11g リリース1(11.1)
E05750-03
 目次 |
 索引 |
| Oracle Database SQL言語リファレンス 11g リリース1(11.1) E05750-03 |
|

この章では、Oracle SQLの基本要素に関する参照情報を説明します。これらの要素は、SQL文の最も単純な構成ブロックです。したがって、第10章〜第19章で説明されている文を使用する前に、この章で説明する概念を理解しておく必要があります。
この章では、次の内容を説明します。
Oracle Databaseが処理する値は、それぞれデータ型を持ちます。値のデータ型は、固定されたプロパティの集合をその値に対応付けます。このプロパティに応じて、Oracleは、あるデータ型の値を別のデータ型の値と区別して扱います。たとえば、NUMBERデータ型の値は加算できますが、RAWデータ型の値は加算できません。
表またはクラスタを作成する場合、各列にデータ型を指定する必要があります。プロシージャまたはストアド・ファンクションを作成する場合は、その各引数にデータ型を指定する必要があります。データ型によって、各列が含むことができる値のドメイン、または各引数が持つことができる値のドメインが決まります。たとえば、DATE列は、2月29日(うるう年を除く)、2または'SHOE'という値を格納できません。列に入る値は、その列のデータ型を受け継ぎます。たとえば、DATE列に'01-JAN-98'を挿入すると、Oracleはそれが有効な日付に変換されることを確認してから、文字列'01-JAN-98'をDATE値として扱います。
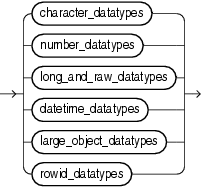
Oracle Databaseには、多くの組込みデータ型、およびデータ型として使用できるいくつかのユーザー定義型のカテゴリがあります。Oracleのデータ型の構文については、次の構文図で示します。この項は、次の4つの項にわかれています。
データ型はスカラーまたは非スカラーです。スカラー型は、アトム値を持ちますが、非スカラー型(コレクションともいう)は一連の値を持ちます。ラージ・オブジェクト(LOB)は、スカラー型の特別な形で、バイナリまたは文字データのラージ・スカラー値を表しています。LOBはサイズが大きいため、他のスカラー型には影響しないいくつかの制限事項があります。これらの制限事項については、関連するSQL構文を参照してください。
Oracleプリコンパイラによって、埋込みSQLプログラムで他のデータ型が区別されます。このようなデータ型は、外部データ型と呼ばれ、ホスト変数に対応付けられています。組込みデータ型およびユーザー定義型を外部データ型と混同しないでください。Oracleによる外部データ型と組込み型またはユーザー定義データ型の間の変換など、外部データ型の詳細は、『Pro*COBOLプログラマーズ・ガイド』および『Pro*C/C++プログラマーズ・ガイド』を参照してください。
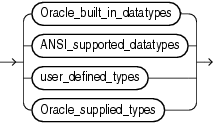
Oracle組込みデータ型の詳細は、「Oracleの組込みデータ型」を参照してください。

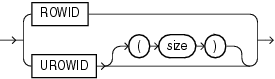
次に、ANSIがサポートしているデータ型について示します。また、「ANSI、DB2、SQL/DSのデータ型」に、ANSIがサポートしているデータ型をOracle組込みデータ型にマップする方法を示します。
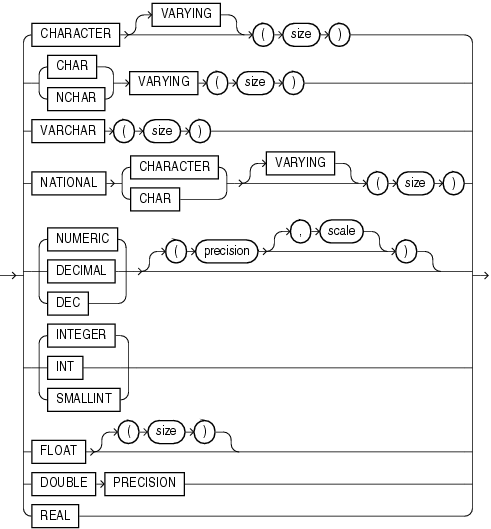
expression_filter_typeの詳細は、「Expression Filter型」を参照してください。次に、Oracleが提供するその他の型を示します。

