11gリリース1(11.1)
E05765-03
 目次 |
 索引 |
| Oracle Database 概要 11gリリース1(11.1) E05765-03 |
|

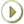
この章では、データベースの可用性の概念を説明し、Oracle Databaseの高可用性製品と機能を紹介します。
この章の内容は、次のとおりです。
企業は、競争力を高め、生産性を上げ、ユーザーがより豊富な情報に基づいてより迅速に意思決定することを支援するために、情報テクノロジ(IT)・インフラストラクチャを活用しています。ただし、このような利点とは別に、このインフラストラクチャに対する依存度も高まっています。収益や顧客を失う、罰則が課される、新聞での悪評が顧客と会社の評判に長く悪影響を及ぼすというリスクも存在します。今日の日進月歩の経済環境に置かれたすべての企業が成功して健全であり続ける上で、高可用性ITインフラストラクチャの構築は非常に重要です。
コンピューティング・テクノロジには、グリッド・コンピューティングと呼ばれる新しいITアーキテクチャのデプロイの実現化に向けた流れもあります。グリッド・コンピューティング・アーキテクチャを使用すると、すべての企業のコンピューティング・ニーズに応じて多くのサーバーおよび記憶域を柔軟なオンデマンド・コンピューティング・リソースにプールできます。低コストのブレード・サーバー、小型で廉価なマルチプロセッサ・サーバー、モジュール記憶域テクノロジ、およびオープン・ソースのオペレーティング・システム(Linuxなど)のようなテクノロジ革新により、グリッド用の素材が提供されます。これらのテクノロジを利用し、Oracle Databaseに用意されているグリッド・テクノロジを活用することにより、企業は、非常に高品質なサービスをユーザーに提供するとともに、IT費用を大幅に削減できます。Oracle Databaseを使用すると、パフォーマンス、スケーラビリティ、セキュリティ、管理性、機能またはシステムの可用性を犠牲にすることなく、エンタープライズ・グリッド・コンピューティングによるコスト面での利点を享受できます。
この章では、停止時間の原因を調査するとともに、損害の大きい停止時間を回避し、障害から迅速にリカバリするためにOracle Databaseに用意されているテクノロジを確認します。
高可用性のITグリッド・インフラストラクチャ設計の課題の1つは、可能性のある停止時間の原因をすべて調査して対処することです。図17-1では、システムの停止時間を計画外停止時間と計画停止時間という2つの主なカテゴリに分けた図を示しています。フォルト・トレラントでリジリエンスのあるITインフラストラクチャを設計する際には、計画外停止時間と計画停止時間の両方の原因を考慮することが重要です。
計画外停止時間の原因は、コンピュータ障害またはデータ障害です。計画停止時間は主に、本番システムに適用する必要があるデータ変更またはシステム変更が原因です。次の項では、これらの停止時間の各原因を調査し、停止時間を回避するために適用できるOracleテクノロジについて説明します。
コンピュータ障害が発生するのは、コンピュータ・システムまたはデータベース・サーバーに予期しないに障害が発生し、サービスが中断される場合です。多くの場合、コンピュータ障害の原因はハードウェアの故障にあります。このようなタイプの障害の最善の解決方法は、クラスタ・テクノロジと高速データベース・クラッシュ・リカバリを利用する方法です。推奨されるソリューションには、Oracle Real Application Clusters(Oracle RAC)を使用したエンタープライズ・グリッド、ファスト・スタート・リカバリ、Oracle Data GuardおよびOracle Streamsがあります。
この項の内容は、次のとおりです。
企業は、Oracle RACを使用して、複数のシステムにわたって可用性とスケーラビリティの高いデータベース・サーバーを構築できます。Oracle RAC環境では、Oracle Databaseは単一の共有データベースに同時にアクセスしながら、クラスタ内の2つ以上のシステム上で稼働します。そのため、複数のハードウェア・システムにまたがる単一のデータベース・システムが、アプリケーションでは単一の統合されたデータベース・システムとして認識されます。これにより、すべてのアプリケーションに対して次のような可用性とスケーラビリティ上の利点がもたらされます。
次のリストに、Oracle RAC環境の機能を示します。
エンタープライズ・グリッド: Oracle RACを使用すると、エンタープライズ・グリッドが有効になります。エンタープライズ・グリッドは、プロセッサ、サーバー、ネットワークおよび記憶域などの標準的な商品価格のコンポーネントによる大規模な構成から構築されます。Oracle RACは、企業の役に立つ処理システム用としてこれらのコンポーネントを利用できる唯一のテクノロジです。Oracle RACとグリッドは、運用コストを劇的に削減でき、システムの適応性、予防性および敏捷性を高めることができる柔軟性も備えています。ノード、記憶域、CPUおよびメモリーを動的にプロビジョニングすることにより、使用状況の改善によってコストをさらに削減しながら、サービス・レベルを簡単かつ効率的に維持できます。また、Oracle RACはOracle RACデータベースにアクセスするアプリケーションからは完全に透過的であるため、既存のアプリケーションを変更せずにOracle RACにデプロイできます。
スケーラビリティ: Oracle RACでは、容量を増加するためにクラスタにノードを追加できる柔軟性があります。これにより、システムを段階的に拡張してコストを節約でき、小規模な単一ノード・システムを大規模なシステムに置き換えなくてすむようになります。標準的な低コストのコンピュータとモジュール・ディスク・アレイによるグリッド・プールにより、Oracle Databaseを使用したこのソリューションが強化されます。既存のシステムを新しい大規模なノードに置き換えてシステムをアップグレードする方法とは対照的に、1つ以上のノードをクラスタに段階的に追加できるため、容量のアップグレード・プロセスがより簡単で迅速になります。Oracle RACに実装されているキャッシュ・フュージョン・テクノロジとOracle DatabaseでサポートされているInfiniBandにより、アプリケーションを変更しなくても容量をほぼ直線比例的にスケーリングできます。
