| Building Enterprise JavaBeans Components |
| Building Enterprise JavaBeans Components |
| C H A P T E R 2 |
|
Design and Programming Issues |
If you're not already familiar with the design and programming issues associated with enterprise beans, you need to consider the differences between various kinds of beans and what they are meant to do. You should be aware of the life cycle of each kind of bean, how methods and exceptions are applied, and how beans are set up for reuse in different application environments. You need to understand how persistence, transactions, and security are handled. This chapter discusses those topics, and ends with a list of recommended readings for further details.
The Enterprise JavaBeans Specification, version 2.0, defines three types of enterprise beans: session beans, entity beans, and message-driven beans. There are also several types of session and entity beans, each with built-in functionality for different purposes. The EJB Builder in the Sun ONE Studio 5 IDE guides you and streamlines the process of creating all these types of enterprise beans.
To help you make design decisions before you start, this chapter describes the enterprise bean types.
FIGURE 2-1 shows the basic choices before you when you use the IDE's template to create enterprise beans.
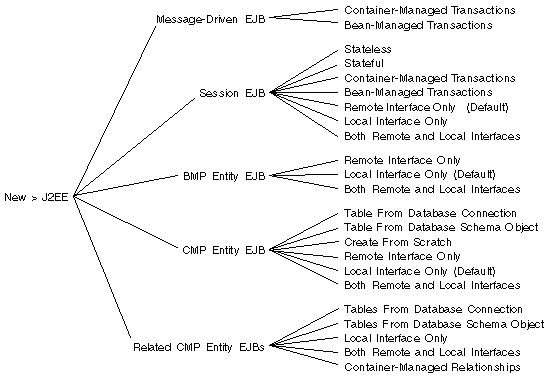 [ D ]
[ D ]A session bean acts as the traffic director for an application, controlling the work flow of the application and encapsulating its business processes. If you think of a model-view-controller architecture, a session bean is like the controller tier, but in an EJB application. On behalf of a client, a session bean can do work such as accessing a database or calculating balances. A session bean doesn't represent database data directly, but it can access the database or manipulate entity beans that access the database.
In the context of an application that uses enterprise beans, a session bean manages the conversation between a single client and the parts of the application that reside on the application server and are managed by the EJB container. These other application parts often include entity beans and (in its own separate tier) the database with which any persistence-capable beans interact.
A session bean can manipulate one or more entity beans, control interactions between them, and bridge gaps between the data represented by the entity beans and the business logic that acts on the data. A single session bean can direct transactional work by several entity beans in the same application.
The conversation (or session) that the session bean manages is transient and so is any data in the session bean. When the client-server session is over, or when the client or the server shuts down, the instance of the session bean that the client created for that session is destroyed. However, the client can store a handle to the session, shut down, and then resume the session later.
A session bean has no primary key. Unlike an entity bean, a session bean is intended for use by only one client at a time. Therefore the session bean can appear anonymous to the client; the bean doesn't need the unique identity that a primary key provides.
Occasionally, a session bean represents an entity, as does the ShoppingCart object in an application for ordering merchandise online. However, most session beans are not intended to save entity state to a database. For example, while a user is shopping, the ShoppingCart bean instance temporarily holds items that the user intends to buy. If the server goes down before the user has actually committed to buying the items, it would be inappropriate to save those items to the database in a transaction. A common design approach is to let that data go and have the user start a new shopping cart with the next session.
The conversation carried on between the client and the session bean can be short and simple, involving only work that can be accomplished by loading the parameters of one method. Or a session bean can manage a long, complicated conversation that involves many methods and database transactions. Such a conversation requires the session bean to retain information between method invocations.
In the first situation, a session that consists of a request and a response, a stateless session bean is best. A stateless bean retains no state between method calls. Such a lightweight bean costs the application few resources, is easy for the container to manage, and promotes faster processing. A stateless bean can provide better scalability to an application that has many clients.
