15 Developing Applications for Windows
This chapter points to sources of information about developing applications for Windows and outlines a procedure for building and debugging external procedures.
This chapter contains these topics:
Finding Information on Application Development for Windows
This section describes where to find information about developing applications specifically for Windows. These products are included on your Oracle Database Server CD-ROM.
Java Enhancements
Oracle Database includes an integrated Java Virtual Machine and JServer Accelerator. Oracle Database also provides Oracle Java Database Connectivity (JDBC) Drivers. For more information, see Oracle Database Java Developer's Guide.
ODP.NET
Oracle Data Provider for .NET (ODP.NET) is an implementation of a data provider for Oracle Database. ODP.NET uses Oracle native APIs to offer fast and reliable access to Oracle data and features from any .NET application. ODP.NET also uses and inherits classes and interfaces available in the Microsoft .NET Framework Class Library. For more information:
XML Support
Oracle XML products include XML Developer's Kit (XDK) and Oracle XML SQL Utility. For more information:
Support for Internet Applications
Oracle Database support for internet applications includes Oracle Portal, which enables you to publish your data to the Web, Oracle HTTP Server, and PL/SQL Embedded Gateway, which offers PL/SQL procedures stored in Oracle Database that can be started through browsers. For more information:
-
Oracle Portal Installation Guide and Tutorial
-
Oracle Enterprise Manager Grid Control Installation and Basic Configuration
Note:
Oracle Portal is available on a separate CD-ROM and included with Oracle Database for Windows.
Oracle COM Automation Feature
Oracle COM Automation feature enables Java stored procedure developers and COM/COM+ developers to load COM+ objects from an Oracle Database. For more information:
Oracle Objects for OLE
Oracle Objects for OLE (OO4O) provides easy access to data stored in Oracle Database servers with any programming or scripting language that supports the Microsoft COM Automation and ActiveX technology. These include Visual Basic, Visual C++, Visual Basic For Applications (VBA), IIS Active Server Pages (VBScript and JavaScript), and others. For more information:
Oracle Services For Microsoft Transaction Server
Oracle Database for Windows permits enhanced deployment of COM/COM+ components in Microsoft Transaction Server, using Oracle Database as the resource manager. For more information:
OLE DB
Oracle Provider for OLE DB is an OLE DB data provider that offers high performance and efficient access to Oracle data by OLE DB and ADO consumers.
Oracle ODBC Driver
Open Database Connectivity (ODBC) provides a common C programming interface for applications to access data from database management systems. Access to databases is managed by the ODBC Driver Manager. The driver manager provides the linkage between an ODBC application and an ODBC driver for a specific database management system.
Oracle ODBC Driver provides access to Oracle databases for applications written using the ODBC interface.
Oracle Technology Network has both Oracle home based ODBC driver and Instant Client enabled ODBC driver.
Note:
Download Instant Client enabled ODBC driver fromhttp://www.oracle.com/technetwork/database/features/instant-client/index.html
Developing Windows Applications
Oracle Database provides a comprehensive set of APIs for Windows application developers and is well suited for both Java, .NET, and COM/COM+ development. Oracle Database is integrated with Microsoft's development and deployment components. Performance and data access on Windows is enhanced in the following areas:
-
Wide variety of data access methods for Windows and internet applications
-
Wizards and assistants to speed application development
-
Microsoft Distributed Transaction Coordinator integration: Oracle Services for Microsoft Transaction Server
-
Platform extensions for internet application development
Developers are able to deploy their database applications more quickly by using the data access method with which they are familiar, rather than having to learn a new one. An Oracle Database server can communicate with Windows clients in a variety of methods, as described in Table 15-1.
Table 15-1 Oracle Data Access Methods
| Development Environment | Data Access Method |
|---|---|
|
Java |
JDBC SQLJ |
|
.NET |
ODP.NET |
|
COM/COM+ |
Oracle Objects for OLE (OO4O) Oracle Provider for OLE DB COM/COM+ Automation Feature |
By using Oracle Database data access interfaces, developers can take advantage of specific Oracle Database features. These interfaces also offer flexibility and adherence to open standards.
