![]()
|
|
Character Profiler |
「Character Profiler」では、複数のテキスト属性に存在する重複しないすべての文字とその出現回数を検出します。
「Character Profiler」は、テキスト属性内の予期しない文字を検出するのに特に役立ちます。このような文字は、継続的なチェック(「Invalid Character Check」を使用)、削除(「Denoise」を使用)、または置換(「Character Replace」を使用)が必要になる場合があります。また、パースの前に、文字の不一致を正規化することも有益です。
作成された結果は、前述の目的に応じて参照データに簡単に追加できます。
また、データのソースに複数の国からのレコードが含まれる場合、「Character Profiler」はデータ内の文字の種別を把握するのに役立ちます。
文字インスタンスを検索する文字列属性。
なし
なし
なし
|
実行モード |
サポート |
|
バッチ |
Yes |
|
リアルタイム・モニタリング |
Yes |
|
リアルタイム応答 |
Yes |
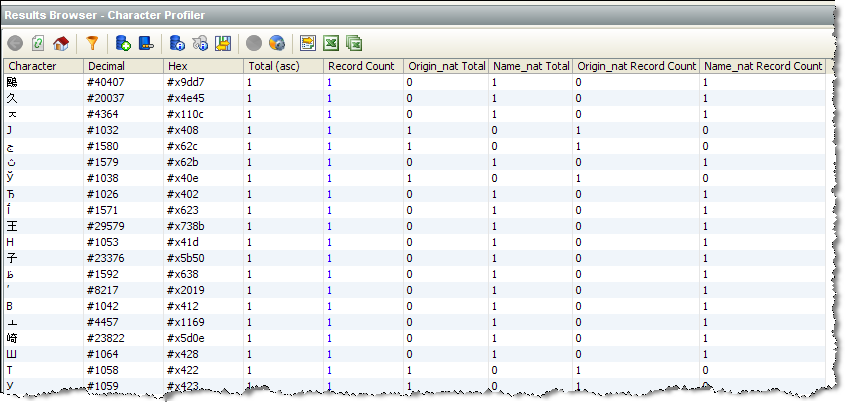
「Character Profiler」では、結果のサマリー・ビューが作成され、次の統計が表示されます。
|
統計 |
意味 |
|
Character |
データ内で検出された文字(後述の注意を参照)。 |
|
Decimal |
10進数のUnicode文字参照。文字参照を参照データで直接使用できるように、文字参照の先頭にハッシュ文字が付いていることに注意してください。 |
|
Hex |
16進数のUnicode文字参照。文字参照を参照データで直接使用できるように、文字参照の先頭に「#x」が付いていることに注意してください。 |
|
Total |
選択した入力属性全体で、文字が出現した合計回数。 |
|
Record Count |
選択した入力属性にその文字を含むレコードの数。 |
|
[Attribute name] Total |
属性内での文字の出現回数。 |
|
[Attribute name] Record Count |
属性にその文字を含むレコードの数。 |
|
注意: 結果ブラウザに四角い文字が表示される場合、その原因は、実際の文字を表示するのに必要なフォントがクライアントにインストールされていないか、(まれに)フォントはインストールされているが、Oracle EDQや他のJavaアプリケーションで正しくレンダリングするにはカスタムのfont.propertiesファイルが必要であることが考えられます。この文字を別のアプリケーション(Microsoft Excelなど)にコピーして貼り付けても正しく表示されない(通常は「?」が表示される)場合は、必要なフォントがインストールされていません。文字を別のアプリケーションに貼り付けると正しく表示される場合、フォントはインストールされていますが、Oracle EDQで文字を表示するにはカスタムのfont.propertiesファイルを追加する必要があります。これについては、サポートに連絡してください。 |
この例では、「Character Profiler」を使用して、Unicodeデータベースの複数言語データに含まれる特異な文字を検出します。ユーザーは、「Total」列を基準にして結果をソート(昇順)し、頻度の低い文字から順に表示しています。
Oracle (R) Enterprise Data Qualityオンライン・ヘルプ バージョン8.1
Copyright (C) 2006,2011 Oracle and/or its affiliates.All rights reserved.