| Download Docs | Site Map | Glossary | |
|
|
|||
| bea.com | products | dev2dev | support | askBEA |
|
|
||||||||
| e-docs > WebLogic Server > Programming WebLogic Enterprise JavaBeans > WebLogic Server Container-Managed Persistence Service - Basic Features |
|
Programming WebLogic Enterprise JavaBeans
|
WebLogic Server Container-Managed Persistence Service - Basic Features
The following sections describe the basic features of the container-managed persistence (CMP) service available with the WebLogic Server EJB container, where "basic" refers to features developers should be familiar with in order to write an EJB application and get it running. For a discussion of advanced CMP features, see WebLogic Server Container-Managed Persistence Service - Advanced Features.
Overview of Container Managed Persistence Service
WebLogic Server's container is responsible for providing a uniform interface between the EJB and the server. The container creates new instances of the EJBs, manages these bean resources, and provides persistent services such as, transactions, security, concurrency, and naming at runtime. In most cases, EJBs from earlier version of WebLogic Server run in the container. However, see the Migration Guide for information on when you would need to migrate your bean code. See prompt> java weblogic.ejbc -normi c:%SAMMPLES_HOME%\server\src\examples\ejb\basic\containerManaged\build\std_ejb_basic_containerManaged.jar for instructions on using the conversion tool.
WebLogic Server's container-managed persistence (CMP) model handles persistence of CMP entity beans automatically at runtime by synchronizing the EJB's instance fields with the data in the database.
WebLogic Server provides persistence services for entity beans. An entity EJB can save its state in any transactional or non-transactional persistent storage ("bean-managed persistence"), or the container can save the EJB's non-transient instance variables automatically ("container-managed persistence"). WebLogic Server allows both choices and a mixture of the two.
If an EJB will use container-managed persistence, you specify the type of persistence services that the EJB uses in the weblogic-ejb-jar.xml deployment file. High-level definitions for automatic persistence services are stored in the persistence-type and persistence-use elements. The persistence-type element defines one or more automatic services that the EJB can use. The persistence-use element defines which service the EJB uses at deployment time.
Automatic persistence services use additional deployment files to specify their deployment descriptors, and to define entity EJB finder methods. For example, WebLogic Server RDBMS-based persistence services obtain deployment descriptors and finder definitions from a particular bean using the bean's weblogic-cmp-rdbms-jar.xml file, described in Using WebLogic Server RDBMS Persistence.
Third-party persistence services cause other file formats to configure deployment descriptors. However, regardless of the file type, you must reference the configuration file in the persistence-type and persistence-use elements in weblogic-ejb-jar.xml.
Note: Configure container-managed persistence beans with a connection pool with maximum connections greater than 1. WebLogic Server's container-managed persistence service sometimes needs to get two connections simultaneously.
Using WebLogic Server RDBMS Persistence
To use WebLogic Server RDBMS-based persistence service with your EJBs:
If you use WebLogic Server's tool, prompt> java weblogic.ejbc -normi c:%SAMMPLES_HOME%\server\src\examples\ejb\basic\containerManaged\build\std_ejb_basic_containerManaged.jar to create this file, it is named weblogic-cmp-rdbms-jar.xml. If you create the file from scratch, you can save it to a different filename. However, you must ensure that the persistence-type and persistence-use elements in weblogic-ejb-jar.xml refer to the correct file.
weblogic-cmp-rdbms-jar.xml defines the persistence deployment descriptors for EJBs using WebLogic Server RDBMS-based persistence services.
In each weblogic-cmp-rdbms-jar.xml file you define the following persistence options:
The primary key is an object that uniquely identifies an entity bean within its home. The container must be able to manipulate the primary key of an entity bean. Each entity bean class may define a different class for its primary key, but multiple entity beans can use the same primary key class. The primary key is specified in the deployment descriptor for the entity bean. You can specify a primary key class for an entity bean with container-managed persistence by mapping the primary key to either a single field or to multiple fields in the entity bean class.
Every entity object has a unique identity within its home. If two entity objects have the same home and the same primary key, they are considered identical. A client can invoke the getPrimaryKey() method on the reference to an entity object's remote interface to determine the entity object's identity within its home. The object identify associated with the a reference does not change during the lifetime of the reference. Therefore, the getPrimaryKey() method always returns the same value when called on the same entity object reference. A client that knows the primary key of an entity object can obtain a reference to the entity object by invoking the findByPrimaryKey(key) method on the bean's home interface.
Primary Key Mapped to a Single CMP Field
In the entity bean class, you can have a primary key that maps to a single CMP field. You use the primkey-field element, a deployment descriptor in the ejb-jar.xml file, to specify the container-managed field that is the primary key. The prim-key-class element must be the primary key field's class.
Primary Key Class That Wraps Single or Multiple CMP Fields
You can have a primary key class that maps to single or multiple fields. The primary key class must be public, and have a public constructor with no parameters. You use the prim-key-class element, a deployment descriptor in the ejb-jar.xml file to specify the name of the entity bean's primary key class. You can only specify the the class name in this deployment descriptor element. All fields in the primary key class must be declared public. The fields in the class must have the same name as the primary key fields in the ejb-jar.xml file.
If your entity EJB uses an anonymous primary key class, you must subclass the EJB and add a cmp-field of type java.lang.Integer to the subclass. Enable automatic primary key generation for the field so that the container fills in field values automatically, and map the field to a database column in the weblogic-cmp-rdbms-jar.xml deployment descriptor.
Finally, update the ejb-jar.xml file to specify the EJB subclass, rather than the original EJB class, and deploy the bean to WebLogic Server.
