|
|
BEA AquaLogic Data Services Platform (DSP) implements the Service Data Objects (SDOs) as its data client-application programming model. SDO is an architecture and set of APIs for working with data objects while disconnected from their source. In DSP, SDOs—whether typed or untyped data objects—are obtained from data services by using the Mediator APIs, or through Data Service controls. (See Introducing Service Data Objects (SDO).)
Client applications manipulate the data objects as required for the business process at hand, and then submit changed objects to the data service, for propagation to the underlying data sources. Although the SDO specification does not define one, it does discuss the need for mediator services, in general, that can send and receive SDOs; the specification also discusses the need for handling updates to data sources, again, without specifying an implementation: The SDO specification leaves the details up to implementors as to how mediator services are implemented, and how they should handle updates to data objects.
As discussed in Update Frameworks and the Data Service Mediator, DSP's Mediator is the process that not only handles the back-and-forth communication between client applications and data services, it also facilitates updates to the various data sources that comprise any data service.
This chapter includes information about DSP's implementation of the SDO data programming model, as well as DSP's update framework. It includes:
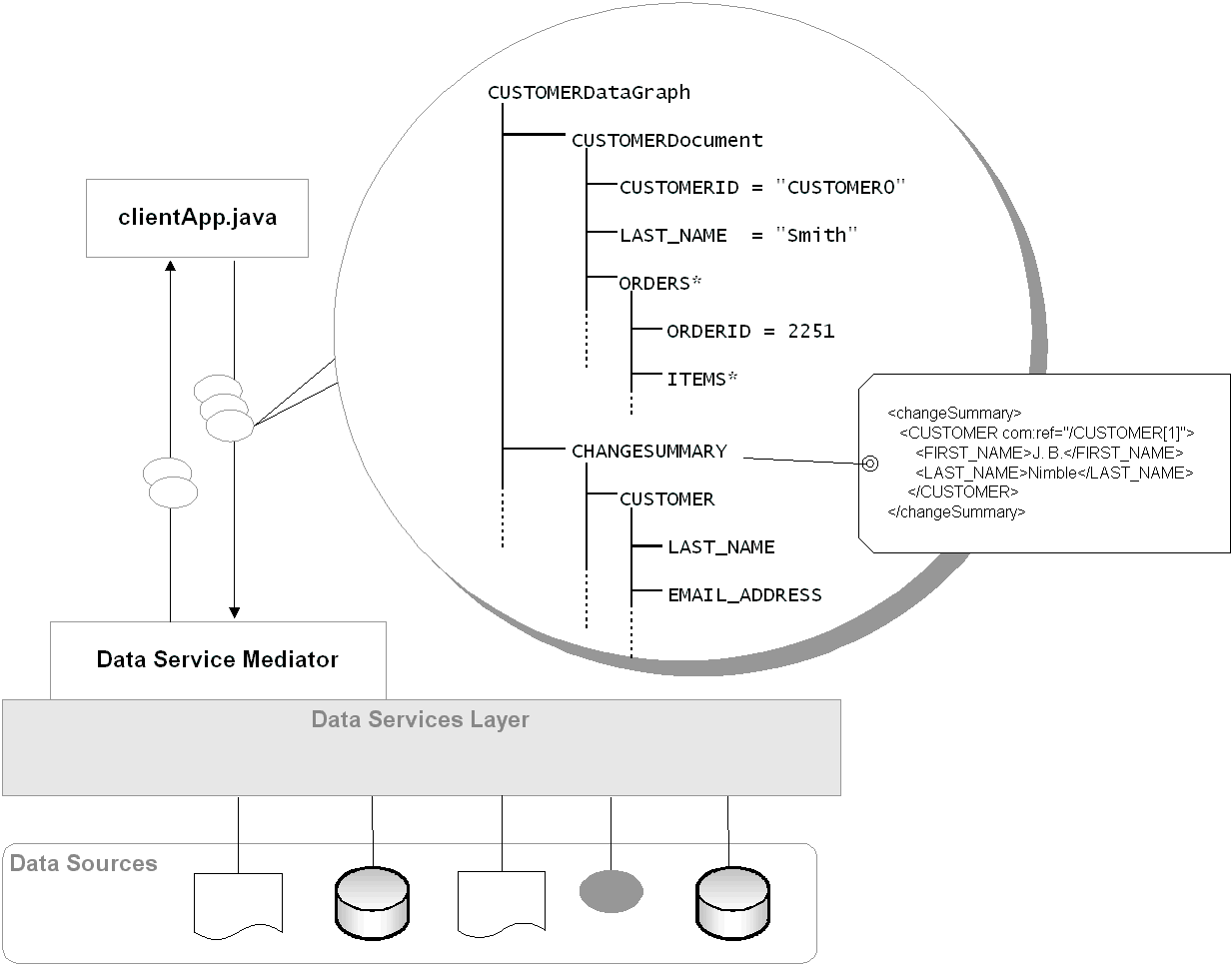
When you invoke a data service's read or navigation function (through the Data Service Mediator API or from a Data Service control), the data service returns a data graph comprising one or more data objects. Data objects and data graphs are two fundamental artifacts of the SDO data programming model. As shown in Figure 2-1, a data graph comprises:
Each of these can be described in more detail, as follows:
The change summary is used by the Mediator (in conjunction with a logical data service's decomposition map) to derive the update plan and ultimately, to update data sources. The change summary submitted with each changed SDO remains intact, regardless of whether or not the submit() succeeds, so it can support rollbacks when necessary.