Of course, the tradeoff is that this bean can do less with data. A stateless bean operates only on the arguments that the client passes to it. Every call to a method of a stateless bean is independent of previous calls.
For example, a stateless bean can get the ZIP code for an address. Each retrieval can be completed in one method call, getZip, because all the information needed to process the retrieval is in the method parameters. Any transactions are completed within the method call and within the container. (Transactions are discussed a little later in this chapter and in Chapter 3.)
The instance variables of a stateless bean can contain state only while the method executes. All instances of a stateless bean are the same when they are pooled. As a result, the EJB container can pool and assign bean instances very flexibly, swapping instances in and out between the client's method calls. In effect, clients can share stateless beans. These beans seem anonymous to their clients.
A session bean can be stateless if it is designed to be used sequentially by many different clients and needs no tailoring to suit a specific client. A stateless bean holds no state information for a specific client. However, the bean can have state that isn't specific to a client, for example, an open database connection.
The conversation between the client and the session bean can be complicated. The bean might need more than one method to encapsulate business logic and the application might need the session bean to remember state between and across method calls. By definition, such a bean is stateful. If your client is an interactive application, or if the session bean's state must be initialized when it is created, use a stateful bean.
The bean's state can be written to a database if necessary. The state is specific to the client and is held in memory during the session, but is not persistent. If a stateful session bean must be removed from memory, the EJB container manages the state. The state of the bean instance can survive a session, but not the client's termination or a server crash.
Notice that the ejbRemove method is not called after a container crash, a timeout while the instance is passivated, or a system exception thrown by a method. You might need to provide a clean-up program for such an event.
A stateful bean is not shared by more than one client. By servicing only one client, the bean can maintain conversational state throughout the session. Stateful bean instances are not pooled.
The online shopping cart mentioned earlier in this chapter is an example of how stateful session beans can be used. Just as the logical business transaction of shopping includes multiple individual decisions by the user, so the stateful bean in this application includes multiple method calls. The ShoppingCart bean must accumulate items that the user has chosen until the user is ready to review the list of items, approve or reject each one, and place the order.
Whether you're programming a stateless or a stateful session bean, you must make one of these selections in the EJB Builder wizard:
For a CMT session bean, you have less coding to do and all the transactions are handled in a predictable, consistent way. Also, the transaction policy that you select for your bean can be changed declaratively. The tradeoff is that each method can be associated with no more than one transaction. The container typically has a transaction begin just before a method starts, and commits the transaction just before the method exits. Nested and multiple transactions are not allowed in a single method.
If you decide to let the EJB container manage your bean's transactions, the container looks for transaction attributes on your bean or on specific methods within your bean. A transaction attribute specifies the scope of a transaction: which methods it includes and how the results of those methods are treated in relation to the transaction. These attributes are assigned as follows.
You don't set transaction attributes for a BMT session bean. All of its transaction boundaries must be explicitly demarcated in the bean class.
To code bean-managed transactions explicitly, you can use the Java Transaction API (the javax.transaction.UserTransaction interface, or JTA) or the JDBC API.
JTA can include transactions for other resources such as the JDBC API. When you use JTA to code transactions in an enterprise bean, you're using the JDBC API for database connections and JTA for transactions.
In handling transactions, your bean's method calls the JTA methods, which then call the lower-level routines of the Java Transaction Service (JTS), the transaction manager used by the Java 2 Platform, Enterprise Edition (J2EE). Because of that level of indirection, JTA lets you demarcate transactions independently of the transaction-manager implementation. A JTA transaction can also span updates to multiple databases from different vendors.
A JDBC transaction is controlled by the transaction manager of the database you're using.
A disadvantage of using JTA is that it doesn't support nested transactions. One transaction must end before another starts.
For more information on transactions, refer to Building J2EE Applications.
At runtime, the application server creates bean instances as requested by EJB clients. A bean instance passes through several stages of activity managed by the EJB container. When the instance is no longer needed, it is destroyed.
The individual stages in a session bean's life, the methods that cause the bean to transition between stages, and the programmer's responsibilities are described next.
