11g リリース1(11.1)
E05768-02
 目次 |
 索引 |
| Oracle Databaseユーティリティ 11g リリース1(11.1) E05768-02 |
|


この章では、SQL*Loaderの従来型パス・ロードとダイレクト・パス・ロードの方法について説明します。この章の内容は、次のとおりです。
ダイレクト・パス・ロードを使用した例は、「事例6: ダイレクト・パス・ロード方式を使用したデータのロード」を参照してください。その他の事例では、従来型パス・ロードを使用しています。(事例のアクセス方法については、「SQL*Loaderの事例」を参照してください。)
SQL*Loaderでデータをロードするには、次の2つの方法があります。
従来型パス・ロードでは、Oracle Databaseの表に対して(1つ以上の)SQL INSERT文が実行されます。ダイレクト・パス・ロードでは、Oracleデータ・ブロックをフォーマットし、データ・ブロックを直接データ・ファイルに書き込むため、Oracle Databaseのオーバーヘッドが大幅に削減されます。ダイレクト・パス・ロードでは、データベース・リソースに対して他のユーザーとの競合が発生しないため、ディスク速度に近い速度でデータをロードできます。この章では、ダイレクト・パス・ロード固有の問題(制限、セキュリティ、バックアップなど)について説明します。
データをロードする表はデータベース中に存在している必要があります。SQL*Loaderでは、表は作成されません。すでにデータが含まれているか、または空である既存の表にロードされます。
ロードを実行するには、次の権限が必要です。
INSERT権限。
REPLACEオプションまたはTRUNCATEオプションを使用して古いデータを削除してから新しくデータをロードする場合には、その表についてのDELETE権限。
図11-1に、従来型パス・ロードおよびダイレクト・パス・ロードでのデータベースへの書込み方法を示します。
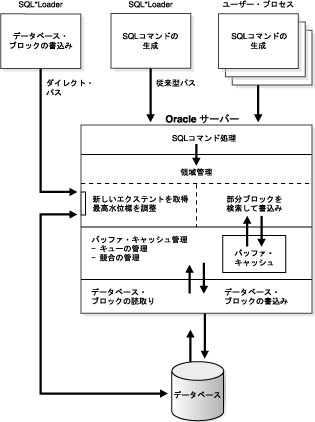
従来型パス・ロードおよびダイレクト・パス・ロードの両方において、ROWID列のテキスト値を指定できます。(これは、SELECT ROWID FROM table_nameの処理の実行時に取得するテキストと同じです。)ROWIDの文字列解釈は、表内の列に対してはROWID型に変換されます。
従来型パス・ロード(デフォルト)では、SQL INSERT文とバインド配列バッファを使用して、データをデータベース表にロードします。この方法は、すべてのOracleのツール製品およびApplicationsで使用されます。
SQL*Loaderで従来型パス・ロードを実行する場合、バッファ・リソースに関して他のすべてのプロセスと同等の処理が行われるため、競合が発生します。このため、ロードにかなりの時間がかかります。また、SQL文が生成され、Oracleに渡されてから実行されるため、さらにオーバーヘッドが発生します。
挿入が発生すると、常に、Oracle Databaseで空き領域のあるブロック(ディスク内に散在して、部分的に書込み可能なブロック)が検索され、そこにデータが書き込まれます。通常のデータベース使用の場合はそれほどでもありませんが、このアクションは大量データのロード速度を大幅に低下させることがあります。
従来型パス・ロードでは、SQL INSERT文を使用します。ただし、従来型パスで単一パーティションに対してロードする場合は、SQL*Loaderで次のような形式のINSERT文のパーティション拡張構文を使用します。
INSERT INTO TABLE T PARTITION (P) VALUES ...
OracleカーネルのSQLレイヤーでは、挿入される行が指定のパーティションに対応するかどうかを判断します。行が指定のパーティションに対応しない場合、その行は拒否され、そのことを示すエラー・メッセージがSQL*Loaderログ・ファイルに記録されます。
ロードを高速にするには、従来型パス・ロードよりダイレクト・ パス・ロードを使用します。ただし、ダイレクト・パス・ロードにはいくつかの制限があるため、従来型パス・ロードを使用する必要がある場合もあります。次のような場合には、従来型パス・ロードを使用します。
ダイレクト・パス・ロード(パラレル・ロードは除く)を使用するには、SQL*Loaderに、表への排他的書込み権限と、すべての索引への排他的読取り権限および書込み権限が必要です。
ダイレクト・パス・ロードでは、クラスタ表に対するロードはサポートされていません。
ダイレクト・パス・ロードでは、既存の索引を新しい索引キーとマージするために、既存の索引をコピーします。既存の索引が非常に大きく、新しいキーの数が非常に少ない場合は、索引をコピーする時間が、ダイレクト・パス・ロードで節約できる時間を相殺してしまうことがあります。
これらの制約は、ダイレクト・パスでロードした行には適用できないため、ロードが継続している間は使用禁止になります。そして、ロードが完了した時点で表全体に適用されます。表が非常に大きく、新しい行の数が少ない場合は、この処理にかかる時間が節約した時間より多くなる可能性があります。
バインド配列バッファに書き込むかわりに、SQL INSERT文を使用して、バインド配列をOracle Databaseに渡します。ダイレクト・パス・ロードは、ダイレクト・パスAPIを使用して、ロードされるデータをサーバーのロード・エンジンに渡します。ロード・エンジンは、渡されたデータから列配列構造体を作成します。
ダイレクト・パス・ロード・エンジンは、列配列構造体を使用してOracleデータ・ブロックをフォーマットし、索引キーを作成します。新しくフォーマットされたデータベース・ブロックが直接データベースに書き込まれます(ホスト・プラットフォームが非同期I/Oをサポートしている場合、非同期書込みを使用して1つのI/O要求に対して複数のブロックを書き込むことができます)。
内部的には、フォーマットされたブロック用に複数のバッファが使用されます。ホスト・プラットフォームで非同期I/Oが可能な場合は、あるバッファに書き込んでいる間に1つ以上のバッファへの書込みが行われます。この場合、I/Oを伴う処理がオーバーラップするため、ロード・パフォーマンスが向上します。
ダイレクト・パス・ロード時には、サーバー側ではなくクライアント側でデータ変換が発生します。初期化パラメータ・ファイルのNLSパラメータ(サーバー側の言語ハンドル)は使用されません。この動作を変更するには、SQL*Loaderの制御ファイルに書式マスクを指定する(初期化パラメータ・ファイルにNLSパラメータを設定することと同じ)か、または適切な環境変数を設定します。たとえば、フィールドに日付書式を指定するには、例11-1に示すとおりSQL*Loaderの制御ファイルに日付書式を設定するか、または例11-2に示すとおり環境変数NLS_DATE_FORMATを設定します。