Building External Procedures
This section describes how to create and use external procedures on Windows. The following files are located in ORACLE_BASE\ORACLE_HOME\rdbms\extproc:
-
extern.cis the code example shown in "Writing an External Procedure" -
make.batis the batch file that builds the dynamic link library -
extern.sqlautomates the instructions described in "Registering an External Procedure" and "Executing an External Procedure"
External Procedures Overview
External procedures are functions written in a third-generation language (C, for example) and callable from within PL/SQL or SQL as if they were a PL/SQL routine or function. External procedures let you take advantage of strengths and capabilities of a third-generation programming language in a PL/SQL environment.
Note:
Oracle Database also provides a special purpose interface, the call specification, that lets you call external procedures from other languages, as long as they are callable by C.The main advantages of external procedures are:
-
Performance, because some tasks are performed more efficiently in a third-generation language than in PL/SQL, which is better suited for SQL transaction processing
-
Code re-usability, because dynamic link libraries (DLLs) can be called directly from PL/SQL programs on the server or in client tools
You can use external procedures to perform specific processes:
-
Solving scientific and engineering problems
-
Analyzing data
-
Controlling real-time devices and processes
Caution:
Special security precautions are warranted when configuring a listener to handle external procedures. See "Modifying Configuration of External Procedures for Higher Security" and Oracle Database Net Services Administrator's Guide for more information.To create and use an external procedure, perform the following sequential steps:
-
Executing an External Procedure
Note:
You must have a C compiler and linker installed on your system to build DLLs.Note:
You can combine the instructions described in the fourth and fifth tasks into one SQL script that automates the task of registering and executing your external procedure. SeeORACLE_BASE\ORACLE_HOME\rdbms\extproc\extern.sqlfor an example of a SQL script that combines these steps.
Installing and Configuring
This section describes installation and configuration of Oracle Database and Oracle Net.
Installing Oracle Database
Follow the steps in Oracle Database Installation Guide for Microsoft Windows (32-Bit) to install these products on your Windows server:
Configuring Oracle Net Services
During database server installation, Oracle Net Configuration Assistant configures listener.ora and tnsnames.ora files for external procedure calls.
When an application calls an external procedure, Oracle Net Listener starts an external procedure agent called EXTPROC. Using a network connection established by the listener, the application passes the following information to EXTPROC:
-
DLL name
-
External procedure name
-
Parameters (if necessary)
EXTPROC then loads the DLL, runs the external procedure, and passes back any values returned by the external procedure.
If you overwrite default listener.ora and tnsnames.ora files, then you must manually configure the following files for the external procedure behavior described previously to occur:
-
ORACLE_BASE\ORACLE_HOME\network\admin\listener.ora -
ORACLE_BASE\ORACLE_HOME\network\admin\tnsnames.oraCaution:
Additional security may be required for the listener in a production environment. See Oracle Database Net Services Administrator's Guide for more information.
Writing an External Procedure
Using a third-generation programming language, you can write functions to be built into DLLs and started by EXTPROC. The following is a simple Microsoft Visual C++ example of an external procedure called FIND_MAX:
Note:
Because external procedures are built into DLLs, they must be explicitly exported. In this example, theDLLEXPORT storage class modifier exports the function FIND_MAX from a dynamic link library.
#include <windows.h>
#define NullValue -1
/*
This function tests if x is at least as big as y.
*/
long __declspec(dllexport) find_max(long x,
short x_indicator,
long y,
short y_indicator,
short *ret_indicator)
{
/* It can be tricky to debug DLL's that are being called by a process
that is spawned only when needed, as in this case.
Therefore try using the DebugBreak(); command.