Table 2-2 summarizes the various SDO data programming artifacts and lists an example of each (as shown in Figure 2-1).
SDO specifies both static (typed) and dynamic (untyped) interfaces for data objects:
The dynamic data API can be used with data types that have not yet been deployed at development time.
Table 2-3 summarizes the advantages of each approach.
SDO's static data API is a typed Java interface generated from a data service's XML schema definition. It is similar to JAXB or XMLBean static interfaces. The interface files, packaged in a JAR, are typically generated by the DSP data services developer using WebLogic Workshop, or by using one of the provided tools (see Developing Static Web Service Clients for more information).
The generated interfaces extend both the dynamic data API (specifically, the DataObject interface) and the XmlObject interface. Thus, the generated interfaces provide typed getters and setters for all properties of the XML datatype.
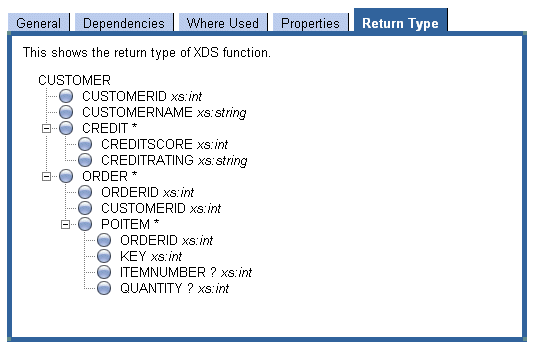
An interface is also generated for each complex property (such as CREDIT and ORDER shown in Figure 2-4), with getters and setters for each of the properties that comprise the complex type.
In addition, for properties that may have multiple occurrences, getters and setters are also generated for manipulating arrays and array elements. A multiple-occurring property is an XML schema element that has its maxOccurs attribute set to either unbounded or greater than one. In the DSP Console Metadata Browser, such elements are flagged with an asterisk—for example, ORDER* and POITEM* (see Figure 2-4) indicate that an array or order data objects (ORDERS[]) will be returned. For results involving repeating objects, you can cast the root element to an array of returned objects (datatypename[])
| Note: | In prior releases of Data Services Platform, an "ArrayOf..." schema element was created to serve as a container for array types returned as part of a Data Graph. Some references to the ArrayOf mechanism may remain in code samples and documentation. |
As an example of how static data APIs get generated, given the CUSTOMER data type shown in Figure 2-4, generating typed client interfaces results in:
When you develop Java client applications that use SDO's static data APIs, you will import these XMLBeans-generated typed interfaces into your Java client code. For example:
import appDataServices.AddressDocument; |
The SDO API interfaces use XMLBeans for object serialization and deserialization. As a client application developer, you rarely need to know such details. However, developers who are integrating DSP with WebLogic Integration workflow components (JPDs, or Java process definitions) will need to modify the default serialization-deserialization in their JPD code that uses data objects. For more information, see Using Workflow with DSP-Enabled Applications.
Since DSP uses XMLBeans, many features of the underlying XMLBeans technology are available in SDO as well. For example, DataObjects can be cast to Strings using the XmlObjects toString( ) method, for printing to output.