A session bean's runtime life cycle starts when an EJB client requests some work from the bean. This stage of the life cycle goes as follows:
The client calls a create method on the bean's home (or local home) interface. In response, the container calls these three methods in sequence:
1. newInstance to create a new instance of the session bean
2. setSessionContext to associate the instance with a session-context object
3. ejbCreate to initialize the instance
|
Note - The IDE generates method signatures for the setSessionContext and ejbCreate methods. It's up to the programmer to complete the body of the methods. |
The client receives a reference to the bean instance's remote object.
Now that a bean instance has been created and initialized, the EJB client asks the instance to do some work. This stage of the life cycle goes as follows:
The client calls a business method on the bean's remote object. In response, the container does the following:
The client receives the result of the business method.
The client is finished with the session and can let go of the bean instance. This stage of the life cycle goes as follows:
The client calls the remove method on either the home (or local home) interface or the remote (or local) interface. In response, the container calls the ejbRemove method to close any open resources that the instance has used. The container removes the instance from memory.
|
Note - The IDE generates the method signature for the ejbRemove method. It's up to the programmer to complete the method's code. |
Ordinarily, in a production environment, many clients concurrently request work from an enterprise bean. To support this need, the container can concurrently create many instances of a stateless session bean and can pool them for use. The container can populate the instance pool at its own discretion.
An instance of a stateless session bean maintains no client-related state information between method calls. Therefore, stateless session bean instances in a pool are interchangeable. The container can call different session beans from the pool to handle requests from a single client.
So that the container always has an adequate supply of stateless session bean instances to serve the volume and frequency of client requests, it keeps adjusting the volume of pooled instances. For example, the container creates new instances of a stateless session bean when the number of client requests increases, and removes instances when memory becomes scarce. To maintain its pool, the container calls the stateless session bean's ejbCreate and ejbRemove methods at its own discretion.
A stateful session bean must maintain its conversational state with the client throughout the client's session. Therefore, the EJB container does not pool instances of stateful session beans. Instead, the container only creates and removes stateful bean instances upon explicit instructions from the client.
However, to control the use of resources, the container might still need to control the number of active stateful session bean instances at a given time. When memory becomes scarce, the container can passivate an instance, writing the instance's conversational state to secondary storage so that it can be used to handle another client's session. On passivation, the container first calls the instance's ejbPassivate method, which the programmer codes to release resources and put all fields in a serializable state. The container then writes the instance's non-transient fields to secondary storage.
When a client calls a business method on a stateful bean instance that has been passivated, the container restores the instance's state from secondary storage and calls the ejbActivate method on the instance. The programmer codes this method to acquire resources that were released by the ejbPassivate method, and to restore the values of fields that were not serializable.
A programmer can choose to implement the session-synchronization interface in a stateful CMT session bean. During the stateful bean's life cycle and at certain points in a transaction, the container uses the interface to notify the instance that it is about to enter or complete a transaction. The programmer can program the methods on this interface to synchronize the bean's instance variables with the data store's most current data, or to abort the transaction. The interface includes three methods: afterBegin, beforeCompletion, and afterCompletion.
|
Note - The IDE generates the method signatures for the session-synchronization methods. It's up to the programmer to complete the code for these methods. |
An entity bean represents persistent data in an underlying data store. This type of bean provides an object view of a set of data such as rows in a database table. Each entity bean instance contains one entity of that data and can also contain business logic that is intrinsic to the entity. A client, or a session bean working on behalf of a client, can use an entity bean to find or insert data in a database.
An entity bean's state isn't dependent on its environment. With its primary key and its remote reference, the bean can survive a crash of the server, the EJB container, or the client. The entity's state automatically reverts to the way it was after the last committed transaction.
