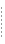
| Download Docs | Site Map | Glossary | |
|
|
|||
| bea.com | products | dev2dev | support | askBEA |
|
|
|
||||||||
| e-docs > Liquid Data for WebLogic > Building Queries and Data Views > Building a Query |
|
Building Queries and Data Views
|
Building a query involves specifying one or more source schemas that describe resource data, selecting a single target schema that describes the shape of the query result, creating source-to-target mappings to further define what the query result will look like, and defining source conditions or filters on the data sources. The query extracts the results based on the conditions and mappings that you define in the query. The results can change dramatically depending on how you do the following:
If you have taken the time to outline a design for the query first, considering all the factors mentioned in the previous section (Designing Queries), constructing it will be a matter of following your design as a blueprint for drag-and-drop query building. Then you can test, fine-tune, and modify as needed to produce variations on the results, or to optimize the query for better performance.
The following sections take you through the basic tasks involved in building a query:
Opening the Source Schemas for the Data Sources You Want to Query
A source schema is the XML schema representation for the structure of the data in a data source. You can use multiple data source schemas per query.
The Sources tab on the Builder Toolbar contains the data sources configured on the Liquid Data Server to which you are connected. Note that a data source type only shows up as a button on the Builder Toolbar if it has been configured in the Server to which you are connecting.
Note: Only data sources that have been configured for access by Liquid Data are available from the Builder Toolbar. For information on how to configure Liquid Data data sources, see the Liquid Data Administration Guide.
For this example, open the schemas for the following two data sources which are already configured on the Liquid Data Samples server:
To do this, follow these steps:
The XML schemas for the each of the data sources are displayed.
Position the schema windows so you can view the data nodes in each schema. You can expand the data nodes by clicking the plus (+) sign. For example, in the PB-WL data source, CUSTOMER is a parent node with subordinate child nodes. The child nodes are the ones you will use as function parameters and map to the target schema.
A target schema is the XML schema representation for the structure of the target data (query result). Only one target schema per project is allowed. If you have a target schema open and decide to choose another, the current target schema is closed and the new one replaces it.
You can use a target schema file that you have saved on your local system or on the network, or one that has been saved to the Liquid Data server repository.
Note: Only target schemas that are saved to the Liquid Data server repository will be available to other Liquid Data users for distributed, team-style development.
For this example, we will use a target schema called amtByState. If this schema is not available in the Samples server repository and you would like to follow along with our example, you can create it yourself and save it locally or to the server repository as a .xsd file.
To create and set the target schema do the following:
<WL_HOME>liquiddata/samples/config/ld_samples/repository/schemas/
Note: It is not necessary to save the target schema to the server Repository in order to use it in your local project—you can save it anywhere on your system. However, we recommend saving schemas to the Repository because it makes projects more "portable" and schema files accessible to all users who log onto this server.
Listing 3-1 XML Source for amtByState.xsd Target Schema File
<?xml version = "1.0" encoding = "UTF-8"?>
<xsd:schema xmlns:xsd = "http://www.w3.org/2001/XMLSchema">
<xsd:element name="customers">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="STATE" minOccurs="0" maxOccurs="unbounded">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="state" type="xsd:string" minOccurs="0" maxOccurs="1"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="CUSTOMER" minOccurs="0" maxOccurs="unbounded">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="FIRST_NAME" type="xsd:string"/>
<xsd:element name="LAST_NAME" type="xsd:string"/>
<xsd:element name="AVERAGE_ORDER" type="xsd:string"/>
<xsd:element name="CUSTOMER_ID" type="xsd:string"/>
<xsd:element name="STATE" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
Note: Remember that only one target schema per project is allowed. The target schema docks on the right side of the desktop area. The target schema may have more data nodes than you need for your result, but it must contain the data nodes required for the query result. Unreferenced nodes are disregarded in the result.
You can make simple changes to a target schema by right-clicking a node. A shortcut menu shows the editing functions that are available.
Mapping Source and Target Schemas
Mapping is a visual relationship structure among the critical data elements in the query. When you combine these relationships with functions, you have a set of instructions for the query generation engine. If you think of the selected data nodes as the nouns (what we want to work on), the functions as the verbs (the action), then the mapping among the data elements creates a logical sentence that expresses the query.
Before you begin creating a query, it is important to expand the nodes in the source schemas to reveal the data elements that you want to use at their lowest level. To expand a node, right click on it and choose Expand.
Note: You can use automatic type casting to ensure that input parameters used in functions and mappings are appropriate to the function in which they are used. When Automatic Type Casting is in effect, Liquid Data verifies (and if necessary promotes) the data types of input parameters for all source-to-target mappings and functions. For more information about automatic type casting, see Using Automatic Type Casting.