This will start your debugger. Uncomment the line with DebugBreak();
in it and you can step right into your code.
*/
/* DebugBreak(); */
/* First check to see if you have any nulls. */
/* Just return a null if either x or y is null. */
if ( x_indicator==NullValue || y_indicator==NullValue) {
*ret_indicator = NullValue;
return(0);
} else {
*ret_indicator = 0; /* Signify that return value is not null. */
if (x >= y) return x;
else return y;
}
}
Building a DLL
After writing your external procedure(s) in a third-generation programming language, use the appropriate compiler and linker to build a DLL, making sure to export the external procedures as noted previously. See your compiler and linker documentation for instructions on building a DLL and exporting its functions.
You can build the external procedure FIND_MAX, created in "Writing an External Procedure", into a DLL called extern.dll by going to ORACLE_BASE\ORACLE_HOME\rdbms\extproc and typing make. After building the DLL, you can move it to any directory on your system.
Starting with Oracle9i release 2, however, the default behavior of EXTPROC is to load DLLs only from ORACLE_HOME\bin or ORACLE_HOME\lib. To load DLLs from other directories, you must set environment variable EXTPROC_DLLS to a colon (:) separated list of DLL names qualified with their complete paths. The preferred way to set this environment variable is through the ENVS parameter in listener.ora.
See Also:
Oracle Database Application Developer's Guide - Fundamentals for more information about EXTPROCRegistering an External Procedure
Once you have built a DLL containing your external procedure(s), you must register your external procedure(s) with Oracle Database:
To create a PL/SQL library to map to the DLL:
-
Set environment variable
EXTPROC_DLLSin theENVSparameter inlistener.ora. For example:SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (SID_NAME=PLSExtProc) (ENVS=EXTPROC_DLLS=C:\oracle\product\10.2.0\db_1\rdbms\extproc\extern.dll) (ORACLE_HOME=C:\oracle\product\10.2.0\db_1) (PROGRAM=extproc) ) )
-
Start SQL*Plus:
C:\> sqlplus
-
Connect to the database with appropriate username and password.
-
Create the PL/SQL library using the
CREATE LIBRARYcommand:SQL> CREATE LIBRARY externProcedures AS 'C:\oracle\product\10.2.0\db_1\rdbms\ extproc\extern.dll';
where
externProceduresis an alias library (essentially a schema object in the database), andC:\oracle\product\10.2.0\db_1\rdbms\extproc\extern.dll
is the path to the Windows operating system
dllextern.dll. This example usesC:\oracle\product\10.2.0as your Oracle base anddb_1as your Oracle home.Note:
The DBA must grant theEXECUTEprivilege on the PL/SQL library to users who want to call the library's external procedure from PL/SQL or SQL. -
Create a PL/SQL program unit specification.