任意型の詳細は、「任意型」を参照してください。

XML型の詳細は、「XML型」を参照してください。
空間型の詳細は、「空間型」を参照してください。
メディア型の詳細は、「メディア型」を参照してください。
次の表にOracle組込みデータ型の概要を示します。構文要素については、前の項の構文を参照してください。データ型のコードは、Oracle Databaseが内部的に使用します。DUMPファンクションによって、列またはオブジェクト属性のデータ型コードが戻されます。
次の項では、Oracle Databaseに格納されるOracleデータ型について説明します。これらのデータ型をリテラルとして指定する方法については、「リテラル」を参照してください。
文字データ型を使用すると、単語や自由形式のテキストなど、データベース・キャラクタ・セットまたは各国語キャラクタ・セットの文字(英数字)を格納できます。文字データ型は、他のデータ型より制限が少ないため、プロパティも少なくなります。たとえば、文字データ型の列は、すべての英数字の値を格納できますが、NUMBER型の列が格納できるのは数値のみです。
文字データは、7ビットASCIIやEBCDICなど、データベース作成時に指定されたキャラクタ・セットの1つに対応しているバイト値で文字列に格納されます。Oracle Databaseは、シングルバイトのキャラクタ・セットとマルチバイトのキャラクタ・セットの両方をサポートします。
次のデータ型が、文字データに対して使用されます。
文字データ型をリテラルとして指定する方法については、「テキスト・リテラル」を参照してください。
CHARデータ型は、固定長の文字列を指定します。Oracleでは、CHAR列に格納される値がすべてsizeで指定した長さを持つように調整されます。列の長さより短い値を挿入すると、列の長さにあわせるため、その値の後に空白が埋め込まれます。列に対して長すぎる値を挿入しようとすると、Oracleはエラーを戻します。
CHAR列のデフォルトの長さは1バイトで、この許容最大値は2000バイトです。CHAR(10)列には、1バイトの文字列を挿入できますが、この文字列は10バイトまで空白埋めされてから格納されます。
CHAR列を持つ表を作成する場合、デフォルトでは列の長さはバイト単位になります。BYTE修飾子は、デフォルトと同じです。CHAR修飾子(たとえば、CHAR(10 CHAR))を使用すると、列の長さは文字単位になります。技術的ないい方をすると、文字は、データベース・キャラクタ・セットのコード・ポイントです。サイズは、データベース・キャラクタ・セットによって異なりますが、1バイトから4バイトです。BYTEおよびCHAR修飾子は、NLS_LENGTH_SEMANTICSパラメータ(デフォルトはバイト・セマンティクス)で指定したセマンティクスを上書きします。パフォーマンス上の理由から、長さセマンティクスの設定にはNLS_LENGTH_SEMANTICSパラメータを使用し、このパラメータを上書きする必要があるときにのみBYTEおよびCHAR修飾子を使用することをお薦めします。
異なるキャラクタ・セットを持つデータベース間で適切にデータを変換するには、CHARデータが正しい書式の文字列で構成されていることを確認してください。
|
参照:
キャラクタ・セット・サポートの詳細は、『Oracle Databaseグローバリゼーション・サポート・ガイド』を参照してください。比較セマンティクスについては、「データ型の比較規則」を参照してください。 |
NCHARデータ型はUnicodeのみのデータ型です。NCHAR列を持つ表を作成する場合、列の長さを文字単位で指定します。使用する各国語キャラクタ・セットは、データベースを作成するときに指定します。
列の最大長は、各国語キャラクタ・セットの定義によって決まります。NCHAR文字データ型の幅指定は、文字数を示します。許容最大列サイズは2000バイトです。
列の長さより短い値を挿入すると、列の長さにあわせるため、その値の後に空白が埋め込まれます。CHAR値をNCHAR列に挿入することや、NCHAR値をCHAR列に挿入することはできません。
次の例では、表pm.product_descriptionsのtranslated_description列と各国語キャラクタ・セットの文字列を比較します。
SELECT translated_description FROM product_descriptions WHERE translated_name = N'LCD Monitor 11/PM';
NVARCHAR2データ型はUnicodeのみのデータ型です。NVARCHAR2列を持つ表を作成する場合、保持できる最大の文字数を指定します。Oracleでは、列の最大長を超えないかぎり、各値を指定されたとおりに正確に列に格納します。
列の最大長は、各国語キャラクタ・セットの定義によって決まります。NVARCHAR2文字データ型の幅指定は、文字数を示します。許容最大列サイズは4000バイトです。
VARCHAR2データ型は、可変長の文字列を指定します。VARCHAR2列を作成する場合、保持できるデータの最大バイト数または最大文字数を指定します。Oracleでは、列の最大長を超えないかぎり、各値を指定されたとおりに正確に列に格納します。最大長を超える値を挿入しようとすると、Oracleはエラーを戻します。
VARCHAR2列には最大長を指定する必要があります。保存される文字列の実際の長さは0(ゼロ)にできますが、最大長は1バイト以上にする必要があります。CHAR修飾子(たとえば、VARCHAR2(10 CHAR))を使用すると、バイトではなく、文字で最大長を指定できます。技術的ないい方をすると、文字は、データベース・キャラクタ・セットのコード・ポイントです。BYTE修飾子(たとえば、VARCHAR2(10 BYTE))を使用すると、明示的にバイトで最大長を指定できます。列定義または属性定義に明示的な修飾子が含まれていないときにその列または属性を持つデータベース・オブジェクトを作成した場合、長さセマンティクスは、そのオブジェクトを作成するセッションのNLS_LENGTH_SEMANTICSパラメータの値によって決定されます。文字での最大長と関係なく、VARCHAR2データの長さは4000バイト以下になります。Oracleは、非空白埋め比較セマンティクスを使用してVARCHAR2値を比較します。
異なるキャラクタ・セットを持つデータベース間で適切にデータを変換するには、VARCHAR2データが正しい書式の文字列で構成されていることを確認してください。キャラクタ・セット・サポートの詳細は、『Oracle Databaseグローバリゼーション・サポート・ガイド』を参照してください。
VARCHARデータ型は、使用しないでください。かわりにVARCHAR2データ型を使用してください。現在、VARCHARデータ型はVARCHAR2データ型と同じ意味で使用されていますが、VARCHARデータ型は、異なる比較セマンティクスで比較される別の可変長文字列のデータ型に変更される予定です。
Oracle Databaseの数値データ型は、正と負の固定小数点数と浮動小数点数、0(ゼロ)、無限大、および操作の未定義の結果である値(非数値、つまりNAN)を格納します。数値データ型をリテラルとして指定する方法については、「数値リテラル」を参照してください。
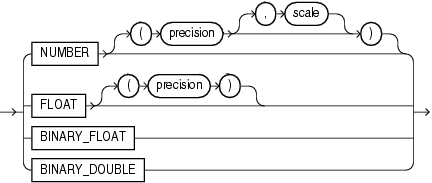
NUMBERデータ型は、0(ゼロ)と、絶対値が1.0×10-130以上1.0×10126未満の範囲にある正と負の固定小数点数を格納します。1.0×10126以上の絶対値を持つ算術式を指定した場合、Oracleはエラーを戻します。NUMBERの各値は1〜22バイトである必要があります。
次の書式で固定小数点数を指定できます。
NUMBER(p,s)
それぞれの意味は、次のとおりです。
pは精度(precision)、つまり最大有効桁数(10進)です。最上位有効桁は最も左側のゼロ以外の桁で、最下位有効桁は最も右側の桁です。Oracleは、100進数で20桁までの精度で数値の移植性を保証します。これは小数点の位置によって39桁(10進)または40桁(10進)になります。
sは位取り(scale)、つまり小数点から最下位有効桁までの桁数です。位取りの有効範囲は-84〜127です。
e表記を使用する場合、位取りは通常、精度よりも大きくなります。位取りが精度より大きい場合、精度は小数点の右側にある最大有効桁数を示します。たとえば、NUMBER(4,5)として定義された列は、小数点の後の最初の桁が0(ゼロ)である必要があり、小数点以下5桁を超える値はすべて丸められます。
入力に対する特別な整合性チェックとして、固定小数点数列の位取りと精度を指定することをお薦めします。位取りと精度を指定しても、すべての値が固定長に強制されるわけではありません。値が精度の有効範囲を超えると、Oracleはエラーを戻します。値が位取りの有効範囲を超えると、Oracleはその値を丸めます。
次の書式で整数を指定できます。
NUMBER(p)
これは、精度がpで、位取りが0の固定小数点数です(NUMBER(p,0)と同じです)。
次の書式で浮動小数点を指定できます。
NUMBER
精度および位取りを指定しない場合、最大の範囲および精度をOracleの数値に指定したことになります。
表2-2に、異なる精度および位取りを使用したOracleのデータの格納方法を示します。
FLOATデータ型は、NUMBERのサブタイプです。このデータ型は、精度とともに指定するか、または精度なしで指定でき、その定義はNUMBERの場合と同じであり、1〜126の範囲で指定します。位取りは指定できませんが、データから解釈されます。FLOATの各値は1〜22バイトである必要があります。
2進精度から10進精度に変換するには、nに0.30103を乗算します。10進精度から2進精度に変換するには、10進精度に3.32193を乗算します。2進精度の126桁は、10進精度の38桁とほぼ等しくなります。
NUMBERとFLOATの違いは、例を使用して説明します。次の例では、同じ値がNUMBER列とFLOAT列に挿入されます。
CREATE TABLE test (col1 NUMBER(5,2), col2 FLOAT(5)); INSERT INTO test VALUES (1.23, 1.23); INSERT INTO test VALUES (7.89, 7.89); INSERT INTO test VALUES (12.79, 12.79); INSERT INTO test VALUES (123.45, 123.45); SELECT * FROM test; COL1 COL2 ---------- ---------- 1.23 1.2 7.89 7.9 12.79 13 123.45 120
この例では、戻されるFLOATの値は、5桁(2進)を超えることはできません。5桁(2進)で表すことができる10進数の最大値は31です。最後の行には、31を超える10進値が含まれています。このため、FLOATの値は、その有効桁数が5桁(2進)を超えないように切り捨てられる必要があります。したがって、123.45は、2桁の有効桁数(10進)のみを持ち、4桁(2進)しか必要のない120に丸められます。
ANSIのFLOATデータを変換する際、Oracle Databaseは、OracleのFLOATデータ型を内部的に使用します。OracleのFLOATは使用可能ですが、BINARY_FLOATおよびBINARY_DOUBLEデータ型の方がより堅牢であるため、これらのデータ型を使用することをお薦めします。詳細は、「浮動小数点数」を参照してください。
浮動小数点数は、最初の桁から最後の桁までの任意の位置に小数点を置くことも、小数点を省略することもできます。指数は、数字の後に増加する桁数を表すときに、オプションで使用されます(たとえば、1.777 e-20)。小数点以下の桁数に制限はないため、浮動小数点数に対して位取りは指定できません。
2進浮動小数点数とNUMBERでは、Oracle Databaseによる内部的な値の格納方法が異なります。NUMBERの場合、値は10進精度を使用して格納されます。NUMBERでサポートされる範囲内および精度内のすべてのリテラルは、NUMBERとして正確に格納されます。これは、リテラルが10進精度(0〜9)を使用して表されるためです。2進浮動小数点数は、2進精度(0および1)を使用して格納されます。このような格納スキームでは、10進精度を使用したすべての値を正確に表すことができません。値を10進精度から2進精度に変換するときに発生するエラーは、その値を2進精度から10進精度に戻すときには発生しない場合が多くあります。リテラル0.1はその一例です。
Oracle Databaseでは、浮動小数点数専用の2種類の数値データ型を提供しています。
32ビットの単精度浮動小数点数データ型です。このデータ型の各値には、長さを示すバイトを含め、5バイトが必要です。
64ビットの倍精度浮動小数点数データ型です。このデータ型の各値には、長さを示すバイトを含め、9バイトが必要です。
NUMBER列では、浮動小数点数は10進精度を持ちます。BINARY_FLOAT列またはBINARY_DOUBLE列では、浮動小数点数は2進精度を持ちます。2進浮動小数点数では、特殊な値である無限大およびNaN(非数値)がサポートされます。
表2-3に示す制限内で、浮動小数点数を指定できます。浮動小数点数を指定する書式については、「数値リテラル」を参照してください。
| 値 | BINARY_FLOAT | BINARY_DOUBLE |
|---|---|---|
|
正の最大有限値 |
3.40282E+38F |
1.79769313486231E+308 |
|
正の最小有限値 |
1.17549E-38F |
2.22507485850720E-308 |
Oracleの浮動小数点データ型の実装は、2進浮動小数点算術の規格である電気電子学会(IEEE)754-1985(IEEE754)規格に準拠しています。浮動小数点データ型は次の点でIEEE754に準拠しています。
SQRTは平方根を実装します。「SQRT」を参照してください。
REMAINDERは余りを実装します。「REMAINDER」を参照してください。
NaNと比較する場合は除きます。Oracleは、NaNが他のすべての値より大きいとみなし、NaNとNaNは等しいと評価します。「浮動小数点条件」を参照してください。
INF、-INFおよびNaNがサポートされています。「浮動小数点条件」を参照してください。
BINARY_FLOATおよびBINARY_DOUBLEの値を整数値のBINARY_FLOATおよびBINARY_DOUBLEに丸める方法として、SQLファンクションROUND、TRUNC、CEILおよびFLOORが提供されています。
BINARY_FLOATおよびBINARY_DOUBLEを10進値に、10進値をBINARY_FLOATおよびBINARY_DOUBLEに丸める方法として、SQLファンクションTO_CHAR、TO_NUMBER、TO_NCHAR、TO_BINARY_FLOAT、TO_BINARY_DOUBLEおよびCASTが提供されています。
浮動小数点データ型は次の点ではIEEE754に準拠していません。
NaNとの比較はサポートされていません。
NaN値は、BINARY_FLOAT_NANまたはBINARY_DOUBLE_NANのいずれかに強制変換されます。
数値データ型をサポートする操作で、操作の引数が様々なデータ型を持つ場合、Oracleが使用するデータ型は、数値の優先順位によって判断されます。数値の優先順位が最も高いデータ型はBINARY_DOUBLEであり、その次がBINARY_FLOAT、最後がNUMBERとなります。したがって、複数の数値に対する操作では、次のようになります。
BINARY_DOUBLEの場合、Oracleは操作の実行前に、すべてのオペランドを暗黙的にBINARY_DOUBLEに変換しようとします。
BINARY_DOUBLEはないが、いずれかがBINARY_FLOATの場合、Oracleは操作の実行前に、すべてのオペランドを暗黙的にBINARY_FLOATに変換しようとします。
NUMBERに変換しようとします。
暗黙的な変換が必要な場合に変換に失敗すると、操作は実行されません。暗黙的な変換の詳細は、表2-10「暗黙的な型変換のマトリックス」を参照してください。
他のデータ型のコンテキストでは、数値データ型の優先順位は、日時データ型と期間データ型よりも低く、文字データ型とその他のすべてのデータ型よりも高くなります。
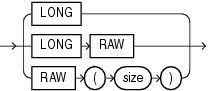
LONG列を持つ表は作成しないでください。かわりに、LOB列(CLOB、NCLOBまたはBLOB)を使用してください。LONG列は、下位互換性のためにサポートされています。
LONG列には、2GB(231)から1を引いたバイト数までの可変長の文字列を格納できます。LONG列には、多くの点でVARCHAR2列と同じ特長があります。LONG列を使用すると、長いテキスト文字列を格納できます。LONG値の長さは、ご使用のコンピュータで利用できるメモリーによって制限される場合もあります。LONGリテラルは、「テキスト・リテラル」の説明のような形式になります。
既存のLONG列もLOB列に変換することをお薦めします。LOB列は、LONG列ほど制限は多くありません。LOB機能はリリースごとに拡張されていますが、LONG機能は最近のリリースでは変更されていません。LONG列からLOB列への変換については、「ALTER TABLE」の「modify_col_properties」および「TO_LOB」を参照してください。
SQL文の中の次の場所でLONG列を参照できます。
LONG値を使用する場合には、次の制限があります。
LONG列を含めることはできません。
LONG属性を持つオブジェクトは作成できません。
LONG列は、WHERE句または整合性制約では指定できません(NULLおよびNOT NULL制約は除く)。
LONG列に索引を付けることはできません。
LONGデータは正規表現では指定できません。
LONG値を戻すことはできません。
LONGデータ型を使用して、PL/SQLプログラム・ユニットの変数または引数を宣言できます。ただし、そのプログラムは、SQLからコールできません。
LONG列、更新された表、ロックされた表は、同一データベース上にある必要があります。
LONG列およびLONG RAW列は、分散型のSQL文で使用できません。また、レプリケートできません。
LONGとLOBの両方の列を持つ表では、1つのSQL文で両方に4000バイトより大きいデータをバインドすることはできません。ただし、いずれか片方にバインドすることは可能です。
また、LONG列はSQL文の次のような部分では使用できません。
GROUP BY句、ORDER BY句、CONNECT BY句またはSELECT文にあるDISTINCT演算子
SELECT文の一意演算子
CREATE CLUSTER文の列リスト
CREATE MATERIALIZED VIEW文のCLUSTER句
GROUP BY句を含む問合せのSELECT構文のリスト
UNION、INTERSECTまたはMINUS集合演算子によって結合されている副問合せまたは問合せのSELECT構文のリスト
CREATE TABLE ...AS SELECT文のSELECT構文のリスト
ALTER TABLE ...MOVE文
INSERT文の副問合せのSELECT構文のリスト
トリガーでは、LONGデータ型は次のように使用されます。
LONG列に挿入できます。
LONG列のデータをCHARやVARCHAR2などの制約があるデータ型に変換できる場合は、トリガー内のSQL文でLONG列を参照できます。
LONGデータ型を使用して宣言できません。
:NEWと:OLDはLONG列で使用できません。
Oracle Call Interfaceを使用して、データベースからLONG値の一部を検索できます。
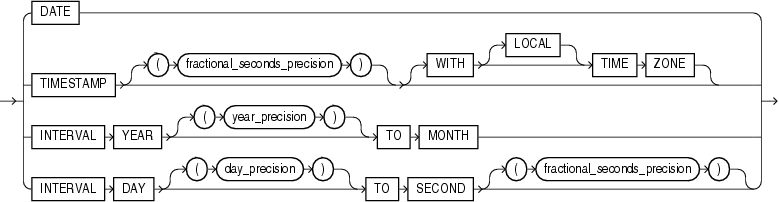
日時データ型には、DATE、TIMESTAMP、TIMESTAMP WITH TIME ZONEおよびTIMESTAMP WITH LOCAL TIME ZONEがあります。日時データ型の値は、「日時」とも呼ばれます。期間データ型には、INTERVAL YEAR TO MONTHおよびINTERVAL DAY TO SECONDがあります。期間データ型の値は、「期間」とも呼ばれます。日時値と期間値をリテラルとして表す方法の詳細は、「日時リテラル」および「期間リテラル」を参照してください。
日時および期間はいずれもフィールドで構成されます。これらのフィールドの値は、データ型の値によって決まります。表2-4に、日時フィールド、および日時と期間の有効な値を示します。
日時データのDML操作で正しい結果を得るには、組込みSQLファンクションDBTIMEZONEおよびSESSIONTIMEZONEで問い合せることによって、データベースおよびセッションのタイムゾーンを確認します。タイムゾーンを手動で設定していない場合、Oracle Databaseは、オペレーティング・システムのタイムゾーンをデフォルトで使用します。オペレーティング・システムのタイムゾーンがOracleで有効でない場合は、Oracleは、協定世界時(UTC)(以前のグリニッジ標準時)をデフォルトの値として使用します。
DATEデータ型は、日付および時刻の情報を格納するために使用します。日付および時刻の情報は、文字データ型および数値データ型で表現できますが、DATEデータ型には特別に対応付けられているプロパティがあります。各DATE値には、世紀、年、月、日、時、分および秒の情報が格納されます。
DATE値をリテラルに指定するか、文字値や数値をTO_DATEファンクションによって日付値に変換できます。これらの方法でのDATE値の表し方の例は「日時リテラル」を参照してください。
ユリウス日は、紀元前4712年1月1日から経過した日数です。ユリウス日によって共通の基準で日付を算定できます。日付ファンクションTO_DATEとTO_CHARで日付書式モデル「J」を使用して、OracleのDATE値とユリウス日の間で変換を行うことができます。
デフォルトの日付値は次のように決まります。
これらのデフォルト値は、次の例(5月に発行)のように、日付が指定されていない場合に日付値を要求する問合せで使用されます。
SELECT TO_DATE('2005', 'YYYY') FROM DUAL; TO_DATE(' --------- 01-MAY-05
次の文では、1997年1月1日をユリウス日で戻します。
SELECT TO_CHAR(TO_DATE('01-01-1997', 'MM-DD-YYYY'),'J') FROM DUAL; TO_CHAR -------- 2450450
TIMESTAMPデータ型は、DATEデータ型の拡張機能です。DATEデータ型の年、月および日に加えて、時、分および秒の値を格納します。このデータ型は、正確な時刻の値の格納に有効です。TIMESTAMPデータ型は、次のように指定します。
TIMESTAMP [(fractional_seconds_precision)]
fractional_seconds_precisionには、オプションで、Oracleが格納する桁数を、SECOND日時フィールドの小数部まで指定します。このデータ型の列を作成する場合、0〜9の値を指定できます。デフォルト値は6です。
TIMESTAMP WITH TIME ZONEは、タイムゾーン地域名またはタイムゾーン・オフセットを値に含むTIMESTAMPの変形です。タイムゾーン・オフセットは、ローカルの時刻とUTC(時および分)との差異です。このデータ型は複数の地域にまたがる日時情報の収集および評価に有効です。
TIMESTAMP WITH TIME ZONEデータ型は、次のように指定します。
TIMESTAMP [(fractional_seconds_precision)] WITH TIME ZONE
fractional_seconds_precisionには、オプションで、Oracleが格納する桁数を、SECOND日時フィールドの小数部まで指定します。このデータ型の列を作成する場合、0〜9の値を指定できます。デフォルト値は6です。
|
参照:
|
TIMESTAMP WITH LOCAL TIME ZONEは、タイムゾーン・オフセットを値に含むTIMESTAMPのもう1つの変形です。これは、TIMESTAMP WITH TIME ZONEとは異なり、データベースに格納されるデータはデータベース・タイムゾーンに対して正規化され、タイムゾーン・オフセットは列データの一部として格納されません。ユーザーがデータを検索すると、Oracleはユーザーのローカル・セッション・タイムゾーンのデータを戻します。タイムゾーン・オフセットは、ローカルの時刻とUTC(時および分)との差異です。このデータ型は、2層アプリケーションでクライアント・システムのタイムゾーンの日時情報を表示する場合に有効です。
TIMESTAMP WITH LOCAL TIME ZONEデータ型は、次のように指定します。
TIMESTAMP [(fractional_seconds_precision)] WITH LOCAL TIME ZONE
fractional_seconds_precisionには、オプションで、Oracleが格納する桁数を、SECOND日時フィールドの小数部まで指定します。このデータ型の列を作成する場合、0〜9の値を指定できます。デフォルト値は6です。
|
参照:
|
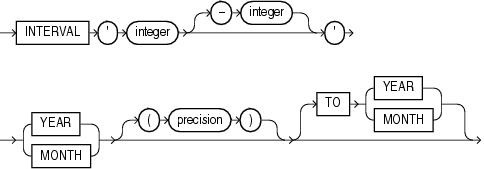
INTERVAL YEAR TO MONTHは、YEARおよびMONTH日時フィールドを使用して期間を格納します。このデータ型は、年および月の値のみが重要な場合に、2つの日時の値の正確な違いを表す場合に有効です。
INTERVAL YEAR TO MONTHは、次のように指定します。
INTERVAL YEAR [(year_precision)] TO MONTH
year_precisionは、YEAR日時フィールドの桁数です。year_precisionのデフォルト値は2です。
期間値をリテラルとして指定すると、高い柔軟性が得られます。期間値をリテラルとして指定する方法の詳細は、「期間リテラル」を参照してください。期間の使用例は、「日時および期間の例」を参照してください。
INTERVAL DAY TO SECONDは、日付、時、分および秒で期間を格納します。このデータ型は、2つの日時の値の正確な違いを表す場合に有効です。
このデータ型は、次のように指定します。
INTERVAL DAY [(day_precision)] TO SECOND [(fractional_seconds_precision)]
それぞれの意味は、次のとおりです。
day_precisionは、DAY日時フィールドの桁数です。有効範囲は0〜9です。デフォルトは2です。
fractional_seconds_precisionは、SECOND日時フィールドの小数部の桁数です。有効範囲は0〜9です。デフォルトは6です。
期間値をリテラルとして指定すると、高い柔軟性が得られます。期間値をリテラルとして指定する方法の詳細は、「期間リテラル」を参照してください。期間の使用例は、「日時および期間の例」を参照してください。
日付(DATE)、タイムスタンプ(TIMESTAMP、TIMESTAMP WITH TIME ZONEおよびTIMESTAMP WITH LOCAL TIME ZONE)および期間(INTERVAL DAY TO SECONDおよびINTERVAL YEAR TO MONTH)データに対して、様々な演算処理を実行できます。Oracleは、次の規則に基づいて結果を計算します。
NUMBER定数を使用できますが、期間値では使用できません。Oracleは、タイムスタンプ値を内部的に日付値に変換し、日時の演算で使用されるNUMBER定数と期間式を日数として解析します。たとえば、SYSDATE+ 1は明日です。SYSDATE -7は1週間前です。SYSDATE + (10/1440)は10分後です。SYSDATEからemployeesサンプル表のhire_date列を引くと、各従業員が雇用されてから経過した日数が戻ります。日付値またはタイムスタンプ値の乗算や除算はできません。
BINARY_FLOATオペランドおよびBINARY_DOUBLEオペランドを暗黙的にNUMBERに変換します。
DATE値には時刻コンポーネントが含まれるため、多くの場合、日付操作の結果には小数部が含まれます。この小数部は、日を単位として表されています。たとえば、1.5日は36時間です。小数部は、DATEデータの一般的な操作を行うOracle組込みファンクションによっても戻されます。たとえば、MONTHS_BETWEENファンクションは、2つの日付の間の月数を戻します。結果の小数部は、月(1か月は31日)を単位として表されます。
DATE値または数値であり、タイムゾーンおよび小数部コンポーネントのいずれも含まない場合、次のようになります。
DATEデータ型専用に設計された組込みファンクションにタイムスタンプ値、期間値または数値を渡すと、OracleはDATE値以外の値を暗黙的にDATE値に変換します。DATEへの暗黙的な変換を実行するファンクションの詳細は、「日時ファンクション」を参照してください。
SELECT TO_DATE('31-AUG-2004','DD-MON-YYYY') + TO_YMINTERVAL('0-1') FROM DUAL; SELECT TO_DATE('29-FEB-2004','DD-MON-YYYY') + TO_YMINTERVAL('1-0') FROM DUAL;
最初の文は、1か月31日の月に1か月が追加され、9月31日となります。これは有効な日付ではないため、この文は失敗します。2つ目の文は、4年に1度のみ存在する日付に1年を追加する計算は無効であるため、失敗します。ただし、2月29日に4年を追加する計算は有効であるため、次の文は成功します。
SELECT TO_DATE('29-FEB-2004', 'DD-MON-YYYY') + TO_YMINTERVAL('4-0') FROM DUAL; TO_DATE(' --------- 29-FEB-08
TIMESTAMP WITH LOCAL TIME ZONEでは、Oracleは、日時の値をデータベース・タイムゾーンからUTCに変換し、演算を実行した後にデータベース・タイムゾーンに変換しなおします。TIMESTAMP WITH TIME ZONEでは、日時の値は常にUTCであるため、変換は必要ありません。
表2-5に、日時の演算処理のマトリックスを示します。ダッシュはサポートされていない処理を表します。
期間値の式を開始時間に追加できます。order_date列を持つサンプル表oe.ordersについて考えます。次の文は、order_date列の値に30日を加算します。
SELECT order_id, order_date + INTERVAL '30' DAY FROM orders ORDER BY order_id, "Due Date";
Oracle Databaseは、指定したタイムゾーン地域に、夏時間が適用されているかを自動的に判断し、それに応じてローカル時刻の値を戻します。日時の値は、境界を除いたすべての指定した地域において、夏時間が適用されているかをOracleが判断するために有効です。夏時間の開始または終了時に、境界が発生します。たとえば、米国の太平洋地域では、夏時間の開始時、時刻は午前2時から午前3時に変更されます。午前2時と午前3時の間の1時間は存在しません。夏時間の終了時、時刻は午前2時から午前1時に変更されます。午前1時と午前2時の間の1時間は繰り返されます。
このような境界を解決するために、OracleはTZRおよびTZD書式要素を使用します。詳細は、表2-17を参照してください。TZRは、日時の入力文字列でタイムゾーン地域を表します。たとえば、Australia/North、UTC、Singaporeなどです。TZDは、夏時間情報を含むタイムゾーン地域の略称書式です。たとえば、米国/太平洋標準時はPST、米国/太平洋夏時間はPDTなどです。TZRおよびTZD書式要素の値を表示するには、V$TIMEZONE_NAMES動的パフォーマンス・ビューのTZNAMEおよびTZABBREV列に問合せを実行してください。
両方のファイルに含まれるすべてのタイムゾーン地域名のリストは、『Oracle Databaseグローバリゼーション・サポート・ガイド』を参照してください。
|
参照:
|
次の例では、日時および期間データ型の指定方法を示します。
CREATE TABLE time_table ( start_time TIMESTAMP, duration_1 INTERVAL DAY (6) TO SECOND (5), duration_2 INTERVAL YEAR TO MONTH);
start_time列は、TIMESTAMP型です。TIMESTAMPの暗黙的な小数部の精度は6です。
duration_1列は、INTERVAL DAY TO SECOND型です。DAYフィールドの最大桁数は6です。また、小数部の最大桁数は5です(その他のすべての日時フィールドの最大桁数は2です)。
duration_2列は、INTERVAL YEAR TO MONTH型です。各フィールド(YEARおよびMONTH)の値の最大桁数は2です。
期間データ型には書式モデルはありません。そのため、これらの表示を調整するには、EXTRACTなどの文字ファンクションを結合させて要素を連結させる必要があります。たとえば、次の例では、hr.employeesとoe.orders表にそれぞれ問合せを行い、期間出力の書式を"yy-mm"から"yy years mm months"に、および"dd-hh"から"dddd days hh hours"に変更します。
SELECT last_name, EXTRACT(YEAR FROM (SYSDATE - hire_date) YEAR TO MONTH ) || ' years ' || EXTRACT(MONTH FROM (SYSDATE - hire_date) YEAR TO MONTH ) || ' months' "Interval" FROM employees ; LAST_NAME Interval ------------------------- -------------------- King 17 years 11 months Kochhar 15 years 8 months De Haan 12 years 4 months Hunold 15 years 4 months Ernst 14 years 0 months Austin 7 years 11 months Pataballa 7 years 3 months Lorentz 6 years 3 months Greenberg 10 years 9 months . . . SELECT order_id, EXTRACT(DAY FROM (SYSDATE - order_date) DAY TO SECOND ) || ' days ' || EXTRACT(HOUR FROM (SYSDATE - order_date) DAY TO SECOND ) || ' hours' "Interval" FROM orders; ORDER_ID Interval ---------- -------------------- 2458 2095 days 18 hours 2397 2000 days 17 hours 2454 2048 days 16 hours 2354 1762 days 16 hours 2358 1950 days 15 hours 2381 1823 days 13 hours 2440 2080 days 12 hours 2357 2680 days 11 hours 2394 1917 days 10 hours 2435 2078 days 10 hours . . .
RAWデータ型とLONG RAWデータ型には、異なるシステム間でデータを移動する際にOracle Databaseによって明示的に変換されないデータが格納されます。これらのデータ型は、バイナリ・データまたはバイト列に使用されます。たとえば、LONG RAWは、図形、音声、文書、またはバイナリ・データの配列の格納に使用できますが、解析方法は用途によって異なります。
LONG RAW列をバイナリLOB(BLOB)へ変換することをお薦めします。LOB列は、LONG列ほど制限は多くありません。詳細は、「TO_LOB」を参照してください。
RAWは、VARCHAR2と同様に可変長データ型ですが、Oracle Net(ユーザー・セッションとインスタンスを接続します)およびOracleのインポート/エクスポート・ユーティリティは、RAWまたはLONG RAWデータの転送時に文字変換を行いません。これに対し、Oracle NetおよびOracleのインポート/エクスポート・ユーティリティは、CHAR、VARCHAR2およびLONGデータをデータベース・キャラクタ・セットからユーザー・セッションのキャラクタ・セットに自動的に変換します。2つのキャラクタ・セットが異なる場合は、ALTER SESSION文のNLS_LANGUAGEパラメータでユーザー・セッションのキャラクタ・セットを設定できます。
RAWデータまたはLONG RAWデータとCHARデータ間で、データを自動的に変換するときに、バイナリ・データは16進数で表されます。1つの16進文字で4ビットのRAWデータを表します。たとえば、ビット列が11001011で表示される1バイトのRAWデータは、CBとして表示または入力されます。
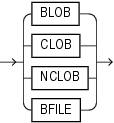
組込みLOBデータ型のBLOB、CLOB、NCLOB(内部ファイルに格納)およびBFILE(外部ファイルに格納)には、構造化されていない大きいデータ(text、image、video、spatial dataなど)を格納できます。BLOB、CLOBおよびNCLOBデータの最大サイズは、232から1を引いたバイト数にLOB記憶域のCHUNKパラメータの値を掛けた値です。データベースの表領域が標準のブロック・サイズで、LOB列を作成したときにLOB記憶域のCHUNKパラメータのデフォルト値を使用した場合には、前述の値は232バイトから1を引いた値にデータベース・ブロック・サイズを掛けた値に等しくなります。BFILEデータの最大サイズは、264バイトから1を引いた値ですが、この最大サイズはオペレーティング・システムによって制限される場合があります。
表を作成するときに、LOB列またはLOBオブジェクト属性に、オプションで表に指定したものとは異なる表領域および記憶特性を指定できます。
LOB列の作成時に行の記憶域を使用可能にしている場合、CLOB、NCLOBおよびBLOBの値は、約4000 バイトを上限としてインラインに格納されます。4000バイトを超えるLOBは、常に外部ファイルに格納されます。詳細は、「ENABLE STORAGE IN ROW」を参照してください。
LOB列には、内部のLOB値(データベース内)または外部のLOB値(データベース外)を参照できるLOBロケータが含まれています。表からLOBを選択すると、実際にはLOBのロケータが戻され、LOB値全体は戻されません。LOBに対するDBMS_LOBパッケージとOracle Call Interface(OCI)の操作は、これらのロケータを介して行われます。
LOBは、LONG型およびLONG RAW型と似ていますが、次の点で異なります。
BLOB、NCLOBおよびCLOBの値は、別々の表領域に格納されます。BFILEデータは、サーバー上の外部ファイルに格納されます。
BFILEデータの最大サイズは、264バイトから1を引いた値ですが、この最大サイズはオペレーティング・システムによって制限される場合があります。
NCLOBの例外を除いて、1つのオブジェクトに1つ以上のLOB属性を定義できます。
NULL、つまり空に設定したり、LOB全体をデータに置き換えられます。BFILEは、NULLに設定したり、別のファイルを指すように設定できます。
INSERT文またはUPDATE文を発行するだけで、インラインLOB列(データベースに格納されているLOB列)またはLOB属性(データベースに格納されているオブジェクト型列の属性)の行にアクセスして移入することができます。
LOB列には、多数のルールおよび制限事項があります。詳細は、『Oracle Database SecureFilesおよびラージ・オブジェクト開発者ガイド』を参照してください。
|
参照:
|
BFILEデータ型を使用すると、Oracle Database外のファイル・システムに格納されているバイナリ・ファイルLOBにアクセスできます。BFILE列または属性には、サーバーのファイル・システム上のバイナリ・ファイルに対するポインタとして機能する、BFILEロケータが格納されます。ロケータには、ディレクトリ名とファイル名が保持されます。
BFILENAMEファンクションを使用すると、実表のデータに影響を与えずにBFILEのファイル名およびパスを変更できます。この組込みSQLファンクションの詳細は、「BFILENAME」を参照してください。
バイナリ・ファイルLOBは、トランザクションには関係なく、リカバリができません。ファイルの統合性と耐久性を提供しているのは基本にあるオペレーティング・システムです。BFILEデータの最大サイズは、264バイトから1を引いた値ですが、この最大サイズはオペレーティング・システムによって制限される場合があります。
データベース管理者は、外部ファイルが存在し、Oracleのプロセスがファイルに対するオペレーティング・システムの読取り権限を持っていることを確認する必要があります。
BFILEデータ型を使用すると、サイズが大きいバイナリ・ファイルの読取り専用のサポートが有効になります。この場合、ファイルを修正またはレプリケートすることはできません。Oracleでは、ファイル・データにアクセスするためのAPIが提供されています。ファイル・データにアクセスするために使用する主なインタフェースは、DBMS_LOBパッケージとOracle Call Interface(OCI)です。
|
参照:
LOBの詳細は、『Oracle Database SecureFilesおよびラージ・オブジェクト開発者ガイド』および『Oracle Call Interfaceプログラマーズ・ガイド』を参照してください。また、「CREATE DIRECTORY」も参照してください。 |
