|
|
リホスティングとは、プロプライエタリ・ハードウェアおよびソフトウェアに閉じ込められた状態のビジネス・ロジックやビジネス・データへの高額投資を守りつつ、拡張性が高いオープン・アーキテクチャに移行して、将来の最新化への道を開く方法です。
Refine for Z/OS Replatformingパッケージで提供される自動移行ツールを使用すると、COBOL、JCL、DB2、VSAMファイルおよびIBM DB2メインフレーム環境の関連アセットのプラットフォームを変更して、Oracle Tuxedoトランザクション・プロセッサとOracleデータベースを含むUNIX環境に移行できます。
プラグインの目的は、次の機能を提供することで複雑な処理に対応することです。
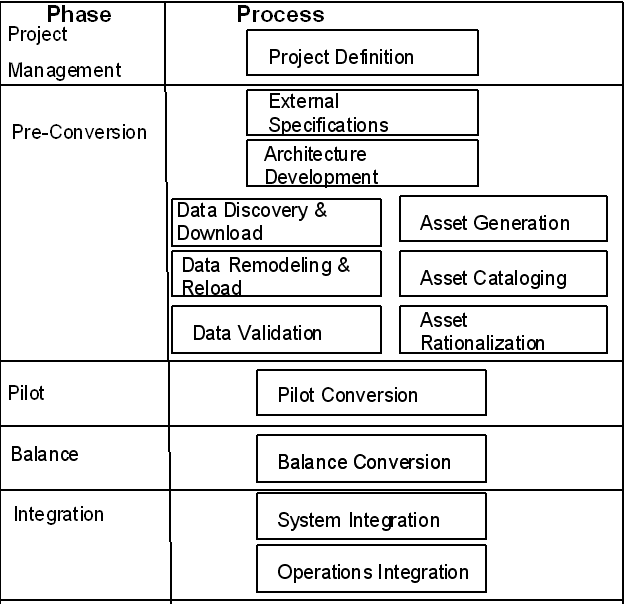
Refine for Z/OS ReplatformingおよびOracle Tuxedo Application Runtime for CICS and Batchは、リホスティング・プロジェクトという枠組みで使用されます。このプロセス・ガイドではリホスティングの概要を説明し、このプロセスでの変換ツールやランタイム・ツールの使用方法を示します。リホスティング・プロジェクトでは、特定のテスト環境、統合環境および本番環境の作成が必要になります。通常、リホスティング・プロジェクトの内容は次のとおりです。
これらは繰り返して行うことができます。通常、プロジェクトは次のフェーズで構成されます。
これらの各フェーズは様々なステップで構成されます。ステップの結果はテストできます。また、ステップは必要に応じて繰り返されます。
リホスティングは、フェーズとステップで編成されたプロジェクトとして実行されます。各ステップは、1つ以上の成果物を生成します。リホスティング・プロジェクトの様々なステップと並行して、プロジェクトの様々なフェーズを検証する一連の並列テスト・ステップが存在します。
1つのプロジェクトには、そのプロジェクト内で様々な役割および責任を負う、様々な人々が関わっています。プロジェクトは環境内で実行されるため、プロジェクトの様々なフェーズおよびステップについて説明するには、まずそのプロジェクトを実行する必要のある環境について説明する必要があります。
リホスティング・プロジェクトを実行するためには5つの異なる環境が必要です。次に示す2つのソース環境(移行前)と3つのターゲット環境(移行後)です。
ニーズによっては同一のプラットフォームを複数配置して、同じプロジェクトの作業をチームで並行して行うことが可能です。
1つのプロジェクトは複数の作業フェーズに分割されており、明瞭な成果物が生成されます。これらの成果物は、プロジェクトの次のフェーズに進む前に検証されます。これらのフェーズを、次に示します。
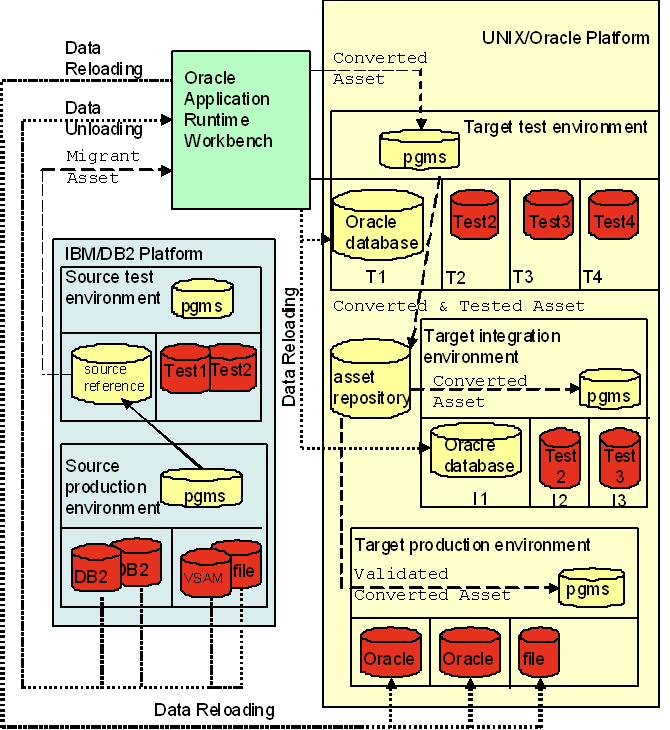
Refine for Z/OS Replatformingを使用して、プログラムのコンポーネントとデータを変換および統合します。次の図は、プログラム・コンポーネントの用途と、異なる環境への移行に備えてソース・ファイルを準備するためにプログラム・コンポーネントがどのように使用されるかを示します。
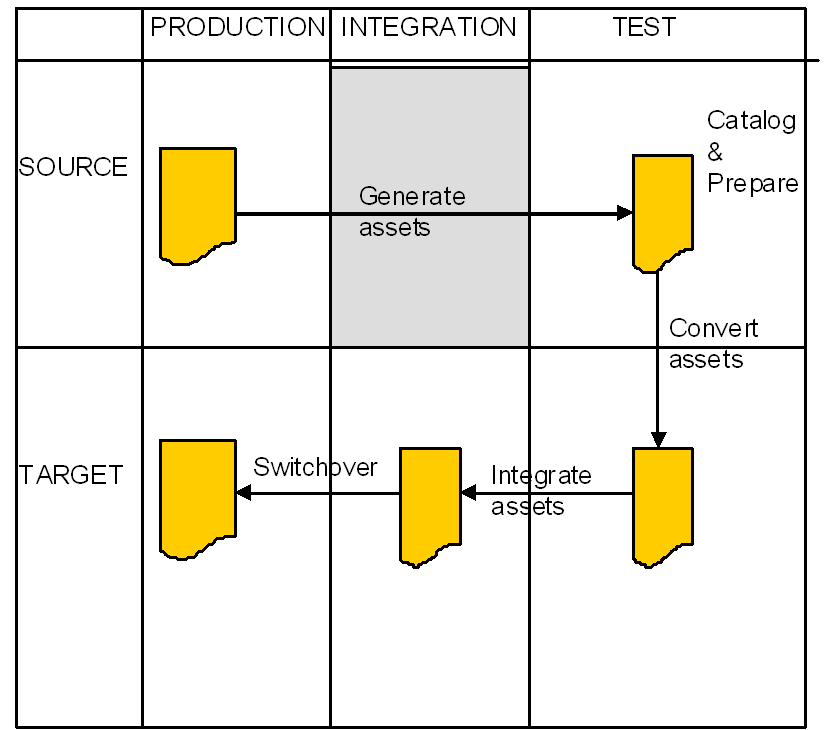
Refine for Z/OS Replatformingのコンポーネントを使用してアセットを変換し、変換後の調整の後で、アセットをソース・テスト環境からターゲット・テスト環境に移動できるようにします。
Oracle Tuxedo Application Runtime for CICS and Batchのコンポーネントを使用し、ターゲット・テスト環境でのテストと統合準備の後で、変換されたアセットを統合します。COBOLプログラム、JCLおよび関連コンポーネントが、UNIX、OracleデータベースおよびTuxedoトランザクション環境に統合されます。これらのコンポーネントは、変換プロセスで生成されるバッチ・コンポーネントおよびCICSコンポーネントとともに作動するかどうかテストされます。
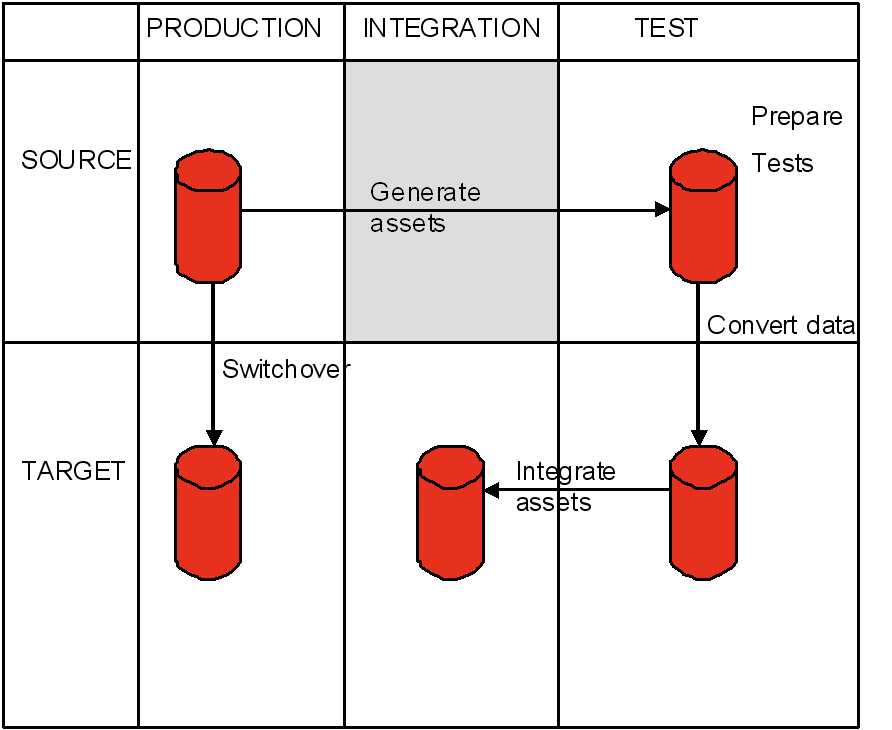
移行するアセットが生成され、ソース・テスト・マシンに移動されます。その後、移行されたアセットは変換され、Oracleデータベースがあるターゲット・テスト・マシンに移動されます。テストの後、データはリホスティング・ツールとプログラムが統合された統合環境に移動され、変換されたデータを使用して品質とパフォーマンスがテストされます。スイッチオーバーが行われると、最新データがソース本番環境からターゲット本番環境に直接変換されます。
Eclipse IDE for Java Developers Galileo (3.5)以上
プラグインをインストールするには、com.oracle.tuxedo.wbplugin_x.x.x.x.jarファイル(Tuxedo ART Workbenchインストール・ディレクトリの下のutils/eclipse_pluginサブディレクトリにあります)を$ECLIPSE_HOME/pluginsディレクトリにコピーしてから、Eclipseを再起動する必要があります。
| 注: | プラグインは一度に1つのバージョンのみ使用できます。新バージョンをインストールする前に、旧バージョンのプラグインをすべて削除する必要があります。 |
| 注: | ただし、バージョンを更新しても、新しいプラグインはEclipse再起動後に有効にならない場合があります。Eclipseを起動してEclipseでこれらのキャッシュを強制的に再初期化する場合、-cleanオプションをコマンド行引数として使用します。 |
プラグインには、Eclipse関連のTuxedo ART Workbenchビュー、メニューおよびツールバーを編成するTuxedo ART Workbenchパースペクティブがあります。また、Tuxedo ART Workbenchプロジェクト用に作成されたナビゲータもあります。
プラグインには、移行プロセスを分析するためのカタロガ・レポート・ビューおよびプロセス・モニター・ビューがあります。
Eclipseプラットフォームで、パースペクティブは、ウィンドウ内で表示可能なアクションおよびビューを決定します。
Tuxedo ART Workbenchパースペクティブは、次のビューから構成されます。
Tuxedo ART Workbenchパースペクティブでは、Tuxedo ART Workbench固有のアクション/コマンドもメニュー項目およびツールバー・ボタンとして表示されます。
Tuxedo ART Workbenchは、内部にあるEclipseの一般的なナビゲータとよく似ています。違いは、Tuxedo ART WorkbenchのナビゲータにはARTプロジェクトのみが表示されることです。
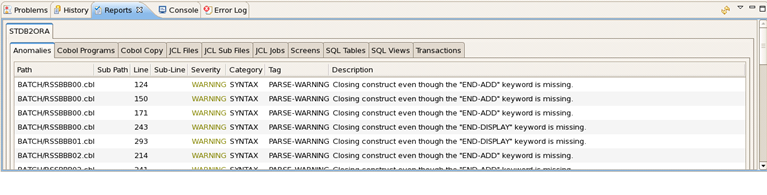
カタロガの出力レポートは、レポート・ビューに表示されます(図1-5を参照)。タブに各レポートが表示されます。ビューはARTパースペクティブに統合されています。「クローズ」ボタンをクリックして閉じるか、メイン・メニューから再度開きます。
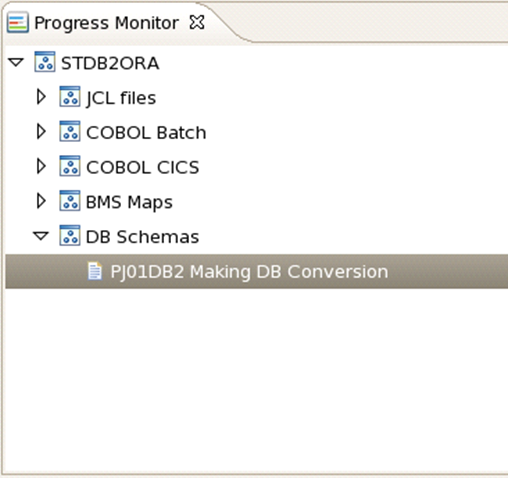
進捗モニター・ビューを使用すると、処理中のソース・ファイルまたはスキーマを確認できます。最初にソース・ツリーが表示され、図1-6に示されているようにソース・タイプ別に編成されている現在のプロジェクト内のソースまたはスキーマの構造が示されます。
カタログ化、JCL変換およびCOBOL変換のプロセスとともに、現在処理中のソース・ファイルがソース・ツリー内でハイライトされます。
DB変換およびファイル変換では、現在処理中のDBスキーマまたはファイル・スキーマがスキーマ・リスト内でハイライトされます。
プラグインには、手順を追って変換タスクを示す移行プロセス・チート・シートが含まれています。チート・シートを開くには、メイン・メニューの「ヘルプ」→チート・シートをクリックし、ARTグループの下のSTDB2ORAサンプルのART移行プロジェクトの作成という名前のチートシートを選択します。
このチート・シートは、Tuxedo ART Workbench Eclipseプラグインを使用したメインフレーム・アーティファクト移行の実行方法を示します。ARTプロジェクトの作成後、すべてのTuxedo ART Workbenchの機能(カタログ化、VSAMファイルの変換、DB2スキーマの変換、COBOLおよびJCLソースの変換など)をEclipseで実行できます。
Tuxedo ART Workbenchグローバル・オプションの一部は、Eclipseの「Preference」ページで設定されます。次の項目が含まれます。
このグローバル・プリファレンスは、デフォルトですべてのARTプロジェクトに影響します。
この項では、メニュー項目とそれらの関連タスクの全般的な概要を説明します。
メニュー項目例の詳細は、付録Bおよび「付録C: Oracle Tuxedo Application Rehosting Workbenchのログ」を参照してください。
図1-7は、Tuxedo ART Workbenchのハイレベル・ワークフローの図です。
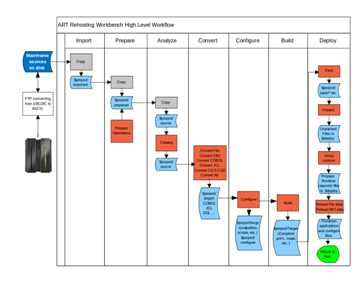
アセットをARTプロジェクトにコピーするプロセスです。インポート・ウィザードを使用してインポートする対象サブディレクトリをユーザーは指定できます。これらのRAWファイルは、移行プロセス全体で変わりません。
準備では、移行アセットを収集し、変換を進めるために事前処理を行うことが必要です。これには、ファイルのトランスコーディング、未認識文字の削除およびファイルの名前変更など、元のアセットの形式の更新プロセスが含まれます。
準備のタスクは、表1-4に示すとおりです。
ソース・アセットにデータを移入し、分析レポートを生成します。
分析のタスクは、表1-5に示すとおりです。
変換フェーズで増分変換がCOBOL変換とJCL変換用にサポートされています。増分変換はPOBファイルと対応ターゲット・ファイルのタイムスタンプに基づきます。そのタイムスタンプが対応ターゲット・ファイルよりも新しい場合のみ、POBファイルの変換が行われます。ただし、RDBMSとFILEの変換における基本的なメカニズムの相違により、変換フェーズではそれらの増分変換をサポートしていません。
変換タスクは、表1-6に示すとおりです。
| 注: | 「ファイル定義の変換」には、バッファ・コンバータと逆コンバータも含まれます。デフォルトでは、これら2つのコンバータは無効になっており、プロジェクトのプロパティ・ページで有効にできます。 |
この手順では、デフォルトのビルド・スクリプト、TUXEDO構成ファイル、CICSとBatchのランタイム環境構成ファイルが生成されます。構成メニューの下にあるウィザードによりユーザー指定オプションでカスタマイズできます。
構成のタスクは、表1-7に示すとおりです。
| 注: | 現時点では、Oracle Databaseへのクライアントとしての接続のみがサポートされています。接続文字列はsqlplus user/password@connect_identifierです。 |
この手順では、データベース・スキーマが作成されます。アプリケーション・コンポーネント、データ再ロード・プログラム、データ・アクセス・プログラムおよびTUXEDO構成ファイルがコンパイルされます。
ビルドのタスクは、表1-8に示すとおりです。
変換済アセットを圧縮して、ローカル・マシンの場合、ターゲット・プラットフォームで解凍するプロセスです。
デプロイメントのタスクは、表1-9に示すとおりです。
ターゲット・プラットフォーム上で変換済アプリケーションをテストのために実行するプロセスです。欠落している実行タスクは、表1-10に示すとおりです。
指定したステップをロールバックします。リセットのタスクは、表1-11に示すとおりです。
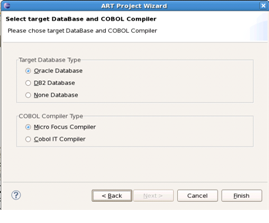
新規プロジェクト・ウィザードを使用して、新しいARTプロジェクトを作成する必要があります。次の手順を実行します。
新しいARTプロジェクトの作成後、図1-13に示されているようにプロジェクトのプロパティ・ページ内のプロジェクト・プロパティを構成する必要があります。
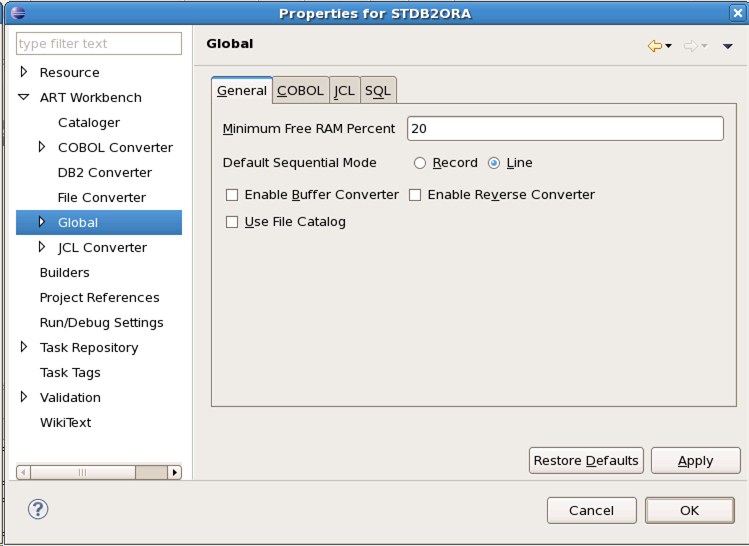
Tuxedo ART Workbenchの構成可能オプションのほとんどは、プロジェクトのプロパティ・ページで構成できます。このページは、Tuxedo ART Workbenchの構成オプションを簡単に表示および変更する手段を提供します。これらのオプションは、タイプ別に編成されます。詳細は、Tuxedo ART Workbenchリファレンス・ガイドの構成ファイルの説明に関する項を参照してください。
この項では、Eclipseプラグイン・インポート・ウィザードを使用する方法について説明します。
プロジェクト作成中に指定したディレクトリのサブディレクトリすべてが、表で最初の列に表示されます。2番目の列をクリックすると、関連サブディレクトリをインポートしたりインポートしないことができます。最後の列はインポートのステータスです。このサブディレクトリが前にインポートされる必要がある場合、「はい」と表示されます。それ以外の場合、「いいえ」と表示されます。
インポート済ソース・ファイルで分析や変換のフェーズをユーザーが実行してから、インポート・ウィザードを実行して、ソース・ファイルが格納されている新規サブディレクトリや新規ソース・ファイルをインポートする場合、後でインポートされたソース・ファイルのみが、分析フェーズで処理されます。ユーザーが分析フェーズの出力を消去する必要がある場合でなければ、これは増分処理です。
この項では、Eclipseプラグイン準備ウィザードを使用する方法に関する情報と手順について説明します。
準備プロセスの前に、インタプリタによりカスタム・スクリプトが自動的に実行されます。ディレクトリ・パスを引数として使用してコールされます。
複数のディレクトリが選択されていると、カスタム・スクリプトが複数回実行されます。その際、毎回ディレクトリ・パスを引数として使用します。
標準出力と標準カスタム・スクリプト実行エラーがログ・ファイルにダンプ出力されます。
EBCDICベースのエンコーディングがIBMメインフレームで使用されます。ASCIIベースのエンコーディングがオープン・システムで使用されます。
このユーティリティを使用して、EBCDICエンコーディングのマルチバイト文字(IBM-1390など)をオープン・システムのマルチバイト文字(Shift-JISなど)に変換できます。ICUで使用されるエンコーディング名は、convで使用されるものと同じであり、UNIX/Linuxで一般的なユーティリティなので、iconvオンライン・ヘルプを参照することで、エンコーディング名を簡単に取得できます。
| ヒント: | uconv -lコマンドをシェルで入力すると、エンコーディング名がリストされます。 |
改行マーカーはDOSシステム(0x0D0Aを使用)とUNIX/Linuxシステム(0x0Aを使用)とで異なります。
このユーティリティを使用して、DOS形式のテキスト・ファイルをUNIX/Linux形式に変換できます。
拡張子を除いてファイル名を大文字に変更する機能が実現されます。
「準備手順の前におけるカスタム・スクリプトの実行」と同様なタスクを実行します。準備タスクにより処理されたソース・ファイルに対してスクリプトがここで適用します。
| 注: | これらのプラクティスおよび方法はTuxedo ART Workbench製品の一部ではありませんが、新しいユーザーを支援する目的でこのガイドに示しています。そうでない場合は先に進み、独自の方法でTuxedo ART Workbenchをカスタマイズし、独自の方法を作り出すことができます。 |
Tuxedo ART Workbenchカタロガは、次の項で説明されています。
Tuxedo ART Workbenchカタロガで使用されるプロセス、概念および用語を理解し、カタロガが必要とする入力、出力および構成を知る必要があります。また、アセットに一貫性があるか、移行できるかどうかを決定するために、どのようにすべてのコンポーネントが個別および一緒に分析されるかを知る必要があります。
Tuxedo ART Workbenchリファレンス・ガイドには、カタロガのすべての機能が詳しく説明されています。概念、用語、入力と出力、および構成の紹介について、カタロガの章の少なくとも最初の3つの項を読んでください。
UNIX/Linuxスキルは、移行プラットフォーム環境で正しく作業し、カタログ化プロセスに伴う特定のアクションを実行するのに必要です。次のことを知っている必要があります。
z/OSコンポーネントおよびプログラミング言語を識別し理解できる必要があります。z/OS環境における一般的なスキル(COBOL、ファイル、DB2、CICS、JCL、ユーティリティ)は十分条件です。
移行プラットフォームとは、カタロガなどのTuxedo ART Workbench移行ツールが実行するプラットフォームのことです。このプラットフォームはIntel互換のハードウェア・プラットフォーム上で実行するLinux をベースにしています。
アクションを実行する前に、Oracle Tuxedo Application Rehosting Workbenchインストレーション・ガイドに記載されている仕様および要件に従い、Tuxedo ART Workbenchをインストールおよび構成する必要があります。
この項ではスコープ構成ウィザードの使用方法について説明します。インポートされたサブディレクトリはすべて、表で最初の列に表示されます。プラグインではソース・タイプを自動的に検出できる場合があり、ルールは次のようになります。
*.cbl: CICS、BatchおよびSubを含めて、COBOLソース・プログラム
