| Netra Data Plane Software Suite 1.1 User's Guide |
| Netra Data Plane Software Suite 1.1 User's Guide |
| A P P E N D I X A |
|
Frequently Asked Questions |
This appendix provides frequently asked questions regarding the Netra Data Plane software and how it interacts with the tejacc compiler.
Legacy Code Integration Questions
Address Resolution Protocol (ARP) Questions
Teja 4.x is an optimizing C compiler (called tejacc) and API system for developing scalable, high-performance applications for embedded multiprocessor architectures. tejacc operates on a system-level view of the application through three techniques:
The techniques yield superior code validation and optimization, leading to more reliable and higher performance systems.
The ticktock tutorial is in Tutorial.
The Teja specific documentation is available from the Teja website:
http://www.teja.com/library/index.html
These three dynamic libraries are user supplied. The libraries describe the configuration of the hardware (processors, memories, buses), software (OS, processes, threads, communication channels, memory pools, mutexes), and mapping (functions to threads, variables to memory banks). The library code runs in the context of the tejacc compiler. The tejacc compiler uses this information as a global system view on the entire system (hardware, user code, mapping, connectivity among components) for different purposes:
The dynamic libraries are run on the host, not on the target.
Two ways to help debug the dynamic libraries are:
2. Set a breakpoint on the teja_user_libraries_loaded function.
3. Type run followed by the same parameters that were passed to tejacc.
Control returns immediately after the user dynamic libraries are loaded.
4. Set a breakpoint on the desired dynamic library function, and type cont.
There might be a bug in the hardware architecture, software architecture, or mapping dynamic libraries. To debug the issue, see How Can I Debug the Dynamic Libraries?.
tejacc gets information about hardware architecture, software architecture, and mapping by executing the configuration code compiled into dynamic libraries. The code is written in C and might contain errors causing tejacc to crash. Upon crashing, you are presented with a Java Hotspot exception, as tejacc is internally implemented in Java.
An alternative version of tejacc.sh called tejacc_dbg.sh is provided to assist debugging configuration code. This program runs tejacc inside the default host debugger (gdb for Linux/Cygwin hosts, dbx for Solaris hosts). The execution automatically stops immediately after the hardware architecture, software architecture, and mapping dynamic libraries have been loaded by tejacc.
You can continue the execution and the debugger stops at the instruction causing the crash. Alternatively, you can set breakpoints in the code before continuing or use any other feature provided by the host debugger.
The dynamic libraries can be combined, but the entry points must be different.
Use regular expressions to map multiple variables to a memory bank, using the function:
For example, to map all variables starting with my_var_ to the OS-based memory bank:
The generated code is located in the top-level-application/code/process directory, where top-level-application is the directory where make was invoked and process is the process name as defined in the software architecture.
If you are generating with optimization there is an additional directory, code/process/.ir. Optimized generation is a two-step process. The .ir directory contains the result of the first step.
The executable image is located in the code/process directory, where process is the process name as defined in the software architecture.
tejacc is a global compiler, and all C files must be provided on the same command-line in order for it to perform global validation and optimization. To compile an application that requires multiple modules, use the srcset CLI option. The syntax for this option is:
See How Can I Compile Multiple Modules on the Same Command-Line?.
You can use the user_defs.mk file in the top level application directory to overwrite any parameter that the generated makefile sets. The substituted value for the parameter is used for the compilation.
You can specify any file other than the default user_defs.mk file using the "external_makefile" property of the process. For example:
If the path is not specified, the top-level application directory is assumed.
| Note - There is no warning or error if the file does not exist, the compilation continues with the generated Makefile parameters. |
You can also specify the user_defs.mk file as a value to the EXTERNAL_DEFINES parameter during the compilation of the generated code. For example:
The user_defs.mk file takes precedence over the value you specify in the software architecture if you use both methods.
For ipfwd, execute build_1g_1060 under src/apps/rlp.
For RLP, you need to modify apps/rlp/src/app/rlp.c and apps/rlp/src/app/rlp_config.h to reflect the exact mapping.
