11gリリース1(11.1)
E05765-03
 目次 |
 索引 |
| Oracle Database 概要 11gリリース1(11.1) E05765-03 |
|

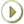
この章では、ビジネス・インテリジェンスの基本概念について説明します。
この章の内容は、次のとおりです。
データ・ウェアハウスは、トランザクション処理ではなく問合せおよび分析用に設計されたリレーショナル・データベースです。通常は、トランザクション・データから導出された履歴データが格納されますが、他のソースからのデータも格納できます。データ・ウェアハウスにより、分析のワークロードがトランザクションのワークロードから分離され、組織は複数のソースからのデータを連結できます。
データ・ウェアハウス環境には、リレーショナル・データベースの他に、ETLソリューション、オンライン分析処理(OLAP)エンジン、Oracle Warehouse Builder、クライアント分析ツール、データを収集してビジネス・ユーザーに配信するプロセスを管理する他のアプリケーションがあります。
この項の内容は、次のとおりです。
すべてのデータ・ウェアハウスでは、次に示す基本的な特性が共通しています。
データ・ウェアハウスは、データの分析に役立つように設計されています。たとえば、会社の売上データの詳細を知るために、売上専用のウェアハウスを構築できます。このウェアハウスを使用すると、「昨年度のこの品目の最大顧客は何か」などの質問に答えることができます。このようにデータ・ウェアハウスは主題(この場合は売上)別に定義できるため、データ・ウェアハウスはサブジェクト指向となっています。
統合は、サブジェクト指向に密接に関連しています。データ・ウェアハウスには、様々なソースからのデータを一貫性のある形式で格納する必要があります。また、名前の競合や単位間の不一致などの問題を解決する必要があります。この目標が達成されて初めて、データ・ウェアハウスは統合されたことになります。
恒常的とは、一度ウェアハウスに格納されたデータは変更されないことを意味します。ウエアハウスの目的が、発生した事柄を分析できることであるため、これは論理的です。
アナリストは、ビジネスの傾向を把握するために大量のデータを必要とします。これは、パフォーマンス要件があるために履歴データをアーカイブに移動する必要のあるオンライン・トランザクション処理(OLTP)システムとはきわめて対照的です。データ・ウェアハウスは時間経過による変化に焦点を当てており、これこそは時系列が意味するものです。
一般に、1つ以上のオンライン・トランザクション処理(OLTP)データベースからデータ・ウェアハウスに、月次、週次または日次でデータが送信されます。データは、通常ステージング・ファイル内で処理されてから、データ・ウェアハウスに追加されます。データ・ウェアハウスのサイズは、数十GBから数TBになるのが普通です。また、データの大多数は少数の非常に大きなファクト表に格納されます。
データ・ウェアハウスとOLTPシステムでは、要件が大きく異なります。ここでは、典型的なデータ・ウェアハウスとOLTPシステムの相違点の例を示します。
データ・ウェアハウスは非定型問合せに適応するように設計されています。データ・ウェアハウスのワークロードは事前に不明な場合があります。このため、データ・ウェアハウスは様々な問合せ操作を適切に実行できるように最適化する必要があります。
OLTPシステムでサポートされるのは、事前定義済の操作のみです。これらの操作のみをサポートするように、アプリケーションの特別なチューニングや設計が必要になる場合があります。
データ・ウェアハウスは、バルク・データ修正テクニックを使用して(夜間または週次で実行される)ETLプロセスにより定期的に更新されます。データ・ウェアハウスをエンド・ユーザーが直接更新することはありません。
OLTPシステムでは、エンド・ユーザーはデータベースに対して個々のデータ修正文を定期的に発行します。OLTPデータベースは常に最新であり、各ビジネス・トランザクションの現在の状態が反映されます。
通常、データ・ウェアハウスでは、全体または一部が非正規化されたスキーマ(スター・スキーマなど)を使用して、問合せパフォーマンスが最適化されます。
OLTPシステムでは、通常は完全に正規化されたスキーマを使用して更新/挿入/削除のパフォーマンスが最適化され、データ整合性が保証されます。
典型的なデータ・ウェアハウスの問合せでは、数千または数百万行がスキャンされます。たとえば、「すべての顧客について先月の総売上を検索する」などです。
典型的なOLTP操作は、少数のレコードにのみアクセスします。たとえば、「この顧客の現行の注文を検索する」などです。
通常、データ・ウェアハウスには、数か月または数年分のデータが格納されます。これは、履歴分析をサポートするためです。
