| Oracle® Warehouse Builderソースおよびターゲット・ガイド 11gリリース2 (11.2) B61349-03 |
|



 前 |
 次 |
Oracle Warehouse Builderのマッピングで、フラット・ファイルをソース・ファイルまたはターゲット・ファイルとして使用できます。
この章では、Oracle Warehouse Builder内でフラット・ファイルをソースおよびターゲットとして使用する方法について説明します。内容は次のとおりです。
ソースとしてフラット・ファイルを使用すると、次の操作が可能です。
キャラクタ・データ・セット・ファイルまたはバイナリ・フラット・ファイルから読み取ることができます。
デリミタ付きファイル、固定長ファイルまたはXMLファイルから読み取ることができます。
SQL*Loaderマッピングでフラット・ファイル演算子を使用すると、直接フラット・ファイルから読み取ることができます。または、外部表を追加し、SQLおよびPL/SQLを使用したマッピングのフラット・ファイル・データにアクセスできます。
また、コード・テンプレート・ベースのマッピングにフラット・ファイル演算子を追加して、ファイル専用に構成されるコード・テンプレートまたはファイルの組込みJDBCドライバを活用する汎用SQLコード・テンプレートを活用できます。
ターゲットとしてフラット・ファイルを使用すると、次の操作が可能です。
キャラクタ・データ・セット・ファイルのみ使用できます。バイナリ・フラット・ファイルは、ターゲットとしてサポートされていません。
デリミタ付きファイルおよび固定長ファイルに書き込むことができます。
フラット・ファイル演算子を使用して、データをフラット・ファイルに書き込むことができます。
|
注意: 同じフラット・ファイルをソース・ファイルおよびターゲット・ファイルとして使用できます。 |
ファイルのメタデータは、列の名前およびデータ型を含むファイルのデータ・レコード構造を示します。ソースとしてフラット・ファイルを使用する前に、フラット・ファイルのメタデータを定義することをお薦めします。
複数のソースからフラット・ファイル・メタデータをインポートできます。
表示可能データを含む文字ファイルについては、フラット・ファイル・サンプル・ウィザードを使用して、フラット・ファイルの内容を表示および分析し、メタデータを推定できます。
COBOLコピーブックについては、コピーブック・ファイルから直接メタデータ定義をインポートできます。
バイナリ・ファイル、フラット・ファイル・サンプル・ウィザードでは処理が複雑すぎるファイルおよび使用できるサンプルがないターゲット・ファイルについては、フラット・ファイルの作成ウィザードを使用してフラット・ファイルのメタデータを明示的に定義できます。
ソース・ファイルおよびターゲット・ファイルのメタデータを格納するフラット・ファイル・モジュールをプロジェクトに作成できます。各フラット・ファイル・モジュールは、メタデータおよびデータのロケーションに関連付ける必要があります。モジュールのロケーションを指定すると、メタデータ・ロケーションおよびデータ・ロケーションに同じロケーションが示されます。モジュールを編集して、メタデータおよびデータに異なるロケーションを指定できます。
ソースまたはターゲットとしてフラット・ファイルを使用する通常のサイクルは、次のとおりです。
フラット・ファイルにアクセスするマッピングがデプロイされるホストからフラット・ファイルが格納されるロケーションにアクセスできることを確認します。
フラット・ファイル・モジュールを作成し、フラット・ファイル・モジュールのロケーションに関連付けます。「フラット・ファイル・モジュールの作成」を参照してください。
文字ファイル、バイナリ・ファイルまたはCOBOLコピーブックのいずれかに基づき、フラット・ファイルを定義して構造を指定します。フラット・ファイル・ウィザードの詳細は、「フラット・ファイル・サンプル・ウィザードの使用」を参照してください。バイナリ・ファイルのフラット・ファイルの作成の詳細は、「フラット・ファイルの作成ウィザードの使用方法」を参照してください。COBOLコピーブックからメタデータをインポートする詳細は、「COBOLコピーブックからのメタデータ定義のインポート」を参照してください。
使用するマッピングのタイプを選択して、ファイルのデータを抽出します。フラット・ファイル演算子または外部表を使用するかどうかを検討します。「外部表演算子およびフラット・ファイル演算子の選択」を参照してください。PL/SQLマッピングを使用する場合、外部表を作成して、データベース表としてファイルの内容を表します。
ソースまたはターゲットとしてフラット・ファイルを使用したPL/SQLまたはSQL*Loader ETLマッピングを設計します。マッピングの作成の詳細は、Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイドを参照してください。
ソースとしてフラット・ファイルを使用するには、フラット・ファイルのメタデータ構造を最初に定義し、メタデータをインポートします。
キャラクタ・データ・セット・ファイルおよびCOBOLコピーブックを含む様々なタイプのファイルからメタデータをインポートできます。
フラット・ファイル・メタデータを定義する手順は、次のとおりです。
フラット・ファイル・モジュールを作成します。
ファイル・メタデータのインポート元となる、ファイル・システム内の一意な各ディレクトリまたはパスのモジュールを作成します。「フラット・ファイル・モジュールの作成」を参照してください。
ファイルの構造を定義します。
フラット・ファイル・サンプル・ウィザードを使用して、フラット・ファイルのサンプルを表示し、レコードの構成およびファイルのプロパティを定義できます。文字列およびASCIIなどの共通のフラット・ファイルの書式をサンプリングおよび定義できます。「フラット・ファイル・サンプル・ウィザードの使用」を参照してください。
複雑なレコード構造のファイルの場合、フラット・ファイル・サンプル・ウィザードがデータのサンプリングに適していない場合があります。このような場合は、フラット・ファイルを作成して適切な構造を定義する必要があります。フラット・ファイルの構造の作成および定義は、「フラット・ファイルの作成ウィザードの使用方法」を参照してください。
COBOLコピーブックには、「COBOLインポート」ダイアログ・ボックスを使用して、コピーブックからメタデータをインポートします。コピーブックに応じて、インポート・オプションを設定することもできます。詳細は、「COBOLコピーブックからのメタデータ定義のインポート」を参照してください。
外部表は、読取り専用の表で、フラット・ファイルなど、シングル・レコード・タイプに関連付けられています。外部表は、非リレーショナル・ソースのデータをリレーショナル表形式で表したものです。マッピングに外部表を使用するとき、列のプロパティは、フラット・ファイルのインポート時に定義したSQLプロパティに基づきます。フラット・ファイルのSQLプロパティの詳細は、「SQLプロパティ」を参照してください。
マッピングのソース表として外部表を使用する場合は、通常のソース表と同様に使用できます。Oracle Warehouse Builderでは、外部表から行を選択するPL/SQLコードが生成されます。表を経由してファイルに並列アクセスすることもできます。また、追加のリレーショナル・ファンクション演算子にアクセスできます。
|
注意: 外部表はソース表としてのみ使用できます。 |
「外部表のインポート」の説明に従って別のデータベースから既存の外部表をインポートするか、「新しい外部表定義の作成」の説明に従って新規の外部表を定義できます。
ソース・データをフラット・ファイルからマッピングに取り込むには、外部表演算子またはフラット・ファイル演算子のいずれかを使用します。通常、外部表の使用がフラット・ファイルから大量のデータをロードする方法として推奨されています。
外部表とフラット・ファイルを比較する場合、次の詳細に注意してください。
外部表演算子およびPL/SQLマッピングにより、ロード中のデータベースのパラレル化の利用を含む最大のパフォーマンスが実現します。マッピングがPL/SQLマッピングなので、すべての変換演算子を使用できます。時間とともに、外部表で作成されたETLマッピングにより、データベース・レベルのパフォーマンスをさらに向上できます。
フラット・ファイル演算子およびSQL*Loaderマッピングは、フラット・ファイルのロードを完全にサポートします。Oracle Warehouse Builderでは、SQL*Loaderマッピングに固有のSQL*Loaderコードが生成されます。より限定された範囲の演算子がSQL*Loaderマッピングでサポートされます。データを中間表にステージングし、最終ターゲットにロードする前にPL/SQLマッピングを使用してさらに変換する必要があります。
外部表とSQL*Loader(フラット・ファイル演算子)の相違点の詳細は、『Oracle Databaseユーティリティ』を参照してください。
異なるタイプのマッピングの詳細は、Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイドを参照してください。
ターゲットとしてフラット・ファイルを使用する場合、メタデータの定義をお薦めしますが必須ではありません。たとえば、マッピングにバインドされていないフラット・ファイル演算子を使用する場合、マッピングで使用する前にフラット・ファイルのメタデータが定義されていない可能性があります。ただし、実際にはターゲットとして既存のファイルを使用するよりもターゲット・ファイルのメタデータを定義した方が便利です。
ターゲットとしての新規フラット・ファイルの作成
フラット・ファイルを作成し、データをロードする前に構造を定義します。
新規フラット・ファイルを設計する手順は、次のとおりです。
フラット・ファイルのモジュールを作成します。「フラット・ファイル・モジュールの作成」を参照してください。
フラット・ファイルの作成ウィザードを使用して、フラット・ファイルのメタデータ構造を設計します。「フラット・ファイルの作成ウィザードの使用方法」を参照してください。
|
注意: マッピングのターゲット・フラット・ファイルも作成できます。バインドされていないフラット・ファイル演算子をマッピングに追加し、ソース表またはソース演算子からフラット・ファイルにマップします。最後に、フラット・ファイル演算子の作成とバインドを実行します。マッピングの詳細は、Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイドを参照してください。 |
フラット・ファイルは、複数のフラット・ファイルをグループ化できるモジュール内に格納されます。
フラット・ファイル・モジュールを作成する手順は次のとおりです。
プロジェクト・ナビゲータの「ファイル」ノードを右クリックして、「新規フラット・ファイル・モジュール」を選択します。
Oracle Warehouse Builderで、モジュールの作成ウィザードの「ようこそ」ページが開きます。
次の手順でモジュールを定義します。
終了ページには、ウィザードの各ページで入力した情報の要約が表示されます。「終了」をクリックすると、ウィザードによりフラット・ファイル・モジュールが作成され、プロジェクト・ナビゲータの「ファイル」に挿入されます。
フラット・ファイル・モジュールを作成した後、「フラット・ファイルの作成ウィザードの使用方法」の説明に従って新しいフラット・ファイルを定義するか、「フラット・ファイル・サンプル・ウィザードの使用」の説明に従って既存のフラット・ファイルをこのモジュールにインポートするか、または「コピーブックのインポート」の説明に従ってCOBOLファイルをインポートできます。
名前と説明ページに、フラット・ファイル・モジュールの名前と説明(オプション)を入力します。
フラット・ファイル・モジュールのロケーションは、既存のファイルのサンプリング元、または新規ファイルの作成先となる、ファイル・システムのパスを識別します。新しいロケーションを定義するか、接続情報ページで既存のロケーションを選択できます。
フラット・ファイル・モジュールには、メタデータとデータのロケーションが含まれます。モジュールのロケーションを指定すると、メタデータ・ロケーションおよびデータ・ロケーションに同じロケーションが示されます。モジュールを編集して、メタデータおよびデータに異なるロケーションを指定できます。
システム内の別のディレクトリまたはパスにあるフラット・ファイルからメタデータをインポートする場合は、便宜上、パスごとに個別のOracle Warehouse Builderモジュールを作成します。たとえば、ファイルがc:\folder1およびc:\folder1\subfolderのパスにあるとします。C_FOLDER1とC_FOLDER1_SUBFOLDERの2つのファイル・モジュールを作成し、対応するパスに関連付けることができます。ただし、モジュールをパスに関連付けても、別のパスのファイルのメタデータ定義のインポートは制限されません。デフォルトとしてパスを定義し、後で別のパスからファイルをインポートできます。
データ・ロケーションでは、ファイル・システム内のフォルダのみが識別され、サブフォルダは含まれません。
接続ページには、名前と説明ページで入力したモジュール名に基づくデフォルトのロケーション名が表示されます。ロケーションを作成しない場合は、既存のロケーションのリストから選択します。
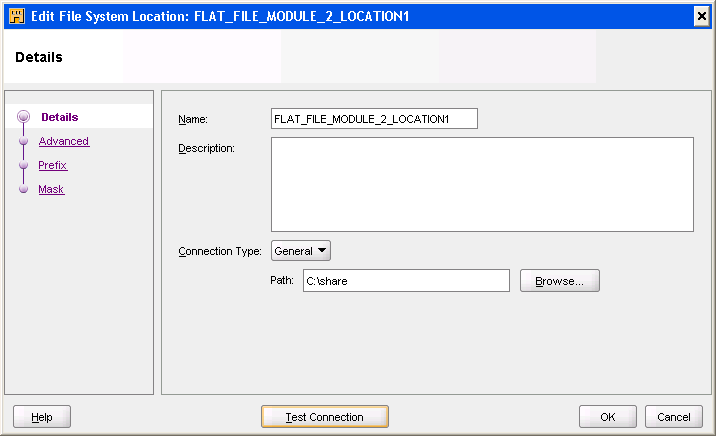
「接続情報」ページで、「編集」をクリックして「ファイルシステムのロケーションの編集」ダイアログ・ボックスを開き、ロケーション詳細を指定します。このロケーションは、メタデータおよびデータのロケーションになります。
「ファイルシステムのロケーションの編集」ダイアログ・ボックスで、ドライブ名を含む完全修飾ディレクトリを入力します。
図3-1に、「場所の編集」ダイアログ・ボックスを示します。
Oracle Warehouse Builderで新規フラット・ファイルの構造を設計するには、フラット・ファイルの作成ウィザードを使用します。この方法は、バイナリ・ファイルを定義する場合でフラット・ファイル・サンプル・ウィザードをソリューションとして使用できない場合に適しています。また、このウィザードを使用して、マッピングのターゲットとして使用するフラット・ファイルを作成できます。