Because each client gets its own instance of the entity bean, many different users can share access to one set of data. If two clients execute the same finder method on an entity bean, they both reference the same remote object. Each find is independent, which eliminates contention problems. Multithreaded code is not needed in an enterprise bean. (However, there might be a situation in which you need to run concurrent processes. With message-driven beans, you can approximate multithreading in a J2EE application. That discussion can be found in Understanding Message-Driven Beans.)
A client finds a particular entity bean by its unique object identifier, which is the bean's primary key.
The container (application server) that you use for deployment can simplify much of your work with entity beans. Whenever feasible, you should let the container manage your enterprise beans' transactions, persistence, and relationships. You can also implement your entity beans' queries most flexibly by using EJB QL.
All transactions that are part of an entity bean are automatically managed by the EJB container. When you have finished coding a bean and have created an EJB module for it, you use the module's property sheets to declare the bean's transaction attributes. The container demarcates the bean's transaction boundaries accordingly. The IDE automatically assigns the default transaction attribute to all business, create, remove, finder, select, and home methods in your entity bean.
You can choose to have your entity bean's persistence managed by the container, or you can code the bean yourself to manage its relationship with the data store.
When you use the IDE to create an entity bean with container-managed persistence, that is, a CMP entity bean, you complete the bean class without writing JDBC calls to the data store. The container provides the code to synchronize your bean's instance variables with the data store. You provide information to the container on how to map the instance variables to columns in database tables.
You use the EJB query language (EJB QL) to define how servers will implement your bean's query methods.
An EJB QL query in a finder method can be used by a client to select an existing entity object. Or, without exposing the result to the client, an EJB QL query in a select method can select objects or values related to the state of an entity bean. To find this kind of information, the EJB QL query can use the bean's abstract persistence schema, which defines the bean's persistent fields and relationships and is part of the bean's deployment descriptor.
When you deploy a J2EE application to an application server, the server looks at your bean's methods and the EJB QL queries you have supplied, and generates its own server-specific SQL statements to do this mapping.
In some cases, you might need to edit the SQL that a given server plugin generates for its own use, assuming that the server allows access to its generated SQL. For example, if your application includes CMP entity beans that were created in the EJB 1.1 environment, and your application is deployed to Sun ONE Application Server 7, you might need to go into the beans' finder methods and complete the server's sparsely generated SQL.
Relationships between entity beans can be managed by the EJB container. If you generate a set of related CMP entity beans from a database in which tables use foreign keys, the IDE automatically preserves these relationships.
Put simply, the advantages of using container-managed persistence are that you have less coding to do and that the resulting entity bean is not dependent on any particular data store.
At some point, you might need to create an EJB application in which you wrap legacy code that isn't supported by mapping tools. Or, you might need to implement complex joins between tables, or even between different databases (for example, non-relational databases). In these situations, depending on the capabilities of the application server you use to deploy your EJB application, you might need to choose bean-managed persistence and code all database calls yourself in the entity bean class. If the server supports the persistence style you need, then container-managed persistence is the best approach. However, as a general rule, bean-managed persistence affords more flexibility in how an entity's state is managed.
The application server creates a pool of entity bean instances to be used by EJB clients. At runtime, a bean instance passes through several stages of activity as requested by the bean's client and as managed by the EJB container. When the instance is no longer needed, it is destroyed.
The individual stages in an entity bean's life, the methods that cause the bean to transition between stages, and the programmer's responsibilities are described next.
An entity bean's runtime life cycle starts when the container creates and pools instances of the bean.
Many EJB clients might concurrently need many entity beans to do work for them. At its own discretion, the container creates and pools multiple, anonymous instances of a bean before they are needed. These instances can be used to run queries with finder methods, or they can be assigned identities. When a particular instance is needed to hold data from the data store, the container transitions a pooled instance into the ready state. (A ready instance has a primary key that uniquely identifies it.) Finally, the container can adjust the size of the pool by constructing new instances or deleting unneeded ones.
To create a new instance for the pool, the container calls:
1. The newInstance method to create a new instance of the entity bean
2. The setEntityContext method to associate the instance with an entity-context object
The instance is now in the pooled state.
