the Partition Exchange Loading feature can be used in Warehouse Builder. Two areas need configuration: the mapping and the target table, dimension, or fact. This section first describes an example mapping, then explains what needs to be configured in the mapping and the target.
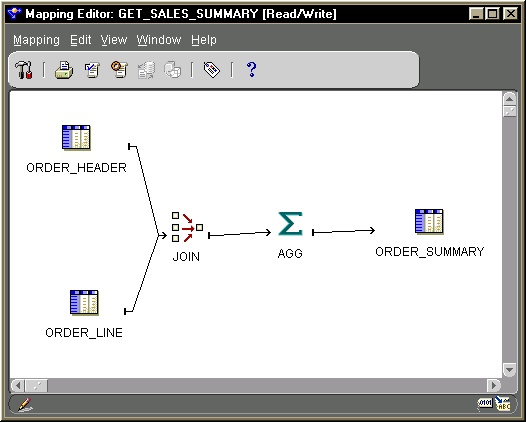
Suppose it has been decided that all new data to ORDER_SUMMARY table will always go into same partition, and most times they go into an empty partition. Partition Exchange Loading into the ORDER_SUMMARY table appears to be a good strategy under these conditions.
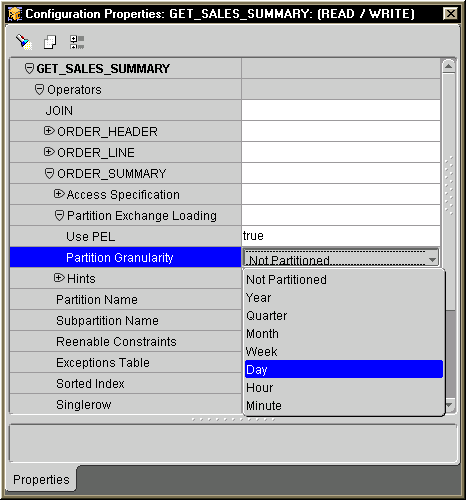
In order to configure the mapping to use PEL, open the Mapping Properties inspector. The Properties inspector for the GET_SALES_SUMMARY is show in Figure D-4. In the property inspector window and within the Operators category, each of the sources and the target starts a property group. Expand the property group for ORDER_SUMMARY as in Figure D-4. You will see a subgroup labeled Partition Exchange Loading. Within this group, two properties must be configured. The first is a Boolean property named set PEL. Set to true for this property. The other property is named Partition Granularity. This property tells Warehouse Builder's PL/SQL code generator how the target table (ORDER_SUMMARY) is partitioned. There are seven levels of partition granularity you can choose from, as shown in Figure D-4.
Suppose the ORDER_SUMMARY table is partitioned by day. We then select Day from the drop-down list as the value for the Partition Granularity property. And that is all we need to do on the mapping in order to enable the Partition Exchange Loading feature. Once the PEL is enabled, the Warehouse Builder code generator will generate a different kind of batch processing code.
After the mapping is configured, there is still one more area of configuration to be done. This second area of configuration is for the target. It turns out that the process for configuring the target is a lot more complicated than the process for configuring the mapping.
To configuring the target, follow these steps:
All the partitions must be created before the PEL method can be used. Warehouse Builder users can use the table/dimension/fact inspector to add partitions and to modify their properties. After a partitioned object has been deployed into database, the DBA can also add more partitions or to merge several partitions together. In the following explanation about Step 1, only the instructions on how to use Warehouse Builder to create partitioned table are given. On the possible DBA operations, please refer to Oracle8i Server Administration Guide.
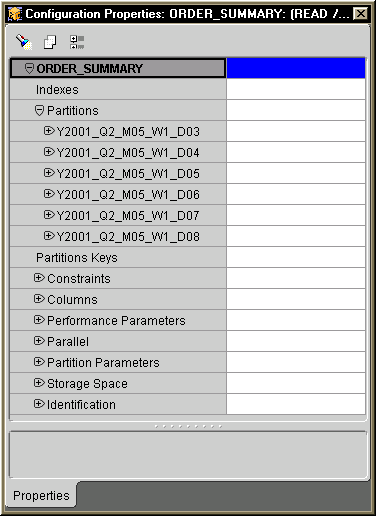
In our example, since we selected Day as partition granularity for ORDER_SUMMARY table when configuring the mapping, we need to create all the needed daily partitions, one for each day of new data. To create partitions for a table, dimension, or fact, use its property inspector. Figure D-5 below shows the property inspector window for the table ORDER_SUMMARY. This figure shows that six partitions have been added for this table. (The instructions on how these partitions are added are not included.)