フラット・ファイルの作成ウィザードを使用するには、フラット・ファイル・モジュールを右クリックして、「新規フラット・ファイル」を選択します。
フラット・ファイルの作成ウィザードに表示される指示に従って、次のステップを完了できます。
名前と説明ページを使用して、フラット・ファイルの名前を入力し、関連付ける一般プロパティを指定します。
名前: この名前でモジュール内のファイルを一意に識別します。空白や記号を含まない名前を入力してください。アンダースコアは使用できます。大文字と小文字を使用できます。名前の先頭に数字を使用しないでください。名前の先頭に予約されている接頭辞OWB$を使用しないでください。
デフォルト物理ファイル名: 物理ファイル名を指定できます。構成プロパティを使用して、この名前をいつでも変更できます。新規のファイルを作成する場合は、この名前を空白にしておくことができます。既存のバイナリ・ファイルを定義する場合は、ファイル名を入力します。ファイル名にはファイル・パスを含めないでください。
キャラクタ・セット: キャラクタ・セットを選択するか、Oracle Warehouse Builderが存在するシステムに定義されたデフォルトのキャラクタ・セットを受け入れます。NLSキャラクタ・セットの詳細は、『Oracle Databaseグローバリゼーション・サポート・ガイド』を参照してください。
説明: ファイルの説明(オプション)を入力できます。
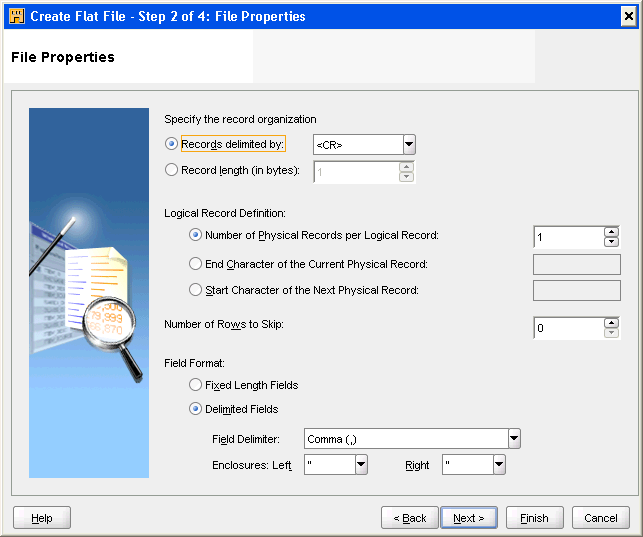
ファイル・プロパティ・ページを使用して、図3-2に示されているようにフラット・ファイルの「レコード編成」、「論理レコード定義」、「スキップする行数」および「フィールド書式」を指定します。
「ファイル・プロパティ」ページを使用して、フラット・ファイルの「レコード編成」、「論理レコード定義」、「スキップする行数」および「フィールド書式」を指定します。
ファイル内でレコードを編成する方法を指定します。ファイル内の各レコードの長さを決定する方法を指定するには、次の2つのオプションのいずれかを選択します。
レコード・デリミタ: このオプションは、各レコードの終了をデリミタで指定する場合に選択してください。次に、レコード・デリミタを指定します。デフォルトのレコード・デリミタである改行(\n)をそのまま使用するか、新しい値を入力できます。レコード・デリミタとして複数の文字および16進数文字を入力できます。16進数文字の形式は、x'<hexadecimal string>'またはX'<hexadecimal string>'です。デリミタ文字が改行(\n)および<CR>ではない場合、16進数文字を使用すると便利です。たとえば、デリミタとして縦線(|)を指定する場合、16進数値のx'7C'を使用します。
レコード長(文字数): このオプションは、すべてのレコードが同じ長さのファイルを作成する場合に選択してください。次に、各レコードの文字数を指定します。マルチバイト・キャラクタのファイルでは、マルチバイト・キャラクタを1文字として計算します。
ウィザードでは、デフォルトで、1物理レコードに1論理レコードが対応するようにファイルが作成されます。このデフォルトを上書きして、複数の物理レコードに対応する論理レコードで構成されたファイルを作成できます。
1論理レコード当たりの物理レコード数: データファイルには、論理レコードごとに固定数の物理レコードが含まれます。
PHYSICAL_RECORD1 PHYSICAL_RECORD2 PHYSICAL_RECORD3 PHYSICAL_RECORD4
前述の例で、論理レコード当たりの物理レコード数が2の場合は、PHYSICAL_RECORD1とPHYSICAL_RECORD2が1つの論理レコードを形成し、PHYSICAL_RECORD3とPHYSICAL_RECORD4が2番目の論理レコードを形成します。
現行の物理レコードの終了文字: データファイルには、可変数の物理レコードが含まれます。物理レコードの末尾には、そのレコードが次の物理レコードに継続することを表す継続文字が付加されます。
次の例では、継続文字はレコードの後のパーセント記号(%)です。
PHYSICAL_RECORD1% PHYSICAL_RECORD2 end log rec 1 PHYSICAL_RECORD3% PHYSICAL_RECORD4 end log rec 2
次の物理レコードの開始文字: データファイルには、可変数の物理レコードが含まれます。物理レコードの先頭には、そのレコードが前の物理レコードから継続していることを表す継続文字が付加されます。
次の例は、レコードの先頭に継続文字がある2つの論理レコードを示しています。
PHYSICAL_RECORD1 %PHYSICAL_RECORD2 end log rec 1 PHYSICAL_RECORD3 %PHYSICAL_RECORD4 end log rec 2
この方法を使用すると、3つ以上のレコードを結合できます。次の例では、レコード先頭の継続文字を使用した、1論理レコード当たり4つの物理レコードを示しています。
PHYSICAL_RECORD1 %PHYSICAL_RECORD2 %PHYSICAL_RECORD25 %PHYSICAL_RECORD26 end log record 1 PHYSICAL_RECORD3 %PHYSICAL_RECORD4 %PHYSICAL_RECORD45 %PHYSICAL_RECORD46 end log record 2
既存のファイルを定義する場合は、「スキップする行数」に実行時にスキップするレコード数を指定します。この操作は、ヘッダーおよびフィールド名レコードのスキップに役立ちます。
新規ターゲット・ファイルを作成するとき、この値は空白のままにできます。
ファイルの書式として「固定長」または「デリミタ付き」を選択します。
デリミタ付きファイルを作成するには、次のプロパティを指定します。
フィールド・デリミタ: フィールド・デリミタでは1つのフィールドの終了位置と別のフィールドの開始位置を示します。フィールド・デリミタは入力するか、リストから選択できます。リストには、一般的なフィールド・デリミタが表示されます。ただし囲み文字以外であれば、どのような文字でもデリミタとして入力できます。デフォルトはカンマ(,)です。複数の文字および16進文字をデリミタとして指定できます。16進数文字の形式は、x'<hexadecimal string>'またはX'<hexadecimal string>'です。たとえば、デリミタとして縦線(|)を指定する場合、16進数値のx'7C'を使用します。
囲み(左および右): フィールド内のテキスト文字列を示す囲み文字を含むデリミタ付きファイルがあります。ファイルに囲み文字が含まれる場合は囲み文字をテキスト・ボックスに入力することも、リストから選択することもできます。リストには、一般的な囲み文字が表示されます。ただし入力する場合はどのような文字でも入力できます。囲みのデフォルトは左右いずれも二重引用符("")です。フィールドの囲み文字として複数の文字および16進数文字を指定できます。
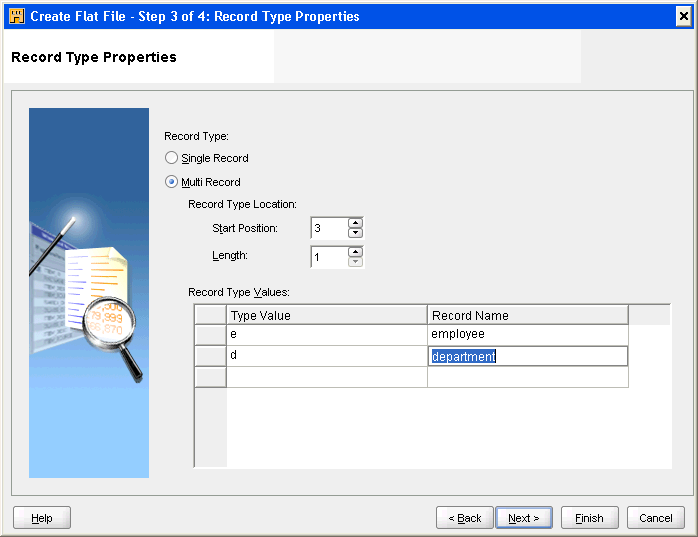
作成するファイルにシングル・レコード・タイプを含めるかマルチ・レコード・タイプを含めるかを指定します。デフォルトは「シングル・レコード」に設定されます。
マルチ・レコード・タイプのファイルの場合は、「マルチ・レコード」を選択します。作成するレコード・タイプごとに、「レコード・タイプ・ロケーション」の下に値を指定し、次にそのタイプの値およびレコード名を指定します。
「レコード・タイプ・ロケーション」に有効なエントリは、ファイル・プロパティ・ページで選択したフィールド書式(「固定長」または「デリミタ付きフィールド」)に応じて異なります。
たとえば、「デリミタ付きフィールド」を選択した場合は、図3-3に示されているようにフィールドの位置を指定します。
固定長ファイルの場合は、「レコード・タイプ・ロケーション」の下に「開始位置」と「長さ」の2つのフィールドが表示されます。フィールドの開始位置と長さを指定します。
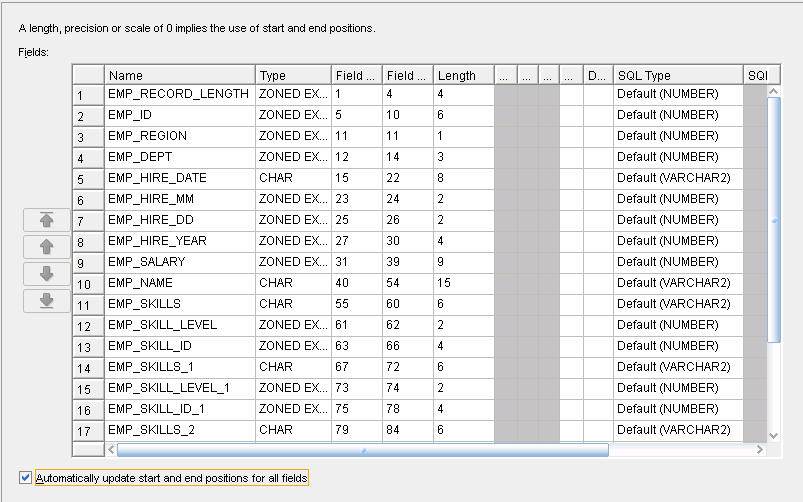
フィールド・プロパティ・ページを使用して、各フィールドのプロパティを定義します。
フラット・ファイルはマッピングにソースまたはターゲットとして直接使用することも、外部表を介して間接的に使用することもできるため、「フィールド・プロパティ」ページには「SQL*Loaderプロパティ」と「SQLプロパティ」の両方が表示されます。スクロール・バーを使用すると、右へスクロールしてすべてのプロパティを表示できます。
ウィザードで最初に表示されるプロパティ・セットは、SQL*Loaderユーティリティ用のプロパティです。マッピングでソースとしてフラット・ファイルを直接使用する場合、SQL*Loaderおよびここで設定するプロパティが使用されます。SQL*Loaderプロパティには、「タイプ」、「長さ」、「精度」、「スケール」、「マスク」、「NULLIF」および「DEFAULTIF」のリレーショナル表へのマッピング方法の詳細が含まれています。詳細は、『Oracle Database概要』を参照してください。
タイプ
SQL*Loaderでのフィールドのデータ型を記述します。ウィザードを使用すると、CHAR、DATE、DECIMAL EXTERNAL、FLOAT EXTERNAL、INTEGER EXTERNAL、ZONEDおよびZONED EXTERNALなど多くのデータ型をインポートできます。SQL*Loaderのフィールドおよびデータ型の詳細は、『Oracle Databaseユーティリティ』を参照してください。
長さ
デリミタ付きファイルの場合は、SQL*Loaderで使用するフィールドの最大長を指定します。
精度
ZONEDやFLOATなどの特定のデータ型の桁数を指定します。詳細は、『Oracle Databaseユーティリティ』を参照してください。
スケール
ZONEDやFLOATなどの特定のデータ型の10進数の桁数を指定します。詳細は、『Oracle Databaseユーティリティ』を参照してください。
マスク
SQL*Loaderで使用するデフォルトの日付マスクはDD-Mon-YYです。このデフォルトを上書きするには、ファイルを定義するときに有効な日付マスクを入力します。たとえば、入力データでSQL*LoaderのデフォルトではなくDD-Mon-YYYYという書式が使用されている場合は、実際の書式をマスクとして入力できます。
NULLIF
SQL*Loaderのデフォルト・アクションを上書きするには、フィールドにNULLIF条件を指定します。たとえば、文字フィールドの内容がすべて空白の場合に、空白を保存するのではなく、そのフィールドにNULLのマークを付けるようにSQL*Loaderに指示できます。このフィールドに有効な構文は、=BLANKS, ='quoted string', =X'ff'(16進数値を示す場合)および!=(「等しくない」論理の場合)です。
DEFAULTIF
SQL*Loaderのデフォルト・アクションを上書きするには、フィールドにDEFAULTIF条件を指定します。たとえば、数値またはDATE型のフィールドがすべて空白の場合、SQL*Loaderではレコード全体が拒否されます。このアクションを上書きにするには、DEFAULTIFプロパティに=BLANKSと入力します。SQL*Loaderは、この条件を評価するとき、数値フィールドにゼロを設定してレコードをロードします。このフィールドに有効な構文は、=BLANKS, ='quoted string', =X'ff'(16進数値を示す場合)および!=(「等しくない」論理の場合)です。
これらのプロパティによって、フラット・ファイル内のフィールドをリレーショナル表の列に変換する方法を指定します。外部表の特性を定義する場合に使用されます。関係演算子のマッピングにフィールドを自動的に生成するためにも使用されます。同様に、フラット・ファイルをターゲットとして使用する場合、これらのプロパティを使用してPL/SQLコードを生成します。
ここで設定するSQLプロパティは、マッピング設計、検証および生成に次のような影響を与えます。
外部表: 1つのフラット・ファイル・レコード・タイプに基づいて外部表を作成する場合、列のプロパティは、フラット・ファイルに定義したSQLプロパティに基づきます。外部表の詳細は、「外部表の使用」を参照してください。
空のマッピング・オブジェクトへのデータの移入: マッピングで空のリレーショナル・オブジェクトにメタデータを移入すると、そのオブジェクトは、フラット・ファイルのソースに定義したSQLプロパティを継承します。
フラット・ファイル・ターゲット: マッピングのターゲットとしてフラット・ファイルを使用すると、そのターゲットはSQLプロパティを継承しません。かわりに、すべてのフィールドはデフォルトのSQL*Loaderデータ型を継承します。
SQLタイプ
Oracle Warehouse Builderでは、CHAR、DATE、FLOAT、BLOBなどの多数のSQLデータ型がサポートされています。
ウィザードでは、設定したSQL*Loaderプロパティに基づいてSQLタイプのデフォルト値が割り当てられます。デフォルトのSQLタイプを使用すると、後でSQL*Loaderプロパティを変更した場合にデフォルト値が更新されます。ただし、リストから新しいSQLタイプを選択してSQLタイプを上書きすると、フラット・ファイルのSQL*Loaderデータ型とは無関係になります。
SQL長
このプロパティは、必要に応じてSQL列の長さを定義します。
SQL精度
このプロパティは、必要に応じてSQL列の精度を定義します。たとえば、NUMBERおよびFLOATフィールドを定義すると、精度を設定できます。
SQLスケール
このプロパティは、必要に応じてSQL列のスケールを定義します。たとえば、NUMBERおよびFLOATフィールドを定義すると、スケールを設定できます。
フィールドの変更に基づいてすべてのフィールドの位置を自動的に再計算する場合は、「すべてのフィールドの開始位置と終了位置を自動的に更新」を選択します。
