10gリリース3(10.1.3.1.0)
B31836-02
 目次 |
 索引 |
| Oracle Application Server パフォーマンス・ガイド 10gリリース3(10.1.3.1.0) B31836-02 |
|

この章では、パフォーマンスを向上するためにDBAが実行する必要があるOracle Application Server Wirelessメッセージ・サーバー用構成手順について説明します。
パフォーマンスの向上には、RAC環境とRACでない環境の両方において、メッセージ・サーバーの一方向処理と双方向処理のパフォーマンスを向上させるSQL最適化も含まれます。この章で説明する内容は次のとおりです。
RAC環境で様々なベンチマーク・テストを行った結果、高度に協調的に動作するようにアプリケーションを注意深く設計し、マルチノードRAC環境で実行する高パフォーマンス型AQを活用できるようにアプリケーションを適切にチューニングする必要があるということが判明しました。
マルチノードRAC環境のスループットは、複数のキューを次のように作成すると、大幅に向上する場合があります。すなわち複数のキューはそれぞれ、(a)各キューと特定のRACノード間にアフィニティが設定されるようにし、(b)RACノード上のエンキューやデキューのリクエストが、アフィニティが設定されているキューからのみメッセージを取得するように作成します。これによって、共有キューにアクセスする際に複数のRACノードからのリクエストで発生するキャッシュ・バッファ待ち状態が防止されます。
パフォーマンスに関する推奨事項の一部は、RACでない環境にも適用されます。
次の各項では、メッセージ・サーバーのパフォーマンスを向上するために必要な構成手順について説明します。
メッセージ・サーバーのパフォーマンスに影響を与える要因の詳細は、「メッセージ・サーバーのパフォーマンスに影響を与える要因」を参照してください。
この項では、Oracle Application Server 10.1.2.0.2 Wirelessメッセージ・サーバーに個別パッチを適用する手順について説明します。
トランザクション数の多い環境で最適なパフォーマンスを実現するようにデータベースをチューニングする必要があります。データベースをチューニングする際の推奨手順は次のとおりです。
REDOログのサイズを500MB以上に設定し、各グループにメンバーを3つ以上作成します(またはグループを3つ作成します)。
log_checkpoint_timeoutを0に設定すると、自動チェックポイントを無効にできます。
これには、次のコマンドを使用します。
alter system set log_checkpoint_timeout=0 scope=both;
パフォーマンスを向上するには、次のコマンドを使用して、LMSを1に設定します。
alter system set gcs_server_processes = 1 scope=spfile sid='*'
表9-1は、データベース・システム・パラメータと推奨値の一覧です。
| データベース・システム・パラメータ | 推奨値 | 備考 |
|---|---|---|
|
REDOログ |
グループごとのメンバーの数は3 |
この設定によりチェックポイントの待機状態を解消します。 |
|
Log_checkpoint_timeout |
0 |
この設定により自動チェックポイントを無効にします。 |
|
システム・グローバル領域 |
1GB以上 |
|
|
共有プール・サイズ |
300MB以上 |
|
|
LMSプロセス |
1 |
|
データベースのチューニングの詳細や、メッセージ・サーバーのパフォーマンスに影響を与えるOS要因の詳細は、「データベースのチューニング」を参照してください。
マルチノードRAC環境のパフォーマンスを最適化する場合のみ、次の手順を実行します。
SQL> @@trans_tbs_create.sql
たとえば、「/product/10.1.0/oradata/orcl」と入力します。
この作成スクリプトはまず、データファイルへのパスを指定せずに表領域の作成を試みます。ASM機能のある一般的なRAC環境では、このスクリプトは問題なく実行されます。ただし、RACでない一般的な環境では、データファイルのパスが指定されていないことを示すエラーが発生し、コマンドは失敗します。スクリプトはこのエラーを認識すると、ユーザーが指定したデータファイル用ベース・ディレクトリとファイル名(trans.dbf)を使用して、表領域の作成を試みます。
SQL> @@trans_tbs_migrate.sql
