11g リリース1(11.1)
E05694-03
 目次 |
 索引 |
| Oracle Database 2日で開発者ガイド 11g リリース1(11.1) E05694-03 |
|

この章では、グローバリゼーション・サポート環境でのアプリケーションの開発方法について説明し、SQLおよびPL/SQL両方を使用してUnicodeプログラミングの使用方法を示します。Unicodeプログラミングによって、複数の言語と互換性のあるSQLおよびPL/SQLコードを記述することができます。
この章の内容は次のとおりです。
Oracle Databaseのグローバリゼーション・サポートにより、各国語でデータを格納、処理、取得できます。さらにデータベース・ユーティリティ、エラー・メッセージ、ソート順序、日付、時刻、通貨、数字、カレンダ規則が、自動的に固有の言語およびロケールに調整されます。
グローバリゼーション・サポートには各国語サポート(NLS)機能が含まれます。各国語サポートは、各国の言語を選択し、データを特定のキャラクタ・セットで格納する機能です。グローバリゼーション・サポートにより、世界のどこからでも同時にアクセスし、実行できる多言語アプリケーションおよびソフトウェア製品を開発できるようになります。アプリケーションにより、ユーザー・インタフェースの内容をレンダリングし、各国語およびユーザーのロケール・プリファレンスでデータを処理できます。
Oracle Databaseの標準機能には次のものが含まれます。
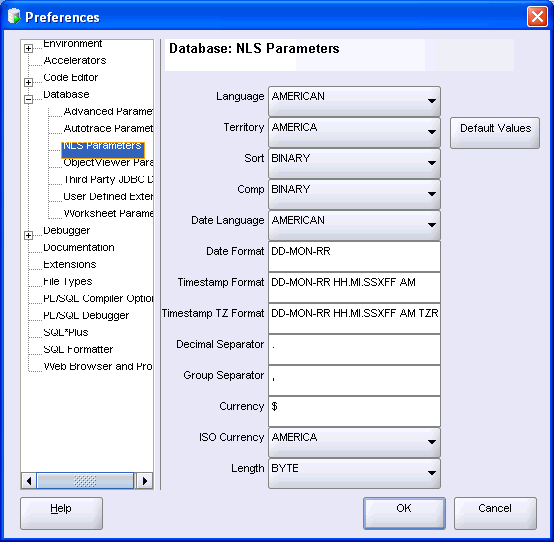
SQL Developerでは各国語サポート・パラメータ・レポートによりグローバリゼーション・サポートのパラメータ値がリストされます。
このレポートのNLSパラメータ値は、「SQL Developer環境におけるNLSパラメータ値の使用」で説明しているように、SQL Developer内のすべてのセッションの最初に使用します。
hr_connに設定します。「OK」をクリックします。
NLS_CALENDAR、NLS_CHARSET、NLS_COMP、NLS_CURRENCY、NLS_DATE_FORMATなどです。

参照:
V$NLS_PARAMETERSビューの詳細は、『Oracle Databaseリファレンス』を参照してください。
Oracleデータベースでは、NLSパラメータ値がデータベース初期化パラメータによって最初に決定されます。DBAは初期化ファイルの値を設定でき、その変更は次のデータベースの設定に影響します。データベース・ユーザーは、次の文を使用することで現在のセッション(データベースへの現在の接続)に対する特定のパラメータ値を変更できます。
ALTER SESSION SET parameter-name = "value";
SQL Developerを使用するときは、データベース初期化ファイルのパラメータ値は使用されないことに注意してください。かわりに、SQL Developerでは次を含むパラメータ値が最初(インストール後)に使用されます。
NLS_LANG,"AMERICAN" NLS_TERR,"AMERICA" NLS_CHAR,"AL32UTF8" NLS_SORT,"BINARY" NLS_CAL,"GREGORIAN" NLS_DATE_LANG,"AMERICAN" NLS_DATE_FORM,"DD-MON-RR"
SQL Developer(すべての接続における「SQL Worksheet」ウィンドウや各国語サポート・パラメータ・レポートなど)のすべてのセッションで使用されるこれらのNLSパラメータ値およびその他のNLSパラメータ値は、NLSパラメータの「Preferences」ペインで表示できます。
NLSパラメータの値を変更するには、次のオプションが必要です。
ALTER SESSION文を使用することで、現在の接続のみの値を変更します。
このように、データベース・アプリケーション開発時に、異なる言語設定をテストすることに大きな柔軟性を得られます。たとえば、ALTER SESSIONを使用して、異なる言語設定を使用する次のPL/SQL文の出力を表示し、接続を切断し再接続することでSQL Developerのデフォルト設定に戻すことができます。
たとえば、プリファレンスのNLS_LANGUAGE値がFRENCHに設定されており、今日が2007年3月1日であると仮定します。「SQL Worksheet」でSELECT sysdate FROM dual;と入力し、「Run Script」アイコンをクリックすると、次のように出力されます。
SYSDATE ------------------------- 01-MARS -07
ALTER SESSION SET NLS_LANGUAGE='AMERICAN';と入力し、前述のSELECT文を入力すると、次のように出力されます。
SYSDATE ------------------------- 01-MAR-07
この例を継続し、現在の接続から切断し、再接続すると、セッションのNLS_LANGUAGE値は(プリファレンスで指定したとおり)FRENCHとなり、SELECT文による出力は次のようになります。
SYSDATE ------------------------- 01-MARS -07
NLSパラメータに対するSQL Developerのユーザー・プリファレンスにより、(現在および今後の)すべてのSQL Developer接続で使用される値が設定されます。データベースのNLSパラメータの「Preferences」ペインでパラメータ値を表示し、変更できます。
「現在のNLSパラメータ値の表示」で説明しているように、これらのプリファレンスはNLSパラメータ値レポートでも表示されます。
各テキスト・ラベルは対応するNLS_xxxパラメータを説明する用語です。
たとえば、スペイン語環境を反映するようにNLS_LANGUAGEパラメータ値を変更するには、「Language」でSPANISHを選択します。
この項では、グローバリゼーション・サポート環境の設定方法を説明します。
ロケールとはシステムやプログラムを実行する言語的および文化的環境のことです。Oracleソフトウェアでロケール動作を指定する最も簡単な方法は、NLS_LANGパラメータを設定することです。このパラメータによって、クライアント・アプリケーションおよびデータベースで使用される言語と地域が設定されます。また、クライアント・プログラムによって入力または表示されるデータのキャラクタ・セットであるクライアントのキャラクタ・セットも設定されます。
NLS_LANGパラメータにより、サーバー・セッション(SQL文の処理など)およびクライアント・アプリケーション(Oracleツールの表示の書式など)の両方で使用する言語および地域環境が設定されます。
インストール時に定義したデフォルトのNLS_LANG動作はほとんどの状況において適切ですが、セッション時に動的にNLS環境を変更することもあります。この場合、ALTER SESSION文を使用することで、NLS_LANGUAGE、NLS_TERRITORYおよびその他のNLSパラメータを変更できます。
ALTER SESSION文を使用してクライアント・キャラクタ・セットの設定を変更できないことに注意してください。ALTER SESSION文はセッション環境のみを変更します。クライアントが新しい設定を獲得せず、ローカル環境を変更しない場合、ローカル・クライアントNLS環境は変更されません。
各国語サポート(NLS)パラメータにより、クライアントおよびサーバー両方でのロケール固有の動作が決定します。NLSパラメータは様々な方法で指定できます。SQLファンクションでユーザー・セッションのパラメータを変更し、パラメータを上書きできます。