You can use drag-and-drop mappings from one element or attribute to another to create conditions on source data and source-to-target mappings that will define the shape of the query result.
Mapping Nodes to Create Conditions on Source Data
Choose one of the following methods to map a source schema node to another source schema node to create a Condition.
Mapping Nodes to Create Source-to-Target Mappings
Choose one of the following methods to map a source schema node to a target schema node.
Note: You cannot map the same node from more than one source schema to a single node in the target schema. For example, if you map STATE (under CUSTOMER) from the Broadband database to state? in the target schema, you cannot successfully map STATE from a second source schema to state? in the target schema. The last mapping completed is the only mapping from source to target that the query generation engine processes. If you need to create a relationship among all three STATE elements, map the element in one source schema to the element in the second source schema. Then map one of the source elements to the target element.
Example: Query Customers by State
Figure 3-1 shows a simple join of the source element STATE in the Broadband source schema (XM-BB-C) with a source element STATE in the Wireless source schema (PB-WL). This action joins the common elements in each schema and disregards those that do not occur in both schemas.
Next, to project a result we designate what the output of this relationship should look when the query runs. By mapping one of the sources to the target, we specify that we want to store the result in the target schema. Because we are collecting only information about states and defining only one element in the target schema, we are in effect asking that Liquid Data fill only that data element in the result when the query runs.
To do this, drag and drop the STATE element in PB-WL source schema onto the state? element (under STATE*) in the Target schema.
See Figure 3-1 for an example of the mappings described in this example.
Figure 3-1 Mapping Element to Element
When you drag and drop a source node onto another source node (either within the same source schema or among different source schemas) you are automatically creating an equality relationship between the two elements/attributes using the eq (equals) function. In other words, the eq function is mapped by default for all drag-and-drop relationships you create among source elements/attributes.
You can also create the same equality relationship the "long" way by dragging and dropping the eq function onto a row in the Conditions tab and then dragging and dropping source elements/attributes into the same row, or by opening the Functions Editor and dragging and dropping the function and elements directly into the Editor.
To use any of the available functions other than eq (equality) function, you must use this second method of dealing directly with the functions as described below.
To edit an existing functional relationship:
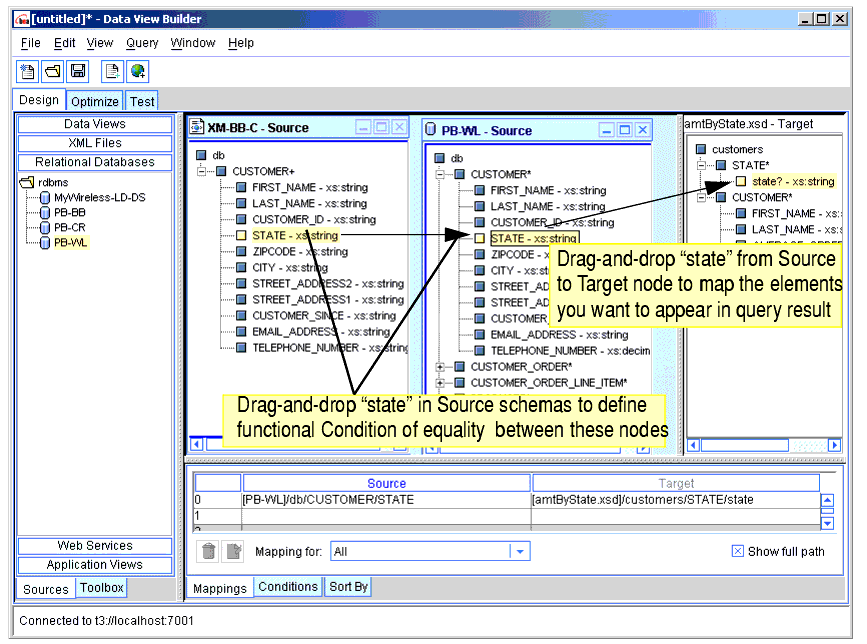
Figure 3-2 shows the functional relationship of equality (eq) between two source elements that was created by default when you mapped the source elements in Example: Query Customers by State. (Note that you could have created this same relationship directly in the Functions Editor the way you would create any other functional relationship between elements/attributes.)
Figure 3-2 Mapping Elements to Functions
To get the view shown in Figure 3-2, click on the Conditions tab, select the row with the condition in it to activate the Edit button, and click the Edit button. This displays the condition in the Functions Editor.
For more information about functions, see What are Functions?.
