11gリリース1(11.1)
E05765-03
 目次 |
 索引 |
| Oracle Database 概要 11gリリース1(11.1) E05765-03 |
|

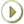
この章では、ユーザー・スキーマに含まれる様々な種類のデータベース・オブジェクトについて説明します。
この章の内容は、次のとおりです。
スキーマとは、データの論理構造の集合、すなわちスキーマ・オブジェクトのことです。スキーマはデータベース・ユーザーによって所有され、そのユーザーと同じ名前を持ちます。各ユーザーが単一のスキーマを所有します。スキーマ・オブジェクトは、SQLで作成および操作できます。スキーマ・オブジェクトには、次のタイプのオブジェクトがあります。
データベースには他に、次のタイプのオブジェクトも保存されており、SQLで作成および操作できますが、スキーマには含まれていません。
スキーマ・オブジェクトは、論理的なデータ記憶域構造です。各スキーマ・オブジェクトは、その情報を格納するディスク上の物理ファイルと1対1では対応しません。Oracle Databaseでは、スキーマ・オブジェクトはデータベースの表領域内に論理的に格納されます。各オブジェクトのデータは、物理的には、表領域の1つ以上のデータファイルに格納されます。Oracle Databaseでは、表、索引およびクラスタなどのいくつかのオブジェクトに関して、表領域のデータファイル内のオブジェクトに割り当てるディスク領域を指定できます。
スキーマと表領域には関連がありません。表領域は異なるスキーマのオブジェクトを含むことができ、スキーマの各オブジェクトは異なる表領域に含めることができます。
図5-1に、オブジェクト、表領域およびデータファイルの関連を示します。

表は、Oracleデータベースにおけるデータ記憶域の基本単位です。データは行と列に格納されます。表は、表名(employeesなど)と列の集合で定義されます。各列には、列名(employee_id、last_nameおよびjob_idなど)、データ型(VARCHAR2、DATEまたはNUMBERなど)および幅を割り当てます。幅は、DATEデータ型の場合のようにデータ型によって事前に決定されている場合があります。列がNUMBERデータ型の場合は、幅のかわりに精度とスケールを定義します。
各列に整合性制約と呼ばれるルールを指定できます。たとえば、NOT NULL整合性制約では、列の各行には値が含まれている必要があります。
表には仮想列を含めることができます。仮想列は通常の列とは異なり、ディスク上の領域を使用しません。詳しく説明すると、データベースによりユーザー指定の一連の式または関数が計算され、必要に応じて仮想列から値が導出されます。仮想列は問合せ、DMLおよびDDL文で使用できます。仮想列の索引付け、統計の収集および整合性制約の作成が可能です。このため、通常の列と同じように扱われます。
また、データファイルに格納される前にデータを暗号化する表の列を指定できます。暗号化を使用すると、ユーザーがオペレーティング・システム・ツールにより直接データファイル内部を参照して、データベース・アクセス制御メカニズムから逃れることを防止できます。
表の作成後に、SQL文を使用してデータ行を挿入します。行は、1つのレコードに対応する列情報の集まりです。挿入した表データは、SQLを使用して問合せ、削除または更新できます。
図5-2にサンプル表を示します。
この項の内容は、次のとおりです。
関連項目
Oracle Databaseでは、表を作成する際に、表の将来のデータを保持するために、表領域にデータ・セグメントが自動的に割り当てられます。表のデータ・セグメントに対する領域の割当てと使用は、次の方法で制御できます。
PCTFREEパラメータとPCTUSEDパラメータを設定します。これにより、データ・セグメントのエクステントを構成するデータ・ブロック内の空き領域の使用を制御できます。
Oracle Databaseでは、クラスタ表のデータは、表領域のデータ・セグメントではなく、クラスタ用に作成されたデータ・セグメントに格納されます。クラスタ化表を作成または変更するときには、記憶域パラメータは指定できません。クラスタに対して設定された記憶域パラメータが、常にそのクラスタ内のすべての表の記憶域を制御します。
表のデータ・セグメント(クラスタ表を扱っている場合はクラスタ用のデータ・セグメント)は、表所有者のデフォルト表領域、またはCREATE TABLE文で指定された特定の表領域に作成されます。
この項の内容は、次のとおりです。
次のような場合、表の行データが大きすぎて、1つのデータ・ブロック内に収まらない場合があります。
Oracle Databaseでは、行連鎖により、その行のデータは、セグメント用に確保された1つ以上のデータ・ブロックの連鎖に格納されます。多くの場合、行連鎖は、行が大きい場合に発生します。大きい行の例には、LONGまたはLONG RAWデータ型の列を含む行、2KBブロックにVARCHAR2(4000)の列が含まれる行、または行に含まれる列の数が多すぎる場合があります。そのような場合の行連鎖は、避けられません。
Oracle Databaseでは、行の移行により、行全体が新しいブロックに収まることを前提として、行全体が新しいデータ・ブロックに移動されます。移行された行の元の行断片には、行の移行先の新しいブロックへのポインタまたは「転送先アドレス」が含まれます。そのため、移動された行のROWIDは変わりません。
Oracle Databaseでは、1つの行断片に格納できる列数は、255列のみです。したがって、1000列の行を表に挿入すると、データベースでは通常、複数のブロックに連鎖された4つの行断片が作成されます。
行が連鎖または移行されると、行の情報を取り出す際に、Oracle Databaseが複数のデータ・ブロックをスキャンする必要があるため、データの取出しに必要なI/Oが増加します。たとえば、索引の読取りに対して1回のI/Oを行い、移行されていない行の表を読み取るために1回のI/Oを行う場合、データベースでは、移行された行の実際の行データを取得するために追加のI/Oが必要になります。
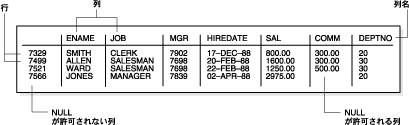
それぞれの行断片は、連鎖されていても連鎖されていなくても、行の全部または一部の列の行ヘッダーとデータを含みます。また、個々の列が複数の行断片にまたがり、結果として複数のデータ・ブロックにまたがっている場合もあります。図5-3に、行断片の形式を示します。
行ヘッダーは、データの前に位置し、次のような情報を含んでいます。
1つのブロックに完全に収まる行は、最低3バイトの行ヘッダーを持っています。各行は、行ヘッダー情報の後に列の長さとデータを格納します。列の長さは、250バイト以下のデータを格納する列については1バイト、250バイトよりも大きなデータを格納する列については3バイトを必要とし、列データの直前に位置します。列データのために必要となる領域は、データ型によって異なります。列のデータ型が可変長である場合、値を保持するために必要な領域は、データの更新によって変動します。
領域を節約するために、NULLを含む列は、列の長さ(ゼロ)のみを格納します。Oracle Databaseでは、NULL列のデータは格納されません。また、Oracle Databaseでは、末尾にあるNULL列の場合は、列の長さも格納されません。
クラスタ化された行には、クラスタ化されていない行と同じ情報が格納されます。また、クラスタ化された行には、それらの行が属するクラスタ・キーを参照する情報も格納されます。
|
関連項目
|
ROWIDは、それぞれの行断片を位置またはアドレスで識別します。状況によっては、ROWIDが行断片に割り当てられた後、ROWIDが変更される場合があります。たとえば、行の移動が可能な場合、ROWIDは、パーティション・キーの更新、フラッシュバック表の操作、表の縮小操作などのために変更される可能性があります。行の移動が無効な場合は、Oracle Databaseユーティリティを使用して行をエクスポートおよびインポートした場合にROWIDが変更される可能性があります。
1つの表内のすべての行は、列の順序が同一です。列は通常、CREATE TABLE文でリストされた順序で格納されますが、これは保証されません。たとえば、表にLONGデータ型の列があると、Oracle Databaseでは、この列は常に最後に格納されます。また、表を変更して新しい列を追加すると、その新しい列は、最後に格納されます。
一般的には、行に必要な領域を少なくするために、NULLを頻繁に格納する列を最後の列にします。ただし、作成する表にLONG列が含まれている場合、NULL列を最後に置く利点はなくなります。
Oracle Databaseの表の圧縮機能は、データベース・ブロック内の重複値の排除に基づいています。データベース・ブロック(ディスク・ページと呼ぶこともあります)に格納された圧縮データは自己完結型です。つまり、ブロック内の非圧縮データを再作成するために必要な情報は、すべてそのブロック内で使用できます。ブロックのすべての行と列にある重複値は、いったんブロックの先頭に格納されます。これを、そのブロックのシンボル表と呼びます。この種の値のすべての出現箇所は、シンボル表の短い参照で置き換えられます。
先頭にあるシンボル表を除き、圧縮データベース・ブロックは通常のデータベース・ブロックとほぼ同じです。通常のデータベース・ブロックに対して動作するデータベース機能とファンクションは、すべて圧縮データベース・ブロックに対しても動作します。圧縮可能なデータベース・オブジェクトは、表やマテリアライズド・ビューなどです。パーティション表の場合は、一部またはすべてのパーティションを圧縮するように選択できます。表領域、表または表のパーティションについて、圧縮属性を宣言できます。表領域レベルで宣言すると、その表領域に作成されたすべての表がデフォルトで圧縮されます。表(またはパーティションや表領域)の圧縮属性を変更すると、変更はその表に送られる新規データにのみ適用されます。そのため、1つの表またはパーティションに圧縮ブロックと通常のブロックの両方が含まれる場合があります。これにより、圧縮によってデータ・サイズが大きくならないことが保証されます。ブロック・サイズが大きくなる場合、そのブロックに圧縮は適用されません。
圧縮は、圧縮された表に対してデータの挿入、更新、バルク挿入またはバルク・ロードが実行されている間に行われます。この種の操作には次のものが含まれます。
