11g リリース1(11.1)
E05768-02
 目次 |
 索引 |
| Oracle Databaseユーティリティ 11g リリース1(11.1) E05768-02 |
|


この章では、SQL*LoaderによるOracle Databaseへのデータのロードについて、基本的な概念を説明します。この章の内容は、次のとおりです。
SQL*Loaderを使用して、外部ファイルのデータをOracle Databaseの表にロードします。強力なデータ解析エンジンによって、あらゆるデータ形式のデータ・ファイルに対応できます。SQL*Loaderを使用して、次のことが可能です。
一般的なSQL*Loaderセッションでは、SQL*Loaderの動作を制御する制御ファイルと1つ以上のデータ・ファイルが入力用に使用されます。SQL*Loaderの出力先は、データがロードされるOracle Database、ログ・ファイル、不良ファイルで、廃棄ファイルに出力される場合もあります。図6-1に、SQL*Loaderセッションの流れの例を示します。
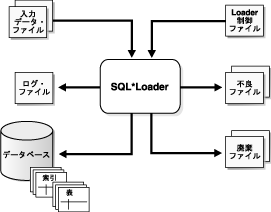
SQL*Loaderは、sqlldrコマンドを指定すると起動します。また、オプションで、セッション特性を確立するパラメータを指定した場合も起動します。
常に、値がほとんど変わらない同じパラメータを使用する場合は、コマンドラインではなく、次の方法でパラメータを指定すると効率的です。
PARFILEパラメータを使用して、そのパラメータ・ファイルの名前をコマンドラインで指定できます。
OPTIONS句を使用して、SQL*Loaderの制御ファイル内に指定することもできます。
コマンドラインで指定したパラメータは、パラメータ・ファイルまたはOPTIONS句で指定したパラメータ値を上書きします。
制御ファイルは、SQL*Loaderが解釈できる言語で記述されたテキスト・ファイルです。制御ファイルは、データの場所、データの分析と解釈方法、データの挿入先などをSQL*Loaderに通知します。
制御ファイルには、大きく分けて3つのセクションがあります。
第1セクションには、セッション全体の情報が記述されます。たとえば、次のような情報です。
第2セクションは、1つ以上のINTO TABLEブロックで構成されています。それぞれのブロックには、表名、その表の列などの、データがロードされる表についての情報が含まれています。
第3セクションはオプションで、このセクションがある場合は、入力データが記述されます。
制御ファイルの構文には、次の注意事項があります。
CONSTANTおよびZONEキーワードは、SQL*Loaderでは特別な意味があり、予約されています。競合を回避するために、表または列の名前にCONSTANTまたはZONEという語を使用しないことをお薦めします。制御ファイルに指定された1つ以上のファイルなどから、SQL*Loaderにデータが読み込まれます。SQL*Loaderから見ると、データ・ファイルのデータはレコードとして構成されています。 データ・ファイルには、固定レコード形式、可変レコード形式またはストリーム・レコード形式があります。レコード形式は、INFILEパラメータを使用して制御ファイルに指定することができます。レコード形式が指定されない場合、デフォルトはストリーム・レコード形式になります。
固定レコード形式のファイルでは、データ・ファイルにあるすべてのレコードが同じバイト長です。この形式は柔軟性はありませんが、その結果、可変長またはストリーム形式よりも高いパフォーマンスを得ることができます。また、固定形式は簡単に指定できます。次に例を示します。
INFILE datafile_name "fix n"
ここでは、特殊なデータ・ファイルが、SQL*Loaderによって全レコードnバイト長の固定レコード形式で解釈されるように指定しています。
例6-1に、固定レコード形式で解釈されるようにデータ・ファイルを指定する制御ファイルを示します。この例では、5つの物理レコードがあります。ピリオド(.)が空白を示すと想定すると、第1の物理レコードは[001,...cd,.]で、11バイト(シングルバイト・キャラクタ・セットと想定)です。第2のレコードは[0002,fghi,\n]で、改行文字(11バイト目)が続きます。改行文字は、固定レコード形式では必要ありません。
文字長セマンティクスが使用されているファイルでも、長さは常にバイト単位で解析されます。これは、文字長セマンティクスで処理されるフィールドとバイト長セマンティクスで処理されるフィールドがファイル内に混在する可能性があるため必要です。詳細は、「文字長セマンティクス」を参照してください。
load data infile 'example.dat' "fix 11" into table example fields terminated by ',' optionally enclosed by '"' (col1, col2) example.dat: 001, cd, 0002,fghi, 00003,lmn, 1, "pqrs", 0005,uvwx,
