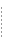| Download Docs | Site Map | Glossary | |
|
|
|||
| bea.com | products | dev2dev | support | askBEA |
|
|
||||||||
| e-docs > WebLogic Server > Programming WebLogic Enterprise JavaBeans > The WebLogic Server EJB Container and Supported Services |
|
Programming WebLogic Enterprise JavaBeans
|
The WebLogic Server EJB Container and Supported Services
The following sections describe the WebLogic Server EJB container and various aspects of EJB behavior in terms of the features and services that the container provides.
For information on the specific topic of container-managed persistence, see WebLogic Server Container-Managed Persistence Service - Basic Features, and WebLogic Server Container-Managed Persistence Service - Advanced Features.
The EJB container is a runtime container for deployed EJBs. It is automatically created when WebLogic Server is started. During the entire life cycle of an EJB object, from its creations to removal, it lives in the container. The EJB container provides a standard set of services, including caching, concurrency, persistence, security, transaction management, locking, environment, memory replication, and clustering for the EJB objects that live in the container.
You can deploy multiple beans in a single container. For each session and entity bean deployed in a container, the container provides a home interface. The home interface allows a client to create, find, and remove entity objects that belong to the entity bean as well as to execute home business methods which are not specific to a particular entity bean object. A client can look up the entity bean's home interface through the Java Naming and Directory Interface (JNDI) or by following an EJB reference, which is preferred. The container is responsible for making the entity bean's home interface available in the JNDI name space. For instructions on looking up the home interface through JNDI, see Programming WebLogic JNDI.
EJB Lifecycle in WebLogic Server
The following sections provide information about how the container supports caching services. They describe the life cycle of EJB instances in WebLogic Server, from the perspective of the server. These sections use the term EJB instance to refer to an actual instance of the EJB bean class. EJB instance does not refer to the logical instance of the EJB as seen from the point of view of a client.
Stateless Session EJB Life Cycle
WebLogic Server uses a free pool to improve performance and throughput for stateless session EJBs. The free pool stores unbound stateless session EJBs. Unbound EJB instances are instances of a stateless session EJB class that are not processing a method call.
The following figure illustrates the WebLogic Server free pool, and the processes by which stateless EJBs enter and leave the pool. Dotted lines indicate the "state" of the EJB from the perspective of WebLogic Server.
Figure 4-1 WebLogic Server free pool showing stateless session EJB life cycle
Initializing Stateless Session EJB Instances
By default, no stateless session EJB instances exist in WebLogic Server at startup time. As clients access individual beans, WebLogic Server initializes new instances of the EJB. However, if you want inactive instances of the EJB to exist in WebLogic Server when it is started, specify how many in the initial-beans-in-free-pool deployment descriptor element, in the weblogic-ejb-jar.xml file.
This can improve initial response time when clients access EJBs, because initial client requests can be satisfied by activating the bean from the free pool (rather than initializing the bean and then activating it). By default, initial-beans-in-free-pool is set to 0.
Note: The maximum size of the free pool is limited either by available memory, or the value of the max-beans-in-free-pool deployment element.
Activating and Pooling Stateless Session EJBs
When a client calls a method on a stateless session EJB, WebLogic Server obtains an instance from the free pool. The EJB remains active for the duration of the client's method call. After the method completes, the EJB instance is returned to the free pool. Because WebLogic Server unbinds stateless session beans from clients after each method call, the actual bean class instance that a client uses may be different from invocation to invocation.
If all instances of an EJB class are active and max-beans-in-free-pool has been reached, new clients requesting the EJB class will be blocked until an active EJB completes a method call. If the transaction times out (or, for non-transactional calls, if five minutes elapse), WebLogic Server throws a RemoteException for a remote client or an EJBException for a local client.
