11g リリース1(11.1)
E05750-03
 目次 |
 索引 |
| Oracle Database SQL言語リファレンス 11g リリース1(11.1) E05750-03 |
|

ファンクションは、データ項目を操作し、結果を戻すという点で演算子に似ていますが、ファンクションと演算子は引数を指定する書式が異なります。次の書式によって、ファンクションでは0(ゼロ)以上の引数を操作できます。
function(argument, argument, ...)
引数を指定しないファンクションは疑似列に似ています(第3章「疑似列」を参照)。ただし、疑似列は、通常、結果セット内の各行に対して異なる値を戻しますが、引数を指定しないファンクションは、各行に対して同じ値を戻します。
この章では、次の内容を説明します。
SQLファンクションは、Oracle Databaseに組み込まれており、適切なSQL文で使用できます。SQLファンクションと、PL/SQLで記述されたユーザー定義ファンクションを混同しないでください。
SQLファンクションが戻す値のデータ型以外のデータ型の引数でSQLファンクションをコールすると、OracleはSQLファンクションを実行する前に、その引数を必要なデータ型に変換します。
SQLファンクションの構文図では、データ型とともに引数が示されています。SQL構文にパラメータfunctionが指定されている場合は、この項で説明するファンクションの1つに置き換えます。ファンクションは、引数のデータ型および戻り値によってグループ化されています。
|
参照:
|
次に、ファンクションのカテゴリを表す構文を示します。
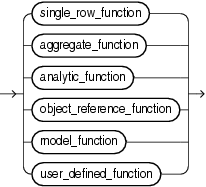
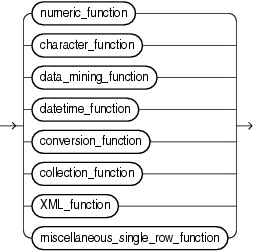
次の項に、前述の図のユーザー定義ファンクション以外の各グループにおける組込みSQLファンクションを示します。すべての組込みSQLファンクションを、アルファベット順に説明します。
単一行ファンクションは、問合せ対象の表またはビューの各行に対して1つの結果行を戻します。これらのファンクションは、SELECT構文のリスト、WHERE句、START WITH句、CONNECT BY句およびHAVING句に指定できます。
数値ファンクションは入力として数値を受け取り、結果として数値を戻します。数値ファンクションのほとんどは、38桁(10進)のNUMBER値を戻します。超越関数(COS、COSH、EXP、LN、LOG、SIN、SINH、SQRT、TANおよびTANH)は、36桁(10進)の値を戻します。超越関数のACOS、ASIN、ATAN、ATAN2は、30桁(10進)の値を戻します。数値ファンクションを次に示します。
文字値を戻す文字ファンクションは、特に指定がないかぎり、次のデータ型の値を戻します。
ファンクションによって戻される値の長さは、戻されるデータ型の最大長によって制限されます。
CHARまたはVARCHAR2型の値を戻すファンクションの戻り値の長さが制限を超えた場合、Oracle Databaseは戻り値から制限を超えた部分を切り捨てて、エラー・メッセージを表示せずにその結果を戻します。
CLOB型の値を戻すファンクションの戻り値の長さが制限を超えた場合、Oracleはエラーを表示し、データを戻しません。
文字値を戻す文字ファンクションを次に示します。
NLS文字ファンクションは、キャラクタ・セットの情報を戻します。NLS文字ファンクションを次に示します。
数値を戻す文字ファンクションの引数には、すべての文字データ型を指定できます。
数値を戻す文字ファンクションを次に示します。
日時ファンクションは、日付(DATE)、タイムスタンプ(TIMESTAMP、TIMESTAMP WITH TIME ZONE、TIMESTAMP WITH LOCAL TIME ZONE)および期間(INTERVAL DAY TO SECOND、INTERVAL YEAR TO MONTH)の値を操作します。
一部の日付ファンクションは、OracleのDATEデータ型(ADD_MONTHS、CURRENT_DATE、LAST_DAY、NEW_TIMEおよびNEXT_DAY)用に設計されています。これらのファンクションの引数にタイムスタンプ値を指定すると、Oracle Databaseは入力された型をDATE値に内部的に変換し、DATE値を戻します。ただし、MONTHS_BETWEENファンクションは数値を戻し、ROUNDおよびTRUNCファンクションはタイムスタンプ値または期間値を受け入れません。
その他の日時ファンクションは、3種類のすべてのデータ型(日付、タイムスタンプ、期間)を受け入れ、それらのいずれかのデータ型の値を戻すように設計されています。
SYSDATE、SYSTIMESTAMP、CURRENT_TIMESTAMPなどの、現在のシステム日時情報を戻す日時ファンクションはすべて、SQL文で参照される回数に関係なく、SQL文ごとに1回評価されます。
日時ファンクションを次に示します。
一般的な比較ファンクションは、値の集合から最大値または最小値(あるいはその両方)を決定します。一般的な比較ファンクションを次に示します。
変換ファンクションは、あるデータ型から他のデータ型に値を変換します。一般に、ファンクション名はdatatype TO datatypeの書式で指定されます。最初のデータ型は入力データ型です。2番目のデータ型は出力データ型です。SQL変換ファンクションを次に示します。
ラージ・オブジェクト・ファンクションは、LOBを操作します。ラージ・オブジェクト・ファンクションを次に示します。
収集ファンクションは、ネストした表およびVARRAYを操作します。SQL収集ファンクションを次に示します。
階層ファンクションは、階層パス情報を結果セットに適用します。
データ・マイニング・ファンクションは、DBMS_DATA_MININGパッケージまたはOracle Data Mining Java APIを使用して作成したモデルを操作します。SQLデータ・マイニング・ファンクションを次に示します。
XMLファンクションは、XML文書またはフラグメントを操作または戻します。出力の書式設定など、これらのファンクションを使用したXMLデータの選択および問合せの詳細は、『Oracle XML DB開発者ガイド』を参照してください。SQL XMLファンクションを次に示します。
エンコーディング・ファンクションおよびデコーディング・ファンクションでは、データベース内のデータを調査およびデコードできます。
NULL関連ファンクションは、NULL処理を簡単にします。NULL関連ファンクションを次に示します。
環境ファンクションおよび識別子ファンクションは、インスタンスとセッションの情報を提供します。これらのファンクションを次に示します。
集計ファンクションは、単一行に基づく結果行を戻すのではなく、行のグループに基づく単一結果行を戻します。集計ファンクションは、SELECT構文のリスト、ORDER BYおよびHAVING句に指定できます。集計ファンクションは、通常、SELECT文のGROUP BY句で使用され、この句の中で問合せ対象の表またはビューの行がグループ化されます。GROUP BY句を含む問合せでは、SELECT構文のリストの要素は、集計ファンクション、GROUP BY式、定数またはこれらのいずれかを含む式になります。Oracleは、集計ファンクションを行の各グループに適用し、各グループに単一の結果行を戻します。
GROUP BY句を指定しないと、SELECT構文のリスト内の集計ファンクションは、問合せ対象の表またはビューのすべての行に適用されます。HAVING句で集計ファンクションを使用して、グループを出力しないこともできます。このとき、出力は、問合せ対象の表またはビューの各行の値ではなく、集計ファンクションの結果に基づきます。
単一の引数を指定する多くの集計ファンクションには、次の句があります。
たとえば、1、1、1、3の平均値はDISTINCTでは2となり、ALLでは1.5となります。どの句も指定しない場合、デフォルトでALLが使用されます。
集計ファンクションには、分析ファンクションの構文の一部であるwindowing_clauseを使用できるものがあります。この句の詳細は、「windowing_clause」を参照してください。この項の最後に示す集計ファンクションのリストでは、windowing_clauseを使用できるファンクションにアスタリスク(*)が付いています。
COUNT(*)、GROUPINGおよびGROUPING_IDを除くすべての集計ファンクションは、NULLを無視します。集計ファンクションに対する引数にNVLファンクションを使用して、NULLをある値で置き換えることができます。COUNTおよびREGR_COUNTはNULLを戻しません。数字または0(ゼロ)を戻します。その他の集計ファンクションでは、データ・セットに行がない場合、または集計ファンクションに対する引数としてNULLを持つ行のみがある場合はNULLを戻します。
集計ファンクションMIN、MAX、SUM、AVG、COUNT、VARIANCEおよびSTDDEVの後に、KEEPキーワードを指定すると、FIRSTまたはLASTファンクションと組み合せて使用することができ、与えられたソート指定に対して、FIRSTまたはLASTとしてランク付けされた一連の行の一連の値を操作できます。詳細は、「FIRST」を参照してください。
集計ファンクションはネストできます。たとえば、次の例では、サンプル・スキーマhrのすべての部門における最高額の給与の平均を計算します。
SELECT AVG(MAX(salary)) FROM employees GROUP BY department_id; AVG(MAX(SALARY)) ---------------- 10925
この計算では、GROUP BY句(department_id)で定義されているグループごとの内部集計(MAX(salary))を評価し、その結果をもう一度集計しています。
集計ファンクションを次に示します。
分析ファンクションは、行のグループに基づいて集計値を計算します。各グループに対して複数の行を戻す点で、集計ファンクションと異なります。行のグループをウィンドウといい、analytic_clauseで定義されます。各行に対して、行のスライディング・ウィンドウが定義されます。このウィンドウによって、カレント行の計算に使用される行の範囲が決定されます。ウィンドウの大きさは、行の物理数値または時間などのロジカル・インターバルに基づきます。
分析ファンクションは、問合せで最後に実行される演算(最後のORDER BY句を除く)の集合です。すべての結合およびすべてのWHERE、GROUP BYおよびHAVING句は、分析ファンクションが処理される前に実行されます。そのため、分析ファンクションは、SELECT構文のリストまたはORDER BY句のみに指定できます。
通常、分析ファンクションは、累積集計、移動集計、センター集計およびレポート集計の実行に使用されます。


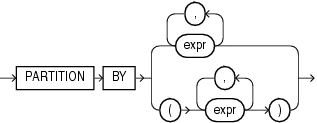
次に、この構文のセマンティクスを示します。
分析ファンクションの名前を指定します(セマンティクスの説明の後に示す分析ファンクションのリストを参照)。
分析ファンクションには引数を0〜3個指定します。引数には、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を指定できます。Oracleは、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換します。個々のファンクションに特に指定がないかぎり、戻り型もその引数のデータ型となります。
OVER analytic_clause句は、ファンクションが問合せ結果セットを操作することを示します。この句は、FROM、WHERE、GROUP BYおよびHAVING句の後に計算されます。SELECT構文のリストのこの句またはORDER BY句に分析ファンクションを指定できます。分析ファンクションに基づいて、問合せの結果をフィルタするには、これらのファンクションを親問合せ内でネストした後、ネストされた副問合せの結果をフィルタします。
analytic_clauseには、次の注意事項があります。
analytic_clauseのどの部分にも、分析ファンクションを指定して分析ファンクションをネストできません。ただし、副問合せで分析ファンクションを指定して、別の分析ファンクションを計算することはできます。
OVER analytic_clauseには、組込み分析ファンクションと同様に、ユーザー定義の分析ファンクションを指定できます。「CREATE FUNCTION」を参照してください。
PARTITION BY句を使用すると、1つ以上のvalue_exprに基づいて、問合せ結果セットをグループに分割できます。この句を省略すると、ファンクションは問合せ結果セットのすべての行を単一のグループとして扱います。
分析ファンクションでquery_partition_clauseを使用するには、構文の上位ブランチ(カッコなし)を使用します。この句をモデルの問合せ(model_column_clauses内)またはパーティション化された外部結合(outer_join_clause内)で使用するには、構文の下位ブランチ(カッコ付き)を使用します。
同じまたは異なるPARTITION BYキーで、同じ問合せに複数の分析ファンクションを指定できます。
問い合せているオブジェクトにパラレル属性があり、query_partition_clauseで分析ファンクションを指定する場合は、ファンクションの計算もパラレル化されます。
有効な値のvalue_exprは、定数、列、非分析ファンクション、ファンクション式、またはこれらのいずれかを含む式です。
order_by_clauseを使用すると、パーティション内でのデータの順序付け方法を指定できます。PERCENTILE_CONTおよび(単一キーのみを適用する)PERCENTILE_DISC以外の分析ファンクションでは、各キーがvalue_exprで定義され、順序付けシーケンスで修飾された複数キーのパーティションの値を順序付けできます。
各ファンクションには、複数の順序式を指定できます。これは、2番目の式が最初の式にある同一値との間の関連性を変換できるため、値をランク付けするファンクションを使用する場合に特に有効です。
order_by_clauseの結果が複数行の個々の値である場合、ファンクションは各行の同じ値を戻します。この動作の詳細は、「SUM」の分析例を参照してください。
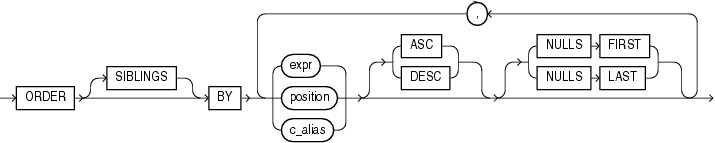
ORDER BY句には次の制限事項があります。
order_by_clauseを分析ファンクションで使用する場合、式(expr)が必要です。SIBLINGSキーワードは無効です(これは、階層問合せでのみ有効です)。位置(position)および列別名(c_alias)も無効です。それ以外で使用する場合、このorder_by_clauseは、問合せまたは副問合せ全体を順序付ける場合に使用するものと同じです。
RANGEキーワードを使用する分析ファンクションでは、次の2つのウィンドウのいずれかを指定する場合に、ORDER BY句で複数のソート・キーを使用できます。
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW。この短縮形は、RANGE UNBOUNDED PRECEDINGです。
RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING。
この2つ以外のウィンドウ境界では、分析ファンクションのORDER BY句でソート・キーを1つしか持てません。この制限事項は、ROWキーワードで指定したウィンドウ境界には適用されません。
順序付けシーケンス(昇順または降順)を指定します。デフォルトはASCです。
NULL値を含む戻された行が順序の最初にくるか、最後にくるかを指定します。
NULLS LASTは昇順のデフォルトで、NULLS FIRSTは降順のデフォルトです。
分析ファンクションは、常に、ファンクションのorder_by_clauseで指定された順序で行を操作します。ただし、ファンクションのorder_by_clauseは結果の順序を保証しません。最終結果の順序を保証するには、問合せのorder_by_clauseを使用してください。
一部の分析ファンクションでは、windowing_clauseを使用できます。7-16ページに示す分析ファンクションのリストでは、windowing_clauseを使用できるファンクションにアスタリスク(*)が付いています。
これらのキーワードは、各行に対して、ファンクションの結果の計算に使用されるウィンドウ(行の物理集合または論理集合)を定義します。ファンクションは、ウィンドウのすべての行に適用されます。ウィンドウは、問合せ結果セット内またはパーティションの上から下まで移動します。
order_by_clauseを指定しないと、この句を指定できません。RANGE句で定義したウィンドウ境界には、order_by_clauseで指定できる式が1つのみのものもあります。詳細は、「ORDER BY句の制限事項:」を参照してください。
分析ファンクションが論理オフセットで戻す値は、常に決定的なものです。ただし、分析ファンクションが物理オフセットで戻す値は、順序式の結果が一意の順序にならないかぎり、非決定的な結果を生成することがあります。order_by_clauseに複数の列を指定して、結果の順序を一意にする必要があります。
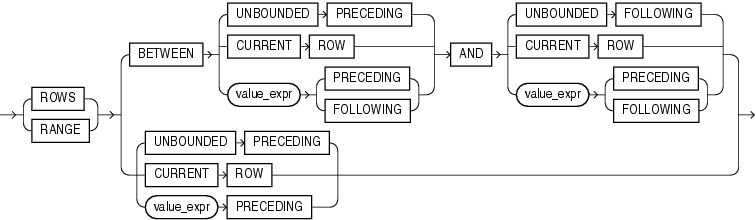
BETWEEN ... AND句を使用すると、ウィンドウにスタート・ポイントおよびエンド・ポイントを指定できます。最初の式(ANDの前)はスタート・ポイントを定義し、2番目の式(ANDの後)はエンド・ポイントを定義します。
BETWEENを省略してエンド・ポイントを1つのみ指定すると、Oracleはそれをスタート・ポイントとみなし、デフォルトでカレント行をエンド・ポイントに指定します。
UNBOUNDED PRECEDINGを指定すると、パーティションの最初の行で、ウィンドウが開始します。これはスタート・ポイントの指定で、エンド・ポイントの指定としては使用できません。
UNBOUNDED FOLLOWINGを指定すると、パーティションの最後の行で、ウィンドウが終了します。これはエンド・ポイントの指定で、スタート・ポイントの指定としては使用できません。
スタート・ポイントとして、ウィンドウがカレント行または値(それぞれROWまたはRANGEを指定したかどうかに基づく)で開始することを指定します。この場合、value_expr PRECEDINGをエンド・ポイントにできません。
エンド・ポイントとして、ウィンドウがカレント行または値(それぞれROWまたはRANGEを明示的に指定したかどうかに基づく)で終了することを指定します。この場合、value_expr FOLLOWINGをスタート・ポイントにできません。
RANGEまたはROWに対して、次のことがいえます。
value_expr FOLLOWINGがスタート・ポイントの場合、エンド・ポイントはvalue_expr FOLLOWINGである必要があります。
value_expr PRECEDINGがエンド・ポイントの場合、スタート・ポイントはvalue_expr PRECEDINGである必要があります。
数値形式の時間間隔で定義されている論理ウィンドウを定義する場合、変換ファンクションを使用する必要があります。
ROWSを指定した場合、次のことがいえます。
value_exprは物理オフセットになります。これは定数または式であり、正数値に評価する必要があります。
value_exprがスタート・ポイントの一部の場合、エンド・ポイントの前にある行に評価する必要があります。
RANGEを指定した場合、次のことがいえます。
value_exprは論理オフセットになります。これは、正数値または期間リテラルに評価する定数または式である必要があります。期間リテラルの詳細は、「リテラル」を参照してください。
order_by_clauseには、式を1つのみ指定できます。
value_exprが数値に対して評価を行う場合、ORDER BY exprは数値データ型またはDATEデータ型である必要があります。
value_exprが間隔値に対して評価を行う場合、ORDER BY exprはDATEデータ型である必要があります。
windowing_clauseを完全に省略した場合、デフォルトでRANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROWになります。
分析ファンクションは、通常、データ・ウェアハウス環境で使用されます。次に示す分析ファンクションのリストでは、windowing_clauseを含む完全な構文を使用できるファンクションには、アスタリスク(*)が付いています。
オブジェクト参照ファンクションは、指定されたオブジェクト型のオブジェクトへの参照となるREF値を操作します。オブジェクト参照ファンクションを次に示します。
モデル・ファンクションは、SELECT文のmodel_clauseでのみ使用できます。新しいモデル・ファンクションを次に示します。
この項では、SQLファンクションをアルファベット順に示し、説明します。
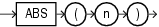
ABSは、nの絶対値を戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
次の例では、-15の絶対値を戻します。
SELECT ABS(-15) "Absolute" FROM DUAL; Absolute ---------- 15
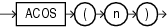
ACOSは、nのアーク・コサインを戻します。引数nは-1〜1の範囲で、ファンクションによって戻される値は0〜π(ラジアン)の範囲です。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。引数がBINARY_FLOATの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、引数と同じ数値データ型を戻します。
次の例では、.3のアーク・コサインを戻します。
SELECT ACOS(.3)"Arc_Cosine" FROM DUAL; Arc_Cosine ---------- 1.26610367

ADD_MONTHSは、日付dateに月数integerを加えて戻します。月は、セッション・パラメータNLS_CALENDARによって定義されます。引数dateには、日時値、または暗黙的にDATEに変換可能な任意の値を指定できます。引数integerには、整数、または暗黙的に整数に変換可能な任意の値を指定できます。戻り型は、dateのデータ型に関係なく常にDATEです。dateが月の最終日の場合、または結果の月の日数がdateの日付コンポーネントよりも少ない場合、戻される値は結果の月の最終日となります。それ以外の場合、結果にはdateと同じ日付コンポーネントが含まれます。
次の例では、サンプル表employeesのhire_date後の月を戻します。
SELECT TO_CHAR( ADD_MONTHS(hire_date,1), 'DD-MON-YYYY') "Next month" FROM employees WHERE last_name = 'Baer'; Next Month ----------- 07-JUL-1994

APPENDCHILDXMLは、ユーザー指定の値を、XPath式で指定したノードの子としてターゲットXMLに追加します。
XMLType_instanceは、XMLTypeのインスタンスです。
XPath_stringは、1つ以上の子ノードが追加されるノードを1つ以上指定するXPath式です。先頭にスラッシュを付けて絶対XPath_stringを指定したり、先頭のスラッシュを省略して相対XPath_stringを指定できます。先頭のスラッシュを省略した場合、相対パスのコンテキストは、デフォルトでルート・ノードに設定されます。
value_exprは、XMLTypeの1つ以上のノードを指定します。これは文字列に変換する必要があります。
namespace_stringは、XPath_stringのネームスペース情報を提供します。このパラメータは、VARCHAR2型である必要があります。次の例では、/Buildingノードの値が「Rented」の場合に、/Ownerノードをoe.warehouses表のwarehouse_specの/Warehouse/Buildingノードに追加します。
UPDATE warehouses SET warehouse_spec = APPENDCHILDXML(warehouse_spec, 'Warehouse/Building', XMLType('<Owner>Grandco</Owner>')) WHERE EXTRACTVALUE(warehouse_spec, '/Warehouse/Building') = 'Rented'; SELECT warehouse_id, warehouse_name, EXTRACTVALUE(warehouse_spec, '/Warehouse/Building/Owner') "Prop.Owner" FROM warehouses WHERE EXISTSNODE(warehouse_spec, '/Warehouse/Building/Owner') = 1; WAREHOUSE_ID WAREHOUSE_NAME Prop.Owner ------------ --------------- ---------- 2 San Francisco Grandco 3 New Jersey Grandco
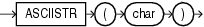
ASCIISTRは、任意のキャラクタ・セットの文字列、または文字列に変換する式を引数として取り、データベース・キャラクタ・セットのASCII文字列を戻します。ASCII文字以外は、\xxxxという書式に変換されます。xxxxは、UTF-16のコード単位です。
次の例では、テキスト文字列「ABÄCDE」をASCII文字列で戻します。
SELECT ASCIISTR('ABÄCDE') FROM DUAL; ASCIISTR(' ---------- AB\00C4CDE

ASCIIは、charの最初の文字の、データベース・キャラクタ・セットでの10進表記を戻します。
charのデータ型は、CHAR、VARCHAR2、NCHARまたはNVARCHAR2です。戻り値のデータ型はNUMBERです。データベース・キャラクタ・セットが7ビットのASCIIの場合、このファンクションはASCII値を戻します。データベース・キャラクタ・セットがEBCDICコードの場合、このファンクションはEBCDIC値を戻します。このファンクションと一致するEBCDIC文字ファンクションは存在しません。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、姓が文字「L」で始まり、ASCII表記が76の従業員を戻します。
SELECT last_name FROM employees WHERE ASCII(SUBSTR(last_name, 1, 1,)) = 76; LAST_NAME ------------------------- Ladwig Landry Lee Livingston
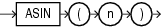
ASINは、nのアーク・サインを戻します。引数nは-1〜1の範囲で、ファンクションによって戻される値は-π/2〜π/2(ラジアン)の範囲です。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。引数がBINARY_FLOATの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、引数と同じ数値データ型を戻します。
次の例では、.3のアーク・サインを戻します。
SELECT ASIN(.3) "Arc_Sine" FROM DUAL; Arc_Sine ---------- .304692654
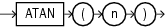
ATANは、nのアーク・タンジェントを戻します。引数nの範囲に制限はなく、ファンクションによって戻される値は-π/2〜π/2(ラジアン)の範囲です。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。引数がBINARY_FLOATの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、引数と同じ数値データ型を戻します。
次の例では、.3のアーク・タンジェントを戻します。
SELECT ATAN(.3) "Arc_Tangent" FROM DUAL; Arc_Tangent ---------- .291456794

ATAN2は、n1およびn2のアーク・タンジェントを戻します。引数n1の範囲に制限はなく、n1とn2の符号により、ファンクションによって戻される値は-π〜π(ラジアン)の範囲です。ATAN2(n1,n2)と、ATAN(n1/n2)は同じです。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。いずれかの引数がBINARY_FLOATまたはBINARY_DOUBLEの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、NUMBERを戻します。
次の例では、.3および.2のアーク・タンジェントを戻します。
SELECT ATAN2(.3, .2) "Arc_Tangent2" FROM DUAL; Arc_Tangent2 ------------ .982793723
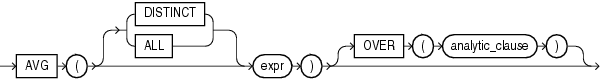
AVGは、exprの平均値を戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
DISTINCTを指定する場合は、analytic_clauseのquery_partition_clauseのみ指定できます。order_by_clauseおよびwindowing_clauseは指定できません。
次の例では、hr.employees表にあるすべての従業員の平均給与を計算します。
SELECT AVG(salary) "Average" FROM employees; Average -------------- 6461.68224
次の例では、employees表の各従業員について、ある期間内に雇用された従業員の平均給与を所属別に計算します。
SELECT manager_id, last_name, hire_date, salary, AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS c_mavg FROM employees ORDER BY manager_id, last_name, hire_date, salary, AVG(salary); MANAGER_ID LAST_NAME HIRE_DATE SALARY C_MAVG ---------- ------------------------- --------- ---------- ---------- 100 Kochhar 21-SEP-89 17000 17000 100 De Haan 13-JAN-93 17000 15000 100 Raphaely 07-DEC-94 11000 11966.6667 100 Kaufling 01-MAY-95 7900 10633.3333 100 Hartstein 17-FEB-96 13000 9633.33333 100 Weiss 18-JUL-96 8000 11666.6667 100 Russell 01-OCT-96 14000 11833.3333 100 Partners 05-JAN-97 13500 13166.6667 . . .
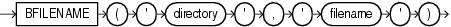
BFILENAMEは、サーバーのファイル・システムの物理LOBバイナリ・ファイルに対応付けられているBFILEロケータを戻します。
directory'は、実際にファイルが存在するサーバーのファイル・システム上のフルパス名に対する別名となるデータベース・オブジェクトです。
filename'は、サーバーのファイル・システムにあるファイルの名前です。
SQL文、PL/SQL文、DBMS_LOBパッケージまたはOCIの操作で、これらをBFILENAMEへの引数として使用するには、まずディレクトリ・オブジェクトを作成し、BFILE値を物理ファイルと対応付ける必要があります。
次の2つの方法で、このファンクションを使用できます。
ディレクトリの引数の大/小文字は区別されます。データ・ディクショナリ内に存在する名前と同じ名前でディレクトリ・オブジェクト名を指定しているかを確認する必要があります。たとえば、CREATE DIRECTORY文で、大/小文字を組み合せた識別子を引用符で囲んで使用してAdminディレクトリ・オブジェクトを作成すると、BFILENAMEファンクションを使用する場合、ディレクトリ・オブジェクトを'Admin'として指定する必要があります。filename引数は、ご使用のオペレーティング・システムの大/小文字および記号の表記規則に従って指定する必要があります。
|
参照:
|
次の例では、サンプル表pm.print_mediaに行を挿入します。BFILENAMEを使用して、$ORACLE_HOME/demo/schema/product_mediaディレクトリにある、サーバーのファイル・システムのバイナリ・ファイルを識別します。次の例では、PMスキーマでのディレクトリのデータベース・オブジェクトmedia_dirの作成方法を示します。
CREATE DIRECTORY media_dir AS '/demo/schema/product_media'; INSERT INTO print_media (product_id, ad_id, ad_graphic) VALUES (3000, 31001, BFILENAME('MEDIA_DIR', 'modem_comp_ad.gif'));
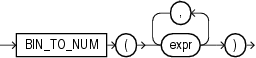
BIN_TO_NUMは、ビット・ベクトルを同等の数値に変換します。このファンクションの各引数は、ビット・ベクトルのビットを表します。このファンクションは、引数として、任意の数値データ型、または暗黙的にNUMBERに変換可能な数値以外のデータ型を取ります。各exprは、0または1に評価される必要があります。このファンクションはOracleのNUMBER値を戻します。
BIN_TO_NUMは、データ・ウェアハウスのアプリケーションで、グルーピング・セットを使用して、マテリアライズド・ビューから対象グループを検索する場合に有効です。
|
参照:
|
次の例では、バイナリの値を数値に変換します。
SELECT BIN_TO_NUM(1,0,1,0) FROM DUAL; BIN_TO_NUM(1,0,1,0) ------------------- 10
次の例では、3つの値を1つのバイナリの値に変換し、BIN_TO_NUMを使用してこのバイナリを数値に変換します。この例では、PL/SQL宣言を使用して元の値を指定します。これらの値は、通常は実際のデータ・ソースから導出されます。
SELECT order_status FROM orders WHERE order_id = 2441; ORDER_STATUS ------------ 5 DECLARE warehouse NUMBER := 1; ground NUMBER := 1; insured NUMBER := 1; result NUMBER; BEGIN SELECT BIN_TO_NUM(warehouse, ground, insured) INTO result FROM DUAL; UPDATE orders SET order_status = result WHERE order_id = 2441; end; / PL/SQL procedure successfully completed. SELECT order_status FROM orders WHERE order_id = 2441; ORDER_STATUS ------------ 7
この逆の(1つの列値から複数の値を抽出する)プロセスの詳細は、「BITAND」の例を参照してください。
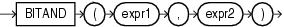
BITANDファンクションは、その入力と出力をビットのベクトルとして扱います。出力は、入力のビット単位ANDになります。
expr1およびexpr2の型はNUMBERであり、結果はNUMBER型になります。BITANDのいずれかの引数がNULLの場合、結果はNULLになります。
引数は、-(2(n-1)) .. ((2(n-1))-1)の範囲にする必要があります。引数をこの範囲外にすると、結果は未定義になります。
結果は、いくつかのステップで計算されます。まず、それぞれの引数Aが値SIGN(A)*FLOOR(ABS(A))に置き換えられます。この変換では、各引数の小数点以下が切り捨てられます。次に、整数値となったそれぞれの引数Aが、nビットの2の補数のバイナリ整数値に変換されます。ビット単位AND演算を使用して、2つのビット値が組み合せられます。最後に、生成されたnビットの2の補数値がNUMBERに変換されます。
BITANDの現行の実装では、n = 128が定義されています。
BINARY_INTEGERで、n = 32のBITANDのオーバーロードをサポートしています。
次の例では、数値6(バイナリ1,1,0)と数値3(バイナリ0,1,1)にAND演算を実行します。
SELECT BITAND(6,3) FROM DUAL; BITAND(6,3) ----------- 2
これは、6と3のバイナリの値を示す次の例と同じです。BITANDファンクションは、バイナリの値の有効桁のみで演算を実行します。
SELECT BITAND( BIN_TO_NUM(1,1,0), BIN_TO_NUM(0,1,1)) "Binary" FROM DUAL; Binary ---------- 2
単一の列値における複数の値のエンコードの詳細は、「BIN_TO_NUM」の例を参照してください。
次の例では、サンプル表oe.ordersのorder_status列で複数の選択項目を1つの数値内の個別のビットとしてエンコードします。たとえば、まだ倉庫にある発注は、バイナリの値001(10進値1)で表されます。陸上輸送で発送される発注は、バイナリの値010(10進値2)で表されます。保険がかけられた荷物は、バイナリの値100(10進値4)で表されます。この例では、DECODEファンクションを使用して、order_status値の3つのビットのそれぞれに2つの値(ビットがオンの場合の値とビットがオフの場合の値)が示されています。
SELECT order_id, customer_id, order_status, DECODE(BITAND(order_status, 1), 1, 'Warehouse', 'PostOffice') "Location", DECODE(BITAND(order_status, 2), 2, 'Ground', 'Air') "Method", DECODE(BITAND(order_status, 4), 4, 'Insured', 'Certified') "Receipt" FROM orders WHERE sales_rep_id = 160 ORDER BY order_id; ORDER_ID CUSTOMER_ID ORDER_STATUS Location Method Receipt ---------- ----------- ------------ ---------- ------ --------- 2455 145 7 Warehouse Ground Insured 2416 104 6 PostOffice Ground Insured 2419 107 3 Warehouse Ground Certified 2420 108 2 PostOffice Ground Certified 2423 145 3 Warehouse Ground Certified 2441 106 5 Warehouse Air Insured
Location列では、まずBITANDによってorder_statusと1(バイナリ001)が比較されます。比較されるのは重要なビット値のみです。したがって、右端のビットが1であるバイナリの値(奇数)は正と評価され、1が戻されます。偶数の場合は0(ゼロ)が戻されます。DECODEファンクションでは、BITANDによって戻された値と1が比較されます。両方とも1の場合、場所はWarehouse(倉庫)になります。これらの値が異なる場合、場所はPostOffice(郵便局)になります。
Method列とReceipt列は、同様に計算されます。Methodでは、BITANDによってorder_statusと2(バイナリ010)にAND演算が実行されます。Receiptでは、BITANDによってorder_statusと4(バイナリ100)にAND演算が実行されます。

CARDINALITYは、ネストした表内の要素数を戻します。戻り型は、NUMBERです。ネストした表が空であるかNULLの集合である場合、CARDINALITYはNULLを戻します。
次の例では、pm.print_mediaサンプル表のネストした表の列ad_textdocs_ntab内の要素数を示します。
SELECT product_id, CARDINALITY(ad_textdocs_ntab) Cardinality FROM print_media ORDER BY product_id, cardinality; PRODUCT_ID CARDINALITY ---------- ----------- 2056 3 2268 3 3060 3 3106 3

CASTは、ある組込みデータ型またはコレクション型の値を、別の組込みデータ型またはコレクション型の値に変換します。
CASTを使用すると、ある組込みデータ型またはコレクション型の値を、別の組込みデータ型またはコレクション型に変換できます。名前のないオペランド(日付や副問合せの結果セットなど)または名前付きのコレクション(VARRAYやネストした表など)を型互換の名前付きコレクションにキャストできます。type_nameは、組込みデータ型またはコレクション型の名前である必要があり、オペランドは、組込みデータ型であるか、またはその値がコレクション値である必要があります。
オペランドでは、exprは組込みデータ型、コレクション型またはANYDATA型のインスタンスのいずれかです。exprがANYDATA型のインスタンスである場合、CASTはANYDATAインスタンスの値を抽出し、その値がキャスト対象の型と一致する場合はその値を戻し、一致しない場合はNULLを戻します。MULTISETは、副問合せの結果セットを取り、コレクション値を戻すようにOracle Databaseに通知します。表5-1に、どの組込みデータ型が、どの組込みデータ型にキャストできるかを示します(CASTは、LONG型、LONG RAW型、またはOracleが提供する型をサポートしていません)。
CASTは、LOBデータ型のいずれも直接的にサポートしていません。CASTを使用して、CLOB値を文字データ型に変換するか、BLOB値をRAWデータ型に変換すると、データベースは暗黙的にLOB値を文字またはRAWデータに変換し、結果値を明示的にターゲットのデータ型にキャストします。結果値がターゲットの型より大きい場合、エラーが戻されます。
CAST ... MULTISETを使用してコレクション値を取得すると、CASTファンクションに渡される問合せ内のSELECT構文のリストのアイテムは、ターゲットのコレクション要素型に対応する属性型に変換されます。
注1: Datetime/Intervalには、DATE、TIMESTAMP、TIMESTAMP WITH TIMEZONE、INTERVAL DAY TO SECONDおよびINTERVAL YEAR TO MONTHが含まれます。
注2: UROWIDが索引構成表のROWIDの値を含んでいる場合、UROWIDをROWIDにキャストすることはできません。
名前付きコレクション型を別の名前付きコレクション型にキャストするには、両方のコレクションの要素が同じ型である必要があります。
副問合せの結果セットが複数行に評価される可能性がある場合は、MULTISETキーワードを指定する必要があります。副問合せの結果である行は、それらの行がキャストされたコレクション値の要素を形成します。MULTISETキーワードを省略すると、副問合せはスカラー副問合せとして処理されます。
次の例では、CASTファンクションをスカラー・データ型とともに使用します。
SELECT CAST('22-OCT-1997' AS TIMESTAMP WITH LOCAL TIME ZONE) FROM dual; SELECT product_id, CAST(ad_sourcetext AS VARCHAR2(30)) Text FROM print_media ORDER BY product_id, text;
後に続くCASTの例は、サンプルの注文入力スキーマoeで使用されているcust_address_typに基づいています。
CREATE TYPE address_book_t AS TABLE OF cust_address_typ; / CREATE TYPE address_array_t AS VARRAY(3) OF cust_address_typ; / CREATE TABLE cust_address ( custno NUMBER, street_address VARCHAR2(40), postal_code VARCHAR2(10), city VARCHAR2(30), state_province VARCHAR2(10), country_id CHAR(2)); CREATE TABLE cust_short (custno NUMBER, name VARCHAR2(31)); CREATE TABLE states (state_id NUMBER, addresses address_array_t);
次の例では、副問合せをキャストします。
SELECT s.custno, s.name, CAST(MULTISET(SELECT ca.street_address, ca.postal_code, ca.city, ca.state_province, ca.country_id FROM cust_address ca WHERE s.custno = ca.custno) AS address_book_t) FROM cust_short s ORDER BY s.custno, s.name;
CASTでは、VARRAY型の列をネストした表に変換します。
SELECT CAST(s.addresses AS address_book_t) FROM states s WHERE s.state_id = 111;
次の例では、この後に示す例で使用するオブジェクトを作成します。
CREATE TABLE projects (employee_id NUMBER, project_name VARCHAR2(10)); CREATE TABLE emps_short (employee_id NUMBER, last_name VARCHAR2(10)); CREATE TYPE project_table_typ AS TABLE OF VARCHAR2(10); /
次のMULTISET式の例は、前述のオブジェクトを使用します。
SELECT e.last_name, CAST(MULTISET(SELECT p.project_name FROM projects p WHERE p.employee_id = e.employee_id ORDER BY p.project_name) AS project_table_typ) FROM emps_short e ORDER BY e.last_name;
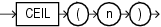
CEILは、n以上の最も小さい整数を戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
次の例では、指定した注文の合計以上である最小の整数を戻します。
SELECT order_total, CEIL(order_total) FROM orders WHERE order_id = 2434; ORDER_TOTAL CEIL(ORDER_TOTAL) ----------- ----------------- 268651.8 268652
CHARTOROWIDは、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型の値をROWIDデータ型に変換します。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、文字表記のROWIDをROWIDに変換します。(実際のROWIDは、各データベース・インスタンスによって異なります。)
SELECT last_name FROM employees WHERE ROWID = CHARTOROWID('AAAFd1AAFAAAABSAA/'); LAST_NAME ------------------------- Greene

CHRは、データベース・キャラクタ・セットまたは各国語キャラクタ・セット(USING NCHAR_CSを指定している場合)の中のnに等しい2進数を持つ文字を、VARCHAR2値として戻します。
シングルバイト・キャラクタ・セットの場合、Oracle Databaseは、n > 256に対してn mod 256に等しい2進数を戻します。マルチバイト・キャラクタ・セットの場合、nは1つのコードポイント全体として解決される必要があります。無効なコードポイントは検証されないため、無効なコードポイントを指定した場合の結果は、予測不能です。
このファンクションは、引数として、NUMBER値、または暗黙的にNUMBER型に変換可能な任意の値を取り、文字を戻します。
次の例は、データベース・キャラクタ・セットがWE8ISO8859P1と定義されているASCIIベースのマシンで実行されています。
SELECT CHR(67)||CHR(65)||CHR(84) "Dog" FROM DUAL; Dog --- CAT
キャラクタ・セットがWE8EBCDIC1047のEBCDICベースのマシンでも同じ結果を戻すには、前述の例を次のように修正する必要があります。
SELECT CHR(195)||CHR(193)||CHR(227) "Dog" FROM DUAL; Dog --- CAT
マルチバイト・キャラクタ・セットの場合、このように連結しても異なる結果となります。たとえば、a1a2(a1は1つ目のバイト、a2は2つ目のバイト)という16進数の値を持つマルチバイト文字の場合、nに対して「a1a2」に等しい2進数または41378を指定する必要があります。
SELECT CHR(41378) FROM DUAL;
次の例のように、a2に等しい2進数と連結されたa1に等しい2進数を指定することはできません。
SELECT CHR(161)||CHR(162) FROM DUAL;
ただし、次の例のように、マルチバイト文字を連結するマルチバイトのコードポイント全体を連結することは可能です。この例では、a1a2とa1a3の16進数を持つマルチバイト文字を連結しています。
SELECT CHR(41378)||CHR(41379) FROM DUAL;
次の例では、各国語キャラクタ・セットがUTF16であると仮定します。
SELECT CHR (196 USING NCHAR_CS) FROM DUAL; CH -- Ä

このファンクションは、DBMS_DATA_MININGパッケージまたはOracle Data Mining Java APIを使用して作成したモデルのクラスタリングで使用するためのものです。このファンクションは、mining_attribute_clauseで指定した一連の予測子のうち、最も確率の高い予測クラスタのクラスタ識別子を戻します。戻り値は、OracleのNUMBERです。
mining_attribute_clauseは、PREDICTIONファンクションと同様に動作します。詳細は、「mining_attribute_clause」を参照してください。
|
参照:
|
次の例では、指定したデータセットの顧客がグループ化されたクラスタを示します。
この例と前提条件のデータ・マイニング操作(dm_sh_clus_sampleモデルおよびdm_sh_sample_apply_preparedビューの作成など)は、デモ・ファイル$ORACLE_HOME/rdbms/demo/dmkmdemo.sqlで確認できます。データ・マイニングのデモ・ファイルの一般情報は、『Oracle Data Mining管理者ガイド』を参照してください。次に、このファンクションの構文の使用例を示します。
SELECT CLUSTER_ID(km_sh_clus_sample USING *) AS clus, COUNT(*) AS cnt FROM km_sh_sample_apply_prepared GROUP BY CLUSTER_ID(km_sh_clus_sample USING *) ORDER BY cnt DESC; CLUS CNT ---------- ---------- 2 580 10 199 6 185 8 115 12 98 16 82 19 81 15 68 18 65 14 27 10 rows selected.

このファンクションは、DBMS_DATA_MININGパッケージまたはOracle Data Mining Java APIを使用して作成したモデルのクラスタリングで使用するためのものです。このファンクションは、指定したモデルに関連付けられたクラスタにある入力行のメンバーシップの確信度のメジャーを戻します。
cluster_idには、モデル内のクラスタの識別子を指定します。このファンクションでは、指定したクラスタの確率を戻します。この句を指定しない場合、最適な予測クラスタに関連付けられた確率が戻ります。cluster_idとCLUSTER_IDファンクションの組合せのない形式を使用して、クラスタIDと確率の最適な予測の組を取得できます。
mining_attribute_clauseは、PREDICTIONファンクションと同様に動作します。詳細は、「mining_attribute_clause」を参照してください。
参照:
次の例では、可能性に基づいて、クラスタ2で最も代表的な顧客を10人決定します。
この例と前提条件のデータ・マイニング操作(dm_sh_clus_sampleモデルおよびdm_sh_sample_apply_preparedビューの作成など)は、デモ・ファイル$ORACLE_HOME/rdbms/demo/dmkmdemo.sqlで確認できます。データ・マイニングのデモ・ファイルの一般情報は、『Oracle Data Mining管理者ガイド』を参照してください。次に、このファンクションの構文の使用例を示します。
SELECT * FROM (SELECT cust_id, CLUSTER_PROBABILITY(km_sh_clus_sample, 2 USING *) prob FROM km_sh_sample_apply_prepared ORDER BY prob DESC) WHERE ROWNUM < 11; CUST_ID PROB ---------- ------ 100052 .9993 100962 .9993 101208 .9993 100281 .9993 100012 .9993 101009 .9992 100173 .9992 101176 .9991 100672 .9991 101420 .9991 10 rows selected.