BLOBデータ型は、構造化されていないバイナリ・ラージ・オブジェクトを格納するために使用します。BLOBオブジェクトは、キャラクタ・セットのセマンティクスを持たないビットストリームとして考えることができます。BLOBオブジェクトには、4GBから1を引いたバイト数にLOB記憶域のCHUNKパラメータの値を掛けた値のサイズまでのバイナリ・データを格納できます。データベースの表領域が標準のブロック・サイズで、LOB列を作成したときにLOB記憶域のCHUNKパラメータのデフォルト値を使用した場合には、前述の値は4GBから1を引いた値にデータベース・ブロック・サイズを掛けた値に等しくなります。
BLOBオブジェクトでは、トランザクションが完全にサポートされます。SQL、DBMS_LOBパッケージまたはOracle Call Interface(OCI)を介して行った変更は、すべてトランザクションに反映されます。BLOB値の操作は、コミットおよびロールバックできます。ただし、1つのトランザクションのPL/SQLまたはOCI変数をBLOBロケータに保存し、そのロケータを別のトランザクションまたはセッションで使用することはできません。
CLOBデータ型は、シングルバイトおよびマルチバイト・キャラクタ・データを格納するために使用します。固定幅および可変幅のキャラクタ・セットがサポートされます。両方のキャラクタ・セットでデータベース・キャラクタ・セットを使用します。CLOBオブジェクトには、4GBから1を引いたバイト数にLOB記憶域のCHUNKパラメータの値を掛けた値のサイズまでの文字データを格納できます。データベースの表領域が標準のブロック・サイズで、LOB列を作成したときにLOB記憶域のCHUNKパラメータのデフォルト値を使用した場合には、前述の値は4GBから1を引いた値にデータベース・ブロック・サイズを掛けた値に等しくなります。
CLOBオブジェクトでは、トランザクションが完全にサポートされます。SQL、DBMS_LOBパッケージまたはOracle Call Interface(OCI)を介して行った変更は、すべてトランザクションに反映されます。CLOB値の操作は、コミットおよびロールバックできます。ただし、1つのトランザクションのPL/SQLまたはOCI変数をCLOBロケータに保存し、そのロケータを別のトランザクションまたはセッションで使用することはできません。
NCLOBデータ型は、Unicodeデータを格納するために使用します。固定幅および可変幅のキャラクタ・セットがサポートされます。両方のキャラクタ・セットで各国語キャラクタ・セットを使用します。NCLOBオブジェクトには、4GBから1を引いたバイト数にLOB記憶域のCHUNKパラメータの値を掛けた値のサイズまでの文字テキスト・データを格納できます。データベースの表領域が標準のブロック・サイズで、LOB列を作成したときにLOB記憶域のCHUNKパラメータのデフォルト値を使用した場合には、前述の値は4GBから1を引いた値にデータベース・ブロック・サイズを掛けた値に等しくなります。
NCLOBオブジェクトでは、トランザクションが完全にサポートされます。SQL、DBMS_LOBパッケージまたはOCIを介して行った変更は、すべてトランザクションに反映されます。NCLOB値の操作は、コミットおよびロールバックできます。ただし、1つのトランザクションのPL/SQLまたはOCI変数をNCLOBロケータに保存し、そのロケータを別のトランザクションまたはセッションで使用することはできません。
データベース内の各行にはアドレスがあります。次の項では、Oracle Databaseにおける行のアドレスの2つの書式について説明します。
Oracle Database固有のヒープ構成表内の行は、ROWIDという行のアドレスを持ちます。疑似列ROWIDを問い合せることによって、ROWIDの行のアドレスを調べることができます。この疑似列の値は、各行のアドレスを表す文字列で、文字列のデータ型はROWIDです。また、ROWIDデータ型を持つ実際の列を含む表やクラスタを作成することもできます。Oracle Databaseでは、このような列の値が有効なROWIDであることは保証されません。ROWID疑似列の詳細は、第3章「疑似列」を参照してください。
ROWIDには、次の情報が含まれています。
USER_OBJECTS、DBA_OBJECTSおよびALL_OBJECTSから取り出すことができます。同じセグメントを共有するオブジェクト(たとえば、同じクラスタ内のクラスタ化された表など)には、同じオブジェクト番号が付けられます。
ROWIDは、BASE 64の値で格納され、文字A〜Z、a〜z、0〜9、プラス記号(+)およびスラッシュ(/)を含めることができます。ROWIDは、直接は使用できません。ROWIDの内容を解析するには、提供されているパッケージDBMS_ROWIDを使用します。パッケージ・ファンクションを使用すると、前述の4つのROWIDの要素に関する情報を抽出して利用できます。
物理アドレスまたは永続アドレス以外のアドレス、またはOracle Databaseが生成したものではないアドレスがある行を持つ表もあります。たとえば、索引構成表の行のアドレスは索引リーフに格納され、移動できます。外部キー表のROWID(たとえば、ゲートウェイを介してアクセスされるDB2)は、標準のOracle ROWIDではありません。
Oracleでは、ユニバーサルROWID(UROWID)を使用して索引構成表および外部キー表のアドレスを格納します。索引構成表には、論理UROWIDがあり、外部キー表には外部キーUROWIDがあります。いずれのタイプのUROWIDも、(ヒープ構成表の物理ROWIDのように)ROWID疑似列に格納されます。
Oracleは、表の主キーに基づいて論理ROWIDを作成します。論理ROWIDは、主キーが変更されないかぎり、変更されません。索引構成表のROWID疑似列はUROWIDデータ型です。この疑似列には、ヒープ構成表のROWID疑似列と同様に(SELECT ... ROWID文を使用して)アクセスできます。索引構成表のROWIDを格納する場合、表にUROWID型の列を定義し、この列にROWID疑似列の値を取り込みます。
表とクラスタを作成するSQL文では、ANSIデータ型、およびIBM社の製品SQL/DSとDB2のデータ型も使用できます。Oracleでは、Oracle Databaseのデータ型の名前と異なるANSIまたはIBMのデータ型の名前を認識します。データ型をOracleの同等のデータ型に変換して、Oracleのデータ型を列のデータ型の名前として記録し、次の表に示す変換に基づいて、Oracleのデータ型で列データを格納します。
| ANSI SQLデータ型 | Oracleデータ型 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
次のSQL/DSとDB2のデータ型には、対応するOracleデータ型がありません。次のデータ型を持つ列は定義しないでください。
データ型がTIMEであるデータは、Oracleの日時データとしても表現できます。
| SQL/DSとDB2データ型 | Oracleデータ型 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ユーザー定義のデータ型は、Oracle組込みデータ型とその他のユーザー定義のデータ型を、アプリケーション内のデータの構造と動作をモデル化するオブジェクト型の構築ブロックとして使用します。次の項で、ユーザー定義型の様々なカテゴリを説明します。
|
参照:
|
オブジェクト型とは、実社会エンティティ(たとえば、発注書など)を抽象化し、アプリケーション・プログラムで処理できるようにしたものです。1つのオブジェクト型は、次の3種類のコンポーネントを持つスキーマ・オブジェクトです。
オブジェクト識別子(キーワードOIDで表される)を使用することによって、オブジェクトを一意に識別し、他のオブジェクトまたはリレーショナル表からそのオブジェクトを参照できます。REFと呼ばれるデータ型のカテゴリが、そのような参照を表します。REFデータ型は、オブジェクト識別子のコンテナです。REF値は、オブジェクトへのポインタとなります。
REF値が、存在しないオブジェクトを指している場合、そのREFはDANGLING(参照先がない)状態であるといいます。DANGLING状態のREFは、NULLであるREFと異なります。REFがDANGLING状態であるかどうかを確認するには、条件IS [NOT] DANGLINGを使用します。たとえば、列型がcustomer_typ(属性cust_emailを持つ)を指しているREFであるcustomer_ref列があるとします。このcustomer_ref列を含むオブジェクト・ビューoc_orders(サンプル・スキーマoe内)は、次のように指定します。
SELECT o.customer_ref.cust_email FROM oc_orders o WHERE o.customer_ref IS NOT DANGLING;
配列とは、順序付けられたデータ要素の集合です。ある特定の配列のすべての要素は、同じデータ型です。各要素には索引があります。索引は、各要素の配列内での位置に対応する番号です。
配列内の要素数は、その配列のサイズを表します。Oracleの配列は可変サイズであるため、VARRAYと呼ばれます。VARRAYを宣言する場合は、最大サイズを指定する必要があります。
VARRAY宣言時に領域は割り当てられません。VARRAYでは、次のような型を定義します。
通常、Oracleは、1つの配列オブジェクトをインライン形式でその行の他のデータと同じ表領域に、またはアウトライン形式でLOBに格納します。この形式は配列オブジェクトのサイズによって決まります。ただし、VARRAYに個別の記憶特性を指定する場合、Oracleはこれをサイズに関係なくアウトライン形式で格納します。VARRAYの格納方法の詳細は、「CREATE TABLE」の「varray_col_properties」を参照してください。
ネストした表は、順序付けられていない要素の集合を表現します。その要素は、組込み型またはユーザー定義型です。ネストした表は、単一列の表として表示できます。ネストした表がオブジェクト型の場合、オブジェクト型のそれぞれの属性を表す複数列の表としても表示できます。
ネストした表の定義では、領域は割り当てられません。ネストした表では、次のものを宣言するための型を定義します。
ネストした表が、リレーショナル表内の列型として使用される場合、またはオブジェクト表の基礎となるオブジェクト型の属性として使用される場合、Oracleは、ネストした表のすべてのデータを単一表に格納し、その単一表を、ネストした表を囲むリレーショナル表またはオブジェクト表に対応付けます。
Oracleは、組込み型またはANSIがサポートする型が不十分な場合に、新しい型を定義するためのSQLに基づくインタフェースを提供します。これらの型の動作は、C/C++、JavaまたはPL/SQLで実装されます。Oracle Databaseは、入出力、異機種間でのクライアント側の新しいデータ型へのアクセス、およびアプリケーションとデータベース間のデータ転送のための最適化で必要な下位レベルのインフラストラクチャ・サービスを自動的に提供します。
これらのインタフェースは、ユーザー定義(またはオブジェクト)型の作成に使用できます。また、Oracleが有効なデータ型を作成するときに使用します。このようなデータ型のいくつかはサーバーで提供され、横方向の幅広いアプリケーション領域(任意型など)および縦方向の固有アプリケーション領域(空間型など)の両方に役立ちます。
Oracleが提供する型については、次の項で説明します。また、それらの型の実装および使用に関するドキュメントの参照先も示します。
任意型は、実際の型が不明なプロシージャ・パラメータおよび表の列の柔軟性が高いモデリングを提供します。これらのデータ型によって、型の記述、データ・インスタンスおよびその他のSQL型の一連のデータ・インスタンスを動的にカプセル化し、アクセスできます。これらの型を構成およびアクセスするには、OCIおよびPL/SQLインタフェースを使用します。
この型には、任意の名前のあるSQL型または名前のない一時型の型の記述を含めることができます。
この型には、指定した型のインスタンスをデータおよび型の記述とともに含めることができます。ANYDATAは、表の列のデータ型として使用できます。また、このデータ型によって、単一列に異機種間の値を格納できます。ユーザー定義型と同様に、SQL組込み型の値も格納できます。
この型には、指定した型の記述およびその型の一連のデータ・インスタンスを含めることができます。ANYDATASETは、柔軟性が必要なプロシージャ・パラメータのデータ型として使用できます。ユーザー定義型と同様に、SQL組込み型のデータ・インスタンスの値も格納できます。
eXtensible Markup Language(XML)は、World Wide Web Consortium(W3C)によって開発された、構造化されたデータおよび構造化されていないデータをWebで表示するための標準書式です。Universal Resource Identifiers(URI)は、WebページなどのWeb上のリソースを識別します。Oracleでは、データベース自体に格納されるデータにアクセスするためにDBUriRef型と呼ばれるURIのクラスと同様に、XMLおよびURIデータを処理するための型が用意されています。また、データベースから外部URIおよび内部URIの両方に格納およびアクセスする型セットを利用できます。
Oracleが提供するこの型は、データベースでのXMLデータの格納および問合せに使用します。XMLTypeは、XPath式を使用したXMLデータへのアクセス、抽出および問合せに使用するメンバー・ファンクションを持ちます。XPathは、XML文書をトラバースするためにW3Cによって開発された別の規格です。OracleのXMLTypeファンクションは、W3Cの多数のXPath式をサポートします。また、Oracleは、既存のリレーショナルまたはオブジェクト・リレーショナル・データからXMLType値を作成するためのSQLファンクションおよびPL/SQLパッケージのセットを提供します。
XMLTypeはシステム定義型であるため、ファンクションの引数として、あるいは表またはビューの列のデータ型として使用できます。また、XMLTypeの表およびビューも作成できます。表にXMLType列を作成する際は、XMLデータをCLOB列に(内部的にはCLOBとして格納されるバイナリXMLとして)格納するか、またはオブジェクトと関連付けて格納するかを選択できます。
また、スキーマを登録し(DBMS_XMLSCHEMAパッケージを使用)、登録したスキーマに適合する表または列を作成できます。この場合、XMLデータは、デフォルトでは基礎となるオブジェクト・リレーショナル列に格納されますが、スキーマ・ベースのデータであっても、CLOB列またはバイナリXML列に格納するように指定できます。
XMLType列の問合せおよびDMLは、格納メカニズムとは関係なく、同様に動作します。
Oracleは、継承階層で関連するURI型のファミリ(URIType、DBUriType、XDBUriTypeおよびHTTPUriType)を提供します。URITypeはオブジェクト型であり、その他はURITypeのサブタイプです。URITypeはスーパータイプであるため、この型の列を作成し、DBUriTypeまたはHTTPUriType型のインスタンスをこの列に格納できます。
HTTPUriTypeを使用すると、外部のWebページまたはファイルのURLを格納できます。Oracleは、Hypertext Transfer Protocol(HTTP)を使用して、これらのファイルにアクセスします。
XDBUriTypeを使用すると、表の任意のURIType列に埋込み可能なURIとして、ドキュメントをXMLデータベース階層に展開できます。XDBUriTypeは、URLで構成されています。URLは、参照先のXML文書の階層名と、XPath構文を表すオプションのフラグメントで構成されています。フラグメントとURL部分は、シャープ記号(#)で区切ります。次に、XDBUriTypeの例を示します。
/home/oe/doc1.xml /home/oe/doc1.xml#/orders/order_item
DBUriTypeを使用すると、データベース内のデータを参照するDBUriRef値を格納できます。この場合、データベースの内部または外部に格納されたデータを参照し、常にデータにアクセスできます。
DBUriRef値は、データベース内のデータを参照するために、XPathのような表現を使用します。データベースをXMLツリーに想定すると、表、行および列がXML文書の要素です。たとえば、サンプルの人材のユーザーhrは次のようにXMLツリーで表します。
<HR> <EMPLOYEES> <ROW> <EMPLOYEE_ID>205</EMPLOYEE_ID> <LAST_NAME>Higgins</LAST_NAME> <SALARY>12000</SALARY> .. <!-- other columns --> </ROW> ... <!-- other rows --> </EMPLOYEES> <!-- other tables..--> </HR> <!-- other user schemas on which you have some privilege on..-->
DBUriRefは、この仮想XML文書のXPath式です。したがって、従業員番号205の従業員のSALARY値をEMPLOYEES表で参照するには、DBUriRefを次のように記述します。
/HR/EMPLOYEES/ROW[EMPLOYEE_ID=205]/SALARY
このモデルを使用すると、CLOB列またはその他の列に格納されたデータを参照し、それらのデータを外部のURLとして外部の世界へ公開できます。
Oracleは、URITypeの様々なサブタイプのインスタンスを作成し、戻すことができるURIFactoryパッケージも提供します。このパッケージは、URL文字列を分析し、URLの種類(HTTP、DBUriなど)を識別し、サブタイプのインスタンスを作成します。DBUriインスタンスを作成する場合は、URLの先頭に接頭辞/oradbを付ける必要があります。たとえば、URIFactory.getURI('/oradb/HR/EMPLOYEES')によってDBUriTypeインスタンスが作成され、URIFactory.getUri('/sys/schema')によってXDBUriTypeインスタンスが作成されます。
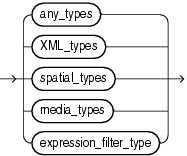
Oracle Spatialは、位置情報アプリケーション、地理情報システム(GIS)・アプリケーションおよびジオイメージング・アプリケーションのユーザーが、空間データ管理をより簡単かつ自然に行えるように設計されています。一度空間データをOracle Databaseに格納すると、そのデータの操作や取得を簡単に行うことができ、データベースに格納された他のすべてのデータと関連付けることもできます。次のデータ型は、Oracle Spatialをインストールしている場合にのみ使用できます。
空間オブジェクトのジオメトリの記述は、ユーザー定義の表の単一行およびオブジェクト型SDO_GEOMETRYの単一列に格納されます。SDO_GEOMETRY型の列を含むすべての表は、表に対して一意の主キーを定義する別の列を持つ必要があります。このような表は、ジオメトリ表と呼ばれる場合があります。
SDO_GEOMETRYオブジェクト型の定義は、次のとおりです。
CREATE TYPE SDO_GEOMETRY AS OBJECT ( sgo_gtype NUMBER, sdo_srid NUMBER, sdo_point SDO_POINT_TYPE, sdo_elem_info SDO_ELEM_INFO_ARRAY, sdo_ordinates SDO_ORDINATE_ARRAY) /
この型はトポロジ・ジオメトリを記述します。この記述は、ユーザー定義の表の単一行およびオブジェクト型SDO_GEOMETRYの単一列に格納されます。
SDO_TOPO_GEOMETRYオブジェクト型の定義は、次のとおりです。
CREATE TYPE SDO_TOPO_GEOMETRY AS OBJECT ( tg_type NUMBER, tg_id NUMBER, tg_layer_id NUMBER, topology_id NUMBER) /
GeoRasterオブジェクト・リレーショナル・モデルでは、ラスター・グリッドまたはイメージ・オブジェクトは、ユーザー定義の表の単一行およびオブジェクト型SDO_GEORASTERの単一列に格納されます。このような表は、GeoRaster表と呼ばれます。
SDO_GEORASTERオブジェクト型の定義は、次のとおりです。
CREATE TYPE SDO_GEORASTER AS OBJECT ( rasterType NUMBER, spatialExtent SDO_GEOMETRY, rasterDataTable VARCHAR2(32), rasterID NUMBER, metadata XMLType) /
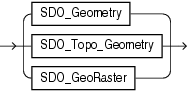
Oracle Multimediaは、マルチメディア・データを記述するために、JavaまたはC++クラスに類似したオブジェクト型を使用します。これらのオブジェクト型のインスタンスは、メタデータおよびメディア・データを含む属性とメソッドで構成されます。Multimediaのデータ型は、ORDSYSスキーマで作成されます。パブリック・シノニムがすべてのデータ型に対して存在するため、スキーマ名を指定せずにアクセスできます。
ORDAudioオブジェクト型は、オーディオ・データの格納および管理をサポートします。
ORDImageオブジェクト型は、イメージ・データの格納および管理をサポートします。
ORDVideoオブジェクト型は、ビデオ・データの格納および管理をサポートします。
ORDDocオブジェクト型は、オーディオ、イメージ、ビデオ・データなどすべての種類のメディア・データの格納および管理をサポートします。この型は、すべてのメディアを単一列に格納する場合に使用します。
ORDDicomオブジェクト型は、医用画像の規格として広く認知されている形式であるDigital Imaging and Communications in Medicine (DICOM)の格納および管理をサポートします。
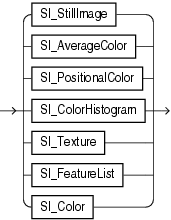
次のデータ型は、ISO-IEC 13249-5 Still Image規格(一般にSQL/MM StillImageと呼ばれる)に準拠しています。
SI_StillImageオブジェクト型は、高さ、幅、フォーマットなどの固有のイメージ特性を持つデジタル・イメージを表します。
SI_Colorオブジェクト型は、色の値をカプセル化します。
SI_AverageColorオブジェクト型は、イメージの平均の色によってそのイメージを特徴付けます。
SI_ColorHistogramオブジェクト型は、RAWイメージのサンプルによって表示される色の相対頻度によって、イメージを特徴付けます。
イメージをn×m個の四角形に分割すると考えた場合、SI_PositionalColorオブジェクト型は、その四角形の最も重要なn×m個の色によってイメージを特徴付けます。
SI_Textureオブジェクト型は、繰り返し出現している項目のサイズ(粗さ)、輝度の変化(コントラスト)および主な方向(方向性)によってイメージを特徴付けます。
SI_FeatureListオブジェクト型は、前述したオブジェクト型(SI_AverageColor、SI_ColorHistogram、SI_PositionalColorおよびSI_Texture)が表すイメージの特徴のうち最大4つの特徴を含むリストです。各特徴は、重み付けされます。
ORDImageSignatureは非推奨になったため、コードに使用されることはありません。現存するこのオブジェクト型は、引き続き従来どおり機能します。
Oracle Expression Filterを使用すると、アプリケーション開発者は、ユーザーの目的のデータを表す条件式を管理および評価できます。Expression Filterには、次のデータ型が含まれます。
Expression Filterは、Expressionと呼ばれる仮想データ型を使用して、条件式をデータベース表のデータとして管理および評価します。Expression Filterでは、VARCHAR2列に属性セットを割り当てることで、この列からExpressionデータ型の列を作成します。この割当てによって、列に格納された式の妥当性を確認するデータ制約が有効になります。
Expressionデータ型でEVALUATE演算子を使用して条件を定義すると、列に格納された式をデータに対して評価できます。Enterprise Editionを使用している場合は、Expressionデータ型の列にExpression Filter索引を定義して、EVALUATE演算子によって問合せを処理することもできます。
ここでは、Oracle Databaseが各データ型の値を比較する方法について説明します。
大きい値は小さい値よりも大きいとみなされます。すべての負の数は、0(ゼロ)およびすべての正の数より小さいとみなされます。したがって、-1は100より小さく、-100は-1より小さいとみなされます。
浮動小数点値NaN(非数値)は、その他の数値よりも大きく、NaNとは等しいとみなされます。
後の日付は前の日付よりも大きいとみなされます。たとえば、29-MAR-2005(2005年3月29日)に相当する日付は05-JAN-2006(2006年1月5日)に相当する日付よりも小さく、05-JAN-2006 1:35pm(2006年1月5日午後1時35分)に相当する日付は05-JAN-2005 10:09am(2005年1月5日午前10時9分)に相当する日付よりも大きいとみなされます。
文字値は、2つのメジャーに基づいて比較されます。
次の項で、2つのメジャーについて説明します。
デフォルトのバイナリ比較では、Oracleは、データベース・キャラクタ・セット内の文字の数値コードを連結した値に従って文字列を比較します。第1の文字の数値が第2の文字の数値よりも大きい場合、第1の文字は第2の文字よりも大きいとみなされます。Oracleは、空白はどの文字よりも小さいとみなします。これは、ほぼすべてのキャラクタ・セットでいえることです。
次に、一般的なキャラクタ・セットを示します。
数値コードのバイナリ順序と、比較する文字の言語順序が一致していない場合は、言語比較が有効です。NLS_SORTパラメータにBINARY以外の設定があり、NLS_COMPパラメータがLINGUISTICに設定されている場合は言語比較が使用されます。言語ソートでは、すべてのSQLのソートおよび比較がNLS_SORTによって指定された言語規則に基づいて行われます。
空白埋め比較セマンティクスでは、2つの値の長さが異なる場合、Oracleはまず短い方の値の最後に空白を追加して、2つの値が同じ長さになるようにします。次に、その2つの値を、最初に異なる文字まで1文字ずつ比較します。最初に異なる文字の位置で、大きい方の文字を持つ値の方が大きいとみなされます。2つの値に異なる文字がない場合、その2つの値は等しいとみなされます。この規則では、2つの値の後続空白数のみが異なる場合、その2つの値は等しいとみなされます。Oracleでは、比較する両方の値が、CHARデータ型、NCHARデータ型、テキスト・リテラルのいずれかの式の場合、またはUSERファンクションの戻り値の場合のみ空白埋め比較セマンティクスを使用します。
非空白埋め比較セマンティクスでは、Oracleは、2つの値を、最初に異なる文字まで1文字ずつ比較します。最初に異なる文字の位置で、大きい方の文字を持つ値の方が大きいとみなされます。長さが異なる2つの値を短い方の値の最後まで比較して、すべて同じ文字だった場合、長い方の値が大きいとみなされます。同じ長さの2つの値に異なる文字がない場合、その2つの値は等しいとみなされます。Oracleでは、比較する片方または両方の値がVARCHAR2データ型またはNVARCHAR2データ型の場合、非空白埋め比較セマンティクスを使用します。
これらの異なる比較セマンティクスを使用して2つの文字値を比較した場合、その結果が異なることもあります。次の表に、それぞれの比較セマンティクスを使用して5組の文字を比較した結果を示します。通常、空白埋め比較と非空白埋め比較の結果は同じです。表に示されている最後の比較では、空白埋め比較と非空白埋め比較の違いが明確になっています。
| 空白埋め比較 | 非空白埋め比較 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ASCIIとEBCDICのキャラクタ・セットの一部を表2-8と表2-9に示します。大文字と小文字は同じではありません。キャラクタ・セットの照合順番は、特定の言語の言語順序と一致しない場合があります。
オブジェクト値は、MAPとORDERの2つの比較ファンクションのいずれかを使用して比較されます。どちらのファンクションでもオブジェクト型インスタンスは比較されますが、両者は別のものです。これらのファンクションは、他のオブジェクト型と比較するオブジェクト型の一部として指定される必要があります。
ネストした表の比較の詳細は、「比較条件」を参照してください。
Oracleでは、データ型の優先順位によって、暗黙的にデータ型を変換するかどうかを判断します(次の項を参照)。Oracleデータ型の優先順位は、次のとおりです。
一般に、式には異なるデータ型の値を含めることができません。たとえば、式では10に5を掛けた値に'JAMES'を加えることはできません。ただし、Oracleでは値をあるデータ型から別のデータ型へ変換する場合の、暗黙的な変換と明示的な変換をサポートしています。
次の理由から、暗黙的な変換または自動変換ではなく、明示的な変換を指定することをお薦めします。
VARCHAR2型へ値を暗黙的に変換すると、NLS_DATE_FORMATパラメータに指定されている値によっては、予期しない年が戻される場合があります。
あるデータ型から別のデータ型への変換が意味を持つ場合、Oracle Databaseは値を自動的に変換します。文字データ型への暗黙的な変換はこれらのルールに従います。
表2-10に、Oracleの暗黙的な変換のマトリックスについて示します。この表は、変換の方向または変換されるコンテキストにかかわらず、すべての可能な変換を示します。詳細は、表の後の説明を参照してください。
次に示す規則に従って、Oracle Databaseは、暗黙的なデータ型変換を実行する方向を確立します。
INSERTおよびUPDATE操作中に、Oracleは変更する列のデータ型に値を変換します。
SELECT FROM操作中に、Oracleは列からターゲット変数の型にデータを変換します。
NUMBERの値と浮動小数点数の値の間では、変換が正確に行われない場合があります。これは、文字型およびNUMBERでは10進精度で数値が示されるのに対し、浮動小数点数では2進精度が使用されているためです。
CLOB値をVARCHAR2などの文字データ型に変換する場合、またはBLOBをRAWデータに変換する場合、変換するデータがターゲットのデータ型より大きいと、データベースはエラーを戻します。
BINARY_FLOATからBINARY_DOUBLEへの変換は正確に行われます。
BINARY_DOUBLEの値がBINARY_FLOATでサポートされている精度のビット数よりも多いビット数を使用している場合、BINARY_DOUBLEからBINARY_FLOATへの変換は正確に行われません。
DATEの値と文字の値を比較する場合、Oracleは文字データをDATEに変換します。
CHARまたはNCHARに変換します。
CHAR/VARCHAR2とNCHAR/NVARCHAR2の演算処理では、OracleはNUMBERに変換します。
CHARとVARCHAR2、NCHARとNVARCHAR2の比較では、異なるキャラクタ・セットが必要な場合があります。このような場合のデフォルトの変換の方向は、データベース・キャラクタ・セットから各国語キャラクタ・セットです。表2-11に、異なるキャラクタ・タイプ間での暗黙的な変換の方向を示します。
CLOBをパラメータとして指定できます。また、OracleはCLOBと文字型間で暗黙的な変換を実行します。このため、CLOBを使用できないファンクションは、暗黙的な変換を使用してCLOBを受け入れます。このような場合、Oracleはファンクションが起動される前にCLOBをCHARまたはVARCHAR2に変換します。CLOBが4000バイトより大きい場合、Oracleは最初の4000バイトのみをCHARに変換します。| CHARへ | VARCHAR2へ | NCHARへ | NVARCHAR2へ | |
|---|---|---|---|---|
|
CHARから |
-- |
|
|
|
|
VARCHAR2から |
|
-- |
|
|
|
NCHARから |
|
|
-- |
|
|
NVARCHAR2から |
|
|
|
-- |
コレクションなどのユーザー定義型は暗黙的に変換できないため、CAST ... MULTISETを使用して明示的に変換する必要があります。
テキスト・リテラル'10'はCHARデータ型です。次の文のように数式で使用すると暗黙的にNUMBERデータ型に変換されます。
SELECT salary + '10' FROM employees;
条件で文字値とNUMBER型の値を比較する場合、NUMBER型の値は文字値に変換されず、文字値が暗黙的にNUMBER型の値に変換されます。次の文では、'200'が暗黙的に200に変換されます。
SELECT last_name FROM employees WHERE employee_id = '200';
次の文では、Oracleがデフォルトの日付書式'DD-MON-YY'を使用して、'03-MAR-97'をDATE値に暗黙的に変換します。
SELECT last_name FROM employees WHERE hire_date = '03-MAR-97';
SQL変換ファンクションを使用すると、データ型の変換を明示的に指定できます。表2-12に、値をあるデータ型から別のデータ型に明示的に変換するSQLファンクションを示します。
Oracleが暗黙的なデータ型変換を行うことができる場合には、LONGおよびLONG RAWの値を指定できません。たとえば、ファンクションや演算子を含む式では、LONGとLONG RAWの値を使用できません。LONGデータ型およびLONG RAWデータ型の制限については、「LONGデータ型」を参照してください。
暗黙的な変換、または書式モデルを指定しない明示的な変換のいずれかによって日時値がテキストに変換される場合、書式モデルはグローバリゼーション・セッション・パラメータの1つによって定義されます。ソースのデータ型に応じて、パラメータ名はNLS_DATE_FORMAT、NLS_TIMESTAMP_FORMATまたはNLS_TIMESTAMP_TZ_FORMATです。これらのパラメータの値は、クライアント環境で、またはALTER SESSION文で指定できます。
書式モデルがセッション・パラメータに依存している場合、明示的な書式モデルが指定されていない変換が動的SQL文のテキストに連結される日時値に適用されると、データベースのセキュリティに悪影響を及ぼす可能性があります。動的SQL文は、実行のためにデータベースに渡される前にそのテキストがフラグメントから連結される文です。動的SQLは、組込みPL/SQLパッケージDBMS_SQLまたはPL/SQL文EXECUTE IMMEDIATEに関連付けられる場合が多いですが、動的に構成されたSQLテキストを引数として渡すことができる場所はこれらのみではありません。次に例を示します。
EXECUTE IMMEDIATE 'SELECT name FROM employee WHERE hiredate > ''' || start_date || '''';
start_dateのデータ型はDATEです。
前述の例では、start_dateの値はセッション・パラメータNLS_DATE_FORMATで指定された書式モデルを使用してテキストに変換されます。結果は、連結されてSQLテキストになります。日時書式モデルは、単純に二重引用符で囲んだリテラル・テキストで構成できます。したがって、セッションのグローバリゼーション・パラメータを明示的に設定できるすべてのユーザーが、前述の変換で生成されるテキストを決定できます。SQL文がPL/SQLプロシージャによって実行される場合、そのプロシージャはセッション・パラメータによるSQLインジェクションに対して脆弱になります。セッション自体より強い権限である定義者の権限でプロシージャが実行されると、ユーザーは機密データに不正にアクセスすることができます。
数値の暗黙的および明示的な変換でも、変換結果がセッション・パラメータNLS_NUMERIC_CHARACTERSに依存する場合があるため、類似した問題が発生する可能性があります。このパラメータは、小数点区切り文字および桁区切り文字を定義します。小数点区切りを一重引用符または二重引用符と定義すると、SQLインジェクションが発生する可能性があります。
|
参照:
|
リテラルと定数値という用語の意味は同じで、固定データ値のことです。たとえば、'JACK'、'BLUE ISLAND'および'101'はすべて文字リテラルです。文字リテラルは、一重引用符で囲みます。一重引用符を付けることで、Oracleは文字リテラルとスキーマ・オブジェクト名を区別します。
この項では、次の内容を説明します。
多くのSQL文とファンクションでは、文字リテラルと数値リテラルを指定する必要があります。式と条件の一部として、リテラルを指定できます。文字リテラルは'text'の表記法を、各国文字リテラルはN'text'の表記法を、数値リテラルはリテラルのコンテキストに応じてintegerまたはnumberの表記法を使用して指定できます。これらの表記法の構文については、次の項で説明します。
Datetime(日時)またはInterval(期間)のデータ型をリテラルとして指定する場合は、データ型に含まれているオプションの精度を考慮する必要があります。Datetime(日時)およびInterval(期間)のデータ型をリテラルとして指定する場合の例は、「データ型」の関連する項を参照してください。
このマニュアルの他の箇所で、式、条件、SQLファンクションおよびSQL文の各構文に示されている'string'に値を指定するときには、必ずこのテキスト・リテラルの表記法を使用してください。このマニュアルでは、テキスト・リテラル、文字リテラルおよび文字列は同じ用語として使用しています。テキスト、文字、文字列リテラルは必ず一重引用符で囲まれています。構文にcharが使用されている場合、テキスト・リテラルを指定するか、または文字データに変換する他の式(たとえば、hr.employees表のlast_name列)を指定します。構文にcharがある場合、一重引用符で囲む必要はありません。
テキスト・リテラルまたは文字列の構文は次のとおりです。
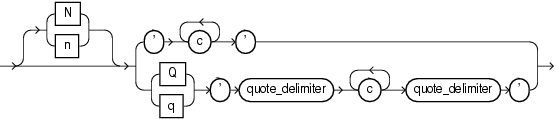
ここで、Nまたはnは、各国語キャラクタ・セット(NCHARまたはNVARCHAR2データ)を使用してリテラルを指定します。デフォルトでは、この表記法を使用して入力したテキストは、サーバーで使用するときにデータベースのキャラクタ・セットによって各国語キャラクタ・セットに変換されます。テキスト・リテラルをデータベースのキャラクタ・セットに変換しているときにデータの消失を避けるためには、環境変数ORA_NCHAR_LITERAL_REPLACEにTRUEを設定してください。このように設定することで、n'を透過的に内部で置き換え、SQLの処理中にテキスト・リテラルを保持します。
構文の上の方のブランチでは、次のようになります。
cは、データベース・キャラクタ・セットの任意の要素です。リテラル内の一重引用符(')の前には、エスケープ文字を付ける必要があります。リテラル内で一重引用符を表すには、一重引用符を2つ使用します。
構文の下の方のブランチでは、次のようになります。
Qまたはqは、代替引用メカニズムが使用されることを示します。このメカニズムを使用すると、様々なデリミタをテキスト文字列に使用できます。
' 'は、開始のquote_delimiterの前と、終了のquote_delimiterの後に付ける2つの一重引用符です。
cは、データベース・キャラクタ・セットの任意の要素です。cで構成されるテキスト・リテラル内に引用符(")を含めることができます。また、一重引用符が直後に付かないquote_delimiterも含めることができます。
quote_delimiterは、空白、タブおよび改行文字を除く、任意のシングルバイト文字またはマルチバイト文字です。quote_delimiterには一重引用符も使用できます。ただし、quote_delimiterがテキスト・リテラル自体に使用されている場合は、一重引用符を直後に付けないようにしてください。開始のquote_delimiterが[、{、<または(のいずれかである場合、終了のquote_delimiterも対応する]、}、>または)である必要があります。それ以外の場合は常に、開始および終了のquote_delimiterは同じ文字である必要があります。
テキスト・リテラルは、次のようにCHARデータ型とVARCHAR2データ型の両方のプロパティを持ちます。
有効なテキスト・リテラルの例を次に示します。
'Hello' 'ORACLE.dbs' 'Jackie''s raincoat' '09-MAR-98' N'nchar literal'
代替引用メカニズムを使用した場合の、有効なテキスト・リテラルの例を次に示します。
q'!name LIKE '%DBMS_%%'!' q'<'So,' she said, 'It's finished.'>' q'{SELECT * FROM employees WHERE last_name = 'Smith';}' nq'Ô ü1234 Ô' q'"name like '['"'
固定小数点数および浮動小数点数を指定するには、数値リテラルの表記法を使用します。