新しいフラット・ファイルのメタデータを定義した後、ソースまたはターゲット・ファイルとして使用するか、ファイルからレコードを使用して外部表を作成できます。
既存のフラット・ファイルをソースとして使用する場合、これらのフラット・ファイルからメタデータをインポートしてからサンプリングできます。「ファイル・インポート」ダイアログ・ボックスを使用して、フラット・ファイルからメタデータをインポートします。このメタデータを既存のファイル・モジュールにインポートする必要があります。
フラット・ファイル・サンプリング・ウィザードを使用する手順は、次のとおりです。
インポートするファイルに対する接続性を確立します。
デザイン・センター・クライアントを実行しているホストでフラット・ファイル・サンプル・ウィザードが実行されるので、ホストからサンプリングするファイルにアクセスできることを確認します。ネットワーク・ファイル・システム(NFS)またはWindowsファイル共有などの方法を使用してネットワークのリモート・ファイル・システムをマウントするか、デザイン・センター・クライアント・ホストのアクセス可能なファイル・システムにファイルまたはファイルの代理セクションをコピーできます。
インポートするフラット・ファイル定義を格納するフラット・ファイル・モジュールを作成します。詳細は、「フラット・ファイル・モジュールの作成」を参照してください。
ファイルのインポート元となる、ファイル・システム内の各フォルダのモジュールを作成するか、同じモジュールを使用して複数のフォルダからファイル定義をインポートします。
フラット・ファイル・モジュールを作成する場合、このモジュールに対応するロケーションは、メタデータおよびデータのロケーションとして使用されるファイル・システムのパスです。モジュールの作成ウィザードの接続情報ページを使用してこのパスを指定します。
フラット・ファイル・ロケーションには、指定したフォルダのサブフォルダは含まれません。
フラット・ファイル・モジュールを右クリックし、「インポート」、「フラット・ファイル」の順に選択します。または、フラット・ファイル・モジュールを選択し、メイン・メニューで「ファイル」、「インポート」、「フラット・ファイル」の順に選択します。
「ファイル・インポート」ダイアログ・ボックスが表示されます。
「サンプル・ファイルの追加」をクリックして、インポートするファイルを選択します。
単一または複数のファイルをモジュールに追加できます。追加したすべてのファイルが「サンプル・ファイル」の下に表示されます。「同一」フィールドのファイルを指定する場合、サンプリングするファイルの定義は「同一」フィールドで指定されたファイルの定義に基づきます。
「インポート」をクリックします。フラット・ファイル・サンプル・ウィザードが起動されます。「サンプル・ファイル」の下に表示された順序で、ファイルがサンプリングされます。
フラット・ファイル・サンプル・ウィザードを使用すると、定義中にフラット・ファイルのサンプルを表示できます。ウィザードの各ステップを使用して、定義を設計し、定義が正しいかどうかを検証できます。詳細は、「フラット・ファイル・サンプル・ウィザードの使用」を参照してください。
バイナリ・ファイルには、フラット・ファイルの作成ウィザードの使用をお薦めします。「フラット・ファイルの作成ウィザードの使用方法」を参照してください。
このウィザードを使用して、ファイルの定義を作成し、フラット・ファイル・モジュールに定義を格納し、プロジェクト・ナビゲータのフラット・ファイル・モジュールの下にファイル名を挿入します。
フラット・ファイル・サンプル・ウィザードは、フラット・ファイルのメタデータを定義する際の補助ツールとして使用します。
このウィザードでは、区切り形式ファイルと固定形式ファイルがサンプリングされます。固定レコード形式のマルチバイト文字ファイルはサンプリングされません。バイナリ・ファイルなど、表示不能なデータを含む、固定レコード書式やその他のファイルの場合は、「フラット・ファイルの作成ウィザードの使用方法」を参照してください。
フラット・ファイル・サンプル・ウィザードが完了すると、メタデータがワークスペースに定義され、マッピングのソース演算子またはターゲット演算子としてフラット・ファイルを使用できます。マッピングの詳細は、Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイドを参照してください。
名前ページを使用して、サンプリングするフラット・ファイルを記述します。
名前: この名前でモジュール内のファイルを一意に識別します。デフォルトでは、ソース・ファイル名に基づき、無効な文字をアンダースコアで置き換えて名前が作成されます。たとえば、ファイル名がmyfile.datであれば、ワークスペース名myfile_datが割り当てられます。
ファイルの名前を変更する場合は、名前に空白や記号は使用しないでください。アンダースコアは使用できます。大文字と小文字を使用できます。名前の先頭に数字を使用しないでください。名前の先頭に予約されている接頭辞OWB$を使用しないでください。
説明: ファイルの説明(オプション)を入力できます。
キャラクタ・セット: キャラクタ・セットでは、データベース・オブジェクトとファイルで表現できる言語を決定します。デフォルトのグローバリゼーション・サポートは、Oracle Warehouse Builderをホスティングしているコンピュータに定義されたキャラクタ・セットと一致します。このキャラクタ・セットがソース・ファイルのキャラクタ・セットと異なる場合は、データのサンプルが判読不可能になることがあります。データ・サンプルをソース固有のキャラクタ・セットで表示するには、リストからそのキャラクタ・セットを選択します。NLSキャラクタ・セットの詳細は、『Oracle Databaseグローバリゼーション・サポート・ガイド』を参照してください。
サンプリングする文字数: この値は、読み取られて表示される文字数を指定します。読み取られる文字数は取消しできないので、適切な文字数が選択されていることを確認してください。マルチ・レコード・ファイルをサンプリングする場合、少なくとも各タイプのいずれかが含まれる十分な大きさのサンプルであることを確認してください。デフォルトでは、最初の10,000文字がサンプリングされます。このフィールドに最適な値を決定するには、「例: レコード・タイプが複数あるフラット・ファイル」を参照してください。
拡張: 単純なフラット・ファイルに対して「拡張」ボタンをクリックしないでください。拡張オプションは複合フラット・ファイルの場合にのみ必要です(「複合フラット・ファイルのフラット・ファイル・ウィザード」を参照)。
「次へ」をクリックして、レコード編成の指定に進みます。すべてのステップで、ウィザードのページの下部に表示されるサンプルが更新されます。スクロール・バーを使用して、サンプル・データを確認できます。
次のプロパティを指定します。
レコード・デリミタ: このオプションは、各レコードの終了をデリミタで指定する場合に選択してください。次に、レコード・デリミタを指定します。デフォルトのレコード・デリミタである改行(<CR>)をそのまま使用するか、新しい値を入力できます。\nおよび<CR>以外の記号には、デリミタとして使用する16進数値の文字を指定します。
レコード長(文字数): このオプションは、ファイル内の各レコードの長さが同一の場合に選択してください。次に、各レコードの文字数を指定します。マルチバイト・キャラクタのファイルでは、マルチバイト・キャラクタを1文字として計算します。
フィールド・デリミタ: フィールド・デリミタでは1つのフィールドの終了位置と別のフィールドの開始位置を示します。フィールド・デリミタは入力するか、リストから選択できます。リストには、一般的なフィールド・デリミタが表示されます。ただし囲み文字以外であれば、どのような文字でもデリミタとして入力できます。デフォルトはカンマ(,)です。フィールド・デリミタとして複数の文字および16進数文字も指定できます。
囲み(左および右): フィールド内のテキスト文字列を示す囲み文字を含むデリミタ付きファイルがあります。ファイルに囲み文字が含まれる場合は囲み文字をテキスト・ボックスに入力することも、リストから選択することもできます。リストには、一般的な囲み文字が表示されます。ただし入力する場合はどのような文字でも入力できます。囲みのデフォルトは左右いずれも二重引用符("")です。複数の文字および16進文字をフィールド囲み文字として指定できます。
フラット・ファイル・サンプル・ウィザードのフィールド・プロパティ・ページを使用して、各フィールドのプロパティを定義します。ウィザードにより、各フィールドに名前が割り当てられます。C1が最初のフィールドに、C2が2番目のフィールドに、という順序で割り当てられます。フィールドの名前を変更するには、フィールドをクリックして新しい名前を入力します。
シングル・レコード・ファイル・タイプの場合は、ウィザードで最初のレコードをフィールド名として使用するように指定できます。そのためには、「フィールド名として最初のレコードを使用」チェック・ボックスを選択します。
「フィールド・プロパティ」ページには、SQL*LoaderプロパティとSQLプロパティの両方が表示されます。スクロール・バーを使用すると、右へスクロールしてすべてのプロパティを表示できます。
所定のデータ型に適用されないプロパティは非アクティブになります。たとえば、CHARの長さは編集できますが、精度とスケールは使用できません。アクティブになっていないプロパティはグレー表示されます。
ウィザードで最初に表示されるプロパティ・セットは、SQL*Loaderユーティリティ用のプロパティです。マッピングでソースとしてフラット・ファイルを直接使用する場合、SQL*Loaderおよびここで設定するプロパティが使用されます。SQL*Loaderプロパティには、「タイプ」、「長さ」、「精度」、「スケール」、「マスク」、「NULLIF」および「DEFAULTIF」のリレーショナル表へのマッピング方法の詳細が含まれています。詳細は、『Oracle Database概要』を参照してください。
2番目に表示されるプロパティ・セットは、「SQLタイプ」、「SQL長」、「SQL精度」および「SQLスケール」のマッピングの詳細を含むSQLプロパティです。これらのプロパティによって、フラット・ファイル内のフィールドをリレーショナル表の列に変換する方法を指定します。詳細は、「SQLプロパティ」を参照してください。
複雑なファイルを使用するには、フラット・ファイル・ウィザードで次のタスクを実行します。拡張モードでは、デリミタ付きで固定長フィールドを使用するファイル、マルチ・レコード・タイプを含むファイル、または論理レコード(1論理レコード当たりに複数の物理レコード)を使用するファイルを定義できます。
名前ページを使用して、サンプリングするフラット・ファイルを記述します。
名前: この名前でワークスペース内のファイルを一意に識別します。デフォルトでは、ソース・ファイル名に基づき、無効な文字をアンダースコアで置き換えて名前が作成されます。たとえば、ファイル名がmyfile.datであれば、ワークスペース名myfile_datが割り当てられます。
ファイルの名前を変更する場合は、名前に空白や記号は使用しないでください。アンダースコアは使用できます。大文字と小文字を使用できます。名前の先頭に数字を使用しないでください。名前の先頭に予約されている接頭辞OWB$を使用しないでください。
説明: ファイルの説明(オプション)を入力できます。
キャラクタ・セット: キャラクタ・セットでは、データベース・オブジェクトとファイルで表現できる言語を決定します。デフォルトのグローバリゼーション・サポートは、Oracle Warehouse Builderをホスティングしているコンピュータに定義されたキャラクタ・セットと一致します。このキャラクタ・セットがソース・ファイルのキャラクタ・セットと異なる場合は、データのサンプルが判読不可能になることがあります。データ・サンプルをソース固有のキャラクタ・セットで表示するには、リストからそのキャラクタ・セットを選択します。NLSキャラクタ・セットの詳細は、『Oracle Databaseグローバリゼーション・サポート・ガイド』を参照してください。
サンプリングする文字数: データファイルからサンプリングする文字数をウィザードに対して指定できます。デフォルトでは、最初の10,000文字がサンプリングされます。このフィールドに最適な値を決定するには、「例: レコード・タイプが複数あるフラット・ファイル」を参照してください。
「拡張」をクリックして、「レコード編成の選択」に進みます。すべてのステップで、ウィザードのページの下部に表示されるサンプルが更新されます。スクロール・バーを使用して、サンプル・データを確認できます。
サンプリングするファイルのレコード編成方法を指定するには、レコード編成ページを使用します。ファイル内の各レコードの長さを決定する方法を指定するには、次の2つのオプションのいずれかを選択します。
レコード・デリミタ: 各レコードの最後がデリミタで指定される場合に、そのレコード・デリミタを指定します。デフォルトのレコード・デリミタである改行(<CR>)をそのまま使用するか、新しい値を入力できます。レコード・デリミタとして複数の文字および16進数文字を指定できます。デリミタが\nまたは<CR>以外の記号の場合、16進数文字の記号を指定します。16進数文字の形式は、x'<hexadecimal string>'またはX'<hexadecimal string>'です。
レコード長(文字数): このオプションは、ファイル内の各レコードの長さが同一の場合に選択してください。次に、各レコードの文字数を指定します。マルチバイト・キャラクタのファイルでは、マルチバイト・キャラクタを1文字として計算します。
フラット・ファイル・サンプル・ウィザードでは、複数の物理レコードに対応する論理レコードで構成されたファイルをサンプリングできます。ファイルに論理レコードが含まれている場合は、「論理レコードを含むファイル」を選択します。次に、ファイルを記述するオプションを1つ選択します。
下部のパネルの論理レコードの表示が更新され、選択内容が反映されます。デフォルトでは、1論理レコード当たり1物理レコードが選択されています。
