
| Download Docs | Site Map | Glossary | |
|
|
|||
| bea.com | products | dev2dev | support | askBEA |
|
|
|
||||||||
| e-docs > Liquid Data for WebLogic > Building Queries and Data Views > Optimizing Queries |
|
Building Queries and Data Views
|
Optimizing Queries
The topics covered here relate directly to tasks you can accomplish in the Data View Builder while building and testing BEA Liquid Data for WebLogicTM queries. See Tuning Performance in Deploying Liquid Data for a broader discussion of factors related to tuning and performance of Liquid Data including query design, data sources, and platform considerations.
The following sections are included here:
Factors in Query Performance
Queries can be designed and built to optimize performance. Query performance tuning and optimization can be accomplished through the following approaches:
This section covers some key factors related to performance and memory that you should consider while designing and building queries with the Data View Builder. Examples and recommendations for some typical scenarios and use cases are provided.
See Tuning Performance in Deploying Liquid Data for a broader discussion of factors related to tuning and performance of Liquid Data including query design, data sources, and platform considerations.
Using the Features on the Optimize Tab
To access tools to improve query performance, click on the Optimize tab. (See Figure 4-1.) You can re-order data sources and add hints to a query from this tab provides as described in the following sections:
Figure 4-1 Optimize Tab
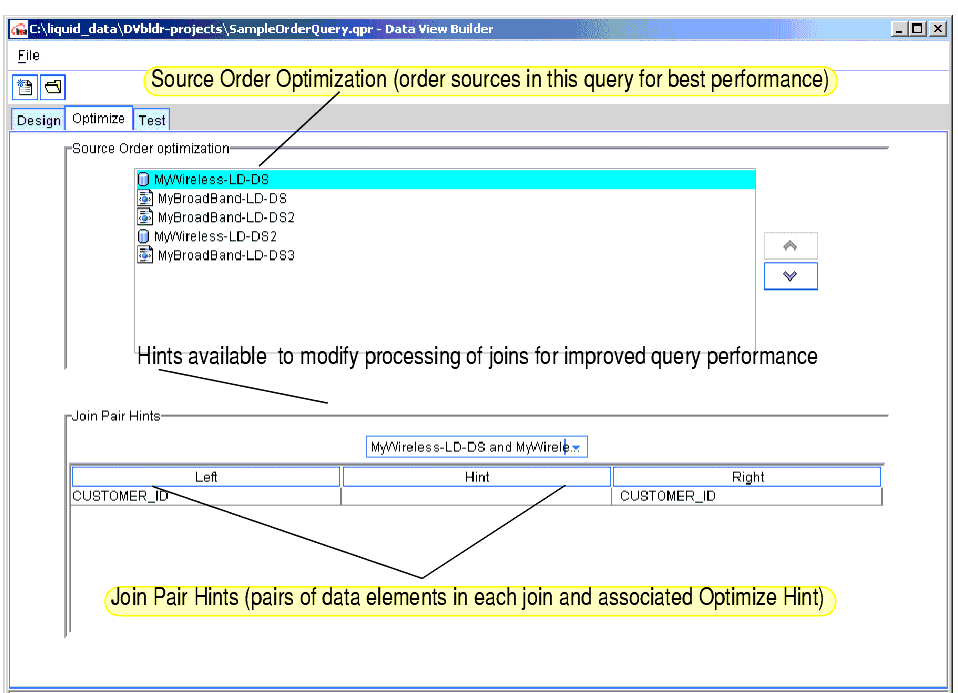
Source Order Optimization
You can re-order source schemas on the top frame on the Optimize tab to improve query performance. To move a schema up or down, select the schema and click the up or down arrow buttons to the right of the list of schemas.
When a query uses data from two sources, the Liquid Data Server brings the two data sources into memory and creates an intermediate result (cross-product) using the two sources. If you specify more than two sources, the Liquid Data Server creates a cross-product of the first two sources, then continues to integrate each additional resource, one at a time, in the order that they appear in FOR clauses.
The size of a source is the number of tuples, or records, used in the query from that source. The size of the intermediate result depends on the input size of the first source multiplied by the input size of the second source and so on. A query is generally more efficient when it minimizes the size of intermediate results.
The order of the FOR clauses in the query matches the order of the data sources in the Source Order list. In general, you should order sources in ascending order by increasing size—that is, the smallest resource should appear first in the list and the largest resource should appear last.
Example: Source Order Optimization
Consider a query to find all managers and the departments they manage that contains a three-way join across three sources: Employees, Employees2 (Employees opened a second time), and Departments. This query joins the Employees schema ID field and the Employees2 schema Manager_id to return all managers, and joins on the Employees schema Dept_id and Departments schema Department_no to return the corresponding department information. The generated XQuery language looks like the following example.
for $EMP1 in document("Employees")/db/EMP
for $EMP2 in document("Employees")/db/EMP
for $DEPT in document("Department")/db/DEPT
where $EMP1/id eq $EMP2/manager_id and
$EMP1/dept_id eq $DEPT/department_no
...This creates a cross-product of Employees ID and Employees Manager_id, then a cross-product with Departments Department_no. If there are 100 employees, and five departments, the query would generate (100 * 100) + (10,000 * 5) intermediate results.