既知の拡張子が見つかると、分析ウィザードでは検索を停止し、検出した拡張子に対応するタイプとしてサブディレクトリのソース・タイプを決定します。
既知の拡張子が見つかると、分析ウィザードでは検索を停止し、検出した拡張子に対応するタイプとしてサブディレクトリのソース・タイプを決定します。
表で最後の列をクリックすると、ユーザーは各サブディレクトリのプロセスを有効または無効にできます。
「サブディレクトリの詳細設定」をクリックすると、多数のオプションが表示されます。各オプションの意味を明確にするには、Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドのカタログに関する項を参照してください。
この項では、カタログ化の手順の入力および出力と、プラットフォーム移行プロセスにおける他の移行の手順との依存関係を説明します。
実行されるすべての移行アクティビティと、Tuxedo ART Workbenchカタロガを使用してアセットに一貫性があるかどうか、ターゲット・プラットフォームに移行できるかどうかの判断方法を説明するために、Simple Application STFILEORAを使用します。STFILEORAはTuxedo ART Workbenchのツールのセットとともに提供されます。
この手順はカタロガの前提条件で、移行プロセス全体の概要を説明するOracle Tuxedo Applicationプロセス・ガイドで記載されているように、ソース・プラットフォームでのソース・ファイルの収集、移行プラットフォームへの転送、適切なファイル構造でのインストール、移行の準備を担当するのはTuxedo ART Workbenchのユーザーです。
アセットの作成は、ソースを取得してから、カタロガ・ツールへの有効な入力として使用できるように構成するまで、いくつかの手順からなります。
Tuxedo ART Workbenchカタロガは移行プロセスで使用されるOracle Tuxedo Application Workbenchスイートの最初のツールなので、実行するプロジェクト全体に一般的な構成手順をここで説明します。
作業領域を構成および標準化すればするほど、移行タスクはより容易になり自動化されます。
次のサンプルで、典型的な構造を示し、同じ構造で作業することをお薦めします。
SampleApp
|-- Logs
|-- param
| `-- system.desc
|-- source
| `-- makefile
|-- trf
|-- tools
|-- tmp
Tuxedo ART Workbenchを使用してプロジェクトで作業するたびに、後で有用になる特定の環境変数を設定することをお薦めします。環境変数で必須なのはREFINEDISTRIBのみで、他は単純化の目的で使用できます。
表1-12は、提案された変数の使用方法を説明しています。
プロジェクト例のSimple Applicationでは、export Linuxコマンドを使用してすべての初期化を含む$PROJECT/.projectという名前の設定ファイルを使用します。このファイルはプロジェクトで作業するために新しいLinuxセッションが開かれるたびに実行されます。
echo "Welcome to SampleApp"
export GROUP=refine
export PROJECT=${HOME}/SampleAppexport LOGS=${PROJECT}/Logsexport SOURCE=${PROJECT}/sourceexport PARAM=${PROJECT}/paramexport REFINEDIR=/product/art_wb11gR1/refine
export PHOENIX=${REFINEDIR}export TMPPROJECT=${PROJECT}/tmpexport REFINEDISTRIB=Linux64
$PROJECT/paramディレクトリにコピーし、必要な変更を行います。$PROJECT/sourceへコピーします。 .projectを$PROJECTの下に作成し、環境および作業変数の設定にリストした変数で初期化します。このファイルの変数はプロジェクトで作業するたびにエクスポートされます。$PROJECT/sourceにコピーします。少なくとも2つの構成ファイルを設定する必要があり、追加の構成ファイルについては高度な使用の項で説明します。
システム記述ファイルはTuxedo ART Workbenchツールのメイン構成ファイルです。
../source global-options catalog = "../param/options-catalog.desc".
system SampleApp root "../source"
global-options
catalog="../param/options-catalog.desc",
no-END-Xxx.
DBMS-VERSION="8".
% Copies
directory "COPY" type COBOL-Library files "*.cpy".
% DDL
directory "DDL" type SQL-SCRIPT files "*.ddl".
% Batch
directory "BATCH" type COBOL-Batch files "*.cbl" libraries "COPY". %, "INCLUDE".
% Cics COBOL Tp
%
directory "CICS" type COBOL-TPR files "*.cbl" libraries "COPY". %, "INCLUDE".
カタロガのオプション・ファイルの目的は、動作に影響する追加の情報をカタロガに与えることです。
Simple Applicationの例では、3つのオプションのみを使用しますが、他のオプションも使用できます。オプションの完全なリストは、Tuxedo ART Workbenchリファレンス・ガイドを参照してください。
%% Options for cataloging the system
job-card-optional.
カタログ化を1つのコマンドで実行することができます。すべての操作は順次実行されます。
${REFINEDIR}/refine r4z-catalog -s $PARAM/system.desc ディレクトリ$LOGS/catalogからコマンドを実行します。
${REFINEDIR}/refine r4z-catalog -s $PARAM/system.desc実行ログは画面に出力され、同時に、コマンドを開始したディレクトリの下のログ・ファイルにリダイレクトされます。
この手順の実行は、カタログ化全体を待つことなく、特定のプログラムをチェックして結果を見たい場合に有用です。
# parse only one program
${REFINEDIR}/refine r4z-preparse-files -s $PARAM/system.desc CICS/PGMM000.cbl# parse a list of programs
# build a list that contains programs with path from source (CICS/PGMM000.cbl)
${REFINEDIR}/refine r4z-preparse-files -s $PARAM/system.desc -f list-of-file この手順の結果は、コンポーネント間の情報を示すsymtab-SampleApp.pobという名前のバイナリ・ファイルです。
cd $LOGDIR/catalog
${REFINEDIR}/refine r4z-analyze -s $PARAM/system.descこの手順で、バイナリ・ファイルに格納された情報が収集され、CSV形式のレポートに印刷されます。
cd $LOGDIR/catalog
$REFINEDIR/refine r4z-fast-final -v M2_L3_3 -s $PARAM/system.desc
Simple Applicationでは、レポートは$PROJECT/source/Reports-SampleAppに生成されます。
この他のレポートはOracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドに記載されています。
カタログ化レポートを使用して、移行する正確なアセット・セットの作成のための様々なアクションを実行し、Tuxedo ART Workbenchの手順のCOBOL変換、JCL変換およびデータ変換を開始できます。
| 注: | これは、カタログ化および変換アクティビティが厳密に順次であるということを意味しているわけではなく、それらは重なる可能性があります。 |
カタログ化の後、各プログラム、Copy、Job、Includeにはその使用に応じたステータスが与えられます。
異常レポートに報告されたすべてのエラーは分析する必要があります。
変換に進む前に、アセットに重大なエラーが含まれないようにする必要があります。
カタログ化はすべての必要な出力(POBファイルおよびカタログ化レポート)が生成されたら完了とみなすことができます。
プロセスとして、プロジェクトの内容によりますが、一般的にカタログ化は次の場合に完了したとみなされます。
makeはターゲットの構成(ファイルまたはアクション)を自動化および最適化するためのUNIXユーティリティです。
makeを使用して移行プロセスを構成する様々な操作を実行することを強くお薦めする理由は次のとおりです。
すべての操作が実装されるソース・ディレクトリにmakefileという名前の記述子ファイルが存在する必要があります(プロジェクトの初期化中にmakefileがソース・ディレクトリに準備される)。
次の2つの項でmake構成およびmakeによるカタロガ機能の使用方法について説明します。
$PARAM内のversion.mk構成ファイルはmakeユーティリティが必要とする変数およびパラメータを設定するのに使用されます。
このファイルでは、各タイプのコンポーネントがインストールされる場所とその拡張機能、使用される様々なツールのバージョンを指定します。このファイルにはログ・ファイルの構成方法も記述されます。
Root = ${PROJECT}#
# Define directory Project
#
Find_Jcl = JCL
Find_Prg = BATCH
Find_Tpr = CICS
Find_Spg =
Find_Map = MAP
SCHEMAS = AV
…
#Logs organisation
#
LOGDIR := $(LOGS)
CATALDIR := $(LOGS)/catalog
PARSEDIR := $(LOGS)/parse
TRADJCLDIR := $(LOGS)/trans-jcl
TRADDIR := $(LOGS)/trans-cbl
DATADIR := $(LOGS)/data
…
Simple Applicationとともに提供されるmakefileは自動的にドキュメント化されます。
> make pob> make pob VERIF=TRUE
Check: Parse of BATCH/PGMMB02.cbl Need Process.. To obtain BATCH/pob/PGMMB02.cbl.pob
サンプル: プログラムBATCH/PGMMB02.cblの解析
> make BATCH/pob/PGMMB02.cbl.pob
make catalog
Makefileを更新して、ターゲットを追加または既存のターゲットを更新できます。
たとえば、独自のスクリプト(report.sh)を作成して、基本のカタログ化レポートを基にしてカスタマイズしたレポートを生成する場合、そのスクリプトは$TOOLSディレクトリに置きます。
構成の不足が原因でmakeによるコマンドが正常に動作しないことがあります。
> make catalog VERIF=TRUE -f makefile.debug
z/OSソース・プラットフォームからターゲット・プラットフォームへ移行する時の最初の問題は、VSAMに関する場合、ファイルを保持するかまたはデータをOracle表に移行するかということです。
Tuxedo ART Workbench File-to-Fileコンバータは、ソース・プラットフォームの形式(順次、相対または索引付きファイル)をターゲット・プラットフォーム上で保持するファイル向けに使用されます。ターゲット・プラットフォームで、これらのファイルはソース・プラットフォームでの編成に相当するターゲットCOBOL (Micro Focus COBOL/COBOL-IT)のファイル編成を使用します。
表1-14は、z/OSにより処理されるファイル編成をリストし、ターゲット・プラットフォームで提案される編成を示します。
| 注: | z/OSファイルのISAM UNIXファイルへの変換には、COBOLアプリケーション・プログラムまたはJCLの変換への直接リンクがありません。 |
PDSの一部であるファイルは、METAW00.NIV1.ESSAI(FIC)などの物理ファイル名自体で識別されます。
このケースでは、PDSに合せて調整されたアンロード用JCLが生成されます。前述の表に示したソースとターゲットのファイル編成が適用されます。
世代別データ・グループ(GDG)ファイルは、その特殊性(アンロードおよび再ロードするGDGアーカイブの数)を維持するように、アンロード・コンポーネントおよび再ロード・コンポーネントによって特別に処理されます。その後、世代ファイルとしてOracle Tuxedo Application Runtime Batchで管理されます(詳細は、Oracle Tuxedo Application Runtime Batchリファレンス・ガイドを参照)。ターゲット・プラットフォームでは、これらのファイルはLINE SEQUENTIAL編成になります。
この章で詳細が説明されている、ファイルからファイルへの移行プロセスの原則的な手順は次のとおりです。
この項ではファイルの移行の開始前に実行する手順について説明します。
z/OSファイルのUNIX/Linuxへの移行は、Tuxedo ART Workbenchカタロガの結果に依存します(詳細は、「分析」を参照してください)。これはCOBOLコンポーネントまたはJCLコンポーネントの変換に影響を与えません。
最初のタスクは、移行するファイルをすべてリストすることで、これにはOracle表から取得されない処理ユニットへの永続ファイル入力などが含まれます。
移行の候補となる各ファイルについて、その構造をCOBOL形式で記述する必要があります。この記述はTuxedo ART Workbench COBOLコンバータによってCOBOLコピーで使用され、「COBOL記述」に記載されている制限の対象になります。
移行ファイル・リストが一度作成されたら、同一構造のファイルをパージすることができます。これは、データのトランスコードと再ロードに必要なプログラム数を減らして、ファイルを移行する際の作業を減らすためです。
パージしたファイル・リストを使用し、最後のタスクとして次のファイルを作成します。
| 注: | populate.shユーティリティ(REFINEDIR/scripts/file/populate.shにある)を使用して、これら2つの構成ファイルを自動生成できます。詳細は、REFINEDIR/scripts/file/README.txtを参照してください。 |
COBOL記述は各ファイルと関連し、アプリケーション・プログラムで使用されるCOBOL記述を表すものとみなされます。この記述はOCCURSおよびREDEFINESの概念を含む、すべてのCOBOLデータ型を使用する複雑なCOBOL構造にすることができます。
多くの場合、このCOBOL記述はCOBOLファイル記述(FD)よりも発展させることができます。たとえば、FDフィールドはPIC X(364)と記述できますが、実際には定義された3倍の領域に相当し、COMP-3ベースの数値表や、いくつかの文字フィールドや数値フィールドなどの複雑な記述を含むことができます。
実際のアプリケーションを説明するのはこのような詳細なCOBOL記述です。このため、特定の物理ファイルを移行するための基盤として使用されます。
ファイル処理の実行の品質はこのCOBOL記述の品質に左右されます。この点から、COBOL記述はファイルとは分離されず、関連するファイルを参照する時は、ファイルとそれを表現するCOBOL記述の両方を意味します。記述はCOBOL形式で、次の名前のファイルで提供される必要があります。
<COPY name>.cpy
| 注: | ソース・プラットフォームのコピー・ブックにファイルの詳細が記述されている場合は、そのコピーをTuxedo ART Workbenchで直接使用および宣言できます。 |
COBOL記述では、同じメモリー・フィールドを記述する方法がいくつかあり、これは異なる構造と記述でオブジェクトを同じ場所に格納することを意味します。
同じメモリー・フィールドに異なる記述のオブジェクトを含めて、ファイルを読み取ることができるので、このデータ領域を適切に解釈するために、使用する記述を決定するメカニズムが必要です。
ある条件に従い、一般的にレコードの1つまたは複数のフィールドの内容により、再定義領域の読取りに使用する記述を決定(識別)できるルールが必要です。
Tuxedo ART Workbenchでは、このルールは識別ルールと呼ばれます。
識別ルールなしでのCOBOL記述内の再定義では、ファイルのトランスコード時に重大なリスクが存在します。そのため、等価でない再定義済フィールドは識別ルールをリクエストします。他方、等価な再定義(テクニカル再定義と呼ばれる)はCOBOL記述内でクレンジングの対象となる必要があります(次の例を参照)。
識別ルールはファイルごとに用意し、相違点と識別される領域を明確に指定する必要があります。ファイルに関しては、ファイル記述の外部のフィールドを参照することはできません。