1論理レコード当たりの物理レコード数: データファイルには、論理レコードごとに固定数の物理レコードが含まれます。
PHYSICAL_RECORD1 PHYSICAL_RECORD2 PHYSICAL_RECORD3 PHYSICAL_RECORD4
前述の例で、論理レコード当たりの物理レコード数が2の場合は、PHYSICAL_RECORD1とPHYSICAL_RECORD2が1つの論理レコードを形成し、PHYSICAL_RECORD3とPHYSICAL_RECORD4が2番目の論理レコードを形成します。
現行の物理レコードの終了文字: データファイルには、可変数の物理レコードが含まれます。物理レコードの末尾には、そのレコードが次の物理レコードに継続することを表す継続文字が付加されます。
次の例では、継続文字はレコードの後のパーセント記号(%)です。
PHYSICAL_RECORD1% PHYSICAL_RECORD2 end log rec 1 PHYSICAL_RECORD3% PHYSICAL_RECORD4 end log rec 2
次の物理レコードの開始文字: データファイルには、可変数の物理レコードが含まれます。物理レコードの先頭には、そのレコードが前の物理レコードから継続していることを表す継続文字が付加されます。
次の例は、レコードの先頭に継続文字がある2つの論理レコードを示しています。
PHYSICAL_RECORD1 %PHYSICAL_RECORD2 end log rec1 PHYSICAL_RECORD3 %PHYSICAL_RECORD4 end log rec 2
この方法を使用すると、3つ以上のレコードを結合できます。次の例では、レコード先頭の継続文字を使用した、1論理レコード当たり4つの物理レコードを示しています。
PHYSICAL_RECORD1 %PHYSICAL_RECORD2 %PHYSICAL_RECORD25 %PHYSICAL_RECORD26 (end log record 1) PHYSICAL_RECORD3 %PHYSICAL_RECORD4 %PHYSICAL_RECORD45 %PHYSICAL_RECORD46 (end log record 2)
論理レコード情報の入力が完了した後で、「次へ」をクリックしてウィザードを続行します。
ファイル形式ページを使用して、ファイル用に「固定長」形式または「デリミタ付き」形式を選択します。フラット・ファイル・サンプル・ウィザードでは、固定レコード・フォーマットのマルチバイト文字ファイルはサンプリングされません。このようなファイルには、フラット・ファイルの作成ウィザードを使用します。詳細は、「フラット・ファイルの作成ウィザードの使用方法」を参照してください。
ファイル形式を選択すると、ウィザードのページの下部に表示されるサンプルが更新されます。サンプル・データ内を移動するには、スクロール・バーを使用します。
ファイルのフィールドは、固定長またはデリミタ付きのいずれかです。
固定長フィールドには、「固定長」を選択します。このオプションを選択する場合、フィールド長ページでフィールド長を定義する必要があります。「フィールド長の指定(固定長ファイルのみ)」を参照してください。
デリミタ付きフィールドの場合は、次のプロパティを指定します。
フィールド・デリミタ: フィールド・デリミタでは1つのフィールドの終了位置と別のフィールドの開始位置を示します。フィールド・デリミタは入力するか、リストから選択できます。リストには、一般的なフィールド・デリミタが表示されます。ただし囲み文字以外であれば、どのような文字でもデリミタとして入力できます。デフォルトはカンマ(,)です。フィールド・デリミタとして複数の文字および16進数文字も指定できます。16進数文字の形式は、x'<hexadecimal string>'またはX'<hexadecimal string>'です。
囲み(左および右): フィールド内のテキスト文字列を示す囲み文字を含むデリミタ付きファイルがあります。ファイルに囲み文字が含まれる場合は囲み文字をテキスト・ボックスに入力することも、リストから選択することもできます。リストには、一般的な囲み文字が表示されます。ただし入力する場合はどのような文字でも入力できます。囲みのデフォルトは左右いずれも二重引用符("")です。複数の文字および16進文字をフィールド囲み文字として指定できます。
「次へ」をクリックしてウィザードを続行します。
ファイル・レイアウト・ページを使用してスキップする行数を指定し、シングル・レコード・タイプまたはマルチ・レコード・タイプを選択します。
「スキップする行数」でスキップするレコードの数を指定します。この操作は、不要なヘッダー情報のスキップに役立ちます。レコードの1つにフィールド名が含まれている場合は、その前にあるヘッダー・レコードをスキップして、フィールド名を含むそのレコードがファイルの最初のレコードとして表示されるようにします。シングル・レコードのファイル・タイプを定義している場合は、後のフラット・ファイル・サンプル・ウィザード: フィールド・プロパティ・ページで、そのレコードをフィールド名として使用するように指示できます。
ファイルに含まれるのがシングル・レコード・タイプとマルチ・レコード・タイプのいずれであるかを指定します。後からこのウィザードで、ファイルをスキャンしてレコード・タイプを検索することができます。マルチ・レコード・タイプの詳細は、「レコード・タイプの選択(マルチ・レコード・タイプのファイルのみ)」を参照してください。
ウィザードのレコード・タイプ・ページを使用して、フラット・ファイルのスキャンによるレコード・タイプの検索、レコード・タイプの追加と削除、およびレコード・タイプへのタイプ値の割当てを行います。
|
注意: この手順は、シングル・レコード・タイプのファイルでは使用されません。データファイルがシングル・レコード・タイプで、固定長のファイル形式の場合は、「フィールド長の指定(固定長ファイルのみ)」に進んでください。データファイルがシングル・レコード・タイプで、デリミタ付きファイル形式の場合は、「フィールド・プロパティの指定」に進んでください。 |
レコード・タイプが複数あるファイルでは、フィールドの1つで、1つのレコード・タイプが次のレコード・タイプと区別されます。フラット・ファイル・サンプル・ウィザードを使用する場合、レコード・タイプ値について各レコードの指定したフィールドをスキャンするように指示します。
図3-4は、"m"と"f"という2つのレコード・タイプを持つカンマ区切りのファイルの例を示しています。この場合、ウィザードで3番目のフィールドをスキャンするように指示します。ウィザードでは"m" および"f"がタイプ値として戻されます。
このウィザードを使用して、レコード・タイプが複数あるフラット・ファイルをサンプリングする場合は、名前ページで指定したサンプルのサイズが、各レコード・タイプを1つ以上含むことのできる大きさになるようにしてください。デフォルトは10000文字です。
必要なすべてのレコード・タイプが表示領域に表示されない場合は、「名前」ページで大きなサンプル・サイズを指定する必要があります。サンプル・サイズがすべてのレコード・タイプを含む十分な大きさであることを確認してください。適度な文字数内にレコード・タイプがすべて表示できない場合は、マスター・ファイルの異なる部分から行を選択して仮のサンプル・ファイルを作成し、データ・セットの代理とすることができます。レコードのレイアウトを把握している場合は、代理のサンプルをスキャンしてから、新しいレコード・タイプを手動で追加できます。
デリミタ付きフラット・ファイルに複数の異なるタイプのレコードが含まれている場合は、フラット・ファイル・サンプル・ウィザードのスキャン機能を使用してレコード・タイプを検索し、ラベルを付けることができます。
デリミタ付きファイルのレコード・タイプ・ページを完了する手順は、次のとおりです。
ファイル内のレコード・タイプを識別する単一フィールドを選択します。
ウィザード・ページの下部パネルにサンプルのすべてのフィールドが表示されます。「フィールド位置」にサンプルに表示される位置を入力できます。特に指定しなければ、ファイル内の第1フィールドにデフォルト設定されます。
「スキャン」をクリックすると、ファイル内でフィールドがスキャンされ、タイプ値が表示されます。各タイプ値にデフォルトのレコード名(RECORD1、RECORD2など)が割り当てられます。
レコード名およびタイプ値を編集できます。
レコード名をクリックして変更するか、リストから別のレコード名を選択します。レコード名をマルチ・レコード・タイプ値に関連付けることはできません。
「次へ」をクリックしてウィザードを続行します。
固定長のフラット・ファイルに複数の異なるタイプのレコードが含まれている場合は、フラット・ファイル・サンプル・ウィザードのスキャン機能を使用してレコード・タイプを検索し、各レコード・タイプにタイプ値を割り当てることができます。
固定長ファイルのレコード・タイプ・ページを完了する手順は、次のとおりです。
ファイル内のレコード・タイプを識別する単一フィールドを指定します。ルーラーを使用するか、「開始位置」および「終了位置」に値を入力します。第1フィールドに基づいてレコードをスキャンする場合は、「開始位置」に0(ゼロ)を入力します。
ウィザード・ページの下部パネルに、ファイル・サンプル内で選択したフィールドが表示され、ルーラーに赤いチェックマークが表示されます。
「スキャン」をクリックします。
ファイル・フィールドがスキャンされ、タイプ値が表示されます。各タイプ値にデフォルトのレコード名(RECORD1、RECORD2など)が割り当てられます。
レコード名およびタイプ値を編集できます。
レコード名をクリックして変更するか、リストから別のレコード名を選択します。レコード名をマルチ・レコード・タイプ値に関連付けることはできません。
「次へ」をクリックしてウィザードを続行します。
フラット・ファイル・サンプル・ウィザードを使用して固定長のフラット・ファイルを定義する場合は、ファイルの各フィールドの長さを定義する必要があります。
フィールド長は、フィールド長を入力するか、ルーラーを使用して定義できます。
各フィールドの長さがわかっている場合は、「フィールド長」にフィールド長を入力します。それぞれの長さはカンマで区切ります。ウィザード・ページの下部に、サンプルの変更内容が表示されます。
ルーラーを使用するには、ルーラー上の任意の数字かハッシュ・マークをクリックします。ルーラーの上に赤いチェックマークが表示され、境界を示す赤い線が表示されます。指定を間違えた場合は、マーカーをダブルクリックして削除するか、別の位置にマーカーを移動します。ルーラーを使用して、ファイル内の各フィールドにマーカーを作成します。
フラット・ファイル・サンプル・ウィザードのフィールド・プロパティ・ページを使用して、各フィールドのプロパティを定義します。ウィザードにより、各フィールドに名前が割り当てられます。C1が最初のフィールドに、C2が2番目のフィールドに、という順序で割り当てられます。フィールドの名前を変更するには、フィールドをクリックして新しい名前を入力します。
シングル・レコード・ファイル・タイプの場合は、ウィザードでファイルの最初のレコードをフィールド名として使用するように指定できます。そのためには、「フィールド名として最初のレコードを使用」チェック・ボックスを選択します。
「フィールド・プロパティ」ページには、SQL*LoaderプロパティとSQLプロパティの両方が表示されます。スクロール・バーを使用すると、右へスクロールしてすべてのプロパティを表示できます。
所定のデータ型に適用されないプロパティは非アクティブになります。たとえば、CHARの長さは編集できますが、精度とスケールは使用できません。アクティブになっていないプロパティはグレー表示されます。
ウィザードで最初に表示されるプロパティ・セットは、SQL*Loaderユーティリティ用のプロパティです。マッピングでソースとしてフラット・ファイルを直接使用する場合、SQL*Loaderおよびここで設定するプロパティが使用されます。SQL*Loaderプロパティには、「タイプ」、「長さ」、「精度」、「スケール」、「マスク」、「NULLIF」および「DEFAULTIF」があります。詳細は、「SQL*Loaderプロパティ」を参照してください。
2番目に表示されるプロパティ・セットはSQLプロパティで、「SQLタイプ」、「SQL長」、「SQL精度」および「SQLスケール」があります。これらのプロパティによって、フラット・ファイル内のフィールドをリレーショナル表の列に変換する方法を指定します。詳細は、「SQLプロパティ」を参照してください。
COBOLプログラマは、物理ファイルとその作成時に使用される論理レコードを定義して、ファイルを作成します。COBOLプログラム自体にレコードを定義できますが、通常はコピーブックという個別のファイルに定義します。これらのコピーブックにユーザー・データのレイアウトおよび形式を指定しますが、ファイル自体の物理的な特性は指定しません。ファイルの物理的な特性により、ファイルの編成方法およびアクセス方法が識別されます。たとえば、レコードの終了文字のCRまたはCR/LFはユーザー・データ定義の一部ではないため、レコード定義に含まれません。
Oracle Warehouse Builderを使用すると、COBOLコピーブックからメタデータをインポートできます。Oracle Warehouse Builderでは、次の操作が自動的に管理されます。
データ・ストレージのフィールドの定義
データ位置の計算
SQL*Loaderでの適切なデータ型定義へのCOBOLデータ特性の変換
COBOLレコードは、一連のデータ要素およびグループとして定義されます。データ要素はアトミック・データ・アイテムです。グループはデータ要素のコンテナです。COBOLレコードに定義される各アイテムは、グループおよび基本アイテムのいずれでもフィールドと呼ばれます。各フィールドの定義には、レコード内のデータの階層を反映するレベル番号が含まれます。グループには、他のグループまたは基本アイテムを格納できます。グループに含まれるアイテムは、下位要素と呼ばれます。基本アイテムのフィールド定義には、主にPICTURE句とUSAGE句で指定されるアイテムの完全なメタデータが含まれます。グループは、その下位要素の特性を継承し、通常はメタデータの詳細を含みません。簡単なコピーブックの例を例3-1に示します。
