| Oracle® Database PL/SQL言語リファレンス 11gリリース2 (11.2) B56260-09 |
|


 前 |
 次 |
コンポジット・データ型には、内部コンポーネントを持つ値が格納されます。コンポジット変数全体をサブプログラムにパラメータとして渡すことや、コンポジット変数の内部コンポーネントに個別にアクセスすることができます。内部コンポーネントは、スカラーまたはコンポジットのいずれかです。スカラー・コンポーネントは、スカラー変数を使用できるすべての場所で使用できます。PL/SQLでは、コレクションとレコードという、2種類のコンポジット・データ型を定義できます。コンポジット・コンポーネントは、同じ型のコンポジット変数を使用できるすべての場所で使用できます。
collectionの内部コンポーネントは、常に同じデータ型であり、要素と呼ばれます。コレクション変数の各要素には、このvariable_name(index)という構文を使用して、その一意の索引によってアクセスできます。コレクション変数を作成するには、コレクション型を定義してからその型の変数を作成するか、%TYPEを使用します。
レコードの内部コンポーネントは、データ型が異なる場合があり、フィールドと呼ばれます。レコード変数の各フィールドには、variable_name.field_nameという構文を使用して、その名前によってアクセスできます。レコード変数を作成するには、RECORD型を定義してからその型の変数を作成するか、%ROWTYPEまたは%TYPEを使用します。
レコードのコレクション、およびコレクションを含むレコードを作成できます。
コレクションに関するトピック
|
関連項目:
|
レコードに関するトピック
|
注意: この章のいくつかの例では、自身のコンポジット変数を出力するプロシージャを定義します。それらのプロシージャのいくつかは、次に示すスタンドアロン・プロシージャを起動し、整数パラメータ(NULL以外の場合)または文字列'NULL'のいずれかを出力します。
CREATE OR REPLACE PROCEDURE print (n INTEGER) IS
BEGIN
IF n IS NOT NULL THEN
DBMS_OUTPUT.PUT_LINE(n);
ELSE
DBMS_OUTPUT.PUT_LINE('NULL');
END IF;
END print;
/
この章のいくつかの例では、コンポジット型の値を戻すファンクションを定義します。 PL/SQLプロシージャとファンクションを完全に理解していなくても、この章の例は理解できます。PL/SQLプロシージャとファンクションの詳細は、第8章「PL/SQLサブプログラム」を参照してください。 |
PL/SQLには、連想配列、VARRAY(可変サイズの配列)およびネストした表の3つのコレクション型があります。表5-1に、それぞれの類似点と相違点の概要を示します。
表5-1 PL/SQLコレクション型
| コレクション型 | 要素の数 |
索引タイプ | 密か疎か |
未初期化時のステータス |
定義される場所 |
ADT属性のデータ型として使用可能かどうか |
|---|---|---|---|---|---|---|
|
指定されていない |
文字列または |
密または疎のいずれか |
空 |
PL/SQLブロック内またはパッケージ内 |
使用不可 |
|
|
指定されている |
整数 |
常に密 |
NULL |
PL/SQLブロック内、パッケージ内またはスキーマ・レベル |
スキーマ・レベルで定義されている場合のみ |
|
|
指定されていない |
整数 |
密で始まり、疎になる可能性あり |
NULL |
PL/SQLブロック内、パッケージ内またはスキーマ・レベル |
スキーマ・レベルで定義されている場合のみ |
要素の数
要素の数が指定されている場合、その数がコレクション内の要素の最大数です。要素の数が指定されていない場合は、索引タイプの上限がコレクション内の要素の最大数になります。
密か疎か
密コレクションとは、要素間に欠損がないコレクションのことで、最初と最後の要素の間にあるすべての要素が定義され、値を含んでいます(要素にNOT NULL制約が指定されていない場合にかぎり、値にNULLを使用できます)。疎コレクションは、要素間に欠損があります。
未初期化時のステータス
空のコレクションは、要素を持たずに存在するコレクションです。空のコレクションに要素を追加するには、EXTENDメソッド(「EXTENDコレクション・メソッド」を参照)を起動します。
NULLのコレクション(基本構造的にNULLであるコレクションとも呼ばれる)は存在しません。NULLのコレクションを存在するコレクションに変えるには、空にするかNULL以外の値を代入してコレクションを初期化する必要があります(詳細は「コレクションのコンストラクタ」および「コレクション変数への値の代入」を参照してください)。EXTENDメソッドを使用して、NULLのコレクションを初期化することはできません。
定義される場所
PL/SQLブロック内に定義されるコレクション型はローカル型です。ブロック内でのみ使用可能であり、スタンドアロン・サブプログラムまたはパッケージ・サブプログラム内にブロックがある場合にのみ、データベースに格納されます。(スタンドアロン・サブプログラムおよびパッケージ・サブプログラムの詳細は、「ネストしたサブプログラム、パッケージ・サブプログラムおよびスタンドアロン・サブプログラム」を参照してください。)
パッケージ仕様部に定義されるコレクション型はパブリック項目です。パッケージ名(package_name.type_name)で修飾することで、パッケージの外から参照できます。パッケージを削除するまでデータベースに格納されます。(パッケージの詳細は、第10章「PL/SQLパッケージ」を参照してください。)
スキーマ・レベルで定義されるコレクション型は、スタンドアロン型です。「CREATE TYPE文」を使用して作成します。「DROP TYPE文」を使用して削除するまでデータベースに格納されます。
ADT属性のデータ型として使用可能かどうか
ADT属性のデータ型にするには、コレクション型がスタンドアロン・コレクション型である必要があります。その他の制限は、「datatypeの制限」を参照してください。
非PL/SQLコンポジット型からPL/SQLコンポジット型への変換
他の言語を使用するコードまたはビジネス・ロジックが存在する場合、通常は配列を変換して、その言語の型をPL/SQLのコレクション型に直接設定できます。次に例を示します。
|
関連項目: あるSQLデータ型またはコレクション型の値を別のSQLデータ型またはコレクション型の値に変換するCASTファンクションの詳細は、『Oracle Database SQL言語リファレンス』 |
連想配列(旧称はPL/SQL表または索引付き表)は、キーと値のペアのセットです。各キーは一意の索引であり、構文variable_name(index)を使用して、関連する値を検索するために使用されます。
索引のデータ型には、文字列型またはPLS_INTEGERを使用できます。索引は、作成された順序ではなく、ソートされた順序で格納されます。文字列型の場合、ソートの順序は初期化パラメータNLS_SORTおよびNLS_COMPで決定されます。
データベース表と同様に、連想配列には次の特性があります。
移入するまで空である(ただし、NULLではない)
数が指定されていない要素を保持できる(要素の位置を知らなくてもアクセスできる)
連想配列には、データベース表とは異なる次の特性があります。
ディスク領域またはネットワーク操作が不要
DML文では操作できない
例5-1では、文字列で索引付けされる連想配列型を定義し、この型の変数を宣言して3つの要素を変数に移入し、1つの要素の値を変更した後に値を(作成された順序ではなくソートされた順序で)出力します。(FIRSTおよびNEXTはコレクション・メソッドです。詳細は「コレクション・メソッド」を参照してください。)
例5-1 文字列で索引付けされている連想配列
DECLARE
-- Associative array indexed by string:
TYPE population IS TABLE OF NUMBER -- Associative array type
INDEX BY VARCHAR2(64); -- indexed by string
city_population population; -- Associative array variable
i VARCHAR2(64); -- Scalar variable
BEGIN
-- Add elements (key-value pairs) to associative array:
city_population('Smallville') := 2000;
city_population('Midland') := 750000;
city_population('Megalopolis') := 1000000;
-- Change value associated with key 'Smallville':
city_population('Smallville') := 2001;
-- Print associative array:
i := city_population.FIRST; -- Get first element of array
WHILE i IS NOT NULL LOOP
DBMS_Output.PUT_LINE
('Population of ' || i || ' is ' || city_population(i));
i := city_population.NEXT(i); -- Get next element of array
END LOOP;
END;
/
結果:
Population of Megalopolis is 1000000 Population of Midland is 750000 Population of Smallville is 2001
例5-2では、PLS_INTEGERで索引付けされている連想配列型と、その型の連想配列を戻すファンクションを定義します。
例5-2 PLS_INTEGERで索引付けされている連想配列を戻すファンクション
DECLARE TYPE sum_multiples IS TABLE OF PLS_INTEGER INDEX BY PLS_INTEGER; n PLS_INTEGER := 5; -- number of multiples to sum for display sn PLS_INTEGER := 10; -- number of multiples to sum m PLS_INTEGER := 3; -- multiple FUNCTION get_sum_multiples ( multiple IN PLS_INTEGER, num IN PLS_INTEGER ) RETURN sum_multiples IS s sum_multiples; BEGIN FOR i IN 1..num LOOP s(i) := multiple * ((i * (i + 1)) / 2); -- sum of multiples END LOOP; RETURN s; END get_sum_multiples; BEGIN DBMS_OUTPUT.PUT_LINE ( 'Sum of the first ' || TO_CHAR(n) || ' multiples of ' || TO_CHAR(m) || ' is ' || TO_CHAR(get_sum_multiples (m, sn)(n)) ); END; /
結果:
Sum of the first 5 multiples of 3 is 45
ここでのトピック
連想配列の定数を宣言する場合、例5-3に示すように、初期値を連想配列に移入するファンクションを作成して、定数宣言でそのファンクションを起動する必要があります。(コンストラクタがVARRAYまたはネストした表に対して行う操作を、ファンクションが連想配列に対して行います。コンストラクタの詳細は、「コレクションのコンストラクタ」を参照してください。)
例5-3 連想配列の定数の宣言
CREATE OR REPLACE PACKAGE My_Types AUTHID DEFINER IS TYPE My_AA IS TABLE OF VARCHAR2(20) INDEX BY PLS_INTEGER; FUNCTION Init_My_AA RETURN My_AA; END My_Types; / CREATE OR REPLACE PACKAGE BODY My_Types IS FUNCTION Init_My_AA RETURN My_AA IS Ret My_AA; BEGIN Ret(-10) := '-ten'; Ret(0) := 'zero'; Ret(1) := 'one'; Ret(2) := 'two'; Ret(3) := 'three'; Ret(4) := 'four'; Ret(9) := 'nine'; RETURN Ret; END Init_My_AA; END My_Types; / DECLARE v CONSTANT My_Types.My_AA := My_Types.Init_My_AA(); BEGIN DECLARE Idx PLS_INTEGER := v.FIRST(); BEGIN WHILE Idx IS NOT NULL LOOP DBMS_OUTPUT.PUT_LINE(TO_CHAR(Idx, '999')||LPAD(v(Idx), 7)); Idx := v.NEXT(Idx); END LOOP; END; END; /
結果:
-10 -ten 0 zero 1 one 2 two 3 three 4 four 9 nine PL/SQL procedure successfully completed.