CREATE TABLEおよびAS SELECT文
INSERT(またはAPPENDヒントを指定したシリアルINSERT)文
データベースにある既存のデータも、ALTER TABLEおよびMOVE文を介して圧縮形式に移行できます。この操作では表に排他ロックが適用されるため、操作が完了するまでは更新およびロードできなくなります。この状況を許容できない場合は、Oracle Databaseオンライン再定義ユーティリティ(DBMS_REDEFINITION PL/SQLパッケージ)を使用できます。
データ圧縮は、LOBのすべての改良型と、行の外に格納されるVARRAYやCLOBに格納されるXMLデータ型など、LOBから導出されるデータ型を除く、すべてのデータ型に使用できます。
表の圧縮は、データベースへのデータのバルク・ロードや、単一行挿入または配列挿入、単一行更新または配列更新の際に実行されます。圧縮に関連したオーバーヘッドは、その時点でほぼ参照可能になります。このオーバーヘッドは、圧縮を検討する際に考慮する必要のある重要なトレードオフです。
圧縮された表またはパーティションは、Oracle Databaseの他の表やパーティションと同様に変更できます。圧縮されたデータの削除には、圧縮されていないデータの削除と同じだけ時間がかかります。新規データの挿入についても同様です。圧縮データの更新速度は、低下する場合があります。Oracle Databaseでは、圧縮された表に対するすべてのDML操作(挿入、更新、削除)をサポートするため、表の圧縮は、データ・ウェアハウス・アプリケーションのみでなくOLTPアプリケーションにも適しています。これら両方の環境では、データは、その読取り専用部分やほとんど変更されない部分(履歴データなど)の圧縮状態が維持されるように編成する必要があります。
NULLは、ある行のある列に値が入っていないことを意味します。NULLは、データがない、不明である、または適切でないことを示します。他の値(ゼロなど)を暗示する目的では、NULLは使用できません。NOT NULL整合性制約または主キー整合性制約が列に対して定義されていない場合にかぎり、列にNULL値を入力できます。これらの制約が列に対して定義されている場合、その列に値を持たない行は挿入できません。
データ値を持つ2つの列の間にはさまれたNULLはデータベースに格納されます。このような場合、NULLには列の長さ(ゼロ)を格納する1バイトのみが必要となります。
行の末尾にあるNULLには、記憶域は不要です。これは、新しい行のヘッダーが、前行の残りの列がNULLであることを知らせるためです。たとえば、表の最後の3列がNULLであれば、その3列には情報は格納されません。列が多い表では、ディスク領域を節約するため、NULLを含む可能性の高い列は最後に定義する必要があります。
NULLとその他の値との比較の大部分は、定義によってTRUEにもFALSEにもならず、UNKNOWNとなります。SQL文の中でNULLを識別するには、IS NULL述語を使用します。NULLをNULL以外の値に変換するには、SQL関数のNVLを使用します。
クラスタ・キー列の値がNULLの場合または索引がビットマップ索引の場合を除いて、NULLに索引を付けることはできません。
列に対してデフォルト値が明示的に定義されていない場合、その列のデフォルトは暗黙的にNULLになります。新しい行が挿入され、列に対する値が省略されたか、キーワードのDEFAULTが提供された場合、デフォルト値が自動的に入力されるように、表の列にデフォルト値を割り当てることもできます。
列のデフォルト値は、実際にINSERT文が値を指定している場合と同様に機能します。デフォルトのリテラルまたは式のデータ型は、その列のデータ型に一致しているか、あるいはそれに変換可能である必要があります。
デフォルト値を持つ行が挿入されると、整合性制約チェックが行われます。たとえば、図5-4では、従業員の部門番号に対する値を持たない行が、emp表に挿入されています。部門番号に値が指定されていないため、Oracle Databaseにより、deptno列のデフォルト値の20が挿入されます。デフォルト値を挿入した後、Oracle Databaseでは、deptno列に定義された外部キー整合性制約のチェックが行われます。
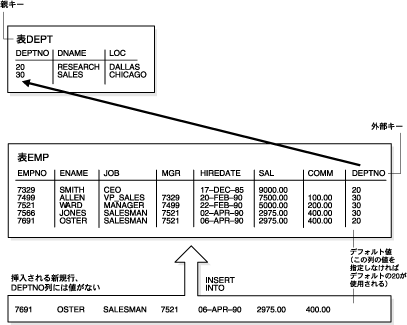
表の列のデータ型によっては、NOT NULL制約およびデフォルト値の両方が設定された列を追加すると、データベースにより操作が最適化され、表がDML用にロックされる時間が短縮される場合があります。
パーティション表では、データをパーティションやサブパーティションと呼ばれる小さく管理しやすい単位に分割できます。索引も同様にパーティション化できます。各パーティションは個別に管理し、他のパーティションから独立して操作できます。これにより、各パーティションの可用性とパフォーマンスに適合する構造を提供しています。
データ型として別の表を指定した表を作成できます。つまり、表の列値として別の表をネストできます。Oracleデータベース・サーバーは、親表の行の外にネストした表のデータを、ネストした表の列に対応付けた格納表を使用して格納します。親行には、ネストした表のインスタンスと対応付けられた一意の集合識別子が入れられます。
Oracle Databaseでは、永続的な表のみでなく、トランザクションまたはセッションの期間中にのみ存在するセッション用データを保持する一時表を作成できます。
CREATE GLOBAL TEMPORARY TABLE文では、トランザクションまたはセッションに固有の一時表が作成されます。トランザクション固有の一時表では、データはトランザクションの期間中のみ存在します。セッション固有の一時表では、データはセッションの期間中のみ存在します。一時表には、セッションのプライベート・データが含まれます。各セッションで表示したり変更できるのは、そのセッションの独自データのみです。一時表のデータについては、DMLロックは取得されません。各セッションに固有のプライベート・データがあるため、一時表にはLOCK文は無効です。
セッション固有の一時表に発行されたTRUNCATE文は、独自のセッションのデータを切り捨てます。同じ表を使用した他のセッションのデータは切り捨てません。
一時表でのDML文では、データ変更のREDOログは生成されません。ただし、データのUNDOログとUNDOログのREDOログは生成されます。セッションの終了時には、一時表からデータが自動的に削除されます。たとえば、ユーザーがログオフした場合や、セッション障害またはインスタンス障害の発生時など、セッションが異常終了した場合です。
一時表の索引は、CREATE INDEX文を使用して作成します。一時表に作成された索引も一時的で、その索引のデータは一時表のデータと同じセッションまたはトランザクション・スコープを持ちます。
一時表と永続表の両方にアクセスするビューを作成できます。また、一時表のトリガーを作成することも可能です。
Oracle Databaseユーティリティは、一時表の定義をエクスポートおよびインポートできます。ただし、ROWS句を使用しても、データ行はエクスポートされません。同様に、一時表の定義はレプリケートできますが、そのデータはレプリケートできません。
この項の内容は、次のとおりです。
一時表は一時セグメントを使用します。永続表とは異なり、一時表とその索引の場合、作成時にセグメントが自動的に割り当てられることはありません。かわりに、最初のINSERT(またはCREATE TABLE AS SELECT)の実行時にセグメントが割り当てられます。このため、最初のINSERTの前にSELECT、UPDATEまたはDELETEが実行されると、表は空のように見えます。
一時表でDDL文(ALTER TABLE、DROP TABLE、CREATE INDEXなど)を実行できるのは、バインドされているセッションがない場合のみです。セッションは、INSERTの実行時に一時表にバインドされます。セッションは、セッションの終了時にTRUNCATEによってアンバインドされます。またトランザクション固有の一時表の場合はCOMMITまたはROLLBACKによってアンバインドされます。
一時セグメントは、トランザクション固有の一時表の場合はトランザクションの終了時に、セッション固有の一時表の場合はセッションの終了時に割当て解除されます。
トランザクション固有の一時表には、ユーザー・トランザクションとその子トランザクションからアクセスできます。ただし、2つのトランザクションが、同じセッションで特定のトランザクション固有の一時表を同時に使用することはできません。異なるセッションであれば、複数のトランザクションが使用できます。
ユーザーのトランザクションが一時表へのINSERTを実行すると、その子トランザクションはその後一時表を使用できなくなります。
子トランザクションが一時表へのINSERTを実行すると、その子トランザクションの終了時に、一時表に対応するデータが削除されます。その後は、ユーザー・トランザクションまたは他の任意の子トランザクションから、一時表にアクセスできます。
外部表は、外部ソースのデータに対して、データベース内の表にあるデータのようにアクセスします。データベースに接続し、DDLを使用して外部表のメタデータを作成できます。外部表のDDLには、Oracle Databaseの列型を記述する部分と、外部データのOracle Databaseデータ列へのマッピングを記述する部分(アクセス・パラメータ)が含まれます。
外部表には、データベースに格納されているデータは示されません。また、外部ソースにおけるデータの格納方法も示されません。かわりに、外部表レイヤーでのサーバーに対するデータの表示方法が記述されています。外部表の定義に合うようにデータファイルのデータに必要な変換を行うのは、アクセス・ドライバおよび外部表レイヤーの役割です。
外部表は読取り専用なため、DML操作はできず、索引は作成できません。また、仮想列もサポートされていません。
この項の内容は、次のとおりです。
外部表の作成時には、その型を指定します。外部表には型ごとにアクセス・ドライバがあり、これにより外部表の型固有のアクセス・パラメータが提供されます。アクセス・ドライバにより、データ・ソースからのデータが外部表の定義に合うように処理されることを保証されます。