Stateful Session EJB Life Cycle
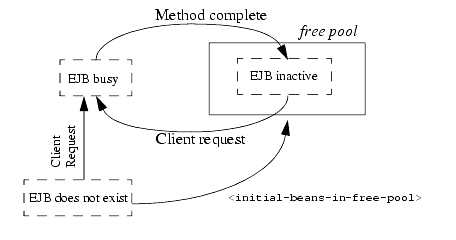
WebLogic Server uses a cache of bean instances to improve the performance of stateful session EJBs. The cache stores active EJB instances in memory so that they are immediately available for client requests. Active EJBs consist of instances that are currently in use by a client, as well as instances that were recently in use, as described in the following sections. The cache is unlike the free pool insofar as stateful session beans in the cache are bound to a particular client, while the stateless session beans in the free pool have no client association.
The following figure illustrates the WebLogic Server cache, and the processes by which stateful EJBs enter and leave the cache. Dotted lines indicate the state of the EJB from the perspective of WebLogic Server.
Figure 4-2 WebLogic Server cache showing stateful session EJB life cycle
Activating and Using Stateful Session EJB Instances
No stateful session EJB instances exist in WebLogic Server at startup time. As clients look up and obtain references to individual beans, WebLogic Server initializes new instances of the EJB class and stores them in the cache.
Passivating Stateful Session EJBs
To achieve high performance, WebLogic Server reserves the cache for EJBs that clients are currently using and EJBs that were recently in use. When EJBs no longer meet these criteria, they become eligible for passivation. Passivation is the process by which WebLogic Server removes an EJB from cache while preserving the EJB's state on disk. While passivated, EJBs use minimal WebLogic Server resources and are not immediately available for client requests (as they are while in the cache).
Note: Stateful session EJBs must abide by certain rules to ensure that bean fields can be serialized to persistent storage. See Stateful Session EJB Requirements for more information.
The max-beans-in-cache deployment element in the weblogic-ejb-jar.xml file provides some control over when EJBs are passivated.
If max-beans-in-cache is reached and EJBs in the cache are not being used, WebLogic Server passivates some of those beans. This occurs even if the unused beans have not reached their idle-timeout-seconds limit. If max-beans-in-cache is reached and all EJBs in the cache are being used by clients, WebLogic Server throws a CacheFullException.
Note: When an EJB becomes eligible for passivation, it does not mean that WebLogic Server passivates the bean immediately. In fact, the bean may not be passivated at all. Passivation occurs only when the EJB is eligible for passivation and there is pressure on server resources, or when WebLogic Server performs regular cache maintenance.
You can specify the explicit passivation of stateful EJBs that have reached idle-timeout-seconds by setting the cache-type element in the weblogic-ejb-jar.xml file. This setting has two values: least recently used (LRU) and not recently used (NRU).
If you specify LRU, the container passivates the bean when idle-timeout-seconds is reached.
If you specify NRU, the container passivates the bean when there is pressure in the cache and idle-timeout-seconds determines how often the container checks to see how full the cache is.
Removing Stateful Session EJB Instances
The max-beans-in-cache and idle-timeout-seconds deployment elements also exert control over when stateful session EJBs are removed from the cache or from disk:
If a stateful session bean is idle for longer than idle-timeout-seconds, WebLogic Server may remove the instance from memory as regular cache maintenance, even if the EJB class is max-beans-in-cache limit has not been reached.
Note: Setting idle-timeout-seconds to 0 stops WebLogic Server from removing EJBs that are idle for a period of time. However, EJBs may still be passivated if cache resources become scarce.
Stateful Session EJB Requirements
The EJB developer must ensure that a call to the ejbPassivate() method leaves a stateful session bean in a condition where WebLogic Server can serialize its data and passivate the bean's instance. During passivation, WebLogic Server attempts to serialize any fields that are not declared transient. This means that you must ensure that all non-transient fields represent serializable objects, such as the bean's remote or home interface.
In general, you should not set the max-beans-in-free-pool element for stateless session beans. The only reason to set max-beans-in-free-pool is to limit access to an underlying resource. For example, if you use stateless session EJBs to implement a legacy connection pool, you do not want to allocate more bean instances than the number of connections that can support your legacy system. When you ask the free pool for a bean instance, there are three possible scenarios that you can follow:
By default, max-beans-in-free-pool is set to 1000. Essentially, it means that Option 3 should never happen because you will always just allocate a new bean instance. However, you are limited by the number of executable threads. In most cases, each thread needs, at most, a single bean instance.
