

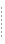


|
|
This chapter explains the design of managed content availability in the portal and provides the steps you take to make content available to users. The chapter includes the following topics:
The portal is designed to enable users to discover all of the enterprise content related to their employee role by browsing or searching portal areas.
Portal users should be able to assemble a My Page that provides access to all of the information they need. For example, to write user documentation, technical writers need to be able to assemble a My Page that includes portlet- or community-based access to documentation standards and conventions, solution white papers, product data sheets, product demonstrations, design specifications, release milestones, test plans, and bug reports, as well as mail-thread discussions that are relevant to customer support and satisfaction. To perform their role, technical writers do not need access to the personnel records that an HR employee or line-manager might require, or to the company financial data that the controller or executive staff might need, for example. A properly designed enterprise portal, then, would reference all of these enterprise documents so that any employee performing any function can access all of the information they need; but a properly designed enterprise portal would also ensure that only the employee performing the role can discover the information.
To enable such managed access to enterprise content:
This chapter describes the following tasks you complete to enable managed discovery of enterprise content through the portal:
For information on document properties and content types, see Configuring Content Types and Document Properties.
For information on content sources, see Configuring Content Sources
For information on the Knowledge Directory, see Managing the Knowledge Directory.
For information on portlets, see Extending Portal Services with Portlets.
For information on Communities, see Managing Communities.
For information on content crawlers, see Enabling Document Discovery with Content Crawlers and Content Services.
For information on search, see Working with Search.
This section describes how to configure the content type objects and document properties objects that enable document filters used by the Knowledge Directory, content crawlers, the Smart Sort utility, and the Search Service. Filters and returned search results are based on the associated portal properties, not properties defined in the source document.
When you add documents to the portal, the portal maps source document fields to portal properties according to mappings you specify in the Global Content Type Map, the particular content type definition, the Global Document Property Map, and any content crawler-specific content type mappings.
To enable content type and property mapping:
Add and configure additional content types, as needed.
For details, see Configuring the Global Content Type Map
Add and configure additional document properties, as needed.
For details, see Configuring the Global Document Property Map
The Global Content Type Map allows you to map source document identifiers (for example, file extensions) to content types. The content type associated with a source document determines how metadata in the source document is mapped to portal properties.
To configure the Global Content Type Map:
The Global Document Property Map provides default mappings for properties common to the documents in your portal. These mappings are applied after the mappings in the content type.
When you import a document into the portal, the portal performs the following actions:
To configure the Global Document Property Map:
Generally, you will be able to determine what source document attributes can be mapped to portal properties, but this might not be as clear in HTML documents. Table 4-1 provides suggestions for mapping HTML attributes to portal properties.
The HTML Accessor handles all common character sets used on the Web, including UTF-8.
This section describes how to configure content sources that enable portal access to content on WWW locations, file systems, and back-end content servers. This section includes the following topics:
Content sources provide access to external content repositories, allowing users and content crawlers to add document records and links in the Knowledge Directory. For example, a content source for a secured Web site can be configured to fill out the Web form necessary to gain access to that site.
Register a content source for each secured Web site or back-end repository from which content can be imported into your portal.
Content sources keep track of what content has been imported, deleted, or rejected by content crawlers accessing the content source. It keeps a record of imported files so that content crawlers do not create duplicate links. To prevent multiple copies of the same link being imported into your portal, set multiple content crawlers that are accessing the same content source to only import content that has not already been imported.
Because a content source accesses secured documents, you must secure access to the content source itself. Content sources, like everything in the portal, have security settings that allow you to specify exactly which portal users and groups can see the content source. Users that do not have Read access to a content source cannot select it, or even see it, when submitting content or building a content crawler.
You can create multiple content sources that access the same repository of information. For example, you might have two Web content sources accessing the same Web site. One of these content sources could access the site as an executive user that can see all of the content on the site. The other content source would access the site as a managerial user that can see some secured content, but not everything. You could then grant executive users access to the content source that accesses the Web site as an executive user, and grant managerial users access to the content source that accesses the Web site as a managerial user.
| Note: | If you crawled the same repository using both of these content sources, you would import duplicate links into your portal. Refer to Content Source Histories. |
Web content sources allow users to import content from the Web into the portal through Web content crawlers or Web document submission. When you install the portal, the World Wide Web content source is created. This content source provides access to any unsecured Web site.
To create a Web content source:
Remote content sources allow users to import content from an external content repository into the portal through remote content crawlers or remote document submission.
The following table describes the steps you take to configure a remote content source.
This section describes how to set up and manage the portal Knowledge Directory. It includes the following topics:
The Knowledge Directory is a portal area that users can browse to discover documents that have been uploaded by users or imported by content crawlers. This information is organized into subfolders in a manner similar to file storage volumes and shares, but you might want to organize it in a more granular fashion to allow you to delegate administrative responsibility and facilitate managed access with ACLs.
The default portal installation includes a Knowledge Directory root folder with one subfolder named Unclassified Documents. Before you create additional subfolders, define a taxonomy, as described in the Deployment Guide for BEA AquaLogic User Interaction G6.
You can specify how the Knowledge Directory displays documents and folders, including whether to generate the display of contents from a Search Service search or a database query, by setting Knowledge Directory preferences.
To set Knowledge Directory preferences:
To create a Knowledge Directory folder:

If you want to modify the ACL that is inherited from the parent folder by default, click Security.
To submit (upload) a document:
Use filters to control what content goes into which folder when crawling in documents or using Smart Sort. A filter sets conditions to sort documents into associated folders in the Knowledge Directory.
A filter is a combination of a basic fields search and statements. The basic fields search operates on the name, description, and full-text content fields associated with documents. Statements can operate on both the content and the properties of documents. Statements can be grouped together in groupings. Groupings are containers for statements or other groupings allowing you to create complex filters. Groupings are analogous to parentheses in mathematical equations.
A single filter can be used by multiple folders. You can also apply multiple filters to one folder.
After you create a filter, you assign it to folders. You can assign filters to any Knowledge Directory folder to which you have the appropriate access. If you assign more than one filter to a folder, you must specify whether content must pass all filters, or at least one filter.
To assign a filter to a folder:

Any content that passes the filters of the destination folder, but does not pass the filters of the destination folder's subfolders can be placed into a default folder.
You can organize crawled content into subcategories by creating a folder in the Knowledge Directory, and using filters on that folder's subfolders. For example, you can create a content crawler that crawls a news Web site and places content into a folder, then use filters on that folder's subfolders to separate the content into Politics, Sports, and Travel.
| Note: | For information on content crawlers, see About Content Crawlers. |
To use filters to organize content using this example:
You can use the Smart Sort Utility to redistribute content in your portal from one folder to another, applying filters according to your needs.