OLTPシステムには、通常は数週または数か月分のデータしか格納されません。OLTPシステムでは、現行のトランザクションの要件を適切に満たすために必要な履歴データのみが格納されます。
データ・ウェアハウスとそのアーキテクチャは、組織の状況に応じて異なります。次の3つのアーキテクチャが一般的です。
図16-1に、データ・ウェアハウスの単純なアーキテクチャを示します。エンド・ユーザーは、データ・ウェアハウスを介して、複数のソース・システムから導出されたデータに直接アクセスします。

図16-1では、従来型OLTPシステムのメタデータと生データの他に、サマリー・データがあります。サマリーでは、時間のかかる処理が事前に行われるため、データ・ウェアハウスではきわめて重要です。たとえば、典型的なデータ・ウェアハウスの問合せでは、8月の売上などが検索されます。
Oracle Databaseでは、サマリーはマテリアライズド・ビューと呼ばれます。
図16-1で示しているように、業務系データをウェアハウスに入れる前に、クリーン・アップおよび処理する必要があります。この操作はプログラムによって実行できますが、ほとんどのデータ・ウェアハウスではかわりにステージング領域が使用されています。ステージング領域により、サマリーの作成とウェアハウス管理全般が簡素化されます。図16-2に、この典型的なアーキテクチャを示します。
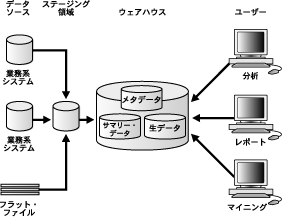
図16-2のアーキテクチャはごく一般的ですが、ウェアハウスのアーキテクチャを組織内の様々なグループ向けにカスタマイズできます。
そのためには、特定のビジネス・ライン向けに設計されたシステムであるデータ・マートを追加します。図16-3に、購買、売上および在庫が分離されている例を示します。この例では、財務アナリストは購買と売上の履歴データを分析できます。

データ・ウェアハウスをビジネス分析に役立てるには、データ・ウェアハウスに定期的にデータをロードする必要があります。データをロードするには、1つ以上の業務系システムからデータを抽出し、ウェアハウスにコピーする必要があります。ソース・システムからデータを抽出してデータ・ウェアハウスに取り込む処理は、一般にETLと呼ばれ、抽出、変換、ロードを表します。ETLでは転送フェーズが省略され、プロセスの他のフェーズがそれぞれ個別であることを意味するため、ETLという頭字語ではあまりに単純すぎるでしょう。データのロードも含め、このプロセス全体のことをETLと呼びます。ETLが詳細に定義された3つのステップではなく広範囲なプロセスを指すことを理解しておく必要があります。
ETLの方法論とタスクは以前からよく知られており、必ずしもデータ・ウェアハウス環境に固有のものではありません。様々な独自アプリケーションおよびデータベース・システムが、企業のITのバックボーンとなっています。データの統合を試み、少なくとも2つのアプリケーションに同じ内容を提供して、アプリケーション間やシステム間で共有する必要があります。多くの場合、このデータの共有は、ETLに類似したメカニズムによって対処されています。
データ・ウェアハウス環境は同じ課題に直面しているのに加えて、データを多数のシステム間で交換するのみでなく、統合、再配置および連結する必要があり、それによりビジネス・インテリジェンスに新たに統一された情報ベースを提供するという問題を抱えています。また、データ・ウェアハウス環境ではデータ量が非常に大きくなる傾向があります。
ETLプロセスでどのような処理が発生するかを考えてみます。抽出時には必要なデータが識別され、データベース・システムやアプリケーションなど多数の異なるソースから抽出されます。通常、必要なデータの特定のサブセットを識別することはできません。したがって、必要以上のデータを抽出することになるため、該当データの識別は後に行われます。ソース・システムの機能(オペレーティング・システムのリソースなど)によっては、この抽出プロセスである程度の変換が発生することがあります。抽出されるデータのサイズは、ソース・システムとビジネス状況に応じて数百KB〜数GBです。2つの(論理的に)同一の抽出間に要する時間についても、同じことが言えます。つまり、期間は数日、数時間、数分、ほぼリアルタイムなど様々です。たとえば、Webサーバーのログ・ファイルは、きわめて短時間のうちに簡単に数百MBに達することがあります。
抽出したデータは、さらに処理するためにターゲット・システムまたは中間システムに物理的に転送する必要があります。選択した転送方法によっては、このプロセスでなんらかの変換処理を実行することもできます。たとえば、ゲートウェイを介してリモート・ターゲットに直接アクセスするSQL文では、SELECT文の一部として2つの列を連結できます。
ロード中にエラーが発生すると、そのエラーがログに記録され、操作を続行できます。
