リリース12
E05660-01
目次
前へ
次へ
| Oracle XML Publisherレポート・デザイナーズ・ガイド リリース12 E05660-01 | 目次 | 前へ | 次へ |
この章では、次のトピックを説明します。
eTextテンプレートは、電子送金(EFT)および電子データ交換(EDI)に関するテキスト出力の生成に使用されるRTFベースのテンプレートです。実行時に、XMLパブリッシャは、このテンプレートを入力XMLデータ・ファイルに適用して、銀行や他の顧客に伝送できる出力テキスト・ファイルを作成します。電子通信を意図した出力であるため、eTextテンプレートは、データの正確な配置に関する厳密な書式指示に従う必要があります。
注意: EFTとは、特定の固定位置書式のフラット・ファイル(テキスト)形式による、銀行への財務データと支払の電子伝送のことです。
EDIは、銀行への支払情報の伝送のみに制限されないことを除いてEFTと同じです。EDIは、企業間で発注書や請求書などのビジネス文書を交換する方法としてよく使用されます。EDIデータはデリミタ・ベースで、フラット・ファイル(テキスト)としても伝送されます。
これらの書式によるファイルは、用紙には印刷されず、フラット・ファイルとして伝送されます。レコードの長さは、数百文字となることが多いため、標準サイズの用紙にレイアウトするのは困難です。
レコード長を確保するために、EFTテンプレートとEDIテンプレートは表を使用して設計されます。各レコードは表で示されます。表の各行は、レコード内の1つのフィールドに対応します。表の列には、フィールドの位置、長さおよび値を指定します。
これらの書式では、XML入力ファイルからのデータについて特別な処理を要求することもできます。この特別な処理は、グローバル・レベル(文字の置換や連番など)またはレコード・レベル(ソートなど)で要求できます。これらの関数を実行するコマンドは、コマンド行で宣言します。グローバル・レベルのコマンドは、設定表で宣言します。
実行時に、XMLパブリッシャは設定コマンドと表のレイアウト仕様に従って、出力ファイルを作成します。
この項は、EDI取引とEFT取引を理解しているユーザーを対象としています。この項の対象者であるeTextテンプレートの作成者には、職務に関する知識と技術的な知識の両方が必要です。つまり、銀行と国単位で固有な支払書式要件を理解するための職務上の専門知識と、XMLデータの構造およびeText固有のコーディング構文コマンド、関数および操作を理解するための十分な技術的専門知識が必要です。
eTextテンプレートには、固定位置ベース(EFTテンプレート)とデリミタ・ベース(EDIテンプレート)の2つのタイプがあります。これらのテンプレートは一連の表で構成されます。表には、レイアウト、設定コマンドおよびデータ・フィールド定義が定義されます。2つのタイプのテンプレートに必要なデータ記述列は異なりますが、使用可能なコマンドと関数は同じです。表には、コマンドのみを指定するか、またはコマンドとデータ・フィールドを指定できます。
次の図に、コマンドの一般的な構造とデータ行を表示するEFTテンプレートのサンプルを示します。

設定コマンドとは、グローバルに適用されるコマンドまたはテンプレートのプログラム要素を定義するコマンドです。これらのコマンドは、テンプレートの初期の表(複数可)に指定する必要があります。設定コマンドの例には、テンプレート・タイプやキャラクタ・セットなどがあります。
データ表には、ソースXMLデータ要素名(または静的データ)と、振込先銀行またはエンティティに必要な特定の配置と書式定義を指定します。データに対して実行する関数や条件文を定義することもできます。
データ表は常に、レベルを定義するコマンド行で開始する必要があります。このレベルによって、表がXMLデータ・ファイルの要素に関連付けられ、階層が確立されます。そのときに、レベルの表に定義されているデータ・フィールドが、XML要素の子要素に相当します。
次の図に、XMLデータ階層とテンプレート・レベルの関係を示します。XML要素RequestHeaderは、レベルとして定義されています。表(FileIDとEncryption)に定義されているデータ要素は、RequestHeader要素の子です。
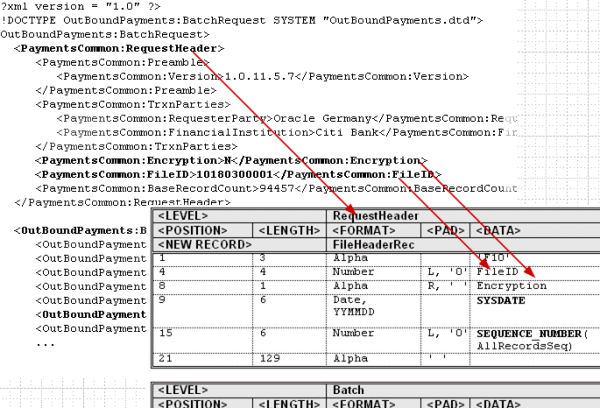
テンプレート内の表の順序によって、レコードの印刷順序が決まります。実行時には、表(レベル)に対応するXML要素の全インスタンスがループされ、その表に属しているレコードが印刷されます。その後、テンプレート内の次の表に移ります。表がネストされている場合は、次の親インスタンスに移る前に、子表のネストしたレコードが生成されます。
次の図に、コマンド行、データ行およびデータ列のヘッダー行の配置を示しています。

コマンド行は、テンプレートにコマンドを指定するために使用されます。コマンド行には常に2つの列(コマンド名とコマンド・パラメータ)があります。コマンド行に列ヘッダーはありません。コマンドは、テンプレートの全般的な設定とレコード構造を制御します。
読みやすくするために、表の任意の位置に空白行を挿入できます。多くの場合、空白行は設定表の各コマンド間に使用されます。XMLパブリッシャでテンプレートが分析される際、空白行は無視されます。
データ列のヘッダーには、データ・フィールドの列ヘッダー(位置、長さ、書式、埋込み、コメントなど)を指定します。通常、列のヘッダー行は、表内ではレベル・コマンドの後(または、ソート・コマンドが使用されている場合は、ソート・コマンドの後)に続きます。列のヘッダー行は、表内ではすべてのデータ行の前に存在している必要があります。読みやすくするために、表内の任意の位置に空の列ヘッダー行を挿入できます。この空白行は実行時には無視されます。
必要なデータ列のヘッダー行は、テンプレート・タイプによって異なります。「データ行の構造」を参照してください。
データ行には、列のヘッダー行に対応するデータ・フィールドが格納されます。
データ行の内容は、テンプレート・タイプによって異なります。「データ行の構造」を参照してください。
データ表には、コマンド行とデータ・フィールド行の組合せが格納されます。各データ表は、その表のXML要素を指定するレベル・コマンド行で開始する必要があります。各レコードは、新しいレコードの開始と前のレコードの終了(ある場合)を指定する新規レコード・コマンドで開始する必要があります。
データ・フィールドに必要な列は、テンプレート・タイプによって異なります。
コマンド行には、常に2つの列(コマンド名とコマンド・パラメータ)があります。サポートされるコマンドは、次のとおりです。
レベル
新規レコード
昇順ソート
降順ソート
表示条件
これらの各コマンドの使用方法については、次の各項で説明します。
レベル・コマンドは、表をXML要素に関連付けます。レベル・コマンドのパラメータはXML要素です。レベルは、XML要素がデータ入力ファイルに出現するたびに、各インスタンスに対して1回印刷されます。
レベル・コマンドはテンプレートの階層を定義します。たとえば、支払XMLデータ抽出が階層の場合、バッチには複数の子支払を指定し、その支払には複数の子請求書を指定できます。XMLでは、この階層が親要素内にネストされた子要素として示されます。レベル・コマンドを介して表をXML要素に関連付けることによって、その表にも同じ階層構造が保持されます。
XML要素の終了タグと同様に、レベル・コマンドには、対応するレベル終了コマンドがあります。子表は、親要素に対して定義された表のレベル・コマンドとレベル終了コマンドの間に定義する必要があります。
XML要素は1つのレベルにのみ関連付けることができます。1つのレベルに属するすべてのレコードは、そのレベルの表またはそのレベルに属するネストした表に存在している必要があります。レベル終了コマンドは、最終的な表の最後に指定されます。