NLSパラメータの設定は、次の2つの方法で変更できます。
ALTER SESSION文でNLSパラメータを設定し、初期化パラメータ・ファイルのセッションに対して設定されたデフォルト値、または環境変数を使用してクライアントで設定されたデフォルト値を上書きします。ALTER SESSION SET NLS_SORT = french;
ALTER SESSION文を使用して行った変更は、現在のユーザー・セッションにのみ適用され、次にログインしたときには変更が適用されません。
ALTER SESSION文でセッションに対して設定されたデフォルト値を上書きします。たとえば、次を実行します。TO_CHAR(hiredate,'DD/MON/YYYY','nls_date_language = FRENCH')
クライアントでのNLS環境変数の使用を含むNLSパラメータを設定する他の方法は、プラットフォーム依存である場合があります。これは、クライアントに対してロケール依存の動作を指定、または初期化パラメータ・ファイルのセッションのデフォルト値の設定を上書きします。たとえば、Linuxシステムの場合は次のようになります。
% setenv NLS_SORT FRENCH
ローカル地域に応じて異なるNLSパラメータを設定することにより、データベース・セッションにおいて異なる文化的設定を使用できます。たとえば、地域がAMERICAと定義されている場合であっても、指定したデータベース・セッションに対する基本通貨としてユーロ(EUR)を設定し、補助通貨として日本の円(JPY)を設定できます。
|
参照:
|
NLS_LANGUAGEパラメータは有効な言語名に対して設定できます。デフォルトはNLS_LANG設定から導出されます。NLS_LANGUAGEにより、次のセッション特性に対するデフォルトの規則が指定されます。
TO_CHARおよびTO_DATEで指定されます)
AM、PM、ADおよびBCに相当する記号
ORDER BY句が指定されている場合の文字データのデフォルトのソート順序(ORDER BYを指定しないかぎり、GROUP BY句ではバイナリ・ソート順序が使用されます)
NLS_LANGUAGEパラメータ値を変更し、その影響を問合せからの結果の表示で確認できます。次の例は、最初にNLS_LANGUAGEをイタリア語に設定し、次にドイツ語に設定したことを示しています。
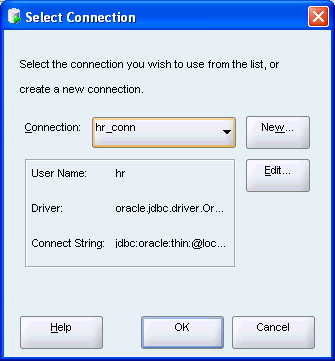
「Connections」で、まず「Data Dictionary Reports」を展開し、次に「About Your Database」、そして「National Language Support Parameters」を展開します。「Select Connection」ダイアログ・ボックスで、接続のリストからhr_connを選択します。現行の言語はNLS_LANGUAGEの後にリストされます。
ALTER SESSION SET NLS_LANGUAGE=ITALIAN;
SELECT文を入力して、イタリア語への変更後の出力書式をチェックします。
SELECT last_name, hire_date, ROUND(salary/8,2) salary FROM employees WHERE employee_id IN (111, 112, 113);
この例では次のように出力されます。月名の略称にイタリア語が使用されていることに注意してください。
LAST_NAME HIRE_DATE SALARY ------------------------- --------- ---------- Sciarra 30-SET-97 962.5 Urman 07-MAR-98 975 Popp 07-DIC-99 862.5
ALTER SESSION SET NLS_LANGUAGE=GERMAN;
SELECT文を入力して、ドイツ語への変更後の出力書式をチェックします。
SELECT last_name, hire_date, ROUND(salary/8,2) salary FROM employees WHERE employee_id IN (111, 112, 113);
この例では次のように出力されます。月名の略称にドイツ語が使用されていることに注意してください。
LAST_NAME HIRE_DATE SALARY ------------------------- --------- ---------- Sciarra 30-SEP-97 962.5 Urman 07-MRZ-98 975 Popp 07-DEZ-99 862.5
NLS_LANGUAGEを設定します。次に例を示します。
ALTER SESSION SET NLS_LANGUAGE=AMERICAN;
NLS_TERRITORYパラメータは有効な任意の地域名に対して設定できます。デフォルトはNLS_LANG設定から導出されます。NLS_TERRITORYにより、次の日付および数値書式特性に対するデフォルトの規則が指定されます。
NLS_TERRITORYパラメータを変更することにより、導出されたすべてのNLSセッション・パラメータが新しい地域のデフォルトの値にリセットされます。
NLS_LANGUAGEパラメータ値を変更し、その影響を問合せからの結果の表示で確認できます。次の例は、NLS_TERRITORYをドイツに設定した結果を示しています。
SELECT文を入力します。
SELECT TO_CHAR(salary,'L99G999D99') salary FROM employees WHERE employee_id IN (100, 101, 102);
たとえば、NLS_TERRITORYがAMERICAの場合、この例では次のように出力されます。
SALARY -------------------- $24,000.00 $17,000.00 $17,000.00 3 rows selected
「Connections」で、まず「Data Dictionary Reports」、次に「About Your Database」、そして「National Language Support Parameters」を展開します。「Select Connection」ダイアログ・ボックスで、接続のリストからhr_connを選択します。現行の地域はNLS_TERRITORYの後にリストされます。
NLS_TERRITORYをドイツに設定します。
ALTER SESSION SET NLS_TERRITORY=GERMANY;
SELECT文を入力して、ドイツへの変更後の出力書式をチェックします。
SELECT TO_CHAR(salary,'L99G999D99') salary FROM employees WHERE employee_id IN (100, 101, 102);
この例では次のように出力されます。3桁区切りがピリオド(.)に変更され、小数点文字がカンマ(,)に変更されました。通貨記号はドル($)からユーロ(€)に変更されました。ただし、基礎となるデータは同じであるため、数字は変更されません(つまり、通貨の換算レートは織り込まれません)。
SALARY -------------------- €4.000,00 €7.000,00 €7.000,00 3 rows selected
NLS_TERRITORYを設定します。次に例を示します。
ALTER SESSION SET NLS_TERRITORY=AMERICA;
|
参照:
|