文字列で索引付けされている連想配列は、NLS_SORT、NLS_COMP、NLS_DATE_FORMATなどの各国語サポート(NLS)のパラメータによって影響を受けます。
ここでのトピック
|
関連項目: 言語ソート・パラメータの詳細は、『Oracle Databaseグローバリゼーション・サポート・ガイド』を参照してください。 |
連想配列の文字列索引の格納順序は、初期化パラメータNLS_SORTおよびNLS_COMPで決まります。文字列で索引付けされている連想配列にデータを移入した後で、いずれかのパラメータ値を変更すると、コレクション・メソッドFIRST、LAST、NEXTおよびPRIOR(「コレクション・メソッド」を参照)から予期しない値が戻されたり例外が呼び出される場合があります。セッション中にこれらのパラメータ値を変更する必要がある場合は、文字列で索引付けされている連想配列に対して操作を実行する前に元の値をリストアしてください。
文字列で索引付けされている連想配列の宣言では、文字列型をVARCHAR2またはそのサブタイプの1つにする必要があります。ただし、連想配列への移入では、TO_CHARファンクションでVARCHAR2に変換できる任意のデータ型の索引を使用できます。(TO_CHARの詳細は、『Oracle Database SQL言語リファレンス』を参照してください。)
VARCHAR2およびそのサブタイプ以外のデータ型の索引を使用する場合は、初期化パラメータの値が変更されても索引の一貫性および一意性が保持されることを確認してください。次に例を示します。
TO_CHAR(SYSDATE)は索引として使用しないでください。
NLS_DATE_FORMATの値が変更された場合は、(TO_CHAR(SYSDATE))も変更される可能性があります。
それぞれ異なるNVARCHAR2の索引でも、同じVARCHAR2値に変換される可能性のある場合は使用しないでください。
大/小文字、アクセント記号またはデリミタ文字のみが異なるCHARまたはVARCHAR2の索引を使用しないでください。
NLS_SORTの値の末尾が_CI(大/小文字を区別しない比較)または_AI(アクセント記号の有無および大/小文字を区別しない比較)である場合、大/小文字、アクセント記号またはデリミタ文字のみが異なる索引は同じ値に変換される可能性があります。
連想配列をパラメータとしてリモート・データベースに渡す場合に、ローカルとリモートのデータベースのNLS_SORT値またはNLS_COMP値が異なると、次のようになります。
コレクション・メソッドFIRST、LAST、NEXTまたはPRIOR(「コレクション・メソッド」を参照)から予期しない値が戻されたり例外が呼び出される場合があります。
ローカル・データベース上では一意の索引でも、リモート・データベース上では一意でない可能性があり、一意でない場合は事前定義の例外VALUE_ERRORが呼び出されます。
連想配列は、次のような場合に適切です。
表が宣言されているサブプログラムの起動またはパッケージの初期化のたびにメモリー内に構成できる比較的小さい参照表
データベース・サーバーとの間のコレクションの受渡し
連想配列型の仮サブプログラム・パラメータを宣言します。Oracle Call Interface(OCI)またはOracleプリコンパイラを使用すると、対応する実パラメータにホスト配列がバインドされます。PL/SQLでは、PLS_INTEGERで索引付けされているホスト配列と連想配列との間で自動的に変換が行われます。
|
注意: スキーマ・レベルでは連想配列型を宣言できません。そのため、連想配列の変数をパラメータとしてスタンドアロン・サブプログラムに渡すには、その変数の型をパッケージ仕様部で宣言する必要があります。このようにすることで、起動されるサブプログラム(この型の仮パラメータを宣言する側)と起動元のサブプログラムまたは無名ブロック(この型の変数を宣言して受け渡す側)の両方でこの型を使用できます。例10-2を参照してください。 |
|
ヒント: データベース・サーバーとの間でのコレクションの受渡しには、連想配列をFORALL文またはBULK COLLECT句とともに使用することが、最も効率的な方法です。詳細は、「FORALL文」および「BULK COLLECT句」を参照してください。 |
連想配列は、一時的なデータの格納に使用されます。連想配列をデータベース・セッションの期間中持続させるには、パッケージ仕様部で連想配列を宣言し、パッケージ本体で移入します。
VARRAY(可変サイズの配列)とは、0個(空の場合)から宣言されている最大サイズまで要素の数を変更できる配列のことです。VARRAY変数の要素にアクセスするには、構文variable_name(index)を使用します。indexの下限は1で、上限は現行の要素の数です。上限は、要素の追加または削除に合わせて変化しますが、最大サイズを超えることはできません。VARRAYをデータベースに格納したりデータベースから取り出しても、その索引と要素の順序は変わりません。
図5-1は、Gradesという名前のVARRAY変数を示していて、最大サイズは10個で、7個の要素が格納されています。Grades(n)は、Gradesのn番目の要素を参照します。Gradesの上限は7で、10を超えることはできません。
VARRAY変数は単一オブジェクトとしてデータベースに格納されます。VARRAY変数が4KB未満の場合は、そのVARRAY変数が列になっている表内に配置され、それ以外の場合は、表の外側に配置されますが、表領域は同じです。
初期化されていないVARRAY変数は、NULLのコレクションです。空にするかNULL以外の値を代入して初期化する必要があります。詳細は、「コレクションのコンストラクタ」および「コレクション変数への値の代入」を参照してください。
例5-4では、ローカルのVARRAY型を定義した後に、この型の変数を宣言(コンストラクタを使用して初期化)し、このVARRAYを出力するプロシージャを定義します。この例では、このプロシージャを3回起動します(変数を初期化した後、2つの要素の値をそれぞれ変更した後、およびコンストラクタを使用してすべての要素の値を変更した後に1回ずつ)。(NULLまたは空の可能性があるVARRAYを出力するプロシージャの例は、例5-24を参照してください。)
例5-4 VARRAY(可変サイズの配列)
DECLARE
TYPE Foursome IS VARRAY(4) OF VARCHAR2(15); -- VARRAY type
-- varray variable initialized with constructor:
team Foursome := Foursome('John', 'Mary', 'Alberto', 'Juanita');
PROCEDURE print_team (heading VARCHAR2) IS
BEGIN
DBMS_OUTPUT.PUT_LINE(heading);
FOR i IN 1..4 LOOP
DBMS_OUTPUT.PUT_LINE(i || '.' || team(i));
END LOOP;
DBMS_OUTPUT.PUT_LINE('---');
END;
BEGIN
print_team('2001 Team:');
team(3) := 'Pierre'; -- Change values of two elements
team(4) := 'Yvonne';
print_team('2005 Team:');
-- Invoke constructor to assign new values to varray variable:
team := Foursome('Arun', 'Amitha', 'Allan', 'Mae');
print_team('2009 Team:');
END;
/
結果:
2001 Team: 1.John 2.Mary 3.Alberto 4.Juanita --- 2005 Team: 1.John 2.Mary 3.Pierre 4.Yvonne --- 2009 Team: 1.Arun 2.Amitha 3.Allan 4.Mae ---
ここでのトピック
|
関連項目:
|
VARRAYは、次のような場合に適切です。
要素の最大数がわかっている。
通常は要素に順番にアクセスする。
VARRAYはすべての要素を同時に格納または取得する必要があるため、要素の数が多い場合は現実的ではないことがあります。
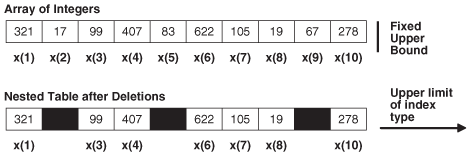
データベース内では、ネストした表は、特に順序を付けずに数が指定されていない行を格納する列型になります。ネストした表の値をデータベースから取り出してPL/SQLのネストした表の変数に入れると、PL/SQLにより1から始まる連続した索引が行に付けられます。これらの索引を使用して、ネストした表の変数の個々の行にアクセスできます。構文はvariable_name(index)です。ネストした表の索引と行の順序は、ネストした表をデータベースに格納したりデータベースから取り出したときに変わる可能性があります。
ネストした表の変数に占有されるメモリー量は、要素の追加または削除に応じて動的に増減します。
初期化されていないネストした表の変数は、NULLのコレクションです。空にするかNULL以外の値を代入して初期化する必要があります。詳細は、「コレクションのコンストラクタ」および「コレクション変数への値の代入」を参照してください。
例5-5では、ローカルのネストした表型を定義した後に、この型の変数を宣言(コンストラクタを使用して初期化)し、このネストした表を出力するプロシージャを定義します。(このプロシージャでは、コレクション・メソッドFIRSTおよびLASTを使用しています。詳細は「コレクション・メソッド」を参照してください。)この例では、このプロシージャを3回起動します(変数を初期化した後、1つの要素の値を変更した後、コンストラクタを使用してすべての要素の値を変更した後に1回ずつ)。2回目にコンストラクタを起動した後は、ネストした表の要素が2つのみになります。要素3を参照すると、エラーORA-06533が発生します。
例5-5 ローカル型のネストした表
DECLARE
TYPE Roster IS TABLE OF VARCHAR2(15); -- nested table type
-- nested table variable initialized with constructor:
names Roster := Roster('D Caruso', 'J Hamil', 'D Piro', 'R Singh');
PROCEDURE print_names (heading VARCHAR2) IS
BEGIN
DBMS_OUTPUT.PUT_LINE(heading);
FOR i IN names.FIRST .. names.LAST LOOP -- For first to last element
DBMS_OUTPUT.PUT_LINE(names(i));
END LOOP;
DBMS_OUTPUT.PUT_LINE('---');
END;
BEGIN
print_names('Initial Values:');
names(3) := 'P Perez'; -- Change value of one element
print_names('Current Values:');
names := Roster('A Jansen', 'B Gupta'); -- Change entire table
print_names('Current Values:');
END;
/
結果:
Initial Values: D Caruso J Hamil D Piro R Singh --- Current Values: D Caruso J Hamil P Perez R Singh --- Current Values: A Jansen B Gupta
例5-6では、スタンドアロン型のネストした表型nt_typeを定義し、この型の変数を出力するスタンドアロン・プロシージャprint_ntを定義します。(このプロシージャでは、コレクション・メソッドFIRSTおよびLASTを使用しています。詳細は「コレクション・メソッド」を参照してください。)無名ブロックで型nt_typeの変数を宣言し、この変数をコンストラクタで空に初期化してから、print_ntを2回起動します(変数を初期化した後、およびコンストラクタですべての要素の値を変更した後に1回ずつ)。
例5-6 スタンドアロン型のネストした表
CREATE OR REPLACE TYPE nt_type IS TABLE OF NUMBER;
/
CREATE OR REPLACE PROCEDURE print_nt (nt nt_type) IS
i NUMBER;
BEGIN
i := nt.FIRST;
IF i IS NULL THEN
DBMS_OUTPUT.PUT_LINE('nt is empty');
ELSE
WHILE i IS NOT NULL LOOP
DBMS_OUTPUT.PUT('nt.(' || i || ') = '); print(nt(i));
i := nt.NEXT(i);
END LOOP;
END IF;
DBMS_OUTPUT.PUT_LINE('---');
END print_nt;
/
DECLARE
nt nt_type := nt_type(); -- nested table variable initialized to empty
BEGIN
print_nt(nt);
nt := nt_type(90, 9, 29, 58);
print_nt(nt);
END;
/
結果:
nt is empty --- nt.(1) = 90 nt.(2) = 9 nt.(3) = 29 nt.(4) = 58 ---
ここでのトピック
|
関連項目:
|
概念上、ネストした表は任意の数の要素がある1次元配列に似ています。ただし、ネストした表と配列には次の重要な相違点があります。
配列では要素の数が宣言されますが、ネストした表では宣言されません。ネストした表のサイズは動的に増やすことができます。
配列は常に密です。ネストした表は、最初は密であっても、要素を削除できるため、疎になる可能性があります。
図5-2は、ネストした表と配列の重要な相違点を示しています。
ネストした表は、次のような場合に適切です。
|
注意: このトピックの内容は、VARRAYおよびネストした表にのみ適用されます。連想配列はコンストラクタを持ちません。このトピックでは、コレクションはVARRAYまたはネストした表のことを意味します。 |
コレクションのコンストラクタ(コンストラクタ)は、コレクション型と同じ名前のシステム定義ファンクションです(この型のコレクションを戻します)。次にコンストラクタを起動する構文を示します。
collection_type ( [ value [, value ]... ] )
パラメータ・リストが空の場合は、コンストラクタから空のコレクションが戻されます。それ以外の場合は、指定した値を含むコレクションが戻されます。セマンティクスの詳細は、「collection_constructor」を参照してください。
戻されたコレクションは、変数の宣言およびブロックの実行部で(同じ型の)コレクション変数に代入できます。
例5-7では、コンストラクタを2回起動します(変数の宣言でVARRAY変数teamを空に初期化するとき、およびブロックの実行部で新しい値を指定するときに1回ずつ)。プロシージャprint_teamは、teamの初期値と最終的な値を表示します。print_teamでは、teamが空であるかどうかを判断するために、コレクション・メソッドCOUNTを使用しています(詳細は「コレクション・メソッド」を参照)。(NULLの可能性があるVARRAYを出力するプロシージャの例は、例5-24を参照してください。)
例5-7 コレクション(VARRAY)変数の空への初期化
DECLARE TYPE Foursome IS VARRAY(4) OF VARCHAR2(15); team Foursome := Foursome(); -- initialize to empty PROCEDURE print_team (heading VARCHAR2) IS BEGIN DBMS_OUTPUT.PUT_LINE(heading); IF team.COUNT = 0 THEN DBMS_OUTPUT.PUT_LINE('Empty'); ELSE FOR i IN 1..4 LOOP DBMS_OUTPUT.PUT_LINE(i || '.' || team(i)); END LOOP; END IF; DBMS_OUTPUT.PUT_LINE('---'); END; BEGIN print_team('Team:'); team := Foursome('John', 'Mary', 'Alberto', 'Juanita'); print_team('Team:'); END; /
結果:
Team: Empty --- Team: 1.John 2.Mary 3.Alberto 4.Juanita ---
コンストラクタを起動してコレクションを作成し、コレクション変数に代入する方法(「コレクションのコンストラクタ」を参照)。
代入文(「代入文」を参照)を使用して、別の既存のコレクション変数の値を代入する方法。
OUTパラメータまたはIN OUTパラメータとしてサブプログラムに渡し、サブプログラム内で値を代入する方法。
コレクション変数のスカラー要素に値を代入するには、要素をcollection_variable_name(index)として参照し、「変数への値の代入」の手順に従って値を代入します。
ここでのトピック
あるコレクションをコレクション変数に代入できるのは、両者のデータ型が同じ場合のみです。要素型が同じであることのみでは不十分です。
例5-8では、VARRAY型のtripletとtrioが同じ要素型VARCHAR(15)になっています。コレクション変数group1とgroup2のデータ型は同じtripletですが、コレクション変数group3のデータ型はtrioです。group1からgroup2への代入は正常に行われますが、group1からgroup3への代入は失敗します。
例5-8 コレクション代入のデータ型の互換性
DECLARE
TYPE triplet IS VARRAY(3) OF VARCHAR2(15);
TYPE trio IS VARRAY(3) OF VARCHAR2(15);
group1 triplet := triplet('Jones', 'Wong', 'Marceau');
group2 triplet;
group3 trio;
BEGIN
group2 := group1; -- succeeds
group3 := group1; -- fails
END;
/
結果:
ERROR at line 10: ORA-06550: line 10, column 13: PLS-00382: expression is of wrong type ORA-06550: line 10, column 3: PL/SQL: Statement ignored
VARRAYまたはネストした表の変数には、値NULLまたは同じデータ型のNULLのコレクションを代入できます。いずれの代入でも、変数はNULLになります。
例5-7では、ネストした表の変数dname_tabをNULL以外の値に初期化します。次に、NULLのコレクションを代入して変数をNULLにした後、別のNULL以外の値に再初期化します。
例5-9 ネストした表の変数へのNULL値の代入
DECLARE
TYPE dnames_tab IS TABLE OF VARCHAR2(30);
dept_names dnames_tab := dnames_tab(
'Shipping','Sales','Finance','Payroll'); -- Initialized to non-null value
empty_set dnames_tab; -- Not initialized, therefore null
PROCEDURE print_dept_names_status IS
BEGIN
IF dept_names IS NULL THEN
DBMS_OUTPUT.PUT_LINE('dept_names is null.');
ELSE
DBMS_OUTPUT.PUT_LINE('dept_names is not null.');
END IF;
END print_dept_names_status;
BEGIN
print_dept_names_status;
dept_names := empty_set; -- Assign null collection to dept_names.