LOAD DATA INFILE 'data.dat' INSERT INTO TABLE emp FIELDS TERMINATED BY "|" ( EMPNO NUMBER(4) NOT NULL, ENAME CHAR(10), JOB CHAR(9), MGR NUMBER(4), HIREDATE DATE 'YYYYMMDD', SAL NUMBER(7,2), COMM NUMBER(7,2), DEPTNO NUMBER(2) )例11-2 環境変数NLS_DATE_FORMATの設定
UNIXのBourneまたはKornシェルの場合:
% NLS_DATE_FORMAT='YYYYMMDD' % export NLS_DATE_FORMAT
UNIXのcshの場合:
%setenv NLS_DATE_FORMAT='YYYYMMDD'
パーティション表またはサブパーティション表へロードする場合は、SQL*Loaderによって、行がパーティション化され、索引(索引もパーティション化できます)がメンテナンスされます。パーティション表またはサブパーティション表のダイレクト・パス・ロードは、パーティションまたはサブパーティションの多い表の場合、非常に多くのリソースを使用することに注意してください。
パーティション表の単一パーティションまたはサブパーティションをロードするとき、SQL*Loaderによって、行がパーティション化され、SQL*Loader制御ファイルに指定されたパーティションまたはサブパーティションにマップできない行はすべて拒否されます。ロードされるデータのパーティションまたはサブパーティションに対応するローカル索引パーティションは、SQL*Loaderによってメンテナンスされます。単一パーティションまたはサブパーティションのダイレクト・パス・ロードでは、グローバル索引はメンテナンスされません。ただし、ダイレクト・パスで単一パーティションに対してロードする場合、SQL*Loaderでは次のような形式のLOAD文のパーティション拡張構文を使用します。
LOAD INTO TABLE T PARTITION (P) VALUES ... LOAD INTO TABLE T SUBPARTITION (P) VALUES ...
パーティション表またはサブパーティション表の1つのパーティションをロードしている間も、その表の他のパーティションに対してはDML操作やダイレクト・パス・ロードを行うことができます。
ダイレクト・パス・ロードでは、データベース処理は最小限に抑えられますが、ロードの開始時と終了時に、それぞれロードの初期化と終了処理のためにOracle Databaseに対するコールが数回実行されます。また、ロードの初期化中に必要なDMLロックがかけられ、ロード終了時に解除されます。ロード中には、索引キーが作成されてソートに使用されたり、必要に応じて新しいエクステントを取得するために領域管理ルーチンを使用することによって、データ・セーブポイントの上限(最高水位標)を調整するなどの動作も発生します。 上限の調整については、「データ・セーブを使用したデータ損失の防止」を参照してください。
ダイレクト・パス・ロードは、従来型パス・ロードよりも処理が高速です。その理由は次のとおりです。
INSERT文を実行しないため、Oracle Databaseの処理負荷が減ります。
INSERT文を処理します。
NOARCHIVELOGパラメータが使用可能な場合
UNRECOVERABLE句が使用可能な場合
NOLOGGINGパラメータが設定されている場合
詳細は、「インスタンス・リカバリおよびダイレクト・パス・ロード」を参照してください。
ダイレクト・パス・ロードを使用するには、次の条件を満たしている必要があります。
この条件が満たされているかどうかを確認するには、MONITOR TABLEというOEMコマンドを使用して、ロードする表のオブジェクトIDを検索します。次に、MONITOR LOCKコマンドを使用して、表にロックがかけられているかどうか調べます。
Oracle9i 以上では、クライアントとサーバーのバージョンが異なる場合にも、SQL*Loaderのダイレクト・パス・ロードを実行できます。ただし、両方がOracle9i リリース1(9.0.1)以上で、クライアントのバージョンは、サーバーのバージョン以下である必要があります。たとえば、Oracle9i リリース1(9.0.1)のデータベースからOracle9i リリース2(9.2)のデータベースへのダイレクト・パス・ロードを実行できます。たとえば、ダイレクト・パス・ロードを使用して、Oracle9i リリース1(9.0.1)のデータベースからOracle8i リリース8.1.7のデータベースに、データはロードできません。
次の機能は、ダイレクト・パス・ロードでは使用できません。
BFILE列のロード
CREATE SEQUENCEの使用。これは、ダイレクト・パスではINSERT文が生成されないため、ダイレクト・パス・ロードでは、次の値をフェッチするSQLが生成されないことが理由です。
前述の制限に加え、単一のパーティションをロードするときには次の制限があります。
前述の制限のいずれにも該当しない場合は、次のようなときにダイレクト・パス・ロードを使用してください。
ダイレクト・パス・ロード時には、すべての整合性制約が適用されます。ただし、すべての制約が同時に適用されるとはかぎりません。ロード中にはNOT NULL制約が施行されます。これらの制約に従っていないレコードは拒否されます。
ロード中およびロード後に、一意制約が施行されます。
一意制約に違反するレコードは拒否されます(制約違反が検出されると、そのレコードはメモリー内で使用不可になります)。
他の行または表に依存する整合性制約(参照制約など)は、ダイレクト・パス・ロード実行前に使用禁止になります。そのため、ロード後に再び使用可能にする必要があります。REENABLEを指定すると、これらの制約はロード終了時に自動的に使用可能に戻されます。制約が再び使用可能になった時点で、表全体(すべての行)に対してチェックが行われます。このチェックでエラーが見つかった行は、指定されたエラー・ログに書き込まれます。詳細は、「ダイレクト・ロード、整合性制約およびトリガー」を参照してください。
ダイレクト・パス・ロードを使用する場合、データベースに定義されているデフォルトの列指定は使用できません。デフォルト値を設定するフィールドに対しては、DEFAULTIF句を使用して指定する必要があります。DEFAULTIF句が指定されておらず、フィールドがNULLである場合は、NULL値がデータベースに挿入されます。
ダイレクト・パス・ロードでは、表のシノニムにデータをロードできます。ただし、そのためには、そのシノニムが表を直接指している必要があります。シノニムがビューのシノニムであるか、他のシノニム用のシノニムである場合は、データはロードできません。
この項では、SQL*Loaderのダイレクト・パス・ロードの使用方法を説明します。