この項の内容は、次のとおりです。
トランスポータブル表領域は、2つのOracleデータベース間で大量のデータを移動する場合に最も高速な方法です。異なるコンピュータ・アーキテクチャやオペレーティング・システム間で表領域を転送することもできます。
従来、最もスケーラブルなデータ転送メカニズムでは、生データを含むフラット・ファイルを移動していました。この種のメカニズムでは、データをソース・データベースからアンロードするかファイルにエクスポートする必要がありました。それから、転送後にターゲット・データベースにロードまたはインポートする必要がありました。トランスポータブル表領域は、このアンロードしてから再ロードするステップを完全にバイパスします。
トランスポータブル表領域を使用すると、Oracle Databaseデータファイル(表データ、索引および他のほぼすべてのOracleデータベース・オブジェクトを含む)を、データベース間で直接転送できます。さらに、トランスポータブル表領域は、データ転送に加えてメタデータの転送用に、インポートおよびエクスポートに似たメカニズムを提供します。
データ・ウェアハウスのトランスポータブル表領域が最も一般的に利用されるのは、ステージング・データベースからデータ・ウェアハウスへとデータを移動する場合、またはデータ・ウェアハウスからデータ・マートにデータを移動する場合です。
テーブル・ファンクションは、PL/SQL、CまたはJavaで実装された変換のパイプライン実行とパラレル実行をサポートします。前述の使用例では、中間のステージング表を使用する必要がありません。中間のステージング表を使用すると、各種の変換ステップを経るデータ・フローが中断されます。
テーブル・ファンクションは、出力として行セットを生成できる関数として定義されます。また、入力として行セットを使用することもできます。テーブル・ファンクションによりデータベース機能が拡張され、次の操作が可能になります。
テーブル・ファンクションは、システム固有のPL/SQLインタフェースを使用してPL/SQLで定義するか、Oracle Data Cartridge Interface(ODCI)を使用してJavaまたはCで定義できます。
外部表により、外部データを仮想表として使用できます。仮想表は、最初に外部データをデータベースにロードしなくても、パラレルで直接問い合せたり結合できます。これにより、SQL、PL/SQLおよびJavaを使用して外部データにアクセスできます。
外部表を使用すると、ロード・フェーズと変換フェーズをパイプライン処理できます。データ・ストリームを中断することなく、変換プロセスをロード・プロセスとマージできます。データベース内のデータに対してさらに比較や変換などの処理を実行するために、データベース内でステージングする必要がなくなります。たとえば、従来型ロードの変換機能を、外部表からのSELECTとともにダイレクト・パスINSERT AS SELECT文に使用できます。図16-4に、パイプライン処理の一般的な例を示します。
外部表と通常の表の重要な違いは、外部で構成された表が読取り専用であることです。外部表では、DML操作(UPDATE/INSERT/DELETE)および索引の作成ができません。
外部表はSQL*Loaderを補完するもので、外部ソース全体を既存のデータベース・オブジェクトと結合して複雑な方法で変換する環境や、外部データ・ボリュームが大きく1度しか使用されない環境で特に役立ちます。これに対してSQL*Loaderは、ステージング表で追加の索引付けが必要となるデータをロードする場合に、より適切な選択肢となります。これは、データが独立した複雑な変換に使用される操作や、以降の処理でデータの一部のみが使用される操作の場合も同様です。
ヒープ構成表を圧縮することでディスク領域を節約できます。表の圧縮を考慮する必要のある典型的なタイプのヒープ構成表は、パーティション表です。
ディスク使用量とメモリー使用量(特にバッファ・キャッシュ)を減少させるために、表とパーティション表をデータベースに圧縮形式で格納できます。通常は、これにより読取り専用操作のパフォーマンスが向上します。また、問合せの実行も高速化されます。ただし、CPUオーバーヘッドの面で少しコストがかかります。
表の圧縮は、多数の外部キーを持つ表など、冗長度の高いデータに使用する必要があります。更新や他のDMLアクティビティが多い表は圧縮しないでください。圧縮された表またはパーティションは更新可能ですが、この種の表の更新時にオーバーヘッドが発生し、更新アクティビティが高いときには領域が多少浪費されて圧縮の妨げとなる場合があります。
チェンジ・データ・キャプチャにより、Oracle Databaseリレーショナル表に対して追加、更新または削除されたデータが効率的に識別および取得され、変更データのアプリケーションでの使用が可能になります。