If you use the original EJB (instead of the subclass) with an anonymous primary key class, WebLogic Server displays the following error message during deployment:
In EJB ejb_name, an 'Unknown Primary Key Class' ( <prim-key-class> == java.lang.Object ) MUST be specified at Deployment time (as something other than java.lang.Object).
Some hints for using primary keys with WebLogic Server include:
Although ejbCreate specifies the primary key class as a return type:
If you need to use BigDecimal as the primary key, you should:
WebLogic Server supports mapping a database column to a cmp-field and a cmr-field concurrently. The cmp-field is read-only in this case. If the cmp-field is a primary key field, specify that the value for the field be set when the create() method is invoked by using the setXXX method for the cmp-field.
Container-Managed Persistence Relationships
The entity bean relies on container-managed persistence to generate the methods that perform persistent data access for the entity bean instances. The generated methods transfer data between entity bean instances and the underlying resource manager. Persistence is handled by the container at runtime. The advantage of using container-managed persistence is that the entity bean can be logically independent of the data source in which the entity is stored. The container manages the mapping between the logical and physical relationships at runtime and manages their referential integrity.
Persistent fields and relationships make up the entity bean's abstract persistence schema. The deployment descriptors indicate that the entity bean uses container-managed persistence, and these descriptors are used as input to the container for data access.
Entity beans can have relationships with other beans. These relationships can be either bidirectional or unidirectional. For example, you can have bidirectional or unidirectional relationships for each of the three types of relationship mappings identified below, such as unidirectional one-to-one relationships or bidirectional one-to-one relationships.
You specify relationships in the ejb-jar.xml file and weblogic-cmp-rdbms-jar.xml. You specify container-managed field mappings in the weblogic-cmp-rdbms-jar.xml file.
WebLogic Server supports three types of relationship mappings that are managed by WebLogic container-managed persistence (CMP):
A WebLogic Server one-to-one relationship involves the physical mapping from a foreign key in one bean to the primary key in another bean. For more information on primary keys, see Using Primary Keys.
The following example shows a one-to one relationship mapped between an employee bean and another employee bean, the employee's manager.
Figure 5-1 Sample mapping of a one-to-one relationship
<weblogic-rdbms-relation>
<relation-name>employee-manager</relation-name>
<weblogic-relationship-role>
<relationship-role-map>
<column-map>
<foreign-key-column>manager-id
</foreign-key-column>
<key-column>id</key-column>
</column-map>
</relationship-role-map>
<relationship-role-name>employee
</relationship-role-name>
</weblogic-relationship-role>
</weblogic-rdbms-relation>
In Figure 5-1, there is a foreign-key-column, called manager-id in the table. This is the field to which the bean on the employee side of the relationship is mapped. Also, there is a foreign-key-column that refers to the primary key column (key-column) called id, in the table to which the bean on the manager side of the relationship is mapped.
If either of the beans in the relationship is mapped to multiple tables, then the table for that bean that contains the foreign key or primary key must also be specified in the relationship-role-map element. For more information on relationship-role-map, see relationship-role-map.
A WebLogic Server one-to-many relationship involves the physical mapping from a foreign key in one bean to the primary key of another. However, in a one-to-many relationship, the foreign key is always contained in the role that occupies the "many" side of the relationship. In a one-to-many relationship, the foreign key is always associated with the bean that is on the many side of the relationship. This means that the specification of the relationship-role-name in the following sample is redundant, but it is included for uniformity.
The following example shows a one-to many relationship mapped between an employees bean and a departments bean.
Figure 5-2 Sample mapping of a one-to-many relationship
<weblogic-rdbms-relation>
<relation-name>employee-department</relation-name>
<weblogic-relationship-role>
<relationship-role-map>
<column-map>
<foreign-key-column>dept-id
</foreign-key-column>
<key-column>id</key-column>
</column-map>
</relationship-role-map>
<relationship-role-name>employee
</relationship-role-name>
</weblogic-relationship-role>
</weblogic-rdbms-relation>
In Figure 5-2, there is a foreign key column, called dept-id in the table. This is the field to which the bean on the employees side of the relationship is mapped. Also, there is a foreign-key-column that refers to the primary key column (key-column) called id, in the table to which the bean on the departments side of the relationship is mapped.
A WebLogic Server many-to-many relationship involves the physical mapping of a join table. Each row in the join table contains two foreign keys that maps to the primary keys of the entities involved in the relationship.
The following example shows a many-to many relationship mapped between a bean called friends and a bean called employees.
Figure 5-3 Sample mapping of a many-to-many relationship
<weblogic-rdbms-relation>
<relation-name>friends</relation-name>
<table-name>FRIENDS</table-name>
<weblogic-relationship-role>
<relationship-role-name>friend
</relationship-role-name>
<relationship-role-name>
<<column-map>
<foreign-key-column>first-friend-id
</foreign-key-column>
<key-column>id</key-column>
</column-map
</relationship-role-map>
<weblogic-relationship-role>
<weblogic-relationship-role>
<relationship-role-name>second-friend
</relationship-role-name>
<relationship-role-map>
<column-map>
<foreign-key-column>second-
friend-id</foreign-key-column>
<key-column>id</key-column>
</column-map>
</relationship-role-map>
</weblogic-relationship-role>
</weblogic-rdbms-relation>
In Figure 5-3, the FRIENDS join table has two columns, called first-friend-id and second-friend-id, Each column contains a foreign key that designates a particular employee who is a friend of another employee. The primary key column (key-column) of the employee table is called id. For this example, assume that the employee bean is mapped to a single table. If the employee bean is mapped to multiple tables, then the table containing the primary key column (key-column) must be specified in the relationship-role-map.
