| Oracle Ultra Search User's Guide Release 9.0.3 Part Number B10043-01 |
|





|
View PDF |
| Oracle Ultra Search User's Guide Release 9.0.3 Part Number B10043-01 |
|
|
View PDF |
This chapter contains the following topics:
Oracle Ultra Search is built on the Oracle database server and Oracle Text technology that provides uniform search-and-locate capabilities over multiple repositories: Oracle databases, other ODBC compliant databases, IMAP mail servers, HTML documents served up by a Web server, files on disk, and more.
Ultra Search uses a `crawler' to index documents; the documents stay in their own repositories, and the crawled information is used to build an index that stays within your firewall in a designated Oracle database. Ultra Search also provides APIs for building content management solutions.
Ultra Search offers the following:
Ultra Search is made up of the following components:
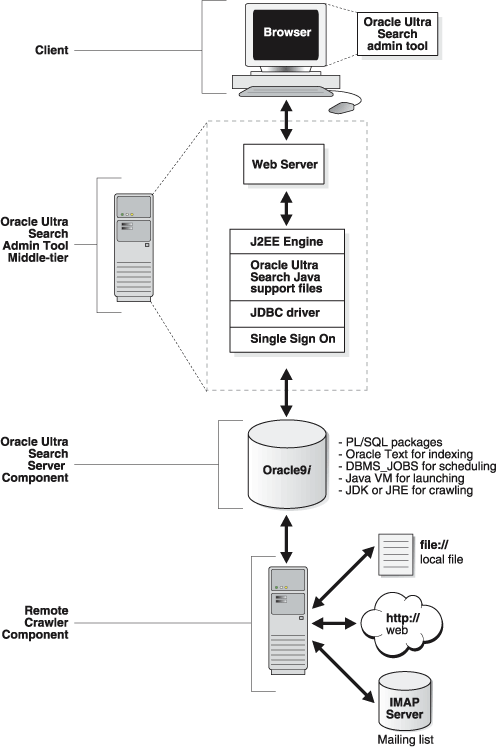
The Ultra Search crawler is a Java process activated by your Oracle server according to a set schedule. When activated, the crawler spawns a configurable number of processor threads that fetch documents from various data sources and index them using Oracle Text. This index is used for querying. Data sources can be Web sites, database tables, files, mailing lists, Oracle Portal page groups, or user-defined data sources.
The crawler maps links and analyzes relationships. The crawler schedule is integrated with and driven from the DBMS_JOB queue mechanism. Whenever the crawler encounters embedded, non-HTML documents during the crawling, it uses Oracle Text filters to automatically detect the document type and filter and index the document.
The Ultra Search server component consists of an Ultra Search repository and Oracle Text. Oracle Text provides the text indexing and search capabilities required to index and query data retrieved from your data sources. The server component is not visible to users; it indexes information from the crawler and serves up the query results.
The administration tool is a JSP Web application to configure and schedule the Ultra Search crawler. The administration tool is typically installed on the same machine as your Web server. You can access the administration tool from any browser in your intranet. The administration tool is independent from the Ultra Search query application. Therefore, the administration tool and query application can be hosted on different machines to enhance security and scalability.
Ultra Search provides the following APIs:
Ultra Search includes highly functional query applications to query and display search results. The query applications are based on Java Server Pages (JSP) and work with any JSP1.1 compliant engine.
Ultra Search is a client program to the Oracle server at run time. It can be deployed in two configurations: in the server tier or in the middle tier.
The Ultra Search default query interface and the administration tool run in any HTML browser client. The administration tool relies on certain Java classes in the middle tier. This logical middle tier can be the same physical machine as the one that runs the database server, or a different one, running Oracle9i AS. The Ultra Search database server component consists of the Ultra Search data dictionary that stores metadata on all the different repositories, as well as the schedules and Java classes needed to drive the crawler. The crawler itself can run either on the database server machine or remotely on another machine.
| See Also:
Chapter 2, "Installing and Configuring Ultra Search" for more information about the components |
Figure 1-1 illustrates the Ultra Search system configuration.
|
 Copyright © 1996, 2002 Oracle Corporation All Rights Reserved. |
|

