

|
|
|
|
|
|
Managing Failover
Failover in a distributed system means the dynamic replacement of service after a system or component failure. This section presents an overview of failover and BEA MessageQ failover features:
BEA MessageQ for OpenVMS has two mechanisms for quickly switching service from a failed component to a backup service point: group failover and recoverable queue failover.
Group Failover
Group failover involves movement of the location of a group from one network node to another. This can be accomplished using the following two methods:
Immediately upon startup, a group establishes network links to all the groups listed in the cross-group connection table. If the first node for a group is not available, a connection is tried to the second node that is listed, and so on.
If no connection can be made to a group, it is marked as DOWN until a connection is made. After the group is started, connections to disconnected groups are retried periodically. This scheme allows clients to transparently establish a connection to a backup node when the primary node fails. (Messages sent to the group while it is unavailable will take the undeliverable message action (UMA).)
Recoverable Queue Failover
The recoverable queue failover involves movement of the recoverable journaling stream associated with the specific queue. This can be accomplished using the failover mechanisms shown in Table 14-1.
Table 14-1
|
Failover Mechanism |
Description |
|
DQF Redirection |
The entire DQF stream for a queue is moved to another queue. This queue may be served in the same group or in a different group. |
|
DQF Queue Merge |
The messages in a DQF journal stream can be merged into another DQF journal stream. |
|
SAF Redirection |
Same as DQF redirection but involves store and forward files of the sending group. |
|
SAF Queue Merge |
The messages in a SAF journal stream can be merged into another SAF journal stream. |
Managing and Planning for Failover
When a system running message queuing groups goes down, the system manager can bring the groups up on a backup node and then bring up the connected processes. When failover is needed, it is best if it is planned and designed early in the application design cycle. It can be difficult to back fit failover handling once an application is in production.
All the failover mechanisms require operational planning. In most cases, failover handling requires that an application code be written to support it.
The physical media (where recoverable journals reside) must be accessible to both the primary node where the application is originally running and the backup node where the application will failover to. In a VMS cluster, this can be rather a simple task because the access to disks can span network nodes. Outside of a VMS cluster, this is still possible, by physically moving or copying the media.
Cold Failover
The cold failover from one node to another requires no special application coding, but has the drawback of being the slowest of the failover schemes, since both BEA MessageQ and the application must be completely restarted.
Due to the fact that the %XGROUP section of the DMQ$INIT.TXT file allows several nodes to be specified as connection points for a group, when an attempt fails to connect a group to a node, BEA MessageQ attempts to connect to the next node in the list. Connections are retried on either a timed basis or when an explicit command is given to force connections.
Refer to Configuring Cross-group Connections, for more information on cross-group configuration.
If one node is down, the group may be moved to the next node in the connection list and started as shown in Figure 14-1.
In the case where the two nodes do not share the same file system, the entire group environment needs to be physically moved before failover can begin. In a VMS cluster environment, all the nodes in the connection list can share files. In that case, failover from one node to another is accomplished by simply starting the group on the new node (as shown in Figure 14-2).
It is possible to automate this failover procedure with appropriate DCL command procedures.
Figure 14-1 Cold Failover For Non-clustered Environment
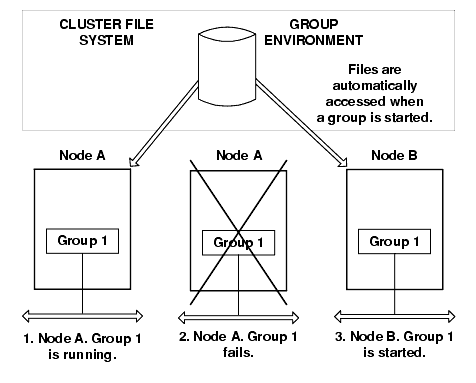
Figure 14-2 Cold Failover For Clustered Environment
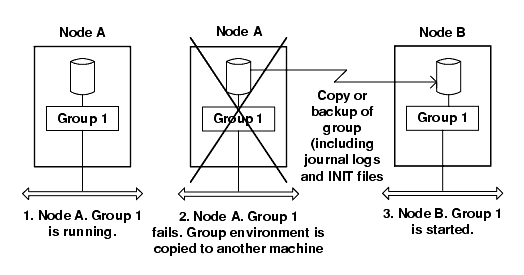
When failing over to a standalone system (a system not part of a VMS cluster), submitter history checking on the receiving system should be disabled using the DMQ$MRS_DISABLE_SH logical name if the following conditions exist:
Submitter history checking does not need to be disabled if the failover system is part of a VMS cluster.
Hot Failover to a Running Shadow Group
Hot failover can be configured to be automatic, or can be managed by a watchdog process.