ダイレクト・パス・ロード用にデータベースを準備するには、セットアップ・スクリプトのcatldr.sqlを実行し、必要なビューを作成します。このスクリプトは、ダイレクト・ロードを行う予定のデータベースそれぞれに対して1回のみ実行します。データベースのインストール時に、ダイレクト・ロードを実行することがわかっている場合は、データベースのインストール中にこのスクリプトを実行することもできます。
SQL*Loaderをダイレクト・パス・ロード・モードで起動するには、次の形式で、コマンドラインまたはパラメータ・ファイル(使用している場合)のDIRECTパラメータにtrueを設定します。
DIRECT=true
|
参照:
|
一時記憶域を使用すると、ダイレクト・パス・ロードのパフォーマンスが向上します。各ブロックがフォーマットされた後、新しい索引キーがソート(一時)セグメントに挿入されます。ロードが終了すると、古い索引と新しいキーがマージされ、新しい索引が作成されます。古い索引、ソート(一時)セグメント、新しい索引セグメントでは、すべてのマージが完了するまで記憶域が必要です。最後に、古い索引と一時セグメントが削除されます。
従来型パス・ロードでは、行が挿入されるたびに索引が更新されます。この方法では一時記憶域は不要ですが、処理に時間がかかります。
メモリーに制限があるシステムでパフォーマンスを向上するには、SINGLEROWパラメータを使用します。詳細は、「SINGLEROWオプション」を参照してください。
|
注意: ダイレクト・ロード時にデータの事前ソートを指定してあり、既存の索引が空である場合、一時セグメントは不要で、マージも行われません。この場合は、索引にキーが直接付加されます。詳細は、「ダイレクト・パス・ロードのパフォーマンスの最適化」を参照してください。 |
複数の索引が作成されると、古い索引の他に、各索引に対応する一時セグメントが同時に存在するようになります。次に、新しいキーは一度に1索引ずつ古い索引とマージされます。新しい各索引が作成されると、古い索引とそれに対応する一時セグメントは削除されます。
新しい索引キーの格納に必要な一時セグメント領域の大きさ(バイト単位)を計算するには、次の式を使用します。
1.3 * key_storage
この式では、キー記憶域が次のように定義されます。
key_storage = (number_of_rows) * ( 10 + sum_of_column_sizes + number_of_columns )
この式における列(column)とは、索引の列を意味します。ここでは、1列につき1バイトを使用しています。さらに、ROWIDやその他のオーバーヘッドとして1行につき10バイトを計算に入れています。
定数1.3は、ソートに必要な追加領域の平均的な大きさを反映しています。この値は、データの順序がきわめてランダムな場合に有効です。データが逆の順序に並んでいると、ソートには2倍のキー記憶域が必要となるため、そのときは定数値を2.0とします。ただし、これは最悪の場合です。
データが完全にソートされている場合は、索引エントリを格納できる領域のみが必要なため、そのときの定数の値は1.0に下がります。詳細は、「高速索引付けのためのデータの事前ソート」を参照してください。
ロードされているデータ・セグメントが、その索引の索引セグメントより新しいものになると、SQL*Loaderによって索引が索引使用禁止状態になります。
SQL文が索引使用禁止状態の索引を参照しようとすると、エラーが発生します。ダイレクト・パス・ロードの実行時に、次のような状況が発生すると、索引またはパーティション索引のパーティションは索引使用禁止状態になります。
SORTED INDEXES句で指定した順序になっていない場合。
ある索引が索引使用禁止状態かどうかを調べるには、次に示す簡単な問合せを実行します。
SELECT INDEX_NAME, STATUS FROM USER_INDEXES WHERE TABLE_NAME = 'tablename';
表の所有者でない場合は、USER_INDEXESのかわりに、ALL_INDEXESまたはDBA_INDEXESを検索してください。
ある索引パーティションが使用禁止状態かどうかを調べるには、次に示す問合せを実行します。
SELECT INDEX_NAME, PARTITION_NAME, STATUS FROM USER_IND_PARTITIONS WHERE STATUS != 'VALID';
表の所有者でない場合は、USER_IND_PARTITIONSのかわりに、ALL_IND_PARTITIONSおよびDBA_IND_PARTITIONSを検索します。
データ・セーブを使用して、インスタンス障害によるデータ損失を回避できます。最後のセーブポイントにロードされたすべてのデータが、インスタンス障害から保護されます。インスタンス障害後にロードを続行する場合は、障害発生前に入力ファイルから何行処理されたか判別し、SKIPパラメータを使用して、処理済の行をスキップします。
表に索引がある場合には、まず索引を削除してからロードを続行します。ロードの終了後、索引を再作成してください。メディア障害およびインスタンス・リカバリの詳細は、「ダイレクト・パス・ロード時のデータ・リカバリ」を参照してください。
ROWSパラメータには、ダイレクト・パス・ロードでデータ・セーブを行う間隔を設定します。ROWSに指定する値は、データベースへの挿入を保存する前に、SQL*Loaderによって入力ファイルから読み込まれる行数です。
データ・セーブは負荷の高い操作です。データ・セーブの間隔が15分以上になるように、ROWSを十分高い値に設定してください。これによって、長時間のダイレクト・パス・ロードの実行中にインスタンス障害が発生したときに、損失する作業量の上限(最高水位標)を指定できます。ROWSに小さい値を設定すると、パフォーマンスおよびデータ・ブロック領域使用率が低下します。
従来型ロードでは、ROWSはコミット操作の前に読み込む行数を意味します。ダイレクト・ロードにおけるデータ・セーブは、従来型ロードにおけるコミットと同様ですが、異なる部分もあります。
類似点は次のとおりです。
一方、従来型との主な相違点は、ダイレクト・パス・ロードのデータ・セーブではロードが完了するまで索引が使用できない(索引使用禁止状態)ということです。
ダイレクト・パス・ロード方法を指定すると、SQL*Loaderのデータ・リカバリ機能が完全にサポートされます。リカバリには大きく分けて2種類あります。
ARCHIVELOGモードで実行する必要があります。
REDOログ・ファイル・アーカイブ機能が使用可能になっている(ARCHIVELOGモードで実行している)場合、ダイレクト・パスでロードしたデータは、SQL*Loaderによってログに記録されます。それによって、メディア・リカバリが可能になります。REDOログ・ファイル・アーカイブの機能が使用可能になっていない(NOARCHIVELOGモードで実行している)場合、メディア・リカバリはできません。
