10gリリース3(10.1.3.2.0)
E05048-01
 目次 |
 索引 |
| Oracle Application Server 高可用性ガイド 10gリリース3(10.1.3.2.0) E05048-01 |
|


障害時リカバリとは、自然災害またはそれ以外の災害によるサイトの壊滅的な障害からシステムを回復することを指します。これら壊滅的な障害の例として、地震、竜巻、洪水、火事などがあります。さらに、システムの計画停止の管理方法も障害時リカバリに含まれます。障害時リカバリを必要とするほとんどの状況において、障害の解決には個々のハードウェアやサブコンポーネントのレプリケーションだけでなく、サイト全体を対象としたレプリケーションを行う必要があります。これは、Oracle Application Server Disaster Recovery(OracleAS Disaster Recovery)ソリューションについても同様です。
この章では、OracleAS Disaster Recoveryソリューション、その環境の構成および設定方法、およびソリューションの高可用性の向上を目的とした管理方法について説明します。ここでは、本番用およびスタンバイ用の2つのサイト内のOracleAS中間層およびInfrastructure層の両方を対象にします。スタンバイ・サイトは、本番サイトに対して、同じように対称的に構成される(同じ数のインスタンス)か、または非対称的に構成されます(Infrastructureサービスに対してより少ないインスタンスまたはOracleAS Disaster Recovery機能のみがサポートされます)。通常の運用では、本番サイトがリクエストを積極的に処理します。スタンバイ・サイトは、本番サイトがホスティングするアプリケーションおよびコンテンツを完全にミラー化した状態またはそれに近い状態で維持されます。
これらのサイトのOracleAS Disaster Recovery機能は、Oracle Application Server Guardを使用して管理します。Oracle Application Server Guardには、各種の管理タスク(これらの管理コマンドの詳細は、第6章「OracleAS Guard asgctlコマンドライン・リファレンス」を参照)がカプセル化されたコマンドライン・ユーティリティ(asgctl)が用意されています。OracleAS Disaster Recoveryソリューションでは、サイト全体で使用できるシステム・サービスの中でも特に次のサービスを活用します。背後では、OracleAS Guardによって、トポロジ内に分散されたOracleAS Recovery Manager(ファイル・システムの構成ファイルの管理)とOracle Data Guard(OracleAS Infrastructureデータベースの管理)が自動的に使用されます。表5-1に、OracleAS Disaster Recoveryの実行計画と、このOracleソフトウェアが背後で使用される方法を要約します。
Oracle Application Server 10gリリース2(10.1.2.0.2)以降、OracleAS Disaster Recoveryソリューションの説明に使用する概念をわかりやすくするために、同じOracle Internet Directoryインスタンスを含む本番サイトまたはスタンバイ・サイトのすべてのファームを示すのに「トポロジ」という用語を使用するようになりました。Oracle Application Server 10gリリース3(10.1.3)用OracleAS Disaster Recoveryソリューションを除き、Oracle Application Server 10gリリース2(10.1.2.0.0)用OracleAS Disaster Recoveryソリューションのマニュアルに記載されている以前のファームの概念は、トポロジという用語に置き換えられています。トポロジという用語は、本番サイトに対して同じOracle Internet Directoryを共有しているすべてのインスタンスを指します。discover topologyコマンドは、Oracle Internet Directoryに問合せを行い、インスタンスのリストを調べ、本番トポロジを記述するトポロジXMLファイルを生成します。discover topology within farmコマンドは、Oracle Internet Directoryを使用できない場合に使用され、OracleAS GuardによってOPMNが使用されてファーム内のトポロジが検出されます。
10.1.3.x環境の場合、discover topology within farmコマンドを使用してください。また、障害時リカバリ・ソリューションの一部として、トポロジにデータベース・インスタンスを手動で追加する場合は、add instanceコマンドを使用することもできます。
これらリカバリの実行計画に加えて、両サイトの構成およびインストールについても説明します。これらのタスクでは、中間層ノードをネーミングする2つの異なる方法、さらにはサイト間およびサイト内でホスト名を解決する2つの方法について説明します。
OracleAS Disaster Recoveryでは、OracleAS Guardスイッチオーバー操作を使用してスタンバイ・サイトに切り替えることで、サービスを中断することなく本番サイトを計画停止できます。計画外停止は、OracleAS Guardフェイルオーバー操作を使用してスタンバイ・サイトにフェイルオーバーすることで管理できます。スイッチオーバーおよびフェイルオーバーの手順については、この章の第5.12項「実行時操作: OracleAS Guardのスイッチオーバーおよびフェイルオーバー操作」で説明します。
この章は、次の項で構成されています。
Identity Management(IM)Infrastructureを地理的に分散配置するレプリケーション方法は、アクティブ/アクティブ構成の例になりますが、Oracle Internet Directory(OID)、OracleAS Metadata Repository(MR)およびOracleAS Single Sign-On(SSO)がレプリケーション構成で設定され、異なる地域に分散配置されるOracleAS Disaster Recoveryソリューションと特徴が似ています。OracleAS Single Sign-Onの各サイトでは、そのローカル・サイトに配置されたそれ自体のOracle Internet DirectoryとOracleAS Metadata Repositoryが使用され、アクティブ/アクティブ構成となります。このように類似していることには、2つの目的があります。1つは、データベース障害が1つのサイトで検出された場合、ユーザー・リクエストが地理的に最も近い領域にルーティングされるようにOracle Internet DirectoryおよびOracleAS Single Sign-Onサーバーを再構成することです。もう1つは、OracleAS Single Sign-On中間層の障害が検出された場合に、トラフィックがリモート中間層にルーティングされるようにネットワークを再構成することです。しかし、このソリューションでは、Infrastructureデータベース内のOracleAS Portal、OracleAS WirelessおよびDistributed Configuration Management(DCM)スキーマの同期化が行われません。これは、これらのいずれでも、Oracle Internet DirectoryとOracleAS Single Sign-Onの情報に使用するレプリカ・モデルがサポートされていないためです。地理的に分散されたIdentity Management Infrastructureの詳細は、『Oracle Identity Management概要および配置プランニング・ガイド』を参照してください。
Oracle Application Server Disaster Recoveryソリューションは、プライマリ(本番/アクティブ)とセカンダリ(スタンバイ)という構成を持つ2つのサイトからなります。両方のサイトには、同数の中間層と同数のOracleAS Infrastructureノードおよび同数のコンポーネントがインストールされている場合もされていない場合もあります。つまり、両サイトのインストールで、中間層およびOracleAS Infrastructureが同じ場合(対称トポロジ)も同じでない場合(非対称トポロジ)もあります。これらのサイトは通常、地理的に分散されます。その場合、Wide Area Network経由でつながっています。
Oracle Application Server Disaster Recoveryソリューションで重要な点は次のとおりです。
この項では、ソリューション全体のレイアウト、関連する主要なコンポーネントおよびそれらのコンポーネントの構成について説明します。この項の内容は次のとおりです。
OracleAS Disaster Recoveryソリューションの実装を計画どおり動作させるには、次の要件を満たしている必要があります。
すでにシステムをインストールしている場合は、スタンバイ・サイトの中間層システムの物理名を変更し、OracleAS Infrastructureの物理ホスト名に仮想ホスト名を作成するだけです(次の項目を参照)。物理ホスト名と仮想ホスト名を変更する手順は、第5.2.1項「ホスト名の計画と割当て」を参照してください。物理ホスト名と仮想ホスト名の詳細は、第1.2.1項「用語」を参照してください。
注意
OracleAS Guardは、Oracle Application Server 10g(9.0.4)、10gリリース2(10.1.2.0.0、10.1.2.0.2、10.1.2.2)および10gリリース3(10.1.3.0.0、10.1.3.1.0、10.1.3.2.0)をサポートしています。
トポロジ内にOracleホームまたはOracle Application Serverインスタンスがあるすべてのシステムに、OracleAS Companion CD 2にあるOracleAS Guardキットをインストールする必要があります。詳細は、Oracle Application Serverのインストレーション・ガイドのOracleAS Disaster Recoveryのインストール情報を参照してください。
デフォルトにより、OracleAS Guardは、すでにJDKまたはJRE環境をインストールしている各10.1.2および10.1.3インストール・タイプにインストールされます。Oracle Application Server 10gリリース3(10.1.3)のWebサーバーおよびプロセス管理、Oracle Application Server 10gリリース2(10.1.2.0.2)のOracleAS Portal、およびOracle HTTP Server(10.1.3.1または10.1.3.2)のように、OracleAS Guardがデフォルトでインストールされていない環境では、OracleAS Companion CD 2にあるOracleAS Guardスタンドアロン・キットをこれらのOracleホームにインストールする必要があります。
Oracle AS Guardキットは、Disaster Recoveryソリューションの一部としてApplication Server中間層と同じDisaster Recoveryトポロジの一部に含まれているデータベース(インフラストラクチャ・データベースは対象外)のOracleホームにもインストールする必要があります。
OracleAS Guardでは、基になるサービスによってサポートされている混在環境をサポートしています。たとえば、OracleAS Guardは、アップグレード・シナリオの中で発生する可能性があるOracle Application Server 10g(9.0.4)とOracle Application Server 10gリリース2(10.1.2)以降のリリースの混在環境をサポートします。この場合、スタンバイ・サイトで中間層はOracle Application Server 10gリリース2(10.1.2)Oracleホームにアップグレードしたが、Infrastructureは依然としてOracle Application Server 10g(9.0.4)Infrastructureであることがあります。このリリース混在環境は、本番サイトの中間層OracleホームのOracle Application Server Disaster Recoveryの同等のホームが同じリリースであるOracle Application Server 10gリリース2(10.1.2)などにアップグレードされ、かつ、そのInfrastructureが依然として前のリリースであるOracle Application Server 10g(9.0.4)Infrastructureなどのままであるかぎり動作します。つまり、トポロジ内のすべてのOracleホームの同等の中間層のリリース番号が、すべての同等の中間層(つまりスタンバイ・サイトと本番サイトの両方)のリリース番号と完全に一致する必要があります。また、Infrastructureもスタンバイ・サイトと本番サイトの両方でリリース番号が完全に一致する必要があり、Oracle AS Guardも両方のサイトで同じバージョンである必要があります。ただし、アップグレードに基づいた要件として、Infrastructureは中間層よりも前のリリースにすることができます。それは、この状況がアップグレード・シナリオの中で発生するためです。
OracleAS Disaster Recoveryでは、本番サイトとスタンバイ・サイトのInfrastructureと中間層の構成についていくつかの基本トポロジがサポートされています。OracleAS Disaster Recoveryでサポートされている基本トポロジは次のとおりです。
OracleAS Disaster Recovery 10gリリース2(10.1.2.0.1)の場合、サポートされていたのは、OracleAS Disaster Recoveryの対称トポロジ環境だけでした。このOracleAS Disaster Recovery環境には、2つの主要な要件があります。
図5-1は、プライマリ・サイトにCold Failover Clusterがある、対称トポロジを持つOracleAS Disaster Recoveryソリューションの例を示しています。これは、Oracle Application Serverの視点から見ると、両方のサイトに2つのOracle Application Server中間層と1つのInfrastructureが含まれているため、対称トポロジとみなされます。
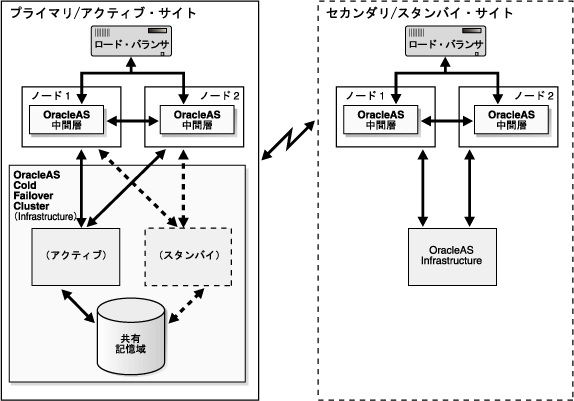
OracleAS Disaster Recoveryソリューションの構成および運用手順では、本番サイトにおける、任意の数の中間層インストールがサポートされます。スタンバイ・サイトには、同じ数の中間層インストールを配置する必要があります。本番サイトとスタンバイ・サイトでは、中間層を相互にミラー化します。
OracleAS Infrastructureの場合は、本番サイトとスタンバイ・サイトで同じ数のインストールが必要とされません(名前またはインスタンスは同一である必要があります)。たとえば、図5-1に示すように、本番サイトにはOracleAS Cold Failover Cluster(Infrastructure)ソリューションを配置し、スタンバイ・サイトには、1つのノードにOracleAS Infrastructureインストールを配置できます。このように、OracleAS Cold Failover Clusterを使用して本番サイトのOracleAS Infrastructureをホストの障害から保護します。また、このソリューションでは仮想ホスト名を利用して、ハードウェアの冗長性を実現できます。OracleAS Cold Failover Clusterの詳細は、OracleAS 10gリリース2(10.1.2.0.2)のドキュメント・セットに含まれている『Oracle Application Server高可用性ガイド』の第6.2.2項「アクティブ/パッシブ型の高可用性トポロジ」を参照してください。
OracleAS Disaster Recoveryソリューションは、様々な単一サイトのOracle Application Serverアーキテクチャを拡張したものです。たとえば、単一サイトのアーキテクチャには、OracleAS Cold Failover Cluster(Infrastructure)と、アクティブ/アクティブ構成のOracle Application Server中間層アーキテクチャを組み合せたものがあります。どのような単一サイト・アーキテクチャがサポートされているかについての最新情報は、Oracle Technology Network(OTN)のWebサイトで最新の動作要件を確認してください。
http://www.oracle.com/technology/products/ias/hi_av/index.html
OracleAS Disaster Recoveryの対称ソリューションの重要な特徴は、次のとおりです。
OracleAS Disaster Recovery 10gリリース2(10.1.2.0.2)以降、サポート対象となる非対称トポロジには、次の単純な非対称スタンバイ・トポロジも含まれています。
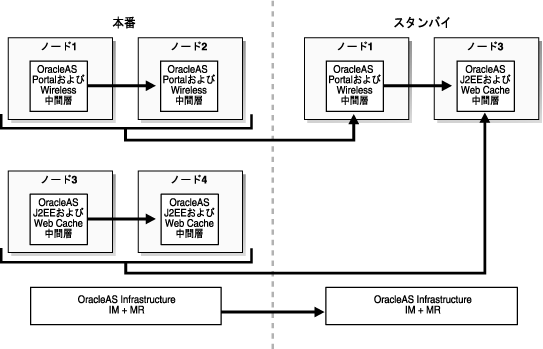
図5-2は、4つの中間層インスタンスと1つのInfrastructure(Oracle Identity ManagementとOracleAS Metadata Repositoryが同じ場所にある)で構成された本番サイトを示しています。この例では、中間層1に配置されたサービスとアプリケーションは、中間層2を含むようにスケール変更されます。さらに、中間層3に配置されたサービスとアプリケーションは、中間層4を含むようにスケール変更されます。障害時リカバリのための本番サイトより少ない数のリソースの要件を満たすために、スタンバイ・サイトでのスケール変更は必要ありません。したがって、本番中間層1と2に配置されたサービスは、スタンバイ・サイトの障害時リカバリの同等の中間層1によって満たされ、このスタンバイ・サイトの中間層1は本番中間層1と同期化されます。同様に、本番中間層3と4に配置されたサービスは、スタンバイ・サイトの障害時リカバリの同等の中間層3によって満たされ、このスタンバイ・サイトの中間層3は本番中間層3と同期化されます。
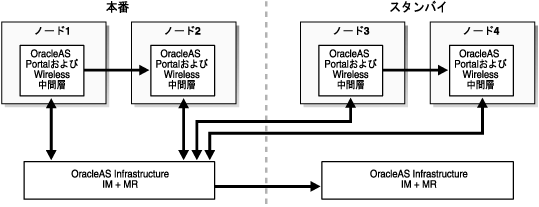
図5-3は、4つの中間層インスタンスで構成された本番サイトを示しています。そのうちの2つの中間層(1と2)と本番のInfrastructureサービスが同じ場所にあり、残りの2つの中間層(3と4)がスタンバイ・サイトにリモート配置されています。スタンバイ・サイトは、Infrastructureサービスに対してのみ障害時リカバリの機能を提供するために使用されます。この構成では、中間層リソースは、アクティブ/アクティブ・モデルで、技術的には1つの本番トポロジとして構成されます。
通常の状態では、アプリケーション・リクエストに対して中間層1〜4がサービスを提供できます。このモデルでは、中間層3と4に配置されたサービスとアプリケーションは、このトポロジに関連する待機時間、ファイアウォールおよびネットワークの問題に対応できると想定されます。障害時リカバリの運用では、維持する必要があるのはInfrastructureサービスのみです。中間層インスタンスの配置とメンテナンスは、通常の本番サイトの管理によって行われます。
一般的に、非対称トポロジのサポートとは、OracleAS Disaster Recoveryのスタンバイ・サイトでは、リソースの数が本番サイトより少なく(または少ない可能性があり)、縮小したOracleホームを維持し、最小レベルのサービス機能が保証されることを意味します。
このトポロジ(図5-4)は、2つのOracleAS Metadata Repositoryを持つ1つのOracleAS Infrastructureと複数の中間層で構成されています。1つのOracleAS Metadata RepositoryはOracle Identity Managementコンポーネント(Oracle Internet DirectoryやOracleAS Single Sign-Onなど)によって使用されます。すべての中間層および拡張されたときにこのトポロジに追加される中間層は、Oracle Identity Managementサービスに、このOracleAS Metadata Repositoryを使用します。もう1つのOracleAS Metadata Repositoryは、OracleAS PortalおよびOracleAS Wireless中間層コンポーネントによって製品メタデータのために使用されます。2つのメタデータ・リポジトリを持つこの配置は2つのDCM本番ファームといえます。
OracleAS Disaster Recoveryのスタンバイ構成は、第5.1.3.1項「対称トポロジ: Oracle Identity ManagementとOracleAS Metadata Repositoryが同じ場所にあるInfrastructureによる本番サイトの完全なミラー」の説明のように対称トポロジとして設定すること(2つのDCMスタンバイ・ファームの構成が必要)も、第5.1.3.2項「非対称トポロジ: Oracle Identity ManagementとOracleAS Metadata Repositoryが同じ場所にあるInfrastructureによる単純な非対称のスタンバイ・トポロジ」の説明のように単純な非対称トポロジとして設定すること(最低1つのDCMスタンバイ・ファームの構成が必要なサービスを保証)もできます。
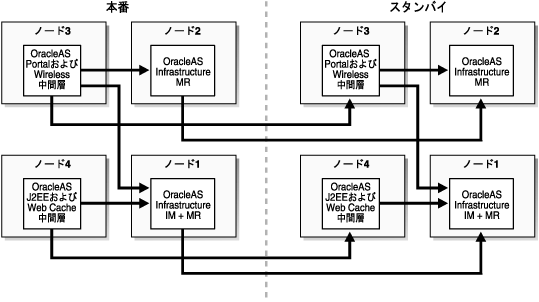
第5.1.3.1項「対称トポロジ: Oracle Identity ManagementとOracleAS Metadata Repositoryが同じ場所にあるInfrastructureによる本番サイトの完全なミラー」、第5.1.3.2項「非対称トポロジ: Oracle Identity ManagementとOracleAS Metadata Repositoryが同じ場所にあるInfrastructureによる単純な非対称のスタンバイ・トポロジ」および第5.1.3.3項「OracleAS PortalのOracleAS Metadata Repositoryは別の場所にあり、Oracle Identity ManagementとOracleAS Metadata Repositoryが同じ場所にあるInfrastructure(部門別トポロジ)」のトポロジは、Oracle Identity ManagementおよびOracleAS Metadata Repository Infrastructureの同じ場所にあるデフォルトのデータベース・リポジトリの配置を示しています。第5.1.3.3項「OracleAS PortalのOracleAS Metadata Repositoryは別の場所にあり、Oracle Identity ManagementとOracleAS Metadata Repositoryが同じ場所にあるInfrastructure(部門別トポロジ)」は、OracleAS Metadata Repositoryが別の場所にあるトポロジも示しています。