Special Use of max-beans-in-free-pool
The following options describe special cases when max-beans-in-free-pool can be set to 0:
EJBs in WebLogic Server Clusters
This section providers information on how the EJB container supports clustering services. It describes the behavior of EJBs and their associated transactions in a WebLogic Server cluster, and explains key deployment descriptors that affect EJB behavior in a cluster.
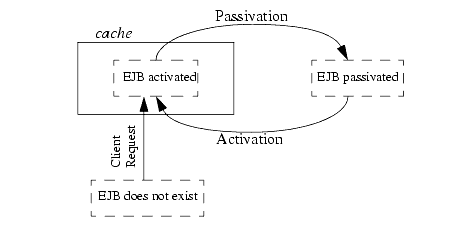
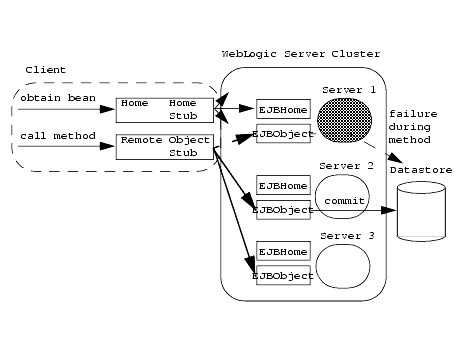
EJBs in a WebLogic Server cluster use modified versions of two key structures: the Home object and the EJB object. In a single server (unclustered) environment, a client looks up an EJB through the EJB's home interface, which is backed on the server by a corresponding Home object. After referencing the bean, the client interacts with the bean's methods through the remote interface, which is backed on the server by an EJB object.
The following figure shows EJB behavior in a single server environment.
Figure 4-3 Single server behavior
Note: Failover of EJBs work only between a remote client and the EJB.
In a WebLogic Server cluster, the client-side representation of the Home object can be replaced by a cluster-aware "stub." The cluster-aware home stub has knowledge of EJB Home objects on all WebLogic Servers in the cluster. The clustered home stub provides load balancing by distributing EJB lookup requests to available servers. It can also provide failover support for lookup requests, because it routes those requests to available servers when other servers have failed.
All EJB types — stateless session, stateful session, and entity EJBs — can have cluster-aware home stubs. Whether or not a cluster-aware home stub is created is determined by the home-is-clusterable deployment element in weblogic-ejb-jar.xml.
In a WebLogic Server cluster, the server-side representation of the EJBObject can also be replaced by a replica-aware EJBObject stub. This stub maintains knowledge about all copies of the EJBObject that reside on servers in the cluster. The EJBObject stub can provide load balancing and failover services for EJB method calls. For example, if a client invokes an EJB method call on a particular WebLogic Server and the server goes down, the EJBObject stub can failover the method call to another, running server.
Whether or not an EJB can use a replica-aware EJBObject stub depends on the type of EJB deployed and, for entity EJBs, the cache strategy selected at deployment time.
This section describes cluster capabilities and limitations for stateful and stateless session EJBs.
Stateless session EJBs can have both a cluster-aware home stub and a replica-aware EJBObject stub. By default, WebLogic Server provides failover services for EJB method calls, but only if a failure occurs between method calls. For example, failover is automatically supported if a failure occurs after a method completes, or if the method fails to connect to a server. When failures occur while an EJB method is in progress, WebLogic Server does not automatically fail over from one server to another.
This default behavior ensures that database updates within an EJB method are not "duplicated" due to a failover scenario. For example, if a client calls a method that increments a value in a datastore and WebLogic Server fails over to another server before the method completes, the datastore would be updated twice for the client's single method call.
If methods are written in such a way that repeated calls to the same method do not cause duplicate updates, the method is said to be "idempotent." For idempotent methods, WebLogic Server provides two weblogic-ejb-jar.xml deployment properties, one at the bean level and one at the method level.