フォルト・トレランス: Oracle RACクラスタ・アーキテクチャのもう1つの主な利点は、複数のノードによって実現される本質的なフォルト・トレランスです。物理ノードは独立して動作しているため、1つ以上のノードに障害が発生してもクラスタ内の他のノードには影響しません。フェイルオーバーはグリッド上の任意のノードで発生します。極端な場合、1つのノードを除くすべてのノードが停止しても、Oracle RACシステムはデータベース・サービスを提供し続けます。このアーキテクチャでは、メンテナンスのためにノードのグループを透過的にオンラインまたはオフラインにすると同時に、クラスタの残りの部分によってデータベース・サービスを提供し続けることができます。Oracle RACには、接続プールをフェイルオーバーするためにOracle Application Serverとの統合が組み込まれています。この機能により、TCPタイムアウトが発生するまで数十分待機することなく、アプリケーションに障害が即座に通知されます。アプリケーションは適切なリカバリ・アクションを即座に実行できます。そして、グリッドのロード・バランシングによってロードが徐々に再分配されます。
Oracle Clusterware: Oracle RACは、クラスタを管理するためのクラスタウェアの完全セットも備えています。Oracle Clusterwareには、ノード・メンバーシップ、メッセージ・サービスおよびロックなど、クラスタの実行に必要なすべての機能が用意されています。Oracle Clusterwareは、一般的なイベントおよび管理APIを備えた完全統合スタックであるため、Oracle Enterprise Managerから一元的に管理できます。クラスタをサポートするために追加ソフトウェアを購入する必要はありません。このため、サード・パーティのクラスタウェアを統合およびテストするために余計な作業を行わずにすみます。また、Oracle Clusterwareは、Oracle Databaseを使用可能なすべてのプラットフォームにわたって同じインタフェースを使用し、同じように動作します。OracleではOracle RACとともに使用するサード・パーティのクラスタウェアを引き続きサポートしますが、サード・パーティのクラスタウェアを使用する必要やメリットはありません。
Oracle Clusterwareのフレームワークの高可用性機能はアプリケーションに応じて拡張できます。つまり、Oracle DatabaseおよびOracle RACの同じ高可用性メカニズムを使用して、カスタム・アプリケーションの可用性を高めることができます。Oracle Clusterwareを使用すると、アプリケーションを監視、再配置および再起動できるため、アプリケーションのフェイルオーバーをデータベースのフェイルオーバーと統合および調和できます。
サービス: Oracle RACは、サービスと呼ばれるエンティティをサポートしています。このサービスを定義することにより、データベースのワークロードをグループ化し、サービスを提供するために割り当てられる最適なインスタンスに処理をルーティングできます。サービスは、データベース・ユーザーまたはアプリケーションのクラスを表します。ビジネス・ポリシーを定義してこれらのサービスに適用し、ピーク処理時用のノードの割当てや、サービス障害の自動処理などのタスクを実行します。サービスを使用してシステム・リソースを必要な場所と時間に応じて適用することにより、ビジネス上の目標を達成します。
計画外停止時間の最も一般的な原因の1つは、システム障害またはクラッシュです。システム障害は、ハードウェア障害、電源障害、およびオペレーティング・システムまたはサーバーのクラッシュの結果として発生します。これらの障害が原因で発生する中断の程度は、影響を受けるユーザーの数やサーバーのリストアに要する時間によって異なります。高可用性システムは、障害が発生したときに障害から迅速かつ自動的にリカバリできるよう設計されています。重要なシステムのユーザーは、障害から迅速にリカバリし、リカバリまでの時間を予測可能にするという確約をIT組織に求めます。この確約時間よりも停止時間が長いと、システム運用に直接影響を及ぼし、収益や生産性の低下に繋がる可能性があります。
Oracle Databaseでは、システム障害およびクラッシュから非常に短時間でリカバリできます。ただし、短時間でのリカバリと同等に重要なのが予測可能性です。Oracle Databaseに含まれているファスト・スタート・リカバリ・テクノロジは、Oracle Databaseに固有のテクノロジで、データベース・クラッシュ・リカバリ時間を自動的にバインドします。データベースによってチェックポイント処理が自己チューニングされ、必要なRecovery Time Objectiveが守られます。これにより、リカバリ時間が短く、予測可能になり、サービス・レベル目標を達成する能力が高まります。ファスト・スタート・リカバリ機能は、負荷の高いデータベースのリカバリ時間を数十分から数秒に短縮できます。
Oracle Data Guardにより、高可用性、データ保護、および企業データの障害時リカバリが保証されます。Data Guardでは、スタンバイ・データベースは、トランザクション一貫性のあるプライマリ(本番)・データベースのコピーとして維持されます。計画停止または計画外停止でプライマリ・データベースが使用できなくなった場合、Data Guardにより任意のスタンバイ・データベースがプライマリ用に切り替えられるため、停止時間が最小限に抑えられます。Oracleクライアントに統合されているData Guardのファスト・スタート・フェイルオーバーと高速アプリケーション通知を使用した自動フェイルオーバーにより、高度なデータ保護とデータ可用性を実現します。
Oracle Streamsを使用して、柔軟な高可用性環境を構成できます。Oracle Streamsを使用すると、本番データベースのローカルまたはリモート・コピーを作成できます。人為的エラーや大災害が発生した場合、このコピーを使用して処理を再開できます。
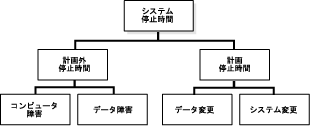
データ障害とは、企業の重要なデータの消失、損害または破損です。データ障害の原因はコンピュータ障害よりも複雑かつ微妙です。この原因には、ストレージ・ハードウェアの障害、人為的エラー、破損またはサイト障害などがあります。
