 Using Language-Sensitive Queries
Using Language-Sensitive Queries
This chapter discusses:
Language-sensitive queries.
PeopleSoft Cube Manager for global implementations.
The Strings table and language-sensitive text in reports.
Structured Query Report (SQR) for PeopleSoft in global implementations.
PS/nVision reporting for global implementations.
International versions of Microsoft Excel.
XML Publisher.
See Also
Working with Multiple Languages
Using Language-Sensitive Queries
PeopleSoft Query supports language-sensitive query output. If you create a query on a table that has a related language record, or if your query includes such a table, PeopleTools automatically performs the language lookup on the related language record. This means that the output of the query appears in the current, preferred language, if translations exist in the related language tables.
For example, if you built a simple query on the Country table (COUNTRY_TBL), the country descriptions in your query would appear in your preferred language, even through you queried the base language record (COUNTRY_TBL) and not the related language record (COUNTRYTBL_LANG). PeopleSoft Query performs the necessary join to the related language table to retrieve the translations; if they don’t exist, it retrieves the descriptions in the database’s base language.
The related language join is performed only when you run the query. Therefore, if you create a query as an English user and then execute the same query as a French user, the output appears in French, even though the query was created in English. The language preference of the user who is running the query drives the language joins.
Note. WHERE criteria, HAVING criteria, and ORDER BY clauses are applied only to the base language data. For example, assuming that the base language of your database is English, if you set a WHERE criterion that restricts country descriptions to those that begin with Ger, PeopleSoft Query retrieves the Allemagne country description when the query is run by a French language user. This is because the English description of Allemagne is Germany.
The automatic language join features in PeopleSoft Query are also used when you access your PeopleSoft database via the PeopleSoft Open Query ODBC interface.
 Using Scheduled Queries
Using Scheduled Queries
For scheduled queries, the system uses the language specified in the user’s profile. It does not use the language selected during sign-in. The system will also use the international and regional settings the user has specified using the My Personalizations page. If no personal setting have been specified, the system uses the default installation international settings.
Note. Most PeopleSoft components appear by default from international settings on the browser if the user has not set any user-specific settings. However, this is not available for scheduled queries or any PeopleSoft Process Scheduler processes.
See Also
PeopleTools 8.51 PeopleBook: PeopleSoft Query
Using PeopleSoft Cube Manager for Global Implementations
In PeopleSoft Cube Manager, you can build Cognos PowerPlay cubes and Hyperion Essbase cubes that display translated data. The cubes themselves do not have to be translated; they work by accessing the translations (stored in related language tables) of language-sensitive query output and tree nodes that correspond to the cube’s members.
This section discusses:
Cognos PowerPlay local-language cubes.
Hyperion Essbase multiple-language cubes.
See Also
Working With Language-Sensitive Application Data
PeopleTools 8.51 PeopleBook: PeopleSoft Cube Manager
Using Cognos PowerPlay Local-Language Cubes
Cognos PowerPlay cubes are not language-sensitive. You must build a separate cube in each language that your implementation supports. Users must then access the language version of the cube that matches their language preferences.
When you build a PowerPlay cube instance, you can override the default language in which the cube is built. If you do not override the language, PeopleSoft Cube Manager builds the PowerPlay cube using the database’s base language.
Each PowerPlay cube instance is built using a single language. This language can be the database’s base language or any non-base language that your implementation supports. If the cube is built in the base language, then all language-sensitive elements appear in the base language. If the cube is built in a non-base language, then the cube’s language-sensitive elements appear in that language using translations of language-sensitive query output and tree nodes. If the language-sensitive fields for the query output and tree nodes have not been translated into the cube’s language, the cube displays the base language descriptions.
To override the language of a Cognos PowerPlay cube:
Select PeopleTools, Cube Manager, Cube Instances.
Use the standard search method to access the Cube Inst Def (cube instance definition) page.
Confirm that the Analysis Platform field is set to Cognos PowerPlay.
Click the Platform Options link.
The PowerPlay Options page appears.
Select the desired language in the Language Override field.
Click OK to close the page.
Save the component.
Using Hyperion Essbase Multiple-Language Cubes
When building a Hyperion Essbase cube instance, you specify the languages that the cube supports. These can be the database base languages and any other languages supported by the implementation. When users access the cube in Essbase Administrator (or in the Essbase Excel Client), they can choose to view aliases for the cube members (stored on Essbase alias tables) in any of the supported languages. The translations of the aliases are derived from language-sensitive query output and tree nodes, so the translated aliases appear only if the tree nodes have been translated and the query data is language-sensitive and has been translated. Specific elements that have not been translated appear in the database’s base language.
See the Essbase documentation for information about using Essbase alias tables.
Specify the languages that supported by an Essbase cube when you define the Essbase cube instance. If no languages are specified, no local-language Essbase alias tables are built, and the cube member descriptions appear in the database’s base language.
To specify the languages of an Essbase cube instance:
Select PeopleTools, Cube Manager, Cube Instances.
Use the standard search method to access the Cube Inst Def (cube instance definition) page.
Confirm that the Analysis Platform field value is Hyperion Essbase.
Click the Platform Options link.
The Essbase Advanced Options page appears.
From the Language Code drop-down list box, select the cube’s supported languages.
To set the value of a prompt field, click in the field and then choose from the list of supported languages. To insert a new language, click the Add button. To remove a language from the list of languages that are supported by the cube, click the Delete button.
Click OK to close the page.
Save the component.
Using the Strings Table for Language-Sensitive Text in Reports
The PeopleTools Strings table (STRINGS_TBL) stores text strings used for language-sensitive labels and other text for PS/nVision and SQR reports. This avoids hard-coding labels into the report files themselves. The use of strings rather than hard-coded text in reports enables translators to translate the report layout in the database without editing the report’s code itself. This enables you to run a single copy of a report in multiple languages while avoiding the duplication of code and report logic.
The Strings table stores string text of three different string types:
A short field description (RFT Short).
A long field description (RFT Long). Only strings of this type can have translated values.
A free-form text string (Text).
The Strings table is keyed by PROGRAM_ID plus the STRING_ID, which enables you to classify strings into groups that are used in similar reports. PROGRAM_ID can refer to a specific SQR or PS/nVision report name, or it can be a mnemonic for a group of common strings that are shared between reports. For RFT Short or RFT Long, the STRING_ID is the field name (validated against the PSDBFIELD or PSDBFIELDLANG table).
For example, PS/nVision string variables include the string ID and the program ID as follows:
%.StringID,ProgramID%
The following example shows the Use Display view for the STRINGS_TBL record definition in Application Designer with PROGRAM_ID and STRING_ID identified as the key fields:
If the language of the requested report is a non-base language and only if the requested string is a long field description type, the system returns the translated string from the related-language table (STRINGS_LNG_TBL) if a translation is available. If no translation exists, the base language string is returned.
The return of language-sensitive string data follows this sequence as shown in the following diagram:
The system locates a string definition in the base language Strings table by using the program ID and string ID.
The text string stored in the base language Strings table can be a short or long field description or a free-form text string that is not associated with a field.
The system determines the string type: short, long, or text.
If the string type is short or text, the system returns the string text directly from the base language Strings table.
The system determines the language of the report request.
Note. If the value is unspecified, the system uses the user’s current language preference setting.
If the language is the system’s base language, the system returns the string value from the base language Strings table.
If the language of the report is a non-base language, the system looks in the related-language table (STRINGS_LNG_TBL) for a row with the program ID, string ID, and correct language code.
If an appropriate row exists in the related-language table, the system returns the translation.
If no translation exists in the related-language table, the system returns the string from the base language table.
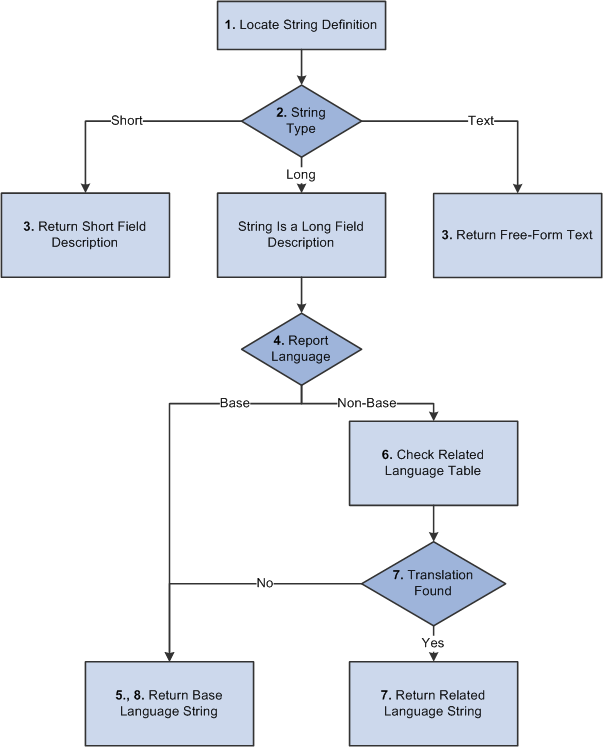
Return of language-sensitive string data
See Also
Using SQR for PeopleSoft in Global Implementations
Using SQR for PeopleSoft in Global Implementations
SQR for PeopleSoft provides a range of features to allow not only for reports in multiple languages, but also for handling international date/time formatting, paper sizes, numeric formatting and much more. This section discusses some of the internationalization features of SQR for PeopleSoft:
Printing for A4 paper.