このファンクションは、DBMS_DATA_MININGパッケージまたはOracle Data Mining Java APIを使用して作成したモデルのクラスタリングで使用するためのものです。このファンクションは、指定した行が属している可能性のあるクラスタを含むオブジェクトのVARRAYを戻します。VARRAYの各オブジェクトは、クラスタIDとクラスタ確率を含むスカラー値の組です。オブジェクト・フィールドには、CLUSTER_IDとPROBABILITYの名前が付き、両方ともOracleのNUMBERになります。
topN引数には、正の整数を指定します。指定すると、予測クラスタの集合は、上位Nの確率値のいずれか持つ予測クラスタに制限されます。topNを指定しないか、NULLに設定すると、すべてのクラスタはコレクションに戻されます。複数のクラスタがN番目の値に一致しても、N個の値のみが戻されます。
cutoff引数には、正の整数を指定し、戻されるクラスタを指定したカットオフ以上の確率を持つクラスタに制限します。NULLをtopNに指定し、必要なカットオフ値をcutoffに指定すると、cutoffのみをフィルタ処理できます。
topNとcutoffをともに指定すると、戻されるクラスタを上位Nの中で、しきい値を超える確率を持つクラスタに制限できます。
mining_attribute_clauseは、PREDICTIONファンクションと同様に動作します。詳細は、「mining_attribute_clause」を参照してください。
次の例では、20%を超える可能性で顧客101362が属する各クラスタで、最も関連性の高い属性(確信度が55%を超える)を示します。
この例と前提条件のデータ・マイニング操作(dm_sh_clus_sampleモデル、ビューおよび型の作成など)は、デモ・ファイル$ORACLE_HOME/rdbms/demo/dmkmdemo.sqlで確認できます。データ・マイニングのデモ・ファイルの一般情報は、『Oracle Data Mining管理者ガイド』を参照してください。次に、このファンクションの構文の使用例を示します。
WITH clus_tab AS ( SELECT id, A.attribute_name aname, A.conditional_operator op, NVL(A.attribute_str_value, ROUND(DECODE(A.attribute_name, N.col, A.attribute_num_value * N.scale + N.shift, A.attribute_num_value),4)) val, A.attribute_support support, A.attribute_confidence confidence FROM TABLE(DBMS_DATA_MINING.GET_MODEL_DETAILS_KM('km_sh_clus_sample')) T, TABLE(T.rule.antecedent) A, km_sh_sample_norm N WHERE A.attribute_name = N.col (+) AND A.attribute_confidence > 0.55 ), clust AS ( SELECT id, CAST(COLLECT(Cattr(aname, op, TO_CHAR(val), support, confidence)) AS Cattrs) cl_attrs FROM clus_tab GROUP BY id ), custclus AS ( SELECT T.cust_id, S.cluster_id, S.probability FROM (SELECT cust_id, CLUSTER_SET(km_sh_clus_sample, NULL, 0.2 USING *) pset FROM km_sh_sample_apply_prepared WHERE cust_id = 101362) T, TABLE(T.pset) S ) SELECT A.probability prob, A.cluster_id cl_id, B.attr, B.op, B.val, B.supp, B.conf FROM custclus A, (SELECT T.id, C.* FROM clust T, TABLE(T.cl_attrs) C) B WHERE A.cluster_id = B.id ORDER BY prob DESC, cl_id ASC, conf DESC, attr ASC, val ASC; PROB CL_ID ATTR OP VAL SUPP CONF ------- ---------- --------------- --- --------------- ---------- ------- .7873 8 HOUSEHOLD_SIZE IN 9+ 126 .7500 .7873 8 CUST_MARITAL_ST IN Divorc. 118 .6000 ATUS .7873 8 CUST_MARITAL_ST IN NeverM 118 .6000 ATUS .7873 8 CUST_MARITAL_ST IN Separ. 118 .6000 ATUS .7873 8 CUST_MARITAL_ST IN Widowed 118 .6000 ATUS .2016 6 AGE >= 17 152 .6667 .2016 6 AGE <= 31.6 152 .6667 .2016 6 CUST_MARITAL_ST IN NeverM 168 .6667 ATUS 8 rows selected.
COALESCEは、式のリストの最初のNULLでないexprを戻します。2つ以上の式を指定する必要があります。すべてのexprがNULLと評価された場合、このファンクションはNULLを戻します。
Oracle Databaseでは、短絡評価を使用します。データベースは、NULLかどうかを判断する前にexpr値のすべてを評価するのではなく、各expr値を評価して、NULLかどうかを判断します。
すべてのexprが数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型である場合、Oracle Databaseは、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、そのデータ型を戻します。
このファンクションはNVLファンクションを一般化したファンクションです。
COALESCEは、CASE式の変形として使用できます。次に例を示します。
COALESCE (expr1, expr2)
これは、次のCASE式と同じです。
CASE WHEN expr1 IS NOT NULL THEN expr1 ELSE expr2 END
次の例も同様です。
COALESCE (expr1, expr2, ..., exprn), for n>=3
これは、次のCASE式と同じです。
CASE WHEN expr1 IS NOT NULL THEN expr1 ELSE COALESCE (expr2, ..., exprn) END
次の例では、サンプル表oe.product_informationを使用して、製品のクリアランス・セールを企画します。製品の表示価格から10%値引きします。表示価格がない場合は、最小価格はセール価格となります。最小価格がない場合、セール価格は「5」となります。
SELECT product_id, list_price, min_price, COALESCE(0.9*list_price, min_price, 5) "Sale" FROM product_information WHERE supplier_id = 102050 ORDER BY product_id, list_price, min_price, "Sale"; PRODUCT_ID LIST_PRICE MIN_PRICE Sale ---------- ---------- ---------- ---------- 1769 48 43.2 1770 73 73 2378 305 247 274.5 2382 850 731 765 3355 5

COLLECTは、任意の型の列を引数に取り、選択された行から、入力された型のネストした表を作成する集計ファンクションです。このファンクションから正確な結果を取得するには、このファンクションをCASTファンクション内で使用する必要があります。
column自体がコレクションである場合、COLLECTの出力はコレクションのネストした表になります。columnがユーザー定義型である場合は、オプションのDISTINCT、UNIQUEおよびORDER BY句を使用できるように、columnにMAPまたはORDERメソッドが定義されている必要があります。
次の例では、oe.customersサンプル表の電話番号のVARRAY列からネストした表を作成します。
CREATE TYPE phone_book_t AS TABLE OF phone_list_typ; / SELECT CAST(COLLECT(phone_numbers) AS phone_book_t) Phone_Book FROM customers ORDER BY phone_book;
COMPOSEは、引数として任意のデータ型の文字列または文字列に変換する式を取り、入力されたものと同じキャラクタ・セットでUnicode文字列を戻します。charのデータ型は、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBです。たとえば、oウムラウト・コードポイントは、ウムラウト・コードポイントによって修飾されたoコードポイントとして戻されます。
COMPOSEは、NFC正規形の文字列を戻します。より排他的な設定の場合は、まずCANONICAL設定を使用してDECOMPOSEを呼び出し、次にCOMPOSEを呼び出すことができます。この組合せによって、NFKC正規形の文字列が戻されます。
暗黙的な変換を使用して、CLOBおよびNCLOBの値がサポートされます。charが文字のLOB値の場合、COMPOSE演算の前にVARCHAR値に変換されます。特定の開発環境で、LOB値のサイズがVARCHARのサポートする長さを超える場合、この演算は失敗します。
次の例は、oウムラウトのコードポイントを戻します。
SELECT COMPOSE ( 'o' || UNISTR('\0308') ) FROM DUAL; CO -- ö

CONCATは、char2に連結されているchar1を戻します。char1およびchar2は、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。char1と同じキャラクタ・セットの文字列が戻されます。そのデータ型は、引数のデータ型によって決まります。
2つの異なるデータ型を連結すると、可逆式変換となるデータ型が戻されます。したがって、引数の1つがLOBの場合、戻り値はLOBとなります。引数の1つが各国語データ型の場合は、戻り値は各国語データ型となります。たとえば、次のようになります。
CONCAT(CLOB, NCLOB)はNCLOBを戻します。
CONCAT(NCLOB, NCHAR)はNCLOBを戻します。
CONCAT(NCLOB, CHAR)はNCLOBを戻します。
CONCAT(NCHAR, CLOB)はNCLOBを戻します。
このファンクションは、連結演算子(||)と同等です。
次の例では、ネストを使用して3つの文字列を連結します。
SELECT CONCAT(CONCAT(last_name, '''s job category is '), job_id) "Job" FROM employees WHERE employee_id = 152 ORDER BY "Job"; Job ------------------------------------------------------ Hall's job category is SA_REP

CONVERTは、文字列を、あるキャラクタ・セットから別のキャラクタ・セットに変換します。
charは変換する値です。charは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。
dest_char_setは、charが変換されるキャラクタ・セットの名前です。
source_char_setは、charをデータベースに格納しているキャラクタ・セットの名前です。デフォルト値はデータベース・キャラクタ・セットです。
CHARとVARCHAR2の戻り値は、VARCHAR2です。NCHARとNVARCHAR2の戻り値は、NVARCHAR2です。CLOBの戻り値はCLOB、NCLOBの戻り値はNCLOBです。
変換先キャラクタ・セットと変換元キャラクタ・セットの引数として、リテラルまたはキャラクタ・セットの名前を含んでいる列を指定できます。
完全に文字を変換するには、変換先キャラクタ・セットが変換元キャラクタ・セットで定義されているすべての文字を表現できる必要があります。文字が変換先キャラクタ・セットに存在しないと、置換文字が使用されます。置換文字は、キャラクタ・セット定義の一部として定義できます。
次の例では、Latin-1文字列をASCIIに変換するキャラクタ・セットの変換を示します。これは、同じ文字列をWE8ISO8859P1データベースからUS7ASCIIデータベースへインポートした場合と同じ結果が得られます。
SELECT CONVERT('Ä Ê Í Õ Ø A B C D E ', 'US7ASCII', 'WE8ISO8859P1') FROM DUAL; CONVERT('ÄÊÍÕØABCDE' --------------------- A E I ? ? A B C D E ?
一般的なキャラクタ・セットを次に示します。
次のようにV$NLS_VALID_VALUESビューを問い合せて、有効なキャラクタ・セットのリストを取得できます。
SELECT * FROM V$NLS_VALID_VALUES WHERE parameter = 'CHARACTERSET'

CORRは、数値の組の集合に対する相関係数を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。Oracleは、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、そのデータ型を戻します。
Oracle Databaseは、expr1またはexpr2がNULLである組を排除した後、このファンクションを(expr1, expr2)の集合に適用します。その後、Oracleは次の計算を行います。
COVAR_POP(expr1, expr2) / (STDDEV_POP(expr1) * STDDEV_POP(expr2))
ファンクションは、NUMBER型の値を戻します。ファンクションが空の集合に適用されると、NULLを戻します。
次の例では、oe.product_informationサンプル表の重さクラスごとの製品の表示価格と最小価格の相関係数を計算します。
SELECT weight_class, CORR(list_price, min_price) "Correlation" FROM product_information GROUP BY weight_class ORDER BY weight_class, "Correlation"; WEIGHT_CLASS Correlation ------------ ----------- 1 .999149795 2 .999022941 3 .998484472 4 .999359909 5 .999536087
次の例では、会社での勤務年数と給与の相関を従業の役職別に示します。結果セットでは、指定した業務の従業員ごとに同じ相関を示します。
SELECT employee_id, job_id, TO_CHAR((SYSDATE - hire_date) YEAR TO MONTH ) "Yrs-Mns", salary, CORR(SYSDATE-hire_date, salary) OVER(PARTITION BY job_id) AS "Correlation" FROM employees WHERE department_id in (50, 80) ORDER BY job_id, employee_id; EMPLOYEE_ID JOB_ID Yrs-Mns SALARY Correlation ----------- ---------- ------- ---------- ----------- 145 SA_MAN +08-07 14000 .912385598 146 SA_MAN +08-04 13500 .912385598 147 SA_MAN +08-02 12000 .912385598 148 SA_MAN +05-07 11000 .912385598 149 SA_MAN +05-03 10500 .912385598 150 SA_REP +08-03 10000 .80436755 151 SA_REP +08-02 9500 .80436755 152 SA_REP +07-09 9000 .80436755 153 SA_REP +07-01 8000 .80436755 154 SA_REP +06-05 7500 .80436755 155 SA_REP +05-06 7000 .80436755 ...
CORR_*ファンクションを次に示します。
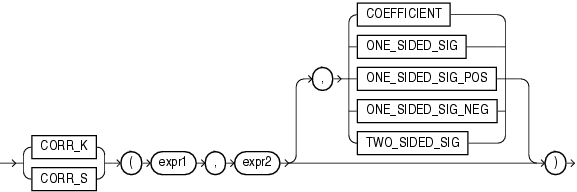
CORRファンクション(「CORR」を参照)は、ピアソンの相関係数を計算し、入力として数式を必要とします。CORR_*ファンクションは、ノンパラメトリックまたは順位相関をサポートします。これらのファンクションを使用すると、式間の相関を順序尺度化して求めることができます(値の順序付けが可能な場合)。相関係数は-1〜1の範囲の値となります。1は完全な正相関、-1は完全な逆相関(一方の変数が減少すると他方の変数が増加する)、および0(ゼロ)に近い値は無相関を表します。
これらのファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。Oracle Databaseは、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、計算を実行してNUMBERを戻します。
expr1およびexpr2は、分析対象の2つの変数です。3つ目の引数はVARCHAR2型の戻り値です。3つ目の引数を指定しない場合、デフォルトでCOEFFICIENTが戻り値になります。戻り値の意味を次の表に示します。
| 戻り値 | 意味 |
|---|---|
|
|
相関の係数 |
|
|
相関の正の片側有意 |
|
|
|
|
|
相関の負の片側有意 |
|
|
相関の両側有意 |
CORR_Sは、スピアマンの順位相関係数(ロー)を計算します。入力式は、観測値の組(xi, yi)の集合である必要があります。このファンクションは、最初に各値を順位に置き換えます。各xiの値は、標本内の他のすべてのxi中での順位に置き換えられ、各yiの値は、他のすべてのyi中での順位に置き換えられます。したがって、各xiおよび各yiは1〜nの値となります。ここでnは、値の組の合計数です。同順位の場合は、値がわずかに異なっていた場合に付けられる順位の平均が割り当てられます。その後このファンクションは、順位の線形相関係数を計算します。
次の例では、スピアマンのロー相関係数を使用して、salaryとcommission_pct、salaryとemployee_idの2つの異なる比較ごとに相関係数を導出します。
SELECT COUNT(*) count, CORR_S(salary, commission_pct) commission, CORR_S(salary, employee_id) empid FROM employees; COUNT COMMISSION EMPID ---------- ---------- ---------- 107 .735837022 -.04482358
CORR_Kは、ケンドールの順位相関係数(タウb)を計算します。CORR_Sと同様に、入力式は観測値の組(xi, yi)の集合です。係数を計算するために、このファンクションは一致した組と一致しない組の数をカウントします。xとyの値がいずれも大きい観測値の組は一致しています。xの値が大きくyの値が小さい観測値の組は一致していません。
タウbでの有意性は、タウbによって示される相関が偶然の結果である確率です(0〜1の値)。この値が小さい場合、タウbが正の値であれば有意な相関が存在します(タウbが負の値の場合は逆相関)。
次の例では、ケンドールのタウb相関係数を使用して、従業員の給与と歩合の割合(パーセント)間に相関があるかどうかを判断します。
SELECT CORR_K(salary, commission_pct, 'COEFFICIENT') coefficient, CORR_K(salary, commission_pct, 'TWO_SIDED_SIG') two_sided_p_value FROM hr.employees; COEFFICIENT TWO_SIDED_P_VALUE ----------- ----------------- .603079768 3.4702E-07
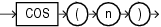
COSは、n(ラジアンで表された角度)のコサインを戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。引数がBINARY_FLOATの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、引数と同じ数値データ型を戻します。
次の例では、180度のコサインを戻します。
SELECT COS(180 * 3.14159265359/180) "Cosine of 180 degrees" FROM DUAL; Cosine of 180 degrees --------------------- -1

COSHは、nの双曲線コサインを戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。引数がBINARY_FLOATの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、引数と同じ数値データ型を戻します。
次の例では、0の双曲線コサインを戻します。
SELECT COSH(0) "Hyperbolic cosine of 0" FROM DUAL; Hyperbolic cosine of 0 ---------------------- 1

COUNTは、問合せによって戻された行の数を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
DISTINCTを指定する場合は、analytic_clauseのquery_partition_clauseのみ指定できます。order_by_clauseおよびwindowing_clauseは指定できません。
exprを指定すると、COUNTはexprがNULLでない行数を戻します。exprのすべての行を数えるか、または異なる値のみを数えることができます。
アスタリスク(*)を指定すると、このファンクションは重複値およびNULL値を含むすべての行を戻します。COUNTはNULLを戻しません。
次の例では、COUNTを集計ファンクションとして使用します。
SELECT COUNT(*) "Total" FROM employees; Total ---------- 107 SELECT COUNT(*) "Allstars" FROM employees WHERE commission_pct > 0; Allstars --------- 35 SELECT COUNT(commission_pct) "Count" FROM employees; Count ---------- 35 SELECT COUNT(DISTINCT manager_id) "Managers" FROM employees; Managers ---------- 18
次の例では、employees表の各従業員について、その従業員の給与より50ドル少ない金額から150ドル多い金額の範囲の給与を得ている従業員の数を計算します。
SELECT last_name, salary, COUNT(*) OVER (ORDER BY salary RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING) AS mov_count FROM employees ORDER BY last_name, salary, COUNT(*); LAST_NAME SALARY MOV_COUNT ------------------------- ---------- ---------- Olson 2100 3 Markle 2200 2 Philtanker 2200 2 Landry 2400 8 Gee 2400 8 Colmenares 2500 10 Marlow 2500 10 Patel 2500 10 . . .
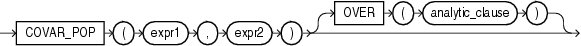
COVAR_POPは、数値の組の集合に対する母集団共分散を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。Oracleは、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、そのデータ型を戻します。
Oracle Databaseは、expr1またはexpr2がNULLであるすべての組を排除した後、このファンクションを(expr1, expr2)の組の集合に適用します。その後、Oracleは次の計算を行います。
(SUM(expr1 * expr2) - SUM(expr2) * SUM(expr1) / n) / n
ここで、nは(expr1, expr2)の組の数です(ただし、expr1およびexpr2の両方がNULLではない場合です)。
ファンクションは、NUMBER型の値を戻します。ファンクションが空の集合に適用されると、NULLを戻します。
次の例では、サンプル表hr.employeesを使用して、勤務時間(SYSDATE - hire_date)と給与の母集団共分散と標本共分散を計算します。
SELECT job_id, COVAR_POP(SYSDATE-hire_date, salary) AS covar_pop, COVAR_SAMP(SYSDATE-hire_date, salary) AS covar_samp FROM employees WHERE department_id in (50, 80) GROUP BY job_id ORDER BY job_id, covar_pop, covar_samp; JOB_ID COVAR_POP COVAR_SAMP ---------- ----------- ----------- SA_MAN 660700 825875 SA_REP 579988.466 600702.34 SH_CLERK 212432.5 223613.158 ST_CLERK 176577.25 185870.789 ST_MAN 436092 545115
次の例では、デモ・スキーマoeの製品の表示価格および最小価格の累積標本共分散を計算します。
SELECT product_id, supplier_id, COVAR_POP(list_price, min_price) OVER (ORDER BY product_id, supplier_id) AS CUM_COVP, COVAR_SAMP(list_price, min_price) OVER (ORDER BY product_id, supplier_id) AS CUM_COVS FROM product_information p WHERE category_id = 29 ORDER BY product_id, supplier_id; PRODUCT_ID SUPPLIER_ID CUM_COVP CUM_COVS ---------- ----------- ---------- ---------- 1774 103088 0 1775 103087 1473.25 2946.5 1794 103096 1702.77778 2554.16667 1825 103093 1926.25 2568.33333 2004 103086 1591.4 1989.25 2005 103086 1512.5 1815 2416 103088 1475.97959 1721.97619 . . .
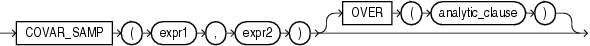
COVAR_SAMPは、数値の組の集合の標本共分散を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。Oracleは、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、そのデータ型を戻します。
Oracle Databaseは、expr1またはexpr2がNULLであるすべての組を排除した後、このファンクションを(expr1, expr2)の組の集合に適用します。その後、Oracleは次の計算を行います。
(SUM(expr1 * expr2) - SUM(expr1) * SUM(expr2) / n) / (n-1)
ここで、nは(expr1, expr2)の組の数です(ただし、expr1およびexpr2の両方がNULLではない場合です)。
ファンクションは、NUMBER型の値を戻します。ファンクションが空の集合に適用されると、NULLを戻します。
「COVAR_POP」の集計の例を参照してください。
「COVAR_POP」の分析の例を参照してください。
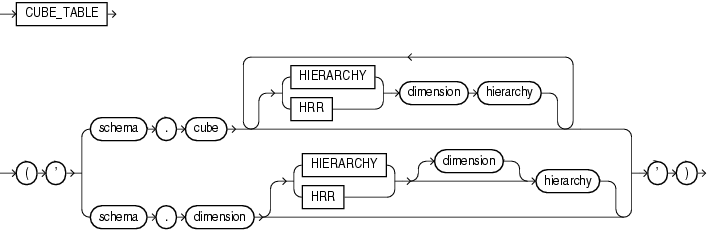
CUBE_TABLEは、キューブまたはディメンションのデータを抽出し、SQLベースのアプリケーションで使用可能な2次元形式のリレーショナル表に戻します。
このファンクションは、1つのVARCHAR2引数を取ります。オプションのHIERARCHY句を使用すると、ディメンション階層を指定できます。キューブでは複数のHIERARCHY句(ディメンションごとに1つ)を使用できます。
次の様々なタイプの表を生成できます。
CUBE_TABLEは表ファンクションであり、SELECT文のコンテキストで常に次の構文で使用されます。
SELECT ... FROM TABLE(CUBE_TABLE('arg'));
次のSELECT文は、GLOBALスキーマのCHANNELのディメンション表を生成します。
SELECT * FROM TABLE(CUBE_TABLE('global.channel')); DIM_KEY LEVEL_NAME LONG_DESCRIP SHORT_DESCRI TOTAL_CHANNEL_ID CHANNEL_ID -------- --------------- ------------ ------------ ---------------- ---------- 1 TOTAL_CHANNEL All Channels All Channels 1 2 CHANNEL Direct Sales Direct Sales 1 2 3 CHANNEL Catalog Catalog 1 3 4 CHANNEL Internet Internet 1 4
次の文は、UNITS_CUBEのキューブ表を生成します。この文は、表をMARKET_ROLLUP階層およびCALENDAR階層に制限します。
SELECT * FROM TABLE(CUBE_TABLE( 'global.units_cube HIERARCHY customer market_rollup HIERARCHY time calendar')); SALES UNITS COST TIME CUSTOMER PRODUCT CHANNEL ---------- ---------- ---------- -------- -------- -------- -------- 134109248 330425 124918967 2 7 1 1 32275009.5 77425 30255208 10 7 1 1 10768750.7 25780 10058324.5 36 7 1 1 109261.64 278 101798.32 36 5 1 1 22371.47 53 20887.54 36 36 1 1 . . .
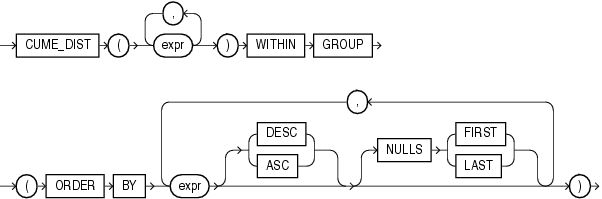

CUME_DISTは、値のグループにある値の累積分布値を計算します。CUME_DISTが戻す値の範囲は、0より大きく1以下です。連結値は、常に同じ累積分布値に対して評価を行います。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。Oracle Databaseは、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、計算を実行してNUMBERを戻します。
CUME_DISTは、ファンクションの引数および対応するソート指定によって識別される不確定な行rに対して、集計グループ内の行の中での行rの関連する位置を計算します。Oracleは、不確定な行rを集計される行のグループに挿入するように計算します。このファンクションの引数は、各集計グループ内の1つの不確定行を識別します。このため、すべての引数は、集計グループ内で定数式と評価される必要があります。定数引数式および集計のORDER BY句の式の位置は、一致します。このため、引数の数は同じであり、その型は互換性がある必要があります。
CUME_DISTは、値のグループにある特定の値の相対位置を計算します。行rについて、昇順で順序付けられているとします。rのCUME_DISTは、rの値以下の値の行数を、評価される行の数(問合せ結果セットまたはパーティション)で割った数です。
次の例では、サンプル表oe.employeesの従業員の中から、給与が15,500ドルであり、歩合が5%の不確定な従業員の累積分布を計算します。
SELECT CUME_DIST(15500, .05) WITHIN GROUP (ORDER BY salary, commission_pct) "Cume-Dist of 15500" FROM employees; Cume-Dist of 15500 ------------------ .972222222
次の例では、購買部門の各従業員の給与のパーセンタイルを計算します。たとえば、事務員の40%が、Himuroの給与以下の給与を得ていることがわかります。
SELECT job_id, last_name, salary, CUME_DIST() OVER (PARTITION BY job_id ORDER BY salary) AS cume_dist FROM employees WHERE job_id LIKE 'PU%' ORDER BY job_id, last_name, salary, cume_dist; JOB_ID LAST_NAME SALARY CUME_DIST ---------- ------------------------- ---------- ---------- PU_CLERK Baida 2900 .8 PU_CLERK Colmenares 2500 .2 PU_CLERK Himuro 2600 .4 PU_CLERK Khoo 3100 1 PU_CLERK Tobias 2800 .6 PU_MAN Raphaely 11000 1

CURRENT_DATEは、セッション・タイムゾーンの現在の日付をDATEデータ型のグレゴリオ暦の値で戻します。
次の例では、CURRENT_DATEがセッション・タイムゾーンによって異なることを示します。
ALTER SESSION SET TIME_ZONE = '-5:0'; ALTER SESSION SET NLS_DATE_FORMAT = 'DD-MON-YYYY HH24:MI:SS'; SELECT SESSIONTIMEZONE, CURRENT_DATE FROM DUAL; SESSIONTIMEZONE CURRENT_DATE --------------- -------------------- -05:00 29-MAY-2000 13:14:03 ALTER SESSION SET TIME_ZONE = '-8:0'; SELECT SESSIONTIMEZONE, CURRENT_DATE FROM DUAL; SESSIONTIMEZONE CURRENT_DATE --------------- -------------------- -08:00 29-MAY-2000 10:14:33

CURRENT_TIMESTAMPは、セッション・タイムゾーンの現在の日付および時刻をTIMESTAMP WITH TIME ZONEデータ型の値で戻します。タイムゾーン・オフセットは、SQLセッションの現在のローカル時刻を反映します。精度の指定を省略した場合のデフォルトは6です。このファンクションとLOCALTIMESTAMPとの違いは、CURRENT_TIMESTAMPは、TIMESTAMP WITH TIME ZONEの値を戻し、LOCALTIMESTAMPはTIMESTAMPの値を戻す点です。
オプションの引数では、precisionは、戻される時刻の値の小数秒の精度を指定します。
次の例では、CURRENT_TIMESTAMPがセッション・タイムゾーンによって異なることを示します。
ALTER SESSION SET TIME_ZONE = '-5:0'; ALTER SESSION SET NLS_DATE_FORMAT = 'DD-MON-YYYY HH24:MI:SS'; SELECT SESSIONTIMEZONE, CURRENT_TIMESTAMP FROM DUAL; SESSIONTIMEZONE CURRENT_TIMESTAMP --------------- --------------------------------------------------- -05:00 04-APR-00 01.17.56.917550 PM -05:00 ALTER SESSION SET TIME_ZONE = '-8:0'; SELECT SESSIONTIMEZONE, CURRENT_TIMESTAMP FROM DUAL; SESSIONTIMEZONE CURRENT_TIMESTAMP --------------- ---------------------------------------------------- -08:00 04-APR-00 10.18.21.366065 AM -08:00
CURRENT_TIMESTAMPで書式マスクを使用する場合は、ファンクションが戻す値と書式マスクを一致させてください。たとえば、次の表の場合を考えます。
CREATE TABLE current_test (col1 TIMESTAMP WITH TIME ZONE);
ファンクションが戻す型のTIME ZONEの部分がマスクに含まれていないため、次の文は正常に実行されません。
INSERT INTO current_test VALUES (TO_TIMESTAMP_TZ(CURRENT_TIMESTAMP, 'DD-MON-RR HH.MI.SSXFF PM'));
次の文では、CURRENT_TIMESTAMPの戻り値の型と一致する正しい書式マスクが使用されています。
INSERT INTO current_test VALUES (TO_TIMESTAMP_TZ (CURRENT_TIMESTAMP, 'DD-MON-RR HH.MI.SSXFF PM TZH:TZM'));

CVファンクションは、SELECT文のmodel_clauseでのみ、かつモデル・ルールの右側でのみ使用できます。戻り値は、ルールの左側から右側に送られたディメンション列またはパーティション列の現在の値です。このファンクションをmodel_clauseで使用するとディメンション列に対する相対索引を作成できます。戻り型は、ディメンション列のデータ型です。引数を指定しない場合、セル参照内のファンクションの相対位置に対応付けられたディメンション列がデフォルトで使用されます。
CVファンクションは、セル参照外でも使用できます。その場合は、dimension_columnが必要です。
次の例では、ディメンション列(マウス・パッドまたはスタンダード・マウス)の1999年および2000年の現在の値が表す製品の売上の合計を、その製品の2001年の売上に割り当てます。
SELECT country, prod, year, s FROM sales_view_ref MODEL PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale s) IGNORE NAV UNIQUE DIMENSION RULES UPSERT SEQUENTIAL ORDER ( s[FOR prod IN ('Mouse Pad', 'Standard Mouse'), 2001] = s[CV( ), 1999] + s[CV( ), 2000] ) ORDER BY country, prod, year; COUNTRY PROD YEAR S ---------- ----------------------------------- -------- --------- France Mouse Pad 1998 2509.42 France Mouse Pad 1999 3678.69 France Mouse Pad 2000 3000.72 France Mouse Pad 2001 6679.41 France Standard Mouse 1998 2390.83 France Standard Mouse 1999 2280.45 France Standard Mouse 2000 1274.31 France Standard Mouse 2001 3554.76 Germany Mouse Pad 1998 5827.87 Germany Mouse Pad 1999 8346.44 Germany Mouse Pad 2000 7375.46 Germany Mouse Pad 2001 15721.9 Germany Standard Mouse 1998 7116.11 Germany Standard Mouse 1999 6263.14 Germany Standard Mouse 2000 2637.31 Germany Standard Mouse 2001 8900.45 16 rows selected.
この例では、ビューsales_view_refが必要です。このビューを作成する方法については、「MODEL句の例:」を参照してください。
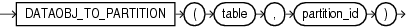
DATAOBJ_TO_PARTITIONは、ドメイン索引データの格納に使用するシステム・パーティション表でデータ・メンテナンスまたは問合せ操作を実行するデータ・カートリッジ開発者にのみ役立ちます。DML操作や問合せ操作は、ドメイン索引の実表での対応する操作によってトリガーされます。
このファンクションは、引数として実表の名前と実表のパーティションのパーティションIDを取ります。これらはともに、適切なODCIIndexメソッドによってファンクションに渡されます。ファンクションは、対応するシステムパーティション表のパーティションIDを戻します。このIDは、システム・パーティション表の該当パーティションで操作(DMLまたは問合せ)を実行する際に使用できます。

DBTIMEZONEファンクションは、データベース・タイムゾーンの値を戻します。戻り型は、タイムゾーン・オフセット('[+|-]TZH:TZM'という書式の文字列型)またはタイムゾーン地域名です。これは、最近のCREATE DATABASEまたはALTER DATABASE文でユーザーが指定したデータベース・タイムゾーンの値によって異なります。
次の例では、データベース・タイムゾーンがUTCタイムゾーンに設定されていると想定します。
SELECT DBTIMEZONE FROM DUAL; DBTIME ------ +00:00

DECODEファンクションは、exprと各searchの値を1つずつ比較します。exprがsearchと等しい場合、Oracle Databaseは対応するresultを戻します。一致する値が見つからない場合は、defaultを戻します。defaultが省略されている場合は、NULLを戻します。
引数は、任意の数値型(NUMBER、BINARY_FLOAT、BINARY_DOUBLE)または文字列型です。
exprおよびsearchが文字データである場合、Oracleは、非空白埋め比較セマンティクスを使用してそれらを比較します。expr、searchおよびresultのデータ型は、CHAR、VARCHAR2、NCHARまたはNVARCHAR2です。戻される文字列は、VARCHAR2データ型で、最初のresultパラメータと同じキャラクタ・セットの文字列です。
search-resultの組が数値である場合、Oracleはすべてのsearch-resultの式と最初のexprを比較して、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、そのデータ型を戻します。
search、resultおよびdefaultの値は、式から導出できます。Oracle Databaseでは、短絡評価を使用します。データベースは、search値のいずれかとexprを比較する前にすべてのsearch値を評価するのではなく、各search値とexprを比較する前にのみ、各search値を評価します。その結果、exprと等しいsearchが見つかると、Oracleはその後のsearchを評価しません。
比較する前に、Oracleはexprと各search値を、最初のsearch値のデータ型に自動的に変換します。Oracleは、戻り値を最初のresultと同じデータ型に自動的に変換します。最初のresultのデータ型がCHARの場合、または最初のresultがNULLの場合、Oracleは戻り値をVARCHAR2データ型の値に変換します。
DECODEファンクションでは、Oracleは2つのNULLを同等とみなします。exprがNULLの場合、Oracleは最初のsearch値のresultもNULLとして戻します。
DECODEファンクションのコンポーネントの最大数は、expr、search、result、defaultを含めて255です。
|
参照:
|
この例では、warehouse_idの値をデコードします。warehouse_idが1の場合「Southlake」を、warehouse_idが2の場合は「San Francisco」を戻します。warehouse_idが1、2、3、4のいずれでもない場合、ファンクションは「Non domestic」を戻します。
SELECT product_id, DECODE (warehouse_id, 1, 'Southlake', 2, 'San Francisco', 3, 'New Jersey', 4, 'Seattle', 'Non domestic') "Location" FROM inventories WHERE product_id < 1775 ORDER BY product_id, "Location";

DECOMPOSEは、Unicodeキャラクタに対してのみ有効です。DECOMPOSEは、任意のデータ型の文字列を引数として取り、入力と同じキャラクタ・セットで分解されたUnicodeの文字列を戻します。たとえば、oウムラウト・コードポイントは、ウムラウト・コードポイントが続く「o」コードポイントとして戻されます。
stringは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。
CANONICALを使用すると標準的な分解が行われ、(たとえば、COMPOSEファンクションを使用して)元の文字列への再構成が可能になります。これはデフォルトであり、NFD正規形の文字列が戻されます。
COMPATIBILITYを使用すると互換モードで分解が行われます。このモードでは、再構成はできません。このモードは、半角および全角のカタカナ文字を分解する場合など、外的な書式またはスタイル情報なしに再構成を行うことが望ましくない場合に有効です。このモードでは、NFKD正規形の文字列が戻されます。
暗黙的な変換を使用して、CLOBおよびNCLOBの値がサポートされます。charが文字のLOB値の場合、COMPOSE演算の前にVARCHAR値に変換されます。特定の開発環境で、LOB値のサイズがVARCHARのサポートする長さを超える場合、この演算は失敗します。
次の例では、文字列「Châteaux」をその要素のコードポイントに分解します。
SELECT DECOMPOSE ('Châteaux') FROM DUAL; DECOMPOSE --------- Cha^teaux
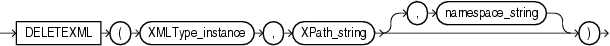
DELETEXMLは、ターゲットXMLのXPath式で一致する単一または複数のノードを削除します。
XMLType_instanceは、XMLTypeのインスタンスです。
XPath_stringは、削除するノードを1つ以上指定するXPath式です。先頭にスラッシュを付けて絶対XPath_stringを指定したり、先頭のスラッシュを省略して相対XPath_stringを指定できます。先頭のスラッシュを省略した場合、相対パスのコンテキストは、デフォルトでルート・ノードに設定されます。XPath_stringで指定したノードの子ノードも削除されます。
namespace_stringは、XPath_stringのネームスペース情報を提供します。このパラメータは、VARCHAR2型である必要があります。次の例では、「APPENDCHILDXML」の例で変更したウェアハウスの1つのwarehouse_specから/Ownerノードを削除します。
UPDATE warehouses SET warehouse_spec = DELETEXML(warehouse_spec, '/Warehouse/Building/Owner') WHERE warehouse_id = 2; SELECT warehouse_id, warehouse_spec FROM warehouses WHERE warehouse_id in (2,3); ID WAREHOUSE_SPEC ---------- ----------------------------------- 2 <?xml version="1.0"?> <Warehouse> <Building>Rented</Building> <Area>50000</Area> <Docks>1</Docks> <DockType>Side load</DockType> <WaterAccess>Y</WaterAccess> <RailAccess>N</RailAccess> <Parking>Lot</Parking> <VClearance>12 ft</VClearance> </Warehouse> 3 <?xml version="1.0"?> <Warehouse> <Building>Rented <Owner>Grandco</Owner> <Owner>ThirdOwner</Owner> <Owner>LesserCo</Owner> </Building> <Area>85700</Area> <DockType/> <WaterAccess>N</WaterAccess> <RailAccess>N</RailAccess> <Parking>Street</Parking> <VClearance>11.5 ft</VClearance> </Warehouse>
DENSE_RANKは、順序付けされた行のグループ内の行のランクを計算し、そのランクをNUMBERとして戻します。ランクは1から始まる連続した整数です。ランクの最大値は、問合せが戻す一意の数値です。ランクの値は、連続した整数です。ランク付け基準と同じ値を持つ行は、同じランクになります。このファンクションは、上位N番および下位N番のレポートに有効です。
このファンクションは、引数に任意の数値データ型を受け入れ、NUMBERを戻します。
DENSE_RANKは、ファンクションの引数によって識別される不確定な行の稠密ランクを、与えられたソート指定で計算します。ファンクションの引数は、各集計グループの単一行を識別するため、すべての引数は各集計グループ内で定数式に評価される必要があります。定数引数式および集計のorder_by_clauseの式の位置は、一致します。このため、引数の数は同じであり、型は互換性がある必要があります。
DENSE_RANKは、他の行について、問合せで戻される各行のランクを計算します。この計算は、order_by_clauseにあるvalue_exprsの値に基づいて行われます。
次の例では、サンプル表oe.employeesから、給与が15,500ドルであり、歩合が5%の仮想の従業員のランクを計算します。
SELECT DENSE_RANK(15500, .05) WITHIN GROUP (ORDER BY salary DESC, commission_pct) "Dense Rank" FROM employees; Dense Rank ------------------- 3
次の文は、人事部門または購買部門で働くすべての従業員の部門名、従業員名および給与を選択します。その後、この2つの部門それぞれについて、一意の各給与に対するランクを計算します。同じ給与は同じランクになります。この例と、「RANK」の例を比較してください。
SELECT d.department_name, e.last_name, e.salary, DENSE_RANK() OVER (PARTITION BY e.department_id ORDER BY e.salary) AS drank FROM employees e, departments d WHERE e.department_id = d.department_id AND d.department_id IN ('30', '40') ORDER BY e.last_name, e.salary, d.department_name, drank; DEPARTMENT_NAME LAST_NAME SALARY DRANK c------------------------------ ------------------------- ---------- ---------- Purchasing Baida 2900 4 Purchasing Colmenares 2500 1 Purchasing Himuro 2600 2 Purchasing Khoo 3100 5 Human Resources Mavris 6500 1 Purchasing Raphaely 11000 6 Purchasing Tobias 2800 3

DEPTHは、UNDER_PATHおよびEQUALS_PATH条件でのみ使用される補助ファンクションです。このファンクションは、同じ相関変数を持つUNDER_PATH条件によって指定されるパスのレベル数を戻します。
correlation_integerは任意のNUMBER整数です。文に複数の一次条件が含まれている場合に、この補助ファンクションをその一次条件と関連付けるために使用します。1未満の値は1として扱われます。
EQUALS_PATHおよびUNDER_PATH条件は、2つの補助ファンクションDEPTHおよびPATHを取ることができます。次に、その2つの補助ファンクションの使用方法を示します。この例では、XML Schemaであるwarehouses.xsd(「SQL文でのXMLの使用方法」で作成)が存在することを前提としています。
SELECT PATH(1), DEPTH(2) FROM RESOURCE_VIEW WHERE UNDER_PATH(res, '/sys/schemas/OE', 1)=1 AND UNDER_PATH(res, '/sys/schemas/OE', 2)=1; PATH(1) DEPTH(2) -------------------------------- -------- /www.example.com 1 /www.example.com/xwarehouses.xsd 2
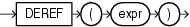
DEREFは、引数exprのオブジェクト参照を戻します。この場合、exprはオブジェクトにREFを戻す必要があります。問合せでこのファンクションを使用しない場合、次の例で示すとおり、かわりにREFのオブジェクトIDを戻します。
サンプル・スキーマoeには、cust_address_typというオブジェクト型が含まれます。「REF制約の例」では、類似する型cust_address_typ_new、およびその型へのREFである1つの列を含む表を作成します。次の例では、その列に挿入を行う方法、およびDEREFを使用して列から情報を抽出する方法を示します。
INSERT INTO address_table VALUES ('1 First', 'G45 EU8', 'Paris', 'CA', 'US'); INSERT INTO customer_addresses SELECT 999, REF(a) FROM address_table a; SELECT address FROM customer_addresses ORDER BY address; ADDRESS -------------------------------------------------------------------------------- 000022020876B2245DBE325C5FE03400400B40DCB176B2245DBE305C5FE03400400B40DCB1 SELECT DEREF(address) FROM customer_addresses; DEREF(ADDRESS)(STREET_ADDRESS, POSTAL_CODE, CITY, STATE_PROVINCE, COUNTRY_ID) -------------------------------------------------------------------------------- CUST_ADDRESS_TYP('1 First', 'G45 EU8', 'Paris', 'CA', 'US')

DUMPは、exprのデータ型コード、長さ(バイト単位)および内部表現を含むVARCHAR2値を戻します。戻される結果は、常にデータベース・キャラクタ・セットの文字です。各コードに対応するデータ型については、表2-1「組込みデータ型の概要」を参照してください。
引数return_fmtには戻り値の書式として、次の値のいずれかを指定します。
return_fmt 17を指定したDUMPの場合、特定の出力書式には依存しないでください。
デフォルトでは、戻り値にキャラクタ・セット情報が含まれません。exprのキャラクタ・セット名を取り出すには、前述の書式のいずれかの値に1000を加えます。たとえば、return_fmtに1008を指定すると、8進表記で結果が戻り、さらにexprのキャラクタ・セット名が得られます。
引数start_positionとlengthを組み合せて、内部表現の戻す部分を指定します。デフォルトでは、10進表記で全体の内部表現が戻されます。
exprがNULLの場合はNULLを戻します。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、文字列式および列からダンプ情報を抽出する方法を示します。
SELECT DUMP('abc', 1016) FROM DUAL; DUMP('ABC',1016) ------------------------------------------ Typ=96 Len=3 CharacterSet=WE8DEC: 61,62,63 SELECT DUMP(last_name, 8, 3, 2) "OCTAL" FROM employees WHERE last_name = 'Hunold' ORDER BY employee_id; OCTAL ------------------------------------------------------------------- Typ=1 Len=6: 156,157 SELECT DUMP(last_name, 10, 3, 2) "ASCII" FROM employees WHERE last_name = 'Hunold' ORDER BY employee_id; ASCII -------------------------------------------------------------------- Typ=1 Len=6: 110,111
EMPTY_BLOBおよびEMPTY_CLOBは、LOB変数を初期化したり、INSERTまたはUPDATE文でLOB列または属性をEMPTYに初期化できる空のLOBロケータを戻します。EMPTYとは、LOBは初期化されていても、データが移入されていない状態をいいます。
このファンクションから戻されるロケータは、DBMS_LOBパッケージまたはOCIへのパラメータとして使用することはできません。
次の例では、サンプル表pm.print_mediaのad_photo列をEMPTYに初期化します。
UPDATE print_media SET ad_photo = EMPTY_BLOB();
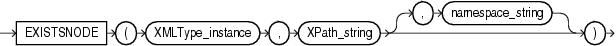
EXISTSNODEは、指定されたパスを使用してXML文書をトラバースした後にノードが存在するかを判断します。XML文書、およびパスを指定するXPath文字列VARCHAR2を含むXMLTypeインスタンスを引数として指定します。オプションのnamespace_stringは、接頭辞のデフォルト・マッピングまたはネームスペース・マッピング(Oracle DatabaseがXPath式を評価する場合に使用)を指定するVARCHAR2値に解決される必要があります。
namespace_string引数のデフォルトは、ルート要素の名前空間になります。Xpath_stringのサブ要素を参照する場合は、namespace_stringを指定する必要があります。また、これらの引数の両方にwho接頭辞を指定する必要があります。
戻り値は、NUMBERです。
次の例では、サンプル表oe.warehousesのwarehouse_spec列のXMLパスに/Warehouse/Dockノードが存在するかを判断します。
SELECT warehouse_id, warehouse_name FROM warehouses WHERE EXISTSNODE(warehouse_spec, '/Warehouse/Docks') = 1 ORDER BY warehouse_id, warehouse_name; WAREHOUSE_ID WAREHOUSE_NAME ------------ ----------------------------------- 1 Southlake, Texas 2 San Francisco 4 Seattle, Washington
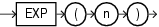
EXPは、eをn乗した値(e = 2.71828183 ...)を戻します。このファンクションは、引数と同じ型の値を戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。引数がBINARY_FLOATの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、引数と同じ数値データ型を戻します。
次の例では、eを4乗した値を戻します。
SELECT EXP(4) "e to the 4th power" FROM DUAL; e to the 4th power ------------------ 54.59815
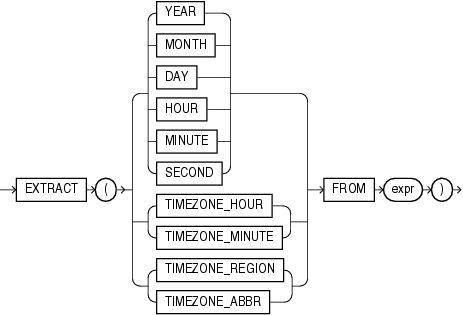
EXTRACTは、日時式または期間式から、指定された日時フィールドの値を抽出して戻します。exprには、要求されたフィールドと互換性のある日時または期間データ型に評価される任意の式を指定できます。
YEARまたはMONTHが要求された場合、exprはデータ型DATE、TIMESTAMP、TIMESTAMP WITH TIME ZONE、TIMESTAMP WITH LOCAL TIME ZONEまたはINTERVAL YEAR TO MONTHの式に評価される必要があります。
DAYが要求された場合、exprはデータ型DATE、TIMESTAMP、TIMESTAMP WITH TIME ZONE、TIMESTAMP WITH LOCAL TIME ZONEまたはINTERVAL DAY TO SECONDの式に評価される必要があります。
HOUR、MINUTEまたはSECONDが要求された場合、exprはデータ型TIMESTAMP、TIMESTAMP WITH TIME ZONE、TIMESTAMP WITH LOCAL TIME ZONEまたはINTERVAL DAY TO SECONDの式に評価される必要があります。DATEは、Oracle Databaseによって時刻フィールドを持たないANSI DATEデータ型として処理されるため、ここでは有効ではありません。
TIMEZONE_HOUR、TIMEZONE_MINUTE、TIMEZONE_ABBR、TIMEZONE_REGIONまたはTIMEZONE_OFFSETが要求された場合、exprはデータ型TIMESTAMP WITH TIME ZONEまたはTIMESTAMP WITH LOCAL TIME ZONEの式に評価される必要があります。
EXTRACTは、exprをANSI日時データ型として解釈します。たとえば、EXTRACTはDATEをレガシーOracle DATEではなく、時刻要素を持たないANSI DATEとして処理します。したがって、DATE値からは、YEAR、MONTHおよびDAYのみを抽出できます。同様に、TIMESTAMP WITH TIME ZONEデータ型からは、TIMEZONE_HOURおよびTIMEZONE_MINUTEのみを抽出できます。
TIMEZONE_REGIONを抽出する場合、戻り値は、適切なタイムゾーン名を含む文字列です。また、TIMEZONE_ABBR(略称)を抽出する場合、戻り値は、適切な略称を含む文字列です。その他の値を抽出する場合、戻り値はグレゴリオ暦での日時値を表す整数です。タイムゾーン値を持つ日時から抽出する場合、戻り値はUTCです。有効なタイムゾーン名およびそれに対する略称を表示するには、V$TIMEZONE_NAMES動的パフォーマンス・ビューに問合せを実行してください。
このファンクションは、次に示す最初の例のように、非常に大規模な表の日時フィールド値を操作する場合に特に有効です。
日時フィールドと日時または期間値の式を組み合せると、あいまいな結果になる場合があります。この場合、Oracle Databaseは、UNKNOWNを戻します(詳細は、次の例を参照してください)。
|
参照:
|
次の例では、oe.orders表から、各月の注文数を戻します。
SELECT EXTRACT(month FROM order_date) "Month", COUNT(order_date) "No. of Orders" FROM orders GROUP BY EXTRACT(month FROM order_date) ORDER BY "No. of Orders" DESC; Month No. of Orders ---------- ------------- 11 15 7 14 6 14 3 11 5 10 9 9 2 9 8 7 10 6 1 5 12 4 4 1 12 rows selected.
次の例では、1998年を戻します。
SELECT EXTRACT(YEAR FROM DATE '1998-03-07') FROM DUAL; EXTRACT(YEARFROMDATE'1998-03-07') --------------------------------- 1998
次の例では、サンプル表hr.employeesから、1998以降に雇用されたすべての従業員を選択します。
SELECT last_name, employee_id, hire_date FROM employees WHERE EXTRACT(YEAR FROM TO_DATE(hire_date, 'DD-MON-RR')) > 1998 ORDER BY hire_date; LAST_NAME EMPLOYEE_ID HIRE_DATE ------------------------- ----------- --------- Landry 127 14-JAN-99 Lorentz 107 07-FEB-99 Cabrio 187 07-FEB-99 . . .
次の例では、結果があいまいになるため、OracleはUNKNOWNを戻します。
SELECT EXTRACT(TIMEZONE_REGION FROM TIMESTAMP '1999-01-01 10:00:00 -08:00') FROM DUAL; EXTRACT(TIMEZONE_REGIONFROMTIMESTAMP'1999-01-0110:00:00-08:00') ---------------------------------------------------------------- UNKNOWN
タイムゾーン数値オフセットが式に指定され、その数値オフセットが複数のタイムゾーン地域をマップする場合、結果があいまいになります。

EXTRACT(XML)は、EXISTSNODEファンクションに似ています。VARCHAR2のXPath文字列を適用し、XMLのフラグメントを含むXMLTypeインスタンスを戻します。先頭にスラッシュを付けて絶対XPath_stringを指定したり、先頭のスラッシュを省略して相対XPath_stringを指定できます。先頭のスラッシュを省略した場合、相対パスのコンテキストは、デフォルトでルート・ノードに設定されます。処理しているXMLでネームスペース接頭辞が使用される場合、オプションのnamespace_stringが必要です。この引数は、接頭辞のデフォルト・マッピングまたはネームスペース・マッピング(Oracle DatabaseがXPath式を評価する場合に使用)を指定するVARCHAR2値に解決される必要があります。
次の例では、サンプル表oe.warehousesのwarehouse_spec列のXMLパスの/Warehouse/Dockノードの値を抽出します。
SELECT warehouse_name, EXTRACT(warehouse_spec, '/Warehouse/Docks') "Number of Docks" FROM warehouses WHERE warehouse_spec IS NOT NULL ORDER BY warehouse_name, "Number of Docks"; WAREHOUSE_NAME Number of Docks ------------------------- ------------------------- New Jersey San Francisco <Docks>1</Docks> Seattle, Washington <Docks>3</Docks> Southlake, Texas <Docks>2</Docks>
この例と、XMLのフラグメントのスカラー値を戻す、「EXTRACTVALUE」の例を比較してみてください。
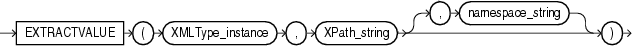
EXTRACTVALUEは、引数としてXMLTypeインスタンスとXPath式を取り、結果として得られるノードのスカラー値を戻します。結果はシングルノードであり、テキスト・ノード、属性または要素のいずれかである必要があります。結果が要素である場合、その要素はシングル・テキスト・ノードを子ノードとして持つ必要があり、このファンクションが戻す値は、その子ノードの値になります。先頭にスラッシュを付けて絶対XPath_stringを指定したり、先頭のスラッシュを省略して相対XPath_stringを指定できます。先頭のスラッシュを省略した場合、相対パスのコンテキストは、デフォルトでルート・ノードに設定されます。
指定されたXPathが複数の子ノードを持つノードを指す場合、または指されたノードが非テキスト・ノードの子を持つ場合は、エラーが戻されます。オプションのnamespace_stringは、接頭辞のデフォルト・マッピングまたはネームスペース・マッピング(OracleがXPath式を評価する場合に使用)を指定するVARCHAR2値に解決される必要があります。
XML Schemaに基づくドキュメントで戻り値の型が推測できる場合は、適切な型のスカラー値が戻ります。その他の場合は、VARCHAR2型の結果が戻ります。XML Schemaに基づかないドキュメントの場合、戻り値は常にVARCHAR2です。
次の例では、入力として、「EXTRACT(XML)」の例と同じ引数を取ります。このファンクションは、EXTRACTファンクションとは異なり、XMLのフラグメントを戻すのではなく、XMLのフラグメントのスカラー値を戻します。
SELECT warehouse_name, EXTRACTVALUE(e.warehouse_spec, '/Warehouse/Docks') "Docks" FROM warehouses e WHERE warehouse_spec IS NOT NULL; WAREHOUSE_NAME Docks -------------------- ------------ Southlake, Texas 2 San Francisco 1 New Jersey Seattle, Washington 3

このファンクションは、DBMS_DATA_MININGパッケージまたはOracle Data Mining Java APIを使用して作成した特徴抽出モデルで使用するためのものです。このファンクションは、行内で最も高い数値を持つ特徴の識別子をOracleのNUMBERで戻します。
mining_attribute_clauseは、PREDICTIONファンクションと同様に動作します。詳細は、「mining_attribute_clause」を参照してください。
次の例では、データセット内の特徴と、それに対応する顧客の件数を示します。
この例と前提条件のデータ・マイニング操作(nmf_sh_sampleモデルおよびnmf_sh_sample_apply_preparedビューの作成など)は、デモ・ファイル$ORACLE_HOME/rdbms/demo/dmnmdemo.sqlで確認できます。データ・マイニングのデモ・ファイルの一般情報は、『Oracle Data Mining管理者ガイド』を参照してください。次に、このファンクションの構文の使用例を示します。
SELECT FEATURE_ID(nmf_sh_sample USING *) AS feat, COUNT(*) AS cnt FROM nmf_sh_sample_apply_prepared GROUP BY FEATURE_ID(nmf_sh_sample USING *) ORDER BY cnt DESC; FEAT CNT ---------- ---------- 7 1443 2 49 3 6 1 1 6 1

このファンクションは、DBMS_DATA_MININGパッケージまたはOracle Data Mining Java APIを使用して作成した特徴抽出モデルで使用するためのものです。このファンクションは、有効な特徴を含むオブジェクトのVARRAYを戻します。VARRAYの各オブジェクトは、特徴IDと特徴値を含むスカラー値の組です。オブジェクト・フィールドには、FEATURE_IDとVALUEの名前が付き、両方ともOracleのNUMBERになります。
オプションのtopN引数は、特徴セットを上位Nの値のいずれかを持つ特徴セットに制限する正の整数です。N番目の値に同順位がある場合でも、N個の値のみが戻されます。この引数を指定しない場合、このファンクションはすべての特徴を戻します。
オプションのcutoff引数は、戻される特徴を、指定したカットオフ以上の特徴値を持つ特徴のみに制限します。cutoffのみをフィルタ処理するには、NULLをtopNに指定し、必要なカットオフ値をcutoffに指定します。
mining_attribute_clauseは、PREDICTIONファンクションと同様に動作します。詳細は、「mining_attribute_clause」を参照してください。
次の例では、指定した顧客レコードに対応する上位の特徴を示し(一致する品質を基準)、各特徴に上位の属性を決定します(0.25を超える係数を基準)。
この例と前提条件のデータ・マイニング操作(モデル、ビューおよび型の作成など)は、デモ・ファイル$ORACLE_HOME/rdbms/demo/dmkmdemo.sqlで確認できます。データ・マイニングのデモ・ファイルの一般情報は、『Oracle Data Mining管理者ガイド』を参照してください。次に、このファンクションの構文の使用例を示します。
WITH feat_tab AS ( SELECT F.feature_id fid, A.attribute_name attr, TO_CHAR(A.attribute_value) val, A.coefficient coeff FROM TABLE(DBMS_DATA_MINING.GET_MODEL_DETAILS_NMF('nmf_sh_sample')) F, TABLE(F.attribute_set) A WHERE A.coefficient > 0.25 ), feat AS ( SELECT fid, CAST(COLLECT(Featattr(attr, val, coeff)) AS Featattrs) f_attrs FROM feat_tab GROUP BY fid ), cust_10_features AS ( SELECT T.cust_id, S.feature_id, S.value FROM (SELECT cust_id, FEATURE_SET(nmf_sh_sample, 10 USING *) pset FROM nmf_sh_sample_apply_prepared WHERE cust_id = 100002) T, TABLE(T.pset) S ) SELECT A.value, A.feature_id fid, B.attr, B.val, B.coeff FROM cust_10_features A, (SELECT T.fid, F.* FROM feat T, TABLE(T.f_attrs) F) B WHERE A.feature_id = B.fid ORDER BY A.value DESC, A.feature_id ASC, coeff DESC, attr ASC, val ASC; VALUE FID ATTR VAL COEFF -------- ---- ------------------------- -------------------- ------- 6.8409 7 YRS_RESIDENCE 1.3879 6.8409 7 BOOKKEEPING_APPLICATION .4388 6.8409 7 CUST_GENDER M .2956 6.8409 7 COUNTRY_NAME United States of Ame .2848 rica 6.4975 3 YRS_RESIDENCE 1.2668 6.4975 3 BOOKKEEPING_APPLICATION .3465 6.4975 3 COUNTRY_NAME United States of Ame .2927 rica 6.4886 2 YRS_RESIDENCE 1.3285 6.4886 2 CUST_GENDER M .2819 6.4886 2 PRINTER_SUPPLIES .2704 6.3953 4 YRS_RESIDENCE 1.2931 5.9640 6 YRS_RESIDENCE 1.1585 5.9640 6 HOME_THEATER_PACKAGE .2576 5.2424 5 YRS_RESIDENCE 1.0067 2.4714 8 YRS_RESIDENCE .3297 2.3559 1 YRS_RESIDENCE .2768 2.3559 1 FLAT_PANEL_MONITOR .2593 17 rows selected.