Unidirectional relationships only navigate in one direction. For example, if entity A and entity B are in a one-to-one, unidirectional relationship and the direction is from entity A to entity B, than entity A is aware of entity B, but entity B is unaware of entity A. This type of relationship is implemented when you specify a cmr-field deployment descriptor element for the entity bean from which navigation can take place and no related cmr-field element is specified for the target entity bean.
You specify the cmr-field element in the weblogic-cmp-rdbms-jar.xml file. For more information on how to specify deployment descriptors, see Specifying and Editing the EJB Deployment Descriptors.
Bidirectional relationships navigate in both directions. These types of container-managed relationships can exist only between beans whose abstract persistence schemas are defined in the same EJB-jar file and therefore managed by the same container. For example, if entity A and entity B are in a one-to-one bidirectional relationship, both are aware of each other.
Removing Beans in Relationships
When a bean with a relationship to another bean is removed, the container automatically removes the relationship.
WebLogic Server provides support for local interfaces for session and entity beans. Local interfaces allow enterprise javabeans to work together within the same EJB container using different semantics and execution contexts. The EJBs are usually co-located within the same EJB container and execute within the same Java Virtual Machine (JVM). This way, they do not use the network to communicate and avoid the over-head of a Java Remote Method Invocation-Internet Inter-ORB Protocol (RMI-IIOP) connection.
EJB relationships with container-managed persistence are now based on the EJB's local interface. Any EJB that participates in a relationship must have a local interface. Local interface objects are lightweight persistent objects. They allow you to do more fine grade coding than do remote objects. Local interfaces also use pass-by-reference. The getter is in the local interface.
In earlier versions of WebLogic Server, you can base relationships on remote interfaces. However, CMP relationships that use remote interfaces should probably not be used in new code.
The EJB container makes the local home interface accessible to local clients through JNDI. To reference a local interface you need to have a local JNDI name. The objects that implement the entity beans' local home interface are called EJBLocalHome objects. You can specify either a jndi-name or local-jndi-name in the weblogic-ejb-jar.xml file. For more information on how to specify deployment descriptors, see Specifying and Editing the EJB Deployment Descriptors
In earlier versions of WebLogic Server, ejbSelect methods were used to return remote interfaces. Now you can specify a result-type-mapping element in the ejb-jar.xml file that indicates whether the result returned by the query will be mapped to a local or remote object.
A local client of a session bean or entity bean can be another EJB, such as a session bean, entity bean, or message-driven bean. A local client can be a servlet as long as it is included as part of the same EAR file and as long as the EAR file is not remote. Clients of a local bean must be part of an EAR or a standalone JAR.
A local client accesses a session or entity bean through the bean's local interface and local home interfaces. The container provides classes that implement the bean's local and local home interfaces. The objects that implement these interfaces are local Java objects. The following diagram shows the container with a local client and local interfaces.
Figure 5-4 Local client and local interfaces
WebLogic Server provides support for both local and uni-directional remote relationships between EJBs. If the EJBs are on the same server and are part of the same JAR file, they can have local relationships. If the EJBs are not on the same server, the relationships must be remote. For a relationship between local beans, multiple column mappings are specified if the key implementing the relation is a compound key. For a remote bean, only a single column-map is specified, since the primary key of the remote bean is opaque. No column-maps are specified if the role just specifies a group-name. No group-name is specified if the relationship is remote.
Changes to the Container for Local Interfaces
Changes made to the structure of the container to accommodate local interfaces include the following additions:
EJB Query Language (QL) is a portable query language that defines finder methods for 2.0 entity EJBs with container-managed persistence. Use this SQL-like language to select one or more entity EJB objects or fields in your query. Because of the declaration of CMP fields in a deployment descriptor, you can create queries in the deployment descriptor for any finder method other than findByPrimaryKey(). findByPrimaryKey is automatically handled by the container. The search space for an EJB QL query consists of the EJB's schema as defined in ejb-jar.xml (the bean's collection of container-managed fields and their associated database columns).
EJB QL Requirement for EJB 2.0 Beans
The deployment descriptors must define each finder query for EJB 2.0 entity beans by using an EJB QL query string. You cannot use WebLogic Query Language (WLQL) with EJB 2.0 entity beans. WLQL is intended for use with EJB 1.1 CMP. For more information on WLQL, see CROSS REF TO 1.1 CHAPTER.
If you have used previous versions of WebLogic Server, your container-managed entity EJBs may use WLQL for finder methods. This section provides a quick reference to common WLQL operations. Use this table to map the WLQL syntax to EJB QL syntax.
Using EJB 2.0 WebLogic QL Extension for EJB QL
WebLogic Server has an SQL-like language, called WebLogic QL, that extends the standard EJB QL. This language works with the finder expressions and is used to query EJB objects from the RDBMS. You define the query in the weblogic-cmp-rdbms-jar.xml deployment descriptor using the weblogic-ql element.
There must be a query element in the ejb-jar.file that corresponds to the weblogic-ql element in the weblogic-cmp-rdbms-jar.xml file. However, the weblogic-cmp-rdbms-jar.xml query element overrides the ejb-jar.xml query element.
The EJB WebLogic QL extension SELECT DISTINCT allows your database to filter duplicate queries. Using SELECT DISTINCT means that the EJB container's resources are not used to sort through duplicated results when SELECT DISTINCT is specified in the EJB QL query.
If you specify a sql-select-distinct element with the value TRUE in a weblogic-ql element's XML stanza for an EJB 2.0 CMP bean, then the generated SQL STATEMENT for the database query will contain a DISTINCT clause.
You specify the sql-select-distinct element in the weblogic-cmp-rdbms-jar.xml file. However, you cannot specify sql-select-distinct if you are running an isolation level of READ_C0MMITED_FOR_UPDATE on an Oracle database. This is because a query on Oracle cannot have both a sql-select-distinct and a READ_C0MMITED_FOR_UPDATE. If there is a chance that this isolation level will be used, for example in a session bean, do not use the sql-select-distinct element.