Currency precision.
Date and time formatting.
Report translation
PSSQR.INI and PSSQR.UNX files.
SQR configuration for processing international text.
SQR configuration for printing international text.
International text in SQR for PeopleSoft programs.
SQR for PeopleSoft supported character set encodings.
See Also
Printing for A4 Paper
PeopleTools supports printing A4, legal, and U.S. letter sized paper. Changing the PAPER_SIZE setting in SETENV.SQC changes the paper size for all reports that share the same file/report/batch server directory.
To print Legal paper, uncomment the following line in the SETENV.SQC file:
#define PAPER_SIZE LEGAL
To print A4 paper, uncomment the previous line and edit it to be:
#define PAPER_SIZE A4
To ensure that you are printing the desired paper size, you must comment out or delete any other #define PAPER_SIZE statements.
Currency Precision
NUMBER.SQC enables you to make use of currency precision, both in terms of character string values (with an edit mask) and numeric values, rounded to a specified precision. Use these functions to achieve your currency precision requirements:
Format_Currency_Amt Format_Currency_Amt_Numeric
See the comments block at the beginning of the NUMBER.SQC SQR include file for documentation of these functions.
Date and Time Formatting
The DATETIME.SQC program provides several procedures to aid in the formatting of date and time values for display in report output. While DATETIME.SQC provides generic procedures for formatting dates and times, the actual format used for date and time values can vary in each report. By default, when printing dates and times, reports use the system-wide default date and time formats that are specified in SETENV.SQC.
During the PeopleSoft installation, you should edit SETENV.SQC to specify the system-wide default format you prefer for date and time values. Edit the following lines in the SETENV.SQC to tell SQR which format you prefer, if it is not otherwise specified in the SQR report source.
#define Year4 '1' !0 = 2 digit year #define Prompt-Date mm/dd/yyyy #define Prompt-Mask 'MDY' #define DateType '0' !iDate 0 = mdy, 1 = dmy 2 = ymd #define TimeDisplay '1' !iTime 0 = 12hr, 1 = 24hr
Based on these settings or any overrides, procedures in DATETIME.SQC provide support for various date formats. This table identifies these formats:
|
SQR Date Format |
Description |
|
{DEFDMY} |
DD/MM/YYYY |
|
{DEFMDY} |
MM/DD/YYYY |
|
{DEFKAN} |
Japanese Kanji-format dates (using the Japanese Imperial calendar). |
|
{DEFROM} |
Japanese Romaji-format dates (using the Japanese Imperial calendar). |
The following table includes examples for SQR for PeopleSoft date formats for the date December 14, 2000:
|
14/12/2000 |
{DEFDMY} |
|
12/14/2000 |
{DEFMDY} |
|
|
{DEFKAN} |
|
H.12.12.14 |
{DEFROM} |
For details about how to include date/time formatting in your own SQR reports, refer to the documentation inside the comment block of the DATETIME.SQC SQR include file on your file server. If you plan to use Japanese date formatting in the SQR report, remember to include #define JapaneseDates at the top of the SQR report.
Report Translation
PeopleTools enables you to print or format SQR output for multiple languages using string definitions that are stored in the Strings table. The procedures defined in SQRTRANS.SQC enable your SQR program to access these strings dynamically.
To enable the use of the Strings table in your SQR program, you must include the PeopleTools SQC file SQRTRANS.SQC, which includes the routines that are necessary to initialize and load translated strings from the Strings table.
SQRTRANS.SQC has four main functions that you can call from the report:
Init_Report_Translation
Get_Field_Information
Append_Report_Translation
Add_Report_Translation
Call the Init_Report_Translation procedure from your SQR program before using any of the String table information. Typically, you should call Init_Report_Translation in the Init-Report section of your SQR program. Init_Report_Translation takes two parameters:
|
Parameter Name |
Description |
|
$Report_ID |
$Report_ID is normally the name of the SQR report. This parameter is used as the program ID when looking up strings in the Strings table. |
|
$Report_Language |
$Report_Language indicates the preferred language for the strings that are being retrieved. Init_Report_Translation attempts to load all strings in the language specified; however, if a translation for any string does not exist, it loads the base language description for that string. |
If you want to change languages during the processing of an SQR report (for example, if you want each page of the report to be in a different language), you can call Init_Report_Translation multiple times within a single SQR program, each time passing a new $Report_Language value.
Call the Get_Field_Information procedure for each string that you want to retrieve from the Strings table. It retrieves the label or string table entry for the field specified and places it in a report variable. You can then print the contents of this variable on your report as a label, column heading, or free text. Get_Field_Information takes four parameters:
|
Parameter Name |
Description |
|
$Report_ID |
$Report_ID is normally the name of your SQR report. This parameter is used as the program ID when looking up strings in the Strings table. You must have already called Init_Report_Translation specifying this $Report_ID before passing it to Get_Field_Information. |
|
$Field_ID |
This is the string ID of the string whose text you want to retrieve. It must exist as an entry in the Strings table under the $Report_ID that you specified. |
|
$Field_Text |
$Field_Text is the output variable. Get_Field_Information populates this variable with the text that corresponds to the $Report_ID and $Field_ID that are specified in the preferred language or in the database’s base language (if a translation doesn’t exist in the preferred language). |
|
$Field_Width |
$Field_Width is an output variable that Get_Field_Information populates with the width of the text string that is returned. |
If your SQR program uses strings from more than one Strings table program ID, call Append_Report_Translation to add the strings from another program ID to the initialization array created by Init_Report_Translation. This function is particularly useful if you have a set of strings that is used across many of your SQR programs. You can group these strings under a generic program ID and use them in multiple SQR programs.
Append_Report_Translation takes a single argument, $Report_ID. It assumes the same language that was specified in Init_Report_Translation. It must be called after Init_Report_Translation.
The Add_Report_Translation procedure calls Init_Report_Translation or Append_Report_Translation, depending on whether the Strings table has been initialized. It takes the same arguments as Init_Report_Translation. If Init_Report_Translation has not yet been called during the processing of this SQR program, this function calls it, passing both parameters. If Init_Report_Translation has already been called, Add_Report_Translation calls Append_Report_Translation, passing only the $Report_ID parameter.
This function is useful in your own SQC files if you cannot be certain that the calling SQR program has already initialized the Strings table. The function ensures that the table is initialized or appended correctly.
Sample Strings Table Enabled SQR Program
The following sample code demonstrates how to use the Strings table to retrieve string values in SQR, using the procedures described in the preceding sections.
!************************************************ ! SAMP001: Report on database's base language * !************************************************ #include 'setenv.sqc' !Set environment begin-report do Init-Report do Process-Main do Reset end-report begin-heading 6 do Get_Field_Information ('SAMP001', 'REPORT_TITLE', $REPORTTITLE, #DWRT) do Get_Field_Information ('SAMP001', 'EXPLAIN_TEXT', $EXPTEXT, #DWET) PRINT $REPORTTITLE (1) CENTER PRINT $EXPTEXT (+2,1) end-heading begin-procedure Init-Report move 'SAMP001' to $ReportID move 'ENG' to $Language_cd do Init_Report_Translation ($ReportID, $Language_cd) do Append_Report_Translation ('GEN') end-procedure begin-procedure Process-Main do Get_Field_Information ('GEN', 'BASELANGUAGE', $BASELANGUAGE, #DWBL) do Get_Field_Information ('GEN', 'ENDOFREPORT', $ENDOFREPORT, #DWER) begin-SELECT LANGUAGE_CD &Base_Language let $langlabel = $BASELANGUAGE || ':' print $langlabel (+1,1) let #fieldpos = #DWBL + 3 print &Base_Language (0,#fieldpos) FROM PSOPTIONS end-SELECT print $ENDOFREPORT (+4,1) end-procedure #Include 'reset.sqc' !Reset printer procedure #Include 'sqrtrans.sqc' !SQR Strings Table procedures
See Also
Using the Strings Table for Language-Sensitive Text in Reports
The PSSQR.INI and PSSQR.UNX Files
Most of the parameters that affect globalization of SQR for PeopleSoft are set in the configuration file. The PeopleSoft system delivers default configuration files, which are located in the PS_HOME\sqr directory. The files are named pssqr.ini on Microsoft Windows, and pssqr.unx on Unix/Linux. Because different configurations are needed for some of the supported languages, PeopleSoft delivers eight configuration files on each platform. These language-specific configuration files are named pssqrlanguage_code.ini or pssqrlanguage_code.unx. When the SQR process is started from PeopleSoft Process Scheduler, one of these configuration files is selected based on the user's language preference set in the My Personalization page. When language-specific files are not found, PeopleSoft Process Scheduler selects pssqr.ini/unx without language_code.