The container cycles instances between the ready state and the pooled state. When the client requests an entity using its identity, but the corresponding instance is not in the ready pool, the container transitions an instance from the pooled state to the ready state. As part of this process, the container calls the ejbActivate method on the instance. The programmer can code this method to acquire resources that are needed by instances with identity, but not by instances in the pooled state. The container then loads the values of the entity's instance variables and associates the instance with its remote object.
Notice that the ejbActivate method does not load the values of the entity's instance variables. For BMP entity beans, this is handled by the ejbLoad method; for CMP entity beans, it's handled by the container.
When the container has too many instances in the ready state, it can passivate one or more instances, moving them into the pooled state. As part of this process, the container calls the ejbPassivate method on the instance. The programmer can code this method to release resources that are not needed by instances in the pooled state. The container also dissociates the instance from its remote object, and stores the current values of the entity's instance variables in the database.
Again, the ejbPassivate method does not store the values of the entity's instance variables in the database. For BMP entity beans, this is handled by the ejbStore method; for CMP entity beans, it's handled by the container.
To remove an inactivated instance from the pool, the container calls the unsetEntityContext method on the instance and dissociates the instance from its entity-context object. The container then destroys the instance.
Whenever an EJB client wants to create a new entity (to insert data into the data store), the client calls a create method on the bean's home interface. In response, the container:
1. Does the appropriate security checking and applies the transaction control specified by the method's transaction attribute.
2. Calls the ejbCreate method on an instance in the pool. In a CMP entity bean, this method initializes the persistent field values to prepare for the container to populate the data store. In a BMP entity bean, this method initializes field values and inserts the record into the database.
3. Creates a remote object for the bean, and associates it with the new bean instance.
4. Calls the ejbPostCreate method on the instance to complete initialization. Because the container has already assigned an identity to the bean instance, the ejbPostCreate method can forward identity information, such as the associated remote (or local) interface or primary key, to another enterprise bean.
The client receives a reference to the instance's remote object. The instance is now in the ready state and can run business methods for the client. See Executing Business Logic.
An EJB client can locate one or more existing entities by calling a finder method on the bean instance's home object. A finder method returns one or more entities that meet specific search criteria. Besides the findByPrimaryKey method, an entity bean can have any number of other finder methods.
When a client calls a finder method on an instance's home object, the following steps happen:
1. The container does the appropriate security checking and applies the transaction control specified by the method's transaction attribute.
2. The container calls a finder method on an anonymous instance in the pool.
3. The finder method returns the primary key of the instance (or multiple keys of multiple instances, if appropriate). Notice that only the primary key is returned.
4. The container locates or creates a remote object with each primary key and returns a reference to the object to the client.
|
Note - The IDE generates a method signature for the findByPrimaryKey method. It's up to the programmer to furnish any other finder methods that a particular bean might need. |
The client can go on to call business methods on the located instance, using the methods named in the remote object. See Executing Business Logic.
When an EJB client needs an entity-bean instance to do some work, the client calls a business method on the instance's remote object. In response, the container:
1. Does the appropriate security checking and applies the transaction control specified by the method's transaction attribute.
2. Calls a business method on the instance.
The business method finishes and the client receives the result. When appropriate, the container passivates the instance as discussed in Creating and Managing a Pool of Bean Instances.
Whenever an EJB client wants to remove an existing entity (to delete data from the data store), the client calls a remove method on the instance's home or remote object. In response, the container:
1. Does the appropriate security checking and applies the transaction control specified by the method's transaction attribute.
2. Calls the ejbRemove method on the instance. A CMP entity bean instance responds by readying the data for the container to delete. A BMP entity bean instance responds by deleting the data.