このマニュアルの他の箇所で、式、条件、SQLファンクションおよびSQL文に示されているinteger(整数)に値を指定するときには、必ずこの表記法を使用してください。
integer(整数)の構文は次のとおりです。
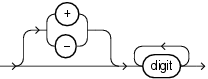
digitは、0、1、2、3、4、5、6、7、8、9のいずれかです。
整数は最大38桁の精度を記憶できます。
有効なinteger(整数)の例を次に示します。
7 +255
このマニュアルの他の箇所で、式、条件、SQLファンクションおよびSQL文に示されているnumberまたはn(数)に値を指定するときには、必ずこれらの表記法を使用してください。
number(数)の構文は次のとおりです。
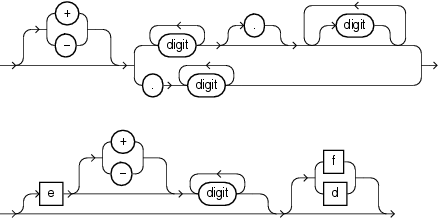
それぞれの意味は、次のとおりです。
digitは、0、1、2、3、4、5、6、7、8、9のいずれかです。
BINARY_FLOAT型の32ビットの2進浮動小数点数であることを示します。
BINARY_DOUBLE型の64ビットの2進浮動小数点数であることを示します。f(F)およびd(D)を省略すると、数はNUMBER型になります。
接尾辞f(F)およびd(D)は、浮動小数点数リテラルでのみサポートされます。文字列ではNUMBERに変換されるため、サポートされません。たとえば、OracleがNUMBERを想定している場合に、文字列'9'を使用すると、文字列は数字の9に変換されます。ただし、文字列'9f'を使用すると、変換は行われず、エラーが戻されます。
NUMBER型の数値は、最大38桁の精度を記憶できます。NUMBER、BINARY_FLOATまたはBINARY_DOUBLEで提供される精度以上の精度がリテラルに必要な場合、値は切り捨てられます。リテラルの範囲がNUMBER、BINARY_FLOATまたはBINARY_DOUBLEでサポートされる範囲を超える場合、エラーが発生します。
初期化パラメータNLS_NUMERIC_CHARACTERSを使用してピリオド(.)以外の小数点文字を設定している場合は、'text'の表記法で数値リテラルを指定する必要があります。この場合、Oracleは自動的にテキスト・リテラルを数値に変換します。
たとえば、NLS_NUMERIC_CHARACTERSパラメータでカンマを小数点文字に設定している場合、数値5.123は次のように指定します。
'5,123'
有効なNUMBERリテラルの例を次に示します。
25 +6.34 0.5 25e-03 -1
有効な浮動小数点数リテラルの例を次に示します。
25f +6.34F 0.5d -1D
値を数値リテラルとして表現できない場合は、次の浮動小数点リテラルを使用することもできます。
Oracle Databaseは、DATE、TIMESTAMP、TIMESTAMP WITH TIME ZONEおよびTIMESTAMP WITH LOCAL TIME ZONEの4つの日時データ型をサポートしています。
DATE値を文字列リテラルに指定するか、文字値や数値をTO_DATEファンクションによって日付値に変換できます。Oracle Databaseが文字列リテラルのかわりにTO_DATE式を受け入れるのは、DATEリテラルの場合だけです。
DATE値をリテラルに指定する場合は、グレゴリオ暦を使用する必要があります。次の例に示すように、ANSIのリテラルを指定できます。
DATE '1998-12-25'
ANSIの日付リテラルには、時刻部分を含めず、書式'YYYY-MM-DD'で指定する必要があります。また、次のように、Oracleの日付値を指定できます。
TO_DATE('98-DEC-25 17:30','YY-MON-DD HH24:MI')
OracleのDATE値のデフォルトの日付書式は、初期化パラメータNLS_DATE_FORMATで指定します。この例は、日付としての2桁の数、月の名前の省略形、年の下2桁および24時間表記の時刻を含む日付書式です。
デフォルト日付書式の文字値が日付式で使用されると、Oracleは自動的にそれらを日付値に変換します。
日付値を指定する場合に時刻コンポーネントを指定しないと、デフォルト時刻の真夜中(24時間表記では00:00:00、12時間表記では12:00:00)が採用されます。日付値を指定する場合に日付を指定しないと、デフォルト日付である現在の月の最初の日が採用されます。
OracleのDATE列には、常に、日付フィールドと時刻フィールドが含まれます。したがって、DATE列を問い合せる場合は、問合せで時刻フィールドを指定するか、またはDATE列の時刻フィールドが真夜中に設定されていることを確認する必要があります。そうでない場合、Oracleは、正しい結果を戻さない場合があります。時刻フィールドを真夜中に設定するには、TRUNC日付ファンクションを使用します。また、問合せに、等価性や非等価性の条件のかわりに大/小条件を含めることもできます。
次の例では、数値列row_numおよびDATE列datecolを持つ表my_tableがあると想定します。
INSERT INTO my_table VALUES (1, SYSDATE); INSERT INTO my_table VALUES (2, TRUNC(SYSDATE)); SELECT * FROM my_table; ROW_NUM DATECOL ---------- --------- 1 03-OCT-02 2 03-OCT-02 SELECT * FROM my_table WHERE datecol = TO_DATE('03-OCT-02','DD-MON-YY'); ROW_NUM DATECOL ---------- --------- 2 03-OCT-02 SELECT * FROM my_table WHERE datecol > TO_DATE('02-OCT-02', 'DD-MON-YY'); ROW_NUM DATECOL ---------- --------- 1 03-OCT-02 2 03-OCT-02
DATE列の時刻フィールドが真夜中に設定されている場合は、前述の例に示すように、DATE列に対して問い合せるか、DATEリテラルを使用して問い合せることができます。
SELECT * FROM my_table WHERE datecol = DATE '2002-10-03';
ただし、DATE列が真夜中以外の値を含む場合、正しい結果を得るためには、問合せで時刻フィールドを排除する必要があります。次に例を示します。
SELECT * FROM my_table WHERE TRUNC(datecol) = DATE '2002-10-03';
Oracleは、問合せの各行にTRUNCファンクションを適用します。これによって、データの時刻フィールドが真夜中である場合、パフォーマンスが向上します。時刻フィールドを真夜中に設定するには、挿入および更新時に次のいずれかの操作を行います。
TO_DATEファンクションを使用して、時刻フィールドをマスクします。
INSERT INTO my_table VALUES (3, TO_DATE('3-OCT-2002','DD-MON-YYYY'));
DATEリテラルを使用します。
INSERT INTO my_table VALUES (4, '03-OCT-02');
TRUNCファンクションを使用します。
INSERT INTO my_table VALUES (5, TRUNC(SYSDATE));
日付ファンクションSYSDATEは、現在のシステムの日付および時刻を戻します。CURRENT_DATEファンクションは、現在のセッションの日付を戻します。SYSDATE、TO_*日時ファンクションおよびデフォルト日付書式の詳細は、「日時ファンクション」を参照してください。
TIMESTAMPデータ型は、年、月、日、時、分、秒、および秒の小数部の値を格納します。TIMESTAMPをリテラルに指定する場合、fractional_seconds_precision値には最大9桁を指定できます。次に例を示します。
TIMESTAMP '1997-01-31 09:26:50.124'
TIMESTAMP WITH TIME ZONEデータ型は、タイムゾーン地域名またはタイムゾーン・オフセットを含むTIMESTAMPの変形です。TIMESTAMP WITH TIME ZONEをリテラルに指定する場合、fractional_seconds_precision値には最大9桁を指定できます。次に例を示します。
TIMESTAMP '1997-01-31 09:26:56.66 +02:00'
2つのTIMESTAMP WITH TIME ZONE値がUTCで同じ時刻を表す場合は、データに格納されたTIME ZONEオフセットにかかわらず、同一であるとみなされます。次に例を示します。
TIMESTAMP '1999-04-15 8:00:00 -8:00'
前述の例文は次の例文と同じです。
TIMESTAMP '1999-04-15 11:00:00 -5:00'
太平洋標準時の午前8時は、東部標準時の午前11時と同じです。
UTCオフセットをTZR(タイムゾーン地域)書式要素に置換できます。次の例では、前述の例と同じ値を持ちます。
TIMESTAMP '1999-04-15 8:00:00 US/Pacific'
夏時間に切り替えられる境界のあいまいさを排除するには、TZRおよび対応するTZD書式要素の両方を使用します。次の例では、前述の例が確実に夏時間の値を戻します。
TIMESTAMP '1999-10-29 01:30:00 US/Pacific PDT'
タイムゾーン・オフセットは日時式を使用して表記することもできます。
SELECT TIMESTAMP '1999-10-29 01:30:00' AT TIME ZONE 'US/Pacific' FROM DUAL;
ERROR_ON_OVERLAP_TIMEセッション・パラメータをTRUEに設定しておくと、TZD書式要素を追加しなかったために日時値があいまいな場合、Oracleはエラーを戻します。パラメータをFALSEに設定しておくと、Oracleはあいまいな日時を、指定した地域の標準時刻として解析します。
TIMESTAMP WITH LOCAL TIME ZONEデータ型は、TIMESTAMP WITH TIME ZONEとは異なり、データベースに格納されるデータはデータベースのタイムゾーンに正規化されます。タイムゾーン・オフセットは、列データの一部として格納されません。TIMESTAMP WITH LOCAL TIME ZONEにはリテラルはありません。他の有効な日時リテラルを使用してこのデータ型の値を示してください。次の表には、TIMESTAMP WITH LOCAL TIME ZONE列に値を挿入するときに使用できる一部の書式と、問合せによって戻される対応する値を示します。
指定した値に時刻コンポーネントがない場合(明示的または暗黙的に)、デフォルトの午前0時の値が戻されます。
期間リテラルは期間を指定します。年および月、または日付、時間、分および秒の違いを指定できます。Oracle Databaseは、YEAR TO MONTHおよびDAY TO SECONDの2種類の期間リテラルをサポートします。各リテラルは先行フィールドを含み、後続フィールドを含むこともあります。先行フィールドは、計測する日付または時刻の基本単位を定義します。後続フィールドは、考慮する基本単位の最小増分値を定義します。たとえば、YEAR TO MONTH期間では、最も近い月に対する年との期間が考慮されます。DAY TO MINUTE期間では、最も近い分に対する日との期間が考慮されます。
数値形式の日付データがある場合、NUMTOYMINTERVALまたはNUMTODSINTERVAL変換ファンクションを使用して、数値データを期間値へ変換できます。
期間リテラルは、主に分析ファンクションとともに使用します。
次の構文を使用して、YEAR TO MONTH期間リテラルを指定します。
それぞれの意味は、次のとおりです。
'integer [-integer]'には、リテラルの先行フィールドおよびオプションの後続フィールドの整数値を指定します。先行フィールドがYEARで、後続フィールドがMONTHの場合、MONTHフィールドの整数値の範囲は0〜11です。
precisionは、先行フィールドの桁数です。先行フィールド精度の有効範囲は0〜9で、デフォルトは2です。
後続フィールドを指定する場合は、その桁数を先行フィールドの桁数より少なく設定する必要があります。たとえば、INTERVAL '0-1' MONTH TO YEARは無効です。
次のINTERVAL YEAR TO MONTHリテラルは、intervalが123年2か月であることを示しています。
INTERVAL '123-2' YEAR(3) TO MONTH
このリテラルの他の書式の例を次に示します。省略バージョンも含みます。
あるINTERVAL YEAR TO MONTHリテラルを別のリテラルに加算または減算して、新しいINTERVAL YEAR TO MONTHリテラルを作成できます。次に例を示します。
INTERVAL '5-3' YEAR TO MONTH + INTERVAL'20' MONTH = INTERVAL '6-11' YEAR TO MONTH
次の構文を使用して、DAY TO SECOND期間リテラルを指定します。
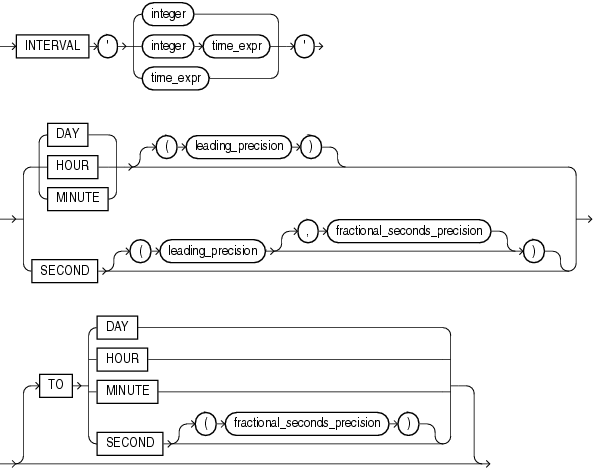
それぞれの意味は、次のとおりです。
integerは日数を指定します。ここで指定した値の桁数が先行精度で指定した桁数より大きい場合、Oracleはエラーを戻します。
time_exprには、HH[:MI[:SS[.n]]]、MI[:SS[.n]]またはSS[.n]書式で時間を指定します(ここで、nは秒の小数部を指定します)。nの桁数が、fractional_seconds_precisionで指定した数より多い場合、nはfractional_seconds_precision値で指定した数に丸められます。先行フィールドがDAYの場合にのみ、1桁の整数および1つの空白の後にtime_exprを指定できます。
leading_precisionは、先行フィールドの桁数です。有効範囲は0〜9です。デフォルトは2です。
fractional_seconds_precisionは、SECOND日時フィールドの小数部の桁数です。有効範囲は1〜9です。デフォルトは6です。
後続フィールドを指定する場合は、その桁数を先行フィールドの桁数より少なく設定する必要があります。たとえば、INTERVAL MINUTE TO DAYは無効です。このため、SECONDが先行フィールドの場合、期間リテラルは後続フィールドを持つことができません。
後続フィールドの有効範囲は次のとおりです。
様々なINTERVAL DAY TO SECONDリテラルの書式の例を次に示します。省略バージョンも含みます。
DAY TO SECOND期間リテラルを別のDAY TO SECOND期間リテラルに加算または減算できます。次に例を示します。
INTERVAL'20' DAY - INTERVAL'240' HOUR = INTERVAL'10-0' DAY TO SECOND
書式モデルは、文字列に格納される日時データや数値データの書式を記述する文字リテラルです。書式モデルによってデータベース内に格納された値の内部表現は変更されません。文字列を日付または数値に変換する場合、書式モデルによって、Oracle Databaseによる文字列の変換方法が決まります。SQL文では、書式モデルをTO_CHARファンクションやTO_DATEファンクションの引数として使用して、次の書式を指定できます。
次に例を示します。
17:45:29'の日時書式モデルは、'HH24:MI:SS'です。
11-Nov-1999'の日時書式モデルは、'DD-Mon-YYYY'です。
$2,304.25'の数値書式モデルは、'$9,999.99'です。
日時および数値書式モデルの要素のリストは、表2-13「数値書式要素」および表2-15「日時書式要素」を参照してください。
いくつかの書式の値は、初期化パラメータの値によって決まります。これらの書式要素によって戻される文字は、初期化パラメータNLS_TERRITORYを使用して暗黙的に指定することもできます。デフォルト日付書式をセッションごとに変更するには、ALTER SESSION文を使用します。
|
参照:
|
この項の後半では、次の書式モデルの使用方法について説明します。
次のファンクションで数値書式モデルを使用できます。
NUMBER、BINARY_FLOATまたはBINARY_DOUBLEデータ型の値をVARCHAR2データ型の値に変換するTO_CHARファンクション
CHARデータ型またはVARCHAR2データ型の値をNUMBERデータ型の値に変換するTO_NUMBERファンクション
CHARおよびVARCHAR2式をBINARY_FLOATまたはBINARY_DOUBLEの値に変換するTO_BINARY_FLOATファンクションおよびTO_BINARY_DOUBLEファンクション
すべての数値書式モデルでは、数値が指定された有効桁数に丸められます。小数点左の有効桁数が書式で指定された桁数より多い場合、シャープ記号(#)が値のかわりに戻されます。通常、このイベントは、TO_CHARファンクションを制限的な数値書式文字列で使用して、丸め処理が行われた場合に発生します。
NUMBERの値が非常に大きく、指定の書式で表せない場合、無限大記号(~)が値のかわりに戻されます。同様に、負のNUMBERの値が非常に小さく、指定の書式で表せない場合、負の無限大記号(-~)が戻されます。
BINARY_FLOATまたはBINARY_DOUBLEの値がCHARまたはNCHARに変換される場合、無限大またはNaN(非数値)のいずれかが入力されると、Oracleは常に値のかわりにシャープ記号を戻します。ただし、書式モデルを省略すると、OracleはInfまたはNanを文字列として戻します。
数値書式モデルは、1つ以上の数値書式要素で構成されます。次の表に、数値書式モデルの要素とその例を示します。
数値書式モデルに書式要素MI、SまたはPRが指定されないかぎり、負の戻り値の先頭には自動的に負の符号が付けられ、正の戻り値の先頭には空白が付けられます。
表2-14に、異なるnumberと'fmt'に対して次の問合せを行った場合の結果を示します。
SELECT TO_CHAR(number, 'fmt') FROM DUAL;
次のファンクションで日時書式モデルを使用できます。
TO_*日時ファンクション(TO*日時ファンクションは、TO_DATE、TO_TIMESTAMPおよびTO_TIMESTAMP_TZです。)
TO_CHARファンクション
日時書式モデルの合計長は最大22文字です。
デフォルト日時書式は、NLSセッション・パラメータNLS_DATE_FORMAT、NLS_TIMESTAMP_FORMATおよびNLS_TIMESTAMP_TZ_FORMATで明示的に指定することも、NLSセッション・パラメータNLS_TERRITORYで暗黙的に指定することもできます。デフォルト日時書式をセッションごとに変更するには、ALTER SESSION文を使用します。
日時書式モデルは、表2-15「日時書式要素」に示す、1つ以上の日時書式要素で構成されます。
TO_*日付ファンクションで使用可能かどうかを示します。TO_CHARでは、すべての書式要素が使用できます。
FF、TZD、TZH、TZMおよびTZRは、タイムスタンプおよび期間書式モデルでは使用できますが、元のDATE書式モデルでは使用できません。
戻される日付値では、その大文字と小文字は対応する書式要素の表記に従います。たとえば、日付書式モデル「DAY」は「MONDAY」、「Day」は「Monday」、「day」は「monday」を生成します。
日付書式モデルでは、次の文字を指定できます。
これらの文字は、戻り値の中で書式モデルに指定された位置と同じ位置に現れます。
Oracle Databaseは、一定の柔軟性によって文字列を日付に変換します。たとえば、TO_DATEファンクションの使用時、句読点文字を含む書式モデルと、句読点文字がないか、一部を使用した入力文字列は同じになり、入力文字列の各数値要素に最大許容桁数が含まれます(たとえば、'MM'に2桁の'05'、'YYYY'に4桁の'2007')。次の文は、エラーを戻しません。
SELECT TO_CHAR (TO_DATE('0297','MM/YY'), 'MM/YY') FROM DUAL; TO_CH ----- 02/07
次の書式文字列はエラーを戻しませんが、FX(厳密な書式一致)書式修飾子では、式および書式文字列が完全に一致する必要があります。
SELECT TO_CHAR(TO_DATE('0207', 'fxmm/yy'), 'mm/yy') FROM DUAL; SELECT TO_CHAR(TO_DATE('0207', 'fxmm/yy'), 'mm/yy') FROM DUAL * ERROR at line 1: ORA-01861: literal does not match format string
いくつかの日時書式要素の機能は、Oracle Databaseを使用している国および言語に依存します。たとえば、次の日時書式要素は、フルスペルで値が戻されます。
これらの値を戻す言語は、初期化パラメータNLS_DATE_LANGUAGEによって明示的に指定することも、初期化パラメータNLS_LANGUAGEによって暗黙的に指定することもできます。日時書式要素YEARとSYEARによって戻される値は常に英語です。
日時書式要素Dは、曜日の数(1〜7)を戻します。この数が1である曜日は、初期化パラメータNLS_TERRITORYによって暗黙的に指定されます。
Oracleは、ISO規格に従った日時書式要素IYYY、IYY、IY、IおよびIWによって戻される値を計算します。これらの値と日時書式要素YYYY、YYY、YY、YおよびWWによって戻される値の相違点については、『Oracle Databaseグローバリゼーション・サポート・ガイド』の「グローバリゼーション・サポート」の章を参照してください。
RR日時書式要素は、YY日時書式要素に似ていますが、20世紀以外の日付値を格納する場合の柔軟性が優れています。RR日時書式要素によって、現在が21世紀でも、年の下2桁を指定するだけで、20世紀の日付を格納できます。
YY日時書式要素でTO_DATEファンクションを使用した場合、日付値は常に現在の年と同じ上2桁で戻されます。そのかわりにRR日時書式要素を使用した場合、年に指定した2桁の数と現在の年の下2桁の数によって戻り値の世紀が変化します。
したがって、次のようになります。
次に、RR日時書式要素の特長を具体的に説明します。
次の問合せが、1950年〜1999年の間に発行されるとします。
SELECT TO_CHAR(TO_DATE('27-OCT-98', 'DD-MON-RR') ,'YYYY') "Year" FROM DUAL; Year ---- 1998 SELECT TO_CHAR(TO_DATE('27-OCT-17', 'DD-MON-RR') ,'YYYY') "Year" FROM DUAL; Year ---- 2017
次の問合せが、2000年〜2049年の間に発行されるとします。
SELECT TO_CHAR(TO_DATE('27-OCT-98', 'DD-MON-RR') ,'YYYY') "Year" FROM DUAL; Year ---- 1998 SELECT TO_CHAR(TO_DATE('27-OCT-17', 'DD-MON-RR') ,'YYYY') "Year" FROM DUAL; Year ---- 2017
発行される年(2000年の前後)にかかわらず、問合せが同じ値を戻していることに注目してください。RR日時書式要素によって、年の上2桁が異なっても同じ値を戻すSQL文を記述できます。
表2-16に、日時書式要素に付加できる接尾辞を示します。
| 接尾辞 | 意味 | 要素の例 | 値の例 |
|---|---|---|---|
|
TH |
序数 |
|
|
|
SP |
フルスペルで表した数 |
|
|
|
SPTHまたはTHSP |
フルスペルで表した序数 |
|
|
TO_CHARファンクションの書式モデルで修飾子FMとFXを使用して、空白の埋め方および書式検査を制御できます。
修飾子は書式モデルに複数指定できます。この場合、後の修飾子は前の修飾子の効果を逆にします。第1の修飾子は、それに後続するモデル部分に対して有効になり、第2の修飾子が指定されると、その後のモデル部分で無効になります。第3の修飾子が指定されると、その後のモデル部分で再び有効になります。以降、同様に続きます。
Fill mode(埋込みモード)です。書式要素が固定幅になるまで後続空白文字と先行0(ゼロ)が埋め込まれます。幅は、関連する書式モデルの最大要素の表示幅と等しくなります。
YYYY要素は4桁(9999の長さ)まで、HH24は2桁(23の長さ)まで、DDDは3桁(366の長さ)まで埋め込まれます。
MONTH、MON、DAYおよびDYには、NLS_DATE_LANGUAGEパラメータおよびNLS_CALENDARパラメータの値によって指定される有効な名前の中で、それぞれ最長のフルスペルの月名、最長の省略形の月名、最長のフルスペルの曜日または最長の省略形の曜日の幅まで、後続空白が埋め込まれます。たとえば、NLS_DATE_LANGUAGEがAMERICANでNLS_CALENDARがGREGORIAN(デフォルト)の場合、MONTHの最大要素はSEPTEMBERであるため、MONTH書式要素のすべての値は表示文字が9文字になるまで埋め込まれます。NLS_DATE_LANGUAGEパラメータおよびNLS_CALENDARパラメータの値は、TO_CHARおよびTO_*日時ファンクションの3番目の引数で指定されるか、または現行セッションのNLS環境から取得されます。
SP、SPTHおよびTHSP接尾辞)には埋め込まれません。
FM修飾子を使用すると、TO_CHARファンクションの戻り値で前述の埋込みは行われなくなります。
Format exact(厳密な書式一致)です。この修飾子は、TO_DATEファンクションの文字引数と日時書式モデルに対して、厳密な一致を指定します。
FXを指定していない場合、Oracleは余分な空白を無視します。
FXを指定していない場合、文字引数における数値によっては先行0(ゼロ)が省略されます。FXが使用可能になっているとき、FM修飾子を指定して、この先行0(ゼロ)のチェックを使用禁止にできます。
文字引数の位置がこれらの条件に違反する場合、Oracleはエラー・メッセージを戻します。
次の文は、日付書式モデルを使用して文字式を戻します。
SELECT TO_CHAR(SYSDATE, 'fmDDTH')||' of '||TO_CHAR (SYSDATE, 'fmMonth')||', '||TO_CHAR(SYSDATE, 'YYYY') "Ides" FROM DUAL; Ides ------------------ 3RD of April, 1998
この文はFM修飾子も使用していることに注目してください。FMを指定しないと、月は、次のように空白を埋め込んで9文字にして戻されます。
SELECT TO_CHAR(SYSDATE, 'DDTH')||' of '|| TO_CHAR(SYSDATE, 'Month')||', '|| TO_CHAR(SYSDATE, 'YYYY') "Ides" FROM DUAL; Ides ----------------------- 03RD of April , 1998
次の文は、2つの連続した一重引用符を含む日付書式モデルを使用することによって、戻り値に一重引用符を含めます。
SELECT TO_CHAR(SYSDATE, 'fmDay')||'''s Special' "Menu" FROM DUAL; Menu ----------------- Tuesday's Special
書式モデル内の文字リテラルにおいても、同じ目的で一重引用符を2つ連続して使用できます。
表2-17に、char値と'fmt'の様々な組合せに対し、次の文がFXを使用した一致条件を満たしているかどうかを示します(tableという名前の表にはDATEデータ型の列date_columnがあります)。
UPDATE table SET date_column = TO_DATE(char, 'fmt');
書式モデルを使用して、データベースから値を戻す場合にOracleが使用する書式を指定できます。
次の文は、部門80の従業員の給与を選択し、TO_CHARファンクションを使用して、その給与を数値書式モデル'$99,990.99'で指定した書式の文字値に変換します。
SELECT last_name employee, TO_CHAR(salary, '$99,990.99') FROM employees WHERE department_id = 80;
Oracleはこの書式モデルによって、ドル記号を先頭に付け、3桁ごとにカンマで区切り、小数点以下2桁を持つ給与を戻します。
次の文は、部門20の各従業員の入社した日付を選択し、TO_CHARファンクションを使用して、その日付を日付書式モデル'fmMonth DD, YYYY'で指定した書式の文字列に変換します。
SELECT last_name employee, TO_CHAR(hire_date,'fmMonth DD, YYYY') hiredate FROM employees WHERE department_id = 20;
Oracleはこの書式モデルによって、2桁の日、世紀も含めた4桁の年で示された入社日付(fmで指定)を空白で埋めないで戻します。
列の値を挿入または更新する場合、指定する値のデータ型は列のデータ型と一致している必要があります。書式モデルを使用して、あるデータ型の値を列が必要とする別のデータ型の値に変換する書式を指定できます。
たとえば、DATE列に挿入する値は、DATEデータ型の値か、またはデフォルト日付書式の文字列値である必要があります(Oracleは、暗黙的にデフォルト日付書式の文字列をDATEデータ型に変換します)。値が別の書式で与えられる場合、TO_DATEファンクションを使用して値をDATEデータ型に変換する必要があります。また、文字列の書式を指定する場合にも、書式モデルを使用する必要があります。
次の文は、TO_DATEファンクションを使用してHunoldの入社日を更新します。文字列'1998 05 20'をDATE値に変換するために、書式マスク'YYYY MM DD'を指定します。
UPDATE employees SET hire_date = TO_DATE('1998 05 20','YYYY MM DD') WHERE last_name = 'Hunold';
次の追加の書式化規則は、文字列値を日付値に変換する場合に適用されます(ただし、書式モデルで修飾子FMとFXを使用して書式検査を制御した場合は適用できません)。
| 元の書式要素 | 元の書式要素のかわりに試行する書式要素 |
|---|---|
'MM' |
|
|
|
|
|
|
|
|
|
|
|
|
|
SYS_XMLGENファンクションは、XML文書を含むXMLType型のインスタンスを戻します。Oracleでは、SYS_XMLGENファンクションの結果をフォーマットするXMLFormatオブジェクトを提供します。
表2-19に、XMLFormatオブジェクトの属性を示します。表に示すように、ファンクションはこの型を実装します。
|
参照:
|
XMLFormatオブジェクトを実装するファンクションは、次のとおりです。
STATIC FUNCTION createFormat( enclTag IN varchar2 := 'ROWSET', schemaType IN varchar2 := 'NO_SCHEMA', schemaName IN varchar2 := null, targetNameSpace IN varchar2 := null, dburlPrefix IN varchar2 := null, processingIns IN varchar2 := null) RETURN XMLGenFormatType deterministic parallel_enable, MEMBER PROCEDURE genSchema (spec IN varchar2), MEMBER PROCEDURE setSchemaName(schemaName IN varchar2), MEMBER PROCEDURE setTargetNameSpace(targetNameSpace IN varchar2), MEMBER PROCEDURE setEnclosingElementName(enclTag IN varchar2), MEMBER PROCEDURE setDbUrlPrefix(prefix IN varchar2), MEMBER PROCEDURE setProcessingIns(pi IN varchar2), CONSTRUCTOR FUNCTION XMLGenFormatType ( enclTag IN varchar2 := 'ROWSET', schemaType IN varchar2 := 'NO_SCHEMA', schemaName IN varchar2 := null, targetNameSpace IN varchar2 := null, dbUrlPrefix IN varchar2 := null, processingIns IN varchar2 := null) RETURN SELF AS RESULT deterministic parallel_enable, STATIC function createFormat2( enclTag in varchar2 := 'ROWSET', flags in raw) return sys.xmlgenformattype deterministic parallel_enable );
行のある列の値がない場合、その列はNULLである、またはNULLを含むといいます。NOT NULL整合性制約またはPRIMARY KEY整合性制約によって制限されていない列の場合は、どのデータ型の列でもNULLを含むことができます。実際のデータ値が不定または値に意味がない場合に、NULLを使用してください。
Oracle Databaseは、長さが0(ゼロ)の文字値をNULLとして処理します。ただし、NULLは値0(ゼロ)と同じではないため、0(ゼロ)の数値を表すためにNULL値を使用しないでください。
NULLを含む算術式は、必ずNULLに評価されます。たとえば、NULLに10を加算しても結果はNULLです。実際、オペランドにNULLを指定した場合、(連結演算子を除く)すべての演算子はNULLを戻します。
ほとんどのスカラー・ファンクションでは、引数としてNULLを指定するとNULLが戻されます。NVLファンクションを使用した場合、NULLが発生したときに値を戻すことができます。たとえば、式NVL(commission_pct,0)は、commission_pctがNULLの場合は0(ゼロ)を戻し、commission_pctがNULLでなければその値を戻します。
集計ファンクションによるNULLの処理の詳細は、「集計ファンクション」を参照してください。
NULLを検査するには、比較条件IS NULLおよびIS NOT NULLのみを使用します。NULLを他の条件で使用して、その結果がNULLの値に依存する場合、結果はUNKNOWNになります。NULLはデータの欠落を表すため、任意の値や別のNULLとの関係で等号や不等号は成り立ちません。ただし、OracleはDECODEファンクションを評価するときに2つのNULLを等しい値とみなします。構文および追加情報については、「DECODE」を参照してください。
コンポジット・キーの場合、2つのNULLは等しいと判断されます。NULLを含む2つのコンポジット・キーは、そのキーのNULL以外のコンポーネントのすべてが等しい場合、同一であると判断されます。
UNKNOWNとして評価される条件は、FALSEと評価される場合とほとんど同じ働きをします。たとえば、UNKNOWNと評価される条件をWHERE句に持つSELECT文からは、行が戻されません。ただし、UNKNOWNと評価される条件はFALSE条件とは異なり、UNKNOWN条件をさらに評価してもUNKNOWNと評価されます。したがって、NOT FALSEはTRUEと評価されますが、NOT UNKNOWNはUNKNOWNと評価されます。
表2-20は、条件にNULLを含む評価の例です。SELECT文のWHERE句でUNKNOWNと評価される条件が使用された場合、その問合せに対して行は戻されません。
NULLを含む論理条件の結果を示した真理値表は、表7-5、表7-6、および表7-7を参照してください。
次の2種類のコメントを作成できます。
コメントは、アプリケーションを読みやすく、メンテナンスしやすくします。たとえば、文にはアプリケーションでのその文の目的を記述したコメントを含めることができます。SQL文中のコメントは文の実行には影響しませんが、ヒントは例外です。この特殊なコメント形式を使用する場合の詳細は、「ヒントの使用方法」を参照してください。
コメントは、文中のキーワード、パラメータまたは句読点の間に入れることができます。次のいずれかの方法を使用します。
SQLの入力に使用するツール製品には、追加の制限事項があるものもあります。たとえば、SQL*Plusを使用している場合、デフォルトでは複数行のコメント内に空白行を入れることはできません。詳細は、データベースのインタフェースとして使用するツール製品のドキュメントを参照してください。
SQL文の中に両方のスタイルのコメントが複数あってもかまいません。コメントのテキストには、使用しているデータベース・キャラクタ・セットの印字可能文字を含めることができます。
次の文には多くのコメントが含まれています。
SELECT last_name, salary + NVL(commission_pct, 0), job_id, e.department_id /* Select all employees whose compensation is greater than that of Pataballa.*/ FROM employees e, departments d /*The DEPARTMENTS table is used to get the department name.*/ WHERE e.department_id = d.department_id AND salary + NVL(commission_pct,0) > /* Subquery: */ (SELECT salary + NVL(commission_pct,0) /* total compensation is salar + commission_pct */ FROM employees WHERE last_name = 'Pataballa'); SELECT last_name, -- select the name salary + NVL(commission_pct, 0),-- total compensation job_id, -- job e.department_id -- and department FROM employees e, -- of all employees departments d WHERE e.department_id = d.department_id AND salary + NVL(commission_pct, 0) > -- whose compensation -- is greater than (SELECT salary + NVL(commission_pct,0) -- the compensation FROM employees WHERE last_name = 'Pataballa') -- of Pataballa. ;
COMMENTコマンドを使用して、スキーマ・オブジェクト(表、ビュー、マテリアライズド・ビュー、演算子、索引タイプ、マイニング・モデル)にコメントを付けることができます。表スキーマ・オブジェクトの一部である列にもコメントを作成できます。スキーマ・オブジェクトおよび非スキーマ・オブジェクトに付けたコメントは、データ・ディクショナリに格納されます。このコメントの形式の詳細は、「COMMENT」を参照してください。
Oracle Databaseのオプティマイザに指示(ヒント)を与えるために、SQL文中でコメントを使用できます。オプティマイザは、オプティマイザの動作を阻止する条件が存在しないかぎり、これらのヒントを使用して文の実行計画を選択します。
文ブロックには、ヒントを含むコメントは1つのみ指定できます。このコメントは、SELECT、UPDATE、INSERT、MERGEまたはDELETEのいずれかのキーワードの後でのみ指定できます。INSERT文では次の2つのヒントのみを使用します。APPENDヒントは常にINSERTキーワードの後で指定し、PARALLELヒントはINSERTキーワードの後で指定できます。
次の構文図は、Oracleが文ブロック内でサポートする両方のスタイルのコメントに含まれるヒントの構文です。ヒント構文は、文ブロックを開始するINSERT、UPDATE、DELETE、SELECTまたはMERGEのいずれかのキーワードの直後でのみ指定できます。
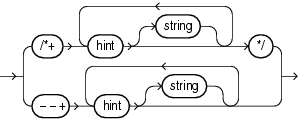
それぞれの意味は、次のとおりです。
hintは、この項で説明するヒントの1つです。プラス記号とヒントの間の空白は入れても入れなくてもかまいません。コメントに複数のヒントが含まれている場合は、1つ以上の空白で区切る必要があります。
stringは、ヒントに含めることができるその他のコメント・テキストです。
--+構文では、コメント全体を単一行で指定する必要があります。
Oracle Databaseは、次の状況ではヒントを無視し、エラーを戻しません。
DELETE、INSERT、MERGE、SELECTまたはUPDATEのいずれかのキーワードの後で指定していない場合。
多くのヒントは、特定の表や索引に適用することも、ビュー内の表や、索引の一部である列によりグローバルに適用することもできます。このようなグローバル・ヒントは、構文要素tablespecおよびindexspecによって定義します。