アプリケーションOracleAS Metadata Repositoryが分散し、Oracle Identity ManagementとOracleAS Metadata Repository Infrastructureが同じ場所にないトポロジでは、Oracle Identity Management Infrastructureと1つのOracleAS Metadata Repository Infrastructureは別々のホストにインストールされ、他のOracleAS Metadata Repositoryは異なるホストに、それぞれのアプリケーションと常駐するようにインストールされます。したがって、1つのOracleAS Metadata Repositoryは、1つのデフォルトInfrastructureインストールを使用した配置の結果であり、1つ以上のOracleAS Metadata Repositoryは、Oracle Application Serverユーザーが、管理またはポリシー、あるいはその両方の理由のために、OracleAS Metadata Repository Creation Assistantなどのツールを使用して、1つ以上のアプリケーションOracleAS Metadata Repositoryのアプリケーション・データを持つ、1つ以上のシステムにインストールした結果である可能性があります。
図5-5は、Oracle Identity ManagementとOracleAS Metadata Repositoryが同じ場所にないInfrastructureで、OracleAS Metadata Repositoryが分散しているOracleAS Disaster Recoveryソリューションの例を示しています。
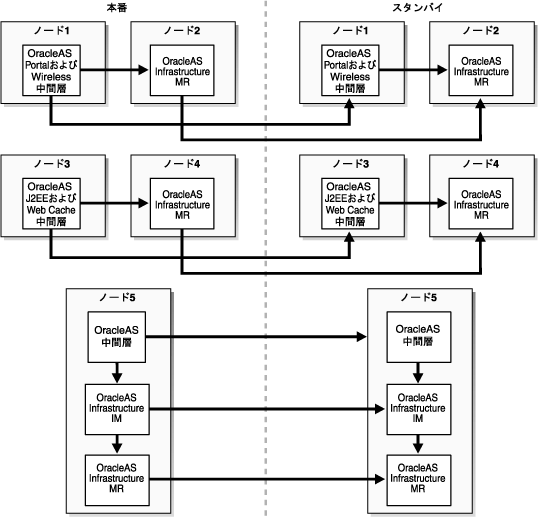
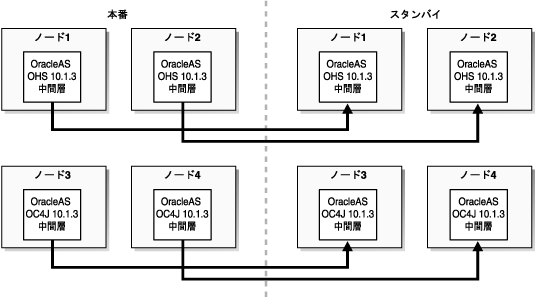
図5-6は、クラスタ(またはOPMNインスタンス)と呼ばれる、4つのノードで構成されるOracle Application Server 10.1.3トポロジにおけるJ2EEサーバーの高可用性をサポートする構成を持つ、OracleAS Disaster Recoveryソリューションの例を示しています。Webサーバー(Oracle HTTP ServerつまりOHS)とプロセス管理(OPMN)のインストール・タイプはノード1と2にインストールされ、J2EEサーバー(OC4J)とプロセス管理(OPMN)のインストール・タイプはノード3と4にインストールされます。Identity Managementはインストールされません。
Oracle Application Server 10.1.3以降では、新しい動的なノード検出メカニズムが、OPMNのコンポーネントであるOracle Notification Server(ONS)内で稼動しています。動的なノード検出により、クラスタによる自己管理が可能になっています。新しいONSノードがクラスタに追加されると、既存の各ONSノードはマルチキャスト・メッセージを使用して新しいノードの存在を通知し、新しいノードとその接続情報を現在のクラスタのマップに追加します。同時に、新しいONSノードのマップには既存のノードすべてが追加されます。これによって、Oracle Application Serverクラスタが最新状態で構成されるという、OracleAS Disaster Recoveryの要件の1つが満たされます。この場合、OPMN構成ファイルopmn.xmlは、新しいOracle Application Serverサーバー・ノードがクラスタに追加されるか、クラスタから削除されるたびに更新されます。このクラスタリング構成は、OHSやOC4Jをはじめとする、ノードにインストールされているOracleASサーバー・コンポーネントのインスタンスすべてに適用されます。
デフォルトでは、OracleAS GuardはOracle Application Serverクラスタ内の各ノードの各Oracleホームにインストールされます。OracleAS GuardクライアントがOracleAS Guardサーバーに接続され、Disaster Recovery管理者がdiscover topology within farmコマンドを実行すると、OracleAS GuardではOPMNを利用してクラスタ内のノードのインスタンスをすべて検出し、OracleAS GuardサーバーにDisaster Recovery XMLトポロジ・ファイルを作成し、このファイルをDisaster Recovery本番トポロジのシステムすべてに伝播します。検証、インスタンス化、同期化、およびスイッチオーバーなど、スタンバイ・サイトに影響を与えるOracleAS Guard操作を実行すると、スタンバイ・トポロジ全体に本番トポロジ・ファイルが自動的に伝播されます。
その後Disaster Recovery管理者は、Oracle Application Serverクラスタの1つ以上のノードを追加または削除した後に、discover topology within farmコマンドを使用できます。クラスタ構成情報は、ONSの動的なノード検出メカニズムによって自動的に管理され、常に最新状態に更新されます。ONSの動的な検出メカニズムの詳細は、『Oracle Containers for J2EE構成および管理ガイド』を参照してください。add instanceおよびremove instanceコマンドを使用してローカル・トポロジ・ファイルのインスタンスを管理し、指定に応じて、この更新されたローカル・トポロジ・ファイルをDisaster Recovery本番環境のインスタンスすべてに伝播することもできます。検証、インスタンス化、同期化、およびスイッチオーバーなど、スタンバイ・サイトに影響を与えるOracleAS Guard操作を実行すると、スタンバイ環境全体に本番トポロジ・ファイルが自動的に伝播されます。ユースケース例については、第5.8項「冗長な複数のOracle Application Server 10.1.3ホームJ2EEトポロジ内のOracle Application Server 10.1.3インスタンスの検出」を参照してください。したがって、ノードがクラスタに追加されているか、Disaster Recovery環境の一部であるこれらのノードにインスタンスが追加されている場合には、discover topology within farmコマンドを実行することが重要です。
図5-7は、バージョンが混在したトポロジをサポートしているOracleAS Disaster Recoveryソリューションの例を示しています。この例では、Oracle Application Server 10.1.3のインスタンスが既存のOIDベースのトポロジ(OracleAS Cluster(IM)10.1.2.0.2)に統合されています。ここでは、統合されたWebサーバー、J2EEサーバーおよびOPMNインストール・オプションを単一のOracleホームに含む複数のOracle Application Server 10gリリース3(10.1.3)を個別のシステムにインストールすることで、冗長な単一のOracle Application Server 10.1.3 OracleホームJ2EEトポロジが実現されています。
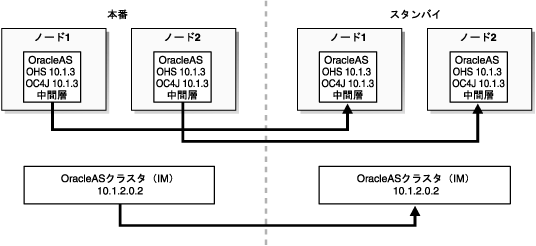
デフォルトでは、OracleAS Guardは各Oracleホームにインストールされます。OracleAS GuardクライアントがIM 10.1.2.0.2 OracleASトポロジのOracleAS Guardサーバーに接続し、discover topologyコマンドを実行すると、OracleAS GuardではOIDを利用して、既存のOIDベース・トポロジ内のOracle Application Server 10.1.2.0.2インスタンスすべてを自動的に認識します。この検出トポロジ操作によって、Disaster Recoveryトポロジ・ファイルが作成され、本番トポロジのインスタンスすべてに伝播されます。検証、インスタンス化、同期化、およびスイッチオーバーなど、スタンバイ・サイトに影響を与えるOracleAS Guard操作を実行すると、スタンバイ・トポロジ全体に本番トポロジ・ファイルが自動的に伝播されます。
Disaster Recoveryの管理者は、asgctlのadd instanceまたはremove instanceコマンドを使用して、ローカル・トポロジ・ファイルの単一のOracle Application Server 10.1.3 J2EEインスタンスを既存のOIDベースの10.1.2.0.2本番トポロジに追加するか、10.1.2.0.2本番トポロジから削除できます。どちらの操作を実行する場合も、ローカル・トポロジ・ファイルが更新され、指定に応じてローカルの更新済トポロジ・ファイルが本番トポロジのインスタンスすべてに伝播されます。検証、インスタンス化、同期化、およびスイッチオーバーなど、スタンバイ・サイトに影響を与えるOracleAS Guard操作を実行すると、スタンバイ・トポロジ全体に本番トポロジ・ファイルが自動的に伝播されます。最終的なトポロジは、既存のOIDベース・トポロジ(OracleAS Cluster(IM)10.1.2.0.2)に統合された冗長な単一のOracle Application Server 10.1.3 OracleホームJ2EEになります。ユースケース例については、第5.9項「既存のOracle Identity Management 10.1.2.0.2トポロジと統合されている冗長な単一のOracle Application Server 10.1.3ホームJ2EEトポロジでのOracle Application Server 10.1.3インスタンスの追加または削除」を参照してください。トポロジ・ファイルの詳細は、第6.2項「OracleAS Guardコマンドの一部に特有の情報」を参照してください。
OracleAS Disaster Recoveryソリューション用にOracleASソフトウェアをインストールする前に、システム・レベルで必要な構成やオプションの構成を行います。これらの構成を実行するタスクには、次のものがあります。
この項では、非対称トポロジで、これらのタスクの実行に必要な手順について説明します。同じ手順は、単純な非対称スタンバイ・サイトにも適用できます。また、OracleAS Metadata Repositoryが分散されているかどうかに関係なく、Oracle Identity ManagementとOracleAS Metadata Repositoryが同じ場所にないトポロジにも適用できます。
物理ホスト名およびネットワーク・ホスト名の設定手順を実行する前に、OracleAS Disaster Recoveryソリューション全体で使用する物理ホスト名およびネットワーク・ホスト名を計画します。ホスト名の計画および割当てにおける全体的なアプローチでは、次の目標を達成する必要があります。
たとえば、本番サイトの中間層コンポーネントが同じサイト内のホストへのアクセスに名前asmid1を使用するのであれば、スタンバイ・サイトの同じコンポーネントはこの同じ名前を使用して、スタンバイ・サイト内にあるasmid1と同等のホストにアクセスする必要があります。同様に、本番サイトのOracleAS Infrastructureの仮想ホスト名にinfraという名前を使用する場合は、スタンバイ・サイトのOracleAS Infrastructureの物理ホスト名にもinfraという仮想ホスト名を使用する必要があります。
本番サイトとスタンバイ・サイトの物理ホスト名は両サイト間で統一する必要がありますが、物理ホスト名を解決した後の適切なホストは異なっていてもかまいません。ホスト名解決は、第5.2.2項「ホスト名解決の構成」で説明します。
注意
図5-8は、ホスト名の計画と割当てのプロセスを示しています。
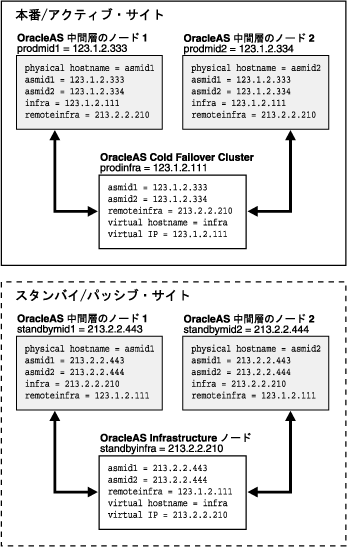
図5-8では、本番サイトに2つの中間層ノードがあります。OracleAS Infrastructureは単一ノードまたはOracleAS Cold Failover Clusterソリューション(単一ノードの OracleAS Infrastructureと同様、1つの仮想ホスト名と仮想IPで表される)にすることができます。2つのサイトの一般名は、中間層ノードの物理ホスト名とOracleAS Infrastructureの仮想ホスト名です。表5-2は、例における物理、ネットワークおよび仮想ホスト名を示しています。
| 物理ホスト名 | 仮想ホスト名 | ネットワーク・ホスト名 |
|---|---|---|
asmid1 |
- |
prodmid1, standbymid1 |
asmid2 |
- |
prodmid2, standbymid2 |
- 1 |
infra |
prodinfra, standbyinfra |
|
1
この例では、物理ホスト名はネットワーク・ホスト名になります。そのため、このネットワーク・ホスト名を、asgctlコマンドの<host>、<host-name>または<standby_topology_host>パラメータ引数に使用します。 |
本番サイトに非OracleASアプリケーションを実行しているホストがあり、そのホストでOracleASを共同ホスティングする場合、このホストの物理ホスト名を変更すると、非OracleASアプリケーションが使用不能になることがあります。このようなケースでは、本番サイトのホスト名はそのままにして、スタンバイ・サイトの物理ホスト名を本番サイトと同じホスト名に変更します。その後で、非OracleASアプリケーションをスタンバイ・ホストにもインストールすることで、このホストは非OracleASアプリケーションに対するスタンバイの役割も果たせます。
第1.2.1項「用語」の説明にあるように、OracleAS Disaster Recoveryソリューションでの物理ホスト名、ネットワーク・ホスト名および仮想ホスト名の用途は他のアプリケーションとは異なります。また、これらの設定方法も異なります。次の項では、様々なタイプのホスト名の設定方法について説明します。
本番サイトとスタンバイ・サイトの両方の各ホストで、中間層ホストの物理ホスト名を変更する必要があります。
Solarisで、ホストの物理ホスト名を変更する手順は次のとおりです。
prompt> hostname
viなどのテキスト・エディタを使用して、/etc/nodenameの名前を、計画した物理ホスト名に編集します。
Windowsで、ホストの物理ホスト名を変更する手順は次のとおりです。
_CLUSTER_NETWORK_NAME_"を入力します。
OracleAS Disaster Recoveryソリューションで使用されるネットワーク・ホスト名は、ドメイン・ネーム・システム(DNS)に定義されます。これらのホスト名はソリューションで使用するネットワークで参照可能で、DNSにより、DNSシステムで割り当てられたIPアドレスを使用して適切なホストへと解決されます。そのため、ネットワーク・ホスト名と対応するIPアドレスを、DNSシステムに追加する必要があります。
図5-8の例では、本番サイトとスタンバイ・サイトを有するネットワーク全体を管理するDNSシステムに、次のエントリを追加する必要があります。
prodmid1.oracle.com IN A 123.1.2.333 prodmid2.oracle.com IN A 123.1.2.334 prodinfra.oracle.com IN A 123.1.2.111 standbymid1.oracle.com IN A 213.2.2.443 standbymid2.oracle.com IN A 213.2.2.444 standbyinfra.oracle.com IN A 213.2.2.210
第1.2.1項「用語」で定義したように、仮想ホスト名はOracleAS Infrastructureにのみ適用されます。仮想ホスト名は、OracleAS Infrastructureのインストール時に指定します。OracleAS Infrastructureインストール・タイプを実行すると、「仮想ホストの指定」という画面が表示され、インストール中のOracleAS Infrastructureの仮想ホスト名を入力するテキスト・ボックスが表示されます。詳細は、Oracle Application Serverのインストレーション・ガイドを参照してください。
図5-8の例の場合は、本番サイトのOracleAS Infrastructureのインストール時に「仮想ホストの指定」画面が表示されたら、仮想ホスト名infraを入力します。スタンバイ・サイトのOracleAS Infrastructureのインストール時にも、同じ仮想ホスト名を入力します。
Oracle RACデータベースを含む環境にDisaster Recoveryソリューションを設定する場合、プライマリ・サイトとスタンバイ・サイト間で移行する仮想ホスト名は、Oracle RACのインスタンスが稼動する各ノードのWindowsおよびUNIXプラットフォームのホスト・ファイルで定義する必要があります。エントリの構文は次のとおりです。
<IP> <HOSTNAME WITH DOMAIN> <HOSTNAME> <VIRTUALHOSTNAME>
ここで<VIRTUALHOSTNAME>は別名を示すので、たとえばracdb1.oracle.comはRAC Node1の別名、racdb2.oracle.comはRAC Node2の別名などのように指定します。同じ別名をスタンバイ・サイトにも同様に作成する必要があります。
OracleAS Disaster Recoveryソリューションでは、第5.2.1項「ホスト名の計画と割当て」で計画して割り当てたホスト名の解決に、次の2つのいずれかのホスト名解決方法を構成できます。それらのコンポーネントには次のものがあります。
UNIXでは、ファイル/etc/nsswitch.confのhostsパラメータを使用して、名前解決の方法の順序を指定できます。次に、hostsエントリの例を示します。
hosts: files dns nis
この文では、ローカル・ホスト名ファイル解決がDNS解決およびNIS(Network Information Service)解決よりも優先されています。ホスト名のIPアドレスへの解決が必要になったら、/etc/hostsファイル(UNIXの場合)またはC:¥WINDOWS¥system32¥drivers¥etc¥hostsファイルが最初に参照されます。ローカル・ホスト名ファイル解決でホスト名を解決できなかったときは、DNSが使用されます(NIS解決は、OracleAS Disaster Recoveryソリューションでは使用されません)。ファイル/etc/nsswitch.confを使用した名前解決の詳細は、UNIXシステムのドキュメントを参照してください。
ホスト名解決のこの方法は、必要なホスト名とそのIPアドレスの対応付けが記載されたローカル・ホストネーミング・ファイルに依存します。UNIXでは、このファイルは/etc/hostsです。Windowsでは、このファイルはC:¥WINDOWS¥system32¥drivers¥etc¥hostsです。
UNIXでOracleAS Disaster Recoveryソリューションのホスト名解決にローカル・ホストネーミング・ファイルを使用するには、本番サイトとスタンバイ・サイト両方の中間層およびOracleAS Infrastructureの各ホストで、次の手順を実行します。
viなどのテキスト・エディタを使用して、/etc/nsswitch.confファイルを編集します。hosts:パラメータで、ホスト名解決の第一の選択肢としてfilesを指定します。
/etc/hostsファイルを編集します。
ホスト・ファイルにエントリを追加する場合は、計画したホスト名をホスト・ファイルの2番目の列に指定してください。そうしないと、asgctlの
注意
verify topology with <host>の操作に失敗し、本番トポロジがスタンバイ・トポロジと対称ではないというエラー・メッセージが表示されます。この種の問題のトラブルシューティングと解決方法は、付録A「高可用性のトラブルシューティング」を参照してください。
たとえば、本番サイト内にある中間層ノードの/etc/hostsファイルを編集している場合は、現行ホストのエントリをリストの最初にして、本番サイト内のすべての中間層ノードの物理ホスト名とそのIPアドレスを入力します(短縮されたホスト名に加えて、完全修飾されたホスト名も含める必要があります。表5-3を参照)。
たとえば、スタンバイ・サイト内にある中間層ノードの/etc/hostsファイルを編集している場合は、スタンバイ・サイト内のOracleAS Infrastructureホストの仮想ホスト名(完全修飾名と短縮名の両方)とそのIPアドレスを入力します。
図5-8の例のasmid1ホストの場合は、次のコマンドを続けて使用します。
ping asmid1
返されたIPアドレスは123.1.2.333のはずです。
ping asmid2
返されたIPアドレスは123.1.2.334のはずです。
ping infra
返されたIPアドレスは123.1.2.111のはずです。
Windowsでは、ホスト名解決の順序を指定する方法は、Windowsのバージョンによって異なります。適切な手順については、ご使用のバージョンのWindowsのドキュメントを参照してください。
表5-3に、図5-8の例における、各本番ノードの/etc/hostsファイルのエントリを示します。これには、各UNIXホストで必須のエントリが含まれています。WindowsのC:¥WINDOWS¥system32¥drivers¥etc¥hostsファイルでも、必要なエントリは同様です。
/etc/hostsファイルにあるネットワーク・ホスト名と仮想ホスト名のエントリ
DNSホスト名解決を使用するようOracleAS Disaster Recoveryソリューションを設定するには、企業全体のDNSサーバーに加えて、サイト固有のDNSサーバーを本番サイトとスタンバイ・サイトに設定する必要があります(企業ネットワークには、冗長性を実現するために複数のDNSサーバーがあるのが一般的です)。図5-9に、この設定の概要を示します。

図5-9のトポロジが機能するには、次のことが要件または前提となります。
/etc/hostsファイルに、本番とスタンバイの両方のサイトのどのホストについても、物理ホスト名、ネットワーク・ホスト名または仮想ホスト名のエントリがないこと。Windowsでは、この要件はファイルC:¥WINDOWS¥system32¥drivers¥etc¥hostsに適用されます。
DNS解決を使用するOracleAS Disaster Recoveryソリューションを設定する手順は次のとおりです。
prodmid1.oracle.com IN A 123.1.2.333 prodmid2.oracle.com IN A 123.1.2.334 prodinfra.oracle.com IN A 123.1.2.111 standbymid1.oracle.com IN A 213.2.2.443 standbymid2.oracle.com IN A 213.2.2.444 standbyinfra.oracle.com IN A 213.2.2.210
oracleasを使用します。上位レベルの企業ドメイン名はoracle.comです。
図5-8の例のエントリは、次のようになります。
本番サイトのDNSサーバーの場合:
asmid1.oracleas IN A 123.1.2.333 asmid2.oracleas IN A 123.1.2.334 infra.oracleas IN A 123.1.2.111
スタンバイ・サイトのDNSサーバーの場合:
asmid1.oracleas IN A 213.2.2.443 asmid2.oracleas IN A 213.2.2.444 infra.oracleas IN A 213.2.2.210
|