外部表のコンテキストでは、データのロードは、外部表からデータを読み取り、データベース内の表にロードする操作を指します。データのアンロードは、データベース内の表からデータを読み取り、外部表に挿入する操作を指します。
外部表のデフォルトの型はORACLE_LOADERです。これを使用して、外部表から表データを読み取り、データベースにロードできます。また、Oracle Databaseには、ORACLE_DATAPUMP型も用意されています。この型を使用すると、データをアンロード(データベース内の表からデータを読み取って外部表に挿入)し、Oracleデータベースに再ロードできます。
外部表の定義は、データ・ソース内のデータの記述とは個別に保持されます。これは次のことを意味します。
外部表の主な用途は、データをデータベース内の実在する表にロードする際の行ソースとすることです。外部表を作成すると、それをSELECT句のソースとして、CREATE TABLE AS SELECTまたはINSERT INTO ... AS SELECT文を使用できます。
SQL文を通して外部表にアクセスするときは、外部表のフィールドは一般の表のフィールドとまったく同じように使用できます。特に、SQLのビルトインのファンクション、PL/SQLファンクション、またはJava関数の引数として使用できます。これにより、外部ソースからのデータを操作できます。データ・ウェアハウスではこの方法により、単純なデータ型変換よりもさらに洗練された変換が可能です。また、データ・ウェアハウスでこのメカニズムを使用してデータのクレンジングを行うこともできます。
外部表に列オブジェクトを格納することはできませんが、コンストラクタ関数を使用すると外部表内の属性から列オブジェクトを作成できます。
外部表のメタデータを作成すると、SQLを使用して外部データに直接またはパラレルで問合せができます。この結果、外部表がビューとして動作するため、外部データに対するSQL問合せが外部データをデータベースにロードすることなく実行できるようになります。
外部表へのパラレル・アクセスの程度は、標準パラレル・ヒントを使用してPARALLEL句で指定します。外部表でパラレル化を使用すると、外部表を導出するデータファイルに同時アクセスができます。単一のファイルに同時アクセスができるかどうかは、アクセス・ドライバの実装およびアクセスされるデータファイルの属性(レコードのフォーマットなど)に依存します。
ビューとは、1つ以上の表または他のビューに含まれているデータを調整して表現したものです。ビューは問合せの出力を受け取り、それを表として扱います。そのためビューは、ストアド・クエリーまたは仮想表とみなすこともできます。多くの場合、ビューは表と同じように使用できます。
たとえば、employees表には、いくつかの列と多数の情報行があります。ユーザーにはそのうちの5つの列または特定の行しか参照させないようにする場合は、他のユーザーがアクセスできるようにビューを作成できます。
図5-5に、実表employeesから導出されたstaffというビューの例を示します。ビューが、実表の5つの列のみを表示していることに注目してください。
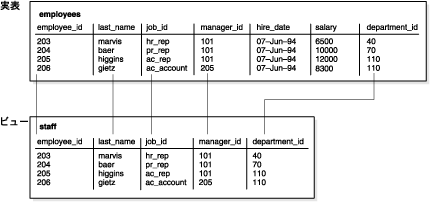
ビューは表から導出されるため、ビューと表には多数の類似点があります。たとえば、ビューには表と同じように最大1000個の列を定義できます。ビューは問合せが可能なだけでなく、いくつかの制限付きでビューのデータを更新、挿入および削除できます。実際にビューに対して実行されるすべての操作は、そのビューの実表のデータに影響し、実表の整合性制約とトリガーの対象になります。
ビューではトリガーを明示的に定義できませんが、ビューから参照される実表に対しては定義できます。Oracle Databaseでは、ビューの論理的制約の定義はサポートされません。
この項の内容は、次のとおりです。
表とは異なり、ビューには記憶域は割り当てられず、実際にデータが格納されることもありません。ビューは、参照する表からデータを抽出または導出する問合せによって定義されます。これらの表は実表と呼ばれます。実表としては、実際の表またはビュー(マテリアライズド・ビューを含む)を使用できます。ビューは他のオブジェクトを基盤としているため、データ・ディクショナリ内のビューの定義(ストアド・クエリー)以外には記憶域が必要ありません。
ビューは、実表に含まれるデータをいろいろな表現形式で表現する手段を提供します。様々なユーザーにあわせてデータの表現形式を変化させることができるため、ビューは非常に強力な機能です。通常、ビューは次の目的で使用されます。
たとえば、図5-5は、staffビューに実表employeesの列salaryまたはcommission_pctが含まれない仕組みを示しています。
たとえば、複数の表の関連した列または行を1つにまとめる結合処理によって、単一のビューを定義できます。ただし、ビューからは、この情報が複数の表から抽出されたものであるということはわかりません。
たとえば、ユーザーが結合の方法を知らなくても、複数の表から情報を選択できるようにします。
たとえば、ビューが基礎にしている表に影響を与えずに、ビューの列名を変更できます。
たとえば、ビューを定義している問合せが表の4つの列の中の3つの列を参照している場合、たとえ5番目の列が追加されてもビューの定義は影響を受けないため、ビューを使用しているすべてのアプリケーションも影響を受けません。
たとえば、GROUP BYビューと表を結合してビューを定義できます。また、UNIONビューと表を結合してビューを定義することもできます。
たとえば、ある問合せで表情報に対して複雑な計算を実行したとします。この問合せをビューとして保存しておくと、そのビューに問合せを行うたびに同じ計算が実行されます。
Oracle Databaseでは、ビューの定義は、ビューを定義する問合せテキストとしてデータ・ディクショナリに保存されます。SQL文でビューを参照すると、Oracle Databaseでは次のように処理されます。
Oracle Databaseでは、新しい共有SQL領域内のビューを参照する文は、既存の共有SQL領域に同様の文が含まれていない場合にのみ解析されます。したがって、ビューを使用すると、共有SQLに対応付けられているメモリーの使用量を減らせるという利点があります。
この項の内容は、次のとおりです。
文字列リテラルまたはグローバリゼーション・サポート・パラメータを引数として持つSQL関数(TO_CHAR、TO_DATEおよびTO_NUMBERなど)が組み込まれているビューを評価する際、Oracle Databaseでは、セッションのグローバリゼーション・サポート・パラメータから、これらのパラメータのデフォルト値を取得します。これらのデフォルト値は、ビュー定義の中でグローバリゼーション・サポート・パラメータを明示的に指定することでオーバーライドできます。
Oracle Databaseでは、元の問合せをビュー定義の問合せとマージする際に、元の問合せを変換することによって、ビューに対する問合せで索引を使用するかどうかが決まります。
次のビューを考えてみます。
CREATE VIEW employees_view AS SELECT employee_id, last_name, salary, location_id FROM employees JOIN departments USING (department_id) WHERE departments.department_id = 10;
ここで、ユーザーは次の問合せを発行します。
SELECT last_name FROM employees_view WHERE employee_id = 9876;
Oracle Databaseでは、次のような問合せが最終的に作成されます。
SELECT last_name FROM employees, departments WHERE employees.department_id = departments.department_id AND departments.department_id = 10 AND employees.employee_id = 9876;
可能な場合、Oracle Databaseは、ビューに対する問合せを、ビュー定義の問合せおよび基礎となるビューの問合せとマージします。Oracle Databaseにより、マージされた問合せは、ビューを参照せずに問合せを発行したかのように最適化されます。そのため、Oracle Databaseでは、列がビュー定義で参照されても、またはビューに対するユーザーの問合せで参照されても、参照される実表の列に対する索引を使用できます。
Oracle Databaseでは、ユーザーの発行した問合せとビュー定義をマージできないこともあります。その場合、Oracle Databaseは参照された列の索引すべてを使用できるとはかぎりません。
ビューは、他のオブジェクト(表、マテリアライズド・ビューまたは他のビュー)を参照する問合せによって定義されるため、参照されるオブジェクトに依存します。Oracle Databaseでは、ビューの依存性は、自動的に処理されます。たとえば、いったん削除されたビューの実表が再作成された場合、Oracle Databaseは、新しい実表がそのビューの既存の定義と一致するかどうかを確認します。
結合ビューは、FROM句(結合)に複数の表またはビューを持ち、かつDISTINCT、AGGREGATION、GROUP BY、START WITH、CONNECT BYおよびROWNUMのいずれの句も使用せず、また集合演算(UNION ALL、INTERSECTなど)も使用しないビューとして定義されます。
更新可能な結合ビューとは、2つ以上の実表またはビューを含み、UPDATE、INSERTおよびDELETEの各操作が実行可能である結合ビューです。ビューのどの列が更新可能であるかを示す情報は、データ・ディクショナリ・ビューALL_UPDATABLE_COLUMNS、DBA_UPDATABLE_COLUMNSおよびUSER_UPDATABLE_COLUMNSに含まれています。本質的に更新可能であるためには、ビューは次の構成メンバーを含むことはできません。
DISTINCT演算子
GROUP BY句、ORDER BY句、CONNECT BY句またはSTART WITH句
SELECT構文のリストのコレクション式
SELECT構文のリストの副問合せ
更新可能でないビューは、INSTEAD OFトリガーを使用して変更できます。