図17-2は、ストレージ障害、人為的エラー、破損およびサイト障害という4つのタイプのデータ障害に焦点を当てています。
データ障害から保護してリカバリするためのソリューションの設計は非常に重要です。システムまたはネットワーク障害によってユーザーがデータにアクセスできなくなる可能性はありますが、適切なバックアップまたはリカバリ・テクノロジなしにデータ障害が発生すると、リカバリ作業に何時間もかかったり、データが失われる場合があります。
Oracle Databaseには、多くのデータ保護機能が用意されています。これらの多くの拡張機能を求める誘引により、データ保護およびリカバリを取り巻く新たな経済的側面が形成されています。過去20年間にわたって、ディスク容量は3桁大きくなった一方、MB当たりのコストは大幅に小さくなりました。この傾向は一向に衰える兆しを見せません。これにより、バックアップ・メディアとしてのディスク記憶域のコストはテープに拮抗するようになりました。また、ディスク記憶域には、オンラインで使用できるという利点と、データにランダムにアクセスできるという利点もあります。
オラクル社ではこのような傾向に後押しされ、リカバリ計画について再考し、これらの経済的力学を利用した段階的なものとすることができました。Oracle Databaseで追加ディスク記憶域を使用することにより、バックアップとリカバリにかかる時間を数時間から数分に短縮できます。実質的に、廉価なディスク記憶域をコストの多大な停止時間と引き換えることが可能です。
この項の内容は、次のとおりです。
単一データベース・インスタンスの記憶域のプロビジョニングは複雑であり、まして企業全体の記憶域のプロビジョニングなどは論外です。以前は、このプロセスに、次のステップが含まれていました。
この後には、パフォーマンスに悪影響を与えるホット・スポットの特定や、競合を減らすためのデータファイルの移動といった難しい作業が控えています。そして、いつかはディスク・クラッシュが発生したり領域が不足し、更新した記憶域構成のバランス再調整のために、ディスクの追加およびすべてのファイルの移動が必要になります。
ただし、この状況は、Oracle Databaseの自動ストレージ管理(ASM)という機能によって大きく変化しました。ASMでは、垂直に統合されたファイル・システムおよびボリューム・マネージャがOracleカーネルに直接提供されているため、データベース記憶域のプロビジョニング作業が大幅に削減されます。
ASMにより、特化されたストレージ製品の費用、インストールおよびメンテナンスが不要になり、可用性が高まります。また、データベース・アプリケーション用の固有の機能が提供されます。ASMは、使用可能なすべての記憶域にまたがって分散され、パフォーマンスを最適化し、ミラー化も行い、データ破損に対する保護機能となります。ASMでは、SAME(Stripe And Mirror Everything)の概念が拡張され、ディスク・レベル全体ではなくデータベース・ファイル・レベルでのミラー化を可能にする柔軟性が拡張されています。
最も重要なことは、ASMにより、データおよびディスクの管理に伴う複雑な仕組みが排除され、ミラー化の設定、ディスクの追加および削除のプロセスが簡略化されることです。(大規模なデータ・ウェアハウスのように)数百、時には数千のファイルを管理するかわりに、ASMを使用するデータベース管理者は、より規模の大きなオブジェクトであるディスク・グループを作成および管理します。ディスク・グループは、1つの論理単位として管理される一連のディスクを表します。基礎となるデータベース・ファイルのファイルの命名と配置を自動化することにより、DBAの時間を節約でき、標準のベスト・プラクティスに確実に準拠できます。
必要な場合、ASMに固有のミラー化メカニズムをストレージ障害に対する保護として使用できます。ミラー化はデフォルトで有効になっており、3重ミラー化も可能です。ASMミラー化により、障害グループを使用してデータの保護レベルを強化できます。障害グループは、障害を許容できる共通のリソース(ディスク・コントローラまたはディスク・アレイ全体)を共有するディスクのセットです。
ASM障害グループを定義した後、データの冗長コピーは別の障害グループにインテリジェントに格納されるため、ストレージ・サブシステム内の任意のコンポーネントに障害が発生しても、データは透過的に保護されて使用可能であることが保証されます。また、ASMでは、データの保護を強化するためにHardware Assisted Resilient Data機能(後述の「データ破損に対する保護」の項を参照)をサポートしています。
停止時間の原因に関するほとんどの調査では、停止時間の最大の原因として人為的エラーがあげられています。不注意による重要データの削除や、UPDATE文の不適切なWHERE句により、意図した以上の行が更新されるなどの人為的エラーを可能なかぎり防止し、それに対する予防措置が機能しなかった場合は、元に戻す必要があります。Oracle Databaseには、このようなエラーが発生した場合に、エラーを迅速に診断してリカバリを行うために役立つ管理者用の使用しやすい強力なツールがあります。また、エンド・ユーザーが管理者の介入なしで問題からのリカバリを行えるようにする機能も装備しているため、管理者のサポート作業が軽減され、損失データや損傷データのリカバリ時間が短縮されます。
次の各項では、人為的エラーを防止するOracleの機能について説明します。
エラーを回避する最善の方法は、ビジネスの実行に本当に必要なデータおよびサービスにユーザー・アクセスを制限することです。Oracle Databaseは、ユーザーの認証、および管理者による職務実行に必要な権限のみのユーザーへの付与を可能にすることで、アプリケーション・データへのアクセスを制御する様々なセキュリティ・ツールを提供しています。また、Oracle Databaseのセキュリティ・モデルには、仮想プライベート・データベース(VPD)機能を使用して行レベルでデータ・アクセスを制限できます。この機能を使用すると、アクセスする必要のないデータからユーザーをさらに隔離できます。