注意 ロード・バランサを使用している場合は、DNSベースの仮想ホスト名を使用して、ホスト・ファイルにIPアドレスの別名を指定する必要があります。これは、ローカル・ホストのOracleAS Guardに対し、discover topology within farmコマンドを使用してトポロジ・ファイルのローカル書込みを実行し、add instanceコマンドを正しく実行してトポロジ・ファイルを更新するために必要です。
これらのサイトいずれかで、OracleAS InfrastructureにOracleAS Cold Failover Clusterソリューションを使用する場合は、クラスタの仮想ホスト名と仮想IPアドレスを入力します。たとえば、前の手順では |
OracleAS Guardは、Oracle Data Guardテクノロジの使用を自動化して、本番とスタンバイのOracleAS Infrastructureデータベースを同期化するため、本番OracleAS InfrastructureはスタンバイOracleAS Infrastructureを参照できる必要があり、その逆も同様です。
これを機能させるには、本番サイトのDNSサーバーに、スタンバイOracleAS InfrastructureホストのIPアドレスを、本番サイトに対して一意のホスト名とともに入力する必要があります。同様に、スタンバイ・サイトのDNSサーバーに、本番OracleAS InfrastructureホストのIPアドレスを、同じホスト名を使用して入力する必要があります。これらのDNSエントリが必要なのは、Oracle Data Guardでは、本番およびスタンバイOracleAS Infrastructureへのリクエストの転送にTNS名が使用されるためです。したがって、tnsnames.oraファイルにも適切なエントリを作成する必要があります。また、OracleAS Guardのasgctlコマンドライン・コマンドにも、ネットワーク・ホスト名を使用する必要があります。
図5-8の例では、リモートOracleAS Infrastructure用に選択した名前がremoteinfraであるとすると、本番サイトのDNSサーバーのエントリは次のようになります。
asmid1.oracleas IN A 123.1.2.333 asmid2.oracleas IN A 123.1.2.334 infra.oracleas IN A 123.1.2.111 remoteinfra.oracleas IN A 213.2.2.210
同様に、スタンバイ・サイトのDNSサーバーのエントリは次のようになります。
asmid1.oracleas IN A 213.2.2.443 asmid2.oracleas IN A 213.2.2.444 infra.oracleas IN A 213.2.2.210 remoteinfra.oracleas IN A 123.1.2.111
この項では、OracleAS Disaster Recoveryソリューションをインストールする手順の概要を示します。これらの手順は、第5.1.3項「サポートされているトポロジ」に示したトポロジに適用できます。第5.2項「OracleAS Disaster Recovery環境の準備」の手順に従ってソリューション環境を設定したら、この項でインストール・プロセスの概要をお読みください。その後に、Oracle Application Serverのインストレーション・ガイドの詳細な手順に従って、ソリューションをインストールします。
OracleAS Disaster Recoveryソリューションをインストールするための全般的な手順は次のとおりです。
インストールを実行するときは、次の点が重要です。
asmid1ホストは、本番サイトのasmid1ホストと同じポートを使用する必要があります。静的ポート定義ファイルを使用します(この項の前述の注意と次の点を参照)。
staticports.iniファイルへのフル・パスを指定します。
この項では、OracleAS Guardとそのコマンドライン・インタフェースであるasgctlの概要について説明します。この概要についてすでに理解している場合は、第5.5項「データベースの認証」に進んでください。この項の項目は次のとおりです。
asgctlコマンドライン・ユーティリティによって、OracleAS Disaster Recoveryの設定および管理に関する複雑で長い手順が大幅に簡素化されました。このユーティリティは、クライアント・コンポーネントとサーバー・コンポーネントで構成される分散ソリューションを提供します。クライアント・コンポーネント(OracleAS Guardクライアント)は、トポロジ上のシステムにインストールできます。サーバー・コンポーネント(OracleAS Guardサーバー)は、デフォルトでは、OracleAS Disaster Recovery環境を構成するプライマリおよびスタンバイOracleホームをホスティングするシステムにインストールされます。
OracleAS Guardクライアントは、すべてのOracle Application Serverインストール・タイプでインストールされます。OracleAS Guardクライアントは、OracleAS Guardサーバーとの接続の確立と維持を試みます。
OracleAS Guardクライアントには、asgctlコマンドライン・インタフェース(CLI)が用意されており(第6章「OracleAS Guard asgctlコマンドライン・リファレンス」を参照)、第5.4.4項「asgctl操作」で説明する管理タスクを実行する一連のコマンドが含まれています。
OracleAS Guardサーバーは、分散サーバーとして(デフォルトでインストールされ)、OracleAS Disaster Recovery構成のすべてのシステムで実行されます。OracleAS Guardクライアントは、OracleAS Disaster Recovery構成とネットワーク接続されている1つのシステムのOracleAS Guardサーバーとアクティブな接続を維持します。この調整サーバーは、必要に応じて、OracleAS Disaster Recovery構成内の他のシステムのOracleAS Guardサーバーと通信し、スタンバイ・サイトのクローニング、インスタンス化、同期化、検証、スイッチオーバーおよびフェイルオーバー操作の処理を実行します。OracleAS Guardサーバーは、OracleAS Guardクライアントから直接発行されたasgctlコマンドを実行したり、ネットワーク内の別のOracleAS GuardサーバーからOracleAS Guardクライアントにかわって発行されたコマンドをそのクライアントのセッション中に実行します。操作を実行する手順は、本番トポロジとスタンバイ・トポロジ両方のすべてのシステムで実行されます。ほとんどの操作手順は、OracleAS Disaster Recovery構成にあるこれらのシステムのOracleAS Guardサーバーで、必要に応じて並列または順番に実行されます。
asgctlコマンドを使用した主なasgctl操作は、次のいずれかの操作のカテゴリに分類されます。
フェイルオーバー操作の前にスタンバイ・トポロジで新しいOracleAS Infrastructureデータベースを識別します(set new primary databaseコマンド)。
特定のホストに対して、OracleAS GuardクライアントからOracleAS Guardサーバーへの接続、およびOracleAS Guardサーバー間の接続を認証するための資格証明を設定します(set asg credentialsコマンド)。例は、set asg credentialsコマンドを参照してください。詳細は、第5.18.1.1項「asgctl資格証明の設定」を参照してください。
OracleAS Guardがトポロジを検出する場合(discover topologyコマンド)、Oracle Internet Directoryに問い合せて、その本番サイトのインスタンス情報を取得するためにOracle Internet Directory認証資格証明(Oracle Internet Directoryパスワード)を提供する必要があります。
コマンドdiscover topology within farmは、Oracle Internet Directoryを使用できない特別な場合に、本番サイトにあるOPMNを使用してOracle Application Server 10.1.3 OPMNトポロジなどのトポロジを検出します。
このコマンドは、Oracle Application Server 10.1.3 J2EEインスタンスをOIDベースの10.1.2.0.2ローカル・トポロジ・ファイルに追加して、バージョンが混在したDisaster Recovery環境をサポートする場合にも役立ちます。たとえば、add instanceコマンドを使用して、Oracle Application Server 10.1.3 J2EEインスタンスをOIDベースの10.1.2.0.2ローカル・トポロジ・ファイルに追加できます。ユースケースについては、第5.9項「既存のOracle Identity Management 10.1.2.0.2トポロジと統合されている冗長な単一のOracle Application Server 10.1.3ホームJ2EEトポロジでのOracle Application Server 10.1.3インスタンスの追加または削除」を参照してください。
using policy <file>パラメータで指定し、インスタンス別にこれらの各asgctlコマンドに許可される実行操作のドメインを定義します。XMLポリシー・ファイルの各インスタンスのリストのエントリは、本番とスタンバイのピア組合せと、正常な操作のための成功要件を定義する特定の属性を論理的に結び付けます。たとえば、前述の操作の1つを実行するときに、対称トポロジの1つのノードを省くことができます。ポリシー・ファイルを使用して、無視するノードを指定します。詳細は、第5.7項「いくつかのasgctlコマンドでのポリシー・ファイルのダンプとポリシー・ファイルの使用」を参照してください。
表5-4は、asgctlのクローニング、インスタンス化、同期、フェイルオーバーおよびスイッチオーバー操作の前後のOracleAS Disaster Recovery本番サイト環境とスタンバイ・サイト環境を示しています。
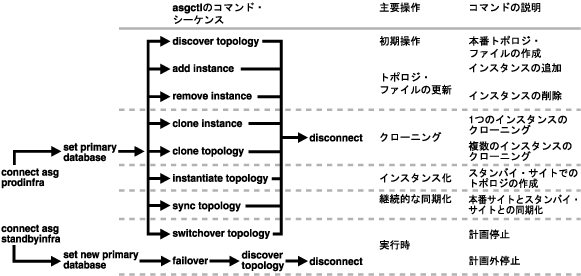
図5-10では、OracleAS Disaster Recoveryの主要操作とこれらの操作に使用されるコマンド・シーケンスを要約しています。たとえば、新たに設定され、稼動し始めたDisaster Recovery環境では、本番サイトに必ずトポロジ・ファイルを作成する必要があります。このファイルを作成するには、connectコマンドを使用してOracleAS GuardクライアントをOracleAS Guardサーバーに接続し、set primary databaseコマンドを使用して本番Infrastructureデータベースを識別し、discover topologyコマンドを実行し、最後にdisconnectコマンドを実行してOracle Application ServerクライアントをOracle Application Serverサーバーから切断します。本質的に、asgctlコマンドを使用してOracleAS Disaster Recovery操作を実行するには、必ずOracleAS GuardクライアントをOracleAS Guardサーバーに接続し、Infrastructureデータベースの場所を識別し、目的のOracleAS Disaster Recovery操作を実行し、最後にOracle Application ServerクライアントをOracle Application Serverサーバーから切断する必要があります。この一般的なシーケンスにおける唯一の例外は、フェイルオーバー操作を実行する場合です。この場合、本番サイトは計画外の問題が原因で、永久に使用不可になっています。この場合には、OracleAS Guardクライアントをスタンバイ・サイトのOracleAS Guardサーバーに接続し、スタンバイ・サイトのInfrastructureを新しいInfrastructureデータベースとして識別し、フェイルオーバー操作を実行します。スタンバイ・サイトではフェイルオーバー操作後にトポロジ・ファイルが作成されないため、このファイルを初めて作成するには、discover topologyコマンドを実行する必要があります。ファイルを作成した後は、OracleAS GuardクライアントをOracleAS Guardサーバーから切断できます。
図5-10に示すasgctlコマンド・シーケンスでは、最も単純なトポロジ構成を想定しています。たとえば、より複雑なケースでは、本番サイトまたはスタンバイ・サイトに複数のMRインスタンスがインストールされている場合、インスタンス化、同期化、スイッチオーバー、フェイルオーバー操作などのDisaster Recoveryの主要操作を実行する前に、set primary databaseコマンドを使用して各インスタンスを識別する必要があります。同様に、インスタンス化、同期化、スイッチオーバー、フェイルオーバーなどのOracleAS Guardの主要操作を実行する前に、接続しているOracleAS Guardサーバーと異なる資格証明を持つトポロジのOracleAS Guardサーバー・システムに対して、OracleAS Guardで資格証明を設定する必要があります。このため、これらのどちらのケースに対しても、Disaster Recoveryの主要操作を実行するには、コマンド・シーケンスで追加のasgctlコマンドが必要になります。詳細は、set asg credentialsコマンドの使用方法を参照してください。
一般的なOracle Application Serverサイトには、複数のファームがあります。OracleAS Guardサーバーとそのias-component ASGプロセスは、障害時リカバリ・サイトのコンテキストでのみ必要であるため、デフォルトではOPMNによって起動されません。この項で後述するように、このias-component ASGプロセスをすべてのOracleホームで起動する必要があります。このコンポーネントのステータスをチェックし、コンポーネントが実行中であるかどうかを調べるには、トポロジ内の各システムで次のopmnctlコマンドを実行します。
On UNIX systems > <ORACLE HOME>/opmn/bin/opmnctl status On windows systems > <ORACLE HOME>¥opmn¥bin¥opmnctl status
本番サイトのOracleAS GuardクライアントとOPMNは、スタンバイ・サイトのOracleAS Guardサービスを起動できないため、OracleAS Guardはスタンバイ・トポロジのInfrastructureノードでopmnctlを使用して直接起動する必要があります。ノードに接続し、UNIXシステム上で次のOPMNコマンドを実行します。
> <ORACLE HOME>/opmn/bin/opmnctl startproc ias-component=ASG
Windowsシステムでは、次のOPMNコマンドを発行してOracleAS Guardを起動します(OracleホームがドライブC:にある場合)。
C:¥<ORACLE HOME>¥opmn¥bin¥opmnctl startproc ias-component=ASG
OracleAS Guardサーバーを起動した後、そのサーバーは一時サーバーではなくなり、スタンバイ・トポロジ内の他のOracleAS Guardサーバーが一時サーバーになります。この構成によって、トポロジ間の通信が実現されます。
Oracle Application Server 10gリリース2(10.1.2)の場合、OracleAS Guardは、Oracle Application Server Cold Failover Clusterと単一インスタンスのデフォルトのOracleAS Infrastructure構成だけでなく、第5.1.3項「サポートされているトポロジ」に示すトポロジもサポートします。
デフォルトでは、OracleAS Guardと、OracleAS Guardのコマンドライン・ユーティリティであるasgctlは、次のデフォルトの構成情報ですべてのインストール・タイプにインストールされます。
<ORACLE_HOME>¥dsa¥docディレクトリにあるOracleAS Guard readme.txtファイルにもリストされています。
port: OracleAS Guardサーバーおよびクライアント用TCP/IPポート。OracleAS Guardでは、たとえばport=7890などのように、7890のデフォルトのポート(port)番号が使用されます。システムに2番目のOracleホームがインストールされている場合、この2番目のOracleホームには異なるOracleAS Guardポート番号が必要です。通常は、port=7891などのように、番号が1つ増分されます。値: 整数。有効な任意のTCP/IPポート番号を表します。デフォルトは7890です。
exec_timeout_secs: オペレーティング・システム・コマンド実行用のタイムアウト値。値: 整数。秒数を表します。デフォルトは60秒です。
trace_flags: オンにするトレース・フラグ。値: 文字列リスト。","で区切ります。デフォルトは未指定です。
backup_mode: 全体バックアップまたは増分バックアップのどちらを実行するかを示します。値: 文字列。"full"または"incremental"のどちらかです。デフォルトは"incremental"です。
backup_path: OracleAS Guardサーバーが使用するバックアップ・ディレクトリ・パス。値: 文字列。ディレクトリ・パスを表します。デフォルトは<ORACLE_HOME>/dsa/backupです。
ha_path: バックアップ・スクリプトを含む高可用性ディレクトリ・パス。値: 文字列。ディレクトリ・パスを表します。デフォルトは<ORACLE_HOME>/backup_restoreです。
port.<host>: 任意のホストのTCP/IPポート。 値: 整数。有効な任意のTCP/IPポート番号を表します。
|
注意
ポート番号を変更する必要がある場合は(ポート番号は、マシン上の各Oracleホームの各OracleAS Guardサーバーに対して一意である必要があり、インストール時に自動的に割り当てられます)、その値を
トポロジ内でポート番号を変更する必要がある場合は、asgctlの |
copyfile_buffersize: ファイルのコピー操作用バッファ・サイズ(キロバイト単位)。値: 整数。最大バッファ・サイズは500Kです。
server_inactive_timeout: サーバーが非アクティブのときに、停止する前に待機する秒数。値: 整数。秒数を表します。デフォルト値は600秒(10分)です。
inventory_location: Oracle Inventoryの代替格納場所。値: 文字列。oraInst.locファイルのフルパスを指定します。
_realm_override: dsaレルムの上書きを指定します。値: 整数。1=上書き、0=上書きなし
<ORACLE_HOME>/dsa/binディレクトリに、Windowsシステムの場合は、<ORACLE_HOME>¥dsa¥binディレクトリにインストールされます。
<ORACLE_HOME>¥dsa¥docディレクトリにあるOracleAS Guard readme.txtファイルを参照してください。
<ORACLE_HOME>/dsa/binディレクトリに、Windowsシステムの場合は、<ORACLE_HOME>¥dsa¥binディレクトリにインストールされます。
OracleAS GuardクライアントがOracleAS Guardサーバーに接続し、本番トポロジ内または本番トポロジとスタンバイ・トポロジの両方で管理操作を実行するセッションを開始する場合は、次のようないくつかのレベルの認証が必要です。
OracleAS Guard管理セッションを開始する場合、OracleAS GuardクライアントとOracleAS Guardサーバーとの間の接続を確立した後、set primary databaseコマンドを使用してプライマリ・トポロジのすべてのOracleAS Infrastructureデータベースを識別する必要があります。Infrastructureの認証は、本番トポロジまたは本番トポロジとスタンバイ・トポロジの両方に関連する操作を開始する前に実行する必要があります。
別の形式のInfrastructureの認証は、フェイルオーバー操作の一部として実行されます。このシナリオでは、本番サイトは停止しており、スタンバイ・サイトにフェイルオーバーしてこのサイトを新しい本番サイトとする必要があります。最初に、フェイルオーバー操作を実行する前にset new primary databaseコマンドを使用してスタンバイ・トポロジの新しいOracleAS Infrastructureデータベースを識別します。詳細は、第5.12.1.2項「計画外停止」を参照してください。
デフォルトでは、これらは、Oracle Application Serverのインストール中に作成され、connect asgコマンドで使用されたOracle Application Serverアカウント(ias_admin/password)でのインスタンス・レベルの認証に使用されるものと同じ認証資格証明です
これらの同じ資格証明は、管理操作を実行する場合に本番トポロジとスタンバイ・トポロジのOracleAS GuardサーバーにOracleAS Guardクライアントが接続するときに使用されます。
特定のOracleAS Guardサーバーに対して異なる資格証明を使用したり、プライマリ・トポロジで使用する資格証明とは異なる一般的なセットの資格証明をスタンバイ・トポロジに設定する必要がある場合があります。OracleAS Guardサーバーに対して資格証明を設定するには、set asg credentialsコマンドと1つ以上のそのパラメータ・オプションを使用し、資格証明を適用するホスト名またはトポロジを新しいセットの資格証明(ユーザー名/パスワード)とともに指定します。
あるトポロジに資格証明を設定した場合、その資格証明はトポロジ全体に継承されます。トポロジ上の個別のホストに資格証明を設定した場合、そのホストの資格証明が、トポロジに設定されたデフォルトの資格証明よりも優先されます。ホスト・システムまたはトポロジ全体にデフォルトの接続資格証明とは異なる資格証明を設定すると、OracleAS Guard管理セッションを開始するたびに、本番トポロジ内または本番トポロジとスタンバイ・トポロジの両方のすべてのOracleAS Guardサーバーに関係する操作を実行する前に、ホスト・システムまたはトポロジのデフォルト接続情報とは異なるすべての資格証明を指定する必要があります。指定しない場合、操作は認証エラーのために失敗します。例は「connect asg」を参照してください。
discover topologyコマンドでは、Oracle Internet Directoryに問い合せて、その本番サイトのインスタンス情報を取得するためにOracle Internet Directory認証資格証明(Oracle Internet Directoryパスワード)を提供する必要があります。詳細およびdiscover topologyコマンドは、後述のセクションを参照してください。