次の記述は、Tuxedo ART Workbenchで必要なCOPYのサンプルです。
01 FV14.
05 FV14-X1 PIC X.
05 FV14-X2 PIC XXX.
05 FV14-X3.
10 FV14-MTMGFA PIC 9(2).
10 FV14-NMASMG PIC X(2).
10 FV14-FILLER PIC X(12).
10 FV14-COINFA PIC 9(6)V99.
05 FV14-X4 REDEFINES FV14-X3.
10 FV14-MTMGFA PIC 9(6)V99.
10 FV14-FILLER PIC X(4).
10 FV14-IRETCA PIC X(01).
10 FV14-FILLER PIC X(2).
10 FV14-ZNCERT.
15 FV14-ZNALEA COMP-2.
15 FV14-NOSCP1 COMP-2.
15 FV14-NOSEC2 COMP-2.
15 FV14-NOCERT PIC 9(4) COMP-3.
15 FV14-FILLER PIC X(16).
05 FV14-X5 REDEFINES FV14-X3.
10 FV14-FIL1 PIC X(16).
10 FV14-MNT1 PIC S9(6)V99.
05 FV14-X6 REDEFINES FV14-X3.
10 FV14-FIL3 PIC X(16).
10 FV14-MNT3 PIC S9(6).
10 FV14-FIL4 PIC X(2).
Field FV14-X3
Rule if FV14-X1 = “A” then FV14-X3
elseif FV14-X1 = “B” then FV14-X4
elseif FV14-X1 = “C” then FV14-X5
else FV14-X6
| 注: | COBOL記述では、フィールドFV14-X3が再定義される最初のフィールドである必要があります。それに続くフィールド、FV14-X4、FV14-X5およびFV14-X6の順序は重要ではありません。 |
01 FV15.
05 FV15-MTMGFA PIC 9(2).
05 FV15-ZNPCP3.
10 FV15-NMASMG PIC X(2).
10 FV15-FILLER PIC X(12).
10 FV15-COINFA PIC 9(6)V99.
05 FV15-ZNB2T REDEFINES FV1 5-ZNPCP3.
10 FV15-MTMGFA PIC 9(4)V99.
10 FV15-FILLER PIC X(4).
10 FV15-IRETCA PIC X(01).
10 FV15-FILLER PIC X(2).
10 FV15-ZNCERT
15 FV15-ZNALEA COMP-2.
15 FV15-NOSCP1 COMP-2.
15 FV15-NOSEC2 COMP-2.
15 FV15-NOCERT PIC 9(4) COMP-3.
15 FV15-FILLER PIC X(16).
前述の例では、2つのフィールド(FV15-ZNPCP3およびFV15-ZNB2T)の構造が異なります。最初のフィールドはEBCDIC英数字、次のフィールドはEBCDICデータおよびCOMP2、COMP3データから構成されます。
識別ルールの実装は、データをUNIXプラットフォームに移行するのに必要です。
Field FV15-ZNPCP3
Rule if FV15-MTMGFA = 12 then FV15-ZNPCP3
elseif FV15-MTMGFA = 08 and FV15-NMASMG = "KC " then FV15-ZNB2T
01 FV1.
05 FV1-ZNPCP3.
10 FV1-MTMGFA PIC 9(6)V99.
10 FV1-NMASMG PIC X(25).
10 FV1-FILLER PIC X(12).
10 FV1-COINFA PIC 9(10).
10 FV2-COINFA REDEFINES FV1-COINFA.
15 FV2-ZNALEA PIC 9(2).
15 FV2-NOSCP1 PIC 9(4).
15 FV2- FILLER PIC 9(4).
10 FV15-MTMGFA PIC 9(6)V99.
10 FV15-FILLER PIC X(4).
10 FV15-IRETCA PIC X(01).
10 FV15-FILLER PIC X(2).
01 FV1. 01 FV1.
05 FV1-ZNPCP3. 05 FV1-ZNPCP3.
10 FV1-MTMGFA PIC 9(6)V99. 10 FV1-MTMGFA PIC 9(6)V99.
10 FV1-NMASMG PIC X(25). 10 FV1-NMASMG PIC X(25).
10 FV1-FILLER PIC X(12). 10 FV1-FILLER PIC X(12).
10 FV1-COINFA PIC 9(10). 10 FV2-COINFA.
10 FV15-MTMGFA PIC 9(6)V99. 15 FV2-ZNALEA PIC 9(2).
10 FV15-FILLER PIC X(4). 15 FV2-NOSCP1 PIC 9(4).
10 FV15-IRETCA PIC X(01). 15 FV2- FILLER PIC X(4).
10 FV15-FILLER PIC X(2). 10 FV15-MTMGFA PIC 9(6)V99.
10 FV15-FILLER PIC X(4).
10 FV15-IRETCA PIC X(01).
10 FV15-FILLER PIC X(2).
前述の例では、2つの記述が単純なEBCDIC英数文字列(バイナリ、パックまたは符号付数字フィールドを除く)に相当します。この種の構造は識別ルールの実装を必要としません。
この項では、データ・ファイルを移行するのに使用されるコンポーネントの生成前に実行するタスクについて説明します。
Tuxedo ART Workbenchの実行前に次の環境変数を設定します。
次を使用して記述された3つのファイルは、Tuxedo ART Workbenchファイル構造に置く必要があります。
ファイルからファイルへの変換ではこれらのファイルを自分で作成する必要があります。
| 注: | データマップおよびマッパー構成ファイルは同じ構成名を使用する必要があります。 |
これらのファイルはTuxedo ART Workbenchのインストール時にファイル構造に自動的に置かれます。これらのファイルの特定のバージョンが特定のz/OSファイルに必要な場合は、$PARAM/fileファイル構造に置かれます。
次の例は3つのファイル、つまり2つのQSAMファイルと1つのVSAM KSDSファイルの構成を示します。これらのファイルを実装するための識別ルールはありません。
db-param.cfg ファイルで、変更する必要のある可能性のあるパラメータはtarget_osパラメータのみです。
# This configuration file is used by FILE & RDBMS converter
# Lines beginning with "#" are ignored
# write information in lower case
# common parameters for FILE and RDBMS
# source information is written into system descriptor file (OS, DBMS=,
# DBMS-VERSION=)
target_rdbms_name:oracle
target_rdbms_version:11
target_os:unix# optional parametertarget_cobol:cobol_mfhexa-map-file:tr-hexa.map
#
# specific parameters for FILE to RDBMS conversion
file:char_limit_until_varchar:29
# specific parameters for RDBMS conversion
rdbms:date_format:YYYY/MM/DD
rdbms:timestamp_format:YYYY/MM/DD HH24 MI SS
rdbms:time_format:HH24 MI SS
# rename object files
# the file param/rdbms/rename-objects-<schema>.txt is automatically loaded # by the tool if it exists.
target_cobol:cobol_mf
hexa-map-file:tr-hexa.map
hexa-map-fileを指定しない場合は、警告がロギングされます。
システム記述ファイルでのカタログ化中に決定されます。
|
||
| 注: | 使用される様々なパラメータの説明は、Oracle Tuxedo Application WorkbenchのリファレンスガイドのFile To Fileコンバータに関する項を参照してください。 |
次の例では、最初の2つのファイルはQSAMファイルなので編成は常に順次です。PJ01AAA.SS.VSAM.CUSTOMERファイルはVSAM KSDSファイルなので編成は索引付きです。パラメータkeys offset 1 bytes length 6 bytes primaryはキーを記述しています。この例では、キーは6バイトの長さでポジション1から開始します。
%% Lines beginning with "%%" are ignored
data map FTFIL001-map system cat::PROJ001
%%
%% Datamap File PJ01DDD.DO.QSAM.KBCOI001
%%
file PJ01DDD.DO.QSAM.KBCOI001
organization Sequential
%%
%% Datamap File PJ01DDD.DO.QSAM.KBCOI002
%%
file PJ01DDD.DO.QSAM.KBCOI002
organization Sequential
%%
%% Datamap File PJ01AAA.SS.VSAM.CUSTOMER
%%
file PJ01AAA.SS.VSAM.CUSTOMER
organization Indexed
keys offset 1 bytes length 6 bytes primary
データマップ構成ファイルに含まれている、移行する各z/OSファイルをリストする必要があります。
| 注: | 使用される様々なパラメータの説明は、Oracle Tuxedo Application WorkbenchのリファレンスガイドのFile To Fileコンバータに関する項を参照してください。 |
%% Lines beginning with "%%" are ignored
ufas mapper FTFIL001
%%
%% Desc file PJ01DDD.DO.QSAM.KBCOI001
%%
file PJ01DDD.DO.QSAM.KBCOI001 transferred
include "#VAR:RECS-SOURCE#/BCOAC01E.cpy"
map record REC-ENTREE defined in "#VAR:RECS-SOURCE#/BCOAC01E.cpy"
source record REC-ENTREE defined in "#VAR:RECS-SOURCE#/BCOAC01E.cpy"
logical name FQSAM01
converter name FQSAM01
%%
%% Desc file PJ01DDD.DO.QSAM.KBCOI002
%%
file PJ01DDD.DO.QSAM.KBCOI002 transferred
include "#VAR:RECS-SOURCE#/BCOAC04E.cpy"
map record REC-ENTREE-2 defined in "#VAR:RECS-SOURCE#/BCOAC04E.cpy"
source record REC-ENTREE-2 defined in "#VAR:RECS-SOURCE#/BCOAC04E.cpy"
logical name FQSAM02
converter name FQSAM02
%%
%% Desc file PJ01AAA.SS.VSAM.CUSTOMER
%%
file PJ01AAA.SS.VSAM.CUSTOMER transferred
include "COPY/ODCSF0B.cpy"
map record VS-ODCSF0-RECORD defined in "COPY/ODCSF0B.cpy"
source record VS-ODCSF0-RECORD in "COPY/ODCSF0B.cpy"
logical name ODCSF0B
converter name ODCSF0B
コピー・ファイルを保持する$PARAM/file/recs-sourceディレクトリを作成します。
COBOL記述ファイルを準備したら、mapper-<構成名>.reファイルに記述したコピー・ファイルを$PARAM/file/recs-sourceディレクトリに置く必要があります。
ソース・プラットフォームからのCOBOLコピー・ブックを使用してファイルを記述する場合(「COBOL記述」の注意を参照)、それが、上述のCOPY/ODCSF0B.cpyの例のように、マッピング・パラメータ・ファイルで直接使用されるコピー・ブックの場所です。
z/OSファイルの移行に使用するコンポーネントを生成するのに、Tuxedo ART Workbenchではfile.shコマンドを使用します。この項ではこのコマンドについて説明します。
file.sh - z/OS移行コンポーネントを生成します。
file.sh [ [-g] [-m] [-i <installation directory>] <configuration name> | -s <installation directory> (<configuration name>,...) ]
file.shでは、Tuxedo ART Workbenchを使用して、z/OSファイルの移行に使用するコンポーネントを生成します。
attributes句がLOGICAL_MODULE_ONLYに設定されている場合を除き、ファイルからファイルへの移行は適用されません。 この場合、このオプションにより、COBOLコンバータで使用する構成ファイルおよびDMLユーティリティの生成が可能になります。すべての構成ファイルは$PARAM/dynamic-configに、DMLファイルは<trf>/DMLディレクトリに作成されます。
file.sh -gmi $HOME/trf FTFIL001
-i $HOME/trfオプションを使用して生成されたアンロードおよびロード・コンポーネントは次の場所に置かれます。
生成されたコンポーネントはプロジェクトの固有のスクリプトを使用して変更することができます。これらのスクリプト(sed、awk、perlなど)は次の場所に置く必要があります。
$PARAM/file/file-modif-source.sh
このファイルが存在している場合、生成プロセスの最後に自動的に実行されます。引数として<configuration name>を使用して呼び出されます。
Makeはターゲット(ファイルまたはアクション)の構成を自動化および最適化することを目的としたUNIXユーティリティです。
すべての操作が実装されるソース・ディレクトリにmakefileという名前の記述子ファイルが存在する必要があります(makefileはプロジェクトの初期化中にソース・ディレクトリに準備されます)。
次の2つの項では、makefileの構成と、makefileを使用したTuxedo ART Workbench File-To-Fileコンバータ機能の使用方法について説明します。
$PARAMのversion.mk構成ファイルを使用して、Makeユーティリティで必要な変数およびパラメータを設定します。
version.mkには、各種のコンポーネントがインストールされる場所とその拡張を、使用される様々なツールのバージョンとともに指定します。このファイルにはログ・ファイルの構成方法も記述されます。
次の一般的な変数を、version.mkファイルでの移行プロセスの最初に設定する必要があります。
また、FILE_SCHEMAS変数はファイルの移行に特有で、処理する様々な構成を示します。
この構成はMakeファイルの使用の前に完了する必要があります。
makefileおよびversion.mkファイルはTuxedo ART Workbench Simple Applicationとともに提供されます。
make FileConvertコマンドを使用して、Tuxedo ART Workbench File-To-Fileコンバータを起動できます。これによりz/OSファイルのUNIX/Linuxターゲット・プラットフォームへの移行に必要なコンポーネントを生成できます。
MakeファイルはFILE_SCHEMAS変数に含まれるすべての構成に対し、-g、-mおよび-iオプションを指定してfile.shツールを起動できます。
VSAMファイルをソース・プラットフォームからOracle UNIXターゲット・プラットフォームへ移行する時の最初の問題は、VSAMに関する場合、ファイルを保持するかまたはデータをOracle表に移行するかということです。
z/OSで処理されるVSAM RRDS、ESDSおよびKSDSのファイル編成は、Tuxedo ART Workbenchを使用してOracleデータベースに移行できます。
Tuxedo ART Workbench File-to-Oracleコンバータは、Oracle表に変換されるこれらのファイルで使用されます。ファイル形式で残っているファイルについては、「File-to-Fileで生成されたコンバータ・プログラムの実行」を参照してください。
この章で詳細が説明されている、ファイルからOracleへの移行プロセスの原則的な手順は次のとおりです。
VSAMファイルのデータのOracle表への移行は、Tuxedo ART Workbenchカタロガの結果に依存します(詳細は、「分析」を参照してください)。ファイルからOracleへの移行はCOBOLおよびJCLの変換に影響を与えるので、COBOLプログラムの変換作業の開始前に完了する必要があります。
この項ではVSAMファイルのOracle表への移行の開始前に実行する手順について説明します。
最初のタスクは移行するすべてのVSAMファイルをリストし(ファイルからファイルへのコンバータの使用とあわせて)、次にOracle表に変換する必要のあるファイルを識別することです。たとえば、レコード・レベルでロックが必要な、後でOracleまたはファイル経由で使用される永続ファイルです。
移行の候補となる各ファイルについて、その構造をCOBOL形式で記述する必要があります。この記述はTuxedo ART Workbench COBOLコンバータによってCOBOLコピーで使用され、「COBOL記述」に記載されている制限の対象になります。
移行ファイル・リストが一度作成されたら、同一構造のファイルをパージすることができます。これは、データのトランスコードと再ロードに必要なプログラム数を減らして、ファイルを移行する際の作業を減らすためです。
パージされたファイルのリストから、最後のタスクは次のファイルのビルドからなります。
| 注: | populate.shユーティリティ(REFINEDIR/scripts/file/populate.shにある)を使用して、これら2つの構成ファイルを自動生成できます。詳細は、REFINEDIR/scripts/file/README.txtを参照してください。 |
COBOL記述は各ファイルと関連し、アプリケーション・プログラムで使用されるCOBOL記述を表すものとみなされます。この記述はOCCURSおよびREDEFINESの概念を含む、すべてのCOBOLデータ型を使用する複雑なCOBOL構造にすることができます。
多くの場合、このCOBOL記述はCOBOLファイル記述(FD)よりも発展させることができます。たとえば、FDフィールドはPIC X(364)と記述できますが、実際には定義された3倍の領域に相当し、COMP-3ベースの数値表や、いくつかの文字フィールドや数値フィールドなどの複雑な記述を含むことができます。
実際のアプリケーションを説明するのはこのような詳細なCOBOL記述です。このため、特定の物理ファイルを移行するための基盤として使用されます。
ファイル処理の実行の品質はこのCOBOL記述の品質に左右されます。この点から、COBOL記述はファイルとは分離されず、関連するファイルを参照する時は、ファイルとそれを表現するCOBOL記述の両方を意味します。記述はCOBOL形式で、次の名前のファイルで提供される必要があります。
<COPY name>.cpy
| 注: | ソース・プラットフォームのコピー・ブックにファイルの詳細が記述されている場合は、そのファイルをTuxedo ART Workbenchで直接使用および宣言できます。 |
表1-18は、COBOL記述の形式の例を示しています。
COBOL記述では、同じメモリー・フィールドを記述する方法がいくつかあり、これは異なる構造と記述でオブジェクトを同じ場所に格納することを意味します。
同じメモリー・フィールドに異なる記述のオブジェクトを含めて、ファイルを読み取ることができるので、このデータ領域を適切に解釈するために、使用する記述を決定するメカニズムが必要です。
ある条件に従い、一般的にレコードの1つまたは複数のフィールドの内容により、再定義領域の読取りに使用する記述を決定(識別)できるルールが必要です。
Tuxedo ART Workbenchでは、このルールは識別ルールと呼ばれます。
識別ルールなしでのCOBOL記述内の再定義では、ファイルのトランスコード時に重大なリスクが存在します。そのため、等価でない再定義済フィールドは識別ルールをリクエストします。他方、等価な再定義(テクニカル再定義と呼ばれる)はCOBOL記述内でクレンジングの対象となる必要があります(次の例を参照)。
識別ルールはファイルごとに用意し、相違点と識別される領域を明確に指定する必要があります。ファイルに関しては、ファイル記述の外部のフィールドを参照することはできません。
次の記述は、Tuxedo ART Workbenchで必要なCOPYのサンプルです。
01 FV14.
05 FV14-X1 PIC X.
05 FV14-X2 PIC XXX.
05 FV14-X3.
10 FV14-MTMGFA PIC 9(2).
10 FV14-NMASMG PIC X(2).
10 FV14-FILLER PIC X(12).
10 FV14-COINFA PIC 9(6)V99.
05 FV14-X4 REDEFINES FV14-X3.
10 FV14-MTMGFA PIC 9(6)V99.
10 FV14-FILLER PIC X(4).
10 FV14-IRETCA PIC X(01).
10 FV14-FILLER PIC X(2).
10 FV14-ZNCERT.
15 FV14-ZNALEA COMP-2.
15 FV14-NOSCP1 COMP-2.
15 FV14-NOSEC2 COMP-2.
15 FV14-NOCERT PIC 9(4) COMP-3.
15 FV14-FILLER PIC X(16).
05 FV14-X5 REDEFINES FV14-X3.
10 FV14-FIL1 PIC X(16).
10 FV14-MNT1 PIC S9(6)V99.
05 FV14-X6 REDEFINES FV14-X3.
10 FV14-FIL3 PIC X(16).
10 FV14-MNT3 PIC S9(6).
10 FV14-FIL4 PIC X(2).
Field FV14-X3
Rule if FV14-X1 = “A” then FV14-X3
elseif FV14-X1 = “B” then FV14-X4
elseif FV14-X1 = “C” then FV14-X5
else FV14-X6
| 注: | COBOL記述では、フィールドFV14-X3が再定義される最初のフィールドである必要があります。それに続くフィールド、FV14-X4、FV14-X5およびFV14-X6の順序は重要ではありません。 |
01 FV15.
05 FV15-MTMGFA PIC 9(2).
05 FV15-ZNPCP3.
10 FV15-NMASMG PIC X(2).
10 FV15-FILLER PIC X(12).
10 FV15-COINFA PIC 9(6)V99.
05 FV15-ZNB2T REDEFINES FV1 5-ZNPCP3.
10 FV15-MTMGFA PIC 9(4)V99.
10 FV15-FILLER PIC X(4).
10 FV15-IRETCA PIC X(01).
10 FV15-FILLER PIC X(2).
10 FV15-ZNCERT
15 FV15-ZNALEA COMP-2.
15 FV15-NOSCP1 COMP-2.
15 FV15-NOSEC2 COMP-2.
15 FV15-NOCERT PIC 9(4) COMP-3.
15 FV15-FILLER PIC X(16).
前述の例では、2つのフィールド(FV15-ZNPCP3およびFV15-ZNB2T)の構造が異なります。最初のフィールドはEBCDIC英数字、次のフィールドはEBCDICデータおよびCOMP2、COMP3データから構成されます。