To redistribute content with the Smart Sort Utility:
The Document Refresh Agent is an intrinsic job that updates the document links in the Knowledge Directory. The Document Refresh Agent visits every link in your portal. For each link, the Document Refresh Agent first determines if the link requires refreshing based on the setting for the document record that was imported into the Knowledge Directory. If the link requires refreshing, the Document Refresh Agent looks at the source document. If the source document has changed, any changed content is updated in the search index, and, optionally, the portal properties are regenerated from the source document. For example, if someone adds a line to the source document or changes the author, as soon as the link is refreshed, portal users can locate the document by searching for this new line of text or searching for the new author.
The Document Refresh Agent also deletes links with missing source documents and links that have expired.
You should run the Document Refresh Agent as frequently as you expect your links to require updates. The Document Refresh Agent knows if other copies of the agent are running and will distribute the work across these agents. However, the more copies of this agent that are running, the more CPU cycles that are used by the Automation Service, so you should limit the number of agents to fit your CPU resources.
For more information on the Document Refresh Agent job, see Running Portal Agents.
To examine the refresh settings for a document:
This section describes how to set up and manage the availability of portlets. It includes the following topics:
Portlets provide customized tools and services, as well as information. The portal comes with many portlets, but you can also create your own, have a Web developer or an AquaLogic User Interaction portlet developer create portlets for you, or download portlets from the AquaLogic User Interaction Support Center.
For information on installing and configuring portlets provided as a software package, refer to the portlet software documentation instead of the procedures in this guide.
For information on developing portlets, see the BEA AquaLogic User Interaction Development Center ( http://dev2dev.bea.com/aluserinteraction/).
There are several steps involved in making a portlet available for users to add to My Pages or community pages:
The following table describes some of the characteristics of portlets you might use in your deployment.
AquaLogic Interaction provides tags that can be used in portlets as an easy way for developers to customize navigation and login components (such as name field, login field, and so on). Two portlets are included in your portal to provide examples of using these tags:
For more information on portal navigation, see Navigation Options.
For more information on using tags, see the BEA AquaLogic User Interaction Development Center ( http://dev2dev.bea.com/aluserinteraction/).
You can enable users to access existing Web applications through the portal. For example, users may need to access an employee benefits system. If they access the benefits system through the portal, they do not have to enter their login credentials separately for that application, and can continue to have the convenience of the portal context, personalization, and navigation.
To surface an existing application through the portal:
To supply login credentials for lockboxes, users do the following:
You can let users add the portlet on their own (My Pages | Add Portlets or
My Communities | Add Portlets), or you can make the portlet mandatory. See Defining Mandatory Portlets.
Caching some portlet content can greatly improve the performance of your portal. When you cache portlet content, the content is saved on the portal for a specified period of time. Each time a user requests this content—by accessing a My Page or community page that includes the cached portlet—the portal delivers the cached content rather than running the portlet code to produce the content.
When you create a portlet, you can specify whether or not the portlet should be cached, and if it is cached, for how long. You should cache any portlet that does not provide user-specific content. For example, you would cache a portlet that produces stock quotes, but not one that displays a user e-mail box.
If you develop portlet code, you can and should define caching parameters.
For more information on portlet caching, refer to the BEA AquaLogic User Interaction Development Center ( http://dev2dev.bea.com/aluserinteraction/) or the documentation provided with the portlet software.
You can configure the following types of preferences for portlets.
Portlet Web services allow you to specify functional settings for your portlets in a centralized location, leaving the display settings to be set in each associated portlet.
Intrinsic portlets are installed on the portal.
To create a Web service for an intrinsic portlet:
Remote portlets extend the base functionality of the default portal and are hosted on a remote server.
To create a Web service for a remote portlet:
Portlet templates allow you to create multiple instances of a portlet, each sharing much of the basic configuration but displaying slightly different information. For example, you might want to create a Regional Sales portlet template, from which you could create different portlets for each region to which your company sells. You might even want to include all the Regional Sales portlets on one page for an executive overview.
After you have created a portlet from a portlet template, there is no further relationship between the two objects. If you make changes to the portlet template, these changes are not reflected in the portlets already created with the template.
To create a portlet (intrinsic or remote):
Portlet bundles are groups of related portlets, packaged together for easy inclusion on My Pages or community pages. When users add portlets to their My Pages or community pages, they can add all the portlets in a bundle or select individual portlets from a bundle. You might want to create portlet bundles for portlets that have related functions or for all the portlets that a particular group of users might find useful. This makes it easier for users to find portlets related to their specific needs without having to browse through all the portlets in your portal.
This section describes how to require or recommend portlets to groups or users. It includes the following topics:
You can force users or groups to include a portlet on their default My Page by making it mandatory for those users or groups. Mandatory portlets display above user-selected portlets. Users cannot remove mandatory portlets from their My Pages.
Because mandatory portlets are added to My Pages, the following portlet types cannot be mandatory: Header, Footer, Content Canvas, and community-only portlets.
To make a portlet mandatory for a particular group:
You can recommend portlets to encourage users to add them to their My Pages. Users can recommend any portlet that can be added to a My Page and to which they have access.
Because recommended portlets are added to My Pages, the following portlet types cannot be recommended: Header, Footer, Content Canvas, and community-only portlets.
You can add one or more portlets to one or more groups' My Pages as a bulk operation.
To add multiple portlets to multiple groups:
This section describes how to set up portal communities and how to enable content managers to create and manage additional communities. It includes the following topics:
A community is similar to a My Page in that it displays portlets. However, communities provide content and services to a group rather than to just an individual user.
You might create communities based on departments in your company. For example, the Marketing department might have a community containing press information, leads volumes, a trade show calendar, and so on. The Engineering department could have a separate community containing project milestones, regulatory compliance requirements, and technical specifications.
You might create communities based on projects your company is working on. For example, a member of the Professional Services department working with a customer to deploy a system could create a community where that group could collaborate on deployment issues. You would probably delete this type of community when the project ends.
Each community is based on a community template, which consists of one or more page templates, which can include portlets. Each page template you add to a community (either through the community template or through the community itself) appears as a link at the top of the community.
Individual community pages have their own security settings, so you can use pages, as well as subcommunities, to control access to different areas of the community.
The first page you add becomes the community Home Page—the default page that displays to users when they visit your community.
Communities can also include the following features:
Page templates include portlets and layout settings that are used as the basis to create pages in communities. A single page template can be used by many different communities, allowing you to keep similar types of pages looking analogous. For example, you might want each department to create a community in which the first page lists the general duties of the group, the department members, and the current projects owned by the department.