権限を持つユーザーが誤りを作成した場合、そのエラーを修復するツールが必要です。Oracle Databaseは、フラッシュバックと呼ばれる人為的エラーを修復する一連のテクノロジを提供します。フラッシュバックにより、データ・リカバリに大きな変化がもたらされます。以前は、数分の内に破壊されたデータベースのリカバリに、数時間かかる場合がありました。フラッシュバック・テクノロジを使用することにより、エラーの発生にかかった時間と同じ時間内で修復が可能になります。フラッシュバック・テクノロジは非常に使用しやすく、1つの短いコマンドを使用してデータベース全体をリカバリできるため、複雑な手順は必要ありません。フラッシュバックはOracle Databaseに固有のテクノロジで、次の機能があります。
表17-1は、フラッシュバック・テクノロジによる人為的エラーの修復方法を示しています。
|
関連項目
|
Oracleログ・ファイルには、Oracleデータベースのアクティビティおよび履歴に関する有用な情報が豊富に含まれています。ログ・ファイルには、データベース・リカバリに必要なすべてのデータが含まれています。これらのファイルには、データベース内のデータおよびメタデータに加えられたすべての変更も記録されています。LogMinerは、SQLを使用したREDOログ・ファイルの読取り、分析および解析が可能な完全なリレーショナル・ツールです。LogMinerによるログ・ファイルの分析を使用すると、データへの変更の追跡または監査、チューニングおよび容量計画に関する補足情報の提供、複雑なアプリケーションのデバッグに関する重要な情報の取得、または削除したデータのリカバリが可能になります。
破損は、I/Oスタック内の不良コンポーネントによって引き起こされます。たとえば、データベースにより、更新トランザクションの結果としてI/Oが発行されます。データベースI/Oは次に対して渡されます。
I/Oシーケンス内のいずれかのコンポーネントに不具合またはハードウェア障害があると、データ内の一部のビットが反転され、破損データがデータベースに書き込まれる場合があります。データベース制御情報やユーザー・データが破損することもあり、その場合は、データベースの機能性や可用性が深刻な打撃を受けるおそれがあります。同様に、ディスク障害もデータベース・ファイルに損害を与え、データベースのリカバリにバックアップが必要となる場合があります。
データ破損に対する保護の内容は、次のとおりです。
Oracle Hardware Assisted Resilient Data(HARD)により、データ破損を未然に防ぎます。データ破損はほとんどありませんが、発生した場合にはデータベース、つまりビジネスに壊滅的な影響があります。ストレージ・デバイス内にOracleのデータ検証アルゴリズムを実装することにより、破損データが永続ストレージ上のデータベース・ファイルに書き込まれるのを防ぐことができます。上位のソフトウェアから下位のハードウェアまでの、このようなエンドツーエンドの検証は、Oracleとストレージ・パートナが提供する独自の機能です。
Oracleが保護情報を検証してデータベース・ブロックに追加し、この保護情報がストレージ・デバイスによって検証されます。HARDにより、データベースとストレージ間のI/Oパスへの破損データの侵入が検出され、データベース業界で今までは防止が不可能だった大規模障害が除去されます。RAIDはデータを物理的に確実に保護することで、ストレージ業界から幅広く支持されていますが、HARDは物理ビットの保護からビジネス・データの保護へと進化することで、データ保護を1つ上のレベルに高めています。
書込み欠落はデータ破損のもう1つの形態ですが、こちらの方が迅速な検出および修復がより困難です。データ・ブロックの書込み欠落が発生するのは、次のような場合です。
Oracle Database 11gより前は、RMANによって検出されたブロック破損はV$DATABASE_BLOCK_CORRUPTIONに記録されていました。Oracle Database 11gでは、RMANを含む複数のデータベース・コンポーネントおよびユーティリティがブロック破損を検出し、そのビューに記録できるようになりました。Oracle Databaseでは、ブロック破損が検出または修復されるとこのビューが自動的に更新されます(たとえば、ブロック・メディア・リカバリまたはデータファイル・リカバリなどを使用)。これには、ブロック破損の検出に要する時間が短縮されるという利点があります。
データ・リカバリ・アドバイザを使用すると、永続的な(ディスク上の)データ障害が自動的に診断され、適切な修復オプションが提示されて、ユーザーのリクエストで修復操作が実行されます。この機能は、次のとおりです。
データ・リカバリ・アドバイザの初期リリースは、Oracle RACをサポートしていません。また、データ・リカバリ・アドバイザを使用してData Guard構成でプライマリ・データベースは管理できますが、データ・リカバリ・アドバイザを使用してフィジカル・スタンバイ・データベースはトラブルシューティングできません。Oracle Enterprise Manager 11g Grid Controlを使用している場合、データ・リカバリ・アドバイザでは、修復計画の推奨時にスタンバイ・データベースの存在のみが考慮されます。
企業データのバックアップのかわりとなるものは存在しません。まれに複数の障害により、ストレージ・サブシステム内でミラー化されているデータであっても使用不可能になることがあります。Oracleでは、すべてのデータを適切にバックアップし、以前のバックアップからデータをリストアし、障害発生直前までにそのデータに行われた変更をリカバリする、オンライン・ツールを提供しています。
大規模なデータベース・システムをバックアップすることは、簡単ではありません。大規模なデータベースは、多数の異なるディスクに分散された数百単位のファイルで構成されている場合があります。重要なファイルのバックアップを怠ると、データベース・バックアップ全体が使用不可能になることがあります。通常、破損したこのようなファイルは、それが必要になって初めて検出されます。Recovery Manager(RMAN)は、Oracle Databaseのバックアップ、リストアおよびリカバリ・プロセスの管理ツールです。RMANにより、バックアップ・ポリシーが作成および維持され、すべてのバックアップおよびリカバリ・アクティビティが分類整理されます。バックアップおよびリストア時にすべてのデータ・ブロックについて破損を分析することにより、破損データがバックアップに伝播するのを防止できます。最も重要なのは、Recovery Managerを使用すると、必要なすべてのデータファイルがバックアップされ、データベースがリカバリ可能であることが保証されることです。