このファンクションは、DBMS_DATA_MININGパッケージまたはOracle Data Mining Java APIを使用して作成した特徴抽出モデルで使用するためのものです。このファンクションは、指定した特徴の値を戻します。feature_id引数を指定しない場合、このファンクションは最も高い特徴値を戻します。この形式とFEATURE_IDファンクションを組み合せて使用すると、特徴と値の最大の組合せを取得できます。
mining_attribute_clauseは、PREDICTIONファンクションと同様に動作します。詳細は、「mining_attribute_clause」を参照してください。
次の例では、特徴3に対応する顧客を、一致する品質の順序で示します。
この例と前提条件のデータ・マイニング操作(モデルおよびビューの作成など)は、デモ・ファイル$ORACLE_HOME/rdbms/demo/dmkmdemo.sqlで確認できます。データ・マイニングのデモ・ファイルの一般情報は、『Oracle Data Mining管理者ガイド』を参照してください。次に、このファンクションの構文の使用例を示します。
SELECT * FROM (SELECT cust_id, FEATURE_VALUE(nmf_sh_sample, 3 USING *) match_quality FROM nmf_sh_sample_apply_prepared ORDER BY match_quality DESC) WHERE ROWNUM < 11; CUST_ID MATCH_QUALITY ---------- ------------- 100210 19.4101627 100962 15.2482251 101151 14.5685197 101499 14.4186292 100363 14.4037396 100372 14.3335148 100982 14.1716545 101039 14.1079914 100759 14.0913761 100953 14.0799737 10 rows selected.
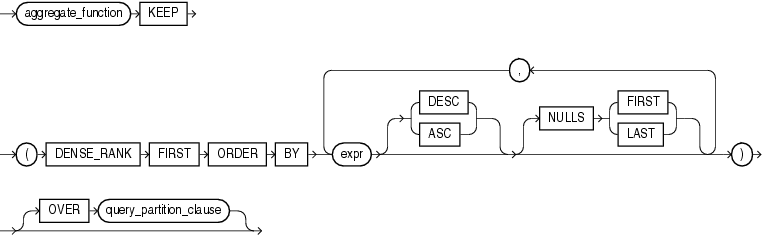
FIRSTファンクションとLASTファンクションは類似しています。両方のファンクションとも、与えられたソート指定に対して、FIRSTまたはLASTとしてランク付けされた一連の行の一連の値を操作する集計ファンクションおよび分析ファンクションです。1つの行のみがFIRSTまたはLASTとしてランク付けされている場合、集計は、1つの要素のみを持つセットを操作します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
ソートされたグループの最初または最後の行の値が必要であり、その値がソート・キーでない場合、FIRSTおよびLASTファンクションは、自己結合またはビューの必要性を排除し、パフォーマンスを向上させます。
aggregate_functionは、MIN、MAX、SUM、AVG、COUNT、VARIANCEまたはSTDDEVファンクションのいずれかです。FIRSTまたはLASTのいずれかにランク付けされた行の値を操作します。1つの行のみがFIRSTまたはLASTとしてランク付けされている場合、集計は、単一(集計ではない)のセットを操作します。
KEEPキーワードはセマンティクスを明確にするためのものです。これはaggregate_functionを修飾し、戻されるaggregate_functionの値がFIRSTまたはLASTのみであることを示します。
DENSE_RANK FIRSTまたはDENSE_RANK LASTは、最小(FIRST)または最大(LAST)稠密ランク(「オリンピック・ランク」)を持つ行のみを集計することを示します。
OVER句を指定すると、FIRSTおよびLASTファンクションを分析ファンクションとして使用できます。OVER句のうち、query_partitioning_clauseの部分のみがこれらのファンクションで有効です。
次の例では、サンプル表hr.employeesの各部門で、歩合が最低である従業員の中での最低給与、および歩合が最高の従業員の中での最高給与を戻します。
SELECT department_id, MIN(salary) KEEP (DENSE_RANK FIRST ORDER BY commission_pct) "Worst", MAX(salary) KEEP (DENSE_RANK LAST ORDER BY commission_pct) "Best" FROM employees GROUP BY department_id ORDER BY department_id, "Worst", "Best"; DEPARTMENT_ID Worst Best ------------- ---------- ---------- 10 4400 4400 20 6000 13000 30 2500 11000 40 6500 6500 50 2100 8200 60 4200 9000 70 10000 10000 80 6100 14000 90 17000 24000 100 6900 12000 110 8300 12000 7000 7000
次の例では、前述の例と同じ計算をしますが、当該部門の各従業員の結果を戻します。
SELECT last_name, department_id, salary, MIN(salary) KEEP (DENSE_RANK FIRST ORDER BY commission_pct) OVER (PARTITION BY department_id) "Worst", MAX(salary) KEEP (DENSE_RANK LAST ORDER BY commission_pct) OVER (PARTITION BY department_id) "Best" FROM employees ORDER BY department_id, salary; LAST_NAME DEPARTMENT_ID SALARY Worst Best ------------------- ------------- ---------- ---------- ---------- Whalen 10 4400 4400 4400 Fay 20 6000 6000 13000 Hartstein 20 13000 6000 13000 . . . Gietz 110 8300 8300 12000 Higgins 110 12000 8300 12000 Grant 7000 7000 7000

FIRST_VALUEは分析ファンクションです。これは、順序付けられた値の集合にある最初の値を戻します。集合内の最初の値がNULLの場合、IGNORE NULLSを指定していないかぎり、ファンクションはNULLを戻します。この設定は、データの稠密化に役立ちます。IGNORE NULLSを指定すると、FIRST_VALUEは集合内の最初のNULLではない値を戻します。すべての値がNULLの場合はNULLを戻します。データの稠密化の例は、「パーティション化された外部結合の使用例:」を参照してください。
exprには、FIRST_VALUEまたは他の分析ファンクションを使用して分析ファンクションをネストできません。ただし、他の組込みファンクション式をexprで使用できます。exprの書式の詳細は、「SQL式」を参照してください。
次の例では、部門90の各従業員について、その部門で給与が一番少ない従業員の名前を選択します。
SELECT department_id, last_name, salary, FIRST_VALUE(last_name) OVER (ORDER BY salary ASC ROWS UNBOUNDED PRECEDING) AS lowest_sal FROM (SELECT * FROM employees WHERE department_id = 90 ORDER BY employee_id) ORDER BY department_id, last_name, salary, lowest_sal; DEPARTMENT_ID LAST_NAME SALARY LOWEST_SAL ------------- ------------------------- ---------- ------------------------- 90 De Haan 17000 Kochhar 90 King 24000 Kochhar 90 Kochhar 17000 Kochhar
例では、FIRST_VALUEファンクションの非決定的な性質が示されています。KochharとDe Haanの給与は同じであるため、Kochharの次の行にDe Haanがあります。Kochharが最初に表示されているのは、副問合せが戻す行がemployee_idで順序付けられているためです。ただし、副問合せが戻す行がemployee_idで降順に順序付けられている場合は、次の例に示すとおり、ファンクションは異なる値を戻します。
SELECT department_id, last_name, salary, FIRST_VALUE(last_name) OVER (ORDER BY salary ASC ROWS UNBOUNDED PRECEDING) as fv FROM (SELECT * FROM employees WHERE department_id = 90 ORDER by employee_id DESC) ORDER BY department_id, last_name, salary, fv; DEPARTMENT_ID LAST_NAME SALARY FV ------------- ------------------------- ---------- ------------------------- 90 De Haan 17000 De Haan 90 King 24000 De Haan 90 Kochhar 17000 De Haan
次の例では、一意キーで順序付けることによって、FIRST_VALUEファンクションを決定的にする方法を示します。
SELECT department_id, last_name, salary, hire_date, FIRST_VALUE(last_name) OVER (ORDER BY salary ASC, hire_date ROWS UNBOUNDED PRECEDING) AS fv FROM (SELECT * FROM employees WHERE department_id = 90 ORDER BY employee_id DESC) ORDER BY department_id, last_name, salary, hire_date; DEPARTMENT_ID LAST_NAME SALARY HIRE_DATE FV ------------- --------------- ---------- --------- ------------------------- 90 De Haan 17000 13-JAN-93 Kochhar 90 King 24000 17-JUN-87 Kochhar 90 Kochhar 17000 21-SEP-89 Kochhar
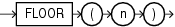
FLOORはn以下の最大整数を戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
次の例では、15.7以下である最大の整数を戻します。
SELECT FLOOR(15.7) "Floor" FROM DUAL; Floor ---------- 15

FROM_TZファンクションは、タイムスタンプ値およびタイムゾーンをTIMESTAMP WITH TIME ZONE値に変換します。time_zone_valueは、'TZH:TZM'書式の文字列、またはオプションのTZD書式を持つTZR書式で文字列を戻す文字式です。
次の例では、タイムスタンプ値をTIMESTAMP WITH TIME ZONEに戻します。
SELECT FROM_TZ(TIMESTAMP '2000-03-28 08:00:00', '3:00') FROM DUAL; FROM_TZ(TIMESTAMP'2000-03-2808:00:00','3:00') --------------------------------------------------------------- 28-MAR-00 08.00.00 AM +03:00
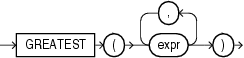
GREATESTは、1つ以上の式のリストの最大値を戻します。Oracle Databaseは、最初のexprを使用して戻り型を判断します。最初のexprが数値である場合、Oracleは、数値の優先順位が最も高い引数を判断し、比較の前に残りの引数をそのデータ型に暗黙的に変換して、そのデータ型を戻します。最初のexprが数値ではない場合、比較の前に、2番目以降の各exprが最初のexprのデータ型に暗黙的に変換されます。
Oracle Databaseは、非空白埋め比較セマンティクスを使用して各exprを比較します。比較では、デフォルトの場合はバイナリが使用され、NLS_COMPパラメータがLINGUISTICに設定され、NLS_SORTパラメータにBINARY以外の設定がある場合は言語が使用されます。文字の比較は、データベース・キャラクタ・セットの文字の数値コードに基づいて行われます。また、文字ごとではなく、一連のバイトとして扱われる文字列全体で行われます。このファンクションによって戻される値が文字データの場合、そのデータ型は、最初のexprが文字データ型の場合はVARCHAR2、最初のexprが各国語キャラクタ・データ型の場合はNVARCHAR2になります。
|
参照:
|
次の文では、最大値を持つ文字列を検索します。
SELECT GREATEST ('HARRY', 'HARRIOT', 'HAROLD') "Greatest" FROM DUAL; Greatest -------- HARRY

GROUP_IDは、GROUP BY指定の結果から、重複するグループを識別します。このファンクションは、問合せ結果から重複グループを除外する場合に有効です。このファンクションは、重複グループを一意に識別するために、OracleのNUMBER値を戻します。このファンクションは、1つのGROUP BY句を含むSELECT文のみに適用できます。
特定のグループ化でn個の重複が存在する場合、GROUP_IDは0〜n-1の範囲の数値を戻します。
次の例では、サンプル表sh.countriesおよびsh.salesの問合せの結果、重複するco.country_regionグループ化に値1を割り当てます。
SELECT co.country_region, co.country_subregion, SUM(s.amount_sold) "Revenue", GROUP_ID() g FROM sales s, customers c, countries co WHERE s.cust_id = c.cust_id AND c.country_id = co.country_id AND s.time_id = '1-JAN-00' AND co.country_region IN ('Americas', 'Europe') GROUP BY co.country_region, ROLLUP (co.country_region, co.country_subregion) ORDER BY co.country_region, co.country_subregion, "Revenue", g; COUNTRY_REGION COUNTRY_SUBREGION Revenue G -------------------- ------------------------------ ---------- ---------- Americas Northern America 944.6 0 Americas 944.6 0 Americas 944.6 1 Europe Western Europe 566.39 0 Europe 566.39 0 Europe 566.39 1
GROUP_IDが1より小さい行のみを戻すには、文の最後に次のHAVING句を追加します。
HAVING GROUP_ID() < 1
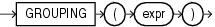
GROUPINGは、通常のグループ化された行と超集合行を区別します。ROLLUPやCUBEなどのGROUP BYの拡張機能は、すべての値の集合がNULLで表される超集合行を生成します。GROUPINGファンクションを使用すると、通常の行に含まれるNULLと超集合行ですべての値の集合を表すNULLを区別できます。
GROUPINGファンクションのexprは、GROUP BY句の式のいずれかと一致する必要があります。行のexprの値がすべての値の集合を表すNULLの場合、このファンクションは1の値を戻します。それ以外の場合は、0(ゼロ)を戻します。GROUPINGファンクションは、OracleのNUMBER値を戻します。これらの用語の詳細は、「SELECT」の「group_by_clause」を参照してください。
次の例では、サンプル表hr.departmentsおよびhr.employeesで、GROUPINGファンクションが1(表の通常の行ではなく超集合行)を戻す場合、それ以外の場合に表示されるNULLのかわりに、文字列「All Jobs」が「JOB」列に表示されます。
SELECT DECODE(GROUPING(department_name), 1, 'All Departments', department_name) AS department, DECODE(GROUPING(job_id), 1, 'All Jobs', job_id) AS job, COUNT(*) "Total Empl", AVG(salary) * 12 "Average Sal" FROM employees e, departments d WHERE d.department_id = e.department_id GROUP BY ROLLUP (department_name, job_id) ORDER BY department, job, "Total Empl", "Average Sal"; DEPARTMENT JOB Total Empl Average Sal ------------------------------ ---------- ---------- ----------- Accounting AC_ACCOUNT 1 99600 Accounting AC_MGR 1 144000 Accounting All Jobs 2 121800 Administration AD_ASST 1 52800 Administration All Jobs 1 52800 All Departments All Jobs 106 77479.2453 Executive AD_PRES 1 288000 Executive AD_VP 2 204000 Executive All Jobs 3 232000 Finance All Jobs 6 103200 Finance FI_ACCOUNT 5 95040 . . .
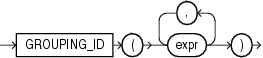
GROUPING_IDは、行に関連するGROUPINGビット・ベクトルに対応する数値を戻します。GROUPING_IDは、ROLLUPやCUBEなど、GROUP BYの拡張機能およびGROUPINGファンクションを含むSELECT文にのみ適用できます。多くのGROUP BY式を含む問合せでは、多くのGROUPINGファンクションを必要とする特定の行のGROUP BYレベルを指定するため、非常に複雑なSQLになります。GROUPING_IDは、このような場合に有効です。
GROUPING_IDは、複数のGROUPINGファンクションの結果をビット・ベクトル(1と0を組み合せた文字列)に連結したものと同じです。GROUPING_IDを使用すると、複数のGROUPINGファンクションを使用する必要がなくなり、行のフィルタ条件の表記が簡単になります。GROUPING_IDを使用すると、要求する行が単一の条件(GROUPING_ID = n)によって識別されるため、行のフィルタ処理が簡単になります。このファンクションは、1つの表に複数のレベルの集計を格納する場合に、特に有効です。
次の例では、サンプル表sh.salesの問合せからグループ化IDを抽出する方法を示します。
SELECT channel_id, promo_id, sum(amount_sold) s_sales, GROUPING(channel_id) gc, GROUPING(promo_id) gp, GROUPING_ID(channel_id, promo_id) gcp, GROUPING_ID(promo_id, channel_id) gpc FROM sales WHERE promo_id > 496 GROUP BY CUBE(channel_id, promo_id) ORDER BY channel_id, promo_id, s_sales, gc; CHANNEL_ID PROMO_ID S_SALES GC GP GCP GPC ---------- ---------- ---------- ---------- ---------- ---------- ---------- 2 999 25797563.2 0 0 0 0 2 25797563.2 0 1 1 2 3 999 55336945.1 0 0 0 0 3 55336945.1 0 1 1 2 4 999 13370012.5 0 0 0 0 4 13370012.5 0 1 1 2 999 94504520.8 1 0 2 1 94504520.8 1 1 3 3
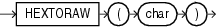
HEXTORAWは、CHAR、VARCHAR2、NCHARまたはNVARCHAR2キャラクタ・セットで16進数を含むcharをRAW値に変換します。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、RAW列を含む簡単な表を作成し、RAWに変換された16進数値を挿入します。
CREATE TABLE test (raw_col RAW(10)); INSERT INTO test VALUES (HEXTORAW('7D'));
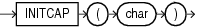
INITCAPは、各単語の最初の文字を大文字、残りの文字を小文字にしてcharを戻します。単語は空白または英数字以外の文字で区切ります。
charは、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型です。戻り値は、charと同じデータ型です。データベースは、基礎となるキャラクタ・セットに対して定義したバイナリ・マッピングに基づいて先頭文字の形式を設定します。大文字と小文字の区別については、「NLS_INITCAP」を参照してください。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、文字列にある各単語を大文字で始めます。
SELECT INITCAP('the soap') "Capitals" FROM DUAL; Capitals --------- The Soap
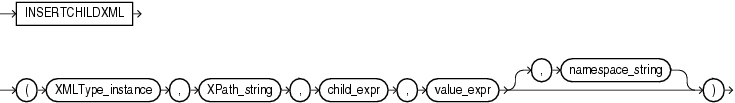
INSERTCHILDXMLは、ユーザー指定の値を、XPath式で指定したノードのターゲットXMLに挿入します。このファンクションと「INSERTXMLBEFORE」を比較してください。
XMLType_instanceは、XMLTypeのインスタンスです。
XPath_stringは、1つ以上の子ノードが挿入されるノードを1つ以上示すXPath式です。先頭にスラッシュを付けて絶対XPath_stringを指定したり、先頭のスラッシュを省略して相対XPath_stringを指定できます。先頭のスラッシュを省略した場合、相対パスのコンテキストは、デフォルトでルート・ノードに設定されます。
child_exprは、挿入する要素または属性のノードを1つ以上指定します。
value_exprは、挿入されるノードを1つ以上指定するXMLTypeのフラグメントです。これは文字列に変換する必要があります。
namespace_stringは、XPath_stringのネームスペース情報を提供します。このパラメータは、VARCHAR2型である必要があります。
次の例では、2番目の/Ownerノードを、「APPENDCHILDXML」の例で更新したウェアハウスの1つのwarehouse_specに追加します。
UPDATE warehouses SET warehouse_spec = INSERTCHILDXML(warehouse_spec, '/Warehouse/Building', 'Owner', XMLType('<Owner>LesserCo</Owner>')) WHERE warehouse_id = 3; SELECT warehouse_spec FROM warehouses WHERE warehouse_id = 3; WAREHOUSE_SPEC ---------------------------------------------------------------------------- <?xml version="1.0"?> <Warehouse> <Building>Rented <Owner>Grandco</Owner> <Owner>LesserCo</Owner> </Building> <Area>85700</Area> <DockType/> <WaterAccess>N</WaterAccess> <RailAccess>N</RailAccess> <Parking>Street</Parking> <VClearance>11.5 ft</VClearance> </Warehouse>
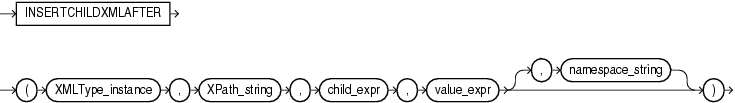
INSERTXMLCHILDAFTERは、1つ以上のコレクション要素をターゲット親要素の子として挿入します。各ターゲットは、指定された既存のコレクション要素の直後に挿入されます。挿入の対象となる既存のXML文書は、スキーマベースまたは非スキーマベースにすることができます。
XMLType_instanceは、挿入の対象となるXMLデータを識別します。
XPath_stringは、対象データ内の親要素の位置を特定します。子データは、それぞれの親要素の下に挿入されます。
child_exprは、挿入される子データの前に配置される既存の子の位置を指定する相対XPath 1.0式です。この式は、親XPathによって示された要素の子要素を指定する必要があります。また、条件を含むこともできます。
value_exprは、挿入するXMLType子要素データです。この引数の各トップレベル要素のノードは、child_exprによって示された要素と同じデータ型である必要があります。
namespace_stringは、親要素、既存の子要素および挿入される子要素XMLデータの名前空間を指定します。
このファンクション、その使用方法および例の詳細は、『Oracle XML DB開発者ガイド』を参照してください。
次の例は、INSERTCHILDXMLの例と似ていますが、この例では、INSERTCHILDXMLの例で追加された/Ownerノードの後に、3番目の/Ownerノードが追加されています。問合せの出力は読み取りやすいように整えられています。
UPDATE warehouses SET warehouse_spec = INSERTCHILDXMLAFTER(warehouse_spec, '/Warehouse/Building','Owner[2]', XMLType('<Owner>ThirdOwner</Owner>')) WHERE warehouse_id = 3; SELECT warehouse_name, EXTRACT(warehouse_spec, '/Warehouse/Building/Owner') "Owners" FROM warehouses WHERE warehouse_id = 3; WAREHOUSE_NAME Owners ----------------------------------- ------------------------------ New Jersey <Owner>LesserCo</Owner> <Owner>GrandCo</Owner> <Owner>ThirdOwner</Owner>
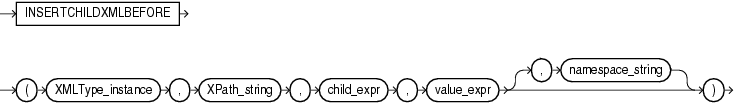
INSERTXMLCHILDBEFOREは、1つ以上のコレクション要素をターゲット親要素の子として挿入します。各ターゲットは、指定された既存のコレクション要素の直前に挿入されます。挿入の対象となる既存のXML文書は、スキーマベースまたは非スキーマベースにすることができます。
XMLType_instanceは、挿入の対象となるXMLデータを識別します。
XPath_stringは、対象データ内の親要素の位置を特定します。子データは、それぞれの親要素の下に挿入されます。
child_exprは、挿入される子データの後に配置される既存の子の位置を指定する相対XPath 1.0式です。この式は、親XPathによって示された要素の子要素を指定する必要があります。また、条件を含むこともできます。
value_exprは、挿入するXMLType子要素データです。この引数の各トップレベル要素のノードは、child_exprによって示された要素と同じデータ型である必要があります。
namespace_stringは、親要素、既存の子要素および挿入される子要素XMLデータの名前空間を指定します。
このファンクション、その使用方法および例の詳細は、『Oracle XML DB開発者ガイド』を参照してください。
次の例は、INSERTCHILDXMLの例と似ていますが、この例では、INSERTCHILDXMLの例で追加された/Ownerノードの前に、3番目の/Ownerノードが追加されています。問合せの出力は読み取りやすいように整えられています。
UPDATE warehouses SET warehouse_spec = INSERTCHILDXMLBEFORE(warehouse_spec, '/Warehouse/Building','Owner[2]', XMLType('<Owner>ThirdOwner</Owner>')) WHERE warehouse_id = 3; SELECT warehouse_name, EXTRACT(warehouse_spec, '/Warehouse/Building/Owner') "Owners" FROM warehouses WHERE warehouse_id = 3; WAREHOUSE_NAME Owners ----------------------------------- ------------------------------ New Jersey <Owner>LesserCo</Owner> <Owner>ThirdOwner</Owner> <Owner>GrandCo</Owner>

INSERTXMLAFTERは、属性のノードではないターゲット・ノードの直後に任意の種類の1つ以上のノードを挿入します。挿入の対象となるXML文書は、スキーマベースまたは非スキーマベースにすることができます。このファンクションはinsertXMLbeforeと似ていますが、ターゲット・ノードの前ではなく後に挿入します。
XMLType_instanceは、挿入のターゲット・ノードを指定します。
XPath_stringは、属性のノードを除く任意の0個以上のノードの位置をターゲット・ノード内で指定するXPath 1.0式です。XMLデータは、これらの各ノードの直後に挿入されます。つまり、指定された各ノードは、value_exprで指定されたノードの前に配置される兄弟ノードとなります。
value_exprは、挿入されるXMLデータです。任意の種類の1つ以上のノードを指定できます。ノードの順序は挿入後も保持されます。
namespace_stringは、ターゲット・ノードのネームスペースです。
このファンクション、その使用方法および例の詳細は、『Oracle XML DB開発者ガイド』を参照してください。
次の例は、INSERTCHILDXMLの例と似ていますが、この例では、INSERTCHILDXMLの例で追加された/Ownerノードの後に、3番目の/Ownerノードが追加されています。問合せの出力は読み取りやすいように整えられています。
UPDATE warehouses SET warehouse_spec = INSERTXMLAFTER(warehouse_spec, '/Warehouse/Building/Owner[1]', XMLType('<Owner>SecondOwner</Owner>')) WHERE warehouse_id = 3; SELECT warehouse_name, EXTRACT(warehouse_spec, '/Warehouse/Building/Owner') "Owners" FROM warehouses WHERE warehouse_id = 3;

INSERTXMLBEFOREは、ユーザー指定の値を、XPath式で指定したノードの前のターゲットXMLに挿入します。 このファンクションはINSERTXMLAFTERと似ていますが、ターゲット・ノードの後ではなく前に挿入します。このファンクションと「INSERTCHILDXML」を比較してください。
XMLType_instanceは、XMLTypeのインスタンスです。
XPath_stringは、1つ以上の子ノードが挿入されるノードを1つ以上示すXPath式です。先頭にスラッシュを付けて絶対XPath_stringを指定したり、先頭のスラッシュを省略して相対XPath_stringを指定できます。先頭のスラッシュを省略した場合、相対パスのコンテキストは、デフォルトでルート・ノードに設定されます。
value_exprは、挿入される1つ以上のノードと親ノード内での位置を定義するXMLTypeのフラグメントです。これは文字列に変換する必要があります。
namespace_stringは、XPath_stringのネームスペース情報を提供します。このパラメータは、VARCHAR2型である必要があります。次の例は、「INSERTCHILDXML」の例と似ていますが、この例では、「INSERTCHILDXML」の例で追加した/Ownerノードの前に、3番目の/Ownerノードを追加します。問合せの出力は読み取りやすいように整えられています。
UPDATE warehouses SET warehouse_spec = INSERTXMLBEFORE(warehouse_spec, '/Warehouse/Building/Owner[2]', XMLType('<Owner>ThirdOwner</Owner>')) WHERE warehouse_id = 3; SELECT warehouse_name, EXTRACT(warehouse_spec, '/Warehouse/Building/Owner') "Owners" FROM warehouses WHERE warehouse_id = 3; Name Owners ------------ -------------------------------------------------------------------- New Jersey <Owner>Grandco</Owner> <Owner>ThirdOwner</Owner> <Owner>LesserCo</Owner>
INSTRファンクションは、stringのsubstringを検索します。このファンクションは、最初に現れた文字stringの位置を示す整数を戻します。INSTRは、入力キャラクタ・セットによって定義された文字を使用して、文字列を算出します。INSTRBは、文字のかわりにバイトを使用します。INSTRCは、完全なUnicodeキャラクタを使用します。INSTR2は、UCS2コードポイントを使用します。INSTR4は、UCS4コードポイントを使用します。
positionは、Oracle Databaseが検索を開始する文字stringの位置を示す0(ゼロ)以外の整数です。positionが負の場合、Oracleはstringの終わりから逆方向にカウントし、結果位置から逆方向に検索します。
occurrenceは、検索するstringが現れたことを示す整数です。occurrenceの値は正である必要があります。occurrenceが1より大きい場合、データベースでは、最初に出現するstringの2番目の文字以降で2番目の出現を検索します。
stringおよびsubstringは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。戻り値のデータ型はNUMBERです。
positionおよびoccurrenceは、NUMBERデータ型か、または暗黙的にNUMBERに変換可能な任意のデータ型で、整数に変換されるものである必要があります。positionおよびoccurrenceのデフォルト値は1です。この場合、Oracleはstringの最初の文字から検索を開始します。検索対象はsubstringが最初に現れる位置です。戻り値は、positionの値にかかわらず、stringの先頭に関係し、文字で表されます。検索が失敗した(stringのposition番目の文字の後にsubstringがoccurrence回現れない)場合、戻り値は0となります。
次の例では、文字列CORPORATE FLOORで文字列ORの検索を3番目の文字から開始します。文字列CORPORATE FLOORで2回目に現れる「OR」の開始位置を戻します。
SELECT INSTR('CORPORATE FLOOR','OR', 3, 2) "Instring" FROM DUAL; Instring ---------- 14
次の例では、最後の文字から、最後から3番目の文字まで、つまりFLOORの最初のOまで逆方向にカウントします。次に、2回目に現れる「OR」を逆方向に検索し、2回目に現れるこの文字列が、検索文字列の2番目の文字で始まることを認識します。
SELECT INSTR('CORPORATE FLOOR','OR', -3, 2) "Reversed Instring" FROM DUAL; Reversed Instring ----------------- 2
次の例では、データベース・キャラクタ・セットがダブルバイトの場合を想定しています。
SELECT INSTRB('CORPORATE FLOOR','OR',5,2) "Instring in bytes" FROM DUAL; Instring in bytes ----------------- 27

ITERATION_NUMBERファンクションは、SELECT文のmodel_clauseにのみ指定でき、model_rules_clauseにITERATE(number)が指定されている場合にのみ使用できます。このファンクションは、モデル・ルールに従って完了した反復を示す整数を戻します。最初の反復では0(ゼロ)を戻します。2回目以降の各反復では、iteration_numberに1を足した整数を戻します。
次の例では、1998年および1999年のマウス・パッドの売上を、それぞれ2001年および2002年のマウス・パッドの売上に割り当てます。
SELECT country, prod, year, s FROM sales_view_ref MODEL PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale s) IGNORE NAV UNIQUE DIMENSION RULES UPSERT SEQUENTIAL ORDER ITERATE(2) ( s['Mouse Pad', 2001 + ITERATION_NUMBER] = s['Mouse Pad', 1998 + ITERATION_NUMBER] ) ORDER BY country, prod, year; COUNTRY PROD YEAR S ---------- ----------------------------------- -------- --------- France Mouse Pad 1998 2509.42 France Mouse Pad 1999 3678.69 France Mouse Pad 2000 3000.72 France Mouse Pad 2001 2509.42 France Mouse Pad 2002 3678.69 France Standard Mouse 1998 2390.83 France Standard Mouse 1999 2280.45 France Standard Mouse 2000 1274.31 France Standard Mouse 2001 2164.54 Germany Mouse Pad 1998 5827.87 Germany Mouse Pad 1999 8346.44 Germany Mouse Pad 2000 7375.46 Germany Mouse Pad 2001 5827.87 Germany Mouse Pad 2002 8346.44 Germany Standard Mouse 1998 7116.11 Germany Standard Mouse 1999 6263.14 Germany Standard Mouse 2000 2637.31 Germany Standard Mouse 2001 6456.13 18 rows selected.
この例では、ビューsales_view_refが必要です。このビューを作成する方法については、「MODEL句の例:」を参照してください。
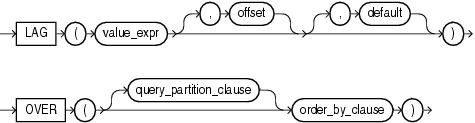
LAGは分析ファンクションです。これは、自己結合せずに、表の1つ以上の行へ同時アクセスを行います。問合せから戻される一連の行およびカーソル位置を指定すると、LAGは、その位置より前にある指定された物理オフセットにある行へアクセスします。
offsetを指定しない場合、デフォルト値は1です。オフセットがウィンドウの有効範囲を超えた場合、オプションのdefault値が戻されます。defaultを指定しない場合、デフォルトはNULLです。
value_exprには、LAGまたは他の分析ファンクションを使用して分析ファンクションをネストできません。ただし、他の組込みファンクション式をvalue_exprで使用できます。
次の例では、employees表の各販売員について、その販売員の直前に雇用された従業員の給与を示します。
SELECT last_name, hire_date, salary, LAG(salary, 1, 0) OVER (ORDER BY hire_date) AS prev_sal FROM employees WHERE job_id = 'PU_CLERK' ORDER BY last_name, hire_date, salary, prev_sal; LAST_NAME HIRE_DATE SALARY PREV_SAL ------------------------- --------- ---------- ---------- Baida 24-DEC-97 2900 2800 Colmenares 10-AUG-99 2500 2600 Himuro 15-NOV-98 2600 2900 Khoo 18-MAY-95 3100 0 Tobias 24-JUL-97 2800 3100
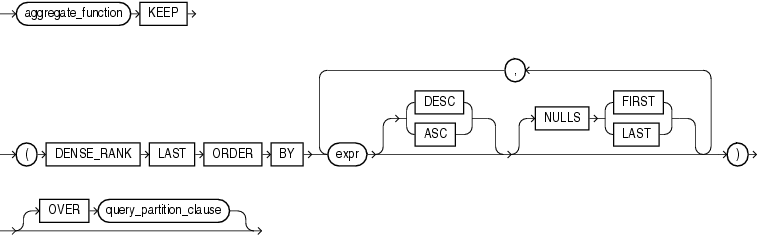
FIRSTファンクションとLASTファンクションは類似しています。両方のファンクションとも、与えられたソート指定に対して、FIRSTまたはLASTとしてランク付けされた一連の行の一連の値を操作する集計ファンクションおよび分析ファンクションです。1つの行のみがFIRSTまたはLASTとしてランク付けされている場合、集計は、1つの要素のみを持つセットを操作します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
このファンクションの詳細および使用例は、「FIRST」を参照してください。
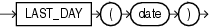
LAST_DAYは、dateを含む月の最終日の日付を戻します。月の最終日は、セッション・パラメータNLS_CALENDARによって定義されます。戻り型は、dateのデータ型に関係なく常にDATEです。
次の文は、現在の月の残りの日数を確認します。
SELECT SYSDATE, LAST_DAY(SYSDATE) "Last", LAST_DAY(SYSDATE) - SYSDATE "Days Left" FROM DUAL; SYSDATE Last Days Left --------- --------- ---------- 30-MAY-01 31-MAY-01 1
次の例では、各従業員の雇用開始日に5か月を加えて、評価日付を戻します。
SELECT last_name, hire_date, TO_CHAR( ADD_MONTHS(LAST_DAY(hire_date), 5)) "Eval Date" FROM employees; LAST_NAME HIRE_DATE Eval Date ------------------------- --------- --------- King 17-JUN-87 30-NOV-87 Kochhar 21-SEP-89 28-FEB-90 De Haan 13-JAN-93 30-JUN-93 Hunold 03-JAN-90 30-JUN-90 Ernst 21-MAY-91 31-OCT-91 Austin 25-JUN-97 30-NOV-97 Pataballa 05-FEB-98 31-JUL-98 Lorentz 07-FEB-99 31-JUL-99 . . .

LAST_VALUEは分析ファンクションです。これは、順序付けられた値の集合にある最後の値を戻します。集合内の最後の値がNULLの場合、IGNORE NULLSを指定していないかぎり、ファンクションはNULLを戻します。この設定は、データの稠密化に役立ちます。IGNORE NULLSを指定すると、LAST_VALUEは集合内の最初のNULLではない値を戻します。すべての値がNULLの場合はNULLを戻します。データの稠密化の例は、「パーティション化された外部結合の使用例:」を参照してください。
exprには、LAST_VALUEまたは他の分析ファンクションを使用して分析ファンクションをネストできません。ただし、他の組込みファンクション式をexprで使用できます。exprの書式の詳細は、「SQL式」を参照してください。
analytic_clauseのwindowing_clauseを省略した場合、デフォルトでRANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROWになります。ウィンドウの最後の値はウィンドウの下部にあり、修復されないため、このデフォルトは予期しない値を戻す場合があります。変更は、現行の行の変更として保持されます。正しい結果を得るには、windowing_clauseをRANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWINGとして指定します。または、windowing_clauseをRANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWINGとして指定することもできます。
次の例では、給与が一番高い従業員の雇用開始日を各行に戻します。
SELECT last_name, salary, hire_date, LAST_VALUE(hire_date) OVER (ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lv FROM (SELECT * FROM employees WHERE department_id = 90 ORDER BY hire_date) ORDER BY last_name, salary, hire_date, lv; LAST_NAME SALARY HIRE_DATE LV --------------- ---------- --------- --------- De Haan 17000 13-JAN-93 17-JUN-87 King 24000 17-JUN-87 17-JUN-87 Kochhar 17000 21-SEP-89 17-JUN-87
この例では、LAST_VALUEファンクションの非決定的な性質を示しています。KochharとDe Haanの給与は同じであるため、Kochharの次の行にDe Haanがあります。Kochharが最初に表示されているのは、副問合せの行がhire_dateで順序付けられているためです。ただし、行がhire_dateで降順に順序付けられている場合は、次の例に示すとおり、ファンクションは異なる値を戻します。
SELECT last_name, salary, hire_date, LAST_VALUE(hire_date) OVER (ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lv FROM (SELECT * FROM employees WHERE department_id = 90 ORDER BY hire_date DESC) ORDER BY last_name, salary, hire_datea, lv; LAST_NAME SALARY HIRE_DATE LV --------------- ---------- --------- --------- De Haan 17000 13-JAN-93 17-JUN-87 King 24000 17-JUN-87 17-JUN-87 Kochhar 17000 21-SEP-89 17-JUN-87
次の2つの例では、一意キーで順序付けることによって、LAST_VALUEファンクションを決定的にする方法を示しています。salaryおよびhire_dateでファンクション内を順序付けると、副問合せの順序付けにかかわらず、同じ結果が戻されます。
SELECT last_name, salary, hire_date, LAST_VALUE(hire_date) OVER (ORDER BY salary, hire_date ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lv FROM (SELECT * FROM employees WHERE department_id = 90 ORDER BY hire_date) ORDER BY last_name, salary, hire_date, lv; LAST_NAME SALARY HIRE_DATE LV --------------- ---------- --------- --------- De Haan 17000 13-JAN-93 17-JUN-87 King 24000 17-JUN-87 17-JUN-87 Kochhar 17000 21-SEP-89 17-JUN-87 SELECT last_name, salary, hire_date, LAST_VALUE(hire_date) OVER (ORDER BY salary, hire_date ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lv FROM (SELECT * FROM employees WHERE department_id = 90 ORDER BY hire_date DESC) ORDER BY last_name, salary, hire_date, lv; LAST_NAME SALARY HIRE_DATE LV --------------- ---------- --------- --------- De Haan 17000 13-JAN-93 17-JUN-87 King 24000 17-JUN-87 17-JUN-87 Kochhar 17000 21-SEP-89 17-JUN-87
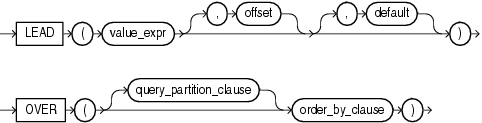
LEADは分析ファンクションです。これは、自己結合せずに、表の1つ以上の行へ同時アクセスを行います。問合せから戻される一連の行およびカーソル位置を指定すると、LEADは、その位置より後にある指定された物理オフセットの行へアクセスします。
offsetを指定しない場合、デフォルト値は1です。オフセットが表の有効範囲を超えた場合、オプションのdefault値が戻されます。defaultを指定しない場合、デフォルト値はNULLです。
value_exprには、LEADまたは他の分析ファンクションを使用して分析ファンクションをネストできません。ただし、他の組込みファンクション式をvalue_exprで使用できます。
次の例では、employees表の各従業員について、その従業員の直後に雇用された従業員の雇用開始日を示します。
SELECT last_name, hire_date, LEAD(hire_date, 1) OVER (ORDER BY hire_date) AS "NextHired" FROM employees WHERE department_id = 30 ORDER BY last_name, hire_date, "NextHired"; LAST_NAME HIRE_DATE NextHired ------------------------- --------- --------- Baida 24-DEC-97 15-NOV-98 Colmenares 10-AUG-99 Himuro 15-NOV-98 10-AUG-99 Khoo 18-MAY-95 24-JUL-97 Raphaely 07-DEC-94 18-MAY-95 Tobias 24-JUL-97 24-DEC-97
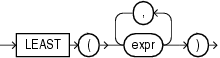
LEASTは、リストされたexpr内の最小値を戻します。比較の前に、2番目以降のすべてのexprは最初のexprのデータ型に暗黙的に変換されます。Oracle Databaseは、非空白埋め比較セマンティクスを使用してexprを比較します。このファンクションによって戻される値が文字データの場合、そのデータ型は常にVARCHAR2になります。
|
参照:
暗黙的な変換の詳細は、表2-10「暗黙的な型変換のマトリックス」を参照してください。2進浮動小数点の比較セマンティクスの詳細は、「浮動小数点数」を参照してください。「データ型の比較規則」も参照してください。 |
次の文では、最小値を持つ文字列を検索します。
SELECT LEAST('HARRY','HARRIOT','HAROLD') "LEAST" FROM DUAL; LEAST ------ HAROLD
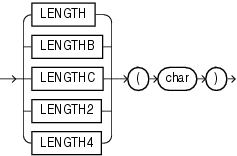
LENGTHの各ファンクションは、charの長さを戻します。LENGTHは、入力キャラクタ・セットによって定義された文字を使用して、長さを算出します。LENGTHBは、文字のかわりにバイトを使用します。LENGTHCは、完全なUnicodeキャラクタを使用します。LENGTH2は、UCS2コードポイントを使用します。LENGTH4は、UCS4コードポイントを使用します。
charは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。戻り値のデータ型はNUMBERです。charのデータ型がCHARの場合、その長さにはすべての後続空白が含まれます。charがNULLの場合、このファンクションはNULLを戻します。
LENGTHBファンクションは、シングルバイトのLOBでのみサポートされます。このファンクションは、マルチバイトのキャラクタ・セットのCLOBとNCLOBでは使用できません。
次の例では、シングルバイトおよびマルチバイトのデータベース・キャラクタ・セットを使用するLENGTHファンクションを使用します。
SELECT LENGTH('CANDIDE') "Length in characters" FROM DUAL; Length in characters -------------------- 7
次の例では、データベース・キャラクタ・セットがダブルバイトの場合を想定しています。
SELECT LENGTHB ('CANDIDE') "Length in bytes" FROM DUAL; Length in bytes --------------- 14