次に、EFTファイルのレコード・レイアウトのサンプル構造を示します。
FileHeaderRecordA
BatchHeaderRecordA
BatchHeaderRecordB
PaymentRecordA
PaymentRecordB
InvoiceRecordA
Batch FooterRecordC
BatchFooterRecordD
FileFooterRecordB
この構造の表レイアウトは、次のようになります。
| <LEVEL> | RequestHeader |
| <NEW RECORD> | FileHeaderRecordA |
| FileHeaderRecordAのデータ行 |
| <LEVEL> | Batch |
| <NEW RECORD> | BatchHeaderRecordA |
| BatchHeaderRecordAのデータ行 | |
| <NEW RECORD> | BatchHeaderRecordB |
| BatchHeaderRecordBのデータ行 |
| <LEVEL> | Payment |
| <NEW RECORD> | PaymentRecordA |
| PaymentRecordAのデータ行 | |
| <NEW RECORD> | PaymentRecordB |
| PaymentRecordBのデータ行 |
| <LEVEL> | Invoice |
| <NEW RECORD> | InvoiceRecordA |
| InvoiceRecordAのデータ行 | |
| <END LEVEL> | Invoice |
| <END LEVEL> | Payment |
| <LEVEL> | Batch |
| <NEW RECORD> | BatchFooterRecordC |
| BatchFooterRecordCのデータ行 | |
| <NEW RECORD> | BatchFooterRecordD |
| BatchFooterRecordDのデータ行 | |
| <END LEVEL> | Batch |
| <LEVEL> | RequestHeader |
| <NEW RECORD> | FileFooterRecordB |
| FileFooterRecordBのデータ行 | |
| <END LEVEL> | RequestHeader |
同じ表に同一レベルの複数のレコードを配置できます。ただし、各表に定義できるのは1つのレベルのみです。前述の例では、BatchHeaderRecordAとBatchHeaderRecordBが同じ表に定義されています。ただし、PaymentのEND LEVELは、子要素Invoiceの後にある、Payment自体の独立した表に定義する必要があることに注意してください。PaymentのEND LEVELは、Invoiceレベルと同じ表には配置できません。
テンプレートではデータ抽出からすべてのレベルを使用する必要はありません。たとえば、抽出に複数のレベル(RequestHeader > Batch > Payment > Invoice)が含まれている場合は、BatchレベルとInvoiceレベルのみを使用できます。ただし、レベルの階層は保持する必要があります。
表の階層によって、レコードの印刷順序が決まります。各親XML要素については、対応する親表のレコードが表に掲載されている順に印刷されます。子表に対応する子XML要素のインスタンスがループされ、指定された順序で子レコードが印刷されます。次に、それを囲んでいる(終了レベルの)親表のレコードが印刷されます(親表がある場合)。
たとえば、前述のEFTテンプレート構造で、入力データ・ファイルには次の内容が含まれていると仮定します。
Batch1
Payment1
Invoice1
Invoice2
Payment2
Invoice1
Batch2
Payment1
Invoice1
Invoice2
Invoice3
この場合は、次の印刷レコードが生成されます。
| レコードの順序 | レコード・タイプ | 説明 |
|---|---|---|
| 1 | FileHeaderRecordA | EFTファイルの単一のヘッダー・レコード |
| 2 | BatchHeaderRecordA | Batch1用 |
| 3 | BatchHeaderRecordB | Batch1用 |
| 4 | PaymentRecordA | Batch1、Payment1用 |
| 5 | PaymentRecordB | Batch1、Payment1用 |
| 6 | InvoiceRecordA | Batch1、Payment1、Invoice1用 |
| 7 | InvoiceRecordA | Batch1、Payment1、Invoice2用 |
| 8 | PaymentRecordA | Batch1、Payment2用 |
| 9 | PaymentrecordB | Batch1、Payment2用 |
| 10 | InvoiceRecordA | Batch1、Payment2、Invoice1用 |
| 11 | BatchFooterRecordC | Batch1用 |
| 12 | BatchFooterRecordD | Batch1用 |
| 13 | BatchHeaderRecordA | Batch2用 |
| 14 | BatchHeaderRecordB | Batch2用 |
| 15 | PaymentRecordA | Batch2、Payment1用 |
| 16 | PaymentRecordB | Batch2、Payment1用 |
| 17 | InvoiceRecordA | Batch2、Payment1、Invoice1用 |
| 18 | InvoiceRecordA | Batch2、Payment1、Invoice2用 |
| 19 | InvoiceRecordA | Batch2、Payment1、Invoice3用 |
| 20 | BatchFooterRecordC | Batch2用 |
| 21 | BatchFooterRecordD | Batch2用 |
| 22 | FileFooterRecordB | EFTファイルの単一のフッター・レコード |
新規レコード・コマンドは、レコードの開始と前のレコード(ある場合)の終了を示します。テンプレート内のすべてのレコードは、新規レコード・コマンドで開始する必要があります。このレコードは、次の新規レコード・コマンドまで、あるいは表の最後またはレベル・コマンドの終了まで続きます。
レコードは、1つのレベルに属する複数要素の編成に対して構成されます。レコード名は、XML入力ファイルに関連付けられていません。
表には複数のレコードを格納できるため、複数の新規レコード・コマンドも格納されます。表内のレコードはすべて同じ階層レベルにあります。これらのレコードは、表に指定されている順序で印刷されます。
新規レコード・コマンドには、パラメータとして名称を指定でき、この名称がレコード名になります。レコード名はレコード・タイプとも呼ばれます。この名称は、生成したレコードのインスタンスをカウントするためのCOUNT関数で使用できます。詳細は、「COUNT」関数を参照してください。
新規レコード・コマンド(または空のレコード)は連続できません。
昇順ソート・コマンドと降順ソート・コマンドは、単一レベルのインスタンスのソートに使用します。ソートする要素は、カンマ区切りのリストで入力します。これはオプションのコマンドです。このコマンドを使用する場合は、(最初の)レベル・コマンドの直後に指定する必要があります。また、このコマンドは、レコードが複数の表に指定されている場合でも、該当するレベルのレコードすべてに適用されます。
