|
|
BEA AquaLogic Data Services Platform handles updates to relational data sources automatically. However, for any non-relational data sources, including Web services, you must provide the update logic by writing an update override class and associating it with the data service. In addition, there are times when you may want (or need) to provide custom update logic for relational data sources as well.
Any data service, logical or physical, can have an associated update override class to perform a variety of customizations.
This chapter explains how to create an update override class (the class comprising the update behavior) and when you may want to do so for relational data sources. It includes the following topics:
An update override provides you with a mechanism for customizing or completely replacing the default update process (as discussed in How It Works: The Decomposition Process). With an update override associated with your data service, you can:
In programming terms, an update override is a Java class; it is a compiled Java source code file that implements the UpdateOverride interface (<UpdateOverride>, one of the DSP APIs located in the com.bea.ld.dsmediator.update package). The UpdateOverride interface has as its sole method an empty performChange( ) method (see Listing 9-1).
As shown in Listing 9-1, the performChange() method takes a DataGraph object (passed to it by the Mediator). This object is the SDO on which your update override class will operate. The DataGraph object contains the data object, the changes to the object, and other artifacts, such as metadata (as discussed in Data Services Platform and Service Data Objects (SDOs) on page 2-2.)
package com.bea.ld.dsmediator.update;
import commonj.sdo.DataGraph;
import commonj.sdo.Property;
public interface UpdateOverride
{
public boolean performChange(DataGraph sdo)
{
}
}
As you can see from the performChange( ) method signature (Listing 9-1), it returns a Boolean value. This value serves as something of a flag to the Mediator, as follows:
The performChange( ) method will be executed whenever a submit is issued for objects bound to the overridden data service.
If the object being passed in the submit() is an array of DataService objects, the array is decomposed into a list of singleton DataService objects. Some of these objects may have been added, deleted, or modified; therefore, the update override might be executed more than once (that is, once per changed object.)
In your code, you should verify that the root data object for the data graph being passed at runtime is an instance of the singleton data object bound to the data service (configured with the update override).
You must create custom update classes to update any non-relational data sources—Web services, XML files, flat-files, and DSP procedures, for example, and for these types of scenarios:
For example, your client application code is adding both a department and a manager; however, manager is also a required field of department. How can you set the department's manager field before the manager exists? As follows:
Once you have written and compiled the Java code that comprises the update override class, you must register the class with the data service. Update overrides can be registered on physical or logical data services: Each data service has an Override Class property that can be associated with a specific Java class file that comprises the implementation of the UpdateOverride.
At runtime, the data service executes the UpdateOverride class when it identifies it as available during the decomposition process (see Logical Data Service Update Process).
For relational sources, you may also want to use custom update classes to apply custom logic to the update process, or if an aspect of the data service design prevents automated updates, as discussed in When Are Update Overrides Required for Relational Data Sources?
DSP automatically updates relational data sources. However, in some cases, such as those listed Table 9-1, DSP cannot automatically update relational data sources, and requires that you provide an update override to handle update processing.
To create an update override class, perform the following steps:
import com.bea.ld.dsmediator.update.UpdateOverride; import commonj.sdo.DataGraph; |
public class SpecialOrders implements UpdateOverride |
public boolean performChange(DataGraph graph) |
javaUpdateExit element tag (in the pragma statement of the data service). For example:
<javaUpdateExit className="SpecialOrderUpdate"/> |
Listing 9-2 is an example of an update override implementation.