LNは、nの自然対数を戻します(nは正の数)。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。引数がBINARY_FLOATの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、引数と同じ数値データ型を戻します。
次の例では、95の自然対数を戻します。
SELECT LN(95) "Natural log of 95" FROM DUAL; Natural log of 95 ----------------- 4.55387689
LNNVLは、条件のオペランドの1つまたは両方がNULLの可能性がある場合にその条件を簡単に評価する方法を提供します。このファンクションは、問合せのWHERE句でのみ使用できます。このファンクションは、引数として条件を取り、その条件がFALSEまたはUNKNOWNの場合はTRUEを戻し、TRUEの場合はFALSEを戻します。LNNVLは、スカラー式を指定できる場所であればどこでも指定でき、有効ではないが、発生する可能性があるNULLを評価するためにIS [NOT] NULL、ANDまたはOR条件が必要であるようなコンテキストでも指定できます。
Oracle Databaseは、LNNVLファンクションをこの方法で内部的に使用して、NOT IN条件をNOT EXISTS条件として書き換える場合があります。この場合、EXPLAIN PLANからの出力によって、この操作がPLAN TABLEに出力されます。conditionでは、どのようなスカラー値でも評価できますが、AND、ORまたはBETWEENを含む複合条件は指定できません。
a = 2およびb=NULLの場合のLNNVLからの戻り値を次の表に示します。
| 条件 | 条件の真偽 | LNNVLの戻り値 |
|---|---|---|
|
a = 1 |
|
|
|
a = 2 |
|
|
|
a |
|
|
|
b = 1 |
|
|
|
b |
|
|
|
a = b |
|
|
歩合を受け取らない従業員を含めて、歩合率が20%未満の従業員数を調べるとします。次の問合せは、20%未満の歩合を実際に受け取る従業員のみを戻します。
SELECT COUNT(*) FROM employees WHERE commission_pct < .2; COUNT(*) ---------- 11
歩合を受け取らない72人の従業員も含めるには、LNNVLファンクションを次のように使用して、この問合せを書き換えます。
SELECT COUNT(*) FROM employees WHERE LNNVL(commission_pct >= .2); COUNT(*) ---------- 83

LOCALTIMESTAMPは、セッションのタイムゾーンの現在の日付および時刻をTIMESTAMPデータ型の値で戻します。これに対して、CURRENT_TIMESTAMPは、TIMESTAMP WITH TIME ZONE値を戻します。
オプションの引数timestamp_precisionには、戻される時刻値の秒の小数部の精度を指定します。
次の例では、LOCALTIMESTAMPとCURRENT_TIMESTAMPの相違を示します。
ALTER SESSION SET TIME_ZONE = '-5:00'; SELECT CURRENT_TIMESTAMP, LOCALTIMESTAMP FROM DUAL; CURRENT_TIMESTAMP LOCALTIMESTAMP ------------------------------------------------------------------- 04-APR-00 01.27.18.999220 PM -05:00 04-APR-00 01.27.19 PM ALTER SESSION SET TIME_ZONE = '-8:00'; SELECT CURRENT_TIMESTAMP, LOCALTIMESTAMP FROM DUAL; CURRENT_TIMESTAMP LOCALTIMESTAMP ----------------------------------- ------------------------------ 04-APR-00 10.27.45.132474 AM -08:00 04-APR-00 10.27.451 AM
LOCALTIMESTAMPで書式マスクを使用する場合は、ファンクションが戻す値と書式マスクを一致させてください。たとえば、次の表の場合を考えます。
CREATE TABLE local_test (col1 TIMESTAMP WITH LOCAL TIME ZONE);
ファンクションが戻す型のTIME ZONEの部分がマスクに含まれていないため、次の文は正常に実行されません。
INSERT INTO local_test VALUES (TO_TIMESTAMP(LOCALTIMESTAMP, 'DD-MON-RR HH.MI.SSXFF'));
次の文では、LOCALTIMESTAMPの戻り値の型と一致する正しい書式マスクが使用されています。
INSERT INTO local_test VALUES (TO_TIMESTAMP(LOCALTIMESTAMP, 'DD-MON-RR HH.MI.SSXFF PM'));
LOGは、n2を底とするn1の対数を戻します。底n1は0(ゼロ)または1以外の任意の正の値で、n2は任意の正の値です。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。いずれかの引数がBINARY_FLOATまたはBINARY_DOUBLEの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、NUMBERを戻します。
次の例では、100の対数を戻します。
SELECT LOG(10,100) "Log base 10 of 100" FROM DUAL; Log base 10 of 100 ------------------ 2
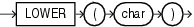
LOWERは、すべての文字を小文字にしてcharを戻します。charは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。戻り値は、charと同じデータ型です。データベースは、基礎となるキャラクタ・セットに対して定義したバイナリ・マッピングに基づいて文字の形式を設定します。小文字の区別については、「NLS_LOWER」を参照してください。
次の例では、文字列を小文字にして戻します。
SELECT LOWER('MR. SCOTT MCMILLAN') "Lowercase" FROM DUAL; Lowercase -------------------- mr. scott mcmillan
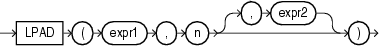
LPADは、expr1の左側にexpr2に指定した文字を連続的に埋め込んでn桁にして戻します。このファンクションは、問合せの出力の書式設定に役立ちます。
expr1およびexpr2は、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。戻される文字列は、expr1が文字データ型の場合はVARCHAR2データ型、expr1が各国語キャラクタ・データ型の場合はNVARCHAR2データ型、expr1がLOBデータ型の場合はLOBデータ型になります。expr1と同じキャラクタ・セットの文字列が戻されます。引数nは、NUMBER型の整数か、またはNUMBER型の整数に暗黙的に変換可能な値である必要があります。
expr2を指定しない場合、デフォルトで空白1個が指定されます。expr1がnより長い場合、このファンクションはnに収まるexpr1の一部を戻します。
引数nは、戻り値が画面に表示される場合の全体の長さです。多くのキャラクタ・セットでは、これは戻り値の文字数でもあります。ただし、マルチバイトのキャラクタ・セットでは、表示される文字列の長さが文字列の文字数と異なる場合もあります。
次の例では、文字列の左側にアスタリスクとピリオド(*.)を埋め込みます。
SELECT LPAD('Page 1',15,'*.') "LPAD example" FROM DUAL; LPAD example --------------- *.*.*.*.*Page 1

LTRIMは、charの左端から、setに指定されたすべての文字を削除します。setを指定しない場合、デフォルトで空白1個が指定されます。charが文字リテラルの場合、一重引用符で囲む必要があります。Oracle Databaseはcharの先頭文字からスキャンし始め、setに指定された文字をすべて削除します。setに指定された文字以外の文字が見つかった時点で結果を戻します。
charおよびsetは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。戻される文字列は、charが文字データ型の場合はVARCHAR2データ型、charが各国語キャラクタデータ型の場合はNVARCHAR2データ型、charがLOBデータ型の場合はLOBデータ型になります。
次の例では、oe.products表内の製品名のグループから、冗長な最初の語を削除します。
SELECT product_name, LTRIM(product_name, 'Monitor ') "Short Name" FROM products WHERE product_name LIKE 'Monitor%'; PRODUCT_NAME Short Name -------------------- --------------- Monitor 17/HR 17/HR Monitor 17/HR/F 17/HR/F Monitor 17/SD 17/SD Monitor 19/SD 19/SD Monitor 19/SD/M 19/SD/M Monitor 21/D 21/D Monitor 21/HR 21/HR Monitor 21/HR/M 21/HR/M Monitor 21/SD 21/SD Monitor Hinge - HD Hinge - HD Monitor Hinge - STD Hinge - STD
MAKE_REFは、オブジェクト識別子が主キーに基づいている、オブジェクト・ビューの行またはオブジェクト表の行に対するREFを作成します。このファンクションは、オブジェクト・ビューを作成する場合などに有効です。
サンプル・スキーマoeには、inventory_typに基づくオブジェクト・ビューoc_inventoriesが格納されています。オブジェクト識別子はproduct_idです。次の例では、3003というproduct_idを含むオブジェクト・ビューoc_inventoriesにある行へのREFを作成します。
SELECT MAKE_REF (oc_inventories, 3003) FROM DUAL; MAKE_REF(OC_INVENTORIES,3003) ------------------------------------------------------------------ 00004A038A0046857C14617141109EE03408002082543600000014260100010001 00290090606002A00078401FE0000000B03C21F040000000000000000000000000 0000000000

MAXはexprの最大値を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
次の例では、hr.employees表の最高給与を検索します。
SELECT MAX(salary) "Maximum" FROM employees; Maximum ---------- 24000
次の例では、各従業員について、その従業員と所属が同じ従業員のうち、一番高い給与を計算します。
SELECT manager_id, last_name, salary, MAX(salary) OVER (PARTITION BY manager_id) AS mgr_max FROM employees ORDER BY manager_id, last_name, salary, mgr_max; MANAGER_ID LAST_NAME SALARY MGR_MAX ---------- ------------------------- ---------- ---------- 100 Cambrault 11000 17000 100 De Haan 17000 17000 100 Errazuriz 12000 17000 100 Fripp 8200 17000 100 Hartstein 13000 17000 100 Kaufling 7900 17000 100 Kochhar 17000 17000 . . .
この問合せを述語のある親問合せで囲むと、各部門で給与の一番高い従業員がわかります。
SELECT manager_id, last_name, salary FROM (SELECT manager_id, last_name, salary, MAX(salary) OVER (PARTITION BY manager_id) AS rmax_sal FROM employees) WHERE salary = rmax_sal ORDER BY manager_id, last_name, salary; MANAGER_ID LAST_NAME SALARY ---------- ------------------------- ---------- 100 De Haan 17000 100 Kochhar 17000 101 Greenberg 12000 101 Higgins 12000 102 Hunold 9000 103 Ernst 6000 108 Faviet 9000 114 Khoo 3100 120 Nayer 3200 120 Taylor 3200 121 Sarchand 4200 122 Chung 3800 123 Bell 4000 124 Rajs 3500 145 Tucker 10000 146 King 10000 147 Vishney 10500 148 Ozer 11500 149 Abel 11000 201 Fay 6000 205 Gietz 8300 King 24000 22 rows selected.

MEDIANは、連続分散モデルを想定する逆分散関数です。このファンクションは、数値または日時値を取り、その中央値、または値のソート後に中央値となる補間された値を戻します。計算では、NULLは無視されます。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。exprのみを指定した場合、このファンクションは引数の数値データ型と同じデータ型を戻します。OVER句を指定した場合、Oracle Databaseは、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、そのデータ型を戻します。
MEDIANの結果の計算では、まず行が順序付けされます。グループ内の行数としてNが使用され、対象の行番号(RN)がRN = (1 + (0.5×(N-1))という式で計算されます。集計ファンクションの最終結果は、行番号がCRN = CEILING(RN)およびFRN = FLOOR(RN)の行の値間の直線補間によって計算されます。
最終結果は次のとおりです。
if (CRN = FRN = RN) then (value of expression from row at RN) else (CRN - RN) * (value of expression for row at FRN) + (RN - FRN) * (value of expression for row at CRN)
MEDIANは、分析ファンクションとして使用できます。その場合、OVER句には、query_partition_clauseのみを指定できます。各行に対して、各パーティション内の一連の値の中央値に該当する値が戻されます。
このファンクションと次のファンクションを比較してください。
MEDIANは、パーセンタイル値がデフォルトで0.5に指定される特別なPERCENTILE_CONTです。
次の問合せは、hr.employees表内の各従業員の給与の中央値を戻します。
SELECT department_id, MEDIAN(salary) FROM employees GROUP BY department_id ORDER BY department_id, median(salary); DEPARTMENT_ID MEDIAN(SALARY) ------------- -------------- 10 4400 20 9500 30 2850 40 6500 50 3100 60 4800 70 10000 80 8900 90 17000 100 8000 110 10150 7000
次の問合せは、hr.employees表内の部門のサブセットのマネージャごとに給与の中央値を戻します。
SELECT manager_id, employee_id, salary, MEDIAN(salary) OVER (PARTITION BY manager_id) "Median by Mgr" FROM employees WHERE department_id > 60 ORDER BY manager_id, employee_id, salary, "Median by Mgr"; MANAGER_ID EMPLOYEE_ID SALARY Median by Mgr ---------- ----------- ---------- ------------- 100 101 17000 13500 100 102 17000 13500 100 145 14000 13500 100 146 13500 13500 100 147 12000 13500 100 148 11000 13500 100 149 10500 13500 101 108 12000 12000 101 204 10000 12000 101 205 12000 12000 108 109 9000 7800 108 110 8200 7800 108 111 7700 7800 108 112 7800 7800 108 113 6900 7800 145 150 10000 8500 145 151 9500 8500 145 152 9000 8500 . . .

MINは、exprの最小値を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
次の例では、hr.employees表の最初の雇用開始日を戻します。
SELECT MIN(hire_date) "Earliest" FROM employees; Earliest --------- 17-JUN-87
次の例では、各従業員について、その従業員が雇用された日以前に雇用された従業員を検索します。その従業員と所属が同じ従業員のサブセットを決定し、そのサブセット内で一番低い給与を戻します。
SELECT manager_id, last_name, hire_date, salary, MIN(salary) OVER(PARTITION BY manager_id ORDER BY hire_date RANGE UNBOUNDED PRECEDING) AS p_cmin FROM employees ORDER BY manager_id, last_name, hire_date, salary, p_cmin; MANAGER_ID LAST_NAME HIRE_DATE SALARY P_CMIN ---------- ------------------------- --------- ---------- ---------- 100 Cambrault 15-OCT-99 11000 6500 100 De Haan 13-JAN-93 17000 17000 100 Errazuriz 10-MAR-97 12000 7900 100 Fripp 10-APR-97 8200 7900 100 Hartstein 17-FEB-96 13000 7900 100 Kaufling 01-MAY-95 7900 7900 100 Kochhar 21-SEP-89 17000 17000 100 Mourgos 16-NOV-99 5800 5800 100 Partners 05-JAN-97 13500 7900 100 Raphaely 07-DEC-94 11000 11000 100 Russell 01-OCT-96 14000 7900 . . .
MODはn2をn1で割った余りを戻します。n1が0の場合は、n2を戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。Oracleは、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、そのデータ型を戻します。
次の例では、11を4で割ったときの余りを戻します。
SELECT MOD(11,4) "Modulus" FROM DUAL; Modulus ---------- 3
このファンクションは、mが負の場合には古典数学のモジュール・ファンクションとは異なる動作をします。古典数学のモジュール・ファンクションは、次の公式を用いたMODファンクションで表すことができます。
m - n * FLOOR(m/n)
次の表に、MODファンクションと古典数学のモジュール・ファンクションの相違を示します。
| m | n | MOD(m,n) | 古典数学のモジュール・ファンクション |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
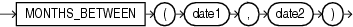
MONTHS_BETWEENは、日付date1とdate2の間の月数を戻します。月および月の最終日は、パラメータNLS_CALENDARによって定義されます。date1がdate2より後の日付の場合、結果は正の値になります。date1がdate2より前の日付の場合、結果は負の値になります。date1およびdate2が、月の同じ日または月の最終日の場合、結果は常に整数になります。それ以外の場合、Oracle Databaseは結果の小数部を1か月31日として計算し、date1とdate2の差を割り出します。
次の例では、2つの日付間の月数を計算します。
SELECT MONTHS_BETWEEN (TO_DATE('02-02-1995','MM-DD-YYYY'), TO_DATE('01-01-1995','MM-DD-YYYY') ) "Months" FROM DUAL; Months ---------- 1.03225806
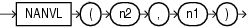
NANVLファンクションは、BINARY_FLOAT型またはBINARY_DOUBLE型の浮動小数点数のみに有効です。このファンクションは、入力値n2がNaN(非数値)の場合は代替値n1を戻すようにOracle Databaseに指示します。n2がNaNでない場合、Oracleはn2を戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。Oracleは、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、そのデータ型を戻します。
|
参照:
暗黙的な変換の詳細は、表2-10「暗黙的な型変換のマトリックス」を参照してください。2進浮動小数点の比較セマンティクスの詳細は、「浮動小数点数」を参照してください。数値の優先順位詳細は、「数値の優先順位」を参照してください。 |
「TO_BINARY_DOUBLE」で作成したfloat_point_demoを使用して、表に2つ目のエントリを挿入します。
Insert INTO float_point_demo VALUES (0,'NaN','NaN'); SELECT * FROM float_point_demo; DEC_NUM BIN_DOUBLE BIN_FLOAT ---------- ---------- ---------- 1234.56 1.235E+003 1.235E+003 0 Nan Nan
次の例では、数値の場合はbin_floatを戻します。数値以外の場合は、0(ゼロ)を戻します。
SELECT bin_float, NANVL(bin_float,0) FROM float_point_demo; BIN_FLOAT NANVL(BIN_FLOAT,0) ---------- ------------------ 1.235E+003 1.235E+003 Nan 0
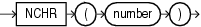
NCHRは、各国語キャラクタ・セットのnumberと同等のバイナリを持つ文字を戻します。戻り値は常にNVARCHAR2です。このファンクションは、CHRファンクションにUSING NCHAR_CS句を指定して使用した場合と同じ結果を戻します。
このファンクションは、引数として、NUMBER値、または暗黙的にNUMBER型に変換可能な任意の値を取り、文字を戻します。
次の例では、NCHAR文字187を戻します。
SELECT NCHR(187) FROM DUAL; NC -- > SELECT CHR(187 USING NCHAR_CS) FROM DUAL; CH -- >

NEW_TIMEは、タイムゾーンtimezone1の日時がdateの時点のタイムゾーンtimezone2の日時を戻します。このファンクションを使用する前に、24時間で表示されるように、NLS_DATE_FORMATパラメータを設定する必要があります。戻り型は、dateのデータ型に関係なく常にDATEです。
引数timezone1およびtimezone2には、次のテキスト文字列のいずれかを指定できます。
次の例では、指定された太平洋標準時と同等の大西洋標準時を戻します。
ALTER SESSION SET NLS_DATE_FORMAT = 'DD-MON-YYYY HH24:MI:SS'; SELECT NEW_TIME(TO_DATE( '11-10-99 01:23:45', 'MM-DD-YY HH24:MI:SS'), 'AST', 'PST') "New Date and Time" FROM DUAL; New Date and Time -------------------- 09-NOV-1999 21:23:45

NEXT_DAYは、charで指定した曜日で、日付dateより後の最初の日付を戻します。戻り型は、dateのデータ型に関係なく常にDATEです。引数charは、セッションの日付言語での曜日である必要があります(フルネームでも省略形でも可)。必要最小限の文字数は、省略形の文字数です。有効な省略形の後に続けて文字が入力されていても、それらの文字は無視されます。戻り値は、引数dateと同じ時、分および秒のコンポーネントを持っています。
次の例では、2001年2月2日以降の最初の火曜日の日付を戻します。
SELECT NEXT_DAY('02-FEB-2001','TUESDAY') "NEXT DAY" FROM DUAL; NEXT DAY ----------- 06-FEB-2001

NLS_CHARSET_DECL_LENは、NCHAR列の宣言の長さを(文字数で)戻します。byte_count引数は、列の幅です。char_set_id引数は、列のキャラクタ・セットIDです。
次の例では、マルチバイト・キャラクタ・セットを使用している場合に、列の幅が200バイトである文字の数を戻します。
SELECT NLS_CHARSET_DECL_LEN (200, nls_charset_id('ja16eucfixed')) FROM DUAL; NLS_CHARSET_DECL_LEN(200,NLS_CHARSET_ID('JA16EUCFIXED')) -------------------------------------------------------- 100
NLS_CHARSET_IDは、キャラクタ・セット名stringに対応するキャラクタ・セットのID番号を戻します。引数stringは、実行時のVARCHAR2値です。string値'CHAR_CS'は、サーバーのデータベース・キャラクタ・セットのID番号を戻します。string値'NCHAR_CS'は、サーバーの各国語キャラクタ・セットのID番号を戻します。
無効なキャラクタ・セット名を指定すると、NULLが戻されます。
次の例では、キャラクタ・セットのIDを戻します。
SELECT NLS_CHARSET_ID('ja16euc') FROM DUAL; NLS_CHARSET_ID('JA16EUC') ------------------------- 830

NLS_CHARSET_NAMEは、ID番号numberに対応するキャラクタ・セット名を戻します。キャラクタ・セット名は、データベース・キャラクタ・セットのVARCHAR2値として戻されます。
numberが有効なキャラクタ・セットIDとして認識されない場合は、このファンクションはNULLを戻します。
次の例では、キャラクタ・セットのID番号2に対応するキャラクタ・セットを戻します。
SELECT NLS_CHARSET_NAME(2) FROM DUAL; NLS_CH ------ WE8DEC

NLS_INITCAPは、各単語の最初の文字を大文字、残りの文字を小文字にしてcharを戻します。単語は空白または英数字以外の文字で区切ります。
charおよび'nlsparam'は、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型です。戻される文字列は、VARCHAR2データ型であり、charと同じキャラクタ・セットです。
'nlsparam'の値は次の書式で指定します。
'NLS_SORT = sort'
sortは、言語ソート基準またはBINARYのいずれかです。言語ソート基準は、大文字と小文字の変換のために特別な言語要件を処理します。これらの要件によって、charと異なる長さの値が戻される場合があります。'nlsparam'を省略すると、このファンクションはセッションに対してデフォルトのソート基準を使用します。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次に、ファンクションによって言語ソート基準がどのように異なる値を戻すかを示します。
SELECT NLS_INITCAP ('ijsland') "InitCap" FROM DUAL; InitCap ------- Ijsland SELECT NLS_INITCAP ('ijsland', 'NLS_SORT = XDutch') "InitCap" FROM DUAL; InitCap ------- IJsland

NLS_LOWERは、すべての文字を小文字にしてcharを戻します。
charおよび'nlsparam'は、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。戻される文字列は、charが文字データ型の場合はVARCHAR2データ型になり、charがLOBデータ型の場合はLOBになります。charと同じキャラクタ・セットの文字列が戻されます。
'nlsparam'の書式および用途は、NLS_INITCAPファンクションと同じです。
次の例では、XGerman言語ソート順序を使用する文字列'citta''を戻します。
SELECT NLS_LOWER ('CITTA''', 'NLS_SORT = XGerman') "Lowercase" FROM DUAL; Lowerc ------ citta'

NLSSORTは、charのソートに使用される文字列のバイトを戻します。
charおよび'nlsparam'は、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型です。戻される文字列はRAWデータ型です。
'nlsparam'の値は次の書式で指定します。
'NLS_SORT = sort'
sortは、言語ソート基準またはBINARYのいずれかです。'nlsparam'を省略すると、このファンクションはセッションに対してデフォルトのソート基準を使用します。BINARYを指定すると、このファンクションはcharを戻します。
'nlsparam'を指定した場合、言語ソート名に接尾辞_aiを追加してアクセント記号の有無を区別しないソートを行うか、または_ciを追加して大/小文字を区別しないソートを行うことができます。アクセント記号の有無および大/小文字を区別しないソートの詳細は、『Oracle Databaseグローバリゼーション・サポート・ガイド』を参照してください。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
このファンクションを使用すると、文字列の2進値を基にしたソートおよび比較ではなく、言語ソート基準を基にしたソートおよび比較を指定できます。次の例では、2つの値を含むテスト表を作成し、戻される値がNLSSORTファンクションによってどのように順序付けられるかを示します。
CREATE TABLE test (name VARCHAR2(15)); INSERT INTO test VALUES ('Gaardiner'); INSERT INTO test VALUES ('Gaberd'); INSERT INTO test VALUES ('Gaasten'); SELECT * FROM test ORDER BY name; NAME --------------- Gaardiner Gaasten Gaberd SELECT * FROM test ORDER BY NLSSORT(name, 'NLS_SORT = XDanish'); NAME --------------- Gaberd Gaardiner Gaasten
次の例では、比較操作でのNLSSORTファンクションの使用方法を示します。
SELECT * FROM test WHERE name > 'Gaberd' ORDER BY name; no rows selected SELECT * FROM test WHERE NLSSORT(name, 'NLS_SORT = XDanish') > NLSSORT('Gaberd', 'NLS_SORT = XDanish') ORDER BY name; NAME --------------- Gaardiner Gaasten
同一の言語ソート基準を使用する比較操作で頻繁にNLSSORTを使用する場合、NLS_COMPパラメータ(データベース用か現行のセッション用のいずれか)にLINGUISTICを設定し、セッションのNLS_SORTパラメータに必要なソート基準を設定するとより効率的です。これによって、現行のセッション中のすべてのソート操作および比較操作において、デフォルトでそのソート基準が使用されるようになります。
ALTER SESSION SET NLS_COMP = 'LINGUISTIC'; ALTER SESSION SET NLS_SORT = 'XDanish'; SELECT * FROM test WHERE name > 'Gaberd' ORDER BY name; NAME --------------- Gaardiner Gaasten

NLS_UPPERは、すべての文字を大文字にしてcharを戻します。
charおよび'nlsparam'は、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。戻される文字列は、charが文字データ型の場合はVARCHAR2データ型になり、charがLOBデータ型の場合はLOBになります。charと同じキャラクタ・セットの文字列が戻されます。
'nlsparam'の書式および用途は、NLS_INITCAPファンクションと同じです。
次の例では、すべての文字を大文字に変換して文字列を戻します。
SELECT NLS_UPPER ('große') "Uppercase" FROM DUAL; Upper ----- GROßE SELECT NLS_UPPER ('große', 'NLS_SORT = XGerman') "Uppercase" FROM DUAL; Upperc ------ GROSSE

NTILEは分析ファンクションです。これは、順序付けられたデータセットをexprに指定した数のバケットに分割し、適切なバケット番号を各行に割り当てます。バケットには1〜exprの番号が付けられます。expr値は、パーティションごとに、正の定数に変換される必要があります。Oracle Databaseではexprは整数とみなされるため、この値が整数ではない定数の場合は整数に切り捨てられます。戻り値は、NUMBERです。
バケット内の行数は、最大で1異なります。残りの値(バケットで割った行数の余り)は、バケット1から順に、1行ずつ分割されます。
exprが行数より大きい場合、行数と等しい数のバケットに行が入れられ、余りのバケットは空になります。
exprには、NTILEまたは他の分析ファンクションを使用して分析ファンクションをネストできません。ただし、他の組込みファンクション式をexprで使用できます。
次の例では、部門100のoe.employees表のsalary列の値を4つのバケットに分割します。この部門のsalary列には6つの値が存在するため、2つの余分な値(6を4で割った余り)は、バケット1および2に割り当てられます。そのため、バケット1および2は、バケット3または4より値が1つ多くなります。
SELECT last_name, salary, NTILE(4) OVER (ORDER BY salary DESC) AS quartile FROM employees WHERE department_id = 100 ORDER BY last_name, salary, quartile; LAST_NAME SALARY QUARTILE ------------------------- ---------- ---------- Chen 8200 2 Faviet 9000 1 Greenberg 12000 1 Popp 6900 4 Sciarra 7700 3 Urman 7800 2
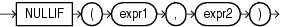
NULLIFは、expr1とexpr2を比較します。同じである場合は、NULLを戻します。異なる場合は、expr1を戻します。expr1には、リテラルNULLを指定できません。
両方の引数が数値データ型である場合、Oracle Databaseは、数値の優先順位が高い方の引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、そのデータ型を戻します。2つの引数が数値ではない場合、それらのデータ型が同じである必要があります。データ型が異なる場合、Oracleはエラーを戻します。
NULLIFファンクションは、次のCASE式と論理的に同じです。
CASE WHEN expr1 = expr 2 THEN NULL ELSE expr1 END
次の例では、サンプル・スキーマhrから、雇用後に職種が変更した従業員を検索します。これは、employees表の現行のjob_idがjob_history表のjob_idと異なるかどうかによって識別されます。
SELECT e.last_name, NULLIF(e.job_id, j.job_id) "Old Job ID" FROM employees e, job_history j WHERE e.employee_id = j.employee_id ORDER BY last_name, "Old Job ID"; LAST_NAME Old Job ID ------------------------- ---------- De Haan AD_VP Hartstein MK_MAN Kaufling ST_MAN Kochhar AD_VP Kochhar AD_VP Raphaely PU_MAN Taylor SA_REP Taylor Whalen AD_ASST Whalen
NUMTODSINTERVALは、nをINTERVAL DAY TO SECONDリテラルに変換します。引数nには、任意のNUMBER値か、またはNUMBER値に暗黙的に変換可能な式を指定できます。引数interval_unitのデータ型は、CHAR、VARCHAR2、NCHARまたはNVARCHAR2です。interval_unitの値にはnの単位を指定します。この値は次の文字列値のいずれかである必要があります。
interval_unitでは、大/小文字は区別されません。カッコ内の先行値および後続値は無視されます。デフォルトでは、戻り値の精度は9です。
次の例では、COUNT分析ファンクションにNUMTODSINTERVALを使用し、各従業員について、雇用開始日から過去100日以内に同じマネージャの部下として配属された従業員の人数を計算します。分析ファンクションの構文の詳細は、「分析ファンクション」を参照してください。
SELECT manager_id, last_name, hire_date, COUNT(*) OVER (PARTITION BY manager_id ORDER BY hire_date RANGE NUMTODSINTERVAL(100, 'day') PRECEDING) AS t_count FROM employees; MANAGER_ID LAST_NAME HIRE_DATE T_COUNT ---------- ------------------------- --------- ---------- 100 Kochhar 21-SEP-89 1 100 De Haan 13-JAN-93 1 100 Raphaely 07-DEC-94 1 100 Kaufling 01-MAY-95 1 100 Hartstein 17-FEB-96 1 . . . 149 Grant 24-MAY-99 1 149 Johnson 04-JAN-00 1 201 Goyal 17-AUG-97 1 205 Gietz 07-JUN-94 1 King 17-JUN-87 1
NUMTOYMINTERVALは、数値nをINTERVAL YEAR TO MONTHリテラルに変換します。引数nには、任意のNUMBER値か、またはNUMBER値に暗黙的に変換可能な式を指定できます。引数interval_unitのデータ型は、CHAR、VARCHAR2、NCHARまたはNVARCHAR2です。interval_unitの値にはnの単位を指定します。この値は次の文字列値のいずれかである必要があります。
interval_unitでは、大/小文字は区別されません。カッコ内の先行値および後続値は無視されます。デフォルトでは、戻り値の精度は9です。
次の例では、SUM分析ファンクションにNUMTOYMINTERVALを使用し、各従業員について、その従業員の雇用日から過去1年の間に雇用された従業員の給与の合計を計算します。分析ファンクションの構文の詳細は、「分析ファンクション」を参照してください。
SELECT last_name, hire_date, salary, SUM(salary) OVER (ORDER BY hire_date RANGE NUMTOYMINTERVAL(1,'year') PRECEDING) AS t_sal FROM employees ORDER BY last_name, hire_date; LAST_NAME HIRE_DATE SALARY T_SAL ------------------------- --------- ---------- ---------- King 17-JUN-87 24000 24000 Whalen 17-SEP-87 4400 28400 Kochhar 21-SEP-89 17000 17000 . . . Markle 08-MAR-00 2200 112400 Ande 24-MAR-00 6400 106500 Banda 21-APR-00 6200 109400 Kumar 21-APR-00 6100 109400
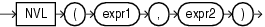
NVLを使用すると、NULL(空白として戻される)を文字列に置換して問合せの結果に含めることができます。expr1がNULLの場合、NVLはexpr2を戻します。expr1がNULLでない場合、NVLはexpr1を戻します。
引数expr1およびexpr2は、任意のデータ型を持つことができます。2つの引数のデータ型が異なる場合、一方のデータ型が他方のデータ型に暗黙的に変換されます。暗黙的に変換できない場合、データベースはエラーを戻します。暗黙的な変換は、次のように実行されます。
expr1が文字データの場合、Oracle Databaseは2つの引数を比較する前にexpr2をexpr1のデータ型に変換し、expr1のキャラクタ・セットでVARCHAR2を戻します。
expr1が数値である場合、Oracleは数値の優先順位が最も高い引数を判断し、その引数のデータ型に他方の引数を暗黙的に変換して、そのデータ型を戻します。次の例では、従業員が歩合を受け取らない場合、従業員名および従業員の歩合「Not Applicable」を表示します。
SELECT last_name, NVL(TO_CHAR(commission_pct), 'Not Applicable') "COMMISSION" FROM employees WHERE last_name LIKE 'B%' ORDER BY last_name; LAST_NAME COMMISSION ------------------------- ---------------------------------------- Baer Not Applicable Baida Not Applicable Banda .1 Bates .15 Bell Not Applicable Bernstein .25 Bissot Not Applicable Bloom .2 Bull Not Applicable
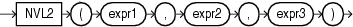
NVL2を使用すると、指定された式がNULLかどうかに基づく問合せによって戻される値を判断できます。expr1がNULLでない場合、NVL2はexpr2を戻します。expr1がNULLの場合、NVL2はexpr3を戻します。
引数expr1は、任意のデータ型を持つことができます。引数expr2およびexpr3は、LONG以外の任意のデータ型を持つことができます。
expr2とexpr3のデータ型が異なる場合、次のようになります。
expr2が文字データの場合、Oracle Databaseは、expr3がNULLの定数ではないかぎり、2つの引数を比較する前にexpr3をexpr2のデータ型に変換します。expr3がNULL定数の場合は、データ型の変換は行われません。Oracleは、expr2のキャラクタ・セットでVARCHAR2を戻します。
expr2が数値である場合、Oracleは、数値の優先順位が最も高い引数を判断し、その引数のデータ型に他方の引数を暗黙的に変換して、そのデータ型を戻します。次の例では、employeesのcommission_pct列がNULLかどうかによって、従業員の収入が給与と歩合か、または給与のみかを示します。
SELECT last_name, salary, NVL2(commission_pct, salary + (salary * commission_pct), salary) income FROM employees WHERE last_name like 'B%' ORDER BY last_name; LAST_NAME SALARY INCOME ------------------------- ---------- ---------- Baer 10000 10000 Baida 2900 2900 Banda 6200 6882 Bates 7300 8468 Bell 4000 4000 Bernstein 9500 11970 Bissot 3300 3300 Bloom 10000 12100 Bull 4100 4100
ORA_HASHファンクションは、指定された式のハッシュ値を計算します。このファンクションは、データのサブセットの分析や、ランダムな標本の生成などの操作に有効です。
expr引数には、Oracle Databaseでハッシュ値を計算するデータを指定します。exprに指定できるデータの長さの制限はありません。このデータは通常、列名です。exprは、LONG型またはLOB型にはできません。また、ネストした表型でない場合は、ユーザー定義オブジェクト型にできません。ネストした表型のハッシュ値は、コレクション内の要素の順序に依存しません。その他のデータ型はすべて、exprでサポートされています。
max_bucket引数には、ハッシュ・ファンクションから戻される最大バケット値を指定します。0(ゼロ)〜4294967295の任意の値を指定できます。デフォルトは4294967295です。
seed_value引数を指定すると、同じデータ・セットに対して様々な結果を生成できます。Oracleは、ハッシュ・ファンクションをexprとseed_valueの組合せに適用します。0(ゼロ)〜4294967295の任意の値を指定できます。デフォルトは0(ゼロ)です。
戻り値はNUMBERです。
次の例では、sh.sales表内の顧客IDと製品IDの各組合せに対してハッシュ値を作成し、そのハッシュ値を最大100個のバケットに分割して、最初のバケット(バケット0(ゼロ))でamount_sold値の合計を戻します。3つ目の引数(5)には、ハッシュ・ファンクションのシード値を指定しています。このシード値を変更すると、同じ問合せで異なるハッシュ結果を得ることができます。
SELECT SUM(amount_sold) FROM sales WHERE ORA_HASH(CONCAT(cust_id, prod_id), 99, 5) = 0; SUM(AMOUNT_SOLD) ---------------- 989431.14

PATHは、UNDER_PATHおよびEQUALS_PATH条件でのみ使用される補助ファンクションです。一次条件で指定されたリソースへの相対パスを戻します。
correlation_integerはNUMBER型の任意の整数で、この補助ファンクションをその一次条件と関連付けるために使用します。1未満の値は1として扱われます。
EQUALS_PATH条件およびUNDER_PATH条件でこの補助ファンクションを使用する例は、関連ファンクション「DEPTH」を参照してください。
PERCENT_RANKは、CUME_DIST(累積分布)ファンクションと似ています。PERCENT_RANKが戻す値の範囲は、0〜1(0および1を含む)です。すべての集合の最初の行のPERCENT_RANKは0(ゼロ)になります。戻り値はNUMBERです。
PERCENT_RANKは、ファンクションの引数および対応するソート指定によって識別される不確定な行rを計算し、行rのランクから1を引いて、集計グループ内の行の数で割ります。不確定な行rをOracle Databaseが集計する行のグループに挿入するように計算します。このファンクションの引数は、各集計グループ内の1つの不確定行を識別します。このため、すべての引数は、集計グループ内で定数式と評価される必要があります。定数引数式および集計のORDER BY句の式の位置は、一致します。このため、引数の数は同じであり、その型は互換性がある必要があります。
PERCENT_RANKは、行rに対して、rのランクから1引いた数を評価される行数(問合せ結果セット全体またはパーティション)より1少ない数で割ります。
次の例では、サンプル表hr.employeesから、給与が15,500ドルであり、歩合が5%である不確定な従業員のパーセント・ランクを計算します。
SELECT PERCENT_RANK(15000, .05) WITHIN GROUP (ORDER BY salary, commission_pct) "Percent-Rank" FROM employees; Percent-Rank ------------ .971962617
次の例では、従業員ごとに、部門内での給与のパーセント・ランクを計算します。
SELECT department_id, last_name, salary, PERCENT_RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS pr FROM employees ORDER BY pr, salary; DEPARTMENT_ID LAST_NAME SALARY PR ------------- ------------------------- ---------- ---------- 10 Whalen 4400 0 40 Marvis 6500 0 . . . 80 Vishney 10500 .176470588 50 Everett 3900 .181818182 30 Khoo 3100 .2 . . . 80 Johnson 6200 .941176471 50 Markle 2200 .954545455 50 Philtanker 2200 .954545455 50 Olson 2100 1 . . .

PERCENTILE_CONTは、連続分散モデルを想定する逆分散関数です。このファンクションは、パーセンタイル値およびソート指定を用い、そのソート指定に従ってそのパーセンタイル値に該当する補間された値を戻します。計算では、NULLは無視されます。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
最初のexprは、パーセンタイル値であるため、0〜1の数値で評価します。このexprは、各集計グループ内の定数である必要があります。ORDER BY句には、Oracleが補間を実行できる型である数値または日時値の単一式を指定します。
PERCENTILE_CONTの結果は、順序付けされた後の値間の直線補間によって計算されます。集計グループで、パーセンタイル値(P)および行数(N)を使用すると、ソート指定に従って行を順序付けた後の行数を計算できます。この行数(RN)は、計算式RN = (1+ (P*(N-1))に従って計算されます。集計ファンクションの最終結果は、行番号がCRN = CEILING(RN)およびFRN = FLOOR(RN)の行の値間の直線補間によって計算されます。
最終結果は次のとおりです。
If (CRN = FRN = RN) then the result is (value of expression from row at RN) Otherwise the result is (CRN - RN) * (value of expression for row at FRN) + (RN - FRN) * (value of expression for row at CRN)
PERCENTILE_CONTファンクションは、分析ファンクションとしても使用できます。その場合、OVER句には、query_partitioning_clauseのみを指定できます。各行に対して、各パーティション内の一連の値から、指定されたパーセンタイルに該当する値を戻します。
MEDIANファンクションは、パーセンタイル値がデフォルトで0.5に指定される特別なPERCENTILE_CONTです。詳細は、「MEDIAN」を参照してください。
次の例では、各部門の給与の中央値を計算します。
SELECT department_id, PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY salary DESC) "Median cont", PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY salary DESC) "Median disc" FROM employees GROUP BY department_id ORDER BY department_id, "Median cont", "Median disc; DEPARTMENT_ID Median cont Median disc ------------- ----------- ----------- 10 4400 4400 20 9500 13000 30 2850 2900 40 6500 6500 50 3100 3100 60 4800 4800 70 10000 10000 80 8900 9000 90 17000 17000 100 8000 8200 110 10150 12000 7000 7000
PERCENTILE_CONTおよびPERCENTILE_DISCは、異なる結果を戻す場合があります。PERCENTILE_CONTは、直線補間後の結果を計算します。PERCENTILE_DISCは、集計された一連の値から値のみを戻します。この例に示すように、パーセンタイル値が0.5の場合、PERCENTILE_CONTは、偶数の要素を持つグループの中間の2つの値の平均を戻します。それに対して、PERCENTILE_DISCは、中間の2つの値の最初の値を戻します。奇数の要素を持つ集計グループでは、どちらのファンクションも中間の要素の値を戻します。
次の例では、0.5のパーセンタイル(Percent_Rank)に対応する部門60の中央値は4800です。部門30の給与にパーセンタイル0.5がないため、2900(パーセンタイル0.4)〜2800(パーセンタイル0.6)の範囲で2850に評価される中央値が補間される必要があります。
SELECT last_name, salary, department_id, PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY salary DESC) OVER (PARTITION BY department_id) "Percentile_Cont", PERCENT_RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) "Percent_Rank" FROM employees WHERE department_id IN (30, 60) ORDER BY last_name, salary, department_id, "Percentile_Cont", "Percent_Rank"; LAST_NAME SALARY DEPARTMENT_ID Percentile_Cont Percent_Rank ------------------------- ---------- ------------- --------------- ------------ Austin 4800 60 4800 .5 Baida 2900 30 2850 .4 Colmenares 2500 30 2850 1 Ernst 6000 60 4800 .25 Himuro 2600 30 2850 .8 Hunold 9000 60 4800 0 Khoo 3100 30 2850 .2 Lorentz 4200 60 4800 1 Pataballa 4800 60 4800 .5 Raphaely 11000 30 2850 0 Tobias 2800 30 2850 .6

PERCENTILE_DISCは、不連続分散モデルを想定する逆分散関数です。このファンクションでは、パーセンタイル値およびソート指定を指定し、そのセットから要素を戻します。計算では、NULLは無視されます。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
最初のexprは、パーセンタイル値であるため、0〜1の数値で評価します。このexprは、各集計グループ内の定数である必要があります。ORDER BY句には、ソート可能な型の単一式を指定します。
指定されたパーセンタイル値Pに対して、PERCENTILE_DISCは、ORDER BY句の式の値をソートし、P以上である(同じソート指定に従う)最小CUME_DIST値を持つ値を戻します。
「PERCENTILE_CONT」の例を参照してください。
次の例では、サンプル表hr.employeesの各従業員の給与の中央値不連続パーセンタイルを計算します。
SELECT last_name, salary, department_id, PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY salary DESC) OVER (PARTITION BY department_id) "Percentile_Disc", CUME_DIST() OVER (PARTITION BY department_id ORDER BY salary DESC) "Cume_Dist" FROM employees where department_id in (30, 60) ORDER BY last_name, salary, department_id, "Percentile_Disc", "Cume_Dist"; LAST_NAME SALARY DEPARTMENT_ID Percentile_Disc Cume_Dist ------------------------- ---------- ------------- --------------- ---------- Austin 4800 60 4800 .8 Baida 2900 30 2900 .5 Colmenares 2500 30 2900 1 Ernst 6000 60 4800 .4 Himuro 2600 30 2900 .833333333 Hunold 9000 60 4800 .2 Khoo 3100 30 2900 .333333333 Lorentz 4200 60 4800 1 Pataballa 4800 60 4800 .8 Raphaely 11000 30 2900 .166666667 Tobias 2800 30 2900 .666666667
部門30の中央値の値は2900です。この値の対応するパーセンタイル(Cume_Dist)は、0.5以上の最小値です。部門60の中央値の値は4800です。この値の対応するパーセンタイルは、0.5以上の最小値です。
POWERは、n2をn1乗した値を戻します。底n2および指数n1は任意の数です。ただし、n2が負の場合、n1は整数である必要があります。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。いずれかの引数がBINARY_FLOATまたはBINARY_DOUBLEの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、NUMBERを戻します。
次の例では、3の2乗を戻します。
SELECT POWER(3,2) "Raised" FROM DUAL; Raised ---------- 9

POWERMULTISETは、入力としてネストした表を取り、入力されたネストした表のすべての空でないサブセットを含む、ネストした表のネストした表(サブ多重集合という)を戻します。
exprには、ネストした表に評価される任意の式を指定できます。
exprがNULLである場合、Oracle DatabaseはNULLを戻します。
exprがネストした表である場合、Oracleはエラーを戻します。
まず、cust_address_tab_typeデータ型のネストした表であるデータ型を作成します。
CREATE TYPE cust_address_tab_tab_typ AS TABLE OF cust_address_tab_typ;
次に、POWERMULTISETファンクションを使用して、customers_demo表から、ネストした表の列cust_address_ntabを選択します。
SELECT CAST(POWERMULTISET(cust_address_ntab) AS cust_address_tab_tab_typ) FROM customers_demo; CAST(POWERMULTISET(CUST_ADDRESS_NTAB) AS CUST_ADDRESS_TAB_TAB_TYP) (STREET_ADDRESS, POSTAL_CODE, CITY, STATE_PROVINCE, COUNTRY_ID) ------------------------------------------------------------------ CUST_ADDRESS_TAB_TAB_TYP(CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP ('514 W Superior St', '46901', 'Kokomo', 'IN', 'US'))) CUST_ADDRESS_TAB_TAB_TYP(CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP ('2515 Bloyd Ave', '46218', 'Indianapolis', 'IN', 'US'))) CUST_ADDRESS_TAB_TAB_TYP(CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP ('8768 N State Rd 37', '47404', 'Bloomington', 'IN', 'US'))) CUST_ADDRESS_TAB_TAB_TYP(CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP ('6445 Bay Harbor Ln', '46254', 'Indianapolis', 'IN', 'US'))) . . .
前述の例では、customers_demo表、およびデータを含むネストした表の列が必要です。この表およびネストした表の列を作成する方法については、「MULTISET演算子」を参照してください。
POWERMULTISET_BY_CARDINALITYは、入力としてネストした表およびカーディナリティを取り、指定されたカーディナリティを持つネストした表のすべての空でないサブセットを含む、ネストした表のネストした表(サブ多重集合という)を戻します。
exprには、ネストした表に評価される任意の式を指定できます。
cardinalityには、任意の整数を指定できます。
exprがNULLである場合、Oracle DatabaseはNULLを戻します。
exprがネストした表である場合、Oracleはエラーを戻します。
まず、ネストした表のすべての行内の要素を複製し、ネストした表の行のカーディナリティを2に増やします。
UPDATE customers_demo SET cust_address_ntab = cust_address_ntab MULTISET UNION cust_address_ntab;
次に、POWERMULTISET_BY_CARDINALITYファンクションを使用して、customers_demo表から、ネストした表の列cust_address_ntabを選択します。
SELECT CAST(POWERMULTISET_BY_CARDINALITY(cust_address_ntab, 2) AS cust_address_tab_tab_typ) FROM customers_demo;
CAST(POWERMULTISET_BY_CARDINALITY(CUST_ADDRESS_NTAB,2) AS CUST_ADDRESS_TAB_TAB_TYP) (STREET_ADDRESS, POSTAL_CODE, CITY, STATE_PROVINCE, COUNTRY_ID) ---------------------------------------------------------------------------------------- CUST_ADDRESS_TAB_TAB_TYP(CUST_ADDRESS_TAB_TYP (CUST_ADDRESS_TYP('514 W Superior St', '46901', 'Kokomo', 'IN', 'US'), CUST_ADDRESS_TYP('514 W Superior St', '46901', 'Kokomo', 'IN', 'US'))) CUST_ADDRESS_TAB_TAB_TYP(CUST_ADDRESS_TAB_TYP (CUST_ADDRESS_TYP('2515 Bloyd Ave', '46218', 'Indianapolis', 'IN', 'US'), CUST_ADDRESS_TYP('2515 Bloyd Ave', '46218', 'Indianapolis', 'IN', 'US'))) CUST_ADDRESS_TAB_TAB_TYP(CUST_ADDRESS_TAB_TYP (CUST_ADDRESS_TYP('8768 N State Rd 37', '47404', 'Bloomington', 'IN', 'US'), CUST_ADDRESS_TYP('8768 N State Rd 37', '47404', 'Bloomington', 'IN', 'US'))) . . .
前述の例では、customers_demo表、およびデータを含むネストした表の列が必要です。この表およびネストした表の列を作成する方法については、「MULTISET演算子」を参照してください。
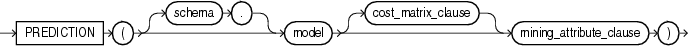
このファンクションは、DBMS_DATA_MININGパッケージまたはOracle Data Mining Java APIで作成したモデルで使用するためのものです。このファンクションは、モデルの最適な予測を戻します。戻されるデータ型は、モデルの作成中に使用するターゲット値の型によって異なります。回帰モデルの場合、このファンクションは期待値を戻します。
COST句は、すべての分類モデルに対して有効です。
COST MODELを指定します。このようなスコアリングのコスト・マトリックスが存在しない場合は、エラーが戻されます。
COST MODEL AUTOを指定します。このとき、格納されたコスト・マトリックスが存在する場合は、このマトリックスを使用して最低のコスト予測が戻されます。格納されたコスト・マトリックスが存在しない場合は、最も高い確率の予測が戻されます。
VALUES句(cost_matrix_clauseの下の方のブランチ)を使用します。表内コスト・マトリックスは、モデルがスコアリングのコスト・マトリックスに関連付けられているかどうかにかかわらず使用できます。
cost_matrix_clause句を指定しない場合、最適な予測は最も高い確率を持つターゲット・クラスになります。2つ以上のクラスが最も高い確率にある場合、そのうちの1つのクラスが選択されます。
これは、モデルの作成時に提供された予測子をマップします。USING *を指定すると、基礎となる入力(表、ビューなど)から取り出すことができる列と式にすべての予測子がマップされます。
mining_attribute_clauseで指定すると、余分な式が自動的に無視されます。
次の例では、提携カードを使用している可能性のある顧客の平均年齢を性別ごとに戻します。PREDICTIONファンクションでは、cust_marital_status、educationおよびhousehold_sizeの予測子のみを考慮します。
この例と前提条件のデータ・マイニング操作(ビューの作成など)は、デモ・ファイル$ORACLE_HOME/rdbms/demo/dmdtdemo.sqlで確認できます。データ・マイニングのデモ・ファイルの一般情報は、『Oracle Data Mining管理者ガイド』を参照してください。次に、このファンクションの構文の使用例を示します。
SELECT cust_gender, COUNT(*) AS cnt, ROUND(AVG(age)) AS avg_age FROM mining_data_apply_v WHERE PREDICTION(DT_SH_Clas_sample COST MODEL USING cust_marital_status, education, household_size) = 1 GROUP BY cust_gender ORDER BY cust_gender; C CNT AVG_AGE - ---------- ---------- F 170 38 M 685 42