この項では、次のメッセージ・サーバー構成について説明します。
デキュー・ナビゲーション・モードをfirstからnextのメッセージに更新すると、メッセージ優先順位のセマンティックは失われますが、スループットはさらに向上します。これには、次の手順を実行します。
ワイヤレス・ユーザーとしてデータベースにログインし、次のコマンドを実行します。
SQL> @@trans_config_update.sql dequeue_navigation_mode next
使用方法: SQL> @@trans_config_update.sql <attr_name> <attr_val>
デフォルトのデキュー・ナビゲーション・モードに戻すには、次のコマンドを実行します。
SQL> @@trans_config_update.sql dequeue_navigation_mode first
高いメッセージング・パフォーマンスをマルチノードRAC環境において実現するには、中間層インスタンス上のメッセージ・サーバー・プロセスとOC4J_Wirelessプロセスが、必ず1つのRACノードにのみ接続する必要があります。このように構成すると、RACノードの数が中間層インスタンスの数より多くても、メッセージ・サーバーが別のRACノードを使用することはありません。図9-1と図9-2は、有効な構成を示しています。
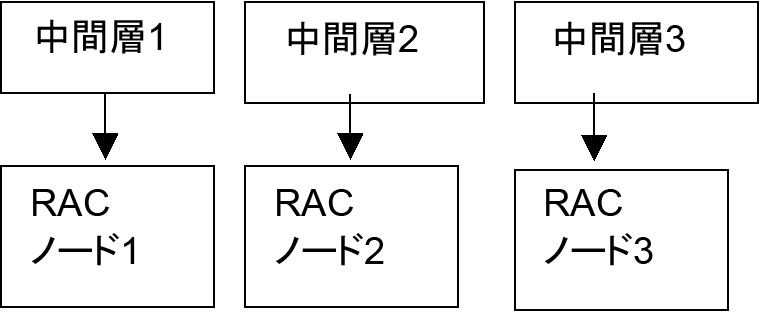
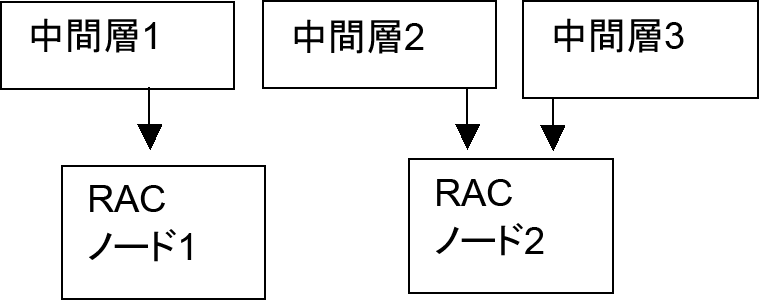
中間層インスタンスを前述のように構成するには、これらのプロセスに対して、カスタマイズした接続文字列をJVMパラメータとして指定します。手順は次のとおりです。
たとえば、<process-type id="messaging_server" module-id="messaging">のXMLを探します。
<module-data>
<category id="start-parameters">
<data id="java-parameters"
value="-Xms64M -Xmx256M -Dwireless.db.instance.string= (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=<%hostname%>)(PORT=<%port%>))(CONNECT_DATA=(SID=<%sid%>)))"/>
</category>
</module-data>
<%hostname%>、<%port%>および<%sid%>のトークンを、各RACノードで適切な値に置換します。
たとえば、<process-type id="OC4J_Wireless" module-id="OC4J">のXMLを探します。
次のJVMパラメータをvalue属性に追加します。
-Dwireless.db.instance.string= (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=<%hostname%>)(PORT=<%port%>))(CONNECT_DATA=(SID=<%sid%>)))
<%hostname%>、<%port%>および<%sid%>のトークンを、各RACノードで適切な値に置換します。
パフォーマンスを向上させるためにメッセージ・サーバーをチューニングするには、次の手順を実行します。
メッセージ・サーバーでは、ステータスID、メッセージID、ストアIDなどの様々なIDを生成するために、trans_midとtrans_didの順序が広範囲に使用されます。
推奨事項: アクセス速度を高速にするために、インスタンスのSGAには、50,000個の順序番号が事前に割り当てられたキャッシュが用意されています。
順序番号の数を100,000個に増やすことで、ディスクI/Oの削減とCR待機時間の短縮もできます。ただし、キャッシュのサイズを大きくすることで、他のアプリケーションのメモリー・フットプリントが減少しないように注意する必要があります。
警告: 順序キャッシュのサイズを大きくするとメッセージIDが不規則になったり、データベースの再起動時にIDに欠番が生じる場合があることを、DBAは認識しておく必要があります。
trans_ids表におけるobject_id列へのアクセス頻度は非常に高いです。
推奨事項: ソフトウェアにより、trans_ids表のobject_id列に作成された索引が強制的に使用されるようになっています。
テストではメッセージング・パフォーマンスが大幅に向上しました。