discover topologyコマンドは、Oracle Internet Directoryに問い合せることによって、本番サイトの同じOracle Internet Directoryを共有する、トポロジ内のすべてのインスタンスを検出します。トポロジのすべてのインスタンスを記述するトポロジXMLファイルが作成され、トポロジ内のすべてのOracleホームに配布されます。このトポロジ・ファイルは、すべてのOracleAS Guard操作で使用されます。
トポロジXMLファイルを内部的に作成するために、OracleAS Disaster Recovery環境を最初に設定するとき、discover topologyコマンドを実行する必要があります。したがって、本番サイトに別のOracleホームを配置した場合や、スイッチオーバーまたはフェイルオーバー操作によって本番サイトからスタンバイ・サイトに役割を変更した場合は、常にトポロジの検出操作を実行する必要があります。詳細は、discover topologyコマンドを参照してください。
トポロジを記述する情報を調べるには、dump topologyコマンドを実行する必要があります。詳細は、dump topologyコマンドを参照してください。トポロジ・ファイルの詳細は、第6.2項「OracleAS Guardコマンドの一部に特有の情報」を参照してください。
プライマリ・トポロジが実行中であり、その構成が有効であることを確認するには、verify topologyコマンドを実行する必要があります。さらに、with hostパラメータを指定した場合、検証操作によって、ローカル・ホスト・システムをメンバーに持つプライマリ・トポロジと、スタンバイ・トポロジが比較され、それらが相互に一致しており、OracleAS Disaster Recoveryの要件を満たしていることが確認されます。詳細は、第5.15.1項「トポロジの検証」およびverify topologyコマンドを参照してください。
dump topologyとverify topologyコマンドの両方で、ポリシー・ファイルを使用する場合は、ダンプおよび検証それぞれのポリシー・ファイル(dump_policy.xmlおよびverify_policy.xml)を編集して使用します。このファイルを各コマンドのusing policy <file>パラメータで指定し、それによって指定されたインスタンスのみをダンプまたは検証します。詳細は、第5.7項「いくつかのasgctlコマンドでのポリシー・ファイルのダンプとポリシー・ファイルの使用」を参照してください。
OracleAS Disaster Recoveryは、第5.1.3項「サポートされているトポロジ」に説明するように各種アプリケーション・サーバー・トポロジのサポートを提供しています。このサポートの一部として、一連のXMLフォーマットのポリシー・ファイルが、dump policiesコマンドを実行するOracleAS Guardクライアントにローカルに維持され、インスタンス別に、各asgctlコマンド(dump topology、verify topology、clone topology、failover、instantiate topology、switchover topologyおよびsync topology)に許可される実行操作のドメインが記録されます。
これらのasgctlコマンドに使用されているデフォルト・ポリシーを調べるには、asgctlプロンプトで次のコマンドを入力します。
ASGCTL> dump policies Generating default policy for this operation Creating policy files on local host in directory "/private1/OraHome2/asr1012/dsa/conf/" ASGCTL>
各XMLポリシー・ファイルの各インスタンスのリストのエントリは、デフォルトでは、本番とスタンバイのピア組合せと、各コマンドの正常な操作のための成功要件を定義する特定の属性を論理的に結び付けます。この方法によって、サポートされているトポロジでこれらの各OracleAS Guard操作を正常に使用する方法を柔軟に規定できます。詳細は、第5.1.3項「サポートされているトポロジ」を参照してください。
各XMLフォーマットのポリシー・ファイルを調べた後、それぞれのポリシー・ファイルを編集し、特定のasgctlコマンドのパラメータ構文using policy <file>にそれを使用することによって、使用するポリシー・ファイルの名前を指定できます。このようにして、この章ですでに説明したOracleAS Guardの操作ごとに、インスタンス別の成功要件の属性値を定義する特定の障害時リカバリ・ポリシーを使用できます。
成功要件の属性値は、次のいずれかです。[optional | mandatory | ignore | group <MinSucceeded=<number>>]それぞれの値の意味は次のとおりです。
Optional: そのインスタンスに障害がある場合、他のインスタンスの処理を続行します。
Mandatory: このインスタンスにエラーが発生した場合、操作全体が失敗することを意味します。
Ignore: インスタンスが操作の一部ではないことを意味します。
Group <MinSucceeded=<number>: Oracleインスタンスのグループを結合することを意味し、指定された数のグループ・メンバーが正常に処理された場合、操作は成功します。指定された数よりも正常に処理されたグループ・メンバーの数が少ない場合、操作は失敗します。
各属性値は、そのピア・グループの成功要件を決定し、asgctl操作に障害が発生した場合に参照され、OracleAS Guardの操作を続行するかどうかが決定されます。たとえば、成功要件が必須であると指定された場合、OracleAS Guardの特定の操作は、本番とスタンバイのピア組合せに指定されたインスタンスに対して正常に実行される必要があります。正常に実行されなかった場合は、OracleAS Guardのその操作が中止され、実行はその開始時点までロールバックされ、エラー・メッセージが返されます。
たとえば、フェイルオーバー操作の非対称トポロジに使用されている次のXMLポリシー・ファイルでは、このasgctl操作がinfraインスタンスには必須であり、portal_1インスタンスおよびportal_2インスタンスにはオプションであり、portal_3インスタンスには無視でき、3つのインスタンスBI_1、BI_2およびBI_3のグループのうち、少なくともいずれか2つに対しては正常に実行される必要があると指定しています。
<policy> <instanceList successRequirement="Mandatory"> <instance>infra</instance> </instanceList > <instanceList successRequirement="Optional"> <instance>portal_1</instance> <instance>portal_2</instance> </instanceList > <instanceList successRequirement="Ignore"> <instance>portal_3</instance> </instanceList > <instanceList successRequirement="Group" minSucceed="2"> <instance>BI_1</instance> <instance>BI_2</instance> <instance>BI_3</instance> </instanceList > </policy>
第5.1.3.5項「冗長な複数のOracle Application Server 10.1.3ホームJ2EEトポロジ」で説明したように、冗長な複数のOracle Application Server 10.1.3ホームJ2EEトポロジで、Oracle Application Server 10.1.3インスタンスの変更を検出できます。一般的な使用例では、Oracle Application Server 10.1.3 J2EEはOC4Jインスタンスを含むノードにインストールされており、既存の冗長な複数のOracle Application Server 10.1.3ホームJ2EEトポロジにこのノードとインスタンスを追加します。次の手順で、一般的な使用例について説明します。
ASGCTL > connect asg prodinfra ias_admin/<adminpwd> Successfully connected to prodinfra:7890 ASGCTL>
opmn.xml内の情報を自動的に更新します。
ASGCTL> discover topology within farm
to topologyキーワードを指定します。検証、インスタンス化、同期化、およびスイッチオーバーなど、スタンバイ・サイトに影響を与えるOracleAS Guard操作を実行すると、スタンバイ・トポロジ全体に本番トポロジ・ファイルが自動的に伝播されます。
ASGCTL> add instance oc4j3 on prodmid2 to topology
第5.1.3.6項「既存のOracle Identity Management 10.1.2.0.2トポロジと統合された冗長な単一Oracle Application Server 10.1.3 OracleホームJ2EEトポロジ」で説明したように、既存のOID 10.1.2.0.2トポロジではOracle Application Server 10.1.3単一ホームJ2EEインスタンスを追加または削除して、バージョンが混在するDisaster Recovery環境を作成または変更できます。次の手順で、一般的な使用例について説明します。
ASGCTL > connect asg prodinfra ias_admin/<adminpwd> Successfully connected to prodinfra:7890 ASGCTL>
ASGCTL> add instance oc4j1 on prodinfra to topology ASGCTL> add instance oc4j2 on prodinfra to topology
各add instanceコマンドを実行すると、OracleAS Guardクライアントの接続先のOracleAS Guardサーバーでローカル・トポロジ・ファイルが更新されます。更新されたトポロジ・ファイルをDisaster Recoveryの本番環境のインスタンスすべてに伝播するには、to topologyキーワードを指定します。この操作によって、既存のOID 10.1.2.0.2本番トポロジに統合されたoc4j1およびoc4j2インスタンスを含む、冗長な単一のOracle Application Server 10.1.3 OracleホームJ2EEトポロジが作成されます。検証、インスタンス化、同期化、スイッチオーバー、フェイルオーバーなど、スタンバイ・サイトに影響を及ぼすOracleAS Guard操作を行うと、スタンバイ・トポロジ全体に本番トポロジ・ファイルが自動的に伝播されます。
スタンバイ・サイト・クローニングとは、1つの本番インスタンスを1つのスタンバイ・システムにクローンするか(clone instanceコマンド)、2つ以上の本番インスタンスを複数のスタンバイ・システムにクローンする(clone topologyコマンド)プロセスです。どちらの場合も、各インスタンスのトポロジXMLファイルはクローン操作によりコピーされて、各インスタンスで一貫したものになり、そのスタンバイ・システムでローカルのみで更新されます。ただし、検証、インスタンス化、同期化、スイッチオーバー、フェイルオーバー操作など、スタンバイ・サイトに影響を及ぼすOracleAS Guard操作が実行されると、本番トポロジ内のローカル・システムにあるXMLトポロジ・ファイルがスタンバイ・トポロジの全ノードのインスタンスすべてにただちに自動的に伝播されます。
clone instanceコマンドを使用して、既存の本番インスタンス・ソースから新しいスタンバイ・インスタンス・ターゲットを作成します。
この操作を実行するためにOracleAS Guardが使用する基礎となるテクノロジの1つとして、ホストの破損に対するOracleASバックアップおよびリストア機能があります。前提条件のリストなどの詳細は、『Oracle Application Server管理者ガイド』のホストの破損の自動リカバリに関する項を参照してください。この機能は、ターゲット・マシンが新しく作成されたOracle環境であることを想定しています。これは、それがOracleソフトウェア・レジストリを上書きするためです。さらに、基礎となる操作のいくつかには、UNIX環境の場合はroot、およびWindowsの場合はAdministratorといった高い権限が必要です。Windowsでは、ユーザーは、クライアントとOracleAS GuardサーバーがAdministrator権限によって起動されていることを確認する必要があります。
クローンには次の2つのフェーズがあります。最初のフェーズは、Oracleホームを作成し、それをシステム環境内に登録することです。2番目のフェーズは、OracleAS Guardインスタンス化操作を実行し、それをOracleAS Disaster Recovery環境にリンクし、Oracleホームをそれに対応する本番ホームと論理的に一致させることです。
様々なインスタンスでの一連のインスタンスのクローン操作は、1つのトポロジのクローン操作と同等です。
clone topologyコマンドは、1つのグループのシステム全体にインスタンスのクローン操作を実行します。クローン操作は、データベースを含まないすべてのOracle Application Serverホームで実行され、ポリシー・ファイルを使用してフィルタできます。データベースを含むOracle Application Serverホームの場合、トポロジのクローン操作によって、操作のインスタンス化フェーズが実行され、スタンバイ・サイトでのOracleホームの作成をスキップできます。この操作は、ポリシー・ファイルを使用することによってトポロジのサブセットに実行できます。
OracleAS Disaster Recoveryのサイトの設定を計画する際には、次の3つの方法論を認識する必要があります。
各操作では、新しくインストールしたOracleホームを既存のサイトに統合したり、それらを本番サイトのスタンバイ・サイトに結合するための様々な方法が必要です。
Oracle Application Server 10gリリース2(10.1.2.0.2)より前は、これがOracleAS Guardがサポートする唯一のタイプのサイトでした。OracleAS Disaster Recovery構成は、デフォルトのInfrastructureおよびOracleAS中間層のインストール・タイプに対してのみサポートされていました。このタイプの構成では、すべてのOracle Application ServerホームはOracleインストーラを使用して作成されました。OracleAS Guardのインスタンス化コマンドによって、本番およびスタンバイのOracleホームと基礎となっているスタンバイOracleデータベース・リポジトリとの間の関係が作成されます。
OracleASサイトでOracleAS Disaster Recoveryが有効化された後、本番OracleホームとスタンバイOracleホームとの間の関係が作成されます。Oracle Application Server 10gリリース2(10.1.2.0.2)の場合、新しいインスタンスをサイトに追加する唯一の方法は、スタンバイの関係を壊し、Oracle Installerを使用して本番サイトで新しいインスタンスを追加し、Oracle Installerを使用してその新しいインスタンスをスタンバイ・サイトに追加し、スタンバイ・サイトを再作成することでした。Oracle Application Server 10gリリース2(10.1.2.0.2)では、clone instanceコマンドを使用してインスタンスをスタンバイ・サイトに追加できます。
たとえば、中間層のサービスを増やすために新しい中間層が必要な場合、新しいインスタンスを本番サイトにインストールします。この操作によって、そのインスタンスのOracle Application Serverホームが作成され、Oracle Application Serverリポジトリ内に必要な関係が確立されます。
Oracle Application Server 10gリリース2(10.1.2.0.2)のOracleAS Guardの非対称トポロジ・サポートでは、このOracleホームは、このサイトのOracleAS Disaster Recoveryソリューションについては無視することもできます。このインスタンスをスタンバイ・サイトに追加する場合は、clone topologyコマンドでスタンバイ・ターゲット・ホストにOracleAS Oracleホームを作成し、このインスタンスに対する本番とスタンバイの関係を確立します。このコマンドを発行する前に、OracleAS Guardのスタンドアロン・キットをターゲット・ホストにインストールして起動し(詳細は、Oracle Application Serverのインストレーション・ガイドのOracleAS Disaster Recoveryのインストール情報を参照)、サイトのトポロジ検出操作を実行して、本番トポロジの新しいインスタンスを検出する必要があります。
Oracle Application Serverは、既存のデータベースにMetadata Repositoryスキーマを作成する機能をサポートしています。OracleAS Guardでは、これらのデータベースが認識および管理され、Metadata Repository構成データがサイトの残りの分散構成データと同期化されますが、スタンバイ・リポジトリも本番とスタンバイの関係も作成されません。この環境は、トポロジのクローン操作を使用してサポートします。
clone topologyコマンドを利用するには、最初にスタンドアロンOracleAS Guardサーバーを各スタンバイ・ホストにインストールして起動します。さらに、スタンドアロンOracleAS Guardのインストールによって作成されたOracleホームにOracleASのバックアップおよびリストア・ユーティリティをインストールします。前提条件のリストなどの詳細は、『Oracle Application Server管理者ガイド』のホストの破損の自動リカバリに関する項を参照してください。clone topologyコマンドによって、スタンバイ・サイトにインスタンスOracleホームと構成情報が作成されます。Infrastructureインスタンスの場合は、暗黙的インスタンス化操作を実行して、OracleAS Disaster Recovery環境を初期化します。トポロジのクローニング操作は、プロファイル・ファイルを使用して、非対称トポロジのインスタンスをフィルタで除外できます。
クローン操作は、次のような状況で便利です。
これらのクローン操作を実行する手順は、次の項で説明します。
スタンバイ・サイトに1つの本番インスタンスをクローニングする場合も、複数の本番インスタンスをクローニングする場合も、前提条件および従う手順は同じです。唯一の相違は、クローニング操作に使用する実際のasgctlコマンドです。このため、この項ではクローニング情報を統合しており、内容が若干異なる場合にのみその旨を示しています。
例として、1つの本番インスタンスをスタンバイ・ホスト・システムに追加するとします。インスタンスのクローン操作を使用すると、Oracleインスタンスをスタンバイ中間層システムにインストールしてからインスタンス化操作を実行するという作業を行わずに済みます。
例として、2つ以上の本番インスタンスをスタンバイ中間層ホスト・システムに追加するとします。トポロジのクローン操作を使用すると、Oracleインスタンスをスタンバイ中間層システムにインストールしてからインスタンス化操作を実行するという作業を行わずに済みます。
トポロジのクローン操作の一部として、本番インスタンスがクローンされ、OracleAS Metadata Repositoryがインスタンス化されます。ただし、OracleAS Metadata Repository Creation Assistantを使用して作成されたOracleAS Metadata Repository構成の場合、インスタンス化操作は実行されません。
ポリシー・ファイルを使用する場合、クローン・ポリシー・ファイル(clone_policy.xml)を編集して使用します。このファイルをclone topologyコマンドのusing policy <file>パラメータで指定し、それによって指定されたインスタンスに対してのみスタンバイ・トポロジをクローンします。詳細は、第5.7項「いくつかのasgctlコマンドでのポリシー・ファイルのダンプとポリシー・ファイルの使用」を参照してください。
複数の本番インスタンスをスタンバイ・サイトにクローニングする前に、次のことを考慮します。
Windowsの場合: %SystemRoot%¥system32¥drivers¥etc¥hosts
UNIXの場合: /etc/hosts
ip_address prodnode1.domain.com prodnode1 vhostdr.domain.com vhostdr
create standby databaseコマンドを使用することをお薦めします。
http://www.gnu.org/software/tar/
本番インスタンスまたはクローニングするインスタンスは、スタンバイ・システムに存在してはなりません。
スタンバイ・サイト・システムにインスタンスとトポロジのクローン操作を実行するための前提条件は次のとおりです。
sc.exe)をスタンバイ・システムにインストールする必要があります。
クローニングの基本手順は、次のクローニング前(UNIXシステムの場合のみ)およびクローニング中の各手順から構成されています。
本番サイトとスタンバイ・サイトの各インスタンスで、次の手順を実行します。
> <ORACLE HOME>/opmn/bin/opmnctl stopproc ias-component=ASG
<ORACLE_HOME>/dsa/bin内のdsaServer.shをすべてのユーザーが実行できることを確認します。実行できない場合は、現在の実行権限を書き留めてから、次のコマンドを実行して実行権限を変更します。
chmod +x dsaServer.sh chmod u+x asgexec
> asgctl.sh startup
本番サイトのインスタンスで、次の手順を実行します。
> asgctl.sh Application Server Guard: Release 10.1.3.2.0 (c) Copyright 2004, 2005 Oracle Corporation. All rights reserved ASGCTL> connect asg prodoc4j oc4jadmin/adminpwd Successfully connected to prodoc4j:7890 ASGCTL> set primary database sys/testpwd@asdb Checking connection to database asdb CLONE INSTANCE -- CLONE AN INSTANCE EXAMPLE ASGCTL> clone instance portal_2 to asmid2 Generating default policy for this operation . . . CLONE TOPOLOGY -- CLONE MULTIPLE INSTANCES EXAMPLE # Command to use if you are using a policy file where <file> # is the full path and file spec of the clone policy file. ASGCTL> clone topology to standbyinfra using policy <file> Generating default policy for this operation . . . ASGCTL> disconnect ASGCTL> exit >