Notice the naming of all the partitions in Figure D-5. Although Warehouse Builder users must manually key in those names when they use Warehouse Builder to add partitions, all partition names must follow a strict naming convention. For example, for the partition that will hold data for May 3, 2001, its name must be Y2001_Q2_M05_W1_D03.
The partition naming convention is in fact very straightforward. For example, the partition name Y2001_Q2_M05_W1_D03 corresponds to Year 2001, Quarter 2, Month 5, Week 1, and Day 3, which is exactly May 3, 2001. But can the same partition be simply named Y2001_M05_D03 without the quarter and week information? The answer is no. The partition name must contain information of all the time levels leading to the intended granularity.
The detailed naming scheme is designed for ease of partition administration later. If the DBA decides to merge all the daily partitions into monthly partitions, the DBA can easily find which partitions to merge together based on their names. For example, all the daily partitions for May 2001 are named like Y2001_Q2_M05*. (Here the asterisk means a wildcard matching a string of characters.) They can be merged to form a renamed partition Y2001_Q2_M05. Furthermore, this naming scheme helps create a consistency between the partitions' name ordering and value ordering. That is, if the partitions are sorted based on the partition names, the partitions holding smaller DATE values will appear earlier.
However, to many people, figuring out to which quarter and week a date belongs, as is required by the naming convention, is not as immediate as figuring out its day, month, and year components. This may lead to errors during partition creations. If partitions are created with errors, it will be extremely difficult to correct them later. To help eliminate errors during partition creations, you may find the two PL/SQL functions toward the end of this appendix very useful.
Function Example 1: GET_PN contains source code for a stand-alone PL/SQL function named get_pn, which stands for get partition name. It can help Warehouse Builder users calculate partition name from a given date value. For example, if we want to find the correct partition name for the partition containing value May 3, 2001, and we want to partition target table by day, the correct partition name can be obtained by issuing a SQL statement that calls the get_pn function as follows:
SQL> SELECT get_pn(TO_DATE('03-MAY-2001','DD-MON-YYYY'), 2 'DAY') partition_name 3 FROM DUAL; PARTITION_NAME --------------------- Y2001_Q2_M05_W1_D03
The first argument is a date value, and the second argument is the partition granularity. The function returns the correct partition name under the intended partition granularity for the partition containing the date value. The above example shows that the correct partition name for the partition containing May 3, 2001 is Y2001_Q2_M05_W1_D03. If, however, the second argument to the get_pn function was Month instead of Day, the partition name result would be Y2001_Q2_M05.
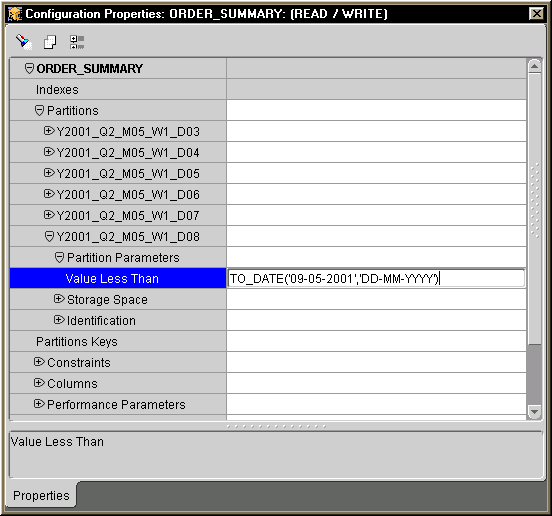
After all the partitions are added with correct names, the partitions must be further configured for their VALUE LESS THAN properties as shown in Figure D-6 below. Figure D-6 shows that the VALUE LESS THAN property for partition Y2001_Q2_M05_W1_D08 is being configured. The property value is TO_DATE(`09-05-2001','DD-MM-YYYY'). Using the name and the VALUE LESS THAN property, Warehouse Builder will generate a DDL script for creating the partitioned table. Part of the DDL script related to the partition shown in Figure D-6 will read as follows.
. . . PARTITION Y2001_Q2_M05_W1_D08 VALUES LESS THAN (TO_DATE(`09-05-2001','DD-MM-YYYY')), . . .
The get_vc function is used in a similar manner as get_pn. First, find any value that would fall within the partition you are trying to calculate the VALUE LESS THAN property value. Then call the get_vc function as follows.