ロード中に失われたデータベース・ファイルをリカバリするには、従来型パスでロードしたデータをリカバリするときと同じ方法を使用してください。
データベース・ファイルは、SQL*Loaderによって直接書き込まれます。そのため、インスタンスを再起動すると、最後にデータをセーブした時点までに挿入したすべての行が、自動的にデータベース・ファイルに存在します。変更がREDOログ・ファイルに記録されていなくても、インスタンス・リカバリは可能です。
インスタンス障害が発生すると、作成中の索引は索引使用禁止状態のままになります。使用禁止状態の索引は、表またはパーティションを使用する前に再構築する必要があります。索引が索引使用禁止状態のままであるかどうかを調べる方法については、「使用禁止状態(Index Unusable)のままの索引」を参照してください。
SQL*Loaderの最大バッファ・サイズよりも長いデータをダイレクト・パスでロードするには、LOBを使用します。LOBに大きいSTREAMSIZE値を使用すると、パフォーマンスが向上します。
次の項で説明するように、PIECEDパラメータを使用すると、最大バッファ・サイズより長いデータもロードできますが、LOBを使用することをお薦めします。
データが論理レコードの最終列である場合、PIECEDパラメータを使用すると、データをセクションごとにロードできます。
列をPIECEDと宣言することによって、LONGフィールドを複数の物理レコード(ピース)に分割することが、ダイレクト・パス・ローダーに通知されます。この場合、SQL*Loaderでは、LONGフィールドの各ピースが物理レコード内で検索された順序で処理されます。レコードが処理される前に、フィールドのすべてのピースが読み込まれます。SQL*Loaderでは、格納前のLONGフィールドは具体化されません。ただし、レコードが処理される前に、フィールドのすべての部分が読み込まれます。
列をPIECEDと宣言する場合、次の制約が適用されます。
PIECEDにできます。
PIECEDフィールドは論理レコードの最終フィールドである必要があります。
WHEN句、NULLIF句またはDEFAULTIF句では、PIECEDフィールドを使用できません。
PIECEDフィールドの領域は、他のフィールドの領域と重複してはいけません。
PIECEDに対応するデータベースの列を索引に含めることはできません。
PIECEDフィールドが含まれている場合は、不良ファイルからそのレコードをロードできません。たとえば、1つのPIECEDフィールドが3つのレコードにまたがっているとします。SQL*Loaderでは、最初のレコードからPIECEDフィールドの第一分割がロードされ、次に同じバッファを使用して2番目のレコードから第二分割がロードされます。その後、同じバッファを使用して同様に3番目のレコードがロードされます。ここでエラーが検出されると、最初の2つのレコードはすでにバッファには存在しないため、3番目のレコードのみが不良ファイルに書き込まれます。その結果、不良ファイルにあるレコードが無効となります。
ダイレクト・パス・ロードでは、使用する時間と一時記憶域を制御できます。
時間を最小化するには、次の方法があります。
領域を最小化するには、次の方法があります。
SQL*Loaderでは、必要に応じて自動的に表にエクステントが追加されますが、これには時間がかかります。新しい表へ高速にロードするには、表の作成に必要なエクステントを事前に割り当ててください。
表に必要な領域を計算するには、『Oracle Database管理者ガイド』のデータベース・ファイルの管理の説明を参照してください。必要な領域を割り当てるには、SQLのCREATE TABLE文でINITIALまたはMINEXTENTS句を使用します。
別の方法として、エクステントの割当て回数が減るようにエクステントのサイズを十分に大きくする方法もあります。
索引付き列を基準にしてデータを事前ソートすると、ダイレクト・パス・ロードのパフォーマンスを改善できます。事前ソートを行うと、ロード時の一時記憶要件を最小限に抑えることができます。また、事前ソートでは、ご使用のオペレーティング・システムまたはアプリケーション用に最適化された高性能ソート・ルーチンを利用できます。
データが事前ソートされていて既存の索引が空でない場合は、事前ソートによって、新しいキーに必要な一時セグメント領域の大きさを最小にできます。ソート・ルーチンは、新しい各キーをキー・リストに追加します。
ソート用の追加領域は必要なく、キーのための領域のみが必要となります。必要な記憶域の大きさを計算するには、ソート係数として1.3ではなく1.0を使用してください。必要な記憶域要件の見積りについては、「一時セグメント記憶域要件」を参照してください。
事前ソートを指定していて既存の索引が空である場合は、最大効率が実現します。新しいキーが索引に挿入されるのみです。一時セグメントと新しい索引が古い空の索引と同時に存在するのではなく、新しい索引のみが存在します。したがって、一時記憶域は不要であり、時間も短縮できます。
SORTED INDEXESは、データを事前ソートしている索引を指定します。この句は、ダイレクト・パス・ロードでのみ使用できます。例については、「事例6: ダイレクト・パス・ロード方式を使用したデータのロード」を参照してください。(事例へのアクセス方法については、「SQL*Loaderの事例」を参照してください。)
一般に、SORTED INDEXES句では1つの索引のみを指定します。通常、これは、ある索引でソートされたデータは、別の索引にとって正しい順序とはかぎらないためです。ただし、複数の索引のデータの順序が同じである場合は、索引すべてを同時に指定できます。
SORTED INDEXES句で指定した索引はすべて、ダイレクト・パス・ロードを開始する前に作成する必要があります。
SORTED INDEXES句で索引を指定しても、データがその索引でソートされていない場合は、ロード終了時に索引は索引使用禁止状態のままになります。データは存在していますが、索引を使用しようとするとエラーになります。索引使用禁止状態の索引がある場合は、ロード後に再構築してください。
SORTED INDEXES句で複数列の索引を指定する場合は、まず索引の最初の列で順序付けが行われ、次に2番目の列で順序付けが行われるように、データをソートしてください。
たとえば、索引の最初の列に都市名があり、2番目の列に名前の名字がある場合、次のリストのように都市別順で、同じ都市の中では名字順に並ぶようにデータをソートします。
Albuquerque Adams Albuquerque Hartstein Albuquerque Klein ... ... Boston Andrews Boston Bobrowski Boston Heigham ... ...