Do this by writing a PL/SQL subprogram that uses the
EXTERNALclause instead of declarations and aBEGIN...ENDblock. TheEXTERNALclause is the interface between PL/SQL and the external procedure. TheEXTERNALclause identifies the following information about the external procedure:-
Name
-
DLL alias
-
Programming language in which it was written
-
Calling standard (defaults to C if omitted)
In the following example,
externProceduresis a DLL alias. You need theEXECUTEprivilege for this library. The external procedure to call isfind_max. If enclosed in double quotation marks, it becomes case-sensitive. TheLANGUAGEterm specifies the language in which the external procedure was written.CREATE OR REPLACE FUNCTION PLS_MAX( x BINARY_INTEGER, y BINARY_INTEGER) RETURN BINARY_INTEGER AS EXTERNAL LIBRARY externProcedures NAME "find_max" LANGUAGE C PARAMETERS ( x long, -- stores value of x x_INDICATOR short, -- used to determine if x is a NULL value y long, -- stores value of y y_INDICATOR short -- used to determine if y is a NULL value RETURN INDICATOR short ); -- need to pass pointer to return value's -- indicator variable to determine if NULL -- This means that my function will be defined as: -- long max(long x, short x_indicator, -- long y, short y_indicator, short * ret_indicator) -
Executing an External Procedure
To run an external procedure, you must call the PL/SQL program unit (that is, the alias for the external function) that registered the external procedure. These calls can appear in any of the following:
-
Anonymous blocks
-
Standalone and packaged subprograms
-
Methods of an object type
-
Database triggers
-
SQL statements (calls to packaged functions only)
In "Registering an External Procedure", PL/SQL function PLS_MAX registered external procedure find_max. Follow these steps to run find_max:
-
Call PL/SQL function
PLS_MAXfrom a PL/SQL routine namedUseIt:SET SERVER OUTPUT ON CREATE OR REPLACE PROCEDURE UseIt AS a integer; b integer; c integer; BEGIN a := 1; b := 2; c := PLS_MAX(a,b); dbms_output.put_line('The maximum of '||a||' and '||b||' is '||c); END; -
Run the routine:
SQL> EXECUTE UseIt;
Multithreaded Agent Architecture
An agent process is started for each session to access a system at the same time leading to several thousand agent processes running concurrently. The agent processes operate regardless of whether each individual agent process is actually active at the moment. Agent processes and open connections can consume a disproportionate amount of system resources. This problem is addressed by using multithreaded agent architecture.
The multithreaded agent architecture uses a pool of shared agent threads. The tasks requested by the user sessions are put in a queue and are picked up by the first available multithreaded agent thread. Because only a small percentage of user connections are active at a given moment, using a multithreaded architecture allows for more efficient use of system resources.
See Also:
-
Part III of Oracle Database Application Developer's Guide - Fundamentals
-
"Multithreaded Agents" in Oracle Database Heterogeneous Connectivity Administrator's Guide
Debugging External Procedures
Usually, when an external procedure fails, its C prototype is faulty. That is, the prototype does not match the one generated internally by PL/SQL. This can happen if you specify an incompatible C datatype. For example, to pass an OUT parameter of type REAL, you must specify float *. Specifying float, double *, or any other C datatype will result in a mismatch.
In such cases, you might get a lost RPC connection to external procedure agent error, which means that agent extproc terminated abnormally because the external procedure caused a core dump. To avoid errors when declaring C prototype parameters, refer to Oracle Database Data Cartridge Developer's Guide.
Using Package DEBUG_EXTPROC
To help you debug external procedures, PL/SQL provides utility package DEBUG_EXTPROC. To install the package, run script dbgextp.sql, which you can find in the PL/SQL demo directory.
To use the package, follow instructions in dbgextp.sql. Your Oracle Database account must have EXECUTE privileges on the package and CREATE LIBRARY privileges.
To debug external procedures:
-
From Windows Task Manager, in the Processes dialog, select ExtProc.exe.
-
Right click, and select Debug.
-
Click OK in the message window.
If you have built your DLL in a debug fashion with Microsoft Visual C++, then Visual C++ is activated.
-
In the Visual C++ window, select Edit
>Breakpoints.Use the breakpoint identified in
dbgextp.sqlin the PL/SQL demo directory.See Also:
-
ORACLE_BASE\ORACLE_HOME\rdbms\extproc\readme.doc(explains how to run the sample and provides debugging advice) -
"Calling External Procedures" in Oracle Database Application Developer's Guide - Fundamentals
-
Accessing Text Files with UTL_FILE
Package UTL_FILE allows your PL/SQL programs to read and write operating system text files. It provides a restricted version of standard operating system stream file I/O, including open, put, get, and close operations. When you want to read or write a text file, you call the function fopen, which returns a file handle for use in subsequent procedure calls. For example, the procedure put_line writes a text string and line terminator to an open file, and the procedure get_line reads a line of text from an open file into an output buffer.
