11g リリース1(11.1)
E05764-01
 目次 |
 索引 |
| Oracle Database 2日でデータ・ウェアハウス・ガイド 11g リリース1(11.1) E05764-01 |
|

この項では、パフォーマンスの問題を識別して削減する方法を説明します。内容は次のとおりです。
システムの正常な実行を保証するために重要なことは、パフォーマンスの問題を排除することです。この項では、これらのボトルネックを検索して排除するいくつかの方法を説明します。内容は次のとおりです。
オプティマイザ統計は、データベース内のデータベースおよびオブジェクトについてより詳細に説明するデータが収集されたものです。これらの統計はデータ・ディクショナリに格納され、問合せオプティマイザにより使用されて各SQL文に最適な実行計画を選択します。オプティマイザ統計には、次が含まれます。
オプティマイザ統計は、データ・ディクショナリに格納されます。オプティマイザ統計は、次に類似するデータ・ディクショナリ・ビューを使用して参照できます。
SELECT * FROM DBA_SCHEDULER_JOBS WHERE JOB_NAME = 'GATHER_STATS_JOB';
データベース内のオブジェクトは常に変更されるので、これらのデータベース・オブジェクトを正確に示すために統計を定期的に更新する必要があります。統計は、Oracle Databaseにより自動的に維持されるか、またはDBMS_STATSパッケージを使用して手動でオプティマイザ統計を維持することもできます。
SQL文を実行するには、Oracle Databaseでは多数のステップを実行する必要があります。これらの各ステップでは、データベースから物理的にデータ行を取得するか、文を発行するユーザー用になんらかの方法でそれらのデータを用意しておきます。Oracle Databaseが文の実行に使用するステップの組合せは、実行計画と呼ばれます。実行計画には、文がアクセスする各表のアクセス・パスおよび適切な結合方法を使用した表の順序(結合順序)が含まれます。
EXPLAIN PLAN文を使用して、オプティマイザがSQL文用に選択した実行計画を調査できます。その文が発行されると、オプティマイザにより実行計画が選択され、計画を説明するデータがデータベース表に挿入されます。単純にEXPLAIN PLAN文を発行し出力表を問い合せることで実行できます。
EXPLAIN PLAN文を使用する一般的なガイドラインは次のとおりです。
UTLXPLAN.SQLを使用して、スキーマ内にあるPLAN_TABLEというサンプルの出力表を作成します。
EXPLAIN PLAN FOR句を含めます。
EXPLAIN PLAN文を発行した後、Oracle Databaseにより提供されたスクリプトの1つまたはパッケージの1つを使用して最新の計画の表の出力を表示します。
EXPLAIN PLAN出力内の実行順序は、最も右側にインデントされた行から始まります。2つの行が等しくインデントされている場合は、通常、上位の行が最初に実行されます。
次の文では、2つのEXPLAIN PLAN文の出力を示し、1つは動的プルーニングを使用し、もう1つは静的プルーニングを使用します。
EXPLAIN PLAN FOR SELECT p.prod_name , c.channel_desc , SUM(s.amount_sold) revenue FROM products p , channels c , sales s WHERE s.prod_id = p.prod_id AND s.channel_id = c.channel_id AND s.time_id BETWEEN '01-12-2001' AND '31-12-2001' GROUP BY p.prod_name , c.channel_desc; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
WITHOUT TO_DATE
---------------------------------------------------------------------------------------------------
| Id| Operation | Name |Rows|Bytes|Cost | Time |Pstart|Pstop|
(%CPU)
---------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 252|15876|305(1)|00:00:06| | |
| 1| HASH GROUP BY | | 252|15876|305(1)|00:00:06| | |
| *2| FILTER | | | | | | | |
| *3| HASH JOIN | |2255| 138K|304(1)|00:00:06| | |
| 4| TABLE ACCESS FULL | PRODUCTS | 72| 2160| 2(0)|00:00:01| | |
| 5| MERGE JOIN | |2286|75438|302(1)|00:00:06| | |
| 6| TABLE ACCESS BY INDEX ROWID | CHANNELS | 5| 65| 2(0)|00:00:01| | |
| 7| INDEX FULL SCAN | CHANNELS_PK | 5| | 1(0)|00:00:01| | |
| *8| SORT JOIN | |2286|45720|299(1)|00:00:06| | |
| 9| PARTITION RANGE ITERATOR | |2286|45720|298(0)|00:00:06| KEY| KEY|
| 10| TABLE ACCESS BY LOCAL INDEX ROWID| SALES |2286|45720|298(0)|00:00:06| KEY| KEY|
| 11| BITMAP CONVERSION TO ROWIDS | | | | | | | |
|*12| BITMAP INDEX RANGE SCAN |SALES_TIME_BIX| | | | | KEY| KEY|
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_DATE('01-12-2001')<=TO_DATE('31-12-2001'))
3 - access("S"."PROD_ID"="P"."PROD_ID")
8 - access("S"."CHANNEL_ID"="C"."CHANNEL_ID")
filter("S"."CHANNEL_ID"="C"."CHANNEL_ID")
12 - access("S"."TIME_ID">='01-12-2001' AND "S"."TIME_ID"<='31-12-2001')
Note the values of KEY KEY for Pstart and Pstop.