表示条件コマンドは、囲まれているレコードまたはデータ・フィールド・グループの表示時期を指定します。コマンド・パラメータはブール式です。trueに評価された場合は、レコードまたはデータ・フィールド・グループが表示され、それ以外の場合はスキップされます。
表示条件コマンドは、レコードまたはデータ・フィールド・グループで使用できます。レコードに使用する場合、表示条件コマンドは、新規レコード・コマンドの後ろに指定し、データ・フィールド・グループに使用する場合は、データ・フィールド行の後ろに指定する必要があります。この場合、表示条件は、レコードが終了するまで残りのフィールドに適用されます。
連続する表示条件コマンドはAND条件として結合されます。結合された表示条件は、同様に囲まれているレコードまたはデータ・フィールド・グループに適用されます。
出力レコードの各データ・フィールドは、テンプレートでは表の行として表されます。FIXED_POSITION_BASEDテンプレートでは、各行に次の属性(または列)があります。
位置
長さ
書式
埋込み
データ
コメント
最初の5つの列は必須で、リストされている順に出現する必要があります。
DELIMITER_BASEDテンプレートでは、各データ行に次の属性(列)があります。
最大長
書式
データ
タグ
コメント
最初の3つの列は必須で、記載されている順に宣言する必要があります。
両方のテンプレート・タイプのコメント列はオプションであり、システムでは無視されます。必要に応じて他の情報列を挿入できます。必須列の後ろにあるすべての列は無視されます。
これらの列の使用ルールは、次のとおりです。
レコード内のフィールドの開始位置を指定します。単位は文字数です。この列はFIXED_POSITION_BASEDテンプレートのみで使用されます。
フィールドの長さを指定します。単位は文字数です。FIXED_POSITION_BASEDテンプレートでは、フィールドはすべて固定長です。データが指定の長さに満たない場合は空白が埋め込まれ、長すぎる場合は切り捨てられます。切捨ては常に右側から行われます。
DELIMITER_BASEDテンプレートでは、フィールドの最大長が指定されています。最大長を超えると、データは切り捨てられ、最大長に満たない場合、データの埋込みは行われません。
データ型と書式設定を指定します。許容されているデータ型は次の3つです。
Alpha
Number
Date
これらの使用法については、「フィールド・レベルのキーワード」を参照してください。
数値データには、3種類のオプション書式設定(Integer、Decimal、書式マスク定義)があります。オプション設定は、次のように、Numberデータ型と一緒に指定します。
Number、Integer
Number、Decimal
Number, <書式マスク>
次に例を示します。
Number, ###,###.00
Integer書式では、数値の整数部分のみが使用され、小数は破棄されます。Decimal書式では、数値の小数部分のみが使用され、整数部分は破棄されます。
次の表に、書式マスクの設定方法の例を示します。マスクを指定すると、#はデータに存在する桁を表示することを表し、0はデータが存在するかどうかに関係なく桁のプレースホルダを表示することを表します。
書式マスクを指定するときは、グループ・セパレータに「,」、小数のセパレータには「.」を必ず使用する必要があります。これらを実際の出力で変更するには、NUMBER THOUSANDS SEPARATORおよびNUMBER DECIMAL SEPARATORの設定コマンドを使用する必要があります。これらのコマンドの詳細は、「設定コマンド表」を参照してください。
次の表に、サンプルのデータ、書式指定子および出力を示します。出力では、デフォルトのグループ・セパレータと小数セパレータが使用されています。
| データ | 書式指定子 | 出力 |
|---|---|---|
| 123456789 | ###,###.00 | 123,456,789.00 |
| 123456789.2 | ###.00 | 123456789.20 |
| 1234.56789 | ###.000 | 1234.568 |
| 123456789.2 | # | 123456789 |
| 123456789.2 | #.## | 123456789.2 |
| 123456789 | #.## | 123456789 |
Dateデータ型書式設定は、常に明示的に記述する必要があります。書式設定は、MMDDYYなど、SQLデータ・スタイルに従います。
一部のEDI(DELIMITER_BASED)書式では、より記述的なデータ型が使用されます。これらのデータ型は、次の表にある3種類のテンプレート・データ型にマッピングされています。
| ASC X12のデータ型 | 書式テンプレートのデータ型 |
|---|---|
| A - 英字 | Alpha |
| AN - 英数字 | Alpha |
| B - バイナリ | Number |
| CD - 複合データ要素 | N/A |
| CH - 文字 | Alpha |
| DT - 日付 | Date |
| FS - 固定長文字列 | Alpha |
| ID - 識別子 | Alpha |
| IV - 増分値 | Number |
| Nn - 数値 | Number |
| PW - パスワード | Alpha |
| R - 小数 | Number |
| TM - 時刻 | Date |
次の設定コマンドを指定したとします。
| NUMBER THOUSANDS SEPARATOR | . |
| NUMBER DECIMAL SEPARATOR | , |
次の表に、この場合のデータ、書式指定子および出力を示します。書式指定子には、設定コマンドの入力に関係なく、デフォルトのセパレータを使用する必要があります。
| データ | 書式指定子 | 出力 |
|---|---|---|
| 123456789 | ###,###.00 | 123.456.789,00 |
| 123456789.2 | ###.00 | 123456789,20 |
| 1234.56789 | ###.000 | 1234,568 |
| 123456789.2 | # | 123456789 |
| 123456789.2 | #.## | 123456789,2 |
| 123456789 | #.## | 123456789 |
この列は、FIXED_POSITION_BASEDテンプレートのみに適用されます。埋め込む側(L=左側、R=右側)と文字を指定します。埋込みは、数値フィールドと英数字フィールドの両方に適用できます。このフィールドが指定されていない場合、Numeric型のフィールドは左側から0(ゼロ)が埋め込まれ、Alpha型のフィールドは右側から空白が埋め込まれます。
使用例:
フィールドを左側から0(ゼロ)で埋め込むには、次のように埋込み列フィールドに入力します。
L, '0'
フィールドを右側から空白で埋め込むには、次のように埋込み列フィールドに入力します。
R, ' '
フィールドを移入する予定のデータ抽出からXML要素を指定します。データ列には、XMLタグ名を単純に指定するか、または式と関数を指定できます。詳細は、「式、制御構造および関数」を参照してください。
DELIMITER_BASEDテンプレートのコメント列として動作します。EDIFACT書式では参照タグを指定し、ASC X12では参照IDを指定します。
この列を使用して、テンプレートに自由形式のコメントを記入します。通常、この列は、ビジネス要件やデータ・フィールドの使用方法を記入するために使用されます。