FSEEK, a UTL_FILE subprogram, adjusts the file pointer forward or backward within the file by the number of bytes specified. In order for UTL_FILE.FSEEK to work correctly, the lines in the file must have platform-specific line terminator characters. On Windows platforms the correct line terminator characters are <CR><LF>.
Accessing Web Data with Intercartridge Exchange
This section discusses the following topics:
Configuring Intercartridge Exchange
You must add a parameter to the registry before using Intercartridge Exchange.
-
Start Registry Editor from the command prompt:
C:\> regedt32
The Registry Editor window appears.
Note:
For another way to configure your registry, see "Managing Registry Parameters with regedt32" -
Add
HTTP_PROXYto the registry subkey of the Oracle home directory that you are using. The location of this parameter is determined by how many Oracle home directories are on your computer. If you have only one home directory, addHTTP_PROXYtoHKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\HOME0.
If you have multiple home directory, add it to
HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\KEY_HOME_NAME -
Choose Add Value from the Edit menu.
The Add Value dialog appears.
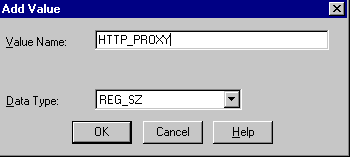
Description of the illustration http.gif
-
Type
HTTP_PROXYin the Value Name field andREG_SZin the Data Type field. -
Click OK.
-
Type
www-proxy.your-sitein the String field.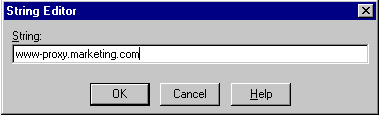
Description of the illustration http2.gif
In this example, the Web site is marketing.com. You will enter the domain name of your actual Web site.
Using Intercartridge Exchange
Intercartridge Exchange enables you to use a stored package called UTL_HTTP to make Hypertext Transfer Protocol (HTTP) calls from PL/SQL, SQL, and SQL*Plus statements.
UTL_HTTP can do both of the following:
-
Access data on the Internet
-
Call Oracle Web Application Server cartridges
UTL_HTTP contains two similar entry points, known as packaged functions, that turn PL/SQL and SQL statements into HTTP callouts:
-
UTL_HTTP.REQUEST -
UTL_HTTP.REQUEST_PIECES
Both packaged functions perform the following tasks:
-
Take a string universal resource locator (URL) of a site
-
Contact that site
-
Return data (typically HTML) obtained from that site
Declarations to use with both packaged functions are described in the following subsections.
Packaged Function UTL_HTTP.REQUEST
UTL_HTTP.REQUEST uses a URL as its argument and returns up to the first 2000 bytes of data retrieved from that URL. Specify UTL_HTTP.REQUEST as follows:
FUNCTION REQUEST (URL IN VARCHAR2) RETURN VARCHAR2;
To use UTL_HTTP.REQUEST from SQL*Plus, enter:
SQL> SELECT UTL_HTTP.REQUEST('HTTP://WWW.ORACLE.COM/') FROM DUAL;
which returns:
UTL_HTTP.REQUEST('HTTP://WWW.ORACLE.COM/')
------------------------------------------------------
<html>
<head><title>Oracle Home Page</title>
<!--changed Jan. 16, 19
1 row selected.
Packaged Function UTL_HTTP.REQUEST_PIECES
UTL_HTTP.REQUEST_PIECES uses a URL as its argument and returns a PL/SQL table of 2000 bytes of data retrieved from the given URL. The final element can be shorter than 2000 characters. The UTL_HTTP.REQUEST_PIECES return type is a PL/SQL table of type UTL_HTTP.HTML_PIECES.