The EJB WebLogic QL extension ORDERBY is a keyword that works with the Finder method to specify the CMP field selection sequence for your selections.
Figure 5-5 WebLogic QL ORDERBY extension showing order by id.
ORDERBY
SELECT OBJECT(A) from A for Account.Bean
ORDERBY A.id
Note: ORDERBY defers all sorting to the DBMS. Thus, the order of the retrieved result depends on the particular DBMS installation on top of which the bean is running
Also, you can specify an ORDERBY with ascending [ASC] or descending [desc] order for multiple fields as follows:.
Figure 5-6 WebLogic QL ORDERBY extension showing order by id. with ASC and DESC
ORDERBY <field> [ASC|DESC], <field> [ASC|DESC]
SELECT OBJECT(A) from A for Account.Bean, OBJECT(B) from B for Account.Bean
ORDERBY A.id ASC; B.salary DESC
WebLogic Server supports the use of the following features with subqueries in EJB QL:
The relationship between WebLogic QL and subqueries is similar to the relationship between SQL queries and subqueries. Use WebLogic QL subqueries in the WHERE clause of an outer WebLogic QL query. With a few exceptions, the syntax for a subquery is the same as a WebLogic QL query.
To specify WebLogic QL, see Using EJB 2.0 WebLogic QL Extension for EJB QL. Use those instructions with a SELECT statement that specifies a subquery as shown the following sample.
The following query selects all above average students as determined by the provided grade number:
SELECT OBJECT(s) FROM studentBean AS s WHERE s.grade > (SELECT AVG(s2.grade) FROM StudentBean AS s2)
Note that in the above query the subquery, (SELECT AVG(s2.grade) FROM StudentBean AS s2), has the same syntax as an EJB QL query.
You can create nested subqueries.The depth is limited by the underlying database's nesting capabilities.
In a WebLogic QL query, the identifiers declared in the FROM clauses of the main query and all of its subqueries must be unique. This means that a subquery may not re-declare a previously declared identifier for local use within that subquery.
For example, the following example is not legal because employee bean is being declared as emp in both the query and the subquery:
SELECT OBJECT(emp)
FROM EmployeeBean As emp
WHERE emp.salary=(SELECT MAX(emp.salary) FROM
EmployeeBean AS emp WHERE employee.state=MA)
Instead, this query should be written as follows:
SELECT OBJECT(emp)
FROM EmployeeBean As emp
WHERE emp.salary=(SELECT MAX(emp2.salary) FROM
EmployeeBean AS emp2 WHERE emp2.state=MA)
The above examples correctly declares the subquery's employee bean to have a different identifier from the main query's employee bean.
The return type of a WebLogic QL subquery can be one of a number of different types, such as:
Single cmp-field Type Subqueries
WebLogic Server supports a return type consisting of a cmp-field. The results returned by the subquery may consists of a single value or collection of values. An example of a subquery that returns value(s) of the type cmp-field is as follows:
SELECT emp.salary FROM EmployeeBean AS emp WHERE emp.dept = `finance'
This subquery selects all of the salaries of employees in the finance department.
WebLogic Server supports a return type consisting of an aggregate of a cmp-field. As an aggregate always consist of a single value, the value returned by the aggregate is always a single value. An example of a subquery that return a value of the type aggregate (MAX) of a cmp-field is as follows:
SELECT MAX(emp.salary) FROM EmployeeBean AS emp WHERE emp.state=MA
This subquery selects the single highest employee salary in Massachusetts.
For more information on aggregate functions, see Using Aggregate Functions.
WebLogic Server supports a return type consisting of a cmp-bean with a simple primary key.
Note: Beans with compound primary keys are NOT supported. Attempts to designate the return type of a subquery to a bean with a compound primary key will result in a failure when you compile the query.
An example of a subquery that returns the value(s) of the type bean with a simple primary key is as follows:
SELECT OBJECT(emp) FROM EMployeeBean As emp WHERE emp.department.budget>1,000,000
This subquery provides a list of all employee in departments with budgets greater than $1,000,000.
Subqueries as Comparison Operands
Use subqueries as the operands of comparison operators. WebLogic QL supports subqueries as the operands of the following Comparison Operators: [NOT]IN, [NOT]EXISTS, and the following Arithmetic Operators: <, >, <=, >=, =, <> with ANY and ALL.
The [NOT]IN comparison operator tests whether the left-had operand is or is not a member of the subquery operand on the right-hand side.
An example of a subquery which is the right-hand operand of the NOT IN operator is as follows:
SELECT OBJECT(item)
FROM ItemBean AS item
WHERE item.itemId NOT IN
(SELECT oItem2.item.itemID
FROM OrderBean AS orders2, IN(orders2.orderItems)oIttem2
The subquery selects all items from all orders.
The main query's NOT IN operator selects all the items that are not in the set returned by the subquery. So the end result is that the main query selects all unordered items.
The [NOT]EXISTS comparison operator tests whether the set returned by the subquery operand is or is not empty.
An example of a subquery which is the operand of the NOT EXISTS operand is as follows:
SELECT (cust) FROM CustomerBean AS cust
WHERE NOT EXISTS
(SELECT order.cust_num FROM OrderBean AS order
WHERE cust.num=order_num)
This is an example of a query with a correlated subquery. See Correlated and UnCorrelated Subqueries for more information. This query returns all customers that have not placed an order.SELECT (cust) FROM CustomerBean AS cust
WHERE cust.num NOT IN
(SELECT order.cust_um FROM OrderBean AS order
WHERE cust.num=order_num)
Use arithmetic operators for comparison when the right-hand subquery operand returns a single value. If the right hand subquery instead returns multiple values, then the qualifiers ANY or ALL must precede the subquery.