3. Commits the transaction as appropriate.
|
Note - The IDE generates a method signature for the ejbRemove method. It's up to the programmer to complete the method. |
At certain points during a transaction, the container must make sure that the data in the bean instance is synchronized with the data in the data store. To do this, the container:
If you wish, you can use the EJB Builder wizard that generates the infrastructure of one CMP entity bean at a time. However, if you want to base several CMP entity beans on database tables that have foreign keys or table-to-table joins, it's easier and more reliable to generate the infrastructure for the whole group of beans at one time. A special EJB Builder wizard displays the tables in a database or schema, and, from the tables you select, generates a corresponding set of CMP entity beans. Along with the beans, the wizard creates logical entities to model foreign keys and joins between database tables, and generates an EJB module to store and track the set of beans and relationships.
A CMP entity bean that you created as part of a set is no different from a CMP entity bean that you created individually. Its function, capacities, properties, and life cycle are the same. However, if you use the wizard to generate a set of related CMP entity beans, you don't have to hand-code information about the enterprise-bean equivalent of joins and foreign keys. The IDE presents these links as logical fields called container-managed relationship (CMR) fields. A CMR field is like a foreign key. In an EJB QL query, you can perform the equivalent of a table-to-table join using a CMR field instead of a CMP field.
In accordance with the Enterprise JavaBeans Specification, the EJB container manages CMRs to ensure referential integrity between associated CMP entity beans. The IDE uses the Collections API to let you manipulate your beans' CMRs. Information about CMRs is stored at the level of the EJB module in which a set of related beans resides.
In the bean class are abstract accessor methods that specify a CMR's directionality and cardinality. For example, in a relationship between the beans Order and LineItems:
A CMR allows for cascade-delete functionality, which is specified declaratively and stored in the deployment descriptor.
A CMR field provides access to local instances of a CMP entity bean; thus, only a bean with local-type interfaces can have CMR fields.
A special kind of enterprise bean acts as a go-between for application components, taking messages from the client and acting on the messages to start processes asynchronously. This is the message-driven bean, which combines many features of enterprise beans with the ability to be a listener for the Java Message Service (JMS) message-oriented middleware (MOM). With message-driven beans, you can approximate threading or parallel processing in an EJB environment.
Whereas in another J2EE application an enterprise bean might respond to RMI calls, a message-driven bean listens to certain resources for messages arriving from other application components, usually the client. When such a message arrives, regardless of what processes or servers are running at the time, the message-driven bean is notified of the message receipt by the invocation of the onMessage method. The message-driven bean then acts on the message, calling a stateless session bean to start a process.
A destination is a resource to which a client sends messages and to which a message-driven bean listens. A destination can be a queue or a topic.
An application using message-driven beans has minimal dependence on the state of other application components. A message-driven bean is designed for one-way operation.
As long as a destination is available, an application client can reliably send a message to it, whether or not the message-driven bean's server or the target application are currently deployed. The container doesn't have to wait for a client-invoked process to complete. The client can even be decoupled from the server while the message-driven bean and its called bean do their work. One or many clients can send messages to one or many servers, invoking multiple processes.
If an application needs to start a process that might go on a long time, if a server might go down, or if, for any other reason, resources might become unavailable before the message arrives, you can use a middle layer of message-driven beans to keep processing going. A message-driven bean is ideal if your client needs to start a process and then continue to be available to the user. For example, in a shopping application, you could use a message-driven bean to check the customer's credit card number for validity while the customer continues to browse the product list. The client component of the application sends a message to the message-driven bean and then continues processing.
The use of message-driven beans can help your application with load balancing and scheduling. For example, you can start processes at your database's off-peak times. Asynchronous processing is particularly advantageous for communications and processing over different time zones and geographically dispersed systems.
If your application needs to interface with another application it doesn't know much about, you can use message-driven beans to loosely couple the applications. Many legacy systems use messaging and can be interfaced in this way with J2EE applications.
A message-driven bean interacts with the JMS environment only when the bean's onMessage method is called. The message-driven beans that you generate using IDE's EJB Builder wizard incorporate JMS transparently, so that you don't have to write JMS code. Because you specify the JMS connections and the message channels (destinations) as properties on the bean, you can easily change a single message-driven bean to point toward a different destination if needed.