例3-1 COBOLコピーブック
01 EMPLOYEE-RECORD.
05 EMP-ID PIC 9(6).
05 EMP-REGION PIC 9.
05 EMP-DEPT PIC 999.
05 EMP-HIRE-DATE.
10 EMP-HIRE-DATE-MM PIC 99.
10 EMP-HIRE-DATE-DD PIC 99.
10 EMP-HIRE-DATE-YYYY PIC 9999.
05 EMP-SALARY PIC 9(9).
05 EMP-NAME PIC X(15).
前述の例は、EMPLOYEE-RECORDの定義を示しています。6つのフィールドが05レベルにあります。EMP-HIRE-DATE以外のフィールドは、すべて基本項目です。基本項目にはPICTURE句があり、ここにデータ特性が定義されています。EMP-HIRE-DATEはグループ・フィールドで、10レベルに下位要素があります。10レベルの各フィールドは基本項目で、PICTURE句があり、データ特性が定義されています。EMP-HIRE-DATEグループ・フィールドを使用して、日付全体を参照できます。このフィールドには月、日、および年の要素があります。各従属フィールドを個別に参照することもできるため、たとえば年のみにアクセスすることもできます。
データ要素の形式と特性を定義するには、USAGE句およびPICTURE句を使用します。USAGE句を指定しない場合、データはDISPLAY形式の外部数値または外部文字になります。PICTURE句およびUSAGE句はデータ型を識別します。COBOLデータ型およびリレーショナル・データ型へのマップ方法の詳細は、表3-1に示されています。
COBOLは、配列と可変長配列をサポートしています。これらの複雑な構造は、OCCURS句によって識別されます。DEPENDING ON句の指定を追加して、可変長配列を定義します。配列には、OCCURS句で配列の要素数を示します。可変長配列には、OCCURS句でxからyの範囲の要素を指定し、DEPENDING ON句で配列の実際の要素数を含むフィールドを識別します。配列または可変長配列を基本フィールドまたはグループに定義できます。例3-2に、基本フィールドに定義された配列の例を示します。
例3-2 基本フィールドに定義された配列
01 EMPLOYEE-RECORD.
05 EMP-ID PIC 9(6).
05 EMP-REGION PIC 9.
05 EMP-DEPT PIC 999.
05 EMP-HIRE-DATE.
10 EMP-HIRE-DATE-MM PIC 99.
10 EMP-HIRE-DATE-DD PIC 99.
10 EMP-HIRE-DATE-YYYY PIC 9999.
05 EMP-SALARY PIC 9(9).
05 EMP-NAME PIC X(15).
05 EMP-SKILL-LEVEL PIC 99 OCCURS 4 TIMES.
05 EMP-SKILL-ID PIC 9(4) OCCURS 4 TIMES.
EMP-SKILL_LEVELおよびEMP-SKILL_IDの2つの独立した配列が定義されています。この例では、レコードにEMP-SKILL-LEVELが4回出現し、その後にEMP-SKILL-IDが4回出現します。ファイルの各レコードは、EMP_SKILL_LEVEL、EMP_SKILL_LEVEL、EMP_SKILL_LEVEL、EMP_SKILL_LEVEL、EMP_SKILL_ID、EMP_SKILL_ID、EMP_SKILL_ID、EMP_SKILL_IDとして構成されます。
例3-3に、基本フィールドで定義された可変長配列の例を示します。
例3-3 基本フィールドに定義された可変長配列
01 EMPLOYEE-RECORD.
05 EMP-ID PIC 9(6).
05 EMP-REGION PIC 9.
05 EMP-DEPT PIC 999.
05 EMP-HIRE-DATE.
10 EMP-HIRE-DATE-MM PIC 99.
10 EMP-HIRE-DATE-DD PIC 99.
10 EMP-HIRE-DATE-YYYY PIC 9999.
05 EMP-SALARY PIC 9(9).
05 EMP-NAME PIC X(15).
05 EMP-SKILL-COUNT PIC 99.
05 EMP-SKILL-LEVEL PIC 99 OCCURS 1 TO 4 TIMES.
DEPENDING ON EMP-SKILL-COUNT.
05 EMP-SKILL-ID PIC 9(4) OCCURS 1 TO 4 TIMES.
DEPENDING ON EMP-SKILL-COUNT.
EMP-SKILL_LEVELおよびEMP-SKILL_IDの2つの独立した配列が定義されています。この例では、EMP-SKILL-COUNTの値によって2つの配列の出現数が決定されます。ファイルのEMP_SKILL_COUNTが1のレコードは、EMP_SKILL_LEVEL、EMP_SKILL_IDとして構成されます。EMP-SKILL-COUNTの値が2の場合は、EMP-SKILL-LEVELが2回出現した後にEMP-SKILL-IDが2回出現します。ファイルのEMP_SKILL_COUNTが2のレコードは、EMP_SKILL_LEVEL、EMP_SKILL_LEVEL、EMP_SKILL_ID、EMP_SKILL_IDとして構成されます。
例3-4に、グループ・フィールドに定義された配列の例を示します。
例3-4 グループ・フィールドに定義された配列
01 EMPLOYEE-RECORD.
05 EMP-ID PIC 9(6).
05 EMP-REGION PIC 9.
05 EMP-DEPT PIC 999.
05 EMP-HIRE-DATE.
10 EMP-HIRE-DATE-MM PIC 99.
10 EMP-HIRE-DATE-DD PIC 99.
10 EMP-HIRE-DATE-YYYY PIC 9999.
05 EMP-SALARY PIC 9(9).
05 EMP-NAME PIC X(15).
05 EMP-SKILLS OCCURS 4 TIMES.
10 EMP-SKILL-LEVEL PIC 99.
10 EMP-SKILL-ID PIC 9(4).
この例は、4つの要素で配列が定義されます。各要素には、EMP_SKILL_LEVELおよびEMP_SKILL_IDフィールドがそれぞれ1回出現します。ファイルの各レコードは、EMP_SKILL_LEVEL、EMP_SKILL_ID、EMP_SKILL_LEVEL、EMP_SKILL_ID、EMP_SKILL_LEVEL、EMP_SKILL_ID、EMP_SKILL_LEVEL、EMP_SKILL_IDとして構成されます。
例3-5に、グループ・フィールドに定義された可変長配列の例を示します。
例3-5 グループ・フィールドに定義された可変長配列
01 EMPLOYEE-RECORD.
05 EMP-ID PIC 9(6).
05 EMP-REGION PIC 9.
05 EMP-DEPT PIC 999.
05 EMP-HIRE-DATE.
10 EMP-HIRE-DATE-MM PIC 99.
10 EMP-HIRE-DATE-DD PIC 99.
10 EMP-HIRE-DATE-YYYY PIC 9999.
05 EMP-SALARY PIC 9(9).
05 EMP-NAME PIC X(15).
05 EMP-SKILL-COUNT PIC 99.
05 EMP-SKILLS OCCURS 4 TIMES DEPENDING ON EMP-SKILL-COUNT.
10 EMP-SKILL-LEVEL PIC 99.
10 EMP-SKILL-ID PIC 9(4).
この例は、最大4つの要素で1つの配列が定義されます。EMP-SKILL-COUNTの値により、配列の出現数が定義されます。したがって、EMP-SKILL-COUNTの値を1に設定すると、EMP_SKILLSの出現回数は1回になります。ファイルのEMP_SKILL_COUNTが1のレコードは、EMP_SKILL_LEVEL、EMP_SKILL_IDとして構成されます。
EMP-SKILL-COUNTの値が2の場合、EMP_SKILLSの出現回数は2回になります。ファイルのEMP_SKILL_COUNTが2のレコードは、EMP_SKILL_LEVEL、EMP_SKILL_ID、EMP_SKILL_LEVEL、EMP_SKILL_IDとして構成されます。
COBOLでは、レコードのデータに複数の定義を使用できます。これらの定義のいずれかを使用してデータにアクセスできます。複数の定義を取得するには、次の3つの方法があります。
COBOLで生成されるファイルには、マルチ・レコード・タイプを使用できます。ファイルの定義にレベル01のアイテムが複数存在する場合、それぞれのレベル01がデータ・レコード領域の個別の定義になります。データ・レコード領域に保持されるレコードは一度に1つのみなので、レベル01の定義も一度に1つのみ使用されます。たとえば、部門レコードおよび従業員レコードの2つのタイプのレコードを含むファイルがあるとします。部門レコードおよび従業員レコードに、レベル01のアイテムが定義されています。各レコードの階層は、レコードのレベル01のアイテムの直後から始まり、レコード全体の定義を提供します。各レコードには、レコード・タイプを識別するフィールドが含まれます。このレコード・タイプは、すべてのレコード定義で同じ位置にあります。
次の例では、レコード・タイプが最初の位置にあります。
データ階層に関する項で説明したように、フィールドはグループ化できます。これらのグループはフィールドの追加定義を提供するものであり、データへのアクセスに使用されます。
COBOLには、フィールドまたはグループを再定義する機能があります。再定義では、新しいロケーションにデータを定義するかわりに、以前に定義したデータ文字の追加定義を行います。
例3-7 フィールドの再定義
01 EMPLOYEE-RECORD.
05 EMP-ID PIC 9(6).
05 EMP-ID-R REDEFINES EMP-ID.
10 EMP-ID-GROUP PIC 99.
10 EMP-ID-NUM PIC 9999.
05 EMP-REGION PIC 9.
05 EMP-DEPT PIC 999.
前述の例では、EMP-IDフィールドが6桁の数値フィールドとして定義されています。再定義により、フィールドが2つのフィールドに分割されます。EMP-ID-GROUPは、EMP-IDフィールドの最初の2桁として定義されます。EMP-ID-NUMはEMP-IDフィールドの下4桁として定義されています。EMP-ID-NUMとEMP-ID-GROUPは両方ともレコード内の先頭位置から始まっています。
例3-8 グループの再定義
01 EMPLOYEE-RECORD. 05 EMP-ID PIC 9(6). 05 EMP-ID-R REDEFINES EMP-ID. 10 EMP-ID-GROUP PIC 99. 10 EMP-ID-NUM PIC 9999. 05 EMP-REGION PIC 9. 05 EMP-DEPT PIC 999. 05 EMP-HIRE-DATE. 10 EMP-HIRE-DATE-MM PIC 99. 10 EMP-HIRE-DATE-DD PIC 99. 10 EMP-HIRE-DATE-YYYY PIC 9999. 05 EMP-SALARY PIC 9(9). 05 EMP-NAME PIC X(15). 05 EMP-SKILLS OCCURS 4 TIMES. 10 EMP-SKILL-LEVEL PIC 99. 10 EMP-SKILL-ID PIC 9(4). 05 EMP-SKILLS-R REDEFINES EMP-SKILLS. 10 EMP-SKILL-LEVEL1 PIC 99. 10 EMP-SKILL-ID1 PIC 9(4). 10 EMP-SKILL-LEVEL2 PIC 99. 10 EMP-SKILL-ID2 PIC 9(4). 10 EMP-SKILL-LEVEL3 PIC 99. 10 EMP-SKILL-ID3 PIC 9(4).