識別ルールの実装は、データをUNIXプラットフォームに移行するのに必要です。
Field FV15-ZNPCP3
Rule if FV15-MTMGFA = 12 then FV15-ZNPCP3
elseif FV15-MTMGFA = 08 and FV15-NMASMG = "KC " then FV15-ZNB2T
01 FV1.
05 FV1-ZNPCP3.
10 FV1-MTMGFA PIC 9(6)V99.
10 FV1-NMASMG PIC X(25).
10 FV1-FILLER PIC X(12).
10 FV1-COINFA PIC 9(10).
10 FV2-COINFA REDEFINES FV1-COINFA.
15 FV2-ZNALEA PIC 9(2).
15 FV2-NOSCP1 PIC 9(4).
15 FV2- FILLER PIC 9(4).
10 FV15-MTMGFA PIC 9(6)V99.
10 FV15-FILLER PIC X(4).
10 FV15-IRETCA PIC X(01).
10 FV15-FILLER PIC X(2).
01 FV1. 01 FV1.
05 FV1-ZNPCP3. 05 FV1-ZNPCP3.
10 FV1-MTMGFA PIC 9(6)V99. 10 FV1-MTMGFA PIC 9(6)V99.
10 FV1-NMASMG PIC X(25). 10 FV1-NMASMG PIC X(25).
10 FV1-FILLER PIC X(12). 10 FV1-FILLER PIC X(12).
10 FV1-COINFA PIC 9(10). 10 FV2-COINFA.
10 FV15-MTMGFA PIC 9(6)V99. 15 FV2-ZNALEA PIC 9(2).
10 FV15-FILLER PIC X(4). 15 FV2-NOSCP1 PIC 9(4).
10 FV15-IRETCA PIC X(01). 15 FV2- FILLER PIC X(4).
10 FV15-FILLER PIC X(2). 10 FV15-MTMGFA PIC 9(6)V99.
10 FV15-FILLER PIC X(4).
10 FV15-IRETCA PIC X(01).
10 FV15-FILLER PIC X(2).
前述の例では、2つの記述が単純なEBCDIC英数文字列(バイナリ、パックまたは符号付数字フィールドを除く)に相当します。この種の構造は識別ルールの実装を必要としません。
この項では、VSAMファイルからOracleデータベースへデータを移行するときに、Tuxedo ART Workbenchにより適用されるリエンジニアリング・ルールについて説明します。
table name句を使用してmapper-<configuration name>.reファイルに規定されます。 VSAMファイル(VSAM ESDS)の場合: Tuxedo ART Workbenchによってテクニカル列*_SEQ_NUM NUMBER(8)が追加されます。
この列は新しい行が表に追加されるたびに増加し、表の主キーになります。
VSAMファイル(VSAM RRDS)の場合: Tuxedo ART Workbenchによってテクニカル列*_RELATIVE_NUMが追加されます。
列のサイズはデータマップのパラメータ・ファイルで提供される情報から推測され、この列が表の主キーになります。
VSAMファイル(VSAM KSDS)の場合: Tuxedo ART Workbenchでは、重複キーを受け入れないかぎり、テクニカル列が追加されず、VSAMファイルの主キーが表の主キーになります。
データをVSAMファイルからOracle表へ移行するときに、次のルールがCOBOL Picture句に適用されます。
|
識別ルールが適用されるOCCURSおよびREDEFINES句の場合、次の3つのリエンジニアリングの可能性が提案されます。
次の例では、ODCSFOBに記述された索引付きVSAMファイルは主キーとしてVS-CUSTIDENTフィールドを使用します。
* ------------------------------------------------------------
* Customer record description
* -Record length : 266
* ------------------------------------------------------------
01 VS-ODCSF0-RECORD.
05 VS-CUSTIDENT PIC 9(006).
05 VS-CUSTLNAME PIC X(030).
05 VS-CUSTFNAME PIC X(020).
05 VS-CUSTADDRS PIC X(030).
05 VS-CUSTCITY PIC X(020).
05 VS-CUSTSTATE PIC X(002).
05 VS-CUSTBDATE PIC 9(008).
05 VS-CUSTBDATE-G REDEFINES VS-CUSTBDATE.
10 VS-CUSTBDATE-CC PIC 9(002).
10 VS-CUSTBDATE-YY PIC 9(002).
10 VS-CUSTBDATE-MM PIC 9(002).
10 VS-CUSTBDATE-DD PIC 9(002).
05 VS-CUSTEMAIL PIC X(040).
05 VS-CUSTPHONE PIC 9(010).
05 VS-FILLER PIC X(100).
* ------------------------------------------------------------
WHENEVER SQLERROR CONTINUE;
DROP TABLE CUSTOMER CASCADE CONSTRAINTS;
WHENEVER SQLERROR EXIT 3;
CREATE TABLE CUSTOMER (
VS_CUSTIDENT NUMBER(6) NOT NULL,
VS_SEQ_NUM NUMBER(8) NOT NULL,
VS_CUSTLNAME VARCHAR2(30),
VS_CUSTFNAME CHAR (20),
VS_CUSTADDRS VARCHAR2(30),
VS_CUSTCITY CHAR (20),
VS_CUSTSTATE CHAR (2),
VS_CUSTBDATE NUMBER(8),
VS_CUSTEMAIL VARCHAR2(40),
VS_CUSTPHONE NUMBER(10),
VS_FILLER VARCHAR2(100),
CONSTRAINT PK_CUSTOMER PRIMARY KEY (
VS_CUSTIDENT)
CONSTRAINT UK_CUSTOMER UNIQUE (
VS_SEQ_NUM)
);
| 注: | コピー・ブックODCSFOBにはフィールドの再定義VS-CUSTBDATE-G PIC 9(008)が含まれ、これはテクニカル・フィールドのため、識別ルールは実装されません。この場合、再定義されたフィールドのみが生成された表VS_CUSTBDATE NUMBER(8)に作成されます。 |
この項では、データをVSAMファイルからOracle表に移行するのに使用するコンポーネントを生成する前に実行するタスクについて説明します。
Tuxedo ART Workbenchの実行前に次の環境変数を設定します。
次を使用して記述された3つのファイルは、Tuxedo ART Workbenchファイル構造に置く必要があります。
ファイルからOracleへの変換のために、Datamap-<構成名>.reおよびmapper-<構成名>.re ファイルを作成する必要があります。
これらのファイルは、Tuxedo ART Workbenchのインストール時にファイル構造に自動的に生成されます。これらのファイルの特定のバージョンが特定のz/OSファイルに必要な場合は、$PARAM/fileファイル構造に置かれます。
db-param.cfg ファイルの場合、ターゲットおよびファイル・パラメータのみが適用される必要があります。
# This configuration file is used by FILE & RDBMS converter
# Lines beginning with "#" are ignored
# write information in lower case
# common parameters for FILE and RDBMS
# source information is written into system descriptor file (OS, DBMS=,
# DBMS-VERSION=)
target_rdbms_name:oracletarget_rdbms_version:11target_os:unix# optional parameter
target_cobol:cobol_mf
hexa-map-file:tr-hexa.map
#
# specific parameters for FILE to RDBMS conversion
file:char_limit_until_varchar:29# specific parameters for RDBMS conversion
rdbms:date_format:YYYY/MM/DD
rdbms:timestamp_format:YYYY/MM/DD HH24 MI SS
rdbms:time_format:HH24 MI SS
# rename object files
# the file param/rdbms/rename-objects-<schema>.txt is automatically loaded # by the tool if it exists.
target_cobol:cobol_mf
hexa-map-file:tr-hexa.map
hexa-map-fileを指定しない場合は、警告がロギングされます。
システム記述ファイルでのカタログ化中に決定されます。
|
||
| 注: | 使用される様々なパラメータの説明は、Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドのFile-To-Fileコンバータに関する項を参照してください。 |
PJ01AAA.SS.VSAM.CUSTOMERファイルはVSAM KSDSファイルなので編成は索引付きです。パラメータkeys offset 1 bytes length 6 bytes primaryはキーを記述しています。この例では、キーは6バイトの長さでポジション1から開始します。
%% Lines beginning with "%%" are ignored
data map STFILEORA-map system cat::STFILEORA
%%
%% Datamap File PJ01AAA.SS.VSAM.CUSTOMER
%%
file PJ01AAA.SS.VSAM.CUSTOMER
organization Indexed
keys offset 1 bytes length 6 bytes primary
データマップ構成ファイルに含まれている、移行する各z/OSファイルをリストする必要があります。
ファイルのパラメータおよびそのオプションは、Oracle表に変換する各VSAMファイル用に含まれる必要があります。次のパラメータを設定する必要があります。
| 注: | 使用される様々なパラメータの説明は、Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドのFile-To-Fileコンバータに関する項を参照してください。 |
%% Lines beginning with "%%" are ignored
ufas mapper STFILEORA
%%
%% Desc file PJ01AAA.SS.VSAM.CUSTOMER
%%
file PJ01AAA.SS.VSAM.CUSTOMER transferred converted
table name CUSTOMER
include "COPY/ODCSF0B.cpy"
map record VS-ODCSF0-RECORD defined in "COPY/ODCSF0B.cpy"
source record VS-ODCSF0-RECORD in "COPY/ODCSF0B.cpy"
logical name ODCSF0B
converter name ODCSF0B
attributes LOGICAL_MODULE_IN_ADDITION
COBOL記述ファイルを準備したら、mapper-<構成名>.reファイルに記述したコピー・ファイルを$PARAM/file/recs-sourceディレクトリに置く必要があります。
ソース・プラットフォームからのCOBOLコピー・ブックを使用してファイルを記述する場合(「COBOL記述」の注意を参照)、それが、上述のCOPY/ODCSF0B.cpyの例のように、マッピング・パラメータ・ファイルで直接使用されるコピー・ブックの場所です。
データのVSAMファイルからOracle表への移行に使用されるコンポーネントを生成するのに、Tuxedo ART Workbenchではfile.shコマンドを使用します。この項ではこのコマンドについて説明します。
file.sh - z/OS移行コンポーネントを生成します。
file.sh [ [-g] [-m] [-i <installation directory>] <configuration name> | -s <installation directory> (<configuration name>,...) ]
file.shでは、Tuxedo ART Workbenchにより、VSAMファイルの移行に使用するコンポーネントを生成します。
$PARAM/dynamic-configに、DMLファイルは<trf>/DMLディレクトリに作成されます。
file.sh -gmi $HOME/trf FTFIL001
Makeはターゲット(ファイルまたはアクション)の構成を自動化および最適化することを目的としたUNIXユーティリティです。
すべての操作が実装されるソース・ディレクトリにmakefileという名前の記述子ファイルが存在する必要があります(makefileはプロジェクトの初期化中にソース・ディレクトリに準備されます)。
次の2つの項では、makefileの構成と、makefileを使用したTuxedo ART Workbench File-To-Fileコンバータ機能の使用方法について説明します。
$PARAMのversion.mk構成ファイルを使用して、Makeユーティリティで必要な変数およびパラメータを設定します。
version.mkには、各種のコンポーネントがインストールされる場所とその拡張を、使用される様々なツールのバージョンとともに指定します。このファイルにはログ・ファイルの構成方法も記述されます。
次の一般的な変数を、version.mkファイルでの移行プロセスの最初に設定する必要があります。
また、FILE_SCHEMAS変数はファイルの移行に特有で、処理する様々な構成を示します。
この構成はMakeファイルの使用の前に完了する必要があります。
makefileおよびversion.mkファイルはTuxedo ART Workbench Simple Applicationとともに提供されます。
make FileConvertコマンドを使用して、Tuxedo ART Workbench File-To-Fileコンバータを起動できます。これによりz/OSファイルのUNIX/Linuxターゲット・プラットフォームへの移行に必要なコンポーネントを生成できます。
MakeファイルはFILE_SCHEMAS変数に含まれるすべての構成に対し、-g、-mおよび-iオプションを指定してfile.shツールを起動できます。
-i $HOME/trfオプションで生成されるアンロード・コンポーネントおよびロード・コンポーネントは、次の場所に配置されます。
CUSTOMER表を作成するのに使用されるSQLスクリプトの名前は次のとおりです。
様々な技術的操作で使用されるスクリプトの名前は次のとおりです。
9個のCOBOLプログラムが生成されます。これらの使用方法については、Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドを参照してください。
ORACLE CUSTOMER表をアクセスするための1つのPRO*COBOLプログラムが生成されます。
生成されたコンポーネントはプロジェクト固有のスクリプトを使用して変更できます。これらのスクリプト(sed、awk、 perlなど)は次の場所に配置する必要があります。
$PARAM/file/file-modif-source.sh
このファイルが存在している場合、生成プロセスの最後に自動的に実行されます。このファイルは、引数として<configuration name>を使用して呼び出されます。
ソース・プラットフォームからDB2/luw (udb) UNIXターゲット・プラットフォームにVSAMファイルを移行するとき、VSAMが関係する場合は、ファイルを維持するかデータをDB2/luw (udb)表に移行するかをまず確認します。
z/OSで処理されるVSAM RRDS、ESDSおよびKSDSのファイル編成は、Tuxedo ART Workbenchを使用してOracleデータベースに移行できます。
Tuxedo ART Workbench File-to-Fileコンバータは、Oracle表に変換されるこれらのファイルで使用されます。ファイル形式が維持されるファイルについては、Oracle Tuxedo Application Workbenchリファレンス・ガイドのFile-to-Fileコンバータに関する項を参照してください。
この章で詳しく説明する、ファイルからDb2/luw (udb)への移行プロセスの原則的な手順は次のとおりです。
VSAMファイルのデータのDB2/luw (udb)表への移行は、カタロガの結果に依存します。ファイルからDb2/luw (udb)への移行はCOBOLおよびJCLの変換に影響を与えるので、COBOLプログラムの変換作業の開始前に完了する必要があります。
この項ではVSAMファイルのDB2/luw (udb)表への移行の開始前に実行する手順について説明します。
まず移行するすべてのVSAMファイルのリストを作成し(File-to-Fileコンバータの使用とあわせて)、次にDB2/luw (udb)表に変換する必要があるファイルを識別します。たとえば、後でDB2/Luwで使用される永続ファイルやレコード・レベルでのロックが必要なファイルです。
移行の候補となる各ファイルについて、その構造をCOBOL形式で記述する必要があります。この記述はTuxedo ART Workbench COBOLコンバータによってCOBOLコピーで使用され、「COBOL記述」に記載されている制限の対象になります。
移行ファイル・リストが一度作成されたら、同一構造のファイルをパージすることができます。これは、データのトランスコードと再ロードに必要なプログラム数を減らして、ファイルを移行する際の作業を減らすためです。
パージされたファイルのリストから、最後のタスクは次のファイルのビルドからなります。
| 注: | populate.shユーティリティ(REFINEDIR/scripts/file/populate.shにある)を使用して、これら2つの構成ファイルを自動生成できます。詳細は、REFINEDIR/scripts/file/README.txtを参照してください。 |
COBOL記述は各ファイルと関連し、アプリケーション・プログラムで使用されるCOBOL記述を表すものとみなされます。この記述はOCCURSおよびREDEFINESの概念を含む、すべてのCOBOLデータ型を使用する複雑なCOBOL構造にすることができます。
多くの場合、このCOBOL記述はCOBOLファイル記述(FD)よりも発展させることができます。たとえば、FDフィールドはPIC X(364)と記述できますが、実際には定義された3倍の領域に相当し、COMP-3ベースの数値表や、いくつかの文字フィールドや数値フィールドなどの複雑な記述を含むことができます。
実際のアプリケーションを説明するのはこのような詳細なCOBOL記述です。このため、特定の物理ファイルを移行するための基盤として使用されます。
ファイル処理の実行の品質はこのCOBOL記述の品質に左右されます。この点から、COBOL記述はファイルとは分離されず、関連するファイルを参照する時は、ファイルとそれを表現するCOBOL記述の両方を意味します。記述はCOBOL形式で、次の名前のファイルで提供される必要があります。
<COPY name>.cpy
| 注: | ソース・プラットフォームのコピー・ブックにファイルの詳細が記述されている場合は、そのファイルをTuxedo ART Workbenchで直接使用および宣言できます。 |
COBOL記述では、同じメモリー・フィールドを記述する方法がいくつかあり、これは異なる構造と記述でオブジェクトを同じ場所に格納することを意味します。
同じメモリー・フィールドに異なる記述のオブジェクトを含めて、ファイルを読み取ることができるので、このデータ領域を適切に解釈するために、使用する記述を決定するメカニズムが必要です。
ある条件に従い、一般的にレコードの1つまたは複数のフィールドの内容により、再定義領域の読取りに使用する記述を決定(識別)できるルールが必要です。Tuxedo ART Workbenchでは、このルールは識別ルールと呼ばれます。
識別ルールなしでのCOBOL記述内の再定義では、ファイルのトランスコード時に重大なリスクが存在します。そのため、等価でない再定義済フィールドは識別ルールをリクエストします。他方、等価な再定義(テクニカル再定義と呼ばれる)はCOBOL記述内でクレンジングの対象となる必要があります(次の例を参照)。
識別ルールはファイルごとに用意し、相違点と識別される領域を明確に指定する必要があります。ファイルに関しては、ファイル記述の外部のフィールドを参照することはできません。
次の記述は、Tuxedo ART Workbenchで必要なCOPYのサンプルです。
01 FV14.
05 FV14-X1 PIC X.
05 FV14-X2 PIC XXX.
05 FV14-X3.
10 FV14-MTMGFA PIC 9(2).
10 FV14-NMASMG PIC X(2).
10 FV14-FILLER PIC X(12).
10 FV14-COINFA PIC 9(6)V99.
05 FV14-X4 REDEFINES FV14-X3.
10 FV14-MTMGFA PIC 9(6)V99.
10 FV14-FILLER PIC X(4).
10 FV14-IRETCA PIC X(01).
10 FV14-FILLER PIC X(2).
10 FV14-ZNCERT.
15 FV14-ZNALEA COMP-2.
15 FV14-NOSCP1 COMP-2.
15 FV14-NOSEC2 COMP-2.
15 FV14-NOCERT PIC 9(4) COMP-3.
15 FV14-FILLER PIC X(16).
05 FV14-X5 REDEFINES FV14-X3.
10 FV14-FIL1 PIC X(16).
10 FV14-MNT1 PIC S9(6)V99.
05 FV14-X6 REDEFINES FV14-X3.
10 FV14-FIL3 PIC X(16).
10 FV14-MNT3 PIC S9(6).
10 FV14-FIL4 PIC X(2).
Field FV14-X3
Rule if FV14-X1 = “A” then FV14-X3
elseif FV14-X1 = “B” then FV14-X4
elseif FV14-X1 = “C” then FV14-X5
else FV14-X6
| 注: | COBOL記述では、フィールドFV14-X3が再定義される最初のフィールドである必要があります。それに続くフィールド、FV14-X4、FV14-X5およびFV14-X6の順序は重要ではありません。 |
01 FV15.
05 FV15-MTMGFA PIC 9(2).
05 FV15-ZNPCP3.
10 FV15-NMASMG PIC X(2).
10 FV15-FILLER PIC X(12).
10 FV15-COINFA PIC 9(6)V99.
05 FV15-ZNB2T REDEFINES FV1 5-ZNPCP3.
10 FV15-MTMGFA PIC 9(4)V99.
10 FV15-FILLER PIC X(4).
10 FV15-IRETCA PIC X(01).
10 FV15-FILLER PIC X(2).
10 FV15-ZNCERT
15 FV15-ZNALEA COMP-2.
15 FV15-NOSCP1 COMP-2.
15 FV15-NOSEC2 COMP-2.
15 FV15-NOCERT PIC 9(4) COMP-3.
15 FV15-FILLER PIC X(16).
前述の例では、2つのフィールド(FV15-ZNPCP3およびFV15-ZNB2T)の構造が異なります。最初のフィールドはEBCDIC英数字、次のフィールドはEBCDICデータおよびCOMP2、COMP3データから構成されます。