可変レコード形式のファイルでは、文字フィールドの各レコード長がデータ・ファイルの各レコードの開始位置に含まれています。この形式は、固定レコード形式より柔軟性があり、ストリーム・レコード形式よりパフォーマンスに優れています。可変レコード形式の場合、たとえば、次のように指定できます。
INFILE "datafile_name" "var n"
nには、レコード長フィールドのバイト数を指定します。指定しない場合、長さは5バイトとみなされます。nに、40より大きい値を指定すると、エラーになります。
例6-2に、ファイル名がexample.datでレコード長フィールドが3バイト長の可変レコード形式の入力データに対する制御ファイルの指定を示します。example.datデータ・ファイルは、3つの物理レコードで構成されています。1つ目のレコードは009(すなわち9)バイト長、2つ目のレコードは010(すなわち1バイトの改行を含めて10)バイト長、3つ目は012(同様に1バイトの改行を含む)バイト長で指定されています。改行文字は、可変レコード形式では必要ありません。ここでは、シングルバイト・キャラクタ・セットであるとします。
文字長セマンティクスが使用されているファイルでも、長さは常にバイト単位で解析されます。これは、文字長セマンティクスで処理されるフィールドとバイト長セマンティクスで処理されるフィールドがファイル内に混在する可能性があるため必要です。詳細は、「文字長セマンティクス」を参照してください。
load data infile 'example.dat' "var 3" into table example fields terminated by ',' optionally enclosed by '"' (col1 char(5), col2 char(7)) example.dat: 009hello,cd,010world,im, 012my,name is,
ストリーム・レコード形式では、レコードをサイズで指定してではなく、SQL*Loaderでレコード終了記号を読み込むことによって、レコードが確認されます。ストリーム・レコード形式は最も柔軟性のある形式ですが、パフォーマンスに影響する場合があります。ストリーム・レコード形式として指定するには、次のように指定します。
INFILE datafile_name ["strterminator_string"]
terminator_stringには、次の'char_string'またはX'hex_string'を指定します。
terminator_stringに、特別な(印字不可能な)文字が含まれる場合、X'hex_string'で指定する必要があります。ただし、一部の印字不可能な文字列('char_string')はバックスラッシュを使用すると指定できます。次に例を示します。
セッションに対してNLS_LANGパラメータに指定されているキャラクタ・セットが、データ・ファイルのキャラクタ・セットと異なる場合、文字列はデータ・ファイルのキャラクタ・セットに変換されます。これは、SQL*Loaderでデフォルトのレコード終了記号が確認される前に行われます。
16進文字列はデータ・ファイルのキャラクタ・セット内にあるとみなされ、変換は実行されません。
UNIXベースのプラットフォームでは、terminator_stringを指定しない場合、デフォルトでLF文字\nが使用されます。
Windows NTでは、terminator_stringを指定しない場合、¥nまたは¥r¥nのうちデータ・ファイル内で先に現れる文字がレコード終了記号として使用されます。データ・ファイルの1つ以上のレコードで、フィールドに¥nが埋め込まれていることがわかっている場合に、¥r¥nをレコード終了記号として使用するには、terminator_stringを指定する必要があります。
例6-3に、terminator_stringが文字列'|\n'で指定されている場合に、ストリーム・レコード形式でデータをロードする方法を示します。バックスラッシュを使用すると、文字列に印字不可能な改行文字を指定することができます。
load data infile 'example.dat' "str '|\n'" into table example fields terminated by ',' optionally enclosed by '"' (col1 char(5), col2 char(7)) example.dat: hello,world,| james,bond,|
入力データは、指定されたレコード形式で物理レコードに編成されます。デフォルトでは、1つの物理レコードが1つの論理レコードになりますが、複数の物理レコードが1つの論理レコードに結合される場合もあります。
論理レコードは、次のいずれかの方針に従って構成できます。