Oracleオブジェクト・リレーショナル・データベースの場合、オブジェクト・ビューを使用すると、リレーショナル・データを、それがオブジェクト型として格納されているかのように検索、更新、挿入および削除できます。また、オブジェクト、REFおよびコレクション(ネストした表とVARRAY)などのオブジェクト・データ型である列を持つビューを定義できます。
インライン・ビューは、スキーマ・オブジェクトではありません。SQL文内でビューのように使用できる、別名(相関名)を持つ副問合せです。
マテリアライズド・ビューは、データの集計、計算、レプリケートおよび分配に使用できるスキーマ・オブジェクトです。この種のビューは、データ・ウェアハウス、意思決定支援および分散コンピューティングやモバイル・コンピューティングなど、様々なコンピュータ環境に適しています。
オプティマイザでは、可能かつ必要な場合を自動的に認識して、マテリアライズド・ビューを使用して問合せのパフォーマンスを改善できます。要求は、マテリアライズド・ビューを使用するように、オプティマイザによって自動的に透過的にリライトされます。その後、問合せは、基礎となるディテール表やビューではなく、マテリアライズド・ビューに送られます。
マテリアライズド・ビューは、いくつかの点で索引に似ています。
索引とは異なり、マテリアライズド・ビューには、SELECT文を使用して直接アクセスできます。必要なリフレッシュのタイプによっては、INSERT、UPDATEまたはDELETE文で直接アクセスすることも可能です。
マテリアライズド・ビューはパーティション化できます。マテリアライズド・ビューは、そのパーティション表および1つ以上の索引上で定義できます。
この項の内容は、次のとおりです。
関連項目
データ・ウェアハウス・アプリケーションは、Oracleデータベースにあるマルチディメンションのデータを、リレーショナル・スキーマにおける参照整合性(RI)制約を特定することによって認識します。RI制約は、各表の間での主キーや外部キーの関係を表します。Oracle Databaseデータ・ディクショナリに問い合せることにより、アプリケーションはRI制約を認識し、それによってデータベース内のマルチディメンションのデータを認識できるようになります。一部の環境では、スキーマの複雑性またはセキュリティ上の理由から、データベース管理者はビューをファクト表およびディメンション表で定義します。Oracle Databaseでは、ビューの制約のための機能が提供されています。各ビュー間の制約定義を許可すると、データベース管理者は実表制約をビューに伝播できるようになり、それによってアプリケーションが制限付きの環境でもマルチディメンションのデータを認識できるようになります。
ビューで定義できるのは、論理的な制約、つまり宣言制約であってOracle Databaseによって規定されていない制約のみです。これらの制約の目的は、ビジネス・ルールの規定ではなく、マルチディメンション・データを識別することです。ビューでは次の制約を定義できます。
ビューの制約が宣言制約の場合、有効な状態はDISABLE、NOVALIDATEのみです。ただし、ビューの制約はより洗練されたクエリー・リライトのために使用される場合があるため、RELYまたはNORELYの状態も認められます。RELY状態にあるビューの制約は、リライトの整合性レベルがトラステッド・モードに設定されている場合に、クエリー・リライトを許可します。
Oracle Databaseでは、マスター表の変更後にマテリアライズド・ビューをリフレッシュして、マテリアライズド・ビューのデータを管理します。リフレッシュ方法には、増分リフレッシュ(高速リフレッシュ)または完全リフレッシュがあります。高速リフレッシュ方法を使用する場合、マスター表に対する変更はマテリアライズド・ビュー・ログまたはダイレクト・ローダー・ログに記録されます。
マテリアライズド・ビューは、必要時に、または定期的にリフレッシュできます。また、マスター表と同じデータベース内のマテリアライズド・ビューは、トランザクションによってマスター表の変更がコミットされるたびにリフレッシュできます。
マテリアライズド・ビュー・ログとは、マスター表に定義されているマテリアライズド・ビューの増分リフレッシュを実行できるように、マスター表の変更を記録するスキーマ・オブジェクトです。
マテリアライズド・ビュー・ログは、それぞれ1つのマスター表に対応付けられています。マテリアライズド・ビュー・ログは、マスター表と同じデータベースおよびスキーマに格納されます。
ディメンションは、1対の列または列セット間の階層(親子)関係を定義します。子レベルの値は、それぞれが親レベルの1つの値にのみ対応付けられます。階層関係は、ある階層レベルから次のレベルへの機能上の依存関係です。ディメンションは、列相互の論理関係のコンテナで、それにはデータ記憶域は割り当てられません。
CREATE DIMENSION文では、次の事項を指定します。
LEVEL句。それぞれがディメンション内の1列または列の集合を識別します。
HIERARCHY句。隣接するレベル間の親子関係を指定します。
ATTRIBUTE句。それぞれが個々のレベルに対応付けられている他の列または列セットを識別します。
ディメンション内の列は、同じ表のもの(非正規化)でも複数の表のもの(完全正規化または一部正規化)でもかまいません。複数の表からの列によるディメンションを定義するには、HIERARCHY句のJOIN句を使用して表を接続します。
たとえば、正規化されているtimeディメンションには、date表、month表およびyear表と、各date行をmonth行に、各month行をyear行に接続する結合条件を含めることができます。完全な非正規化のtimeディメンションでは、date、monthおよびyear列はすべて同じ表に格納されます。正規化されているかどうかに関係なく、列相互の階層関係をCREATE DIMENSION文で指定する必要があります。
シーケンス・ジェネレータは、連続的な数値を生成します。また、ディスクI/Oやトランザクション・ロックなどのオーバーヘッドを発生させずに、一意の連続的な数を生成するため、マルチユーザー環境では特に有効です。たとえば、2人のユーザーがemployees表に新しい従業員の行を同時に挿入しているとします。順序を使用してemployee_id列に一意の従業員番号を生成すると、一方のユーザーは、他方のユーザーが従業員番号を入力するのを待機する必要はありません。どちらのユーザーにも、順序により、正しい値が自動的に生成されるためです。
したがって、このシーケンス・ジェネレータによってシリアライズ(2つのトランザクションの文が連続番号を同時に生成する必要がある状態)が低減されます。このシリアライズを避けることによって、トランザクションのスループットが改善され、ユーザーの待ち時間が大幅に短縮されます。
順序番号とは、データベース内で定義される最大38桁の整数です。順序の定義には、次のように一般的な情報を指定します。
Oracle Databaseでは、特定のデータベースのすべての順序定義が、SYSTEM表領域内の単一のデータ・ディクショナリ表に行として保存されます。したがって、SYSTEM表領域は常時オンラインであるため、すべての順序定義がいつでも使用できます。
順序番号は、順序を参照するSQL文によって使用されます。文を発行して、新しい順序番号を生成することも、現行の順序番号を使用することもできます。ユーザーのセッションにおける文が順序番号を生成すると、その特定の順序番号はそのセッションのみに使用可能となります。順序を参照する各ユーザーは、現行の順序番号にアクセスできます。
順序番号は表からは独立して生成されます。そのため、同じシーケンス・ジェネレータを複数の表に対して使用できます。順序番号の生成は、データに対して一意の主キーを自動的に生成する場合や、複数の行または表にまたがるキーを統合する場合に有効です。最終的にロールバックされたトランザクションで生成されて使用された個々の順序番号はスキップされます。必要に応じて、アプリケーションは、これらの順序番号を受け取って再利用するように作成することもできます。
シノニムとは、表、ビュー、マテリアライズド・ビュー、順序、プロシージャ、ファンクション、パッケージ、型、Javaクラスのスキーマ・オブジェクト、ユーザー定義オブジェクト型または他のシノニムの別名です。シノニムは単なる別名であるため、データ・ディクショナリ内の定義以外に記憶域は必要ありません。
シノニムは、セキュリティと便利さのために使用されます。たとえば、次のような利点があります。
パブリック・シノニムとプライベート・シノニムの両方を作成できます。パブリック・シノニムは、PUBLICという名前の特別なユーザー・グループが所有しており、データベースのすべてのユーザーがアクセスできます。プライベート・シノニムは、特定のユーザーのスキーマに含まれており、そのユーザーが他のユーザーに対するシノニムの使用許可を制御します。
シノニムは、分散システム内の位置を含めて、基礎になるオブジェクトの識別を隠すため、分散データベース環境でもそれ以外の環境でもきわめて役立ちます。基礎となるオブジェクトを改名または移動する必要がある場合、シノニムのみを再定義すればよいので便利です。シノニムに基づくアプリケーションは、今後も変更なしに機能し続けることができます。
また、分散データベース・システム内のユーザーのために、シノニムによってSQL文を単純化できます。実表の識別を隠したり、SQL文の複雑さを低減するために、データベース管理者はパブリック・シノニムを作成する場合があります。その理由と作成方法を次の例で説明します。この例では、次のような状況を想定します。
この時点で、データベースのユーザーが、次のようなSQL文を使用してSALES_DATA表を問い合せる必要があります。
SELECT * FROM jward.sales_data;
問合せを実行するには、表を含むスキーマと表の名前の両方を含める必要があることに注意してください。
データベース管理者が次のSQL文によって、パブリック・シノニムを作成するとします。
CREATE PUBLIC SYNONYM sales FOR jward.sales_data;
パブリック・シノニムが作成されると、ユーザーは、次のような単純なSQL文でSALES_DATA表を問い合せることができます。
SELECT * FROM sales;