最後の手順で、インスタンスのクローニング操作が完了し、操作を開始する前の状態にシステムが戻ります。この時点でasgctlを起動し、本番システムに接続し、トポロジを検出し、検証操作を実行して、本番トポロジとスタンバイ・トポロジが有効で、予期したとおりに両方のトポロジが一致しているかどうかを調べます。
次の条件を満たしている場合、Oracle Application Server Guardを使用して、スタンバイのインスタンス化とスタンバイの同期化を実行できます。
次の項目では、スタンバイのインスタンス化とスタンバイの同期化について説明します。
OracleAS Guardコマンドラインasgctlユーティリティのリファレンス情報は、第6章「OracleAS Guard asgctlコマンドライン・リファレンス」を参照してください。
スタンバイのインスタンス化操作では、スタンバイ・サイトで論理的な本番サイトのミラー化を設定し、維持するためのいくつかの操作を実行します。OracleAS Guardは、障害時リカバリの機能を実現するために、本番サイトとスタンバイ・サイト間での分散操作の調整に使用されます。設定操作は次のとおりです。
instantiate_policy.xml)を編集して使用します。このファイルをinstantiate topologyコマンドのusing policy <file>パラメータで指定し、それによって指定されたインスタンスに対してのみスタンバイ・トポロジをインスタンス化します。詳細は、第5.7項「いくつかのasgctlコマンドでのポリシー・ファイルのダンプとポリシー・ファイルの使用」を参照してください。
スタンバイのインスタンス化操作を実行する手順では、次の例を使用します。この例では、OracleAS Guardクライアントを起動して、discover topologyコマンドを実行してトポロジ・ファイルを作成してあると想定しています。
CFC環境にOracleAS Disaster Recovery構成があり、インスタンス化操作を実行しようとしている場合は、第6.2.1.1項「CFC環境でインスタンス化およびフェイルオーバー操作を実行するときの特別な考慮事項」を参照してください。
ASGCTL > connect asg prodinfra ias_admin/<adminpwd> Successfully connected to prodinfra:7890 ASGCTL>
ASGCTL> set primary database sys/testpwd@asdb
verify_policy.xml)およびインスタンス化ポリシー・ファイル(instantiate_policy.xml)を編集して使用し、ファイル内に各インスタンスの成功要件の属性を指定します。詳細は、第5.7項「いくつかのasgctlコマンドでのポリシー・ファイルのダンプとポリシー・ファイルの使用」を参照してください。
ASGCTL> dump policies Generating default policy for this operation Creating policy files on local host in directory "/private1/OraHome2/asr1012/dsa/conf/"
standbyinfraが使用されています。
ASGCTL> verify topology with standbyinfra
standbyinfraが使用されています。このコマンドは、すべてのOracleホームがOracleインストーラ・ソフトウェアを使用してインストールされていると想定しています。using policy <file>パラメータを指定します。ここで<file>は、instantiate_policy.xmlファイルのパスとファイルの指定を表します。
ASGCTL> instantiate topology to standbyinfra using policy <file>
asgctlのinstantiate topologyコマンドを使用して、スタンバイのインスタンス化を実行するたびに、同期化操作も実行されます。したがって、インスタンス化操作の後、すぐに別の同期化操作を実行する必要はありません。インスタンス化操作の後に一定期間経過した場合は、プライマリ・サイトとスタンバイ・サイトが一致していることを確認します。その後、トポロジの同期化操作を実行し、プライマリ・サイトで行われたすべての変更がセカンダリ・サイトに適用されるようにします。
OracleAS Guardの同期化操作は、スタンバイ・サイトとプライマリ・サイトを同期化し、2つのサイトを論理的に一致させます。この操作は、次のような状況の場合に必要になります。
完全な同期化を指定することも増分の同期化を指定することもできます。デフォルトでは、増分の同期化が実行されます。これは最も高いパフォーマンスを提供します。ただし、次の3つの状況では、完全な同期化を指定する必要があります。
同期化操作の際に検証操作が実行されて、必要なOracleAS Disaster Recovery環境が維持されていることが確認されます。また、Oracle Application Serverトポロジに新しいOracle Application Serverインスタンスをインストールした場合は、OracleAS Guardによってこれらのインストールが検出されます。
ポリシー・ファイルを使用する場合、同期化ポリシー・ファイル(sync_policy.xml)を編集して使用します。このファイルをsync topologyコマンドのusing policy <file>パラメータで指定し、それによって指定されたインスタンスに対してのみスタンバイ・トポロジを同期化します。詳細は、第5.7項「いくつかのasgctlコマンドでのポリシー・ファイルのダンプとポリシー・ファイルの使用」を参照してください。
次の例では、OracleAS Guardクライアントを起動して、discover topologyコマンドを実行してトポロジ・ファイルを作成してあると想定しています。
スタンバイの同期化を実行する手順は次のとおりです。
ASGCTL > connect asg prodinfra ias_admin/<adminpwd> Successfully connected to prodinfra:7890 ASGCTL>
ASGCTL> set primary database sys/testpwd@asdb
ASGCTL> sync topology to standbyinfra
実行時操作には、スケジューリングした停止と計画外停止を含む停止の操作(第5.12.1項「停止」を参照)、asgctlコマンドライン・ユーティリティを使用した実行中のOracleAS Guard操作を監視する操作およびトラブルシューティング(第5.15項「OracleAS Guard操作の監視とトラブルシューティング」を参照)があります。
停止には、スケジューリングした停止と計画外停止の2つのカテゴリがあります。
次のサブセクションではこれらの停止について説明します。
スケジューリングした停止とは、計画停止のことです。この停止は、ビジネス・アプリケーションをサポートするテクノロジ・インフラストラクチャの定期的なメンテナンスのために必要で、この間に、ハードウェアのメンテナンスや修復とアップグレード、ソフトウェアのメンテナンスとパッチ適用、アプリケーションの変更とパッチ適用、およびシステムのパフォーマンスと管理機能強化を目的とした変更などのタスクが実行されます。スケジューリングした停止は、本番サイトまたはスタンバイ・サイトのどちらでも実行できます。次に、本番サイトまたはスタンバイ・サイトに影響を与えるスケジューリングした停止について説明します。
現行の本番環境があるサイト全体が使用できなくなります。サイトレベルのメンテナンスの例には、スケジューリングした停電、サイトのメンテナンス、定期的に計画されたスイッチオーバー操作などがあります。
これは、ハードウェア・メンテナンスのためにスケジューリングした、OracleAS Cold Failover Clusterの停止時間です。この停止時間は、ハードウェア・クラスタ全体に影響を与えます。クラスタレベルのメンテナンスの例には、クラスタ・インターコネクトの修復、クラスタ管理ソフトウェアのアップグレードなどがあります。
スケジューリングした停止では、次の項で説明するサイト・スイッチオーバー操作を実行する必要があります。
サイト・スイッチオーバーは、本番サイトの計画停止の際に実行されます。スイッチオーバー時には、本番サイトとスタンバイ・サイトの両方が使用可能である必要があります。データベースREDOログは、中間層およびOracleAS Infrastructureインストールの構成ファイルのバックアップおよびリストアと同時に適用されます。
サイト・スイッチオーバー時は、DNS情報が長時間キャッシュされないように配慮する必要があります。そのため、サイトのDNS情報の変更、具体的にはTime-To-Live(TTL)値の変更が必要です。手順は、第5.16.2項「DNS名の手動変更」を参照してください。
ポリシー・ファイルを使用する場合、スイッチオーバー・ポリシー・ファイル(switchover_policy.xml)を編集して使用します。このファイルをswitchover topologyコマンドのusing policy <file>パラメータで指定し、それによって指定されたインスタンスに対してのみスタンバイ・トポロジにスイッチオーバーします。詳細は、第5.7項「いくつかのasgctlコマンドでのポリシー・ファイルのダンプとポリシー・ファイルの使用」を参照してください。この例では、ポリシー・ファイルの使用例は示しません。
CFC環境にOracleAS Disaster Recovery構成があり、スイッチオーバー操作を計画している場合は、第6.2.1.3項「CFC環境でスイッチオーバー操作を実行するときの特別な考慮事項」を参照してください。
本番サイトからスタンバイ・サイトにスイッチオーバーする手順は次のとおりです。
prodinfra: -->ASG_DGA-13051: Error performing a physical standby switchover. prodinfra: -->ASG_DGA-13052: The primary database is not in the proper state to perform a switchover. State is "SESSIONS ACTIVE"
次は、10.1.2.xベースの環境にのみ適用されます。
UNIXシステムの場合、次のようにしてApplication Server Controlを停止し(iasconsole)、emagentプロセスを停止します。
> <ORACLE_HOME>/bin/emctl stop iasconsole
UNIXシステムの場合、emagentプロセスが実行されていないかをチェックするために、次のコマンドを入力します。
> ps -ef | grep emagent
UNIXシステムの場合、stop iasconsoleの操作の後でemagentプロセスが依然として実行されている場合は、前のpsコマンドで示したようにプロセスID(PID)を取得し、次のようにしてemagentプロセスを停止します。
> kill -9 <emagent-pid>
Windowsシステムの場合、「サービス」コントロール パネルを開きます。OracleAS10gASControlサービスを見つけて、このサービスを停止します。
asgctl.shは<ORACLE_HOME>/dsa/binにあり、Windowsシステムでは、asgctl.batは<ORACLE_HOME>¥dsa¥binにあります。
> asgctl.sh Application Server Guard: Release 10.1.2.0.2 (c) Copyright 2004, 2005 Oracle Corporation. All rights reserved ASGCTL> connect asg prodinfra ias_admin/<adminpwd>
ASGCTL> set primary database sys/testpwd@asdb
shutdown_asdb_instance.shスクリプトを作成し、スクリプト内で指定している場所にコピーします。これはOracleホーム内の場所である必要があります。
#shutdown_asdb_instance.sh for asdb instance #in /private/oracle/product/10.1.0/asdb on db_site1_node1 & db_site2_node1 export ORACLE_HOME=/private/oracle/product/10.1.0/asdb $ORACLE_HOME/bin/srvctl stop database -d asdb $ORACLE_HOME/bin/srvctl disable database -d asdb
ASGCTL> run at instance asdb shutdown_asdb_instance.sh
using policy <file>パラメータを指定します。<file>は、switchover_policy.xmlファイルのパスとファイルの指定を表します。
ASGCTL> switchover topology to standbyinfra
ASGCTL> disconnect ASGCTL>
この項では、スイッチオーバー操作に関する次のような特別な考慮事項について説明します。
switchover_policy.xmlポリシー・ファイルを編集してノードをIgnoreに設定するだけでなく、このノードで実行中のすべてのプロセスを停止する必要があります。たとえば、プライマリ・サイトで実行されている2つのOracle Identity Managementインスタンスがim.machineA.us.oracle.comとim.machineB.us.oracle.comであり、もう1つのノード(im.machineB.us.oracle.com)がスイッチオーバー・サイトで無視される場合、スイッチオーバー操作が正常に実行されるためには、システム管理者はそのノード(im.machineB.us.oracle.com)上で実行されているすべてのプロセスを停止することも必要です。
switchover topology to <primary site>)にデータベースをOracle RACの1つのノードでのみ起動するため、プライマリ・サイトの残りのOracle RACインスタンスは手動で起動する必要があります。
本番サイトに影響を与える計画外停止は、そのサイトが使用不能になり、本番サイトがリストアされて妥当な期間内にサービスを提供する可能性がない場合に発生します。これには、火事、洪水、地震、停電などの本番サイトでのサイトレベルの停止があります。
計画外停止が発生した場合は、本番サイトからスタンバイ・サイトへのフェイルオーバー操作の実行が保証されます。
サイト・フェイルオーバー操作は、本番サイトの計画外停止の際に実行されます。フェイルオーバー操作では、構成データとInfrastructureデータを、一貫性のあった時点までリストアする必要があります。OracleAS Guardでは、最後にsync操作を行った時点から、一貫性のある方法でサイトのサービスが開始されます。フェイルオーバー操作によって、最後の同期化の時点までリストアされます。
ポリシー・ファイルを使用する場合、フェイルオーバー・ポリシー・ファイル(failover_policy.xml)を編集して使用します。このファイルをfailoverコマンドのusing policy <file>パラメータで指定し、それによって指定されたインスタンスのみがスタンバイ・トポロジにフェイルオーバーされるようにします。詳細は、第5.7項「いくつかのasgctlコマンドでのポリシー・ファイルのダンプとポリシー・ファイルの使用」を参照してください。
CFC環境にOracleAS Disaster Recovery構成があり、フェイルオーバー操作を実行しようとしている場合は、第6.2.1.1項「CFC環境でインスタンス化およびフェイルオーバー操作を実行するときの特別な考慮事項」を参照してください。
本番サイトからスタンバイ・サイトにフェイルオーバーする手順は次のとおりです。
ASGCTL> connect asg standbyinfra ias_admin/<adminpwd> Successfully connected to stanfbyinfra:7890
start_asdb_db.shスクリプトを作成し、スクリプト内で指定している場所にコピーします。これはOracleホーム内の場所である必要があります。
#start_asdb_db.sh for asdb database #in /private/oracle/product/10.1.0/asdb on db_site1_node1 & db_site2_node1 export ORACLE_HOME=/private/oracle/product/10.1.0/asdb $ORACLE_HOME/bin/srvctl enable database -d asdb $ORACLE_HOME/bin/srvctl start database -d asdb
ASGCTL> run at instance asdb start_asdb_db.sh
ASGCTL> set new primary database sys/testpwd@asdb
ASGCTL> failover
10.1.2.x環境の場合、次のコマンドを実行してトポロジを検出します。
ASGCTL> discover topology oidpassword=oidpwd
10.1.3.x環境の場合、次のコマンドを実行してトポロジを検出します。
ASGCTL> discover topology within farm
また、次のadd instanceコマンドを使用して、スタンドアロン・データベース・インスタンスをDRトポロジに追加することもできます。
add instance asdb on vhostdr.oracle.com
この項では、プライマリ・サイトでもスタンバイ・サイトでもOracle Real Application Clustersデータベースを使用しないOracleAS Disaster Recoveryトポロジの設定方法について説明します。これは基本的に、OracleAS Disaster Recoveryの最も単純な構成です。Real Application Clustersデータベースを使用したOracleAS Disaster Recoveryトポロジについては、次の項の第5.14項「Oracle Real Application Clustersデータベースを使用するOracleAS Disaster Recovery」で説明します。
この項の項目は次のとおりです。
次の前提条件に注意してください。
スタンドアロンのOracleAS Guardインストーラの実行方法の詳細は、ご使用のプラットフォームのOracle Application Serverのインストレーション・ガイドで、「高可用性環境へのインストール」の章を参照してください。
create standby databaseコマンドを実行する前に実行する必要があります。
create standby databaseコマンドを実行する前に、asgctlのset primary databaseコマンドをプライマリ・サイトとスタンバイ・サイトの両方に発行して、OracleAS Guard内のサービス名マッピングを定義する必要があります。
create standby databaseコマンドによって上書きされます。
create standby databaseコマンドは、プライマリ・サイトのデータベースが存在するソース・プライマリ・ノードから、ASGクライアントによって発行される必要があります。
create standby databaseコマンドの実行後に、orapwファイルをデータベースの作成先であるスタンバイ・サイト・インスタンスから共有の場所にコピーする必要があります。また、共有の場所へのコピー後は、そのファイルが作成されたローカル・ディスクからファイルへのsymlinkを作成する必要があります。
instantiate、failoverまたはswitchover操作の後に実行する必要があります。
表5-5 プライマリ・サイトおよびスタンバイ・サイトのホスト名とデータベース名
| プライマリ・サイト | スタンバイ・サイト | |
|---|---|---|
|
物理ホスト名 |
prodnode1 |
standbynode1 |
|
仮想ホスト名 |
vhostdr |
vhostdr |
|
データベース名 |
orcl.oracle.com |
orcl.oracle.com |
|
データベースSID |
orcl |
orcl |
hostsファイルで設定します。次に、例を示します。プライマリ・サイトで、%SystemRoot%¥system32¥drivers¥etc¥hosts(Windows)または/etc/hosts(UNIX)を編集し、次のようなエントリを追加します。
ip_address prodnode1.domain.com prodnode1 vhostdr.domain.com vhostdr
スタンバイ・サイトで、同じhostsファイルを編集し、次のようなエントリを追加します。
ip_address standbynode1.domain.com standbynode1 vhostdr.domain.com vhostdr
複数のデータベースを単一の障害時リカバリ・トポロジに配置する場合は、次のことを考慮します。
create standby databaseコマンドを起動する前に、データベースごとにset primary databaseコマンドを起動する必要があります。create standby databaseは、プライマリ・データベースが存在するシステムから実行する必要があるからです。例:
set primary database sys/<pass>@orcl1 create standby database orcl1 on standbynode1 set primary database sys/<pass>@orcl2 create standby database orcl2 on standbynode1
instantiate、switchover、sync、failover操作など、他のすべての障害時リカバリ操作でも、障害時リカバリ・トポロジに含まれるデータベースごとにset primary databaseコマンドを起動する必要があります。次に、例を示します。
set primary database sys/<pass>@orcl1 set primary database sys/<pass>@orcl2 sync topology to standbynode1
OHOME1にOracle 10gR1 db、OHOME2にOracle 10gR2 dbがある場合)、上位バージョンのデータベースのOracleホーム(この場合は、OHOME2)からデータベース・リスナーを実行することをお薦めします。
次の手順を実行して、プライマリ・サイトでもスタンバイ・サイトでもReal Application Clustersデータベースを使用しないOracleAS Disaster Recoveryトポロジを設定します。
> DBHOME/bin/sqlplus / as sysdba SQL> shutdown;
Windowsの場合は、次のoradimコマンドを実行してOracle SIDを削除します。