By default, these configuration files are assigned a character set and font that are correct for each language. However, it is also possible to customize the files to better suit your integration needs and report requirements. The following sections describe the details of configurations you can specify in the pssqr.ini/unx files.
Note. On DB2 UDB for OS/390 and z/OS initialization files, PSSQRLANGUAGECDINI and PSSQRINI are provided as members of the SQRSRC dataset on TSO. PeopleSoft Process Scheduler selects a language-specific initialization file if it exists in the SQRSRC dataset by replacing the %SQRINI% meta-string on shell JCT at process runtime. Because of the limitation in PeopleSoft Process Scheduler running on z/OS, it is not possible to use a different character set on language-specific INI files on z/OS. The language-specific configuration files are provided to make different font configurations for some languages. If you need to process multiple character sets for a single database using PeopleSoft Process Scheduler on z/OS, you must set up multiple PeopleSoft Process Schedulers.
See Also
SQR Configuration for Processing International Text
SQR Configuration for Printing International Text
SQR Configuration for Processing International Text
SQR for PeopleSoft uses Unicode for internal storage of character data regardless of whether you are running against a Unicode encoded PeopleSoft database. This enables a single instance of SQR to process data in virtually any language.
Although SQR runs using Unicode internally, it automatically converts data read from and written to files to the appropriate non-Unicode encoding based on configurations made in the pssqr.ini/unx file. You can modify the delivered configuration to use different non-Unicode encoding based on your integration and reporting needs. Further, you can use Unicode as the input and output character set if your printer or external system communicating with SQR by file can process Unicode data.
The PeopleSoft system delivers pssqr.ini/unx files with configurations for each supported language and database connection. Manual configuration is not required for basic processing of supported languages or to connect to a Unicode database. The information in this section will help you customize SQR for PeopleSoft to better suit your integration and reporting requirements.
See The PSSQR.INI and PSSQR.UNX Files.
Advanced PSSQR.INI/UNX Settings
The following parameters under the [Environment: Common] or [Environment: <Database type>] sections of the pssqr.ini/unx file control the character set SQR uses for specific operations. The ENCODING parameter sets the default encoding for all types of operations. You can, however, control encodings for each operation independently by adding the parameters in the [Environment: Common] section of the file.
ENCODING ENCODING-SQR-SOURCE ENCODING-FILE-OUTPUT ENCODING-FILE-INPUT ENCODING-REPORT-OUTPUT ENCODING-CONSOLE
If an individual encoding parameter is explicitly included, this specific setting overrides the default encoding specified by the ENCODING parameter.
The ENCODING-SQR-SOURCE parameter specifies the encoding in which the SQR source (*.SQR, *.SQC) files are encoded.
The ENCODING-FILE-OUTPUT and ENCODING-FILE-INPUT parameters control the character set that is used to read and write files using the SQR OPEN command.
If no character set is specified explicitly in the OPEN command, the character set specified in these parameters is used to read or write the file. If SQR detects a byte-order mark (BOM) at the top of file, it always reads as a Unicode file, regardless of this setting.
The ENCODING-REPORT-OUTPUT parameter determines the encoding used for report output types LP, HP, PS, and CSV.
The parameter should be set to a character set that contains all the characters you expect to print using SQR and, if you intend to print the output on a printer, it should also be set to the character set that the printer supports. Output in SPF, HTML, Enhanced HTML, and PDF format is not controlled by this parameter. SPF HTML, and Enhanced HTML always use Unicode for their output, and PDF output is controlled exclusively by the font configuration.
The ENCODING-CONSOLE parameter determines the character set that is used to write progress and other messages to the console during an SQR run.
In Microsoft Windows, the encoding used by DOS consoles, such as the one that is used by SQR, is known as an OEM encoding; this is often different from the character set that is used by Microsoft Windows. See Microsoft's web site for a list of Microsoft Windows OEM code pages. For Unix/Linux systems, this setting should match the character set that is supported by your terminal device.
If the ENCODING parameter is not set, SQR determines the encoding to use based on the machine locale.
If the same parameter is not set in the [Environment: Common] and [Environment: <Database Type>] sections of the pssqr.ini/unx file, the configuration in the [Environment: <Database Type>] section overrides the configuration in the [Environment: Common] section.
See Also
The PSSQR.INI and PSSQR.UNX Files
SQR Configuration for Printing International Text
SQR for PeopleSoft is a Unicode application. It can generate reports that contain multiple languages, such as English, French, Japanese, and Thai, on a single report and even on a single page, if you use advanced reporting output types like PDF, SPF, HTML, or Enhanced HTML. However, for other output types that SQR supports, printing or generating reports in languages other than the Western European languages might require special considerations. This section provides some hints for customizing or resolving international text printing issues with SQR for PeopleSoft.
This section discusses how to:
Set up encoding parameters.
Set up fonts.
Set up PDF fonts.
Set up files for PCL and line printing.
Set up files for PostScript printing.
This section also discusses limitations of SQR for PeopleSoft to print international text.
SQR for PeopleSoft represents fonts internally as numbers, and the pssqr.ini/unx file controls the mapping between the font numbers for some printer types. The [Fonts] section in the pssqr.ini/unx file controls the font mappings of the following output types:
SPF Viewer
WP (Microsoft Windows Printer)
Enhanced HTML
By default, this section is not configured with language-specific fonts. This is because Microsoft Windows and HTML browsers have a font linking mechanism that allows them to select an appropriate language-specific font automatically when the font specified does not have characters to show. However, Microsoft Windows and the browser's font linking works differently based on versions, availability of fonts on the system, and the configuration of Microsoft Windows and the browser. If you experience problems showing characters for these output types, you should try the configuration described in this section
To set up fonts:
Open the appropriate pssqr.ini/unx file for your language, located in PS_HOME\sqr.
In the [Fonts] section, the following default values appear.
Use the chart to replace each of the entries for your target language.
3=Courier New,fixed 300=Courier New,fixed,bold 4=Arial,proportional 400=Arial,proportional,bold 5=Times New Roman,proportional 500=Times New Roman,proportional,bold 6=AvantGarde,proportional 8=Palatino,proportional 800=Palatino,proportional,bold 11=Symbol,symbol 900=unknown,proportional 901=Times New Roman,proportional 28825=MS UI Gothic,proportional
|
Font Number |
Traditional Chinese |
Thai |
|||
|
3 |
MS Gothic, proportional |
SimHei, proportional |
MingLiu, proportional |
CordiaUPC, proportional |
GulimChe, proportional |
|
300 |
MS Gothic, proportional, bold |
SimHei, proportional, bold |
MingLiu, proportional, bold |
CordiaUPC, proportional, bold |
GulimChe, proportional, bold |
|
4 |
MS Gothic, proportional |
SimHei, proportional |
MingLiu, proportional |
CordiaUPC, proportional |
GulimChe, proportional |
|
400 |
MS Gothic, proportional, bold |
SimHei, proportional, bold |
MingLiu, proportional, bold |
CordiaUPC, proportional, bold |
GulimChe, proportional, bold |
|
5 |
MS Mincho, proportional |
SimSun, proportional |
MingLiu, proportional |
AngsanaUPC, proportional |
BatangChe, proportional |
|
500 |
MS Mincho, proportional, bold |
SimSun, proportional, bold |
MingLiu, proportional, bold |
AngsanaUPC, proportional, bold |
BatangChe, proportional, bold |
|
6 |
MS Gothic, proportional |
SimHei, proportional |
MingLiu, proportional |
CordiaUPC, proportional |
GulimChe, proportional |
|
8 |
MS Gothic, proportional |
SimHei, proportional |
MingLiu, proportional |
CordiaUPC, proportional |
GulimChe, proportional |
|
800 |
MS Gothic, proportional, bold |
SimHei, proportional, bold |
MingLiu, proportional, bold |
CordiaUPC, proportional, bold |
GulimChe, proportional, bold |
|
901 |
MS Mincho, proportional |
SimSun, proportional |
MingLiu, proportional |
CordiaUPC, proportional |
GulimChe, proportional |
|
28825 |
MS UI Gothic, proportional |
N/A |
N/A |
N/A |
N/A |
For PDF output, SQR for PeopleSoft has an internal font linking mechanism by which you can link up to 10 fonts for a single font number. This allows you to get character coverage that is not possible by using single font. With this feature, you can print reports containing multiple languages without rewriting your program to show each language in a different font. PeopleSoft delivers the pssqr.ini/unx file with world-ready configuration; therefore, you usually do not need to modify the pssqr.ini/unx file to print non-Western European languages. Many major business languages can be printed in PDF independent of the user's language settings on the My Personalization page. For example, you can output Greek data in PDF even when your My Personalizations language is set to English.