日付および時刻の表示を制御し、ローカル書式に基づいて時刻、曜日、月および年のそれぞれの表記規則を許可できます。たとえば、日付を表示する場合、英国ではDD/MM/YYYY書式を使用して表示されますが、中国では一般的にYYYY-MM-DD書式が使用されます。
次の表で説明しているように、日付には複数の異なる書式を使用できます。
| 国 | 説明 | 例 |
|---|---|---|
|
エストニア |
dd.mm.yyyy |
28.02.2005 |
|
ドイツ |
dd.mm.rr |
28.02.05 |
|
中国 |
yyyy-mm-dd |
2005-02-28 |
|
英国 |
dd/mm/yyyy |
28/02/2005 |
|
米国 |
mm/dd/yyyy |
02/28/2005 |
NLS_DATE_FORMATにより、TO_CHARおよびTO_DATEファンクションを使用するためのデフォルトの日付書式が定義されます。NLS_TERRITORYでは、NLS_DATE_FORMATパラメータのデフォルト値が決定されます。NLS_DATE_FORMATの値は、有効な任意の日付書式モデルです。次に例を示します。
NLS_DATE_FORMAT = "MM/DD/YYYY"
文字列リテラルを日付書式に追加するには、その文字列リテラルを二重引用符で囲みます。日付書式に二重引用符を使用する場合は、値全体を一重引用符で囲む必要があることに注意してください。次に例を示します。
NLS_DATE_FORMAT = '"Date: "MM/DD/YYYY'
Oracleのデフォルトの日付書式が、特定の地域で使用される文化固有の規則に常に対応しているとはかぎりません。'DS'および'DL'書式モデルをそれぞれ使用し、SQLで短い日付書式および長い日付書式を使用することにより、ローカライズされた書式で日付を取得できます。次の例は、短い日付書式および長い日付書式の使用例を示しています。
「Connections」で、まず「Data Dictionary Reports」、次に「About Your Database」、そして「National Language Support Parameters」を展開します。「Select Connection」ダイアログ・ボックスで、接続のリストからhr_connを選択します。現行の日付書式はNLS_DATE_FORMATの後に、現行の地域はNLS_TERRITORYの後にリストされます。
NLS_TERRITORYをアメリカに設定します。
ALTER SESSION SET NLS_TERRITORY = America;
SELECT hire_date, TO_CHAR(hire_date,'DS') "Short", TO_CHAR(hire_date,'DL') "Long" FROM employees WHERE employee_id IN (111, 112, 113);
この例では次のように出力されます。
HIRE_DATE Short Long ---------------- ---------- ----------------------------------- 30-SEP-97 9/30/1997 Tuesday, September 30, 1997 07-MAR-98 3/7/1998 Saturday, March 07, 1998 07-DEC-99 12/7/1999 Tuesday, December 07, 1999
NLS_TERRITORYおよびNLS_DATE_FORMATを設定します。次に例を示します。
ALTER SESSION SET NLS_TERRITORY=AMERICA; ALTER SESSION SET NLS_DATE_FORMAT="MM/DD/YYYY";
NLS_DATE_LANGUAGEにより、TO_CHARおよびTO_DATEファンクションで生成される曜日名および月名の言語が指定されます。NLS_DATE_LANGUAGEでは、NLS_LANGUAGEにより暗黙的に指定された言語が上書きされます。NLS_DATE_LANGUAGEパラメータにはNLS_LANGUAGEパラメータと同じ構文があり、サポートされるすべての言語が有効値です。
NLS_DATE_LANGUAGEパラメータにより、次に使用される言語も決定されます。
デフォルトの日付書式では、NLS_DATE_LANGUAGEパラメータによって決定される月名の略称が使用されます。たとえば、デフォルトの日付書式がDD-MON-YYYYであり、NLS_DATE_LANGUAGE = FRENCHである場合、日付は次のように挿入されます。
INSERT INTO table_name VALUES ('12-F騅r.-2007');
次の例は、NLS_DATE_LANGUAGEをフランス語に設定した結果を示しています。
「Connections」で、まず「Data Dictionary Reports」、次に「About Your Database」、そして「National Language Support Parameters」を展開します。「Select Connection」ダイアログ・ボックスで、接続のリストからhr_connを選択します。現行の曜日名および月名の言語はNLS_DATE_LANGUAGEの後にリストされます。
NLS_DATE_LANGUAGEをフランス語に設定します。
ALTER SESSION SET NLS_DATE_LANGUAGE = FRENCH;
SELECT TO_CHAR(SYSDATE, 'Day:Dd Month yyyy') FROM DUAL
この例では次のように出力されます。
TO_CHAR(SYSDATE,'DAY:DDMONTHYYYY') ---------------------------------- Lundi :05 Mars 2007
NLS_DATE_LANGUAGEを設定します。次に例を示します。
ALTER SESSION SET NLS_DATE_LANGUAGE=AMERICAN;
|
参照:
|
この項では、NLS_TIMESTAMP_FORMATおよびNLS_TIMESTAMP_TZ_FORMATパラメータの使用方法を説明します。時刻書式の例のいくつかは次の表のとおりです。
| 国 | 説明 | 例 |
|---|---|---|
|
エストニア |
hh24:mi:ss |
13:50:23 |
|
ドイツ |
hh24:mi:ss |
13:50:23 |
|
中国 |
hh24:mi:ss |
13:50:23 |
|
英国 |
hh24:mi:ss |
13:50:23 |
|
米国 |
hh:mi:ssxff am |
1:50:23.555 PM |
NLS_TIMESTAMP_FORMATにより、TIMESTAMPおよびTIMESTAMP WITH LOCAL TIME ZONEデータ型のデフォルトの日付書式が定義されます。NLS_TERRITORYでは、NLS_TIMESTAMP_FORMATのデフォルト値が決定されます。NLS_TIMESTAMP_FORMATの値は有効な任意の日付時間書式モデルです。
次の例はNLS_TIMESTAMP_FORMATの値を示しています。
NLS_TIMESTAMP_FORMAT = 'YYYY-MM-DD HH:MI:SS.FF'
NLS_TIMESTAMP_TZ_FORMATパラメータにより、TIMESTAMPおよびTIMESTAMP WITH LOCAL TIME ZONEデータ型のデフォルトの日付書式が定義されます。これにはTO_CHARおよびTO_TIMESTAMP_TZファンクションが使用されます。NLS_TERRITORYパラメータでは、NLS_TIMESTAMP_TZ_FORMATパラメータのデフォルト値が決定されます。NLS_TIMESTAMP_TZ_FORMATの値は、有効な任意の日付時間書式モデルです。