For more information about using the Functions Editor and working with functions on the UI, see XQuery Functions and The Function Editor in Starting the Builder and Touring the GUI.
Supported Mapping Relationships
Data View Builder and Liquid Data support any of the Mapping actions described in the following table.
Table 3-1 Supported Mapping Relationships
|
Creates an equality relationship between the two elements/attributes using the eq (equals) function. The eq function is used by default for all drag-and-drop mappings created among source elements/attributes to create a condition that will filter for matching items found. |
|
|
The data becomes an input parameter to a function. (You can also provide constants and variables as function parameters.) Each function has its own specification of parameters. The output from a function can be input to another function. For an example of this, see Example 2: Aggregates in Query Cookbook (specifically, the step Ex 2: Step 8. Add the "count" Function within the Aggregates example). |
|
|
By mapping a source to a target, you are projecting, or storing, the data onto the target schema. All query examples provided in this documentation show how to map source schema elements/attributes to target elements/attributes. For example, see Example: Return Customers by Name and Example: Query Customers by ID and Sort by State. |
|
|
A function (f1)output can be another function's (f2) input. For an example of this, see Example 2: Aggregates in Query Cookbook (specifically, the step Ex 2: Step 8. Add the "count" Function within the Aggregates example). |
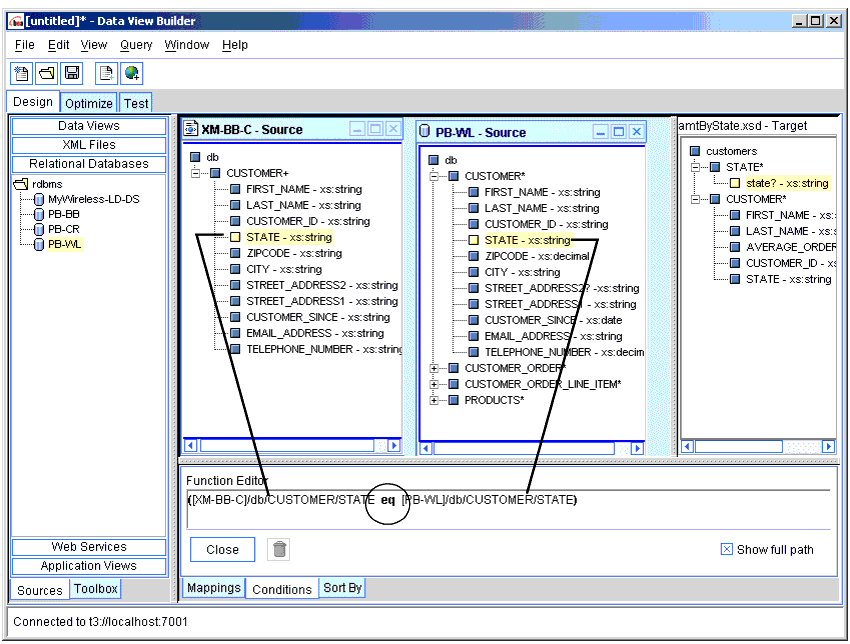
Mapped elements/attributes in a query are displayed on the Mappings tab. You can change your mind and remove a mapping by selecting the row or cell that contains it and then clicking the trashcan button. (See Figure 3-3.)
You can create conditions or filters on source data by doing any of the following:
Functions are used as the verbs or actions in condition statements that establish relationships between or operations on data source elements or attributes. (The data source elements/attributes become one type of parameter to the functions.) A function is a built-in executable process that manipulates the data to perform a task. You must pass one or more parameters, which can be source data, variables, or constant values, for the function to produce output. The function returns a result to you based on the conditional statements you build and how you specify where to store the result.
In the previous example (Example: Query Customers by State) we defined the default equality relationship between two source elements (by dragging and dropping the CUSTOMER "STATE" element from one source to another); then defined the result by dragging and dropping the CUSTOMER "STATE" element from one of the source schemas onto the analogous "STATE" element in the target schema.
If you need to find out something other than information based on equality, you will need to use a different function. For example, suppose you want to find out how many customer IDs in the Broadband database are not equal to those in the Wireless database. The default functional action is to look for equality. If you simply map one customer ID source element/attribute to the other, the query engine looks for those instances of matching data, or equality.
(For the relationship of not equal to, you need to go to Builder Toolbar—>Sources tab—>Functions panel, expand the Operators node, and choose the ne function.)
When any functional relationship is involved besides equality, you must chose from the list of functions available in the Builder Toolbar—>Sources tab—>Functions panel. At that point you are applying a filter of your choice. It is very important to choose the function before you map the elements. Most of the Data View Builder functions are standard XML query language functions supported by the W3C. For related information about using functions, see the Functions Reference.