テンプレートは、常に設定コマンドを指定する表で開始します。設定コマンドは、テンプレート・タイプ、出力キャラクタ・セット、プログラム要素(たとえば、連番や連結)などのグローバル属性を定義します。
設定コマンドは、次のとおりです。
テンプレート・タイプ
出力キャラクタ・セット
新規レコード文字
無効な文字
置換文字
3桁セパレータ
小数セパレータ
レベル定義
連番定義
連結定義
次の各図に、設定表の例をいくつか示します。


このコマンドはテンプレートのタイプを指定します。FIXED_POSITION_BASEDとDELIMITER_BASEDの2つのタイプがあります。
FIXED_POSITION_BASEDテンプレートは、固定長のレコード書式(EFTなど)に対して使用します。これらの書式では、レコードのフィールドはすべて固定長です。データが指定の長さに満たない場合は空白で埋め込まれ、長い場合は切り捨てられます。データの埋込みと切捨てに関するデフォルト動作は、システムで指定されます。固定位置ベースの書式の例には、ヨーロッパにおけるEFT、米国におけるNACHA ACHファイルがあります。
DELIMITER_BASEDテンプレートでは、データの埋込みは行われず、最大フィールド長に達した場合のみデータが切り捨てられます。空のフィールドは許容されます(データがnullの場合)。データ・フィールドの分割には指定のデリミタが使用されます。フィールドが空の場合は、2つのデリミタが相互に隣接して表示されます。DELIMITER_BASEDテンプレートの例には、ASC X12 820、UN EDIFACT書式(PAYMUL、DIRDEB、およびCREMUL)などのEDI書式があります。
EDI書式では、レコードはセグメントと呼ばれることがあります。EDIセグメントは、レコードと同様に処理されます。新規レコード・コマンドで各セグメントを開始してレコード名を指定します。新規レコード・コマンドの直後には、出力データの一部としてセグメント名を指定するデータ・フィールドが必要です。
DELIMITER_BASEDテンプレートの場合は、適切なデータ・フィールド・デリミタをデータ・フィールド間の個別の行に挿入します。各データ・フィールド行の後ろにはデリミタ行を挿入します。2つの連続したデリミタ行を定義することで、空のフィールドに対するプレースホルダを挿入できます。
空のフィールドは、後続のフィールドを適切に識別するには、空のフィールドにプレースホルダを挿入する必要があるという構文上の理由でよく使用されます。
データ・フィールド、複合データ・フィールドおよびレコードの終了を表すための、異なるデリミタがあります。一部の書式ではデリミタ文字を選択できます。すべての場合で、構文エラーを回避するという同じ目的のために、同じデリミタを一貫して使用する必要があります。
DELIMITER_BASEDテンプレートの場合、<POSITION>列と<PAD>列は適用されません。これらはデータ表から除外されます。
一部のDELIMITER_BASEDテンプレートには、最小長と最大長の仕様があります。この場合は、Oracle Paymentsによって長さが検証されます。
書式によっては、データ抽出にはない特定の追加データ・レベルが必要です。たとえば、一部の書式では、支払を支払日別にグループ化する必要があります。レベル定義コマンドを使用すると、支払日グループが入力抽出ファイルにない場合でも、支払日グループを定義してテンプレート内のレベルとして参照できます。
レベル定義コマンドを使用する場合は、抽出に存在する基本レベルを宣言します。レベル定義コマンドは、抽出の基本レベルよりも1レベル上位の新規レベルを挿入します。新規レベルは、基本レベルのインスタンス・グループとして機能します。
レベル定義コマンドは設定コマンドの1つです。したがって、設定表に定義する必要があります。このコマンドには3種類のサブコマンドがあります。
基本レベル・コマンド - 新規レベルのベースとなっている抽出からレベル(XML要素)を定義します。レベル定義コマンドには、常に基本レベル・サブコマンドが1つ必要です。
グループ化基準 - XML抽出要素を定義します。これらの要素は、新規レベルのインスタンスを形成する基本レベル・インスタンスのグループ化に使用されます。グループ化基準コマンドのパラメータは、グループ化条件を指定する要素のカンマ区切りリストです。
要素の順序によって、グループ化の階層が決まります。基本レベルのインスタンスは、最初に、第1の基準に従って複数のグループに分割され、次に、各グループが第2の基準に従ってさらに細分化されます(以下同様)。最終的な各サブグループは、新規レベルのインスタンスとみなされます。
グループ昇順ソートまたはグループ降順ソート - グループのソートを定義します。<DEFINE LEVEL>および<END DEFINE LEVEL>コマンドの間の任意の位置に<GROUP SORT ASCENDING>または<GROUP SORT DESCENDING>コマンド行を挿入します。ソート・コマンドのパラメータは、グループのソートに使用する要素のカンマ区切りリストです。
次の表に、バッチで細分化した5種類の支払例を示します。
| 支払インスタンス | PaymentDate(グループ化基準1) | PayeeName(グループ化基準2) |
|---|---|---|
| Payment1 | PaymentDate1 | PayeeName1 |
| Payment2 | PaymentDate2 | PayeeName1 |
| Payment3 | PaymentDate1 | PayeeName2 |
| Payment4 | PaymentDate1 | PayeeName1 |
| Payment5 | PaymentDate1 | PayeeName3 |
テンプレートで、次のような設定表を作成し、「PaymentDate」と「PayeeName」に従ってグループ化した基本レベル「Payment」から、「PaymentsByPayDatePayee」と呼ばれるレベルを作成します。グループ昇順ソート・コマンドを追加してそれぞれをソートします。
| <DEFINE LEVEL> | PaymentsByPayDatePayee |
| <BASE LEVEL> | Payment |
| <GROUPING CRITERIA> | PaymentDate、PayeeName |
| <GROUP SORT ASCENDING> | PaymentDate、PayeeName |
| <END DEFINE LEVEL> | PaymentsByPayDatePayee |
5種類の支払によって、次の4つのグループ(インスタンス)が新規レベルに対して生成されます。
| 支払グループ・ インスタンス | グループ基準 | グループでの支払 |
|---|---|---|
| Group1 | PaymentDate1、PayeeName1 | Payment1、Payment4 |
| Group2 | PaymentDate1、PayeeName2 | Payment3 |
| Group3 | PaymentDate1、PayeeName3 | Payment5 |
| Group4 | PaymentDate2、PayeeName1 | Payment2 |
新規インスタンスの順序は、レコードが印刷される順序になります。複数のグループ化基準を評価して新規レベルのインスタンスを形成する場合の基準は、階層を形成するものと考えることができます。最初の基準が最上位階層で、最後の基準が最下位階層です。
一般に、EFT書式には書式固有の2種類のデータ・グループ化シナリオがあります。一部の書式では、グループ・レコードのみが印刷され、他の書式では、グループが、グループ内にネストされた個別の要素レコードとともに印刷されます。次の2つの例では、これらのシナリオを、前述の5種類の支払およびグループ化条件に基づいて示しています。