前述の例では、各要素を拡張してそのフィールドが示されるように、EMP-SKILL配列が再定義されています。前述の例と同様に、EMP-SKILLS-Rの定義がEMP-SKILLSと同じデータ領域を定義しています。EMP-SKILL-LEVELの最初の出現位置は、EMP-SKILL-LEVEL1のレコードの位置と同じです。
COBOLプログラムにより、異なる編成のファイルを作成できます。これには、次のファイルが含まれます。
行順: 行順ファイルは、このファイル・タイプが主にデータの表示に使用されるため、一般的にテキスト・ファイルと呼ばれます。これらのファイルのレコードは、書き込まれた順序でのみアクセスできます。行順ファイルには、可変長レコードが含まれます。レコード・デリミタがファイルの各レコードを分割します。使用されるレコード・デリミタは、オペレーティング・システムによって異なり、各レコードの最後の文字の後に挿入されます。
レコード順次編成: レコード順次編成ファイルも書き込まれた順序でアクセスが行われます。このファイル編成は行順次編成よりも柔軟性があります。レコードは、固定長または可変長です。レコード順次編成は、バイナリ・データまたはパック済データ、あるいはその他の印刷不能文字があるデータを含む順次編成ファイルに使用します。固定長ファイルでは、ファイルに書き込まれたすべてのレコードが同じ長さになります。必要に応じて、長さを統一するためにレコードに空白が追加されます。可変長レコードの場合は、それぞれのレコードの実際の長さに従ってレコードが書き込まれます。各レコードの先頭には、レコード記述語(RDW)が挿入されます。RDWにはレコードの実際の長さが含まれています。RDWはレコードの一部とはみなされず、データ定義にも含まれません。一般的に、可変長レコードは多数の小さなレコードといくつかの大きなレコードがある場合に使用します。可変長レコードは、インポートする前に変換する必要があります。
相対ファイル: 相対ファイルは、書き込まれた順序でなくランダムにアクセスすることもできます。レコードは可変長として宣言できますが、固定長として書き込まれます。ランダム・アクセスには、キーではなく相対レコード番号を使用します。相対ファイルは、インポートする前に順次ファイルに変換する必要があります。
索引付きファイル: 索引付きファイルは、書き込まれた順序でなくキー・フィールドによってアクセスすることもできます。索引ファイルのレコードは固定長または可変長です。索引ファイルは、データを格納するファイルと索引を格納するファイルの2つの物理ファイルで構成されます。索引付きファイルは、インポートする前に順次ファイルに変換する必要があります。
データ・ストレージに使用されるファイル形式は、COBOLアプリケーションによって決定されます。この情報はコピーブックに定義されません。
COBOLファイルをリレーショナル・データベースにインポートする場合、データをリレーショナル・データベースにマップする方法を計画する必要があります。
レコード
最上位の各レコード・タイプのレベル01の構造が表のマッピングに検討されます。多くの場合、ファイルのレコードは独立した情報源になるよう設計されます。これがファイルと表の大きな違いです。表は、一般的に密接に関連した情報を格納するよう設計されます。ファイルのレコードを検討する場合、情報に対して複数の表を定義した方がよいかどうか検討する必要があります。多くの場合、関連情報の編成に使用されるグループは独立した表の適切な候補になります。たとえば、アドレス情報に定義されているグループがあれば、名前とアドレス表に自然と対応します。同様に、配列も、可変長や固定長を問わず、多くの場合に独立した表の適切な候補になります。
配列
Oracle Warehouse Builderは、配列を定義するために、配列内の各要素を個別に指定して配列を正規化します。この方法は、可変長配列の定義にも使用されます。SQL*Loaderを使用してすべての可変長配列はロードできません。可変長配列がレコードの末尾にある場合、SQL*Loaderで可変長配列をロードできることがあります。可変長配列が埋め込まれているレコードを可変長のまま物理的に格納する必要がないため、この方法を使用してレコードをロードできる場合があります。「例: シングル・レコード・タイプの可変長配列のCOBOLファイルからのデータの抽出」を参照してください。
SQLデータ型へのCOBOLデータ型のマッピング
USAGE句とPICTURE句は、データ要素の形式と文字を定義するために使用します。PICTURE句とUSAGE句を両方使用して、スカラー・データ型、長さ、精度およびスケールを指定します。表3-1に、COBOLファイルに適用されるデータ要素定義を示します。各データ型の表記、およびそのデータ型のSQL*Loaderデータ型定義へのマッピング方法が記載されています。PICTUREは、データを記述するマスクを表します。カッコ内の値は、直前のPICTURE要素の繰返し回数です。したがって、X(n)でn = 5の場合は、X型(英数字)の文字が5つあることを示します。
表3-1 COBOLデータ型および同等のSQL*Loaderデータ型
| COBOLデータ型 | SQL Loaderデータ型 | 説明 |
|---|---|---|
|
X(n) |
|
英数字データ。各Xは、指定されたキャラクタ・セットの使用可能な1文字を表します。 |
|
A(n) |
CHAR(n) |
英字データ。各Aは、アルファベットまたは空白の任意の文字を表します。 |
|
9(n) |
|
数値データ。各9は、1桁の数字を表します。 |
|
+- mantissa +- exponent |
FLOAT EXTERNAL (length) |
外部浮動小数点データ。 |
|
S9(n)v9(m) SIGN TRAILING |
ZONED(precision, scale)、precision = n+m、scale = m |
数値データ。各9は、1桁の数字を表します。vは、暗黙の小数点位置を表します。符号は、最終バイトに保持されます。 |
|
9(n)v9(m) |
ZONED(precision, scale)、precision = n+m、scale = m |
数値データ。各9は、1桁の数字を表します。vは、暗黙の小数点位置を表します。 |
|
9(n)v9(m) S9(n)v9(m) |
SMALLINT INTEGER(length 2、4または8) SIGNED|を使用する場合があります。 UNSIGNED BYTEORDER句が必要な場合があります。 スケールで式を処理します。 |
2を基数とする内部形式のデータ。 フィールドのサイズは、値mで変わります。 n+m = 1-4、length = 2 n+m = 5-9、length = 4 n+m = 10-18、length =8 |
|
使用不可 |
FLOAT BYTEORDER句が必要な場合があります。 |
単精度浮動小数点数、4バイト長 |
|
使用不可 |
DOUBLE BYTEORDER句が必要な場合があります。 |
倍精度浮動小数点数、8バイト長 |
|
9(n)v9(m) S9(n)v9(m) |
DECIMAL (precision, scale)、precision = n+m、scale = m |
10を基数とする内部形式の数値データ。この句は、各桁が最小記憶域を使用する必要があることを示します。通常、各バイトは2桁で、最後の半バイトに符号が格納されます。 |
|
X(n) 9(n)v9(m) S9(n)v9(m) |
通常は使用されません。 |
データの内部形式は未定義です。多くの場合、BINARYと同じように格納されますが、基数は反転することがあります。 |
|
G(n) |
GRAPHIC(n) |
シフトインおよびシフトアウト文字を含まないグラフィック・データ |
|
05 V 49 V-LN PIC S9(4) COMP 05 V-DATA PIC X(n) |
VARCHAR(max length)は、SMALLINTのサイズが同じシステム間でのみ正しくロードできます。 |
可変長文字フィールド |
|
05 V 49 V-LN PIC S9(4) COMP 05 V-DATA PIC G(n) |
VARGRAPHIC(max length)は、SMALLINTのサイズが同じシステム間でのみ正しくロードできます。 |
シフトインおよびシフトアウト文字を含まない可変長グラフィック・データ |
COBOLのメタデータをインポートするには、フラット・ファイル・モジュールを作成し、COBOLコピーブックからメタデータ定義をインポートする必要があります。
コピーブックのインポート
COBOLコピーブックからメタデータをインポートする手順は、次のとおりです。
「フラット・ファイル・モジュールの作成」の説明に従って、フラット・ファイル・モジュールを作成します。COBOLコピーブックのロケーション詳細を入力します。
新しく作成したモジュールを右クリックし、「インポート」、「COBOL」の順に選択します。
「COBOLインポート」ダイアログ・ボックスが表示されます。
別の方法で「COBOLインポート」ダイアログ・ボックスを開くには、新しく作成したモジュールを選択し、ファイル、「インポート」、「COBOL」の順に選択します。
「コピーブックの追加」をクリックして、インポートする必要があるコピーブックを参照します。
複数のコピーブックを同時に追加できます。コピーブックを追加すると、コピーブックのインポート・スプレッド表の「コピーブック」フィールドにコピーブックのディレクトリ・パスが表示されます。「ファイル」フィールドを使用して、インポートしたコピーブックの名前を編集します。「説明」フィールドを使用して、インポートしたコピーブックの説明(オプション)を追加します。
「コピーブックの表示」をクリックして、インポートしているコピーブックのメタデータ構造を表示します。
「セッション・オプション」をクリックして、「COBOLセッション・オプションのインポート」ダイアログ・ボックスを開きます。このダイアログ・ボックスで指定される値の詳細は、「COBOLセッション・オプションのインポート」を参照してください。
「OK」をクリックし、COBOLインポート・ウィンドウの「インポート」をクリックします。
このダイアログ・ボックスを使用して、テンプレート・ファイルおよび他のプロパティを指定できます。インポートしているコピーブックに基づいて、デフォルトの物理ファイル・プロパティを受け入れるかどうかを決定します。または、物理的な特性のインポート元のテンプレート・ファイルを選択します。インポート後にファイルの一部の物理プロパティも編集できます。
テンプレート・ファイルを指定するには、「フラット・ファイル・プロパティをコピー」リストからファイルを選択します。
「フラット・ファイル・プロパティをコピー」リストの「デフォルトのプロパティ」オプションを保持すると、次のプロパティとともに固定長のファイル(デリミタなし)が定義されます。
0レコードのスキップ
falseに設定する列名として最初の行を使用
レコード・デリミタを\nに設定
1論理レコード当たり1物理レコード
マルチ・レコード・コピーブックをインポートする場合、マルチ・レコードに設定されます。
「フラット・ファイル・プロパティをコピー」リストからファイルを選択した場合は、このファイルの物理特性が、新しくインポートしたコピーブックで使用されます。
グループをインポートしない: グループ・アイテムの定義を抑止します。これにより、下位のアイテムのみがインポートされます。次に、フィールドを使用した例を示します。
05 EMP-HIRE-DATE.
10 EMP-HIRE-MONTH PIC 99.
10 EMP-HIRE-DAY PIC 99.
10 EMP-HIRE-YEAR PIC 9999.
「グループをインポートしない」オプションを選択すると、EMP-HIRE-MONTH、EMP-HIRE-DAYおよびEMP-HIRE-YEARの3つのフィールドのみが作成されます。オプションを選択しないと、インポート時にEMP-HIRE-DATE、EMP-HIRE-MONTH、EMP-HIRE-DAY、EMP-HIRE-YEARの4つのフィールドが作成されます。
再定義をインポートしない: 冗長な再定義フィールドのインポートを回避します。次に、コピーブック定義を使用した例を示します。
05 HIRE_DATE. 10 HIRE_MONTH PIC 99. 10 HIRE_DAY PIC 99. 10 HIRE_YEAR PIC 9999. 05 HIRE_DATE_ALPHA REDEFINES HIRE_DATE. 10 HIRE_MONTH PIC XX. 10 HIRE_DAY PIC XX. 10 HIRE_YEAR PIC XXXX.