PREDICTION_BOUNDSファンクションは、汎用化された線形モデルにのみ使用します。このファンクションは、LOWERとUPPERの2つのNUMBERフィールドを持つオブジェクトを戻します。回帰マイニング・ファンクションの場合は、予測の値に限度が適用されます。分類マイニング・ファンクションの場合は、確率値に限度が適用されます。リッジ回帰を使用してGLMが構築されたか、または構築中に共分散マトリックスに異常があると認識された場合は、両方のフィールドにNULLが戻されます。
confidence_levelには、(0,1)の範囲の数値を指定します。この句を省略した場合、デフォルト値は0.95になります。
class_value引数は、分類モデルに対して有効ですが、回帰モデルには有効ではありません。デフォルトでは、最も高い確率の予測の限度が戻されます。class_value引数を使用すると、ターゲット値に固有の限度値を除外できます。confidence_levelにNULLを指定すると、デフォルトでconfidence_levelを残したままclass_valueを指定できます。
PREDICTION_BOUNDSに対するmining_attribute_clauseの動作は、PREDICTIONの場合と同じです。詳細は、「mining_attribute_clause」を参照してください。
次の例では、98%の確度で年齢が25〜45才と予測される顧客の分布を戻します。
この例と前提条件のデータ・マイニング操作は、デモ・ファイル$ORACLE_HOME/rdbms/demo/dmglcdem.sqlで確認できます。次に、このファンクションの構文の使用例を示します。データ・マイニングのデモ・ファイルの一般情報は、『Oracle Data Mining管理者ガイド』を参照してください。
SELECT count(cust_id) cust_count, cust_marital_status FROM (SELECT cust_id, cust_marital_status FROM mining_data_apply_v WHERE PREDICTION_BOUNDS(glmr_sh_regr_sample,0.98 USING *).LOWER > 24 AND PREDICTION_BOUNDS(glmr_sh_regr_sample,0.98 USING *).UPPER < 46) GROUP BY cust_marital_status; CUST_COUNT CUST_MARITAL_STATUS -------------- -------------------- 46 NeverM 7 Mabsent 5 Separ. 35 Divorc. 72 Married

このファンクションは、DBMS_DATA_MININGパッケージまたはOracle Data Mining Java APIで作成した任意の分類モデルで使用するためのものです。また、指定した予測のコストのメジャーをOracleのNUMBERとして戻します。
オプションのclassパラメータを指定すると、このファンクションは指定したクラスのコストを戻します。classパラメータを指定しない場合、最適な予測に関連付けられたコストが戻されます。この形式とPREDICTIONファンクションを組み合せて使用すると、予測値とコストの最適な組合せを取得できます。
COST句は、すべての分類モデルに対して有効です。
COST MODELを指定します。このようなスコアリングのコスト・マトリックスが存在しない場合は、エラーが戻されます。
COST MODEL AUTOを指定します。このとき、格納されたコスト・マトリックスを使用してコストが戻されます。格納されたコスト・マトリックスが存在しない場合は、単位コスト・マトリックス(対角線上は0の値、それ以外の場所は1の値)が適用されます。これは、1から指定されたクラスの確率を引いた値と同じです。
VALUES句(cost_matrix_clauseの下の方のブランチ)を使用します。表内コスト・マトリックスは、モデルがスコアリングのコスト・マトリックスに関連付けられているかどうかにかかわらず使用できます。
mining_attribute_clauseは、PREDICTIONファンクションと同様に動作します。詳細は、「mining_attribute_clause」を参照してください。
次の例では、イタリア在住で、提携カードの使用を薦める上で最もコストが低い顧客を10人検索します。
この例と前提条件のデータ・マイニング操作は、デモ・ファイル$ORACLE_HOME/rdbms/demo/dmdtdemo.sqlで確認できます。データ・マイニングのデモ・ファイルの一般情報は、『Oracle Data Mining管理者ガイド』を参照してください。次に、このファンクションの構文の使用例を示します。
WITH cust_italy AS ( SELECT cust_id FROM mining_data_apply_v WHERE country_name = 'Italy' ORDER BY PREDICTION_COST(DT_SH_Clas_sample, 1 COST MODEL USING *) ASC, 1 ) SELECT cust_id FROM cust_italy WHERE rownum < 11; CUST_ID ---------- 100081 100179 100185 100324 100344 100554 100662 100733 101250 101306 10 rows selected.
このファンクションは、DBMS_DATA_MININGパッケージまたはOracle Data Mining Java APIで作成した決定ツリー・モデルと単一機能のAdaptive Bayes Network(ABN)モデルで使用するためのものです。このファンクションは、入力行のスコアリングに関連するモデル固有の情報を含むXML文字列を戻します。今回のリリースでは、戻り値は次の書式になります。
<Node id= "integer"/>
ここで、integerはデータ・マイニングのツリー・ノードの識別子です。出力の形式は、変更される可能性があります。今後のリリースでは、追加の予測情報を提供するように拡張される可能性があります。
mining_attribute_clauseは、PREDICTIONファンクションと同様に動作します。詳細は、「mining_attribute_clause」を参照してください。
次の例では、DT_SH_Clas_sample決定ツリー・モデルの関連する予測子であるmining_data_apply_vビューから、すべての属性を使用します。テクニカル・サポートで働く25才未満の顧客の場合、DT_SH_Clas_sampleモデルを持つレコードのスコアリングの結果からツリー・ノードが戻されます。
この例と前提条件のデータ・マイニング操作(ビューの作成など)は、デモ・ファイル$ORACLE_HOME/rdbms/demo/dmdtdemo.sqlで確認できます。データ・マイニングのデモ・ファイルの一般情報は、『Oracle Data Mining管理者ガイド』を参照してください。次に、このファンクションの構文の使用例を示します。
SELECT cust_id, education, PREDICTION_DETAILS(DT_SH_Clas_sample using *) treenode FROM mining_data_apply_v WHERE occupation = 'TechSup' AND age < 25 ORDER BY cust_id; CUST_ID EDUCATION TREENODE ---------- --------------------- ------------------------- 100234 < Bach. <Node id="21"/> 100320 < Bach. <Node id="21"/> 100349 < Bach. <Node id="21"/> 100419 < Bach. <Node id="21"/> 100583 < Bach. <Node id="13"/> 100657 HS-grad <Node id="21"/> 101171 < Bach. <Node id="21"/> 101225 < Bach. <Node id="21"/> 101338 < Bach. <Node id="21"/> 9 rows selected.

このファンクションは、DBMS_DATA_MININGパッケージまたはOracle Data Mining Java APIで作成した分類モデルで使用するためのものです。このファンクションは、他の型のモデルに対しては無効です。また、指定した予測の確率をOracleのNUMBERとして戻します。
オプションのclassパラメータを指定すると、このファンクションは指定したクラスの確率を戻します。これは、指定したターゲット・クラス値の選択に関連付けられた確率と同じです。
classパラメータを指定しない場合、最適な予測に関連付けられた確率が戻されます。この形式とPREDICTIONファンクションを組み合せて使用すると、予測値と確率の最適な組合せを取得できます。
mining_attribute_clauseは、PREDICTIONファンクションと同様に動作します。詳細は、「mining_attribute_clause」を参照してください。
次の例では、提携カードを使用している可能性が最も高いイタリア在住の顧客を10人戻します。
この例と前提条件のデータ・マイニング操作(ビューの作成など)は、デモ・ファイル$ORACLE_HOME/rdbms/demo/dmdtdemo.sqlで確認できます。データ・マイニングのデモ・ファイルの一般情報は、『Oracle Data Mining管理者ガイド』を参照してください。次に、このファンクションの構文の使用例を示します。
SELECT cust_id FROM ( SELECT cust_id FROM mining_data_apply_v WHERE country_name = 'Italy' ORDER BY PREDICTION_PROBABILITY(DT_SH_Clas_sample, 1 USING *) DESC, cust_id) WHERE rownum < 11; CUST_ID ---------- 100081 100179 100185 100324 100344 100554 100662 100733 101250 101306 10 rows selected.
このファンクションは、DBMS_DATA_MININGパッケージまたはOracle Data Mining Java APIを使用して作成した分類モデルで使用するためのものです。このファンクションは、他の型のモデルに対しては無効です。このファンクションは、複数クラスの分類の使用例で、すべてのクラスを含むオブジェクトのVARRAYを戻します。オブジェクト・フィールドには、PREDICTION、PROBABILITYおよびCOSTの名前が付きます。PREDICTIONフィールドのデータ型は、モデルの作成中に使用するターゲット値の型によって異なります。他の2つのフィールドは、両方ともOracleのNUMBERになります。要素は最適な予測から最低の予測の順序で戻されます。
bestNには、戻されるターゲット・クラスを最も高い確率(コスト・マトリックス句が指定されている場合は、最も低いコスト)のNに制限するために、正の整数を指定します。複数のクラスがN番目の値にあっても、N個の値のみが戻されます。cutoffのみでフィルタ処理するには、このパラメータにNULLを指定します。
cutoffには、戻されるターゲット・クラスを、指定したカットオフ値以上(コスト・マトリックス句が指定されている場合は、指定したコスト以下)の確率を持つターゲット・クラスに制限するために、NUMBER値を指定します。bestNにNULLを指定すると、cutoffのみでフィルタ処理できます。bestNとcutoffの両方に値を指定すると、戻される予測は、bestNで、かつ確率(またはcost_matrix_clause指定時のコスト)がしきい値を超えるもののみに制限されます。
cost_matrix_clause句は、すべての分類モデルに対して有効です。この句を指定すると、bestNとcutoffの両方は、予測の確率ではなく予測コストに関して処理されます。bestNの値は、結果をNの最適(最低)コストを持つターゲット・クラスに制限し、cutoffは、ターゲット・クラスを、指定したカットオフ以下のコストを持つターゲット・クラスに制限します。
この句を指定すると、コレクションの各オブジェクトは、予測値を含むスカラー値(データ型はモデルの作成時に使用されるターゲット値の型によって異なる)、予測確率および予測コスト(両方ともOracleのNUMBER)になります。
この句を指定しない場合、VARRAYの各オブジェクトは、予測値と予測確率を含むスカラーの組になります。戻されるデータ型は、前述の説明と同様です。
COST MODELを指定します。このようなコスト・マトリックスが存在しない場合は、エラーが戻されます。
COST MODEL AUTOを指定します。この場合、次のようになります。
VALUES句(cost_matrix_clauseの下の方のブランチ)を使用します。表内コスト・マトリックスは、モデルがスコアリングのコスト・マトリックスに関連付けられているかどうかにかかわらず使用できます。
mining_attribute_clauseは、PREDICTIONファンクションと同様に動作します。詳細は、「mining_attribute_clause」を参照してください。
次の例では、提携カードの使用および不使用の可能性とコストを、10人の顧客それぞれで示します。この例はバイナリ・ターゲットを持ちますが、このような問合せは「Low」、「Med」、「High」などの複数クラスの分類でも有効です。
この例と前提条件のデータ・マイニング操作は、デモ・ファイル$ORACLE_HOME/rdbms/demo/dmdtdemo.sqlで確認できます。データ・マイニングのデモ・ファイルの一般情報は、『Oracle Data Mining管理者ガイド』を参照してください。次に、このファンクションの構文の使用例を示します。
SELECT T.cust_id, S.prediction, S.probability, S.cost FROM (SELECT cust_id, PREDICTION_SET(dt_sh_clas_sample COST MODEL USING *) pset FROM mining_data_apply_v WHERE cust_id < 100011) T, TABLE(T.pset) S ORDER BY cust_id, S.prediction; CUST_ID PREDICTION PROBABILITY COST ---------- ---------- ----------- ----- 100001 0 .96682 .27 100001 1 .03318 .97 100002 0 .74038 2.08 100002 1 .25962 .74 100003 0 .90909 .73 100003 1 .09091 .91 100004 0 .90909 .73 100004 1 .09091 .91 100005 0 .27236 5.82 100005 1 .72764 .27 100006 0 1.00000 .00 100006 1 .00000 1.00 100007 0 .90909 .73 100007 1 .09091 .91 100008 0 .90909 .73 100008 1 .09091 .91 100009 0 .27236 5.82 100009 1 .72764 .27 100010 0 .80808 1.54 100010 1 .19192 .81 20 rows selected.

PRESENTNNVファンクションは、SELECT文のmodel_clauseでのみ、およびモデル・ルールの右側でのみ使用できます。このファンクションは、cell_referenceがmodel_clauseの実行前に存在し、PRESENTNNVの評価時にNULLではない場合にexpr1を戻します。それ以外の場合はexpr2を戻します。このファンクションは、NVL2とは異なります。NVL2は、model_clauseの実行前の状態のデータを評価するのではなく、実行時のデータを評価します。
次の例では、2002年のマウス・パッドの売上を含む行が存在し、その売上値がNULLではない場合、その売上値を変更しません。その行が存在し、売上値がNULLの場合、その売上値を10に設定します。その行が存在しない場合、売上値を10に設定して行を作成します。
SELECT country, prod, year, s FROM sales_view_ref MODEL PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale s) IGNORE NAV UNIQUE DIMENSION RULES UPSERT SEQUENTIAL ORDER ( s['Mouse Pad', 2002] = PRESENTNNV(s['Mouse Pad', 2002], s['Mouse Pad', 2002], 10) ) ORDER BY country, prod, year; COUNTRY PROD YEAR S ---------- ----------------------------------- -------- --------- France Mouse Pad 1998 2509.42 France Mouse Pad 1999 3678.69 France Mouse Pad 2000 3000.72 France Mouse Pad 2001 3269.09 France Mouse Pad 2002 10 France Standard Mouse 1998 2390.83 France Standard Mouse 1999 2280.45 France Standard Mouse 2000 1274.31 France Standard Mouse 2001 2164.54 Germany Mouse Pad 1998 5827.87 Germany Mouse Pad 1999 8346.44 Germany Mouse Pad 2000 7375.46 Germany Mouse Pad 2001 9535.08 Germany Mouse Pad 2002 10 Germany Standard Mouse 1998 7116.11 Germany Standard Mouse 1999 6263.14 Germany Standard Mouse 2000 2637.31 Germany Standard Mouse 2001 6456.13 18 rows selected.
この例では、ビューsales_view_refが必要です。このビューを作成する方法については、「例」を参照してください。
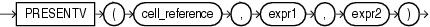
PRESENTVファンクションは、SELECT文のmodel_clauseでのみ、およびモデル・ルールの右側でのみ使用できます。このファンクションは、cell_referenceが存在する場合、model_clauseを実行する前にexpr1を戻します。それ以外の場合はexpr2を戻します。
次の例では、2000年のマウス・パッドの売上を含む行が存在する場合、2001年のマウス・パッドの売上を2000年のマウス・パッドの売上値に設定します。その行が存在しない場合、2001年のマウス・パッドの売上値を0(ゼロ)に設定して行を作成します。
SELECT country, prod, year, s FROM sales_view_ref MODEL PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale s) IGNORE NAV UNIQUE DIMENSION RULES UPSERT SEQUENTIAL ORDER ( s['Mouse Pad', 2001] = PRESENTV(s['Mouse Pad', 2000], s['Mouse Pad', 2000], 0) ) ORDER BY country, prod, year; COUNTRY PROD YEAR S ---------- ----------------------------------- -------- --------- France Mouse Pad 1998 2509.42 France Mouse Pad 1999 3678.69 France Mouse Pad 2000 3000.72 France Mouse Pad 2001 3000.72 France Standard Mouse 1998 2390.83 France Standard Mouse 1999 2280.45 France Standard Mouse 2000 1274.31 France Standard Mouse 2001 2164.54 Germany Mouse Pad 1998 5827.87 Germany Mouse Pad 1999 8346.44 Germany Mouse Pad 2000 7375.46 Germany Mouse Pad 2001 7375.46 Germany Standard Mouse 1998 7116.11 Germany Standard Mouse 1999 6263.14 Germany Standard Mouse 2000 2637.31 Germany Standard Mouse 2001 6456.13 16 rows selected.
この例では、ビューsales_view_refが必要です。このビューを作成する方法については、「MODEL句の例:」を参照してください。
PREVIOUSファンクションは、SELECT文のmodel_clauseでのみ、およびmodel_rules_clauseのITERATE ... [ UNTIL ]句でのみ使用できます。このファンクションは、各反復の最初にcell_referenceの値を戻します。
次の例では、反復の最初と最後にあるcur_valの値の差が1未満になるまで、最大1000回ルールを繰り返します。
SELECT dim_col, cur_val, num_of_iterations FROM (SELECT 1 AS dim_col, 10 AS cur_val FROM dual) MODEL DIMENSION BY (dim_col) MEASURES (cur_val, 0 num_of_iterations) IGNORE NAV UNIQUE DIMENSION RULES ITERATE (1000) UNTIL (PREVIOUS(cur_val[1]) - cur_val[1] < 1) ( cur_val[1] = cur_val[1]/2, num_of_iterations[1] = num_of_iterations[1] + 1 ); DIM_COL CUR_VAL NUM_OF_ITERATIONS ---------- ---------- ----------------- 1 .625 4
RANKは、一連の値における値のランクを計算します。戻り型は、NUMBERです。
ランク付け基準と同じ値を持つ行は、同じランクになります。Oracle Databaseは連結行の数を連結ランクに追加して、次のランクを計算します。そのため、ランクは連続した数値でない場合があります。このファンクションは、上位N番および下位N番のレポートに有効です。
RANKは、ファンクションの引数として識別される不確定な行のランクを、指定されたソート指定に従って計算します。ファンクションの引数は、各集計グループの単一行を識別するため、すべての引数は各集計グループ内で定数式に評価される必要があります。定数引数式および集計のORDER BY句の式の位置は、一致します。このため、引数の数は同じであり、その型は互換性がある必要があります。
RANKは、ある問合せが戻す他の行について、その問合せが戻す各行のランクを計算します。この計算は、order_by_clauseにあるvalue_exprsの値に基づいて行われます。
次の例では、サンプル表hr.employeesから、給与が15,500ドルであり、歩合が5%である不確定な従業員のランクを計算します。
SELECT RANK(15500, .05) WITHIN GROUP (ORDER BY salary, commission_pct) "Rank" FROM employees; Rank ---------- 105
同様に、次の問合せは、従業員の給与から給与が15,500ドルのランクを戻します。
SELECT RANK(15500) WITHIN GROUP (ORDER BY salary DESC) "Rank of 15500" FROM employees; Rank of 15500 -------------- 4
次の例では、サンプル・スキーマhrの部門80の従業員を、その給与および歩合に基づいてランク付けします。給与が同じ場合は同じランクになるため、連続しないランクになります。この例と、「DENSE_RANK」の例を比較してください。
SELECT department_id, last_name, salary, commission_pct, RANK() OVER (PARTITION BY department_id ORDER BY salary DESC, commission_pct) "Rank" FROM employees WHERE department_id = 80 ORDER BY department_id, last_name, salary, commission_pct, "Rank"; DEPARTMENT_ID LAST_NAME SALARY COMMISSION_PCT Rank ------------- ------------------------- ---------- -------------- ---------- 80 Abel 11000 .3 5 80 Ande 6400 .1 31 80 Banda 6200 .1 32 80 Bates 7300 .15 26 80 Bernstein 9500 .25 14 80 Bloom 10000 .2 9 80 Cambrault 7500 .2 23 80 Cambrault 11000 .3 5 80 Doran 7500 .3 24 80 Errazuriz 12000 .3 3 80 Fox 9600 .2 12 80 Greene 9500 .15 13 80 Hall 9000 .25 16 80 Hutton 8800 .25 18 80 Johnson 6200 .1 32 80 King 10000 .35 11 80 Kumar 6100 .1 34 80 Lee 6800 .1 30 80 Livingston 8400 .2 20 80 Marvins 7200 .1 27 80 McEwen 9000 .35 17 80 Olsen 8000 .2 21 80 Ozer 11500 .25 4 80 Partners 13500 .3 2 80 Russell 14000 .4 1 80 Sewall 7000 .25 29 80 Smith 7400 .15 25 80 Smith 8000 .3 22 80 Sully 9500 .35 15 80 Taylor 8600 .2 19 80 Tucker 10000 .3 10 80 Tuvault 7000 .15 28 80 Vishney 10500 .25 8 80 Zlotkey 10500 .2 7

RATIO_TO_REPORTは分析ファンクションです。このファンクションは、ある値の集合の合計に対する、その値の比率を計算します。exprがNULLの場合は、値もNULLになります。
値の集合は、query_partition_clauseによって決まります。この句を省略すると、比率は、問合せによって戻されるすべての行で計算されます。
exprには、RATIO_TO_REPORTまたは他の分析ファンクションを使用して分析ファンクションをネストできません。ただし、他の組込みファンクション式をexprで使用できます。exprの書式の詳細は、「SQL式」を参照してください。
次の例では、すべての事務員の給与の合計に対する各事務員の給与の割合の値を計算します。
SELECT last_name, salary, RATIO_TO_REPORT(salary) OVER () AS rr FROM employees WHERE job_id = 'PU_CLERK' ORDER BY last_name, salary, rr; LAST_NAME SALARY RR ------------------------- ---------- ---------- Baida 2900 .208633094 Colmenares 2500 .179856115 Himuro 2600 .18705036 Khoo 3100 .223021583 Tobias 2800 .201438849
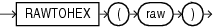
RAWTOHEXは、rawを16進表記で表した文字値に変換します。
SQL組込みファンクションとして使用される場合、RAWTOHEXは、LONG、LONG RAW、CLOB、BLOBまたはBFILE以外のすべてのスカラー・データ型の引数を取ります。このファンクションは、rawの値を構成するバイトの16進表記でVARCHAR2値を戻します。各バイトは、2桁の16進数で表されます。
次の例は、RAW列の値に等しい16進を戻します。
SELECT RAWTOHEX(raw_column) "Graphics" FROM graphics; Graphics -------- 7D
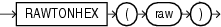
RAWTONHEXは、rawを16進表記で表した文字値に変換します。RAWTONHEX (raw)は、TO_NCHAR(RAWTOHEX(raw))と同じです。戻り値は、常に各国語キャラクタ・セットです。
次の例は、RAW列の値に等しい16進を戻します。
SELECT RAWTONHEX(raw_column), DUMP ( RAWTONHEX (raw_column) ) "DUMP" FROM graphics; RAWTONHEX(RA) DUMP ----------------------- ------------------------------ 7D Typ=1 Len=4: 0,55,0,68

REFは、引数としてオブジェクト表またはオブジェクト・ビューの行に関連付けられた相関変数(表別名)を取ります。変数または行にバインドされたオブジェクト・インスタンスについてのREF値が戻ります。
サンプル・スキーマoeには、次のように定義されたcust_address_typという型が含まれます。
Attribute Type ----------------------------- ---------------- STREET_ADDRESS VARCHAR2(40) POSTAL_CODE VARCHAR2(10) CITY VARCHAR2(30) STATE_PROVINCE VARCHAR2(10) COUNTRY_ID CHAR(2)
次の例では、サンプル型oe.cust_address_typに基づく表(addresses表)を作成した後、その表に行を挿入し、その表からその型のオブジェクト・インスタンスのREF値を取り出します。
CREATE TABLE addresses OF cust_address_typ; INSERT INTO addresses VALUES ( '123 First Street', '4GF H1J', 'Our Town', 'Ourcounty', 'US'); SELECT REF(e) FROM addresses e; REF(E) ----------------------------------------------------------------------------------- 00002802097CD1261E51925B60E0340800208254367CD1261E51905B60E034080020825436010101820000
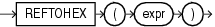
REFTOHEXは、引数exprを16進で表した文字値に変換します。exprは、REFを戻す必要があります。
サンプル・スキーマoeにはwarehouse_typが含まれています。次の例では、その型を基に、ある列のREF値をそれに等しい16進を含む文字値に変換する方法を示します。
CREATE TABLE warehouse_table OF warehouse_typ (PRIMARY KEY (warehouse_id)); CREATE TABLE location_table (location_number NUMBER, building REF warehouse_typ SCOPE IS warehouse_table); INSERT INTO warehouse_table VALUES (1, 'Downtown', 99); INSERT INTO location_table SELECT 10, REF(w) FROM warehouse_table w; SELECT REFTOHEX(building) FROM location_table; REFTOHEX(BUILDING) -------------------------------------------------------------------------- 0000220208859B5E9255C31760E034080020825436859B5E9255C21760E034080020825436

REGEXP_COUNTは、ソース文字列でパターンが発生した回数を戻すことによって、REGEXP_INSTRファンクションの機能を補完します。このファンクションは、入力キャラクタ・セットによって定義された文字を使用して、文字列を評価します。また、patternの発生回数を示す整数を戻します。一致する値が見つからない場合は0(ゼロ)を戻します。
source_charは、検索値として使用される文字式です。これは通常は文字列であり、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。
patternは正規表現です。これは通常はテキスト・リテラルであり、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型です。最大512バイトを指定できます。patternのデータ型がsource_charのデータ型と異なる場合、Oracle Databaseはpatternをsource_charのデータ型に変換します。REGEXP_COUNTは、pattern内の部分正規表現のカッコを無視します。たとえば、パターン'(123(45))'は、'12345'と同じです。patternで指定できる演算子のリストは、付録C「Oracleの正規表現のサポート」を参照してください。
positionは、Oracleが検索を開始する文字source_charの位置を示す正の整数です。デフォルトは1で、source_charの最初の文字から検索が開始されます。1番目のpatternの出現が検出されると、その後に続く文字以降の2番目の出現が検索されます。
match_paramは、ファンクションのデフォルトの検索動作を変更するためのテキスト・リテラルです。match_paramには次の値を1つ以上指定できます。
'i': 大/小文字を区別せずに検索します。
'c': 大/小文字を区別して検索します。
'n': 任意の文字に一致する文字であるピリオド(.)を、改行文字の一致に使用します。このパラメータを指定しない場合、ピリオドは改行文字には一致しません。
'm': ソース文字列を複数行として処理します。Oracleは、キャレット(^)およびドル記号($)を、それぞれ、ソース文字列全体の開始または終了としてのみではなく、ソース文字列内の任意の場所にある任意の行の開始または終了としても解釈します。このパラメータを指定しない場合、Oracleはソース文字列を単一行として処理します。
'x'は空白文字を無視します。デフォルトでは、空白文字は空白文字として一致します。
複数の矛盾する値を指定すると、最後の値が使用されます。たとえば、'ic'を指定すると、大/小文字を区別する検索が行われます。前述以外の文字を指定すると、エラーが戻されます。
match_paramを指定しない場合、次のようになります。
次の例では、pattern内の部分正規表現のカッコが無視されることを示します。
SELECT REGEXP_COUNT('123123123123123', '(12)3', 1, 'i') REGEXP_COUNT FROM DUAL; REGEXP_COUNT ------------ 5
次の例では、ファンクションは3番目の文字でソース文字列の評価を開始するため、patternの最初の出現はスキップされます。
SELECT REGEXP_COUNT('123123123123', '123', 3, 'i') COUNT FROM DUAL; COUNT ---------- 3
REGEXP_INSTRは、正規表現パターンで文字列を検索できるようにINSTRの機能を拡張したものです。このファンクションは、入力キャラクタ・セットによって定義された文字を使用して、文字列を評価します。また、return_option引数の値に基づいて、一致したサブストリングの開始位置または終了位置を示す整数を戻します。一致する値が見つからない場合は0(ゼロ)を戻します。
このファンクションは、POSIX正規表現規格およびUnicode Regular Expression Guidelinesに準拠しています。詳細は、付録C「Oracleの正規表現のサポート」を参照してください。
source_charは、検索値として使用される文字式です。これは通常は文字列であり、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。
patternは正規表現です。これは通常はテキスト・リテラルであり、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型です。最大512バイトを指定できます。patternのデータ型がsource_charのデータ型と異なる場合、Oracle Databaseはpatternをsource_charのデータ型に変換します。patternで指定できる演算子のリストは、付録C「Oracleの正規表現のサポート」を参照してください。
positionは、Oracleが検索を開始する文字source_charの位置を示す正の整数です。デフォルトは1で、source_charの最初の文字から検索が開始されます。
occurrenceは、source_charに出現するpatternのうちのどれを検索するかを示す正の整数です。デフォルトは1で、最初に出現するpatternが検索されます。occurrenceが1より大きい場合、1番目のpatternが検出された後に続く1文字目から、2番目(以降)の出現を検索します。この動作は、最初の出現の2番目の文字から2番目の出現を検索するINSTRファンクションとは異なります。
return_optionには、出現した文字と関連して戻すものを指定できます。
match_parameterは、ファンクションのデフォルトの検索動作を変更するためのテキスト・リテラルです。このパラメータの動作は、REGEXP_COUNTのこのファンクションの動作と同じです。詳細は、「REGEXP_COUNT」を参照してください。
patternの場合、subexprは、ファンクションのターゲットとなるpattern内の部分正規表現を示す0から9までの整数になります。subexprは、カッコで囲まれたpatternのフラグメントです。部分正規表現はネストできます。部分正規表現は、その左側のカッコがpatternに出現する順に番号付けされます。たとえば、次の正規表現を考えます。
0123(((abc)(de)f)ghi)45(678)
この正規表現には、abcdefghi、abcdef、abc、de、678の順に5つの部分正規表現があります。
subexprが0(ゼロ)の場合、patternに一致するサブストリング全体の位置が戻されます。subexprが0(ゼロ)より大きい場合、一致したサブストリング内の部分正規表現番号subexprに対応するサブストリング・フラグメントの位置が戻されます。patternにsubexprの部分正規表現が1つもない場合、このファンクションは0(ゼロ)を戻します。NULLのsubexpr値は、NULLを戻します。subexprのデフォルト値は0(ゼロ)です。
次の例では、文字列を調べて、空白以外の文字を検索します。Oracleは、文字列の最初の文字から検索を開始し、空白以外の文字が6つ目に出現する開始位置(デフォルト)を戻します。
SELECT REGEXP_INSTR('500 Oracle Parkway, Redwood Shores, CA', '[^ ]+', 1, 6) "REGEXP_INSTR" FROM DUAL; REGEXP_INSTR ------------ 37
次の例では、文字列を調べて、大/小文字を区別せずにs、rまたはpで始まり、任意の6つのアルファベット文字が続く単語を検索します。Oracleは、文字列の3つ目の文字から検索を開始し、大文字か小文字のs、rまたはpで始まる7文字の単語が2つ目に出現した後の文字の、文字列内の位置を戻します。
SELECT REGEXP_INSTR('500 Oracle Parkway, Redwood Shores, CA', '[s|r|p][[:alpha:]]{6}', 3, 2, 1, 'i') "REGEXP_INSTR" FROM DUAL; REGEXP_INSTR ------------ 28
次の例では、subexpr引数を使用してpattern内の特定の部分正規表現を検索します。最初の文は、最初の部分正規表現にある最初の文字のソース文字列(123)の位置を戻します。
SELECT REGEXP_INSTR('1234567890', '(123)(4(56)(78))', 1, 1, 0, 'i', 1) "REGEXP_INSTR" FROM DUAL; REGEXP_INSTR ------------------- 1
次の文は、2番目の部分正規表現にある最初の文字のソース文字列(45678)の位置を戻します。
SELECT REGEXP_INSTR('1234567890', '(123)(4(56)(78))', 1, 1, 0, 'i', 2) "REGEXP_INSTR" FROM DUAL; REGEXP_INSTR ------------------- 4
次の文は、4番目の部分正規表現にある最初の文字のソース文字列(78)の位置を戻します。
SELECT REGEXP_INSTR('1234567890', '(123)(4(56)(78))', 1, 1, 0, 'i', 4) "REGEXP_INSTR" FROM DUAL; REGEXP_INSTR ------------------- 7
REGEXP_REPLACEは、正規表現パターンで文字列を検索できるようにREPLACEの機能を拡張したものです。デフォルトでは、このファンクションは、正規表現パターンに一致するすべての文字をreplace_stringに置き換えてsource_charを戻します。source_charと同じキャラクタ・セットの文字列が戻されます。このファンクションは、1つ目の引数がLOBではない場合はVARCHAR2を戻し、1つ目の引数がLOBの場合はCLOBを戻します。
このファンクションは、POSIX正規表現規格およびUnicode Regular Expression Guidelinesに準拠しています。詳細は、付録C「Oracleの正規表現のサポート」を参照してください。
source_charは、検索値として使用される文字式です。これは通常は文字列であり、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。
patternは正規表現です。これは通常はテキスト・リテラルであり、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型です。最大512バイトを指定できます。patternのデータ型がsource_charのデータ型と異なる場合、Oracle Databaseはpatternをsource_charのデータ型に変換します。patternで指定できる演算子のリストは、付録C「Oracleの正規表現のサポート」を参照してください。
replace_stringは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。replace_stringがCLOBまたはNCLOBの場合、replace_stringは32KBに切り捨てられます。replace_stringには、最大500個の部分正規表現への後方参照を\nという書式で指定できます。nは、1〜9の数値です。replace_string内でnがバックスラッシュ文字に評価される場合、その前にエスケープ文字(\\)を付ける必要があります。後方参照表現の詳細は、「Oracleの正規表現のサポート」の表C-1に示す説明を参照してください。
positionは、Oracleが検索を開始する文字source_charの位置を示す正の整数です。デフォルトは1で、source_charの最初の文字から検索が開始されます。
occurrenceは、置換操作の対象となる文字を示す、負ではない整数です。
occurrenceが1より大きい場合、1番目のpatternが検出された後に続く1文字目から、2番目(以降)の出現を検索します。この動作は、最初の出現の2番目の文字から2番目の出現を検索するINSTRファンクションとは異なります。
match_parameterは、ファンクションのデフォルトの検索動作を変更するためのテキスト・リテラルです。このパラメータの動作は、REGEXP_COUNTのこのファンクションの動作と同じです。詳細は、「REGEXP_COUNT」を参照してください。次の例では、phone_numberを調べて、xxx.xxx.xxxxというパターンを検索します。その後、このパターンを(xxx) xxx-xxxxという書式に変更します。
SELECT REGEXP_REPLACE(phone_number, '([[:digit:]]{3})\.([[:digit:]]{3})\.([[:digit:]]{4})', '(\1) \2-\3') "REGEXP_REPLACE" FROM employees ORDER BY "REGEXP_REPLACE"; REGEXP_REPLACE -------------------------------------------------------------------------------- (515) 123-4444 (515) 123-4567 (515) 123-4568 (515) 123-4569 (515) 123-5555 . . .
次の例では、country_nameを調べます。文字列内のNULLでない各文字の後に空白を挿入します。
SELECT REGEXP_REPLACE(country_name, '(.)', '\1 ') "REGEXP_REPLACE" FROM countries; REGEXP_REPLACE -------------------------------------------------------------------------------- A r g e n t i n a A u s t r a l i a B e l g i u m B r a z i l C a n a d a . . .
次の例では、文字列を調べて、2つ以上の空白を検索します。検索された2つ以上の空白を、それぞれ1つの空白に置換します。
SELECT REGEXP_REPLACE('500 Oracle Parkway, Redwood Shores, CA', '( ){2,}', ' ') "REGEXP_REPLACE" FROM DUAL; REGEXP_REPLACE -------------------------------------- 500 Oracle Parkway, Redwood Shores, CA
REGEXP_SUBSTRは、正規表現パターンで文字列を検索できるようにSUBSTRの機能を拡張したものです。REGEXP_INSTRと似ていますが、REGEXP_INSTRはサブストリングの位置ではなくサブストリング自体を戻します。このファンクションは、一致文字列の内容のみが必要で、ソース文字列内での位置は必要ない場合に有効です。このファンクションは、文字列をVARCHAR2またはCLOBデータとして、source_charと同じキャラクタ・セットで戻します。
このファンクションは、POSIX正規表現規格およびUnicode Regular Expression Guidelinesに準拠しています。詳細は、付録C「Oracleの正規表現のサポート」を参照してください。
source_charは、検索値として使用される文字式です。これは通常は文字列であり、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。
patternは正規表現です。これは通常はテキスト・リテラルであり、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型です。最大512バイトを指定できます。patternのデータ型がsource_charのデータ型と異なる場合、Oracle Databaseはpatternをsource_charのデータ型に変換します。patternで指定できる演算子のリストは、付録C「Oracleの正規表現のサポート」を参照してください。
positionは、Oracleが検索を開始する文字source_charの位置を示す正の整数です。デフォルトは1で、source_charの最初の文字から検索が開始されます。
occurrenceは、source_charに出現するpatternのうちのどれを検索するかを示す正の整数です。デフォルトは1で、最初に出現するpatternが検索されます。occurrenceが1より大きい場合、1番目のpatternが検出された後に続く1文字目から、2番目(以降)の出現を検索します。この動作は、最初の出現の2番目の文字から2番目の出現を検索するSUBSTRファンクションとは異なります。
match_parameterは、ファンクションのデフォルトの検索動作を変更するためのテキスト・リテラルです。このパラメータの動作は、REGEXP_COUNTのこのファンクションの動作と同じです。詳細は、「REGEXP_COUNT」を参照してください。
patternの場合、subexprは、ファンクションによって戻されるpattern内の部分正規表現を示す0から9までの負でない整数になります。このパラメータは、REGEXP_INSTRファンクションの場合と同じセマンティクスを持ちます。詳細は、「REGEXP_INSTR」を参照してください。次の例では、文字列を調べて、カンマで区切られた最初のサブストリングを検索します。Oracle Databaseは、後にカンマが付いているカンマでない1つ以上の文字の前にあるカンマを検索します。該当するサブストリングが、前後のカンマを含めて戻されます。
SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA', ',[^,]+,') "REGEXPR_SUBSTR" FROM DUAL; REGEXPR_SUBSTR ----------------- , Redwood Shores,
次の例では、文字列を調べて、1つ以上の英数字を含むサブストリング、および任意でピリオド(.)が続くhttp://を検索します。Oracleは、http://と、スラッシュ(/)または文字列の末尾のいずれかとの間で、3〜4つのこのサブストリングを検索します。
SELECT REGEXP_SUBSTR('http://www.example.com/products', 'http://([[:alnum:]]+\.?){3,4}/?') "REGEXP_SUBSTR" FROM DUAL; REGEXP_SUBSTR ---------------------- http://www.example.com/
次の2つの例では、subexpr引数を使用してpattern内の特定の部分正規表現を戻します。最初の文は、pattern内の最初の部分正規表現を戻します。
SELECT REGEXP_SUBSTR('1234567890', '(123)(4(56)(78))', 1, 1, 'i', 1) "REGEXP_SUBSTR" FROM DUAL; REGEXP_SUBSTR ------------------- 123
次の文は、pattern内の4番目の部分正規表現を戻します。
SELECT REGEXP_SUBSTR('1234567890', '(123)(4(56)(78))', 1, 1, 'i', 4) "REGEXP_SUBSTR" FROM DUAL; REGEXP_SUBSTR ------------------- 78
線形回帰ファンクションは次のとおりです。
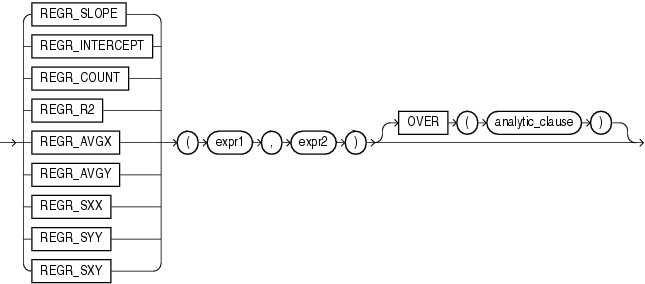
線形回帰ファンクションは、微分最小2乗法で求めた回帰直線を数値の組の集合に対応付けます。これは、集計ファンクションまたは分析ファンクションとして使用できます。
これらのファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。Oracleは、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、そのデータ型を戻します。
Oracleは、expr1またはexpr2がNULLであるすべての組を排除した後、このファンクションを(expr1 , expr2)の集合に適用します。Oracleは、データでの引渡し中、同時にすべての回帰ファンクションを計算します。
expr1は、従属変数の値(y値)として解析されます。expr2は、独立変数の値(x値)として解析されます。
REGR_SLOPEは、直線の傾きを戻します。戻り値は数値データ型で、NULLになる場合もあります。NULL (expr1, expr2)の組を排除した後、このファンクションは次の計算を行います。
COVAR_POP(expr1, expr2) / VAR_POP(expr2)
REGR_INTERCEPTは、回帰ファンクションのy切片を戻します。戻り値は数値データ型で、NULLになる場合もあります。NULL (expr1, expr2)の組を排除した後、このファンクションは次の計算を行います。
AVG(expr1) - REGR_SLOPE(expr1, expr2) * AVG(expr2)
REGR_COUNTは整数を戻します。この整数は、回帰ファンクションに適応させるために使用されるNULLでない数値の組です。
REGR_R2は、回帰に対する決定係数(Rの2乗または適合度とも呼ぶ)を戻します。戻り値は数値データ型で、NULLになる場合もあります。VAR_POP (expr1)およびVAR_POP (expr2)は、NULLの組が排除された後に評価されます。戻り値は次のとおりです。
NULL if VAR_POP(expr2) = 0 1 if VAR_POP(expr1) = 0 and VAR_POP(expr2) != 0 POWER(CORR(expr1,expr),2) if VAR_POP(expr1) > 0 and VAR_POP(expr2 != 0
これ以外のすべての回帰ファンクションの戻り値は数値データ型で、NULLになる場合もあります。
REGR_AVGXは、回帰直線の独立変数(expr2)の平均を求めます。NULL (expr1、expr2)の組を排除した後、このファンクションは次の計算を行います。
AVG(expr2)
REGR_AVGYは、回帰直線の従属変数(expr1)の平均を求めます。NULL (expr1、expr2)の組を排除した後、このファンクションは次の計算を行います。
AVG(expr1)
REGR_SXY、REGR_SXX、REGR_SYYは補助ファンクションです。これらは、様々な診断統計の計算に使用されます。
expr1、expr2)の組を排除した後、REGR_SXXは次の計算を行います。
REGR_COUNT(expr1, expr2) * VAR_POP(expr2)
expr1、expr2)の組を排除した後、REGR_SYYは次の計算を行います。
REGR_COUNT(expr1, expr2) * VAR_POP(expr1)
expr1、expr2)の組を排除した後、REGR_SXYは次の計算を行います。
REGR_COUNT(expr1, expr2) * COVAR_POP(expr1, expr2)
次の例は、サンプル表sh.salesおよびsh.productsに基づいています。
次の例では、分析書式で使用される様々な線形回帰ファンクションを比較します。これらのファンクションの分析書式は、モデル別で従業員ごとに予測される給与の検索などの計算で、回帰統計を使用する場合に有効です。次の個々の線形回帰ファンクションについての項では、これらのファンクションの集計書式の例を示します。
SELECT job_id, employee_id ID, salary, REGR_SLOPE(SYSDATE-hire_date, salary) OVER (PARTITION BY job_id) slope, REGR_INTERCEPT(SYSDATE-hire_date, salary) OVER (PARTITION BY job_id) intcpt, REGR_R2(SYSDATE-hire_date, salary) OVER (PARTITION BY job_id) rsqr, REGR_COUNT(SYSDATE-hire_date, salary) OVER (PARTITION BY job_id) count, REGR_AVGX(SYSDATE-hire_date, salary) OVER (PARTITION BY job_id) avgx, REGR_AVGY(SYSDATE-hire_date, salary) OVER (PARTITION BY job_id) avgy FROM employees WHERE department_id in (50, 80) ORDER BY job_id, employee_id; JOB_ID ID SALARY SLOPE INTCPT RSQR COUNT AVGX AVGY ---------- ----- ---------- ----- --------- ----- ------ ---------- --------- SA_MAN 145 14000 .355 -1707.035 .832 5 12200.000 2626.589 SA_MAN 146 13500 .355 -1707.035 .832 5 12200.000 2626.589 SA_MAN 147 12000 .355 -1707.035 .832 5 12200.000 2626.589 SA_MAN 148 11000 .355 -1707.035 .832 5 12200.000 2626.589 SA_MAN 149 10500 .355 -1707.035 .832 5 12200.000 2626.589 SA_REP 150 10000 .257 404.763 .647 29 8396.552 2561.244 SA_REP 151 9500 .257 404.763 .647 29 8396.552 2561.244 SA_REP 152 9000 .257 404.763 .647 29 8396.552 2561.244 SA_REP 153 8000 .257 404.763 .647 29 8396.552 2561.244 SA_REP 154 7500 .257 404.763 .647 29 8396.552 2561.244 SA_REP 155 7000 .257 404.763 .647 29 8396.552 2561.244 SA_REP 156 10000 .257 404.763 .647 29 8396.552 2561.244 ...
次の例では、サンプル表hr.employeesを使用して、勤務時間(SYSDATE - hire_date)と給与に関する線形回帰モデルの傾きと回帰を計算します。結果はjob_id別にグループ化されます。
SELECT job_id, REGR_SLOPE(SYSDATE-hire_date, salary) slope, REGR_INTERCEPT(SYSDATE-hire_date, salary) intercept FROM employees WHERE department_id in (50,80) GROUP BY job_id ORDER BY job_id; JOB_ID SLOPE INTERCEPT ---------- ----- ------------ SA_MAN .355 -1707.030762 SA_REP .257 404.767151 SH_CLERK .745 159.015293 ST_CLERK .904 134.409050 ST_MAN .479 -570.077291
次の例では、サンプル表hr.employeesを使用して、勤務時間(SYSDATE - hire_date)と給与について、job_id別の数を計算します。結果はjob_id別にグループ化されます。
SELECT job_id, REGR_COUNT(SYSDATE-hire_date, salary) count FROM employees WHERE department_id in (30, 50) GROUP BY job_id ORDER BY job_id, count; JOB_ID COUNT ---------- ---------- PU_CLERK 5 PU_MAN 1 SH_CLERK 20 ST_CLERK 20 ST_MAN 5
次の例では、サンプル表hr.employeesを使用して、勤務時間(SYSDATE - hire_date)と給与の線形回帰に対する決定係数を計算します。
SELECT job_id, REGR_R2(SYSDATE-hire_date, salary) Regr_R2 FROM employees WHERE department_id in (80, 50) GROUP by job_id ORDER BY job_id, Regr_R2; JOB_ID REGR_R2 ---------- ---------- SA_MAN .83244748 SA_REP .647007156 SH_CLERK .879799698 ST_CLERK .742808493 ST_MAN .69418508
次の例では、サンプル表hr.employeesを使用して、勤務時間(SYSDATE - hire_date)と給与の平均値を計算します。結果はjob_id別にグループ化されます。
SELECT job_id, REGR_AVGY(SYSDATE-hire_date, salary) avgy, REGR_AVGX(SYSDATE-hire_date, salary) avgx FROM employees WHERE department_id in (30,50) GROUP BY job_id ORDER BY job_id, avgy, avgx; JOB_ID AVGY AVGX ---------- ---------- ---------- PU_CLERK 2950.3778 2780 PU_MAN 4026.5778 11000 SH_CLERK 2773.0778 3215 ST_CLERK 2872.7278 2785 ST_MAN 3140.1778 7280
次の例では、サンプル表hr.employeesを使用して、勤務時間(SYSDATE - hire_date)と給与の線形回帰について、3種類の診断統計を計算します。
SELECT job_id, REGR_SXY(SYSDATE-hire_date, salary) regr_sxy, REGR_SXX(SYSDATE-hire_date, salary) regr_sxx, REGR_SYY(SYSDATE-hire_date, salary) regr_syy FROM employees WHERE department_id in (80, 50) GROUP BY job_id ORDER BY job_id; JOB_ID REGR_SXY REGR_SXX REGR_SYY ---------- ---------- ----------- ---------- SA_MAN 3303500 9300000.0 1409642 SA_REP 16819665.5 65489655.2 6676562.55 SH_CLERK 4248650 5705500.0 3596039 ST_CLERK 3531545 3905500.0 4299084.55 ST_MAN 2180460 4548000.0 1505915.2
REMAINDERはn2をn1で割った余りを戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。Oracleは、数値の優先順位が最も高い引数を判断し、残りの引数をそのデータ型に暗黙的に変換して、そのデータ型を戻します。
MODファンクションはREMAINDERと似ていますが、MODの式ではFLOORを使用します。これに対してREMAINDERではROUNDを使用します。詳細は、「MOD」を参照してください。
n1が0(ゼロ)であるか、またはn2が無限大の場合、Oracleが戻すものは次のようになります。
n1が0ではない場合、余りはn2 - (n1*N)となります。Nは、n2/n1に最も近い整数です。n2/n1がx.5と等しい場合、Nは最も近い偶数の整数です。
n2が浮動小数点数で、余りが0(ゼロ)の場合、余りの符号はn2の符合になります。NUMBER値の場合、0の余りには符号は付きません。
次の例では、「例」で作成されたfloat_point_demo表を使用して、2つの浮動小数点数を割り、算出された余りを戻します。
SELECT bin_float, bin_double, REMAINDER(bin_float, bin_double) FROM float_point_demo; BIN_FLOAT BIN_DOUBLE REMAINDER(BIN_FLOAT,BIN_DOUBLE) ---------- ---------- ------------------------------- 1.235E+003 1.235E+003 5.859E-005