Each page template specifies a particular page layout. The page layout determines where particular types of portlets can be displayed on the page. For example, if you want to include a Content Canvas portlet on a page, you must choose a page layout that allows you to do so.
There are three possible parts to a page layout, which are combined in different ways in the available page layouts:
The following page layouts are available (the dark gray sections are content canvas areas).
When you create community pages based on a page template, you have the option to have the pages you are creating inherit any future changes to the template. For example, if you choose to have a community page inherit the template, when you add a portlet on the template, the portlet is added to the associated community pages.
When you create a community, it is based on a community template. Community templates allow you to define the minimum requirements for communities, including page templates and, optionally, a header or footer for the community page. Community creators can add new content and services, but cannot remove the content, services, or design provided by the community template. A single community template can be used by many different communities, allowing you to keep similar types of communities looking similar. For example, you might want all communities based on departments to look similar and contain similar content, while you might want communities based on projects to look different.
You can add Header and Footer portlets to a community in one of two ways:
If you use branding portlets (the Header, Footer, and Content Canvas portlets provided with your portal), community administrators can edit portlet settings such as the text, icon, and color of the header or footer. This allows communities to have similar, but distinct headers and footers.
To create a community template:
If you create a community based on a community template, you can choose to have the community you are creating inherit any future changes to the template. If you choose to inherit changes, any change applied to the community template affects the community. For example, if a page template is removed from a community template, the page created from this template will be removed from your community as well.
You must have Edit privilege to the community and Create Communities activity right to create a community or a subcommunity.
Subcommunities (along with Pages) allow you to create separately-secured subsections in a community, so it can have a more restrictive security than the main community. For example, you might have a Marketing Community that includes an Advertising Subcommunity. This subcommunity might have distinct owners or might be accessible to only a subset of the Marketing Community.
A subcommunity is just a community folder stored in another community folder. Therefore, the subcommunity inherits the security and design of the parent community, but you can then change these settings to suit the needs of the subcommunity. You can also change the relationships of communities and subcommunities just by rearranging the folder structure.
| Note: | If you choose to display a community Knowledge Directory in the subcommunity, it is separate from the community Knowledge Directory in the parent community. |
User community access determines subcommunity access:
You must have Create Communities activity right to create a subcommunity.
To create a subcommunity in a new community:
| Note: | Subcommunities can be nested up to 10 levels deep. |
| Caution: | The Related Communities tab displays peer communities—the communities that are stored in the same administrative folder as your community. For this reason, consider carefully where to store communities and the administrative folder structure necessary to make related communities useful. |
Community pages appear as links in a community. You can create a community page in a community folder or in a community editor. Like communities, pages are based on templates from which you can choose whether or not to inherit future changes. Like other portal objects, community pages can be copied (to another community folder), localized, migrated, and can have unique security settings.
If you inherit the page template, you cannot delete portlets associated with the page template, but you can add portlets to the page created from the template. If you do not inherit the page template, you can delete portlets associated with the template, add new portlets, and change the page layout.
A group is a set of portal users to whom you grant specific access privileges. You can create community groups without affecting portal groups. You create community groups so that you can easily assign responsibilities to community members. For example, you might have a group that is responsible for maintaining schedules in the community. If you later want to make your community group available outside of the community, you can move the group from the community folder to another administrative folder.
You must have the Create Groups activity right to create a community group.
 Edit this Community on the right.
Edit this Community on the right. You can create and manage portlets in the community. You need access to portlet Web services or portlet templates and must have Create Portlets activity right to create portlets.
Portlets created in the Community Editor are only available within the community. If you later want to make portlets available outside of the community, you can move the portlet from the community folder to a higher level administrative folder.
| Note: | Removing community portlets from the community deletes them from the portal. |
To create portlets available only to this community:
Edit this Community on the right. To display these portlets to community users, you must add these portlets to the appropriate community page.
Community membership controls the community selection in the My Community section of the portal. It also controls the mandatory tabs in the community navigation. You can control who can join, edit, and administer the community.
Users must have Select rights to join the community.
To change the access rights of each member of the community:
You can make a community mandatory for the members of one or more groups. Users cannot remove themselves from mandatory communities. You can also display tabs for mandatory communities in the banner at the top of the portal, alongside the My Pages and My Communities tabs.
To make a community mandatory for a particular group:
You can recommend communities to encourage users to join them. Users can recommend any community to which they have access.
You can subscribe one or more groups to one or more communities as a bulk operation.
To add multiple communities to multiple groups:
The community Knowledge Directory is an optional part of a community that allows you to provide access to additional community-specific content through a folder hierarchy. There are two folders that are always present in a community Knowledge Directory:
You can also create your own folders and fill them with links to Web sites, user profiles of community experts, documents from the portal Knowledge Directory, and pages in other communities. Users can browse these links from the community Knowledge Directory, or you can display the links in a Community Links portlet.
| Note: | You might want to create a Community Links portlet that includes links to important secondary community pages and then invite users to add the portlet to their My Pages. This provides direct access to those community pages; users do not have to navigate to the community home page and then click the community page they want. |
To create community Knowledge Directory folders and or to create a community Links portlet:
 Content Snapshot and specify the community page to which you want to add the portlet.
Content Snapshot and specify the community page to which you want to add the portlet.
This section describes how to crawl WWW locations, file system locations, and back-end content and mail servers to make documents in these repositories available through portal links. This section includes the following topics:
For a summary of AquaLogic Interaction content crawlers, as well as guidelines on best practices for deploying content crawlers, see the Deployment Guide for BEA AquaLogic User Interaction G6.
For information on installing and configuring AquaLogic Interaction remote content crawlers, follow the product documentation included with your software instead of the documentation in this guide.
Content crawlers import, from back-end content sources, document records that contain descriptive information, such as content type and properties, document ACL (read access only), and links to these documents into Knowledge Directory subfolders according to property-based filters, as shown in the following figure.