An example of a subquery which uses the `=' operator is as follows:
SELECT OBJECT (order)
FROM OrderBean AS order, IN(order.orderItems)oItem
WHERE oItem.quantityOrdered =
(SELECT MAX (subOItem.quantityOrdered)
FROM Order ItemBean AS subOItem
WHERE subOItem,item itemID = ?1)
AND oItem.item.itemId = ?1
For a given itemId, the subquery returns the maximum quantity ordered of that item. Note that this aggregate returned by the subquery is a single value as required by the `=' operator.
For the same given itemId, the main query's `=' comparison operator checks which order's OrderItem.quantity Ordered equals the maximum quantity returned by the subquery. The end result is that the query returns the OrderBean that contains the maximum quantity of a given item that has been ordered.
Use arithmetic operators in conjunction with ANY or ALL, when the right-hand subquery operand may return multiple values.
An example of a subquery which uses ANY and ALL is as follows:
SELECT OBJECT (order)
FROM OrderBean AS order, IN(order.orderItems)oItem
WHERE oItem.quantityOrdered > ALL
(SELECT subOItem.quantityOrdered
FROM OrderBean AS suborder IN (subOrder.orderItems)subOItem
WHERE subOrder,orderId = ?1)
For a given orderId, the subquery returns the set of orderItem.quantityOrdered of each item ordered for that orderId. The main query's `>' ALL operator looks for all orders whose orderItem.quantityOrdered exceeds all values in the set returned by the subquery. The end result is that the main query returns all orders in which all orderItem.quantityOrdered exceeds every orderItem.quantityOrdered of the input order.
Note that since the subquery can return multi-valued results that they `>'ALL operator is used rather then the `>' operator.
All of the arithmetic operators, <, >, <= >=, =, <> are use, as in the above examples.
Correlated and UnCorrelated Subqueries
WebLogic Server supports both correlated and Uncorrelated subqueries.
Uncorrelated subqueries may be evaluated independently of the outer query. An example of an uncorrelated subquery is as follows:
SELECT OBJECT(emp) FROM EmployeeBean AS emp
WHERE emp.salary>
(SELECT AVG(emp2.salary) FROM EmployeeBean AS emp2)
This example of a uncorrelated subquery selects the employees whose salaries are above average. This examples uses the `>' arithmetic operator.
Correlated subqueries are subqueries in which values from the outer query are involved in the evaluation of the subquery. An example of a correlated subquery is as follows:
SELECT OBJECT (mainOrder) FROM OrderBean AS mainOrder
WHERE 10>
(SELECT COUNT (DISTINCT subOrder.ship_date)
FROM OrderBean AS subOrder
WHERE subOrder.ship_date>mainOrder.ship_date
AND mainOrder.ship_date IS NOT NULL
This example of a correlated subquery selects the last 10 shipped Orders. This example uses the NOT IN operator.
Note: Keep in mind that correlated subqueries can involve more processing overhead the uncorrelated subqueries.
DISTINCT Clause with Subqueries
Use the DISTINCT clause in a subquery to enable an SQL SELECT DISTINCT in the subquery's generated SQL. Using a DISTINCT clause in a subquery is different from using one in a main query because the EJB container enforces the DISTICNT clause in a main query; whereas the DISTICT clause in the subquery is enforced by the generated SQL, SELECT DISTINCT. An example of a DISTINCT clause in a subquery is as follows:
SELECT OBJECT (mainOrder) FROM OrderBean AS mainOrder
WHERE 10>
(SELECT COUNT (DISTINCT subOrder.ship_date)
FROM OrderBean AS subOrder
WHERE subOrder.ship_date>mainOrder.ship_date
AND mainOrder.ship_date IS NOT NULL
This example of a selects the last 10 shipped Orders.
WebLogic Server supports aggregate functions with WebLogic QL. You only use these functions as SELECT clause targets, not as other parts of a query, such as a WHERE clause. The aggregate functions behave like SQL functions. They are evaluated over the range of the beans returned by the WHERE conditions of the query
To specify WebLogic QL, see Using EJB 2.0 WebLogic QL Extension for EJB QL. Use those instructions with a SELECT statement that specifies an aggregate function as shown in the samples shown in the following table.
A list of the supported functions and sample statements follow:
You can return aggregate functions in ResultSets as described below.
Using Queries that Return ResultSets
WebLogic Server supports ejbSelect() queries that return the results of multi-column queries in the form of a java.sql.ResultSet. To support this feature, WebLogic Server now allows you to use the SELECT clause to specify a comma delimited list of target fields as shown in the following query:
SELECT emmp.name, emp.zip FROM EmployeeBean AS emp
This query returns a java.sqlResultSet with rows whose columns are the values Employee's Name and Employee's Zip.
To specify WebLogic QL, see Using EJB 2.0 WebLogic QL Extension for EJB QL. Use those instructions with a query specifying a ResultSet as shown in the above query to specify WebLogic QL, see Using EJB 2.0 WebLogic QL Extension for EJB QL. Use those instructions with a SELECT statement that specifies an aggregate query like the samples shown in the following table.
ResultSets created in EJB QL can only return cmp-field values or aggregates of cmp-field values, they cannot return beans.
In addition, you can create powerful queries, as described in the following example, when you combine cmp-fields and aggregate functions.
The following rows (beans) show the salaries of employees in different locations:
CMP fields showing salaries of employees in California
CMP fields showing salaries of employees in Arizona
CMP fields showing salaries of employees in Texas
Note: Each row represents a bean.