At the bean level, if you set stateless-bean-methods-are-idempotent to "true", WebLogic Server assumes that the method is idempotent and will provide failover services for the EJB method, even if a failure occurs during a method call.
At the method level, you can use the idempotent-methods deployment property to accomplish the same thing:
<idempotent-methods>
<method>
<description>...</description>
<ejb-name>...</ejb-name>
<method-intf>...</method-intf>
<method-name>...</method-name>
<method-params>...</method-params>
</method>
The following figure illustrates stateless session EJBs in a WebLogic Server clustered environment.
Figure 4-4 Stateless session EJBs in a clustered server environment
To enable stateful session EJBs to use cluster-aware home stubs, set home-is-clusterable to "true." This provides failover and load balancing for stateful EJB lookups. Stateful session EJBs configured this way use replica-aware EJBObject stubs. For more information on in-memory replication for stateful session EJBs, see In-Memory Replication for Stateful Session EJBs.
Note: Load balancing and failover are discussed extensively in Using WebLogic Server Clusters. See these three sections: "EJB and RMI Objects", "Load Balancing for EJBs and RMI Objects" and "Replication and Failover for EJBs and RMIs".
In-Memory Replication for Stateful Session EJBs
The following sections describe how the EJB Container supports replication services. The WebLogic Server EJB container supports clustering for stateful session EJBs. Whereas in WebLogic Server 5.1 only the EJBHome object is clustered for stateful session EJBs, the EJB container can also replicate the state of the EJB across clustered WebLogic Server instances.
Replication support for stateful session EJBs is transparent to clients of the EJB. When a stateful session EJB is deployed, WebLogic Server creates a cluster-aware EJBHome stub and a replica-aware EJBObject stub for the stateful session EJB. The EJBObject stub maintains a list of the primary WebLogic Server instances on which the EJB instance runs, as well as the name of a secondary WebLogic Server to use for replicating the bean's state.
Each time a client of the EJB commits a transaction that modifies the EJB's state, WebLogic Server replicates the bean's state to the secondary server instance. Replication of the bean's state occurs directly in memory, for best performance in a clustered environment.
Should the primary server instance fail, the client's next method invocation is automatically transferred to the EJB instance on the secondary server. The secondary server becomes the primary WebLogic Server for the EJB instance, and a new secondary server handles possible additional failovers. Should the EJB's secondary server fail, WebLogic Server enlists a new secondary server instance from the cluster.
Clients of a stateful session EJB are therefore guaranteed to have quick access to the latest committed state of the EJB, except under the special circumstances described in Limitations of In-Memory Replication. For more information on the use of replication groups, see Using Replication Groups.
Requirements and Configuration for In-Memory Replication
To replicate the state of a stateful session EJB in a WebLogic Server cluster, make sure that the cluster is homogeneous for the EJB class. In other words, deploy the same EJB class to every WebLogic Server instance in the cluster, using the same deployment descriptor. In-memory replication is not supported for heterogeneous clusters.
By default, WebLogic Server does not replicate the state of stateful session EJB instances in a cluster. This models the behavior released with WebLogic Server Version 6.0. To enable replication, set the replication-type deployment parameter in the weblogic-ejb-jar.xml deployment file to InMemory.
Figure 4-5 XML sample enabling replication
<stateful-session-clustering>
...
<replication-type>InMemory</replication-type>
</stateful-session-clustering>
Limitations of In-Memory Replication
By replicating the state of a stateful session EJB, clients are generally guaranteed to have the last committed state of the EJB, even if the primary WebLogic Server instance fails. However, in the following rare failover scenarios, the last committed state may not be available:
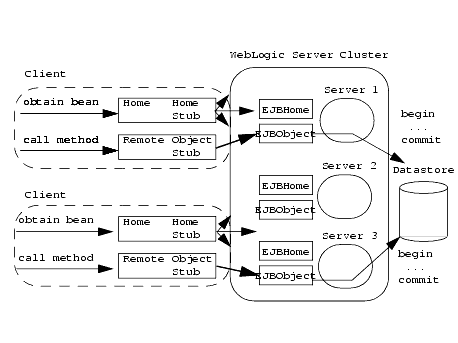
As with all EJB types, entity EJBs can utilize cluster-aware home stubs once you set home-is-clusterable to "true."