第1のシナリオ: グループ・レコードのみ
EFTファイルの構造:
BatchRec
PaymentGroupHeaderRec
PaymentGroupFooterRec
| レコード連番 | レコード・タイプ | 説明 |
|---|---|---|
| 1 | BatchRec | |
| 2 | PaymentGroupHeaderRec | グループ1用(PaymentDate1、PayeeName1) |
| 3 | PaymentGroupFooterRec | グループ1用(PaymentDate1、PayeeName1) |
| 4 | PaymentGroupHeaderRec | グループ2用(PaymentDate1、PayeeName2) |
| 5 | PaymentGroupFooterRec | グループ2用(PaymentDate1、PayeeName2) |
| 6 | PaymentGroupHeaderRec | グループ3用(PaymentDate1、PayeeName3) |
| 7 | PaymentGroupFooterRec | グループ3用(PaymentDate1、PayeeName3) |
| 8 | PaymentGroupHeaderRec | グループ4用(PaymentDate2、PayeeName1) |
| 9 | PaymentGroupFooterRec | グループ4用(PaymentDate2、PayeeName1) |
第2のシナリオ: グループ・レコードと個別のレコード
EFTファイルの構造:
BatchRec
PaymentGroupHeaderRec
PaymentRec
PaymentGroupFooterRec
生成される出力:
| レコード連番 | レコード・タイプ | 説明 |
|---|---|---|
| 1 | BatchRec | |
| 2 | PaymentGroupHeaderRec | グループ1用(PaymentDate1、PayeeName1) |
| 3 | PaymentRec | Payment1用 |
| 4 | PaymentRec | Payment4用 |
| 5 | PaymentGroupFooterRec | グループ1用(PaymentDate1、PayeeName1) |
| 6 | PaymentGroupHeaderRec | グループ2用(PaymentDate1、PayeeName2) |
| 7 | PaymentRec | Payment3用 |
| 8 | PaymentGroupFooterRec | グループ2用(PaymentDate1、PayeeName2) |
| 9 | PaymentGroupHeaderRec | グループ3用(PaymentDate1、PayeeName3) |
| 10 | PaymentRec | Payment5用 |
| 11 | PaymentGroupFooterRec | グループ3用(PaymentDate1、PayeeName3) |
| 12 | PaymentGroupHeaderRec | グループ4用(PaymentDate2、PayeeName1) |
| 13 | PaymentRec | Payment2用 |
| 14 | PaymentGroupFooterRec | グループ4用(PaymentDate2、PayeeName1) |
レベル定義コマンドで定義した新規レベルは、抽出で発生するレベルと同じようにテンプレートで使用できます。ただし、新規レベルのレコードが参照できるのは、そのレコードのグループ化基準に定義されている基本レベルのフィールドのみです。他の基本レベルのフィールドは要約関数以外では参照できません。
たとえば、PaymentGroupHeaderRecは、そのフィールドにあるPaymentDateとPayeeNameを参照できます。SUM関数では、PaymentAmount(支払レベル・フィールド)も参照できます。ただし、他の支払レベル・フィールド(PaymentDocName、PaymentDocNumなど)は参照できません。
レベル定義コマンドには、常にグループ化基準サブコマンドが1つ必要です。また、レベル定義コマンドには、対応するレベル定義終了コマンドがあります。サブコマンドは、レベル定義コマンドとレベル定義終了コマンドの間に指定する必要があり、順不同で宣言できます。
連番定義コマンドは連番を定義します。この連番をSEQUENCE_NUMBER関数とともに使用すると、生成したEFTレコードまたは抽出インスタンス(データベース・レコード)のいずれかに索引を付けることができます。EFTレコードはテンプレートに定義されている物理レコードです。データベース・レコードは抽出からのレコードです。混乱を回避するために、レコードという用語は常にEFTレコードを指し、データベース・レコードは抽出要素インスタンスまたはレベルと呼びます。
連番定義コマンドには、4種類のサブコマンド(リセット・レベル、増分基準、開始、最大)があります。
リセット・レベル・サブコマンドは、連番の開始番号をリセットする位置を定義します。このサブコマンドは必ず指定する必要があります。たとえば、各支払にバッチで番号を付けるには、リセット・レベルをBatchとして定義し、複数のバッチにわたって番号付けを継続する場合は、RequestHeaderとして定義します。
場合によっては、連番がテンプレート外でリセットされることがあります。たとえば、周期的な連番が日付でリセットされるように定義されている場合があります。この場合、リセット・レベルには、PERIODIC_SEQUENCEキーワードが使用されます。支払ファイルに使用した最後の連番がデータベースに保存されます。データベース内での連番のリセットは外部イベントによって制御されます。支払ファイルの次回実行での連番は、このデータベースから開始番号で抽出されます(開始サブコマンドを参照)。
増分基準サブコマンドは、連番をレコードに基づいて増分するか、抽出インスタンスに基づいて増分するかを指定します。このサブコマンドに使用できるパラメータは、RECORDとLEVELです。
すべてのレコードの連番を増分するには、RECORDを入力します。
あるレベルの新規インスタンスすべての連番を増分するには、LEVELを入力します。
複数のレコードがあるレベルで、レベル・ベースの増分を使用すると、そのレベルの全レコードに同じ連番が割り当てられます。レコード・ベースの増分では、該当するレベルにある各レコードに新しい連番が割り当てられます。
レベル・ベースの増分の場合、連番を使用できるのは、1つのレベルのフィールドに対してのみです。たとえば、ある抽出に、batch > payment > invoiceという階層があり、レベル・ベースの増分基準の連番を、バッチ・レベルでのリセット付きで定義したとします。この場合は、支払(payment)または請求書(invoice)レベルのいずれかのフィールドで連番を使用できますが、両方には使用できません。複数の階層レベルにまたがって連番機能を指定することはできません。
ただし、このルールはレコード連番による増分基準には適用されません。レコード連番は複数のレベルにまたがって指定できます。
レベルとレコード連番の両方の増分基準の場合、連番のレベルは、その連番が定義されている位置に基づいて暗黙的に決定されます。
連結定義コマンドは、親レベルのフィールドで使用するために、子レベルの抽出要素の連結に使用します。たとえば、このコマンドを使用して、支払に属する請求書すべての請求番号と期日を連結し、支払レベル・フィールドで使用します。