Although it is possible to print Chinese, Japanese, or Korean text in a PDF report without modifying the pssqr.ini/unx configuration, printing Chinese, Japanese, and Korean text in a single report requires special configuration. Font linking data is configured in the pssqr.ini/unx file and is transparent to the user. Depending on your reporting requirements, you can add or remove fonts from the delivered configuration, and you can control which actual font to use down to a single character level. This section explains how to add fonts for PDF output.
The [PDF Fonts] section in the pssqr.ini/unx file supports multiple fonts mapped to a single font number.
The [PDF Fonts: Exclusion Ranges] section of the file specifies exclusion ranges for fonts listed in the [PDF Fonts] section. If an exclusion range is set, then when a character is covered by a font, that font is not used to print the character. Exclusion ranges are set in Unicode format, in hexadecimal or decimal. The base configuration does not contain an exclusion range.
The [TrueType Fonts] section of the file specifies the mapping from TrueType font names used in the [PDF Fonts] configuration section, along with the physical file path of the font on the operating system. For TrueType collection (.ttc) files, the font directory number should also be specified (in the format font name=file path, directory number.
The font path is the directory where the font resides. The default is SQRDIR. On Microsoft Windows, the font directory is looked up as well. Fonts residing in other directories must be specified by their full physical pathnames.
The [PDF Fonts] information in the pssqr.ini/unx file is language-specific for Chinese, Japanese, and Korean languages; the information is the same for other supported languages due to Unicode characteristics. If you want to add another language (for example, Russian), you should refer to the documentation for adding new languages.
See the PeopleTools 8.51 installation guide for your database platform.
See Adding New Languages.
See Enterprise PeopleTools 8.51 PeopleBook: SQR Language Reference for PeopleSoft.
Sample Steps for Adding a Font for PDF Output: User Defined Font for Japanese
For computing in the Japanese language, it is common to use user-defined characters. A user-defined character is a character that is not encoded in standard character sets like JIS X 0208 or Unicode, and sometimes variants of glyphs existing in standard character sets. This kind of character is often used for a person's name. Unicode has space allocated to encode such user-defined characters, and users can create fonts that include characters not defined in Japanese fonts.
On Microsoft Windows, users can create user-defined fonts using a program called EUDCEDIT to design and define private characters. This program creates a TrueType font file named "eudc.tte" under the Microsoft Windows font folder. As an example of adding fonts for PDF output from SQR for PeopleSoft, perform the following steps to add the "eudc.tte" font to the PeopleSoft-delivered configuration file for Japanese, pssqrjpn.ini:
Open the pssqrjpn.ini file from PS_HOME\sqr and add the following line under [TrueType Fonts] section:
[TrueType Fonts] Font Path=... Cumberland=... GaijiFont=eudc.tte
As explained in this section, you do not need to specify a full path for the font residing in the Microsoft Windows font folder, and you can specify a name different from the actual name of the font ("GaijiFont" means a user defined font in Japanese. The actual font name that "eudc.tte" itself has is "EUDC").
Under the [PDF Fonts] section, add "GaijiFont" at the end of the font list.
For example, for font number 3:
3=Courier,HeiseiKakuGo-W5,Cumberland,MHei-Medium,STSong-Light,HYGoThic-Medium, Angsana,GaijiFont
Define exclusion ranges in the [PDF Fonts: Exclusion Ranges] section, to exclude higher priority fonts to show characters in the Unicode private use range where characters in eudc.tte are defined.
Chinese fonts have glyphs defined in the Unicode private use range mainly to include characters defined in national character standards like GBK but not defined in earlier versions of Unicode. Thai fonts also have Thai presentation form characters mapped in the Unicode private use range. As we are working on a Japanese configuration and Chinese characters and Thai presentation forms are rarely needed in a Japanese context, we will configure these fonts not to print characters in the Unicode private range, and private range characters are always printed using "GaijiFont," which we just added. The Unicode private use range is from 0xE000 to 0xF8FF. Chinese fonts are third and fourth in the font link list, and the Thai font is seventh. Therefore, the exclusion definition looks like the following (exclusion range setting for second font comes from original configuration of pssqrjpn.ini, that excludes extended Latin characters from Japanese font):
3=,0x0000-0x02FF,,0xE000-0xF8FF,0xE000-0xF800,0xE000-0xF800,,
Considerations for Printing Chinese, Japanese, and Korean Text in a Single PDF Output
Unicode application printing of Chinese, Japanese, and Korean text in a single context requires special consideration in the use of fonts, because Unicode encodes ideographs used in Chinese, Japanese, and Korean languages in unified codepoints. A Unicode character is unique in meaning, but the glyph (the shape of the character) might be different depending on the language context. A commonly used technique in resolving this glyph difference is to use a language-specific font for Chinese, Japanese, and Korean, based on external context.
The PeopleSoft system delivers different font linking configurations for Chinese, Japanese, and Korean languages in language-specific pssqr.ini/unx files. In the Simplified Chinese configuration, the Simplified Chinese font is given higher priority than other Chinese, Japanese, or Korean fonts, so that a Simplified Chinese glyph is used for most Chinese ideographs. At runtime, PeopleSoft Process Scheduler picks up language-specific pssqr.ini/unx files with appropriate font linking data for the language, based on the user's My Personalization language setting. If you set your language as Traditional Chinese, the configuration file that uses the Traditional Chinese font for the majority of ideographic characters will be picked up. It is recommended that you set up the language in the My Personalization page when you are printing reports that include Chinese, Japanese, and Korean data. If you do not use any Chinese, Japanese, and Korean languages for the My Personalization page, the default configuration is used and in this case the printed glyph image might be different from what you expect to see.
If you have a reporting requirement to print a mix of Chinese and Japanese in a single report and you need to show each language in the correct glyph image for that language, you will need to use the ALTER-PRINTER command to programmatically change the font in your SQR program based on external data, such as the Language Code of the data. For this purpose, pssqr.ini/unx files are provided with the following font numbers, each of which uses fonts specific for each Chinese, Japanese, and Korean locale.
28825, 28752 (Japanese).
37110, 37058 (Simplified Chinese).
33269 (Traditional Chinese).
Setting Up Files for PCL and Line Printing
Most of the configurations for printing international text from SQR for PeopleSoft are performed by setting options in the pssqr.ini/unx file. However, for some of the printer-specific settings, you must set parameters in SQR for PeopleSoft programs because of the SQR for PeopleSoft syntax.
For example, SQR for PeopleSoft enables users to control printer parameters for PCL format in DEFINE-PRINTER or ALTER-PRINTER commands. PeopleTools provides default setup values for PCL format in three SQC files (ptset01.sqc, ptset02.sqc and ptset02a.sqc). If you intend to print languages in PCL format other than those covered by Latin1, you must add printer setup parameters to the SQC files.
Before you perform the configuration tasks described in this section, make sure that you have properly configured your printers to print in the target language.
If your printer does not have the fonts for the languages you want to print, you might need to purchase fonts in ROM from your printer vendor and install them on your printer.
The parameters you set for PCL printing must be consistent with the ENCODING parameters set in the pssqr.ini/unx file. You must set up the ENCODING parameters for each language before you set the parameters for PCL printing.
To set up PCL printing parameters for Japanese:
Open setenv.sqc file under PS_HOME\sqr.
Uncomment the following parameter:
#define PRINT_JAPANESE
Save and close the file.
To set up PCL printing parameters for languages other than Japanese:
Note. If you intend to print a language other than those covered by Latin1 and if it is not Japanese, follow these steps to set up the SQC files. The values presented here are examples and can vary depending on your printer. You should check your printer manual for the appropriate fonts and symbol sets.
Open the ptset01.sqc file located under PS_HOME\sqr.
Between the declare printer DEFAULT-HP and end-declare statements, add the following information with the appropriate values:
font symbol-set
The values you set differ from language to language. The following table shows sample values for several languages commonly used by PeopleSoft customers.
|
Language |
Font |
Symbol Set |
|
Central/Eastern European |
No need to set. |
2N |
|
Traditional Chinese |
33269 |
18T |
|
Simplified Chinese |
37058 |
18C |
For example, if you are setting ptset01.sqc for Simplified Chinese printing, try the following setting:
declare-printer DEFAULT-HP #ifdef PRINT_JAPANESE init-string=<27>&t31P font=28825 symbol-set=19K #endif font=37058 symbol-set=18C point-size=7.2 pitch=17 end-declare
Under the declare printer DEFAULT-LP statement, locate the init-string parameter.
Modify the init-string parameter based on the language to print. The following example shows sample values for HP LaserJet printer’s line printer mode. Consult your printer manual for correct values for this parameter.
|
Language |
init-string |
|
Eastern European |
<27>E<27>(2N<27>&l0O<27>&l6C<27>&l0E<27>&l95F<27>(s16.66H<27>&k2G |
|
Traditional Chinese |
<27>E<27>(18T<27>&l0O<27>&16C<27>&10E<27>&195F<27>(s16.66H<27>&k2G<27>(s1p7.25v0s0b33269T |
|
Simplified Chinese |
<27>E<27>(18C<27>&l0O<27>&16C<27>&10E<27>&195F<27>(s16.66H<27>&k2G<27>(s1p7.25v0s0b37058T |
Save and close the file.