識別ルールの実装は、データをUNIXプラットフォームに移行するのに必要です。
Field FV15-ZNPCP3
Rule if FV15-MTMGFA = 12 then FV15-ZNPCP3
elseif FV15-MTMGFA = 08 and FV15-NMASMG = "KC " then FV15-ZNB2T
01 FV1.
05 FV1-ZNPCP3.
10 FV1-MTMGFA PIC 9(6)V99.
10 FV1-NMASMG PIC X(25).
10 FV1-FILLER PIC X(12).
10 FV1-COINFA PIC 9(10).
10 FV2-COINFA REDEFINES FV1-COINFA.
15 FV2-ZNALEA PIC 9(2).
15 FV2-NOSCP1 PIC 9(4).
15 FV2- FILLER PIC 9(4).
10 FV15-MTMGFA PIC 9(6)V99.
10 FV15-FILLER PIC X(4).
10 FV15-IRETCA PIC X(01).
10 FV15-FILLER PIC X(2).
01 FV1.
05 FV1-ZNPCP3.
10 FV1-MTMGFA PIC 9(6)V99.
10 FV1-NMASMG PIC X(25).
10 FV1-FILLER PIC X(12).
10 FV1-COINFA PIC 9(10).
10 FV15-MTMGFA PIC 9(6)V99.
10 FV15-FILLER PIC X(4).
10 FV15-IRETCA PIC X(01).
10 FV15-FILLER PIC X(2). 01 FV1.
05 FV1-ZNPCP3.
10 FV1-MTMGFA PIC 9(6)V99.
10 FV1-NMASMG PIC X(25).
10 FV1-FILLER PIC X(12).
10 FV2-COINFA.
15 FV2-ZNALEA PIC 9(2).
15 FV2-NOSCP1 PIC 9(4).
15 FV2- FILLER PIC X(4).
10 FV15-MTMGFA PIC 9(6)V99.
10 FV15-FILLER PIC X(4).
10 FV15-IRETCA PIC X(01).
10 FV15-FILLER PIC X(2).
前述の例では、2つの記述が単純なEBCDIC英数文字列(バイナリ、パックまたは符号付数字フィールドを除く)に相当します。この種の構造は識別ルールの実装を必要としません。
この項では、VSAMファイルからDB2/luw (udb)データベースへデータを移行するときに、Tuxedo ART Workbenchにより適用されるリエンジニアリング・ルールについて説明します。
table name句を使用してmapper-<configuration name>.reファイルに規定されます。 VSAMファイル(VSAM ESDS)の場合: Tuxedo ART Workbenchによってテクニカル列*_SEQ_NUM NUMERIC(8)が追加されます。
この列は新しい行が表に追加されるたびに増加し、表の主キーになります。
VSAMファイル(VSAM RRDS)の場合: Tuxedo ART Workbenchによってテクニカル列*_RELATIVE_NUMが追加されます。
列のサイズはデータマップのパラメータ・ファイルで提供される情報から推測され、この列が表の主キーになります。
VSAMファイル(VSAM KSDS)の場合: Tuxedo ART Workbenchでは、重複キーを受け入れないかぎり、テクニカル列が追加されず、VSAMファイルの主キーが表の主キーになります。
データをVSAMファイルからOracle表へ移行するときに、次のルールがCOBOL Picture句に適用されます。
|
識別ルールが適用されるOCCURSおよびREDEFINES句の場合、次の3つのリエンジニアリングの可能性が提案されます。
次の例では、ODCSFOBに記述された索引付きVSAMファイルは主キーとしてVS-CUSTIDENTフィールドを使用します。
* ------------------------------------------------------------
* Customer record description
* -Record length : 266
* ------------------------------------------------------------
01 VS-ODCSF0-RECORD.
05 VS-CUSTIDENT PIC 9(006).
05 VS-CUSTLNAME PIC X(030).
05 VS-CUSTFNAME PIC X(020).
05 VS-CUSTADDRS PIC X(030).
05 VS-CUSTCITY PIC X(020).
05 VS-CUSTSTATE PIC X(002).
05 VS-CUSTBDATE PIC 9(008).
05 VS-CUSTBDATE-G REDEFINES VS-CUSTBDATE.
10 VS-CUSTBDATE-CC PIC 9(002).
10 VS-CUSTBDATE-YY PIC 9(002).
10 VS-CUSTBDATE-MM PIC 9(002).
10 VS-CUSTBDATE-DD PIC 9(002).
05 VS-CUSTEMAIL PIC X(040).
05 VS-CUSTPHONE PIC 9(010).
05 VS-FILLER PIC X(100).
* ------------------------------------------------------------
DROP TABLE CUSTOMER ;
COMMIT ;
CREATE TABLE CUSTOMER (
VS_CUSTIDENT NUMERIC (6) NOT NULL,
VS_CUSTLNAME VARCHAR (30),
VS_CUSTFNAME CHAR (20),
VS_CUSTADDRS VARCHAR (30),
VS_CUSTCITY CHAR (20),
VS_CUSTSTATE CHAR (2),
VS_CUSTBDATE NUMERIC (8),
VS_CUSTEMAIL VARCHAR (40),
VS_CUSTPHONE NUMERIC (10),
VS_FILLER VARCHAR (100),
CONSTRAINT PKCUSTOMER PRIMARY KEY (
VS_CUSTIDENT)) ;
COMMIT ;
| 注: | コピー・ブックODCSFOBにはフィールドの再定義VS-CUSTBDATE-G PIC 9(008)が含まれ、これはテクニカル・フィールドのため、識別ルールは実装されません。この場合、再定義されたフィールドのみが生成された表VS_CUSTBDATE NUMBER(8)に作成されます。 |
この項では、データをVSAMファイルからDB2/luw (udb)表に移行するために使用するコンポーネントを生成する前に実行するタスクについて説明します。
Tuxedo ART Workbenchの実行前に次の環境変数を設定します。
次を使用して記述された3つのファイルは、Tuxedo ART Workbenchファイル構造に置く必要があります。
ファイルからDb2/luw (udb)への変換のために、Datamap-<構成名>.reおよびmapper-<構成名>.re ファイルを作成する必要があります。
これらのファイルは、Tuxedo ART Workbenchのインストール時にファイル構造に自動的に生成されます。これらのファイルの特定のバージョンが特定のz/OSファイルに必要な場合は、$PARAM/fileファイル構造に置かれます。
db-param.cfg ファイルの場合、ターゲットおよびファイル・パラメータのみが適用される必要があります。
# This configuration file is used by FILE & RDBMS converter
# Lines beginning with "#" are ignored
# write information in lower case
# common parameters for FILE and RDBMS
# source information is written into system descriptor file (OS, DBMS=,
# DBMS-VERSION=)
target_rdbms_name:udbtarget_rdbms_version:9target_os:unix# optional parametertarget_cobol:cobol_mfhexa-map-file:tr-hexa.map
#
# specific parameters for FILE to RDBMS conversion
file:char_limit_until_varchar:29# specific parameters for RDBMS conversion
rdbms:date_format:YYYY/MM/DD
rdbms:timestamp_format:YYYY/MM/DD HH24 MI SS FF6
rdbms:time_format:HH24 MI SS
# rename object files
# the file param/rdbms/rename-objects-<schema>.txt is automatically loaded # by the tool if it exists.
target_cobol:cobol_mf
hexa-map-file:tr-hexa.map
hexa-map-fileを指定しない場合は、警告がロギングされます。
カタロガのシステム記述ファイルによって決定されます。
|
||
| 注: | 使用される様々なパラメータの説明は、Tuxedo ART Workbenchリファレンス・ガイドのFile-to-Fileコンバータに関する項を参照してください。 |
PJ01AAA.SS.VSAM.CUSTOMERファイルはVSAM KSDSファイルなので、編成は索引付きです。パラメータkeys offset 1 bytes length 6 bytes primaryはキーを記述しています。この例では、キーは6バイトの長さでポジション1から開始します。
%% Lines beginning with "%%" are ignored
data map STFILEUDB-map system cat::STFILEUDB
%%
%% Datamap File PJ01AAA.SS.VSAM.CUSTOMER
%%
file PJ01AAA.SS.VSAM.CUSTOMER
organization Indexed
keys offset 1 bytes length 6 bytes primary
データマップ構成ファイルに含まれている、移行する各z/OSファイルをリストする必要があります。
ファイルのパラメータおよびそのオプションは、DB2/luw (udb)表に変換する各VSAMファイル用に含まれる必要があります。次のパラメータを設定する必要があります。
| 注: | 使用される様々なパラメータの説明は、Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドのFile-To-Fileコンバータに関する項を参照してください。 |
%% Lines beginning with "%%" are ignored
ufas mapper STFILEUDB
%%
%% Desc file PJ01AAA.SS.VSAM.CUSTOMER
%%
file PJ01AAA.SS.VSAM.CUSTOMER transferred converted
table name CUSTOMER
include "COPY/ODCSF0B.cpy"
map record VS-ODCSF0-RECORD defined in "COPY/ODCSF0B.cpy"
source record VS-ODCSF0-RECORD in "COPY/ODCSF0B.cpy"
logical name ODCSF0B
converter name ODCSF0B
attributes LOGICAL_MODULE_IN_ADDITION
COBOL記述ファイルを準備したら、mapper-<構成名>.reファイルに記述したコピー・ファイルを$PARAM/file/recs-sourceディレクトリに置く必要があります。
ソース・プラットフォームからのCOBOLコピー・ブックを使用してファイルを記述する場合(「COBOL記述」の注意を参照)、それが、上述のCOPY/ODCSF0B.cpyの例のように、マッピング・パラメータ・ファイルで直接使用されるコピー・ブックの場所です。
データのVSAMファイルDB2/luw (udb)表への移行に使用されるコンポーネントを生成するのに、Tuxedo ART Workbenchではfile.shコマンドを使用します。この項ではこのコマンドについて説明します。
file.sh - z/OS移行コンポーネントを生成します。
file.sh [ [-g] [-m] [-i <installation directory>] <configuration name> | -s <installation directory> (<configuration name>,...) ]
file.shでは、Tuxedo ART Workbenchにより、VSAMファイルの移行に使用するコンポーネントを生成します。
$PARAM/dynamic-configに、DMLファイルは<trf>/DMLディレクトリに作成されます。
file.sh -gmi $HOME/trf FTFIL001
Makeはターゲット(ファイルまたはアクション)の構成を自動化および最適化することを目的としたUNIXユーティリティです。
すべての操作が実装されるソース・ディレクトリにmakefileという名前の記述子ファイルが存在する必要があります(makefileはプロジェクトの初期化中にソース・ディレクトリに準備されます)。
次の2つの項では、makefileの構成と、makefileを使用したTuxedo ART Workbench File-To-Fileコンバータ機能の使用方法について説明します。
$PARAMのversion.mk構成ファイルを使用して、Makeユーティリティで必要な変数およびパラメータを設定します。
version.mkには、各種のコンポーネントがインストールされる場所とその拡張を、使用される様々なツールのバージョンとともに指定します。このファイルにはログ・ファイルの構成方法も記述されます。
次の一般的な変数を、version.mkファイルでの移行プロセスの最初に設定する必要があります。
また、FILE_SCHEMAS変数はファイルの移行に特有で、処理する様々な構成を示します。
この構成はMakeファイルの使用の前に完了する必要があります。
makefileおよびversion.mkファイルはTuxedo ART Workbench Simple Applicationとともに提供されます。
make FileConvertコマンドを使用して、Tuxedo ART Workbench File-To-Fileコンバータを起動できます。これによりz/OSファイルのUNIX/Linuxターゲット・プラットフォームへの移行に必要なコンポーネントを生成できます。
MakeファイルはFILE_SCHEMAS変数に含まれるすべての構成に対し、-g、-mおよび-iオプションを指定してfile.shツールを起動できます。
-i $HOME/trfオプションで生成されるアンロード・コンポーネントおよびロード・コンポーネントは、次の場所に配置されます。
CUSTOMER表を作成するのに使用されるSQLスクリプトの名前は次のとおりです。
様々な技術的操作で使用されるスクリプトの名前は次のとおりです。
9個のCOBOLプログラムが生成されます。これらの使用方法については、Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドを参照してください。
DB2/luw (udb) CUSTOMER表をアクセスするための1つの埋込みSQLプログラムが生成されます。
生成されたコンポーネントはプロジェクト固有のスクリプトを使用して変更できます。これらのスクリプト(sed、awk、 perlなど)は次の場所に配置する必要があります。
$PARAM/file/file-modif-source.sh
このファイルが存在している場合、生成プロセスの最後に自動的に実行されます。引数として<configuration name>を使用して呼び出されます。
z/OS DB2ソース・プラットフォームからOracle UNIXターゲット・プラットフォームへ移行する時の最初の問題は、どの表を移行するべきかということです。すべてのDB2表を移行するわけではない場合、移行するオブジェクトのサブセットを示すDB2 DDLを作成する必要があります。
この章で詳しく説明する、DB2からOracleへの移行プロセスの原則的な手順は次のとおりです。
DB2からOracleへの移行はカタロガの結果に依存します。DB2からOracleへの移行はCOBOL変換に影響を与えるので、プログラムの変換作業の開始前に完了する必要があります。
この項では、DB2データベースからOracleデータベースへデータを移行するときに、Tuxedo ART Workbenchにより適用されるリエンジニアリング・ルールについて説明します。
Oracleへの移行に含まれるDB2オブジェクトのリストは生成されたOracleオブジェクトの作成で説明します。
Tuxedo ART Workbenchの名前の変更ルールの適用を除き、Oracleへの移行時に、移行されたDB2オブジェクトの名前は保持されます(「名前の変更ルールの準備および実装」を参照)。
列プロパティによりアプリケーション・プログラムの動作を変更できます。
次の表にすべてのDB2の列プロパティと、ターゲットOracleデータベース用に変換する方法を示します。
Oracle Tuxedo Application Rehosting Workbenchでは、DDLソース・ファイル内の様々な名前(表名や列名)を変更できます。
| 注: | Tuxedo ART Workbenchを実行するときにOracleの予約語がDDLソースで検出されると、エラーが報告されますが、Tuxedo ART WorkbenchはDDLの分析を続行します。 |
名前の変更ルールはrename-objects-<schema name>.txt.という名前のファイルに置かれます。このファイルは$PARAM/rdbmsパラメータで示されたディレクトリに置かれます。
% Modification applied to the AUALPH0T table
column;AUANPR0U;AUALPH0T;NUM_ALPHA;MW_NUM_ALPHA
Tuxedo ART Workbenchでは、CLOBおよびBLOBデータ型をダウンロードできます。DB2アンロード・ユーティリティは、CLOB列またはBLOB列の各行を別個のファイルにダウンロードします(PDSまたはHFSデータセット・タイプ)。このユーティリティ(DSNUTILB)は、すべての列のデータおよびNULLテクニカル・フラグを一意のMVSメンバー・ファイルにダウンロードします。ただし、個別のCLOBまたはBLOBファイルのファイル名で置き換えられるCLOBまたはBLOB列は除きます。
MVSシステム構成によっては、PDSデータセット・タイプで一部のファイルが許可されないため、CLOBまたはBLOB列のダウンロードに別のデータセット・タイプを選択しなければならないこともあります。
この2つの制約に基づいて、db-param.cfg構成ファイルで正しいパラメータを設定する必要があります(「構成ファイルの実装」を参照)。
Tuxedo ART Workbenchでは、シングル・バイト・データのトランスコーディングが提供されています。ただし、DB2データにMBCS文字が含まれる場合は、DSNUPROCアンロード・ユーティリティを選択してcsvデータ形式を設定する必要があります。MBCSトランスコーディングは、転送ツールによって行われます。
この制約に基づいて、db-param.cfg構成ファイルで正しいパラメータを設定する必要があります(「構成ファイルの実装」を参照)。
この例では、DB2 DDLに、主キーおよびXCUSTIDENという名前の一意の索引を持つ、ODCSF0という名前の表が含まれます。
DROP TABLE ODCSF0;
COMMIT;
CREATE TABLE ODCSF0
(CUSTIDENT DECIMAL(6, 0) NOT NULL,
CUSTLNAME CHAR(030) NOT NULL,
CUSTFNAME CHAR(020) NOT NULL,
CUSTADDRS CHAR(030) NOT NULL,
CUSTCITY CHAR(020) NOT NULL,
CUSTSTATE CHAR(002) NOT NULL,
CUSTBDATE DATE NOT NULL,
CUSTEMAIL CHAR(040) NOT NULL,
CUSTPHONE CHAR(010) NOT NULL,
PRIMARY KEY(CUSTIDENT))
IN DBPJ01A.TSPJ01A
CCSID EBCDIC;
COMMIT;
CREATE UNIQUE INDEX XCUSTIDEN
ON ODCSF0
(CUSTIDENT ASC) USING STOGROUP SGPJ01A;
COMMIT;
移行ルールの適用後、名前の変更ルールを実装せずに、次のOracleオブジェクトが取得されます。
WHENEVER SQLERROR CONTINUE;
DROP TABLE ODCSF0 CASCADE CONSTRAINTS;
WHENEVER SQLERROR EXIT 3;
CREATE TABLE ODCSF0 (
CUSTIDENT NUMBER(6) NOT NULL,
CUSTLNAME CHAR(30) NOT NULL,
CUSTFNAME CHAR(20) NOT NULL,
CUSTADDRS CHAR(30) NOT NULL,
CUSTCITY CHAR(20) NOT NULL,
CUSTSTATE CHAR(2) NOT NULL,
CUSTBDATE DATE NOT NULL,
CUSTEMAIL CHAR(40) NOT NULL,
CUSTPHONE CHAR(10) NOT NULL);
WHENEVER SQLERROR CONTINUE;
DROP INDEX XCUSTIDEN;
WHENEVER SQLERROR EXIT 3;
CREATE UNIQUE INDEX XCUSTIDEN ON ODCSF0
(
CUSTIDENT ASC
);
WHENEVER SQLERROR CONTINUE;
ALTER TABLE ODCSF0 DROP CONSTRAINT CONSTRAINT_01;
WHENEVER SQLERROR EXIT 3;
ALTER TABLE ODCSF0 ADD
CONSTRAINT CONSTRAINT_01 PRIMARY KEY (CUSTIDENT);
この項では、DB2データをOracleに移行するのに使用するコンポーネントを生成する前に実行するタスクについて説明します。
移行するDB2 DDLソース・ファイルがカタログ操作の準備前に検出されます。移行プロセス中に、SQL CREATEコマンドだけが処理されOracleに移行されますが、すべての有効なDB2構文が受け入れられます。
DB2からOracleへの移行では、すべてのTuxedo ART Workbenchツールで使用するカタロガ内のsystem.descシステム記述ファイルに、パラメータを設定する必要があります。
スキーマは一貫性のあるオブジェクトのセットから構成される必要があります(たとえば、スキーマに存在しない表に対してのCREATE INDEXはありません)。
デフォルトでは、DB2 DDLのSQLコマンドに接頭辞として修飾子または認可IDが付いている場合、その接頭辞はTuxedo ART Workbenchによってスキーマ名として使用されます。たとえば、CREATE TABLE <修飾子または認可ID>.表名のように使用します。
スキーマ名は、system.descファイルのglobal-options句を使用して、Tuxedo ART Workbenchが決定することもできます。
system STDB2ORA root ".."
global-options
catalog="..",
sql-schema=<schema name>.
また、各DDLディレクトリのスキーマ名は、system.descファイルのdirectory options句を使用して、Tuxedo ART Workbenchが決定することもできます。詳細は、カタロガのオプション句に関する項を参照してください。
directory "DDL" type SQL-SCRIPT
files "*.sql"
options SQL-Schema = "<schema name>".