パブリック・シノニムSALESは、表SALES_DATAの名前とその表を含むスキーマ名を隠していることに注意してください。
索引は、表とクラスタに対応付けるオプションの構造体です。表の1つ以上の列に索引を作成し、その表に対するSQL文の実行を高速化できます。このマニュアルでも、索引を使用すると特定の情報をすばやく見つけることができます。同様に、Oracle Databaseの索引を使用すると表データに高速にアクセスできます。適切に使用すると、索引はディスクI/Oを低減する基本的な手段になります。
表には、列の組合せが索引ごとに異なるかぎり、いくつもの索引を作成できます。列の組合せを個別に指定すると、同じ列を使用して複数の索引を作成できます。たとえば、次の文では有効な組合せを指定しています。
CREATE INDEX employees_idx1 ON employees (last_name, job_id); CREATE INDEX employees_idx2 ON employees (job_id, last_name);
Oracle Databaseは、パフォーマンスの機能性を補足する複数の索引体系を提供しています。
また、Oracle Databaseではアプリケーションまたはカートリッジ固有のファンクション索引やドメイン索引もサポートしています。
索引の有無によって、SQL文の表現を変更する必要はありません。索引は、単なるデータへの高速なアクセス・パスです。実行のスピードにのみ影響を与えます。索引の付いたデータ値では、索引はその値を含んでいる行の位置を直接示すポインタとして機能します。
索引は、関連する表のデータから論理的にも物理的にも独立しています。索引は、実表や他の索引に影響を及ぼさずにいつでも作成または削除できます。索引を削除しても、すべてのアプリケーションは機能を続けます。ただし、索引設定されていたデータへのアクセスは低速になる場合があります。索引は独立した構造体であるため、記憶域を必要とします。
作成された索引は、Oracle Databaseによって自動的にメンテナンスされ、使用されます。Oracle Databaseでは、行の新規追加、更新または削除など、データに対する変更が、関連するすべての索引に自動的に反映され、ユーザーによる操作は不要です。
新たにいくつかの行が挿入されても、索引付きのデータ検索のパフォーマンスはほとんど一定です。ただし、表に対して数多くの索引が存在すると、更新、削除および挿入のパフォーマンスは低下します。これは、Oracle Databaseでは表に関連する索引も更新する必要があるためです。
オプティマイザは、既存の索引を使用して別の索引を作成できます。この結果、索引作成がはるかに高速になります。
この項の内容は、次のとおりです。
索引には、一意索引と非一意索引の2種類があります。一意索引によって、キー列(1つまたは複数)に重複値を持つ行が複数存在しないことが保証されます。非一意索引の場合は、列値にこのような制限はありません。
一意索引は、CREATE UNIQUE INDEXを使用して、明示的に作成することをお薦めします。主キーまたは一意制約による一意索引の作成では、新規索引の作成は保証されず、作成される索引が一意索引となる保証もありません。
索引には、参照用と非参照用の2種類があります。非参照用索引はDML操作により維持され、オプティマイザでは使用できません。
索引を使用不可にしたり削除する代替手段として、その索引を非参照用にすることもできます。
コンポジット索引(連結索引とも呼ばれる)は、表の中の複数の列に対して作成される索引です。コンポジット索引を構成する複数の列は、どんな順序で指定してもかまいません。また、コンポジット索引の列は表の中で隣接している必要もありません。
SELECT文のWHERE句でコンポジット索引のすべての列または列の先頭部分を参照する場合には、コンポジット索引によってデータの検索速度を向上させることができます。そのため、定義で使用する列の順序は重要です。通常、最も頻繁にアクセスされる列または最も選択的な列が最初になります。
図5-6は、VENDOR_IDおよびPART_NO列にコンポジット索引を設定したVENDOR_PARTS表を示しています。

通常のコンポジット索引は、最大32列で形成されます。ビットマップ索引の場合、列の最大数は30です。キー値は、データ・ブロック内の使用可能データ領域のおよそ2分の1(オーバーヘッド分を差し引いたもの)を超えることはできません。
索引とキーという用語は同じ意味で使用されることがありますが、これらの用語には違いがあります。索引は、データベース内に実際に格納される構造体であり、ユーザーはSQL文を使用して作成、変更および削除します。作成された索引により、表データへの高速なアクセス・パスが提供されます。一方、キーは厳密に論理的な概念です。キーは、整合性制約と呼ばれる、データベースのビジネス・ルールを規定するOracle Databaseのもう1つの機能に対応しています。
Oracle Databaseでは索引を使用して一部の整合性制約を規定するため、キーと索引という2つの用語はよく同じ意味で使用されます。ただし、これらの用語を混同しないでください。
索引内に複数のNULL値を持つ行が存在する場合、それぞれの行は別個のものとみなされます。ただし、索引内にNULLでない同一の値を持つ行が2行以上存在する場合は、それらの行は同一とみなされます。したがって、一意索引では、行にNULL値が含まれていると、同一の行として処理されません。この規則は、NULL以外の値が存在しない場合、つまり、行全体がNULLの場合には適用されません。
Oracle Databaseでは、すべてのキー列がNULLの表の行には、索引は作成されません。ただし、ビットマップ索引の場合や、クラスタ・キーの列値がNULLの場合は例外です。
表に索引を設定する場合、その表の1つ以上の列を含むファンクションと式について、索引を作成できます。ファンクション索引では、ファンクションや式の値が計算され、索引に格納されます。ファンクション索引は、Bツリーまたはビットマップ索引として作成できます。
索引作成に使用するファンクションには、算術式あるいはPL/SQLファンクション、パッケージ・ファンクション、CコールアウトまたはSQL関数を含む式を使用できます。式に集計関数を含むことはできず、DETERMINISTICにする必要があります。オブジェクト型を含む列の索引を作成する場合は、マップ・メソッドなど、そのオブジェクトのメソッドをファンクションとして使用できます。ただし、LOB列、REFまたはネストした表の列には、ファンクション索引を作成できません。また、オブジェクト型にLOB、REFまたはネストした表が含まれる場合も作成できません。
この項の内容は、次のとおりです。
ファンクション索引は、WHERE句にファンクションを含む文を効率的に評価するメカニズムを提供します。式の値は計算されて、索引に格納されます。ただし、INSERT文とUPDATE文の処理中には、Oracle Databaseでは文を処理するために従来どおりファンクションを評価する必要があります。
たとえば、次の索引を作成する場合を考えます。
CREATE INDEX idx ON table_1 (a + b * (c - 1), a, b);
Oracle Databaseでは、次のような問合せを処理するときにこの索引を使用できます。
SELECT a FROM table_1 WHERE a + b * (c - 1) < 100;
UPPER(column_name)またはLOWER(column_name)でファンクション索引を定義すると、大文字/小文字区別の検索が容易になります。たとえば、次の索引があります。
CREATE INDEX uppercase_idx ON employees (UPPER(first_name));
この索引により、次のような問合せの処理が容易になります。
SELECT * FROM employees WHERE UPPER(first_name) = 'RICHARD';
また、ファンクション索引は、SQL文に効率的な言語照合機能を提供するグローバリゼーション・サポート・ソート索引にも使用できます。
オプティマイザを使用するには、ファンクション索引に関する統計を収集する必要があります。この統計がないと、SQL文の処理に索引を使用できません。
オプティマイザでは、WHERE句の式による問合せに、ファンクション索引に対する索引レンジ・スキャンを使用できます。たとえば、次の問合せで考えてみます。
SELECT * FROM t WHERE a + b < 10;
a+bの索引が作成されていれば、オプティマイザは索引レンジ・スキャンを使用できます。レンジ・スキャンのアクセス・パスは、述語(WHERE句)の選択性が低い場合に特に便利です。また、式がファンクション索引で具象化されていると、より正確な式を必要とする述語の選択性をオプティマイザで見積ることができます。
オプティマイザは、SQL文の式を解析し、文の式ツリーとファンクション索引を比較して、式のマッチングを実行します。この比較は大文字/小文字が区別され、ブランクは無視されます。
ファンクション索引は、その索引を定義している式に使用されたファンクションに依存しています。ファンクションがPL/SQLファンクションまたはパッケージ・ファンクションの場合は、ファンクションの仕様に変更があると索引は使用禁止になります。
ファンクション索引を作成するには、CREATE INDEXまたはCREATE ANY INDEX権限が付与されている必要があります。
ファンクション索引を使用する手順は次のとおりです。
この後の各項では、追加の要件について説明します。
ファンクション索引に使用するユーザー記述の関数は、現在も将来も入力引数値の集合に対して常に同じ出力戻り値を戻すことを示すために、DETERMINISTICキーワードで宣言する必要があります。
索引所有者は、ファンクション索引の定義に使用する関数に対してEXECUTE権限を持つ必要があります。Oracle Databaseでは、EXECUTE権限が取り消されると、索引にDISABLEDマークが設定されます。索引所有者は、この関数に対するEXECUTE WITH GRANT OPTION権限がなくても、基礎となる表にSELECT権限を付与できます。
ファンクション索引は、それを使用するファンクションに依存します。ファンクション、またはそのファンクションを含むパッケージの仕様部が再定義されると(または、索引所有者のEXECUTE権限が取り消されると)、次の条件が成立します。