Automatic Synchronized Cluster Failover
In automatic synchronized cluster failover, a customer (for example, a system manager) maintains a running copy of the group on each of the backup nodes. Only one of the groups is the primary group. The primary group holds a cluster lock which prevents the other secondary (backup) groups from starting any BEA MessageQ servers other than the COM Server and Event Logger. When the primary group goes down for any reason it will release the cluster lock and one of the secondary groups will obtain the lock and become the primary group. After a secondary group becomes the primary it will startup all of its servers. A secondary group can perform local messaging while waiting to become the primary group, but it cannot perform any cross-group messaging.
Implementing Automatic Synchronized Failover
Automatic synchronized cluster failover is enabled by default via the logical DMQ$GROUP_SYNCHRONIZE which is predefined in the COM section of the DMQ$SET_SERVER_LOGICALS.COM file. When this logical is set to YES, or not defined at all, a cluster lock is used by BEA MessageQ to determine which group is the primary group. Therefore, a group may be started on multiple nodes within a cluster. Only one of the groups (first one up) may hold the cluster lock. A group cannot become the primary group until it gains the cluster lock. The cluster lock name is DMQ$PRIMARY_GRP_bbbb_ggggg, where bbbb is the bus number and ggggg is the group number.
If a group cannot obtain the cluster lock it will log the following message in the EVL log.
COM_SERVER 9-JAN-2000 12:03:10.77 I This group is waiting to become the primary
When a group obtains the cluster lock it will log the following message in the EVL log.
COM_SERVER 13-JAN-2000 23:48:50.22 I This group is the primary
If a group is not the primary group, it will only start up the COM server and Event Logger. This is important because the primary and backup groups:
In non-automatic hot failover, a customer (for example, a system manager) maintains a running copy of the group on another node, but it is set up in such a way that it has no cross group links and has no journal files opened. When a failover is needed, the cross group links from the failed group are terminated, and files are closed. (This may occur naturally in the event of a hardware failure on the machine). Then BEA MessageQ allows links from the shadow group to be set and files opened.
For both primary and backup nodes, the %XGROUP table must have the Gen Cnt field set to D (disabled). Listing 14-1 shows a sample of the cross-group connection table.
Listing 14-1 Sample Cross-Group Connection Table
--------------------------------------------------------------------------
%XGROUP ***** Cross-Group Connection Table ******
*
* gen buf buf recon dly win transport
*gname gnumber node cnt warn max type endpt
* kb kb sec sec msg
*--------- ------- ----------- --- --- --- --- --- --- ----- ----
ONE 1 BIGVAX Y -1 75 0 -1 -1 DECNET
TWO 2 GVAX01 D -1 -1 -1 -1 -1 DECNET
TWO 2 GVAX02 D -1 -1 -1 -1 -1 DECNET
TWO 2 GVAX03 D -1 -1 -1 -1 -1 DECNET
*
%EOS
--------------------------------------------------------------------------
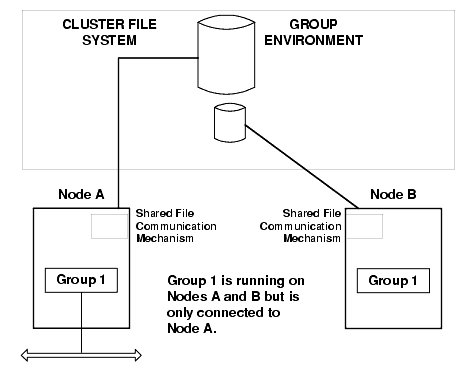
Figure 14-3 shows a normal condition when nodes share files on the cluster before a failover occurs.
Figure 14-3 Normal File Sharing for a Running Group
 Implementing Non-Automatic Hot Failover
Implementing Non-Automatic Hot Failover
Any backup copy of a group must be started without any cross-group connections. This is important since two groups with the same group address cannot share the network simultaneously. The group links can be disabled using the DMQ$INIT.TXT file (XGROUP Table).
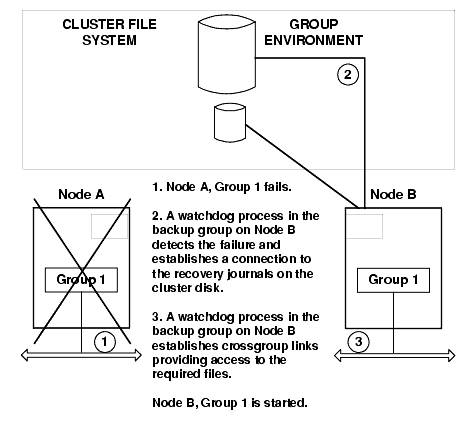
Failover is then accomplished by explicitly tearing down the links to one node (if they have not dropped as a result of the failure), and then forcing links to the next node in the failover list (as shown in Figure 14-4).
This procedure works for nonrecoverable messaging, but runs into difficulty if the backup group has message recovery services (MRS) enabled. The problem is that only one recovery service can own recovery journals (DQF, SAF, PCJ or DLJ file) at one time. The journals can not be shared between the original and backup group.