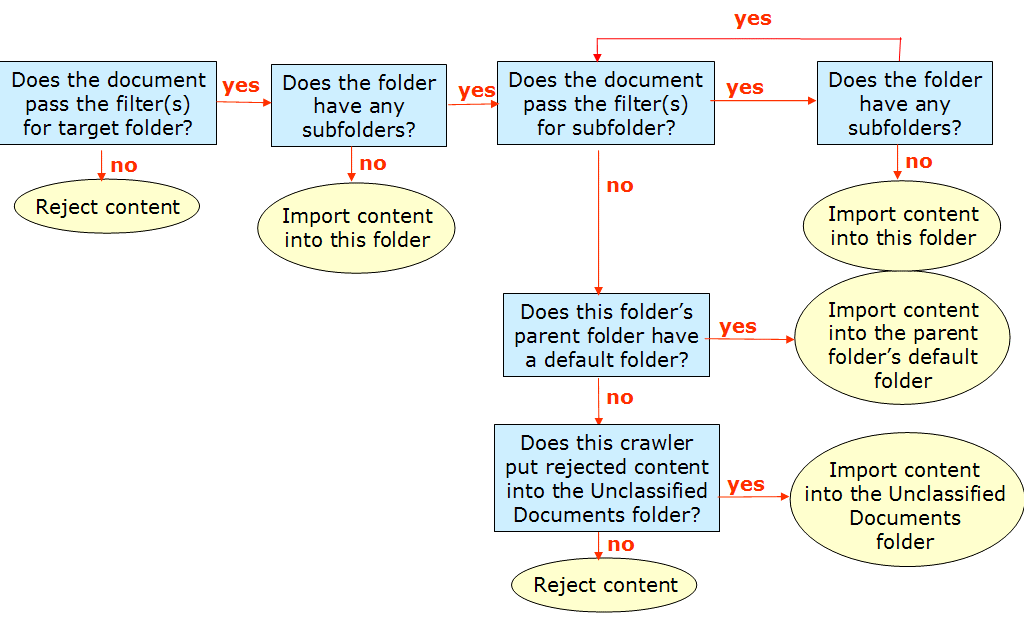
There might be cases where imported content does not pass the filters on any folder, even the destination folder. In these cases you can either choose to not import the rejected content, or to place the rejected content into the Unclassified Documents folder. If you place the rejected content into the Unclassified Documents folder, you can view this content in the Knowledge Directory edit mode. You can later move these document records into the Knowledge Directory.
The following table summarizes the metadata AquaLogic Interaction content crawlers can import.
Content crawlers also index the full document text, and this index is used by the Search Service to make documents available through the Search tool.
To facilitate maintenance, we recommend you implement several instances of each content crawler type, configured for limited, specific purposes.
For file system content crawlers, you might want to implement a content crawler that mirrors an entire file system folder hierarchy by specifying a top-level starting point and its subfolders. Although the content in your folder structure is available on your network, replicating this structure in the portal offers several advantages:
However, you might find it easier to maintain controlled access, document updates, or document expiration by creating several content crawlers that target specific folders.
If you plan to crawl WWW locations, familiarize yourself with the pages you want to import. Often, you can find one or two pages that contain links to everything of interest. For example, most companies offer a list of links to their latest press releases, and most Web magazines offer a list of links to their latest articles. When you configure your content crawler for this source, you can target these pages and exclude others to improve the efficiency of your crawl jobs.
If you know that certain content will no longer be relevant after a date—for example, if the content is related to a fiscal year, a project complete date, or the like—you might want to create a content crawler specifically for the date-dependent content. When the content is no longer relevant, you can run a job that removes all content created by the specific content crawler.
For remote content crawlers, you might want to limit the target for mail content crawlers to specific user names; you might want to limit the target for document content crawlers to specific content types.
For additional considerations and best practices, see the Deployment Guide for BEA AquaLogic User Interaction G6.
Content services allow you to specify general settings for your remote content repository, leaving the target and security settings to be set in the associated remote content crawler. This allows you to crawl multiple locations in the same content repository without having to repeatedly specify all the settings.
If you plan to use an AquaLogic Interaction content Web service (AquaLogic Interaction Content Services) to crawl document repositories, follow the product documentation provided with that software instead of the procedures in this guide. AquaLogic Interaction remote content crawlers include a migration package that enables you to import pre-configured remote server and Web service objects.
The following table describes the steps you take to configure a target-specific content service.
|
|
If you need to define a new content type and properties for your content, follow the procedures in Configuring Content Types and Document Properties.
|
|
Note: For information on how to organize crawled content in folders, see Using Filters to Organize Crawled Content.
|
|
To import security, the domain and group information for the source being crawled must be mapped to an authentication source prefix in the global ACL sync map. If you run a content crawler and find that some or all of the security has not been imported, map the domain in the global ACL sync map and run the content crawler again.
|
Before you have a content crawler import content into the public folders of your portal, test it by running a job that crawls document records into a temporary folder.
When you create the test folder, remove the Everyone group, and any other public groups, from the Security page on the folder to ensure that users cannot access the test content.
The following table provides a summary test plan for your content crawlers.
Examine the target folder and ensure the content crawler has generated records and links for desired content and has not created unwanted records and links.
If you iterate this testing step after modifying the content crawler configuration, make sure you delete the contents of the test folder and clear the deletion history for the content crawler as described in Clearing the Deletion History.
|
|
Make sure that all documents are given the right content types, and that these content types correctly map properties to source document attributes.
Go to the Knowledge Directory, and look at the properties and content types of a few of the documents this content crawler imported to see if they are the properties and content types you expected.
If you iterate this testing step after modifying the content crawler configuration, make sure you configure the content crawler to refresh these links. For information on refreshing links, see Keeping Document Records Up-to-Date.
|
|
To test that document properties have been configured to enable filters and search, browse to the test folder, and perform a search using the same expression used by the filter you are testing. Either cut and paste the text from the filter into the portal search box or use the Advanced Search tool to enter expressions involving properties. Select the Search Only in this Folder option. The links that are returned by your search are for the documents that will pass your filter.
|
This section describes how to maintain document records imported by content crawlers. It includes the following topics:
The Document Refresh Agent is an intrinsic job that updates the records in the Knowledge Directory. The Document Refresh Agent examines every link in your portal. For each link, the document refresh agent first determines if the link requires refreshing based on the document record setting set when the file was uploaded or by the content crawler that created the link.
To administer refresh settings for the content crawler:
Content crawlers keep a history of actions performed on crawled document records, including the deletion history. If you delete records, the content crawler remembers that the content was imported and deleted and it will not attempt to re-import this content. If you later decide to import records for that content, you must clear the deletion history.
To clear the deletion history:
By carefully targeting your content crawler to generate content on only one topic, you allow for the easy removal of a topic that becomes irrelevant, without disturbing unrelated content.
To remove all the content ever imported by a particular content crawler:
The next time the Document Refresh Agent runs, it will delete all of the records created by this content crawler.
This section describes how to implement search for documents that reside in the Knowledge Directory, in communities, or in the collection of crawled links. It includes the following topics:
This section describes how to customize portal search. It includes the following topics:
For information on default behavior for search syntax and results ranking, see Default Behavior of Search Service.
You configure best bets with the Search Results Manager. Best bets associate specific search phrases you specify with a set of search results, in rank order. In addition, users can go directly to the highest ranking result, the top best bet, instead of seeing the normal search results.