WITH TO_DATE
--------------------------------------------------------------------------------------------------
|Id| Operation | Name | Rows | Bytes |Cost(%CPU)| Time | Pstart| Pstop |
--------------------------------------------------------------------------------------------------
| 0| SELECT STATEMENT | | 252 | 15876 | 31 (20)| 00:00:01 | | |
| 1| HASH GROUP BY | | 252 | 15876 | 31 (20)| 00:00:01 | | |
|*2| HASH JOIN | | 21717 | 1336K| 28 (11)| 00:00:01 | | |
| 3| TABLE ACCESS FULL |PRODUCTS| 72 | 2160 | 2 (0)| 00:00:01 | | |
|*4| HASH JOIN | | 21717 | 699K| 26 (12)| 00:00:01 | | |
| 5| TABLE ACCESS FULL |CHANNELS| 5 | 65 | 3 (0)| 00:00:01 | | |
| 6| PARTITION RANGE SINGLE| | 21717 | 424K| 22 (10)| 00:00:01 | 20 | 20 |
|*7| TABLE ACCESS FULL |SALES | 21717 | 424K| 22 (10)| 00:00:01 | 20 | 20 |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("S"."PROD_ID"="P"."PROD_ID")
4 - access("S"."CHANNEL_ID"="C"."CHANNEL_ID")
7 - filter("S"."TIME_ID">=TO_DATE('2001-12-01 00:00:00', 'yyyy-mm-dd hh24:mi:ss') AND
"S"."TIME_ID"<=TO_DATE('2001-12-31 00:00:00', 'yyyy-mm-dd hh24:mi:ss'))
Note the values of 20 20 for Pstart and Pstop.
最初の実行計画は、PstartおよびPstopそれぞれのKEY KEY値を使用して動的プルーニングを表示します。動的プルーニングは、実行時間にデータベースによりアクセスするパーティションを特定する必要があることを意味します。静的プルーニングの場合は、解析時間にデータベースにより、より効果的な実行のためにアクセスするパーティションを把握します。
明示的な日付変換を使用して実行計画を頻繁に改善できます。明示的な日付変換の使用は、最適なパーティション・プルーニングおよび索引の使用のためのベスト・プラクティスです。
決定事項に関するヒントは通常オプティマイザによって作成されます。オプティマイザによって管理されていないデータについての情報をアプリケーション開発者として保持している場合があります。ヒントによってメカニズムが提供され、特定の基準に基づく問合せ実行プランを選択するためにオプティマイザに通知されます。
たとえば、ユーザーが特定の問合せに対して特定の索引が選択可能であることを把握している場合があります。この情報に基づいて、オプティマイザが選択するより、より効率的な実行プランが選択できる場合があります。このような場合、ヒントを使用して、オプティマイザに通知し、最適な実行プランを使用します。
デフォルトでは、Oracle Warehouse Builderには、一般的なデータ・ロードを最適化するヒントが含まれます。詳細は、『Oracle Warehouse Builderユーザーズ・ガイド』を参照してください。
システムがアイドル状態である間に昨年の売上表のサマリーを迅速に実行することを想定します。この場合は、次の文を発行できます。
SELECT /*+ PARALLEL(s,16) */ SUM(amount_sold) FROM sales s WHERE s.time_id BETWEEN TO_DATE('01-JAN-2005','DD-MON-YYYY') AND TO_DATE('31-DEC-2005','DD-MON-YYYY');
データ・ウェアハウスでヒントを使用するもう1つの一般的な方法は、圧縮の使用によるレコードの効率的なロードを保証することです。次のSQLに示すように、APPENDヒントを使用します。
... INSERT /* +APPEND */ INTO my_materialized_view ...