通常、データ・ウェアハウスでは、分析のためにリレーショナル・データを1つ以上のデータベースからデータ・ウェアハウスに抽出して転送する必要があります。チェンジ・データ・キャプチャにより、表全体ではなく変更があったデータのみがすばやく識別され、処理されて、変更データが後で使用できるようになります。
チェンジ・データ・キャプチャは、リレーショナル・データベースの外部でデータを段階的に処理するための中間フラット・ファイルに依存しません。ユーザー表に対するINSERT、UPDATEおよびDELETE操作からの変更データを取得します。変更データはチェンジ・テーブルと呼ばれるデータベース・オブジェクトに格納され、制御された方法でアプリケーションで使用可能になります。
データ・ウェアハウスでパフォーマンス改善のために採用されているテクニックの1つは、サマリーを作成することです。サマリーは特殊な集計ビューで、問合せを実行する前に高コストの結合および集計操作を計算して結果をデータベースの表に格納することで、問合せの実行時間を短縮します。たとえば、地域別、製品別の売上合計を含む表を作成できます。
このマニュアルおよびデータ・ウェアハウス関連書で言及しているサマリーまたは集計は、Oracle Databaseではマテリアライズド・ビューというスキーマ・オブジェクトを使用して作成されます。マテリアライズド・ビューは、問合せパフォーマンスの改善や複製データの提供など、様々な役割を果します。
従来、サマリーを使用している組織は、手動によるサマリー作成、作成するサマリーの識別、サマリーの索引付けと更新、さらに使用サマリーに関するユーザーへのアドバイスなどの作業に、大量の時間と労力を費やしています。サマリー管理によりデータベース管理者のワークロードが軽減され、ユーザーは定義済のサマリーを知る必要がなくなります。データベース管理者は1つ以上のマテリアライズド・ビューを作成しますが、これがサマリーに相当します。エンド・ユーザーは、詳細データ・レベルで表やビューを問い合せます。
SQL問合せは、Oracle Databaseのクエリー・リライト・メカニズムにより、サマリー表を使用するように自動的にリライトされます。このメカニズムにより、問合せから結果を戻すための応答時間が短縮されます。データ・ウェアハウス内のマテリアライズド・ビューは、エンド・ユーザーやデータベース・アプリケーションに対して透過的です。
通常、マテリアライズド・ビューにはクエリー・リライト・メカニズムを介してアクセスしますが、エンド・ユーザーやデータベース・アプリケーションはサマリーに直接アクセスする問合せを構成できます。ただし、サマリーに対する変更はそれを参照する問合せに影響するため、ユーザーにこの操作を許可するかどうかは重大な考慮事項となります。
Oracle Databaseでは、一連のマテリアライズド・ビューの分析およびアドバイザ用のファンクションおよびプロシージャがDBMS_ADVISORパッケージとして提供されており、スキーマの多数のマテリアライズド・ビューでの選択に役立ちます。これらのファンクションは総称してSQLアクセス・アドバイザと呼ばれ、どのPL/SQLプログラムからでもコールできます。SQLアクセス・アドバイザは、仮説によるワークロードまたはユーザー定義ワークロード、あるいはSQLキャッシュから取得したワークロードに基づいて、マテリアライズド・ビューを推奨します。SQLアクセス・アドバイザは、Oracle Enterprise Managerから実行するか、DBMS_ADVISORパッケージを起動して実行します。
ビットマップ索引は、データ・ウェアハウス環境で広範囲に使用されています。通常、この環境では大量のデータと非定型問合せを扱いますが、同時DMLトランザクションのレベルは高くありません。この種のアプリケーションに対するビットマップ索引の利点は次のとおりです。
従来のBツリー索引を使用して大きな表に完全な索引を作成すると、領域という面で膨大なコストがかかります。索引は表中のデータの何倍にも膨れ上がることがあるからです。それに対して、ビットマップ索引は通常、表中で索引を付けるデータのサイズより小さくてすみます。
索引では、特定のキー値が含まれる行にポインタが提供されます。通常の索引では、キー値と、そのキー値を持つ行のROWIDの対応リストを格納します。ビットマップ索引では、ROWIDのリストが各キー値のビットマップで置換されます。
ビットマップの各ビットは存在するROWIDに対応します。ビットが設定されている場合は、対応するROWIDを持つ行にはキー値が含まれることになります。マッピング機能がビット位置を実際のROWIDに変換するため、ビットマップ索引は通常の索引と同じ機能を果します。異なるキー値の数が多くない場合、ビットマップ索引は領域を節約できます。