package RTLServices;
import com.bea.ld.dsmediator.update.UpdateOverride;
import commonj.sdo.DataGraph;
import java.math.BigDecimal;
import java.math.BigInteger;
import retailer.ORDERDETAILDocument;
import retailerType.LINEITEMTYPE;
import retailerType.ORDERDETAILTYPE;
public class OrderDetailUpdate implements UpdateOverride
{
public boolean performChange(DataGraph graph){
ORDERDETAILDocument orderDocument =
(ORDERDETAILDocument) graph.getRootObject();
ORDERDETAILTYPE order =
orderDocument.getORDERDETAIL().getORDERDETAILArray(0);
BigDecimal total = new BigDecimal(0);
LINEITEMTYPE[] items = order.getLINEITEMArray();
for (int y=0; y < items.length; y++) {
BigDecimal quantity =
new BigDecimal(Integer.toString(items[y].getQuantity()));
total = total.add(quantity.multiply(items[y].getPrice()));
}
order.setSubTotal(total);
order.setSalesTax(
total.multiply(new BigDecimal(".06")).setScale(2,BigDecimal.ROUND_UP));
order.setHandlingCharge(new BigDecimal(15));
order.setTotalOrderAmount(
order.getSubTotal().add(
order.getSalesTax().add(order.getHandlingCharge())));
System.out.println(">>> OrderDetail.ds Exit completed");
return true;
}
}
In the sample class shown in Listing 9-2, an OrderDetailUpdate class implements the UpdateOverride class, and, as required by the interface, defines a performChange( ) method. Listing 9-2 demonstrates a common coding pattern for update overrides:
ORDERDETAILDocument orderDocument =
(ORDERDETAILDocument) graph.getRootObject();
|
get call and index value. For example, to obtain the first such object:
ORDERDETAILTYPE order =
orderDocument.getORDERDETAIL().getORDERDETAILArray(0)
|
| Note: | See Update Override Programming Patterns for some other common programming patterns. |
Listing 9-3 shows an example of an update override class that invokes a data service procedure. Since UpdateOverrides are invoked locally, within the DSP server, the sample uses the typed Mediator API. As shown in Listing 9-3, several Web services operations (to create, delete, and modify a customers address) have been registered with a Data Service.
public class CustomerAddressUpdate implements UpdateOverride {
public boolean performChange(DataGraph graph) {
bool status = true; // assume the best
ChangeSummary changeSum = datagraph.getChangeSummary();
// If no changes, do nothing.
if (changeSum.getChangedDataObjects().size()==0) {
return true;
}
// Get the DataGraph's root DataObject and cast to customer object to
// enable getting DataGraph constituents
CUSTOMERDocument custDoc = (CUSTOMERDocument) graph.getRootObject();
ADDRESS[] addr = custDoc.ADDRESS().getADDRESSArray();
int i;
try {
CUSTOMER custDS = CUSTOMER.getInstance(
new InitialContext(), "RTLApp" );
// For each address in the Customer's address array, call the Web Service's
// update, delete, or create procedure as appropriate
for( i = 0; i < addr.length; i++ ) {
if ( changeSum.isModified( addr[ i ] ) ) {
custDS.invokeProcedure("modifyCustomerAddress",
new Object [] {addr[ i ]} );
}
else if ( changeSum.isDeleted( addr[ i ] ) ) {
custDS.invokeProcedure("deleteCustomerAddress",
new Object [] {addr[ i ]});
}
else if ( changeSum.isCreated( addr[ i ] ) ) {
custDS.invokeProcedure("createCustomerAddress",
new Object [] {addr[ i ]} );
}
else {
// throw an exception for IllegalState
}
}
} // end for
}
catch( Exception ex ) {
System.err.println( ex.printStackTrace() );
throw ex;
}
return status;
}
}The example in Listing 9-3 is for a Web service running locally on the WebLogic Server instance, so it does not include basic setup code to obtain context and location. (If the Web service is not local to the WebLogic Server instance, your code must obtain an InitialContext and providing appropriate location and security properties. See Obtaining a WebLogic JNDI Context for Data Services Platform for more information about InitialContext.)
Listing 9-4 shows an update override alters the update plan in order to enforce referential integrity by removing product information from the middle of a list and adds it back at the end.
// delete order, item, product, due to RI between ITEM and Product
// product has to be deleted after items
public boolean performChange(DataGraph graph)
{
DataServiceMediatorContext context = DataServiceMediatorContext.currentContext();
UpdatePlan up =context.getCurrentUpdatePlan( graph, false );
Collection dsCollection = up.getDataServiceList();
DataServiceToUpdate ds2u = null;
for (Iterator it=dsCollection.iterator();it.hasNext();)
{
ds2u = (DataServiceToUpdate)it.next();
if (ds2u.getDataServiceName().compareTo("ld:DataServices/PRODUCT.ds") == 0 ) {
// remove product from the mid of list and add it back at the end
up.removeContainedDataService( ds2u.getDataGraph() );
up.addDataService(ds2u.getDataGraph(), ds2u );
};
}
context.executeUpdatePlan( up );
return false;
}
}
Data service updates should always be tested to ensure that changes occur as expected. You can test submits using the Test View in BEA WebLogic Workshop.