> oradim -delete -sid orcl
UNIXの場合は、oratabファイル内でデータベースSID/データベース名のエントリをコメント・アウトします。Real Application Clusters以外のデータベースでは、oratabファイル内のこのエントリの形式は次のとおりです。
DBSID:oracle_home
> DBHOME/bin/sqlplus / as sysdba SQL> startup
create standby databaseコマンドは、standbynode1に同じ名前の既存のデータベースがある場合、それを上書きします。
ASGCTL> connect asg prodnode1 oc4jadmin/<adminpwd> ASGCTL> set trace on all ASGCTL> add instance orcl on vhostdr ASGCTL> dump topology ASGCTL> verify topology ASGCTL> set noprompt ASGCTL> set primary database sys/<passwd>@orcl ASGCTL> create standby database orcl on standbynode1 ASGCTL> verify topology with standbynode1 ASGCTL> instantiate topology to standbynode1 ASGCTL> sync topology to standbynode1
プライマリ・サイトでスケジューリングした停止を行う場合は、ASGCTLのswitchoverコマンドを実行してスタンバイ・サイトにスイッチオーバーします。計画外停止がある場合は、第5.13.5項「フェイルオーバー手順」の説明に従ってフェイルオーバーの手順を実行する必要があります。
prodnode1で、次のようにswitchoverコマンドを実行します。
ASGCTL> connect asg oc4jadmin/<adminpwd> ASGCTL> verify topology with standbynode1 ASGCTL> set primary database sys/<passwd>@orcl ASGCTL> switchover topology to standbynode1 ASGCTL> disconnect
スケジューリングした停止が終了したら、スタンバイ・サイトからプライマリ・サイトにスイッチバックします。
standbynode1で次のコマンドを実行して、プライマリ・サイトにスイッチバックします。
ASGCTL> connect asg standbynode1 oc4jadmin/<adminpwd> ASGCTL> verify topology with prodnode1 ASGCTL> set primary database sys/<passwd>@orcl ASGCTL> switchover topology to prodnode1
プライマリ・サイトに予期しない障害が発生した場合は、フェイルオーバーの手順を実行してスタンバイ・サイトにフェイルオーバーします。スケジューリングした停止については、かわりに第5.13.3項「スイッチオーバー手順」の手順を実行してください。
スタンバイ・サイトにフェイルオーバーするには、次のコマンドをスタンバイ・サイトで実行して、新しいプライマリとしてアクティブにします。
ASGCTL> connect asg standbynode1 oc4jadmin/<adminpwd> ASGCTL> set primary database sys/<passwd>@orcl ASGCTL> set new primary database sys/<passwd>@orcl ASGCTL> failover
asgctlのfailover操作の実行後は、create standby databaseコマンドでリモート・ホストにスタンバイ・データベースを作成してからinstantiate topology操作を実行してください。
この項では、OracleAS Metadata RepositoryでReal Application Clustersデータベースを使用するOracleAS Disaster Recoveryトポロジの構成方法について説明します。Real Application Clustersデータベースは、プライマリ・サイトとスタンバイ・サイトの両方で使用することも、プライマリ・サイトのみで使用する(スタンバイ・サイトではReal Application Clusters以外のデータベースを使用する)こともできます。次のサブセクションでは、これらのケースについて説明します。
この項では、プライマリ・サイトとスタンバイ・サイトの両方でOracle Real Application Clustersデータベースを使用するトポロジでOracleAS Disaster Recoveryを設定する方法について説明します。
この項の項目は次のとおりです。
次の前提条件に注意してください。
スタンドアロンのOracleAS Guardインストーラの実行方法の詳細は、ご使用のプラットフォームのOracle Application Serverのインストレーション・ガイドで、「高可用性環境へのインストール」の章を参照してください。
oradim -delete -sid <DBSID>コマンドを使用します。また、UNIXプラットフォームではoratabからデータベース・エントリを削除します。
create standby databaseコマンドを実行する前に、DBCA(Database Configuration Assistant)を使用して、プライマリ・サイトにOMF(Oracle Managed Files)またはASM(自動ストレージ管理)以外のストレージ・オプションで新しいデータベース・インスタンスを作成します。
create standby databaseコマンドによって上書きされます。
sync topologyコマンドが失敗し、欠落アーカイブ・ログのエラーを受信した場合は、tnspingを使用してスタンバイ・ノードにpingを試行します。スタンバイ・ノードにpingできない場合は、そのノードのリスナーを停止し再起動してからtnspingを再試行します。
表5-6 プライマリ・サイトおよびスタンバイ・サイトのホスト名とデータベース名
hostsファイルで設定します。次に、例を示します。プライマリ・サイトで、%SystemRoot%¥system32¥drivers¥etc¥hosts(Windows)または/etc/hosts(UNIX)を編集し、次のようなエントリを追加します。
ip_address prodnode1.domain.com prodnode1 vracnode1.domain.com vracnode1
スタンバイ・サイトで、同じhostsファイルを編集し、次のようなエントリを追加します。
ip_address standbynode1.domain.com standbynode1 vracnode1.domain.com vracnode1
次の手順を実行して、プライマリ・サイトとスタンバイ・サイトでReal Application Clustersデータベースを使用するOracleAS Disaster Recoveryトポロジを構成します。
> DBHOME/bin/srvctl stop database -d orcl > DBHOME/bin/srvctl disable database -d orcl
create standby databaseコマンドの実行時にエラーが発生します。Windowsの場合は、次のoradimコマンドを実行してOracle SIDを削除します。
> oradim -delete -sid orcl1
UNIXの場合は、oratabファイル内でデータベースSID/データベース名のエントリをコメント・アウトします。Real Application Clustersデータベースでは、oratabファイル内のこのエントリの形式は次のとおりです。
DBuniqueName:oracle_home
> DBHOME/bin/srvctl stop database -d orcl > DBHOME/bin/srvctl disable database -d orcl
> DBHOME/bin/sqlplus / as sysdba SQL> startup
これらのコマンドについては、次の点に注意してください。
orcl(データベース名)を使用してoratabエントリを検出します。Windowsの場合、orcl1(データベースSID)を使用してレジストリ・エントリを検出します。
orcl(データベース名)を使用しますが、Windowsの場合、orcl1(データベースSID)を使用します。
ASGCTL> connect asg prodnode1 oc4jadmin/<adminpwd> ASGCTL> set trace on all UNIX only: ASGCTL> add instance orcl on vracnode1 Windows only: ASGCTL> add instance orcl1 on vracnode1 ASGCTL> dump topology ASGCTL> verify topology ASGCTL> set noprompt UNIX only: ASGCTL> set primary database sys/<passwd>@orcl Windows only: ASGCTL> set primary database sys/<passwd>@orcl1 UNIX only: ASGCTL> create standby database orcl on standbynode1 Windows only: ASGCTL> create standby database orcl1 on standbynode1 ASGCTL> verify topology with standbynode1 ASGCTL> instantiate topology to standbynode1
UNIXでは、このエントリにデータベース名(orcl)、Windowsでは、データベースSID(orcl1)が使用され、それぞれのエントリ名に_remote<n>が追加されています(<n>は数字)。
場合によっては、<n>の番号が上がり、LOG_ARCHIVE_DEST_<n>パラメータのSERVICE属性で指定されたエントリ_remote<n>も同様に伝播する必要があります。
> CRSHOME/bin/crs_stop ora.prodnode2.LISTENER_PRODNODE2.lsnr > CRSHOME/bin/crs_start ora.prodnode2.LISTENER_PRODNODE2.lsnr
UNIX only: > tnsping orcl_remote1 Windows only: > tnsping orcl1_remote1
sync topologyコマンドを使用するには、すべてのインスタンスが稼動している必要があります。
ASGCTL> connect asg oc4jadmin/<adminpwd> UNIX only: ASGCTL> set primary database sys/<passwd>@orcl Windows only: ASGCTL> set primary database sys/<passwd>@orcl1 ASGCTL> sync topology to standbynode1
この項では、プライマリ・サイトのスケジューリングした停止に対する準備を行うため、ASGCTLのswitchoverコマンドを実行してプライマリ・サイトからスタンバイ・サイトに切り替える方法について説明します。
スケジューリングした停止が終了したら、プライマリ・サイトにスイッチバックできます。詳細は、第5.14.1.4項「スイッチバック手順(プライマリ・サイトへのスイッチバック)」を参照してください。
計画外停止については、かわりに第5.14.1.5項「フェイルオーバー手順」の手順を実行してください。
スケジューリングした停止を実行するためにスタンバイ・サイトにスイッチオーバーする手順は次のとおりです。
prodnode1で次のコマンドを実行します。
> srvctl stop database -d orcl > srvctl disable database -d orcl
prodnode1で単一のデータベース・インスタンスを起動します。
> DBHOME/bin/sqlplus / as sysdba SQL> startup
ASGCTL> connect asg oc4jadmin/<adminpwd> ASGCTL> verify topology with standbynode1 UNIX only: ASGCTL> set primary database sys/<passwd>@orcl Windows only: ASGCTL> set primary database sys/<passwd>@orcl1 ASGCTL> switchover topology to standbynode1 ASGCTL> disconnect
プライマリ・データベースは排他的にマウントする必要があるというメッセージがコンソールに表示される場合は、複数のReal Application Clustersデータベース・インスタンスが稼動していることを意味します。データベース・インスタンスを1つのみ起動する方法については、前述の手順を参照してください。
SQL> shutdown immediate;
initorcl1.oraファイル内のパラメータを変更します。
DBHOME/dbs/initorcl1.ora(UNIX)またはDBHOME¥database¥initorcl1.ora(Windows)のバックアップ・コピーを作成します。このファイルは次の手順で編集します。
DBHOME/dbs/initorcl1.ora(UNIX)またはDBHOME¥database¥initorcl1.ora(Windows)で、パラメータの値が次のように設定されていることを確認します。
*.cluster_database_instances=2 *.cluster_database=TRUE *.remote_listener='LISTENERS_ORCL'
initorcl1.oraをstandbynode1からstandbynode2の対応するディレクトリ(UNIXではDBHOME/dbs、WindowsではDBHOME¥database)にコピーします。
initorcl2.oraに変更します。
initorcl2.oraファイルを更新してインスタンス固有のパラメータを修正します。たとえば、次のような行があるとします。
*.service_names=orcl1 *.instance_name=orcl1
これを次のように修正します。
*.service_names=orcl2 *.instance_name=orcl2
mkdir $ohome/admin/<dbname>/admin
UNIXでは、このエントリにデータベース名(orcl)、Windowsでは、データベースSID(orcl1)が使用され、それぞれのエントリ名に_remote<n>が追加されています(<n>は数字)。
場合によっては、<n>の番号が上がり、LOG_ARCHIVE_DEST_<n>パラメータのSERVICE属性で指定されたエントリ_remote<n>も同様に伝播する必要があります。
> CRSHOME/bin/crs_stop ora.standbynode2.LISTENER_STANDBYNODE2.lsnr > CRSHOME/bin/crs_start ora.standbynode2.LISTENER_STANDBYNODE2.lsnr
UNIX only: > tnsping orcl_remote1 Windows only: > tnsping orcl1_remote1
SQL> startup; UNIX only: SQL> create spfile='<ORADATASHAREDLOCATION>/orcl/spfileorcl.ora' from pfile='<DBHOME>/dbs/initORCL2.ora'; Windows only: SQL> create spfile='<ORADATASHAREDLOCATION>¥orcl¥spfileorcl.ora' from pfile='<DBHOME>/database/initORCL2.ora'; SQL> shutdown immediate;
standbynode1でinitORCL1.oraを変更し、次の行のみを残します。
cat initORCL1.ora SPFILE='<ORADATASHAREDLOCATION>/ORCL/spfileorcl.ora'
standbynode2でinitORCL2.oraを変更し、次の行のみを残します。
cat initORCL2.ora SPFILE='<ORADATASHAREDLOCATION>/ORCL/spfileorcl.ora'
> srvctl enable database -d orcl > srvctl start database -d orcl
プライマリ・サイトのスケジューリングした停止が終了したら、次の手順を実行してプライマリ・サイトにスイッチバックします。
スイッチバック先のプライマリ・サイトでは、1つのノードのみでReal Application Clustersデータベースが起動している必要があることに注意してください。これを行うには、CRSではなく、SQL*Plusを使用して手動でデータベースを起動します。この方法は、次の手順1で説明します。
これは、sync topologyコマンドにおいて、同期対象のデータベース(つまりprodnode1)に対するメディア・リカバリの実行が必要となる場合があるためです。メディア・リカバリは、データベースの排他的なマウントを必要とします。
prodnode1でReal Application Clustersデータベースを停止して、CRSを介したデータベースの自動再起動を無効にします。
> DBHOME/bin/srvctl stop database -d orcl > DBHOME/bin/srvctl disable database -d orcl
prodnode1で、単一のデータベース・インスタンスを起動します。
> DBHOME/bin/sqlplus / as sysdba SQL> startup
ASGCTL> connect asg standbynode1 oc4jadmin/<adminpwd> ASGCTL> verify topology with prodnode1 ASGCTL> set trace on all ASGCTL> sync topology to prodnode1
> srvctl stop database -d orcl > srvctl disable database -d orcl > DBHOME/bin/sqlplus / as sysdba SQL> startup
ASGCTL> connect asg standbynode1 oc4jadmin/<adminpwd> ASGCTL> verify topology with prodnode1 UNIX only: ASGCTL> set primary database sys/<passwd>@orcl Windows only: ASGCTL> set primary database sys/<passwd>@orcl1 ASGCTL> switchover topology to prodnode1 ASGCTL> disconnect
> DBHOME¥bin¥sqlplus / as sysdba SQL> shutdown immediate; > DBHOME¥bin¥srvctl enable database -d ORCL > DBHOME¥bin¥srvctl start database -d ORCL
ASGCTL> connect asg prodnode1 oc4jadmin/<adminpwd> UNIX only: ASGCTL> set primary database sys/<passwd>@orcl Windows only: ASGCTL> set primary database sys/<passwd>@orcl1 ASGCTL> sync topology to standbynode1 ASGCTL> disconnect
この項では、スタンバイ・サイトへのフェイルオーバー手順について説明します。ここで説明する手順は、プライマリ・サイトの計画外停止に対して使用してください。スケジューリングした停止については、第5.14.1.3項「スイッチオーバー手順」の手順を参照してください。
ASGCTL> connect asg standbynode1 oc4jadmin/<adminpwd> UNIX only: ASGCTL> set primary database sys/<passwd>@orcl UNIX only: ASGCTL> set new primary database sys/<passwd>@orcl Windows only: ASGCTL> set primary database sys/<passwd>@orcl1 Windows only: ASGCTL> set new primary database sys/<passwd>@orcl1 ASGCTL> set trace on all ASGCTL> failover ASGCTL> disconnect
> DBHOME¥bin¥sqlplus / as sysdba SQL> shutdown immediate; > srvctl enable database -d rac > srvctl start database -d rac
この項では、プライマリ・サイトのみでOracle Real Application Clustersデータベースを使用するOracleAS Disaster Recoveryの設定方法について説明します。スタンバイ・サイトでは、標準のOracleデータベースを使用します。
この項の項目は次のとおりです。
次の前提条件に注意してください。
スタンドアロンのOracleAS Guardインストーラの実行方法の詳細は、ご使用のプラットフォームのOracle Application Serverのインストレーション・ガイドで、「高可用性環境へのインストール」の章を参照してください。
create standby databaseコマンドを実行する前に実行する必要があります。
oradim -delete -sid <DBSID>コマンドを使用します。また、UNIXプラットフォームではoratabからデータベース・エントリを削除します。
create standby databaseコマンドを実行する前に、DBCA(Database Configuration Assistant)を使用して、プライマリ・サイトにOMF(Oracle Managed Files)またはASM(自動ストレージ管理)以外のストレージ・オプションで新しいデータベース・インスタンスを作成します。
create standby databaseコマンドによって上書きされます。
sync topologyコマンドが失敗し、欠落アーカイブ・ログのエラーを受信した場合は、tnspingを使用してスタンバイ・ノードにpingを試行します。スタンバイ・ノードにpingできない場合は、そのノードのリスナーを停止し再起動してからtnspingを再試行します。
表5-7 プライマリ・サイトおよびスタンバイ・サイトのホスト名とデータベース名
| プライマリ・サイト | スタンバイ・サイト | |
|---|---|---|