Add the following to TEJACC_CFLAGS in the application makefile:
You can create an auxiliary file that modifies the behavior of the generated makefile and then invoke the generated Makefile with the EXTERNAL_MAKEFILE variable set to this file name, Or use the "external_makefile" property in the software architecture (both mechanisms are explained below). This causes the generated makefile to include the file after setting up all the parameters but before invoking any compilation command. You can then overwrite any parameter that the generated Makefile is setting and the new value for that parameter will be in effect for the compilation.
You can specify a file name using the "external_makefile" property of the process. To set the new value for the property, invoke the following: teja_process_set_property(process_obj,"external_makefile","new file name with or without path")
If the path is not specified, the top level application directory will be assumed. The path can be relative to the top level application directory or an absolute value. There will not be any warning or error if the file does not exist, the compilation will continue with the generated Makefile parameters. If you prefer, you can also specify this external defines filename as a value to the EXTERNAL_DEFINES parameter during the compilation of the generated code. For example, gmake EXTERNAL_DEFINES=../../user_defs.mk. This value will take precedence over the value specified in the software architecture if both of the approaches are used.
An example of user_defs.mk is USR_CFLAGS=-xO3.
The generated Makefile can be invoked as:
This has the effect of adding the -xO3 flag to the compilation lines.
| Note - Refer to Overview of the Late-Binding API for more information on the Late-Binding API. |
The late-binding API is the Teja equivalent of OS system calls. However, OS calls are fixed in precompiled libraries, and late-binding API calls are generated based on contextual information. This situation ensures that the late-binding API calls are small and optimized. See What Is Context-Sensitive Generation?.
The late-binding API addresses the following services:
A memory pool is a portion of contiguous memory that is preallocated at system startup. The memory pool is subdivided into equal-sized nodes and allocated. You declare memory pools in the software architecture using teja_memory_pool_declare(). Memory pools enable you to choose size implementation type, producers, consumers, and so on. In the application code, you can write data to the channel using teja_channel_send() and read from the channel using teja_wait(). The send and wait primitives are Late-Binding API calls (see What Is the Late-Binding API?), so they benefit from context-sensitive generation.
A channel is a pipe-like mechanism to send data from one thread to another. Channels are declared in the software architecture using teja_channel_declare(), which enables you to choose the size and number of nodes, implementation type, and so on. In the application code, you can get nodes from or put nodes in the memory pool, using teja_memory_pool_get_node() and teja_memory_pool_put_node. The allocation mechanism is more efficient than malloc() and free(). The get_node and put_node primitives are Late-Binding API calls, so they benefit from context-sensitive generation.
Use the teja_late-binding-object-type_declare call to declare all late-binding objects (memory pool, channel, mutex, queue) in the software architecture. The first parameter of this call is a string containing the name of the object. In the application code, the late-binding objects are accessed as a C preprocessor symbolic interpretation of the object name. The name is no longer a string. tejacc makes these symbols available to the application by processing the software architecture dynamic library.
The following function in the software architecture can define a C preprocessor symbol used in application code:
int teja_process_add_preprocessor_symbol (teja_process_t process, const char * symbol, const char * value); |
| Note - In the application, the symbol is accessed as a C preprocessor symbol, not as a string. |
| Note - Refer to the Netra Data Plane Software Suite 1.1 Reference Manual for detailed description of the API functions. |
Use the mutex API, which is composed of:
Use the Channel API or the Queue API.
The Channel API is composed of:
Use the Memory Pool API, which is composed of:
The RLP application requires some minimal changes to run under the LDoms enviroment.
1. Update the src/app/rlp.c file to reflect the total number of strands given to the LWRTE domain.
2. Change the src/app/rlp_config.h file so that the stat thread is configured to run on the last strand (CPU number) available for your LDom partition.
The NUM_STRANDS macro requires this change from the default value of strand 31.
3. Change the src/config/rlp_map.c and src/config/rlp_swarch.c files to reflect the new architecture of your LWRTE domain under LDoms.
The ipfwd application requires some minimal changes to run under the LDoms enviroment.
1. In apps/ipfwd./src/config/ipfwd_map.c, do the following:
Comment out teja_map_function_to_thread("_main", "main_thd16") and main_thd > 16.