When end-users enter a banner search query that matches a best bet search phrase, the best bet results appear as the first results in the relevance-ranked result list. The phrase "Best Bet" appears next to each best bet result to inform the user that the result has been judged especially relevant to his or her query.
Best bets apply only to the portal banner search box and search portlet. Best bets are not used by other portal search interfaces, such as advanced search and object selection search.
| Note: | Best bets are case-insensitive. |
You can create hundreds of best bets, each mapping to a maximum of 20 results.
Since best bets are handled by the Search Service and are not managed portal objects, best bets do not migrate from development to production environments; you must re-create them in the production environment.
The highest ranking best bet result for a given search term is the top best bet. If best bets are set for a term, instead of seeing search results, users can go directly to the top best bet result (an object such as a community or document) by doing one of the following:
 . For example:
. For example:
http://portal.company.com/portal/server.pt?tbb=HR department
| Note: | If your search term contains spaces, they will be converted to %20. |
.| Note: | For information on how to enable this button using the Search tag, see the BEA AquaLogic User Interaction Development Center at http://dev2dev.bea.com/aluserinteraction/. |
If there are no best bets set for the term the user entered, the search results for the term are displayed instead.
If an object is a top best bet for any search terms, those terms are listed on the Properties and Names page of the object's editor.
When a user enters a query into a search box in the portal, the portal searches the properties specified on the Banner Fields page of the Search Results Manager. The default banner field properties are Name, Description, and Full-Text Content. However, you can also add other properties, such as Keyword, Department, or Author, to further refine the search results.
Another way of controlling the search results is by modifying the relevance weight for banner field properties. Overweighting a property increases its relevancy ranking; and underweighting it decreases it. For example, you can manipulate the search to first return documents whose content matches the search string (by overweighting the Full-Text Content property) followed by documents whose name matches the search string (by underweighting the Name property). When users type widgets, documents with widgets in the content appear first in a relevance-ranked search result; they are followed by documents or files with widgets in their names.
Banner field settings apply to the banner search box, advanced search, object selection search, or any other portal search interfaces.
To configure the weights of existing banner fields:
Since banner fields and relevance weights are a Search Service setting and not managed portal objects, the settings do not migrate from development to production environments; you must re-create them in the production environment.
Automatic spell correction is applied to the individual terms in a basic search when the terms are not recognized by the Search Service. Spell correction is not applied to quoted phrases.
For example, if a user queries for portel server but the term portel is unknown to the Search Service, items matching the terms portal and server would be returned instead. The same applies to Internet style mode and query operators mode. So, for instance, a search for portel <NEAR> server would return documents containing the terms portal and server in close proximity, but only if there are no matches for portel and server in close proximity.
Automatic spell correction is enabled by default. You can disable it from the Search Results Manager in the administrative portal user interface.
To disable the automatic spell correction:
The Search Service allows you to create a thesaurus (or synonym list), load it into the server, and enable thesaurus expansion for all user queries. Thesaurus expansion allows a term or phrase in a user's search to be replaced with a set of custom related terms before the actual search is performed. This feature improves search quality by handling unique, obscure, or industry-specific terminology.
For example, with conventional keyword matching, a search for the term gadgets might not return documents that discuss portlets or Web services. But, by creating a thesaurus entry for gadgets, it is possible to avoid giving users zero search results because of differences in word usage. The entries allow related terms or phrases to be weighted for different contributions to the relevance ranking of search results. For example, gadgets is not really a synonym for Web services, so a document that actually contains gadgets should rank higher than one that contains Web services.
The entries are lower-case, comma-delimited lists of the form:
gadgets,portlets,web services[0.5]
In this example, the number [0.5] corresponds to a non-default weighting for the phrase web services.
| Note: | Thesaurus entries must be lower-case. |
Thesaurus entries can be created to link closely related terms or phrases, specialized terminology, obsolete terminology, abbreviations and acronyms, or common misspellings. The expansion works by simply replacing the first term in an entry with an OR query consisting of all the terms or phrases in the entry. The weights are then taken into consideration when matching search results are ranked.
The thesaurus expansion feature is best used for focused, industry- or domain-specific examples. It is not intended to cover general semantic relationships between words or across languages, as with a conventional paper thesaurus. Although the Search Service thesaurus expansion can definitely improve search quality, adding entries for very general or standard terms can actually degrade search quality if it leads to too many search result matches.
After you enable this feature, you must create the synonym list in the database, described next.
To set up the search thesaurus:
| Note: | Thesaurus entries must be in lower-case. |
The thesaurus is a comma-delimited file, also known as a CDF. Each line in the file represents a single thesaurus entry. The first comma-delimited element on a line is the name of the thesaurus entry. The remaining elements on that line are the search tokens that should be treated as synonyms for the thesaurus entry. Each synonym can be assigned a weight that determines the amount each match contributes to the overall query score. For example, a file that contains the following two lines defines thesaurus entries for couch and dog:
couch,sofa[0.9],divan[0.5],davenport[0.4]
dog,canine,doggy[0.85],pup[0.7],mutt[0.3]
Searches for couch generate results with text matching terms couch, sofa, divan, and davenport. Searches for dog generate results that have text matching terms dog, canine, doggy, pup, and mutt. In the example shown, the term dog has the same contribution to the relevance score of a matching item as the term canine. This is equivalent to a default synonym weighting of 1.0. In contrast, the presence of the term pup contributes less to the relevance score than the presence of the term dog, by a factor of 0.7 (70%).
The example thesaurus entries constitute a complete comma-delimited file. No other information is needed at the beginning or the end of the file.
Entries can also contain spaces. For example, a file that contains the following text creates a thesaurus entry for New York City:
new york city,big apple[0.9],gotham[0.5]
Searches for the phrase "new york city" will return results that also include results containing "big apple" and "gotham." Thesaurus expansion for phrase entries only occurs for searches on the complete phrase, not the individual words that constitute the phrase. Similarly, the synonym entries are treated as phrases and not as individual terms. So while a search for "new york city" returns items containing "big apple" and "gotham," a search for new (or for york, or for city, or for "new york") will not. Conversely, an item that contains big or apple but not the phrase "big apple" will not be returned by a search for "new york city."
Comma-delimited files support all UTF8-encoded characters; they are not limited to ASCII. However, punctuation should not be included. For example, if you want to make ne'er-do-well a synonym of wastrel, replace the punctuation with whitespace:
wastrel,ne er do well[0.7]
This matches documents that contain ne'er-do-well, ne er do well or some combination of these punctuations and spaces (such as ne'er do well). If you want your synonym to match documents that contain neer-do-well, which does not separate the initial ne and er with an apostrophe, you must include a separate synonym for that, such as:
wastrel,ne er do well[0.7],neer do well[0.7]
Finally, comment lines can be specified by beginning the line with a "#":
# furniture entries
couch,sofa[0.9],divan[0.5],davenport[0.4]
#chair,stool[5.0]
# animal entries
dog,canine[0.9],doggy[0.85],pup[0.7],mutt[0.3]
In this example, the Search Service parses two thesaurus entries: couch and dog. There will be no entry for chair.