The following SELECT statement shows a query that uses ResultSets and the aggregate function (AVG) along with a GROUP BY statement and an ORDER BY statement using a descending sort to retrieve results from a multi-column query.
SELECT e.location, AVG(e.salary)
FROM Finder EmployeeBean AS e
GROUP BY e.location
ORDER BY 2 DESC
The query shows the average salary in of employees at each location in descending order. The number, 2 means that the ORDERBY sort is on the second item in the SELECT statement. The GROUP BY clause specifies the AVEAGE salary of employees with a matching e.location attribute.
The ResultSet, in descending order is as follows:
Note: You can only use integers as ORDERBY arguments in queries that return ResultSets. WebLogic Server does not support the use of integers as ORDERBY arguments in any Finder or ejbselect() that returns beans.
EJB QL Error-Reporting Enhancements
Compiler error messages in EJB QL provide a visual aid to identify which part of the query is in error and allow the reporting of more than one error per compilation.
Visual Indicator of Error in Query
When an error is reported, EJB QL indicates the location of the problem within these symbols: =>> <<=. These symbols are highlighted in red in the following sample compiler error report.
ERROR: Error from appc: Error while reading 'META-INF/FinderEmployeeBeanRDBMS.xml'. The error was:
Query:
EJB Name: FinderEmployeeEJB
Method Name: findThreeLowestSalaryEmployees
Parameter Types: (java.lang.String)
Input EJB Query: SELECT OBJECT(e) FROM FinderEmployeeBean e WHERE f.badField = '2' O
R (e.testId = ?1) ORDERBY e.salary
SELECT OBJECT(e ) FROM FinderEmployeeBean e
WHERE =>> f.badField <<= = '2' OR ( e.testId = ?1 ) ORDERBY e.salary
Invalid Identifier in EJB QL expression:
Problem, the path expression/Identifier 'f.badField' starts with an identifier: 'f'. The identifier 'f', which can be either a range variable identifier or a collection member identifier, is required to be declared in the FROM clause of its query or in the FROM clause of a parent query.
'f' is not defined in the FROM clause of either its query or in any parent query.
Action, rewrite the query paying attention to the usage of 'f.badField'.
Multiple Errors Reported after a Single Compilation
If a query contains multiple errors, EJB QL is now capable of reporting more than one of these after a single compilation. Previously, the compiler could only report one error per compilation. Reporting of subsequent errors required recompilation.
Note: The compiler is not guaranteed to report all errors after a single compilation.
Dynamic queries allow you to construct and execute EJB-QL queries programmatically in your application code. Queries are expressions that allow you to request information of EJB objects from the RDBMS. This feature is only available for use with EJB 2.0 CMP beans. Using dynamic queries provides the following benefits:
Setting method-permission for the createQuery() method of the weblogic.ejb.QueryHome interface controls access to the weblogic.ejb.Query object necessary to executes the dynamic queries.
If you specify method-permission for the createQuery() method, the method-permission settings apply to the execute and find methods of the Query class.
The following code sample demonstrates how to execute a dynamic query.
InitialContext ic=new InitialContext();
FooHome fh=(FooHome)ic.lookup("fooHome");
QueryHome qh=(QueryHome)fh;
Sring ejbql="SELECT OBJECT(e)FROM EmployeeBean e WHERE e.name='rob'"
Query query=qh.createQuery();
query.setMaxElements(10)
Collection results=query.find(ejbql);
BLOB and CLOB DBMS Column Support for the Oracle DBMS
WebLogic Server supports Oracle Binary Large Object (BLOB) and Character Large Object (CLOB) DBMS columns with EJB CMP. BLOBs and CLOBs are data types used for efficient storage and retrieval of large objects. CLOBs are string or char objects; BLOBs are binary or serializable objects such as pictures that translate into large byte arrays.
BLOBs and CLOBs map a string variable, a value of OracleBlob or OracleClob, to a BLOB or CLOB column. WebLogic Server maps CLOBs only to the data type java.lang.string. At this time, no support is available for mapping char arrays to a CLOB column.
Using BLOB or CLOB may slow performance because of the size of the BLOB or CLOB object.
Specifying a BLOB Using the Deployment Descriptor
The following XML code shows how to specify a BLOB object using the dbms-column element in weblogic-cmp-rdbms-jar-xml file.
Figure 5-7 Specifying a BLOB object
<field-map>
<cmp-field>photo</cmp-field>
<dbms-column>PICTURE</dbms-column>
<dbms_column-type>OracleBlob</dbms-column-type>
</field-map>
Specifying a CLOB Using the Deployment Descriptors
The following XML code shows how to specify a CLOB object using the dbms-column element in the weblogic-cmp-rdbms-jar-xml file.
Figure 5-8 Specifying a CLOB object
<field-map>
<cmp-field>description</cmp-field>
<dbms-column>product_description</dbms-column>
<dbms_column-type>OracleClob</dbms-column-type>
</field-map>
Use the cascade delete mechanism to remove entity bean objects. When cascade delete is specified for a particular relationship, the lifetime of one entity object depends on another. You can specify cascade delete for one-to-one and one-to-many relationships; many-to-many relationships are not supported. The cascade delete() method uses the delete features in WebLogic Server, and the database cascade delete() method instructs WebLogic Server to use the underlying database's built-in support for cascade delete.
To enable this feature, you must recompile the bean code for the changes to the deployment descriptors to take effect.
Use one of the following two methods to enable cascade delete.
With the cascade delete() method you use WebLogic Server to remove objects. If an entity is deleted and the cascade delete element is specified for a related entity bean, then the removal is cascaded and any related entity bean objects are also removed.