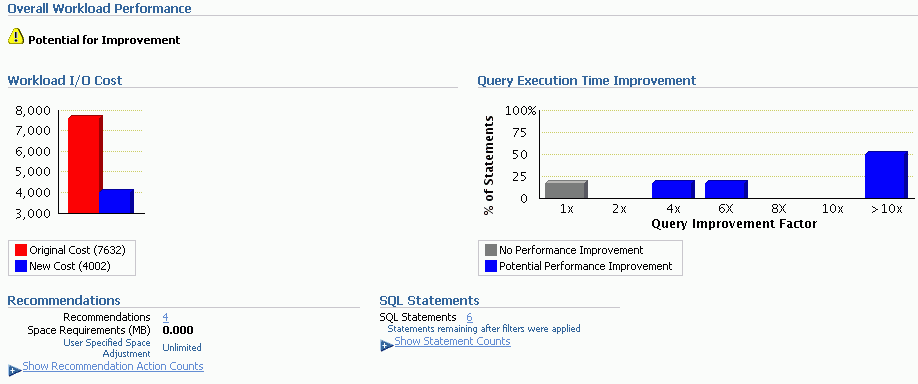
SQLチューニング・アドバイザおよびSQLアクセス・アドバイザを使用すると、特定のSQL文またはSQL文のセットを調べるアドバイス・モードで問合せオプティマイザを起動でき、SQL文の効率を向上させる推奨事項が提供されます。SQLチューニング・アドバイザおよびSQLアクセス・アドバイザはSQLプロファイルの作成、SQL文の再構築、付加的な索引またはマテリアライズド・ビューの作成、およびオプティマイザ統計のリフレッシュなどの様々なタイプの推奨事項を作成できます。さらに、Oracle Enterprise Managerを使用すると、数回のマウス・クリックでこれらの推奨事項を受け入れ、実装できます。
SQLアクセス・アドバイザは、主に索引およびマテリアライズド・ビューの追加および削除などのスキーマ変更の推奨事項を作成する場合に使用します。また、パーティション計画も推奨します。SQLチューニング・アドバイザは、SQLプロファイルの作成、SQL文の再構築などの他のタイプの推奨事項の作成に使用します。新しい索引を作成してパフォーマンスが大幅に向上できる場合、SQLチューニング・アドバイザは索引の作成を推奨する可能性があります。ただし、これらの推奨事項は、典型的なSQL文のセットを含んだSQLワークロードを使用してSQLアクセス・アドバイザを実行し、検証する必要があります。
SQLチューニング・アドバイザを使用して、単一または複数のSQL文をチューニングできます。複数のSQL文をチューニングする場合、SQLチューニング・アドバイザはSQL文間の相互依存を認識しないことに注意してください。かわりに、多数のSQL文に対してSQLチューニング・アドバイザを実行すると有効です。
SQLチューニング・アドバイザを実行してSQLパフォーマンスを検証する手順は、次のとおりです。
「SQLアドバイザ」ページが表示されます。
「SQLチューニング・アドバイザのスケジュール」ページが表示されます。推奨される名前は「名前」フィールドに表示され、変更が可能です。その後「包括」を選択して実行する包括的な分析を取得します。「スケジュール」の「即時」を選択します。適切なSQLチューニング・セットを選択した後、「OK」をクリックします。
「推奨」ページが表示されます。

リソースの使用量を最小化できるので、次の機能を使用してデータ・ウェアハウスのパフォーマンスを向上させることができます。
データ・ウェアハウスにはサイズの大きな表が含まれていることが多く、これらのサイズの大きな表を管理する技術およびこれらの表全体に良質な問合せのパフォーマンスを提供する技術の両方が必要になります。この項では、パーティション化とこれらの要件に対処するための主要な方法を説明します。データ・ウェアハウスの問合せのパフォーマンスに関連する2つの機能は、パーティション・プルーニングとパーティションワイズ結合です。
パーティション・プルーニングは、データ・ウェアハウスに必須のパフォーマンス機能です。パーティション・プルーニングでは、オプティマイザによりSQL文のFROM句およびWHERE句が分析され、パーティション・アクセス・リストの作成時に不必要なパーティションが排除されます。これにより、Oracle Databaseを使用してSQL文に関連するパーティションでのみ操作を実行できます。レンジ・パーティション化列またはリスト・パーティション化列にある範囲述語、LIKE述語、等価述語およびIN-リスト述語を使用する場合とハッシュ・パーティション化列にある等価述語およびIN-リストを使用する場合は、Oracle Databaseによりパーティションがプルーニングされます。
パーティション・プルーニングによりディスクから取得するデータ量を大幅に削減し処理時間の使用を短縮できるので、問合せのパフォーマンスおよびリソース使用量が向上します。グローバルなパーティション索引を使用して異なる列の索引および表をパーティション化する場合は、基礎となる表が排除できない場合でもパーティション・プルーニングにより索引パーティションが排除されます。