The results in Test View depend on the type of changes being made, specifically, whether you are testing read and navigate functions or DSP procedures. For functions, the submit() returns the data.
For procedures, the Test View displays:
"Side effect function executed successfully." |
For information on testing submits, refer to the Data Services Developer's Guide.
While Test View gives you a quick way to test simple update cases in the data services you create, for more substantial testing and troubleshooting you can use an update override class to inspect the decomposition mapping and update plan for the update.
The override class is also the mechanism you can use to extend and override the Mediator's default update processing. You can use it to implement updates for data services that would otherwise not support updates, such as non-relational sources. See Developing the UpdateOverride Class on page 9-6 for information about override classes.
Although an update override class can programmatically access several update framework artifacts, including the update plan, decomposition map, and the tree of modified data objects, the content available at any time depends on the data service context, as follows:
Figure 9-2 illustrates the context visibility within an update override.
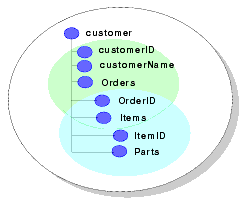
Considerations for implementing update override classes for physical level data services include the following:
Additional considerations concerning update overrides for relational data services include:
For physical non-relational data services, your performChange( ) method must:
In an update override, you can modify the server-side update process as much or as little as you like, at any step of the way, to accomplish your goal. This section provides some code samples that illustrate common update override programming patterns, including:
Remember that an Update Override class is simply a Java class that implements the UpdateOverride interface. You can give the class any valid Java filename, but should use a meaningful name for common-sense reasons. After writing the class, you must register it with the data service, by setting the name of the class in the data service's Update Override Property field.
The class must include an implementation of the performChange( ) method; it is inside this method that you provide all custom code required for the programming task at hand. The performChange( ) method returns a boolean value that either continues or aborts processing by the Mediator, as discussed in How It Works: The Decomposition Process on page 2-18. The level of customization that you provide in your performChange( ) method determines whether you should return true or false, as noted in each of the sections below.
To customize the entire decomposition and update process, the performChange( ) method can implement the following types of routines:
If your performChange( ) method does take over all processing, it should return false so that the Mediator does not proceed with automated decomposition.
The performChange( ) method can include code to inspect changed data object values and raise DataServiceException to signal errors, rolling back the transaction in such cases.
Return true to have the Mediator proceed with update propagation using the objects as changed.
To access the change plan and decomposition map for an update, you first must get the data service's Mediator context. The context enables you to view the decomposition map, produce an update plan, execute the update plan, and access the container data service instance for the data service object currently being processed.
The following code snippet shows how to get the context:
DataServiceMediatorContext context =
DataServiceMediatorContext().getInstance();Once you have the context, you can access the decomposition map as follows:
DecompositionMapDocument.DecompositionMap dm =
context.getCurrentDecompositionMap(); Once you have a decomposition map, you can use its toString() method to obtain the string rendering of the XML that map, as shown in Listing 9-5. (Note that although you can access the default decomposition map, you should not modify it.)
In addition to accessing the decomposition map, you can access the update plan in the override class. You can modify values in the tree, remove nodes, or rearrange them (to change the order in which they are applied). However, if you modify the update plan, you should execute the plan within the override if you want to keep the changes. As you modify the values in the tree, remove nodes or rearrange them, the update plan will track your changes automatically in the change list.
<xml-fragment xmlns:upd="update.dsmediator.ld.bea.com">
<Binding>
<DSName>ld:DataServices/CUSTOMERS.ds</DSName>
<VarName>f1603</VarName>
</Binding>
<AttributeLineage>
<ViewProperty>CUSTOMERID</ViewProperty>
<SourceProperty>CUSTOMERID</SourceProperty>
<VarName>f1603</VarName>
</AttributeLineage>
<AttributeLineage>
<ViewProperty>CUSTOMERNAME</ViewProperty>
<SourceProperty>CUSTOMERNAME</SourceProperty>
<VarName>f1603</VarName>
</AttributeLineage>
<upd:DecompositionMap>
<Binding>
<DSName>ld:DataServices/getCustomerCreditRatingResponse.ds</DSName>
<VarName>getCustomerCreditRating</VarName>
</Binding>
<AttributeLineage>
<ViewProperty>CREDITSCORE</ViewProperty>
<SourceProperty>
getCustomerCreditRatingResult/TotalScore
</SourceProperty>
<VarName>getCustomerCreditRating</VarName>
</AttributeLineage>
...