In certain situations, message-driven beans are not appropriate. For example:
At runtime, an application client sends messages to a destination to which a message bean is listening. When these messages arrive, the application server creates instances of the bean to service the client's requests.
This type of bean has a very simple life cycle. As with a stateless session bean, its instances pass through several stages of activity managed by the EJB container, and when an instance is no longer needed, it is destroyed.
The individual stages in a message-driven bean's life, the methods that cause the bean to transition between stages, and the EJB programmer's responsibilities are described next.
A message-driven bean's runtime life cycle starts when a client sends a message to a queue or a topic, to be consumed (read and processed) by a message-driven bean. In response, the EJB container calls these three methods in sequence:
1. newInstance to create new instances of the message-driven bean
2. setMessageDrivenContext to associate each instance with a message-driven-context object
3. ejbCreate to initialize the instances
|
Note - The IDE generates method signatures for the setMessageDrivenContext and ejbCreate methods. It's up to the programmer to complete the body of the methods as needed. |
After sending the message, the client doesn't need to be involved again unless results are returned.
Now that instances of the message-driven bean have been created and initialized, the instance and the container collaborate as follows:
Eventually, if appropriate, the client can make a separate call to the session bean or another enterprise bean in the server and receive the result of the business method.
When the message-driven bean has handed off its assigned task to another bean in the application, its job is done. The container calls the ejbRemove method on the message-driven bean instance to close any open resources that the instance has used. The container removes the instance from memory.
|
Note - The IDE generates the method signature for the ejbRemove method. It's up to the programmer to complete the method's code, if needed. |
As is true for stateless session beans, the container can concurrently create and pool many instances of a message-driven bean. The container populates the instance pool at its own discretion, creating new instances when the number of arriving messages increases and removing instances when memory becomes scarce.
An instance of a message-driven bean maintains no state information, and so message-driven bean instances in a pool are identical and interchangeable.
The J2EE specification does not guarantee that messages to multiple instances of a message-driven bean will be delivered in any particular order; therefore, the application must be able to handle out-of-order messages.
The needs of your application dictate whether and how to combine message-driven, session, and entity beans. In some cases, you might get the best results by using only one kind of bean. In the case of a very simple application (for example, an application that performs only one CRUD operation), you might place a single session bean or entity bean in the EJB module. In other cases, you will want to exercise the full power and capability of several types of enterprise beans.
You can continue to increase the scope and power of an application by adding enterprise beans to an EJB module. EJB applications are highly extensible.
Here are a few possible combinations of enterprise beans and other components in applications:
These scenarios and more are discussed in detail in Building J2EE Applications.
In the bean class, you define how your bean is to handle problems it encounters at runtime. A system-level problem (such as an unavailable database connection, a database so full that an SQL insert fails, or an object that can't be found) is expressed in a system exception that uses the javax.ejb.EJBException interface. The container sees an exception of this kind, wraps it in a remote exception, and passes it back to the client to be handled by a system administrator.
An application-level problem (such as an error in the business logic of an enterprise bean, or an input error), can be addressed with a predefined exception such as the javax.ejb package offers, or with a customized exception that the programmer writes. The container sees an exception of this kind and passes it back to the client for handling.
When you use the Sun ONE Studio 5 IDE wizards to create an enterprise bean or its methods, the IDE includes the required exceptions in the method signatures. For example, java.rmi.RemoteException is included in the signature of all methods on the home and remote interfaces. As another example, javax.ejb.CreateException is included in the signature of all create methods.
When you create a method using the GUI support available from the IDE's Explorer window, you are also given the option of specifying application-level exceptions that should be thrown by the method. These application exceptions are automatically added to both the remote (or local) interface and the bean class.
The basic design of enterprise beans makes them reusable in different applications and deployable in different servers. Toward that end, all the information that a particular server needs to know at runtime is captured in an XML meta-file called the deployment descriptor. This descriptor file includes information about the bean's structure, its relationships to other beans, where its data store is, what is needed for the user to gain access to the data store, and all other external dependencies.