Recovery Managerは、ユーザー指定の期間内でデータベースをリストアするために必要なファイルを自動的に追跡します。Recovery Managerは、データベースの残りの部分がオンラインのまま、中断されていた操作を自動的に再開し、破損したログ・ファイルを処理し、個々のデータ・ブロックをリストアできます。
RMANは、データベースのバックアップおよびリカバリ機能を大幅に強化します。RMANは、フラッシュ・リカバリ領域へのすべてのデータのバックアップおよびリカバリを自動管理できます。フラッシュ・リカバリ領域は、Oracleデータベース内のすべてのリカバリ関連ファイルおよびアクティビティ用の統合されたディスク・ベースの格納位置です。テープのかわりにディスクにバックアップすることで、より高速のバックアップが可能になります。しかしさらに重要なことは、データベースのメディア・リカバリが必要な場合に、データベースのリカバリ時間を大幅に短縮する、データファイルのバックアップをすぐに使用できることです。
フラッシュ・リカバリ領域のファイルは、Recovery Managerにより管理されます。RMANは、フラッシュ・リカバリ領域のすべてのバックアップを作成し、この領域を管理します。アーカイバはREDOデータをフラッシュ・リカバリ領域に書き込み、RMANでは、不要になった古いバックアップおよびアーカイブREDOログが自動的に削除(またはテープに移動)されます。RETENTION POLICYを7日間のリカバリ期間に設定すると、RMANにより、データベースを7日前までリカバリするために必要なすべてのバックアップが保持されます。7日より前の時点までリカバリする必要がある場合は、テープからデータがリストアされます。Oracle Enterprise Managerには、ベスト・プラクティスの実装を含む、フラッシュ・バックアップおよびリカバリを実行するための完全インタフェースが用意されています。
増分バックアップは、Oracle8データベースで最初にリリースされてからRMANの一部となっています。増分バックアップにより、前回のバックアップ以降に変更されたブロックのみが記録されます。Oracle Databaseには、ブロック・チェンジ・トラッキングが実装されているため、増分バックアップをより速く取得できます。Oracle Databaseは、すべてのデータベース変更の物理位置を追跡します。RMANは、この変更追跡情報を自動的に使用して、増分バックアップ時に読み取る必要があるブロックを判断し、そのブロックに直接アクセスしてバックアップします。この増分バックアップを、前に作成したイメージ・バックアップとマージすることにより、リカバリ時間を最小限に抑えることができます。次第に増加する更新されたバックアップに基づくバックアップ方法によって、メディア・リカバリに必要な時間を最小限にできます。バックアップ方法の変更追跡部分を使用して増分バックアップを行うことにより、日次バックアップに必要な時間が短縮され、ネットワークを介してバックアップを実行する際のネットワーク帯域幅を節約でき、ログに記録されていない変更がデータベースをリカバリでき、バックアップ・ファイルの記憶域が削減され、データベースのリカバリ時間が短縮されます。
Oracle Databaseのバックアップおよびリカバリには、他にも多くの革新的機能が用意されています。
BEGIN BACKUPコマンド
関連項目
データ保護機能により、サイトの処理を不可能にする壊滅的な事象からサイトを長期的に保護します。例としては、ファイルの破損、自然災害、停電、通信障害、さらにはテロなどがあります。Oracle Databaseは、本番データベースのローカルまたはリモート・コピーを作成し保持する、様々なデータ保護ソリューションを提供します。破損または災害が発生した場合、データのユーザーはリモート・データベースにアクセスすることで自分のタスクを続行できます。
データ保護の最もシンプルな形式は、データベース・バックアップのオフサイト・ストレージです。データ・センターが適正な時間内にサービスを再開できない場合、バックアップを他のサイトのシステムでリストアでき、ユーザーはこのバックアップ・システムに接続できます。ただし、他のシステムでバックアップをリストアするには時間がかかり、しかもバックアップは完全には最新でない可能性があります。より迅速なリカバリを可能にし、災害時でさえも継続的なデータベース・サービスを可能にする機能として、OracleはData Guardを提供しています。これについては、次の各項で説明します。
Data Guardは、あらゆるOracle Database障害時リカバリ計画の基盤となるものです。Data Guardには、本番データベースのスタンバイ・コピーを設定および保持できる機能が用意されています。このスタンバイ・データベースは、本番データベースから見て地球の反対側に配置することも、同じデータ・センターに配置することも可能です。Data Guardには、複雑なタスクを自動化する拡張機能があり、優れた監視、アラートおよび制御メカニズムが用意されています。このため、データベースはデータ・センターの災害に耐えることができます。また、フェイルオーバーが必要な場合にはサーバーをスタンバイ・データベースに動的に追加できるため、Data Guardはグリッド・クラスタ間で透過的に動作します。
Oracle Data Guardは、Redo Applyテクノロジを使用するフィジカル・スタンバイ・データベース、スナップショット・スタンバイ・データベース、およびSQL Applyテクノロジを使用するロジカル・スタンバイ・データベースをサポートしています。
Redo ApplyモードのData Guardは、フィジカル・スタンバイ・データベースと呼ばれる本番データベースのコピーを保持し、それを本番データベースと常に同期させます。プライマリ・データベースのREDOデータは、スタンバイに送信され、メディア・リカバリの際に物理的に適用されます。スタンバイ・データベースは、物理的にプライマリと同一です(ただし、遅延が生じる場合があります)。また、REDOの適用中にスタンバイ・データベースを読取り専用モードでオープンできるため、スタンバイ・データベースを使用して本番データベースからレポート処理をオフロードすることもできます。スタンバイ・データベースで作成されたバックアップを使用して本番データベースのリカバリを実行できるため、バックアップ処理を本番データベースからオフロードすることもできます。