アクセスする表は、文で示されるとおり正確に指定する必要があります。文が表の別名を使用している場合は、ヒントでも表名を使用せずに別名を使用します。ただし、文でスキーマ名を指定している場合でも、ヒント内ではスキーマ名を表名に含めないでください。
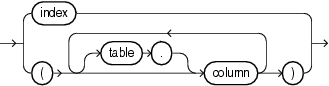
ヒントの仕様でtablespecの後にindexspecを指定する場合、表名と索引名をカンマで区切ることができます。ただし、このカンマは必須ではありません。indexspecを複数指定する場合もカンマで区切ることができます(必須ではありません)。
多くのヒントでオプションの問合せブロック名を指定して、ヒントが適用される問合せブロックを指定できます。この構文によって、インライン・ビューに適用されるヒントを外部問合せ内で指定できます。
問合せブロックの引数の構文は、@queryblockの形式になります。ここでqueryblockは問合せ内で問合せブロック指定する識別子です。queryblock識別子は、システムで生成されるかまたはユーザーによって指定されます。ヒントが適用される問合せブロック内でヒントを指定する場合は、@queryblock構文を指定しません。
EXPLAIN PLAN文を使用して取得できます。変換前の問合せブロック名は、NO_QUERY_TRANSFORMATIONヒントを使用している問合せに対してEXPLAIN PLANを実行することで調べることができます。「NO_QUERY_TRANSFORMATIONヒント」を参照してください。
QB_NAMEヒントで指定できます。「QB_NAMEヒント」を参照してください。
表2-21に、機能のカテゴリに分類したヒントと、各ヒントの構文とセマンティクスの参照先を示します。表の後には、ヒントをアルファベット順に説明します。
この項では、すべてのヒントの構文とセマンティクスをアルファベット順に説明します。