次の1つのファイルのみは、$PARAMで記述されたTuxedo ART Workbenchのファイル構造に置く必要があります。
これらのファイルは、Tuxedo ART Workbenchのインストール時にファイル構造に自動的に生成されます。これらのファイルの特定のバージョンが必要な場合は、$PARAM/rdbmsファイル構造に置かれます。
Tuxedo ART Workbenchの実行前に次の環境変数を設定します。
#
# This configuration file is used by FILE & RDBMS converter
# Lines beginning by "#" are ignored
# write information in lower case
#
# common parameters for FILE and RDBMS
# source information is written into system descriptor file (OS, DBMS=, # DBMS-VERSION=)
target_rdbms_name:oracle
target_rdbms_version:11
target_os:unix
# optional parameter
target_cobol:cobol_mf
hexa-map-file:tr-hexa.map
#
# specific parameters for FILE to RDBMS conversion
file:char_limit_until_varchar:29
# specific parameters for RDBMS conversion
rdbms:date_format:YYYY/MM/DD
rdbms:timestamp_format:YYYY/MM/DD HH24 MI SS FF6
rdbms:time_format:HH24 MI SS
rdbms:lobs_fname_length:75
rdbms:jcl_unload_lob_file_system:pds
rdbms:jcl_unload_utility_name:dsnutilb
#rdbms:jcl_unload_format_file:csv
# rename object files
# the file param/rdbms/rename-objects-<schema>.txt is automatically loaded by # the tool if it exists.
パラメータtarget_<xxxxx>およびrdbms:<xxxxx>だけが適用される必要があります。
target_cobol:cobol_mf
hexa-map-file:tr-hexa.map
hexa-map-fileを指定しない場合は、警告がロギングされます。
次のrdbmsパラメータは、z/OS DB2により使用され、DSNZPARMに格納される日付、タイムスタンプおよび時間形式を示します。
これらのパラメータは再ロード操作およびCOBOLの日付および時間の操作に影響を与えます。これらはオプションで、DB2データベースにDATE、TIMEまたはTIMESTAMPフィールドが含まれる場合のみ必要です。
| 警告: | これらのパラメータを正しく設定することが重要です。 |
次のrdbmsパラメータはオプションで、DB2スキーマにCLOBまたはBLOBデータ型が含まれる場合にのみ必要です。
| 警告: | これらのパラメータを正しく設定することが重要です。 |
rdbms:jcl_unload_lob_file_system:pds / hfs PDSで作成できるメンバー・ファイル数は制限されています。DB2アンロード・ユーティリティはCLOB/BLOB列ごとに新しいメンバー・ファイルを作成するため、PDSデータセット・タイプで作成できる最大LOBSファイル数を超えることがあり、その場合はHFSデータセット・タイプを選択する必要があります。詳細は、DB2 MVSの管理者に問い合せてください。デフォルトでは、"pds"を使用します。
rdbms:lobs_fname_length:75DB2アンロード用JCLによって表データ・ファイルに書き込まれるCLOBまたはBLOBファイル名の最大長を計算する必要があります。
| 注: | rdbms:jcl_unload_utility_nameパラメータには、値"dsnutilb"を設定する必要があります。 |
MVSにDB2アンロード・ユーティリティがあるかどうかによって、値を変更することもできます。
| 注: |
データのDB2データベースからOracleデータベースへの移行に使用されるコンポーネントを生成するのに、Tuxedo ART Workbenchではrdbms.shコマンドを使用します。この項ではこのコマンドについて説明します。
rdbms.sh - DB2からOracleデータベースへの移行コンポーネントを生成。
rdbms.sh [ [-c|-C] [-g] [-m] [-r] [-i <installation directory>] <schema name> ] -s <installation directory> (<schema name>,...) ]
rdbms.shでは、z/OS DB2データベースをUNIX Oracleデータベースに移行するために使用されるTuxedo ART Workbenchのコンポーネントを生成します。
$TMPPROJECTに生成されます: DDL Oracle、SQL*LOADERのCTLファイル、COBOLコンバータで使用されるXMLファイル、構成ファイル(mapper.reおよびDatamap.re)。エラーまたは警告が発生してもプロセスは中断しません。
$TMPPROJECTに生成します。このオプションの前に-Cまたは-cコマンドを指定してrdbms.shコマンドを実行する必要があります。
config-cobolファイル(COBOL変換構成ファイル)にある、オプションsql-remove-schema-qualifierを使用して、スキーマ名もCOBOLコンポーネントから削除できます。
$PARAM/dynamic-configに作成されます。
rdbms.sh -Cgrmi $HOME/trf PJ01DB2
Makeはターゲット(ファイルまたはアクション)の構成を自動化および最適化することを目的としたUNIXユーティリティです。
すべての操作が実装されるソース・ディレクトリにmakefileという名前の記述子ファイルが存在する必要があります(makefileはプロジェクトの初期化中にソース・ディレクトリに準備されます)。
次の2つの項では、makefileの構成と、makefileを使用したTuxedo ART Workbench File-To-Fileコンバータ機能の使用方法について説明します。
$PARAMのversion.mk構成ファイルを使用して、Makeユーティリティで必要な変数およびパラメータを設定します。
version.mkには、各種のコンポーネントがインストールされる場所とその拡張を、使用される様々なツールのバージョンとともに指定します。このファイルにはログ・ファイルの構成方法も記述されます。
次の一般的な変数を、version.mkファイルでの移行プロセスの最初に設定する必要があります。
また、RDBMS_SCHEMAS変数はDB2の移行に特有で、処理する様々なスキーマを示します。
この構成はMakeファイルの使用の前に完了する必要があります。
makefileおよびversion.mkファイルはTuxedo ART Workbench Simple Applicationとともに提供されます。
make RdbmsConvertコマンドを使用して、Tuxedo ART Workbench File-To-Fileコンバータを起動できます。これによりDB2データベースからOracleへの移行に必要なコンポーネントを生成できます。
Makeファイルは rdbms.shツールを、-C、-g、-r、-mおよび-iオプションを使用して、RDBMS_SCHEMAS変数に含まれるすべてのスキーマに対して起動できます。
-i $HOME/trfオプションで生成されるアンロード・コンポーネントおよびロード・コンポーネントは、次の場所に配置されます。
生成されたコンポーネントはプロジェクト固有のスクリプトを使用して変更できます。これらのスクリプト(sed、awk、 perlなど)は次の場所に配置する必要があります。
$PARAM/rdbms/rdbms-modif-source.sh
このファイルが存在している場合、生成プロセスの最後に自動的に実行されます。これは、引数として<schema name>を使用して呼び出されます。
COBOLコンバータを実行する前に、移行するアセットの一貫性をチェックし、構文またはアセットの一貫性(欠落または未使用コンポーネント)に関連するエラーを修正するために、カタログ化は必須です。
データ移行プロセスは、COBOL変換が開始する前に実行する必要があります。この依存性は、データ移行ツールがCOBOLコンバータにより読み取られる構成ファイルを生成することが原因です。データ変換からの構成ファイルはOracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドに記載されています。
Tuxedo ART Workbench COBOLコンバータ・プロセスへの入力は次のとおりです。
変換用のメイン構成ファイルはconfig-COBOLです。これは次のものを含む他の追加の構成ファイルを参照します。
すべての必要な構成ファイルのサンプルはSimple Applicationにあります。必要に応じて値をチェックおよび適用する必要があります。
COBOLコンバータが使用するすべての構成ファイルは、Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドの「COBOLコンバータ」の章に記載されています。
COBOL変換の前提条件の準備の後、次の例をモデルとして使用して、メイン構成ファイルを準備します。
| 注: | 次のファイルが使用できます。 |
post-translation-fileは特定の変換を実行する必要があるときに使用されます。このファイルは手動で作成します。rdbms-conversion-fileはDB2からOracleデータベースへ移行するときに使用されます。このファイルはDB2-to-Oracleコンバータによって生成されます。conv-ctrl-list-fileはOracle表に変換するファイルがあるときに使用されます。このファイルはFile-to-Fileコンバータにより生成される必要があります。Config:
"Config version 1.0"
# sql-rules : none.
/* GENERAL */
target-dir: "../trf/".
keywords-file: "../param/keywords-file".
rename-call-map-file: "../param/rename-call-map-file".
accept-date : MW-DATE.
accept-day : MW-DAY.
# post-translation-file: "../param/renov.desc".
hexa-map-file: "../param/tr-hexa.map".
# rdbms-conversion-file : "dynamic-config/rdbms-conv.txt".
conv-ctrl-list-file : "dynamic-config/Conv-ctrl.txt".
on-size-error-call : "ABORT".
dcrp. /* Without reconcilation of copies files */
end
keywords-fileは、COBOLコンバータが、Tuxedo ART Workbench COBOLコンバータにより体系的に名前が変更されない可能性のある予約済キーワードを含む特定の変数の名前を変更するのに役立つヒント・ファイルです。
これは、変数がMicro Focus COBOLまたはCOBOL-ITの予約済キーワードでない場合でも、顧客独自の目的で名前の変更操作(一括変更)を行うための、WorkBenchにより提供されるリエンジニアリング・メカニズムです。
次のエントリをメイン構成ファイルconfig-cobolに配置します。
keywords-file: "../param/keywords-file"
( TAB . MW-TAB )
( DOUBLE . MW-DOUBLE )
( POS . MW-POS )
)
この例では、アイテムTABはすべてMW-TABで置換されます。
tr-hexa.mapファイルはEBCDIC (z/OSのコード・セット)とASCII (Linux/UNIXのコード・セット)16進数値間のマッピング表です。
次のエントリをメイン構成ファイルconfig-cobolに配置します。
hexa-map-file: "../param/tr-hexa.map"
このファイルは、Tr-Hexa-Mapのような変換ルールにより使用され、ソートや文字列の比較で異なる動作を引き起こす可能性のある値および文字列での、EBCDICとASCIIコード間の違いに関係する問題を、ユーザーが解決するのに役立ちます。
| 注: | hexa-map-fileはオプションの項目で、指定しない場合、警告がロギングされます。 |
このスクリプトは、REFINEDIR/scripts/convert-hexa-copy-to-map.shに配置されます。
REFINEDIR/scripts/convert-hexa-copy-to-map.sh convertmw_copy_file
convertmw_copy_file: location of the CONVERTMW.cpy file
スクリプトにより、現在のディレクトリ(PARAMディレクトリである必要があります)にtr-hexa.mapファイルが生成されます。
z/OSでのスペースの16進数コードは40で、UNIXでのスペースの16進数コードは20です。
01 VarName pic X value X'40'.
*{ Tr-Hexa-Map 1.4.2.1*01 VarName pic X value X'40'.
*--
01 VarName pic X value X'20'.
*}
00;00
01;01
02;02
03;03
37;04
2d;05
2e;06
2f;07
...
40;20
...
rename-call-map-fileは古いコール名と新しいコール名の間のマッピング・ファイルです。
これはTr-Rename-External-Callのような変換ルールにより使用され、これによりユーザーは必要に応じて特定の変更を行うことができます。
次のエントリをメイン構成ファイルconfig-cobolに配置します。
rename-call-map-file: "../param/rename-call-map-file"
(
("MQGET" . "MWMQGET") ("KIX-ABEND" . "KIX_ABEND") ("KIX-ASKTIME" . "KIX_ASKTIME"))
この例ではMQGETへのすべてのコールはMWMQGETに変更されます。
変換コマンドのオプションにより可能になることがたくさんあります(詳細は、Oracle Tuxedo Application Workbenchリファレンス・ガイドを参照)。この項では、次の例について説明します。
プログラム(バッチおよびCICS)とサブプログラムの区別は必須で、オプション-cobol-typeは次の値をとります。
$REFINEDIR/refine cobol-convert -v version -loop -limit=50 -s $PARAM/system.desc -c $PARAM/config-cobol -cobol-type batch
COBOLコンバータはすべてのコンポーネントを記述したシステム記述ファイルにより、変換するバッチ・プログラムがどれかを認識します。ここでversionはM2_L5_7などのリリース・バージョンです。
$REFINEDIR/refine cobol-convert -v version -loop -limit=50 -s $PARAM/system.desc -c $PARAM/config-cobol -cobol-type tpr
PGMM002.cblなどの、次のコマンドを呼び出す1つのプログラムを変換する場合$REFINEDIR/refine cobol-convert -v version -loop -limit=50 -s $PARAM/system.desc -c $PARAM/config-cobol -cobol-type tpr CICS/PGMM002.cbl
$REFINEDIR/refine cobol-convert -v version -loop -limit=50 -s $PARAM/system.desc -c $PARAM/config-cobol -cobol-type sub
$REFINEDIR/refine cobol-convert -v version -loop -limit=50 -s $PARAM/system.desc -c $PARAM/config-cobol -cobol-type tpr -cics
ログ・ファイルはコマンド行が実行するディレクトリに生成されます。特定のディレクトリまたはファイルにログを作成する場合は、-log-file-baseと、その後に実行ログを格納するファイルのパスと名前を指定して使用します。
$REFINEDIR/refine cobol-convert -v version -loop -limit=50 -s $PARAM/system.desc -log-file-base $LOGS/trans-cbl/translate-cobol-datetime -c $PARAM/config-cobol -cobol-type sub
この例では、ログ・ファイルは$LOGS/trans-cbl/translate-cobol-datetimeに生成されます。ログ・ディレクトリはあらかじめ作成しておく必要があります。
コピーブックの調整は、COBOLコンバータにより暗黙的に実行、またはすべてのプログラムが生成された後で個別に実行できます(dcrpオプションの使用による。「config-COBOLの構成」を参照)
調整を個別に適用するには、次のスクリプトを変換されたプログラムが置かれたディレクトリ(Simple Applicationの場合、$PROJECT/trfディレクトリ)から実行する必要があります。
for file in `find * -name '*-copies'`
do
$REFINEDIR/scripts/reconcil-copy-opt-imbr $PROJECT/trf $file .cbl
done
空のまたは切り捨てられたプログラムについては、ユーザーは$Logsに生成された実行ログを参照して、変換中に発生したエラーを分析できます。
コンパイルは変換に対する検証手順です。プログラムが正常にコンパイルされない場合は、完全に変換されたとみなすことはできません。
次の変数によりコンパイル環境がMicro Focus COBOLまたはCOBOL-ITのコンパイル用に正しく構成されていることをチェックする必要があります。
コンパイル・オプション・ファイルを準備する必要があります。Simple Applicationで使用されるコンパイル・オプションは次のとおりです。
SOURCEFORMAT"FREE"
DEFAULTBYTE"00"
ADDRSV"COMP-6"
COMP-6"2"
ALIGN"8"
NOTRUNCCALLNAME
NOTRUNCCOPY
NOCOPYLBR
COPYEXT"cpy,cbl"
RWHARDPAGE
PERFORM-TYPE"OSVS"
NOOUTDD
INDD
NOTRUNC
HOSTARITHMETIC
NOSPZERO
INTLEVEL"4"
SIGN"EBCDIC"
ASSIGN"EXTERNAL"
NOBOUND
SETTINGS
REPORT-LINE"256"
WARNING"2"
TRACE
LIST()
詳細は、Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドを参照してください。
プログラムBATCH/PGMMB00.cblをコンパイルするコマンドは次のとおりです。
# From $PROJECT/trf/BATCH
cd $PROJECT/trf/BATCH
export COBCPY=../DML:../Master-copy/COPY:../fixed-copy:.
export PCCINCLUDE="include=../Master-copy/COPY, include=../fixed-copies, include=."
cob -ug PGMMB00.cbl -C "use(../../compil_tools/opt.dir)" -C "list(PGMMB00.lst)" -C XREF -C SETTINGS 2> PGMMB00.err
| 注: | プログラムをコンパイルする最良の方法は、コンパイルmakefileを使用する方法です。コンパイル・オプションおよび必要な構成を設定し、これらの操作に設計されたmakeツールを使用して、コンパイル手順を実行できます。 |
Simple Applicationの例の場合、他のプロジェクトに使用できるコンパイルmakefileがあります。「Makeファイルの使用」を参照してください。
Simple Applicationの例とともに提供されるmakefileは、すべての変換操作を実装しており、次を適用することで他のプロジェクトでも使用できます。
この構成は、カタログ化の手順で開始された先行する構成に追加するものです。
makeコマンドを使用する前に、ユーザーはSimple Applicationで提供されたversion.mkの値をチェックする必要があります。
#
# Defined extensions converted files
#
ext_trad = cbl
ext_trad_copy = cpy
ext_trad_ksh = ksh
ext_trad_map = bms
#
# Define Version variables
# Information
# with GLOBAL_VERSION=CURRENT all -v option in the makefile are ignored
#
GLOBAL_VERSION = M2_L3_5
CATALOG = $(GLOBAL_VERSION)
TRAD = $(GLOBAL_VERSION)
TRAD_JCLZ = $(GLOBAL_VERSION)
DATA_TOOLS = $(GLOBAL_VERSION)
RECONCIL_COPY = $(GLOBAL_VERSION)
TIMEOUT = 900
TIMEOUT_PARSE = 300
#
# Define Config and opt files
#
FILE_TRAD_JCL = "$(PARAM)/config-trad-JCL.desc"
FILE_TRAD_COBOL = "$(PARAM)/config-cobol"
COMM_TRADJCL = "-c $(FILE_TRAD_JCL)"
COMM_RECONCIL_COPY = "reconcil-copy-opt-imbr"
COBOL変換を実行するには次のコマンドを$SOURCE:から実行します。
コピーブックを調整するには次のコマンドを$SOURCEから呼び出します。
make reconcil_copy
変換中にエラー・メッセージが発生したり、COBOLコンバータが異常終了することがあります。エラーの発生時に続行する方法の例として、特定のエラーを次に示します。
特に変換プロセスの最初で、構成ファイルが欠落している可能性があり、次のエラーを表示してCOBOLコンバータが異常終了することがあります。
Parsing config /home2/wkb7/simpleapp/param/config-cobol...
*FATAL*: Hexa-map-file: this file '/home2/wkb7/simpleapp/param/tr-hexa.map' does not exist
Error: Uncaught throw of :MESSAGE-ERROR to :MESSAGE-ERROR.
1 (abort) Quit process.
Type :b for backtrace, :c <option number> to proceed, or :? for other options
欠落している構成ファイルを追加するか、リクエストされたファイル(この例ではtr-hexa.map)が不要な場合はメイン構成ファイルのその行を無効にします。
Parsing config /home2/wkb7/simpleapp/param/config-cobol...
Creating target file /home2/wkb7/simpleapp/trf/CICS/PGMM002.cbl ...
*FATAL INTERNAL ERROR*: Can't find POB file /home2/wkb7/simpleapp/source/CICS/pob/PGMM002.cbl.pob; please re-catalog the system.
FIN
Rest in peace, Refine...
プログラムがまだカタログ化されていないか、または.pobファイルが誤って削除されました。再カタログ化してリクエストされたファイルを生成します。
Creating target file /home2/wkb7/simpleapp/trf/CICS/PGMM002.cbl ...
*FATAL INTERNAL ERROR*: POB file /home2/wkb7/simpleapp/source/CICS/pob/PGMM002.cbl.pob is less recent than source file /home2/wkb7/simpleapp/source/CICS/PGMM002.cbl; please re-catalog the system.
このエラーは、ソース・プログラムの変更日がその対応するPOBファイルよりも最近である場合に発生します。POBファイルが生成された後でソース・プログラムが更新されることがあるので、プログラムを再カタログ化して最新の変更が含まれていることを確認します。
解析エラーを含むプログラム、特にカタログ化中に致命的なエラーが発生したプログラムは変換されません。一般的にCOBOLコンバータは重大度がFATALよりも下のエラーを含むプログラムは変換されます。
Program name is PGMM002
Warning:-- Parse-Error at line 163
*FATAL*: file CICS/PGMM002.cbl contains true parse errors, ABORTING!
FIN
Rest in peace, Refine...
プログラムのソース・コードをチェックしてエラーを修正し、プログラムをカタログ化して再度変換します。
解析エラーの詳細は、カタログ化レポートおよびログで参照できます。原則として、カタログ化手順中に特定されたエラーを修正する前に、変換作業を開始しないでください。
JCLトランスレータを実行する前に、移行するアセットの一貫性をチェックし、構文またはアセットの一貫性(欠落または未使用コンポーネント)に関連するエラーを修正するために、カタログ化は必須です。
データ移行プロセスは、JCL変換が開始する前に実行する必要があります。この依存性は、ファイル移行ツールがJCLトランスレータにより読み取られる構成ファイルを生成することが原因です。データ変換からの構成ファイルはOracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドに記載されています。
Tuxedo ART Workbench JCLトランスレータ・プロセスへの入力は次のとおりです。
カタロガにより生成された変換するJCLのASTに加え、Tuxedo ART Workbench JCLトランスレータは次のような様々な変換の要素を指定するメイン構成ファイルを入力として取得します。
このファイルは、標準のテキスト・エディタを使用して記述したり、後述する他の情報ソースから生成することが簡単にできます。ここでは、Tuxedo ART Workbenchツールとともに提供される、STFILEORA Simple ApplicationでJCLファイルを変換するために作成された構成ファイルの例について説明します。
メイン構成ファイルは次のいずれかの個別のサブファイルも参照します。
Tuxedo ART Workbenchは構成ファイルの例とともに提供されます。
JCL変換用のメイン構成ファイルは、このガイドではconfig-trad-JCL.descと呼ばれ、Simple Applicationアプリケーションとともに使用されます。
次の項では様々な構成パラメータと構成サブファイルについて説明し、この章の最後では完全なサンプルを提供します。
2つのオプションtop-skeletonおよびbottom-skeletonにより指定されたサブファイルは、それぞれ生成されたスクリプトのヘッダー・ファイルおよびフッター・ファイルを表します。これらのファイルはカスタマイズできます。
top-skeleton = "../param/top-ksh.txt"
bottom-skeleton = "../param/bottom-ksh.txt"
#@(#)-------------------------------------------------------------------
#@(#)- SCRIPT NAME == $[JOBNAME].ksh --- VERSION OF $[DATE]
#@(#)- AUTHOR ==
#@(#)- TREATMENT ==
#@(#)- OBSERVATIONS == MAINFRAME MIGRATION
#@(#)- …..