フィジカル・スタンバイ・データベースは、障害やデータ・エラーからの保護機能として有効です。エラーまたは災害の発生時に、フィジカル・スタンバイ・データベースをオープンして使用することで、データ・サービスをアプリケーションおよびエンド・ユーザーに提供できます。スタンバイ・データベースへの変更の適用には優れたメディア・リカバリ・メカニズムが使用されているため、スタンバイ・データベースはすべてのアプリケーションでサポートされ、最大のトランザクション・ワークロードにも簡単に効率よく対処できます。
スナップショット・スタンバイ・データベースは、フィジカル・スタンバイ・データベースから作成する更新可能なスタンバイ・データベースです。スナップショット・スタンバイ・データベースは、プライマリ・データベースからREDOデータを受け取ってアーカイブしますが、スタンバイ・データベースが読取り/書込みモードでオープンされている間は、プライマリ・データベースのREDOデータを適用しません。このため、通常、時間が経つにつれてスナップショット・スタンバイ・データベースとプライマリ・データベースの相違が大きくなります。また、スナップショット・スタンバイ・データベースをローカルで更新すると、この相違はさらに大きくなります。
REDOデータはスナップショット・スタンバイ・データベースをフィジカル・スタンバイ・データベースに戻すまで適用されないため、ローカルで行われたスナップショット・スタンバイ・データベースの更新はすべて破棄されます。単一コマンドを使用して、スナップショット・スタンバイ・データベースをフィジカル・スタンバイ・データベースに戻すことができます。この時点で、スナップショット・スタンバイ状態で行われた変更は破棄され、Redo Applyにより、アーカイブされたREDOを使用してフィジカル・スタンバイ・データベースとプライマリ・データベースが自動的に再同期されます。
SQL ApplyモードのData Guardは、プライマリ・データベースからREDOデータを受け取り、これをSQLトランザクションに変換し、オープン状態のスタンバイ・データベースに適用します。ロジカル・スタンバイ・データベースは、物理的にはプライマリ・データベースと異なる場合もありますが、論理的にはプライマリ・データベースと同一で、プライマリ・データベースが破棄された場合には、処理を引き継ぐことができます。トランザクションはSQLを使用してオープン状態のデータベースに適用されるため、スタンバイ・データベースは、他のタスクに対して同時に使用でき、本番データベースと物理構造が異なる場合もあります。たとえば、ロジカル・スタンバイ・データベースは、意思決定支援用として使用することや、プライマリ・データベースにはない別の索引やマテリアライズド・ビューを使用してレポート用として最適化することが可能です。
最も重要なのは、SQL Applyはデータ保護機能であることです。これは、SQL Applyは、ログ・ファイル内の変更前の値とロジカル・スタンバイ・データベース内の変更前の値を比較することにより、論理的な破損をチェックできるためです。これにより、ロジカル・スタンバイ・データベースは、起こり得る最大範囲の破損からデータを保護できるようになります。
ロジカル・スタンバイ・データベースは、リカバリ中に読取り/書込みI/Oが可能なため、SQL ApplyによってREDOログへの変更が適用されている間も、スタンバイ・データベースを問い合せることができます。
フィジカルとロジカルの両方のスタンバイ・データベースで、同じ転送サービスが使用されます。Data Guardでは、同期転送方式と非同期転送方式を選択できます。Data Guardの同期転送サービスにより、データ損失ゼロの保護が実現されるため、プライマリ・データベースに障害が発生した場合、以前にコミットしたすべてのトランザクションの保持に必要なREDOデータがスタンバイ・サイトで使用可能になります。
また、REDOデータをスタンバイ・サイトに非同期方式で転送することもできます。これにより、潜在的なデータ損失を最小限に抑えると同時に、遠距離転送であっても最適なパフォーマンスを実現し、ネットワーク障害からデータを保護できます。
リアルタイム適用により、Data Guardの適用サービスでは、現行ログ・ファイルがスタンバイ・データベースにアーカイブされるのを待機せずに、REDOデータをプライマリ・データベースから受信すると同時にスタンバイ・データベースに適用できます。これにより、スタンバイ・データベースをプライマリ・データベースと密接に同期できるため、最新かつリアルタイムのレポートを使用できるようになります。また、スイッチオーバーおよびフェイルオーバー時間を短縮できるため、ビジネスの計画停止時間と計画外停止時間の短縮につながります。さらに、フラッシュバック・データベースをプライマリとスタンバイの両方のデータベースで使用することを選択して、データベースを過去のある時点の状態に短時間で戻し、ユーザー・エラーを撤回できます。あるいは、スタンバイ・データベースにフェイルオーバーすると決定したが、これらのユーザー・エラーはすでにスタンバイ・データベースに適用されている場合(リアルタイム適用が有効であったため)、スタンバイ・データベースを安全な過去のある時点の状態にフラッシュバックできます。これら2つの機能を使用すると、スタンバイ・データベースを最新の状態に維持するか、または本番データベースでの人為的エラーがスタンバイ・データベースに伝播することを防ぐためにRedo Applyを遅延させるかを選択するという、ときには必要な妥協が解消されます。
プライマリ・データベースとスタンバイ・データベース、およびこれらによる各種対話は、SQL*Plusを使用して管理できます。Data Guardには、管理を容易にするために、Data Guard Broker分散管理フレームワークも用意されています。これにより、Data Guard構成の作成、保守および監視が自動化されて一元化されます。Oracle Enterprise ManagerまたはBroker独自の特別なコマンドライン・インタフェース(DGMGRL)を使用すると、Brokerの管理機能を利用できます。使用しやすいOracle Enterprise Manager GUIからマウスをシングルクリックするのみで、プライマリ・データベースからいずれかのタイプのスタンバイ・データベースに対するフェイルオーバー処理を開始できます。BrokerとOracle Enterprise Managerを使用すると、スタンバイ・データベースを簡単に管理かつ操作できます。フェイルオーバーやスイッチオーバーなどのアクティビティを容易にすることにより、エラーが発生する可能性が大幅に小さくなります。