連結定義コマンドには3種類のサブコマンド(基本レベル、要素、デリミタ)があります。
基本レベル・サブコマンドは、操作対象の子レベルを指定します。各親レベル・インスタンスでは、連結操作によって、連結文字列を生成するための子レベルのインスタンス全体がループされます。
項目サブコマンドは、各項目の生成に使用する操作を指定します。項目は、連結文字列を生成するためにまとめて連結される子レベルの式です。
デリミタ・サブコマンドは、文字列内の連結された項目を区切るデリミタを指定します。
SUBSTR関数は、連結された文字列を、別のフィールドに配置できる細分化した文字列に分解するために使用します。たとえば、次の表は支払での5種類の請求書を示しています。
| Invoice | InvoiceNum |
|---|---|
| 1 | car_parts_inv0001 |
| 2 | car_parts_inv0002 |
| 3 | car_parts_inv0003 |
| 4 | car_parts_inv0004 |
| 5 | car_parts_inv0005 |
次の連結定義を使用します。
| <DEFINE CONCATENATION> | ConcatenatedInvoiceInfo |
| <BASE LEVEL> | Invoice |
| <ELEMENT> | InvoiceNum |
| <DELIMITER> | ',' |
| <END DEFINE CONCATENATION> | ConcatenatedInvoiceInfo |
支払レベル・フィールドでConcatenatedInvoiceInfoを参照できます。文字列は次のようになります。
car_parts_inv0001,car_parts_inv0002,car_parts_inv0003,car_parts_inv0004,car_parts_inv0005
ConcatenatedInvoiceInfoの最初の40文字のみを使用する場合は、次のようにTRUNCATE関数またはSUBSTR関数を使用します。
TRUNCATE(ConcatenatedInvoiceInfo, 40)
SUBSTR(ConctenatedInvoiceInfo, 1, 40)
これらのいずれかの文を実行すると、結果は次のようになります。
car_parts_inv0001,car_parts_inv0002,car_
次の40文字を分離するには、SUBSTR関数を使用します。
SUBSTR(ConcatenatedInvoiceInfo, 41, 40)
結果は、次の文字列になります。
parts_inv0003,car_parts_inv0004,car_par
書式によっては、Oracle Applicationsでのデータ入力に使用したキャラクタ・セットとは異なるキャラクタ・セットが必要になります。たとえば、一部のドイツの書式にはASCIIの出力ファイルが必要ですが、データはドイツ語で入力されています。元のキャラクタ・セットと目的のキャラクタ・セットの間に不整合がある場合は、ASCIIに相当する文字を定義して、元のキャラクタ・セットを置換できます。たとえば、ドイツ語のaウムラウトをaoで置換できます。
一部の書式では、特定の文字を使用できません。既知の無効な文字が出力ファイルに転送されないように、無効な文字コマンドを使用して特定の文字にフラグを設定します。
置換文字コマンドを使用するには、左側の列に置換対象の文字を指定し、右側の列に置き換える文字を指定します。置換対象の文字は、元のキャラクタ・セットで入力する必要があります。この入力が必要なのは、出力する予定のないキャラクタ・セットを書式テンプレートで使用する場合のみです。置き換える文字は、必要な出力キャラクタ・セットで入力します。
DELIMITER_BASED書式で、データにデリミタがある場合は、エスケープ文字「?」を使用してその意図を保持できます。次に例を示します。
First name?+Last nameとFist name+Last nameは等価です。
Which source??とWhich source?は等価です。
データにエスケープ文字が使用されている場合は、エスケープ文字自体にエスケープ文字を付加する必要があることに注意してください。
置換文字コマンドは、エスケープ文字の要件をサポートするために使用できます。デリミタはソースとして指定し、エスケープ文字とデリミタはターゲットとして指定します。たとえば、前述の例では、次のようにコマンドを入力します。
| <REPLACEMENT CHARACTERS> | |
| + | ?+ |
| ? | ?? |
| <END REPLACEMENT CHARACTERS> |
無効な文字コマンドには、システム・エラーの原因となる無効な文字を使用した文字列のパラメータが含まれています。
置換文字は、キャラクタ・セットの変換前または変換時に処理されます。キャラクタ・セット変換は、書式処理の前に、XML抽出で直接実行されます。キャラクタ・セット変換が終了すると、出力キャラクタ・セットの観点から無効な文字がチェックされます。無効な文字がない場合は、書式処理に進みます。
実行時に明示的および暗黙的なレコード区切りを定めるための文字(複数可)を指定するには、新規レコード文字コマンドを使用します。新規のレコード・コマンドはそれぞれ明示的なレコード区切りを表し、表の最後はそれぞれ暗黙的なレコード区切りを表します。パラメータは、カンマで区切られた定数文字名のリストです。
一部の書式にはレコード区切りがありません。生成される出力は単一行のデータです。この場合、新規レコード文字コマンドのパラメータ・フィールドは空のままにしてください。
デフォルトの3桁のセパレータ(グループ・セパレータ)はカンマ(「,」)で、デフォルトの小数セパレータは「.」です。3桁セパレータ・コマンドおよび小数セパレータ・コマンドを使用すると、デフォルト以外のセパレータを指定できます。たとえば、グループ・セパレータとして「.」を定義し、小数セパレータとして「,」を定義するには、次のように入力します。
| NUMBER THOUSANDS SEPARATOR | . |
| NUMBER DECIMAL SEPARATOR | , |
数値の書式設定の詳細は、「書式列」を参照してください。
この項では、テンプレートでの式のルールと使用方法を説明します。サポートされる制御構造と関数についても説明します。
式は、データ・フィールドのデータ列および一部のコマンド・パラメータで使用できます。式とは、XML抽出フィールド、リテラル、関数および演算子のグループです。式はネストできます。式にはIF制御構造も含まれます。式が評価されると、常に結果が生成されます。評価に関する副次的な効果は許容されません。式は、評価結果に基づいて次の3種類のカテゴリに分類されます。
ブール式 - trueまたはfalseのブール値を戻す式。この種の式が使用できるのは、IF-THEN-ELSE制御構造および表示条件コマンドのパラメータのみです。
数値式 - 数値を戻す式。この種の式は、数値データ・フィールドで使用でき、数値パラメータを必要とする関数およびコマンドにも使用できます。
文字式 - 英数文字列を戻す式。この種の式は、文字列データ・フィールド(Alpha書式タイプ)で使用でき、文字列パラメータを必要とする関数およびコマンドにも使用できます。
サポート対象の唯一の制御構造はIF-THEN-ELSEです。この制御構造は式で使用できます。構文は次のとおりです。
IF <boolean_expressionA> THEN
<numeric or character expression1>
[ELSIF <boolean_expressionB THEN
<numeric or character expression2>]
...