DISABLEDマークが設定されます。
DISABLED索引の問合せは、オプティマイザが索引を使用するために選択すると、失敗します。
DISABLED索引のDML操作は、索引にさらにUNUSABLEマークが設定され、初期化パラメータSKIP_UNUSABLE_INDEXESがTRUEに設定されていない場合は、失敗します。
ファンクションの変更後に索引を再度使用可能にするには、ALTER INDEX ... ENABLE文を使用します。
Oracle Databaseでは、索引を作成する際に、索引のデータを保持するための索引セグメントが表領域内に自動的に割り当てられます。索引セグメントへの領域の割当てと、確保された領域の使用は、次の方法で制御できます。
PCTFREEパラメータを設定すると制御できます。
索引セグメントの表領域は、所有者のデフォルト表領域またはCREATE INDEX文で指定された表領域です。索引を、その索引に対応する表と同じ表領域に格納する必要はありません。また、Oracle Databaseでは、索引と表データを並行して取得できるため、索引とその表をそれぞれ別のディスク・ドライブ上の異なる表領域内に格納して、索引を使用する問合せのパフォーマンスを向上させることができます。
この項の内容は、次のとおりです。
索引データのために使用できる領域は、Oracle Databaseブロック・サイズから、ブロック・オーバーヘッド、エントリ・オーバーヘッド、ROWIDおよび索引が作成される値1つ当たり1バイトの合計を引いたものです。
索引を作成する際に、Oracle Databaseは、索引を付ける列をフェッチしてソートし、ROWIDを各行の索引値とともに保存します。次に、Oracle Databaseは、索引の一番下から順にロードします。たとえば、次の文を考えてみます。
CREATE INDEX employees_last_name ON employees(last_name);
Oracle Databaseは、last_name列に基づいてemployees表をソートします。次に、このソート順に、last_nameとそれに対応するROWIDという形で索引をロードします。索引を使用するときに、Oracle Databaseは、ソートされたlast_name値を迅速に検索し、その値に対応するROWID値を使用して、求めるlast_name値を持つ行を見つけます。
Oracle Databaseは、索引の格納にBツリーを使用して、データ・アクセスを高速化します。索引がない場合は、データの順次スキャンを行って値を検索する必要があります。行数がnの場合、検索される行数の平均はn/2になります。したがって、データの量が多くなるほど、正確な結果を得られません。
ブロック幅範囲(リーフ・ブロック)に分割されている、順序付けされた値リストを考えてみます。範囲のエンド・ポイントはブロックへのポインタとともに検索ツリーに格納できるため、nエントリのログ(n)タイムで値を検索できます。これがOracle Database索引の基本原理です。
図5-7に、Bツリー索引の構造を示します。
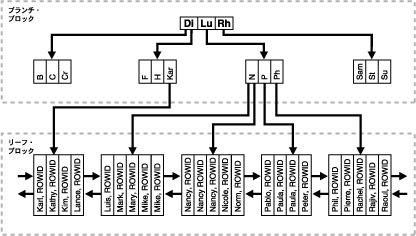
Bツリー索引の上位ブロック(ブランチ・ブロック)には、下位レベルの索引ブロックを指す索引データが含まれます。最下位レベルの索引ブロック(リーフ・ブロック)には、すべての索引対象のデータ値と、実際の行を検出するためのROWIDが含まれます。リーフ・ブロックは二重にリンクされます。文字データを持つ列の索引は、データベース・キャラクタ・セットにおける文字のバイナリ値を基盤にしています。
一意索引の場合、データ値ごとにROWIDが1つ存在します。非一意索引の場合、ROWIDはソートするためのキーに含まれるため、非一意索引は索引キーとROWIDによってソートされます。クラスタ索引を除いて、NULLのみを含んでいるキーに索引は定義できません。2つの行にNULLのみを含めても、一意索引には違反しません。
ブロックには2つの種類があります。
ブランチ・ブロックには次のものが格納されます。
ブロックにn個のキーがある場合、n+1個のポインタがあります。キーおよびポインタの数は、ブロックのサイズによって制限されます。
リーフ・ブロックはすべて、ルート・ブランチ・ブロックからの深さが同じになります。リーフ・ブロックには次のものが格納されます。
キーとROWIDのペアはすべて、左右の兄弟関係にリンクされています。これらは(キー、ROWID)によってソートされます。
Bツリー構造の利点は、次のとおりです。
索引の一意スキャンは、データへの最も効率的なアクセス方法の1つです。このアクセス方法は、Bツリー索引からデータを戻す際に使用されます。一意(Bツリー)索引のすべての列が等価条件で指定されると、オプティマイザは一意スキャンを選択します。
索引レンジ・スキャンは、選択的なデータにアクセスする際の一般的な操作です。これは境界(両側に境界あり)または非有界(片側または両側)になります。データは、索引列の昇順で戻されます。値が同一の複数行は、ROWIDによって昇順でソートされます。
キー圧縮により、索引または索引構成表内で主キーの列値の各部を圧縮し、繰り返される値による記憶域のオーバーヘッドが低減します。
通常、索引のキーには、グループ化要素および一意要素という2つの要素があります。一意要素を持つようにキーを定義しなければ、Oracle Databaseがグループ化要素にROWIDを追加して一意要素を提供します。キー圧縮は、複数の一意要素で共有できるように、グループ化要素を分割し、格納する方法です。
この項の内容は、次のとおりです。
キー圧縮により、索引キーが接頭辞エントリ(グループ化要素)と接尾辞エントリ(一意要素)に分割されます。圧縮するために、接頭辞エントリが索引ブロック内の接尾辞エントリ間で共有されます。圧縮されるのは、Bツリー索引のリーフ・ブロックのキーのみです。ブランチ・ブロックの場合、キーの接尾辞は切り捨てることができますが、キーは圧縮されません。
キー圧縮は、複数の索引ブロック間ではなく、1つの索引ブロック内で実行されます。接尾辞エントリは、索引行の圧縮版を形成します。各接尾辞エントリは、同じ索引ブロックに格納されている接頭辞エントリを参照します。
デフォルトで、接頭辞は、最終列を除く、すべてのキー列で構成されます。たとえば、3列(column1, column2, column3)からなるキーの場合、デフォルトの接頭辞は(column1, column2)です。値リスト(1,2,3)、(1,2,4)、(1,2,7)、(1,3,5)、(1,3,4)、(1,4,4)の場合は、接頭辞内で重複する(1,2)、(1,3)が圧縮されます。
また、接頭辞の長さは、接頭辞に含まれる列数として指定できます。たとえば、接頭辞の長さを1と指定すると、その接頭辞はcolumn1、接尾辞は(column2, column3)となります。値リスト(1,2,3)、(1,2,4)、(1,2,7)、(1,3,5)、(1,3,4)、(1,4,4)の場合は、接頭辞内で重複する1が圧縮されます。
非一意索引の接頭辞の最大長はキー列の数であり、一意索引の接頭辞の最大長は、キー列の数から1を差し引いた値です。
接頭辞エントリは、それと等しい値を持つ接頭辞エントリが索引ブロックに含まれていない場合にのみ、索引ブロックに書き込まれます。接頭辞エントリは、索引ブロックに書き込まれた直後から共有可能になり、最後に削除した参照側の接尾辞エントリが索引ブロックから消去されるまで使用可能のままです。
キー圧縮を使用すると、領域が大幅に節約になり、索引ブロック当たりで格納できるキー数が増え、I/Oが減少してパフォーマンスが向上します。
ただし、索引の記憶域必要量は減少しますが、索引スキャン中にキー列値を再構築するためのCPUタイムが増大することがあります。また、各接頭辞エントリには、対応する4バイトのオーバーヘッドが生じるため、記憶域のオーバーヘッドが大きくなります。
キー圧縮は、次のように様々な状況で役立ちます。
stock_ticker, transaction_time)など、(項目, タイムスタンプ)形式のキーを持つ一意索引にも見られます。多数の行が同じstock_ticker値を持ち、transaction_timeによって一意性が保たれます。特定の索引ブロックでは、stock_ticker値が接頭辞エントリとして一度のみ格納されます。索引ブロックの他のエントリでは、transaction_time値が共通のstock_ticker接頭辞エントリを参照する接尾辞エントリとして格納されます。
VARRAYまたはNESTED TABLEデータ型を含む索引構成表の場合は、コレクション・データ型の要素ごとにオブジェクト識別子が繰り返されます。キー圧縮を使用すると、重複するオブジェクト識別子の値を圧縮できます。
ただし、キー圧縮を使用できない場合があります。たとえば、単一の属性キーを持つ一意索引の場合、一意要素はありますが、共有するグループ化要素がないため、キー圧縮は使用できません。
逆キー索引を作成する場合は、標準の索引とは異なり、列の順序は保ちながら、索引が定義されている各列(ROWIDを除く)のバイトを逆にします。索引に対する変更が少数のリーフ・ブロックに集中するOracle Real Application Clustersでは、この機能によりパフォーマンスの低下を防ぐことができます。索引のキーを逆にすることにより、挿入値は索引のリーフ・キー全体に分散されます。
逆キーを使用すると、その索引に対する索引レンジ・スキャンは実行できなくなります。逆キー索引では辞書的に連続しているキーが隣接して格納されないため、キー指定フェッチまたは全索引(表)スキャンしか実行できません。
状況によっては、逆キー索引を使用することで、OLTPのOracle Real Application Clustersアプリケーションが高速になる場合があります。たとえば、電子メール・アプリケーションでメール・メッセージの索引を保存し、ユーザーが古いメッセージを保存する場合、索引は最新のメールに対するポインタと同様に古いメッセージに対するポインタもメンテナンスする必要があります。
REVERSEキーワードは、逆キー索引を作成するための簡単なメカニズムを備えています。CREATE INDEX文のオプションの索引仕様部にREVERSEキーワードを指定します。
CREATE INDEX i ON t (a,b,c) REVERSE;