Read-Write Entity EJBs in a Cluster
read-write entity EJBs in a cluster behave similarly to entity EJBs in a non-clustered system, in that:
Figure 4-6 shows read-write entity EJBs in a WebLogic Server clustered environment. The three arrows on Home Stub point to all three servers and show multiple client access.
Figure 4-6 Read-write entity EJBs in a clustered server environment
Note: In the preceding figure, the set of three arrows for both home stubs refers to the EJBHome on each server.
read-write entity EJBs support automatic failover on a safe exception, if home-is-clusterable is set to true. For example, failover is automatically supported if there is a failure after a method completes, or if the method fails to connect to a server.
When you configure a cluster, you supply a cluster address that identifies the Managed Servers in the cluster. The cluster address is used in entity and stateless beans to construct the host name portion of URLs. If the cluster address is not set, EJB handles may not work properly. For more information on cluster addresses, see Using WebLogic Server Clusters.
The following sections provide information on how the EJB container supports transaction management services. They describe EJBs in several transaction scenarios. EJBs that engage in distributed transactions (transactions that make updates in multiple datastores) guarantee that all branches of the transaction commit or roll back as a logical unit.
The current version of WebLogic Server supports Java Transaction API (JTA), which you can use to implement distributed transactional applications.
Also, two-phase commit is supported for both 1.1 and 2.0 EJBs. The two-phase commit protocol is a method of coordinating a single transaction across two or more resource managers. It guarantees data integrity by ensuring that transactional updates are committed in all participating databases, or are fully rolled back out of all the databases, reverting to the state prior to the start of the transaction.
Transaction Management Responsibilities
Session EJBs can rely on their own code, their client's code, or the WebLogic Server container to define transaction boundaries. EJBs can use container- or client-demarcated transaction boundaries, but they cannot define their own transaction boundaries unless they observe certain restrictions.
Note: If the EJB provider does not specify a transaction attribute for a method in the ejb-jar.xml file, WebLogic Server uses the supports attribute by default.
The sequence of transaction events differs between container-managed and bean-managed transactions.
Using javax.transaction.UserTransaction
To define transaction boundaries in EJB or client code, you must obtain a UserTransaction object and begin a transaction before you obtain a Java Transaction Service (JTS) or JDBC database connection. To obtain the UserTransaction object, use this command:
ctx.lookup("javax.transaction.UserTransaction");
If you start a transaction after obtaining a database connection, the connection has no relationship to the new transaction, and there are no semantics to "enlist" the connection in a subsequent transaction context. If a JTS connection is not associated with a transaction context, it operates similarly to a standard JDBC connection that has autocommit equal to true, and updates are automatically committed to the datastore.
Once you create a database connection within a transaction context, that connection becomes "reserved" until the transaction either commits or rolls back. To maintain performance and throughput for your applications, always ensure that your transaction completes quickly, so that the database connection can be released and made available to other client requests. See Preserving Transaction Resources for more information.
Note: You can associate only a single database connection with an active transaction context.
Restriction for Container-Managed EJBs
You cannot use the javax.transaction.UserTransaction method within an EJB that uses container-managed transactions.
There are two ways to begin a transaction: explicitly with a user transaction or automatically using the EJB container. To do this you set the isolation level for the transaction. The isolation level defines how concurrent transactions accessing a persistent store are isolated from one another for read purposes.
Setting User Transaction Isolation Levels
You set the isolation level for user transactions in the beans java code. When the application runs, the transaction is explicitly started. See Figure 4-7 for a code sample of how to set the level.