書式の値は引用符で囲む必要があります。次に例を示します。
NLS_TIMESTAMP_TZ_FORMAT = 'YYYY-MM-DD HH:MI:SS.FF TZH:TZM'
次の例では、NLS_TIMESTAMP_TZ_FORMAT値が設定されます。また、TO_TIMESTAMP_TZファンクションを使用し、SELECT文で明示的に設定した書式を表しています。
「Connections」で、まず「Data Dictionary Reports」、次に「About Your Database」、そして「National Language Support Parameters」を展開します。「Select Connection」ダイアログ・ボックスで、接続のリストからhr_connを選択します。現行の日付書式はNLS_TIMESTAMP_TZ_FORMATの後にリストされます。
NLS_TIMESTAMP_TZ_FORMATを設定します。
ALTER SESSION SET NLS_TIMESTAMP_TZ_FORMAT = 'YYYY-MM-DD HH:MI:SS.FF TZH:TZM';
NLS_TIMESTAMP_TZ_FORMATを設定します。次に例を示します。
ALTER SESSION SET NLS_TIMESTAMP_TZ_FORMAT='DD-MON-RR HH.MI.SSXFF AM TZR';
|
参照:
|
この項では、カレンダ定義について説明します。
次のカレンダ情報は地域別に格納されます。
週の最初の曜日はNLS_TERRITORYパラメータにより決定されます。
2005年1月1日は、2004年のISOの週番号53となります。ISOの週は月曜日に始まり、日曜日に終わります。ISO規格をサポートするために、OracleにはIW日付書式要素が用意されています。これによりISOの週番号が戻されます。
年の最初の暦週はNLS_TERRITORYパラメータにより決定されます。
暦法はNLS_CALENDARパラメータで指定します。
世界中で様々な暦法が使用されています。NLS_CALENDARによって、Oracle Databaseで使用する暦法が指定されます。デフォルト値はGregorianです。値は有効な任意のカレンダ書式名です。
NLS_CALENDARパラメータには、次の値のいずれかを指定できます。
次の例では、NLS_CALENDARの値をEnglish Hijrahに設定しています。イスラム暦1424年のラマダンの最初の日の値が表示されています。他のNLSパラメータにはSQL Developerのデフォルト設定が反映されます。
「Connections」で、まず「Data Dictionary Reports」、次に「About Your Database」、そして「National Language Support Parameters」を展開します。「Select Connection」ダイアログ・ボックスで、接続のリストからhr_connを選択します。現行の日付書式はNLS_DATE_FORMATの後に、現行の地域はNLS_CALENDARの後にリストされます。
NLS_CALENDARをEnglish Hijrahに設定するには、次の手順を実行します。
ALTER SESSION SET NLS_CALENDAR='English Hijrah';
SELECT TO_DATE('01-Ramadan-1428') FROM DUAL;
この例では次のように出力されます。
TO_DATE('01-RAMADAN-1428') ------------------------- 13 September 2007
NLS_CALENDARを設定します。次に例を示します。
ALTER SESSION SET NLS_CALENDAR='GREGORIAN';
|
参照:
|
データベースでは、数字列を正確に解釈するために、各セッションで使用される数値書式設定の規則を認識している必要があります。たとえば、数値の入力時に小数点文字としてピリオドまたはカンマのどちらを使用するか(234.00または234,00)などを認識している必要があります。同じように、アプリケーションでは、数値情報をクライアント側の書式で表示できる必要があります。
次の表に数値書式の例を示します。
| 国 | 数値書式 |
|---|---|
|
エストニア |
1 234 567,89 |
|
ドイツ |
1.234.567,89 |
|
中国 |
1,234,567.89 |
|
英国 |
1,234,567.89 |
|
米国 |
1,234,567.89 |
数値書式はNLS_TERRITORYパラメータの設定から導出されますが、NLS_NUMERIC_CHARACTERSパラメータで上書きできます。
NLS_NUMERIC_CHARACTERSにより、グループ・セパレータおよび小数点記号が指定されます。グループ・セパレータとは、千や100万などを示すために整数グループを区切る文字です。この文字はG数値書式モデルで戻されます。小数点記号は、数値の整数部と小数部を区切ります。NLS_NUMERIC_CHARACTERSを設定すると、NLS_TERRITORYの設定から導出されるデフォルト値が上書きされます。値は、グループ・セパレータおよび小数点記号に指定できる2つの任意の数字です。
任意の文字を小数点文字またはグループ・セパレータに指定できます。2つの文字はシングルバイトであり、お互いに異なる文字である必要があります。これらの文字に、数字、プラス記号(+)、マイナス記号(-)、小なり記号(<)、大なり記号(>)を使用することはできません。どちらかの文字を空白にすることができます。
小数点文字としてカンマを設定し、グループ・セパレータとしてピリオドを設定するには、NLS_NUMERIC_CHARACTERSパラメータを次のように指定します。
ALTER SESSION SET NLS_NUMERIC_CHARACTERS = ",.";
SQL文には、数値リテラルまたはテキスト・リテラルを表す数値を含むことができます。数値リテラルは引用符で囲みません。数値リテラルはSQL言語構文の一部で、小数点文字として常にドットを使用し、グループ・セパレータは含まれません。テキスト・リテラルは引用符で囲みます。テキスト・リテラルは、必要に応じて、現行のNLS設定に従って、暗黙的または明示的に数値に変換されます。
次の例では、ALTER SESSION文で指定された小数点文字とグループ・セパレータを使用して数値4000の書式を設定しています。
「Connections」で、まず「Data Dictionary Reports」、次に「About Your Database」、そして「National Language Support Parameters」を展開します。「Select Connection」ダイアログ・ボックスで、接続のリストからhr_connを選択します。現行の数値書式はNLS_NUMERIC_CHARACTERSの後にリストされます。
NLS_NUMERIC_CHARACTERSを指定したグループ・セパレータおよび小数点文字に設定します。
ALTER SESSION SET NLS_NUMERIC_CHARACTERS = ",.";
二重引用符を使用します。
'9G999D99'を使用して4000を表示します。
SELECT TO_CHAR(4000, '9G999D99') FROM DUAL;
この例では次のように出力されます。グループ・セパレータはピリオド(.)で、小数点文字はカンマ(,)です。
TO_CHAR(4000,'9G999D99') ------------------------ 4.000,00