デキュー操作のデフォルト実装では、firstメッセージがナビゲーション・モードとして使用されます(dequeue_option.navigation = DBMS_AQ.FIRST_MESSAGE)。
推奨事項: ナビゲーション・モードをnextメッセージに変更してください(dequeue_option.navigation = DBMS_AQ.NEXT_MESSAGE)。詳細は、「デキュー・ナビゲーション・モードの更新」を参照してください。
テストではメッセージング・パフォーマンスが若干向上しました。しかし、このパフォーマンス向上方法には制限事項があります。nextメッセージをナビゲーション・モードに設定すると、キューからメッセージを選択するために使用されるカーソルがキャッシュされ、デキュー操作によってキューのスナップショットが取得されます。したがって、キューにエンキューされた新しいメッセージは参照できなくなります。エンキューされた新しいメッセージの優先順位が高く、スナップショット内のメッセージよりも先に処理する必要がある場合、この方法は問題になります。したがって、この変更は、受信するメッセージがすべて同じ優先順位であることが判明している場合にのみ適用してください。
大量のトランザクションを処理するシステムでは、多数のREDOが生成されます。そのため、ログ・スイッチにおいてチェックポイントが頻繁に発生する場合があります。チェックポイントは、データベースのalert.logファイルに記録されます。
推奨事項: チェックポイントとログ・スイッチの実行頻度を減らしてください。
チェックポイントの待機状態を解消するには、REDOログのサイズを500MB以上に設定し、各グループにメンバーを3つ以上作成します(またはグループを3つ作成します)。さらに、log_checkpoint_timeoutパラメータを0に設定すると、自動チェックポイントを無効にできます。
高いスループットを実現するには、リソース共有に関連するデータベース・パラメータを細かくチューニングします。
推奨事項: SGAおよび共有プールのサイズは、十分なサイズに設定してください。
SGAは1GB以上に設定します。
共有プールは300MB以上に設定します。
テストではメッセージング・パフォーマンスが大幅に向上しました。
2つのRACノードでベンチマーク・テストを行った結果、高度に協調的に動作するようにアプリケーションを注意深く設計し、マルチノードRAC環境で実行する高パフォーマンス型AQを最大限に活用できるようにアプリケーションを適切にチューニングする必要があるということが判明しました。
推奨事項: ソフトウェアにより、複数のキューが作成されています。すなわち複数のキューはそれぞれ、(a)各キューと特定のRACノード間にアフィニティが設定されるようにし、(b)RACノード上のエンキューやデキューのリクエストが、アフィニティが設定されているキューからのみメッセージを取得するように作成されています。これによって、共有キューにアクセスする際に複数のRACノードからのリクエストで発生するキャッシュ・バッファ待ち状態が防止されます。
テストではメッセージング・パフォーマンスが大幅に向上しました。
複数のノードからメッセージ・サーバーの表に対して頻繁にデータが挿入される場合は、データ・ブロック、表セグメント・ヘッダーおよび他のグローバル・リソース要求に対する同時アクセスにより、パフォーマンス問題が発生していました。
ASSMを使用すると、表の空き領域の管理に関連付けられたデータ構造が、個々のインスタンスに使用できる非結合セットに分割されます。ASSMにより、挿入用に十分な空き領域のあるデータ・ブロックが、各インスタンスで個別に管理されるため、個々のインスタンスで動作するプロセス間のパフォーマンス問題が改善されます。
推奨事項: メッセージ・サーバー(トランスポート)の表と索引では、ASSM表領域を使用してください。「マルチRAC環境のパフォーマンスの最適化」を参照してください。
複数のキューが必要になったことで、中間層インスタンスのバランシングも必要になります。
ある中間層インスタンス上のクライアントやメッセージ・サーバーが、使用可能なRACノードに不均等に分散して接続している場合は、キューが順番に処理されない場合があります。さらに、あるキューのエンキュー元やデキュー元が多すぎると、そのRACノードのスループット・パフォーマンスが低下する場合があります。
推奨事項: このような不均衡を防止するには、中間層インスタンスのmessaging_serverプロセスとOC4J_Wirelessプロセスを、1つの特定RACノードに関連付けてください。詳細は、「中間層インスタンスにおけるノード固有DB接続文字列の追加」を参照してください。