REPLACEは、replacement_stringですべてのsearch_stringを変換してcharを戻します。replacement_stringを指定しない場合またはNULLの場合、すべてのsearch_stringが削除されます。search_stringがNULLの場合、charが戻されます。
charと同様に、search_stringおよびreplacement_stringは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。charと同じキャラクタ・セットの文字列が戻されます。このファンクションは、1つ目の引数がLOBではない場合はVARCHAR2を戻し、1つ目の引数がLOBの場合はCLOBを戻します。
REPLACEは、TRANSLATEファンクションに関連する機能を提供します。TRANSLATEは、単一文字を1対1で置き換えます。REPLACEファンクションでは、1つの文字列の置換および複数の文字列の削除を実行できます。
次の例では、JをBLに置換します。
SELECT REPLACE('JACK and JUE','J','BL') "Changes" FROM DUAL; Changes -------------- BLACK and BLUE

ROUNDは、nを小数点以下integer桁に丸めた値を戻します。integerを指定しない場合、nは小数点以下が丸められます。integerが負の場合、nは小数点の左側に丸められます。
nには、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を指定できます。integerを指定しない場合、このファンクションは、nの数値データ型と同じデータ型で値ROUND(n, 0)を戻します。integerを指定すると、このファンクションはNUMBERを戻します。
ROUNDは、次の規則を使用して実行されます。
nが0の場合、ROUNDはintegerに関係なく常に0を戻します。
nが負の場合、ROUND(n, integer)は、-ROUND(-n, integer)を戻します。
nが正の場合は、次のとおりです。
ROUND(n, integer) = FLOOR(n * POWER(10, integer) + 0.5) * POWER(10, -integer)
NUMBER値に適用されたROUNDが、浮動小数点で表現された同じ値に適用されたROUNDと少し異なる場合があります。この結果の相違は、NUMBERと浮動小数点値の内部表現の違いから発生します。相違が発生した場合、その相違は丸められた桁で1になります。
|
参照:
暗黙的な変換の詳細は、表2-10「暗黙的な型変換のマトリックス」を参照してください。Oracle Databaseによる |
次の例では、数値を小数点以下1桁に丸めます。
SELECT ROUND(15.193,1) "Round" FROM DUAL; Round ---------- 15.2
次の例では、数値の小数点の左1桁を丸めます。
SELECT ROUND(15.193,-1) "Round" FROM DUAL; Round ---------- 20

ROUNDは、dateを書式モデルfmtで指定した単位に丸めた結果を戻します。このファンクションは、NLS_CALENDARセッション・パラメータの影響を受けません。このファンクションはグレゴリオ暦の規則に従って動作します。戻される値は、dateに異なる日時データ型を指定した場合でも、常にDATEデータ型です。fmtを省略すると、dateは最も近い日に丸められます。date式は、DATE値に変換される必要があります。
次の例では、次の年の最も近い日に丸めます。
SELECT ROUND (TO_DATE ('27-OCT-00'),'YEAR') "New Year" FROM DUAL; New Year --------- 01-JAN-01

ROW_NUMBERは分析ファンクションです。このファンクションは、order_by_clauseに指定された行の、1から始まる順序シーケンスで、このファンクションが適用される各行(パーティションの各行、または問合せが戻す各行)に一意の数値を割り当てます。
指定された範囲のROW_NUMBER値を取得する問合せ内に、ROW_NUMBERを使用した副問合せをネストすることで、内側の問合せの結果から正確な行のサブセットを得ることができます。この方法でこのファンクションを使用すると、上位N番、下位N番および内部N番のレポートを実行できます。一貫した結果を戻すには、問合せで決定的なソート順序を使用する必要があります。
exprには、ROW_NUMBERまたは他の分析ファンクションを使用して分析ファンクションをネストできません。ただし、他の組込みファンクション式をexprで使用できます。exprの書式の詳細は、「SQL式」を参照してください。
次の例では、hr.employees表で各部門の最も支給額の高い上位3人の従業員を検索します。従業員が3人未満の部門については、3行未満の行が戻されます。
SELECT department_id, first_name, last_name, salary FROM ( SELECT department_id, first_name, last_name, salary, ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary desc) rn FROM employees ) WHERE rn <= 3 ORDER BY department_id, salary DESC, last_name;
次の例は、sh.sales表の結合問合せです。1999年の売上高が上位5つの製品について2000年の売上高を検索し、2000年と1999年の差を比較します。各販売チャネルにおいて売上高上位の10製品が計算されます。
SELECT sales_2000.channel_desc, sales_2000.prod_name, sales_2000.amt amt_2000, top_5_prods_1999_year.amt amt_1999, sales_2000.amt - top_5_prods_1999_year.amt amt_diff FROM /* The first subquery finds the 5 top-selling products per channel in year 1999. */ (SELECT channel_desc, prod_name, amt FROM ( SELECT channel_desc, prod_name, sum(amount_sold) amt, ROW_NUMBER () OVER (PARTITION BY channel_desc ORDER BY SUM(amount_sold) DESC) rn FROM sales, times, channels, products WHERE sales.time_id = times.time_id AND times.calendar_year = 1999 AND channels.channel_id = sales.channel_id AND products.prod_id = sales.prod_id GROUP BY channel_desc, prod_name ) WHERE rn <= 5 ) top_5_prods_1999_year, /* The next subquery finds sales per product and per channel in 2000. */ (SELECT channel_desc, prod_name, sum(amount_sold) amt FROM sales, times, channels, products WHERE sales.time_id = times.time_id AND times.calendar_year = 2000 AND channels.channel_id = sales.channel_id AND products.prod_id = sales.prod_id GROUP BY channel_desc, prod_name ) sales_2000 WHERE sales_2000.channel_desc = top_5_prods_1999_year.channel_desc AND sales_2000.prod_name = top_5_prods_1999_year.prod_name ORDER BY sales_2000.channel_desc, sales_2000.prod_name ; CHANNEL_DESC PROD_NAME AMT_2000 AMT_1999 AMT_DIFF --------------- --------------==-------------------------------- ---------- ---------- ---------- Direct Sales 17" LCD w/built-in HDTV Tuner 628855.7 1163645.78 -534790.08 Direct Sales Envoy 256MB - 40GB 502938.54 843377.88 -340439.34 Direct Sales Envoy Ambassador 2259566.96 1770349.25 489217.71 Direct Sales Home Theatre Package with DVD-Audio/Video Play 1235674.15 1260791.44 -25117.29 Direct Sales Mini DV Camcorder with 3.5" Swivel LCD 775851.87 1326302.51 -550450.64 Internet 17" LCD w/built-in HDTV Tuner 31707.48 160974.7 -129267.22 Internet 8.3 Minitower Speaker 404090.32 155235.25 248855.07 Internet Envoy 256MB - 40GB 28293.87 154072.02 -125778.15 Internet Home Theatre Package with DVD-Audio/Video Play 155405.54 153175.04 2230.5 Internet Mini DV Camcorder with 3.5" Swivel LCD 39726.23 189921.97 -150195.74 Partners 17" LCD w/built-in HDTV Tuner 269973.97 325504.75 -55530.78 Partners Envoy Ambassador 1213063.59 614857.93 598205.66 Partners Home Theatre Package with DVD-Audio/Video Play 700266.58 520166.26 180100.32 Partners Mini DV Camcorder with 3.5" Swivel LCD 404265.85 520544.11 -116278.26 Partners Unix/Windows 1-user pack 374002.51 340123.02 33879.49 15 rows selected.
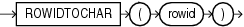
ROWIDTOCHARは、ROWIDの値をVARCHAR2データ型に変換します。この変換の結果は常に18文字です。
次の例では、employees表のROWID値を文字値に変換します。(結果はサンプル・データベースのビルドごとに異なります。)
SELECT ROWID FROM employees WHERE ROWIDTOCHAR(ROWID) LIKE '%JAAB%' ORDER BY ROWID; ROWID ------------------ AAAFfIAAFAAAABSAAb
ROWIDTONCHARは、ROWID値をNVARCHAR2データ型に変換します。この変換の結果は、常に、各国語キャラクタ・セットの文字で、18文字です。
次の例では、ROWID値をNVARCHAR2文字列に変換します。
SELECT LENGTHB( ROWIDTONCHAR(ROWID) ) Length, ROWIDTONCHAR(ROWID) FROM employees ORDER BY length; LENGTH ROWIDTONCHAR(ROWID ---------- ------------------ 36 AAAL52AAFAAAABSABD 36 AAAL52AAFAAAABSABV . . .
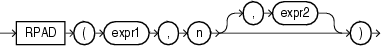
RPADは、expr1の右にexpr2で指定した文字を必要に応じて連続的に埋め込み、長さnにして戻します。このファンクションは、問合せの出力の書式設定に役立ちます。
expr1およびexpr2は、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。戻される文字列は、expr1が文字データ型の場合はVARCHAR2データ型、expr1が各国語キャラクタ・データ型の場合はNVARCHAR2データ型、expr1がLOBデータ型の場合はLOBデータ型になります。expr1と同じキャラクタ・セットの文字列が戻されます。引数nは、NUMBER型の整数か、またはNUMBER型の整数に暗黙的に変換可能な値である必要があります。
expr1はNULL以外である必要があります。expr2を指定しない場合、デフォルトで空白1個が指定されます。expr1がnより長い場合、このファンクションはnに収まるexpr1の一部を戻します。
引数nは、戻り値が画面に表示される場合の全体の長さです。多くのキャラクタ・セットでは、これは戻り値の文字数でもあります。ただし、マルチバイトのキャラクタ・セットでは、表示される文字列の長さが文字列の文字数と異なる場合もあります。
次の例では、空白にアスタリスクを埋め込んで、給与額の単純なチャートを作成します。
SELECT last_name, RPAD(' ', salary/1000/1, '*') "Salary" FROM employees WHERE department_id = 80 ORDER BY last_name, "Salary"; LAST_NAME Salary ------------------------- --------------- Abel ********** Ande ***** Banda ***** Bates ****** Bernstein ******** Bloom ********* Cambrault ********** Cambrault ****** Doran ****** Errazuriz *********** Fox ******** Greene ******** Hall ******** Hutton ******* Johnson ***** King ********* . . .
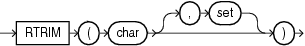
RTRIMは、charの右端から、setに指定されたすべての文字を削除します。このファンクションは、問合せの出力の書式設定に役立ちます。
setを指定しない場合、デフォルトで空白1個が指定されます。charが文字リテラルの場合、一重引用符で囲む必要があります。RTRIMはLTRIMと同様の働きをします。
charおよびsetは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。戻される文字列は、charが文字データ型の場合はVARCHAR2データ型、charが各国語キャラクタデータ型の場合はNVARCHAR2データ型、charがLOBデータ型の場合はLOBデータ型になります。
次の例では、文字列の右端にあるすべてのピリオド、スラッシュおよび等号を文字列から削除します。
SELECT RTRIM('BROWNING: ./=./=./=./=./=.=','/=.') "RTRIM example" FROM DUAL; RTRIM exam ---------- BROWNING:

SCN_TO_TIMESTAMPは、引数として、システム変更番号(SCN)と評価される数値を取り、そのSCNに関連付けられた概数のタイムスタンプを戻します。戻り値のデータ型はTIMESTAMPです。このファンクションは、SCNに関連付けられたタイムスタンプを調べる場合に有効です。たとえば、このファンクションをORA_ROWSCN疑似列とともに使用して、行への最新の変更にタイムスタンプを関連付けることができます。
次の例では、ORA_ROWSCN疑似列を使用して行への最新の変更のシステム変更番号を判断し、SCN_TO_TIMESTAMPを使用してそのSCNをタイムスタンプに変換します。
SELECT SCN_TO_TIMESTAMP(ORA_ROWSCN) FROM employees WHERE employee_id = 188;
このような問合せを使用して、Oracleフラッシュバック問合せで使用するためにシステム変更番号をタイムスタンプに変換することもできます。
SELECT salary FROM employees WHERE employee_id = 188; SALARY ---------- 3800 UPDATE employees SET salary = salary*10 WHERE employee_id = 188; COMMIT; SELECT salary FROM employees WHERE employee_id = 188; SALARY ---------- 38000 SELECT SCN_TO_TIMESTAMP(ORA_ROWSCN) FROM employees WHERE employee_id = 188; SCN_TO_TIMESTAMP(ORA_ROWSCN) --------------------------------------------------------------------------- 28-AUG-03 01.58.01.000000000 PM FLASHBACK TABLE employees TO TIMESTAMP TO_TIMESTAMP('28-AUG-03 01.00.00.000000000 PM'); SELECT salary FROM employees WHERE employee_id = 188; SALARY ---------- 3800

SESSIONTIMEZONEは、現行のセッションのタイムゾーンを戻します。戻り型は、タイムゾーン・オフセット('[+|]TZH:TZM'という書式の文字列型)またはタイムゾーン地域名です。これは、最近のALTER SESSION文でユーザーが指定したセッション・タイムゾーンの値によって異なります。
次の例では、現行のセッションのタイムゾーンを戻します。
SELECT SESSIONTIMEZONE FROM DUAL; SESSION ------- -08:00

SETは、重複を排除することによってネストした表を単一の集合に変換します。このファンクションは、各要素が一意であるネストした表を戻します。戻されるネストした表のデータ型は、入力されたネストした表と同じです。
ネストした表の要素の型は、比較可能な型である必要があります。スカラー型以外の型の比較の可能性は、「比較条件」を参照してください。
次の例では、customers_demo表から、ネストした表列cust_address_ntabの一意の要素を選択します。
SELECT customer_id, SET(cust_address_ntab) address FROM customers_demo ORDER BY customer_id;
CUSTOMER_ID ADDRESS(STREET_ADDRESS, POSTAL_CODE, CITY, STATE_PROVINCE, COUNTRY_ID) ----------- ------------------------------------------------------------------------ 101 CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP('514 W Superior St', '46901', 'Kokomo', 'IN', 'US')) 102 CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP('2515 Bloyd Ave', '46218', 'Indianapolis', 'IN', 'US')) 103 CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP('8768 N State Rd 37', '47404', 'Bloomington', 'IN', 'US')) 104 CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP('6445 Bay Harbor Ln', '46254', 'Indianapolis', 'IN', 'US')) 105 CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP('4019 W 3Rd St', '47404', 'Bloomington', 'IN', 'US')) . . .
この例では、表customers_demoと、データを含むネストした表の列が1つ必要です。この表およびネストした表の列を作成する方法については、「MULTISET演算子」を参照してください。
SIGNは、nの符号を戻します。このファンクションは、引数として、任意の数値データ型、または暗黙的にNUMBERに変換可能な数値以外のデータ型を取り、NUMBERを戻します。
NUMBER型の値の場合、符号は次のとおりです。
浮動小数点数(BINARY_FLOATおよびBINARY_DOUBLE)の場合、このファンクションは数値の符号ビットを戻します。符号ビットは次のとおりです。
次の例では、ファンクションの引数(-15)が0より小さいことを示します。
SELECT SIGN(-15) "Sign" FROM DUAL; Sign ---------- -1
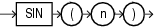
SINは、n(ラジアンで表された角度)のサインを戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。引数がBINARY_FLOATの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、引数と同じ数値データ型を戻します。
次の例では、30度のサインを戻します。
SELECT SIN(30 * 3.14159265359/180) "Sine of 30 degrees" FROM DUAL; Sine of 30 degrees ------------------ .5
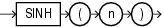
SINHは、nの双曲線サインを戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。引数がBINARY_FLOATの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、引数と同じ数値データ型を戻します。
次の例では、1の双曲線サインを戻します。
SELECT SINH(1) "Hyperbolic sine of 1" FROM DUAL; Hyperbolic sine of 1 -------------------- 1.17520119
SOUNDEXは、charと同じ音声表現を持つ文字列を戻します。このファンクションによって、綴りが異なっても発音が類似した英単語を比較できます。
音声表現については、『The Art of Computer Programming, Volume 3: Sorting and Searching』(Donald E. Knuth著)で次のように定義されています。
b, f, p, v = 1 c, g, j, k, q, s, x, z = 2 d, t = 3 l = 4 m, n = 5 r = 6
charは、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型です。戻り値は、charと同じデータ型です。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、「Smyth」と同じ音声表現を持つ従業員を戻します。
SELECT last_name, first_name FROM hr.employees WHERE SOUNDEX(last_name) = SOUNDEX('SMYTHE') ORDER BY last_name, first_name; LAST_NAME FIRST_NAME ---------- ---------- Smith Lindsey Smith William
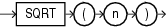
SQRTは、nの平方根を戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
次の例では、26の平方根を戻します。
SELECT SQRT(26) "Square root" FROM DUAL; Square root ----------- 5.09901951

STATS_BINOMIAL_TESTは、有効な値が2つのみである二値変数に使用する直接確立法です。このファンクションは、標本の割合と指定された割合との差をテストします。このテストでは通常、小さいサイズの標本が使用されます。
このファンクションは4つの引数を取ります。expr1はテスト対象の標本、expr2は割合を求める値、pはテストの基準となる割合です。4つ目の引数はVARCHAR2型の戻り値です。4つ目の引数を指定しない場合、デフォルトでTWO_SIDED_PROBが戻り値になります。表5-3に、戻り値の意味を示します。
EXACT_PROBでは、pと一致する割合が戻される確率が戻されます。標本における割合が、50%と大幅に異なるか(有意差があるか)どうかをテストする場合、通常、pを0.50に設定します。割合が異なるかどうかのみをテストする場合、戻り値にTWO_SIDED_PROBを使用します。割合がexpr2の値より大きいかどうかをテストする場合、戻り値にONE_SIDED_PROB_OR_MOREを使用します。割合がexpr2より小さいかどうかをテストする場合、戻り値にONE_SIDED_PROB_OR_LESSを使用します。
次の例では、母集団の69%が男性であるという仮定に基づいて観測された男性数が、実際の男性数と正確に同一となる確率を判断します。
SELECT AVG(DECODE(cust_gender, 'M', 1, 0)) real_proportion, STATS_BINOMIAL_TEST (cust_gender, 'M', 0.68, 'EXACT_PROB') exact, STATS_BINOMIAL_TEST (cust_gender, 'M', 0.68, 'ONE_SIDED_PROB_OR_LESS') prob_or_less FROM sh.customers;
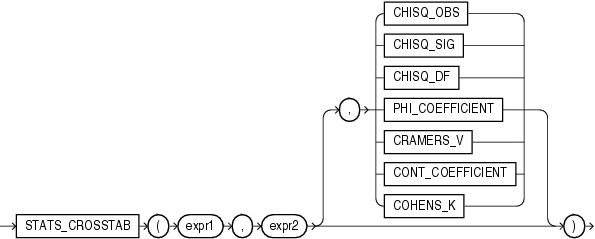
クロス集計は、2つの名義変数の分析に使用する方法です。STATS_CROSSTABファンクションは、2つの式とVARCHAR2型の戻り値の3つの引数を取ります。expr1およびexpr2は、分析対象の2つの変数です。このファンクションは、3つ目の引数に従って1つの数値を戻します。3つ目の引数を指定しない場合、デフォルトでCHISQ_SIGが戻り値になります。表5-4に、戻り値の意味を示します。
| 戻り値 | 意味 |
|---|---|
|
|
カイ2乗の観測値 |
|
|
カイ2乗の観測値の有意性 |
|
|
カイ2乗の自由度 |
|
|
ファイ係数 |
|
|
クラメールのV統計 |
|
|
一致係数 |
|
|
コーエンのカッパ |
次の例では、性別と収入水準の関連の強さを判断します。
SELECT STATS_CROSSTAB (cust_gender, cust_income_level, 'CHISQ_OBS') chi_squared, STATS_CROSSTAB (cust_gender, cust_income_level, 'CHISQ_SIG') p_value, STATS_CROSSTAB (cust_gender, cust_income_level, 'PHI_COEFFICIENT') phi_coefficient FROM sh.customers; CHI_SQUARED P_VALUE PHI_COEFFICIENT ----------- ---------- --------------- 251.690705 1.2364E-47 .067367056
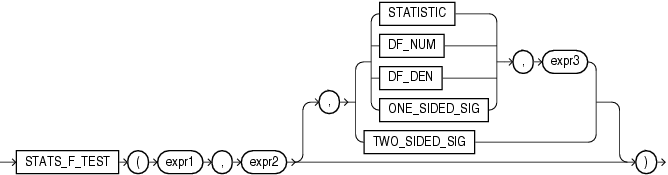
STATS_F_TESTは、2つの分散に有意差があるかどうかをテストします。fの観測値は、他方の分散に対する一方の分散の比率です。この値が1と大きく異なる場合は、通常、有意差があることを示しています。
このファンクションは3つの引数を取ります。expr1はグループ変数または独立変数で、expr2は値の標本です。このファンクションは、3つ目の引数に従って1つの数値を戻します。3つ目の引数を指定しない場合、デフォルトでTWO_SIDED_SIGが戻り値になります。表5-5に、戻り値の意味を示します。
| 戻り値 | 意味 |
|---|---|
|
|
fの観測値 |
|
|
分子の自由度 |
|
|
分母の自由度 |
|
|
fの片側有意 |
|
|
fの両側有意 |
片側有意は常に上側確率に関連します。最後の引数expr3は、expr1で指定した2つのグループのうち、大きい値または分子(棄却域が上側確率の値)のグループを示します。
fの観測値は、2つ目のグループの分散に対する1つ目のグループの分散の比率です。fの観測値の有意性は、2つの分散が偶然に異なる確率で、0(ゼロ)〜1の数値です。この有意性の値が小さい場合、2つの分散に有意差があることを示しています。各分散の自由度は、標本における観測数から1を引いた値です。
次の例では、男性と女性のクレジット利用限度額に有意差があるかどうかを判断します。p_valueが0(ゼロ)に近くなく、f_statisticが1に近いという結果は、男性と女性のクレジット利用限度額の差が有意でないことを示しています。
SELECT VARIANCE(DECODE(cust_gender, 'M', cust_credit_limit, null)) var_men, VARIANCE(DECODE(cust_gender, 'F', cust_credit_limit, null)) var_women, STATS_F_TEST(cust_gender, cust_credit_limit, 'STATISTIC', 'F') f_statistic, STATS_F_TEST(cust_gender, cust_credit_limit) two_sided_p_value FROM sh.customers; VAR_MEN VAR_WOMEN F_STATISTIC TWO_SIDED_P_VALUE ---------- ---------- ----------- ----------------- 12879896.7 13046865 1.01296348 .311928071
STATS_KS_TESTは、2つの標本を比較して、それらが同じ母集団に属しているか、または同じ分布を持つ母集団に属しているかをテストするKolmogorov-Smirnovファンクションです。このファンクションでは、標本の母集団が正規分布に従うとは仮定されません。
このファンクションは、2つの式とVARCHAR2型の戻り値の3つの引数を取ります。expr1には、データを2つのサンプルに分類する値を指定します。expr2には、各サンプルの値を指定します。expr1に、行を1つのみか3つ以上のサンプルに分類する値を指定すると、エラーが発生します。このファンクションは、3つ目の引数に従って1つの値を戻します。3つ目の引数を指定しない場合、デフォルトでSIGが戻り値になります。表5-6に、戻り値の意味を示します。
| 戻り値 | 意味 |
|---|---|
|
|
Dの観測値 |
|
|
Dの有意性 |
次の例では、Kolmogorov-Smirnov検定を使用して、男性と女性に対する売上の分布が偶然であるかどうかを判断します。
SELECT stats_ks_test(cust_gender, amount_sold, 'STATISTIC') ks_statistic, stats_ks_test(cust_gender, amount_sold) p_value FROM sh.customers c, sh.sales s WHERE c.cust_id = s.cust_id; KS_STATISTIC P_VALUE ------------ ---------- .003841396 .004080006
STATS_MODEは、引数として値の集合を取り、最も出現頻度の高い値を戻します。複数の最頻値が存在する場合、Oracle Databaseは1つの最頻値を選択し、その値のみを戻します。
複数の最頻値(存在する場合)を取得する場合は、次の不確定な問合せに示すとおり、他のファンクションの組合せを使用する必要があります。
SELECT x FROM (SELECT x, COUNT(x) AS cnt1 FROM t GROUP BY x) WHERE cnt1 = (SELECT MAX(cnt2) FROM (SELECT COUNT(x) AS cnt2 FROM t GROUP BY x));
次の例では、hr.employees表の部門ごとの給与の最頻値を戻します。
SELECT department_id, STATS_MODE(salary) FROM employees GROUP BY department_id ORDER BY department_id, stats_mode(salary); DEPARTMENT_ID STATS_MODE(SALARY) ------------- ------------------ 10 4400 20 6000 30 2500 40 6500 50 2500 60 4800 70 10000 80 9500 90 17000 100 6900 110 8300 7000
複数の最頻値が存在し、そのすべての最頻値を取得する必要がある場合は、次の例に示すとおり、他のファンクションの組合せを使用します。
SELECT commission_pct FROM (SELECT commission_pct, COUNT(commission_pct) AS cnt1 FROM employees GROUP BY commission_pct) WHERE cnt1 = (SELECT MAX (cnt2) FROM (SELECT COUNT(commission_pct) AS cnt2 FROM employees GROUP BY commission_pct)) ORDER BY commission_pct; COMMISSION_PCT -------------- .2 .3
Mann-Whitney検定では、2つの独立した標本を比較して、2つの母集団が同じ分布ファンクションを持つという帰無仮説を、2つの分布ファンクションは異なるという対立仮説に対してテストします。
STATS_MW_TESTでは、STATS_T_TEST_*ファンクションとは異なり、標本間の差が正規分布するとは仮定されません。このファンクションは、3つの引数とVARCHAR2型の戻り値を取ります。expr1には、データをグループに分類する値を指定します。expr2には、各グループの値を指定します。このファンクションは、3つ目の引数に従って1つの値を戻します。3つ目の引数を指定しない場合、デフォルトでTWO_SIDED_SIGが戻り値になります。表7-7に、戻り値の意味を示します。
ZまたはUの観測値の有意性は、2つの分散が偶然に異なる確率で、0(ゼロ)〜1の数値です。この有意性の値が小さい場合、2つの分散に有意差があることを示しています。各分散の自由度は、標本における観測数から1を引いた値です。
| 戻り値 | 意味 |
|---|---|
|
|
Zの観測値 |
|
|
Uの観測値 |
|
|
Zの片側有意 |
|
|
Zの両側有意 |
片側有意は常に上側確率に関連します。最後の引数expr3は、expr1で指定した2つのグループのうち、大きい値(棄却域が上側確率の値)のグループを示します。
STATS_MW_TESTは、値の順位の合計における差を確認して、標本が同じ分布からのものである確率を計算します。標本が同じ分布に属している場合、各標本の合計値は近くなります。
次の例では、Mann-Whitney検定を使用して、男性と女性に対する売上の分布が偶然であるかどうかを判断します。
SELECT STATS_MW_TEST (cust_gender, amount_sold, 'STATISTIC') z_statistic, STATS_MW_TEST (cust_gender, amount_sold, 'ONE_SIDED_SIG', 'F') one_sided_p_value FROM sh.customers c, sh.sales s WHERE c.cust_id = s.cust_id; Z_STATISTIC ONE_SIDED_P_VALUE ----------- ----------------- -1.4011509 .080584471

STATS_ONE_WAY_ANOVAファンクションによる一元配置分散分析では、分散の2つの異なる推定値を比較して、(複数のグループまたは変数の)平均値の差をテストして統計学的有意差を求めます。1つ目の推定値は、各グループまたはカテゴリ内の分散に基づきます。これは、群内平均平方または平均平方誤差と呼ばれます。2つ目の推定値は、グループの平均値の分散に基づきます。これは、群間平均平方と呼ばれます。グループの平均値に有意差がある場合、その群間平均平方は期待値より大きくなり、群内平均平方に一致しません。グループの平均平方が一貫している場合、2つの分散の推定値はほぼ同じになります。
STATS_ONE_WAY_ANOVAは、2つの式とVARCHAR2型の戻り値の3つの引数を取ります。expr1には、データをグループの集合に分割する独立変数またはグループ変数を指定します。expr2には、グループの各構成要素に対応する値を含む従属変数(数式)を指定します。このファンクションは、3つ目の引数に従って1つの数値を戻します。3つ目の引数を指定しない場合、デフォルトでSIGが戻り値になります。表5-8に、戻り値の意味を示します。
一元配置分散分析の有意性は群間平均平方と群内平均平方の比率に対するf検定の片側有意を求めることによって判断されます。f検定では片側有意を使用する必要があります。これは、群間平均平方は、群内平均平方以上のみになるためです。そのため、STATS_ONE_WAY_ANOVAが戻す有意性は、グループ間の差が偶然である確率で、0(ゼロ)〜1の数値です。この数値が小さいほど、グループ間の有意差が大きくなります。f検定の実行の詳細は、「STATS_F_TEST」を参照してください。
次の例では、収入水準内での売上平均の差と、収入水準間での売上平均の差の有意性を判断します。p_valuesが0(ゼロ)に近いという結果は、男性と女性の両方に対して、様々な収入水準の人々に販売された商品の金額には有意差があることを示しています。
SELECT cust_gender, STATS_ONE_WAY_ANOVA(cust_income_level, amount_sold, 'F_RATIO') f_ratio, STATS_ONE_WAY_ANOVA(cust_income_level, amount_sold, 'SIG') p_value FROM sh.customers c, sh.sales s WHERE c.cust_id = s.cust_id GROUP BY cust_gender ORDER BY cust_gender; C F_RATIO P_VALUE - ---------- ---------- F 5.59536943 4.7840E-09 M 9.2865001 6.7139E-17
t検定ファンクションを次に示します。
STATS_T_TEST_ONE: 1標本t検定
STATS_T_TEST_PAIRED: 対応のある2標本t検定(クロスt検定とも呼ばれる)
STATS_T_TEST_INDEP: 同じ分散(併合分散)を持つ独立した2つのグループのt検定
STATS_T_TEST_INDEPU: 異なる分散(非併合分散)を持つ独立した2つのグループのt検定
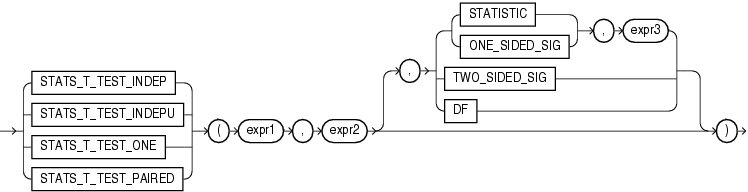
t検定では、平均値の差の有意性を測定します。この検定を使用して、2つのグループの平均値の比較、または1つのグループの平均値と定数の比較を行えます。1標本および2標本STATS_T_TEST_*ファンクションは、2つの式とVARCHAR2型の戻り値の3つの引数を取ります。このファンクションは、3つ目の引数に従って1つの数値を戻します。3つ目の引数を指定しない場合、デフォルトでTWO_SIDED_SIGが戻り値になります。表5-9に、戻り値の意味を示します。
| 戻り値 | 意味 |
|---|---|
|
|
tの観測値 |
|
|
自由度 |
|
|
tの片側有意 |
|
|
tの両側有意 |
2つの独立したSTATS_T_TEST_*ファンクションは、3つ目の引数がSTATISTICまたはONE_SIDED_SIGとして指定されている場合、4つ目の引数(expr3)を取ることができます。この場合、expr3は、expr1のどちらの値が大きい値(棄却域が上側確率の値)であるかを示します。
tの観測値の有意性は、tの値が偶然得られた確率で、0(ゼロ)〜1の数値です。この値が小さいほど、平均値間の有意差が大きくなります。片側有意は常に上側確率に関連します。1標本および対応のあるt-testの場合、最初の式が大きい値になります。独立したt-testの場合、expr3で指定した値が大きい値になります。
自由度は、tの観測値を求めるために使用したt検定の種類によって異なります。たとえば、1標本t検定(STATS_T_TEST_ONE)の場合、自由度は標本における観測数から1を引いた値です。
STATS_T_TEST_ONEファンクションでは、expr1には標本を指定し、expr2には標本平均値の比較対象となる定数平均値を指定します。このt-testの場合にのみ、expr2はオプションとなります。定数平均値は、デフォルトで0になります。このファンクションは、標本平均値と既知の平均値の差を、平均値の標準誤差で割ってt値を求めます(STATS_T_TEST_PAIREDでは、平均値の差の標準誤差で割ります)。
次の例では、平均表示価格と定数値60の差の有意性を判断します。
SELECT AVG(prod_list_price) group_mean, STATS_T_TEST_ONE(prod_list_price, 60, 'STATISTIC') t_observed, STATS_T_TEST_ONE(prod_list_price, 60) two_sided_p_value FROM sh.products; GROUP_MEAN T_OBSERVED TWO_SIDED_P_VALUE ---------- ---------- ----------------- 139.545556 2.32107746 .023158537
STATS_T_TEST_PAIREDファンクションでは、expr1およびexpr2には、比較する平均値の計算元の2つの標本をそれぞれ指定します。このファンクションは、標本平均値の差を、平均値の差の標準誤差で割ってt値を求めます(STATS_T_TEST_ONEでは、平均値の標準誤差で割ります)。
STATS_T_TEST_INDEPおよびSTATS_T_TEST_INDEPUファンクションでは、expr1はグループ列で、expr2は値の標本です。併合分散用のファンクション(STATS_T_TEST_INDEP)は、同様の分散を持つ2つの分布において、平均値が同じか異なるかをテストします。非併合分散用のファンクション(STATS_T_TEST_INDEPU)は、既知の有意差のある分散を持つ2つの分布においても、平均値が同じか異なるかをテストします。
これらのファンクションを使用する前に、標本の分散に有意差があるかどうかを判断しておくことをお薦めします。有意差がある場合、そのデータは異なる形状の分布に属している可能性があり、平均値の差が有効でない場合があります。f検定を実行して、分散の差を判断できます。分散に有意差がない場合、STATS_T_TEST_INDEPを使用します。有意差がある場合は、STATS_T_TEST_INDEPUを使用します。f検定の実行の詳細は、「STATS_F_TEST」を参照してください。
次の例では、各分布の分散が同様である(併合分散)として、男性と女性に対する平均売上間の差の有意性を判断します。
SELECT SUBSTR(cust_income_level, 1, 22) income_level, AVG(DECODE(cust_gender, 'M', amount_sold, null)) sold_to_men, AVG(DECODE(cust_gender, 'F', amount_sold, null)) sold_to_women, STATS_T_TEST_INDEP(cust_gender, amount_sold, 'STATISTIC', 'F') t_observed, STATS_T_TEST_INDEP(cust_gender, amount_sold) two_sided_p_value FROM sh.customers c, sh.sales s WHERE c.cust_id = s.cust_id GROUP BY ROLLUP(cust_income_level) ORDER BY income_level, sold_to_men, sold_to_women, t_observed; INCOME_LEVEL SOLD_TO_MEN SOLD_TO_WOMEN T_OBSERVED TWO_SIDED_P_VALUE ---------------------- ----------- ------------- ---------- ----------------- A: Below 30,000 105.28349 99.4281447 -1.9880629 .046811482 B: 30,000 - 49,999 102.59651 109.829642 3.04330875 .002341053 C: 50,000 - 69,999 105.627588 110.127931 2.36148671 .018204221 D: 70,000 - 89,999 106.630299 110.47287 2.28496443 .022316997 E: 90,000 - 109,999 103.396741 101.610416 -1.2544577 .209677823 F: 110,000 - 129,999 106.76476 105.981312 -.60444998 .545545304 G: 130,000 - 149,999 108.877532 107.31377 -.85298245 .393671218 H: 150,000 - 169,999 110.987258 107.152191 -1.9062363 .056622983 I: 170,000 - 189,999 102.808238 107.43556 2.18477851 .028908566 J: 190,000 - 249,999 108.040564 115.343356 2.58313425 .009794516 K: 250,000 - 299,999 112.377993 108.196097 -1.4107871 .158316973 L: 300,000 and above 120.970235 112.216342 -2.0642868 .039003862 107.121845 113.80441 .686144393 .492670059 106.663769 107.276386 1.08013499 .280082357 14 rows selected.
次の例では、各分布の分散に既知の有意差がある(非併合分散)として、男性と女性に対する平均売上間の差の有意性を判断します。
SELECT SUBSTR(cust_income_level, 1, 22) income_level, AVG(DECODE(cust_gender, 'M', amount_sold, null)) sold_to_men, AVG(DECODE(cust_gender, 'F', amount_sold, null)) sold_to_women, STATS_T_TEST_INDEPU(cust_gender, amount_sold, 'STATISTIC', 'F') t_observed, STATS_T_TEST_INDEPU(cust_gender, amount_sold) two_sided_p_value FROM sh.customers c, sh.sales s WHERE c.cust_id = s.cust_id GROUP BY ROLLUP(cust_income_level) ORDER BY income_level, sold_to_men, sold_to_women, t_observed; INCOME_LEVEL SOLD_TO_MEN SOLD_TO_WOMEN T_OBSERVED TWO_SIDED_P_VALUE ---------------------- ----------- ------------- ---------- ----------------- A: Below 30,000 105.28349 99.4281447 -2.0542592 .039964704 B: 30,000 - 49,999 102.59651 109.829642 2.96922332 .002987742 C: 50,000 - 69,999 105.627588 110.127931 2.3496854 .018792277 D: 70,000 - 89,999 106.630299 110.47287 2.26839281 .023307831 E: 90,000 - 109,999 103.396741 101.610416 -1.2603509 .207545662 F: 110,000 - 129,999 106.76476 105.981312 -.60580011 .544648553 G: 130,000 - 149,999 108.877532 107.31377 -.85219781 .394107755 H: 150,000 - 169,999 110.987258 107.152191 -1.9451486 .051762624 I: 170,000 - 189,999 102.808238 107.43556 2.14966921 .031587875 J: 190,000 - 249,999 108.040564 115.343356 2.54749867 .010854966 K: 250,000 - 299,999 112.377993 108.196097 -1.4115514 .158091676 L: 300,000 and above 120.970235 112.216342 -2.0726194 .038225611 107.121845 113.80441 .689462437 .490595765 106.663769 107.276386 1.07853782 .280794207 14 rows selected.

STATS_WSR_TESTは、対応のある標本のウィルコクソンの符号順位検定であり、標本間の差の中央値と0(ゼロ)に有意差があるかどうかを判断します。差の絶対値は、標本を順序付けし、順位に符号を付けて求められます。また、帰無仮説によって、正の差の順位の合計が、負の差の順位の合計に等しいと仮定されます。
このファンクションは3つの引数を取ります。expr1およびexpr2は分析対象の2つの標本で、3つ目の引数はVARCHAR2型の戻り値です。3つ目の引数を指定しない場合、デフォルトでTWO_SIDED_SIGが戻り値になります。表5-10に、戻り値の意味を示します。
| 戻り値 | 意味 |
|---|---|
|
|
Zの観測値 |
|
|
Zの片側有意 |
|
|
Zの両側有意 |
片側有意は常に上側確率に関連します。expr1が大きい値(棄却域が上側確率の値)になります。

STDDEVは、数値の集合であるexprの標本標準偏差を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。このファンクションは、STDDEV_SAMPがNULLを戻すことに対して、入力データが1行のみの場合にSTDDEVが0(ゼロ)を戻すという点で、STDDEV_SAMPと異なります。
Oracle Databaseは、VARIANCE集計ファンクションに対して定義された分散の平方根として標準偏差を計算します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
DISTINCTを指定する場合は、analytic_clauseのquery_partition_clauseのみ指定できます。order_by_clauseおよびwindowing_clauseは指定できません。
次の例では、サンプル表hr.employeesの給与値の標本標準偏差を戻します。
SELECT STDDEV(salary) "Deviation" FROM employees; Deviation ---------- 3909.36575
次の例では、hire_dateで順序付けられたサンプル表hr.employeesの部門80の給与の値の累積標準偏差を戻します。
SELECT last_name, salary, STDDEV(salary) OVER (ORDER BY hire_date) "StdDev" FROM employees WHERE department_id = 30 ORDER BY last_name, salary, "StdDev"; LAST_NAME SALARY StdDev ------------------------- ---------- ---------- Baida 2900 4035.26125 Colmenares 2500 3362.58829 Himuro 2600 3649.2465 Khoo 3100 5586.14357 Raphaely 11000 0 Tobias 2800 4650.0896

STDDEV_POPは母集団標準偏差を計算し、母集団分散の平方根を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
このファンクションは、VAR_POPファンクションの平方根と同じです。VAR_POPがNULLを戻す場合、このファンクションもNULLを戻します。
次の例では、サンプル表sh.salesにある売上高の母集団標準偏差および標本標準偏差を戻します。
SELECT STDDEV_POP(amount_sold) "Pop", STDDEV_SAMP(amount_sold) "Samp" FROM sales; Pop Samp ---------- ---------- 896.355151 896.355592
次の例では、サンプル表hr.employeesの部門ごとの給与の母集団標準偏差を戻します。
SELECT department_id, last_name, salary, STDDEV_POP(salary) OVER (PARTITION BY department_id) AS pop_std FROM employees ORDER BY department_id, last_name, salary, pop_std; DEPARTMENT_ID LAST_NAME SALARY POP_STD ------------- ------------------------- ---------- ---------- 10 Whalen 4400 0 20 Fay 6000 3500 20 Hartstein 13000 3500 30 Baida 2900 3069.6091 . . . 100 Urman 7800 1644.18166 110 Gietz 8300 1850 110 Higgins 12000 1850 Grant 7000 0

STDDEV_SAMPは標本累積標準偏差を計算し、標本分散の平方根を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
このファンクションは、VAR_SAMPファンクションの平方根と同じです。VAR_SAMPがNULLを戻す場合、このファンクションもNULLを戻します。
「STDDEV_POP」の集計の例を参照してください。
次の例では、employees表の部門ごとの給与の標本標準偏差を戻します。
SELECT department_id, last_name, hire_date, salary, STDDEV_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cum_sdev FROM employees ORDER BY department_id, last_name, hire_date, salary, cum_sdev; DEPARTMENT_ID LAST_NAME HIRE_DATE SALARY CUM_SDEV ------------- --------------- --------- ---------- ---------- 10 Whalen 17-SEP-87 4400 20 Fay 17-AUG-97 6000 4949.74747 20 Hartstein 17-FEB-96 13000 30 Baida 24-DEC-97 2900 4035.26125 30 Colmenares 10-AUG-99 2500 3362.58829 30 Himuro 15-NOV-98 2600 3649.2465 30 Khoo 18-MAY-95 3100 5586.14357 30 Raphaely 07-DEC-94 11000 . . . 100 Greenberg 17-AUG-94 12000 2121.32034 100 Popp 07-DEC-99 6900 1801.11077 100 Sciarra 30-SEP-97 7700 1925.91969 100 Urman 07-MAR-98 7800 1785.49713 110 Gietz 07-JUN-94 8300 2616.29509 110 Higgins 07-JUN-94 12000 Grant 24-MAY-99 7000
SUBSTRの各ファンクションは、charのpositionの文字からsubstring_length文字分の文字列を抜き出して戻します。SUBSTRは、入力キャラクタ・セットによって定義された文字を使用して、長さを計算します。SUBSTRBは、文字のかわりにバイトを使用します。SUBSTRCは、完全なUnicodeキャラクタを使用します。SUBSTR2は、UCS2コードポイントを使用します。SUBSTR4は、UCS4コードポイントを使用します。
positionが0の場合、1として処理されます。
positionが正の場合、Oracle Databaseはcharの始めから数えて最初の文字を検索します。
positionが負の場合、Oracleはcharの終わりから逆方向に数えます。
substring_lengthを指定しないと、Oracleはcharの終わりまでのすべての文字を戻します。substring_lengthが1より小さい場合、NULLを戻します。
charは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。positionおよびsubstring_lengthは、NUMBERデータ型か、または暗黙的にNUMBERに変換可能な任意のデータ型で、整数である必要があります。戻り値は、charと同じデータ型です。引数としてSUBSTRに渡された浮動小数点数は、自動的に整数に変換されます。
次の例では、「ABCDEFG」の指定されたサブストリングを戻します。
SELECT SUBSTR('ABCDEFG',3,4) "Substring" FROM DUAL; Substring --------- CDEF SELECT SUBSTR('ABCDEFG',-5,4) "Substring" FROM DUAL; Substring --------- CDEF
データベース・キャラクタ・セットがダブルバイトの場合を想定します。
SELECT SUBSTRB('ABCDEFG',5,4.2) "Substring with bytes" FROM DUAL; Substring with bytes -------------------- CD
SUMは、exprの値の合計を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
DISTINCTを指定する場合は、analytic_clauseのquery_partition_clauseのみ指定できます。order_by_clauseおよびwindowing_clauseは指定できません。
次の例では、サンプル表hr.employeesにあるすべての給与の合計を計算します。
SELECT SUM(salary) "Total" FROM employees; Total ---------- 691400
次の例では、サンプル表hr.employeesの各マネージャについて、そのマネージャの下で働く従業員の現在の給与以下の給与の累積合計を計算します。RaphaelyおよびCambraultが同じ累積を持っています。これは、RaphaelyおよびCambraultが同じ給与であるため、Oracle Databaseが給与の値を同時に追加し、同じ累積合計を両方の行に対して適用したためです。
SELECT manager_id, last_name, salary, SUM(salary) OVER (PARTITION BY manager_id ORDER BY salary RANGE UNBOUNDED PRECEDING) l_csum FROM employees ORDER BY manager_id, last_name, salary, l_csum; MANAGER_ID LAST_NAME SALARY L_CSUM ---------- --------------- ---------- ---------- MANAGER_ID LAST_NAME SALARY L_CSUM ---------- ------------------------- ---------- ---------- 100 Cambrault 11000 68900 100 De Haan 17000 155400 100 Errazuriz 12000 80900 100 Fripp 8200 36400 100 Hartstein 13000 93900 100 Kaufling 7900 20200 100 Kochhar 17000 155400 100 Mourgos 5800 5800 100 Partners 13500 107400 100 Raphaely 11000 68900 100 Russell 14000 121400 . . . 149 Hutton 8800 39000 149 Johnson 6200 6200 149 Livingston 8400 21600 149 Taylor 8600 30200 201 Fay 6000 6000 205 Gietz 8300 8300 King 24000 24000
SYS_CONNECT_BY_PATHは、階層問合せのみで有効です。このファンクションは、ルートからノードへの列の値のパスを、CONNECT BY条件によって戻された各行をcharで区切った列の値とともに戻します。
columnおよびcharは、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型です。戻される文字列は、VARCHAR2データ型であり、columnと同じキャラクタ・セットです。
次の例では、従業員KochharからKochharのすべての従業員(およびそれらの従業員の従業員)への従業員名のパスを戻します。
SELECT LPAD(' ', 2*level-1)||SYS_CONNECT_BY_PATH(last_name, '/') "Path" FROM employees START WITH last_name = 'Kochhar' CONNECT BY PRIOR employee_id = manager_id; Path ------------------------------ /Kochhar/Greenberg/Chen /Kochhar/Greenberg/Faviet /Kochhar/Greenberg/Popp /Kochhar/Greenberg/Sciarra /Kochhar/Greenberg/Urman /Kochhar/Higgins/Gietz /Kochhar/Baer /Kochhar/Greenberg /Kochhar/Higgins /Kochhar/Mavris /Kochhar/Whalen /Kochhar
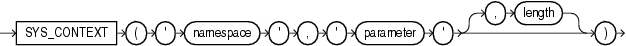
SYS_CONTEXTは、コンテキストnamespaceに関連付けられたparameterの値を戻します。このファンクションは、SQL文およびPL/SQL文で使用できます。
namespaceおよびparameterには、文字列、またはネームスペースまたは属性を指定する文字列に変換する式を指定できます。コンテキストnamespaceはすでに作成されている必要があり、関連付けられたparameterおよびその値は、DBMS_SESSION.set_contextプロシージャを使用して設定されている必要があります。namespaceは有効なSQL識別子である必要があります。parameter名には、すべての文字列を指定できます。大/小文字を区別しますが、長さは30バイト以下です。
戻り値のデータ型はVARCHAR2です。戻り値のデフォルトの最大サイズは、256バイトです。オプションのlengthパラメータを指定して、このデフォルトを上書きできます。このパラメータは、NUMBERか、または暗黙的にNUMBERに変換可能な値である必要があります。値の有効範囲は1〜4000バイトです。無効な値を指定すると、Oracle Databaseはその値を無視してデフォルト値を使用します。
Oracleでは、現行のセッションを記述するUSERENVという組込みネームスペースを提供しています。ネームスペースUSERENVの事前定義パラメータについては、表5-11を参照してください。
|
参照:
|
次の例では、データベースにログインしたユーザー名を戻します。
CONNECT OE/password SELECT SYS_CONTEXT ('USERENV', 'SESSION_USER') FROM DUAL; SYS_CONTEXT ('USERENV', 'SESSION_USER') ------------------------------------------------------ OE
次の例では、hr_appsの作成時に、コンテキストhr_appsに関連付けられたPL/SQLパッケージの属性group_noに対する値として設定されたグループ番号を戻します。
SELECT SYS_CONTEXT ('hr_apps', 'group_no') "User Group" FROM DUAL;
表5-12に、非推奨になったネームスペースUSERENVのパラメータを示します。これらのパラメータはどれも指定しないでください。かわりに、「コメント」列で提案する代替手段を使用します。