These examples are of entries that contain only ASCII characters. This utility supports non-ASCII characters as well, as long as they are UTF8-encoded.
| Note: | Some editors, especially when encoding UTF-8, insert a byte order mark at the beginning of the file. Files with byte order marks are not supported, so remove the byte order mark before running the customize utility. |
A CDF thesaurus file can have at most 50,000 distinct entries (lines). Each entry can have at most 50 comma-delimited elements (including the name of the entry). If either of these limits are exceeded, the customize utility will exit with an appropriate error message.
The comma-delimited file is converted to a binary format in the next step. The conversion removes and replaces certain files used by the Search Service, and this removal and replacement cannot be done while the Search Service is running.
The customize utility can be found in the bin\native directory of the Search Service installation, for example, C:\bea\alui\ptsearchserver\6.1\bin\native\customize.exe. The utility must be run from a command prompt, taking command-line arguments for the thesaurus CDF file and the path to the Search Service installation:
customize -r <thesaurus file> <SEARCH_HOME>
where SEARCH_HOME is the root directory of the Search Service installation, for example, C:\bea\alui\ptsearchserver\6.1. This is not an environment variable that needs to be set; the directory merely needs to be specified directly on the command line. For example, if your thesaurus file is located in \temp, you enter:
customize -r \temp\thesaurus.cdf C:\bea\alui\ptsearchserver\6.1
When you run the customize utility, the files in SEARCH_HOME\common are removed and replaced by files of the same name, though their contents now represent the mappings created by the customize utility. The customize utility has a command-line mode for reverting to the set of mappings files that shipped with the Search Service (and hence removing any thesaurus customizations). This mode uses the -default flag in place of -r <thesaurusfile>, but otherwise is identical to the invocations shown above:
customize -default C:\bea\alui\ptsearchserver\6.1
The files produced by the customize utility are loaded when the Search Service starts.
Users can use the Sort By drop-down list on the search results page to sort results by object type or by folder location in the Knowledge Directory or Administrative Object Directory. You can customize this drop-down list to include additional categories relevant for your users. If you use a property in your portal documents named Region, for example, you can customize the Sort By drop-down list to include Sort By Region: New England, Midwest, and so forth.
The first issue to consider when assessing whether categorizing search results by a particular property is a good idea is whether the property will be defined for a substantial percentage of all search results. For instance, if 90% of search results do not have the property defined, then when categorizing by that property, most everything will fall under "All Others", and the categorization will not be very useful. For that reason, as a rule of thumb it is not generally recommended to add a custom categorization option for a property which is undefined for more than half of all documents and administrative objects.
The other issue to consider is whether the values for the property will make reasonable category titles. In order for categorization to work well for a property, each value should be a single word or a short noun phrase, for example, New England, Midwest, Product Management, Food and Drug Administration, and so forth. The values should not be full sentences or long lists of keywords, for example, "This content crawler crawls the New York Times finance section". The entire contents of the property value for each item will be considered as a single unit for the purposes of categorization, so it will look odd if a full sentence is returned as a category title.
The first step in the process of adding a new categorization option is to ensure that documents and objects include the property you want to use to sort by category. For information on setting up maps from source document attributes to portal properties, see Configuring Content Types and Document Properties. Ensure that the property that defines the category for sorting has the following configuration:
To enable results sorting by property, add the following settings within the <Search> section of portalconfig.xml:
<CategoryName_1 value="CategoryName"/>
<CategoryField_1 value="PTObjectID"/>
CategoryName is the name you want to appear in the Sort By drop-down list, for example, Region.
ObjectID is the integer that identifies the property object. To find the object ID, right-click the link to the property object and then choose Properties. This will yield a link that looks something like this:
http://portal.company.com/portal/server.pt?open=36&objID=200&parentname=ObjMgr&parentid=5&mode=1&in_hi_userid=1&cached=true
The objId argument is the one containing the integer you want. In this link, the object ID is 200, so complete the CategoryField entry as follows:
<CategoryField_1 value="PT200"/>
You can add multiple custom categorization options by adding analogous tags named CategoryName_2, CategoryField_2, CategoryName_3, CategoryField_3, and so forth. In portalconfig.xml, the Category tags must be numbered consecutively without skipping. For example, if there is a <CategoryName_3> tag, there must be tags for Category 1 and 2.
For more information about the portalconfig.xml file, see Configuring Advanced Properties and Logging.
Grid search consists of shared files (for example, C:\cluster) and search nodes. When you start up the Search Service, it looks at the cluster.nodes file in the shared files location to determine the host, port, and partition of each node in the cluster. It monitors and communicates the availability of the search nodes and distributes queries appropriately.
The Search Service also automatically repairs and reconciles search nodes that are out of sync with the cluster. At startup, nodes will check their local TID against the current cluster checkpoint and index queues. If the current node is out-of-date with respect to the rest of the cluster, it must recover to a sufficiently current transaction level (at or past the lowest cluster node TID) before servicing requests for the cluster. Depending upon how far behind the local TID is, this operation may require retrieval of the last-known-good checkpoint data in addition to replaying queued index requests.
Although the Search Service performs many actions automatically to keep your cluster running properly, there are some maintenance and management tasks you perform manually to ensure quality search in your portal. This section includes the following topics:
As users create, delete, and change objects in the portal, the search index gets updated. In some cases, the portal updates the search index immediately; in other cases, the search is not updated until the next time the Search Update Agent runs. The following table describes the cases in which the search index is updated immediately (I) or updated by the Search Update Agent (SU).
| Note: | If the Knowledge Directory preferences are set to use the search index to display browse mode, changes will not display until the Search Update Agent runs. The Knowledge Directory edit mode and the Administrative Object Directory display objects according to the database, and therefore show changes immediately. |
The Search Update job is located in the Intrinsic Operations administrative folder. It performs the following actions on the search index:
The default frequency of the Search Update job is one hour, which is suitable for most portal deployments; but, if your search index is very large, the Search Update Agent might not be able to finish in one hour. For information on modifying Search Update job settings, see Running Portal Agents.
Your search index might get out of sync with your database if, during the course of a crawl, the Search Service became unavailable or a network failure prevented an indexing operation from completing. Another possibility is that a Search Service with empty indices was swapped into an existing portal with pre-existing documents and folders.