実際のSQL文に応じて、Oracle Databaseにより静的プルーニングおよび動的プルーニングが使用されます。静的プルーニングは事前にアクセスされたパーティションの情報とともにコンパイル時に発生し、一方動的プルーニングは実行時に発生し、これは文によってアクセスされる正確なパーティションを事前に把握していることを意味します。静的プルーニングのサンプルの使用例は、パーティション・キー列に固定リテラルがあるWHERE条件を含むSQL文です。動的プルーニングの例は、WHERE条件内の演算子または関数の使用です。
パーティション・プルーニングは、プルーニングが発生するオブジェクトの統計に影響するので、文の実行計画にも影響します。
パーティションワイズ結合では、結合がパラレルで実行される場合にパラレル実行サーバー間で交換されるデータの量を最小化することにより問合せのレスポンス時間が削減されます。これによりレスポンス時間が大幅に削減され、CPUおよびメモリー・リソース両方の使用量を改善します。Oracle Real Application Clusters環境では、パーティションワイズ結合は相互接続のデータ通信を回避するか、少なくとも制限します。このことは大規模な結合操作に対する良質なスケーラビリティを実現するために重要です。
パーティションワイズ結合では、全体的または部分的です。Oracle Databaseにより使用する結合のタイプが決定されます。
データ・ウェアハウス環境では、常にパーティション化を考慮する必要があります。
パーティション化を評価する手順は、次のとおりです。
「SQLアドバイザ」ページが表示されます。
「SQLアクセス・アドバイザ」ページが表示されます。
「推奨オプション」ページが表示されます。
「スケジュール」ページが表示されます。
SQLACCESStest1を入力し、「次へ」をクリックします。「確認」ページが表示されます。「発行」をクリックします。

「確認」ページが表示されます。
データ・ウェアハウスでは、マテリアライズド・ビューを使用して売上の合計などの集計データを計算して格納できます。また、それらを使用して集計を加えてまたは集計を除いて結合を計算でき、コストの高い計算と同様、頻繁に実行されるサイズの大きな表間のコストの高い結合にも便利です。マテリアライズド・ビューにより、大規模な結合または問合せを処理する前にサマリーが作成されたデータを計算して格納するので、大規模または重要なクラスの問合せのためのコストの高い結合および集計に関連付けられたオーバーヘッドは排除されます。これらの環境でマテリアライズド・ビューは多くの場合、サマリーと呼ばれます。
マテリアライズド・ビューを作成して保持する主な利点の1つは、表またはビューで表されるSQL文を、詳細表で定義される1つ以上のマテリアライズド・ビューにアクセスする文に変換する問合せのリライト機能を利用できることです。変換はユーザーおよびアプリケーションに対して透過的で、SQL文内のマテリアライズド・ビューを使用したり参照する必要はありません。問合せのリライト機能は透過的なので、索引と同様にアプリケーション・コード内のSQLを無効にすることなく、マテリアライズド・ビューを追加または削除できます。
基礎となる表に大量のデータが含まれる場合、必要な集計の計算またはこれらの表間の結合の計算は、コストが高く時間がかかる処理になります。このような場合、問合せにより応答が返されるまで数分または数時間かかります。マテリアライズド・ビューにはすでに計算された集計と結合が含まれているので、Oracle Databaseによって強力な問合せのリライト・プロセスが使用され、マテリアライズド・ビューを使用した問合せに迅速に応答します。
ビットマップ索引はデータ・ウェアハウス環境において広く使用されています。データ・ウェアハウス環境では通常、大量のデータおよび非定型問合せがありますが、DMLトランザクションが同時に発生することは稀です。索引が表内のデータのサイズの数倍である場合があるため、サイズの大きな表に従来のBツリーを完全に索引付けすると、ディスク領域に関してコストが非常に高くなる可能性があります。ビットマップ索引は通常、表内の索引付けされたデータのサイズのほんの一部にすぎません。このようなアプリケーションの場合、ビットマップ索引には次のような特性があります。