print_dept_names_status;
dept_names := dnames_tab (
'Shipping','Sales','Finance','Payroll'); -- Re-initialize dept_names
print_dept_names_status;
END;
/
結果:
dept_names is not null.
dept_names is null.
dept_names is not null.
ネストした表の変数には、SQL MULTISET演算またはSQL SETファンクションの起動結果を代入できます。
SQLのMULTISET演算子は、2つのネストした表を1つのネストした表に統合します。2つのネストした表の要素は、同等のデータ型を持っている必要があります。MULTISET演算子の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。
SQL SETファンクションはネストした表を引数に取り、別個の要素を含む同じデータ型のネストした表を戻します(重複する要素は結果から削除されます)。SETファンクションの詳細は、『Oracle Database SQL言語リファレンス』を参照してください。
例5-10では、複数のMULTISET演算と1つのSETファンクションの起動結果をネストした表の変数answerに代入し、代入するたびにプロシージャprint_nested_tableを使用してanswerを出力します。このプロシージャでは、コレクション・メソッドFIRSTおよびLASTを使用しています(詳細は「コレクション・メソッド」を参照)。
例5-10 ネストした表の変数へのSET演算結果の代入
DECLARE
TYPE nested_typ IS TABLE OF NUMBER;
nt1 nested_typ := nested_typ(1,2,3);
nt2 nested_typ := nested_typ(3,2,1);
nt3 nested_typ := nested_typ(2,3,1,3);
nt4 nested_typ := nested_typ(1,2,4);
answer nested_typ;
PROCEDURE print_nested_table (nt nested_typ) IS
output VARCHAR2(128);
BEGIN
IF nt IS NULL THEN
DBMS_OUTPUT.PUT_LINE('Result: null set');
ELSIF nt.COUNT = 0 THEN
DBMS_OUTPUT.PUT_LINE('Result: empty set');
ELSE
FOR i IN nt.FIRST .. nt.LAST LOOP -- For first to last element
output := output || nt(i) || ' ';
END LOOP;
DBMS_OUTPUT.PUT_LINE('Result: ' || output);
END IF;
END print_nested_table;
BEGIN
answer := nt1 MULTISET UNION nt4;
print_nested_table(answer);
answer := nt1 MULTISET UNION nt3;
print_nested_table(answer);
answer := nt1 MULTISET UNION DISTINCT nt3;
print_nested_table(answer);
answer := nt2 MULTISET INTERSECT nt3;
print_nested_table(answer);
answer := nt2 MULTISET INTERSECT DISTINCT nt3;
print_nested_table(answer);
answer := SET(nt3);
print_nested_table(answer);
answer := nt3 MULTISET EXCEPT nt2;
print_nested_table(answer);
answer := nt3 MULTISET EXCEPT DISTINCT nt2;
print_nested_table(answer);
END;
/
結果:
Result: 1 2 3 1 2 4 Result: 1 2 3 2 3 1 3 Result: 1 2 3 Result: 3 2 1 Result: 3 2 1 Result: 2 3 1 Result: 3 Result: empty set
コレクションは1次元のみですが、コレクションを要素に持つコレクションを使用して、多次元コレクションのモデルを作成できます。
例5-11のnvaは、2次元のVARRAY(整数のVARRAYのVARRAY)です。
例5-11 2次元のVARRAY(VARRAYのVARRAY)
DECLARE
TYPE t1 IS VARRAY(10) OF INTEGER; -- varray of integer
va t1 := t1(2,3,5);
TYPE nt1 IS VARRAY(10) OF t1; -- varray of varray of integer
nva nt1 := nt1(va, t1(55,6,73), t1(2,4), va);
i INTEGER;
va1 t1;
BEGIN
i := nva(2)(3);
DBMS_OUTPUT.PUT_LINE('i = ' || i);
nva.EXTEND;
nva(5) := t1(56, 32); -- replace inner varray elements
nva(4) := t1(45,43,67,43345); -- replace an inner integer element
nva(4)(4) := 1; -- replace 43345 with 1
nva(4).EXTEND; -- add element to 4th varray element
nva(4)(5) := 89; -- store integer 89 there
END;
/
結果:
i = 73
例5-12のntb1は文字列のネストした表のネストした表で、ntb2は整数のVARRAYのネストした表です。
例5-12 ネストした表のネストした表と整数のVARRAYのネストした表
DECLARE
TYPE tb1 IS TABLE OF VARCHAR2(20); -- nested table of strings
vtb1 tb1 := tb1('one', 'three');
TYPE ntb1 IS TABLE OF tb1; -- nested table of nested tables of strings
vntb1 ntb1 := ntb1(vtb1);
TYPE tv1 IS VARRAY(10) OF INTEGER; -- varray of integers
TYPE ntb2 IS TABLE OF tv1; -- nested table of varrays of integers
vntb2 ntb2 := ntb2(tv1(3,5), tv1(5,7,3));
BEGIN
vntb1.EXTEND;
vntb1(2) := vntb1(1);
vntb1.DELETE(1); -- delete first element of vntb1
vntb1(2).DELETE(1); -- delete first string from second table in nested table
END;
/
例5-13のaa1は連想配列の連想配列で、ntb2は文字列のVARRAYのネストした表です。
例5-13 連想配列のネストした表と文字列のVARRAYのネストした表
DECLARE
TYPE tb1 IS TABLE OF INTEGER INDEX BY PLS_INTEGER; -- associative arrays
v4 tb1;
v5 tb1;
TYPE aa1 IS TABLE OF tb1 INDEX BY PLS_INTEGER; -- associative array of
v2 aa1; -- associative arrays
TYPE va1 IS VARRAY(10) OF VARCHAR2(20); -- varray of strings
v1 va1 := va1('hello', 'world');
TYPE ntb2 IS TABLE OF va1 INDEX BY PLS_INTEGER; -- associative array of varrays
v3 ntb2;
BEGIN
v4(1) := 34; -- populate associative array
v4(2) := 46456;
v4(456) := 343;
v2(23) := v4; -- populate associative array of associative arrays
v3(34) := va1(33, 456, 656, 343); -- populate associative array varrays
v2(35) := v5; -- assign empty associative array to v2(35)
v2(35)(2) := 78;
END;
/
連想配列の変数と値NULLを比較したり、連想配列を互いに比較することはできません。
「ネストした表が等しいかどうかの比較」を除き、関係演算子(表2-5を参照)を使用して2つのコレクション変数をそのまま比較することはできません。この制限は、暗黙的な比較にも適用されます。たとえば、コレクション変数はDISTINCT、GROUP BYまたはORDER BY句には使用できません。
たとえば、あるコレクション変数が別のコレクション変数より小さいかどうかを判別するには、そのコンテキストで「より小さい」の意味を定義して、TRUEまたはFALSEを戻すファンクションを記述する必要があります。ファンクションの記述の詳細は、第8章「PL/SQLサブプログラム」を参照してください。
ここでのトピック
VARRAYおよびネストした表の変数は、「IS [NOT] NULL演算子」を使用して値NULLと比較できますが、関係演算子の等価演算子(=)および不等価演算子(<>、!=、~=または^=)を使用して比較することはできません。
例5-14では、VARRAYおよびネストした表の変数とNULLを正しく比較しています。
例5-14 VARRAYおよびネストした表の変数とNULLの比較
DECLARE
TYPE Foursome IS VARRAY(4) OF VARCHAR2(15); -- VARRAY type
team Foursome; -- varray variable
TYPE Roster IS TABLE OF VARCHAR2(15); -- nested table type
names Roster := Roster('Adams', 'Patel'); -- nested table variable
BEGIN
IF team IS NULL THEN
DBMS_OUTPUT.PUT_LINE('team IS NULL');
ELSE
DBMS_OUTPUT.PUT_LINE('team IS NOT NULL');
END IF;
IF names IS NOT NULL THEN
DBMS_OUTPUT.PUT_LINE('names IS NOT NULL');
ELSE
DBMS_OUTPUT.PUT_LINE('names IS NULL');
END IF;
END;
/
結果:
team IS NULL names IS NOT NULL
2つのネストした表の変数が同じネストした表型を持ち、ネストした表型にレコード型の要素が含まれていない場合は、関係演算子の等価演算子(=)および不等価演算子(<>、!=、~=、^=)を使用して、2つの変数が等しいかどうかを比較できます。2つのネストした表の変数は、同じ要素のセット(順不同)を含む場合のみ等価です。
例5-15では、ネストした表の変数が等しいか等しくないかを関係演算子で比較しています。
例5-15 ネストした表が等しいかどうかの比較
DECLARE TYPE dnames_tab IS TABLE OF VARCHAR2(30); -- element type is not record type dept_names1 dnames_tab := dnames_tab('Shipping','Sales','Finance','Payroll'); dept_names2 dnames_tab := dnames_tab('Sales','Finance','Shipping','Payroll'); dept_names3 dnames_tab := dnames_tab('Sales','Finance','Payroll'); BEGIN IF dept_names1 = dept_names2 THEN DBMS_OUTPUT.PUT_LINE('dept_names1 = dept_names2'); END IF; IF dept_names2 != dept_names3 THEN DBMS_OUTPUT.PUT_LINE('dept_names2 != dept_names3'); END IF; END; /
結果:
dept_names1 = dept_names2 dept_names2 != dept_names3
ネストした表の変数の比較、および一部の変数プロパティのテストは、SQL MULTISET条件(『Oracle Database SQL言語リファレンス』を参照)を使用して実行できます。
例5-16では、SQL MULTISET条件とネストした表の変数を引数に取る2つのSQLファンクションCARDINALITY(『Oracle Database SQL言語リファレンス』を参照)およびSET(『Oracle Database SQL言語リファレンス』を参照)を使用します。