ALL_ROWSヒントは、文ブロックが最高のスループットになるよう(リソースの消費が最小になるよう)、オプティマイザに最適化の指示をします。たとえば、オプティマイザは問合せの最適化アプローチを使用して、この文を最高のスループットに最適化します。
SELECT /*+ ALL_ROWS */ employee_id, last_name, salary, job_id FROM employees WHERE employee_id = 7566;
ALL_ROWSまたはFIRST_ROWSヒントのいずれかをSQL文で指定する場合に、この文でアクセスする表の統計情報がデータ・ディクショナリにないと、オプティマイザは該当する表に割り当てられている記憶域など、デフォルトの統計値を使用して欠落している統計値を推定し、実行計画を選択します。このような推定値は、DBMS_STATSパッケージで収集した値ほど正確でない場合があるため、統計情報の収集にはDBMS_STATSパッケージを使用する必要があります。
アクセス・パスまたは結合操作のヒントをALL_ROWSまたはFIRST_ROWSヒントとともに指定する場合、オプティマイザでは、ヒントで指定されたアクセス・パスまたは結合操作が優先されます。

APPENDヒントは、ダイレクト・パス・インサート文を使用するようオプティマイザに指示します。
INSERTはシリアル・モードでのデフォルトです。シリアル・モードでは、ダイレクト・パスはAPPENDヒントを指定する場合にのみ使用できます。
NOAPPENDヒントを指定する場合にのみ使用できます。
INSERTをパラレルにするかどうかの決定は、APPENDヒントとは関係ありません。
ダイレクト・パス・インサートの場合、データは現在表に割り当てられている既存の空き領域を使用せず、表の最後に追加されます。その結果、ダイレクト・パス・インサートは、従来型INSERTよりも高速に処理されます。
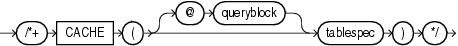
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
CACHEヒントは、全表スキャンの実行時に、この表に対して取り出されたブロックを、バッファ・キャッシュ内のLRUリストの最高使用頻度側に入れるようオプティマイザに指定します。このヒントは、小規模な参照表で有効です。
次の例では、CACHEヒントが表のデフォルト・キャッシュ仕様を上書きします。
SELECT /*+ FULL (hr_emp) CACHE(hr_emp) */ last_name FROM employees hr_emp;
CACHEおよびNOCACHEヒントは、V$SYSSTATデータ・ディクショナリ・ビューで示すように、システム統計情報table scans (long tables)およびtable scans (short tables)に影響を与えます。
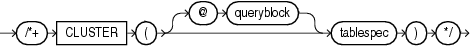
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
CLUSTERヒントは、クラスタ・スキャンを使用して、指定した表にアクセスするようオプティマイザに指示します。このヒントは、クラスタ化された表にのみ適用されます。

Oracleでは、置換しても安全な場合には、SQL文内のリテラルをバインド変数に置き換えることができます。この置換処理は、CURSOR_SHARING初期化パラメータを使用して制御します。CURSOR_SHARING_EXACTヒントは、この動作を行わないようオプティマイザに指示します。このヒントを指定すると、Oracleは、リテラルのバインド変数への置換を試行せずにSQL文を実行します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
DRIVING_SITEヒントは、データベースによって選択されたサイトとは異なるサイトで問合せを実行するようオプティマイザに指示します。このヒントは、分散化された問合せの最適化を使用している場合に有効です。
次に例を示します。
SELECT /*+ DRIVING_SITE(departments) */ * FROM employees, departments@rsite WHERE employees.department_id = departments.department_id;
この問合せがヒントなしで実行されている場合、departmentsからの行がローカル・サイトに送信され、そこで結合が実行されます。このヒントを使用している場合、employeesからの行がリモート・サイトに送信され、そこで問合せが実行されて結果セットがローカル・サイトに戻されます。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
DYNAMIC_SAMPLINGヒントは、動的なサンプリングを制御する方法をオプティマイザに指示し、より正確な述語の選択性と表および索引に対する統計情報を調べることでサーバーのパフォーマンスを改善します。
DYNAMIC_SAMPLINGの値は、0〜10の範囲で設定できます。このレベルが高いほど、コンパイラは多くのリソースを動的なサンプリングに費やし、その適用範囲も広がります。tablespecを指定しない場合、サンプリングのデフォルトは、カーソルのレベルになります。
integerの値は0〜10となり、サンプリングの度合いを示します。
カーディナリティ統計情報が表にすでに存在する場合、オプティマイザはその情報を使用します。存在しない場合、オプティマイザは動的なサンプリングによってカーディナリティ統計情報を推定します。
tablespecを指定しており、カーディナリティ統計情報がすでに存在している場合は、次のようになります。
WHERE句)がない場合、オプティマイザは既存の統計情報を信頼し、このヒントを無視します。たとえば、employeesが分析される場合、次の問合せは動的なサンプリングにはなりません。
SELECT /*+ dynamic_sampling(e 1) */ count(*) FROM employees e;
動的なサンプリングを特定の表に適用するには、次の形式のヒントを使用します。
SELECT /*+ dynamic_sampling(employees 1) */ * FROM employees WHERE ...

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
FACTヒントは、スター型変換のコンテキストで使用されます。このヒントは、tablespec内で指定されている表をファクト表とみなす必要があることをオプティマイザに指示します。

FIRST_ROWSヒントは、最初のn行を最も効率的に戻す計画を選択し、個々のSQL文を最適化して応答時間を速くするようOracleに指示します。integerには、戻される行数を指定します。
たとえば、オプティマイザは問合せの最適化アプローチを使用して、次の文を最善の応答時間に最適化します。
SELECT /*+ FIRST_ROWS(10) */ employee_id, last_name, salary, job_id FROM employees WHERE department_id = 20;
この例では、各部門に多数の従業員がいます。ユーザーは、部門20の最初の10人の従業員を迅速に表示する必要があります。
オプティマイザは、DELETEおよびUPDATEの文ブロック、およびソートまたはグループ化などのブロッキング操作を含むSELECT文ブロックではこのヒントを無視します。Oracle Databaseでは最初の行を戻す前に、この文でアクセスされるすべての行を取り出す必要があるため、このような文は最善の応答時間に最適化することができません。このヒントをこのような文で指定する場合は、データベースを最善のスループットに最適化します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
FULLヒントは、指定した表に対して全表スキャンを実行するようオプティマイザに指示します。次に例を示します。
SELECT /*+ FULL(e) */ employee_id, last_name FROM hr.employees e WHERE last_name LIKE :b1;
Oracle Databaseは、WHERE句内の条件によって使用可能になるlast_name列に索引がある場合でも、employees表に対して全表スキャンを実行し、この文を実行します。
employees表は、FROM句の中に別名eを持つため、ヒントは表名ではなく別名で表を参照する必要があります。スキーマ名がFROM句の中で指定されている場合でも、ヒントではスキーマ名を指定しないでください。
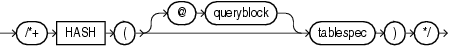
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
HASHヒントは、ハッシュ・スキャンを使用して、指定した表にアクセスするようオプティマイザに指示します。このヒントは、テーブル・クラスタ内に格納されている表にのみ適用されます。

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEXヒントは、指定した表について索引スキャンを使用するようオプティマイザに指示します。ファンクション索引、ドメイン索引、Bツリー索引、ビットマップ索引およびビットマップ結合索引について、INDEXヒントを使用できます。
ヒントの動作は、indexspecの仕様によって異なります。
INDEXヒントが使用可能な単一の索引を指定すると、データベースはこの索引でスキャンを実行します。オプティマイザは、全表スキャンおよび表上の別の索引のスキャンを考慮しません。
INDEXではなくINDEX_COMBINEヒントの使用をお薦めします。これは、後者のほうがより多目的なヒントであるためです。INDEXヒントが使用可能な索引のリストを指定すると、オプティマイザは、リスト内の各索引でのスキャンのコストを検討し、最低のコストで索引スキャンを実行します。アクセス・パスのコストが最低となる場合、データベースは、このリストから複数の索引をスキャンするように選択し、結果をマージすることもあります。データベースは、全表スキャンおよびヒント内でリスト化されていない索引でのスキャンを検討しません。
INDEXヒントが索引を指定しない場合、オプティマイザは、表にある使用可能な各索引でのスキャンのコストを検討し、最低のコストで索引スキャンを実行します。アクセス・パスのコストが最低となる場合、データベースは複数の索引をスキャンするように選択し、結果をマージすることもあります。オプティマイザは全表スキャンを検討しません。
次に例を示します。
SELECT /*+ INDEX (employees emp_department_ix)*/ employee_id, department_id FROM employees WHERE department_id > 50;
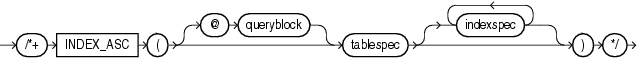
(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_ASCヒントは、指定した表について索引スキャンを使用するようオプティマイザに指示します。文で索引レンジ・スキャンを使用する場合、Oracle Databaseは索引付きの値の昇順で索引エントリをスキャンします。各パラメータは、「INDEXヒント」と同じ目的で使用されます。
レンジ・スキャンのデフォルトの動作は、索引付きの値の昇順で索引エントリをスキャンします。降順索引の場合は、降順でスキャンします。このヒントは索引のデフォルトの順序を変更しないため、INDEXヒントにないものは指定しません。ただし、デフォルトの動作を変更する必要がある場合は、INDEX_ASCヒントを使用して昇順レンジ・スキャンを明示的に指定できます。

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_COMBINEヒントは、表へのビットマップ・アクセス・パスを使用するようオプティマイザに指示します。indexspecがINDEX_COMBINEヒントから省略されている場合、オプティマイザは、表のスキャンにかかるコスト効率が最大になる索引のブールの組合せを使用します。indexspecを指定すると、オプティマイザは、指定した索引のブールのいくつかの組合せの使用を試行します。各パラメータは、「INDEXヒント」と同じ目的で使用されます。次に例を示します。
SELECT /*+ INDEX_COMBINE(e emp_manager_ix emp_department_ix) */ * FROM employees e WHERE manager_id = 108 OR department_id = 110;

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_DESCヒントは、指定した表に降順索引スキャンを使用するようオプティマイザに指示します。文で索引レンジ・スキャンを使用しており、索引が昇順の場合、Oracleは索引付きの値の降順で索引エントリをスキャンします。パーティション索引では、結果は各パーティション内で降順になります。降順索引の場合、このヒントは降順を効果的に取り消すため、索引エントリは昇順でスキャンされます。各パラメータは、「INDEXヒント」と同じ目的で使用されます。次に例を示します。
SELECT /*+ INDEX_DESC(e emp_name_ix) */ * FROM employees e;
(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_FFSヒントは、全表スキャンではなく高速全索引スキャンを実行するようオプティマイザに指示します。
各パラメータは、「INDEXヒント」と同じ目的で使用されます。次に例を示します。
SELECT /*+ INDEX_FFS(e emp_name_ix) */ first_name FROM employees e;
(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_JOINヒントは、アクセス・パスとして索引結合を使用するようオプティマイザに指示します。ヒントが正しく機能するためには、問合せの解決に必要なすべての列を含む索引が最小限の数だけ存在している必要があります。
各パラメータは、「INDEXヒント」と同じ目的で使用されます。たとえば、次の問合せは、索引結合を使用してmanager_idおよびdepartment_id列にアクセスします。これらの列はどちらも、employees表内で索引付けされています。
SELECT /*+ INDEX_JOIN(e emp_manager_ix emp_department_ix) */ department_id FROM employees e WHERE manager_id < 110 AND department_id < 50;

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_SSヒントは、指定した表について索引スキップ・スキャンを実行するようオプティマイザに指示します。文で索引レンジ・スキャンを使用する場合、Oracleは索引付きの値の昇順で索引エントリをスキャンします。パーティション索引では、結果は各パーティション内で昇順になります。
各パラメータは、「INDEXヒント」と同じ目的で使用されます。次に例を示します。
SELECT /*+ INDEX_SS(e emp_name_ix) */ last_name FROM employees e WHERE first_name = 'Steven';

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_SS_ASCヒントは、指定した表について索引スキップ・スキャンを実行するようオプティマイザに指示します。文で索引レンジ・スキャンを使用する場合、Oracle Databaseは索引付きの値の昇順で索引エントリをスキャンします。パーティション索引では、結果は各パーティション内で昇順になります。各パラメータは、「INDEXヒント」と同じ目的で使用されます。
レンジ・スキャンのデフォルトの動作は、索引付きの値の昇順で索引エントリをスキャンします。降順索引の場合は、降順でスキャンします。このヒントは索引のデフォルトの順序を変更しないため、INDEX_SSヒントにないものは指定しません。ただし、デフォルトの動作を変更する必要がある場合は、INDEX_SS_ASCヒントを使用して昇順レンジ・スキャンを明示的に指定できます。

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_SS_DESCヒントは、指定した表について索引スキップ・スキャンを実行するようオプティマイザに指示します。文で索引レンジ・スキャンを使用しており、索引が昇順の場合、Oracleは索引付きの値の降順で索引エントリをスキャンします。パーティション索引では、結果は各パーティション内で降順になります。降順索引の場合、このヒントは降順を効果的に取り消すため、索引エントリは昇順でスキャンされます。
各パラメータは、「INDEXヒント」と同じ目的で使用されます。次に例を示します。
SELECT /*+ INDEX_SS_DESC(e emp_name_ix) */ last_name FROM employees e WHERE first_name = 'Steven';