Table 2-5 lists static data API gettings and setters.
|
DSP client application developers can use the Data Services Platform Console to view the XML schema types associated with data services (see Figure 2-4, CUSTOMER Return Type Displayed in DSP Console's Metadata Browser, on page 2-6). The Return Type tab indicates the data type of each element—string, int, or complex type, for example. The XML schema data types are mapped to data objects in Java using the data type mappings shown in Table 2-6.
The dynamic data API has generic property getters and setters, such as set( ) and get( ), as well as getters and setters for specific Java data types (String, Date, List, BigInteger, and BigDecimal, for example). Table 2-7 lists representative APIs from SDO's dynamic data API. The propertyName argument indicates the name of the property whose value you want to get or set; propertyValue is the new value. The dynamic data API also includes methods for setting and getting a DataObject's property by indexValue. This includes methods for getting and setting properties as primitive types, which include setInt( ), setDate( ), getString( ), and so on.
Unlike the static data API, which eliminates underscores in method names generated from types that might include such characters ("LAST_NAME" results in a getLASTNAME( ) method, for example), the dynamic data API requires that field names be referenced precisely, as in get("LAST_NAME"). As an example, assuming that you have a reference to a CUSTOMER data object, you can use the dynamic data API to get the LAST_NAME property as follows:
String lastName = (String) customer.get("LAST_NAME");
|
For a complete reference of the dynamic data API, see the DSP Javadoc ( DSP Mediator API Javadoc on page 1-13). For documentation on the SDO 1.0 API see the DataObject interface in the commonj.sdo package. It is available at:
Table 2-7 lists dynamic data API gettings and setters.
One of the benefits of DSP's use of XMLBeans technology is support for XPath in the dynamic data API. XPath expressions give you a great deal of flexibility in how you locate data objects and attributes in the dynamic data API's accessors. For example, you can filter the results of a get() method invocation based on data elements and values:
company.get("CUSTOMER[1]/POITEMS/ORDER[ORDERID=3546353]")The SDO implementation goes beyond basic XPath 1.0 support by adding zero-based array index notation (".index_from_0") to XPath's standard bracketed notation ([n]). As an example, Table 2-8 compares the XPath standard and SDO augmented notations to refer to the same element, the first ORDER child node under CUSTOMER (Table 2-8).
Zero-based indexing is convenient for Java programmers who are accustomed to zero-based counters, and may want to use counter values as index values without adding 1.
DSP fully supports both the traditional index notation and the augmented notation. However, note that the SDO pre-processor transparently replaces the zero-based form with one-based forms, to avoid conflicts with elements whose names include dot numbers, such as <myAcct.12>.
Keep in mind these other points regarding DSP's XPath support:
("CUSTOMER//POITEM")
|
In this example, the wildcard matches all purchase order arrays below the CUSTOMER root, which includes either of the following:
CUSTOMER/ORDERS/POITEM |
CUSTOMER/RETURNS/POITEM |
Because this notation introduces type ambiguity (types can be either ORDERS or RETURNS), it is not supported by the DSP SDO implementation.
<ORDER ID="3434"> |
is accessed with the following path:
ORDER/@ID |
| Note: | For more examples of using XPath expressions with SDOs, see Step 2: Accessing Data Object Properties. |
The dynamic data API returns generic data objects. To obtain information about the properties of a data object, you can use methods available in SDO's Type interface. The Type interface (located in the commonj.sdo package) provides several methods for obtaining information, at runtime, about data objects, including a data object's type, its properties, and their respective types.
According to the SDO specification, the Type interface (see Table 2-9) and the Property interface (see Table 2-10) comprise a minimal metadata API that can be used for introspecting the model of data objects. For example, the following obtains a data object's type and prints a property's value:
DataObject o = ...;
|
Once you have an object's data type, you can obtain all its properties (as a list) and access their values using the Type interface's get Properties() method, as shown in Listing 2-1.
public void printDataObject(DataObject dataObject, int indent) {
Type type = dataObject.getType();
List properties = type.getProperties();
for (int p=0, size=properties.size(); p < size; p++) {
if (dataObject.isSet(p)) {
Property property = (Property) properties.get(p);
// For many-valued properties, process a list of values
if (property.isMany()) {
List values = dataObject.getList(p);
for (int v=0; count=values.size(); v < count; v++) {
printValue(values.get(v), property, indent);
}
else { // Forsingle-valued properties, print out the value
printValue(dataObject.get(p), property, indent);
}
}
}
}Table 2-9 lists other useful methods in the Type interface.