2. In apps/ipfwd.10g/src/config/ipfwd_swarch.c, do the following:
a. Comment out
processors[16] = "app.cmt1board.cmt1_chip.strand16";
and similar lines greater than 16.
b. Commnet out
thd[15] = teja_thread_create(init, "main_thd16");
and similar lines greater than 16.
c. Assign stat_thd to 15 by entering the following:
d. Comment out
thd[31] = teja_thread_create(init, "stat_thd");
3. In apps/ipfwd.10g/src/app/ipfwd_config.h, change NUM_STRANDS to 16.
| Note - Strand number of 16 is only used in this example. You can use any multiple of 4, from 4 through 28. |
Generally, queues are more efficient than channels. Consider the following guidelines when deciding between queues or channels:
If a queue is used by one producer and one consumer, there is no need to block during the queue read. For example, in the ipfwd application, each queue has only one producer and consumer, and does not need to block. See FIGURE A-1.
FIGURE A-1 Example for the ipfwdApplication

| Note - If the Teja Queue API is used instead of Fast Queue, then locks are generated implicitly during compile time. |
It is not necessary to block Ethernet interface reads, as there is only one thread reading from or writing to a particular interface port or DMA channel at any given time.
A strand is not being used or consuming the pipeline only when the strand is parked. Even when a strand is calling teja_wait(), the CPU consumes cycles because the strand does a busy wait. If the strand performs busy polls, the polls can be optimized so that other strands on the same CPU core utilize the CPU. This optimization is accomplished by executing instructions that release the pipeline to other strands until the instruction completes.
Consider IP-forwarding type applications. When the packet receiving stream approaches line rate, it is better to let the strand perform busy poll for arriving packets. At less than the line rate, the polling mechanism is optimized by inserting large instructions between polls. Under this methodology, the pipeline releases and enables other strands to utilize unused CPU cycles.
When the role is determined from the code, the application (for example, ipfwd.c) can be made more adaptable to the number of flows and physical interfaces without modifying any mapping files. However, this is your preference and in some situations, the Software Architecture API can provide a better role for a strand.
Methods of parking strands are no different in an LDoms environment. Un-utilized strands are automatically parked. If a strand is assigned to a logical domain but is not used, then that strand should be parked. Strands that are not assigned to the LWRTE logical domain are not visible to that domain and cannot be parked.
You must assign complete cores to LWRTE. Otherwise, you have no control over the resources consumed by other domains on the core.
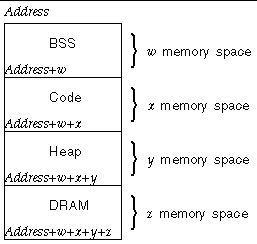
bss_mem is a location where all global and static variables are stored.
| Note - The sum of BSS and the code size must not exceed 5 Mbytes of memory. |
When the example of What Is bss_mem? is inserted into the code, all subsequent variables using .*_dram are superseded. To clarify, all variables suffixed with _dram are mapped to the DRAM memory region. All other variables are mapped to the BSS.
The heap region is used by teja_malloc(). Every time teja_malloc() is called, the heap space is reduced.
FIGURE A-2 illustrates the allocation of memory for BSS, code, heap, and DRAM.
FIGURE A-2 Memory Allocation Stack
Some of the warnings are marginal warnings that are accepted by a regular C compiler, but not the tejacc compiler.
The Light Weight Internet Protocol Library (LWIP lib) consists of essential functions for implementing a basic User Datagram Protocol (UDP) or Transport Control Protocol/Internet Protocol (TCP/IP) stack.
The eth_* API supports only physical Ethernet devices at this time. IPC is designed to run on top of Logical Domain Communication (LDC, a HyperVisor protocol) and on the eth_* API.
TABLE A-1 describes the options for tejacc to enable optimization:
Context-sensitive generation is the ability of the tejacc compiler to generate minimal and optimized system calls based on global context information provided from:
In the traditional model, the operating system is completely separated from the compiler and the operating system calls are fixed in precompiled libraries. In the tejacc compiler, each system call is generated based on the context.