例5-16 ネストした表のSQL MULTISET条件による比較
DECLARE
TYPE nested_typ IS TABLE OF NUMBER;
nt1 nested_typ := nested_typ(1,2,3);
nt2 nested_typ := nested_typ(3,2,1);
nt3 nested_typ := nested_typ(2,3,1,3);
nt4 nested_typ := nested_typ(1,2,4);
PROCEDURE testify (
truth BOOLEAN := NULL,
quantity NUMBER := NULL
) IS
BEGIN
IF truth IS NOT NULL THEN
DBMS_OUTPUT.PUT_LINE (
CASE truth
WHEN TRUE THEN 'True'
WHEN FALSE THEN 'False'
END
);
END IF;
IF quantity IS NOT NULL THEN
DBMS_OUTPUT.PUT_LINE(quantity);
END IF;
END;
BEGIN
testify(truth => (nt1 IN (nt2,nt3,nt4))); -- condition
testify(truth => (nt1 SUBMULTISET OF nt3)); -- condition
testify(truth => (nt1 NOT SUBMULTISET OF nt4)); -- condition
testify(truth => (4 MEMBER OF nt1)); -- condition
testify(truth => (nt3 IS A SET)); -- condition
testify(truth => (nt3 IS NOT A SET)); -- condition
testify(truth => (nt1 IS EMPTY)); -- condition
testify(quantity => (CARDINALITY(nt3))); -- function
testify(quantity => (CARDINALITY(SET(nt3)))); -- 2 functions
END;
/
結果:
True True True False False True False 4 3
コレクション・メソッドはPL/SQLサブプログラムであり、コレクションに関する情報を戻すファンクションまたはコレクションに対する操作を実行するプロシージャのいずれかです。コレクション・メソッドを使用すると、コレクションの使用およびアプリケーションのメンテナンスが簡単になります。表5-2に、コレクション・メソッドの概要を示します。
表5-2 コレクション・メソッド
| メソッド | 型 | 説明 |
|---|---|---|
|
|
プロシージャ |
コレクションから要素を削除します。 |
|
|
プロシージャ |
VARRAYまたはネストした表の末尾から要素を削除します。 |
|
|
プロシージャ |
VARRAYまたはネストした表の末尾に要素を追加します。 |
|
|
ファンクション |
VARRAYまたはネストした表の指定された要素が存在する場合のみ |
|
|
ファンクション |
コレクションの最初の索引を戻します。 |
|
|
ファンクション |
コレクションの最後の索引を戻します。 |
|
|
ファンクション |
コレクション内の要素の数を戻します。 |
|
|
ファンクション |
コレクションに格納できる要素の最大数を戻します。 |
|
|
ファンクション |
指定された索引の前の索引を戻します。 |
|
|
ファンクション |
指定された索引の後の索引を戻します。 |
コレクション・メソッドを起動する基本構文は、次のとおりです。
collection_name.method
構文の詳細は、「コレクション・メソッドの起動」を参照してください。
コレクション・メソッドの起動は、その型(ファンクションまたはプロシージャ)のPL/SQLサブプログラムの起動を指定できるすべての場所(SQL文を除く)で使用できます。(PL/SQLサブプログラムの概要は、第8章「PL/SQLサブプログラム」を参照してください。)
サブプログラム内で、コレクション・パラメータは引数のプロパティがバインドされていることを前提にしています。コレクション・メソッドは、そのようなパラメータに適用できます。VARRAYパラメータの場合、パラメータ・モードに関係なく、LIMITの値は常にパラメータの型定義から導出されます。
ここでのトピック
DELETEは、コレクションから要素を削除するプロシージャです。このメソッドには次の形式があります。
DELETEはすべての型のコレクションからすべての要素を削除します。
この操作を実行すると、削除された要素に割り当てられていたメモリーは即座に解放されます。
連想配列またはネストされた表(VARRAYではない)から削除する場合は次のとおりです。
DELETE(n)は、nの索引を持つ要素が存在する場合にその要素を削除します。それ以外の場合は何も実行しません。
DELETE(m,n)は、mとnの両方が存在し、m <= nの場合に、mからnの範囲の索引を持つすべての要素を削除します。それ以外の場合は何も実行しません。
これら2つのDELETE形式を使用する場合、PL/SQLは削除された要素のプレースホルダを保持します。したがって、削除された要素はコレクションの内部サイズに含まれるため、削除された要素に有効な値を代入してリストアすることができます。
例5-17では、ネストした表の変数を宣言し、6つの要素を使用して初期化した後で、2番目の要素を削除してからリストアし、次に、要素の範囲を削除し、削除した要素の1つをリストアしてから、すべての要素を削除します。リストアされた要素は、それに対応する削除された要素と同じメモリー量を占有します。プロシージャprint_ntは、初期化の後および各DELETE操作の後に、ネストした表の変数を出力します。型nt_typeおよびプロシージャprint_ntは、例5-6で定義しています。
例5-17 ネストした表でのDELETEメソッド
DECLARE nt nt_type := nt_type(11, 22, 33, 44, 55, 66); BEGIN print_nt(nt); nt.DELETE(2); -- Delete second element print_nt(nt); nt(2) := 2222; -- Restore second element print_nt(nt); nt.DELETE(2, 4); -- Delete range of elements print_nt(nt); nt(3) := 3333; -- Restore third element print_nt(nt); nt.DELETE; -- Delete all elements print_nt(nt); END; /
結果:
nt.(1) = 11 nt.(2) = 22 nt.(3) = 33 nt.(4) = 44 nt.(5) = 55 nt.(6) = 66 --- nt.(1) = 11 nt.(3) = 33 nt.(4) = 44 nt.(5) = 55 nt.(6) = 66 --- nt.(1) = 11 nt.(2) = 2222 nt.(3) = 33 nt.(4) = 44 nt.(5) = 55 nt.(6) = 66 --- nt.(1) = 11 nt.(5) = 55 nt.(6) = 66 --- nt.(1) = 11 nt.(3) = 3333 nt.(5) = 55 nt.(6) = 66 --- nt is empty ---
例5-18では、文字列で索引付けされている連想配列に要素を移入してからすべての要素を削除し、これにより、要素に割り当てられていたメモリーは解放されます。次に、削除した要素を置き換えます(つまり、削除した要素と同じ索引を持つ新しい要素を追加します)。新たに置き換えた要素は、それに対応する削除された要素と同じメモリー量を占有しません。最後に、1つの要素を削除してから、要素の範囲を削除します。プロシージャprint_aa_strは、各操作の効果を表示します。
例5-18 文字列で索引付けされている連想配列でのDELETEメソッド
DECLARE
TYPE aa_type_str IS TABLE OF INTEGER INDEX BY VARCHAR2(10);
aa_str aa_type_str;
PROCEDURE print_aa_str IS
i VARCHAR2(10);
BEGIN
i := aa_str.FIRST;
IF i IS NULL THEN
DBMS_OUTPUT.PUT_LINE('aa_str is empty');
ELSE
WHILE i IS NOT NULL LOOP
DBMS_OUTPUT.PUT('aa_str.(' || i || ') = '); print(aa_str(i));
i := aa_str.NEXT(i);
END LOOP;
END IF;
DBMS_OUTPUT.PUT_LINE('---');
END print_aa_str;
BEGIN
aa_str('M') := 13;
aa_str('Z') := 26;
aa_str('C') := 3;
print_aa_str;
aa_str.DELETE; -- Delete all elements
print_aa_str;
aa_str('M') := 13; -- Replace deleted element with same value
aa_str('Z') := 260; -- Replace deleted element with new value
aa_str('C') := 30; -- Replace deleted element with new value
aa_str('W') := 23; -- Add new element
aa_str('J') := 10; -- Add new element
aa_str('N') := 14; -- Add new element
aa_str('P') := 16; -- Add new element
aa_str('W') := 23; -- Add new element
aa_str('J') := 10; -- Add new element
print_aa_str;
aa_str.DELETE('C'); -- Delete one element
print_aa_str;
aa_str.DELETE('N','W'); -- Delete range of elements
print_aa_str;
aa_str.DELETE('Z','M'); -- Does nothing
print_aa_str;
END;
/
結果:
aa_str.(C) = 3 aa_str.(M) = 13 aa_str.(Z) = 26 --- aa_str is empty --- aa_str.(C) = 30 aa_str.(J) = 10 aa_str.(M) = 13 aa_str.(N) = 14 aa_str.(P) = 16 aa_str.(W) = 23 aa_str.(Z) = 260 --- aa_str.(J) = 10 aa_str.(M) = 13 aa_str.(N) = 14 aa_str.(P) = 16 aa_str.(W) = 23 aa_str.(Z) = 260 --- aa_str.(J) = 10 aa_str.(M) = 13 aa_str.(Z) = 260 --- aa_str.(J) = 10 aa_str.(M) = 13 aa_str.(Z) = 260 ---
TRIMは、VARRAYまたはネストした表の末尾から要素を削除するプロシージャです。このメソッドには次の形式があります。
TRIMは、コレクションに1つ以上の要素が含まれる場合に、末尾から1つの要素を削除します。それ以外の場合は、事前定義の例外SUBSCRIPT_BEYOND_COUNTを呼び出します。
TRIM(n)は、コレクションの末尾にn個以上の要素が含まれる場合に、末尾からn個の要素を削除します。それ以外の場合は、事前定義の例外SUBSCRIPT_BEYOND_COUNTを呼び出します。
TRIMは、コレクションの内部サイズを操作します。つまり、DELETEで要素が削除されてもその要素のプレースホルダが保持されている場合、TRIMはその要素が存在するものとみなします。したがって、削除された要素をTRIMで削除することができます。
PL/SQLは切り捨てられた要素のプレースホルダを保持しません。したがって、切り捨てられた要素はコレクションの内部サイズに含まれないため、切り捨てられた要素に有効な値を代入して要素をリストアすることはできません。
|
注意: TRIMとDELETEの間の相互作用には依存しないでください。ネストした表は、固定サイズの配列のように扱う(DELETEのみを使用する)か、またはスタックのように扱う(TRIMとEXTENDのみを使用する)ようにしてください。 |
例5-19では、ネストした表の変数を宣言し、6つの要素で初期化した後で、末尾の要素を切り捨て、4番目の要素を削除してから、末尾の2つの要素を切り捨てます(切り捨てる要素の1つは、削除した4番目の要素です)。プロシージャprint_ntは、初期化の後とTRIM操作およびDELETE操作の後に、ネストした表の変数を出力します。型nt_typeおよびプロシージャprint_ntは、例5-6で定義しています。
例5-19 ネストした表でのTRIMメソッド