SQL> SELECT get_vc(TO_DATE('08-MAY-2001','DD-MON-YYYY'), 2 'DAY') value_less_than 3 FROM DUAL; VALUE_LESS_THAN ----------------------------------- TO_DATE('09-05-2001','DD-MM-YYYY')
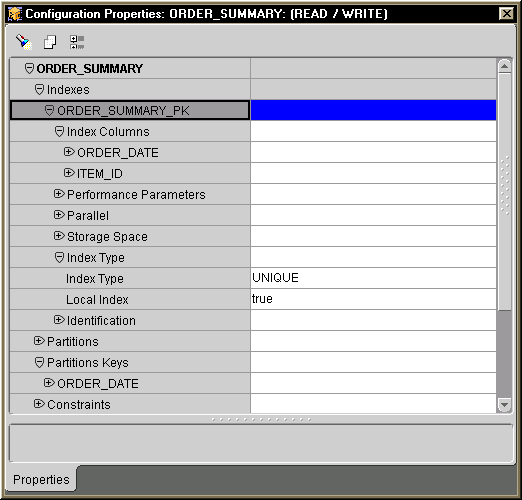
Figure D-7 above shows an index (ORDER_SUMMARY_PK) is added to ORDER_SUMMARY table. This index has two columns, ORDER_DATE and ITEM_ID. The Index Type parameter is set to UNIQUE and the Local Index parameter is set to true. If other indexes existed on the ORDER_SUMMARY table, they should all be configured in this way, i.e., with the Local Index parameter set to true.
Finally, remember that if an index is created as a local index, the partition key column must be the leading column of the index, or the Oracle server does not create the index. In Figure D-7 above, the partition key is ORDER_DATE. It is the leading column in index ORDER_SUMMARY_PK.
The very last step in configuring the target is for specifying that all primary and unique key constraints are created with the USING INDEX option. Using the USING INDEX option, a constraint will not trigger automatic index creation when it is being added to the table. Instead, the server will look among existing indexes for one with same column list as that of the constraint. This naturally implies that each primary or unique key constraint must be backed by a user-defined unique local index.
Figure D-8 below shows an example in which the primary key constraint on ORDER_SUMMARY table is specified with the USING INDEX option. The index that supports this option was created in Step 2 earlier.
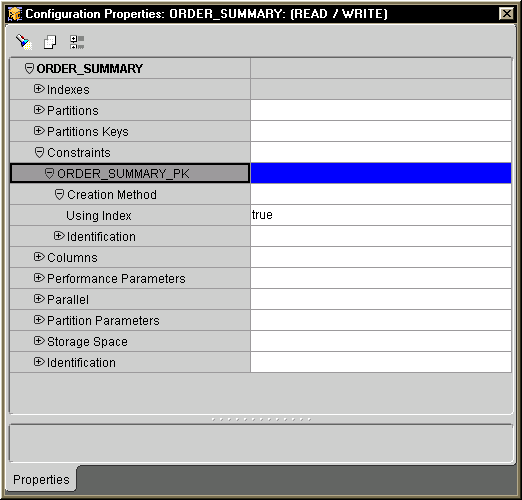
Indexes and constraints can share the same name without problem, and it is customary to create a constraint and its underlying index with the same name as shown in Figure D-7 and Figure D-8.
There are several restrictions that Warehouse Builder users need to be aware of. These restrictions are necessary to minimize the complexity of implementation of the PEL feature. Some of the restrictions might be lifted in future releases.
Currently, only one partition key column is allowed, and this column must be of DATE data type. Numeric partition key is not supported in Warehouse Builder. This will most likely be enhanced in near future releases.
The current PEL method supports only the natural calendar system adopted worldwide. Specific business calendar systems with user-defined fiscal and quarter endings are currently not supported. But this support will most likely be added in near future releases.
The current release requires that all partitions of a target (table, dimension, or fact) must be created in the same tablespace. This requirement is needed for eliminating user intervention during the PEL process. Otherwise, users must pass a runtime parameter to the PEL mapping to specify the target tablespace.
This requirement is established for the same purpose as the restriction 3. Users are thus not required to pass a runtime parameter specifying the index tablespace. However, the index tablespace can be different from the data tablespace.
There can be three possible methods for doing incremental loading into a target, which cumulates historical data. This type of target is usually a fact table. The three loading methods are
The qualitative performance advantages of PEL can clearly be seen in the section on General Feature Description. This section demonstrates the quantitative performance advantage of the PEL over the other two incremental loading methods.
An experiment is performed on a four-processor Sun Ultra 450 server. Each CPU has a speed of 400MHz. The memory size is 2GB. There are twenty 9.1GB internal disk drives. The database is created using Oracle8i Release 3.