Open ptset02.sqc from PS_HOME\sqr and repeat steps 2 through 4.
Open ptset02a.sqc PS_HOME\sqr and repeat steps 2 through 4.
Setting up Files for PostScript Output
In addition to PCL and line printer format, SQR for PeopleSoft supports output in PostScript format, which can be printed with a printer that has PostScript interpreter. However, you configure fonts in a setup file provided for PostScript printing.
The parameters you set for PostScript printing must to be consistent with the ENCODING parameters you set in the pssqr.ini/unx file.
By default, the setup file provided for PostScript printing is configured for printing Western European languages. Depending on the encoding parameter in the pssqr.ini/unx file, you must either “re-encode” fonts, or use different fonts that support specific languages other than those set in the configuration file by default (you may need to use printer pre-installed fonts that support specific languages, or install external fonts on your printers). Consult your printer manual for the character sets your printer supports.
To set up files for PostScript output:
Open the postscri.str file from PS_HOME\bin\sqr\db_platform\binw or from the directory where the SQR executable resides.
If you are using select character sets, such as Latin9, it is possible to print the entire repertoire of the character set just by re-encoding PostScript fonts.
The PeopleSoft system delivers PostScript code and re-encoding data for Microsoft Windows CP1252 and CP1250 on Microsoft Windows, and Latin1, Latin9, and Latin2 on Unix/Linux. The default is CP1252 on Microsoft Windows and Latin1 on Unix/Linux. If you are using other character sets, the PeopleSoft system provides re-encoding data and you will need to modify part of the setup file. For example, the following example is for using the Latin9 character set on Unix/Linux platforms:
Locate the following section:
% ISO Latin1 /CODE [] 160 /space ...
Comment out the “CODE” section entirely, by adding a percent sign (%) at the beginning of each line.
Locate the following section:
% ISO Latin9 % (enable this array when you set ENCODING/ENCODING-REPORT-OUTPUT=ISO-8859-15 % and comment out above array for ISO Latin1) % /CODE [ % 160 /space …
Remove the percent signs in front of each line for the entire “CODE” section.
Note. If you plan to use CP1250 on Microsoft Windows or Latin2 on Unix/Linux, you will need to ensure that fonts installed on printer have the characters needed for these character sets. Depending on the printer and the fonts installed, you may not be able to print the entire repertoire of these Eastern European character sets using provided re-encoding data. Note also that if you plan to use character sets other than those discussed previously in this section, you will need to ensure that the printer has fonts supporting the specific character set you want to use. You may need to install additional fonts, and may also need to re-encode the fonts by adding your own font re-encoding data.
Some other character sets, including character sets commonly used for Japanese, Korean, and Chinese, can be printed by using PostScript fonts supporting the specific language. You can replace the font names in the setup file in the following way:
Locate the following section:
/Fonts [ % Array of point sizes and font names
Replace each font with the name of the appropriate font installed on your printer that can print the target language. For CJK languages (Chinese, Japanese, and Korean), PostScript printers accept the font names in the following format:
(Font Name)-(CMap name)
Font Name represents the name of the font installed on your printer that supports the language that you want to print. CMap is a file the PostScript printer used to find the glyph that corresponds to the codepoint passed to the printer. You need to use the CMap that matches the encoding specified in the ENCODING parameter in the pssqr.ini/unx file.
The following example shows setup values for each of the CJK languages. Supported font names and CMap files may vary depending on your printer. For details, refer to your printer documentation.
|
Language |
Report Output Encoding |
Serif Typeface |
San Serif Typeface |
|
Japanese |
SJIS |
Ryumin-Light-RKSJ-H |
GothicBBB-Medium-RKSJ-H |
|
Traditional Chinese |
Big5 |
MSung-Light-B5-H |
MHei-Medium-B5-H |
|
Simplified Chinese |
CP936 |
STSong-Light-GBK-EUC-H |
STHeiti-Regular-GBK-EUC-H |
|
Korean |
CP949 |
HYSMyoeongJo-Medium-KSCms-UHC-H |
HYGoThic-Medium-KSCms-UHC-H |
If you do not need to re-encode the fonts you have set, you must comment out the following section entirely by adding a percent sign (%) in front of each line. (For CJK character sets, you do not need to re-encode fonts; however, you might need to do so for other languages.)
% % Re-encode all the fonts except for symbol/dingbats % (do not re-encode CJK fonts - if you intend to use CJK fonts comment % out the below section entirely) % /Courier /Courier CODE ReEncode /Courier-Bold /Courier-Bold CODE ReEncode /Helvetica /Helvetica CODE ReEncode /Helvetica-Bold /Helvetica-Bold CODE ReEncode …
Save and close the file.
Limitations in Printing International Text from SQR for PeopleSoft
The following limitations apply when printing international text from SQR for PeopleSoft:
SQR for PeopleSoft does not support languages that require bi-directional text rendering, such as Arabic and Hebrew.
The default configuration of report formats other than PDF, SPF, WP, HTML, and Enhanced HTML is to use non-Unicode character sets (ISO or commonly used national standard character sets on Unix/Linux, and the Microsoft Windows character set on Microsoft Windows).
The ability to print language data for LP, HP, PS, CSV, and HT output types is limited by the character set used for output. For example, you can print Western European languages like English, French, Spanish, and Portuguese using the Latin1 character set (which is used in pssqr.unx), but you cannot add Polish data using Latin1 because the Polish language uses characters not encoded in the Latin1 character set. You can configure the pssqr.ini/unx files to generate output types other than HT in Unicode-based character sets like UCS-2 or UTF-8, but in these cases you need to ensure that your printer or viewer application supports Unicode natively.
If you intend to print output using the LP, HP, or PS format, SQR for PeopleSoft's ability to print international characters is also limited by the fonts installed on the printers. For example, you can print Japanese on a PostScript printer if a Japanese font like Ryumin-Light is installed on the printer. However, if your printer does not natively provide font support, the printer output with international text may not be printed as intended. Unlike with PDF output, SQR for PeopleSoft currently does not support downloading host-based fonts, including True Type fonts, to the printer as part of the print job. Printing from Adobe Reader or SPF Viewer is not affected by this limitation.
International Text in SQR for PeopleSoft Programs
This section discusses:
System variables to check encoding settings.
String length.
OPEN command.
System Variables to Check Encoding Settings
You can reference the values set for the ENCODING parameters in pssqr.ini/unx from your SQR for PeopleSoft programs using the following system variables:
$sqr-encoding
Stores value set to the ENCODING parameter of pssqr.ini/unx. If no value is set for this parameter, SQR automatically determines the appropriate encoding for input and output based on the operating system locale and stores values in this variable.
$sqr-encoding-database-api
Stores value set to ENCODING-DATABASE-API parameter of pssqr.ini/unx file. Except for DB2 UDB for Linux, Unix, and Microsoft Windows, the value for this parameter is automatically determined by the system and cannot be overridden by editing pssqr.ini/unx. In this case, this variable stores the encoding value automatically determined and used by system. For example, on an Oracle platform, this variable value is always UTF-8.
$sqr-encoding-file-input
Stores value set to ENCODING-FILE-INPUT parameter in pssqr.ini/unx file. If no value is set for this parameter, the input files are considered to be encoded in the encoding specified in the ENCODING parameter and this variable stores the same value as $sqr-encoding.
$sqr-encoding-file-output
Stores value set to ENCODING-FILE-OUTPUT parameter in pssqr.ini/unx file. If no value is set for this parameter, the same encoding set in the ENCODING parameter is used for file output encoding and this variable stores the same value as $sqr-encoding.
$sqr-encoding-report-output
Stores value set to ENCODING-REPORT-OUTPUT parameter in pssqr.ini/unx file. If no value is set for this parameter, the same encoding set in the ENCODING parameter is used for report output encoding and this variable stores the same value as $sqr-encoding.
$sqr-encoding-source
Stores value set to ENCODING-SQR-SOURCE parameter in pssqr.ini/unx file. If no value is set for this parameter, SQR source files are considered to be encoded in the character set encodings specified in the ENCODING parameter and this variable stores the same value as $sqr-encoding.
$sqr-encoding-console
Stores value set to ENCODING-CONSOLE parameter in pssqr.ini/unx file. If no value is set for this parameter, the same encoding set in the ENCODING parameter is used for console output encoding and this variable stores the same value as $sqr-encoding.
Note. The system variables are read-only and cannot be overwritten at runtime. They can be used with functions and commands that take encodings as parameters, such as substrt(), lengtht(), and open.
When you work with strings in SQR, you must consider three different ways of measuring string length:
The number of characters in the string.
The number of print columns occupied by these characters.