Figure 4-7 Sample Java Code setting user transaction isolation levels
import javax.transaction.Transaction;
import java.sql.Connection
import weblogic.transaction.TxHelper:
import weblogic.transaction.Transaction;
import weblogic.transaction.TxConstants;
User Transaction tx = (UserTransaction)
ctx.lookup("javax.transaction.UserTransaction");//Begin user transaction
tx.begin();
//Set transaction isolation level to TRANSACTION_READ_COMMITED
Transaction tx = TxHelper.getTransaction();
tx.setProperty (TxConstants.ISOLATION_LEVEL, new Integer
(Connection.TRANSACTION_READ_COMMITED));
//perform transaction work
tx.commit();
Setting Container-Managed Transaction Isolation Levels
You set the isolation level for container-managed transactions in the transaction-isolation element of the weblogic-ejb-jar.xml deployment file. WebLogic Server passes this value to the underlying database. The behavior of the transaction depends both on the EJB's isolation level setting and the concurrency control of the underlying persistent store. For more information on setting container-managed transaction isolation levels, see Programming WebLogic JTA.
Limitations of TransactionSerializable
Many datastores provide limited support for detecting serialization problems, even for a single user connection. Therefore, even if you set transaction-isolation to TransactionSerializable, you may experience serialization problems due to the limitations of the datastore.
Refer to your RDBMS documentation for more details about isolation level support.
Special Note for Oracle Databases
Oracle uses optimistic concurrency. As a consequence, even with a setting of TransactionSerializable, Oracle does not detect serialization problems until commit time. The message returned is:
java.sql.SQLException: ORA-08177: can't serialize access for this transaction
Even if you use the TransactionSerializable setting for an EJB, you may receive exceptions or rollbacks in the EJB client if contention occurs between clients for the same rows. To avoid these problems, make sure that the code in your client application catches and examines the SQL exceptions, and that you take the appropriate action to resolve the exceptions, such as restarting the transaction.
In addition, use WebLogic Server's optimistic concurrency strategy with a ReadCommitted isolation level.
You specify the locking mechanism that the EJB uses by setting the concurrency-strategy deployment parameter in weblogic-ejb-jar.xml. You set concurrency-strategy at the individual EJB level, so that you can mix locking mechanisms within the EJB container.
The following excerpt from weblogic-ejb-jar.xml shows how to set an optimistic concurrency strategy for an EJB.
<entity-descriptor>
<entity-cache>
...
<concurrency-strategy>Optimistic</concurrency-strategy>
</entity-cache>
...
</entity-descriptor>
With WebLogic Server, set the isolation level for transactions as follows:
Distributing Transactions Across Multiple EJBs
WebLogic Server does support transactions that are distributed over multiple datasources; a single database transaction can span multiple EJBs on multiple servers. You can explicitly enable support for these types of transactions by starting a transaction and invoking several EJBs. Or, a single EJB can invoke other EJBs that implicitly work within the same transaction context. The following sections describe these scenarios.
Calling Multiple EJBs from a Single Transaction Context
In the following code fragment, a client application obtains a UserTransaction object and uses it to begin and commit a transaction. The client invokes two EJBs within the context of the transaction. The transaction attribute for each EJB is set to Required:
Figure 4-8 Beginning and committing a transaction
import javax.transaction.*;
...
u = (UserTransaction) jndiContext.lookup("javax.transaction.UserTransaction");u.begin();
account1.withdraw(100);
account2.deposit(100);
u.commit();
...
In the above code fragment, updates performed by the "account1" and "account2" EJBs occur within the context of a single UserTransaction. The EJBs commit or roll back as a logical unit. This is true regardless of whether "account1" and "account2" reside on the same WebLogic Server, multiple WebLogic Servers, or a WebLogic Server cluster.
The only requirement for wrapping EJB calls in this manner is that both "account1" and "account2" must support the client transaction. The beans' trans-attribute element must be set to Required, Supports, or Mandatory.
Encapsulating a Multi-Operation Transaction
You can also use a "wrapper" EJB that encapsulates a transaction. The client calls the wrapper EJB to perform an action such as a bank transfer. The wrapper EJB responds by starting a new transaction and invoking one or more EJBs to do the work of the transaction.