ビットマップ索引は、WHERE句に複数の条件を含む問合せに最も効率的です。一部の条件は満たしているがすべては満たしていない行については、表自体にアクセスする前に除外します。これによって、応答時間が短縮されます。多くの場合は劇的に改善されます。可能な値が小さいため、性別列はビットマップ索引の優れた候補となります。
パラレル問合せおよびパラレルDMLは、従来の索引のみでなく、ビットマップ索引に対しても機能します。また、索引のパラレル作成と連結索引もサポートしています。
Oracle DatabaseでSQL文をパラレル実行すると、同時に多数のプロセスが連携して1つのSQL文を実行します。文の実行に必要なタスクを多数のプロセスで分割して実行すると、Oracle Databaseでは、1つのプロセスで実行する場合と比較して、より高速に実行できます。これは、パラレル実行またはパラレル処理と呼ばれます。
パラレル実行では、意思決定支援システム(DSS)およびデータ・ウェアハウスに対応付けられた大規模なデータベースにおいて、集中データ処理の応答時間が大幅に削減されます。対称型マルチプロセッサ(SMP)、クラスタ化されたシステムおよび大規模クラスタ・システムでは、パラレル実行によりパフォーマンスが大幅に改善されます。それは1つのOracle Databaseシステムで、文の処理を多数のCPUで分割できるためです。特定のタイプのオンライン・トランザクション処理(OLTP)およびハイブリッド・システムに、パラレル実行を実装することもできます。
パラレル化とは、すべての問合せ作業を1つのプロセスで行わずに、多数のプロセスで同時に行えるように1つの作業を分割する考え方です。たとえば、1つのプロセスで12か月分をすべて処理するかわりに、12のプロセスが1年のそれぞれの月を分担して処理するなどがこの例です。これにより、パフォーマンスの大幅な改善が期待できます。
パラレル実行では、ハードウェア・リソースの使用が最適化され、システムのパフォーマンスの向上に役立ちます。システムのCPUとディスク・コントローラの負荷がすでに大きい場合は、パフォーマンスを改善するため、パラレル実行を使用する前にシステムの負荷を軽減するか、またはハードウェア・リソースを増やす必要があります。
Oracle RAC環境では、パラレル実行は、特定のサービスに対するサービスの配置によって制御されています。つまり、パラレル・プロセスはサービスを構成したノードで実行されます。Oracle Databaseのデフォルトの動作では、パラレル処理は、データベースに接続する際に使用したサービスが提供されるインスタンスでのみ実行されます。これは、パラレル・リカバリやGV$queriesの処理などの他のパラレル操作には影響しません。
パラレル実行に適さない作業もあります。たとえば、OLTP操作の多くは比較的高速であり数秒以内で完了されるので、全体の実行時間に対し、パラレル実行利用のオーバーヘッドが大きくなる傾向にあります。
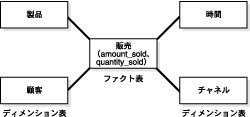
パラレル実行を使用しない場合は、SQL文の順次実行に必要な処理のすべてを1つのサーバー・プロセスが実行します。たとえば、全表スキャン(SELECT * FROM empなど)を実行するには、図16-5に示すように、1つのプロセスで操作全体を実行します。
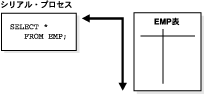
図16-6では、複数のパラレル実行サーバーがemp表のスキャンを実行しています。この表はグラニュルと呼ばれるロード単位に動的に分割され(動的パーティション化)、各グラニュルは単一のパラレル実行サーバーにより読み取られます。グラニュルはコーディネータにより生成されます。各グラニュルは、emp表の物理ブロックの範囲です。実行サーバーへのグラニュルのマッピングは静的ではなく、実行時に決定されます。実行サーバーがグラニュルに対応するemp表の行の読取りを終了したとき、グラニュルがまだ残っている場合、コーディネータから別のグラニュルを取得します。この操作は、すべてのグラニュルが使い果され、emp表全体が読み取られるまで継続されます。パラレル実行サーバーは結果をパラレル実行コーディネータに送り返し、それぞれの結果が組み立てられて、最終的な全表スキャンになります。
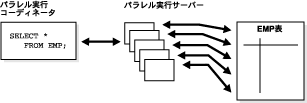
SQL問合せの問合せ計画では、まずパラレル実行コーディネータがSQL問合せ内の各演算子をパラレル・ピースに分割し、それらを問合せで指定した順序に従って実行します。次に、演算子を実行するパラレル実行サーバーによって作成された部分的な実行結果を統合します。1つの操作に割り当てられたパラレル実行サーバーの数が、その操作の並列度(DOP)となります。同じSQL文中の複数の操作の並列度は、すべて同じです。