エンキューとデキューにおけるスレッドの数は、全体的なスループットに大きく影響します。そこで、実際のドライバとクライアント・アプリケーションを使用してから、最高の結果になるようにスレッド数を再度チューニングする必要があることに注意してください。RACノード上のキューにエンキュー元やデキュー元が多すぎると、そのキュー(および同じRACノード上の他のキュー)のスループットが低下する場合があります。エンキュー元やデキュー元(これらは、ドライバ送信処理スレッドとドライバ受信処理スレッド、またはクライアント送信処理スレッドとクライアント受信処理スレッドで制御される)の最適数は、RACノード、中間層マシン、ディスク・ストレージなどの物理的なハードウェア特性にも左右されます。
推奨事項: 各エンキュー処理スレッド(送信の場合はクライアント送信処理スレッド、受信の場合はドライバ受信処理スレッド)で生成される負荷が均等であると仮定すると、設定するスレッド数は、負荷が数分間続いた後のキュー内のメッセージ数によって異なります。キューがほとんど空の状態で、エンキュー・スレッド(送信の場合はクライアント送信処理スレッド)の数の値を大きくすると、エンキュー率が上昇する場合があります。キューのサイズが一定範囲を超えて増加し始めた場合(クライアント側でメッセージのエンキューを行う処理によって増加し続けた場合)は、デキュー・スレッド(送信の場合はドライバ送信処理スレッド)の数の値を大きくします。各RACノード上のキューのサイズが一定の値(100,000メッセージのテストで2,000メッセージ未満)になったとき、最高の結果になります。その差は微妙であるため、最高の結果を実現するには、繰り返してテストを実行する必要があります。ドライバとクライアントの両方においてスレッドの数が少なすぎても多すぎても、実現可能な最大スループットの値は小さくなります。
Oracle Streams AQのタイム・マネージャ・プロセスは、init.oraパラメータであるAQ_TM_PROCESSESで制御できます。このパラメータをゼロ以外の値に設定することで、キュー・メッセージの時間を監視したり、遅延や有効期限のプロパティが指定されているメッセージを処理できます。テスト環境においてこのパラメータを10に設定してテストを行いました。そうすると、AQのキュー・モニター・プロセスで問題が発生し、あるプロセスでは短いループの中でそのプロセスのCPU使用率が100%になり、他のプロセスに使用できるCPU時間が減少しました。この問題は、対応するプロセスを強制終了しても、そのプロセスのかわりに別のプロセスが作成されるため、解決しませんでした。オラクル社のAQチームでは、この問題に対処するためにこのパラメータ値を9に設定することをお薦めします。
AQチームによると、Oracle Streams AQリリース10.1ではこれがコーディネータ・スレーブ型アーキテクチャに変更されているため、実際にOracle Streams AQやStreamsがシステムで使用されている場合、コーディネータのプロセスが自動的に作成されます。このプロセスはQMNCと呼ばれ、システムの負荷に応じてスレーブを動的に作成します。スレーブの名前はqXXXで、Oracle Streams AQやStreamsのために様々なバックグラウンド・タスクを実行します。プロセス数は自動的に決定されて絶えず調整されるため、AQ_TM_PROCESSESを設定する必要はありません。しかし、テスト環境でこのパラメータを削除すると、メッセージ・サーバーによって必要以上のキューが作成されることが判明しました。値を9に設定した場合は、メッセージ・サーバーは適切に動作し、必要な数だけキューが作成されました。
そこで、次の現象が発生するかどうかを調べてください。
前述の現象のいずれかが発生した場合は、次の作業を実行します。
SQL> show parameter aq_tm_processes;
SQL> alter system set aq_tm_processes=9 scope=memory sid='*';
SQL> execute transport.drop_all_queues;
次の情報は、http://metalink.oracle.comのMetalink Note 363147.1の抜粋です。
RHEL3からRHEL4にアップグレードすると、RACのインターコネクト環境のシステム構成によっては、パフォーマンスが低下することがあります。このノートでは、問題を特定して解決するための手順について説明します。
この項の内容は、次のユーザーを対象としています。