To specify cascade delete, use the cascade-delete element in the ejb-jar.xml deployment descriptor elements. This is the default method. Make no changes to your database settings, and WebLogic Server will cache the entity objects for removal when the cascade delete is triggered.
Specify cascade delete using the cascade-delete element in the ejb-jar.xml file as follows:
Figure 5-9 Specifying a cascade delete
<ejb-relation>
<ejb-relation-name>Customer-Account</ejb-relation-name>
<ejb-relationship-role>
<ejb-relationship-role-name>Account-Has-Customer
</ejb-relationship-role-name>
<multiplicity>one</multiplicity>
<cascade-delete/>
</ejb-relationship-role>
</ejb-relation>
Note: This cascade delete() method can only be specified for a ejb-relationship-role element contained in an ejb-relation element if the other ejb-relationship-role element in the same ejb-relation element specifies a multiplicity attribute with a value of one.
Database Cascade Delete Method
The database cascade delete() method allows an application to take advantage of a database's built-in cascade delete support, and possibly improve performance. If the db-cascade-delete element is not already specified in the weblogic-cmp-rdbms-jar.xml file, do not enable any of the database's cascade delete functionality, because this will produce incorrect results in the database.
The db-cascade-delete element in the weblogic-cmp-rdbms-jar.xml file specifies that a cascade delete operation will use the built-in cascade delete facilities of the underlying DBMS. By default, this feature is turned off and the EJB container removes the beans involved in a cascade delete by issuing an individual SQL DELETE statement for each bean.
If db-cascade-delete element is specified in the weblogic-cmp-rdbms-jar.xml, the cascade-delete element must be specified in the ejb-jar.xml.
When db-cascade-delete is enabled, additional database table setup is required. For example, the following setup for the Oracle database table will cascade delete all of the employees if the dept is deleted in the database.
Figure 5-10 Oracle table setup for cascade delete
CREATE TABLE dept
(deptno NUMBER(2) CONSTRAINT pk_dept PRIMARY KEY,
dname VARCHAR2(9) );
CREATE TABLE emp
(empno NUMBER(4) PRIMARY KEY,
ename VARCHAR2(10),
deptno NUMBER(2) CONSTRAINT fk_deptno
REFERENCES dept(deptno)
ON DELETE CASCADE );
Updates made by a transaction must be reflected in the results of queries, finders, and ejbSelects issued during the transactions. Because this requirement can slow performance, a new option enables you to specify that the cache be flushed before the query for the bean is executed.
If this option is turned off, which is the default behavior, the results of the current transactions are not reflected in the query. If this option is turned on, the container flushes all changes for cached transactions written to the database before executing the new query. This way, the changes show up in the results.
To enable this option, in weblogic-cmp-rdbms-jar.xml file set the include-updates element to true.
Figure 5-11 Specifying that results of transactions be reflected in the query
<weblogic-query>
<query-method>
<method-name>findBigAccounts</method_name>
<method-params>
<method-param>double</method-param>
</method-params>
</query-method>
<weblogic-ql>WHERE BALANCE>10000 ORDERBY NAME</weblogic-ql>
<include-updates>true</include-updates>
</weblogic-query>
The default is false, which provides the best performance. Updates made to the cached transaction are reflected in the result of a query; no changes are written to the database, and you do not see the changes in the query result.
Whether you use this feature depends on whether performance is more important than current and consistent data.
Java Data Types for CMP Fields
The following table provides a list of the Java data types for CMP fields used in WebLogic Server and shows how they map to the Oracle extensions for the standard SQL data types.
Table 5-1 Java data types for CMP fields
Do not use the SQL CHAR data type for database columns that are mapped to CMP fields. This is especially important for fields that are part of the primary key, because padding blanks that are returned by the JDBC driver can cause equality comparisons to fail when they should not. Use the SQL VARCHAR data type instead of SQL CHAR.
A CMP field of type byte[] cannot be used as a primary key unless it is wrapped in a user-defined primary key class that provides meaningful equals() and hashCode() methods. This is because the byte[] class does not provide useful equals and hashCode.
The concurrency strategy specifies how the EJB container should manage concurrent access to an entity bean. Although the Database option is the default concurrency strategy for WebLogic Server, you may want to specify other options for your entity bean depending on the type of concurrency access the bean requires. WebLogic Server provides the following concurrency strategy options:
|
Places an exclusive lock on cached entity EJB instances when the bean is associated with a transaction. Other requests for the EJB instance are block until the transaction completes. This option was the default locking behavior for WebLogic Server versions 3.1 through 5.1 |
|
|
Defers locking requests for an entity EJB to the underlying datastore. WebLogic Server allocates a separate entity bean instance and allows locking and caching to be handled by the database. This is the default option. |
|
|
Holds no locks in the EJB container or database during a transaction. The EJB container verifies that none the data updated by the transaction has changed before committing the transaction. If any updated data changed, the EJB container rolls back the transaction. |
|
|
Used only for read-only entity beans. Activates a new instance for each transaction so that requests proceed in parallel. WebLogic Server calls ejbLoad() for ReadOnly beans are based on the read-timeout-seconds parameter. |
Concurrency Strategy for Read-Write EJBs
You can use the Exclusive, Database, and ReadOnly concurrency strategies for read-write EJBs. WebLogic Server loads EJB data into the cache at the beginning of each transaction, or as described in Using cache-between-transactions to Limit Calls to ejbLoad(). WebLogic Server calls ejbStore() at the successful commit of a transaction.
Specifying the Concurrency Strategy
You specify the locking mechanism that the EJB uses by setting the concurrency-strategy deployment parameter in weblogic-ejb-jar.xml. You set concurrency-strategy at the individual EJB level, so that you can mix locking mechanisms within the EJB container.