ダイレクト・パス・ロードのパフォーマンスを最大限に引き出すには、最も大きな一時セグメント領域を必要とする索引に基づいて、データを事前ソートしてください。たとえば、主キーが1つの数値列で、2次キーが3つのテキスト列で構成される場合、2次キーで事前ソートすることによって、ソート時間と記憶要件の両方を最小にできます。
最も大きな記憶域を必要とする索引がどれであるかを知るには、次の手順に従ってください。
ROWS値が小さいことが原因でデータ・セーブが頻繁に発生する場合、ダイレクト・パス・ロードのパフォーマンスは低下します。ROWS値が小さい場合、セーブ後に最後のデータ・ブロックには書込みが行われないため、データ・ブロック領域が無駄になります。
ダイレクト・パス・ロードは従来型ロードより何倍も高速なため、ダイレクト・ロードの場合には、ROWSの値は従来型ロードの場合よりかなり大きくする必要があります。
データ・セーブ時には、SQL*Loaderのすべてのバッファへの書込みが正常に終了するまで、ロードは停止します。ROWSの値は、安全性を確保できる範囲で、できるだけ大きくしてください。数千行をロードしてみて、1行当たりの平均ロード時間を計ってみることをお薦めします。その値から、ROWSに設定する値が求められます。
たとえば、1分当たり20,000行がロードされるとします。この場合、処理途中に実行するセーブの間隔を10分以内にするには、ROWSを200,000(20,000行/分×10分間)に設定してください。
ダイレクト・ロードを大幅に高速化する1つの方法は、REDOログの使用を最小限に抑えることです。それには3通りの方法があります。アーカイブを使用禁止にする方法、ロードをリカバリ不可能に指定する方法、ロードされるオブジェクトに対してSQLのNOLOGGINGパラメータを設定する方法です。この項では、すべての方法を説明します。
アーカイブが使用禁止の場合、ダイレクト・パス・ロードでは全体イメージのREDOログは生成されません。SQLのARCHIVELOGおよびNOARCHIVELOGパラメータを使用して、アーカイブ・モードを設定します。アーカイブの詳細は、『Oracle Database管理者ガイド』を参照してください。
時間およびREDOログ・ファイルの領域を節約するには、データのロード時に制御ファイルでSQL*LoaderのUNRECOVERABLE句を使用します。リカバリ不可能を指定したロードの場合は、ロードされたデータはREDOログ・ファイルに記録されません。かわりに、操作を無効にするために必要なREDOログ(無効REDOログ)が生成されます。
UNRECOVERABLE句は、ロード・セッション中にロードされたすべてのオブジェクト(データ・セグメントおよび索引セグメントの両方)に適用されます。このため、ロードされた表についてはメディア・リカバリはできません。ただし、他のユーザーが行ったデータベース変更のログは、引き続き記録されます。
UNRECOVERABLE句を指定してロードしたデータについてメディア・リカバリが必要になった場合、ロードしたデータ・ブロックには、論理的に破損したというマークが付けられます。
データをリカバリするには、データを削除して再作成します。データがリカバリ不能にならないように、データのロード後、すぐにバックアップを取ってください。
デフォルトでは、ダイレクト・パス・ロードはRECOVERABLEです。
次に、制御ファイルのUNRECOVERABLE句の指定例を示します。
UNRECOVERABLE LOAD DATA INFILE 'sample.dat' INTO TABLE emp (ename VARCHAR2(10), empno NUMBER(4));
データまたは索引のセグメントにSQLのNOLOGGINGパラメータが設定されていると、そのセグメントに対する全体イメージのREDOログは使用できません(無効REDOログが生成されます)。NOLOGGINGパラメータを使用すると、ログが記録されないオブジェクトに対しより優れた制御が可能です。
列配列の行数によって、ストリーム・バッファが作成される前にロードされた行数を判断します。STREAMSIZEパラメータで、クライアントからサーバーへ送ったデータのストリーム・サイズ(バイト単位)を指定します。
列配列の行数の値を指定するには、COLUMNARRAYROWSパラメータを使用します。ダイレクト・パスを使用してVARRAYをロードすると、COLUMNARRAYROWSパラメータはデフォルトで100に設定され、クライアント・オブジェクトのキャッシュ・スラッシングを回避します。
ダイレクト・パス・ストリーム・バッファのサイズを指定するには、STREAMSIZEパラメータを使用します。
これらのパラメータの最適な値は、使用しているシステム、入力データ型およびOracleの列データ型によって異なります。独自の構成用に最適な値を使用することで、SQL*Loaderのログ・ファイルでの経過時間が少なくなります。
これらのパラメータのデフォルト値のリストは、「SQL*Loaderの起動」で説明したとおり、パラメータを指定しないでSQL*Loaderを起動すると参照できます。
複数CPUシステムでダイレクト・パス・ロードを実行する場合、列配列の行数およびストリーム・バッファのサイズを指定すると、特に有効です。詳細は、「複数CPUシステムのダイレクト・パス・ロードの最適化」を参照してください。
同じ日付値またはタイムスタンプ値のロードが何度も行われるダイレクト・パス・ロードを実行する場合、総ロード時間の大部分が日付およびタイムスタンプのデータの変換に使用される可能性があります。特に、複数の日付列がロードされる場合にこのような状況が発生します。この場合、SQL*Loaderの日付キャッシュを使用することによってパフォーマンスを向上できます。
日付キャッシュを使用すると、入力データ内に多数の重複する日付値が存在する場合、日付変換が実行される回数が減ります。この機能を使用すると、ロード中に予測される一意の日付の数を指定できます。
日付キャッシュは、デフォルトで使用可能です。日付キャッシュ機能を使用禁止にするには、0(ゼロ)に設定します。
デフォルトの日付キャッシュ・サイズは1000要素です。デフォルトのサイズを使用し、1000を超える一意の入力値がロードされると、日付キャッシュはこの表に対して自動的に使用禁止となります。これによって、過剰および不要なルックアップ時間によって、パフォーマンスが低下する可能性がなくなります。ただし、デフォルトを使用するかわりに0(ゼロ)以外の値を日付キャッシュに指定し、キャッシュ量がこの値を超えた場合、日付キャッシュは使用禁止になりません。最大値を超えた入力データは、適切な変換ルーチンによって明示的に変換されます。
日付キャッシュは、1つの表のみに対応付けできます。複数の表で日付キャッシュの共有はできません。次のすべての条件を満たす場合にのみ、表に対して日付キャッシュが作成されます。
DATE_CACHEパラメータが0(ゼロ)以外に設定されている
日付キャッシュの統計はログ・ファイルに書き込まれます。これらの統計を使用して、次のとおりダイレクト・パス・ロードのパフォーマンスを向上できます。
キャッシュ・サイズを大きくしてもパフォーマンスが向上しない場合は、デフォルトの動作に戻すか、またはキャッシュ・サイズを0(ゼロ)に設定します。パフォーマンス全体の向上は、ロードされる他の列のデータ型によっても異なります。ロードされる日付列の総数がロードされる他のデータ型より大きい場合、パフォーマンスは大幅に向上します。