The Search Service Manager lets you specify when and how often the Search Update Agent repairs your search index. Instead of just synchronizing only particular objects, the repair also synchronizes all objects in the database with the search index. Searchable objects in the database are compared with IDs in the search index. If an object ID in the database is not in the search index, the Search Update Agent attempts to re-index the object; if an ID in the search index is not in the database, the Search Update Agent removes the object from the search index.
Run the Search Update Agent for purposes of background maintenance or complete repopulation of the search index.
A checkpoint is a snapshot of your search cluster that is stored in the cluster folder (for example, C:\bea\alui\cluster), a shared repository available to all nodes in the cluster. When initializing a new cluster node, or recovering from a catastrophic node failure, the last known good checkpoint will provide the initial index data for the node's partition and any transaction data added since the checkpoint was written will be replayed to bring the node up to date with the rest of the cluster.
You manage checkpoints on the Checkpoint Manager page of the Search Cluster Manager. You can perform the following actions with the Checkpoint Manager:
| Note: | For instructions on using the Search Cluster Manager, refer to online help. |
Since checkpoint data is of significant size, limit the number of checkpoints maintained by the system. Specify how many checkpoints to keep on the Settings page of the Search Cluster Manager. Refer to online help for details.
Your search cluster is made up of one or more partitions, each of which is made up of one or more nodes. As your search collection becomes larger, the collection can be partitioned into smaller pieces to facilitate more efficient access to the data. As the Search Service becomes more heavily utilized, replicas of the existing partitions, in the form of additional nodes, can be used to distribute the load. Additional nodes also provide fault-tolerance; if a node becomes unavailable, queries are automatically issued against the remaining nodes.
| Note: | If a partition becomes unavailable, the cluster will continue to provide results; however, the results will be incomplete (and thus indicated in the query response). |
You manage the partitions and nodes in your search cluster on the Topology Manager page of the Search Cluster Manager. You can perform the following actions with the Topology Manager:
Search logs are kept for the search cluster as well as for each node in the search cluster. The cluster logs are stored in the \cluster\log folder, for example, C:\bea\alui\cluster\log\cluster.log. The cluster logs include cluster-wide state changes (such as cluster initialization, node failures, and node recoveries), errors, and warnings.
The node logs are stored in the node's logs folder, for example, C:\bea\alui\ptsearchserver\6.1\node1\logs. There are two kinds of node logs: event logs and trace logs. Event logs capture major node-local state changes, errors, warnings, and events. Trace logs capture more detailed tracing and debugging information.
There are several ways to view the logs:
A new cluster log is created with each new checkpoint. The log that stores all activity since the last checkpoint is called cluster.log. When a new checkpoint is created, the cluster.log file is saved with the name <checkpoint>.log, for example, 0_1_5116.log.
The Command Line Admin Utility allows you to perform the same functions you can perform in the Search Cluster Manager as well as the following additional functions:
The Command Line Admin Utility is located in bin\native folder in the Search Service installation folder, for example, C:\bea\alui\ptsearchserver\6.1\bin\native\cadmin.exe. Invoking the command with no arguments displays a summary of the available options:
% $RFHOME/bin/cadmin
Usage: cadmin <command> [command-args-and-options] [--cluster-home <CLUSTER_HOME>]
The status command displays the status of the cluster. By default, the status command displays a terse, one-line summary of the current state of the cluster:
% cadmin status --cluster-home=/shared/search
2005-04-22 13:54:13 checkpoint_xxx 0/1/198 0/1/230 impaired
If you add the verbose flag, the status command displays the full set of information, including the status of every node in the cluster:
% cadmin status --verbose --cluster-home=/shared/search
2005-04-22 13:54:13 /shared/search checkpoint_xxx
cluster-state: impaired
cluster-tid: 0/1/198 0/1/230
partition-states: complete impaired
node p0n0: 0 192.168.1.1 15244 0/1/198 0/1/460 run
node p0n1: 0 192.168.1.2 15244 0/1/198 0/1/460 run
node p1n0: 1 192.168.1.3 15244 0/1/198 0/1/230 run
node p1n1: 1 192.168.1.4 15244 0/1/100 0/1/120 offline
You can also use the status command to repeatedly emit status requests at a specified interval:
% cadmin status --period=10 --count=5
2005-04-22 13:54:13 checkpoint_xxx 0/1/198 0/1/230 impaired
2005-04-22 13:54:23 checkpoint_xxx 0/1/198 0/1/230 impaired
2005-04-22 13:54:33 checkpoint_xxx 0/1/198 0/1/230 impaired
2005-04-22 13:54:43 checkpoint_xxx 0/1/198 0/1/230 impaired
2005-04-22 13:54:53 checkpoint_xxx 0/1/400 0/1/428 complete
You can request information about specific nodes within the cluster. This displays the same type of information that is displayed as part of the verbose cluster status request:
% cadmin nodestatus p0n0 p1n0
node p0n0: 0 192.168.1.1 15244 0/1/198 0/1/460 run
node p1n0: 1 192.168.1.3 15244 0/1/198 0/1/230 run
As with cluster status, you can request periodic status output:
% cadmin nodestatus p0n0 p1n0 --period=10
2005-04-22 13:54:13 p0n0 0 192.168.1.1 15244 0/1/198 0/1/460 run
2005-04-22 13:54:13 p1n0 0 192.168.1.1 15244 0/1/198 0/1/460 run
2005-04-22 13:54:23 p0n0 0 192.168.1.1 15244 0/1/198 0/1/460 run
2005-04-22 13:54:23 p1n0 0 192.168.1.1 15244 0/1/198 0/1/460 run
You can modify the run level of the cluster, or of individual nodes within the cluster. For example, you might want to place nodes in standby mode prior to changing cluster topology or shutting them down. Transitioning from standby to any of the operational modes (recover, readonly, stall, run) will validate the node's state against the cluster state and will trigger a checkpoint restore if one is warranted.
Transitions to readonly or offline modes are also potentially useful: readonly mode halts incorporation of new index data on a node; offline mode will cause the search server to exit.
To set run level of p0n0 and p1n0 to standby:
% cadmin runlevel standby p0n0 p1n0
To set run level of the entire cluster to run (affects only non-offline nodes):
% cadmin runlevel run
You can purge the contents of the search collection. You might want to purge the cluster in staging or development systems, or if you want to clean out the search collection without re-installing all the nodes. Purging the search collection may also be useful in a dire situation where the contents of the cluster are corrupted beyond repair and good checkpoints are not available for recovery.
By default, the checkpoints and index queue are left in place. This allows you to rebuild the local index on a node whose archive appears to be corrupted.