Table 2-10 lists the methods of the Property interface.
In DSP, data graphs are passed between data services and client applications: when a client application invokes a read function on a data service, for example, a data graph is sent to the client application. The client application modifies the content as appropriate—adds an order to a customer order, for example—and then submits the changed data graph to the data service. The Data Service Mediator is the process that receives the updated data objects and propagates changes to the underlying data sources.
The Data Service Mediator is the linchpin of the update process. It uses information from submitted SDOs (change summary, for example) in conjunction with other artifacts to derive an update plan for changing underlying data sources. For relational data sources, updates are automatic. The artifacts that comprise DSP's update framework, including the Mediator, and how the default update process works, are described in more detail below.
As mentioned previously, the SDO specification does not define any specific mediators, but allows for the variety needed to support any type of back-end data sources. DSP's implementation of an SDO mediator service is the Data Service Mediator (or DSP Mediator) shown in Figure 2-1. The DSP Mediator plays an important role in facilitating updates to the various data sources that comprise any data service. It is the core mechanism for the DSP update framework; the update framework also encompasses several programming artifacts, as follows:
From a lower-level perspective, an update plan is a Java object that comprises a tree of DataServiceToUpdate instances — the names of the data services that comprise the changed data objects. DataServiceToUpdate, KeyPair, UpdatePlan, and DataServiceMediatorContext have been implemented as classes in the SDO Mediator APIs, specifically in:
|
See DSP Mediator API Javadoc on page 1-13 for information on product Javadocs.
An important characteristic of the SDO model is that back-end data sources associated with modified objects are not changed until the submit() method is called on the data service bound to the objects.
After receiving a data object (the changed SDO) from a calling client application, the Mediator always looks for an update override class first (regardless of whether the data service is a physical or logical data service). If an update override class is available, it is instantiated and executed.
| Note: | Update overrides are covered in detail in Customizing Data Service Update Behavior. This chapter covers the basics of the default update processing only. |
The Mediator first determines the data lineage—the origins of the data—by using the data service's decomposition function to map each constituent in a data object to its underlying data source or data service. In addition, any inverse functions specified for the data service are used by the Mediator to define a complete decomposition map.
| Note: | The usage of inverse functions is described in "Best Practices and Advanced Topics", Data Services Developer's Guide. |
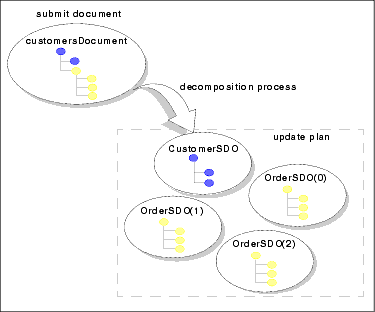
As discussed above, for any logical data service, DSP's Mediator uses the decomposition function to create a decomposition map that identifies constituent data services and then instantiates data objects that correspond to the data objects' changed values. For example, as shown in Figure 2-11, a customersDocument object that comprises updated customer information (from a Customer data service) and three updated Orders (from an Orders data service) would be decomposed into four objects.
An important distinction between logical and physical data service updates is as follows:
For a physical data service, changes to the data sources are propagated immediately (unless an update override class is associated with the data service).
| Note: | Neither a decomposition map nor an update plan is needed for a physical data service. |
Upon receiving an SDO (whether from a submit( ) method invocation, or as a projection from a higher-level data service), the Mediator first checks for an UpdateOverride class associated with the data service.
| Note: | For non-relational data sources, an update override is always required, since there is no automatic update processing for non-relational data sources. |
For relational data sources without an update override, updates are handled automatically. However, non-relational data sources such as Web services, flat files, XML files, require an update override class that contains the processing logic necessary to make changes to the data source.
A logical data service can comprise any number of logical or physical data services. When a top-level data service function executes, the lower-level logical data services that it comprises are "folded in" so that the function appears to be written directly against physical data services. Only information that has been projected in the top-level data service is passed to the next lower-level data service.