NLS_NUMERIC_CHARACTERSを設定します。次に例を示します。
ALTER SESSION SET NLS_NUMERIC_CHARACTERS=". ";
基数記号と3桁区切りは、ロケールで定義できます。たとえば、小数点は、米国ではピリオド(.)ですが、フランスではカンマ(,)です。金額$1,234の持つ意味は国によって異なるため、金額をロケールごとに適切に表示することが重要です。
世界中で様々な通貨書式が使用されています。標準的な書式の一部を次の表に示します。
| 国 | 通貨書式 |
|---|---|
|
エストニア |
1 234,56 kr |
|
ドイツ |
1.234,56€ |
|
中国 |
¥1,234.56 |
|
英国 |
£1,234.56 |
|
米国 |
$1,234.56 |
|
参照:
|
NLS_CURRENCYパラメータでは、L数値書式モデルで戻される文字列の各国通貨記号を指定します。NLS_CURRENCYを設定すると、NLS_TERRITORYで暗黙的に定義された設定が上書きされます。値には、有効な任意の通貨記号を指定できます。
次の例では、NLS_CURRENCY値によって置換されるL数値書式モデルを含む書式を使用して給与合計を表示しています。
SELECT TO_CHAR(salary, 'L099G999D99') "salary" FROM employees WHERE salary > 11000
この例では次のように出力されます。この場合、ドル記号($)がL数値書式モデルです。
salary --------------------- $024,000.00 $017,000.00 $017,000.00 $012,000.00 $014,000.00 $013,500.00 $012,000.00 $011,500.00 $013,000.00 $012,000.00 10 rows selected
|
参照:
|
NLS_ISO_CURRENCYパラメータでは、C数値書式モデルで戻される文字列の各国通貨記号を指定します。NLS_ISO_CURRENCYを設定すると、NLS_TERRITORYで暗黙的に定義された値が上書きされます。値には、有効な任意の文字列を指定できます。
各国通貨記号は不明確な場合があります。たとえば、ドル記号($)は米国ドルを指すこともオーストラリア・ドルを指すこともあります。ISO仕様には、特定の地域または国に対して固有の通貨記号が定義されています。たとえば、米国ドルに対するISO通貨記号はUSDです。オーストラリア・ドルに対するISO通貨記号はAUDです。
NLS_ISO_CURRENCYパラメータの構文はNLS_TERRITORYパラメータの構文と同じで、サポート対象地域すべてが有効値です。
次の例では、適切な書式モデルを使用してフランス用のISO通貨記号および給与書式を設定しています。
「Connections」で、まず「Data Dictionary Reports」、次に「About Your Database」、そして「National Language Support Parameters」を展開します。「Select Connection」ダイアログ・ボックスで、接続のリストからhr_connを選択します。現行のISO通貨書式はNLS_ISO_CURRENCYの後にリストされます。
NLS_ISO_CURRENCYをフランスに設定します。
ALTER SESSION SET NLS_ISO_CURRENCY=FRANCE;
SELECT TO_CHAR(salary, 'C099G999D99') "Salary" FROM employees WHERE department_id = 60;
この例では次のように出力されます。
Salary ------------------ EUR009,000.00 EUR006,000.00 EUR004,800.00 EUR004,800.00 EUR004,200.00 5 rows selected
NLS_ISO_CURRENCYを設定します。次に例を示します。
ALTER SESSION SET NLS_ISO_CURRENCY=AMERICA;
|
参照:
|
NLS_DUAL_CURRENCYを使用すると、NLS_TERRITORYで暗黙的に定義されたデフォルトの二重通貨記号が上書きされます。値には有効な任意の記号を指定できます。
NLS_DUAL_CURRENCYはユーロ移行期間中にユーロ通貨記号をサポートするために導入されました。
|
参照:
|
ソート順序は言語によって異なります。ある言語ではアルファベットの文字の並びに応じてソートされ、ある言語では文字の画数でソートされ、またある言語では語の発音によってソートされます。また、文字のアクセントの扱いも言語によって異なります。たとえば、デンマーク語の文字Æは、Zの後に来ます。また、YとÜは同じ文字の変形とみなされます。
言語ソート・パラメータを使用することで、データのソート方法を定義できます。基本的な言語定義では、文字列を独立した文字の連続として扱います。
NLS_SORTパラメータにより、ORDER BY問合せの照合順序(言語ソート)が指定されます。これにより、NLS_LANGUAGEパラメータから導出されたデフォルトのNLS_SORT値は上書きされます。NLS_SORTの値はBINARY、または有効な任意の言語ソート名です。
NLS_SORT = BINARY | sort_name
値がBINARYである場合、照合順序は基礎となるコード体系の数値コードに基づきます。データ型に応じて、これはデータベース・キャラクタ・セットまたは各国語キャラクタ・セットのバイナリ・ソート順序のいずれかです。値が言語ソートの名前である場合、ソートは定義したソートの順序に基づきます。NLS_LANGUAGEパラメータによってサポートされるほとんどの(すべてではありません)言語は同じ名前の言語ソートをサポートします。
NLS_SORTパラメータ値を変更し、その結果を問合せの結果の表示で確認できます。次の例ではNLS_SORTを最初にバイナリに設定して、次にスペイン語(SPANISH_M)に設定した結果を示しています。スペインでは伝統的にch、ll、ñを独自の文字として扱い、それぞれc、l、nの次に来ます。
「Connections」で、まず「Data Dictionary Reports」、次に「About Your Database」、そして「National Language Support Parameters」を展開します。「Select Connection」ダイアログ・ボックスで、接続のリストからhr_connを選択します。現行の照合書式はNLS_SORTの後にリストされます。
NLS_SORTをバイナリに設定します。
ALTER SESSION SET NLS_SORT=BINARY;
ORDER BY句のあるSELECT文を入力し、変更後の出力を確認します。
SELECT last_name FROM employees WHERE last_name LIKE 'C%' ORDER BY last_name;
この例では次のように出力されます。
LAST_NAME ------------------------- Cabrio Cambrault Cambrault Chen Chung Colmenares 6 rows selected
NLS_SORTをSPANISH_Mに設定します。
ALTER SESSION SET NLS_SORT=spanish_m;
SELECT文を入力し、変更後の出力を確認します。
SELECT last_name FROM employees WHERE last_name LIKE 'C%' ORDER BY last_name;