The experiment uses each of the three loading methods to do exactly the same loading operations. The loading operations consist of a series of inserts into a target table. Each insert is for loading one-day worth of new data, with a volume of 500,000 rows. In this case the target is partitioned (by day), and each batch goes into one partition. The most important aspect about the target is that there is an index created on it. The index is built on four numeric columns and one DATE column. If the target is partitioned (as is true in Methods 1 and 2), the index is also local.
In this setting, Method 1 (the PEL) will have advantage over other two methods in index maintenance. Method 1 will also have advantage over Method 2 in doing parallel direct-path insert.
Method 2, which employs partitions for index maintenance, will be able to avoid having to traverse in the global index structure that can grow larger as more data are loaded.
The results confirmed the qualitative analysis discussed so far. Method 3 (no PEL on non-partitioned table) is clearly not a good choice. (Imagine what the loading time would be after one year!) Method 2 does maintain independence of load time from already loaded data, but it is about three times slower than the PEL. The lack of parallelism is believed to be the main culprit for the loss of performance in Method 2.
This section is presented only for the purpose of helping Warehouse Builder users better understand how the Partition Exchange Loading works so that they can better plan and use this feature. The explanation below should not be taken as a recipe for custom warehouse construction because the method reported herein might be subject to patent protection, and Oracle only supports the PEL-style PL/SQL code that is generated from Warehouse Builder without modifications.
The PEL technique is a set-based processing method (or generally called batch processing method in the data warehouse field). Therefore, to actually run a mapping with the PEL technique, the processing mode must be set to set-based or set-based with fail-over.
When a mapping using the PEL technique is run, the following things happen, in this order.
Step 1: Find target's tablespace name. If the target has more than one tablespace, the loading process is aborted with an error message like the following.
Step 2: Find the tablespace name for all indexes. If there are more than one tablespace name found, the loading process is aborted with an error message like the following.
Fatal error: all partitions of local indexes on table RT_OWNER.ORDER_SUMMARY must be in one tablespace
Step 3. Create a temporary table that has same schema definition as the target. Should this step fail, the loading process is aborted with the following error message.
Step 4: Parallel direct-path load into the temporary table. If there is anything wrong in this step, the batch processing terminates with an Oracle server error, but the entire loading process is not aborted. The loading process may drop down to row-by-row auditing mode to find error details if the set-based with fail-over mode is selected.
Step 5: Find partition name from the first row of freshly loaded data. If this step fails, the following error message is logged in Warehouse Builder audit trail.
Step 6: If the target partition is not empty, then parallel direct-path insert into the target partition. Oracle server errors may occur and be logged in Warehouse Builder audit trail. But the loading process is not aborted. It may drop down to row-by-row processing if user so configured the mapping. No matter if errors occur, the mapping terminates.
Step 7: If the target partition is empty, all indexes are created on the temporary table. If errors occur in this step, the loading process is not aborted. The row-based process may be invoked if user selected set-based with fail-over mode.
Step 8: Add all constraints, including primary/unique key constraints and foreign key constraints. If errors occur in this step, the loading process is not aborted. The row-based process may be invoked if user selected set-based with fail-over mode.
Step 9: Exchange partition. If error occurs, the loading process is aborted with the following error message.
Step 10. Drop the temporary table. If any error occurs, a warning is logged in Warehouse Builder audit trail, but the mapping is still considered being successful. The warning looks like the following.
Deploy this function in any Oracle database (version 8 or later).
CREATE OR REPLACE FUNCTION get_pn (p_date IN DATE, p_granularity IN VARCHAR2) RETURN VARCHAR2 IS x_pn VARCHAR2(30); x_granularity VARCHAR2(30) := UPPER(p_granularity); BEGIN x_pn := 'Y'||TO_CHAR(p_date, 'YYYY'); IF x_granularity != 'YEAR' THEN x_pn := x_pn||'_Q'||TO_CHAR(p_date,'Q'); IF x_granularity != 'QUARTER' THEN x_pn := x_pn||'_M'||TO_CHAR(p_date,'MM'); IF p_granularity != 'MONTH' THEN x_pn := x_pn||'_W'||TO_CHAR(p_date,'W'); IF p_granularity != 'WEEK' THEN x_pn := x_pn||'_D'||TO_CHAR(p_date,'DD'); IF p_granularity != 'DAY' THEN x_pn := x_pn||'_H'||TO_CHAR(p_date,'HH24'); IF p_granularity != 'HOUR' THEN x_pn := x_pn||'_M'||TO_CHAR(p_date,'MI'); END IF; END IF; END IF; END IF; END IF; END IF; RETURN x_pn; END get_pn; /
Deploy this function in any Oracle database (version 8 or later).