複数CPUシステムでダイレクト・パス・ロードを実行する場合、SQL*Loaderではデフォルトでマルチスレッドが使用されます。この場合の複数CPUシステムは、2つ以上のCPUを持つ単一のシステムとして定義されます。
マルチスレッド・ロードとは、可能な場合、列配列をストリーム・バッファに変換し、ストリーム・バッファ・ロードがパラレルで実行されることを表します。この最適化は、次の場合に最も効果的です。
変換は、ストリーム・バッファのロード時にパラレルで実行されます。
この処理の状態は、次の例に示すとおり、SQL*Loaderのログ・ファイルに記録されます。
Total stream buffers loaded by SQL*Loader main thread: 47 Total stream buffers loaded by SQL*Loader load thread: 180 Column array rows: 1000 Stream buffer bytes: 256000
この例では、SQL*Loaderのロード・スレッドがメイン・スレッドをオフロードしています。これによって、ロード・スレッドがサーバーで現行のストリームをロードする一方で、メイン・スレッドは、次のストリーム・バッファを作成できます。
ロード・スレッドを使用して、できるだけ多くのストリーム・バッファ・ロードを実行することが目的です。これによって、列配列の行数の増加、またはストリーム・バッファのサイズの削減(あるいはその両方)を実現できます。SQL*Loaderのログ・ファイルの経過時間を監視することで、変更による効果を確認できます。詳細は、「列配列の行数およびストリーム・バッファ・サイズの指定」を参照してください。
単一CPUシステム上では、最適化はデフォルトで無効になります。サーバーが他のシステム上にある場合は、マルチスレッドを手動で有効にするとパフォーマンスが向上します。
マルチスレッド・オプションを有効または無効にするには、SQL*LoaderのコマンドラインでMULTITHREADINGパラメータを使用するか、またはSQL*Loaderの制御ファイルにMULTITHREADINGパラメータを指定します。
従来型パスとダイレクト・パスの両方について、SQL*Loaderでは表のすべての既存の索引がメンテナンスされます。
索引のメンテナンスを回避するには、次のいずれかの方法を使用します。
SKIP_UNUSABLE_INDEXESパラメータを使用します。
SKIP_INDEX_MAINTENANCEパラメータを使用します(ダイレクト・パスの場合に限定されるため、注意して使用してください)。
索引のメンテナンスを回避すると、ダイレクト・パス・ロード中に必要な領域を最小限にできます。その方法は次のとおりです。
表の全行数に対してロードする行数が多い場合、索引のメンテナンスを避けることは合理的です。ただし、比較的少数の行を大きな表に追加する場合は、索引の再ソートに非常に時間がかかることがあります。そのような場合は、従来型パス・ロードを使用するか、SQL*LoaderのSINGLEROWパラメータを使用します。詳細は、「SINGLEROWオプション」を参照してください。
従来型パス・ロードでは、行配列の挿入には標準SQL INSERT文を使用します。このとき、整合性制約および挿入トリガーは自動的に適用されます。ただし、ダイレクト・パスでデータをロードする場合は、SQL*Loaderでは一部の整合性制約およびすべてのデータベース・トリガーが使用禁止になります。このセクションでは、これらの機能に関するダイレクト・パス・ロードの使用について説明します。
整合性制約には、ダイレクト・パス・ロード時に自動的に使用禁止になるものがあります。また、使用禁止にならないものもあります。制約の詳細は、『Oracle Databaseアドバンスト・アプリケーション開発者ガイド』の制約によるデータ整合性のメンテナンスを参照してください。
ダイレクト・パス・ロード時でも使用可能な制約は、次のとおりです。
NOT NULL制約は列配列の作成時にチェックされます。NOT NULL制約に違反する行はすべて拒否されます。
ダイレクト・パス・ロード時にUNIQUE制約が使用可能であっても、その制約に違反する行もロードされます。(これは、そのような行が拒否される従来型パスとは異なります。)UNIQUE制約は、ダイレクト・パス・ロードの最後で索引が再作成されるときに検証されます。違反が検出されると、索引は索引使用禁止状態のままになります。詳細は、「使用禁止状態(Index Unusable)のままの索引」を参照してください。
次の制約は、ダイレクト・パス・ロード時にデフォルトで自動的に使用禁止になります。
EVALUATE CHECK_CONSTRAINTS句を指定すると、CHECK制約の自動的な使用禁止を変更できます。SQL*Loaderでは、ダイレクト・パス・ロード中にCHECK制約が評価されます。CHECK制約に違反する行はすべて拒否されます。次の例に、SQL*Loader制御ファイルでのEVALUATE CHECK_CONSTRAINTS句の使用方法を示します。
LOAD DATA INFILE * APPEND INTO TABLE emp EVALUATE CHECK_CONSTRAINTS FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' (c1 CHAR(10) ,c2) BEGINDATA Jones,10 Smith,20 Brown,30 Taylor,40
REENABLE句を指定しておくと、ロードの完了時に、整合性制約が自動的に使用可能に戻されます。REENABLE句の構文は次のとおりです。


DISABLED_CONSTRAINTSパラメータはオプションで、読みやすくするために使用します。EXCEPTIONS句を使用する場合は、指定する表がすでに存在していて、その表への挿入が可能である必要があります。ここで指定する表には、整合性制約のいずれかに違反したすべての行のROWIDが格納されます。また、違反があった制約名も格納されます。この例外表の作成方法の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。
SQL*Loaderログ・ファイルには、使用禁止となっていた制約、および使用可能に戻された制約が記録されます。また、エラーが原因で制約を使用可能に戻せなかった場合または検査できなかった場合はそのエラーが記録されます。さらに、ロードした表のそれぞれに指定された例外表の名前もログ・ファイルに書き込まれます。
REENABLE句を使用しない場合は、表のすべての行が検査されるときに制約を手動で使用可能に戻す必要があります。ここで新しいデータにエラーが見つかると、エラー・メッセージが生成されます。例外表を指定した場合は、違反のあった制約名と不良データのROWIDが、その表に書き込まれます。
REENABLE句を使用すると、制約を自動的に使用可能に戻し、新しい行すべてを検証できます。新しいデータにエラーが見つからなかった場合は、検証された制約に自動的にマークを付けられます。新しいデータにエラーが見つかった場合は、ログ・ファイルにエラー・メッセージが書き込まれ、SQL*Loaderによって制約の状態にENABLE NOVALIDATEというマークが付けられます。例外表を指定した場合は、違反のあった制約名と不良データのROWIDが、その表に書き込まれます。