|
物理ホスト名 |
prodnode1、prodnode2 |
standbynode1 |
|
仮想ホスト名 |
vracnode1、vracnode2 |
vracnode1 |
|
データベース名 |
orcl.oracle.com |
orcl.oracle.com |
|
データベースSID |
orcl2(prodnode2) |
orcl1(standbynode) |
hostsファイルで設定します。次に、例を示します。プライマリ・サイトで、%SystemRoot%¥system32¥drivers¥etc¥hosts(Windows)または/etc/hosts(UNIX)を編集し、次のようなエントリを追加します。
ip_address prodnode1.domain.com prodnode1 vracnode1.domain.com vracnode1
スタンバイ・サイトで、同じhostsファイルを編集し、次のようなエントリを追加します。
ip_address standbynode1.domain.com standbynode1 vracnode1.domain.com vracnode1
次の手順を実行して、プライマリ・サイトではReal Application Clustersデータベースを使用し、スタンバイ・サイトではReal Application Clusters以外のデータベースを使用するOracleAS Disaster Recoveryトポロジを構成します。
> DBHOME/bin/srvctl stop database -d orcl
Windowsの場合は、次のoradimコマンドを実行してOracle SIDを削除します。
> oradim -delete -sid orcl1
UNIXの場合は、oratabファイル内でデータベースSID/データベース名のエントリをコメント・アウトします。Real Application Clusters以外のデータベースでは、oratabファイル内のこのエントリの形式は次のとおりです。
DBSID:oracle_home
> DBHOME/bin/srvctl stop database -d orcl > DBHOME/bin/srvctl disable database -d orcl
> DBHOME/bin/sqlplus / as sysdba SQL> startup
これらのコマンドについては、次の点に注意してください。
orcl(データベース名)を使用してoratabエントリを検出します。Windowsの場合、orcl1(データベースSID)を使用してレジストリ・エントリを検出します。
orcl(データベース名)を使用しますが、Windowsの場合、orcl1(データベースSID)を使用します。
ASGCTL> connect asg prodnode1 oc4jadmin/<adminpwd> ASGCTL> set trace on all UNIX only: ASGCTL> add instance orcl on vracnode1 Windows only: ASGCTL> add instance orcl1 on vracnode1 ASGCTL> dump topology ASGCTL> verify topology ASGCTL> set noprompt UNIX only: ASGCTL> set primary database sys/<passwd>@orcl Windows only: ASGCTL> set primary database sys/<passwd>@orcl1 UNIX only: ASGCTL> create standby database orcl on standbynode1 Windows only: ASGCTL> create standby database orcl1 on standbynode1 ASGCTL> verify topology with standbynode1 ASGCTL> instantiate topology to standbynode1
UNIXでは、このエントリにデータベース名(orcl)、Windowsでは、データベースSID(orcl1)が使用され、それぞれのエントリ名に_remote<n>が追加されています(<n>は数字)。
場合によっては、<n>の番号が上がり、LOG_ARCHIVE_DEST_<n>パラメータのSERVICE属性で指定されたエントリ_remote<n>も同様に伝播する必要があります。
> CRSHOME/bin/crs_stop ora.prodnode2.LISTENER_PRODNODE2.lsnr > CRSHOME/bin/crs_start ora.prodnode2.LISTENER_PRODNODE2.lsnr
UNIX only: > tnsping orcl_remote1 Windows only: > tnsping orcl1_remote1
sync topologyコマンドを使用するには、すべてのインスタンスが稼動している必要があります。
ASGCTL> connect asg oc4jadmin/<adminpwd> UNIX only: ASGCTL> set primary database sys/<passwd>@orcl Windows only: ASGCTL> set primary database sys/<passwd>@orcl1 ASGCTL> sync topology to standbynode1
この項では、プライマリ・サイトのスケジューリングした停止に対する準備を行うため、ASGCTLのswitchoverコマンドを実行してプライマリ・サイトからスタンバイ・サイトに切り替える方法について説明します。
スケジューリングした停止が終了したら、プライマリ・サイトにスイッチバックできます。詳細は、第5.14.2.4項「スイッチバック手順」を参照してください。
計画外停止については、かわりに第5.14.2.5項「フェイルオーバー手順」の手順を実行してください。
スケジューリングした停止を実行するためにスタンバイ・サイトにスイッチオーバーする手順は次のとおりです。
prodnode1で次のコマンドを実行します。
> srvctl stop database -d orcl > srvctl disable database -d orcl
prodnode1で単一のデータベース・インスタンスを起動します。
> DBHOME/bin/sqlplus / as sysdba SQL> startup
ASGCTL> connect asg oc4jadmin/<adminpwd> ASGCTL> verify topology with standbynode1 UNIX only: ASGCTL> set primary database sys/<passwd>@orcl Windows only: ASGCTL> set primary database sys/<passwd>@orcl1 ASGCTL> switchover topology to standbynode1 ASGCTL> disconnect
プライマリ・データベースは排他的にマウントする必要があるというメッセージがコンソールに表示される場合は、複数のReal Application Clustersデータベース・インスタンスが稼動していることを意味します。データベース・インスタンスを1つのみ起動する方法については、前述の手順を参照してください。
この項では、スケジューリングした停止が終了したときにプライマリ・サイトにスイッチバックする手順について説明します。
スイッチバック先のプライマリ・サイトでは、1つのノードのみでReal Application Clustersデータベースが起動している必要があることに注意してください。これを行うには、CRSではなく、SQL*Plusを使用して手動でデータベースを起動します。この方法は、次の手順1で説明します。
これは、sync topologyコマンドにおいて、同期対象のデータベース(つまりprodnode1)に対するメディア・リカバリの実行が必要となる場合があるためです。メディア・リカバリは、データベースの排他的なマウントを必要とします。
prodnode1でReal Application Clustersデータベースを停止して、CRSを介したデータベースの自動再起動を無効にします。
> DBHOME/bin/srvctl stop database -d orcl > DBHOME/bin/srvctl disable database -d orcl
prodnode1で、単一のデータベース・インスタンスを起動します。
> DBHOME/bin/sqlplus / as sysdba SQL> startup
ASGCTL> connect asg standbynode1 oc4jadmin/<adminpwd> ASGCTL> verify topology with prodnode1 UNIX only: ASGCTL> set primary database sys/<passwd>@orcl Windows only: ASGCTL> set primary database sys/<passwd>@orcl1 ASGCTL> switchover topology to prodnode1
sync topologyコマンドを使用するには、すべてのインスタンスが稼動している必要があります。
> DBHOME¥bin¥sqlplus / as sysdba SQL> shutdown immediate; > DBHOME¥bin¥srvctl enable database -d ORCL > DBHOME¥bin¥srvctl start database -d ORCL
ASGCTL> connect asg prodnode1 oc4jadmin/<adminpwd> UNIX only: ASGCTL> set primary database sys/<passwd>@orcl Windows only: ASGCTL> set primary database sys/<passwd>@orcl1 ASGCTL> sync topology to standbynode1 ASGCTL> disconnect
この項では、スタンバイ・サイトへのフェイルオーバー手順について説明します。ここで説明する手順は、プライマリ・サイトの計画外停止に対して使用してください。スケジューリングした停止については、第5.14.2.3項「スイッチオーバー手順」の手順を参照してください。
スタンバイ・サイトでfailoverコマンドを実行し、新しいプライマリ・サイトとしてアクティブにします。
ASGCTL> connect asg standbynode1 oc4jadmin/<adminpwd> UNIX only: ASGCTL> set primary database sys/<passwd>@orcl UNIX only: ASGCTL> set new primary database sys/<passwd>@orcl Windows only: ASGCTL> set primary database sys/<passwd>@orcl1 Windows only: ASGCTL> set new primary database sys/<passwd>@orcl1 ASGCTL> set trace on all ASGCTL> failover ASGCTL> disconnect
OracleAS Disaster Recoveryソリューションを設定し、スタンバイ・トポロジをインスタンス化し、スタンバイ・トポロジを同期化したら、OracleAS Guardクライアントのコマンドライン・ユーティリティのasgctlを使用して、OracleAS Guard調整サーバーからasgctl操作の監視およびトラブルシューティング・タスクを実行するコマンドを発行できます。通常のOracleAS Guardの監視またはトラブルシューティング・セッションでは、次のようなタスクを実行します。
OracleAS Guardクライアントからasgctlコマンドを発行すると、OracleAS Guard調整サーバーにリクエストが送られます。OracleAS Guard調整サーバーはこのリクエストを本番トポロジとスタンバイ・トポロジのOracleAS Guardサーバーに転送します。その後、ステータス・メッセージがOracleAS Guardクライアントに返され、特定のタスクに問題が発生した場合はエラー・メッセージも返されます。エラー・メッセージの詳細は、第5.15.7項「エラー・メッセージ」を参照してください。
プライマリ・トポロジが実行状態にあり、構成が有効であることを確認するには、asgctlプロンプトで次のasgctlコマンドを入力します。
ASGCTL> connect asg ias_admin/iastest2
Successfully connected to prodinfra:7890
ASGCTL> discover topology oidpassword=oidpwd
ASGCTL> verify topology
Generating default policy for this operation
prodinfra:7890
HA directory exists for instance asr1012.infra.us.oracle.com
asmid2:7890
HA directory exists for instance asmid2.asmid2.us.oracle.com
asmid1:7890
HA directory exists for instance asmid1.asmid1.us.oracle.com
ASGCTL>
ポリシー・ファイルを使用する場合は、検証ポリシー・ファイル(verify_policy.xml)を編集して使用し、ファイル内に各インスタンスの成功要件の属性を指定します。verifyコマンドにusing policy <file>パラメータを指定します。ここで<file>は、verify_policy.xmlファイルのパスとファイルの指定を表します。詳細は、第5.7項「いくつかのasgctlコマンドでのポリシー・ファイルのダンプとポリシー・ファイルの使用」を参照してください。
ローカル・ホストをメンバーに持つプライマリ・トポロジとスタンバイ・トポロジを比較して、両方のトポロジが一致していること、および両方のトポロジがOracleAS Disaster Recoveryの要件を満たしていることを確認するには、asgctlプロンプトで次のasgctlコマンドを入力して、スタンバイ・ホスト・システムの名前を指定します。
ASGCTL> dump policies Generating default policy for this operation Creating policy files on local host in directory "/private1/OraHome2/asr1012/dsa/conf/"
ASGCTL> verify topology with standbyinfra
Generating default policy for this operation
prodinfra:7890
HA directory exists for instance asr1012.infra.us.oracle.com
asmid2:7890
HA directory exists for instance asmid2.asmid2.us.oracle.com
asmid1:7890
HA directory exists for instance asmid1.asmid1.us.oracle.com
standbyinfra:7890
HA directory exists for instance asr1012.infra.us.oracle.com
asmid2:7890
HA directory exists for instance asmid2.asmid2.us.oracle.com
asmid1:7890
HA directory exists for instance asmid1.asmid1.us.oracle.com
prodinfra:7890
Verifying that the topology is symmetrical in both primary and standby configuration
ASGCTL>
# Command to use if you want to use a policy file # verify topology with standbyinfra using policy <file>
OracleAS Guardクライアントが接続しているトポロジのすべてのノードで、現在実行されているすべての操作のステータスを表示するには、asgctlプロンプトで次のasgctlコマンドを入力します。
ASGCTL> show operation ************************************* OPERATION: 19 Status: running Elapsed Time: 0 days, 0 hours, 0 minutes, 28 secs TASK: syncFarm TASK: backupFarm TASK: fileCopyRemote TASK: fileCopyRemote TASK: restoreFarm TASK: fileCopyLocal
完了した操作(現行セッションでOracleAS Guardクライアントが接続されているトポロジのノード上で実行されていない操作)のみを表示するには、asgctlプロンプトで次のasgctlコマンドを入力します。
ASGCTL> show operation history ************************************* OPERATION: 7 Status: success Elapsed Time: 0 days, 0 hours, 0 minutes, 0 secs TASK: getTopology TASK: getInstance ************************************* OPERATION: 16 Status: success Elapsed Time: 0 days, 0 hours, 0 minutes, 0 secs TASK: getTopology TASK: getInstance ************************************* OPERATION: 19 Status: success Elapsed Time: 0 days, 0 hours, 1 minutes, 55 secs TASK: syncFarm TASK: backupFarm TASK: fileCopyRemote TASK: fileCopyRemote TASK: restoreFarm TASK: fileCopyLocall
サーバーで実行されている特定の操作を停止するには、asgctlプロンプトで次のasgctlコマンドを入力し、停止する操作番号を指定します。停止する操作番号は、asgctlのshow operation fullコマンドを入力すると表示されます。
ASGCTL> show operation full ************************************* OPERATION: 19 Status: running Elapsed Time: 0 days, 0 hours, 0 minutes, 28 secs Status: running . . . ASGCTL> stop operation 19
特定のイベントにトレース・フラグを設定し、出力をasgctlログ・ファイルに記録するには、asgctlプロンプトで次のasgctlコマンドを入力し、onキーワードを指定して、有効にするトレース・フラグを入力します。この場合、トレース・フラグDBは、Oracle Database環境の処理に関するトレース情報が表示されることを示します。有効にすることができるその他のトレース・フラグの詳細は、set traceコマンドを参照してください。設定できるすべてのトレース・フラグの一覧も、set traceコマンドを参照してください。
ASGCTL> set trace on db
ローカル・ホストが接続されているトポロジに関する詳細情報を書き込むには、asgctlプロンプトで次のasgctlコマンドを入力し、出力される情報を書き込むファイルのパスと名前を指定します。この出力では、dump topologyコマンドを実行した場合と同じ結果が表示されますが、この場合はファイルに書き込まれるので、将来参照するために保存しておくことが可能です。
ASGCTL> dump topology to c:¥dump_mid_1.txt
OracleAS Disaster Recoveryソリューションの実行時に表示されるエラー・メッセージは、付録B「OracleAS Guardエラー・メッセージ」に分類して説明しています。
クライアント・リクエストが本番サイトのエントリ・ポイントに送信されるようにするには、DNS解決を使用します。サイトのスイッチオーバーまたはフェイルオーバーが実行される際には、クライアント・リクエストが本番の役割を果たす新しいサイトに透過的にリダイレクトされる必要があります。このリダイレクションを可能にするには、本番サイトへのリクエストを解決するワイド・エリアDNSをスタンバイ・サイトにスイッチオーバーする必要があります。DNSスイッチオーバーは、ワイド・エリア・ロード・バランサを使用するか手動でDNS名を変更することによって行えます。
次のサブセクションではDNSスイッチオーバー操作について説明します。
ワイド・エリア・ロード・バランサ(グローバル・トラフィック・マネージャ)が本番サイトとスタンバイ・サイトの前面に配置されているときは、両サイトに対して、障害検出サービスとパフォーマンスベースのルーティング・リダイレクションが提供されます。さらに、このロード・バランサは、信頼できるDNSネーム・サーバーと同等の機能を提供できます。
通常の運用時は、本番サイトのロード・バランサの名前とIPの対応付けにより、ワイド・エリア・ロード・バランサを構成できます。DNSスイッチオーバーが必要な際には、ワイド・エリア・ロード・バランサのこの対応付けが変更され、スタンバイ・サイトのロード・バランサのIPに対応付けられます。これにより、本番の役割を引き継いだスタンバイ・サイトにリクエストが転送されるようになります。
DNSスイッチオーバーのこの方法は、サイトのスイッチオーバーとフェイルオーバーの両方に対応できます。ワイド・エリア・ロード・バランサを使用する利点の1つは、名前とIPの新しい対応付けがすぐに有効になるという点です。不利な点は、ワイド・エリア・ロード・バランサへの追加投資が必要になることです。
DNSスイッチオーバーのこの方法には、元は本番サイトのロード・バランサのIPアドレスに対応付けられていた名前とIPの対応付けを手動で変更することが関係しています。この対応付けを変更して、スタンバイ・サイトのロード・バランサのIPアドレスに対応付けます。スイッチオーバーを実行する手順は次のとおりです。
DNSスイッチオーバーのこの方法は、計画的なサイトのスイッチオーバー操作にのみ対応できます。手順2のTTL値は、クライアント・リクエストを処理しきれない時間に設定する必要があります。TTLの変更とは、実質的にはアドレス解決時間を短縮させるためにキャッシュ・セマンティックを変更することを表しているからです。そのため、キャッシュ時間が短縮されたことにより、DNSリクエストが増加する可能性があります。
HTTPリクエストを、サーバー・ロード・バランサを使用して複数のOracle HTTP Serverインスタンスに送信する場合、一部のアプリケーション(Application Server ControlコンソールやOracle Web Services Managerなど)に対するWebアクセスが、HTTP Serverの物理ホストにリダイレクトされることがあります。