The "wrapper" EJB can explicitly obtain a transaction context before invoking other EJBs, or WebLogic Server can automatically create a new transaction context, if the EJB's trans-attribute element is set to Required or RequiresNew. The trans-attribute element is set in the ejb-jar.xml file. All EJBs invoked by the wrapper EJB must be able to support the transaction context (their trans-attribute elements must be set to Required, Supports, or Mandatory).
Distributing Transactions Across EJBs in a WebLogic Server Cluster
WebLogic Server provides additional transaction performance benefits for EJBs that reside in a WebLogic Server cluster. When a single transaction utilizes multiple EJBs, WebLogic Server attempts to use EJB instances from a single WebLogic Server instance, rather than using EJBs from different servers. This approach minimizes network traffic for the transaction.
In some cases, a transaction can use EJBs that reside on multiple WebLogic Server instances in a cluster. This can occur in heterogeneous clusters, where all EJBs have not been deployed to all WebLogic Server instances. In these cases, WebLogic Server uses a multitier connection to access the datastore, rather than multiple direct connections. This approach uses fewer resources, and yields better performance for the transaction.
However, for best performance, the cluster should be homogeneous — all EJBs should reside on all available WebLogic Server instances.
WebLogic Server allows you to control when and how the EJB container inserts newly created beans into the database.You specify your preference by setting the delay-database-insert-until deployment descriptor element in the weblogic-cmp-rdbms-jar.xml file. This element allows you to choose:
The permitted values for the delay-database-insert-until element are:
Figure 4-9 Sample xml specifying delay-database-insert-until
<delay-database-insert-until>ejbPostCreate</delay-database-insert-until> -->
By default, the database insert occurs after the client calls the ejbPostCreate method. The EJB container delays inserting the new bean when you specify either the ejbCreate or ejbPostCreate options for the delay-database-insert-until element in the weblogic-cmp-rdbms-jar.xml file. Setting either of these options specifies the precise time at which the EJB Container inserts a new bean that uses RDBMS CMP into the database.
You must specify that the EJB Container delaying the database insert until after ejbPostCreate when a cmr-field is mapped to a foreign-key column that does not allow null values. In this case, set the cmr-field to a non-null value in ejbPostCreate before the bean is inserted into the database.
Note: You may not set the cmr-fields during a ejbCreate method call, before the primary key of the bean is known.
BEA recommends that you specify the delay the database insert until after ejbPostCreate if the ejbPostCreate method modifies the bean's persistent field. Doing so yields better performance by avoiding an unnecessary store operation.
For maximum flexibility, avoid creating related beans in their ejbPostCreate method. Creating these additional instances may make delaying the database insert impossible if database constraints prevent related beans from referring to a bean that has not yet been created.
Multiple instances of same type of container-managed persistence (cmp) entity beans are often changed in a single transaction. Each cmp entity bean instance is often an entry in a database table, and the EJB container will make a database update for every cmp entity bean instance. Sometimes, a transaction needs to update thousands of cmp entity bean instances, so it will cause thousands of database roundtrips. This is not a very efficient process, and becomes a performance bottleneck.
Application developers often have to take the performance impact or use SQL statements directly to update entries in the database; neither solution is desirable.
The EJB batch operations features solves this problem by updating multiple entries in a database table in one SQL statement. Batch operations support increases the performance of container-managed persistence (CMP) bean creation by enabling the EJB container to perform multiple database inserts, deletes or updates for CMP beans in one SQL statement, thereby economizing network roundtrips.
To permit batch database inserts, updates or deletes, set the enable-batch-operations element in the weblogic-cmp-rdbms-jar.xml file to True.
The batch operations feature includes database operation ordering functionality that can prevent constraint errors by sorting database dependency between batch inserts, updates and deletes. For example, performing an update before an insert or after a delete triggers a constraint error.