逆キー索引を標準の索引にREBUILD(再作成)するには、キーワードNOREVERSEを指定します。
ALTER INDEX i REBUILD NOREVERSE;
NOREVERSEキーワードを指定しないで逆キー索引を再作成すると、逆キー索引が再作成されて生成されます。
索引を使用する目的は、特定のキー値が含まれる行へのポインタを提供することです。通常の索引では、そのキー値を持つ行に対応する各キーのROWIDのリストが格納されます。Oracle Databaseでは、各ROWIDとともに各キー値が繰り返し格納されます。ビットマップ索引では、ROWIDのリストのかわりに、各キー値のビットマップを使用します。
ビットマップの各ビットは、存在するROWIDに対応します。ビットが設定されている場合は、対応するROWIDを持つ行にはキー値が含まれることになります。マッピング機能がビット位置を実際のROWIDに変換するため、内部的には別の表現が使用されていても、ビットマップ索引は通常の索引と同じ機能を果します。異なるキー値の数が多くない場合、ビットマップ索引は領域を有効に使用できます。
ビットマップ索引は、WHERE句に指定されたいくつかの条件に対応する索引を効率的にマージします。一部の条件は満たしているがすべては満たしていない行については、表自体にアクセスする前に除外します。これによって、応答時間が短縮されます。多くの場合は劇的に改善されます。
この項の内容は、次のとおりです。
ビットマップ索引は、大量のデータと非定型問合せを扱うものの、同時実行トランザクションのレベルは高くないデータ・ウェアハウス・アプリケーションに対して効果的です。この種のアプリケーションに対するビットマップ索引の利点は次のとおりです。
従来のBツリー索引を使用して大きな表に完全な索引を作成すると、領域という面で膨大なコストがかかります。索引は表中のデータの何倍にも膨れ上がることがあるからです。それに対して、ビットマップ索引は通常、表中で索引を付けるデータのサイズより小さくてすみます。
ビットマップ索引は、数多くの並列トランザクションがデータを更新するOLTPアプリケーションには適していません。むしろ、ユーザーがデータの更新より問合せを実行することが多い、データ・ウェアハウス・アプリケーションの意思決定支援システムに適しています。
ビットマップ索引はまた、主として大小の比較による問合せの対象とされる列には適していません。たとえば、通常特定の値との比較におけるWHERE句に現れる給与の列には、Bツリー索引の方が適しています。ビットマップ化された索引は、特にAND、ORおよびNOT演算子と組み合せた等価問合せでのみ有効です。
ビットマップ索引は、Oracle Databaseオプティマイザおよび実行エンジンと統合されます。また、他のOracle Database実行メソッドとシームレスに組み合せて使用できます。たとえば、オプティマイザが2つの表をハッシュ結合するように決めたとします。片方の表ではビットマップ索引を、もう一方の表では通常のBツリー索引を使用します。オプティマイザはビットマップ索引と他の使用可能なアクセス方法(通常のBツリー索引または全表スキャンなど)を検討し、可能な場合にはパラレル化も考慮に入れながら、最適な方法を選択します。
パラレル問合せおよびパラレルDMLは、従来の索引のみでなく、ビットマップ索引に対しても機能します。パーティション表のビットマップ索引は、ローカル索引であることが必要です。索引のパラレル作成と連結索引もサポートされています。
ビットマップ索引の使用によるメリットは、カーディナリティの低い列、つまり表内の行数に比べて個別値の数が少ない列において、最も大きくなります。列の個別値の数が表内の行数の1%より少ない場合、または列内の値が100回以上繰り返される場合は、列はビットマップ索引の候補となります。値の繰返しが少なく、カーディナリティが高い列でも、その列が問合せのWHERE句で複雑な条件に含まれることが頻繁にある場合は、ビットマップ索引の候補になります。
たとえば、100万行ある表で個別の値が10,000個ある列は、ビットマップ索引の候補です。この列に対しては、Bツリー索引よりビットマップ索引の方が効果的です。この列を他の列と組み合せて問い合せることが多い場合は、特に効果的です。
Bツリー索引は、カーディナリティの高いデータ、つまりCUSTOMER_NAMEやPHONE_NUMBERといった可能な値の多いデータにおいて最も効率的です。Bツリー索引は、索引を設定したデータよりも大きくなる場合があります。一方、ビットマップ索引は、適切に使用すればBツリー索引より相当小さなサイズですみます。
非定型の問合せ(またそれと同様の状況)では、ビットマップ索引を使用すると問合せのパフォーマンスが劇的に向上します。問合せのWHERE句のAND条件とOR条件については、結果のビットマップをROWIDに変換する前に、対応するブール演算をビットマップに直接実行すると解決をスピードアップできます。結果の行数が少なければ、全表スキャンを行う必要はないため、問合せはすぐに終了します。
表5-1に、ある会社の顧客データの一部を示します。
MARITAL_STATUS、REGION、GENDERおよびINCOME_LEVELはすべて、カーディナリティの低い列です。可能な値は、MARITAL_STATUSおよびREGIONには3つ、GENDERには2つ、INCOME_LEVELには4つしかありません。そのため、これらの列にはビットマップ索引を作成するのが適切といえます。一方、CUSTOMER#はカーディナリティの高い列であるため、ビットマップ索引は作成しません。この場合は、一意のBツリー索引を使用する方が、表示と検索が効率的になります。
表5-2に、この例のREGION列に対するビットマップ索引を示します。これは、各地域に対応する3つのビットマップからなっています。
| REGION='east' | REGION='central' | REGION='west' |
|---|---|---|
|
1 |
0 |
0 |
|
0 |
1 |
0 |
|
0 |
0 |
1 |
|
0 |
0 |
1 |
|
0 |
1 |
0 |
|
0 |
1 |
0 |
ビットマップの各エントリまたはビットはCUSTOMER表の1つの行に対応しています。各ビットの値は対応する行の値に依存しています。たとえば、ビットマップREGION='east'では、1が最初のビットとなっています。これはCUSTOMER表の最初の行で、REGIONがeastになっているためです。REGIONの値がeastの行は他にないため、ビットマップREGION='east'の残りのビットは0です。
顧客の人口統計を調べているアナリストが、「既婚の顧客のうちcentralまたはwest地域に住んでいる人はどれくらいいるのか」尋ねてきたとします。この質問は、次のSQL問合せで表現できます。
SELECT COUNT(*) FROM CUSTOMER WHERE MARITAL_STATUS = 'married' AND REGION IN ('central','west');
ビットマップ索引を使用すると、図5-8に示すとおり、結果のビットマップから該当する値を数えて、この問合せを非常に効果的に処理できます。基準に該当する特定の顧客を識別するときは、結果のビットマップを使用して表にアクセスできます。

他のほとんどのタイプの索引とは異なり、ビットマップ索引にはNULL値を持つ行が含まれる場合があります。NULLの索引作成は、集計関数COUNTによる問合せなど、いくつかのタイプのSQL文に使用できます。
他の索引の場合と同じように、ビットマップ索引もパーティション表に対して作成できます。ただし、制限が1つだけあります。ビットマップ索引はパーティション表に対してローカルであることが必要です。グローバル索引にはできません。グローバル・ビットマップ索引は、非パーティション表でのみサポートされます。
単一表には、ビットマップ索引以外に、複数の表を結合するためのビットマップ索引であるビットマップ結合索引を作成できます。ビットマップ結合索引は、制限を事前に実行するため、結合するデータのボリュームを削減する効率的な方法です。ビットマップ結合索引は、表列の値ごとに、対応する行のROWIDを1つ以上の別の表に格納します。データ・ウェアハウス環境では、結合条件はディメンション表の主キー列とファクト表の外部キー列の等価内部結合になります。
ビットマップ結合索引は、格納に関して、事前に結合をマテリアライズするマテリアライズド結合ビューよりもはるかに効率的です。これは、マテリアライズド結合ビューがファクト表のROWIDを圧縮しないためです。
索引構成表には、プライマリBツリーの改良型となる記憶域組織があります。データが順不同のコレクション(ヒープ)として格納される通常の表(ヒープ構成表)とは異なり、索引構成表のデータは主キーによるソート形式でBツリー索引構造に格納されます。Bツリーの各索引エントリには、索引構成表の行の主キー列値のみでなく、非キー列値も格納されます。
索引構成表は、図5-9に示されているとおり、通常の表と1つ以上の列の索引からなる構成にやや類似していますが、データベース・システムは表とBツリー索引という2つの記憶域構造を別個にメンテナンスするかわりに、1つのBツリー索引のみをメンテナンスします。また行のROWIDではなく、非キー列値が索引エントリに格納されます。そのため、Bツリーの各索引エントリには <primary_key_value, non_primary_key_column_values>が含まれます。

アプリケーションは、通常の表と同じように、SQL文を使用して索引構成表を操作します。ただし、データベース・システムは、対応するBツリー索引を操作することですべての操作を実行します。
表5-3に、索引構成表と通常の表の違いをまとめます。
この項の内容は、次のとおりです。
索引構成表は、主キーまたはその有効な接頭辞である任意のキーの使用により、表の行に対するアクセスを高速化します。Bツリーのリーフ・ブロックに行の非キー列が存在することにより、追加のブロック・アクセスが回避されます。さらに、行が主キーの順序で格納されるため、主キー(または有効な接頭辞)によるレンジ・アクセスでは最小限のブロック・アクセスのみが行われます。
アクセス頻度の高い列へのアクセスをさらに高速化するには、行オーバーフローのセグメント(次を参照)を使用して、アクセス頻度の低い非キー列をBツリーのリーフ・ブロックからオプションの(ヒープ構造の)オーバーフロー・セグメントにプッシュできます。これにより、Bツリーのリーフ・ブロックに実際に格納される行の部分のサイズおよび内容を制限できるため、各リーフ・ブロック内の行数を多く、かつBツリーを小さくできる場合があります。