[ELSE
<numeric or character expression3]
END IF一般的に、制御構造は数値または英数文字列に対して評価する必要があります。制御構造は、数値式または文字式とみなされます。ELSIF句とELSE句はオプションで、ELSIF句は必要に応じていくつでも指定できます。制御構造はネストできます。
IN述語はIF-THEN-ELSE制御構造でサポートされています。次に例を示します。
IF PaymentAmount/Currency/Code IN ('USD', 'EUR', 'AON', 'AZM') THEN
PayeeAccount/FundsCaptureOrder/OrderAmount/Value * 100
ELSIF PaymentAmount/Currency/Code IN ('BHD', 'IQD', 'KWD') THEN
PayeeAccount/FundsCaptureOrder/OrderAmount/Value * 1000
ELSE
PayeeAccount/FundsCaptureOrder/OrderAmount/Value
END IF; サポートされる関数は、次のとおりです。
SEQUENCE_NUMBER: レコード要素の索引です。この関数は連番定義コマンドとともに使用されます。この関数のパラメータは1つで、連番定義コマンドで定義された連番です。実行時には、レコード内でこの関数が参照されるたびにその連番値を1つ増分します。
COUNT: 子レベル抽出インスタンスまたは特定のタイプの子レベル・レコードをカウントします。COUNT関数は、カウントするエンティティよりも上のレベルで宣言します。この関数には引数が1つあり、それがレベルの場合は、現行(親)レベル・インスタンスに属する(子)レベルのインスタンスすべてがカウントされます。
たとえば、カウント対象レベルがPayment(支払)で、現行レベルがBatch(バッチ)の場合、COUNT関数はバッチ内の支払件数合計を戻します。ただし、現行レベルがRequestHeader(要求ヘッダー)の場合は、すべてのバッチにわたるファイルの支払件数合計を戻します。引数がレコード・タイプの場合、COUNT関数は、現行レベルのインスタンスに属する(子レベルの)レコード・タイプに対して生成されたレコードすべてをカウントします。
INTEGER_PART、DECIMAL_PART: 数値の整数部分または小数部分を戻します。この関数は、ネストした式とコマンド(表示条件とグループ基準)で使用されます。データ列の数値フィールドに対する最終的な書式処理には、Integer/Decimal書式を使用してください。
IS_NUMERIC: 引数が数値かどうかをブール・テストします。IF制御構造でのみ使用されます。
TRUNCATE: 第1引数の文字列を第2引数の長さに切り捨てます。第1引数が第2引数で指定した長さに満たない場合は、第1引数を未変更の状態で戻します。この関数は、SQLのsubstr()機能のサブセットを使いやすくしたものです。
SUM: XML抽出フィールド引数の子インスタンスすべてを合計します。フィールドは数値であることが必要です。合計対象フィールドは、SUM関数が宣言されたレベルよりも常に低いレベルであることが必要です。
MIN、MAX: XML抽出フィールド引数の子インスタンスすべての最小と最大を検索します。フィールドは数値であることが必要です。操作対象フィールドは、関数が宣言されたレベルよりも常に低いレベルであることが必要です。
FORMAT_DATE: 日付文字列を必要な日付書式に設定します。次に例を示します。
FORMAT_DATE("1900-01-01T18:19:20", "YYYY/MM/DD HH24:MI:SS")
次の出力が生成されます。
1900/01/01 18:19:20
FORMAT_NUMBER: 表示対象の数字を必要な書式に設定します。次に例を示します。
FORMAT_NUMBER("1234567890.0987654321", "999,999.99")
次の出力が生成されます。
1,234,567,890.10
MESSAGE_LENGTH: EFTメッセージ内のメッセージの長さを戻します。
RECORD_LENGTH: EFTメッセージ内にあるレコードの長さを戻します。
INSTR: テキスト・フィールド内の名前付き文字の数値位置を戻します。
SYSDATE、DATE: 現在の日時を取得します。
POSITION: XML文書ツリー構造内のノードの位置を戻します。
REPLACE: 文字列を別の文字列に置き換えます。
CONVERT_CASE: 文字列または文字を大文字または小文字に変換します。
CHR: ASCII値である引数の文字表現を取得します。
LPAD、RPAD: 文字列値の左側または右側の埋込みを生成します。
AND、OR、NOT: 要素上の演算子関数です。
他のSQL関数には次のものがあります。SQL関数に対応する構文を使用してください。
TO_DATE
LOWER
UPPER
LENGTH
GREATEST
LEAST
DECODE
CEIL
ABS
FLOOR
ROUND
CHR
TO_CHAR
SUBSTR
LTRIM
RTRIM
TRIM
IN
TRANSLATE
この項では、予約されているキーワードとフレーズおよびその使用方法を示します。サポートされている演算子、XML抽出フィールドの参照ルールおよびリテラルの使用ルールについても説明します。
キーワードとキーワード・フレーズには、次の4種類のカテゴリがあります。
コマンドと列ヘッダーのキーワード
コマンド・パラメータと関数パラメータのキーワード
フィールド・レベルのキーワード
式のキーワード
次のキーワードは、表示されているとおりに(<>で囲み、すべて太字の大文字で)使用する必要があります。
<LEVEL> - データ表の最初のエントリです。表をXML要素に関連付け、表の階層を指定します。
<END LEVEL> - 現行レベルの終了を宣言します。表の最後または独立した表で使用できます。
<POSITION> - データ・フィールド行の第1列の列ヘッダーです。レコード内でのデータ・フィールドの開始位置を指定します。
<LENGTH> - データ・フィールド行の第2列の列ヘッダーです。データ・フィールドの長さを指定します。
<FORMAT> - データ・フィールド行の第3列の列ヘッダーです。データ型と書式設定を指定します。
<PAD> - データ・フィールド行の第4列の列ヘッダーです。埋込みのスタイルと文字を指定します。
<DATA> - データ・フィールド行の第5列の列ヘッダーです。データ・ソースを指定します。
<COMMENT> - データ・フィールド行の第6列の列ヘッダーです。自由形式のコメントを可能にします。
<NEW RECORD> - 新規レコードを指定します。
<DISPLAY CONDITION> - レコードを印刷する際の条件を指定します。
<TEMPLATE TYPE> - テンプレート・タイプ(FIXED_POSITION_BASEDまたはDELIMITER_BASED)を指定します。
<OUTPUT CHARACTER SET> - 出力を生成する際に使用するキャラクタ・セットを指定します。
<NEW RECORD CHARACTER> - 実行時に明示的および暗黙的に新規レコードを表すために使用する文字(複数可)を指定します。
<DEFINE LEVEL> - テンプレートに書式固有のレベルを定義します。
<BASE LEVEL> - レベル定義コマンドと連結定義コマンドのサブコマンドです。
<GROUPING CRITERIA> - レベル定義コマンドのサブコマンドです。
<END DEFINE LEVEL> - レベルの終了を表します。
<DEFINE SEQUENCE> - テンプレート・フィールドで使用するレコード・ベースまたは抽出要素ベースの連番を定義します。
<RESET AT LEVEL> - 連番定義コマンドのサブコマンドです。
<INCREMENT BASIS> - 連番定義コマンドのサブコマンドです。
<START AT> - 連番定義コマンドのサブコマンドです。
<MAXIMUM> - 連番定義コマンドのサブコマンドです。
<MAXIMUM LENGTH> - データ・フィールド行の第1列の列ヘッダーです。データ・フィールドの最大長を指定します。DELIMITER_BASEDテンプレート専用です。
<END DEFINE SEQUENCE> - 連番コマンドの終了を表します。
<DEFINE CONCATENATION> - 親レベル・フィールドを文字列として参照できる子レベル項目の連結を定義します。
<ELEMENT> - 連結定義コマンドのサブコマンドです。