ファスト・スタート・フェイルオーバーを使用すると、本番データベースからスタンバイ・データベースへのデータベース処理のフェイルオーバーを人間の介在なしに完全に自動化できるため、フォルト・トレラントなスタンバイ・データベース環境の作成が可能になります。ファスト・スタート・フェイルオーバーにより、管理者は、フェイルオーバー操作を起動および実装するために複雑な手動ステップを実行する必要がなくなるため、プライマリ・データベースが消失する事態が発生しても、同期化された指定のスタンバイ・データベースに自動的に迅速かつ確実にフェイルオーバーできます。これにより、停止時間は大幅に短縮されます。ファスト・スタート・フェイルオーバーは、Oracle Enterprise ManagerまたはData Guard Brokerを使用して設定します。Data Guard環境を監視するオブザーバにより、必要に応じてフェイルオーバーが自動的にトリガーされて完了します。ファスト・スタート・フェイルオーバーが発生した後、構成への再接続時に、古いプライマリ・データベースはBrokerによって新しいスタンバイ・データベースとして自動的に復元されます。これにより、Data Guard構成では構成における障害時の保護を簡単かつ迅速にリストアできるため、Data Guard構成の堅牢性が向上します。これらの機能により、Data Guardは、透過的なビジネスの継続性の維持に役立つのみでなく、障害時リカバリ構成の管理コストも削減します。
特に複数のタイムゾーンのユーザーをサポートしているグローバル・エンタープライズでは、計画停止時間は運用に大きな損害を与える可能性があります。このような場合、計画的な中断を最小化するようシステムを設計することが重要です。計画停止時間には、ルーチン操作、定期的なメンテナンスおよび新規デプロイメントが含まれます。
ルーチン操作とは頻繁なメンテナンス作業を指し、これには、バックアップ、パフォーマンス管理、ユーザーやセキュリティの管理およびバッチ操作があります。また、パッチのインストールやシステムの再構成などの定期メンテナンスは、データベース、アプリケーション、オペレーティング・システム、ミドルウェアまたはネットワークを更新するために必要となる場合があります。新規デプロイメントは、ハードウェア、オペレーティング・システム、データベース、アプリケーション、ミドルウェアまたはネットワークへの大規模なアップグレード時に必要となる場合があります。アップグレードを実行するタイミングのみでなく、その変更によるアプリケーション全体への影響も考慮する必要があります。
インターネットは、データのグローバル共有を容易にしましたが、データ可用性に対する新しい問題と要件も提起しました。世界各国のユーザーが1日24時間データにアクセスするため、メンテナンスのための時間帯はなくなったも同然です。計画停止時間による運用の中断は、計画外停止時間による中断と同様に深刻な問題となっています。ユーザーが影響を受けない時間枠は、存在しません。データベースに格納されるデータ量が膨大になると、メンテナンス操作に非常に時間がかかります。このような作業は、データのユーザーに影響を与えずに行うことが重要です。
この項の内容は、次のとおりです。
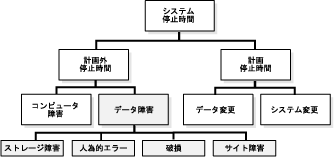
図17-3は、オンライン・スキーマおよびデータ再編成、パーティション表とパーティション索引、およびリソースの動的プロビジョニングという、データ変更が原因である3つのタイプの停止時間に焦点を当てています。
この項の内容は、次のとおりです。
Oracle Databaseでは、データベース操作やユーザーに対するデータ可用性を阻害せずに、ほとんどのメンテナンス操作を実行できます。データベースがオンライン状態で、エンド・ユーザーがデータの読取りまたは更新を行っている場合でも、索引の追加、再作成または断片化解消が可能です。同様に、オンライン状態での表の再配置や断片化解消も可能です。表の再定義、表タイプの変更、列の追加、削除または名前変更、および記憶域パラメータの変更は、基盤となるデータの表示または更新を行っているエンド・ユーザーの操作を中断せずに実行できます。Oracle Databaseには、次の機能があります。
データベースが大きくなると、その管理作業が極端に膨大になることがあります。管理者は、データベース表および索引をパーティション化する機能を使用することにより、大きい表を、小さく管理の容易な表に分割できます。パーティション化により、大半の操作やスキーマ変更をオンライン状態に維持しながら、メンテナンス作業を一度に1パーティションずつ行うことができます。このため、メンテナンス中にデータが受ける影響は最小限になります。また、パーティションにより、パラレル実行が可能になるため、ほとんどの操作の実行時間が大幅に短縮されます。
パーティションの他の利点としては、障害の伝播防止があります。メディア障害や破損などの障害は、障害が発生したディスク上のパーティション以外には伝播されません。影響を受け、リカバリを必要とするのは、そのパーティションのみです。これにより、リカバリ時間が短縮されるのみでなく、障害が発生したパーティションのリカバリ中に、他の影響を受けていないパーティションをオンライン状態に維持できます。
一般に、大きい表の中のすべてのデータが、同じアクセス特性を持っているわけではありません。通常、保留中のオーダーはクローズされたオーダーよりも頻繁にアクセスされ、または前四半期の販売実績は3年前の四半期の販売実績よりも頻繁に分析されます。パーティション化により、データのインテリジェントなストレージ管理が可能になります。頻繁にアクセスされるデータは、最速のディスク上に格納し、アクセスの集中するデータは、多数のドライブにストライプ化できます。
計画的なシステム変更が行われるのは、ルーチン操作、定期的なメンテナンス操作および新規デプロイメントを実行する場合です。計画的なシステム変更には、データベース内の組織データ構造の外部で行われる運用環境の計画的変更が含まれます。
計画的なシステム変更によるサービス・レベルでの影響は、次の条件に応じて大きく異なります。
この項の内容は、次のとおりです。