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
LEADINGヒントは、実行計画において、指定した一連の表を接頭辞として使用するようオプティマイザに指示します。このヒントは、ORDEREDヒントより多目的なヒントです。次に例を示します。
SELECT /*+ LEADING(e j) */ * FROM employees e, departments d, job_history j WHERE e.department_id = d.department_id AND e.hire_date = j.start_date;
図形結合の依存性により、指定の表を指定の順序の最初に結合できない場合、LEADINGヒントは無視されます。2つ以上の競合するLEADINGヒントを指定すると、指定したすべてのヒントが無視されます。ORDEREDヒントを指定すると、このヒントがすべてのLEADINGヒントに優先します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
MERGEヒントを使用すると、問合せ内のビューをマージできます。
ビューの問合せブロックにGROUP BY句、またはSELECTリスト内のDISTINCT演算子が含まれている場合、複雑なビューのマージが可能であれば、オプティマイザはビューをアクセス文のみにマージできます。複雑なマージは、副問合せに相関関係がない場合、IN副問合せをアクセス文にマージする際に使用することもできます。
次に例を示します。
SELECT /*+ MERGE(v) */ e1.last_name, e1.salary, v.avg_salary FROM employees e1, (SELECT department_id, avg(salary) avg_salary FROM employees e2 GROUP BY department_id) v WHERE e1.department_id = v.department_id AND e1.salary > v.avg_salary;
引数なしでMERGEヒントを使用する場合、ビューの問合せブロック内に配置する必要があります。ビュー名を引数としてMERGEヒントを使用する場合、周囲の問合せに挿入する必要があります。

MODEL_MIN_ANALYSISヒントは、スプレッドシート・ルールのコンパイル時間の最適化(主に、詳細な依存グラフ分析)を省略するようオプティマイザに指示します。スプレッドシートのアクセス構造に選択的に移入するためのフィルタの作成や制限されたルールのプルーニングなど、他のスプレッドシートの最適化は、引き続きオプティマイザによって使用されます。
スプレッドシート・ルールの数が数百を超えると、スプレッドシート分析に長い時間がかかることがあるため、このヒントによってコンパイル時間を減らします。

MONITORヒントは、文の実行時間が長くない場合でも、問合せのリアルタイムのSQL監視を強制します。このヒントは、パラメータCONTROL_MANAGEMENT_PACK_ACCESSがDIAGNOSTIC+TUNINGに設定されている場合にのみ有効です。

NATIVE_FULL_OUTER_JOINヒントは、ネイティブ完全外部結合を使用するようオプティマイザに指示します。ネイティブ完全外部結合は、ハッシュ結合に基づくネイティブ実行メソッドです。

NOAPPENDヒントは、INSERT文が有効な間、パラレル・モードを無効にして従来型のINSERTを使用するようにオプティマイザに指示します。従来型のINSERTはシリアル・モードでのデフォルトです。また、ダイレクト・パス・インサートはパラレル・モードでのデフォルトです。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NOCACHEヒントは、全表スキャンの実行時に、この表に対して取り出されたブロックを、バッファ・キャッシュ内のLRUリストの最低使用頻度側に入れるようオプティマイザに指定します。これは、バッファ・キャッシュ内のブロックの通常動作です。次に例を示します。
SELECT /*+ FULL(hr_emp) NOCACHE(hr_emp) */ last_name FROM employees hr_emp;
CACHEおよびNOCACHEヒントは、V$SYSSTATビューで示すように、システム統計情報table scans(long tables)およびtable scans(short tables)に影響を与えます。
(「ヒントでの問合せブロックの指定」を参照)
NO_EXPANDヒントは、OR条件を持つ問合せ用のOR拡張、またはWHERE句内にあるINリストを検討しないようオプティマイザに指示します。通常、オプティマイザは、OR拡張を使用しない場合よりもコストが低減できると判断すると、OR拡張の使用を検討します。次に例を示します。
SELECT /*+ NO_EXPAND */ * FROM employees e, departments d WHERE e.manager_id = 108 OR d.department_id = 110;

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_FACTヒントは、スター型変換のコンテキストで使用されます。このヒントは、問合せ対象の表をファクト表とみなす必要がないことをオプティマイザに指示します。

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
NO_INDEXヒントは、指定した表について1つ以上の索引を使用しないようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_INDEX(employees emp_empid) */ employee_id FROM employees WHERE employee_id > 200;
各パラメータは「INDEXヒント」と同じ目的で使用されますが、次の変更が加えられています。
NO_INDEXヒントと同様になります。
NO_INDEXヒントは、ファンクション索引、Bツリー索引、ビットマップ索引、クラスタ索引およびドメイン索引に適用されます。NO_INDEXヒントと索引ヒント(INDEX、INDEX_ASC、INDEX_DESC、INDEX_COMBINEまたはINDEX_FFS)の両方が同じ索引を指定する場合、データベースは、NO_INDEXヒントと、指定した索引の索引ヒントの両方を無視し、これらの索引を文の実行中に使用することを検討します。

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
NO_INDEX_FFSヒントは、指定された表の指定された索引の高速全索引スキャンを除外するようオプティマイザに指示します。各パラメータは、「INDEXヒント」と同じ目的で使用されます。次に例を示します。
SELECT /*+ NO_INDEX_FFS(items item_order_ix) */ order_id FROM order_items items;
(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
NO_INDEX_SSヒントは、指定された表の指定された索引のスキップ・スキャンを除外するようオプティマイザに指示します。各パラメータは、「INDEXヒント」と同じ目的で使用されます。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_MERGEヒントは、外部問合せとインライン・ビュー問合せを結合して単一の問合せにしないようオプティマイザに指示します。
このヒントを使用すると、ビューへのアクセス方法に強い影響を与えることができます。たとえば、次の文は、ビューseattle_deptがマージされないようにします。
SELECT /*+NO_MERGE(seattle_dept)*/ e1.last_name, seattle_dept.department_name FROM employees e1, (SELECT location_id, department_id, department_name FROM departments WHERE location_id = 1700) seattle_dept WHERE e1.department_id = seattle_dept.department_id;
ビューの問合せブロック内でNO_MERGEヒントを使用する場合は、引数なしで指定します。また、周囲の問合せでNO_MERGEを指定する場合には、ビュー名を引数として指定します。

NO_MONITORヒントは、問合せの実行時間が長い場合でも、問合せのSQLのリアルタイム監視を無効にします。

NO_NATIVE_FULL_OUTER_JOINヒントは、指定された各表を結合する場合にネイティブ実行メソッドを除外するようオプティマイザに指示します。かわりに、完全外部結合は、左側外部結合とアンチ結合の論理和として実行されます。
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_PARALLELヒントは、表を作成するか変更したDDL内のPARALLELパラメータを上書きします。次に例を示します。
SELECT /*+ NO_PARALLEL(hr_emp) */ last_name FROM employees hr_emp;
NOPARALLELヒントは現在非推奨になっています。NO_PARALLELヒントをかわりに使用します。

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
NO_PARALLEL_INDEXヒントは、索引を作成するか変更したDDL内のPARALLELパラメータを上書きし、パラレル索引スキャン操作を防止します。
NOPARALLEL_INDEXヒントは現在非推奨になっています。NO_PARALLEL_INDEXヒントをかわりに使用します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_PUSH_PREDヒントは、結合述語をビューにプッシュしないようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_MERGE(v) NO_PUSH_PRED(v) */ * FROM employees e, (SELECT manager_id FROM employees ) v WHERE e.manager_id = v.manager_id(+) AND e.employee_id = 100;
(「ヒントでの問合せブロックの指定」を参照)
NO_PUSH_SUBQヒントは、実行計画における最後の手順として、マージされていない副問合せを評価するようオプティマイザに指示します。これにより、副問合せのコストが比較的高い場合や、副問合せによって行数が大幅に減少しない場合に、パフォーマンスが向上する場合があります。

このヒントは、オプティマイザがパラレル結合のビットマップ・フィルタ処理を使用するのを防ぎます。
NO_QUERY_TRANSFORMATIONヒントは、すべての問合せ変換をスキップするようオプティマイザに指示します。この中には、OR拡張、ビュー・マージ、副問合せのネスト解除、スター型変換、マテリアライズド・ビュー・リライトなどが含まれますが、これのみに限定されません。次に例を示します。
SELECT /*+ NO_QUERY_TRANSFORMATION */ employee_id, last_name FROM (SELECT * FROM employees e) v WHERE v.last_name = 'Smith';

RESULT_CACHE_MODE初期化パラメータがFORCEに設定されていると、オプティマイザは、問合せ結果を結果キャッシュにキャッシュします。この場合、NO_RESULT_CACHEヒントにより、このような現行の問合せのキャッシュが無効になります。
問合せがOCIクライアントから実行され、OCIクライアントの結果キャッシュが有効になっている場合、NO_RESULT_CACHEヒントにより現行の問合せキャッシュが無効になります。
(「ヒントでの問合せブロックの指定」を参照)
NO_REWRITEヒントは、パラメータQUERY_REWRITE_ENABLEDの設定を上書きして、問合せブロック用のクエリー・リライトを無効にするようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_REWRITE */ sum(s.amount_sold) AS dollars FROM sales s, times t WHERE s.time_id = t.time_id GROUP BY t.calendar_month_desc;
NOREWRITEヒントは現在非推奨になっています。NO_REWRITEヒントをかわりに使用します。
(「ヒントでの問合せブロックの指定」を参照)
NO_STAR_TRANSFORMATIONヒントは、問合せのスター型問合せ変換を実行しないようオプティマイザに指示します。
(「ヒントでの問合せブロックの指定」を参照)
NO_UNNESTヒントを使用するとネスト解除をオフに切り替えます。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_USE_HASHヒントは、指定された表を内部表として使用して、指定された各表を別の行のソースに結合する際にハッシュ結合を除外するようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_USE_HASH(e d) */ * FROM employees e, departments d WHERE e.department_id = d.department_id;

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_USE_MERGEヒントは、指定された表を内部表として使用して、指定された各表を別の行のソースに結合する際にソート/マージ結合を除外するようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_USE_MERGE(e d) */ * FROM employees e, departments d WHERE e.department_id = d.department_id ORDER BY d.department_id;
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_USE_NLヒントは、指定された表を内部表として使用して、指定された各表を別の行のソースに結合する際に、ネストしたループ結合を除外するようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_USE_NL(l h) */ * FROM orders h, order_items l WHERE l.order_id = h.order_id AND l.order_id > 3500;
このヒントを指定すると、指定された表についてハッシュ結合とソート/マージ結合のみが検討されます。ただし、ネストしたループのみを使用して表を結合する場合もあります。この場合、オプティマイザは、それらの表に関するヒントを無視します。

NO_XMLINDEX_REWRITEヒントは、現行の問合せにXMLIndex索引を使用しないようにオプティマイザに指示します。次に例を示します。
SELECT /*+NO_XMLINDEX_REWRITE*/ count(*) FROM table WHERE existsNode(OBJECT_VALUE, '/*') = 1;

NO_XML_QUERY_REWRITEヒントは、SQL文のXPath式のリライトを禁止するようオプティマイザに指示します。このヒントは、XPath式のリライトを禁止することで、現行の問合せでのXMLIndex索引の使用も禁止します。次に例を示します。
SELECT /*+NO_XML_QUERY_REWRITE*/ XMLQUERY('<A/>') FROM dual;

OPT_PARAMヒントを使用すると、現行の問合せ中にのみ初期化パラメータを設定できます。このヒントは、パラメータOPTIMIZER_DYNAMIC_SAMPLING、OPTIMIZER_INDEX_CACHING、OPTIMIZER_INDEX_COST_ADJ、OPTIMIZER_SECURE_VIEW_MERGINGおよびSTAR_TRANSFORMATION_ENABLEDに対してのみ有効です。たとえば、次のヒントは、ヒントを追加した文のパラメータSTAR_TRANSFORMATION_ENABLEDをTRUEに設定します。
SELECT /*+ OPT_PARAM('star_transformation_enabled' 'true') */ * FROM ... ;
文字列のパラメータ値は、一重引用符で囲まれます。数値のパラメータ値は、一重引用符で囲まずに指定されます。

ORDEREDヒントは、FROM句に現れる順序で表を結合するようOracleに指示します。ORDEREDヒントより多目的なLEADINGヒントを使用することをお薦めします。
結合を要求するSQL文からORDEREDヒントを削除すると、オプティマイザが表の結合順序を選択します。各表から選択した行数をオプティマイザが把握していないと考えられる場合、ORDEREDヒントを使用して結合順序を指定することがあります。この情報を使用すると、オプティマイザによる選択よりも効率良く内部表と外部表を選択できます。
次の問合せは、ORDEREDヒントの使用例です。
SELECT /*+ORDERED */ o.order_id, c.customer_id, l.unit_price * l.quantity FROM customers c, order_items l, orders o WHERE c.cust_last_name = :b1 AND o.customer_id = c.customer_id AND o.order_id = l.order_id;

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
PARALLELヒントは、指定された数の同時サーバーをパラレル操作に使用するようオプティマイザに指示します。このヒントは、文のSELECT、INSERT、MERGE、UPDATEおよびDELETE部分と表のスキャン部分に適用されます。
パラレル制限に違反すると、ヒントは無視されます。
integer値は、指定された表の並列度を指定します。DEFAULTを指定するか、いかなる値も指定しない場合、問合せコーディネータはデフォルトの並列度を決定するために初期化パラメータの設定を検証する必要があります。次の例では、PARALLELヒントが、employees表定義内で指定された並列度を上書きします。
SELECT /*+ FULL(hr_emp) PARALLEL(hr_emp, 5) */ last_name FROM employees hr_emp;
次の例では、PARALLELヒントが、employees表定義内で指定された並列度を上書きし、初期化パラメータが決定したデフォルトの並列度を使用するようオプティマイザに指示します。
SELECT /*+ FULL(hr_emp) PARALLEL(hr_emp, DEFAULT) */ last_name FROM employees hr_emp;
Oracleは、一時表に関するパラレル・ヒントを無視します。パラレル実行の詳細は、「CREATE TABLE」および『Oracle Database概要』を参照してください。

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
PARALLEL_INDEXヒントは、パーティション索引について索引レンジ・スキャン、全体スキャンおよび高速全体スキャンをパラレル化するために、指定された数の同時サーバーを使用するようオプティマイザに指示します。
integer値は、指定された索引の並列度を示します。DEFAULTを指定するか、いかなる値も指定しない場合、問合せコーディネータはデフォルトの並列度を決定するために初期化パラメータの設定を検証する必要があります。たとえば、次のヒントは、3つのパラレル実行プロセスが使用されることを示します。
SELECT /*+ PARALLEL_INDEX(table1, index1, 3) */

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
PQ_DISTRIBUTEヒントは、結合表の行を、プロデューサおよびコンシューマ問合せサーバーに分散させる方法をオプティマイザに指示します。この分散処理により、パラレル結合操作のパフォーマンスが向上します。
分散の値は、HASH、BROADCAST、PARTITIONおよびNONEです。表2-22で説明するとおり、6つの組合せの表分散のみが有効です。
たとえば、rとsという2つの表がハッシュ結合によって結合されている場合、次の問合せには、ハッシュ分散を使用するためのヒントが含まれます。
SELECT /*+ORDERED PQ_DISTRIBUTE(s HASH, HASH) USE_HASH (s)*/ column_list FROM r,s WHERE r.c=s.c;
外部表rをブロードキャストするための問合せは、次のとおりです。
SELECT /*+ORDERED PQ_DISTRIBUTE(s BROADCAST, NONE) USE_HASH (s) */ column_list FROM r,s WHERE r.c=s.c;

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
PUSH_PREDヒントは、結合述語をビューにプッシュするようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_MERGE(v) PUSH_PRED(v) */ * FROM employees e, (SELECT manager_id FROM employees ) v WHERE e.manager_id = v.manager_id(+) AND e.employee_id = 100;
(「ヒントでの問合せブロックの指定」を参照)
PUSH_SUBQヒントは、実行計画の初期段階で実行可能な手順で、マージされていない副問合せを評価するようオプティマイザに指示します。通常、マージされていない副問合せは、実行計画の最終手順で実行されます。副問合せのコストが比較的低く、副問合せによって行数が大幅に減少する場合、副問合せの早期評価によってパフォーマンスが向上する可能性があります。
このヒントは、副問合せがリモート表か、マージ結合によって結合されている表に適用される場合には効果がありません。
このヒントは、パラレル結合のビットマップ・フィルタ処理の使用をオプティマイザに強制します。
(「ヒントでの問合せブロックの指定」を参照)
QB_NAMEヒントを使用すると、問合せブロックの名前を定義できます。この名前は外部問合せ内のヒントまたはインライン・ビュー内のヒントで使用でき、名前が付けられた問合せブロックにある表で実行する問合せに影響をおよぼします。
2つ以上の問合せブロックが同じ名前の場合、または同じ問合せブロックが異なる名前でヒントが2回行われている場合、オプティマイザは、その問合せブロックを参照するすべての名前とヒントを無視します。このヒントを使用して名前が付けられていない問合せブロックには、システムが生成する一意の名前が付けられます。この名前は計画表に表示できます。また、問合せブロック内のヒントや問合せブロック・ヒントでも使用できます。次に例を示します。
SELECT /*+ QB_NAME(qb) FULL(@qb e) */ employee_id, last_name FROM employees e WHERE last_name = 'Smith';

RESULT_CACHEヒントは、メモリー内の現行の問合せまたは問合せのフラグメントの結果をキャッシュし、今後の問合せまたは問合せのフラグメントの実行時にキャッシュした結果を使用するようデータベースに指示します。このヒントは、トップレベル問合せ、subquery_factoring_clauseまたはFROM句のインライン・ビューで認識されます。キャッシュ結果は、共有プールの結果のキャッシュ・メモリー部分に保存されます。
作成に使用されたデータベース・オブジェクトが正常に修正されると、キャッシュ結果は自動的に無効化されます。このヒントは、RESULT_CACHE_MODE初期化パラメータの設定よりも優先されます。
問合せが結果キャッシュに使用できるのは、問合せで必要とされるすべてのファンクション(たとえば、組込みファンクション、ユーザー定義ファンクションまたは仮想列)が決定的である場合にかぎられます。
問合せがOCIクライアントから実行され、OCIクライアントの結果キャッシュが有効になっている場合、RESULT_CACHEヒントにより現行の問合せのクライアントのキャッシュが有効になります。

(「ヒントでの問合せブロックの指定」を参照)
REWRITEヒントは、可能な場合、コストを考慮することなく、マテリアライズド・ビューに関する問合せをリライトするようオプティマイザに指示します。REWRITEヒントは、ビュー・リストとともに、またはビュー・リストなしで使用します。ビュー・リストとともにREWRITEを使用し、リストに適切なマテリアライズド・ビューが含まれている場合、Oracleはコストを考慮せずにそのビューを使用します。
Oracleでは、リスト外のビューを検討しません。ビュー・リストを指定しない場合、Oracleは適切なマテリアライズド・ビューを検索し、最終計画のコストを考慮することなく常にそのビューを使用します。
(「ヒントでの問合せブロックの指定」を参照)
STAR_TRANSFORMATIONヒントは、変換を行う際に最適な計画を使用するようオプティマイザに指示します。このヒントを使用しない場合、オプティマイザは、変換された問合せ用の最適な計画のかわりに、変換なしで生成された最適な計画を使用するという、問合せの最適化に関する決定を行う場合があります。次に例を示します。
SELECT /*+ STAR_TRANSFORMATION */ * FROM sales s, times t, products p, channels c WHERE s.time_id = t.time_id AND s.prod_id = p.product_id AND s.channel_id = c.channel_id AND p.product_status = 'obsolete';
ヒントが指定された場合でも、変換が実行される保証はありません。オプティマイザは、妥当と考えられる場合にかぎって副問合せを生成します。副問合せが生成されない場合には、変換された問合せが存在しないため、ヒントに関係なく、未変換の問合せに関する最適な計画が使用されます。
(「ヒントでの問合せブロックの指定」を参照)
UNNESTヒントは、副問合せの本体のネストを解除し、その副問合せを含む問合せブロック本体にマージするようオプティマイザに指示します。これによって、アクセス・パスおよび結合の評価時に、オプティマイザが副問合せと問合せブロックを総合して考慮できるようになります。
副問合せのネストを解除する前に、オプティマイザは、文が有効かどうかをまず検討します。文は、経験則に基づくテストと問合せ最適化テストに合格する必要があります。UNNESTヒントは、副問合せブロックの有効性のみをチェックするようオプティマイザに指示します。副問合せブロックが有効な場合、経験則またはコストをチェックすることなく副問合せのネストを解除できます。
|
参照:
|
(「ヒントでの問合せブロックの指定」を参照)
USE_CONCATヒントは、問合せのWHERE句内で組み合わされたOR条件を、集合演算子UNION ALLを使用して複合問合せに変換するようオプティマイザに指示します。このヒントを使用しない場合、この変換は、連結を使用した問合せのコストが、使用しない場合よりも低い場合にのみ実行されます。USE_CONCATヒントは、コストより優先します。次に例を示します。
SELECT /*+ USE_CONCAT */ * FROM employees e WHERE manager_id = 108 OR department_id = 110;