With database ordering feature enabled, the EJB container sorts out these dependencies, and sends batch operations to the database in such way that does not cause any database exceptions. To enable this database ordering, set the order-database-operations element of weblogic-cmp-rdbms-jar.xml to True.
Enabling database ordering instructs the EJB container to do two things:
For more information on the order-database-operations element, see order-database-operations.
Batch Operations Guidelines and Limitations
When using batch operations, you must set the boundary for the transaction, as batch operations only apply to the inserts, updates or deletes between transaction begin and transaction commit.
Note: Batch operations only work with drivers that support the addBatch() and executeBatch() methods. If the EJB container detects unsupported drivers, it reports that batch operations are not supported and disables batch operations.
There are several limitations on using batch operations:
For more information on the enable-batch-operations element, see enable-batch-operations.
The following sections provide information on how the EJB container supports resource services. In WebLogic Server, EJBs can access JDBC connection pools by directly instantiating a JDBC pool driver. However, it is recommended that you instead bind a JDBC datasource resource into the WebLogic Server JNDI tree as a resource factory.
Using resource factories enables the EJB to map a resource factory reference in the EJB deployment descriptor to an available resource factory in a running WebLogic Server. Although the resource factory reference must define the type of resource factory to use, the actual name of the resource is not specified until the bean is deployed.
The following sections explain how to bind JDBC datasource and URL resources to JNDI names in WebLogic Server.
Note: WebLogic Server also supports JMS connection factories.
Setting Up JDBC Data Source Factories
Follow these steps to bind a javax.sql.DataSource resource factory to a JNDI name in WebLogic Server. Note that you can set up either a transactional or non-transactional JDBC datasource as necessary.
With a non-transactional data source, the JDBC connection operates in auto commit mode, committing each insert and update operation to the database immediately, rather than as part of a container-managed transaction.
With a transactional data source, multiple insert and update operations in a method can be submitted as a single, container-managed transaction that either commits or rolls back as a logical unit.
Note: Entity beans that use container-managed persistence should always use a transactional data source, rather than a non-transactional data source, to preserve data consistency.
To create a JDBC data source factory:
where jndi_name is the full WebLogic Server JNDI name to bind to the datasource and pool_name is the name of the WebLogic Server connection pool you created in step 1.
For example, to set up a non-transactional connection pool for demonstration purposes, you might enter:
weblogic.jdbc.DataSource.weblogic.jdbc.demoPool=demoPool
This binds a datasource for the "demoPool" pool to the JNDI name, "weblogic.jdbc.demoPool".
weblogic.jdbc.TXDataSource.jndi_name=pool_name
where jndi_name is the full WebLogic Server JNDI name to bind to the transactional datasource and pool_name is the name of the WebLogic Server connection pool you created in step 1.
For example, to set up a transactional connection pool for demonstration purposes, you might enter:
weblogic.jdbc.TXDataSource.weblogic.jdbc.jts.demoPool=demoPool
This binds a transactional datasource for the "demoPool" pool to the JNDI name, "weblogic.jdbc.jts.demoPool".
Setting Up URL Connection Factories
To set up a URL connection factory in WebLogic Server, bind a URL string to a JNDI name using these instructions:
<WebServer URLResource="weblogic.httpd.url.testURL=http:// localhost:7701/testfile.txt" DefaultWebApp="default-tests"/>
<VirtualHostName=guestserver" targets="myserver,test_web_server "URLResource="weblogic.httpd.url.testURL=http:// localhost:7701/testfile.txt" VirtualHostNames="guest.com"/>
WebLogic Server fully supports EJB links as defined in the EJB 2.0 Specification. You can link an EJB reference that is declared in one application component to an enterprise bean that is declared in the same J2EE application.
The value of the ejb-link element must be the ejb-name of the target EJB. The target EJB can be in any EJB JAR file in the same J2EE application as the referencing application component.
Because ejb-names are not required to be unique across EJB JAR files, you may need to provide the qualified path for the link.
<ejb-link>../products/product.jar#ProductEJB</ejb-link>
|

|

|