SYS_DBURIGenは、引数として1つ以上の列または属性、およびオプションでROWIDを取り、特定の列または行オブジェクトへのDBUriTypeデータ型のURLを生成します。これによって、データベースからXML文書を検索するためのURLを使用できるようになります。
参照されるすべての列または属性は、サンプル表に存在する必要があります。これらは、主キーの役割を果たす必要があります。実際に表の主キーに一致する必要はありませんが、一意の値を参照する必要があります。複数の列を指定すると、最後の列以外のすべての列はデータベースの行を識別し、指定された最後の列は行にある列を識別します。
デフォルトでは、URLはフォーマットされたXML文書を指します。ドキュメントのテキストのみを指す場合は、オプションの'text()'を指定します
列または属性を含む表またはビューが、問合せのコンテキストで指定されるスキーマを持たない場合、Oracle Databaseは、表名またはビュー名をパブリック・シノニムとして解析します。
次の例では、SYS_DBURIGenファンクションを使用して、サンプル表hr.employeesのemployee_id = 206である行のemail列へのDBUriTypeデータ型のURLを生成します。
SELECT SYS_DBURIGEN(employee_id, email) FROM employees WHERE employee_id = 206; SYS_DBURIGEN(EMPLOYEE_ID,EMAIL)(URL, SPARE) -------------------------------------------------------------------- DBURITYPE('/PUBLIC/EMPLOYEES/ROW[EMPLOYEE_ID=''206'']/EMAIL', NULL)
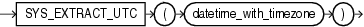
SYS_EXTRACT_UTCは、タイムゾーン・オフセットまたはタイムゾーン地域名を含む日時値から協定世界時(UTC)(以前のグリニッジ標準時)を抽出します。
次の例では、指定された日時からUTCを抽出します。
SELECT SYS_EXTRACT_UTC(TIMESTAMP '2000-03-28 11:30:00.00 -08:00') FROM DUAL; SYS_EXTRACT_UTC(TIMESTAMP'2000-03-2811:30:00.00-08:00') ----------------------------------------------------------------- 28-MAR-00 07.30.00 PM

SYS_GUIDは、16バイトで構成されたグローバルな一意の識別子(RAW値)を生成して戻します。多くのプラットフォームでは、生成された識別子は、ホスト識別子、プロセス、またはファンクションをコールするプロセスやスレッドのスレッド識別子、およびそのプロセスやスレッドに対する非反復値(バイトの順序)で構成されています。
次の例では、サンプル表hr.locationsに列を追加後、一意の識別子を各行に挿入し、グローバルな一意識別子の16バイトのRAW値を32文字の16進表記で戻します。
ALTER TABLE locations ADD (uid_col RAW(32)); UPDATE locations SET uid_col = SYS_GUID(); SELECT location_id, uid_col FROM locations ORDER BY location_id, uid_col; LOCATION_ID UID_COL ----------- ---------------------------------------------------------------- 1000 09F686761827CF8AE040578CB20B7491 1100 09F686761828CF8AE040578CB20B7491 1200 09F686761829CF8AE040578CB20B7491 1300 09F68676182ACF8AE040578CB20B7491 1400 09F68676182BCF8AE040578CB20B7491 1500 09F68676182CCF8AE040578CB20B7491 . . .
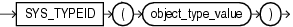
SYS_TYPEIDは、オペランドで最も指定される型の型IDを戻します。この値は、主に、置換可能な列の基礎となる型判別式の列を識別するために使用されます。たとえば、型判別式の列に索引を構築するために、SYS_TYPEIDによって戻される値を使用できます。
このファンクションは、オブジェクト型のオペランドのみで使用してください。すべての最終ルート・オブジェクト型(型階層に属さない最終型)は、NULL型のIDを持ちます。Oracle Databaseは、型階層に属するすべての型に、NULL以外の一意の型IDを割り当てます。
次の例では、「置換可能な表および列のサンプル:」で作成された表personsおよびbooksを使用します。最初の問合せは、persons表に格納されたオブジェクト・インスタンスの最も指定される型を戻します。
SELECT name, SYS_TYPEID(VALUE(p)) "Type_id" FROM persons p; NAME Type_id ------------------------- -------------------------------- Bob 01 Joe 02 Tim 03
次の問合せは、books表に格納された作者の最も指定される型を戻します。
SELECT b.title, b.author.name, SYS_TYPEID(author) "Type_ID" FROM books b; TITLE AUTHOR.NAME Type_ID ------------------------- -------------------- ------------------- An Autobiography Bob 01 Business Rules Joe 02 Mixing School and Work Tim 03
SYS_TYPEIDファンクションを使用すると、表の型判別式の列に索引を作成できます。「置換可能な列の索引の作成例:」を参照してください。
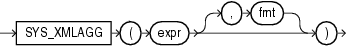
SYS_XMLAGGは、exprによって表されるすべてのXML文書またはXMLフラグメントを集約し、単一のXML文書を生成します。このファンクションは、デフォルト名ROWSETの新しい囲み要素を追加します。XML文書を別の方法でフォーマットする場合は、XMLFormatオブジェクトのインスタンスであるfmtを指定します。
次の例では、SYS_XMLGENファンクションを使用して、従業員名の最初の文字がRであるサンプル表employeesの各行に対して、XML文書を生成した後、デフォルトの囲み要素ROWSETの1つのXML文書にすべての行を集約します。
SELECT SYS_XMLAGG(SYS_XMLGEN(last_name)) XMLAGG FROM employees WHERE last_name LIKE 'R%' ORDER BY xmlagg; XMLAGG -------------------------------------------------------------------------------- <?xml version="1.0"?> <ROWSET> <LAST_NAME>Rajs</LAST_NAME> <LAST_NAME>Raphaely</LAST_NAME> <LAST_NAME>Rogers</LAST_NAME> <LAST_NAME>Russell</LAST_NAME> </ROWSET>
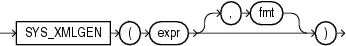
SYS_XMLGENは、データベースの特定の行および列を評価する式を取り、XML文書を含むXMLType型のインスタンスを戻します。exprは、スカラー値、ユーザー定義型またはXMLTypeインスタンスです。
exprがスカラー値である場合、ファンクションはスカラー値を含むXML要素を戻します。
exprが型である場合、ファンクションはXML要素へユーザー定義型の属性をマップします。
exprがXMLTypeインスタンスである場合、ファンクションはデフォルトのタグ名がROWであるXML要素でドキュメントを囲みます。
デフォルトでは、XML文書の要素はexprの要素と一致します。たとえば、exprが列名に変換される場合、XMLの囲み要素は同じ列名になります。XML文書を別の方法でフォーマットする場合は、XMLFormatオブジェクトのインスタンスであるfmtを指定します。
|
参照:
|
次の例では、サンプル表oe.employeesからemployee_id値が205の従業員の電子メールIDを検出し、EMAIL要素を持つXML文書を含むXMLTypeのインスタンスを生成します。
SELECT SYS_XMLGEN(email) FROM employees WHERE employee_id = 205; SYS_XMLGEN(EMAIL) ------------------------------------------------------------------- <?xml version="1.0"?> <EMAIL>SHIGGINS</EMAIL>

SYSDATEは、データベースが存在するオペレーティング・システムの現在の日付と時刻のセットを戻します。戻り値のデータ型はDATEです。戻り値の書式は、NLS_DATE_FORMAT初期化パラメータの値によって異なります。このファンクションに引数は不要です。分散SQL文では、このファンクションはローカル・データベースのオペレーティング・システムの日付と時刻のセットを戻します。CHECK制約の条件でこのファンクションは使用できません。
次の例では、オペレーティング・システムの現在の日付および時刻を戻します。
SELECT TO_CHAR (SYSDATE, 'MM-DD-YYYY HH24:MI:SS') "NOW" FROM DUAL; NOW ------------------- 04-13-2001 09:45:51

SYSTIMESTAMPは、データベースが存在するシステムの、秒の小数部とタイムゾーンを含む日付を戻します。戻り型は、TIMESTAMP WITH TIME ZONEです。
次の例では、システムのタイムスタンプを戻します。
SELECT SYSTIMESTAMP FROM DUAL; SYSTIMESTAMP ------------------------------------------------------------------ 28-MAR-00 12.38.55.538741 PM -08:00
次の例では、秒の小数部を明示的に指定する方法を示します。
SELECT TO_CHAR(SYSTIMESTAMP, 'SSSSS.FF') FROM DUAL; TO_CHAR(SYSTIME --------------- 55615.449255
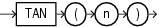
TANは、n(ラジアンで表された角度)のタンジェントを戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。引数がBINARY_FLOATの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、引数と同じ数値データ型を戻します。
次の例では、135度のタンジェントを戻します。
SELECT TAN(135 * 3.14159265359/180) "Tangent of 135 degrees" FROM DUAL; Tangent of 135 degrees ---------------------- - 1
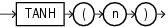
TANHは、nの双曲線タンジェントを戻します。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。引数がBINARY_FLOATの場合、このファンクションはBINARY_DOUBLEを戻します。それ以外の場合、引数と同じ数値データ型を戻します。
次の例では、5の双曲線タンジェントを戻します。
SELECT TANH(.5) "Hyperbolic tangent of .5" FROM DUAL; Hyperbolic tangent of .5 ------------------------ .462117157
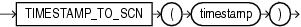
TIMESTAMP_TO_SCNは、引数としてタイムスタンプ値を取り、そのタイムスタンプに関連付けられたシステム変更番号(SCN)の概数を戻します。戻り値のデータ型はNUMBERです。このファンクションは、特定のタイムスタンプに関連付けられたSCNを調べる場合に有効です。
次の例では、行をoe.orders表に挿入し、TIMESTAMP_TO_SCNを使用して、挿入操作のシステム変更番号を判断します。(実際に戻されるSCNは、システムごとに異なります。)
INSERT INTO orders (order_id, order_date, customer_id, order_total) VALUES (5000, SYSTIMESTAMP, 188, 2345); 1 row created. COMMIT; Commit complete. SELECT TIMESTAMP_TO_SCN(order_date) FROM orders WHERE order_id = 5000; TIMESTAMP_TO_SCN(ORDER_DATE) ---------------------------- 574100

TO_BINARY_DOUBLEは、倍精度の浮動小数点数を戻します。
exprには、文字列か、またはNUMBER、BINARY_FLOATまたはBINARY_DOUBLE型の数値を指定できます。exprがBINARY_DOUBLEの場合、このファンクションはexprを戻します。
fmt'引数および'nlsparam'引数はexprが文字列の場合にのみ有効です。これらの引数は、TO_CHAR(数値)ファンクションの場合と同じ用途に使用されます。
expr文字列には、浮動小数点数の書式要素(F、f、Dまたはd)は使用できません。
文字列またはNUMBERからBINARY_DOUBLEへの変換は、正確に行われない場合があります。これは、NUMBERおよび文字列型では単精度、BINARY_DOUBLEで倍精度を使用して数値を表現するためです。
BINARY_FLOATからBINARY_DOUBLEへの変換は正確に行われます。
次の例では、それぞれ異なる数値データ型の3つの列を持つ次の表を使用します。
CREATE TABLE float_point_demo (dec_num NUMBER(10,2), bin_double BINARY_DOUBLE, bin_float BINARY_FLOAT); INSERT INTO float_point_demo VALUES (1234.56,1234.56,1234.56); SELECT * FROM float_point_demo; DEC_NUM BIN_DOUBLE BIN_FLOAT ---------- ---------- ---------- 1234.56 1.235E+003 1.235E+003
次の例では、NUMBERデータ型の値をBINARY_DOUBLEデータ型の値に変換します。
SELECT dec_num, TO_BINARY_DOUBLE(dec_num) FROM float_point_demo; DEC_NUM TO_BINARY_DOUBLE(DEC_NUM) ---------- ------------------------- 1234.56 1.235E+003
次の例では、dec_num列およびbin_double列から抽出されたダンプ情報を比較します。
SELECT DUMP(dec_num) "Decimal", DUMP(bin_double) "Double" FROM float_point_demo; Decimal Double --------------------------- --------------------------------------------- Typ=2 Len=4: 194,13,35,57 Typ=101 Len=8: 192,147,74,61,112,163,215,10

TO_BINARY_FLOATは、単精度の浮動小数点数を戻します。
exprには、文字列か、またはNUMBER、BINARY_FLOATまたはBINARY_DOUBLE型の数値を指定できます。exprがBINARY_FLOATの場合、このファンクションはexprを戻します。
fmt'引数および'nlsparam'引数はexprが文字列の場合にのみ有効です。これらの引数は、TO_CHAR(数値)ファンクションの場合と同じ用途に使用されます。
expr文字列には、浮動小数点数の書式要素(F、f、Dまたはd)は使用できません。
文字列またはNUMBERからBINARY_FLOATへの変換は、正確に行われない場合があります。これは、NUMBERおよび文字列型では単精度、BINARY_FLOATでは倍精度を使用して数値を表現するためです。
BINARY_DOUBLE値に、BINARY_FLOATがサポートする数を超える精度ビットが使用されている場合、BINARY_DOUBLEからBINARY_FLOATへの変換は正確に行われません。
次の例では、「TO_BINARY_DOUBLE」で作成したfloat_point_demo表を使用して、NUMBERデータ型の値をBINARY_FLOATデータ型の値に変換します。
SELECT dec_num, TO_BINARY_FLOAT(dec_num) FROM float_point_demo; DEC_NUM TO_BINARY_FLOAT(DEC_NUM) ---------- ------------------------ 1234.56 1.235E+003
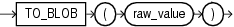
TO_BLOBは、LONG RAWおよびRAW値をBLOB値に変換します。
次の例は、RAW列の値としてBLOBを戻します。
SELECT TO_BLOB(raw_column) blob FROM raw_table; BLOB ----------------------- 00AADD343CDBBD
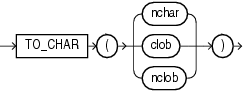
TO_CHAR(文字)は、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータをデータベース・キャラクタ・セットに変換します。戻り値は常にVARCHAR2です。
このファンクションを使用してキャラクタLOBをデータベース・キャラクタ・セットに変換すると、変換するLOB値がターゲットの型よりも大きい場合、エラーが戻されます。
このファンクションは任意のXMLファンクションと組み合せて使用できますが、生成される日付の書式は、XMLスキーマの標準書式ではなく、データベースの書式になります。
|
参照:
|
次の例では、単純な文字列を文字データとして解析します。
SELECT TO_CHAR('01110') FROM DUAL; TO_CH ----- 01110
この例と、「TO_CHAR(数値)」の最初の例を比較してください。
次の例では、pm.print_media表のCLOBデータをデータベース・キャラクタ・セットに変換します。
SELECT TO_CHAR(ad_sourcetext) FROM print_media WHERE product_id = 2268; TO_CHAR(AD_SOURCETEXT) -------------------------------------------------------------------- ****************************** TIGER2 2268...Standard Hayes Compatible Modem Product ID: 2268 The #1 selling modem in the universe! Tiger2's modem includes call management and Internet voicing. Make real-time full duplex phone calls at the same time you're online. **********************************

TO_CHAR(日時)は、DATE、TIMESTAMP、TIMESTAMP WITH TIME ZONEまたはTIMESTAMP WITH LOCAL TIME ZONEデータ型の日時値または期間値を日付書式fmtで指定された書式のVARCHAR2データ型に変換します。fmtを省略すると、次のように、dateはVARCHAR2値に変換されます。
DATE値は、デフォルトの日付書式の値に変換されます。
TIMESTAMPおよびTIMESTAMP WITH LOCAL TIME ZONE値は、デフォルトのタイムスタンプ書式の値に変換されます。
TIMESTAMP WITH TIME ZONE値は、タイムゾーン書式のデフォルトのタイムスタンプの値に変換されます。
日時書式の詳細は、「書式モデル」を参照してください。
'nlsparam'引数には、月と日の名前および略称が戻される言語を指定します。この引数は、次の書式で指定します。
'NLS_DATE_LANGUAGE = language'
'nlsparam'を指定しないと、このファンクションはセッションのデフォルト日付言語を使用します。
次の例で使用する表は、次のとおりです。
CREATE TABLE date_tab ( ts_col TIMESTAMP, tsltz_col TIMESTAMP WITH LOCAL TIME ZONE, tstz_col TIMESTAMP WITH TIME ZONE);
次の例では、TO_CHARを別のTIMESTAMPデータ型に適用した結果を示します。TIMESTAMP WITH LOCAL TIME ZONE列の結果は、セッションのタイムゾーンを識別します。これに対して、TIMESTAMPおよびTIMESTAMP WITH TIME ZONE列の結果は、セッションのタイムゾーンを識別しません。
ALTER SESSION SET TIME_ZONE = '-8:00'; INSERT INTO date_tab VALUES ( TIMESTAMP'1999-12-01 10:00:00', TIMESTAMP'1999-12-01 10:00:00', TIMESTAMP'1999-12-01 10:00:00'); INSERT INTO date_tab VALUES ( TIMESTAMP'1999-12-02 10:00:00 -8:00', TIMESTAMP'1999-12-02 10:00:00 -8:00', TIMESTAMP'1999-12-02 10:00:00 -8:00'); SELECT TO_CHAR(ts_col, 'DD-MON-YYYY HH24:MI:SSxFF') AS ts_date, TO_CHAR(tstz_col, 'DD-MON-YYYY HH24:MI:SSxFF TZH:TZM') AS tstz_date FROM date_tab ORDER BY ts_date, tstz_date; TS_DATE TSTZ_DATE ------------------------------ ------------------------------------- 01-DEC-1999 10:00:00.000000 01-DEC-1999 10:00:00.000000 -08:00 02-DEC-1999 10:00:00.000000 02-DEC-1999 10:00:00.000000 -08:00 SELECT SESSIONTIMEZONE, TO_CHAR(tsltz_col, 'DD-MON-YYYY HH24:MI:SSxFF') AS tsltz FROM date_tab ORDER BY sessiontimezone, tsltz; SESSIONTIM TSLTZ ---------- ------------------------------ -08:00 01-DEC-1999 10:00:00.000000 -08:00 02-DEC-1999 10:00:00.000000 ALTER SESSION SET TIME_ZONE = '-5:00'; SELECT TO_CHAR(ts_col, 'DD-MON-YYYY HH24:MI:SSxFF') AS ts_col, TO_CHAR(tstz_col, 'DD-MON-YYYY HH24:MI:SSxFF TZH:TZM') AS tstz_col FROM date_tab ORDER BY ts_col, tstz_col; TS_COL TSTZ_COL ------------------------------ ------------------------------------- 01-DEC-1999 10:00:00.000000 01-DEC-1999 10:00:00.000000 -08:00 02-DEC-1999 10:00:00.000000 02-DEC-1999 10:00:00.000000 -08:00 SELECT SESSIONTIMEZONE, TO_CHAR(tsltz_col, 'DD-MON-YYYY HH24:MI:SSxFF') AS tsltz_col FROM date_tab ORDER BY sessiontimezone, tsltz_col; 2 3 4 SESSIONTIM TSLTZ_COL ---------- ------------------------------ -05:00 01-DEC-1999 13:00:00.000000 -05:00 02-DEC-1999 13:00:00.000000

TO_CHAR(数値)は、nを、オプションの数値書式fmtを使用してVARCHAR2データ型の値に変換します。n値には、NUMBER、BINARY_FLOATまたはBINARY_DOUBLE型の値を指定できます。fmtを指定しないと、nの有効桁数を保持するために十分な長さのVARCHAR2値に変換されます。
nが負の場合、書式が適用された後で符号が適用されます。したがって、TO_CHAR(-1, '$9')は、$-1ではなく-$1を戻します。
日時書式の詳細は、「書式モデル」を参照してください。
'nlsparam'引数には、数値書式要素によって戻される次の文字を指定します。
この引数は、次の書式で指定します。
'NLS_NUMERIC_CHARACTERS = ''dg'' NLS_CURRENCY = ''text'' NLS_ISO_CURRENCY = territory '
文字dおよびgは、それぞれ小数点文字および桁区切りを表します。これらは、異なるシングルバイト文字である必要があります。引用符付き文字列の中では、パラメータ値を囲む一重引用符を2つ使用する必要があります。通貨記号には10文字使用できます。
'nlsparam'またはパラメータのいずれか1つを省略すると、このファンクションはセッションのデフォルト・パラメータ値を使用します。
次の文は、暗黙的な変換を使用して、文字列と数値を数値に結合します。
SELECT TO_CHAR('01110' + 1) FROM dual; TO_C ---- 1111
この例と、「TO_CHAR(文字)」の最初の例を比較してください。
次の例では、出力で通貨記号の左側に空白埋めが行われます。
SELECT TO_CHAR(-10000,'L99G999D99MI') "Amount" FROM DUAL; Amount -------------- $10,000.00- SELECT TO_CHAR(-10000,'L99G999D99MI', 'NLS_NUMERIC_CHARACTERS = '',.'' NLS_CURRENCY = ''AusDollars'' ') "Amount" FROM DUAL; Amount ------------------- AusDollars10.000,00-
オプションの数値書式fmtでは、Lは各国通貨記号を、MIは後に付くマイナス記号(-)を表します。すべての数値書式要素のリストは、表2-17「FX書式モデル修飾子による文字データと書式モデルの一致」を参照してください。
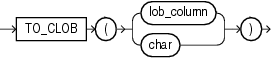
TO_CLOBは、LOB列またはその他の文字列のNCLOB値をCLOB値に変換します。charは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。Oracle Databaseは、基礎となるLOBデータを各国語キャラクタ・セットからデータベース・キャラクタ・セットに変換することによって、このファンクションを実行します。
次の文は、サンプル表pm.print_mediaのNCLOBデータをCLOBに変換し、CLOB列に挿入します。
UPDATE PRINT_MEDIA SET AD_FINALTEXT = TO_CLOB (AD_FLTEXTN);

TO_DATEは、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型のcharを、DATEデータ型の値に変換します。
|
注意: このファンクションは、データを別の日時データ型へは変換しません。他の日時変換の詳細は、「TO_TIMESTAMP」、「TO_TIMESTAMP_TZ」、「TO_DSINTERVAL」および「TO_YMINTERVAL」を参照してください。 |
fmtは、charの書式を指定する日時書式モデルです。fmtを指定しない場合、charはデフォルトの日付書式である必要があります。デフォルトの日付書式は、NLS_TERRITORY初期化パラメータによって暗黙的に決まります。NLS_DATE_FORMATパラメータによって明示的に設定することもできます。fmtがJ(ユリウス日)の場合、charは整数である必要があります。
'nlsparam'引数は、日付変換のTO_CHARファンクションの場合と同じ用途で使用されます。
引数charにDATE値を持つTO_DATEファンクションは使用しないでください。戻されるDATE値は、fmtまたはデフォルトの日付書式によって、元のcharとは異なる世紀の値を持つことがあります。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、文字列をタイムスタンプに変換します。
SELECT TO_DATE( 'January 15, 1989, 11:00 A.M.', 'Month dd, YYYY, HH:MI A.M.', 'NLS_DATE_LANGUAGE = American') FROM DUAL; TO_DATE(' --------- 15-JAN-89
戻された値は、NLS_TERRITORYパラメータが'AMERICA'に設定されている場合は、デフォルトの日付書式を反映します。異なるNLS_TERRITORYの値が設定されている場合は、異なるデフォルトの日付書式となります。
ALTER SESSION SET NLS_TERRITORY = 'KOREAN'; SELECT TO_DATE( 'January 15, 1989, 11:00 A.M.', 'Month dd, YYYY, HH:MI A.M.', 'NLS_DATE_LANGUAGE = American') FROM DUAL; TO_DATE( -------- 89/01/15


TO_DSINTERVALは、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型の文字列を、INTERVAL DAY TO SECOND型に変換します。
TO_DSINTERVALは、2つの書式のいずれかの引数を取ります。
SQL書式では、daysは0(ゼロ)〜999999999の整数、hoursは0(ゼロ)〜23の整数、minutesとsecondsは0(ゼロ)〜59の整数になります。frac_secsは秒の小数部であり、.0〜.999999999になります。日付と時間は1つ以上の空白で区切ります。これ以外に、書式要素の間にも空白を使用できます。
ISO書式では、days、hours、minutesおよびsecondsは、0(ゼロ)〜999999999の整数になります。frac_secsは秒の小数部であり、.0〜.999999999になります。値に空白は使用できません。
次の例では、1990年1月1日から100日以上勤務している従業員をhr.employees表から検索します。
SELECT employee_id, last_name FROM employees WHERE hire_date + TO_DSINTERVAL('100 00:00:00') <= DATE '1990-01-01' ORDER BY employee_id; EMPLOYEE_ID LAST_NAME ----------- --------------- 100 King 101 Kochhar 200 Whalen
TO_LOBは、long_column列のLONGまたはLONG RAW値をLOB値に変換します。このファンクションはLONGまたはLONG RAW列に対してのみ、およびINSERT文における副問合せのSELECT構文のリストにおいてのみ適用できます。
このファンクションを使用する前に、LOB列を作成して変換されたLONG値を受け取る必要があります。LONG値を変換する場合は、CLOB列を作成します。LONG RAW値を変換する場合は、BLOB列を作成します。
索引構成表を作成する場合は、CREATE TABLE ... AS SELECT文の副問合せで、TO_LOBファンクションを使用してLONG列をLOB列に変換することはできません。LONG列を含まない索引構成表を作成し、INSERT ...AS SELECT文でTO_LOBファンクションを使用してください。
|
参照:
|
次の例では、不確定な表old_tableのLONGデータに対するTO_LOBファンクションの使用方法を示します。
CREATE TABLE new_table (col1, col2, ... lob_col CLOB); INSERT INTO new_table (select o.col1, o.col2, ... TO_LOB(o.old_long_col) FROM old_table o;

TO_MULTI_BYTEは、シングルバイト文字を、対応するマルチバイト文字に変換してcharを戻します。charのデータ型は、CHAR、VARCHAR2、NCHARまたはNVARCHAR2です。戻り値は、charと同じデータ型です。
char内に同等のマルチバイト文字がないシングルバイト文字は、シングルバイト文字として出力されます。このファンクションは、ご使用のデータベース・キャラクタ・セットに、シングルバイト文字およびマルチバイト文字の両方が含まれている場合にのみ有効です。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、シングルバイトAからUTF8のマルチバイトAへの変換を示します。
SELECT dump(TO_MULTI_BYTE( 'A')) FROM DUAL; DUMP(TO_MULTI_BYTE('A')) ------------------------ Typ=1 Len=3: 239,188,161
TO_NCHAR(文字)は、文字列、CHAR、VARCHAR2、CLOBまたはNCLOB値を各国語キャラクタ・セットに変換します。戻り値は常にNVARCHAR2です。このファンクションは、各国語キャラクタ・セットでUSING句を指定したTRANSLATE ... USINGファンクションと同じです。
次の例では、oe.customers表のVARCHAR2データを各国語キャラクタ・セットに変換します。
SELECT TO_NCHAR(cust_last_name) FROM customers WHERE customer_id=103; TO_NCHAR(CUST_LAST_NAME) -------------------------------------------------- Taylor
TO_NCHAR(日時)は、DATE、TIMESTAMP、TIMESTAMP WITH TIME ZONE、TIMESTAMP WITH LOCAL TIME ZONE、INTERVAL MONTH TO YEARまたはINTERVAL DAY TO SECONDデータ型の文字列をデータベース・キャラクタ・セットから各国語キャラクタ・セットに変換します。
次の例では、状態が9であるすべての注文のorder_dateを各国語キャラクタ・セットに変換します。
SELECT TO_NCHAR(ORDER_DATE) AS order_date FROM ORDERS WHERE ORDER_STATUS > 9 ORDER BY order_date; ORDER_DATE -------------------------------------------------------------------------- 06-DEC-99 02.22.34.225609 PM 13-SEP-99 10.19.00.654279 AM 14-SEP-99 09.53.40.223345 AM 26-JUN-00 10.19.43.190089 PM 27-JUN-00 09.53.32.335522 PM

TO_NCHAR(数値)は、nを各国語キャラクタ・セットの文字列に変換します。n値には、NUMBER、BINARY_FLOATまたはBINARY_DOUBLE型の値を指定できます。このファンクションは、引数と同じ型の値を戻します。オプションのfmt、nに対応する'nlsparam'は、DATE、TIMESTAMP、TIMESTAMP WITH TIME ZONE、TIMESTAMP WITH LOCAL TIME ZONE、INTERVAL MONTH TO YEARまたはINTERVAL DAY TO SECONDデータ型です。
次の例では、oe.ordersサンプル表のcustomer_id値を各国語キャラクタ・セットに変換します。
SELECT TO_NCHAR(customer_id) "NCHAR_Customer_ID" FROM orders WHERE order_status > 9 ORDER BY "NCHAR_Customer_ID"; NCHAR_Customer_ID ---------------------------------------- 102 103 148 148 149
TO_NCLOBは、LOB列またはその他の文字列のCLOB値をNCLOB値に変換します。charは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。Oracle Databaseは、charのキャラクタ・セットをデータベース・キャラクタ・セットから各国語キャラクタ・セットに変換することによって、このファンクションを実行します。
次の例では、TO_NCLOBファンクションでデータを変換後、pm.print_media表のNCLOB列に文字データを挿入します。
INSERT INTO print_media (product_id, ad_id, ad_fltextn) VALUES (3502, 31001, TO_NCLOB('Placeholder for new product description'));

TO_NUMBERは、exprを、NUMBERデータ型の値に変換します。exprには、BINARY_DOUBLE値、またはオプションの書式モデルfmtによって指定された書式の数値を含むCHAR、VARCHAR2、NCHAR、NVARCHAR2データ型の値を指定できます。
BINARY_FLOATのexprを指定できます。ただし、浮動小数点はその内部表示によってのみ解釈されるため、この指定は意味がありません。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、文字列データを数値に変換します。
UPDATE employees SET salary = salary + TO_NUMBER('100.00', '9G999D99') WHERE last_name = 'Perkins';
このファンクションの'nlsparam'引数は、数値変換のTO_CHARファンクションの場合と同じ用途に使用されます。詳細は、「TO_CHAR(数値)」を参照してください。
SELECT TO_NUMBER('-AusDollars100','L9G999D99', ' NLS_NUMERIC_CHARACTERS = '',.'' NLS_CURRENCY = ''AusDollars'' ') "Amount" FROM DUAL; Amount ---------- -100

TO_SINGLE_BYTEは、マルチバイト文字を、対応するシングルバイト文字に変換してcharを戻します。charのデータ型は、CHAR、VARCHAR2、NCHARまたはNVARCHAR2です。戻り値は、charと同じデータ型です。
char内に同等のシングルバイト文字がないマルチバイト文字は、マルチバイト文字として出力されます。このファンクションは、ご使用のデータベース・キャラクタ・セットに、シングルバイト文字およびマルチバイト文字の両方が含まれている場合にのみ有効です。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、UTF8のマルチバイトAからシングルバイトのASCIIのAへの変換を示します。
SELECT TO_SINGLE_BYTE( CHR(15711393)) FROM DUAL; T - A

TO_TIMESTAMPは、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型のcharを、TIMESTAMPデータ型の値に変換します。
オプションのfmtは、charの書式を指定します。fmtを指定しない場合、charはデフォルト書式のTIMESTAMPデータ型である必要があります。このデータ型は、NLS_TIMESTAMP_FORMAT初期化パラメータによって決まります。オプションの'nlsparam'引数は、日付変換のTO_CHARファンクションの場合と同じ用途で使用されます。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、文字列をタイムスタンプに変換します。文字列がデフォルトのTIMESTAMP書式ではないため、書式マスクを指定する必要があります。
SELECT TO_TIMESTAMP ('10-Sep-02 14:10:10.123000', 'DD-Mon-RR HH24:MI:SS.FF') FROM DUAL; TO_TIMESTAMP('10-SEP-0214:10:10.123000','DD-MON-RRHH24:MI:SS.FF') --------------------------------------------------------------------------- 10-SEP-02 02.10.10.123000000 PM
|
参照:
デフォルトの |

TO_TIMESTAMP_TZは、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型のcharを、TIMESTAMP WITH TIME ZONEデータ型の値に変換します。
オプションのfmtは、charの書式を指定します。fmtを指定しない場合、charはデフォルト書式のTIMESTAMP WITH TIME ZONEデータ型である必要があります。オプションの'nlsparam'は、日付変換のTO_CHARファンクションの場合と同じ用途で使用されます。
次の例では、文字列をTIMESTAMP WITH TIME ZONE値に変換します。
SELECT TO_TIMESTAMP_TZ('1999-12-01 11:00:00 -8:00', 'YYYY-MM-DD HH:MI:SS TZH:TZM') FROM DUAL; TO_TIMESTAMP_TZ('1999-12-0111:00:00-08:00','YYYY-MM-DDHH:MI:SSTZH:TZM') -------------------------------------------------------------------- 01-DEC-99 11.00.00.000000000 AM -08:00
次の例では、サンプル表oe.order_itemsおよびoe.ordersを使用して、UNION演算のNULL列をTIMESTAMP WITH LOCAL TIME ZONEとしてキャストします。
SELECT order_id, line_item_id, CAST(NULL AS TIMESTAMP WITH LOCAL TIME ZONE) order_date FROM order_items UNION SELECT order_id, to_number(null), order_date FROM orders; ORDER_ID LINE_ITEM_ID ORDER_DATE ---------- ------------ ----------------------------------- 2354 1 2354 2 2354 3 2354 4 2354 5 2354 6 2354 7 2354 8 2354 9 2354 10 2354 11 2354 12 2354 13 2354 14-JUL-00 05.18.23.234567 PM 2355 1 2355 2 ...
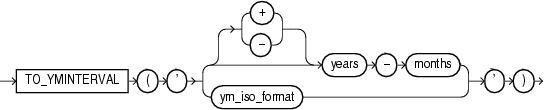
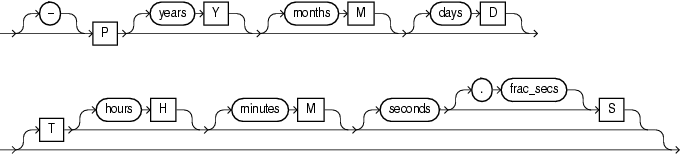
TO_YMINTERVALは、CHAR、VARCHAR2、NCHARまたはNVARCHAR2データ型の文字列を、INTERVAL YEAR TO MONTH型に変換します。
TO_YMINTERVALは、2つの書式のいずれかの引数を取ります。
SQL書式では、yearsは0(ゼロ)〜999999999の整数、monthsは0(ゼロ)〜11の整数になります。これ以外に、書式要素の間に空白を使用できます。
ISO書式では、yearsとmonthsは、0(ゼロ)〜999999999の整数になります。Days、hours、minutes、secondsおよびfrac_secsは、負でない整数になります。負の整数を指定した場合は、無視されます。値に空白は使用できません。
次の例では、サンプル表hr.employeesの各従業員の雇用された後から1年と2か月後の日付を計算します。
SELECT hire_date, hire_date + TO_YMINTERVAL('01-02') "14 months" FROM employees; HIRE_DATE 14 months --------- --------- 17-JUN-87 17-AUG-88 21-SEP-89 21-NOV-90 13-JAN-93 13-MAR-94 03-JAN-90 03-MAR-91 21-MAY-91 21-JUL-92 . . .
TRANSLATEは、from_string内のすべての文字をto_string内の対応する文字に置換してexprを戻します。from_string内に存在しないexpr内の文字は置換されません。引数from_stringには、to_stringより多い文字を指定できます。この場合、from_stringの終わりにある余分な文字には、to_string内に対応する文字がありません。これらの余分な文字がexpr内にある場合、それらの文字は戻り値から削除されます。
from_string内に1つの文字が複数回現れた場合は、最初の出現に対応するto_stringマッピングが使用されます。
戻り値からfrom_string内のすべての文字を削除するために、to_stringに空の文字列を使用することはできません。Oracle Databaseは空の文字列をNULLと解析するため、このファンクションにNULLの引数がある場合、NULLが戻されます。from_string内の文字をすべて削除するには、from_stringの先頭に別の文字を結合し、この文字をto_stringとして指定します。たとえば、TRANSLATE( expr, 'x0123456789', 'x')では、すべての数字がexprから削除されます。
TRANSLATEは、REPLACEファンクションに関連する機能を提供します。REPLACEファンクションでは、単一の文字列から別の単一の文字列への置換、および文字列の削除を実行できます。TRANSLATEでは、1回の操作で複数の単一文字を1対1で置き換えることができます。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の文は、本のタイトルを、ファイル名などに使用するために文字列に変換します。from_stringには、空白、アスタリスク、スラッシュおよびアポストロフィの4つの文字(およびエスケープ文字のアポストロフィ)が含まれています。to_stringには、3つのアンダースコアのみが含まれています。from_stringの4つ目の文字に対応する置換文字がないため、戻り値ではアポストロフィが削除されています。
SELECT TRANSLATE('SQL*Plus User''s Guide', ' */''', '___') FROM DUAL; TRANSLATE('SQL*PLUSU -------------------- SQL_Plus_Users_Guide
TRANSLATE ... USINGは、charをデータベース・キャラクタ・セットと各国語キャラクタ・セット間の変換に指定されたキャラクタ・セットに変換します。
引数charは変換する式です。
USING CHAR_CS引数を指定すると、charがデータベース・キャラクタ・セットに変換されます。出力データ型はVARCHAR2です。
USING NCHAR_CS引数を指定すると、charが各国語キャラクタ・セットに変換されます。出力データ型はNVARCHAR2です。
このファンクションは、OracleのCONVERTファンクションに似ていますが、入力または出力のデータ型にNCHARまたはNVARCHAR2を使用する場合は、CONVERTではなくこのファンクションを使用する必要があります。入力にUCS2コードポイントまたはバックスラッシュ(\)が含まれる場合は、UNISTRファンクションを使用してください。
次の文は、サンプル表oe.product_descriptionsのデータを使用して、TRANSLATE ... USINGファンクションの使用方法を示しています。
CREATE TABLE translate_tab (char_col VARCHAR2(100), nchar_col NVARCHAR2(50)); INSERT INTO translate_tab SELECT NULL, translated_name FROM product_descriptions WHERE product_id = 3501; SELECT * FROM translate_tab; CHAR_COL NCHAR_COL -------------------- -------------------------------------------------- . . . C pre SPNIX4.0 - Sys C pro SPNIX4.0 - Sys C til SPNIX4.0 - Sys C voor SPNIX4.0 - Sys . . . UPDATE translate_tab SET char_col = TRANSLATE (nchar_col USING CHAR_CS); SELECT * FROM translate_tab; CHAR_COL NCHAR_COL ------------------------- ------------------------- . . . C per a SPNIX4.0 - Sys C per a SPNIX4.0 - Sys C pro SPNIX4.0 - Sys C pro SPNIX4.0 - Sys C for SPNIX4.0 - Sys C for SPNIX4.0 - Sys C til SPNIX4.0 - Sys C til SPNIX4.0 - Sys . . .