Figure 14-4 Hot Failover for a Running Group
The solution to this problem is to tell the recovery system of the backup group to start up but remain idle. This is done by setting the logical name DMQ$MRS_DISABLE_JOURNALING to YES in the MRS section of the DCL command procedure, DMQ$USER:DMQ$SET_SERVER_LOGICALS.COM.
The journal files may then be opened only when a MSG_TYPE_MRS_JRN_ENABLE message is sent to the MRS Server indicating that it should open the journals. Failover of recoverable messaging from the primary to the backup group is completed by sending the MSG_TYPE_MRS_JRN_ENABLE message to the MRS Server in the backup group.
Detecting a Failure While the Failing Group Is Still Running
Some applications may want to initiate failover from the primary group to the backup group when the primary group is still running. The heuristic for handling this type of failover is rather complex and is often application dependent.
To close all journal files, the MSG_TYPE_MRS_JRN_DISABLE message must be sent to the MRS Server. Therefore, the way to initiate the failover is to send a MSG_TYPE_MRS_JRN_DISABLE control message to the MRS Server of the group that is failing. This tells MRS to close all journal files. LINK_MANAGEMENT control messages are then used to disconnect the primary group from the network.
A MSG_TYPE_MRS_JRN_ENABLE message is sent to the MRS Server of the backup group causing it to open the journals. Finally, the links to the backup group are brought up and messaging can continue.
Programming Considerations
Unless automatic synchronized cluster failover is used, significant programming effort is required for hot failover to be successful in a production environment. Usually, a watchdog program is coded to run on the primary and backup nodes. This program maintains information on the state of both primary and backup node and periodically decides whether the primary or backup node owns the processing.
A communication mechanism is needed between the watchdog programs. It may be as simple as a shared file that is polled periodically.
The heuristic for determining that a failover operation is required will vary according to the application. One scheme that works in a VMS cluster environment is to use the OpenVMS lock manager so that a lock is granted when some critical process dies.
Failover of Recoverable Messaging to and from a Single Target
Two methods for handling failover of a single Destination Queue File (DQF) are the DQF REDIRECT (Failover) option and the MERGE (QTRANSFER) option.
Redirecting Recoverable Data Streams
The DQF Redirect option works for redirecting an entire recoverable data stream from one queue to another queue (which may or may not be in the same group). The DQF journal must be closed before the failover can be attempted. If the link to the group is down, but the group is still running, you will need to explicitly force the recovery system to close the files. You can perform this failover dynamically using the RE option of DMQ$MGR_UTILITY journal control menu. Refer to Figure 14-5.
The entire DQF data stream must be on the same disk drive to be redirected (renamed) to a new DQF data stream. OpenVMS does not allow file renaming across devices.
Figure 14-5 DQF or SAF Redirecting for Failover

Merging Recoverable Data Streams
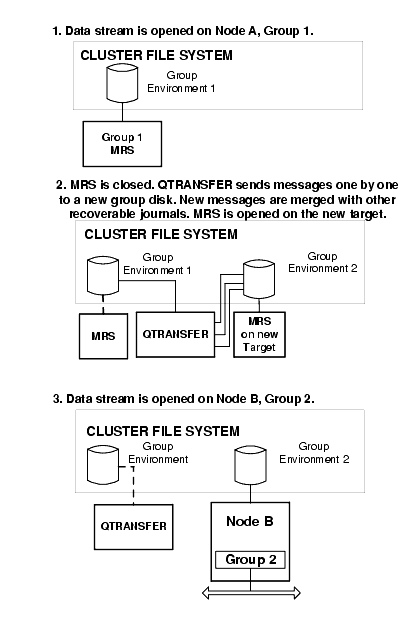
The MERGE option on the DQF screen allows you to merge a recoverable data stream with another data stream. The merging is controlled by the QTRANSFER Server that handles the moving of the contents of a DQF journal. This is accomplished by enveloping each message and sending the messages one by one to the MRS Server of the target group. The MRS Server then unpacks the envelope, writes (merges) the message to the DQF journal, and forwards it to the target queue
You can manage the merging option using the ME option on the DQF screen.
For the QTRANSFER process to work, the first DQF must be closed, either because the group serving the DQF is down, or because the DQF was explicitly closed using a control message. The QTRANSFER Server is then told to initiate the transfer by another control message. This is managed by a dialog between the QTRANSFER Server and the MRS Server.
Figure 14-6 shows major steps in the MERGE process.
Figure 14-6 Data Stream Merging for Failover
Supporting Failover of SAF Files
The SAF failover works identically to the DQF failover. However, it may be a much more complex operation because the senders may be distributed across many systems.
In general, redirecting a SAF data stream involves:
You can start the SAF failover using the Redirect (RE) option on the SAF screen.

|
|
|
Copyright © 2000 BEA Systems, Inc. All rights reserved.
|