</upd:DecompositionMap>
</upd:DecompositionMap>
<ViewName>ld:DataServices/Customer.ds</ViewName>
</xml-fragment>
After possibly validating or modifying the values in the submitted data object, the function retrieves the update plan by passing in the current data object to the following function:
DataServiceMediatorContext.getCurrentUpdatePlan()The update plan can be augmented in several ways, including:
After executing the update plan, the performChange( ) method should return false so that the Mediator does not attempt to apply the update plan.
The update plan lets you modify the values to be updated to the source. It also lets you modify the update order.
You can programmatically walk the update plan to view its contents by using your own method, similar to the navigateUpdatePlan(). As shown in Listing 9-6, navigateUpdatePlan() method takes a Collection object and uses an iterator to recursively walk the plan.
public boolean performChange(DataGraph datagraph){
UpdatePlan up = DataServiceMediatorContext.currentContext().
getCurrentUpdatePlan( datagraph );
navigateUpdatePlan( up.getDataServiceList() );
return true;
}
private void navigateUpdatePlan( Collection dsCollection ) {
DataServiceToUpdate ds2u = null;
for (Iterator it=dsCollection.iterator();it.hasNext();) {
ds2u = (DataServiceToUpdate)it.next();
// print the content of the SDO
System.out.println (ds2u.getDataGraph() );
// walk through contained SDO objects
navigateUpdatePlan (ds2u.getContainedDSToUpdateList() ); }
}
A sample update plan report would look like the following
UpdatePlan
SDOToUpdate
DSName: ... :PO_CUSTOMERS
DataGraph: ns3:PO_CUSTOMERS to be added
CUSOTMERID = 01
ORDERID = unset
PropertyMap = null
Now consider an example in which a line item is deleted along with the order that contains it. Given the original data, Listing 9-7 illustrates an update plan in which item 1001 will be deleted from Order 100, and then the Order is deleted.
UpdatePlan
SDOToUpdate
DSName:...:PO_CUSTOMERS
DataGraph: ns3:PO_CUSTOMERS to be deleted
CUSTOMERID = 01
ORDERID = 100
PropertyMap = null
SDOToUpdate
DSName:...:PO_ITEMS
DataGraph: ns4:PO_ITEMS to be deleted
ORDERID = 100
ITEMNUMBER = 1001
PropertyMap = null
In this case, the execution of the update plan is as follows: before deleting the PO_CUSTOMERS, the contained SDOToUpdates routines are visited and processed. So the PO_ITEMS is deleted first and then PO_CUSTOMERS is deleted.
If the contents of the Update Plan are changed the new plan can then be executed. The update exit should then return false, signaling that no further automation should occur.
The plan can then be propagated to the data source, as described in Executing an Update Plan.
After modifying an update plan, you can execute it. Executing the update plan causes the Mediator to propagate changes to the indicated data sources.
Given a modified update plan named up, the following statement executes it:
context.executeUpdatePlan(up);On a data service that is being processed for an update plan, you can get the container of the SDO being processed. The container must exist in the original changed object tree, as decomposed. If no container exists, null is returned. Consider the following example:
String containerDS = context.getContainerDataServiceName();
DataObject container = context.getContainerSDO();
In this example, if in the update override class for the Orders data service the you ask to see the container, the Customer data service object for the Order instance being processed would be returned. If that Customer instance was in the update plan, then it would be returned. If it was not in the update plan, then it would be decomposed from CustOrders and returned.
The update plan only shows what has been changed. In some cases, the container will not be in the update plan. When the code asks for the container, it will be returned from the update plan if present; otherwise, it will be decomposed from the source SDO.
Other data services may be accessed and updated from an update override. The data service the Mediator API can be used to access data objects, modify and submit them. Alternatively, the modified data objects can be added to the update plan and updated when the update plan is executed. If the data object is added to the update plan, it will be updated within the current context and its container will be accessible inside its data service update override.