Note: You can use automatic type casting to ensure that input parameters used in functions and mappings are appropriate to the function in which they are used. When Automatic Type Casting is in effect, Liquid Data verifies (and if necessary promotes) the data types of input parameters for all source-to-target mappings and functions. For more information about automatic type casting, see Using Automatic Type Casting.
Using Constants and Variables in Functions
Instead of choosing an existing element/attribute as a parameter value, you can use one of these methods to specify that a constant value should be used instead of a data element from a source schema.
Enabling and Disabling Conditions
Conditions are displayed in the Design view on the Conditions tab. If you want to test your query without one or more of the conditions you have set, but still keep the condition configured for possible later use, you can disable a condition. Conversely, you can enable a disabled condition.
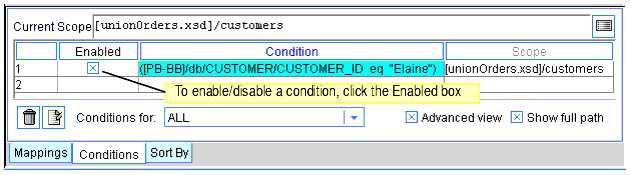
To enable or disable a condition, click the Enabled box to the left of the Condition. (See Figure 3-4.) When the box is checked, the condition is used when the query is generated; when the box is blank, the condition is not used in the generated query.
Figure 3-4 Enabling or Disabling a Condition
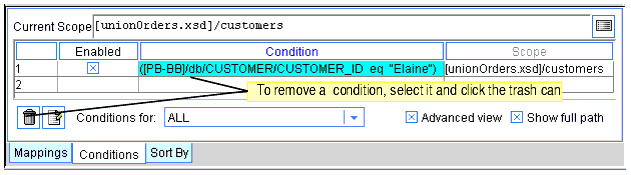
Conditions are displayed in the Design view on the Conditions tab. You can change your mind and remove a condition by selecting the row or cell that contains it and then clicking the trashcan button. (See Figure 3-5.)
Figure 3-5 Removing a Condition
Adding or Deleting Parameters in a Condition Statement
To add or delete a parameter, select the row that contains the condition you want to edit and click the Edit button to bring up the Functions Editor.
In the Functions Editor, you can select the parameter you want to delete and click the trash can or use the options on the Edit menu to modify the condition statement.
You can drag and drop different functions into the Functions Editor from the Functions panel on the Builder Toolbar—>Toolbox tab.
You can show or hide data types on all source and target elements/attributes in schema windows. Select View—>Data Types to display the data type of any source or target element/attribute, as well as required function parameter types. (An "X" next to the Data Types option on the View menu indicates that it is on.)
You can use automatic type casting to ensure that input parameters used in functions and mappings are appropriate to the function in which they are used.
Note: For a complete reference showing how Liquid Data transforms source element/attribute data types to data types of target elements/attributes, see the Type Casting Reference.
Select Automatic Type Casting on the Query menu to ensure that Liquid Data will assign (cast) a new data type when the source node data type does not match the mapped target node data type, and the source node is eligible to be type cast to the target node data type. (An "X" next to the Automatic Type Casting option on the Query menu indicates that it is on.)
When function parameters have a numeric type mismatch, the Liquid Data server can promote the input source to the input type required by the function if the promotion adheres to the prescribed promotion hierarchy. The promotion hierarchy exists only for numeric values.
If the type mismatch requires casting in the reverse order, the server does not attempt type casting. In this case, Liquid Data attempts to type cast but the results may be unpredictable. For example, if the required function input type is xs:decimal, then source data that is integer, long, int, short, or byte can easily be promoted to a data type with more precision or larger number of digits. The server will complete that task. If the input function type is xs:double or xs:float and the required input type is xs:integer or xs:byte, Liquid Data tries to type cast successfully, but there may be unpredictable rounding or truncating. All other type mismatches, such as xs:date, xs:dateTime, or xs:string, require a type cast to avoid a type mismatch error.
Clear the Automatic Type Casting check box to disable this feature.
Exceptions to Automatic Type Casting
Liquid Data does not type cast comparison operators (such as eq, le, ge, ne, gt, lt, or ne) or any functions that accept xsext:anytype.
Type casting does not apply to function parameters (as well as target schema elements/attributes) that require these data types:
Automatic type casting does not succeed in all cases. If the source data is not compatible with the data type of the target node, automatic type casting will not improve the query results. For example, mapping a date to a numeric type may not produce useful results if the data is not relevant. You may not see an error on a type mismatch until the Liquid Data Server tries to run the query.
|

|

|