For example, characters from the Latin alphabet normally require one print column; characters in Japanese often require two.
The number of bytes used to store the character.
SQR uses the Unicode UCS-2 method of encoding characters, which means that every character occupies two bytes; however, your database may use a different encoding that requires a different number of bytes for each character.
SQR provides the following functions to help you manage string length according to each of these criteria.
Note. Although SQR uses Unicode internally, it can still read/write with non-Unicode (ANSI) databases and files. Refer to the OPEN command in the SQR documentation for details.
Length() and Substr() deal with the number of characters in a string. As the PeopleSoft system field lengths (as defined in Application Designer) are character-based, the Length( ) and Substr( ) functions are useful for calculating the length of the string as it is stored in the database.
For example, the following code determines whether string &abc will fit into a database field that is 10 characters long. If the string won’t fit into the field, the code truncates the string to use only the first 10 characters.
If length(&abc) > 10 then &abc = substr(&abc,1,10) End-if
Lengthp() and Substrp() deal with the number of print columns required to print the character using a monospace (nonproportional) font.
For example, the following code determines whether string &abc will fit into a print area that is 10 columns wide. If the string won’t fit into the print area, the code truncates the string to use only the first 10 columns of characters.
If lengthp(&abc) > 10 then &abc = substrp(&abc,1,10) End-if
Lengtht() and Substrt() deal with the number of bytes that the string occupies in a specified character set. Typically, you would use lengtht( ) and substrt( ) if you are writing to a file in a specific character set, and you need to check or limit the byte length of the string in the output file, as would be required by most interface files.
For example, the following code determines whether string &abc will require more than 10 bytes in an output file. If the string is more than 10 bytes, the code truncates the string to use only the first 10 bytes worth of characters. The SQR system variable $sqr-encoding-file-output is used to reference the SQR.INI ENCODING-FILE-OUTPUT variable, which determines the default character set of any file that is written to by the SQR OPEN command. You can substitute any valid PeopleSoft system encoding for the $sqr-encoding-file-output variable.
If lengtht(&abc, $sqr-encoding-file-output) >10 then &abc = substrt(&abc, $sqr-encoding-file-output,1,10) End-if
The SQR OPEN command, used to read and write files from within SQR programs, enables the report designer to specify the character set of the file being opened. You can specify a character set explicitly in the OPEN command. If you do not specify a character set, the SQR program uses the character set specified in the pssqr.ini/unx parameter ENCODING-FILE-OUTPUT or ENCODING-FILE-INPUT, depending on whether you are opening the file for reading or writing.
To integrate with a third-party system, specify the character set for SQR programs to match the target data. For example, a mainframe-based payroll system may expect an EBCDIC format file. Specifying the character set directly in the OPEN command enables the SQR program to be independent of the pssqr.ini/unx settings and enables the SQR program to create the file directly in the character set expected by the target system (without the need to convert the output in a separate step).
As another example, if you are generating text output for a mail merge in Microsoft Word, you can specify UCS-2 or Unicode-Little-Endian to the ENCODING parameter of the OPEN statement, so that Microsoft Word can import the Unicode file including international text.
See Also
Selecting and Configuring Character Sets and Language Input and Output
SQR for PeopleSoft-Supported Character Set Encodings
This section lists the character set encodings that are supported by SQR for this PeopleTools release. The character set encodings are organized by the following character sets:
Arabic
Baltic
Celtic
Chinese (Simplified)
Chinese (Traditional)
Cyrillic
Gurmukhi
Greek
Hebrew
Icelandic
Japanese
Korean
Latin
Latin (Canadian French)
Latin (Central European)
Latin (Southeastern European)
Malayalam
Nordic
Slavic
Symbol
Thai
Turkish
Unicode
Vietnamese
Explanation of the Following Tables
The Encoding Parameter column lists the values that you can specify in the ENCODING parameter in the pssqr.ini/unx file.
ENCODING-REPORT-OUTPUT applies to all output types.
In the Output Supported column of the following tables, note the following:
|
PCL denotes PCL printing format. Values in parentheses next to PCL, for example PCL (8V), are symbol sets. If PCL is not listed for an encoding parameter, the encoding is not supported output. Additional hardware support (font ROM) may be required to get correct output. |
|
|
PS denotes a PostScript printer. |
|
|
CSV denotes comma-separated value format. CSV (*) means output is supported but Microsoft Excel may not read the output correctly. To read the output in Microsoft Excel, use a supported encoding other than those indicated with an asterisk (*). |
|
|
Flat file denotes that the output is generated by the WRITE command or that the text encoding is readable with the READ command. |
SPF, HTML, Enhanced HTML, and PDF can output all the supported languages and encodings. For SPF, HTML, and Enhanced HTML, SQR uses UTF-8 encoding (Unicode), even if ENCODING and ENCODING-REPORT-OUTPUT is set to non-Unicode encoding in the pssqr.ini/unx file. For PDF, character support is dependent on the fonts listed in the [PDF Fonts] section of the pssqr.ini/unx file.
Data processing of Arabic/Hebrew and other languages normally written in right-to-left order is supported, but SQR for PeopleSoft does not generate reports in right-to-left page order.
The following table lists the supported encodings for the Arabic character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP720 |
Arabic - Transparent ASMO |
PCL (8V), Flat file |
|
CP708 |
ASMO708 |
Flat file |
|
CP20240 |
IBM EBCDIC - Arabic |
Flat file |
|
CP28596 |
ISO 8859-6 (Arabic) |
CSV, Flat file |
|
Arabic |
ISO 8859-6 (Arabic) |
PCL (11N), CSV, Flat file |
|
CP10004 |
Macintosh Arabic |
CSV (*), Flat file |
|
CP1256 |
MS Windows Arabic |
PCL (9V), CSV, Flat file |
|
CP864 |
MS-DOS Arabic |
CSV (*), Flat file |
|
MacArabic |
Macintosh Arabic |
Flat file |
The following table lists the supported encodings for the Baltic character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP28594 |
ISO 8859–4 (Baltic) |
CSV, Flat file |
|
ISO-8859–4, Latin4 |
ISO 8859–4 (Baltic) |
4N, CSV (*), Flat file |
|
CP1257 |
MS Windows Baltic |
CSV, Flat file |
|
CP775 |
MS-DOS Baltic |
PCL (19L), CSV (*), Flat file |
The following table lists the supported encodings for the Celtic character set:
|
Encoding Parameter |
Description |
Output Support |
|
ISO-8859–14 |
ISO 8859–14 (Latin 8) |
Flat file |
The following table lists the supported encodings for the Simplified Chinese character set:
|
Encoding Parameter |
Description |
Output Support |
|
CCSID935 |
IBM EBCDIC 935 |
Flat file |
|
GB18030 |
GB 18030-2000 |
Flat file |
|
GB2312 |
GB 2312-80 |
PCL (18C), PS, , CSV, Flat file |
|
HZ |
HZ GB2312-80 |
Flat file |
|
CP936 |
MS Windows Schinese/MS-DOS Schinese (GBK) |
PCL (18C), PS. CSV, Flat file |
|
EUC-CN |
Simplified Chinese EUC |
PS, CSV (*), Flat file |
Chinese (Traditional)
The following table lists the supported encodings for the Traditional Chinese character set:
|
Encoding Parameter |
Description |
Output Support |
|
Big5 |
Big5 |
PCL (18T), PS, CSV, Flat file |
|
CCSID937 |
IBM EBCDIC 937 |
Flat file |
|
CNS-11643-1986 |
CNS-11643-1986 |
CSV (*), Flat file |
|
CNS-11643-1992 |
CNS-11643-1992 |
CSV (*), Flat file |
|
GB12345 |
GB12345 |
Flat file |
|
CP10002 |
Macintosh Traditional Chinese |
Flat file |
|
CP950 |
MS Windows Tchinese/MS-DOS Tchinese (Big5) |
PCL (18T), PS, CSV, Flat file |
|
EUC-TW |
Traditional Chinese EUC |
PS, CSV (*), Flat file |
|
HKSCS |
Hong Kong Supplementary Character Set |
Flat file |
The following table lists the supported encodings for the Cyrillic character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP20880 |
IBM EBCDIC - Cyrillic (Russian) |
Flat file |
|
CP21025 |
IBM EBCDIC - Cyrillic (Serbian, Bulgarian) |
Flat file |
|
CP28595 |
ISO 8859-5 (Cyrillic) |
CSV, Flat file |
|
ISOLatinCyrillic |
ISO 8859-5 (Cyrillic) |
PCL (5T), CSV, Flat file |
|
CP10007 |
Macintosh Cyrillic |
CSV (*), Flat file |
|
CP1251 |
MS Windows Cyrillic (Slavic) |
PCL (5T), CSV, Flat file |
|
CP855 |
MS-DOS Cyrillic |
CSV (*), Flat file |
|
CP866 |
MS-DOS Russian |
CSV (*), Flat file |
|
CP20866 |
Russian — K018 |
CSV (*), Flat file |
|
CP21866 |
Ukranian — K018 — RU |