リダイレクトされたリクエストが常にロード・バランサに送信されるようにするには、ロード・バランサにOracle HTTP Serverの仮想ホストを構成します。
たとえば、Oracle HTTP Serverがポート7777をリスニングし、ロード・バランサbigip.acme.comがポート80をリスニングしている場合、httpd.confファイルに次のエントリを設定します。
NameVirtualHost *:7777 <VirtualHost *:7777> ServerName bigip.us.oracle.com Port 80 ServerAdmin youyour.address RewriteEngine On RewriteOptions inherit </VirtualHost>
この項は、次のサブセクションで構成されています。
asgctlを使用した一般的なOracleAS Guardセッションには、次のようなタスクがあります。これらのタスクについては、次のサブセクションで説明します。
asgctlコマンドライン・インタフェースがサポートされている利点の1つは、これらのasgctlコマンドを、第5.17.1.4項「asgctlスクリプトの作成と実行」の説明に従って適切な順序でスクリプトに入力し、第5.17.2項「OracleAS Guard asgctlスクリプトの定期的なスケジュール」および第5.17.3項「Enterprise Manager Job Systemを使用したOracleAS Guardジョブの実行」に従ってスクリプトとして実行できることです。
特定のコマンドのヘルプを表示するには、asgctlプロンプトにasgctlコマンドを入力し、ヘルプ情報を表示するコマンド名を指定します。また、すべてのコマンドのヘルプを表示するには、asgctlプロンプトで次のasgctlコマンドを入力します。
ASGCTL> help connect asg [<host>] [<ias_administrator_account>/<password>]
disconnect
exit
quit
add instance <instance_name> on <instance_host> [to topology]
clone topology to <standby_topology_host> [using policy <file>] [no standby]
clone instance <instance> to <standby_topology_host> [no standby
discover topology [oidhost=<host>] [oidsslport=<sslport>] [oiduser=<user>] oidpassword=<pass>
discover topology within farm
dump farm [to <file>] (Deprecated)
dump topology [to <file>] [using policy <file>]
dump policies
failover [using policy <file>]
help [<command>]
instantiate farm to <standby_farm_host> (Deprecated)
instantiate topology to <standby_topology_host> [using policy <file>]
remove instance <instance_name> [from topology]
set asg credentials <host> <ias_administrator_account>/<password> [for topology]
set asg credentials <host> ias_admin/<password> [for farm] (Deprecated)
set primary database <username>/<password>@<servicename> [pfile <filename> | spfile <filename>]
set new primary database <username>/<password>@<servicename> [pfile <filename> | spfile <filename>]
set noprompt
set trace on|off <traceflags>
sync farm to <standby_farm_host> [full | incr[emental]] (Deprecated)
sync topology to <standby_topology_host> [full | incr[emental]] [using policy <file>]
startup [asg]
startup farm (Deprecated)
startup topology
shutdown [local]
shutdown farm (Deprecated)
shutdown topology
show op[eration] [full] [[his]tory]
show env
stop op[eration] <op#>
switchover farm to <standby_farm_host> (Deprecated)
switchover topology to <standby_topology_host> [using policy <file>]
verify farm [with <host>](Deprecated)
verify topology [with <host>] [using policy <file>] ASGCTL>
プライマリ・トポロジのOracleAS Infrastructureデータベースを識別するには、asgctlプロンプトで次のasgctlコマンドを入力し、OracleAS Infrastructureデータベースにアクセスするsysdba権限があるデータベース・アカウントのユーザー名とパスワード、およびOracleAS InfrastructureデータベースのTNSサービス名を指定します。
ASGCTL> set primary database sys/testpwd@asdb Checking connection to database asdb ASGCTL>
スタンバイ・サイトの場合も、プライマリ・データベースで指定する値と同じ値を使用します。これは、プライマリとスタンバイのOracleAS Infrastructureデータベースのサービス名とパスワードを同じにする必要があるためです。プライマリ・データベースは、インスタンス化、同期化、スイッチオーバーまたはフェイルオーバー操作を実行する前に設定する必要があります。
トポロジにOracleAS Metadata Repositoryが複数ある場合は、set primary databaseコマンドを使用して、それぞれを認証する必要があります。
トポロジXMLファイルを内部的に作成するために、OracleAS Disaster Recovery環境を最初に設定するとき、discover topologyコマンドを実行する必要があります。したがって、本番サイトに別のOracleホームを配置した場合や、スイッチオーバーまたはフェイルオーバー操作によって本番サイトからスタンバイ・サイトに役割を変更した場合は、常にトポロジの検出操作を実行する必要があります。discover topologyコマンドは、Oracle Internet Directoryに、本番サイトの同じOracle Internet Directoryを共有する、トポロジ内のすべてのインスタンスについて問い合せます。トポロジ・ファイルの詳細は、第6.2項「OracleAS Guardコマンドの一部に特有の情報」を参照してください。asgctlプロンプトで次のasgctlコマンドを入力し、トポロジを検出します。
10.1.3.x環境の場合:
ASGCTL> discover topology within farm ASGCTL> connect asg prodinfra oc4jadmin/adminpwd Successfully connected to asmid:7890 ASGCTL> discover topology within farm Warning: If OID is part of your environment, you should use it for discovery Discovering topology on host "infra" with IP address "a.b.c.d" asmid:7890 Discovering instances within the topology using OPMN Gathering instance information for "1013inst.asmid.oracle.com" from host "asmid.us.oracle.com" The topology has been discovered. A topology.xml file has been written to each home in the topology. ASGCTL>
また、次のadd instanceコマンドを使用して、スタンドアロン・データベース・インスタンスを障害時リカバリ・トポロジに追加することもできます。
ASGCTL> add instance asdb on vhostdr.oracle.com
本番トポロジが本番サイトのOracleAS Guardに認識された後、後続のコマンドのいずれかを実行し、スタンバイ・サイトに関連する後続のasgctl操作を実行できます。詳細は、discover topologyを参照してください。
一連のasgctlコマンド名と引数を含むスクリプトを作成するには、適当なエディタを開いて、実行する操作に応じた正しい順序でasgctlコマンドを入力します。スクリプト・ファイルを保存し、asgctlを起動するときに次のようにスクリプトを実行します。
> ASGCTL @myasgctlscript.txt
一連のasgctlコマンドを指定したスクリプトの例は、set echoコマンドを参照してください。
asgctlスクリプトのコマンドの実行に使用するために、後ですべての対話型プロンプトが無視される非プロンプト状態を設定できます。詳細は、asgctlのset nopromptコマンドを参照してください。
定期的なトポロジの同期化操作を実行してスタンバイ・トポロジとプライマリ・トポロジの同期化を維持するなど、OracleAS Guard操作を定期的に実行するために、OracleAS Guardのasgctlスクリプトの定期的な実行を自動化できます。
UNIXシステムの場合は、cronジョブを設定してasgctlスクリプトを実行できます。asgctlスクリプトを/etcの下の適切なサブディレクトリ、cron.hourly、cron.daily、cron.weeklyまたはcron.monthlyにコピーします。スクリプトのコピー先に選択したディレクトリの名前に応じて、スクリプトは時間、日、週または月単位で実行されます。または、crontabを編集して、asgctlスクリプトを実行する時間を指定したエントリを作成することもできます。詳細は、cronおよびcrontabに関するマニュアルのページを参照してください。
Windowsシステムの場合は、「コントロール パネル」のタスク・スケジューラまたはスケジュールされたタスクを使用して、asgctlスクリプトを毎日、毎週、または毎月実行したり、特定の時間に実行したりできます。また、様々なオプションの付いたサード・パーティ製のスケジューラ・ソフトウェアを購入して、asgctlスクリプトを実行する時間や頻度を設定することもできます。詳細は、Windowsオペレーティング・システムのヘルプを参照してください。
Enterprise Manager Job Systemを使用して、asgctlスクリプトを特定の時間間隔または特定の日時(あるいはその両方)に実行するように自動化したり、さらに別のカスタム設定に設定したりすることができます。その場合は、Enterprise Managerの「ジョブ・アクティビティ」ページにアクセスして、asgctlスクリプトを実行するユーザー自身のホスト・コマンド・ジョブ、つまりジョブ・タスクを作成します。ジョブ・タスク(スクリプト)はasgctlを起動し、指定された順序に従ってasgctlコマンドを実行します。OracleAS Guardジョブを作成したら、EMジョブ・ライブラリに保存します。このライブラリは、頻繁に使用されるジョブのリポジトリであり、ここで、カスタム設定と選択した時間に従ってジョブが実行されます。詳細は、Enterprise Managerのオンライン・ヘルプ、および『Oracle Enterprise Manager概要』を参照してください。
この項では、OracleAS Metadata Repository Creation Assistantを使用して作成した複数のOracleAS Metadata RepositoryとOracleAS Metadata Repositoryの特別な考慮事項について説明します。
デフォルトでは、asgctlのconnectコマンドで指定した資格証明は、OracleAS Guardサーバーが他のOracleAS Guardサーバーに接続する際に必ず使用されます。しかし、次のような使い方が必要になる場合もあります。
ホスト・システムの資格証明がasgctlのconnectコマンドで使用されているものと異なる場合は、OracleAS Guardサーバーが構成内の各ホスト・システムに接続できるように、OracleAS Guard資格証明を設定する必要があります。
同じトポロジに属する、すべてのホスト・システムに異なる資格証明を設定するには、asgctlプロンプトに次のasgctlコマンドを入力します。資格証明が適用されるホスト・システムのノード名、Oracle Application Serverのインストール時に作成したias_adminアカウント名とias_adminアカウントのパスワード、およびキーワードのfor topologyを指定します。
これらの設定は、現行セッションに有効です。
ASGCTL> set asg credentials standbyinfra ias_admin/<iasadminpwd> for topology
キーワードのfor topologyを指定した場合は、資格証明は、指定したシステムと同じトポロジに属するすべてのホスト・システムに設定されます。キーワードを指定しない場合、資格証明は指定したホスト・システムにのみ適用されます。
set asg credentialsコマンドは、トポロジ内の特定のサーバーに異なる資格証明を適用する場合にも使用できます。前述の例では、スタンバイ・トポロジ内のすべてのノードに同じ資格証明を適用し、プライマリ・トポロジに使用する資格証明とは異なる資格証明を設定しました。次のコマンドでは、スタンバイ・トポロジ内の特定のノードであるstandbyinfraノードに、資格証明を設定します。
ASGCTL> set asg credentials standbyinfra ias_admin/<iasadminpwd>
つまり、あるトポロジに資格証明を設定した場合、この資格証明はトポロジ全体に継承されます。トポロジ上の個別のホストに資格証明を設定した場合、(そのホストの)資格証明が、トポロジに設定されたデフォルトの資格証明よりも優先されます。
また、Oracle Internet DirectoryとOracleAS Metadata Repositoryが同じ場所にあって、PortalのOracleAS Metadata Repositoryが別の場所にあるような、複数のInfrastructureが存在するトポロジでは、OracleAS Guardでインスタンス化、同期化、スイッチオーバー、フェイルオーバーなどの重要な操作を実行する前に、Infrastructureが存在する各システムに対してOracleAS Guardで資格証明を設定する必要があります。set asg credentialsに、例を示します。
プライマリ・トポロジ内のOracleAS Infrastructureデータベースを識別するには、asgctlプロンプトに次のasgctlコマンドを入力します。プライマリ・トポロジ内のOracleAS Infrastructureデータベースにアクセスするsysdba権限のあるデータベース・アカウントのユーザー名とパスワードを指定し、OracleAS InfrastructureデータベースのTNSサービス名を指定します。
ASGCTL> set primary database sys/testpwd@asdb Checking connection to database asdb ASGCTL>
スタンバイ・サイトの場合も、プライマリ・データベースで指定する値と同じ値を使用します。これは、プライマリとスタンバイのOracleAS Infrastructureデータベースのサービス名とパスワードが必ず同じであるためです。
本番サイトまたはスタンバイ・サイトに複数のOracleAS Metadata Repositoryインスタンスがインストールされており、インスタンス化、同期化、スイッチオーバーまたはフェイルオーバー操作を実行する場合、それらの操作を実行する前に、各OracleAS Metadata Repositoryインスタンスに対してset primary databaseコマンドを実行することによって、OracleAS Metadata Repositoryインスタンスすべてを識別する必要があります。set asg credentialsに、例を示します。
OracleAS Guardは、デフォルトのポート(port)番号である7890を使用します。たとえば、port=7890として設定されます。システムに追加のOracleホームがインストールされている場合、各Oracleホームは一意のOracleAS Guardポート番号を持つ必要があります。その番号は、通常はport=7891などのように1ずつ増加します。詳細は、第5.4.6項「サポートされるOracleAS Disaster Recovery構成」を参照してください。
次の項目は、OracleAS Metadata Repository Creation Assistantを使用して作成したOracleAS Metadata Repository構成の特別な考慮事項です。これらのメタデータ・リポジトリ・データベースは、ユーザー・データを含むスキーマとともにOracleホームにインストールされます。この理由により、OracleAS Disaster Recoveryに関するいくつかの特別な考慮事項があります。
次の項では、OracleAS Disaster Recovery環境のいくつかの追加の特別な考慮事項について説明します。
サイトにOracleAS Disaster Recoveryを設定する際に注意する必要がある特別な考慮事項は次のとおりです。
どちらの場合も、Oracle Internet Directoryに格納されているインスタンス名は、本番サイトのインストールが実行された元のホスト名で構成されます。OracleAS Disaster Recoveryサイトに対称トポロジがある場合、OracleAS Disaster Recoveryのスタンバイ・ピアは、本番サイトと同じようにインストールする必要があり、OracleAS Guard 10gリリース2(10.1.2.0.2)以上のインスタンスのクローニング操作またはトポロジのクローニング操作の場合、操作は構成をミラー化するように実行する必要があります。
スタンバイが非対称トポロジで、本番サイトの物理ホストがスタンバイ・サイトに存在しない場合、ポリシー・ファイル機能を使用して、そのインスタンス名をトポロジからフィルタで除外する必要があります(詳細は第5.7項「いくつかのasgctlコマンドでのポリシー・ファイルのダンプとポリシー・ファイルの使用」を参照)。トポロジの検出操作を実行するホストのホスト・ファイルは、元のホスト名を、クローンされた新しいホスト・システムの対応するIPに対応付けしている必要があります。
OracleAS Guard操作で、スタンバイ・サイトの構成ファイルが、プライマリ・サイトのバックアップ操作によって本番サイトの構成ファイルと同期化され、スタンバイ・サイトにリストアされます。
非対称トポロジの場合、スタンバイ・サイトは本番サイトよりノードの数が少なく、ons.conf構成ファイルのノード名リストは、本番サイトのノード名リストと異なります。したがって、ons.conf構成ファイルは、ファイルのバックアップ・リストから除外し、スタンバイ・サイトにリストアされないようにします。除外しない場合、ons.conf構成ファイルにリストされているノードは、本番サイトのノード・リストを反映し、スタンバイ・サイトの実際のノード・リストは反映しなくなります。これによって、存在しないノードにOPMNがpingを実行し続けるという非効率が発生します。
さらに、非対称トポロジの場合、Oracleホームのdsa.conf構成ファイルには、スタンバイ・サイトとは異なる特別な設定が本番サイトに含まれていることもあります。たとえば、inventory_locationパラメータ設定は、スタンバイ・サイトとプライマリ・サイトでは異なることがあります。この場合、dsa.conf構成ファイルも、ファイルのバックアップ・リストから除外し、スタンバイ・サイトにリストアされないようにします。除外しない場合、この例では、スイッチオーバーまたはフェイルオーバー操作の後のOraInventoryの場所はスタンバイ・サイトでは正しくありません。
どちらの場合も、次のようにバックアップおよびリストアの除外ファイルを変更し、これらのどちらの構成ファイルも、ファイルのバックアップ・リストから除外し、どちらもスタンバイ・サイトにリストアされないようにします。
# Exclude Files # - Add additional files to this list that you want to be ignored # - during the configuration file backup/restore c:¥oracle¥ias1012¥opmn¥conf¥ons.conf c:¥oracle¥ias1012¥dsa¥dsa.conf
dsa.confファイルで設定されたディレクティブが、現在、本番サイトとして動作しているサイトで必要な場合は、同期化にdsa.confファイルも含め、スイッチオーバーまたはフェイルオーバー後の手順を追加して、物理サイト固有のディレクティブを編集したほうがよいこともあります。
OmniPortletおよびWebクリッピング・ポートレットのプリファレンス・ストア・ロケーションを、デフォルトの事前設定済ロケーション以外に変更した場合(OmniPortletの場合はprovider.xmlファイル、Webクリッピングの場合はmds-config.xmlファイルの値を変更する)、スイッチオーバー操作後にスタンバイ・サイトのXMLファイルを編集する必要があります。この作業が必要になるのは、スイッチオーバー操作では、更新されたXMLファイルがコピーされないためです。
表5-8に、OmniPortletおよびWebクリッピング・ポートレットのXMLファイルの場所を示します。
プリファレンス・ストア・ロケーションをカスタマイズしない場合、スイッチオーバー操作後にXMLファイルを編集する必要はありません。
いくつかの追加の特別な考慮事項の詳細は、第6.2項「OracleAS Guardコマンドの一部に特有の情報」を参照してください。
|
 Copyright © 2007, Oracle. All Rights Reserved. |
|