論理レコードが作成されると、フィールドが設定されます。フィールド設定では、制御ファイルのフィールド指定を使用して、論理レコードのデータのどの部分が制御ファイルのフィールドに対応しているのかをSQL*Loaderで判断します。2つ以上のフィールド指定に同じデータを使用できます。また、論理レコードに、制御ファイルのフィールド指定で使用されないデータを含めることもできます。
ほとんどの場合、制御ファイルのフィールドに、論理レコードの特定の位置や長さの指定が必要です。この部分は、次のような形式で指定します。
nバイト数に、データ・フィールドの残りの長さについての情報が含まれています。LOBデータは、非常に長いデータであるため、LOBFILEからロードすると有効です。LOBFILEでは、LOBデータのインスタンスは、フィールド(事前に決められたサイズ、デリミタ付き、Length-Value)内にあるとみなされますが、これらのフィールドは、レコードに編成されていません(LOBFILEにはレコードの概念がありません)。そのため、レコードを扱うことによって発生する処理のオーバーヘッドを回避できます。このようなデータの編成方法は、LOBのロードにとって理想的です。
たとえば、従業員名、従業員IDおよび従業員の履歴をロードする場合にLOBFILEを使用するとします。従業員名および従業員IDをメイン・データ・ファイルから読み込み、非常に長い従業員の履歴をLOBFILEから読み込むことができます。
また、簡単にXMLデータをロードする場合にLOBFILEを使用するとします。XML列を使用して、構造化データおよび半構造化データのモデルを保持できます。そのようなデータは、非常に長いデータです。
SDFとプライマリ・データ・ファイルの概念は類似しています。プライマリ・データ・ファイルと同様に、SDFは、レコードおよびフィールドで構成されたレコードの集まりです。SDFは、制御ファイルごとに指定されます。SDFをデータ・ソースとして命名できるのは、collection_fld_specのみです。
SDFを指定するには、SDFパラメータを使用します。SDFパラメータの後に、ファイル指定文字列、または1つ以上のファイル指定文字列を含むデータ・フィールドにマップされたFILLERフィールドを指定します。
従来型パス・ロード中に、データ・ファイルのデータ・フィールドが、データベースの列に変換されます(概念的にはダイレクト・パス・ロードと同様ですが、実装は異なります)。変換には、次の2つの手順があります。
INSERT文に対応するバインド配列を移入します。
INSERT文を実行してデータベースにデータを格納します。
Oracle Databaseでは、列のデータ型を使用して最終的な格納形式にデータを変換します。データ・ファイル内のフィールドとデータベース内の列の違いに注意する必要があります。 また、SQL*Loader制御ファイルで定義されているフィールドのデータ型が、データベースの列のデータ型と同じではないことにも注意してください。
入力ファイルから読み込まれたすべてのレコードが、データベースに挿入されるわけではありません。挿入されないレコードは、不良ファイルまたは廃棄ファイルに書き込まれます。
不良ファイルには、SQL*LoaderまたはOracle Databaseによって拒否レコードが書き込まれます。不良ファイルを指定していない場合に拒否されたレコードがあると、SQL*Loaderによって不良ファイルが自動的に作成されます。ファイルの名前はデータ・ファイルと同じで、拡張子は.badになります。次に、その理由を示します。
入力形式が不適切なデータ・ファイル・レコードは、SQL*Loaderによって拒否されます。たとえば、2番目の囲みデリミタがない場合や、デリミタ付きフィールドが最大長を超えている場合、レコードは、SQL*Loaderによって拒否されます。拒否レコードは、不良ファイルに書き込まれます。
データ・ファイル・レコードは、SQL*Loaderによって受け取られた後、Oracle Databaseに送られ、行として表に挿入されます。Oracle Databaseによって有効であると判断された行は、表に挿入されます。行が無効であると判断された場合、レコードは拒否され、不良ファイルに書き込まれます。行が無効であると判断される例としては、キーが重複している場合、必須入力フィールドに対応するデータがNULL値の場合、またはフィールドにOracleデータ型ではないデータ型が指定された場合が考えられます。
SQL*Loaderの実行によって、廃棄ファイルをコールするファイルが作成されることがあります。ファイルが作成されるのは必要な場合のみで、廃棄ファイルを使用可能にすることを指定してある場合にかぎります。廃棄ファイルには、制御ファイルに指定されているレコード選択基準に一致しなかったため、ロード対象から除外されたレコードが入ります。
したがって、廃棄ファイルには、データベースのどの表にも挿入されなかったレコードが格納されます。廃棄ファイルに格納可能なレコードの最大数を指定できます。レコードのデータがいずれかの表に書き込まれる場合、このレコードは廃棄ファイルには書き込まれません。