For example, if a shared memory communication channel is declared in the software architecture as having only one producer and one consumer, the tejacc compiler can generate that channel as a mutex-free circular buffer. On a traditional operating system the mutex would have to be included because the usage of the function call was not known when the library was built. See Overview of the Late-Binding API for more information on the Late-Binding API.
Functions marked with the inline keyword or with the -finline command-line option get inlined throughout the entire application, even across files.
You can port preexisting applications to the Teja environment. There are two methods to integrate legacy application C code with newly compiled Teja application code:
By linking legacy code the to Teja code as libraries, the legacy code is not compiled and changes are minimized. The legacy library is also linked to the Teja generated code, so those libraries must be available on the target system, where performance is not an important factor.
For example, to port a UNIX legacy application to Teja running on UNIX is simple, because all of the UNIX libraries are available. However, porting a UNIX application to Teja running on bare hardware might require additional effort, because the bare hardware system does not have all the necessary OS libraries. In this situation, you must provide the missing functions.
Introducing calls to the Teja API in the legacy source code enables context-sensitive and late-binding optimizations to be activated in the legacy code. This method provides higher performance than the linking method.
Heavy memory allocation operations such as malloc and free are substituted with Teja preallocated memory pools, generated in a context-sensitive manner. The same advantage applies to mutexes, queues, communication channels, and functions such as select(), which are substituted with teja_wait().
| Note - See How Can I Reuse Legacy C Code in a Teja Application?. |
C++ code can be integrated with a Teja application by two methods:
Teja generates C code, so the final program is in C. Mixing C++ and Teja code is similar to mixing C++ and C code. This topic has been discussed extensively in C and C++ literature and forums. Basically, declare the C++ functions you call from Teja to have C linkage. For example:
#include <iostream> extern "C" int print(int i, double d) { std::cout << "i = " << i << ", d = " << d; } |
Compile the C++ code natively with the C++ compiler and link it to the generated Teja code. The Teja code can call the C++ functions with C linkage.
For detailed discussions of advanced topics such as overloading, templates, classes, and exceptions, refer to these URLs:
The third-party packages at the following web sites can be used to translate code from C++ to C. Sun has not verified the functionality of these software programs:
| Note - This latter URL requires registration with the Sun Download Center. |
The limit is 5 Mbyte. If the application exceeds this limit, the generated makefile indicates so with a static check.
TABLE A-2 lists the default memory setup in Sun CMT hardware architecture:
These values are changed in the memory bank properties of the hardware architecture. For example, to move the end of DRAM to 0x110000000, add the following code to your hardware architecture:
teja_memory_t mem; char * new_value = "0x110000000"; ... mem = teja_lookup_memory (board, "dram_mem"); teja_memory_set_property (mem, TEJA_PROPERTY_MEMORY_SIZE, new_value); |
You can increase the size of DRAM as explained in How Is Memory Organized in the Sun CMT Hardware Architecture?.
To enable ARP in RLP, you need to make the following changes:
1. Modify rlp_config.h to give IP addresses to the network ports.
a. Assign an IP address to the network ports of the system, running lwrte.
# define IP_BY_PORT(port) \((port == 0)? __GET_IP(192, 12, 1, 2): \(port == 1)? __GET_IP(192, 12, 2, 2): \(port == 2)? __GET_IP(192, 12, 3, 2): \(port == 3)? __GET_IP(192, 12, 4, 2): \(0)) |
b. Tell the RLP application, the remote IP address to which its going to send IP packets.
# define DEST_IP_BY_PORT(port) \((port == 0)? __GET_IP(192, 12, 1, 1): \ (port == 1)? __GET_IP(192, 12, 2, 1): \ (port == 2)? __GET_IP(192, 12, 3, 1): \ (port == 3)? __GET_IP(192, 12, 4, 1): \ (0)) |
c. Assign netmask to each port, to define a subnet.
2. Compile the RLP application with ARP=on
| Netra Data Plane Software Suite 1.1 User's Guide | 820-2374-10 |
Copyright © 2007, Sun Microsystems, Inc. All Rights Reserved.