ダイレクト・パス・ロードが始まると、表挿入トリガーも使用禁止になります。行のロードおよび索引の再作成が完了すると、使用禁止になっていたトリガーはすべて使用可能に戻されます。ログ・ファイルには、ロード時に使用禁止になっていたすべてのトリガーのリストが示されます。トリガーを使用可能に戻すときに1つでもエラーがあると、使用可能にできません。
整合性制約と異なり、挿入トリガーは、使用可能に戻っても表全体に対して再び適用されません。つまり、ダイレクト・パスでロードされた行に対しては、挿入トリガーは起動しません。ダイレクト・パスでロードした場合は、新しい行への挿入トリガーに相当する処理はすべて、アプリケーション側で実行する必要があります。
アプリケーションは整合性制約を実行する場合、通常は挿入トリガーを使用します。アプリケーションが使用する挿入トリガーのほとんどは単純なため、Oracleの自動整合性制約に置き換えることができます。
挿入トリガーは、Oracleの自動整合性制約に置き換えられない場合があります。たとえば、挿入トリガーの中で表のルックアップ関数を使用して整合性チェックを行っている場合、自動制約は使用できません。これは、自動制約はカレント行における定数および列以外は参照できないためです。このようなトリガーと同じ処理を実現する方法が2つあります。この項ではその方法について説明します。
いずれの方法の場合も、表に対して事前に行うべき作業があります。次に示す一般的なガイドラインに従って、表を準備してください。
CONSTANTパラメータを使用して、ロードしたすべての行に「新データ」を示すフラグを付けます。
この手順に従って準備すると、新しくロードした行が識別できるため、古い行に影響を与えずに新しいデータを操作できます。
一般に、挿入トリガーと同じ処理を実現する場合は、データベース更新トリガーを使用します。これは最も単純な方法です。例外を呼び出さない挿入トリガーの場合は、常にこの方法を使用できます。
トリガーをコピーします。「new.column_name」というすべての箇所を「old.column_name」に変更してください。
トリガーの動作によっては、この操作中に表に対する排他的更新アクセスが必要となる場合もあります。排他的更新アクセスを実行すると、他のユーザーが修正する行に、誤ってこのトリガーが適用されることはありません。
挿入トリガーの中で例外を呼び出している場合、それと同じ処理を行うには、さらに作業が必要です。例外を呼び出すということは、表にその行を挿入しないということです。この処理を更新トリガーで実現するには、ロードした行に削除フラグを付けておく必要があります。
この場合、「新データ」列を削除フラグに使用することはできません。更新トリガーでは、その起動元である列を修正できないためです。したがって、表にもう1列追加する必要があります。ここで追加する列は、削除する行を示すためのものです。NULL値の場合は、行が有効であることを示します。挿入トリガーで例外を呼び出すと、常に、更新トリガーによって追加列にフラグが設定されます。これによって、その行が無効であることが示されます。
要約すると、挿入トリガーで例外を呼び出している場合は、次の条件を満たすと、同じ処理を更新トリガーで実現できます。
次に示すプロシージャは、どのような場合でも使用できますが、その実装はより複雑になります。このプロシージャは、挿入トリガーで例外を呼び出すときに使用できます。そのとき、2番目の列を追加する必要はありません。また、更新トリガーとは処理が異なるため、表に対する排他的アクセス権限がなくても使用できます。
SQL*Loaderでは、トリガーおよび制約を使用禁止にするために、ロードされる表にいくつかのロックを獲得する必要があります。競合するプロセスが表のトリガーまたは制約を使用可能にしているときに、SQL*Loaderでその表のトリガーまたは制約を使用禁止にしようとした場合、SQL*Loaderではその表に関して排他的アクセス権を獲得することはできません。
この場合、SQL*Loaderでは、できるかぎり問題のないように処理が実行されます。ロード終了前に、SQL*Loaderでは使用禁止のトリガーおよび制約が使用可能に戻されます。ただし、表ロックが原因でSQL*Loaderの処理を継続できなくなった場合は、SQL*Loaderでトリガーや制約を使用可能にする処理も実行されないことがあります。この場合、トリガーおよび制約は、手動で使用可能にするまで永続的に使用できない状態になります。
このような状況はまれですが、発生する可能性はあります。このような状況を回避するには、ダイレクト・ロードの処理中は、表のトリガーまたは制約を使用可能にするアプリケーションを実行しないことをお薦めします。
適切なロックを獲得できなかったためにダイレクト・ロードが終了した場合は、ログ・ファイルを確認してください。ログ・ファイルには、使用禁止になっていたトリガーおよび制約と、それらを使用可能に戻そうと試みた履歴が記録されます。SQL*Loaderによって使用可能に戻せなかったトリガーや制約は、『Oracle Database SQL言語リファレンス』で説明されているALTER TABLE文のENABLE句を使用して、手動で使用可能にする必要があります。
トリガーまたは整合性制約の問題があっても、より高速なロードを実現する場合は、従来型パスによる同時ロードの使用を考えてください。つまり、複数CPUシステムで同時に複数のセッションでロードを実行します。入力データ・ファイルを論理レコードの境界で別々のファイルに分割し、それらの各入力データ・ファイルを従来型パス・ロード・セッションでロードします。このロードには、次のような特長があります。
この項では、データのロードに必要な所要時間を最小限にするために使用される、同時処理の3つの基本モデルについて説明します。
同時に複数の従来型パス・ロード・セッションを実行する方法の詳細は、「従来型パスの同時ロードによるパフォーマンスの向上」を参照してください。同一または異なるオブジェクトを制限なしで同時にロードする場合に、この方法を使用できます。
セグメント間同時処理は、異なるオブジェクトを同時にロードする場合に使用できます。この方法は、異なる表の同時ダイレクト・パス・ロード、または同じ表の異なるパーティションの同時ダイレクト・パス・ロードに適用できます。
1つのパーティションのダイレクト・パス・ロードを行う場合は、次のことを考慮します。
CHECK制約は使用禁止にする必要があります。
SQL*Loaderでは、複数のセッションを同時に実行して、同一の表またはパーティション表の同一パーティションに対してダイレクト・パス・ロードを実行できます。複数のSQL*Loaderセッションを実行すると、システムで使用可能なリソースを与えられればダイレクト・パス・ロードのパフォーマンスが向上します。
このデータ・ロード方法は、DIRECTおよびPARALLELパラメータにtrueを設定することによって使用でき、「パラレル・ダイレクト・パス・ロード」とも呼ばれます。
並列化はユーザーによって管理されるものだということを理解しておいてください。PARALLELパラメータにtrueを設定した場合、複数の同時ダイレクト・パス・ロード・セッションのみが可能になります。
パラレル・ダイレクト・パス・ロードには次の制限があります。
CHECK制約は使用禁止にする必要があります。