Whenever you create an enterprise bean, the IDE generates a starter deployment descriptor for the bean. You use the bean's property sheets to declare whatever you know of the bean's external dependencies. When you assemble beans into an EJB module, the IDE gives you the opportunity to override the default values of bean properties, and to set properties for the EJB module as a whole. These properties can also be set through the EJB module's property sheets. At deployment time, the IDE generates the EJB module's deployment descriptor, incorporating all specified properties.
The EJB container offers you mechanisms for securing your application, that is, for restricting the set of users who can call methods on an enterprise bean. You can specify the security policies for your application either declaratively or programmatically. Declarative security is specified within the deployment descriptor, and therefore it can be changed at any point up through deployment. Programmatic security is defined within the code of the enterprise bean, and therefore it is supplied by the programmer.
In most cases, declarative security is preferable. It's easier to provide, and it's configurable throughout the development, assembly, and deployment process.
Programmatic security is more complicated. However, it provides a more granular control of security, and therefore it's sometimes the only option to meet the security requirements of an application. For example, if you want to perform different logic within the body of a method depending on the identity of the caller, you must use programmatic security.
To specify security policies for your enterprise beans, you define a set of security roles for your application. A security role is a set of users who share common permissions for executing the methods of your enterprise beans.
With declarative security, each security role is assigned a set of bean methods that callers in that role are permitted to execute. At runtime, the container checks the security role of each caller, and decides whether the caller is permitted to execute the requested method.
In providing programmatic security, you can use methods supplied by the container (getCallerPrincipal and isCallerInRole) to determine the identity or role of the caller, and then you can use conditional logic as appropriate.
You declare security roles and method permissions after you have assembled the enterprise beans into an EJB module. On the module's property sheet, you define security roles for the EJB module. On the property sheet of the assembled EJB component, you define, for each security role, the list of methods that a caller in that role is permitted to execute.
When you take the declarative approach, you can modify the security permissions at any time during development and testing. Also, you can use different security roles and method permissions for each different EJB module that includes your bean.
Programmatic security allows you to determine:
With this information, you can branch your logic conditionally, depending on the identity or role of the caller.
To programmatically determine the identity of the caller, you use the getCallerPrincipal method on the javax.ejb.EJBContext object. This returns a java.security.Principal object, which allows you to get the caller's name. You might use this to query a database for more information about the caller.
To programmatically determine whether the caller has a particular logical role, use the isCallerInRole(String roleName) method on the javax.ejbEJBContext object. This returns a Boolean value indicating whether the caller has the specified logical role. If you use the isCallerInRole method, you must also declare the roleName used in your code as a security-role reference on the bean's property sheet.
At assembly time, when the bean is included in an EJB module, the assembler can map the bean's security-role reference to one of the security roles defined in the EJB module. Therefore, the programmer does not need to know the actual security role names before they are determined at assembly time.
For more information on implementing security features in enterprise beans and J2EE applications, refer to Building J2EE Applications.
The enterprise beans that you create using the Sun ONE Studio 5 IDE are typically deployed on Sun ONE Application Server 7, the commercial application server that comes with the IDE. You can test your enterprise beans on this server to see how they will behave under different application conditions, and you can also deploy your applications to this server for production purposes. The examples in this manual that illustrate use of an application server use Sun ONE Application Server 7.
Refer to the Sun ONE Studio 5 Release Notes for information on any other application servers and server plugins that are available for the IDE.
The entity beans you create using the IDE can be tested using the database that is included: PointBase Server 4.2 Restricted Edition. The examples in this manual use PointBase as the database.
In addition to the specifications and blueprints mentioned earlier in this book, there are many information resources for EJB programmers. For example, the following documents suggest ways that you can improve the design and programming of your enterprise beans:
| Building Enterprise JavaBeans Components | 817-2330 |
Copyright © 2003, Sun Microsystems, Inc. All rights reserved.