<DELIMITER> - 連結定義コマンドのサブコマンドです。
<END DEFINE CONCATENATION> - 連結定義コマンドの終了を表します。
<SORT ASCENDING> - レベルのインスタンスに対する書式固有のソート方法です。
<SORT DESCENDING> - レベルのインスタンスに対する書式固有のソート方法です。
次のキーワードは、すべて太字でない大文字のフォントで入力する必要があります。
PERIODIC_SEQUENCE - 連番定義コマンドのレベル・サブコマンドでのリセットに使用されます。このキーワードは、テンプレート外で連番がリセットされることを意味します。
FIXED_POSITION_BASED、DELIMITER_BASED - テンプレート・タイプ・コマンドで使用され、テンプレート・タイプを指定します。
RECORD、LEVEL - 連番定義コマンドの増分基準サブコマンドで使用されます。RECORDを指定すると、新規レコードに連番が使用されるたびに連番が増分されます。LEVELを指定すると、そのレベルの新規インスタンスに対してのみ連番が増分されます。
Alpha - <FORMAT>列で、データ型が英数字であることを指定します。
Number - <FORMAT>列で、データ型が数値であることを指定します。
Integer - <FORMAT>列で、Numberキーワードとともに使用されます。数値の整数部分を取得します。このキーワードは、INTEGER関数が式で使用され、Integerキーワードが<FORMAT>列でのみ使用されること以外は、INTEGER関数と同じ機能を果たします。
Decimal - <FORMAT>列で、Numberキーワードとともに使用されます。数値の小数部分を取得します。このキーワードは、DECIMAL関数が式で使用され、Decimalキーワードが<FORMAT>列でのみ使用されること以外は、DECIMAL関数と同じ機能を果たします。
Date - <FORMAT>列で、データ型が日付であることを指定します。
L、R - <PAD>列で、埋め込む側(左または右)を指定します。
式で使用するキーワードとフレーズは、太字の大文字フォントにする必要があります。
IF THEN ELSE IF THEN ELSE END IF - これらのキーワードは常にグループで使用されます。これらのキーワードを使用してIF制御構造の式を指定します。
IS NULL、IS NOT NULL - これらのフレーズはIF制御構造で使用されます。これらのキーワードを使用してブール述語の一部を形成し、式がNULLか、NULLでないかをテストします。
演算子には、ブール・テスト演算子と式演算子の2つのグループがあります。ブール・テスト演算子には、=、<>、<、>、>=および<=があります。これらのブール・テスト演算子は、IF制御構造でのみ使用できます。式演算子には、()、||、+、-および*があります。これらの式演算子は式の中で使用できます。
| 記号 | 使用方法 |
|---|---|
| = | 等価テスト。IF制御構造でのみ使用されます。 |
| <> | 非等価テスト。IF制御構造でのみ使用されます。 |
| > | 超過テスト。IF制御構造でのみ使用されます。 |
| < | 未満テスト。IF制御構造でのみ使用されます。 |
| >= | 以上テスト。IF制御構造でのみ使用されます。 |
| <= | 以下テスト。IF制御構造でのみ使用されます。 |
| () | 関数引数と式グループのデリミタ。()内の式グループは常に最初に評価されます。()はネストできます。 |
| || | 文字列連結演算子。 |
| + | 加算演算子。いずれかのオペランドが数値でない場合は、暗黙的な型変換が実行される可能性があります。 |
| - | 減算演算子。いずれかのオペランドが数値でない場合は、暗黙的な型変換が実行される可能性があります。 |
| * | 乗算演算子。いずれかのオペランドが数値でない場合は、暗黙的な型変換が実行される可能性があります。 |
| DIV | 除算演算子。いずれかのオペランドが数値でない場合は、暗黙的な型変換が実行される可能性があります。「/」はXPATH構文の一部であるため、使用されないことに注意してください。 |
| IN | 全メンバーとの等価テスト。 |
| NOT IN | IN演算子を無効にします。全メンバーとの非等価テスト。 |
XML要素はあらゆる式に使用できます。XML要素は、実行時に対応するフィールド値に置換されます。フィールド名では、大/小文字が区別されます。
XML抽出フィールドをテンプレートで使用する場合は、XPATH構文に従う必要があります。これは、XMLパブリッシャ・エンジンがXML要素を正しく解釈するために必要です。
XMLパブリッシャの書式処理では、常にコンテキスト要素とみなされる抽出要素があります。XMLパブリッシャで表のデータ行が処理される場合は、その表のレベル要素がコンテキスト要素です。たとえば、XMLパブリッシャでPayment表のデータ行が処理される場合は、Paymentがコンテキスト要素になります。抽出要素の参照に使用する相対XPATHは、コンテキスト要素の観点から指定されます。
たとえば、Paymentデータ表のPayeeName要素を参照する必要がある場合は、次の相対パスを指定します。
Payee/PayeeInfo/PayeeName
XML要素階層の各レイヤーは、バックスラッシュ(/)で区切られます。ネストされた要素には、この表記法を使用します。直下のレベルの子要素に対する相対パスは、単に要素名そのものです。たとえば、Payment表にあるTransactionID要素名をそのまま使用できます。
子レベルの表で親レベルの要素を参照するには、「../」表記法を使用できます。たとえば、Payment表でBatchName要素を参照する必要がある場合は「../BatchName」と指定します。この「../」によって、Batchがコンテキストとして提供されます。このコンテキストでは、BatchNameがBatch直下の子であるため、BatchName要素名を直接使用できます。この表記法は、任意のレベルの親要素まで移動します。たとえば、Paymentデータ表のRequesterParty要素(RequestHeader内)を参照する必要がある場合は、次のように指定できます。
../../TrxnParties/RequesterParty
テンプレート内の任意の場所で抽出要素を参照する場合は、常に絶対パスを使用できます。絶対パスはバックスラッシュ(/)で開始します。前述の例にあるPayment表のPayeeNameの場合、絶対パスは/BatchRequest/Batch/Payment/Payee/PayeeInfo/PayeeNameとなります。
絶対パス構文によってパフォーマンスが向上します。
レベル定義、連番定義、連結定義などの設定コマンドで定義された識別子は、グローバルとみなされます。これらの識別子はテンプレートの任意の場所で使用できます。絶対パスや相対パスは不要です。設定コマンドの基本レベルとリセット・レベルも指定できます。XMLパブリッシャでは、識別子の正しいコンテキストが検索できるようになります。
相対パス構文を使用する場合は、次のコマンドの基本レベルに対して相対パス構文を指定する必要があります。
連結定義コマンドの要素サブコマンド
レベル定義コマンドのグループ化基準サブコマンド
連番定義コマンドの開始サブコマンドの抽出フィールド参照は、絶対パスで指定してください。
レベル・コマンドの抽出要素を参照するルールは、データ・フィールドに対するルールと同じです。たとえば、Batchレベルの表とネストしたPaymentレベルの表がある場合は、そのPayment表のPayment要素名をそのまま指定できます。これは、Payment表のレベル・コマンドを評価するコンテキストがBatchであるためです。
ただし、Paymentレベルをスキップし、Batch表の直下にInvoiceレベルの表がある場合は、Invoice表のレベル要素としてPayment/Invoiceを指定する必要があります。
テンプレートに必要なXPATH構文は、UNIX/LINUXディレクトリ構文と非常に類似しています。コンテキスト要素はカレント・ディレクトリに相当します。カレント・ディレクトリに相対するファイルを指定したり、「/」で開始する絶対パスを使用することができます。
最後に、レベル定義コマンドの基準サブコマンドをグループ化した結果の抽出フィールド参照は、一重引用符で指定する必要があります。この指定によって、抽出フィールドを値としてではなくグループ化基準として使用することをXMLパブリッシャ・エンジンに示します。