DECLARE nt nt_type := nt_type(11, 22, 33, 44, 55, 66); BEGIN print_nt(nt); nt.TRIM; -- Trim last element print_nt(nt); nt.DELETE(4); -- Delete fourth element print_nt(nt); nt.TRIM(2); -- Trim last two elements print_nt(nt); END; /
結果:
nt.(1) = 11 nt.(2) = 22 nt.(3) = 33 nt.(4) = 44 nt.(5) = 55 nt.(6) = 66 --- nt.(1) = 11 nt.(2) = 22 nt.(3) = 33 nt.(4) = 44 nt.(5) = 55 --- nt.(1) = 11 nt.(2) = 22 nt.(3) = 33 nt.(5) = 55 --- nt.(1) = 11 nt.(2) = 22 nt.(3) = 33 ---
EXTENDは、VARRAYまたはネストした表の末尾に要素を追加するプロシージャです。コレクションは空でもかまいませんが、NULLは許可されません。(コレクションを空にしたりNULLのコレクションに要素を追加するには、コンストラクタを使用します。詳細は、「コレクションのコンストラクタ」を参照してください。)
EXTENDメソッドには次の形式があります。
EXTENDは、コレクションに1つのNULL要素を追加します。
EXTEND(n)は、コレクションにn個のNULL要素を追加します。
EXTEND(n,i)は、コレクションにi番目の要素のコピーをn個追加します。
EXTENDは、コレクションの内部サイズを操作します。つまり、DELETEで要素が削除されてもその要素のプレースホルダが保持されている場合、EXTENDはその要素が存在するものとみなします。
例5-20では、ネストした表の変数を宣言し、3つの要素を使用して初期化した後で、最初の要素のコピーを2つ追加し、次に、5番目(最後)の要素を削除してから、NULL要素を1つ追加します。EXTENDでは、削除された5番目の要素が存在するものとみなされるため、追加されたNULL要素は6番目の要素になります。プロシージャprint_ntは、初期化の後とEXTEND操作およびDELETE操作の後に、ネストした表の変数を出力します。型nt_typeおよびプロシージャprint_ntは、例5-6で定義しています。
例5-20 ネストした表でのEXTENDメソッド
DECLARE nt nt_type := nt_type(11, 22, 33); BEGIN print_nt(nt); nt.EXTEND(2,1); -- Append two copies of first element print_nt(nt); nt.DELETE(5); -- Delete fifth element print_nt(nt); nt.EXTEND; -- Append one null element print_nt(nt); END; /
結果:
nt.(1) = 11
nt.(2) = 22
nt.(3) = 33
---
nt.(1) = 11
nt.(2) = 22
nt.(3) = 33
nt.(4) = 11
nt.(5) = 11
---
nt.(1) = 11
nt.(2) = 22
nt.(3) = 33
nt.(4) = 11
---
nt.(1) = 11
nt.(2) = 22
nt.(3) = 33
nt.(4) = 11
nt.(6) = NULL
---
EXISTSは、VARRAYまたはネストした表の指定された要素が存在するかどうかを表示するファンクションです。
EXISTS(n)は、コレクションにn番目の要素が存在する場合にTRUEを戻し、それ以外の場合はFALSEを戻します。nが範囲外の場合、EXISTSは事前定義の例外SUBSCRIPT_OUTSIDE_LIMITを呼び出さずに、FALSEを戻します。
削除された要素の場合、DELETEによりその要素のプレースホルダが保持されていても、EXISTS(n)はFALSEを戻します。
例5-21では、ネストした表を4つの要素で初期化した後、2番目の要素を削除して、1番目から6番目の要素の値またはステータスのいずれかを出力します。
例5-21 ネストした表でのEXISTSメソッド
DECLARE TYPE NumList IS TABLE OF INTEGER; n NumList := NumList(1,3,5,7); BEGIN n.DELETE(2); -- Delete second element FOR i IN 1..6 LOOP IF n.EXISTS(i) THEN DBMS_OUTPUT.PUT_LINE('n(' || i || ') = ' || n(i)); ELSE DBMS_OUTPUT.PUT_LINE('n(' || i || ') does not exist'); END IF; END LOOP; END; /
結果:
n(1) = 1 n(2) does not exist n(3) = 5 n(4) = 7 n(5) does not exist n(6) does not exist
FIRSTおよびLASTはファンクションです。1つ以上の要素を持つコレクションの場合、FIRSTおよびLASTはそれぞれ最初と最後の要素の索引を戻します(削除された要素のプレースホルダがDELETEにより保持されていても、それらの要素は無視されます)。コレクションの要素が1つのみの場合、FIRSTおよびLASTは同じ索引を戻します。コレクションが空の場合、FIRSTとLASTはNULLを戻します。
ここでのトピック
PLS_INTEGERで索引付けされている連想配列の場合、最初の要素および最後の要素は、それぞれ最小および最大の索引を持つ要素です。
例5-22では、PLS_INTEGERで索引付けされている連想配列のFIRSTとLASTの値を表示してから最初と最後の要素を削除し、再度、FIRSTとLASTの値を表示します。
例5-22 PLS_INTEGERで索引付けされている連想配列のFIRSTとLASTの値
DECLARE
TYPE aa_type_int IS TABLE OF INTEGER INDEX BY PLS_INTEGER;
aa_int aa_type_int;
PROCEDURE print_first_and_last IS
BEGIN
DBMS_OUTPUT.PUT_LINE('FIRST = ' || aa_int.FIRST);
DBMS_OUTPUT.PUT_LINE('LAST = ' || aa_int.LAST);
END print_first_and_last;
BEGIN
aa_int(1) := 3;
aa_int(2) := 6;
aa_int(3) := 9;
aa_int(4) := 12;
DBMS_OUTPUT.PUT_LINE('Before deletions:');
print_first_and_last;
aa_int.DELETE(1);
aa_int.DELETE(4);
DBMS_OUTPUT.PUT_LINE('After deletions:');
print_first_and_last;
END;
/
結果:
Before deletions: FIRST = 1 LAST = 4 After deletions: FIRST = 2 LAST = 3
文字列で索引付けされている連想配列の場合、最初の要素および最後の要素は、それぞれ最小および最大のキー値を持つ要素です。キー値の順序はソートされています(詳細は、「文字列で索引付けされている連想配列に影響を与えるNLSパラメータ値」を参照してください)。
例5-23では、文字列で索引付けされている連想配列のFIRSTとLASTの値を表示してから最初と最後の要素を削除し、再度、FIRSTとLASTの値を表示します。
例5-23 文字列で索引付けされている連想配列のFIRSTとLASTの値
DECLARE
TYPE aa_type_str IS TABLE OF INTEGER INDEX BY VARCHAR2(10);
aa_str aa_type_str;
PROCEDURE print_first_and_last IS
BEGIN
DBMS_OUTPUT.PUT_LINE('FIRST = ' || aa_str.FIRST);
DBMS_OUTPUT.PUT_LINE('LAST = ' || aa_str.LAST);
END print_first_and_last;
BEGIN
aa_str('Z') := 26;
aa_str('A') := 1;
aa_str('K') := 11;
aa_str('R') := 18;
DBMS_OUTPUT.PUT_LINE('Before deletions:');
print_first_and_last;
aa_str.DELETE('A');
aa_str.DELETE('Z');
DBMS_OUTPUT.PUT_LINE('After deletions:');
print_first_and_last;
END;
/
結果:
Before deletions: FIRST = A LAST = Z After deletions: FIRST = K LAST = R
空ではないVARRAYの場合、FIRSTは常に1を戻します。どのVARRAYでも、LASTは常にCOUNTと同じです(例5-26を参照)。
例5-24では、team.FIRSTおよびteam.LASTを境界とするFOR LOOP文を使用して、VARRAYのteamを出力します。VARRAYは常に密であるため、ループの内側のteam(i)は常に存在します。
例5-24 FOR LOOP内のFIRSTおよびLASTによるVARRAYの出力
DECLARE
TYPE team_type IS VARRAY(4) OF VARCHAR2(15);
team team_type;
PROCEDURE print_team (heading VARCHAR2)
IS
BEGIN
DBMS_OUTPUT.PUT_LINE(heading);
IF team IS NULL THEN
DBMS_OUTPUT.PUT_LINE('Does not exist');
ELSIF team.FIRST IS NULL THEN
DBMS_OUTPUT.PUT_LINE('Has no members');
ELSE
FOR i IN team.FIRST..team.LAST LOOP
DBMS_OUTPUT.PUT_LINE(i || '. ' || team(i));
END LOOP;
END IF;
DBMS_OUTPUT.PUT_LINE('---');
END;
BEGIN
print_team('Team Status:');
team := team_type(); -- Team is funded, but nobody is on it.
print_team('Team Status:');
team := team_type('John', 'Mary'); -- Put 2 members on team.
print_team('Initial Team:');
team := team_type('Arun', 'Amitha', 'Allan', 'Mae'); -- Change team.
print_team('New Team:');
END;
/
結果:
Team Status: Does not exist --- Team Status: Has no members --- Initial Team: 1. John 2. Mary --- New Team: 1. Arun 2. Amitha 3. Allan 4. Mae ---
ネストした表の場合、LASTはCOUNTと同じです。ただし、ネストした表の中から要素を削除すると、LASTはCOUNTより大きくなります(例5-27を参照)。
例5-25では、team.FIRSTおよびteam.LASTを境界とするFOR LOOP文を使用して、ネストした表のteamを出力します。ネストした表は疎の場合があるため、team.EXISTS(i)がTRUEの場合のみ、FOR LOOP文はteam(i)を出力します。
例5-25 FOR LOOP内のFIRSTおよびLASTによるネストした表の出力
DECLARE
TYPE team_type IS TABLE OF VARCHAR2(15);
team team_type;
PROCEDURE print_team (heading VARCHAR2) IS
BEGIN
DBMS_OUTPUT.PUT_LINE(heading);
IF team IS NULL THEN
DBMS_OUTPUT.PUT_LINE('Does not exist');
ELSIF team.FIRST IS NULL THEN
DBMS_OUTPUT.PUT_LINE('Has no members');
ELSE
FOR i IN team.FIRST..team.LAST LOOP
DBMS_OUTPUT.PUT(i || '. ');
IF team.EXISTS(i) THEN
DBMS_OUTPUT.PUT_LINE(team(i));
ELSE
DBMS_OUTPUT.PUT_LINE('(to be hired)');
END IF;
END LOOP;
END IF;
DBMS_OUTPUT.PUT_LINE('---');
END;
BEGIN
print_team('Team Status:');
team := team_type(); -- Team is funded, but nobody is on it.
print_team('Team Status:');
team := team_type('Arun', 'Amitha', 'Allan', 'Mae'); -- Add members.
print_team('Initial Team:');
team.DELETE(2,3); -- Remove 2nd and 3rd members.