Flat file |
The following table lists the supported encodings for the Greek character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP20423 |
IBM EBCDIC - Greek |
Flat file |
|
CP28597 |
ISO 8859-7 (Greek) |
CSV, Flat file |
|
Greek |
ISO 8859-7 (Greek) |
CSV, Flat file |
|
CP10006 |
Macintosh Greek 1 |
CSV (*), Flat file |
|
CP1253 |
MS Windows Greek |
CSV, Flat file |
|
CP737 |
MS-DOS Greek 437G |
CSV (*), Flat file |
|
CP869 |
MS-DOS Modern Greek |
CSV (*), Flat file |
The following table lists the supported encodings for the Gurmukhi character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP10010 |
Macintosh Romanian |
CSV (*), Flat file |
The following table lists the supported encodings for the Hebrew character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP38598 |
ISO 8859-8 (Hebrer Logical Ordering) |
CSV, Flat file |
|
Hebrew |
ISO 8859-8 (Hebrer Logical Ordering) |
CSV, Flat file |
|
CP28598 |
ISO 8859-8 (Hebrer Visual Ordering) |
Flat file |
|
CP10005 |
Macintosh Hebrew |
CSV (*), Flat file |
|
CP1255 |
MS Windows Hebrew |
CSV, Flat file |
|
CP862 |
MS-DOS Hebrew |
CSV (*), Flat file |
|
MacHebrew |
Macintosh Hebrew |
Flat file |
The following table lists the supported encodings for the Icelandic character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP10079 |
Macintosh Icelandic |
CSV (*), Flat file |
|
CP861 |
MS-DOS Icelandic |
CSV (*), Flat file |
The following table lists the supported encodings for the Japanese character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP21027 |
Ext Alpha Lowercase |
Flat file |
|
CCSID-1027 |
IBM EBCDIC - Japanese |
CSV (*), Flat file |
|
CP20290 |
IBM EBCDIC - Japanese Kana Extension |
Flat file |
|
CCSID939, EBCDIK1027 |
IBM EBCDIC MBCS-HOST - Japanese (1027+ 0300) |
CSV (*), Flat file |
|
CCSID-290 |
IBM EBCDIK - Japanese Kana Extension |
CSV (*), Flat file |
|
CCSID930, EBCDIK290 |
IBM EBCDIK MBCS-HOST - Japanese (290+0300) |
PDF, CSV (*), Flat file |
|
CCSID-942 |
IBM MBCS-PC OS2 (1041+941) - Japanese |
CSV (*), Flat file |
|
ISO-2022-JP |
ISO 2022-JP |
CSV (*), Flat file |
|
EUC-J, JEUC |
Japanese EUC |
PS, CSV (*), Flat file |
|
JIS_X_0201 |
JIS X 0201 |
CSV (*), Flat file |
|
JIS_X_0208 |
JIS X 0208 |
CSV (*), Flat file |
|
CP10001 |
Macintosh Japanese |
Flat file |
|
Shift-JIS, SJIS |
MS Windows Japanese/MS-DOS Japanese |
PCL (19K), PS, CSV, Flat file |
|
CP932 |
MS Windows Japanese/MS-DOS Japanese |
PCL (19K), PS, CSV, Flat file |
The following table lists the supported encodings for the Korean character set:
|
Encoding Parameter |
Description |
Output Support |
|
ISO-2022-KR |
ISO-2022-KR |
CSV (*) |
|
EUC-KR |
Korean EUC |
PS, CSV (*), Flat file |
|
CP1361 |
Korean Johab |
PS, CSV (*), Flat file |
|
Johab |
Korean Johab |
PS, CSV (*), Flat file |
|
CP10003 |
Macintosh Korean |
Flat file |
|
CP949 |
MS Windows Korean/MS-DOS Korean |
PS, CSV, Flat file |
The following table lists the supported encodings for the Latin character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP20277 |
IBM EBCDIC - Denmark/Norway |
Flat file |
|
CP20278 |
IBM EBCDIC - Finland/Sweden |
Flat file |
|
CP20297 |
IBM EBCDIC - France |
Flat file |
|
CP20273 |
IBM EBCDIC - Germany |
Flat file |
|
CP20871 |
IBM EBCDIC - Icelandic |
Flat file |
|
CP500 |
IBM EBCDIC - International |
CSV (*), Flat file |
|
CP20280 |
IBM EBCDIC - Italy |
Flat file |
|
CP20833 |
IBM EBCDIC - Korean Extended |
Flat file |
|
CP20284 |
IBM EBCDIC - Latin America/Spain |
Flat file |
|
CCSID1047 |
IBM EBCDIC - Latin1/Open System |
Flat file |
|
CP875 |
IBM EBCDIC - Modern Greek |
CSV (*), Flat file |
|
CP870 |
IBM EBCDIC - Multilingual/ROECE (Latin2) |
CSV (*), Flat file |
|
CP20285 |
IBM EBCDIC - United Kingdom |
Flat file |
|
CP20269 |
ISO 6937 Non-Spacing Accent |
Flat file |
|
CP28591 |
ISO 8859-1 (Latin 1) |
CSV (*), Flat file |
|
ISO-8859-1, Latin1 |
ISO 8859-1 (Latin 1) |
PCL (0N), PS, CSV, Flat file |
|
ISO-8859-15 |
ISO 8859-15 (Latin 9) |
CSV (*), Flat file |
|
ISO-8859-2, Latin2 |
ISO 8859-2 (Central Europe) |
PCL (2N), CSV, Flat file |
|
CP28593 |
ISO 8859-3 (Latin 3) |
CSV (*), Flat file |
|
CP10082 |
Macintosh Croatia |
CSV (*), Flat file |
|
CP10029 |
Macintosh Latin2 |
CSV (*), Flat file |
|
CP1252 |
MS Windows Latin1 |
PCL (19U), PS, CSV, Flat file |
|
CP850 |
MS-DOS Multilingual Western Europe |
PCL (12U), CSV (*), Flat file |
|
CP860 |
MS-DOS Portuguese |
Flat file |
|
CP20261 |
T.61 |
Flat file |
|
hp-roman8 |
HP Roman8 |
PCL (8U), Flat file |
Latin (Canadian French)
The following table lists the supported encodings for the Latin (Canadian French) character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP863 |
MS-DOS Canadian French |
CSV (*), Flat file |
Latin (Central European)
The following table lists the supported encodings for the Latin (Central European) character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP28592 |
ISO 8859-2 (Central Europe) |
CSV, Flat file |
|
CP1250 |
MS Windows Central European |
PCL (9E), CSV, Flat file |
Latin (Southeast European)
The following table lists the supported encodings for the Latin (Southeast European) character set:
|
Encoding Parameter |
Description |
Output Support |
|
ISO-8859-3, Latin3 |
ISO 8859-3 (Latin 3) |
CSV, Flat file |
Latin (U.S. English)
The following table lists the supported encodings for the Latin (U.S. English) character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP20105 |
IA5 IRV International Alphabet No.5 |
Flat file |
|
EBCDIC, CP037 |
IBM EBCDIC - U.S./Canada |
PS, CSV (*), Flat file |
|
CP037 |
IBM EBCDIC - U.S./Canada |
CSV (*), Flat file |
|
CP437 |
MS-DOS U.S. |
CSV (*), Flat file |
|
ASCII, ANSI |
US-ASCII |
PCL (0U), PS, CSV, Flat file |
Latin (Western European)
The following table lists the supported encodings for the Latin (Western European) character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP10000 |
Macintosh Roman |
CSV (*), Flat file |
The following table lists the supported encodings for the Malayalam character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP10017 |
Macintosh Malayalam |
Flat file |
The following table lists the supported encodings for the Nordic character set:
|
Encoding Parameter |
Description |
Output Support |
|
ISO-8859-10, Latin6 |
ISO 8859-10 (Latin 6) |
PCL (6N), Flat file |
|
CP865 |
MS-DOS Nordic |
CSV (*), Flat file |
The following table lists the supported encodings for the Slavic character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP852 |
MS-DOS Slavic |
PCL (17U), CSV (*), Flat file |
The following table lists the supported encodings for the Symbol character set:
|
Encoding Parameter |
Description |
Output Support |
|
Adobe-Symbol-Encoding |
Adobe Symbol Encoding |
Flat file |
|
CP10008 |
Macintosh RSymbol |
Flat file |
The following table lists the supported encodings for the Thai character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP20838 |
IBM EBCDIC - Thai |
Flat file |
|
Thai |
ISO 8859-11 (Thai) |
CSV, Flat file |
|
CP874 |
MS Windows Thai/MS-DOS Thai |
CSV, Flat file |
The following table lists the supported encodings for the Turkish character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP20905 |
IBM EBCDIC - Turkish |
CSV (*), Flat file |
|
CP1026 |
IBM EBCDIC - Turkish (Latin 5) |
CSV (*), Flat file |
|
CP28599 |
ISO 8859-9 (Latin 5) |
CSV, Flat file |
|
ISO-8859-9, Latin5 |
ISO 8859-9 (Latin 5) |
PCL (5N), CSV, Flat file |
|
CP10081 |
Macintosh Turkish |
CSV (*), Flat file |
|
CP1254 |
MS Windows Turkish |
PCL (5T), CSV, Flat file |
|
CP857 |
MS-DOS Turkish |
PCL (9T), CSV (*), Flat file |
The following table lists the supported encodings for the Unicode character set:
|
Encoding Parameter |
Description |
Output Support |
|
Java |
Java Encoding (represents Unicode in US-ASCII) |
Flat file |
|
Big-Endian |
Unicode Big-Endian Order |
CSV (*), Flat file |
|
BMP |
Unicode BMP |
Flat file |
|
Little-Endian |
Unicode Little-Endian Order |
CSV, Flat file |
|
UCS-2, UCS2 |
Unicode UCS-2 Encoding |
CSV (*), Flat file |
|
UTF-8, UTF8 |
Unicode UTF-8 Encoding |
CSV (*), Flat file |
|
UTF8-EBCDIC |
UTF-8 EBCDIC |
Flat file |
The following table lists the supported encodings for the Vietnamese character set:
|
Encoding Parameter |
Description |
Output Support |
|
CP1258 |
MS Windows Vietnam |
CSV, Flat file |
Using PS/nVision Reporting for Global Implementations
In PS/nVision, you can specify the language of the user who is designing or requesting a report, the language of the user who makes a report request, and the language of the ultimate audience of a report (the person or group of people for whom the report was generated). The primary goal of these features is to allow a single layout to produce several instances of a report in a requested alternate language or group of languages. To that end, the features are designed to present reports to end users in their preferred languages. Thus, there is a distinction between the designer’s language and the user’s language.