グローバル・キャッシュ・ブロック損失とIPフラグメンテーション障害によって、RACインターコネクトのパフォーマンスが低下します。RACクラスタのLinux OSをRHEL3(2.4.21)からRHEL4(2.6.9)にアップグレードすると、グローバル・キャッシュ・ブロック損失率が1.5/秒まで上昇し、GC CRブロック損失が上位5位の待機イベントになることが判明しました。また、スループット・パフォーマンスは最大30%低下しました。GCブロック損失数は、パケット再組立てエラーの数に関連しています。これらの現象は、リリース番号によって異なりません。RHEL4を使用するシステムで発生する可能性があります。
さらなる分析により、RHEL3とRHEL4との間で、Intel社製e1000ドライバのイーサネット・フロー制御設定が変更されたことが、この現象の原因であることが判明しました。
この問題は、次の社内システム構成とお客様のシステム構成で確認されています。
同様の問題が発生しているかどうかを確認する方法は次のとおりです。
RHEL4(2.6.9)では、e1000ネットワーク・アダプタのRXフロー制御がデフォルトで無効になりますが、RHEL3ではこれが有効になります。このアダプタのRXフロー制御を有効にすると、ブロック損失とパケット再組立て障害が発生しなくなります。
フロー制御を設定するには、次の構文を使用します(ここでは、例としてeth1を使用します)。
完全な構文は、FlowControl value: 0-3(0=なし、1=RXのみ、2=TXのみ、3=RxとTx)です。各アダプタの値はカンマで区切って指定します。
e1000ネットワーク・アダプタのあるIntel Xeonサーバーの場合、RHEL3(2.4)では、ネットワーク・アダプタのRX(スイッチから送信されたフレームに対するe1000レスポンス)フロー制御がデフォルトで有効になります。しかし、RHEL4(2.6.9)にアップグレードすると、RXフロー制御はデフォルトで無効になるため、ブロック損失が発生します。この設定に変更される理由は現在も調査中です。フロー制御のデフォルト設定は、カーネルのe1000ドライバのバージョンとe1000カード本体のバージョンの両方によって異なることに注意してください。様々なチップセットと様々なe1000ドライバをベースとするIntel GigE NICの可用性も、この問題を複雑にしています。前述の問題の組合せを調べ、推奨される解決策を使用する必要があります。この動作は、RHEL4やすべてのIntel GigE NICで発生するわけではありません。Linux 2.4とLinux 2.6.9では、どちらのTXフロー制御もデフォルトでは無効にされます。TXフロー制御を有効にすることはお薦めしません。
この項では、RACインスタンスのいずれかに障害が発生した場合(またはオフラインになった場合)に、メッセージ・サーバーが実行する処理について説明します。
ドライバ・キューとサービス・キューが作成されると、メッセージ・サーバーは1次ノードと2次ノードをキューに割り当てます。デフォルトでは、1次ノードがアクティブ・ノード(現在キューにアフィニティが設定されているノード)になります。1次ノードに障害が発生すると、AQは2次ノードをアクティブにします。つまり、アフィニティを2次ノードに割り当てます。
メッセージ・サーバーはこのような変更を追跡でき、かつ変更を追跡する必要があります。ノードに接続する際に、エンキュー用とデキュー用の適切なキューを選択する必要があるためです。
現在の実装では、軽量のDBMSジョブが一定の間隔(2分ごと)でキューのアフィニティを監視し、キューとRACノードとのマッピング(メッセージ・サーバーで使用)を自動更新します。
したがって、ノードに障害が発生した場合、メッセージ・サーバーではアフィニティが変更されたキューからメッセージの処理を続行します。障害のあったノードがオンラインに復旧すると、マッピングはDBMSジョブによって自動的に再び割り当てられます。DBAが何もしなくても、単一インスタンスの障害は自動的に処理されます。
RACインスタンスを停止する予定があり、その停止時間中にDBMSジョブを待たずに、キューとRACノードとのマッピングを更新する場合は、RACノードを停止した後、次の手順を使用して更新を強制適用することができます。
SQL> execute transport.monitor_queues;
この項では、RACノードと中間層が永続的に追加されたり削除された場合に必要となるメッセージ・サーバー再構成手順について説明します。
RACノードを永続的に追加したり削除する場合は、メッセージ・サーバーを再構成して、キューを適切に作成できるようにする必要があります。そのためには、次の手順を実行します。