この例では次のように出力されます。Colmenaresは現在Chenの前に来ます。
LAST_NAME ------------------------- Cabrio Cambrault Cambrault Colmenares Chen Chung 6 rows selected
NLS_SORTを設定します。次に例を示します。
ALTER SESSION SET NLS_SORT=BINARY;
|
参照:
|
比較演算子を使用するとき、文字は指定したコード体系のバイナリ・コードにより、比較されます。バイナリ・コードより高い場合、文字は他よりも大きくなります。バイナリでの言語順序は特定の言語の言語順序と一致しない場合があるため、このような比較が言語的に正確ではない可能性があります。
NLS_COMPパラメータの値はSQL操作の比較動作に影響します。値にはBINARY(デフォルト)またはLINGUISTICを指定できます。バイナリ比較ではなく言語比較を実行する場合は、NLS_COMPパラメータを使用することで、SQL文のNLSSORTファンクションを使用する面倒な処理を回避できます。NLS_COMPをLINGUISTICに設定すると、SQLによりNLS_SORTパラメータの値に基づいた言語比較が実行されます。
NLS_COMPパラメータ値を変更し、その結果を問合せ結果を表示することで確認できます。次の例では、従業員名に対しバイナリ比較を実行した後にスペイン語の言語比較を実行したことを示しています。
「Connections」で、まず「Data Dictionary Reports」、次に「About Your Database」、そして「National Language Support Parameters」を展開します。「Select Connection」ダイアログ・ボックスで、接続のリストからhr_connを選択します。現行の比較演算子書式はNLS_COMPの後にリストされます。
NLS_SORTをスペイン語に設定し、NLS_COMPをBINARYに設定します。
ALTER SESSION SET NLS_SORT=spanish_m NLS_COMP=binary;
Cで始まる従業員を戻すSELECT文を入力します。
SELECT last_name FROM employees WHERE last_name LIKE 'C%';
この例では次のように出力されます。
LAST_NAME ------------------------- Cabrio Cambrault Cambrault Chen Chung Colmenares 6 rows selected
NLS_COMPをLINGUISTICに設定します。
ALTER SESSION SET NLS_COMP=linguistic;
SELECT文を入力し、変更後の出力を確認します。
SELECT last_name FROM employees WHERE last_name LIKE 'C%';
この例では次のように出力されます。2つの行、ChenおよびChungは戻されません。これは、スペイン語ではchはcの後に続く別の文字として扱われ、chは、スペイン語の言語比較が実行されたときに除外されるためです。
LAST_NAME ------------------------- Cabrio Cambrault Cambrault Colmenares 4 rows selected
NLS_COMPを設定します。次に例を示します。
ALTER SESSION SET NLS_COMP=BINARY;
|
参照:
|
データベースの操作では、大/小文字および文字のアクセントが区別されます。場合によっては、大/小文字を区別しない、またはアクセントを区別しない比較を実行する必要があります。大/小文字を区別しない、またはアクセントを区別しないソートを指定するには、NLS_SORTセッション・パラメータを使用します。
大/小文字を区別しない、またはアクセントを区別しないソートを指定するには、次の手順を実行します。
_CIを付けます。次に例を示します。
_AIを付けます。次に例を示します。
シングルバイト・キャラクタ・セットの場合、文字列のバイト数と文字数は同じです。マルチバイト・キャラクタ・セットの場合は、1文字または1つのコード・ポイントが1つ以上のバイトで構成されています。可変幅キャラクタ・セットの場合は、バイト長に基づく文字数の計算が困難な場合があります。列の長さをバイト数単位で計算することをバイト・セマンティクス、文字数単位で計算することをキャラクタ・セマンティクスと呼びます。
キャラクタ・セマンティクスは、可変幅のマルチバイト文字列の記憶要件を定義する場合に役立ちます。たとえば、Unicodeデータベース(AL32UTF8)で、VARCHAR2列を英語の5文字とともに5文字の中国語文字を格納できるように定義する必要があるとします。バイト・セマンティクスを使用すると、この列には、長さ3バイトである中国語文字用に15バイトと、長さ1バイトである英語文字用に5バイト、合計20バイトが必要です。キャラクタ・セマンティクスを使用すると、この列に必要な文字数は10となります。
次の式ではバイト・セマンティクスが使用されています。VARCHAR2式のBYTE修飾子およびSQLファンクション名のB接尾辞に注意してください。
次の式ではキャラクタ・セマンティクスが使用されています。VARCHAR2式のCHAR修飾子に注意してください。
NLS_LENGTH_SEMANTICSパラメータによって、BYTE(デフォルト)またはCHARセマンティクスが指定されます。デフォルトでは、文字データ型CHARおよびVARCHAR2が、文字単位ではなくバイト単位で指定されます。このため、表定義でCHAR(20)と指定すると、文字データを格納するために20バイトが割り当てられます。
NLS_LENGTH_SEMANTICSによって、CHAR、VARCHAR2およびLONGの各列をバイト・セマンティクスまたはキャラクタ・セマンティクスのいずれかを使用して作成できます。NCHAR、NVARCHAR2、CLOBおよびNCLOBの各列は、常に文字ベースです。既存の列は影響を受けません。
「Connections」で、まず「Data Dictionary Reports」、次に「About Your Database」、そして「National Language Support Parameters」を展開します。「Select Connection」ダイアログ・ボックスで、接続のリストからhr_connを選択します。現行のセマンティクス書式はNLS_LENGTH_SEMANTICSの後にリストされます。
NLS_LENGTH_SEMANTICSをBYTEに設定します。
ALTER SESSION SET NLS_LENGTH_SEMANTICS=BYTE;
CREATE TABLE SEMANTICS_BYTE(SOME_DATA VARCHAR2(20));
SEMANTICS_BYTEのデータ型をチェックします。「Connections」タブを選択しhr_conn接続を展開して、「Tables」にすべての表を表示します。SEMANTICS_BYTE表を選択します。SOME_DATA列のデータ型は、VARCHAR2(20 BYTE)としてリストされます。
NLS_LENGTH_SEMANTICSをCHARに設定します。
ALTER SESSION SET NLS_LENGTH_SEMANTICS=CHAR;
CREATE TABLE SEMANTICS_CHAR(SOME_DATA VARCHAR2(20));