UTL_HTTP.REQUEST_PIECES, which uses type UTL_HTTP.HTML_PIECES, is specified as:
type html_pieces is table of varchar2(2000) index by binary_integer; function request_pieces (url in varchar2, max_pieces natural default 32767) return html_pieces;
A call to REQUEST_PIECES can look like this example. Note the use of PL/SQL table method COUNT to discover the number of pieces returned; it can be zero or more:
declare pieces utl_http.html_pieces;
begin
pieces := utl_http.request_pieces('http://www.oracle.com/');
for i in 1 .. pieces.count loop
.... -- process each piece
end loop;
end;
The second argument to UTL_HTTP.REQUEST_PIECES (MAX_PIECES) is optional. MAX_PIECES is the maximum number of pieces (each 2000 characters in length, except for the last, which can be shorter) that UTL_HTTP.REQUEST_PIECES returns. If provided, that argument is usually a positive integer.
For example, the following block retrieves up to 100 pieces of data (each 2000 bytes, except perhaps the last) from the URL. The block prints the number of pieces retrieved and the total length, in bytes, of the data retrieved.
set serveroutput on
declare
x utl_http.html_pieces;
begin
x := utl_http.request_pieces('http://www.oracle.com/', 100);
dbms_output.put_line(x.count || ' pieces were retrieved.');
dbms_output.put_line('with total length ');
if x.count < 1
then dbms_output.put_line('0');
else dbms_output.put_line
((2000 * (x.count - 1)) + length(x(x.count)));
end if;
end;
which displays:
Statement processed.
4 pieces were retrieved.
with total length
7687
Elements of the PL/SQL table returned by UTL_HTTP.REQUEST_PIECES are successive pieces of data obtained from the HTTP request to that URL.
UTL_HTTP Exception Conditions
This subsection describes exceptions (errors) that can be raised by packaged functions UTL_HTTP.REQUEST and UTL_HTTP.REQUEST_PIECES.
UTL_HTTP.REQUEST
PRAGMA RESTRICT_REFERENCES enables display of exceptions:
create or replace package utl_http is function request (url in varchar2) return varchar2; pragma restrict_references (request, wnds, rnds, wnps, rnps);
UTL_HTTP.REQUEST_PIECES
PRAGMA RESTRICT_REFERENCES enables display of exceptions:
create or replace package utl_http is type html_pieces is table of varchar2(2000) index by binary_integer; function request_pieces (url in varchar2, max_pieces natural default 32767) return html_pieces; pragma restrict_references (request_pieces, wnds, rnds, wnps, rnps);
Exception Conditions and Error Messages
If initialization of the HTTP callout subsystem fails for environmental reasons (such as lack of available memory), then exception UTL_HTTP.INIT_FAILED is raised:
init_failed exception;
If the HTTP call fails due to failure of the HTTP daemon or because the argument to REQUEST or REQUEST_PIECES cannot be interpreted as a URL (because it is NULL or has non-HTTP syntax), then exception UTL_HTTP.REQUEST_FAILED is raised:
request_failed exception;
Unless explicitly caught by an exception handler, these first two exceptions are reported by a generic message that shows them as "user-defined" exceptions, even though they are defined in this system package:
ORA-06510: PL/SQL: unhandled user-defined exception
If any other exception is raised during processing of the HTTP request (for example, an out-of-memory error), then function UTL_HTTP.REQUEST or UTL_HTTP.REQUEST_PIECES reraises that exception.
If no response is received from a request to the given URL, because the function made no contact with a site corresponding to that URL, then a formatted HTML error message may be returned:
<HTML> <HEAD> <TITLE>Error Message</TITLE> </HEAD> <BODY> <H1>Fatal Error 500</H1> Can't Access Document: http://home.nothing.comm. <P> <B>Reason:</B> Can't locate remote host: home.nothing.comm. <P> <P><HR> <ADDRESS><A HREF="http://www.w3.org"> CERN-HTTPD3.0A</A></ADDRESS> </BODY> </HTML>
If UTL_HTTP.REQUEST or UTL_HTTP.REQUEST_PIECES raises an exception or returns an HTML-formatted error message, yet you believe that the URL argument is correct, try contacting that same URL with a browser to verify network availability from your computer.