CREATE OR REPLACE FUNCTION get_vc (p_date IN DATE, p_granularity IN VARCHAR2 DEFAULT 'DAY') RETURN VARCHAR2 IS x_vc VARCHAR2(80); x_granularity VARCHAR2(30) := UPPER(p_granularity); x_year NUMBER; x_quarter NUMBER; x_month NUMBER; x_day NUMBER; x_hour NUMBER; x_minute NUMBER; BEGIN IF x_granularity NOT IN ('YEAR', 'QUARTER', 'MONTH', 'WEEK', 'DAY', 'HOUR', 'MINUTE') THEN x_granularity := 'DAY'; END IF; x_year := TO_NUMBER(TO_CHAR(p_date, 'YYYY')); IF x_granularity = 'YEAR' THEN x_year := x_year + 1; x_vc := 'TO_DATE(''01-01-'||x_year||''',''DD-MM-YYYY'')'; ELSE x_quarter := TO_NUMBER(TO_CHAR(p_date, 'Q')); IF x_granularity = 'QUARTER' THEN x_quarter := x_quarter + 1; IF x_quarter = 5 THEN x_year := x_year + 1; x_quarter := 1; END IF; IF x_quarter = 1 THEN x_vc := 'TO_DATE(''01-01-'||x_year||''',''DD-MM-YYYY'')'; ELSIF x_quarter = 2 THEN x_vc := 'TO_DATE(''01-04-'||x_year||''',''DD-MM-YYYY'')'; ELSIF x_quarter = 3 THEN x_vc := 'TO_DATE(''01-07-'||x_year||''',''DD-MM-YYYY'')'; ELSE x_vc := 'TO_DATE(''01-10-'||x_year||''',''DD-MM-YYYY'')'; END IF; ELSE x_month := TO_NUMBER(TO_CHAR(p_date, 'MM')); IF x_granularity = 'MONTH' THEN x_month := x_month + 1; IF x_month = 13 THEN x_year := x_year + 1; x_month := 1; END IF; x_vc := 'TO_DATE(''01-'||TO_CHAR(x_month,'09')||'-'||x_year|| ''',''DD- MM-YYYY'')'; ELSE IF x_granularity = 'WEEK' THEN IF p_date+7 > LAST_DAY(p_date) THEN x_day := 1; x_month := x_month + 1; IF x_month = 13 THEN x_year := x_year + 1; x_month := 1; END IF; ELSE x_day := (TRUNC(TO_NUMBER(TO_CHAR(p_date,'DD'))/7)+1)*7+1; END IF; x_vc := 'TO_DATE('''||TO_CHAR(x_day,'09')||'-'|| TO_CHAR(x_month,'09')||'-'||x_year|| ''',''DD- MM-YYYY'')'; ELSE IF x_granularity = 'DAY' THEN x_vc := 'TO_DATE('''||TO_CHAR(p_date+1,'DD-MM-YYYY')|| ''',''DD-MM-YYYY'')'; ELSE x_day := TO_NUMBER(TO_CHAR(p_date,'DD')); IF x_granularity = 'HOUR' THEN x_hour := TO_NUMBER(TO_CHAR(p_date,'HH24')); IF x_hour = 23 THEN x_vc := 'TO_DATE('''||TO_CHAR(p_date+1,'DD-MM-YYYY')|| ''',''DD-MM-YYYY'')'; ELSE x_hour := x_hour + 1; x_vc := 'TO_DATE('''||TO_CHAR(p_date,'DD-MM-YYYY')|| TO_CHAR(x_hour,'09')|| ''',''DD-MM-YYYY HH24'')'; END IF; ELSE x_minute := TO_NUMBER(TO_CHAR(p_date,'MI')); IF x_minute = 59 THEN IF x_hour = 23 THEN x_vc := 'TO_DATE('''||TO_CHAR(p_date+1,'DD-MM-YYYY')|| ''',''DD-MM-YYYY'')'; ELSE x_hour := x_hour + 1; x_vc := 'TO_DATE('''||TO_CHAR(p_date,'DD-MM-YYYY')|| TO_CHAR(x_hour,'09')|| ''',''DD-MM-YYYY HH24'')'; END IF; ELSE x_minute := x_minute + 1; x_vc := 'TO_DATE('''||TO_CHAR(p_date,'DD-MM-YYYY HH24:')|| TO_CHAR(x_minute,'09')|| ''',''DD-MM-YYYY HH24: MI'')'; END IF; END IF; END IF; END IF; END IF; END IF; END IF; RETURN x_vc; END get_vc; /
|
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|