The following excerpt from weblogic-ejb-jar.xml shows how to set the concurrency strategy for an EJB. In the following sample XML, the code specifies the default locking mechanism, Database.
Figure 5-12 Sample XML specifying the concurrency strategy
<entity-descriptor>
<entity-cache>
...
<concurrency-strategy>Database</concurrency-strategy>
</entity-cache>
...
</entity-descriptor>
If you do not specify a concurrency-strategy, WebLogic Server performs database locking for entity EJB instances.
A description of each concurrency strategy is covered in the following sections.
Exclusive Concurrency Strategy
The Exclusive concurrency strategy was the default in WebLogic Server 5.1 and 4.5.1. This locking method provides reliable access to EJB data, and avoids unnecessary calls to ejbLoad() to refresh the EJB instance's persistent fields. However, exclusive locking does not provide the best model for concurrent access to the EJB's data. Once a client has locked an EJB instance, other clients are blocked from the EJB's data even if they intend only to read the persistent fields.
The EJB container in WebLogic Server can use exclusive locking mechanism for entity EJB instances. As clients enlist an EJB or EJB method in a transaction, WebLogic Server places an exclusive lock on the EJB instance for the duration of the transaction. Other clients requesting the same EJB or method are blocked until the current transaction completes.
The Database concurrency strategy is the default option for WebLogic Server and the recommended mechanism for EJB 1.1 and EJB 2.0 beans. It improves concurrent access for entity EJBs. The WebLogic Server container defers locking services to the underlying database. Unlike exclusive locking, the underlying data store can provide finer granularity for locking EJB data, and deadlock detection.
With the database locking mechanism, the EJB container continues to cache instances of entity EJB classes. However, the container does not cache the intermediate state of the EJB instance between transactions. Instead, WebLogic Server calls ejbLoad() for each instance at the beginning of a transaction to obtain the latest EJB data. The request to commit data is subsequently passed along to the database. The database, therefore, handles all lock management and deadlock detection for the EJB's data.
Deferring locks to the underlying database improves throughput for concurrent access to entity EJB data, while also providing deadlock detection. However, using database locking requires more detailed knowledge of the underlying datastore's lock policies, which can reduce the EJB's portability among different systems.
When using the Database concurrency strategy instead of Optimistic with the caching-between-transactions element set to "True," you will receive a warning message from the compiler indicating that cache-between-transactions should be disabled. If this condition exists, WebLogic Server automatically disables caching-between-transactions.
Optimistic Concurrency Strategy
The Optimistic concurrency strategy does not hold any locks in the EJB container or the database while the transaction is in process. When you specify this option, The EJB container makes sure that the data being updated by a transaction has not changed. It performs a "smart update" by checking the fields before it commits the transaction.
To verify that you want the data checked for validity, enable optimistic checking by setting the verify-columns deployment descriptor element in the weblogic-cmp-rdbms-jar.xml file. The verify-columns element specifies that the columns in a table be checked for validity when you use the optimistic concurrency strategy.
A version column must be created with an initial value of 0, and must increment by 1 whenever the row is modified.
The EJB container manages the version and timestamp columns and ensures that these columns are kept up to date.
If the EJB is mapped to multiple tables, optimistic checking is only performed on the tables that are updated during the transaction.
Note: By default, caching between transactions is not enabled for this feature. You must explicitly enable it. See Using cache-between-transactions to Limit Calls to ejbLoad()for instructions.
WebLogic Server provides support for concurrent access to read-only entity beans. This caching strategy activates an instance of a read-only entity bean for each transaction so that requests may be processed in parallel.
Previously, read-only entity beans used the exclusive locking concurrency strategy. This strategy places an exclusive lock on cached entity bean instances when the bean is associated with a transaction. Other requests for the entity bean instance are block until the transaction completes.
To avoid reading from the database, WebLogic Server copies the state for an EJB 2.0 CMP bean from the existing instance in the cache. For this release, the default concurrency strategy for read-only entity beans is the ReadOnly option.
You can specify read-only entity bean caching at the application-level or the component-level.
To enable read-only entity bean caching:
WebLogic Server continues to support read-only entity beans with the read-timeout element set in the deployment descriptor. If the ReadOnly option is selected in the concurrency strategy element and the read-timeout-seconds element is set in the weblogic-ejb-jar.xml file, when a read-only bean is invoked, WebLogic Server checks whether the cached data is older than the read-timeout setting. If it is, the bean's ejbLoad is called. Otherwise, the cached data is used. So, previous versions of read-only entity beans will work in this version of WebLogic Server.
Restrictions for ReadOnly Concurrency Strategy
Entity EJBs using the read-only concurrency strategy must observe the following restrictions:
Because the bean's underlying data may be updated by an external source, calls to ejbLoad() are governed by the deployment parameter, read-timeout-seconds.
As application developers develop their entity beans, the underlying table schema must change. With the automatic database detection feature enabled, the WebLogic Server EJB container automatically changes the underlying table schema as entity beans change, ensuring that tables always reflect the most recent value of deployment descriptor values.
Even if a table already exists, if any container-managed persistence fields have been added or deleted for that table, the container will recreate the table during deployment. To ensure that the container only changes tables it created, container-created tables include an extra column, called wls_temp.
Note: Use this feature during development only, not during production.
Enabling Automatic Database Detection
Enable this feature using the create-default-dbms-tables element in weblogic-cmp-rdbms-jar.xml. The precise behavior of this feature varies, depending on the value of the element. The following table summarizes how behavior varies depending on the value:
Behavior When Type Conflict Detected
If the database type WebLogic Server detects differs from the database type defined in the deployment descriptor, WebLogic Server will issue a warning and give preference to the type defined in the deployment descriptor.
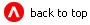
|

|

|