REPLACE、TRUNCATEおよびINSERTは使用できません(これは、個別のロードによって整合性がとられないためです)。パラレル・ロードの前に表を切り捨てる必要がある場合は、手動で行ってください。
1つのパーティションのパラレル・ダイレクト・パス・ロードを行う場合は、まず、データをパーティション化してください(そうしない場合は、パーティション不一致によるレコード拒否のオーバーへッドのため、ロード速度が遅くなります)。
入力元となるデータ・ファイルは、SQL*Loaderセッションごとに異なります。同じ表にダイレクト・ロードを実行するセッションすべてに対して、PARALLEL句にtrueを設定する必要があります。構文は次のとおりです。

PARALLELは、コマンドラインまたはパラメータ・ファイルに指定できます。また、OPTIONS句を使用して制御ファイルに指定することもできます。
たとえば、1つの表について3つのSQL*Loaderダイレクト・パス・ロード・セッションを起動するには、オペレーティング・システムのプロンプトで、次の各コマンドを実行します。コマンドをそれぞれ入力した後に、パスワードを入力するように要求されます。
sqlldr USERID=scott CONTROL=load1.ctl DIRECT=TRUE PARALLEL=true sqlldr USERID=scott CONTROL=load2.ctl DIRECT=TRUE PARALLEL=true sqlldr USERID=scott CONTROL=load3.ctl DIRECT=TRUE PARALLEL=true
このコマンドは、別々のセッションで実行するか、またはオペレーティング・システムがサポートしている場合には別々のバックグラウンド・ジョブとして実行してください。複数の制御ファイルを使用していることに注意してください。そうすることによって、ダイレクト・パス・ロードで使用するファイルをより柔軟に指定できます。
PARALLEL句を使用してロードを実行すると、SQL*Loaderによって同時実行セッションごとに一時セグメントが作成されます。それらの一時セグメントは、ロード完了時に マージされます。マージによって作成されたセグメントは、セグメントの最高水位標より上にあるデータベースの既存のセグメントに追加されます。各ローダー・セッションの各セグメントで使用された最後のエクステントは、空き領域をすべて切り捨ててから、SQL*Loaderセッションの他のエクステントと組み合せることができます。
パラレル・ダイレクト・パス・ロードを実行する場合、SQL*Loaderによって割り当てられる一時セグメントの属性を指定してできるオプションがあります。これらのオプションは、FILEおよびSTORAGEパラメータを使用して指定します。これらのパラメータはパラレル・ロードに対してのみ有効です。
最大の入出力スループットを得るために、同時実行のダイレクト・パス・ロード・セッションで、各ファイルを別のディスクに置いて使用することをお薦めします。SQL*Loader制御ファイルでは、ロードされるオブジェクト(表またはパーティション)の表領域にある有効なデータ・ファイルであれば、OPTIONS句のFILEパラメータを使用してファイル名を指定できます。
次に例を示します。
LOAD DATA INFILE 'load1.dat' INSERT INTO TABLE emp OPTIONS(FILE='/dat/data1.dat') (empno POSITION(01:04) INTEGER EXTERNAL NULLIF empno=BLANKS ...
同時実行する各SQL*Loaderセッションのコマンドラインでも、FILEパラメータを指定できます。ただし、その指定は、そのセッションでロードされるすべてのオブジェクトにグローバルに適用されます。
パラレル・ダイレクト・パス・ロードでは、Oracle DatabaseのFILEパラメータに次の制限があります。
STORAGEパラメータを使用して、パラレル・ダイレクト・パス・ロード用に割り当てられる一時セグメントの記憶域属性を指定できます。STORAGEパラメータが使用されない場合は、ロードされるオブジェクト(表、パーティション)が存在するセグメントの記憶域属性が使用されます。また、STORAGEパラメータが指定されてない場合は、SQL*LoaderでEXTENTS用にデフォルトの2KBが使用されます。
たとえば、STORAGEパラメータを指定するためには、次のOPTIONS句が使用されます。
OPTIONS (STORAGE=(INITIAL 100M NEXT 100M PCTINCREASE 0))
STORAGEパラメータを使用できるのは、SQL*Loader制御ファイル内のみでコマンドラインでは使用できません。STORAGEパラメータは、PCTINCREASEを0(ゼロ)に設定する、INITIALまたはNEXT値を設定する以外には、使用しないでください。暗黙的に無視される可能性があります。
すべてのデータのロード完了後に、制約およびトリガーを手動で使用可能にしてください。
それぞれのSQL*Loaderセッションで、ダイレクト・パス・ロードの後に表の制約が使用可能に戻されることがあるため、あるセッションで、他のセッションがデータのロードを終える前に、制約が使用可能に戻される可能性があります。この場合、ロードを完了する最初のセッションでは、残りのセッションで表のロックが共有されているため、制約を使用可能にできなくなります。
ダイレクト・パス・ロードの後、一部の制約が使用可能に戻っていない可能性があるため、ロードの完了後、制約の状態を調べ、制約が使用可能になったことを確認する必要があります。
主キーおよび一意制約が有効の場合、表に索引が作成されます。その後、その表が非常に大きい場合は、ダイレクト・パス・ロード後に索引を使用可能にするまでに非常に長い時間がかかる可能性があります。ロード後に、これらの制約を手動で有効にしてください(また、自動で有効にする機能を指定しないでください)。これによって、必要な索引をパラレルに手動で作成し、制約を有効にするまでの時間を節約できます。
ロードするデータの形式について制御が可能な場合は、次に示すヒントを利用してロード・パフォーマンスを改善できます。
sqlldrプロセスのNLS_LANG)
すべてのキャラクタ・セットが同じ場合、 パフォーマンスは最適化されます。ダイレクト・パスでは、データ・ファイル・キャラクタ・セットとデータベース・サーバー・キャラクタ・セットが同じである場合、最適なパフォーマンスが得られます。キャラクタ・セットが同じ場合、キャラクタ・セット変換用バッファは割り当てられません。
SORTED INDEX句を使用します。
NULLIF句およびDEFAULTIF句は必要な場合以外は使用しないようにします。これらの句は、関連する句を持つ各列にロードされるすべての行について、評価される必要があります。
CONCATENATE句およびCOLUMNARRAYROWS句の両方に大きい値を指定する場合は、パフォーマンスへの影響に注意します。詳細は、「CONCATENATEを使用した論理レコードの作成」を参照してください。
さらに、「外部表使用時のパフォーマンスのヒント」で説明しているパフォーマンスのヒントは、SQL*Loaderにも適用できます。
|
 Copyright © 2007 Oracle Corporation. All Rights Reserved. |
|