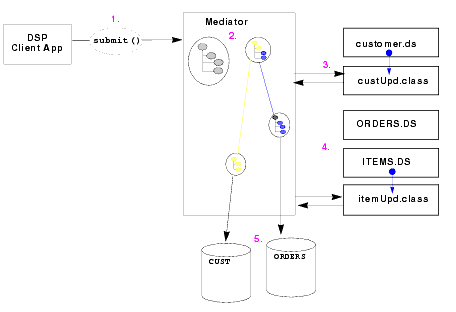
Figure 2-12 provides an overview of the steps involved in updating a logical data service:
| Note: | An update override class can exist at each layer of a multi-layered data service. Thus, a logical data service comprising several layers of other logical data services checks for an update override at each constituent layer. If a mid-layer data service has no update override, the update framework bypasses the instantiation of an SDO object, instead directly creating the SDO objects for the underlying data service. This is true in the case of a logical data service with an update override or a physical data service. |
The performChange( ) method can access and modify the update plan and decomposition map, or perform any other custom processing, including taking over complete processing.
The performChange( ) method returns a Boolean value that either continues or aborts processing by the Mediator, as follows:
| Note: | See Customizing Data Service Update Behavior, for complete information about customizing behavior. |
Most RDBMSs can automatically generate primary keys, which means that if you are adding new data objects to a data service that is backed by a relational database, you may want or need to handle a primary key as a return value in your code. For example, if a submitted data graph of objects includes a new data object, such as a new Customer, DSP generates the necessary primary key.
For data inserts of autonumber primary keys, the new primary key value is generated and returned to the client. Only primary keys of top-level data objects (top-level of a multi-level data service) are returned; nested data objects that have computed primary keys are not returned.
By returning the top-level primary key of an inserted tuple, DSP allows you to re-fetch tuples based on their new primary keys, if necessary.
The Mediator saves logical primary-foreign keys as a KeyPair (see the KeyPair class in the Mediator API). A KeyPair object is a property map that is used to populate foreign-key fields during the process of creating a new data object:
The value of the property will be propagated from the parent to the child, if the property is an autonumber primary key in the container, which is a new record in the data source after the autonumber has been generated.
The KeyPair object is used to identify corresponding data elements at adjacent levels of a decomposition map; it ensures that a generated primary key value for a parent (container) object will be mapped to the foreign key field of the child (contained) element.
As an example, Figure 2-13 shows property mapping for the decomposition of a Customers data service.
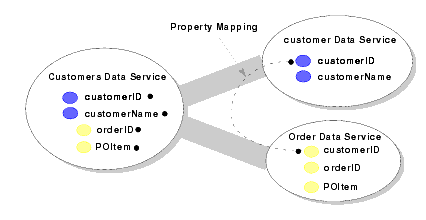
DSP manages the primary-foreign key relationships between data services; how the relationship is managed depends on the layer (of a multi-layered data service), as follows:
Properties[] keys = ds.submit(doc); |
A tuble is basically a record; in the context of data services, a tuble may comprise data that spans several layers of data services.
DSP propagates the effects of changes to a primary or foreign key.
For example, given an array of Customer objects with a primary key field CustID into which two customers are inserted, the submit would return an array of two properties with the name being CustID, relative to the Customer type, and the value being the new primary key value for each inserted Customer.
DSP manages primary key dependencies during the update process. It identifies primary keys and can infer foreign keys in predicate statements. For example, in a query that joins data by comparing values, as in:
|
The Mediator performs various services given the inferred key/foreign key relationship when updating the data source.
If a predicate dependency exists between two SDOToUpdate instances (data objects in the update plan) and the container SDOToUpdate instance is being inserted or modified and the contained SDOToUpdate instance is being inserted or modified, then a key pair list is identified that indicates which values from the container SDO should be moved to the contained SDO after the container SDO has been submitted for update.
This Key Pair List is based on the set of fields in the container SDO and the contained SDO that were required to be equal when the current SDO was constructed, and the key pair list will identify only those primary key fields from the predicate fields.
The KeyPair maps a container primary key to container field only. If the KeyPair does not container's complete primary key is not identified by the map then no properties are specified to be mapped.
A Key Pair List contains one or more items, identifying the node names in the container and contained objects that are mapped.
When computable by SDO submit decomposition, foreign key values are set to match the parent key values.
Foreign keys are computed when an update plan is produced.
Each submit() to the Mediator operates as a transaction. Depending upon whether the submit() succeeds or fails, you should do one of two things:
All submits perform immediate updates to data sources. If a data object submit occurs within the context of a broader transaction, commits or rollbacks of the containing transaction have no effect on the submitted data object or its change summary, but they will affect any data source updates that participated in the transaction.


|