SEMANTICS_CHARのデータ型をチェックします。「Connections」タブを選択しhr_conn接続を展開して、「Tables」にすべての表を表示します。SEMANTICS_CHAR表を選択します。SOME_DATA列のデータ型は、VARCHAR2(20 CHAR)としてリストされます。
SEMANTICS_BYTEおよびSEMANTICS_CHAR表を削除します。「Tables」ナビゲーション階層で、各表の名称を右クリックして、メニューから「Table」を選択してから「Drop」を選択します。「Apply」をクリックしてから「Confirmation」ダイアログ・ボックスで「OK」をクリックします。
NLS_LENGTH_SEMANTICSを設定します。次に例を示します。
ALTER SESSION SET NLS_LENGTH_SEMANTICS=BYTE;
この項では、複数の言語アプリケーション用にデプロイできるSQLおよびPL/SQLのUnicode関連の機能を説明します。Unicodeデータは挿入および取得できます。データはデータベースおよびクライアント間で透過的に変換され、クライアント・プログラムがデータベース・キャラクタ・セットおよび各国キャラクタ・セットから独立していることを保証します。
Unicodeとはエンコードされたユニバーサル・キャラクタ・セットです。このセットを使用すると、1つのキャラクタ・セットを使用して任意の言語の情報を格納できます。Unicodeには、プラットフォーム、プログラムまたは言語に関係なく、すべての文字に対する一意のコード値が用意されています。
Unicodeには次のような利点があります。
Unicode文字は、Oracleデータベースにおいて次の2つの方法で格納できます。
CHARデータ型として格納できるように、Unicodeデータベースを作成できます。
NCHARデータ型の列にUnicode文字を格納できます。NCHARデータ型はUnicodeデータ型専用です。
参照:
SQL NCHARデータ型にはNCHARおよびNVARCHAR2という2つのデータ型があります。
SQL Developerでは、各列のタイプに適切な値を選択することにより、表を作成または編集するダイアログ・ボックスでこれらのデータ型を指定できます。また、「SQL Worksheet」を使用し、CREATE TABLE文を入力することで、各列名およびデータ型を指定できます。
|
参照:
|
NCHARデータ型として表の列またはPL/SQL変数を定義するとき、長さは文字数として指定されます。たとえば、次の文により最大文字長が30の列が1つ作成されます。
CREATE TABLE table1 (column1 NCHAR(30));
列の最大バイト数は、最大文字数と各文字の最大バイト数の積です。
たとえば、各国語キャラクタ・セットがUTF8の場合、最大バイト長は30文字に1文字当たり3バイトを乗算した値、つまり90バイトとなります。
すべてのNCHARデータ型に使用する各国語キャラクタ・セットは、データベースの作成時に定義します。各国語キャラクタ・セットはUTF8またはAL16UTF16のいずれかです。デフォルトはAL16UTF16です。
使用可能な最大列サイズは、各国語キャラクタ・セットがUTF8の場合は2000文字、AL16UTF16の場合は1000文字です。実際のデータが最大バイト制限の2000の対象となります。2つのサイズ制限は同時に満たす必要があります。PL/SQLでは、NCHARデータの最大長は32767バイトです。NCHAR変数は32767文字まで定義できますが、実際のデータは32767バイトを超えることはできません。列の長さより短い値を挿入すると、最大文字長と最大バイト長のいずれか小さい方の値まで空白で埋められます。
NVARCHAR2データ型は、各国語キャラクタ・セットを使用する可変長文字列を指定します。NVARCHAR2列を使用して表を作成するときは、列の最大文字数を指定します。NVARCHAR2の長さは、NCHARの場合と同様に文字単位です。Oracle Databaseでは値が列の最大長を超えないかぎり、ユーザーが指定したとおりに各値が列内に格納されます。文字列の値が最大長まで埋め込まれることはありません。
使用可能な最大列サイズは、各国語キャラクタ・セットがUTF8の場合は4000文字、AL16UTF16の場合は2000文字です。バイト単位では、NVARCHAR2列の最大長は4000バイトです。バイト数の上限と文字数の上限の両方を満たす必要があるため、実際にNVARCHAR2列に使用できる最大文字数は、4000バイトに書込み可能な文字数となります。
PL/SQLでは、NVARCHAR2変数の最大長は32767バイトです。NVARCHAR2変数は32767文字まで定義できますが、実際のデータは32767バイトを超えることはできません。
次の文により、最大文字長が2000で最大バイト長が4000のNVARCHAR2列を1つ含む表が作成されます。
CREATE TABLE table2 (column2 NVARCHAR2(2000));
Unicode文字列リテラルは、次の方法でSQLおよびPL/SQLに入力できます。
Nを付加します。この接頭辞によって、その後に続く文字列リテラルがNCHAR文字列リテラルであることが明示的に示されます。たとえば、N'résumé'はNCHAR文字列リテラルです。この方法に関する制限は、「NCHARリテラルの置換」を参照してください。
NCHR(n)SQLファンクションを使用します。NCHR(n)SQLファンクションは、各国語キャラクタ・セット(AL16UTF16またはUTF8)内の文字コードの数を戻します。複数のNCHRn)ファンクションを連結した結果は、NVARCHAR2データになります。このように、クライアントとサーバーのキャラクタ・セット変換を行わずに、NVARCHAR2文字列を直接作成できます。たとえば、NCHR(32)は空白文字を表します。NCHR(n)は各国語キャラクタ・セットに関連付けられているため、結果値の移植性はその各国語キャラクタ・セットで実行されるアプリケーションに限定されます。この移植性が重要な場合は、UNISTRファンクションを使用して移植性の制限を解除します。
UNISTR('string')SQLファンクションを使用します。UNISTR('string')ファンクションは、文字列を各国語キャラクタ・セットに変換します。移植性を確保してデータを保持するには、ASCII文字とUnicodeエンコーディングのみを¥xxxx形式で含めます。xxxxは、UTF-16エンコーディング形式で文字コード値を表す16進値です。たとえば、UNISTR('G¥0061ry')は'Gary'を表します。ASCII文字は、データベース・キャラクタ・セットに変換されてから、各国語キャラクタ・セットに変換されます。Unicodeエンコーディングは、各国語キャラクタ・セットに直接変換されます。
最後の2つの方法を使用すると、すべてのUnicode文字列リテラルをエンコードできます。
|
参照:
|
SQLまたはPL/SQL文の一部として、接頭辞Nあり、またはなしの任意のリテラルのテキストが文の残りに同じ文字で囲まれます。クライアント側では、文はクライアント・キャラクタ・セットで、NLS_LANGパラメータによって定義されたキャラクタ・セットで決定されます。サーバー側では、文はデータベース・キャラクタ・セットです。
SQLまたはPL/SQL文がクライアントからデータベースに送信されると、キャラクタ・セットはそれに応じて変換されます。データベース・キャラクタ・セットにテキスト・リテラルで使用されるすべての文字が含まれない場合、データはこの変換で消失します。これはCHARテキスト・リテラルよりもNCHAR文字列リテラルに大きく影響します。これはN'リテラルがデータベース・キャラクタ・セットから独立するように設計されており、クライアント・キャラクタ・セットで許可されるすべてのデータを含むことができるためです。