print_team('Current Team:');
END;
/
結果:
Team Status: Does not exist --- Team Status: Has no members --- Initial Team: 1. Arun 2. Amitha 3. Allan 4. Mae --- Current Team: 1. Arun 2. (to be hired) 3. (to be hired) 4. Mae ---
COUNTは、コレクション内の要素の数を戻すファンクションです(削除された要素がDELETEにより保持されていても、それらは無視されます)。
ここでのトピック
VARRAYの場合、COUNTは常にLASTと同じです。VARRAYのサイズを(EXTENDまたはTRIMメソッドを使用して)増減させると、COUNTの値が変更されます。
例5-26では、4つの要素を使用して初期化し、EXTEND(3)に続いてTRIM(5)を実行してから、VARRAYのCOUNTとLASTの値を表示します。
例5-26 VARRAYのCOUNTとLASTの値
DECLARE
TYPE NumList IS VARRAY(10) OF INTEGER;
n NumList := NumList(1,3,5,7);
PROCEDURE print_count_and_last IS
BEGIN
DBMS_OUTPUT.PUT('n.COUNT = ' || n.COUNT || ', ');
DBMS_OUTPUT.PUT_LINE('n.LAST = ' || n.LAST);
END print_count_and_last;
BEGIN
print_count_and_last;
n.EXTEND(3);
print_count_and_last;
n.TRIM(5);
print_count_and_last;
END;
/
結果:
n.COUNT = 4, n.LAST = 4 n.COUNT = 7, n.LAST = 7 n.COUNT = 2, n.LAST = 2
ネストした表の場合、COUNTはLASTと同じです。ただし、ネストした表の中から要素を削除すると、COUNTはLASTより小さくなります。
例5-27では、4つの要素を使用して初期化し、3番目の要素を削除した後で末尾にNULL要素を2つ追加してから、ネストした表のCOUNTとLASTの値を表示します。最後に、1番目から8番目の要素のステータスを出力します。
例5-27 ネストした表のCOUNTとLASTの値
DECLARE
TYPE NumList IS TABLE OF INTEGER;
n NumList := NumList(1,3,5,7);
PROCEDURE print_count_and_last IS
BEGIN
DBMS_OUTPUT.PUT('n.COUNT = ' || n.COUNT || ', ');
DBMS_OUTPUT.PUT_LINE('n.LAST = ' || n.LAST);
END print_count_and_last;
BEGIN
print_count_and_last;
n.DELETE(3); -- Delete third element
print_count_and_last;
n.EXTEND(2); -- Add two null elements to end
print_count_and_last;
FOR i IN 1..8 LOOP
IF n.EXISTS(i) THEN
IF n(i) IS NOT NULL THEN
DBMS_OUTPUT.PUT_LINE('n(' || i || ') = ' || n(i));
ELSE
DBMS_OUTPUT.PUT_LINE('n(' || i || ') = NULL');
END IF;
ELSE
DBMS_OUTPUT.PUT_LINE('n(' || i || ') does not exist');
END IF;
END LOOP;
END;
/
結果:
n.COUNT = 4, n.LAST = 4 n.COUNT = 3, n.LAST = 4 n.COUNT = 5, n.LAST = 6 n(1) = 1 n(2) = 3 n(3) does not exist n(4) = 7 n(5) = NULL n(6) = NULL n(7) does not exist n(8) does not exist
LIMITは、コレクションに格納可能な要素の最大数を戻すファンクションです。コレクションに要素の最大数がない場合、LIMITはNULLを戻します。最大サイズがあるのはVARRAYのみです。
例5-28では、4つの要素を持つ連想配列、2つの要素を持つVARRAY、3つの要素を持つネストした表について、LIMITとCOUNTの値を表示します。
例5-28 様々なコレクション型のLIMITとCOUNTの値
DECLARE
TYPE aa_type IS TABLE OF INTEGER INDEX BY PLS_INTEGER;
aa aa_type; -- associative array
TYPE va_type IS VARRAY(4) OF INTEGER;
va va_type := va_type(2,4); -- varray
TYPE nt_type IS TABLE OF INTEGER;
nt nt_type := nt_type(1,3,5); -- nested table
BEGIN
aa(1):=3; aa(2):=6; aa(3):=9; aa(4):= 12;
DBMS_OUTPUT.PUT('aa.COUNT = '); print(aa.COUNT);
DBMS_OUTPUT.PUT('aa.LIMIT = '); print(aa.LIMIT);
DBMS_OUTPUT.PUT('va.COUNT = '); print(va.COUNT);
DBMS_OUTPUT.PUT('va.LIMIT = '); print(va.LIMIT);
DBMS_OUTPUT.PUT('nt.COUNT = '); print(nt.COUNT);
DBMS_OUTPUT.PUT('nt.LIMIT = '); print(nt.LIMIT);
END;
/
結果:
aa.COUNT = 4 aa.LIMIT = NULL va.COUNT = 2 va.LIMIT = 4 nt.COUNT = 3 nt.LIMIT = NULL
PRIORおよびNEXTは、コレクション内を前後に移動できるファンクションです(削除された要素がDELETEにより保持されていても、それらは無視されます)。このメソッドは、疎コレクション内の移動に便利です。
索引を指定すると次のようになります。
先行する要素が存在する場合、PRIORはそのコレクション要素の索引を戻します。存在しない場合、PRIORはNULLを戻します。
任意のコレクションcの場合、c.PRIOR(c.FIRST)はNULLを戻します。
後続の要素が存在する場合、NEXTはそのコレクション要素の索引を戻します。存在しない場合、NEXTはNULLを戻します。
任意のコレクションcの場合、c.NEXT(c.LAST)はNULLを戻します。
指定された索引が存在していなくてもかまいません。ただし、コレクションcがVARRAYで、索引がc.LIMITより大きい場合は次のようになります。
c.PRIOR(index)はc.LASTを戻します。
c.NEXT(index)はNULLを戻します。
次に例を示します。
DECLARE TYPE Arr_Type IS VARRAY(10) OF NUMBER; v_Numbers Arr_Type := Arr_Type(); BEGIN v_Numbers.EXTEND(4); v_Numbers (1) := 10; v_Numbers (2) := 20; v_Numbers (3) := 30; v_Numbers (4) := 40; DBMS_OUTPUT.PUT_LINE(NVL(v_Numbers.prior (3400), -1)); DBMS_OUTPUT.PUT_LINE(NVL(v_Numbers.next (3400), -1)); END; /
結果:
4 -1
例5-29では、ネストした表を6つの要素で初期化した後、4番目の要素を削除して、1番目から7番目の要素のPRIORとNEXTの値を表示します。4番目と7番目の要素は存在しません。値はNULLですが、2番目の要素は存在します。
例5-29 PRIORおよびNEXTメソッド
DECLARE TYPE nt_type IS TABLE OF NUMBER; nt nt_type := nt_type(18, NULL, 36, 45, 54, 63); BEGIN nt.DELETE(4); DBMS_OUTPUT.PUT_LINE('nt(4) was deleted.'); FOR i IN 1..7 LOOP DBMS_OUTPUT.PUT('nt.PRIOR(' || i || ') = '); print(nt.PRIOR(i)); DBMS_OUTPUT.PUT('nt.NEXT(' || i || ') = '); print(nt.NEXT(i)); END LOOP; END; /
結果:
nt(4) was deleted. nt.PRIOR(1) = NULL nt.NEXT(1) = 2 nt.PRIOR(2) = 1 nt.NEXT(2) = 3 nt.PRIOR(3) = 2 nt.NEXT(3) = 5 nt.PRIOR(4) = 3 nt.NEXT(4) = 5 nt.PRIOR(5) = 3 nt.NEXT(5) = 6 nt.PRIOR(6) = 5 nt.NEXT(6) = NULL nt.PRIOR(7) = 6 nt.NEXT(7) = NULL
文字列で索引付けされている連想配列の場合、前の索引および次の索引はキー値で決まり、キー値の順序はソートされています(詳細は、「文字列で索引付けされている連想配列に影響を与えるNLSパラメータ値」を参照してください)。例5-1では、FIRST、NEXTおよびWHILE LOOP文を使用して連想配列の要素を出力しました。
例5-30では、疎であるネストした表の要素を、FIRSTとNEXTを使用して最初から最後まで出力し、LASTとPRIORを使用して最後から最初まで出力します。
例5-30 疎であるネストした表の要素の出力
DECLARE
TYPE NumList IS TABLE OF NUMBER;
n NumList := NumList(1, 2, NULL, NULL, 5, NULL, 7, 8, 9, NULL);
idx INTEGER;
BEGIN
DBMS_OUTPUT.PUT_LINE('First to last:');
idx := n.FIRST;
WHILE idx IS NOT NULL LOOP
DBMS_OUTPUT.PUT('n(' || idx || ') = ');
print(n(idx));
idx := n.NEXT(idx);
END LOOP;
DBMS_OUTPUT.PUT_LINE('--------------');
DBMS_OUTPUT.PUT_LINE('Last to first:');
idx := n.LAST;
WHILE idx IS NOT NULL LOOP
DBMS_OUTPUT.PUT('n(' || idx || ') = ');
print(n(idx));
idx := n.PRIOR(idx);
END LOOP;
END;
/
結果:
First to last: n(1) = 1 n(2) = 2 n(3) = NULL n(4) = NULL n(5) = 5 n(6) = NULL n(7) = 7 n(8) = 8 n(9) = 9 n(10) = NULL -------------- Last to first: n(10) = NULL n(9) = 9 n(8) = 8 n(7) = 7 n(6) = NULL n(5) = 5 n(4) = NULL n(3) = NULL n(2) = 2 n(1) = 1
パッケージ仕様部で定義されたコレクション型は、同一定義のローカル・コレクション型またはスタンドアロン・コレクション型と互換性がありません。
例5-31では、パッケージ仕様部と無名ブロックで、同じコレクション型NumListを定義します。パッケージでは、NumListのパラメータを取るプロシージャprint_numlistを定義します。また、無名ブロックでは、型pkg.NumList(パッケージで定義した型)の変数n1と、型NumList(このブロックで定義した型)の変数n2を宣言します。無名ブロックは、n1をprint_numlistに渡せますが、n2をprint_numlistに渡すことはできません。
例5-31 同一定義のパッケージ・コレクション型とローカル・コレクション型
CREATE OR REPLACE PACKAGE pkg AS TYPE NumList IS TABLE OF NUMBER; PROCEDURE print_numlist (nums NumList); END pkg; / CREATE OR REPLACE PACKAGE BODY pkg AS PROCEDURE print_numlist (nums NumList) IS BEGIN FOR i IN nums.FIRST..nums.LAST LOOP DBMS_OUTPUT.PUT_LINE(nums(i)); END LOOP; END; END pkg; / DECLARE TYPE NumList IS TABLE OF NUMBER; -- local type identical to package type n1 pkg.NumList := pkg.NumList(2,4); -- package type n2 NumList := NumList(6,8); -- local type BEGIN pkg.print_numlist(n1); -- succeeds pkg.print_numlist(n2); -- fails END; /
結果:
pkg.print_numlist(n2); -- fails * ERROR at line 7: ORA-06550: line 7, column 3: PLS-00306: wrong number or types of arguments in call to 'PRINT_NUMLIST' ORA-06550: line 7, column 3: PL/SQL: Statement ignored
例5-32では、例5-31のパッケージ仕様部で定義したコレクション型NumListと同じスタンドアロン・コレクション型NumListを定義します。また、無名ブロックでは、型pkg.NumList(パッケージで定義した型)の変数n1と、スタンドアロン型NumListのn2を宣言します。無名ブロックは、n1をprint_numlistに渡せますが、n2をprint_numlistに渡すことはできません。
例5-32 同一定義のパッケージ・コレクション型とスタンドアロン・コレクション型
CREATE OR REPLACE TYPE NumList IS TABLE OF NUMBER; -- standalone collection type identical to package type / DECLARE n1 pkg.NumList := pkg.NumList(2,4); -- package type n2 NumList := NumList(6,8); -- standalone type BEGIN pkg.print_numlist(n1); -- succeeds pkg.print_numlist(n2); -- fails END; /
結果:
pkg.print_numlist(n2); -- fails * ERROR at line 7: ORA-06550: line 7, column 3: PLS-00306: wrong number or types of arguments in call to 'PRINT_NUMLIST' ORA-06550: line 7, column 3: PL/SQL: Statement ignored
RECORD型を定義し、次にその型の変数を宣言します。
事前に宣言されているレコード変数と同じ型のレコード変数を宣言するには、%TYPEを使用します。
データベースの表またはビュー内の行の全体または一部を表すレコード変数を宣言するには、%ROWTYPEを使用します。
構文およびセマンティクスの詳細は、「レコード変数の宣言」を参照してください。
ここでのトピック
RECORD型のレコード変数の場合、型を定義するときに別の初期値を指定しないかぎり、各フィールドの初期値はNULLになります。%TYPEを使用して宣言したレコード変数の場合、各フィールドは、参照レコード内の対応するフィールドの初期値を継承します。詳細は、例5-34を参照してください。
%ROWTYPEを使用して宣言したレコード変数の場合、各フィールドの初期値はNULLになります。詳細は、例5-39を参照してください。
レコード定数を宣言する場合、例5-33に示すように、初期値をレコードに移入するファンクションを作成して、定数宣言でそのファンクションを起動する必要があります。
例5-33 レコード定数の宣言
CREATE OR REPLACE PACKAGE My_Types AUTHID DEFINER IS TYPE My_Rec IS RECORD (a NUMBER, b NUMBER); FUNCTION Init_My_Rec RETURN My_Rec; END My_Types; / CREATE OR REPLACE PACKAGE BODY My_Types IS FUNCTION Init_My_Rec RETURN My_Rec IS Rec My_Rec; BEGIN Rec.a := 0; Rec.b := 1; RETURN Rec; END Init_My_Rec; END My_Types; / DECLARE r CONSTANT My_Types.My_Rec := My_Types.Init_My_Rec(); BEGIN DBMS_OUTPUT.PUT_LINE('r.a = ' || r.a); DBMS_OUTPUT.PUT_LINE('r.b = ' || r.b); END; /
結果:
r.a = 0 r.b = 1 PL/SQL procedure successfully completed.