JOBNAME
DATE
ファイルがOracle表に変換されるとき、メイン構成ファイルは次のようなサブ構成ファイルを参照する必要があります。
file-list-in-table = "../param/dynamic-config/File-in-table.txt"
このサブファイルはFile-to-Fileコンバータにより生成されます。このファイルはJCLトランスレータにOracle表に変換されるファイルを示し、これらのファイルを含む手順を適切に変換できるようにします。例では、PJ01AAA.SS.VSAM.CUSTOMERが変換されるファイルです。
たとえば、JCLソースにOracle表に変換されるファイルが含まれている場合、対応するシェル・スクリプトはBatch Runtime機能m_ProgramExecを-bオプションを指定して使用し、COBOLプログラムを実行します。-bオプションはデータベースへの接続がプログラムの実行前に開いている必要があることを示します。例:
m_ProgramExec -b RSSABB01
オプションpost-translation-fileによって指定されたサブファイルには、Tuxedo ART Workbenchコンバータの後のポストトランスレーションの自動実行に使用される一連のルールが含まれています。Workbenchリファレンス・ガイドのポストトランスレーション構成ファイルに関する項を参照してください。
メイン構成ファイル内のポストトランスレーション・エントリは次のとおりです。
post-translation-file = "../param/renov.desc"
一般的なオプションのroot-skeleton、target-proc、label-end、FSNの管理などはOracle Tuxedo Application Workbenchリファレンス・ガイドのJCLトランスレータの項で説明しています。
% config.desc :
%
root-skeleton = "../trf-jcl/"
target-proc = "../trf-jcl/Master-Proc"
use-sort=mf-sort
%
var-dataroot = "${DATA}/"var-tmp = "${TMP}/"var-spool = "${SPOOL}/"% Ksh heading
%
top-skeleton = "../param/top-ksh.txt"
% KSH footer
%
bottom-skeleton = "../param/bottom-ksh.txt"
% Files passed in tables
file-list-in-table = "../param/dynamic-config/File-in-table.txt"
% Post-Translation Configuration File
post-translation-file = "../param/renov.desc"
% Suffix of translated ksh du ksh traduit
suffix-skeleton = "ksh"
% Management of FSN to keep
set-no-delete-fsn = SORTIE ( ZIP390 ),
ENTREE ( ZIP390 ),
* ( DB2CMD,CSQUTIL ),
CFTIN ( CFTUTIL ),
SYSUT1 ( DUMMY ),
* ( ADRDSSU ).
% Management of FSN to delete
set-delete-fsn = SYSOUT ( IDCAMS ),
SYSEXEC ( CSCOLMVS ),
SYSTSIN ( * ),
SYSPUNCH ( * ),
TOOLIN ( * ),
SYSUDUMP ( * ),
SYSDBOUT ( * ),
SYSABOUT ( * ),
SYSTSPRT ( * ),
SORTLIB ( * ),
OPLIB ( * ),
STEPLIB ( * ),
JOBLIB ( * ).
このファイルは、プログラムが起動されるインスタンスを検出するためのソースJCLの解釈方法、およびこの起動操作の変換方法、つまりIKJEFT01、DLIBATCHおよびその他の標準ランチャの事前定義済の構成を記述しています。
global-options jclz-launcher-spec-file = "launchers".
LAUNCHER DFSRRC00
IndexProg : 2,
IndexPSB : 3
END
LAUNCHER DB2BATCH
IndexProg : 2,
IndexPSB : 3
END
LAUNCHER SWCP7110
IndexProg : 2,
IndexParm : 4,
Separator : ";"
一般オプションroot-skeleton、target-proc、label-endなどはOracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドのJCLトランスレータの項で説明しています。
%
% config.desc :
%
%
root-skeleton = "../trf-jcl/"
target-proc = "../trf-jcl/Master-Proc"
use-sort=mf-sort
%
%
var-dataroot = "${DATA}/"var-tmp = "${TMP}/"var-spool = "${SPOOL}/"%
% Ksh heading
-------------------------------------------------------------------------
%
top-skeleton = "../param/top-ksh.txt"
% Ksh heading -------------------------------------------------------------------------
%
% KSH footer ------------------------------------------------------------------------
%
bottom-skeleton = "../param/bottom-ksh.txt"
%
% KSH footer --------------------------------------------------------------------------
%
% File passed in table
%
file-list-in-table = "../param/dynamic-config/File-in-table.txt"
% Suffix of translated ksh
suffix-skeleton = "ksh"
% Management of FSN to keep
set-no-delete-fsn = SYSIN ( DSNUTILB ),
OUTPUT ( ZIP390 ),
INPUT ( ZIP390 ),
* ( DB2CMD,CSQUTIL ),
CFTIN ( CFTUTIL ),
SYSUT1 ( DUMMY ),
* ( ADRDSSU ).
% Management of FSN to delete
set-delete-fsn = SYSOUT ( IDCAMS ),
SYSEXEC ( CSCOLMVS ),
SYSTSIN ( * ),
SYSIN ( IDCAMS,XMFSORT,ICEMAN,SPOOL,SORT ),
SYSPUNCH ( * ),
TOOLIN ( * ),
SYSUDUMP ( * ),
SYSDBOUT ( * ),
SYSABOUT ( * ),
SYSTSPRT ( * ),
SORTLIB ( * ),
OPLIB ( * ),
STEPLIB ( * ),
JOBLIB ( * ).
Tuxedo ART Workbench JCLトランスレータは、移行プラットフォーム(Linux)で実行し、1つのジョブ・ファイル、一連のジョブ・ファイルまたはシステム・コンテンツ全体を自動的に変換できます。
次のコマンドを使用して変換を実行できます。ログ・ファイルは$LOGS/trad-jclに生成されます。
入力ファイルとして同じ名前(.ksh接尾辞を除く)のKornシェル・スクリプトを作成する場合。
cd $LOGS/trans-jcl
$REFINEDIR/refine jclz-unix -v version -s $PARAM/system.desc -c $PARAM/config-trad-JCL.desc JCL/defvcust.jcl
次のコマンドを起動するJCLファイルのリストを変換する場合。
cd $LOGS/trans-jcl
$REFINEDIR/refine jclz-unix -v version -s $PARAM/system.desc -c $PARAM/config-trad-JCL.desc -f jcl-files-list
次のコマンドを起動するすべてのJCLファイルを変換する場合。
cd $LOGS/trans-jcl
$REFINEDIR/refine jclz-unix -v version -s $PARAM/system.desc -c $PARAM/config-trad-JCL.desc
JCL変換の制限により、またはサイト固有の変換が必要な場合、反復的なポストトランスレーション・タスクを自動的に実行する場合があります。
ポストトランスレーションのメカニズムにより、別の内容で行の1ブロックを変更できます。
ポストトランスレーションの使用方法を示すために、次の例では、/prtvcust.ksh JCLスクリプト内のm_ProgramExec IEFBR14 ""を含む行の後にコメントを追加しています。
# by user John Doe on YY/MM/DD
regle add-comment-1
filtre [
+JCL/prtvcust.ksh
]
transform [
m_FileAssign -m R -a R -d SHR VKSDCUST ${DATA}/METAW00.VSAM.CUSTOMERm_ProgramExec PGMMB01 ""
]
into [
m_FileAssign -m R -a R -d SHR VKSDCUST ${DATA}/METAW00.VSAM.CUSTOMERm_ProgramExec PGMMB01 ""
# Added comment
$REFINEDIR/M2_L3_5/scripts/post-trans -c=\#META-RENOV\# -r=$PROJECT/param/renov-jcl.desc JCL/prtvcust.ksh < JCL/prtvcust.ksh > JCL/prtvcust.ksh.renov
grep -v "#META-RENOV#" JCL/prtvcust.ksh.renov > JCL/prtvcust.ksh
エラー・メッセージを確認します。JCLトランスレータは生成されたスクリプトの実行中に発生したエラー・メッセージを出力します。"UNDEFINED"、"NIL"、"UNTRANSLATED"をキーワードにして検索して、メッセージが存在するかどうかを確認します。エラー・メッセージとその説明の完全なリストは、『Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイド』にあります。
次のことができるようになるため、Tuxedo ART Workbenchを使用する場合はmakefileの使用をお薦めします。
makefileはプロジェクトの初期化時に操作が実装されたソース・ディレクトリに置かれる必要があります。
「カタロガ」の「Make構成」を参照してください。
$SOURCEファイル・システムのすべてのJCLを変換する場合
make trad_jcl
ソースをコンパイルするために、収集が必要な情報があります。これらの情報を構成ウィザードに入力できます。
COBOL ITをターゲットCOBOLコンパイラとして選択して、ISAMファイルをオープン・システムで使用する場合、BDB DbHomeの場所を設定する必要があり、それがデータベースとログ・ファイルが格納されるディレクトリを指している必要があります。詳細は、COBOL-IT Compiler Suite Enterprise Editionのリファレンス・マニュアルのOracle Berkeley DBに関する項または『Berkeley DB Programmer's Reference Guide』の「The Berkeley DB Environment」を参照してください。
ビルドが完了すると、ルートmakefileとサブmakefileが関連サブディレクトリの下に生成されます。また、fixed-copyディレクトリ全体がworkbenchインストール・ディレクトリからビルド・ディレクトリにコピーされます。
Tuxedoウィザードの主要機能は、Batch RuntimeとCICS Runtime用にubbconfigファイルを生成することです。
構成可能な項目には、Tuxedoの場所、IPC KEY、マシン名、APPDIRなどが含まれます。詳細は、Oracle 12cリリース2 (12.1.3)を参照してください。
CICSウィザードの主要機能は、CICS Runtime用にsetenvファイルを生成することです。構成可能な項目には、CICS Runtimeの場所、共通の作業領域とモニター設定用のIPC KEYが含まれます。
詳細は、Oracle Tuxedo Application Runtime for CICS and Batch 12cリリース2 (12.1.3)を参照してください。
Batchウィザードの主要機能は、Batch Runtime用にjesconfigとsetenvファイルを生成することです。構成可能な項目には、Batch Runtimeの場所、JESROOTなどが含まれます。
詳細は、Oracle Tuxedo Application Runtime for CICS and Batch 12cリリース2 (12.1.3)を参照してください。
IMSウィザードの主要な機能は、IMS Runtime用にsetenvファイルを生成することです。構成可能な項目には、IMS Runtimeの場所などがあります。
詳細は、Oracle Tuxedo Application Runtime for IMS 12cリリース2 (12.1.3)を参照してください。
アプリケーション・コンポーネント、データ再ロード・プログラム、データ・アクセス・プログラムおよびTUXEDO構成ファイルをビルドするように、ビルド手順によりユーザーをガイドします。
Gmakeユーティリティはビルド・タスク実行時に使用されます。関連makefileは前の手順で生成されます。
3つのtarファイルが生成されます。それらには、デプロイ・ディレクトリの下にあるファイルがすべて格納されます。このtarファイルはデプロイの準備ができています。
Batch Runtimeの環境を準備します。詳細は、Oracle Tuxedo Application Runtime for CICS and Batch 12cリリース2 (12.1.3)を参照してください。
CICS Runtimeの環境を準備します。詳細は、Oracle Tuxedo Application Runtime for CICS and Batch 12cリリース2 (12.1.3)を参照してください。
IMS Runtime環境を準備します。詳細は、Oracle Tuxedo Application Runtime for IMS 12cリリース2 (12.1.3)を参照してください。
定義されているファイルがすべて、表に表示されます。表で最後の列をクリックすると、ソース場所の下にあるファイルがリストされます。
「終了」をクリックすると、ユーザーが指定した場所にリロードの結果がすべて格納されます。
この手順は前の手順と似ていますが、ユーザーが指定したファイル・パスではなくデータベースに結果データが格納されます。
ART Batch Runtimeを起動または停止して、ART Batch Runtimeのジョブを操作します。
この項では、Tuxedo ART Workbenchを使用して生成されたコンポーネント(「コンポーネントの生成」を参照)を使用する、アンロード、転送および再ロードのタスクについて説明します。
アンロードに使用されるコンポーネント($HOME/trf/unload/fileに生成)は、ソースz/OSプラットフォームにインストールする必要があります。生成されたJCLは、JOBカード、ライブラリ・アクセス・パス、入力および出力ファイル(データ・セット名: DSN)へのアクセス・パスを含む、特定のサイトの制約への適合が必要な場合があります。
再ロードに使用されるコンポーネント($HOME/trf/reload/fileに生成)はターゲット・プラットフォームにインストールする必要があります(実行時)。
次の環境変数をターゲット・プラットフォームに設定する必要があります。
アンロード用JCLがデータマップ・パラメータ・ファイル(Datamap-<configuration name>.re)にリストされた各z/OSファイルに対して生成されます。これらのアンロード用JCLの名前は<論理ファイル名>.jclunloadです。
| 注: | .jclunload拡張子は、z/OSで実行する場合には削除する必要があります。 |
ファイルは、サイトで使用可能なファイル転送ツール(CFT、FTPなど)を使用して、バイナリ形式で、ソースz/OSプラットフォームとターゲット・プラットフォーム間で転送される必要があります。
トランスコードおよび再ロードに使用される生成されたCOBOLプログラムの名前は次のとおりです。
マッピング・パラメータ・ファイル(mapper-<configuration name>.re)での例で、生成されるプログラムは次のとおりです。
シーケンシャル・ファイルの移行時には、ターゲットのCOBOL LINE SEQUENTIAL出力ファイルが生成されます。
…
SELECT SORTIE
ASSIGN TO "SORTIE"
ORGANIZATION IS LINE SEQUENTIAL
FILE STATUS IS IO-STATUS.
…
VSAM KSDSファイルの移行時には、INDEXED出力ファイルが生成されます。
…
SELECT MW-SORTIE
ASSIGN TO "SORTIE"
ORGANIZATION IS INDEXED
ACCESS IS DYNAMIC
RECORD KEY IS VS-CUSTIDENT
FILE STATUS IS IO-STATUS.
…
これらのCOBOLプログラムは、Tuxedo ART Workbenchリファレンス・ガイドのCOBOLコンバータに関する項に記載されたオプションを使用して、ターゲットのCOBOLコンパイラでコンパイルされる必要があります。
トランスコードおよび再ロード・スクリプトは次のパラメータを使用します。
loadfile-<logical file name>.ksh [-t/-l] [-c <method>]
loadgdg-<logical file name>.ksh [-t/-l] [-c <method>]
マッピング・パラメータ・ファイル(mapper-<configuration name>.re)での例で、生成されるスクリプトは次のとおりです。
デフォルトでは、入力ファイルは$DATA_SOURCEで示されたディレクトリに置かれ、出力ファイルは$DATAで示されたディレクトリに置かれます。
これらのファイルはマッピング・パラメータ・ファイル(mapper-<configuration name>.re)で使用される論理ファイル名を使用して名前付けされます。
実行ログは$MT_LOGで示されたディレクトリに作成されます。
問題が発生すると、ゼロ以外のリターン・コードが生成されます。
この確認は次のloadfile-<論理ファイル名>.kshのオプションを使用します。
-c ftp:<name of transferred physical file>:<name of FTP log under UNIX>
| 注: | このオプションは、再ロード後、z/OSから転送された物理ファイルとターゲット・プラットフォームに再ロードされたファイルに、同じレコード数が含まれていることを検証します。このチェックは、FTPログと再ロード・プログラムの実行レポートを使用して実行されます。レコード数が異なる場合は、エラー・メッセージが生成されます。 |
この項では、ファイルをソースからターゲット・プラットフォームへ移行するときに発生した使用エラーにより生じる問題について説明します。
Tuxedo ART Workbenchツールを実行するときに、ユーザーは次のことを確認する必要があります。
Mapper-log-<構成名>ファイルにエラーが含まれているか(共通の問題と解決策を参照)。エラー・メッセージと関連する説明はOracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドの付録にリストされています。
Refine error...
Mapper-log-STFILEORAログ・ファイルの内容には次が含まれます。
file PJ01AAA.SS.QSAM.CUSTOMER.REPORT loaded/unloaded
file logical name MW-SYSOUT
*** Unknown file organization : *UNDEFINED*
mapping record MW-SYSOUT
record MW-SYSOUT: logical name MW-SYSOUT
record MW-SYSOUT: logical name MW-SYSOUT
移行するファイルがmapper-<configuration name>.reファイルに存在し、Datamap.<configuration name>.reファイルには存在しません。
Refine error...
Mapper-log-STFILEORA1ログ・ファイルの内容には次が含まれます。
file PJ01AAA.SS.QSAM.CUSTOMER.REPORT loaded/unloaded
file logical name MW-SYSOUT
file is sequential: no primary key
*** record `MW-SYSOUT in COPY/MW_SYSOU2T.cpy' not found ***
*** ERROR: all records omitted ***
mapping records
Refine error...
Mapper-log-STFILEORA2ログ・ファイルの内容には次が含まれます。
file PJ01AAA.SS.QSAM.CUSTOMER.REPORT loaded/unloaded
file logical name MW-SYSOUT
file is sequential: no primary key
*** record `MW-SYSOUTTT in COPY/MW_SYSOUT.cpy' not found ***
record MW-SYSOUT reselected (all records omitted)
mapping record MW-SYSOUT
record MW-SYSOUT: logical name MW-SYSOUT
Refine error...
Mapper-log-STFILEORA3ログ・ファイルの内容には次が含まれます。
*=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-==-=-=-=-=-=-=-=-=-=-=-=-
############################################################################
Control of schema STFILEORA3
External Variable PARAM is not set!
ERROR : Check directive files for schema STFILEORA3
この項では、Tuxedo ART Workbenchを使用して生成されたコンポーネント(「コンポーネントの生成」を参照)を使用する、アンロード、転送および再ロードのタスクについて説明します。
アンロードに使用されるコンポーネント($HOME/trf/unload/fileに生成)は、ソースz/OSプラットフォームにインストールする必要があります。生成されたJCLは、JOBカード、ライブラリ・アクセス・パス、入力および出力ファイル(データ・セット名: DSN)へのアクセス・パスを含む、特定のサイトの制約への適合が必要な場合があります。
再ロードに使用されるコンポーネント($HOME/trf/reload/fileに生成)はターゲット・プラットフォームにインストールする必要があります(実行時)。
Oracleオブジェクトの作成に使用されるコンポーネント($HOME/SQL/file/<スキーマ名>に生成)はターゲット・プラットフォームにインストールする必要があります(実行時)。
表1-34は、ターゲット・プラットフォームに設定する必要がある環境変数を示しています。
次の変数はOracle Tuxedo Application Rehosting Workbenchインストレーション・ガイドの情報に従って設定する必要があります。
アンロード用JCLがデータマップ・パラメータ・ファイル(Datamap-<configuration name>.re)にリストされた各z/OSファイルに対して生成されます。これらのアンロード用JCLの名前は<logical file name>.jclunloadです。これらのJCLは、IDCAMSユーティリティのREPRO機能を使用してファイルをアンロードします。
| 注: | .jclunload拡張子は、z/OSで実行する場合には削除する必要があります。 |
ファイルは、サイトで使用可能なファイル転送ツール(CFT、FTPなど)を使用して、バイナリ形式で、ソースz/OSプラットフォームとターゲットUNIXプラットフォーム間で転送される必要があります。
トランスコードおよび再ロードに使用される生成されたCOBOLプログラムの名前は次のとおりです。
RELTABLE-ODCSF0.pco
これらのCOBOLプログラムは、Oracle Tuxedo Application Workbenchリファレンス・ガイドのCOBOLコンバータに関する項に記載されているオプションを使用して、ターゲットのCOBOLコンパイラでコンパイルされる必要があります。
各プログラムはSQL*LOADERユーティリティで使用できるようになる出力ファイルを生成します。
loadtable-<…>.ksh スクリプトのオプション-dにより、Oracleオブジェクトを作成できます。
トランスコードおよび再ロード・スクリプトには次のパラメータがあります。
loadtable-<logical file name>.ksh [-d] [-t/-l] [-c <method>]
マッピング・パラメータ・ファイル(mapper-<configuration name>.re)での例で、生成されるスクリプトは次のとおりです。
デフォルトでは、入力ファイルは$DATA_SOURCEで示されたディレクトリに置かれ、出力ファイルは$DATAで示されたディレクトリに置かれます。
これらのファイルはマッピング・パラメータ・ファイル(mapper-<configuration name>.re)構成ファイルで使用される論理ファイル名を使用して名前付けされます。
実行ログは$MT_LOGで示されたディレクトリに作成されます。
問題が発生すると、ゼロ以外のリターン・コードが生成されます。
この確認は次のloadtable-<論理ファイル名>.kshのオプションを使用します。
-c ftp:<name of transfered physical file>:<name of FTP log under UNIX>
| 注: | このオプションにより、再ロード後、z/OSから転送された物理ファイルとターゲット・プラットフォームに再ロードされたファイルに、同じレコード数が含まれていることを検証できます。この確認は、FTPログと再ロード・プログラムの実行レポートを使用して実行されます。レコード数が異なる場合は、エラー・メッセージが生成されます。 |
COBOLおよびPRO*COBOLアクセス・ルーチンは『Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイド』に記載されたターゲットのCOBOLコンパイル・オプションを使用してコンパイルされる必要があります。
この項では、ファイルをソースからターゲット・プラットフォームへ移行するときに発生した使用エラーにより生じる問題について説明します。
Tuxedo ART Workbenchツールを実行するときに、ユーザーは次のことを確認する必要があります。
Mapper-log-<構成名>ファイルにエラーが含まれているか(共通の問題と解決策を参照)。エラー・メッセージとその説明は、Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドの付録に記載されています。
*=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-==-=-=-=-=-=-=-=-=-=-=-
Target output directory /home2/wkb9/trf is missing
Check parameters: -i <output_directory> <schema>
ERROR : usage : file.sh [ [-g] [-m] [-i <output_directory>] <schema_name> | -s <output_directory> (<schema>,...) ]
abort
Mapper-log-STFILEORA2ログ・ファイルの内容には次が含まれます。
file PJ01AAA.SS.VSAM.CUSTOMER Oracle
file logical name ODCSF0B
*** Unknown file organization : INDEXD
mapping record VS-ODCSF0-RECORD
record VS-ODCSF0-RECORD: logical name VS
record VS-ODCSF0-RECORD: logical name VS
record VS-ODCSF0-RECORD REDEFINES:
field VS-CUSTBDATE as opaque (default strategy)
record VS-ODCSF0-RECORD REDEFINES:
field VS-CUSTBDATE as opaque (default strategy)
このファイルはINDEXEDではなくINDEXDのファイル編成で構成されています。
file.sh -gmi $HOME/trf STFILEORAの実行時に次のメッセージが表示されます。
*=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-==-=-=-=-=-=-=-=-=-=-=-
##########################################################################
Control of configuration STFILEORA
##############################
Control of templates
OK: Use Default Templates list file
File name is /REFINE/convert-data/default/file/file-templates.txt
##############################
Control of Mapper
##############################
COMPONENTS GENERATION
…
Parsing mapper file /home2/wkb9/tmp/mapper-STFILEORA.re.tmp ...