互換性のないデータベース・キャラクタ・セットへの変換時のデータ消失を回避するために、クライアント環境変数ORA_NCHAR_LITERAL_REPLACEをTRUEに設定してNCHARリテラル置換を使用できます。これによりクライアント側のNリテラルを、文の実行時にUnicodeにデコードされる内部書式で置換できるようになります。デフォルトでは、下位互換性を維持するためにNCHARリテラル置換は無効です。
|
参照:
|
動作をグローバリゼーション・サポートの規則に依存しているすべてのSQLファンクションで、NLSパラメータを指定できます。これらのファンクションは、TO_CHAR、TO_DATE、TO_NUMBER、NLS_UPPER、NLS_LOWER、NLS_INITCAPおよびNLSSORTです。
これらのファンクションのNLSパラメータを指定すると、セッションのNLSパラメータに依存せずにファンクションを評価できます。この機能は、数字や日付が文字列リテラルとして含まれているSQL文で重要となる場合があります。
たとえば、日付に対する言語がAMERICANであることを評価するには、次の2つの問合せがあります。
ALTER SESSIONを使用してNLS_DATE_LANGUAGEパラメータおよびNLS_CALENDARパラメータを設定します。
ALTER SESSION SET NLS_DATE_LANGUAGE=American; SELECT last_name FROM employees WHERE hire_date > '01-JAN-1999';
WHERE句、TO_DATEファンクションでNLS_DATE_LANGUAGEパラメータを指定します。
SELECT last_name FROM employees WHERE hire_date > TO_DATE('01-JAN-1999','DD-MON-YYYY', 'NLS_DATE_LANGUAGE = AMERICAN');
このようにセッション言語に依存しないSQL文を必要に応じて定義できます。これらの文は、文字列リテラルをビュー内のSQL文、CHECK制約、またはトリガーで表示するときに必要となります。
ロケール依存のSQLファンクションでオプションのNLSパラメータを明示的に指定する必要があるのは、セッションのNLSパラメータ値に依存しないことが必要となるSQL文のみです。通常、SQLファンクションでNLSパラメータにセッションのデフォルト値を使用すると、パフォーマンスが改善されます。
すべての文字ファンクションは、シングルバイトとマルチバイトの両方の文字をサポートします。単位を明示的に示した場合を除いて、文字ファンクションはバイト単位ではなく文字単位で動作します。
SQLファンクションでビューやトリガーが評価される場合、NLSファンクションパラメータには現行のセッションからのデフォルト値が使用されます。SQLファンクションでCHECK制約が評価される場合は、データベースの作成時にNLSパラメータに指定されたデフォルト値が使用されます。
NLSパラメータはSQLファンクションでパラメータ = 値のように指定します。次に例を示します。
'NLS_DATE_LANGUAGE = AMERICAN'
SQLファンクションで次のNLSパラメータを指定できます。
NLS_DATE_LANGUAGE NLS_NUMERIC_CHARACTERS NLS_CURRENCY NLS_ISO_CURRENCY NLS_DUAL_CURRENCY NLS_CALENDAR NLS_SORT
一部の言語では、1つの小文字が複数の大文字に対応したり、1つの大文字が複数の小文字に対応します。したがって、NLS_UPPER、NLS_LOWERおよびNLS_INITCAPファンクションの出力の長さは入力の長さと異なることがあります。次の表で、特定のSQLファンクションに対し、どのNLSパラメータが有効であるかを示します。
例6-1は、SQLファンクションでNLSパラメータを使用する方法を示すSELECT文を示しています。これらのSELECT文を実行した後(SQLワークショップでグループとして実行可能)、「Script Output」ペインにおける各文の出力を確認します(多くの文の出力は非常に長いです)。
SELECT TO_DATE('1-JAN-99', 'DD-MON-YY', 'NLS_DATE_LANGUAGE = American') "01/01/99" FROM DUAL; SELECT TO_CHAR(hire_date, 'DD/MON/YYYY', 'NLS_DATE_LANGUAGE = French') "Hire Date" FROM employees; SELECT TO_CHAR(SYSDATE, 'DD/MON/YYYY', 'NLS_DATE_LANGUAGE = ''Traditional Chinese'' ') "System Date" FROM DUAL; SELECT TO_CHAR(13000, '99G999D99', 'NLS_NUMERIC_CHARACTERS = '',.''') "13K" FROM DUAL; SELECT TO_CHAR(salary, '99G999D99L', 'NLS_NUMERIC_CHARACTERS = '',.'' NLS_CURRENCY = ''EUR''') salary FROM employees; SELECT TO_CHAR(salary, '99G999D99C', 'NLS_NUMERIC_CHARACTERS = ''.,'' NLS_ISO_CURRENCY = Japan') salary FROM employees; SELECT NLS_UPPER(last_name, 'NLS_SORT = Swiss') "Last Name" FROM employees; SELECT last_name FROM employees ORDER BY NLSSORT(last_name, 'NLS_SORT = German');
|
参照:
|
NLSパラメータNLS_LANGUAGE、NLS_TERRITORYおよびNLS_DATE_FORMATはNLSSORT以外のSQLファンクションでは使用できません。
NLS_LANGUAGEは、NLS_DATE_LANGUAGEのセッションの値を妨げます。たとえばTO_CHARファンクションでNLS_LANGUAGEを指定すると、そのセッションのNLS_DATE_LANGUAGEパラメータ値と異なる場合は、Oracle Databaseから無視されます。
NLS_DATE_FORMATパラメータおよびNLS_TERRITORY_FORMATパラメータは必要な書式モデルを妨げる可能性があるので、パラメータとしては受け入れられません。TO_CHARファンクションまたはTO_DATEファンクションでNLSパラメータを使用する場合は、日付書式を指定する必要があります。したがってNLS_DATE_FORMATパラメータおよびNLS_TERRITORY_FORMATパラメータはこれらの変換ファンクションには有効ではありません。TO_CHARファンクションまたはTO_DATEファンクションでNLS_DATE_FORMATまたはNLS_TERRITORY_FORMATを指定すると、Oracle Databaseはエラーを返します。
|
参照:
|
|
 Copyright © 2005, 2008, Oracle Corporation. All Rights Reserved. |
|