Oracle Databaseは、ローリング方式によるOracle RACシステムのノードへのパッチの適用をサポートします。ローリング・アップグレードを実行するには、次の高度な手順を実行する必要があります。
Oracle RACシステムの実行中は、データベース・クライアントにかわってすべてのノードがトランザクションをアクティブに処理します。パッチ適用の手順1では、パッチが適用される最初のインスタンスを静止させます。手順2では、Oracleパッチ・ツール(Opatch)を使用して、静止中のインスタンスにパッチを適用します(たとえば、インスタンス1のOracleホームが更新されます)。手順3では、パッチが適用されたインスタンスが再度アクティブ化され、クラスタに再結合します。これで、Oracle RACシステムでは、1つのインスタンスがクラスタ内の他のノードよりも高いメンテナンス・レベルで実行されるようになりました。
Oracle RACシステムは、このパッチが元の問題を解決し、他の問題を引き起こしていないことを確認するために、任意の期間にわたってこの複合モードで実行できます。次に、この手順がクラスタ内の残りのノードに対して繰り返されます。クラスタ内のすべてのノードにパッチが適用されると、ローリング・パッチ更新が完了し、すべてのノードで同じバージョンのOracle Databaseソフトウェアが実行されるようになります。さらに、Opatchにはパッチの適用をロールバックする機能もあります。この機能では、更新されたインスタンスで異常な動作が見られた場合、クラスタ全体を停止することなく、問題のパッチをアンインストール、すなわちロールバックできます。ロールバック手順はパッチ適用手順と同じですが、この場合、Opatchユーティリティにより、以前に適用したパッチが削除されます。
Oracle Databaseは、ローリング方式によるデータベース・ソフトウェア・アップグレードのインストールおよびパッチ・セットの適用をサポートします。ここでは、Data Guard SQL Applyおよびロジカル・スタンバイ・データベースが使用され、データベースの停止時間はほとんどありません。
また、Oracle Clusterwareも、ソフトウェア・アップグレードおよびパッチ・セットの適用についてローリング方式によるアップグレードをサポートします。さらに、Oracle Database 11gでは、ASMもローリング・リリース・アップグレードをサポートします。
フィジカル・スタンバイ・データベースのユーザーは、ローリング・アップグレードの期間中に構成へのロジカル・スタンバイ・データベースの追加を選択することも、一時ロジカル・スタンバイ・データベースを使用して第2のスタンバイ・データベースの作成を回避することもできます。一時ロジカル・スタンバイ・データベースは、Oracle Database 11gにおけるData Guardの新機能で、ローリング・データベース・アップグレードを実行するために、フィジカル・スタンバイ・データベースをロジカル・スタンバイ・データベースに一時的に変換できます。このため、アップグレードが完了した後、ロジカル・スタンバイ・データベースをフィジカル・スタンバイ・データベースに戻すことができます。一時ロジカル・スタンバイ・データベースを使用すると、アップグレードを実行するために別のロジカル・スタンバイ・データベースを作成する必要がなくなります。
Oracleでは、ローリング・アップグレードおよびローリング・パッチ更新をサポートしているため、企業のデータベース管理者が管理タスクを行うためのメンテナンス時間枠がほとんど不要となり、24時間365日の連続稼働が可能になります。
Oracle Databaseは、動的再構成に対するサポートの拡張を継続しているため、必要に応じて、サービスを中断せずにハードウェア内の変更に対応できます。Oracle Databaseは、次のようなハードウェア構成への変更を動的にサポートします。
Oracle Databaseがオペレーティング・システムを監視して、CPU数の変更を検出します。CPU_COUNT初期化パラメータをデフォルトに設定した場合、データベースのワークロードは、新規に追加されたプロセッサを動的に利用できます。
Oracle Databaseでは、自動メモリー管理を使用して、SGA、PGAおよびサブコンポーネント間でメモリーを自動的に移動して最適なパフォーマンスを確保できます。また、初期化パラメータSGA_TARGET、PGA_AGREEGATE_TARGETおよびSERVER_MEMORY_TARGETを動的に変更して、アクティブなインスタンスのメモリーを追加および削除できます。
前述の機能により、システム変更の影響が解消され、エンタープライズ・グリッド・コンピューティングにおける基本要件である必要に応じた容量のプロビジョニングが真に可能になります。
ITインフラストラクチャの実装を成功させる鍵は、運用面のベスト・プラクティスです。技術のみでは不十分です。OracleのMaximum Availability Architecture(MAA)は、可用性の高いシステムを構築するための完全に統合された実証済のブループリントです。MAAのブループリントには、Oracle RACおよびOracle Clusterware、Data Guard、Recovery Manager、フラッシュバック・テクノロジ、Streams、Enterprise Managerを含むOracle Databaseの主要機能を統合的に使用して高可用性を実現する方法が詳述されています。
Oracleテクノロジが関与するHAシステムの設計は複雑であったり当て推量が含まれるものであってはならないという理念に基づいて概念化されているため、MAAの設計と構成の推奨事項は、広範囲にわたって検討およびテストされており、最適なシステムの可用性と信頼性を実現できます。また、MAAは、サーバー、記憶域、ネットワーキングおよびアプリケーション・サーバーを含む可用性の高いシステムの他の重要なコンポーネントの構成と統合にも対処しています。MAAに基づいたシステム・アーキテクチャを持つ企業は、高可用性とデータ保護に関するビジネス上の要件を迅速かつ効率的に満たすことができます。
MAAの詳細は、http://www.oracle.com/technology/deploy/availability/htdocs/maa.htmを参照してください。
|
 Copyright © 1993, 2008 Oracle Corporation. All Rights Reserved. |
|