Oracleには、データベースで分析操作を実行するための多数のSQL操作が導入されています。たとえば、ランキング、移動平均、累計、対比レポート、期間対比などです。これらの計算の一部は従来でもSQLを使用して実行できましたが、この構文はパフォーマンスを大幅に改善します。
この項の内容は、次のとおりです。
集計は、データ・ウェアハウスの基盤となる部分です。ウェアハウスでの集計効率を改善するために、Oracle Databaseには問合せとレポートを容易かつ高速にするGROUP BY句の拡張機能が用意されています。これらの拡張機能を使用すると、次の操作ができます。
これらの拡張機能を使用すると、必要なデータ・グループをGROUP BY句で正確に指定できます。これにより、CUBE操作を実行しなくても複数のディメンション間で効率的な分析が可能になります。キューブ全体を計算すると大きな処理負荷が発生するため、キューブをグルーピング・セットで置き換えるとパフォーマンスを大幅に改善できます。CUBE、ROLLUPおよびグルーピング・セットは、異なる方法でグループ化された行のUNION ALLに等価の結果セットを1つ生成します。
パフォーマンスを強化するために、これらの拡張機能をパラレル化できます。つまり、複数のプロセスがこれらの文をすべて同時に実行できます。これらの機能により集計計算の効率が向上し、データベースのパフォーマンスとスケーラビリティが強化されます。
意思決定支援システムで重要な概念の1つが多次元分析、つまり必要なディメンションのすべての組合せから企業を検査することです。ディメンションという用語は、質問の指定に使用される任意のカテゴリという意味で使用されます。最も一般的に指定されるディメンションは時間、地理、製品、部門および物流チャネルですが、潜在的なディメンションは企業のアクティビティと同様に制限はありません。通常、特定のディメンション値の集合に関連付けられたイベントやエンティティは、ファクトと呼ばれます。ファクトは、営業単位や各国通貨、収益、顧客数、生産高など、追跡する価値のあるデータです。
ここでは、多次元要求の例を使用して説明します。
これらの要求には、いずれも複数のディメンションが含まれています。多次元による多くの質問では、通常は時間、地理または予算にまたがって集計されたデータと、データ・セットの比較が必要になります。
Oracleは、分析SQL関数ファミリを使用した拡張SQL分析処理機能を備えています。これらの分析関数を使用して次の計算を実行できます。
ランキング関数には、累積分布、パーセント・ランクおよびNタイルがあります。変動ウィンドウの計算を使用すると、合計や平均などの移動集計と累積集計を求めることができます。LAG/LEAD分析を使用すると、行間を直接参照できるため、期間ごとの変化を計算できます。FIRST/LAST分析を使用すると、順序付けしたグループ内の最初と最後の値を求めることができます。
その他の機能としてCASE式があります。CASE式は、様々な場合に役立つif-thenロジックを提供します。
パフォーマンスを強化するために、分析関数をパラレル化できます。つまり、複数のプロセスがこれらの文をすべて同時に実行できます。これらの機能により計算が容易かつ効率的になり、データベースのパフォーマンスとスケーラビリティが強化され、簡素化が促進されます。
OracleのMODEL句は、SQL計算に新たなレベルの機能と柔軟性をもたらします。MODEL句を使用すると、問合せ結果から多次元配列を作成し、この配列に計算式を適用して新規の値を計算できます。計算式には、基本的な演算や再帰型を使用した連立方程式を使用できます。一部のアプリケーションでは、MODEL句でPCベースのスプレッドシートを置き換えることができます。SQLでのモデルには、スケーラビリティ、管理性、コラボレーションおよびセキュリティにおけるOracle Databaseの長所が生かされています。中核となる問合せエンジンは、処理できるデータ数に制限がありません。データベース内でモデルを定義して実行すると、大きいデータセットを個別のモデル化環境の間で転送する必要がありません。モデルはワークグループ間で簡単に共有できるため、すべてのアプリケーションで計算の一貫性が確実に保たれます。モデルを共有できるのみでなく、アクセスもOracle Databaseのセキュリティ機能で厳密に制御できます。MODEL句は、その豊富な機能によりあらゆるタイプのアプリケーションを強化できます。
Oracleオンライン分析処理(OLAP)により、分析コンテンツが幅広くなり、問合せ応答時間が短縮されるため、SQLアプリケーションの能力が強化されます。SQL問合せインタフェースにより、OLAPを認識せずに任意のアプリケーションでキューブおよびディメンションを問い合せることができるようになります。