主キー索引を持つヒープ構成表では主キー列が表と索引の両方に格納されますが、ここでは主キー列値がBツリー索引のみに格納されるため、そのような重複は起こりません。
行は主キーの順序で格納されるため、キー圧縮を使用すると多大な追加の記憶域が確保できます。
索引構成表の2次索引で主キーベースの論理ROWIDを使用すると、物理ROWIDとは逆に、高可用性が確保できます。これはROWIDの論理的性質により、実表の行が移動する表の再編成操作の後にも、2次索引が使用不可能にはならないためです。同時に、論理ROWIDで物理推測を使用すると、2次索引ベースの索引構成表のアクセス・パフォーマンスを実現することも可能です。これは通常の表に対する2次索引ベースのアクセス・パフォーマンスに匹敵します。
Bツリー索引エントリはキー値とROWIDのみで成り立っているので、サイズは通常小さくてすみます。ただし索引構成表では、Bツリー索引エントリはすべての行で成り立っているため大きくなる場合があります。この場合、Bツリー索引の稠密クラスタ・プロパティは破棄されることがあります。
この問題に対処するために、Oracle DatabaseにはOVERFLOW句が用意されています。必要に応じて、オーバーフロー表領域を指定して、行を次の2つの部分に分割できます。分割した各部分はそれぞれ、索引とオーバーフロー記憶域セグメントに格納されます。
OVERFLOWでは、PCTTHRESHOLDとINCLUDINGの2つの句を使用して、行を2つの部分に分けて格納するかどうか、またその場合どの非キー列で行を分割するかのOracle Databaseによる判断方法を制御できます。PCTTHRESHOLDを使用すると、ブロック・サイズの割合としてしきい値を指定できます。非キー列値のすべてが指定したサイズ制限に収まる場合、行は分割されません。そうでない場合は、サイズ制限に収まらない最初の非キー列から開始して、残りの非キー列すべてが表の行オーバーフロー・セグメントに格納されます。
INCLUDING句を使用すると、列名を指定して、その列の後のCREATE TABLE文に現れる非キー列を行オーバーフロー・セグメントに格納させることができます。PCTTHRESHOLDベースの制限のため、場合によっては追加の非キー列をオーバーフローに格納する必要があることに注意してください。
索引構成表の2次索引がサポートされることにより、主キーでもその接頭辞でもない列を使用して、索引構成表に効率よくアクセスできます。
Oracle Databaseは、論理行識別子を使用して索引構成表の2次索引を組み立てます。この識別子は、表の主キーに基づいており、論理ROWIDと呼ばれます。論理ROWIDには、行のブロック位置を識別する物理推測が含まれます。Oracle Databaseは、これらの物理推測を使用して、主キー検索をバイパスし、索引構成表のリーフ・ブロックを直接プローブできます。索引構成表の行には永続物理アドレスがないため、行が新しいブロックに移動すると物理推測が陳腐化することがあります。
通常の表の場合、2次索引によるアクセスでは、行を含むデータ・ブロックをフェッチするために、2次索引のスキャンと付加的なI/Oが必要になります。索引構成表の場合、2次索引によるアクセスは、次のように物理推測を使用するかどうかと、その正確さに応じて異なります。
Oracle Databaseでは、パーティション化または非パーティション化された索引構成表のビットマップ索引がサポートされています。索引構成表のビットマップ索引の作成には、マッピング表が必要です。
マッピング表は、索引構成表の論理ROWIDを格納するヒープ構成表です。具体的には、マッピング表の各行には対応する索引構成表の行の論理ROWIDが格納されます。すなわちマッピング表では、索引構成表の行の論理ROWIDとマッピング表の行の物理ROWIDの1対1のマッピングができます。
索引構成表のビットマップ索引はヒープ構成表のビットマップ索引に似ていますが、索引構成表のビットマップ索引で使用されるROWIDは実表のROWIDではなく、マッピング表のROWIDです。索引構成表にはそれぞれ1つのマッピング表があり、その索引構成表で作成されたすべてのビットマップ索引がそのマッピング表を使用します。
ビットマップ索引には、ヒープ構成と索引構成のどちらの実表においても、検索キーを使用してアクセスします。キーが見つかると、ビットマップのエントリは物理ROWIDに変換されます。ヒープ構成表の場合、この物理ROWIDは実表へのアクセスに使用されます。索引構成表の場合は、マッピング表へのアクセスに使用されます。マッピング表にアクセスすると、論理ROWIDが取得できます。この論理ROWIDは索引構成表へのアクセスに使用されます。
索引構成表のビットマップ索引は論理ROWIDを格納しませんが、性質は論理的です。
列値の範囲、ハッシュまたはリストごとに索引構成表をパーティション化できます。パーティション化列は、主キー列のサブセットを形成する必要があります。通常の表と同様、パーティション化索引構成表にはローカル・パーティション化された(同一キーおよび非同一キーの)索引もグローバル・パーティション化された(同一キーの)索引もサポートされています。
UROWIDデータ型の列は、索引構成表の行を特定する論理主キーベースのROWIDを保持できます。Oracle Databaseでは、ヒープ構成表または索引構成表のUROWIDデータ型の索引をサポートしています。索引のUROWID列では、等価述語をサポートしています。等価以外の述語、またはUROWIDデータ型の列の順序付けのための述語の場合、索引は使用されません。
主キーベースのアクセスにおける優れた問合せパフォーマンス、高可用性の要素、および記憶域に関する要件の少なさから、索引構成表は次のようなアプリケーションに最適といえます。
Oracle Databaseは、複合データ型(文書、空間データ、イメージおよびビデオ・クリップなど)の索引に対応し、特化した索引作成テクニックを使用するために、拡張索引作成機能を提供します。この機能を使用すると、アプリケーション固有の索引管理ルーチンを索引タイプ・スキーマ・オブジェクトとしてカプセル化し、オブジェクト型の表の列や属性のドメイン索引(アプリケーション固有の索引)を定義できます。また、拡張可能索引作成機能により、アプリケーション固有の演算子を効率的に処理できます。
ドメイン索引の構造と内容は、カートリッジと呼ばれるアプリケーション・ソフトウェアによって制御されます。Oracleデータベース・サーバーは、ドメイン索引の作成、メンテナンスおよび検索のために、このアプリケーションと対話します。索引構造そのものは、索引構成表としてOracleデータベースに格納するか、ファイルとして外部に格納できます。
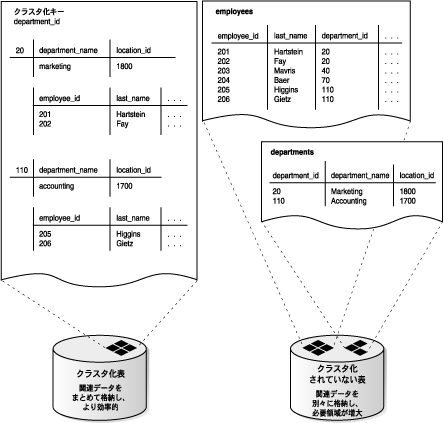
クラスタは、表データを格納するためのオプションの方法です。クラスタは同じデータ・ブロックを共有する表のグループです。これらの表グループは共通の列を共有し、頻繁に併用されます。たとえば、employeesおよびdepartments表はdepartment_id列を共有しています。employees表とdepartments表をクラスタ化すると、Oracle Databaseではemployees表とdepartments表における各部門の行すべてが、同じデータ・ブロックに物理的に格納されます。
図5-10に、employees表とdepartments表をクラスタ化する際の例を示します。
クラスタは、異なる表の関連した行を、同じデータ・ブロック内にまとめて格納するため、クラスタを適切に使用すると、次のような利点があります。
department_id)は、employees表とdepartments表の両方で同じ値を持つ多数の行に対して一度のみ格納されていることに注意してください。 ハッシュ・クラスタは、通常の索引クラスタ(ハッシュ関数ではなく索引がキーになっているクラスタ)の場合と同様の方法で表データをグループ化します。ただし、行は、行のクラスタ・キー値にハッシュ関数を適用した結果に基づいてハッシュ・クラスタに格納されます。キーの値が同じすべての行は、ディスク上にまとめて格納されます。
等式を条件にした問合せを使用して表を問い合せる(部門10のすべての行を戻すなど)ことが多い場合、索引表または索引クラスタよりも、ハッシュ・クラスタのほうが適切です。ハッシュ・クラスタを使用する問合せでは、指定されたクラスタ・キー値がハッシュ化されます。結果として生成されるハッシュ・キー値は、指定された行が格納されているディスク領域を直接指します。
ハッシングは、データ検索のパフォーマンスを改善するために表データを格納するオプションの方法です。ハッシングを使用するには、ハッシュ・クラスタを作成し、そのクラスタに表をロードします。Oracle Databaseでは、表の行はハッシュ・クラスタ内に物理的に格納され、ハッシュ関数の結果に従って取得されます。
ソート済のハッシュ・クラスタを使用すると、データが挿入順に使用されるアプリケーションでは、データの検索を高速化できます。
Oracle Databaseにより、ハッシュ関数を使用して生成される数値の分布(ハッシュ値と呼ばれる)は、特定のクラスタ・キーの値に基づいています。ハッシュ・クラスタのキーは、索引クラスタのキーと同様に、単一の列またはコンポジット・キー(複数列のキー)にすることができます。Oracle Databaseでは、ハッシュ・クラスタ内で行を検索または格納するために、ハッシュ関数を行のクラスタ・キー値に適用します。結果として得られるハッシュ値は、クラスタ内の1つのデータ・ブロックに対応します。Oracle Databaseは、発行された文による読取り/書込みをそのデータ・ブロックに対して実行します。
ハッシュ・クラスタは、索引を持つクラスタ化されていない表、または索引クラスタにかわるものです。索引付きの表または索引クラスタでは、Oracle Databaseは、別個の索引に格納されたキー値を使用して、表内の行を見つけます。索引付きの表またはクラスタの行を検索または格納するには、次のように最低2回のI/Oを実行する必要があります。
|
 Copyright © 1993, 2008 Oracle Corporation. All Rights Reserved. |
|