すべてのフィールドをインポートするには、「再定義をインポートしない」オプションの選択を解除します。このオプションを選択すると、HIRE_DATE、HIRE_MONTH、HIRE_DAY、HIRE_YEARの最初の4つのフィールドのみがインポートされます。
メタデータのインポート時に、グループ化フィールドおよび再定義フィールドを含む不要なメタデータのコピーブックを確認することをお薦めします。後でファイルを編集して、不要な定義を削除することもできます。
COBOLデータファイルからデータを抽出するには、最初に対応するコピーブックをインポートする必要があります。インポートに次のコピーブックを検討してください。
01 EMPLOYEE-RECORD.
05 EMP-RECORD-LENGTH PIC 9(4).
05 EMP-ID PIC 9(6).
05 EMP-REGION PIC 9.
05 EMP-DEPT PIC 999.
05 EMP-HIRE-DATE.
10 EMP-HIRE-MM PIC 99.
10 EMP-HIRE-DD PIC 99.
10 EMP-HIRE-YEAR PIC 9999.
05 EMP-SALARY PIC 9(9).
05 EMP-NAME PIC X(15).
05 EMP-SKILLS OCCURS 4 TIMES.
10 EMP-SKILL-LEVEL PIC 99.
10 EMP-SKILL-ID PIC 9999.
「コピーブックのインポート」の説明に従って、コピーブックをインポートします。
インポートしたコピーブックのファイル・プロパティを設定するには、プロジェクト・ナビゲータのファイルを右クリックして、「開く」をクリックします。「フラット・ファイルの編集」ダイアログ・ボックスで、「ファイル・プロパティの定義」の説明に従ってファイル・プロパティを定義します。
「名前」、「一般」および「構造」タブを使用して、ファイル・プロパティを指定します。
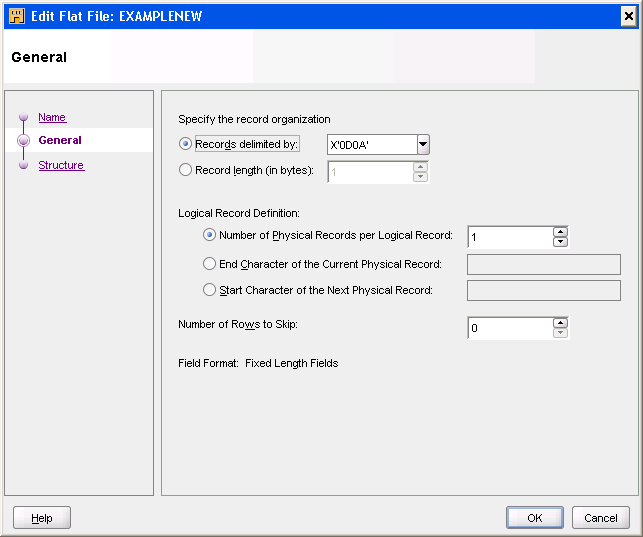
「一般」タブを使用して、次のファイル・プロパティを設定します。
レコード・デリミタ: このファイルのレコード・デリミタをバイナリ値のX'0D0A'に設定する必要があります。
論理レコード定義: この例では、1物理レコード当たり1論理レコードがあります。
フィールド書式: このレコードの各フィールドは、一定の位置にあります。したがって、デフォルトで「固定長フィールド」オプションが選択されます。
レコード・タイプ: このコピーブックには、単一のレコード・タイプが含まれます。したがって、デフォルトで「シングル・レコード」オプションが選択されます。
フィールド・プロパティを図3-5に示します。
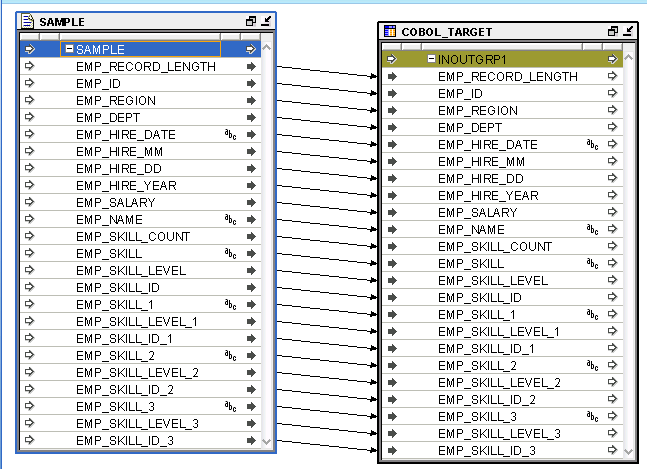
ソースとしてインポートしたCOBOLファイルを使用して、マッピングを作成します。マッピングにバインドされていない表演算子を挿入して、COBOLファイルから表演算子に任意のフィールドをマップします。
マッピングを右クリックし、「構成」をクリックして「構成プロパティ」ダイアログ・ボックスを開きます。コード生成言語として、「SQL*LOADER」を選択します。他のSQL*Loader設定を調整します。
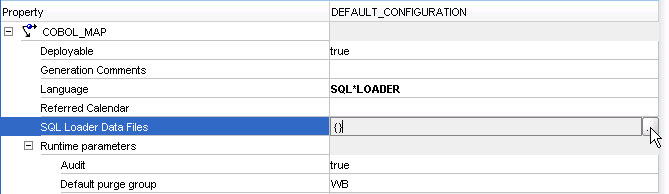
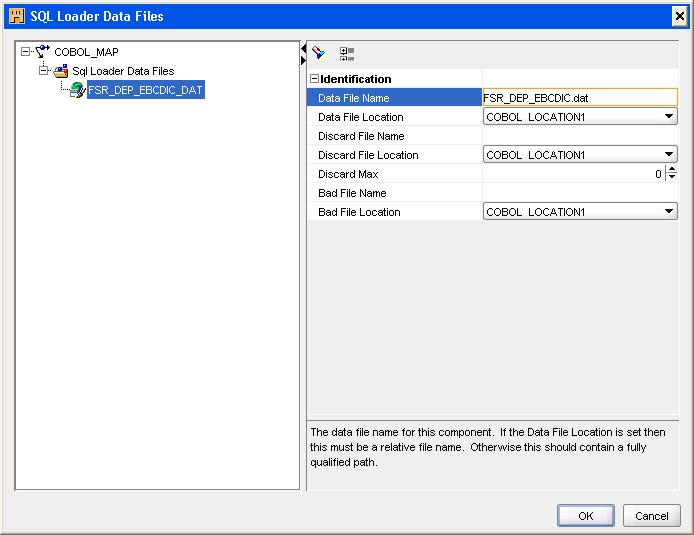
「SQL*Loaderデータファイル」をクリックし、図3-9に示されているような省略記号をクリックして「SQL*Loaderデータファイル」ダイアログ・ボックスを開きます。
「SQL*Loaderデータファイル」ダイアログ・ボックスで、「SQL*Loaderデータファイル」を右クリックして、「作成」を選択します。「SQL*Loaderデータファイル」の下に新しいデータファイル・ノードが追加されます。
データファイル名を入力して、データをロードするデータファイルのロケーションを選択します。データのエラーによってターゲット表にロードされないレコードを格納するには、不正なファイルを指定します。SQL*Loaderロード・チェックが原因でロードされないレコードを格納するには、廃棄ファイルを指定します。
マッピングの構成プロパティを定義した後、表およびマッピングをデプロイし、COBOLデータをターゲット表にロードするマッピングを開始できます。
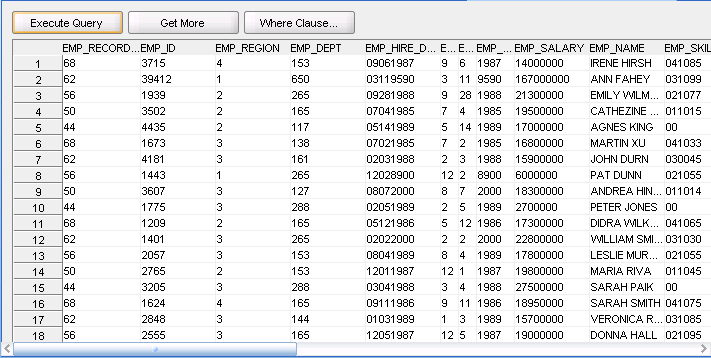
マッピングをデプロイするには、マッピングを右クリックして、「配布」を選択します。マッピングのデプロイ後、マッピングを開始します。マッピングを右クリックして「開始」を選択します。マッピングを実行すると、マッピングの構成中に指定したデータファイルからデータが読み込まれ、ターゲット表にロードされます。
ターゲット表のデータを表示するには、表を右クリックして、「データ」を選択します。図3-11に、表のデータを示します。
「フラット・ファイルの編集」ダイアログ・ボックスを使用して、ファイルの定義を表示および編集できます。
ファイル定義を更新する手順は、次のとおりです。
プロジェクト・ナビゲータで、ファイル定義を選択します。
ファイルを右クリックし、「開く」を選択します。
Oracle Warehouse Builderの「フラット・ファイルの編集」ダイアログ・ボックスに、次のタブが表示されます。
「名前」タブ: このタブを使用して、ファイルの名前と説明を編集します。
「一般」タブ: このタブを使用して、物理レコード・サイズ、1論理レコード当たりの物理レコード数、デリミタ文字および囲み文字などの一般ファイル・プロパティを変更します。
「レコード」タブ: このタブは、マルチ・レコード・タイプのフラット・ファイルにのみ使用できます。このタブを使用して、レコード・タイプの位置を変更するか、レコード・タイプを追加、削除または編集します。
「構造」タブ: このタブを使用して、フィールドのレベル属性、SQL*LoaderプロパティおよびSQLプロパティを編集します。
このタブを使用して、ファイルの名前、デフォルトの物理ファイル名、説明およびキャラクタ・セットを編集します。詳細は、「フラット・ファイルの説明」を参照してください。
このタブを使用して、物理レコード・サイズ、1論理レコード当たりの物理レコード数、デリミタ文字および囲み文字、スキップする行数、フィールド書式などの一般プロパティを変更します。一般プロパティの詳細は、「フラット・ファイルのファイル・プロパティの定義」を参照してください。
マルチ・レコード・タイプのファイルの場合、レコード・タイプ・ロケーションのレコード・タイプを判別するフィールドの位置を指定します。
フィールド位置: このフィールドには、レコード・タイプのインジケータを含む列が表示されます。この値は変更可能です。たとえば、2つのレコード・タイプを持つフラット・ファイルで、次のリストに示すように、3番目の列の内容で各レコード・タイプが区別される場合、このフィールドの値は3になります。
レコード・タイプ1: 2002 0115 E 4564564
レコード・タイプ2: 2003 1231 D 659871 Q HKLIH
レコード・タイプの値: この表には各レコード・タイプ、レコード・タイプを他のレコード・タイプと区別する値、およびレコード・タイプに付けた名前が表示されます。表3-2では、前述の2つのサンプル・レコードについて、レコード・タイプの値の例を示します。
新規レコード・タイプを追加するには、「新規」をクリックして、タイプ値、およびレコード・タイプを説明するレコード名を入力します。
レコード・タイプを削除するには、削除する各レコード・タイプの左側にあるフィールドを選択して、「削除」をクリックします。
マルチ・レコード・タイプの固定長ファイルの場合、レコード・タイプ・ロケーションは、レコード・タイプのインジケータを決定する次の2つのフィールドで構成されます。
開始位置: レコード・タイプを指定するフィールドの開始位置。
長さ: フィールドの長さ。
「構造」タブを使用して、フィールド名、データ型、マスク、SQL*LoaderプロパティおよびSQLプロパティを編集します。フィールドを追加または削除できます。また、フィールド・マスク、NULLIF条件またはDEFAULTIF条件も追加できます。
マルチ・レコード・タイプのファイルの場合、「レコード名フィールドで各レコード・タイプを選択できます。選択したレコードのフィールド・プロパティが表示されます。詳細は、「フラット・ファイルのフィールド・プロパティの定義」を参照してください。
外部表は、Oracle Database9i以上で使用可能なデータベース・オブジェクトです。
外部表は、フラット・ファイルのデータをリレーショナル形式で表現した表です。外部表は読取り専用の表で、通常のソース表と同様に動作します。外部表を作成および定義すると、外部表のメタデータがワークスペースに保存されます。フラット・ファイルから外部表にデータをロードし、マッピングを使用してデータを変換して、変換したデータをターゲット表にロードできます。
次の各項では、外部表について説明します。
前提作業
作成する各外部表は、既存のフラット・ファイル内のシングル・レコード・タイプに対応します。まず、「文字データファイルの定義」の説明に従って、最初にワークスペース内にファイルを定義します。
新しい外部表定義を作成する手順は、次のとおりです。
プロジェクト・ナビゲータで、「データベース」ノード、続いて「Oracle」ノードを開きます。
外部表を作成するモジュールを展開します。
「外部表」を右クリックして、「新規外部表」を選択します。
Oracle Warehouse Builderで、外部表の作成ウィザードの「ようこそ」ページが開きます。このウィザードを使用して、次のページを完了します。
名前ページを使用して、外部表の名前と説明(オプション)を定義します。「名前」フィールドに名前を入力します。物理ネーミング・モードでは、1から200の有効な文字数で名前を入力する必要があります。物理モードで空白は使用できません。論理モードでは、一意の名前を4000文字以内で入力できます。外部表の名前はモジュール内で一意である必要があります。論理ネーミング・モードでは、空白を使用できます。
「説明」フィールドを使用して、外部表の説明(オプション)を入力します。
ウィザードに、ファイルの選択ページが表示されます。ウィザードには、ワークスペース内の使用可能なすべてのフラット・ファイルが一覧表示されます。外部表の基になるファイルを選択します。長いファイル・リストから検索するには、ファイル名の最初の数文字を入力して、実行をクリックします。
マルチ・レコード・タイプのファイルを選択した場合は、ファイルの選択ページの下部で、レコード・タイプ名も選択する必要があります。外部表には1つのレコード・タイプしか表示されません。
この段階でファイルを指定しないこともできます。ウィザードでファイルを指定しない場合、後から外部表のプロパティ・シートでレコード・タイプ、アクセス・パラメータ、データファイルなどの情報を指定できます。
フラット・ファイルのロケーションのリストからロケーションを選択できます。また、ロケーションは指定しなくてもかまいません。ウィザードでロケーションを指定しない場合、後から外部表のプロパティ・シートでロケーションを指定できます。
|
注意: 外部表自体をデプロイする前に、外部表に関連付けられているロケーションをデプロイする必要があります。 |
フラット・ファイルから外部表を作成することも、既存の外部表をOracle Warehouse Builderにインポートすることもできます。
外部表をインポートする手順は、次のとおりです。
プロジェクト・ナビゲータで、「外部表」を右クリックして、「インポート」を選択します。
データベース・オブジェクトまたはOracle Warehouse Builderメタデータ・ファイルをインポートするかどうか指定します。
外部表エディタを使用して外部表定義を編集します。エディタを開くには、プロジェクト・ナビゲータで外部表の名前を右クリックして「エディタを開く」を選択します。「外部表の編集」ダイアログ・ボックスが表示されます。編集できるタブとプロパティは、ワークスペースにおける外部表の定義内容に応じて異なります。
外部表プロパティ・ウィンドウには次のタブが表示されます。
外部表の名前を変更するには、「名前」タブを使用します。表の名前を変更するときと同じルールが外部表にも適用されます。詳細は、Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイドを参照してください。