可能な場合にパラレルで操作を実行すると、システムでのリソースの使用を最大化できます。特定の時点でリソースによる制限がない場合、データベース操作をより速く実行できます。操作はCPUリソース、I/O容量、メモリーまたは(クラスタ内の)相互接続のトラフィックによって制限される場合があります。データベース操作のパフォーマンスを向上させるには、パフォーマンスの問題に焦点を当て、その問題を排除する必要があります(問題が他のリソースに移行する可能性を考慮し、排除する必要があります)。Oracle Databaseでは、使用可能なリソースの使用を最大化する機能を提供し、また不要なリソースの使用も回避します。
パラレル実行を使用すると、通常ディシジョン・サポート・システム(DSS)およびデータ・ウェアハウスに関連付けられているサイズの大きなデータベース上で、データ集中型の操作のレスポンス時間を大幅に削減できます。また、特定のタイプのオンライン・トランザクション処理(OLTP)およびハイブリッド・システム上で、パラレル実行の実装もできます。パラレル実行はパラレル化とも呼ばれます。パラレル化のタスクの概念を簡潔に説明すると、1つのプロセスで問合せに関するすべての処理を実行するのではなく、多くのプロセスが同時に各処理を実行します。たとえば、1年間ですべての四半期を1つのプロセスで処理せずに、四半期それぞれを4つのプロセスで処理します。これを使用するとパフォーマンスの大幅な向上が見込めます。パラレル実行では、次のプロセスを向上できます。
また、パラレル実行を使用して、Oracleデータベース内のオブジェクト型にアクセスできます。たとえば、パラレル実行により、ラージ・オブジェクト(LOB)にアクセスできます。
パラレル実行は、次のすべての特性を持つシステム上で有効です。
これらの特性を持たないシステムでは、パラレル実行を使用しても大幅にパフォーマンスが向上しない場合があります。実際に、大容量を使用しているシステムまたはI/O帯域幅の少ないシステム上では、システムのパフォーマンスが低下する可能性があります。
パラレル実行では、SQL文の実行タスクが複数の小さな単位に分割され、各ユニットは個別のプロセスで実行されます。また、受信するデータ(表、索引、パーティション)もグラニュルと呼ばれる単位に分類されます。問合せを並行して実行するユーザー・シャドウ・プロセスは、パラレル実行のコーディネータまたは問合せコーディネータとしての役割を持ちます。問合せコーディネータの役割は次のとおりです。
パラレル実行コーディネータでは、2つ以上のインスタンスのパラレル実行サーバーでSQL文を処理する場合があります。単一の操作に関連付けられているパラレル実行サーバーの数は、並列度と呼ばれます。
単一の操作は、ORDER BY操作または索引なしの列表に対して結合を実行する全表スキャンなどのSQL文の一部です。
並列度(DOP)を指定する方法は次のとおりです。
PARALLELヒントを持つ文レベルでの指定
ALTER SESSION FORCE PARALLEL文を発行してセッション・レベルでの指定
表でDOPを4に設定する場合を想定します。
次の文を発行します。
ALTER TABLE orders PARALLEL 4;
待機イベントはサーバー・プロセスによって増分した統計で、サーバー・プロセスは、イベントが完了し、処理の続行が可能となるまで待機する必要があることを示します。セッションの待機理由は様々で、大量の入力に対する待機、ディスクへの書込み操作などのサービスを完了するためのオペレーティング・システムに対する待機、またはロックやラッチを待機する時間が含まれます。
各セッションがリソースを待機する間、有効な動作は実行されません。待機イベントの多くが問題の原因となります。待機イベント・データにより、ラッチ競合、バッファ競合およびI/O競合などのパフォーマンスに影響を与える可能性のある問題の症状が明らかになります。
|
 Copyright © 2007 Oracle Corporation. All Rights Reserved. |
|