PL/SQLブロック内に定義されるRECORD型はローカル型です。ブロック内でのみ使用可能であり、スタンドアロン・サブプログラムまたはパッケージ・サブプログラム内にブロックがある場合にのみ、データベースに格納されます。(スタンドアロン・サブプログラムおよびパッケージ・サブプログラムの詳細は、「ネストしたサブプログラム、パッケージ・サブプログラムおよびスタンドアロン・サブプログラム」を参照してください)。
パッケージ仕様部に定義されるRECORD型はパブリック項目です。パッケージ名(package_name.type_name)で修飾することで、パッケージの外から参照できます。パブリック項目は、DROP PACKAGE文を使用してパッケージを削除するまで、データベースに格納されます。(パッケージの詳細は、第10章「PL/SQLパッケージ」を参照してください。)
スキーマ・レベルではRECORD型を宣言できません。したがって、RECORD型はADT属性のデータ型にできません。
RECORD型を定義するには、型の名前とフィールドを指定します。フィールドを定義するには、フィールド名とデータ型を指定します。デフォルトでは、フィールドの初期値はNULLです。フィールドにNOT NULL制約を指定できますが、指定する場合は、初期値にNULL以外の値を指定する必要があります。NOT NULL制約がない場合、NULL以外の初期値はオプションです。
例5-34では、DeptRecTypという名前のRECORD型を定義し、loc_id以外の各フィールドに初期値を指定します。次に、型DeptRecTypの変数dept_recと、型dept_rec%TYPEの変数dept_rec_2を宣言します。最後に、この2つのレコード変数のフィールドを出力し、両方のレコードにおいてloc_idの値がNULLであり、その他のすべてのフィールドの値がデフォルト値であることを示します。
例5-34 RECORD型の定義および変数の宣言
DECLARE
TYPE DeptRecTyp IS RECORD (
dept_id NUMBER(4) NOT NULL := 10,
dept_name VARCHAR2(30) NOT NULL := 'Administration',
mgr_id NUMBER(6) := 200,
loc_id NUMBER(4)
);
dept_rec DeptRecTyp;
dept_rec_2 dept_rec%TYPE;
BEGIN
DBMS_OUTPUT.PUT_LINE('dept_rec:');
DBMS_OUTPUT.PUT_LINE('---------');
DBMS_OUTPUT.PUT_LINE('dept_id: ' || dept_rec.dept_id);
DBMS_OUTPUT.PUT_LINE('dept_name: ' || dept_rec.dept_name);
DBMS_OUTPUT.PUT_LINE('mgr_id: ' || dept_rec.mgr_id);
DBMS_OUTPUT.PUT_LINE('loc_id: ' || dept_rec.loc_id);
DBMS_OUTPUT.PUT_LINE('-----------');
DBMS_OUTPUT.PUT_LINE('dept_rec_2:');
DBMS_OUTPUT.PUT_LINE('-----------');
DBMS_OUTPUT.PUT_LINE('dept_id: ' || dept_rec_2.dept_id);
DBMS_OUTPUT.PUT_LINE('dept_name: ' || dept_rec_2.dept_name);
DBMS_OUTPUT.PUT_LINE('mgr_id: ' || dept_rec_2.mgr_id);
DBMS_OUTPUT.PUT_LINE('loc_id: ' || dept_rec_2.loc_id);
END;
/
結果:
dept_rec: --------- dept_id: 10 dept_name: Administration mgr_id: 200 loc_id: ----------- dept_rec_2: ----------- dept_id: 10 dept_name: Administration mgr_id: 200 loc_id: PL/SQL procedure successfully completed.
例5-35では、name_recおよびcontactという2つのRECORD型を定義します。型contactには型name_recのフィールドを含めます。
例5-35 RECORDフィールドを持つRECORD型(ネストされたレコード)
DECLARE TYPE name_rec IS RECORD ( first employees.first_name%TYPE, last employees.last_name%TYPE ); TYPE contact IS RECORD ( name name_rec, -- nested record phone employees.phone_number%TYPE ); friend contact; BEGIN friend.name.first := 'John'; friend.name.last := 'Smith'; friend.phone := '1-650-555-1234'; DBMS_OUTPUT.PUT_LINE ( friend.name.first || ' ' || friend.name.last || ', ' || friend.phone ); END; /
結果:
John Smith, 1-650-555-1234
例5-36では、full_nameというVARRAY型と、contactというRECORD型を定義します。型contactには型full_nameのフィールドを含めます。
例5-36 VARRAYフィールド持つRECORD型
DECLARE TYPE full_name IS VARRAY(2) OF VARCHAR2(20); TYPE contact IS RECORD ( name full_name := full_name('John', 'Smith'), -- varray field phone employees.phone_number%TYPE ); friend contact; BEGIN friend.phone := '1-650-555-1234'; DBMS_OUTPUT.PUT_LINE ( friend.name(1) || ' ' || friend.name(2) || ', ' || friend.phone ); END; /
結果:
John Smith, 1-650-555-1234
パッケージ仕様部で定義されたRECORD型は、同一定義のローカルRECORD型と互換性がありません。
例5-37では、パッケージpkgと無名ブロックで、同じRECORD型rec_typeを定義します。パッケージでは、rec_typeのパラメータを取るプロシージャprint_rec_typeを定義します。無名ブロックでは、パッケージ型(pkg.rec_type)の変数r1と、ローカル型(rec_type)の変数r2を宣言します。無名ブロックは、r1をprint_rec_typeに渡せますが、r2をprint_rec_typeに渡すことはできません。
例5-37 同一定義のパッケージRECORD型とローカルRECORD型
CREATE OR REPLACE PACKAGE pkg AS TYPE rec_type IS RECORD ( -- package RECORD type f1 INTEGER, f2 VARCHAR2(4) ); PROCEDURE print_rec_type (rec rec_type); END pkg; / CREATE OR REPLACE PACKAGE BODY pkg AS PROCEDURE print_rec_type (rec rec_type) IS BEGIN DBMS_OUTPUT.PUT_LINE(rec.f1); DBMS_OUTPUT.PUT_LINE(rec.f2); END; END pkg; / DECLARE TYPE rec_type IS RECORD ( -- local RECORD type f1 INTEGER, f2 VARCHAR2(4) ); r1 pkg.rec_type; -- package type r2 rec_type; -- local type BEGIN r1.f1 := 10; r1.f2 := 'abcd'; r2.f1 := 25; r2.f2 := 'wxyz'; pkg.print_rec_type(r1); -- succeeds pkg.print_rec_type(r2); -- fails END; /
結果:
pkg.print_rec_type(r2); -- fails * ERROR at line 14: ORA-06550: line 14, column 3: PLS-00306: wrong number or types of arguments in call to 'PRINT_REC_TYPE' ORA-06550: line 14, column 3: PL/SQL: Statement ignored
%ROWTYPE属性を使用すると、データベースの表またはビュー内の行の全体または一部を表すレコード変数を宣言できます。このレコードは、行の全体または一部のすべての列に対して、同じ名前とデータ型のフィールドを持ちます。行の構造が変更されると、それに応じてレコードの構造も変更されます。
このレコードのフィールドは、対応する列の制約または初期値を継承しません(例5-39を参照)。
ここでのトピック
常にデータベースの表またはビュー内の行の全体を表すレコード変数を宣言するには、次の構文を使用します。
variable_name table_or_view_name%ROWTYPE;
このレコードは、表またはビューのすべての列に対して、同じ名前とデータ型のフィールドを持ちます。
例5-38では、表departmentsの行を表すレコード変数を宣言し、フィールドに値を代入してからフィールドを出力します。この例を例5-34と比較してください。
例5-38 データベース表の行全体を表す%ROWTYPE変数
DECLARE
dept_rec departments%ROWTYPE;
BEGIN
-- Assign values to fields:
dept_rec.department_id := 10;
dept_rec.department_name := 'Administration';
dept_rec.manager_id := 200;
dept_rec.location_id := 1700;
-- Print fields:
DBMS_OUTPUT.PUT_LINE('dept_id: ' || dept_rec.department_id);
DBMS_OUTPUT.PUT_LINE('dept_name: ' || dept_rec.department_name);
DBMS_OUTPUT.PUT_LINE('mgr_id: ' || dept_rec.manager_id);
DBMS_OUTPUT.PUT_LINE('loc_id: ' || dept_rec.location_id);
END;
/
結果:
dept_id: 10 dept_name: Administration mgr_id: 200 loc_id: 1700
例5-39では、2つの列を持つ表を作成し、それぞれの列に初期値とNOT NULL制約を指定します。次に、この表の行を表すレコード変数を宣言してからフィールドを出力し、初期値またはNOT NULL制約が変数に継承されなかったことを示します。
データベースの表またはビュー内の行の一部を表すことができるレコード変数を宣言するには、次の構文を使用します。
variable_name cursor%ROWTYPE;
カーソルは問合せに関連付けられています。問合せにより選択されるすべての列に対して、レコード変数の中には、対応する型互換のフィールドが存在している必要があります。問合せにより表またはビュー内のすべての列が選択される場合、変数は行の全体を表しますが、それ以外の場合は、行の一部を表します。カーソルは、明示カーソルまたは強いカーソル変数のいずれかである必要があります。
例5-40では、サンプル・スキーマHRのemployees表から列first_name、last_nameおよびphone_numberのみを選択する問合せが指定された明示カーソルを宣言します。次に、カーソルにより選択される各列に対応するフィールドを持つレコード変数を宣言します。この変数はemployeesの行の一部を表します。この例を例5-35と比較してください。
例5-40 データベース表の行の一部を表す%ROWTYPE変数
DECLARE
CURSOR c IS
SELECT first_name, last_name, phone_number
FROM employees;
friend c%ROWTYPE;
BEGIN
friend.first_name := 'John';
friend.last_name := 'Smith';
friend.phone_number := '1-650-555-1234';
DBMS_OUTPUT.PUT_LINE (
friend.first_name || ' ' ||
friend.last_name || ', ' ||
friend.phone_number
);
END;
/
結果:
John Smith, 1-650-555-1234
例5-40では、結合問合せが指定された明示カーソルを定義した後、このカーソルにより選択される各列に対応するフィールドを持つレコード変数を宣言します。(結合の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。)
%ROWTYPE属性を使用して、仮想列を持つ表の行全体を表すレコード変数を定義する場合、そのレコードを表に挿入できません。かわりに、仮想列以外の各レコード・フィールドを表に挿入する必要があります。
例5-42では、仮想列を持つ表の行全体を表すレコード変数を作成し、レコードに移入してから、そのレコードを表に挿入した結果、ORA-54013エラーが発生します。
例5-42 %ROWTYPEレコードの表への挿入(間違った例)
DROP TABLE plch_departure; CREATE TABLE plch_departure ( destination VARCHAR2(100), departure_time DATE, delay NUMBER(10), expected GENERATED ALWAYS AS (departure_time + delay/24/60/60) ); DECLARE dep_rec plch_departure%ROWTYPE; BEGIN dep_rec.destination := 'X'; dep_rec.departure_time := SYSDATE; dep_rec.delay := 1500; INSERT INTO plch_departure VALUES dep_rec; END; /
結果:
DECLARE
*
ERROR at line 1:
ORA-54013: INSERT operation disallowed on virtual columns
ORA-06512: at line 8
例5-43では、仮想列以外の各レコード・フィールドを表に挿入することで、例5-42の問題を解決しています。
例5-43 %ROWTYPEレコードの表への挿入(正しい例)
DECLARE dep_rec plch_departure%rowtype; BEGIN dep_rec.destination := 'X'; dep_rec.departure_time := SYSDATE; dep_rec.delay := 1500; INSERT INTO plch_departure (destination, departure_time, delay) VALUES (dep_rec.destination, dep_rec.departure_time, dep_rec.delay); end; /
結果:
PL/SQL procedure successfully completed.