TREATは式の宣言型を変更します。
このファンクションを使用する場合は、typeに対するEXECUTEオブジェクト権限が必要です。
typeは、スーパータイプまたはexprの宣言型のサブタイプである必要があります。exprの最も指定される型がtype(またはtypeのサブタイプ)である場合、TREATはexprを戻します。exprの最も指定される型がtype(またはtypeのサブタイプ)ではない場合、TREATはNULLを戻します。
exprの宣言型がREF型の場合にのみ、REFを指定できます。
exprの宣言型がexprのソース型へのREFである場合、typeはサブタイプまたはexprのソース型のスーパータイプである必要があります。DEREF(expr)の最も指定される型がtype(またはtypeのサブタイプ)である場合、TREATはexprを戻します。DEREF(expr)の最も指定される型がtype(またはtypeのサブタイプ)ではない場合、TREATはNULLを戻します。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、「置換可能な表および列のサンプル:」で作成された表oe.personsを使用します。次の例では、persons表のすべての人物の給与属性を検索します。従業員ではない人物のインスタンスの値はNULLです。
SELECT name, TREAT(VALUE(p) AS employee_t).salary salary FROM persons p; NAME SALARY ------------------------- ---------- Bob Joe 100000 Tim 1000
TREATファンクションを使用すると、置換可能列のサブタイプ属性に索引を作成できます。「置換可能な列の索引の作成例:」を参照してください。
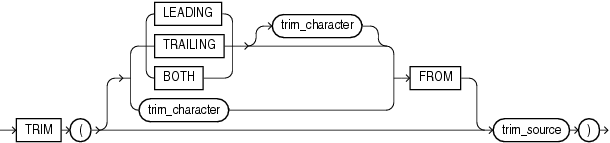
TRIMによって、文字列の先行または後続文字(またはその両方)を切り捨てることができます。trim_characterまたはtrim_sourceが文字リテラルの場合、一重引用符で囲む必要があります。
LEADINGを指定すると、Oracle Databaseはtrim_characterと等しい先行文字を削除します。
TRAILINGを指定すると、Oracleはtrim_characterと等しい後続文字を削除します。
BOTHを指定するか、またはいずれも指定しない場合、Oracleはtrim_characterと等しい先行および後続文字を削除します。
trim_characterを指定しないと、デフォルト値は空白になります。
trim_sourceのみを指定すると、Oracleは先行および後続空白を削除します。
VARCHAR2データ型で戻します。値の最大長は、trim_sourceの長さです。
trim_sourceまたはtrim_characterのいずれかがNULLの場合、TRIMはNULLを戻します。
trim_characterとtrim_sourceは両方とも、VARCHAR2またはVARCHAR2に暗黙的に変換できる任意のデータ型です。戻される文字列は、trim_sourceが文字データ型の場合はVARCHAR2データ型になり、trim_sourceがLOBデータ型の場合はLOBになります。trim_sourceと同じキャラクタ・セットの文字列が戻されます。
次の例では、hrスキーマの従業員の雇用日から先行0(ゼロ)を切り捨てます。
SELECT employee_id, TO_CHAR(TRIM(LEADING 0 FROM hire_date)) FROM employees WHERE department_id = 60 ORDER BY employee_id; EMPLOYEE_ID TO_CHAR(T ----------- --------- 103 3-JAN-90 104 21-MAY-91 105 25-JUN-97 106 5-FEB-98 107 7-FEB-99
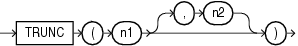
TRUNC(数値)ファンクションは、n1を小数第n2位までに切り捨てた値を戻します。n2を指定しない場合、n1の小数点以下を切り捨てます。n2が負の場合は、小数点の左n2桁を切り捨てて、0(ゼロ)にします。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。n2を指定しない場合、このファンクションは、引数の数値データ型と同じデータ型を戻します。n2を指定すると、このファンクションはNUMBERを戻します。
次の例では、数値を切り捨てます。
SELECT TRUNC(15.79,1) "Truncate" FROM DUAL; Truncate ---------- 15.7 SELECT TRUNC(15.79,-1) "Truncate" FROM DUAL; Truncate ---------- 10

TRUNC(日付)ファンクションは、時刻部分を書式モデルfmtで指定された単位まで切り捨てたdateを戻します。このファンクションは、NLS_CALENDARセッション・パラメータの影響を受けません。このファンクションはグレゴリオ暦の規則に従って動作します。戻される値は、dateに異なる日時データ型を指定した場合でも、常にDATEデータ型です。fmtを省略すると、dateは最も近い日に切り捨てられます。fmtで使用できる書式モデルについては、「ROUNDおよびTRUNC日付ファンクション」を参照してください。
次の例では、日付を切り捨てます。
SELECT TRUNC(TO_DATE('27-OCT-92','DD-MON-YY'), 'YEAR') "New Year" FROM DUAL; New Year --------- 01-JAN-92
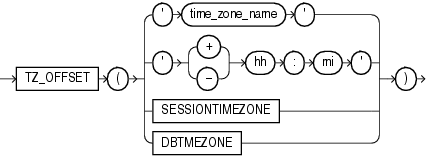
TZ_OFFSETは、文が実行された日付に基づいた引数に対応するタイムゾーン・オフセットを戻します。有効なタイムゾーン名、UTCからのタイムゾーン・オフセット(それ自体を戻します)、またはキーワードSESSIONTIMEZONEまたはDBTIMEZONEを入力できます。time_zone_nameの有効な値を表示するには、V$TIMEZONE_NAMES動的パフォーマンス・ビューのTZNAME列を問い合せます。
次の例では、UTCからUS/東部タイムゾーンのタイムゾーン・オフセットを戻します。
SELECT TZ_OFFSET('US/Eastern') FROM DUAL; TZ_OFFS ------- -04:00

UIDは、セッション・ユーザー(ログインしているユーザー)を一意に識別する整数を戻します。
次の例では、現行のユーザーのUIDを戻します。
SELECT UID FROM DUAL;
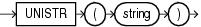
UNISTRは、引数としてテキスト・リテラルまたは文字データに変換する式を取り、各国語キャラクタ・セットで戻します。データベースの各国語キャラクタ・セットは、AL16UTF16またはUTF8です。UNISTRでは、文字列への文字のUnicodeエンコーディング値の指定を可能にすることによって、Unicode文字列リテラルがサポートされます。これは、NCHAR列にデータを挿入する場合などに有効です。
Unicodeエンコーディング値は、\xxxxという形式です。xxxxは、文字のUCS-2エンコーディング形式での16進数値です。付加される文字は2つのコード単位としてエンコードされます。1つ目は高サロゲート範囲(U+D800〜U+DBFF)からエンコードされ、2つ目は低サロゲート範囲(U+DC00〜U+DFFF)からエンコードされます。バックスラッシュ自体を文字列に含めるには、バックスラッシュをもう1つ追加します(\\)。
移植性およびデータ保護のために、UNISTR文字列の引数にはASCII文字およびUnicodeエンコーディング値のみを指定することをお薦めします。
次の例では、ASCII文字およびUnicodeエンコーディング値をUNISTRファンクションに渡した後、そのUNISTRファンクションによって各国語キャラクタ・セットで文字列が戻されます。
SELECT UNISTR('abc\00e5\00f1\00f6') FROM DUAL; UNISTR ------ abcåñö
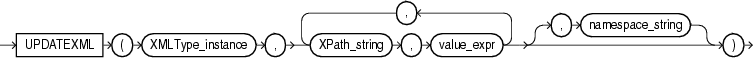
UPDATEXMLは、引数としてXMLTypeインスタンスおよびXPath値の組を取り、更新された値を持つXMLTypeインスタンスを戻します。XPath_stringがXML要素の場合、対応するvalue_exprはXMLTypeインスタンスです。XPath_stringが属性またはテキスト・ノードの場合、value_exprは任意のスカラー・データ型となります。先頭にスラッシュを付けて絶対XPath_stringを指定したり、先頭のスラッシュを省略して相対XPath_stringを指定できます。先頭のスラッシュを省略した場合、相対パスのコンテキストは、デフォルトでルート・ノードに設定されます。
各XPath_stringおよびこれに対応するvalue_exprのターゲットのデータ型は一致する必要があります。オプションのnamespace_stringは、接頭辞のデフォルト・マッピングまたはネームスペース・マッピング(Oracle DatabaseがXPath式を評価する場合に使用)を指定するVARCHAR2値に解決される必要があります。
XML要素を更新してNULLにした場合、属性および子要素が削除されるため、要素は空になります。要素のテキスト・ノードを更新してNULLにした場合、その要素のテキスト値が削除されるため、要素自体は残りますが空になります。
多くの場合、このファンクションはメモリー内のXML文書を実体化して、その値を更新します。ただし、UPDATEXMLは、直接オブジェクト・リレーショナル列の値を更新するように、その列でのUPDATE文に対して最適化されます。この最適化には、次の条件があります。
次の例では、サンプル・スキーマOE(XMLType型のwarehouse_spec列を持つ)にあるSan Francisco倉庫のドック数を4に更新します。
SELECT warehouse_name, EXTRACT(warehouse_spec, '/Warehouse/Docks') "Number of Docks" FROM warehouses WHERE warehouse_name = 'San Francisco'; WAREHOUSE_NAME Number of Docks -------------------- -------------------- San Francisco <Docks>1</Docks> UPDATE warehouses SET warehouse_spec = UPDATEXML(warehouse_spec, '/Warehouse/Docks/text()',4) WHERE warehouse_name = 'San Francisco'; 1 row updated. SELECT warehouse_name, EXTRACT(warehouse_spec, '/Warehouse/Docks') "Number of Docks" FROM warehouses WHERE warehouse_name = 'San Francisco'; WAREHOUSE_NAME Number of Docks -------------------- -------------------- San Francisco <Docks>4</Docks>
UPPERは、すべての文字を大文字にしてcharを戻します。charは、CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOBまたはNCLOBデータ型です。戻り値は、charと同じデータ型です。データベースは、基礎となるキャラクタ・セットに対して定義したバイナリ・マッピングに基づいて文字の形式を設定します。大文字の区別については、「NLS_UPPER」を参照してください。
次の例では、各従業員の姓を大文字で戻します。
SELECT UPPER(last_name) "Uppercase" FROM employees;

USERは、セッション・ユーザー(ログインしているユーザー)の名前をVARCHAR2データ型で戻します。Oracle Databaseは、空白埋め比較セマンティクスでこのファンクションの値を比較します。
分散SQL文では、UIDファンクションおよびUSERファンクションは、ローカル・データベース上のユーザーを識別します。CHECK制約の条件でこれらのファンクションは使用できません。
次の例では、現行のユーザーおよびユーザーのUIDを戻します。
SELECT USER, UID FROM DUAL;
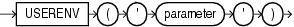
|
注意:
|
USERENVは現行のセッションについての情報を戻します。この情報は、アプリケーション固有の監査証跡表を書き込む場合、またはセッションで現在使用されている言語固有の文字を判断する場合に有効です。CHECK制約の条件で、USERENVは使用できません。表5-13に、parameter引数の値を示します。
SESSIONIDおよびENTRYIDパラメータを使用するコール(NUMBERを戻す)以外のUSERENVへのすべてのコールは、VARCHAR2データを戻します。
| パラメータ | 戻り値 |
|---|---|
|
|
注意: 商業用のアプリケーションによっては、このコンテキスト値を使用する可能性があります。このコンテキスト領域の使用に対する制限については、これらのアプリケーションのドキュメントを参照してください。 参照:
|
|
|
現行の監査エントリ番号を戻します。監査エントリIDの順序は、ファイングレイン監査レコードと通常の監査レコードで共通です。この属性を分散SQL文で使用することはできません。 |
|
|
|
|
|
言語名のISO略称を戻します。これは、既存の' |
|
|
現行のセッションで使用している言語(language)および地域(territory)を、データベース・キャラクタ・セット(character set)も含めた次の書式で戻します。 language_territory.characterset |
|
|
監査セッション識別子を戻します。この属性を分散SQL文で使用することはできません。 |
|
|
現行のセッションの端末に対するオペレーティング・システム識別子を戻します。分散SQL文では、このパラメータはローカル・セッションの識別子を戻します。分散環境では、リモートの |
次の例では、現行のセッションのLANGUAGEパラメータを戻します。
SELECT USERENV('LANGUAGE') "Language" FROM DUAL; Language ----------------------------------- AMERICAN_AMERICA.WE8ISO8859P1

VALUEは、引数としてオブジェクト表の行に関連付けられた相関変数(表別名)を取り、オブジェクト表に格納されたオブジェクト・インスタンスを戻します。オブジェクト・インスタンスの型は、オブジェクト表と同じ型です。
次の例では、「置換可能な表および列のサンプル:」で作成されたoe.personsサンプル表を使用します。
SELECT VALUE(p) FROM persons p; VALUE(P)(NAME, SSN) ------------------------------------------------------------- PERSON_T('Bob', 1234) EMPLOYEE_T('Joe', 32456, 12, 100000) PART_TIME_EMP_T('Tim', 5678, 13, 1000, 20)

VAR_POPは、数値の集合にあるNULLを削除した後、この集合の母集団分散を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
ファンクションが空の集合に適用されると、NULLを戻します。このファンクションは、次の計算を行います。
(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / COUNT(expr)
次の例では、employees表にある給与の人口分散を計算します。
SELECT VAR_POP(salary) FROM employees; VAR_POP(SALARY) --------------- 15140307.5
次の例では、sh.sales表での1998年における月ごとの売上について、累積の母集団および標本分散を計算します。
SELECT t.calendar_month_desc, VAR_POP(SUM(s.amount_sold)) OVER (ORDER BY t.calendar_month_desc) "Var_Pop", VAR_SAMP(SUM(s.amount_sold)) OVER (ORDER BY t.calendar_month_desc) "Var_Samp" FROM sales s, times t WHERE s.time_id = t.time_id AND t.calendar_year = 1998 GROUP BY t.calendar_month_desc ORDER BY t.calendar_month_desc, "Var_Pop", "Var_Samp"; CALENDAR Var_Pop Var_Samp -------- ---------- ---------- 1998-01 0 1998-02 2269111326 4538222653 1998-03 5.5849E+10 8.3774E+10 1998-04 4.8252E+10 6.4336E+10 1998-05 6.0020E+10 7.5025E+10 1998-06 5.4091E+10 6.4909E+10 1998-07 4.7150E+10 5.5009E+10 1998-08 4.1345E+10 4.7252E+10 1998-09 3.9591E+10 4.4540E+10 1998-10 3.9995E+10 4.4439E+10 1998-11 3.6870E+10 4.0558E+10 1998-12 4.0216E+10 4.3872E+10

VAR_SAMPは、数値の集合にあるNULLを削除した後、この集合の標本分散を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
ファンクションが空の集合に適用されると、NULLを戻します。このファンクションは、次の計算を行います。
(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / (COUNT(expr) - 1)
このファンクションは、1つの要素の集合を入力するとVARIANCEは0を戻し、VAR_SAMPはNULLを戻すという点を除いては、VARIANCEに似ています。
次の例では、サンプル表employeesにある給与の標本分散を計算します。
SELECT VAR_SAMP(salary) FROM employees; VAR_SAMP(SALARY) ---------------- 15283140.5
「VAR_POP」の分析の例を参照してください。
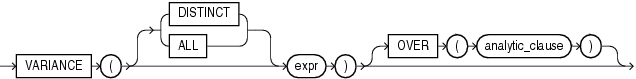
VARIANCEはexprの分散を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
exprの分散の計算結果は、次のようになります。
DISTINCTを指定する場合は、analytic_clauseのquery_partition_clauseのみ指定できます。order_by_clauseおよびwindowing_clauseは指定できません。
このファンクションは、引数として、任意の数値データ型、または暗黙的に数値データ型に変換可能な数値以外のデータ型を取ります。また、引数の数値データ型と同じデータ型を戻します。
次の例では、サンプル表employeesにあるすべての給与の合計を計算します。
SELECT VARIANCE(salary) "Variance" FROM employees; Variance ---------- 15283140.5
次の例では、雇用日で順序付けられた部門30の給与の値の累積分散を戻します。
SELECT last_name, salary, VARIANCE(salary) OVER (ORDER BY hire_date) "Variance" FROM employees WHERE department_id = 30 ORDER BY last_name, salary, "Variance"; LAST_NAME SALARY Variance ------------------------- ---------- ---------- Baida 2900 16283333.3 Colmenares 2500 11307000 Himuro 2600 13317000 Khoo 3100 31205000 Raphaely 11000 0 Tobias 2800 21623333.3
VSIZEは、exprの内部表現でのバイト数を戻します。exprがNULLの場合はNULLを戻します。
このファンクションは、CLOBデータを直接的にサポートしていません。ただし、暗黙的なデータ変換を使用してCLOBを引数として渡すことはできます。
次の例では、部門10の従業員のlast_name列のバイト数を戻します。
SELECT last_name, VSIZE (last_name) "BYTES" FROM employees WHERE department_id = 10 ORDER BY employee_id; LAST_NAME BYTES --------------- ---------- Whalen 6

WIDTH_BUCKETを使用すると、ヒストグラムの幅が同じサイズに分割された等幅ヒストグラムを作成できます。このファンクションと、等高ヒストグラムを作成するNTILEを比較してください。各バケットが実際の数値線幅のclosed-open間隔であることが理想です。たとえば、間隔に10が含まれ20が排除されることを示すために、バケットは10.00〜19.999...のスコアに割り当てられます。これは、[10, 20]と表すこともできます。
指定された式に対して、WIDTH_BUCKETは、この式の値が評価された後に該当するバケット数を戻します。
exprは、ヒストグラムが作成される式です。この式は、数値または日時値、あるいは数値または日時値に暗黙的に変換可能な値に評価される必要があります。exprがNULLと評価された場合、式はNULLを戻します。
min_valueおよびmax_valueは、exprの許容域のエンド・ポイントに解決される式です。これらの式は両方とも数値または日時値に評価される必要があり、いずれもNULLに評価されません。
num_bucketsは、バケット数を示す定数に解決される式です。この式は、正の整数に評価される必要があります。Oracle Databaseは、必要に応じて、0(ゼロ)の下位バケットおよびnum_buckets+1の上位バケットを作成します。これらのバケットは、min_value未満およびmax_valueより大きい値を処理し、エンド・ポイントの妥当性チェックに有効です。
次の例では、サンプル表oe.customersのスイスの顧客のcredit_limit列に10バケットのヒストグラムを作成し、各顧客のバケット数(「クレジット・グループ」)を戻します。最大値を超えるクレジット利用限度額を持つ顧客は、上位バケット11に割り当てられます。
SELECT customer_id, cust_last_name, credit_limit, WIDTH_BUCKET(credit_limit, 100, 5000, 10) "Credit Group" FROM customers WHERE nls_territory = 'SWITZERLAND' ORDER BY "Credit Group", customer_id, cust_last_name, credit_limit; CUSTOMER_ID CUST_LAST_NAME CREDIT_LIMIT Credit Group ----------- -------------------- ------------ ------------ 825 Dreyfuss 500 1 826 Barkin 500 1 827 Siegel 500 1 853 Palin 400 1 843 Oates 700 2 844 Julius 700 2 835 Eastwood 1200 3 836 Berenger 1200 3 837 Stanton 1200 3 840 Elliott 1400 3 841 Boyer 1400 3 842 Stern 1400 3 848 Olmos 1800 4 849 Kaurusmdki 1800 4 828 Minnelli 2300 5 829 Hunter 2300 5 850 Finney 2300 5 851 Brown 2300 5 852 Tanner 2300 5 830 Dutt 3500 7 831 Bel Geddes 3500 7 832 Spacek 3500 7 833 Moranis 3500 7 834 Idle 3500 7 838 Nicholson 3500 7 839 Johnson 3500 7 845 Fawcett 5000 11 846 Brando 5000 11 847 Streep 5000 11

XMLAGGは集計ファンクションです。XMLフラグメントのコレクションを取り、集計されたXML文書を戻します。NULLを戻す引数は結果から排除されます。
XMLAGGは、ノードのコレクションを戻す点を除いて、SYS_XMLAGGに似ていますが、XMLFormatオブジェクトを使用した書式設定は受け入れません。また、XMLAGGは、SYS_XMLAGGとは異なり、出力を要素タグで囲みません。
このorder_by_clauseにかぎり、他の使用方法とは異なり、数値リテラルは列の位置として認識されず、単に数値リテラルとして解釈されます。
次の例では、従業員のジョブIDと姓を要素の内容とするEmployee要素を含むDepartment要素を生成します。
SELECT XMLELEMENT("Department", XMLAGG(XMLELEMENT("Employee", e.job_id||' '||e.last_name) ORDER BY last_name)) as "Dept_list" FROM employees e WHERE e.department_id = 30; Dept_list ------------------------------------------------------------- <Department> <Employee>PU_CLERK Baida</Employee> <Employee>PU_CLERK Colmenares</Employee> <Employee>PU_CLERK Himuro</Employee> <Employee>PU_CLERK Khoo</Employee> <Employee>PU_MAN Raphaely</Employee> <Employee>PU_CLERK Tobias</Employee> </Department>
XMLAGGが行を集計するため、結果は単一行となります。GROUP BY句を使用して、戻された行の集合を複数のグループにまとめることができます。
SELECT XMLELEMENT("Department", XMLAGG(XMLELEMENT("Employee", e.job_id||' '||e.last_name))) AS "Dept_list" FROM employees e GROUP BY e.department_id; Dept_list --------------------------------------------------------- <Department> <Employee>AD_ASST Whalen</Employee> </Department> <Department> <Employee>MK_MAN Hartstein</Employee> <Employee>MK_REP Fay</Employee> </Department> <Department> <Employee>PU_MAN Raphaely</Employee> <Employee>PU_CLERK Khoo</Employee> <Employee>PU_CLERK Tobias</Employee> <Employee>PU_CLERK Baida</Employee> <Employee>PU_CLERK Colmenares</Employee> <Employee>PU_CLERK Himuro</Employee> </Department> . . .

XMLCastは、value_expressionをdatatypeで指定されたスカラーSQLデータ型にキャストします。value_expression引数は、評価されるSQL式です。datatype引数のデータ型は、NUMBER、VARCHAR2、および任意の日時データ型です。
XMLCDataは、value_exprを評価してCDATAセクションを生成します。value_exprは文字列に変換する必要があります。このファンクションの戻り値は、次の書式になります。
<![CDATA[string]]>
結果値が無効なXML CDATAセクションの場合は、エラーが戻されます。
次の条件がXMLCDataに適用されます。
次の文は、DUAL表を使用して、XMLCDataの構文を示します。
SELECT XMLELEMENT("PurchaseOrder", XMLAttributes(dummy as "pono"), XMLCdata('<!DOCTYPE po_dom_group [ <!ELEMENT po_dom_group(student_name)*> <!ELEMENT po_purch_name (#PCDATA)> <!ATTLIST po_name po_no ID #REQUIRED> <!ATTLIST po_name trust_1 IDREF #IMPLIED> <!ATTLIST po_name trust_2 IDREF #IMPLIED> ]>')) "XMLCData" FROM DUAL; XMLCData ---------------------------------------------------------- <PurchaseOrder pono="X"><![CDATA[ <!DOCTYPE po_dom_group [ <!ELEMENT po_dom_group(student_name)*> <!ELEMENT po_purch_name (#PCDATA)> <!ATTLIST po_name po_no ID #REQUIRED> <!ATTLIST po_name trust_1 IDREF #IMPLIED> <!ATTLIST po_name trust_2 IDREF #IMPLIED> ]> ]]> </PurchaseOrder>

XMLCOLATTVALは、XMLフラグメントを作成し、各XMLフラグメントの名前がcolumn、属性がnameとなるように、結果としてできたXMLを展開します。
AS句を使用して、name属性の値を列名以外の値に変更できます。この場合、文字列リテラルのc_aliasを指定するか、またはEVALNAME value_exprを指定します。後者の場合は、値の式が評価され、その結果(文字列リテラル)が別名として使用されます。別名は、最大4000文字まで指定可能です。
value_exprの値を指定する必要があります。value_exprがNULLの場合、要素は戻されません。
value_exprにオブジェクト型の列を指定することはできません。
次の例では、従業員のサブセットに対してEmp要素を作成します。このとき、Empの内容として、employee_id、last_nameおよびsalaryの各要素がネストされます。ネストされた各要素にはcolumnという名前が付き、属性値として列名を持つname属性が与えられます。
SELECT XMLELEMENT("Emp", XMLCOLATTVAL(e.employee_id, e.last_name, e.salary)) "Emp Element" FROM employees e WHERE employee_id = 204; Emp Element -------------------------------------------------------------------- <Emp> <column name="EMPLOYEE_ID">204</column> <column name="LAST_NAME">Baer</column> <column name="SALARY">10000</column> </Emp>
これらの2つのファンクションの出力の比較については、「XMLFOREST」を参照してください。
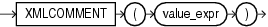
XMLCommentは、value_exprの評価結果を使用してXMLコメントを生成します。value_exprは文字列に変換する必要があります。このファンクションには、2つの連続したダッシュ(ハイフン)を含めることはできません。このファンクションの戻り値は、次の書式になります。
<!--string-->
value_exprがNULLである場合、このファンクションはNULLを戻します。
次の例は、DUAL表を使用して、XMLComment構文を示します。
SELECT XMLCOMMENT('OrderAnalysisComp imported, reconfigured, disassembled') AS "XMLCOMMENT" FROM DUAL; XMLCOMMENT -------------------------------------------------------------------------------- <!--OrderAnalysisComp imported, reconfigured, disassembled-->

XMLCONCATは、入力として一連のXMLTypeインスタンスを取り、各行について一連の要素を連結し、連結した結果を戻します。XMLCONCATはXMLSEQUENCEの逆の処理をします。
NULL式は結果から排除されます。値のすべての式がNULLの場合、このファンクションはNULLを戻します。
次の例では、従業員のサブセットの名前と姓に対してXML要素を作成し、作成した要素を連結して戻します。
SELECT XMLCONCAT(XMLELEMENT("First", e.first_name), XMLELEMENT("Last", e.last_name)) AS "Result" FROM employees e WHERE e.employee_id > 202; Result ---------------------------------------------------------------- <First>Susan</First> <Last>Mavris</Last> <First>Hermann</First> <Last>Baer</Last> <First>Shelley</First> <Last>Higgins</Last> <First>William</First> <Last>Gietz</Last> 4 rows selected.

XMLDiffファンクションは、XmlDiff C APIのSQLインタフェースです。このファンクションは、2つのXML文書を比較し、Xdiffスキーマに基づいたXMLの差異を取得します。diff文書がXMLType文書として戻されます。
integerには、CファンクションXmlDiffのhashLevelを表す数値を指定します。ハッシュを使用しない場合は、この引数を0(ゼロ)に設定するか、または引数全体を省略します。ハッシュを使用しないでフラグを指定する場合は、この引数を0(ゼロ)に設定する必要があります。
stringには、ファンクションの動作を制御するフラグを指定します。これらのフラグは、セミコロンで区切られた1つ以上の名前で指定します。これらの名前は、XmlDiffファンクションの定数の名前と同じです。次の例では、2つのXML文書を比較し、差異をXMLType文書として戻します。
SELECT XMLDIFF( XMLTYPE('<?xml version="1.0"?> <bk:book xmlns:bk="http://nosuchsite.com"> <bk:tr> <bk:td> <bk:chapter> Chapter 1. </bk:chapter> </bk:td> <bk:td> <bk:chapter> Chapter 2. </bk:chapter> </bk:td> </bk:tr> </bk:book>'), XMLTYPE('<?xml version="1.0"?> <bk:book xmlns:bk="http://nosuchsite.com"> <bk:tr> <bk:td> <bk:chapter> Chapter 1. </bk:chapter> </bk:td> <bk:td/> </bk:tr> </bk:book>') ) FROM DUAL;
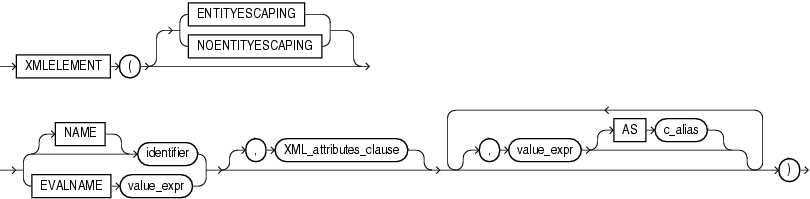
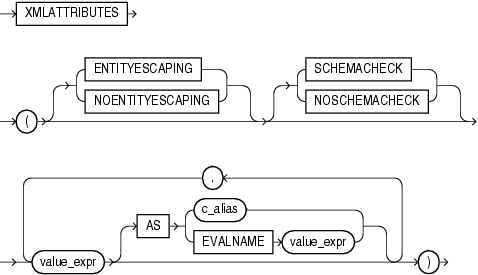
XMLELEMENTは、identifierに対する要素名を取るか、またはEVALNAME value_exprの要素名、要素に対する属性のオプションのコレクション、およびその要素の内容を構成する引数を評価します。このファンクションはXMLType型のインスタンスを戻します。XMLELEMENTは、戻されたXMLに属性を格納できる点を除いてSYS_XMLGENに似ていますが、XMLFormatオブジェクトを使用した書式設定は受け入れません。
次の項に示すとおり、通常は、XMLELEMENTファンクションはネストされており、ネスト構造のXML文書を生成します。
ENTITYESCAPINGおよびNONENTITYESCAPINGキーワードについては、『Oracle XML DB開発者ガイド』を参照してください。
囲みタグに使用するOracle Databaseの値を指定する必要があります。この場合、文字列リテラルのidentifierを指定するか、またはEVALNAME value_exprを指定します。後者の場合は、値の式が評価され、その結果(文字列リテラル)が識別子として使用されます。この識別子は、最大4000文字まで指定可能で、列名または列の参照である必要はありません。式またはNULLは指定できません。
要素の内容を構成するオブジェクトは、XMLATTRIBUTESキーワードの後に指定します。XML_attributes_clauseでは、value_exprがNULLの場合、その値の式に対する属性は作成されません。value_exprの型に、オブジェクト型またはコレクションは指定できません。AS句を使用してvalue_exprに別名を指定すると、c_aliasまたは評価された値の式(EVALNAME value_expr)は、最大4000文字まで指定可能になります。
構文図のXML_attributes_clauseに続くオプションのvalue_exprは、次のようになります。
value_exprがスカラー式である場合、AS句は省略できます。この場合、Oracleは列名を要素名として使用します。
value_exprがオブジェクト型またはコレクションである場合、AS句は必須です。この場合、Oracleは指定されたc_aliasを囲みタグとして使用します。
value_exprがNULLの場合、その値の式に対する要素は作成されません。次の例では、一連の従業員について、従業員の名前と雇用日を指定する、ネストされた要素を持つEmp要素を生成します。
SELECT XMLELEMENT("Emp", XMLELEMENT("Name", e.job_id||' '||e.last_name), XMLELEMENT("Hiredate", e.hire_date)) as "Result" FROM employees e WHERE employee_id > 200; Result ------------------------------------------------------------------- <Emp> <Name>MK_MAN Hartstein</Name> <Hiredate>17-FEB-96</Hiredate> </Emp> <Emp> <Name>MK_REP Fay</Name> <Hiredate>17-AUG-97</Hiredate> </Emp> <Emp> <Name>HR_REP Mavris</Name> <Hiredate>07-JUN-94</Hiredate> </Emp> <Emp> <Name>PR_REP Baer</Name> <Hiredate>07-JUN-94</Hiredate> </Emp> <Emp> <Name>AC_MGR Higgins</Name> <Hiredate>07-JUN-94</Hiredate> </Emp> <Emp> <Name>AC_ACCOUNT Gietz</Name> <Hiredate>07-JUN-94</Hiredate> </Emp> 6 rows selected.
次の例では、XMLELEMENTファンクションにXML_attributes_clauseを使用して、トップレベル要素に対する属性値を持つ、ネストされたXML要素を作成します。
SELECT XMLELEMENT("Emp", XMLATTRIBUTES(e.employee_id AS "ID", e.last_name), XMLELEMENT("Dept", e.department_id), XMLELEMENT("Salary", e.salary)) AS "Emp Element" FROM employees e WHERE e.employee_id = 206; Emp Element --------------------------------------------------------------- <Emp ID="206" LAST_NAME="Gietz"> <Dept>110</Dept> <Salary>8300</Salary> </Emp>
last_nameにはAS identifier句が指定されていません。その結果、戻されたXMLは、デフォルトで列名last_nameを使用します。
最後に、次の例では、XML_attributes_clauseに副問合せを使用して、別の表から要素の属性に情報を取り出します。
SELECT XMLELEMENT("Emp", XMLATTRIBUTES(e.employee_id, e.last_name), XMLELEMENT("Dept", XMLATTRIBUTES(e.department_id, (SELECT d.department_name FROM departments d WHERE d.department_id = e.department_id) as "Dept_name")), XMLELEMENT("salary", e.salary), XMLELEMENT("Hiredate", e.hire_date)) AS "Emp Element" FROM employees e WHERE employee_id = 205; Emp Element ------------------------------------------------------------------- <Emp EMPLOYEE_ID="205" LAST_NAME="Higgins"> <Dept DEPARTMENT_ID="110" Dept_name="Accounting"/> <salary>12000</salary> <Hiredate>07-JUN-94</Hiredate> </Emp>


XMLExistsは、指定されたXQuery式から空でないXQueryシーケンスが戻されるかどうかをチェックします。空でないXQueryシーケンスが戻される場合、このファンクションはTRUEを戻し、それ以外の場合はFALSEを戻します。引数XQuery_stringはリテラル文字列ですが、XML_passing_clauseを使用してバインドするXQuery変数を含めることができます。
XML_passing_clauseのexprは、XMLTypeまたはSQLスカラー・データ型のインスタンスを戻し、XQuery式を評価するためのコンテキストとして使用されます。PASSING句には、識別子を指定せずに1つのexprのみを指定できます。各exprの評価結果は、XQuery_stringの対応する識別子にバインドされます。exprの後にAS句が続かない場合、式の評価結果はXQuery_stringの評価用のコンテキスト項目として使用されます。

XMLFORESTは、各引数パラメータをXMLに変換し、変換された引数を連結したXMLフラグメントを戻します。
value_exprがスカラー式である場合、AS句は省略できます。この場合、Oracle Databaseは列名を要素名として使用します。
value_exprがオブジェクト型またはコレクションである場合、AS句は必須です。この場合、Oracleは指定された式を囲みタグとして使用します。この場合、文字列リテラルのc_aliasを指定するか、またはEVALNAME value_exprを指定します。後者の場合は、値の式が評価され、その結果(文字列リテラル)が識別子として使用されます。この識別子は、最大4000文字まで指定可能で、列名または列の参照である必要はありません。式またはNULLは指定できません。
value_exprがNULLの場合、そのvalue_exprに対する要素は作成されません。
次の例では、従業員のサブセットに対してEmp要素を作成します。このとき、Empの内容として、employee_id、last_nameおよびsalaryの各要素がネストされます。
SELECT XMLELEMENT("Emp", XMLFOREST(e.employee_id, e.last_name, e.salary)) "Emp Element" FROM employees e WHERE employee_id = 204; Emp Element ---------------------------------------------------------------- <Emp> <EMPLOYEE_ID>204</EMPLOYEE_ID> <LAST_NAME>Baer</LAST_NAME> <SALARY>10000</SALARY> </Emp>
これらの2つのファンクションの出力の比較については、「XMLCOLATTVAL」を参照してください。
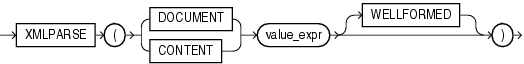
XMLParseは、value_exprの評価結果からXMLインスタンスを解析して生成します。value_exprは文字列に変換する必要があります。value_exprがNULLである場合、このファンクションはNULLを戻します。
DOCUMENTを指定する場合、value_exprは単一ルートのXML文書である必要があります。
CONTENTを指定する場合、value_exprは有効なXML値である必要があります。
WELLFORMEDを指定する場合、value_exprは整形式XML文書である必要があります。これは、入力が正しい書式であることを確認する、データベースによる妥当性チェックが実行されないためです。次の例は、DUAL表を使用して、XMLParseの構文を示します。
SELECT XMLPARSE(CONTENT '124 <purchaseOrder poNo="12435"> <customerName> Acme Enterprises</customerName> <itemNo>32987457</itemNo> </purchaseOrder>' WELLFORMED) AS PO FROM DUAL; PO ----------------------------------------------------------------- 124 <purchaseOrder poNo="12435"> <customerName> Acme Enterprises</customerName> <itemNo>32987457</itemNo> </purchaseOrder>

XMLPatchファンクションは、XmlPatch C APIのSQLインタフェースです。このファンクションは、指定された変更を適用してXML文書を修正します。修正されたXMLType文書が戻されます。
XMLType文書の名前を指定します。2番目の引数には、最初の文書に適用する変更を含むXMLType文書を指定します。変更は、Xdiff XMLスキーマに基づいている必要があります。
stringには、ファンクションの動作を制御するフラグを指定します。これらのフラグは、セミコロンで区切られた1つ以上の名前で指定します。これらの名前は、XmlPatch Cファンクションの定数の名前と同じです。次の例では、別のXMLType文書に指定された変更を適用してXMLType文書を修正し、修正したXMLType文書を戻します。
SELECT XMLPATCH( XMLTYPE('<?xml version="1.0"?> <bk:book xmlns:bk="http://nosuchsite.com"> <bk:tr> <bk:td> <bk:chapter> Chapter 1. </bk:chapter> </bk:td> <bk:td> <bk:chapter> Chapter 2. </bk:chapter> </bk:td> </bk:tr> </bk:book>'), XMLTYPE('<?xml version="1.0"?> <xd:xdiff xsi:schemaLocation="http://xmlns.example.com/xdb/xdiff.xsd http://xmlns.example.com/xdb/xdiff.xsd" xmlns:xd="http://xmlns.example.com/xdb/xdiff.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:bk="http://nosuchsite.com"> <?oracle-xmldiff operations-in-docorder="true" output-model="snapshot" diff-algorithm="global"?> <xd:delete-node xd:node-type="element" xd:xpath="/bk:book[1]/bk:tr[1]/bk:td[2]/bk:chapter[1]"/> </xd:xdiff>') ) FROM DUAL;

XMLPIは、identifierとvalue_exprの評価結果(オプション)を使用して、XMLの処理命令を生成します。通常、処理命令は、XML文書のすべてまたは一部に関連付けられたアプリケーション情報に使用されます。アプリケーションはこの処理命令を使用して、XML文書の最適な処理方法を決定します。
囲みタグに使用するOracle Databaseの値を指定する必要があります。この場合、文字列リテラルのidentifierを指定するか、またはEVALNAME value_exprを指定します。後者の場合は、値の式が評価され、その結果(文字列リテラル)が識別子として使用されます。この識別子は、最大4000文字まで指定可能で、列名または列の参照である必要はありません。式またはNULLは指定できません。
オプションのvalue_exprは文字列に変換する必要があります。オプションのvalue_exprを指定しない場合、デフォルトは長さが0(ゼロ)の文字列です。このファンクションの戻り値は、次の書式になります。
<?identifier string?>
XMLPIには、次の制限事項があります。
identifierは、処理命令の有効な対象である必要があります。
xmlは、identifierと組み合せて指定することはできません。
identifierには、連続文字?>を含めることはできません。次の文は、DUAL表を使用して、XMLPIの構文の使用を示します。
SELECT XMLPI(NAME "Order analysisComp", 'imported, reconfigured, disassembled') AS "XMLPI" FROM DUAL; XMLPI -------------------------------------------------------------------------------- <?Order analysisComp imported, reconfigured, disassembled?>

XMLQUERYでは、SQL文のXMLデータを問い合せることができます。このファンクションは、文字列リテラル、オプションのコンテキスト項目、および他のバインド変数としてXQuery式を取り、これらの入力値を使用してXQuery式の評価結果を戻します。
XQuery_stringは、プロローグを含む完全なXQuery式です。
XML_passing_clauseのexprは、XMLTypeまたはSQLスカラー・データ型のインスタンスを戻し、XQuery式を評価するためのコンテキストとして使用されます。PASSING句には、識別子を指定せずに1つのexprのみを指定できます。各exprの評価結果は、XQuery_stringの対応する識別子にバインドされます。exprの後にAS句が続かない場合、式の評価結果はXQuery_stringの評価用のコンテキスト項目として使用されます。
RETURNING CONTENTは、XQuery式の評価結果がXML 1.0文書か、またはXML 1.0セマンティクスに準拠したドキュメント・フラグメントのいずれかであることを示します。
NULL値を戻します。NULL ON EMPTYキーワードがデフォルトで実装されます。このキーワードは、意味を明確にするために示されます。次の文では、XML_passing_clauseのoe.warehouses表のwarehouse_spec列をコンテキスト項目として指定します。この文は、領域が50Kより大きいウェアハウスに関する特定の情報を戻します。
SELECT warehouse_name, EXTRACTVALUE(warehouse_spec, '/Warehouse/Area'), XMLQuery( 'for $i in /Warehouse where $i/Area > 50000 return <Details> <Docks num="{$i/Docks}"/> <Rail> { if ($i/RailAccess = "Y") then "true" else "false" } </Rail> </Details>' PASSING warehouse_spec RETURNING CONTENT) "Big_warehouses" FROM warehouses; WAREHOUSE_ID Area Big_warehouses ------------ --------- -------------------------------------------------------- 1 25000 2 50000 3 85700 <Details><Docks></Docks><Rail>false</Rail></Details> 4 103000 <Details><Docks num="3"></Docks><Rail>true</Rail></Details> . . .

XMLROOTでは、既存のXML値のXMLルート情報(プロローグ)のバージョンとスタンドアロンのプロパティを指定して、新しいXML値を作成できます。value_exprがすでにプロローグを持っている場合、エラーが戻されます。入力がNULLの場合、このファンクションはNULLを戻します。
戻り値は次の書式になります。
<?xml version = "version" [ STANDALONE = "{yes | no}" ]?>
value_exprでは、XML値を指定します。この値に対してプロローグ情報を指定します。
VERSION句のvalue_exprは、有効なXMLバージョンを表す文字列である必要があります。VERSIONにNO VALUEを指定すると、バージョンはデフォルトで1.0になります。
STANDALONE句を指定しない場合や、NO VALUEを指定した場合は、ファンクションの戻り値にスタンドアロンのプロパティは存在しません。
次の文は、DUAL表を使用して、XMLROOTの構文を示します。
SELECT XMLROOT ( XMLType('<poid>143598</poid>'), VERSION '1.0', STANDALONE YES) AS "XMLROOT" FROM DUAL; XMLROOT -------------------------------------------------------------------------------- <?xml version="1.0" standalone="yes"?> <poid>143598</poid>

XMLSEQUENCEには2つの書式があります。
XMLTypeインスタンスを取り、XMLTypeにあるトップレベルのノードのVARRAYを戻します。この書式のかわりに、SQL/XML標準関数XMLTableを使用すると効果的です。この関数を使用すると、SQLコードがより読みやすくなります。Oracle Database10g リリース2(10.2)より前のリリースでは、このリリースのXMLTable関数でより効果的に実行されるいくつかの機能を、XMLSequenceがSQL関数TABLEを使用して実行していました。
REFCURSORインスタンスおよびオプションのXMLFormatオブジェクトのインスタンスを取り、カーソルの各行に対して、XMLSequence型としてXML文書を戻します。
XMLSEQUENCEはXMLTypeのコレクションを戻すため、このファンクションをTABLE句で使用して、コレクション値をネスト解除することで複数行にし、SQL問合せでの処理をさらに進めることができます。
次の例では、XMLSEQUENCEが複数の要素を持つXML文書をVARRAY型の単一要素ドキュメントに分割する方法を示しています。この例では、TABLEキーワードが、コレクションを副問合せのFROM句で使用できる表の値とみなすように、Oracle Databaseに指示しています。
SELECT EXTRACT(warehouse_spec, '/Warehouse') as "Warehouse" FROM warehouses WHERE warehouse_name = 'San Francisco'; Warehouse ------------------------------------------------------------ <Warehouse> <Building>Rented</Building> <Area>50000</Area> <Docks>1</Docks> <DockType>Side load</DockType> <WaterAccess>Y</WaterAccess> <RailAccess>N</RailAccess> <Parking>Lot</Parking> <VClearance>12 ft</VClearance> </Warehouse> 1 row selected. SELECT VALUE(p) FROM warehouses w, TABLE(XMLSEQUENCE(EXTRACT(warehouse_spec, '/Warehouse/*'))) p WHERE w.warehouse_name = 'San Francisco'; VALUE(P) ---------------------------------------------------------------- <Building>Rented</Building> <Area>50000</Area> <Docks>1</Docks> <DockType>Side load</DockType> <WaterAccess>Y</WaterAccess> <RailAccess>N</RailAccess> <Parking>Lot</Parking> <VClearance>12 ft</VClearance> 8 rows selected.
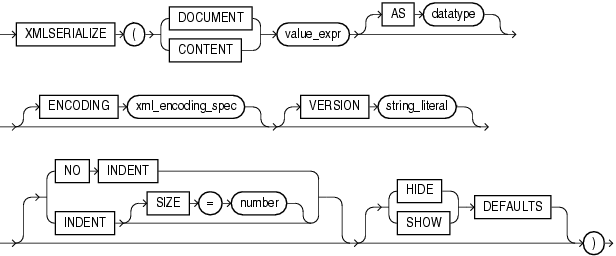
XMLSerializeは、value_exprの内容を含む文字列またはLOBを作成します。
DOCUMENTを指定する場合、value_exprは有効なXML文書である必要があります。
CONTENTを指定する場合、value_exprは単一ルートのXML文書である必要はありません。ただし、有効なXMLコンテンツである必要があります。
datatypeは、文字列型(VARCHAR2またはVARCHARは使用可能、NVARCHARまたはNVARCHAR2は使用不可)、BLOBまたはCLOBです。デフォルトはCLOBです。
datatypeがBLOBの場合は、ENCODING句を指定して、指定したエンコーディングをプロローグで使用できます。
string_literalとして指定したバージョン(<?xml version="..." ...?>)を使用するには、VERSION句を指定します。
NO INDENTを指定します。出力をN個の空白の相対インデントを使用して出力整形するには、INDENT SIZE = Nを指定します。Nは整数です。Nが0の場合、出力整形によって各要素の後に改行文字が挿入され、各要素は独自の行に配置されますが、その他の意味のないすべての空白は出力で省略されます。SIZEを指定せずにINDENTを指定すると、2個の空白インデントが使用されます。この句を指定しない場合、動作(出力整形されるかどうか)は予測不能です。
HIDE DEFAULTSおよびSHOW DEFAULTSは、XMLスキーマベースのデータにのみ適用されます。SHOW DEFAULTSを指定し、XMLスキーマがデフォルト値を定義するオプションの要素または属性が入力データにない場合、それらの要素または属性はデフォルト値を使用して出力に含まれます。HIDE DEFAULTSを指定した場合、そのような要素または属性は出力に含まれません。HIDE DEFAULTSがデフォルトの動作です。次の文は、DUAL表を使用して、XMLSerializeの構文を示します。
SELECT XMLSERIALIZE(CONTENT XMLTYPE('<Owner>Grandco</Owner>')) FROM DUAL;




XMLTableは、XQueryの評価結果をリレーショナル行および列にマップします。SQLを使用して、このファンクションで戻される結果を仮想リレーショナル表として問い合せることができます。
XMLNAMESPACES句には、XMLネームスペースの宣言が含まれます。これらの宣言は、XQuery式(評価されたXQuery_string)と、XML_table_columnのPATH句のXPath式で参照されます。XQuery式は行を計算し、XPath式はXMLTableファンクション全体の列を計算します。COLUMNS句のPATH式に修飾名を使用する場合は、XMLNAMESPACES句を指定する必要があります。
XQuery_stringは、完全なXQuery式で、プロローグ宣言を含むことができます。
XML_passing_clauseのexprは、XMLTypeまたはSQLスカラー・データ型のインスタンスを戻し、XQuery式を評価するためのコンテキストとして使用されます。PASSING句には、識別子を指定せずに1つのexprのみを指定できます。各exprの評価結果は、XQuery_stringの対応する識別子にバインドされます。exprの後にAS句が続かない場合、式の評価結果はXQuery_stringの評価用のコンテキスト項目として使用されます。
COLUMNS句では、XMLTableで作成する仮想表の列を定義します。
COLUMNS句を指定しない場合、XMLTableは、COLUMN_VALUEという名前の単一のXMLType疑似列を戻します。
XMLTableがXMLType, datatypeというXMLスキーマ・ベースの記憶域とともに使用される場合以外は、datatypeが必要です。この場合、datatypeの指定を省略すると、Oracle XML DBは、XMLスキーマに基づいてデータ型を推測します。データベース側で、ノードの正しい型が判断できないときは、デフォルト型であるVARCHAR2(4000)が使用されます。
FOR ORDINALITYは、生成された行番号の列になるように指定します。FOR ORDINALITY句は、最大で1つにする必要があります。これは、NUMBER列として作成されます。
PATH句では、XQuery式の文字列でアドレス指定されるXQuery結果の部分を列の内容として使用するように指定します。PATHを指定しない場合、XQuery式のcolumnとみなされます。たとえば、次のようになります。
XMLTable(... COLUMNS xyz
これは、次の式と同じです。
XMLTable(... COLUMNS xyz PATH 'XYZ')
異なるPATH句を使用すると、XQuery結果を異なる仮想表の列に分割できます。
DEFAULT句では、PATH式の結果が空のシーケンスの場合に使用する値を指定します。exprは、デフォルト値の生成用に評価するXQuery式です。次の例では、warehouses表のwarehouse_spec列の各値にXQuery '/Warehouse'を適用した結果を、列WaterおよびRailのある仮想リレーショナル表に変換します。
SELECT warehouse_name warehouse, warehouse2."Water", warehouse2."Rail" FROM warehouses, XMLTABLE('/Warehouse' PASSING warehouses.warehouse_spec COLUMNS "Water" varchar2(6) PATH '/Warehouse/WaterAccess', "Rail" varchar2(6) PATH '/Warehouse/RailAccess') warehouse2; WAREHOUSE Water Rail ----------------------------------- ------ ------ Southlake, Texas Y N San Francisco Y N New Jersey N N Seattle, Washington N Y
XMLTRANSFORMは、引数としてXMLTypeインスタンスおよびXSLスタイルシート(それ自体がXMLTypeインスタンス)を取ります。このファンクションは、スタイルシートをインスタンスに適用して、XMLTypeを戻します。
このファンクションは、データをデータベースから取得するように、スタイルシートに従ってデータを編成する場合に有効です。
XMLTRANSFORMファンクションを使用するには、XSLスタイルシートが必要です。次に、ノード内の要素をアルファベット順に並べる単純なスタイルシートの例を示します。
CREATE TABLE xsl_tab (col1 XMLTYPE); INSERT INTO xsl_tab VALUES ( XMLTYPE.createxml( '<?xml version="1.0"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" > <xsl:output encoding="utf-8"/> <!-- alphabetizes an xml tree --> <xsl:template match="*"> <xsl:copy> <xsl:apply-templates select="*|text()"> <xsl:sort select="name(.)" data-type="text" order="ascending"/> </xsl:apply-templates> </xsl:copy> </xsl:template> <xsl:template match="text()"> <xsl:value-of select="normalize-space(.)"/> </xsl:template> </xsl:stylesheet> ')); 1 row created.
次の例では、XSLスタイルシートxsl_tabを使用して、サンプル表oe.warehousesにあるwarehouse_specの要素をアルファベット順に並べます。
SELECT XMLTRANSFORM(w.warehouse_spec, x.col1).GetClobVal() FROM warehouses w, xsl_tab x WHERE w.warehouse_name = 'San Francisco'; XMLTRANSFORM(W.WAREHOUSE_SPEC,X.COL1).GETCLOBVAL() -------------------------------------------------------------------------------- <Warehouse> <Area>50000</Area> <Building>Rented</Building> <DockType>Side load</DockType> <Docks>1</Docks> <Parking>Lot</Parking> <RailAccess>N</RailAccess> <VClearance>12 ft</VClearance> <WaterAccess>Y</WaterAccess> </Warehouse>
表5-14に、ROUNDおよびTRUNC日付ファンクションで使用できる書式モデル、および日付の丸めと切捨ての単位を示します。デフォルトのモデルDDでは、午前0時(真夜中)を基準に丸めおよび切捨てを行い、日付を戻します。
書式モデルDAY、DYおよびDによって使用される週の開始日は、NLS_TERRITORY初期化パラメータによって暗黙的に指定されています。
PL/SQLまたはJavaでユーザー定義ファンクションを作成し、SQLまたはSQL組込みファンクションにはない機能を持たせることができます。ユーザー定義ファンクションは、式を指定できる場所であればどこでも、SQL文に指定できます。
たとえば、SQL文の次の場所でユーザー定義ファンクションを使用できます。
SELECT文のSELECT構文のリスト
WHERE句の条件
CONNECT BY句、START WITH句、ORDER BY句およびGROUP BY句
INSERT文のVALUES句
UPDATE文のSET句
オプションの式のリストは、ファンクション、パッケージまたは演算子の属性と一致する必要があります。
DISTINCTおよびALLキーワードは、ユーザー定義集計ファンクションのみで有効です。
|
参照:
|
ユーザー定義ファンクションをSQL文で使用するには、トップレベル・ファンクションとして作成するか、またはパッケージ仕様部で宣言する必要があります。
SQLの式の中でユーザー・ファンクションを使用するには、ユーザーがユーザー・ファンクションのEXECUTE権限を持っている必要があります。ユーザー・ファンクションで定義したビューを問い合せるには、そのビューに対するSELECT権限が必要です。ビューから選択するには、個別のEXECUTE権限は必要ありません。
SQL文内では、データベースの列名は、パラメータなしのファンクション名より優先順位が高くなります。たとえば、Human Resourcesのマネージャが、hrスキーマに次の2つのオブジェクトを作成する場合は、次のようにします。
CREATE TABLE new_emps (new_sal NUMBER, ...); CREATE FUNCTION new_sal RETURN NUMBER IS BEGIN ... END;
その後、次の2つの文のように、new_salを参照するとnew_emps.new_sal列を参照することになります。
SELECT new_sal FROM new_emps; SELECT new_emps.new_sal FROM new_emps;
new_salファンクションにアクセスするには、次のように入力します。
SELECT hr.new_sal FROM new_emps;
SQLの式内で使用できるユーザー・ファンクションのコール例を次に示します。
circle_area (radius) payroll.tax_rate (empno) hr.employees.tax_rate (dependent, empno)@remote
hrスキーマからtax_rateユーザー・ファンクションをコールし、tax_table内のss_no列とsal列に対してこのファンクションを実行するには、次のように指定します。
SELECT hr.tax_rate (ss_no, sal) INTO income_tax FROM tax_table WHERE ss_no = tax_id;
INTO句は、結果をincome_tax変数に配置するために使用できるPL/SQLです。
オプションのスキーマ名またはパッケージ名を1つのみ指定すると、最初の識別子はスキーマ名またはパッケージ名のいずれかになります。たとえば、PAYROLL.TAX_RATEという参照内のPAYROLLがスキーマ名かパッケージ名かを判断するには、Oracle Databaseは次の手順を実行します。
PAYROLLパッケージをチェックします。
PAYROLLパッケージが検出されない場合は、トップレベルのTAX_RATEファンクションを含むスキーマ名PAYROLLを検索します。このようなファンクションが検出されない場合は、エラーを戻します。
PAYROLLパッケージが検出されると、PAYROLLパッケージの中でTAX_RATEファンクションを検索します。このようなファンクションが検出されない場合は、エラーを戻します。
また、ユーザーが定義したシノニムを使用して、ストアド・トップレベル・ファンクションを参照することもできます。
|
 Copyright © 1996, 2008, Oracle Corporation. All Rights Reserved. |
|