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
USE_HASHヒントは、指定された各表を、ハッシュ結合を使用して別の行のソースに結合するようオプティマイザに指示します。次に例を示します。
SELECT /*+ USE_HASH(l h) */ * FROM orders h, order_items l WHERE l.order_id = h.order_id AND l.order_id > 3500;
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
USE_MERGEヒントは、指定された各表を、ソート/マージ結合を使用して別の行のソースに結合するようオプティマイザに指示します。次に例を示します。
SELECT /*+ USE_MERGE(employees departments) */ * FROM employees, departments WHERE employees.department_id = departments.department_id;
LEADINGおよびORDEREDヒントとともに、USE_NLおよびUSE_MERGEヒントを使用することをお薦めします。オプティマイザは、参照表を結合の内部表にする必要がある場合に、これらのヒントを使用します。参照表が外部表の場合、ヒントは無視されます。
USE_NLヒントは、指定された表を内部表として使用し、指定された各表をネストしたループ結合とともに別の行のソースに結合するようオプティマイザに指示します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
USE_NLヒントは、指定された表を内部表として使用し、指定された各表をネストしたループ結合とともに別の行のソースに結合するようオプティマイザに指示します。
LEADINGおよびORDEREDヒントとともに、USE_NLおよびUSE_MERGEヒントを使用することをお薦めします。オプティマイザは、参照表を結合の内部表にする必要がある場合に、これらのヒントを使用します。参照表が外部表の場合、ヒントは無視されます。
次の例では、ネストしたループがヒントによって強制される場合、全表スキャンを介してordersがアクセスされ、各行にフィルタ条件l.order_id = h.order_idが適用されます。フィルタ条件を満たす各行については、索引order_idを介してorder_itemsがアクセスされます。
SELECT /*+ USE_NL(l h) */ h.customer_id, l.unit_price * l.quantity FROM orders h ,order_items l WHERE l.order_id = h.order_id;
INDEXヒントを問合せに追加すると、ordersの全表スキャンを回避し、より大規模なシステムで使用される実行計画と同様の実行計画を生成できる場合があります。ただし、ここでは特に効果的ではない場合があります。

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
USE_NL_WITH_INDEXヒントは、指定された表を内部表として使用し、指定された表をネストしたループ結合とともに別の行のソースに結合するようオプティマイザに指示します。次に例を示します。
SELECT /*+ USE_NL_WITH_INDEX(l item_product_ix) */ * FROM orders h, order_items l WHERE l.order_id = h.order_id AND l.order_id > 3500;
次の条件が適用されます。
次の項で説明するとおり、Oracle Databaseは、特定のスキーマに対応付けられたオブジェクトと、特定のスキーマに対応付けられていないオブジェクトを認識します。
スキーマは、論理的なデータの構造(スキーマ・オブジェクト)の集まりです。スキーマは、データベース・ユーザーによって所有され、そのユーザーと同じ名前を持ちます。各ユーザーは、1つのスキーマを所有します。スキーマ・オブジェクトは、SQLを使用して作成および操作できます。スキーマ・オブジェクトには次のタイプのオブジェクトがあります。
次のタイプのオブジェクトもデータベースに格納され、SQLで作成および操作されますが、スキーマには含まれません。
各タイプのオブジェクトは、このマニュアルの第10章〜第19章のデータベース・オブジェクトを作成する文の項で説明されています。これらの文は、キーワードCREATEで始まります。たとえば、クラスタの定義については、「CREATE CLUSTER」を参照してください。
ほとんどのデータベース・オブジェクトでは、作成時に名前を指定する必要があります。名前は、この後の項に示す規則に従って付けてください。
スキーマ・オブジェクトの中には、名前を付けることができる、または名前を付ける必要のある部分で構成されるものもあります。たとえば、表やビューの中の列、索引と表のパーティションおよびサブパーティション、表に対する整合性制約、パッケージ内に格納されるオブジェクト(プロシージャおよびストアド・ファンクションを含む)などです。この項では、次の内容について説明します。
すべてのデータベース・オブジェクトには、名前があります。SQL文では、引用識別子または非引用識別子を使用して、オブジェクトの名前を表します。
データベース・オブジェクトを指定する場合、引用識別子または非引用識別子を使用できます。データベース名、グローバル・データベース名およびデータベース・リンク名では大/小文字は区別されませんが、大文字として保存されます。このような名前を引用識別子として指定する場合、引用符は特に警告もなく無視されます。ユーザー名とパスワードのネーミング規則の詳細は、「CREATE USER」を参照してください。
特に指定がないかぎり、次の規則は、引用識別子と非引用識別子の両方に適用されます。
識別子にピリオドで区切られた複数の部分が含まれる場合、各属性の長さは最大30バイトにできます。ピリオドによる各セパレータおよび周囲の二重引用符は1バイトとしてカウントします。たとえば、次のように列を識別するとします。
"schema"."table"."column"
スキーマ名、表名、列名の長さはそれぞれ30バイトです。各引用符やピリオドはシングルバイト文字のため、この例での識別子の総バイト長は、最大98バイトになります。
名前は、データベース・オブジェクトにアクセスするために使用するOracle製品固有のその他の予約語によって、さらに制限されることもあります。
|
参照:
|
DUALおよびキーワード(DIMENSION、SEGMENT、ALLOCATE、DISABLEなど、SQL文中の大文字の単語)が含まれます。これらの文字は予約語ではありません。ただし、Oracleは固有の方法でこれらの文字を内部的に使用します。したがって、これらの文字をオブジェクトおよびオブジェクトの部分の名前として使用した場合、使用しているSQL文が読みにくくなり、予期しない結果になることがあります。特に、SYS_またはORA_で始まる文字をスキーマ・オブジェクト名として使用しないでください。また、SQL組込みファンクションの名前を、スキーマ・オブジェクトまたはユーザー定義ファンクションの名前として使用しないでください。
引用識別子には、すべての文字、句読点および空白を使用できます。ただし、引用識別子と非引用識別子のいずれにも、二重引用符またはNULL文字(たとえば\0)は使用できません。
次のスキーマ・オブジェクトは、1つのネームスペースを共有します。
次の各スキーマ・オブジェクトは、固有のネームスペースを持ちます。
表およびビューが同じネームスペースにあるため、同じスキーマの表およびビューが同じ名前を持つことはできません。ただし、表と索引は異なるネームスペースに存在します。このため、同じスキーマ内の表と索引には、同じ名前を付けることができます。
データベース内の各スキーマには、その中のオブジェクトのために固有のネームスペースがあります。たとえば、異なるスキーマ内の2つの表は異なるネームスペースに存在し、同じ名前を付けることができます。
次の各非スキーマ・オブジェクトは、固有のネームスペースを持ちます。
これらのネームスペース内のオブジェクトはスキーマに含まれないため、これらのネームスペースはデータベース全体で使用されます。
名前を二重引用符で囲むことによって、同じネームスペース内の異なるオブジェクトに対して次の名前を指定できます。
employees "employees" "Employees" "EMPLOYEES"
ただし、Oracleは次の名前を同じ名前として解析するため、同じネームスペース内の異なるオブジェクトには、次の名前を使用できません。
employees EMPLOYEES "EMPLOYEES"
NLS_SORTによって決定される言語固有の規則は考慮されません。この動作は、ファンクションNLS_UPPERではなく、SQLファンクションUPPERを識別子に適用することに対応しています。データベース・キャラクタ・セットの大文字化規則によって、特定の自然言語としては不適切な結果となる場合があります。たとえば、データベース・キャラクタ・セットの大文字化規則に従うと、ドイツ語で使用される小文字のシャープs(ß)に大文字形式はありません。この文字は識別子が大文字に変換されるときに変更されませんが、ドイツ語で予期される大文字形式は2文字連続の大文字S(SS)です。同様に、小文字iの大文字形式は、データベース・キャラクタ・セットの大文字化規則に従うと大文字Iですが、トルコ語およびアゼルバイジャン語で予期される大文字形式は、上に点が付いた大文字Iです。
データベース・キャラクタ・セットの大文字化規則では、識別子はセッションのすべての言語構成で同様に解釈されます。識別子が特定の自然言語で正しく表示されるようにする場合は、引用符で囲んで小文字形式を保持するか、またはその識別子を使用するときは常に言語的に正しい大文字形式を使用することができます。
次に、有効なスキーマ・オブジェクト名の例を示します。
last_name horse hr.hire_date "EVEN THIS & THAT!" a_very_long_and_valid_name
これらのすべての例は、「スキーマ・オブジェクトのネーミング規則」に示す規則に従っています。次の例は、30文字を超えているため、無効となります。
a_very_very_long_and_valid_name
列別名、表別名、ユーザー名およびパスワードは、オブジェクトまたはオブジェクトの部分ではありませんが、特に指定がないかぎり、同様にこれらのネーミング規則に従う必要があります。
オブジェクトとその部分に名前を付ける場合に有効なガイドラインを次に示します。
オブジェクトに名前を付ける場合は、短くて簡単な名前とわかりやすい名前のバランスを考えてください。迷ったときには、わかりやすい名前にしてください。これは、データベース内のオブジェクトは、多くの人々が長期間にわたって使用する可能性があるためです。payment_due_dateのかわりにpmddという名前を使用すると、10年後の担当者は表の列の理解に苦労することになります。
一貫したネーミング規則を使用すると、アプリケーション上の各表の働きが理解しやすくなります。そのような規則の例として、FINANCEアプリケーションに属している表の名前をすべてfin_で始めるような場合が考えられます。
同一のエンティティや属性に対しては、複数の表にまたがっていても同じ名前を使用してください。たとえば、employeesサンプル表とdepartmentsサンプル表の部門番号列には、どちらにもdepartment_idという名前を付けます。
SQL文のコンテキストでスキーマ・オブジェクトとそれらの部分を参照する方法について説明します。次の項目について説明します。
次に、オブジェクトやそれらの部分を参照するための一般的な構文を示します。

それぞれの意味は、次のとおりです。
objectは、オブジェクトの名前です。
schemaは、オブジェクトを含むスキーマです。この修飾子を指定することによって、自分のスキーマ以外のスキーマ内のオブジェクトを参照できます。その場合には、自分のスキーマ以外のスキーマ内のオブジェクトを参照するための権限が必要です。この修飾子を指定しないと、自分自身のスキーマ内のオブジェクトを参照するものとみなされます。スキーマ・オブジェクトのみがschemaで修飾できます。スキーマ・オブジェクトについては、規則7を参照してください。規則7に示す非スキーマ・オブジェクトはスキーマ・オブジェクトではないため、schemaでは修飾できません。ただし、パブリック・シノニムは例外で、「PUBLIC」で修飾できます。この場合、引用符が必要です。
partは、オブジェクトの部分です。この識別子によって、スキーマ・オブジェクトの部分(たとえば、表の列またはパーティション)を参照できます。なお、すべてのタイプのオブジェクトが部分を持っているとはかぎりません。
dblinkは、Oracle Databaseの分散オプションを使用している場合にのみ適用されます。オブジェクトを含むデータベースの名前です。この修飾子dblinkを指定することによって、ローカル・データベース以外のデータベース内のオブジェクトを参照できます。このdblinkを指定しないと、自分自身のローカル・データベース内のオブジェクトを参照するものとみなされます。なお、すべてのSQL文でリモート・データベースのオブジェクトにアクセスできるとはかぎりません。
オブジェクトを参照する際のコンポーネントを区切っているピリオドの前後には、空白を入れることができます。ただし、通常は入れません。
SQL文内のオブジェクトが参照される場合、OracleはそのSQL文のコンテキストを検討して、該当するネームスペース内でそのオブジェクトの位置を確認します。そのオブジェクトの位置を確認してから、そのオブジェクトに対して文が指定する操作を実行します。指定した名前のオブジェクトが適切なネームスペース内に存在しない場合、Oracleはエラーを戻します。
次の例で、OracleがSQL文内のオブジェクト参照を変換する方法について説明します。名前departmentsで識別される表にデータ行を追加する次の文を考えます。
INSERT INTO departments VALUES ( 280, 'ENTERTAINMENT_CLERK', 206, 1700);
文のコンテキストに基づいて、Oracleは、departmentsが次のようなオブジェクトであると判断します。
Oracleは、文を発行したユーザーのスキーマ外のネームスペースを考慮する前に、そのユーザーのスキーマ内のネームスペースからオブジェクト参照を変換しようとします。この例では、Oracleは次の方法で名前departmentsを変換しようとします。
departmentsに追加しようとします。オブジェクトがその処理にとって正しい型でない場合、Oracleはエラーを戻します。この場合、departmentsは、表またはビュー、あるいは表またはビューとなるプライベート・シノニムである必要があります。departmentsが順序である場合、Oracleはエラーを戻します。
departmentsが順序のパブリック・シノニムである場合、Oracleはエラーを戻します。
パブリック・シノニムに、依存表またはユーザー定義型がある場合は、依存オブジェクトと同じスキーマに、シノニムと同じ名前でオブジェクトを作成することはできません。
シノニムに、依存表またはユーザー定義型がない場合は、依存オブジェクトと同じスキーマに、依存オブジェクトと同じ名前で、オブジェクトを作成できます。すべての依存オブジェクトが無効になり、次のアクセス時に妥当性チェックが再実行されます。
自分が所有するスキーマ以外のスキーマ内のオブジェクトを参照するには、次のように、オブジェクト名の前にスキーマ名を付けます。
schema.object
たとえば、次の文は、サンプル・スキーマhr内のemployees表を削除します。
DROP TABLE hr.employees;
ローカル・データベース以外のデータベース内のオブジェクトを参照するには、オブジェクト名の後に、そのデータベースへのデータベース・リンクの名前を続けます。データベース・リンクはスキーマ・オブジェクトであり、これによってOracleがリモート・データベースに接続され、そこにあるオブジェクトにアクセスします。この項では、次の項目について説明します。
「CREATE DATABASE LINK」を使用して、データベース・リンクを作成します。この文では、データベース・リンクに関する次の情報を指定できます。
これらの情報はデータ・ディクショナリに格納されます。
データベース・リンクを作成するとき、データベース・リンク名を指定する必要があります。データベース・リンク名は、他のオブジェクト型の名前とは異なります。データベース・リンク名は128バイト以内の長さで指定し、ピリオド(.)とアットマーク(@)を使用できます。
データベース・リンクに付ける名前は、データベース・リンクが参照するデータベースの名前、およびデータベース名の階層内のそのデータベースの位置に一致している必要があります。次に、データベース・リンク名の書式を示します。

それぞれの意味は、次のとおりです。
databaseには、データベース・リンクが接続するリモート・データベースのグローバル名の名前の部分を指定します。このグローバル名は、リモート・データベースのデータ・ディクショナリに格納されます。この名前は、GLOBAL_NAMEデータ・ディクショナリ・ビューで確認できます。
domainには、データベース・リンクが接続するリモート・データベースのグローバル名のドメイン部分を指定します。データベース・リンクの名前にdomainを指定しないと、Oracleは、現在、データ・ディクショナリに存在しているローカル・データベースのドメインに、データベース・リンク名を付加します。
connect_descriptorによって、データベース・リンクをさらに修飾できます。接続修飾子を使用する場合、同じデータベースに複数のデータベース・リンクを作成できます。たとえば、接続修飾子を使用して、同じデータベースにアクセスするOracle Real Application Clustersの異なるインスタンスに、複数のデータベース・リンクを作成できます。
database.domainの組合せは、サービス名と呼ばれることもあります。
リモート・データベースに接続するために、ユーザー名およびパスワードを使用します。データベース・リンクでは、ユーザー名およびパスワードはオプションです。
データベース接続文字列は、Oracle Netがリモート・データベースにアクセスするために使用する仕様です。データベース接続文字列の記述方法については、使用しているネットワーク・プロトコル用のOracle Netのドキュメントを参照してください。データベース・リンク用のデータベース文字列はオプションです。
データベース・リンクは、分散オプションを指定してOracleを使用している場合にのみ利用できます。データベース・リンクを含むSQL文の発行時に、次のいずれかの方法でデータベース・リンク名を指定します。
database、domain、およびオプションのconnect_descriptorコンポーネントを含む完全なデータベース・リンク名を指定します。
databaseおよびオプションのconnect_descriptorコンポーネントを含むが、domainコンポーネントを含まない、部分的なデータベース・リンク名を指定します。
Oracleは、リモート・データベースに接続する前に次のタスクを実行します。
GLOBAL_NAMEデータ・ディクショナリ・ビューで見ることができます。
GLOBAL_NAMESパラメータの値がtrueの場合は、Oracleは、データベース・リンク名のdatabase.domain部分がリモート・データベースの完全なグローバル名に一致しているかどうかを確認します。この条件が満たされている場合、Oracleは手順2で選択したユーザー名とパスワードを使用して接続を続行します。それ以外の場合、Oracleはエラーを戻します。
リモート・データベースの完全なグローバル名が、データベース・リンクのdatabase.domain部分と一致する必要があるという要件を無効にするには、初期化パラメータGLOBAL_NAMESか、ALTER SYSTEMまたはALTER SESSION文のGLOBAL_NAMESパラメータにFALSEを設定します。
表および索引はパーティション化できます。パーティション化されたスキーマ・オブジェクトは、パーティションと呼ばれる多数の部分で構成され、各パーティションのすべての論理属性は同じです。たとえば、表のパーティションはすべて同じ列定義と制約定義を共有し、索引のパーティションはすべて同じ索引列を共有します。
拡張パーティションおよび拡張サブパーティション名を使用した場合、1つのパーティションまたはサブパーティションのみ、パーティション・レベルおよびサブパーティション・レベルの操作(あるパーティションまたはサブパーティションからのすべての行の削除など)ができます。拡張された名前がない場合、そのような操作には述語(WHERE句)を指定する必要があります。レンジおよびリスト・パーティション表では、パーティション・レベル操作を述語で表そうとすると(特にレンジ・パーティション・キーで複数の列を使用しているときは)、非常に複雑になる可能性があります。ハッシュ・パーティションおよびサブパーティションの場合、述語の使用はより難しくなります。これは、これらのパーティションおよびサブパーティションが、システムが定義するハッシュ・ファンクションに基づいているためです。
拡張パーティション名を使用した場合、パーティションを表のように使用できます。この方法のメリットは、これらのビューに対する権限を他のユーザーやロールに付与する(または取り消す)ことによって、パーティション・レベルのアクセス制御機構を構築できることです。このメリットは、レンジ・パーティション表に最も有効です。パーティションを表として使用するには、単一のパーティションからデータを選択してビューを作成し、そのビューを表として使用します。
構文にpartition_extended_name要素またはsubpartition_extended_name要素が指定されているSQL文には、拡張パーティション表名および拡張サブパーティション表名を指定できます。
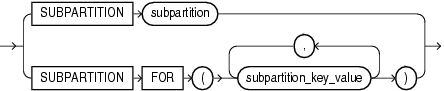
DML文INSERT、UPDATE、DELETE、およびANALYZE文では、パーティション名またはサブパーティション名をカッコで囲む必要があります。細かな違いですが、partition_extension_clauseに影響します。
partition_extended_name、subpartition_extended_nameおよびpartition_extension_clauseでは、PARTITION FOR句およびSUBPARTITION FOR句を使用すると、名前がなくてもパーティションを参照できます。これらの句は、すべてのタイプのパーティション化に有効であり、特に時間隔パーティションで役立ちます。データが表に挿入されると、必要に応じて時間隔パーティションが自動的に作成されます。
それぞれのpartition_valueには、パーティション化キー列ごとに1つの値を指定します。複数列のパーティション化キーには、パーティション化キーごとに1つの値を指定します。コンポジット・パーティションには、パーティション化キーごとに1つの値を指定し、続いてサブパーティション化キーごとに1つの値を指定します。すべてのパーティション化キーの値は、カンマで区切られます。時間隔パーティションには、1つのpartition_valueのみを指定できます。この値は、有効なNUMBERまたは日時値にする必要があります。SQL文は、指定した値を含むパーティションまたはサブパーティションで動作します。
現在、拡張パーティション表名および拡張サブパーティション表名を使用するときには、次の制限があります。
PARTITION FOR句およびSUBPARTITION FOR句は、ビューでのDDL操作に対しては無効になります。
次の文のsalesは、パーティションsales_q1_2000を持つパーティション表です。単一パーティションsales_q1_2000のビューを作成でき、それを表のように使用できます。この例では、パーティションから行が削除されます。
CREATE VIEW Q1_2000_sales AS SELECT * FROM sales PARTITION (SALES_Q1_2000); DELETE FROM Q1_2000_sales WHERE amount_sold < 0;
SQL文のオブジェクト型の属性とメソッドを参照するには、参照を表の別名で完全に修飾する必要があります。次の例では、cust_address_typ型、およびcust_address_typに基づくcust_address列を持つ表customersを含むサンプル・スキーマoeについて考えます。
CREATE TYPE cust_address_typ OID '82A4AF6A4CD1656DE034080020E0EE3D' AS OBJECT ( street_address VARCHAR2(40) , postal_code VARCHAR2(10) , city VARCHAR2(30) , state_province VARCHAR2(10) , country_id CHAR(2) ); / CREATE TABLE customers ( customer_id NUMBER(6) , cust_first_name VARCHAR2(20) CONSTRAINT cust_fname_nn NOT NULL , cust_last_name VARCHAR2(20) CONSTRAINT cust_lname_nn NOT NULL , cust_address cust_address_typ . . .
次に示すとおり、SQL文では、postal_code属性への参照は表別名を使用して完全に修飾する必要があります。
SELECT c.cust_address.postal_code FROM customers c; UPDATE customers c SET c.cust_address.postal_code = 'GU13 BE5' WHERE c.cust_address.city = 'Fleet';
引数を取らないメンバー・メソッドを参照する場合は、空のカッコを付ける必要があります。たとえば、サンプル・スキーマoeには、メンバー・ファンクションgetCatalogNameを含むcatalog_typに基づくオブジェクト表categories_tabが含まれます。SQL文でこのメソッドをコールするには、次の例のように、空のカッコを付ける必要があります。
SELECT TREAT(VALUE(c) AS catalog_typ).getCatalogName() "Catalog Type" FROM categories_tab c WHERE category_id = 90; Catalog Type ------------------------------------ online catalog
|
 Copyright © 1996, 2008, Oracle Corporation. All Rights Reserved. |
|