Note. Your Microsoft Windows locale must be able to support the sign-in language.
Most of the strings in PS/nVision output are fetched from the Strings table, and they are delivered with the report instance. However, many labels used in macros and dialog boxes have to be translated directly in the file, as they cannot be fetched at runtime. When a PS/nVision report happens to contain labels in macros or dialog boxes, the layout needs to be translated in Microsoft Excel, and a separate copy of the layout maintained for each language. In this case, each language has its own version of the file, and the same rules for locating the appropriate language of the PS/nVision layout spreadsheet files are used as for Crystal Reports described previously. Each PS/nVision layout and drill-down directory can contain a subdirectory for each language. PS/nVision searches the appropriate directory for the user’s current language, and performs the appropriate fallback if a translation is not found.
Language-sensitive features of PS/nVision can be separated into two distinct parts:
|
Design-Time Features |
These are features related to designing PS/nVision layouts. |
|
Runtime Features |
These are features activated when a user makes a PS/nVision report request. |
See Also
Enterprise PeopleTools 8.51 PeopleBook: PS/nVision
PS/nVision Design-Time Globalization Features
The following design-time features of PS/nVision adapt to the current user’s language, enabling you to build a layout that can produce reports in multiple languages:
Use the PeopleSoft nVision Layout Definition dialog box: String tab to set up string criteria for the current cell selection:
To set up string criteria for the current cell selection:
Open the PeopleSoft nVision Layout Definition dialog box.
Select the String tab.
The String tab in the PeopleSoft nVision Layout Definition dialog box appears.
Use this tab to insert a string from the Strings table into a cell in your layout.
Clear the nVision Only String box, if appropriate.
By default, this tab displays only the strings that were created for use with PS/nVision—those with a program ID of NVISION. If you want to select from all available strings, clear the nVision Only String box.
If the nVision Only String box is cleared, select a Program ID.
Note. If the nVision Only String check box is selected, the program ID is NVISION.
In the String ID field, select the ID of the string you want to insert.
Select any of the strings assigned to the program ID that you specified.
Click Apply to save your changes and define string criteria for a different cell, or click OK to save your changes and close the dialog box.
If you clicked Apply, and you want to reuse all or part of the criteria you just applied, select the Retain Contents box. This preserves all the dialog box information when you navigate to a new cell selection. Then repeat steps 3 through 5 to define additional string criteria.
See Also
Using the Strings Table for Language-Sensitive Text in Reports
PS/nVision Run-Time Language Features
The features described below are activated when a user makes a PS/nVision report request.
As PS/nVision looks for a file (such as a Microsoft Excel spreadsheet, layout, or template), it steps through the directories listed in the appropriate paths. The paths are defined in different ways for the PeopleTools development environment and the Web. For the PeopleTools development environment, the paths are defined in PeopleSoft Configuration Manager. In the web, the paths are defined in the [nVision] section of the PeopleSoft Process Scheduler configuration file (psprcs.cfg).
Before looking in each directory, PS/nVision looks in a subdirectory named by the user’s language code. If the file is not there, or if the appropriate directory does not exist, PS/nVision looks in the directory named in the path. If the file is not there, PS/nVision moves to the next directory in the path and repeats the process.
For example, when searching for NVSUSER files for a user with France as the preferred language and the defined path for macros is PS_HOME\EXCEL, PS/nVision searches for PS_HOME\EXCEL\FRA directory first. If the files are not found, PS/nVision uses the files in the PS_HOME\EXCEL.
This feature supports users who need or prefer different layouts and for users of different languages. For example, it may be necessary to create an earnings report differently in Germany and France because differences in accounting rules or management requirements dictate different criteria and formatting. So, if a French user runs a PS/nVision report, PeopleTools first looks in the FRA directory under the PS/nVision directory that is defined for an installation. If the required report layout isn’t found in the FRA directory, PeopleTools uses the generic report layout in the base PS/nVision directory.
The PS/nVision Report Request page includes a Language Template text box on the Advanced Options page. In the Foreign Language Translation field, enter an alternate language code to automatically generate a translated report. If you are applying a scope to the report request, enter a string containing one or more PS/nVision variables.
If you enter one or more variables in the Foreign Language Translation field, then the value of each variable is interpreted at runtime to get the language code for each report instance. This enables retrieval of the language code from a tree node or value table that is associated with the values in the scope.
The syntax of this variable is as follows:
%DES.[scopefield].{detailfield|.nodefield|detailfield.nodefield}%
Note that the field names required vary, depending on the type of scope you’re using. However, the periods between the values must always exist—except in the case of a trailing period. The scopefield parameter is optional. If you don’t specify one, PS/nVision uses the first scope field you defined. If you want to use a field other than the first one defined in the scope, then you must specify which one.
You can provide a detailfield, nodefield, or both. PS/nVision uses the appropriate field type based on your scope. Consequently, specifying one of each type enables you to change your scope definition without necessarily changing this variable. The detail and node table fields you specify should store PeopleSoft language codes and can be found on the same node or detail value table associated with the scopefield. Typically, the field name used is LANGUAGE_CD.
The following example shows a common implementation of this variable (note the inclusion of the extra period):
%DES..LANGUAGE_CD.LANGUAGE_CD%
If your scope consists of multiple scope fields (PRODUCT and BUSINESS_UNIT), your variable might look like this:
%DES.BUSINESS_UNIT.LANGUAGE_CD.LANGUAGE_CD%
If you don’t include a scopefield or detailfield value, it’s important that you still include the extra periods that follow those values. For example:
%DES...nodefield% %DES.scopefield..nodefield%
However, if you don’t include a nodefield, then there’s no need to include the trailing period after the detailfield. For example:
%DES..detailfield%
Using a scopefield to drive the language of the PS/nVision report enables you to run a single report in multiple languages. Each time the contents of the scopefield change, PS/nVision resets the language of the report and reloads the strings and other language-sensitive objects in the new language. This enables you to create a PS/nVision report in multiple languages so that the report can be separated and delivered to multiple recipients, each of whom may have a different language preference.
When retrieving node or detail row and column labels, PS/nVision uses the appropriate alternate language record, if one has been defined through Application Designer, to get labels in the user’s language.
When retrieving a descriptive value for a PS/nVision variable, such as Business Unit Description, PS/nVision determines whether the table being queried has a related language record and if the field being retrieved is on that record. If so, and if the user does not use the base language, PS/nVision retrieves the value from the related language record or, if the row doesn’t exist on the related language record, from the base record.
See Also
International Versions of Microsoft Excel
Microsoft Excel is available in numerous languages. PeopleTools is designed to work with all international editions of the supported release of Microsoft Excel.
Note. Downloaded data such as numbers and dates are formatted in the Microsoft Excel spreadsheet according to the regional settings on the user's machine.
See Also
PeopleTools 8.51 Hardware and Software Requirements Guide
XML Publisher
XML Publisher supports translation of report templates. You can create template translation files for the template's "translatable units" only when the report template or sub-template is in the RTF format. When the translation exercise is complete, the translation file is uploaded and integrated into the XML Publisher translation system.
More information on template translation can be found in the XML Publisher PeopleBook.
See Maintaining Template Translations.