A better plan would be to combine Employees with Departments first, then combine that result with Employees2. The effect is to generates (100 * 5) + (500 * 100) intermediate results. The generated XQuery language looks like the following example.
for $EMP1 in document("Employees")/db/EMP
for $DEPT in document("Department")/db/DEPT
for $EMP2 in document("Employees")/db/EMP
where $EMP1/id eq $EMP2/manager_id and
$EMP1/dept_id eq $DEPT/department_no
...
Optimization Hints for Joins
A query hint is a way to supply more information to the Liquid Data server about how to process the join.
The Optimize tab on the Data View Builder provides a drop-down menu for where you can select a hint for each join in the query that helps the Liquid Data Server choose the most appropriate join algorithm. (See the Optimize tab in Figure 4-1.)
Query hints appear in the query as character strings enclosed within braces {--! hint !--}. They specify which join algorithm should be selected when the query runs. The Join Hints frame contains a drop-down list of data source pairs, and a table that shows all the joins for each pair. Only source pairs that have join conditions across them appear in the drop-down list. For each join condition in the table, you can provide a hint about how to join the data most efficiently.
After you run the query, you can always return to the Optimize view to change the source orders and the hints for each join operation.
Choosing the Best Hint
The Liquid Data Server has three hints to choose from when it processes a join request. By default no hints are specified. To add a hint, select the join to which you want the hint to apply and choose a hint from the drop-down Query Hints list. The available hints are shown below.
Apply these rules to determine the correct hint to choose.
Notes:
Using Parameter Passing Hints (ppleft or ppright)
Choose a Parameter Passing hint when one of the sources has fewer objects than the other. In order to use the parameter passing hints (ppleft and ppright) effectively, you need to know which data sources contain the larger data sets.
When you choose the direction for the Parameter Passing hint, always choose the data source to the left or right with the larger number of items as the receiver. For example, if there are more items on the right side of the equality, then pass the parameter to the Right. The direction indicated in the hint identifies the side in the equation that receives the parameter. In other words, the hints are named for the receiver.
Consider the following example, which is described fully in Example 1: Simple Joins in Query Cookbook.
Listing 4-1 XQuery with ppright Hints
{-- Generated by Data View Builder 1.0 --}<customers>
{
for $PB-WL.CUSTOMER_1 in document("PB-WL")/db/CUSTOMER
where ($#wireless_id of type xs:string eq $PB-WL.CUSTOMER_1/CUSTOMER_ID)
return
<customer id={$PB-WL.CUSTOMER_1/CUSTOMER_ID}>
<first_name>{ xf:data($PB-WL.CUSTOMER_1/FIRST_NAME) }</first_name>
<last_name>{ xf:data($PB-WL.CUSTOMER_1/LAST_NAME) }</last_name>
<orders>
{
for $PB-BB.CUSTOMER_ORDER_3 in document("PB-BB")/db/CUSTOMER_ORDER
where
($PB-WL.CUSTOMER_1/CUSTOMER_ID eq {--! ppright !--} $PB-BB.CUSTOMER_2/CUSTOMER_ID)
return
<order id={$PB-BB.CUSTOMER_ORDER_3/ORDER_ID} date={$PB-BB.CUSTOMER_ORDER_3/ORDER_DATE}></order>
}
</orders>
</customer>
}
</customers>
Let's focus on the second join in the example; the join between PB-WL customer IDs and PB-BB customer IDs:
where
($PB-WL.CUSTOMER_1/CUSTOMER_ID eq {--! ppright !--} $PB-BB.CUSTOMER_2/CUSTOMER_ID)
In the example above, the where clause indicates that the PB-WL data source CUSTOMER table will output only one customer ID. We can assume the PB-BB data source has a larger amount of customer IDs. We can optimize the join by providing the hint shown above (ppright), which tells the server to retrieve the PB-WL customer information first and then pass the CUSTOMER ID as a parameter to the right to look for matches in the PB-BB data source. The engine will thus require much less memory and respond faster than if no hint was provided. Then it might have iterated through multiple records, and for each one asked the database to select the one with a highly optimized query.
Using a Merge Hint
Choose a Merge hint when Both the sources in the join are relational databases, and Both the sources are large and cannot fit into memory.
The following example shows the XQuery for a Merge hint.
Listing 4-2 XQuery with Merge Hint
<root>
{
for $Wireless.CUSTOMER_1 in document("Wireless")/db/CUSTOMER
for $Broadband.CUSTOMER_2 in document("Broadband")/db/CUSTOMER
where ($Wireless.CUSTOMER_1/CUSTOMER_ID eq {--!merge!--} $Broadband.CUSTOMER_2/CUSTOMER_ID)
return
<row>
<CUSTOMER_ID>{ xf:data($Broadband.CUSTOMER_2/CUSTOMER_ID) }</CUSTOMER_ID>
</row>
}
</root>
A merge join requires a minimal amount of memory to operate; however, it requires that the input be sorted on join attributes. A query using a merge join might have slower response time than a query without a hint, but the memory footprint is typically much smaller with the merge join.
|

|

|