OLAPオプションを使用すると、キューブ、ディメンションおよび階層に関する一連のリレーショナル・ビューが自動的に生成されます。SQLアプリケーションによってこれらのビューが問い合せられ、アナリストや意思決定者の役に立つ情報が豊富なこれらのオブジェクトのコンテンツが表示されます。また、実表などのシステム生成ビューを使用して、アプリケーションに求められる構造に適合するカスタム・ビューを作成することもできます。
アナリストは、任意のSQL問合せおよび分析ツールを使用して、データを選択、表示および分析できます。お気に入りのツールやアプリケーション、またはOracle Databaseで提供されるいずれかのツール(Oracle Application ExpressやBusiness Intelligence Publisherなど)を使用できます。
この項の内容は、次のとおりです。
Oracleでは、多次元のオブジェクトおよび分析をデータベースに統合することにより、多次元分析の利点と、Oracle Databaseの信頼性、可用性、セキュリティおよびスケーラビリティの利点を兼ね備えています。
Oracle OLAPは、Oracle Databaseに完全に統合されています。技術レベルでは、これは次のことを意味します。
組織は多大な利点を享受できます。Oracle OLAPには、簡素化によってもたらされる強みがあります。つまり、1つのデータベース、標準的な管理とセキュリティ、標準的なインタフェースと開発ツールという強みです。
Oracle OLAPを使用すると、魅力的な分析コンテンツによってデータベースおよびアプリケーションの機能を簡単に高めることができます。Oracleの多次元のオブジェクトおよび計算にシステム固有の方法でSQLを使用してアクセスできるため、独自のインタフェースを使用するシステムと比較しても、任意のタイプのダッシュボード、レポート、ビジネス・インテリジェンスおよび分析アプリケーションは大幅に開発しやすくなります。さらに、SQLによるアクセスが可能であるということは、従来の限定されたOLAPアプリケーション・コレクションのみでなく、任意のデータベース・アプリケーションがOracle OLAPの分析機能を使用できることを意味します。
Oracle OLAPはOracle Databaseに完全に埋め込まれているため、一般的なスタンドアロンのOLAPサーバーのように管理に習熟するまでに時間がかかることはありません。特別な管理スキルに投資せずに、既存のDBAスタッフを活用できます。
Oracleの埋込み型のOLAPテクノロジによる管理上の主な利点の1つに、キューブの自動メンテナンスがあります。スタンドアロンのOLAPサーバーの場合、キューブをリフレッシュするという作業負担はすべて管理者に負わされています。この作業は複雑で、間違いを起こしやすいジョブです。管理者は、変更されたデータをリレーショナル・ソースから抽出し、このデータをソース・システムからスタンドアロンのOLAPサーバーが稼働しているシステムに移動し、キューブをロードして再構築するプロシージャを作成する必要があります。また、管理者は、このプロセス中に変更された値のセキュリティに関する責任も負うことになります。
一方、Oracle OLAPを使用すると、キューブのリフレッシュはOracle Databaseによって完全に処理されます。ディメンション・オブジェクトの失効が追跡され、ソース表のデルタが自動的に記録され、リフレッシュ・プロセス中に変更された値のみが自動的に適用されます。管理者は適切な間隔でリフレッシュをスケジュールするのみで、他のすべての作業はOracle Databaseによって処理されます。
Oracle OLAPでは、Oracle Databaseの標準的なセキュリティ機能を使用して多次元データが保護されます。
一方、スタンドアロンのOLAPサーバーの場合、管理者はリレーショナル・ソース・システムとOLAPサーバー・システムで、セキュリティ管理が2回必要です。また、リレーショナル・システムからスタンドアロンのOLAPシステムへデータを移動する際のセキュリティも管理する必要があります。
ビジネス・インテリジェンスおよび分析アプリケーションでのアクションのほとんどは、階層のドリルアップおよびドリルダウン、期間対比、親の構成比、将来期間の予測などの集計値の比較、およびこれに類似した多数の計算によって占められています。多くの場合、これらのアクションは本質的に、潜在する階層型の集計領域全体にわたってランダムに実行されます。Oracle OLAPでは、定義された多次元領域ですべての集計が事前に計算または効率的に即時に計算されるため、従来のビジネス・インテリジェンス・アプリケーションとは比較にならないパフォーマンスを実現します。
Oracle OLAPの問合せではOracle共有のカーソルが利用されるため、メモリー要件が大幅に削減され、パフォーマンスが向上します。