列を追加または編集するには、「列」タブを使用します。表に列を追加するときと同じルールが外部表にも適用されます。詳細は、Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイドを参照してください。
外部表のメタデータを提供するフラット・ファイルの名前を表示するには、「ファイル」タブを使用します。マルチ・レコード・タイプのソース・フラット・ファイルの場合、「ファイル」タブには外部表に関連付けられている「レコード名」も表示されます。この関係を更新するか、別のファイルとレコードに変更するには、外部表を調整します。詳細は、「外部表の定義とファイル内のレコードとの同期化」を参照してください。
「ファイル」タブは次の条件で表示されます。
新規外部表ウィザードを使用して外部表を作成し、ファイル名を指定した場合。
新規外部表ウィザードではファイル名を指定していないが、外部表の定義をファイルおよびレコードと調整した場合。
フラット・ファイルのロケーションを表示または変更するには、「ロケーション」タブを使用します。使用可能なロケーションが「ロケーション」リストに表示されます。このリストからロケーションを選択します。
外部表のデータ・ルールを定義するには、「データ・ルール」タブを使用します。データ・ルールの使用方法の詳細は、Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイドを参照してください。
アクセス・パラメータでは、外部表にファイルが指定されていない場合にフラット・ファイルを読み取る方法を定義します。外部表エディタに、「ファイル」タブのかわりに「アクセス・パラメータ」タブが表示される場合もあります。
アクセス・パラメータのタブは次の条件で表示されます。
別のワークスペースから外部表をインポートした場合。この場合は、アクセス・パラメータの表示と編集ができます。
外部表をOracleデータベースに作成し、その定義をインポートした場合。この場合は、アクセス・パラメータの表示と編集ができます。
外部表の作成ウィザードを使用して外部表を作成し、参照ファイルを指定しなかった場合。アクセス・パラメータは空です。外部表を生成する前に、外部表の定義をフラット・ファイル・レコードと調整するか、独自のアクセス指定を手動で入力する必要があります。
アクセス・パラメータにより、ソース・データファイル内のフィールドを列として、外部表でどのように表現するかが記述されます。たとえば、INTEGER(2)データ型のフィールドemp_idがデータファイルに含まれている場合、アクセス・パラメータで、そのフィールドを外部表内の文字列の列に変換するように指定できます。
外部表の生成方法とデプロイ方法に影響を及ぼすアクセス・パラメータは変更できますが、変更しないことをお薦めします。変更内容は検証されません。外部表およびアクセス・パラメータの詳細は、『Oracle Databaseユーティリティ』を参照してください。
|
注意: Oracle Warehouse Builderに外部表をインポートする際、表のアクセス・パラメータ定義は4000文字に切り捨てられます。このため、DDL生成エラーが発生する可能性があります。 |
Oracle Warehouse Builderでは、外部表に関連付けられているファイルに対するメタデータの変更を反映して、外部表定義を更新できます。そのためには、外部表とソース・ファイルを同期化します。
外部表定義とファイル内のレコードを同期化する手順は、次のとおりです。
プロジェクト・ナビゲータで、外部表を右クリックして、「同期化」を選択します。
「同期化」ダイアログ・ボックスが表示されます。
「同期化するオブジェクトを選択してください」リストを使用して、外部表を同期化するフラット・ファイルを指定します。
デフォルトでは、外部表の作成に使用されたフラット・ファイルがこのリストに表示されます。リストを開いて、フラット・ファイル・モジュールおよびモジュールに含まれるフラット・ファイルのリストを確認します。
「一致方針」リストを使用して、一致する項目の検索方法、およびフラット・ファイルの情報で外部表を更新する方法を指定します。一致方針のオプションは次のとおりです。
オブジェクトIDによる一致: この方針では、外部表列参照のフィールドIDが、フラット・ファイル内のフィールドIDと比較されます。
オブジェクト名による一致: この方針では、外部表内の物理名が、フラット・ファイル内の物理名と比較されます。
オブジェクト位置による一致: この方針では、物理名やIDに関係なく、位置によって項目が照合されます。外部表の最初の属性はファイル内の最初のレコードによって調整され、2番目の属性はファイル内の2番目のレコードによって調整されます。外部表と新しいレコードを調整する場合は、この方針を使用します。
「同期化方針」リストを使用して、既存の外部表定義と指定したレコードとの間のメタデータの差異を処理する方法を指定します。
マージ: 既存の外部表定義のメタデータと指定したレコードのメタデータが結合されます。
置換: 外部表定義から既存のレコードのメタデータが削除され、新しいファイル・レコードのメタデータが外部表に追加されます。
「同期化プランの表示」をクリックして、「同期化プラン」ダイアログ・ボックスを開きます。
同期化の実行中に行われるアクションを表示できます。
新しい方針を選択して、「リフレッシュ・プラン」をクリックします。
スプレッド表で、「ソース」ノードを開いて、各列に実行されるアクションを表示します。
「OK」をクリックして、外部表定義の同期化を完了します。
|
注意: 外部表をワークスペースにインポートしたり、外部表のアクセス・パラメータを手動で定義する場合、外部表の一部の構成プロパティは、外部表プロパティ・ウィンドウの「アクセス・パラメータ」タブの設定によって無効になります。 |
外部表の物理プロパティを構成する手順は、次のとおりです。
プロジェクト・ナビゲータから外部表を選択します。
「編集」メニューから「構成」を選択します。ツールバーから「構成」アイコンをクリックすることもできます。
構成プロパティ・ウィンドウが表示されます。
プロパティを構成するには、空白部分をクリックしてリストから選択します。
「アクセス指定」では、Oracle Warehouse BuilderがSQL*Loader経由で外部表をロードする際に使用する次のファイルの名前とロケーションを指定できます。
不正なファイル: 不正なファイルの名前とロケーションを指定すると、エラーが原因でロードされなかったすべてのレコードをこのファイルに書き込むようOracleデータベースに指示することになります。たとえば、不正なファイルに書き込まれるレコードには、フィールドを外部表の列に変換する際に、データ型エラーが原因でロードされなかったレコードなどがあります。存在する不正なファイルを指定すると、そのファイルは上書きされます。
廃棄ファイル: 廃棄ファイルの名前とロケーションを指定すると、ファイルに設定されたSQL*Loaderのロード条件に基づいてロードされなかったすべてのレコードをこのファイルに書き込むようOracleデータベースに指示することになります。存在する廃棄ファイルを指定すると、そのファイルは上書きされます。
ログ・ファイル: ログ・ファイルの名前とロケーションを指定すると、外部表に関連するメッセージをこのファイルに記録するようOracleデータベースに指示することになります。存在するログ・ファイルを指定すると、新しいメッセージが追加されます。
これらの各ファイルについて、ファイルの名前とロケーションを指定するか、「未使用」または「デフォルトのロケーションを使用」を選択できます。
「拒否」では、拒否できる行数を指定できます。デフォルトでは、拒否できる行数に制限はありません。「無制限に拒否」をfalseに設定する場合は、「拒否できる数」に数値を入力します。
パラレル: パラレル処理を有効にします。単一のシステムを使用している場合、パフォーマンスを向上するには、この値をNONPARALLELに設定します。複数のシステムを使用している場合は、デフォルトのPARALLELをそのまま使用します。データ・ファイルは、アクセス・ドライバによって、個別に処理可能なチャンクに分割されます。次のファイル、レコードおよびデータ特性によって、ファイルのパラレル処理が禁止されます。
シーケンシャルなデータ・ソース(テープ・ドライブやパイプなど)。
マルチバイト・キャラクタ・セット内にあり、文字列中で任意のバイトから始まっているために文字境界を決定できないデータ。この制限は、レコード当たりのバイト数が固定されているデータファイルには適用されません。
VARフォーマットのレコード。
外部表をワークスペースにインポートしたり、ソース・ファイルを指定せずに外部表を作成した場合は、これらのプロパティを構成しないでください。データ特性のプロパティは、外部表プロパティ・ウィンドウの「アクセス・パラメータ」タブの設定によって無効になります。
「データ特性」では、次のプロパティを設定できます。
エンディアン: 「エンディアン」プロパティのデフォルトは「プラットフォーム」です。この指定によって、フラット・ファイルのエンディアンはそのファイルが存在するプラットフォームのエンディアンに一致するものとみなされます。ファイルがWindowsプラットフォーム上に存在する場合、データはリトル・エンディアン・データとして処理されます。ファイルがSun SolarisまたはIBM MVSに存在する場合、データはビッグ・エンディアンとして処理されます。フラット・ファイルのエンディアン値が判明している場合は、ビッグ・エンディアンまたはリトル・エンディアンを選択できます。ファイルがUTF16で、エンディアンを示すマークがファイルの先頭に含まれている場合、そのエンディアンが使用されます。
文字列のサイズ: このプロパティは、UTF16など、マルチバイト・キャラクタ・セットのデータを処理する方法を指定します。デフォルトでは、データファイル内の文字列の長さはバイト数であるとみなされます。文字列のサイズが文字数で指定されるように、選択内容を変更することもできます。
外部表をワークスペースにインポートしたり、ソース・ファイルを指定せずに外部表を作成した場合は、これらのプロパティを構成しないでください。フィールド編集のプロパティは、外部表プロパティ・ウィンドウの「アクセス・パラメータ」タブの設定によって無効になります。
「フィールド編集」では、データファイル内の文字フィールドで実行される余白切捨てのタイプを指定できます。デフォルト設定では、切捨ては実行されません。これ以外の切捨てオプションを指定すると、パフォーマンスが低下する場合があります。また、文字フィールドの左側、右側、または両側の空白を切り捨てるように、切捨てオプションを設定することもできます。
また、SQL*Loaderの切捨て機能に従って切捨てを実行するオプションも設定できます。SQL*Loaderの切捨てを選択すると、固定長ファイルの場合は右側が切り捨てられます。囲みを持つように指定されたデリミタ付きファイルの場合は、フィールドに囲みがない場合にのみ左側が切り捨てられます。
レコード内の欠落フィールドの処理方法を指示できます。値の欠落したフィールドをNULLにするオプションをtrueに設定すると、値の欠落したフィールドはNULLに設定されます。このプロパティをfalseに設定すると、値の欠落したフィールドは拒否され、指定した不正なファイルに書き込まれます。
詳細は、Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイドを参照してください。
ファイルが外部表に関連付けられている場合、指定されたファイル名があり、その名前が使用されます。ユーザーは、別のファイルを指定する必要があるかどうか、または複数のファイルを指定する必要があるかどうかを構成できます。
データファイルを追加する手順は、次のとおりです。
「データファイル」ノードを右クリックして「作成」を選択します。
データファイルの名前(DATAFILE1など)を入力します。入力した名前は、「構成プロパティ」ダイアログ・ボックスの右パネルに新規ノードとして表示されます。
定義したデータファイルごとに、次の値を入力します。
データファイルのロケーション: フラット・ファイルのロケーション。
データファイル名: 拡張子を含むフラット・ファイル名。たとえば、myflatfile.datと入力します。