If the DataService Mediator API is used to perform the update, a new DataService context is established for that submit, just as if it were being executed from the client. This submit() acts just like a client submit — changes are not reflected in the data object. Instead, the object must be re-fetched to see the changes made by the submit.
DSP uses the underlying WebLogic Server for logging. WebLogic logging is based on the JDK 1.4 logging APIs (available in the java.util.logging package). You can contribute to the log (from an update override) by acquiring a DataServiceMediatorContext instance, and then calling the getLogger() method on the context, as follows:
DataServiceMediatorContext context =
DataServiceMediatorContext().getInstance();
Logger logger = context.getLogger()
|
You can then contribute to the log by issuing the appropriate logger call with a specific log level. The log level implies the severity of the event. When WebLogic Server message catalogs and the NonCatalogLogger generate messages, they convert the message severity to a weblogic.logging.WLLevel object. A WLLevel object can specify any of the values listed in Table 9-4, from lowest to highest impact:
Development_time logging is written to the following location:
<bea_home>\user_projects\domains\<domain_name>
Given the specified logging level, the Mediator logs the information shown in Table 9-5.
Listing 9-8 shows a sample log entry.
<Nov 4, 2004 11:50:10 AM PST> <Notice> <LiquidData> <000000> <Demo - begin client sumbitted DS: ld:DataServices/Customer.ds><Nov 4, 2004 11:50:10 AM PST> <Notice> <LiquidData> <000000> <Demo - ld:DataServices/Customer.ds number of execution: 1 total execution time:171>
<Nov 4, 2004 11:50:10 AM PST> <Info> <LiquidData> <000000> <Demo - ld:DataServices/CUSTOMERS.ds number of execution: 1 total execution time:0>
<Nov 4, 2004 11:50:10 AM PST> <Info> <LiquidData> <000000> <Demo - EXECUTING SQL: update WEBLOGIC.CUSTOMERS set CUSTOMERNAME=? where CUSTOMERID=? AND CUSTOMERNAME=? number of execution: 1 total execution time:0>
<Nov 4, 2004 11:50:10 AM PST> <Info> <LiquidData> <000000> <Demo - ld:DataServices/PO_ITEMS.ds number of execution: 3 total execution time:121>
<Nov 4, 2004 11:50:10 AM PST> <Info> <LiquidData> <000000> <Demo - EXECUTING SQL: update WEBLOGIC.PO_ITEMS set ORDERID=? , QUANTITY=? where ITEMNUMBER=? AND ORDERID=? AND QUANTITY=? AND KEY=? number of execution: 3 total execution time:91>
<Nov 4, 2004 11:50:10 AM PST> <Notice> <LiquidData> <000000> <Demo - end clientsumbitted ds: ld:DataServices/Customer.ds Overall execution time: 381>
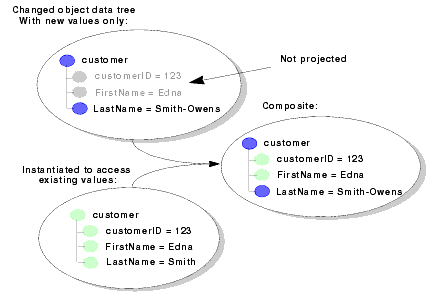
Locking mechanisms are used in numerous types of multi-user systems for concurrency control—to ensure that data is consistent, across transactions and regardless of the number of users acting on the system at the same time. Optimistic locking mechanisms are so-called because they typically only lock data at the time it is being updated (written to), not when it is being read.
DSP uses optimistic locking as its concurrency control policy, locking data only when updates are being attempted. When DSP receives submitted data graph, it compares the values of the data used to instantiate the original data objects with the original values in the data graph to ensure that the data was not changed by another user process during the time the data objects were being modified by a client application.
The Mediator compares fields from the original and the source; by default, Projected is used as the point of comparison (see Table 9-6).
You can specify the fields to be compared at the time of the update for each table. Note that primary key column must match, and BLOB and floating types might not be compared. Table 9-6 describes the options.
| Note: | If DSP cannot read data from a database table because another application has a lock on the table, queries issued by DSP are queued until the application releases the lock. You can prevent this by setting transaction isolation (on your WebLogic Server's JDBC connection pool) to read uncommitted. See Setting the Transaction Isolation Level in the Administration Guide for details on how to set the transaction isolation level. |


|