Oracle Real Application Clusters(Oracle RAC)を使用してOracle Databaseをインストールすると、OLAPアプリケーションは、他の任意のアプリケーションと同様のパフォーマンス、スケーラビリティ、フェイルオーバーおよびロード・バランシング上の利点を享受できます。
これらのすべての機能はコスト削減につながります。既存のスタッフのスキルを活用できるため、管理コストを削減できます。さらに、ディメンション・オブジェクトのリフレッシュという、他のシステムでは管理者に任されている複雑なタスクは、Oracle Databaseによって管理されます。また、標準のセキュリティ機能も管理コストの削減に貢献します。アプリケーションの開発コストも削減できます。これは、SQLに関する知識を備えた大勢のアプリケーション開発者やSQLベースの多数の開発ツールを利用できることが、アプリケーションのより迅速な開発とデプロイにつながるためです。Oracle OLAPは、SQLベースの任意の開発ツールが利用できます。Oracle OLAPの効率的な集計管理、共有カーソルの使用、および低コストの商用コンポーネントから高度な拡張性を持つシステムを構築可能なOracle RACにより、ハードウェアのコストも削減できます。
Oracle Data Miningは、Oracle Databaseの埋込みデータ・マイニング・コンポーネントです。データがデータベースを出ることはなく、データ準備、モデル構築およびモデルのスコアリングはすべてデータベース内で実行されます。データがデータベースを出ることはないため、スケーラビリティ、管理性およびユーザー・アクセスが大幅に向上します。これにより、Oracle Databaseはアプリケーション開発者に、データ・マイニングをデータベース・アプリケーションとシームレスに統合するためのインフラストラクチャを提供します。データ・マイニングは、コール・センター、ATM、ERMおよびビジネス・プランニングなどのアプリケーションでよく使用されます。
Oracle Database 11gでは、Oracle Data MiningモデルはSYSスキーマのデータ・ディクショナリ・オブジェクトとして実装されます。一連の新しいデータ・ディクショナリ・ビューは、マイニング・モデルとそのプロパティを示します。新しいシステムおよびオブジェクト権限により、マイニング・モデル・オブジェクトへのアクセスが制御されます。
Oracle Data Mining 11gでは、新たに一般化線形モデル(GLM)をサポートしています。Oracle Data Miningは、分類用と回帰用の2つの形式のGLMをサポートしています。
Oracle Data MiningのGLMでは、一般的に30以下の入力属性をサポートしている従来の実装とは異なり、何百何千もの入力属性を処理できます。
モデルの構築、テストおよびスコアリングなどのデータ・マイニング・アクティビティは、PL/SQL API、Java APIおよびSQLデータ・マイニング関数を使用して実行されます。Java APIは、データ・マイニング規格JSR 73に準拠しています。Java APIおよびPL/SQL APIは、完全に相互運用可能です。
Oracle Data Miningでは必要に応じて、ビニング、正規化および異常値処理などのアルゴリズムに必要なすべてのデータ準備を自動的に実行できます。また、ユーザー指定のデータ変換をアルゴリズム固有のデータ準備に統合することにより、テストおよびスコアリングを簡略化できます。このようなモデルはスーパーモデルです。
SQLデータ・マイニング関数は、データ・マイニング・モデルをデプロイするためのSQL言語を操作します。データ・マイニング関数は、分類、回帰、クラスタ化および機能抽出モデルのスコアリングをサポートします。標準的なSQL文のコンテキストでは、事前に作成されたモデルを新規データや将来の処理用として戻された結果に適用できます。
予測分析は、単純なルーチンでデータ・マイニング・プロセスを取得するテクノロジです。ワンクリック・データ・マイニングとも呼ばれる予測分析により、データ・マイニング・プロセスを簡略化して自動化します。このプロシージャにより、分析処理の結果が戻されます。モデルや他の中間オブジェクトは保存されません。DBMS_PREDICTIVE_ANALYTICS PL/SQLパッケージにより、予測分析に次のプロシージャが実装されます。
EXPLAIN: ターゲット属性との関係が深い順に属性をランク付けします。
PREDICT: ターゲット属性の値を予測します。
PROFILE: 同じターゲット値を持つレコードを識別するルールを作成します。
Oracle Data Miningは、次のアルゴリズムをサポートしています(一般化線形モデルは、Oracle Database 11gの新機能です)。
|
 Copyright © 1993, 2008 Oracle Corporation. All Rights Reserved. |
|