execute transport.drop_all_queues;
キューは起動時に自動的に作成されます。
最適なスループットを実現するにはロード・バランシングが不可欠であるため、メッセージ・サーバー用に構成されているRACノードの数と同数以上の中間層インスタンスを用意することが重要です。
RACノードの数より中間層インスタンスの数が少ない場合、メッセージ・サーバーは、中間層インスタンスが接続されているRACノードのみを使用します。
逆に、RACノードの数より中間層インスタンスの数が多い場合は、第1.4.1項の説明に従って、中間層インスタンスのDB接続文字列を構成できます。ただし、RACノード上のキューにエンキュー元やデキュー元が多すぎると、そのキュー(および同じRACノード上の他のキュー)のスループットが低下する場合があることに注意してください。エンキュー元やデキュー元(これらは、ドライバ送信処理スレッドとドライバ受信処理スレッド、またはクライアント送信処理スレッドとクライアント受信処理スレッドで制御される)の最適数は、RACノード、中間層マシン、ディスク・ストレージなどの物理的なハードウェア特性に左右されます。
この項では、テスト・シナリオの設定とテスト結果について説明します。
この項では、マシン、ソフトウェア、ハードウェアおよびRACの設定について説明します。
テストを実行する際、6台の同一マシンを使用しました。
3台のマシンに中間層をインストールし、3台のノードで構成されるRACにデータベースを配置しました。IMは別のマシンにインストールしました。
6台のマシン(3台は中間層、残り3台はRACノード)はいずれも、4GBのメモリー、3.0GHzのIntel Xeon CPUが2基(OSからは4基に見える)搭載されています。
OS: Red Hat Enterprise Linux AS R4(Nahant Update 3)
Oracle Application Server 10.1.2.0.2
DBおよびCRSは10.2.0.2です。ASMは2.0です。
データベース・サーバーはRAC内に構成しました。DBサーバーが同じデータベースにアクセスできるようにするには、3台のサーバー間で共有できるネットワーク・ストレージ・ユニットが必要です。これは、ファイバ・チャネルでサーバーに接続されるSANディスク(表9-2を参照)を使用することで解決しました。SANを使用すると、データベース・サーバーからのディスク・アクセスが高速にでき容易になります。また、Webベースのクライアント・ツールを使用して構成も簡単にできます。
一方向テストは、パフォーマンス向上用コードの実装前と実装後に実行しました。テスト・シナリオの詳細と結果は次のとおりです。
テストの実行に使用したメッセージの合計数: 各中間層で100,000メッセージ
実行したクライアント・プログラムの数: 各中間層マシンで1つ
実行したメッセージ・サーバーの台数: 各中間層マシンで1台
各中間層からメッセージを送信するクライアント・スレッドの数: 10個
各中間層から各クライアント・スレッドが送信するメッセージの数: 10,000個
送信処理間の間隔: 0
各中間層メッセージ・サーバー・インスタンスにあるドライバ送信スレッドの数: 8個
パフォーマンス向上用パッチを適用した後、一方向スループットの結果は図9-3のようになりました。
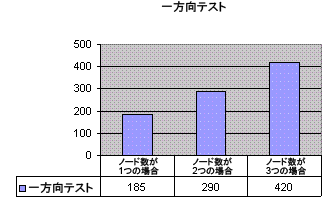
表9-3は、ダミー・ドライバを使用して生成された一方向テスト・データを示しています。
双方向テストは、パフォーマンス向上措置の適用前と適用後に実行しました。テスト・シナリオの詳細と結果は次のとおりです。
テストの実行に使用したメッセージの合計数: 各中間層で20,000メッセージ
実行したクライアント・プログラムの数: 各中間層マシンで1つ
実行したメッセージ・サーバーの台数: 各中間層マシンで1台
クライアント構成:
各中間層から実行するクライアントの受信スレッド・セットの数: 4個
ドライバ構成:
各中間層メッセージ・サーバー・インスタンスにあるドライバ送信スレッドの数: 3個
各中間層メッセージ・サーバー・インスタンスにあるドライバ受信スレッドの数: 2個
双方向テスト・シナリオの結果は、次のとおりです。
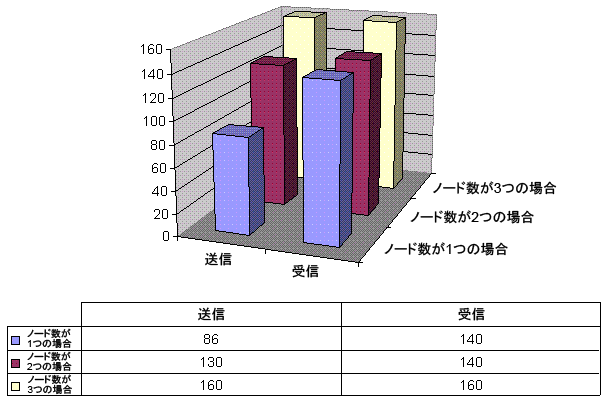
表9-4は、ダミー・ドライバを使用して生成された双方向テスト・データを示しています。
|
 Copyright © 2001, 2008, Oracle. All Rights Reserved. |
|