SQL*Loaderで処理が開始されると、ログ・ファイルが作成されます。 ログ・ファイルを作成できない場合、処理は終了します。このログ・ファイルにはロード中に発生したエラーに関する記述など、ロードに関する詳細情報が記録されます。
SQL*Loaderでデータをロードするには、次の方法があります。
従来型パス・ロードでは、入力レコードがフィールド指定を基に解析され、各データ・フィールドが対応するバインド配列にコピーされます。バインド配列が一杯になるか、または最終レコードが読み込まれた時点で配列の挿入が実行されます。
SQL*Loaderでは、バインドの配列に挿入後、LOBフィールドが格納されます。そのため、LOBフィールドの処理にエラーが発生した場合(たとえば、LOBFILEがないなど)、LOBフィールドは空のままになります。配列の挿入の実行後にLOBデータがロードされるため、BEFOREおよびAFTER行トリガーはLOB列に対して機能しない場合もあります。これは、SQL*Loaderで列にLOBの内容をロードする機会を持つ前にトリガーが起動されるためです。たとえば、LOB列C1にデータをロードして、BEFORE行トリガーを使用してそのLOB列の内容を調べ、その結果を基に、他の列C2にロードされる値を導出するとします。これは、トリガーの起動時にLOBの内容がロードされていないため不可能です。
ダイレクト・パス・ロードでは、入力レコードがフィールド指定を基に解析され、入力フィールド・データが列のデータ型に変換されて列配列が作成されます。この列配列は、Oracle Databaseブロック形式でデータ・ブロックを作成するブロック・フォーマッタに渡されます。新しくフォーマットされたデータベース・ブロックはデータベースに直接書き込まれるため、通常行われるデータ処理の大部分が省略されます。ダイレクト・パス・ロードによる処理は、従来型パス・ロードと比較すると非常に高速ですが、制限事項がいくつかあります。
パラレル・ダイレクト・パス・ロードでは、複数のダイレクト・パス・ロード・セッションで 同じデータ・セグメントを同時にロードできます(セグメント内の並列化が可能です)。パラレル・ダイレクト・パスには、ダイレクト・パスより多くの制約事項があります。
外部表ロードでは、データ・ファイルに含まれているデータの外部表が作成されます。ロード処理では、INSERT文が実行され、データ・ファイルのデータがターゲット表に挿入されます。
従来型パス・ロードおよびダイレクト・パス・ロードではなく、外部表ロードを使用した場合のメリットは、次のとおりです。
INSERT文の一部としてSQL関数およびPL/SQLファンクションを使用することによってロードされるデータを変更できます。外部表とSQL*Loaderのレコード解析は類似しているため、通常、同じレコード形式での大幅なパフォーマンスの違いはありません。ただし、外部表とSQL*Loaderのアーキテクチャは異なるため、状況によって、より適切な方法を選択する必要があります。
次の状況では、最適なロード・パフォーマンスを得るために外部表を使用します。
次の状況では、最適なロード・パフォーマンスを得るためにSQL*Loaderを使用します。
オブジェクト、コレクションおよびLOBのバルク・ロードにSQL*Loaderを使用できます。オブジェクトの概念およびオブジェクト・サポートのOracle実装の詳細は、『Oracle Database概要』および『Oracle Database管理者ガイド』を参照してください。
SQL*Loaderでは、次の2つのオブジェクト型のロードがサポートされています。
表の列が、なんらかのオブジェクト型である場合、その列のオブジェクトは列オブジェクトと呼ばれます。概念的には、そのようなオブジェクトは、行の単一の列位置に全体が格納されます。これらのオブジェクトにはオブジェクト識別子がなく、参照することはできません。
列オブジェクトのオブジェクト型がNOT FINALであると宣言されると、SQL*Loaderで導出された型(またはサブタイプ)を列オブジェクトにロードできます。
これらのオブジェクトはオブジェクト表と呼ばれる表に格納され、オブジェクト表にはオブジェクトの属性に対応する列があります。さらに、そのオブジェクト表にはシステムが生成するSYS_NC_OID$という列があり、その列に、表の各オブジェクトに対してシステムが生成する一意の識別子(OID)が格納されます。他の表の列は、これらのオブジェクトをOIDを使用して参照できます。
列オブジェクトのオブジェクト型がNOT FINALであると宣言されると、SQL*Loaderで導出された型(またはサブタイプ)を列オブジェクトにロードできます。
SQL*Loaderでは、次の2つのコレクション型のロードがサポートされています。
ネストした表は、別の表に列があるように見える表です。別の表に対して実行できるすべての操作は、ネストした表に対しても実行できます。
VARRAYは、可変サイズの配列です。配列は、要素と呼ばれる、一連の組込み型またはオブジェクトの順序付けられた集合です。各配列の要素は同一の型であり、VARRAY内の要素の位置に対応する一意の番号(index)を持ちます。