どのレコード変数にも、各フィールドには個別に値を代入できます。
場合によっては、あるレコード変数の値を別のレコード変数に代入できます。
データベースの表またはビュー内の行の全体または一部を表すレコード変数の場合は、対象となる行をレコード変数に代入できます。
ここでのトピック
次の場合にかぎり、あるレコード変数の値を別のレコード変数に代入できます。
2つの変数が同じRECORD型を持つ場合(例5-44を参照)
代入先の変数がRECORD型で、代入元の変数が%ROWTYPEでそれぞれ宣言され、両者のフィールドの数と順序が一致し、対応するフィールドのデータ型が同じである場合(例5-45を参照)
コンポジット変数のレコード・コンポーネントの場合は、コンポジット変数の型が一致している必要があります(例5-46を参照)。
例5-44 同じRECORD型のレコードから別のレコードへの代入
DECLARE
TYPE name_rec IS RECORD (
first employees.first_name%TYPE DEFAULT 'John',
last employees.last_name%TYPE DEFAULT 'Doe'
);
name1 name_rec;
name2 name_rec;
BEGIN
name1.first := 'Jane'; name1.last := 'Smith';
DBMS_OUTPUT.PUT_LINE('name1: ' || name1.first || ' ' || name1.last);
name2 := name1;
DBMS_OUTPUT.PUT_LINE('name2: ' || name2.first || ' ' || name2.last);
END;
/
結果:
name1: Jane Smith name2: Jane Smith
例5-45 RECORD型のレコードへの%ROWTYPEレコードの代入
DECLARE
TYPE name_rec IS RECORD (
first employees.first_name%TYPE DEFAULT 'John',
last employees.last_name%TYPE DEFAULT 'Doe'
);
CURSOR c IS
SELECT first_name, last_name
FROM employees;
target name_rec;
source c%ROWTYPE;
BEGIN
source.first_name := 'Jane'; source.last_name := 'Smith';
DBMS_OUTPUT.PUT_LINE (
'source: ' || source.first_name || ' ' || source.last_name
);
target := source;
DBMS_OUTPUT.PUT_LINE (
'target: ' || target.first || ' ' || target.last
);
END;
/
結果:
source: Jane Smith target: Jane Smith
例5-46では、あるネストしたレコードの値を別のネストしたレコードに代入します。これらのネストしたレコードは同じRECORD型を持ちますが、これらがネストされているレコードは同じではありません。
例5-46 同じRECORD型のネストしたレコードから別のレコードへの代入
DECLARE
TYPE name_rec IS RECORD (
first employees.first_name%TYPE,
last employees.last_name%TYPE
);
TYPE phone_rec IS RECORD (
name name_rec, -- nested record
phone employees.phone_number%TYPE
);
TYPE email_rec IS RECORD (
name name_rec, -- nested record
email employees.email%TYPE
);
phone_contact phone_rec;
email_contact email_rec;
BEGIN
phone_contact.name.first := 'John';
phone_contact.name.last := 'Smith';
phone_contact.phone := '1-650-555-1234';
email_contact.name := phone_contact.name;
email_contact.email := (
email_contact.name.first || '.' ||
email_contact.name.last || '@' ||
'example.com'
);
DBMS_OUTPUT.PUT_LINE (email_contact.email);
END;
/
結果:
John.Smith@example.com
データベースの表またはビュー内の行の全体または一部を表すレコード変数の場合は、対象となる行をレコード変数に代入できます。
ここでのトピック
SELECT select_list INTO record_variable_name FROM table_or_view_name;
select_listの各列に対して、レコード変数の中には、対応する型互換のフィールドが存在している必要があります。select_list内の列は、レコード・フィールドと同じ順序で並んでいる必要があります。
例5-47のレコード変数rec1は、employees表の行の一部(列last_nameおよびemployee_id)を表しています。SELECT INTO文は、job_idが'AD_PRES'の行をemployeesから選択し、選択した行の列last_nameおよびemployee_idの値をrec1の対応するフィールドに代入しています。
例5-47 SELECT INTOを使用したレコード変数への値の代入
DECLARE
TYPE RecordTyp IS RECORD (
last employees.last_name%TYPE,
id employees.employee_id%TYPE
);
rec1 RecordTyp;
BEGIN
SELECT last_name, employee_id INTO rec1
FROM employees
WHERE job_id = 'AD_PRES';
DBMS_OUTPUT.PUT_LINE ('Employee #' || rec1.id || ' = ' || rec1.last);
END;
/
結果:
Employee #100 = King
FETCH cursor INTO record_variable_name;
カーソルは問合せに関連付けられています。問合せにより選択されるすべての列に対して、レコード変数の中には、対応する型互換のフィールドが存在している必要があります。カーソルは、明示カーソルまたは強いカーソル変数のいずれかである必要があります。
例5-48のRECORD型EmpRecTypの各変数は、employees表の行の一部(列employee_idおよびsalary)を表しています。カーソルおよびファンクションの両方は、型EmpRecTypの値を戻します。このファンクションでは、列employee_idおよびsalaryの値がFETCH文により型EmpRecTypのローカル変数の対応するフィールドに代入されます。
例5-48 ファンクションが戻すレコードへのFETCHによる値の代入
DECLARE
TYPE EmpRecTyp IS RECORD (
emp_id employees.employee_id%TYPE,
salary employees.salary%TYPE
);
CURSOR desc_salary RETURN EmpRecTyp IS
SELECT employee_id, salary
FROM employees
ORDER BY salary DESC;
highest_paid_emp EmpRecTyp;
next_highest_paid_emp EmpRecTyp;
FUNCTION nth_highest_salary (n INTEGER) RETURN EmpRecTyp IS
emp_rec EmpRecTyp;
BEGIN
OPEN desc_salary;
FOR i IN 1..n LOOP
FETCH desc_salary INTO emp_rec;
END LOOP;
CLOSE desc_salary;
RETURN emp_rec;
END nth_highest_salary;
BEGIN
highest_paid_emp := nth_highest_salary(1);
next_highest_paid_emp := nth_highest_salary(2);
DBMS_OUTPUT.PUT_LINE(
'Highest Paid: #' ||
highest_paid_emp.emp_id || ', $' ||
highest_paid_emp.salary
);
DBMS_OUTPUT.PUT_LINE(
'Next Highest Paid: #' ||
next_highest_paid_emp.emp_id || ', $' ||
next_highest_paid_emp.salary
);
END;
/
結果:
Highest Paid: #100, $26460 Next Highest Paid: #101, $18742.5
SQLのINSERT文、UPDATE文およびDELETE文には、影響のある行をPL/SQLレコード変数に戻すことができる、オプションのRETURNING INTO句があります。この句の詳細は、「RETURNING INTO句」を参照してください。
例5-49では、従業員の給与をUPDATE文で更新し、従業員の名前および新しい給与をレコード変数に戻します。
例5-49 UPDATE文を使用したレコード変数への値の代入
DECLARE
TYPE EmpRec IS RECORD (
last_name employees.last_name%TYPE,
salary employees.salary%TYPE
);
emp_info EmpRec;
old_salary employees.salary%TYPE;
BEGIN
SELECT salary INTO old_salary
FROM employees
WHERE employee_id = 100;
UPDATE employees
SET salary = salary * 1.1
WHERE employee_id = 100
RETURNING last_name, salary INTO emp_info;
DBMS_OUTPUT.PUT_LINE (
'Salary of ' || emp_info.last_name || ' raised from ' ||
old_salary || ' to ' || emp_info.salary
);
END;
/
結果:
Salary of King raised from 26460 to 29106
値NULLをレコード変数に代入すると、その各フィールドに値NULLが代入されます。この代入は再帰的です(つまり、フィールドがレコードの場合は、それに属するフィールドにも値NULLが代入されます)。
例5-50では、レコード変数にNULLを代入する前後に、レコード変数のフィールド(そのうちの1つがレコード)を出力します。
例5-50 レコード変数へのNULLの代入
DECLARE
TYPE age_rec IS RECORD (
years INTEGER DEFAULT 35,
months INTEGER DEFAULT 6
);
TYPE name_rec IS RECORD (
first employees.first_name%TYPE DEFAULT 'John',
last employees.last_name%TYPE DEFAULT 'Doe',
age age_rec
);
name name_rec;
PROCEDURE print_name AS
BEGIN
DBMS_OUTPUT.PUT(NVL(name.first, 'NULL') || ' ');
DBMS_OUTPUT.PUT(NVL(name.last, 'NULL') || ', ');
DBMS_OUTPUT.PUT(NVL(TO_CHAR(name.age.years), 'NULL') || ' yrs ');
DBMS_OUTPUT.PUT_LINE(NVL(TO_CHAR(name.age.months), 'NULL') || ' mos');
END;
BEGIN
print_name;
name := NULL;
print_name;
END;
/
結果:
John Doe, 35 yrs 6 mos NULL NULL, NULL yrs NULL mos
レコードがNULLかどうか、または等しいかどうかは、そのままテストできません。次のBOOLEAN式は違反となります。
My_Record IS NULL
My_Record_1 = My_Record_2
My_Record_1 > My_Record_2
このようなテストは、独自のファンクションを記述して実装する必要があります。ファンクションの記述の詳細は、第8章「PL/SQLサブプログラム」を参照してください。
SQLのINSERT文に対するPL/SQLの拡張機能によって、レコードを表に挿入できます。レコードは、表の行を表している必要があります。詳細は、「INSERT文の拡張機能」を参照してください。表へのレコードの挿入の制限については、「レコードの挿入/更新に関する制限」を参照してください。
例5-51では、表scheduleを作成してから、デフォルト値をレコードに入力し、毎週そのレコードを表に挿入して表を初期化しています。(COLUMN書式設定コマンドはSQL*Plusのコマンドです。)
例5-51 デフォルト値のレコードの挿入による表の初期化
DROP TABLE schedule;
CREATE TABLE schedule (
week NUMBER,
Mon VARCHAR2(10),
Tue VARCHAR2(10),
Wed VARCHAR2(10),
Thu VARCHAR2(10),
Fri VARCHAR2(10),
Sat VARCHAR2(10),
Sun VARCHAR2(10)
);
DECLARE
default_week schedule%ROWTYPE;
i NUMBER;
BEGIN
default_week.Mon := '0800-1700';
default_week.Tue := '0800-1700';
default_week.Wed := '0800-1700';
default_week.Thu := '0800-1700';
default_week.Fri := '0800-1700';
default_week.Sat := 'Day Off';
default_week.Sun := 'Day Off';
FOR i IN 1..6 LOOP
default_week.week := i;
INSERT INTO schedule VALUES default_week;
END LOOP;
END;
/
COLUMN week FORMAT 99
COLUMN Mon FORMAT A9
COLUMN Tue FORMAT A9
COLUMN Wed FORMAT A9
COLUMN Thu FORMAT A9
COLUMN Fri FORMAT A9
COLUMN Sat FORMAT A9
COLUMN Sun FORMAT A9
SELECT * FROM schedule;
結果:
WEEK MON TUE WED THU FRI SAT SUN ---- --------- --------- --------- --------- --------- --------- --------- 1 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 2 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 3 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 4 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 5 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 6 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off
レコードのコレクションを効率的に表に挿入するには、INSERT文をFORALL文内に置きます。FORALL文の詳細は、「FORALL文」を参照してください。
SQLのUPDATE文に対するPL/SQLの拡張機能によって、レコードを使用して1つ以上の表の行を更新できます。レコードは、表の行を表している必要があります。詳細は、「UPDATE文の拡張機能」を参照してください。レコードを使用した表の行の更新に関する制限については、「レコードの挿入/更新に関する制限」を参照してください。
例5-52では、新しい値をレコードに入力し、そのレコードを使用して表の最初の3つの行を更新することによって、(例5-51で定義した)表scheduleの最初の3週間のデータを更新しています。
例5-52 レコードを使用した行の更新
DECLARE
default_week schedule%ROWTYPE;
BEGIN
default_week.Mon := 'Day Off';
default_week.Tue := '0900-1800';
default_week.Wed := '0900-1800';
default_week.Thu := '0900-1800';
default_week.Fri := '0900-1800';
default_week.Sat := '0900-1800';
default_week.Sun := 'Day Off';
FOR i IN 1..3 LOOP
default_week.week := i;
UPDATE schedule
SET ROW = default_week
WHERE week = i;
END LOOP;
END;
/
SELECT * FROM schedule;
結果:
WEEK MON TUE WED THU FRI SAT SUN ---- --------- --------- --------- --------- --------- --------- --------- 1 Day Off 0900-1800 0900-1800 0900-1800 0900-1800 0900-1800 Day Off 2 Day Off 0900-1800 0900-1800 0900-1800 0900-1800 0900-1800 Day Off 3 Day Off 0900-1800 0900-1800 0900-1800 0900-1800 0900-1800 Day Off 4 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 5 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 6 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off
レコードのコレクションを使用して行セットを更新するには、UPDATE文をFORALL文内に置きます。FORALL文の詳細は、「FORALL文」を参照してください。
レコード変数が使用できるのは、次の位置に限定されます。
UPDATE文のSET句の右側
INSERT文のVALUES句の中
RETURNING句のINTO副次句の中
レコード変数は、SELECTリスト、WHERE句、GROUP BY句またはORDER BY句では使用できません。
キーワードROWを指定できる位置は、SET句の左側のみです。また、ROWと副問合せは一緒に使用できません。
UPDATE文では、ROWが使用されている場合、許可されるSET句は1つのみです。
INSERT文のVALUES句にレコード変数が含まれている場合は、その句の中で他の変数または値を使用することはできません。
RETURNING句のINTO副次句にレコード変数が含まれている場合は、その副次句の中で他の変数または値を使用することはできません。
次の内容はサポートされません。
ネストしたRECORD型
RECORD型を戻すファンクション
EXECUTE IMMEDIATE文を使用したレコードの挿入および更新