Parse error at character position 1346 in file:
/home2/wkb9/tmp/mapper-STFILEORA.re.tmp.
The illegal text is: "converrted
table name CUSTOMER
include \"COPY/ODCSF0B.cpy\"
map record VS-ODCSF0-RECORD defin"
While parsing in grammar UFAS-CONVERTER::MAPPER-INPUT-GRAMMAR,
CONVERRTED is a symbol, which is not a legal token
at this point in the input. The legal tokens at this point are:
:END "templates" "filler" "field" "file" "one-for-n" "multi-record" "table" "transferred" "mode-tp" ... [14 others]
*ERROR*: parse error is found in /home2/wkb9/tmp/mapper-STFILEORA.re.tmp.
Refine error...
/tmp/refine-exit-status.snICMmElNYF25625
マッピング・ファイルで‘CONVERTED’という語句に入力エラーが起こりました。
file.sh -gmi $HOME/trf STFILEORAの実行時に次のメッセージが表示されます。
*=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-==-=-=-=-=-=-=-==-=-=-=
##########################################################################
Control of configuration STFILEORA
##############################
Control of templates
Project Templates list file is missing /home2/wkb9/param/file/file-templates.txt
OK: Use Default Templates list file
File name is /Qarefine/release/M2_L4_1/convert-data/default/file/file-templates.txt
##############################
Control of Mapper
##############################
COMPONENTS GENERATION
…
Point 1 !!
Warning: Can't find file in file table named PJ01AAA.SS.VSAM.CUSTOMERS
Point 2 !!
…
Refine error...
/tmp/refine-exit-status.IvmFDYsYDdr31956
ERROR : generation aborted
Abort
Oracle表に変換するファイルの名前が、Datamapファイルに存在する名前と一致しません。
この項では、Tuxedo ART Workbenchを使用して生成されたコンポーネント(「コンポーネントの生成」を参照)を使用する、アンロード、転送および再ロードのタスクについて説明します。
アンロードに使用されるコンポーネント($HOME/trf/unload/fileに生成)は、ソースz/OSプラットフォームにインストールする必要があります。生成されたJCLは、JOBカード、ライブラリ・アクセス・パス、入力および出力ファイル(データ・セット名: DSN)へのアクセス・パスを含む、特定のサイトの制約への適合が必要な場合があります。
再ロードに使用されるコンポーネント($HOME/trf/reload/fileに生成)はターゲット・プラットフォームにインストールする必要があります(実行時)。
Oracleオブジェクトの作成に使用されるコンポーネント($HOME/SQL/file/<スキーマ名>に生成)はターゲット・プラットフォームにインストールする必要があります(実行時)。
次の環境変数をターゲット・プラットフォームに設定する必要があります。
次の変数はOracle Tuxedo Application Rehosting Workbenchインストレーション・ガイドの情報に従って設定する必要があります。
アンロード用JCLがデータマップ・パラメータ・ファイル(Datamap-<configuration name>.re)にリストされた各z/OSファイルに対して生成されます。これらのアンロード用JCLの名前は<logical file name>.jclunloadです。これらのJCLは、IDCAMSユーティリティのREPRO機能を使用してファイルをアンロードします。
| 注: | .jclunload拡張子は、z/OSで実行する場合には削除する必要があります。 |
ファイルは、サイトで使用可能なファイル転送ツール(CFT、FTPなど)を使用して、バイナリ形式で、ソースz/OSプラットフォームとターゲットUNIXプラットフォーム間で転送される必要があります。
トランスコードおよび再ロードに使用される生成されたCOBOLプログラムの名前は次のとおりです。
RELTABLE-ODCSF0.sqb
これらのCOBOLプログラムは、Tuxedo ART Workbenchリファレンス・ガイドのCOBOLコンバータに関する項に記載されたオプションを使用して、ターゲットのCOBOLコンパイラでコンパイルされる必要があります。
各プログラムはSQL*LOADERユーティリティで使用できるようになる出力ファイルを生成します。
loadtable-<…>.ksh スクリプトのオプション-dにより、Oracleオブジェクトを作成できます。
トランスコードおよび再ロード・スクリプトには次のパラメータがあります。
loadtable-<logical file name>.ksh [-d] [-t/-l] [-c <method>]
マッピング・パラメータ・ファイル(mapper-<configuration name>.re)での例で、生成されるスクリプトは次のとおりです。
デフォルトでは、入力ファイルは$DATA_SOURCEで示されたディレクトリに置かれ、出力ファイルは$DATAで示されたディレクトリに置かれます。
これらのファイルはマッピング・パラメータ・ファイル(mapper-<configuration name>.re)構成ファイルで使用される論理ファイル名を使用して名前付けされます。
実行ログは$MT_LOGで示されたディレクトリに作成されます。
問題が発生すると、ゼロ以外のリターン・コードが生成されます。
この確認は次のloadtable-<論理ファイル名>.kshのオプションを使用します。
-c ftp:<name of transfered physical file>:<name of FTP log under UNIX>
| 注: | このオプションにより、再ロード後、z/OSから転送された物理ファイルとターゲット・プラットフォームに再ロードされたファイルに、同じレコード数が含まれていることを検証できます。この確認は、FTPログと再ロード・プログラムの実行レポートを使用して実行されます。レコード数が異なる場合は、エラー・メッセージが生成されます。 |
COBOLおよび埋込みSQLアクセス・ルーチンは、Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドに記載されたCOBOLのコンパイル・オプションを使用してコンパイルされる必要があります。
この項では、ファイルをソースからターゲット・プラットフォームへ移行するときに発生した使用エラーにより生じる問題について説明します。
Tuxedo ART Workbenchツールを実行するときに、ユーザーは次のことを確認する必要があります。
Mapper-log-<構成名>ファイルにエラーが含まれているか(共通の問題と解決策を参照)。エラー・メッセージと関連する説明はOracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドの付録にリストされています。
*=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-==-=-=-=-=-=-=-=-=-=-=-
Target output directory /home2/wkb9/trf is missing
Check parameters: -i <output_directory> <schema>
ERROR : usage : file.sh [ [-g] [-m] [-i <output_directory>] <schema_name> | -s <output_directory> (<schema>,...) ]
abort
Mapper-log-STFILEUDB2ログ・ファイルの内容には次が含まれます。
file PJ01AAA.SS.VSAM.CUSTOMER Oracle
file logical name ODCSF0B
*** Unknown file organization : INDEXD
mapping record VS-ODCSF0-RECORD
record VS-ODCSF0-RECORD: logical name VS
record VS-ODCSF0-RECORD: logical name VS
record VS-ODCSF0-RECORD REDEFINES:
field VS-CUSTBDATE as opaque (default strategy)
record VS-ODCSF0-RECORD REDEFINES:
field VS-CUSTBDATE as opaque (default strategy)
このファイルはINDEXEDではなくINDEXDのファイル編成で構成されています。
file.sh -gmi $HOME/trf STFILEUDBの実行時に次のメッセージが表示されます。
*=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-==-=-=-=-=-=-=-=-=-=-=-
##########################################################################
Control of configuration STFILEUDB
##############################
Control of templates
OK: Use Default Templates list file
File name is /REFINE/convert-data/default/file/file-templates-db2luw.txt
##############################
Control of Mapper
##############################
COMPONENTS GENERATION
…
Parsing mapper file /home2/wkb9/tmp/mapper-STFILEUDB.re.tmp ...
Parse error at character position 1346 in file:
/home2/wkb9/tmp/mapper-STFILEUDB.re.tmp.
The illegal text is: "converrted
table name CUSTOMER
include \"COPY/ODCSF0B.cpy\"
map record VS-ODCSF0-RECORD defin"
While parsing in grammar UFAS-CONVERTER::MAPPER-INPUT-GRAMMAR,
CONVERRTED is a symbol, which is not a legal token
at this point in the input. The legal tokens at this point are:
:END "templates" "filler" "field" "file" "one-for-n" "multi-record" "table" "transferred" "mode-tp" ... [14 others]
*ERROR*: parse error is found in /home2/wkb9/tmp/mapper-STFILEUDB.re.tmp.
Refine error...
/tmp/refine-exit-status.snICMmElNYF25625
マッピング・ファイルで‘CONVERTED’という語句に入力エラーが起こりました。
file.sh -gmi $HOME/trf STFILEORAの実行時に次のメッセージが表示されます。
*=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-==-=-=-=-=-=-=-==-=-=-=
##########################################################################
Control of configuration STFILEUDB
##############################
Control of templates
Project Templates list file is missing /home2/wkb9/param/file/file-templates.txt
OK: Use Default Templates list file
File name is /Qarefine/release/M2_L4_1/convert-data/default/file/file-templates.txt
##############################
Control of Mapper
##############################
COMPONENTS GENERATION
…
Point 1 !!
Warning: Can't find file in file table named PJ01AAA.SS.VSAM.CUSTOMERS
Point 2 !!
…
Refine error...
/tmp/refine-exit-status.IvmFDYsYDdr31956
ERROR : generation aborted
Abort
DB2/luw (udb)表に変換するファイルの名前が、Datamapファイルに存在する名前と一致しません。
この項では、Tuxedo ART Workbenchを使用して生成されたコンポーネント(「コンポーネントの生成」を参照)を使用する、アンロード、転送および再ロードのタスクについて説明します。
アンロードに使用されるコンポーネント($HOME/trf/unload/rdbmsに生成)は、ソースz/OSプラットフォームにインストールする必要があります。生成されたJCLは、JOBカード、ライブラリ・アクセス・パス、入力および出力ファイル(データ・セット名: DSN)へのアクセス・パスを含む、特定のサイトの制約への適合が必要な場合があります。
DBのロード/アンロード用COBOLプログラム($HOME/trf/DSNUTILS/<schema name>に生成)は、コンパイルしてターゲット・プラットフォームにインストールする必要があります(実行時)。
再ロードに使用されるコンポーネント($HOME/trf/reload/rdbmsに生成)はターゲット・プラットフォームにインストールする必要があります(実行時)。
表1-36は、ターゲット・プラットフォームに設定する必要がある環境変数を示しています。
|
|||
『Oracle Tuxedo Application Workbenchリファレンス・ガイド』およびその他のOracleドキュメントの説明に従って設定します。
|
|||
『Oracle Tuxedo Application Workbenchリファレンス・ガイド』およびその他のOracleドキュメントの説明に従って設定します。
|
次の変数はOracle Tuxedo Application Rehosting Workbenchインストレーション・ガイドの情報に従って設定する必要があります。
再ロード・スクリプトloadrdbms-<表名>.kshはSQL*LDR Oracleユーティリティを使用します。このユーティリティがアクセスできるのはORACLEサーバーに限られるため、このスクリプトはORACLEサーバーで使用する必要があり、クライアント接続では使用できません。特にこの再ロード手順では、この変数に@<oracle_sid>文字列を含めることはできません。
COBOLプログラムによって呼び出されるパッケージの機能(COBOLコンバータによって変換)をターゲット・プラットフォーム(ランタイム)にインストールする必要があります。
パッケージは、REFINEDIR/convert-data/fixed-components/MWDB2ORA.plbおよびREFINEDIR/convert-data/fixed-components/MWDB2ORA_CONST.plbに配置されます。MWDB2ORA_CONST.plbパッケージを変更して、これらのパッケージをDB2-to-Oracleコンバータに関する項で説明されているように、SQLPLUSの下にインストールする必要があります。
各DB2表をアンロードするには、IBMアンロード・ユーティリティを使用するJCLを実行します。通常、アンロード・ユーティリティによって各表に3つのファイルが作成されます。
表にCLOBまたはBLOBデータ型が含まれる場合、アンロード・ユーティリティで次が作成されます。
これらのアンロード用JCLの名前は<表名>.jclunloadです。
表名が8文字よりも長い場合、Tuxedo ART Workbenchはできるだけ元の名前に近い8文字の名前をz/OS JCLの名前とみなします。この名前の変更プロセスにより、各表名の一意性が保たれます。
この章で使用される例では、ODCSF0という表名が、z/OS JCLの名前を付けるときにODCSF0X1に伸ばされます。
アンロードされたデータ・ファイルは、サイトで使用可能なファイル転送ツール(CFT、FTPなど)を使用して、バイナリ形式で、ソースz/OSプラットフォームとターゲットUNIXプラットフォーム間で転送される必要があります。
LOGおよびSYSPUNCHファイルはテキスト・モードで転送される必要があります。
ターゲットUNIXプラットフォームに転送されたファイルは$DATA_SOURCEディレクトリに格納される必要があります。
CLOBおよびBLOBデータ・ファイルはバイナリ・モードで転送し、$DATA_SOURCE/<schema_name>.<column_name>ディレクトリに格納する必要があります。
MBCSデータ・ファイルはテキスト・モードで転送し、転送ツールによって適切にトランスコードする必要があります。詳細は、Oracle Tuxedo Application Workbenchリファレンス・ガイドを参照してください。
| 注意: | MVSでは、Rehosting Workbenchは6文字の名前に数値を加えたもの(表の最初のCLOBまたはBLOB列には1、2番目には2など)を データセットまたはディレクトリの<column_name>とみなします。UNIX/Linuxプラットフォームでは、loadrdbms.shスクリプトは実際のcolumn_nameを使用します。 |
Oracleオブジェクト(表、索引、制約など)を作成するスクリプトは$HOME/trf/SQL/rdbms/<スキーマ名>ディレクトリに作成されます。これらはターゲットOracleインスタンスで実行される必要があります。
<スキーマ名>.lstファイルにはすべての表の名前が階層的な順序で(親表の次に子表)含まれます。
表1-37に、Tuxedo ART Workbenchで管理されるDB2オブジェクトとそれを作成するために使用するスクリプトの名前をリストします。
トランスコードに使用される生成されたCOBOLプログラムの名前は次のとおりです。
この章で使用される生成されたプログラムの例は次のとおりです。
このプログラムはターゲットCOBOLコンパイラと、Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドに記載されたオプションを使用してコンパイルされる必要があります。
このプログラムは出力時にRECORD SEQUENTIALファイルを生成し、それは次にSQL*LOADERユーティリティに読み取られます。
SELECT MW-SORTIE
ASSIGN TO "SORTIE"
ORGANIZATION IS RECORD SEQUENTIAL
ACCESS IS SEQUENTIAL
FILE STATUS IS IO-STATUS.
CLOB列のトランスコードに使用される、生成されたCOBOLプログラムの名前は次のとおりです。
CLOB_<table name>_<column_name>.cbl
データのトランスコードおよび再ロードを可能にするスクリプトが次のディレクトリに生成されます。
$HOME/trf/reload/rdbms/<schema name>/ksh
loadrdbms-<table name>.kshloadrdbms-ODCSF0.ksh
各スクリプトは、トランスコードを実行するCOBOLプログラムを開始し、次にSQL*LOADERユーティリティを開始します。SQL*LOADERにより使用されるCTLファイルの名前は次のとおりです。
<table name>.ctl.この章の例で使用されるCTLファイルの名前は次のとおりです。
ODCSF0.ctl
トランスコードおよび再ロード・スクリプトには次のパラメータがあります。
loadrdbms-<table name>.ksh [-t | [-O|-T]] [-l] [-c: <method>]
DB2オブジェクトの移行の例での例で、生成されるスクリプトは次のとおりです。
このチェックでは、loadrdbms-<表名>.kshの次のオプションを使用します。
-c rows
| 注意: | このオプションでは、再ロードの後でDB2アンロード・ユーティリティにより、再ロードされたOracle表にz/OSからアンロードされた対応する表と同数のレコードが含まれることを確認します。レコード数が異なる場合は、エラー・メッセージが生成されます。 |
この項では、データをDB2データベースからターゲットOracleデータベースへ移行するときに発生した使用エラーにより生じる問題について説明します。
Tuxedo ART Workbenchツールを実行するときに、ユーザーは次のことを確認する必要があります。
rdbms-converter-<スキーマ名>.logファイルにエラーが含まれているか(共通の問題と解決策を参照)。エラー・メッセージとその説明は、Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイドの付録に記載されています。
Fatal RDBMS error.
Error: RDBMS-0105: Catalog for /home2/wkb9/param/system.desc is out of date
and needs to be updated externally.
Refine error...
Refine error...
/tmp/refine-exit-status.MOaZwgTphIN14075
ERROR : conversion aborted . Can not read /home2/wkb9/tmp/outputs/SCHEMA/rdbms-converter-SCHEMA.log log file
abort
*=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-==-=-=-=-=-=-=-=-=--=-
#########################################################################
CONVERSION OF DDLs and CTL files and GENERATION of directive files
ERROR : Configuration file /db-param.cfg is missing !
ERROR : Error in reading configuration file
Abort
*=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-==-=-=-=-=-=-=-=-=-=-=-
Target output directory /home2/wkb9/bad-directory is missing
Check parameters: -i <output_directory> <schema>
ERROR : usage : rdbms.sh [ [-c|-C] [-g] [-m] [-r] [-i <output_directory>] <schema_name> ] -s <output_directory> (<schema>,...) ]
abort
$REFINEDIR/$VERS/rdbms.sh -c WWARNの実行時に次のメッセージが表示されます。
*=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-==-=-=-=-=-=-=-=-
WARNING: some unsupported db2 objects have been ignored by this tool.
Check file /home2/wkb9/tmp/outputs/WWARN/unsupported-WWARN.log to see a detail of those objects.
ERROR:
RDBMSWB-0199: conversion aborted due to 26 Warning message(s). Check previous error messages and try -C option instead of -c
abort
DDLにサポートされていない機能が含まれます。警告ファイルを確認してください。-cオプションを-Cオプションに置き換えることで、この中断を無視できます。
 
|