VARRAY型の作成時に、最大数を指定する必要があります。VARRAY型を宣言すると、リレーショナル表の列のデータ型、オブジェクト型属性、またはPL/SQL変数として使用することができます。
LOBは、ラージ・オブジェクト型です。今回のリリースのSQL*Loaderでは、4つのLOB型のロードをサポートしています。
BLOB: 構造化されていないバイナリ・データを含むLOB。
CLOB: 文字データを含むLOB。
NCLOB: データベースの各国語キャラクタ・セットの文字を含むLOB。
BFILE: サーバー側のオペレーティング・システム・ファイルのデータベース表領域外に格納されるBLOB。
LOBは列データ型で、NCLOB以外は、オブジェクトの属性データ型です。LOBには、実際の値、NULLまたは「値なし(空)」を指定できます。
SQL*Loaderでは、データベース内のパーティション・オブジェクトのロードをサポートしています。Oracle Databaseでは、グループ化されたパーティション(部分)で構成される表または索引が、パーティション・オブジェクトに相当します。一般に、パーティションは共通の論理属性によってグループ化されます。たとえば、2000年度の売上データを、月別にパーティション化するとします。この場合、各月のデータは、売上表の中のそれぞれ別のパーティションに保存されます。このパーティションはそれぞれ、データベース内の異なるセグメントに保存されます。また、パーティションごとに異なる物理属性を指定できます。
次に、パーティション・オブジェクトがサポートされたことによって、SQL*Loaderでロードが可能になったものを示します。
アプリケーション開発のために、ダイレクト・パス・ロードAPIが提供されています。詳細は、『Oracle Call Interfaceプログラマーズ・ガイド』を参照してください。
SQL*Loaderの機能が様々な事例で示されています。事例は、ユーザーscottが、デモンストレーション用のOracle Databaseのemp表およびdept表を所有している場合を想定して作成してあります。(事例の中では、さらに列が追加されていることもあります。)
事例は、簡単なものから複雑なものの順に1〜11の番号が付けられています。
次に、事例の概要を示します。
resumeというCLOB列をemp表に追加し、FILLERフィールド(res_file)を使用して、複数のLOBFILEをemp表にロードします。
VARRAYに格納します。カスタマ表およびVARRAYの注文商品を参照する注文表をロードします。
通常、各事例は次の種類のファイルで構成されています。
これらのファイルは、Oracle Databaseのインストール時にインストールされます。ファイルは、$ORACLE_HOME/rdbms/demoディレクトリにあります。
事例用のサンプル・データが制御ファイルに含まれている場合、その事例の.datファイルはありません。
事例2では特別な設定が不要なため、事例2の.sqlスクリプトはありません。事例7では、開始(セットアップ)スクリプトと終了(クリーンアップ)スクリプトの両方を実行する必要があります。
表6-1に、各事例に関連のあるファイルを示します。
通常、事例は次の手順で実行します(カレント・ディレクトリは、事例ファイルの格納場所である$ORACLE_HOME/rdbms/demoにしてください)。
sqlplusと入力し、[Enter]を押してSQL*Plusを起動します。ユーザー名のプロンプトで、scottと入力します。パスワードのプロンプトで、tigerと入力します。SQLプロンプトが表示されます。
SQL> @ulcase1
事例用の表が準備および移入されると、システム・プロンプトに戻ります。
sqlldr USERID=scott CONTROL=ulcase1.ctlLOG=ulcase1.log
CONTROLパラメータとLOGパラメータを適切な制御ファイル名とログ・ファイル名に置き換え、[Enter]を押します。パスワードを入力するように要求されたら、tigerと入力して[Enter]を押します。
実行する事例に固有な注意事項がないかどうか、制御ファイルの内容を確認してください。たとえば、事例6では、SQL*LoaderのコマンドラインにDIRECT=TRUEを追加する必要があります。
事例用のログ・ファイルは、$ORACLE_HOME/rdbms/demoディレクトリにあらかじめ用意されているわけではありません。これは、各事例のログ・ファイルは、事例を実行したときに生成されるためです(ただし、LOGパラメータを使用していることが条件です)。ログ・ファイルを生成しない場合は、コマンドラインでLOGパラメータを指定しないようにします。
事例の実行結果を確認するには、SQL*Plusを起動して、事例でロードされた表から選択操作を実行します。次のように行います。
|
 Copyright © 2007 Oracle Corporation. All Rights Reserved. |
|