To purge the search collection, but keep checkpoints:
% cadmin purge
| Caution: | As a safeguard against performing this operation by accident, all cluster nodes must be in standby mode and you must confirm the action before the purge command is sent out. |
The purge command causes a node to generate empty archive collections (document, spell, and mappings) and perform a soft-restart to load them into memory. Before reloading, the admin utility updates the checkpoint files in the shared repository to prevent the nodes from automatically reloading from an existing checkpoint.
To purge the search collection and delete existing checkpoints:
% cadmin purge --remove-checkpoints
You can request a cluster checkpoint at any time (in addition to any periodic checkpoints initiated by the cluster):
% cadmin checkpoint
Since creating a checkpoint is a time-consuming process, the admin utility displays its progress:
Checkpoint using nodes: p0n0 p1n1 p2n0
Node p0n0 copying data
Node p1n1 copying data
Node p2n0 copying data
0%..10%..20%..30%..40%..50%..60%..70%..80%..90%..100%
Checkpoint complete in \\cluster_home\checkpoint_xxx
If the cluster has insufficient active nodes to perform the checkpoint, the admin utility displays appropriate feedback:
Node p0n0 is offline
Node p0n1 is offline
Unable to checkpoint at this time: partition 0 is unavailable
Any error messages encountered during the checkpoint process also display:
Checkpoint using nodes: p0n0 p1n1 p2n0
Node p0n0 copying data
Node p1n1 copying data
Node p2n0 copying data
0%..10%..20%..
Node p1n1 is offline
Checkpoint aborted
You can request a checkpoint restore at any time.:
% cadmin restore
Since restoring from a checkpoint is a time-consuming process, the admin utility displays its progress:
Restoring cluster from \\cluster_home\checkpoint_xxx
Node p0n0 retrieving data
Node p0n1 retrieving data
0%..10%..20%..30%..40%..50%..60%..70%..80%..90%..100%
Node p0n0 restarted
Node p0n1 restarted
Restoration complete
You use the same command to add or remove nodes from the search cluster as you do to repartition the cluster:
% cadmin topology new.nodes
The difference is how you change the cluster.nodes file:
Issue a "soft reset" to the cluster through the command line utility, which causes all nodes to re-examine the cluster topology file and thus recognize the new node. When the new node receives a soft reset, it recognizes that it needs to catch up to the rest of the cluster and begins the automated index recovery process from the last checkpoint.
Since changing cluster topology can be a time-consuming process, the admin utility displays its progress. Here's an example of what the output might be when you add and remove nodes:
Current topology:
<contents of current cluster.nodes file>
New topology:
<contents of new.nodes file>
Nodes to add: p0n2, p1n2, p2n2
Nodes to remove: p0n0, p1n0, p2n0
Is this correct (y/n)? y
Applying changes...
p0n2 has joined
p2n0 has left
...
Changes applied successfully
Here's an example of what the output might be when you repartition the cluster:
Current topology:
<contents of current cluster.nodes file>
New topology:
<contents of new.nodes file>
Nodes to add: p3n0, p3n1
Is this correct (y/n)? y
CAUTION: the requested changes require repartitioning the search collection
The most recent checkpoint is checkpoint_xxx from 2004-04-22 16:00:00
Is this correct (y/n)? y
Repartitioning from 3 partitions into 4
0%
5%
<progress messages>
100%
Repartitioning successful
Applying changes...
p0n2 has joined
p2n0 has left
...
Changes applied successfully
If the repartition fails, the search collection leaves the cluster in its original state, if at all possible, and provides information about the failure. The cluster.nodes file is rolled back to the previous state after making sure that the last-known good checkpoint refers to an un-repartitioned checkpoint directory.
You can abort a long-running checkpoint or cluster reconfiguration operation by exiting from the command line utility with Control-C. The cluster will be restored to its state prior to attempting the checkpoint or topology reconfiguration.
In the case of a checkpoint operation, the utility sends a "checkpoint abort" command to the checkpoint coordinator to cleanly abort the checkpoint create/restore operation.
In the case of a cluster reconfiguration, the utility restores the original cluster.nodes file and initiates a soft restart of the affected cluster nodes to restore the cluster to its previous configuration.
A snapshot query allows you to display the results of a query in a portlet or e-mail the results to users. You can select which repositories to search (including Publisher and Collaboration), and limit your search by language, object type, folder, property, and text conditions.
The editor prompts you to send an invitation to view the query. Follow the editor instructions to do so.
This section describes federated searches, which allow your users to search external repositories for content or allow users of other portals to search your portal for content. This section includes the following topics:
Federated searches connect separate AquaLogic Interaction portals with one another and with external repositories. Federated searches empower dispersed organizations to deploy multiple portals and link them together, thereby combining local control over content with global scope. Federated searches provide end-users a single interface and unified result set for searches over multiple AquaLogic Interaction portals, as well as parallel querying of external Internet and intranet-based search engines.
When you install the portal, the Public Access Incoming Federated Search is created. This allows other AquaLogic Interaction portals to search this portal as the Guest user.
To allow other search relationships, you must create new incoming or outgoing federated searches. Whether your portal is requesting or serving content, you and the other administrators involved need to agree upon the following issues prior to establishing federated searches:
If both portals share a common external database of users, such as an LDAP server or NT domain, you must grant the shared users access to the appropriate content on the serving portal. This provides the greatest degree of content security without requiring any additional administrative work.
If the portals involved do not share a database of user information, you must create one or more portal users in the serving portal that can be impersonated by users of the requesting portal.
For every request issued, the requesting portal sends an ID and password to identify itself to the serving portal. You must enter the same ID and password in both the requesting portal outgoing federated search and the serving portal incoming federated search.
Incoming federated searches can be configured to allow unauthenticated users to search the portal as a guest.
AquaLogic Interaction portals can use federated search to search other AquaLogic Interaction portals. To enable this, you must configure a trust relationship between the searching (outgoing) and searched (incoming) portals. To establish the trust relationship, the two participating portals must agree upon a name and password combination that will be used to ensure that requests are coming from a trusted source. This information is recorded as the portal identification name and password.
There are outgoing and incoming federated searches:
To create a search Web service:
To create an outgoing federated search:
To create an incoming federated search:
If there is a non-portal repository that you want to search, BEA or another vendor might have written a search Web service to access it. If not, BEA provides an Enterprise Web Development Kit that allows you to easily write your own Search Web services in Java or .NET. For details, visit the BEA AquaLogic User Interaction Development Center ( http://dev2dev.bea.com/aluserinteraction/).
To create an outgoing federated search that accesses a non-portal repository.


|

 . This displays text, including a URL, that you can paste into an e-mail and send to users.
. This displays text, including a URL, that you can paste into an e-mail and send to users.