| Oracle® Database高可用性概要 12cリリース1 (12.1) B71280-03 |
|


 前 |
 次 |
Oracle MAAは、Oracle Databaseに対する高可用性アーキテクチャの設計、実装および操作に関するベスト・プラクティスの推奨事項を提示します。この章では、MAA参照アーキテクチャの各層で使用される主なコンポーネントと、実現されるサービス・レベルの詳細な説明を示します。
この章の内容は次のとおりです。
第2章「高可用性およびデータ保護 - 要件からのアーキテクチャの取得」には、Bronze、Silver、GoldおよびPlatinumの4つのMAA参照アーキテクチャの概要が記載されています。各参照アーキテクチャ(別名HA層)には、ともにデプロイされた場合に、高可用性およびデータ保護の指定されたサービス・レベルを確実に実現する、Oracleの最適な機能セットが使用されています。図7-1に、各HA層で使用されているテクノロジの概要を示します。
上で説明されている各アーキテクチャは、第6章「可用性を最大化するための運用前提条件」、MAAのテクニカル・ホワイト・ペーパーに記載されているその他のベスト・プラクティス、および『Oracle Database高可用性ベスト・プラクティス』に記述されている運用上および構成上のベスト・プラクティスを使用して実装します。MAAベスト・プラクティスに関するドキュメントの参照情報の詳細は、1.5項「最大可用性アーキテクチャ実装のロードマップ」を参照してください。
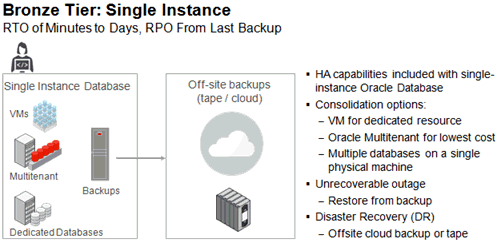
Bronze層では、できるかぎり少ないコストで、基本的なデータベース・サービスを提供しています。コストを削減し、実装の複雑さを低減するかわりに、HAとデータ保護のレベルが下げられています。図7-2に、Bronze層の概要を示します。
Bronzeで使用されるのは単一インスタンスのOracle Databaseで、Oracle Databaseインスタンスが実行されているサーバーが停止した場合に、自動フェイルオーバーに使用されるクラスタリング・テクノロジはありません。サーバーを使用できなくなった場合、またはデータベースをリカバリできない場合に、どれほど迅速に代替システムをプロビジョニングできるか、あるいはバックアップをリストアできるかを示す関数がRTOです。完全なサイト停止の最悪のシナリオでは、代替場所でこれらのタスクを実行するための時間も必要で、これには数日を要する場合もあります。
Oracle Recovery Manager (RMAN)は、Oracle Databaseの定期バックアップの実行に使用されます。リカバリ不可能な停止が発生した場合は、最後のバックアップ取得後に生成されたデータがRPOということになります。データベース・バックアップのコピーは、アーカイブと、プライマリ・データ・センターが災害に見舞われた場合の災害時リカバリの2つの目的で、リモートの場所またはクラウドにも保持されます。
Bronze層は、次のトピックで説明する主なコンポーネントで構成されています。
Bronzeでは、Oracle Database Enterprise Editionに含まれているHAおよびデータ保護の機能を、追加の費用なしで使用できます。
Oracle Restartは、ハードウェアまたはソフトウェア障害の後、あるいはデータベースのホスト・コンピュータの再起動時には必ず、データベース、リスナーおよびその他のOracleコンポーネントを自動的に再起動します。
物理的な破損および論理的なブロック内破損を対象としたOracle破損保護チェック。インメモリー破損が検出されると、ディスクへの書込みが阻止され、多くの場合は自動的に修復されます。詳細は、Oracle Databaseのブロック破損の防止、検出および修復を参照してください。
自動ストレージ管理(ASM)はOracleの統合ファイル・システムで、ディスク障害から保護するためのローカル・ミラー化を含むボリューム・マネージャです。
Oracle Flashbackテクノロジは、個々のトランザクション、表またはデータベース全体の修復に適した粒度レベルでの高速なエラー修正を可能にします。
Oracle Recovery Manager (RMAN)を使用すると、Oracle Databaseに最適化された信頼性の高いバックアップとリカバリを低コストで実現できます。
オンライン・メンテナンスには、データベース・メンテナンスのオンライン再定義と再編成、オンライン・ファイル移動およびオンライン・パッチ適用が含まれます。
Bronze層にデプロイされるデータベースには、開発およびテストのデータベース、およびデータベース統合やDatabase as a Service (DBaaS)としてのデプロイ候補として一番最初にあげられることが多い、比較的小規模な作業グループや部門ごとのアプリケーションをサポートしているデータベースがあります。
Oracle Multitenantは、Oracle Database 12c以降のデータベース統合および仮想化のMAAベスト・プラクティスです。その他の統合オプションは次のとおりです
オペレーティング・システムの仮想化 - 仮想マシン
スキーマ統合
Oracle RACを使用した、単一の物理マシンまたはクラスタへの複数の離散データベースの統合
Oracle Multitenantとその他の統合方法との間のトレードオフの詳細は、Oracle MAAのテクニカル・ホワイト・ペーパー『データベース統合の高可用性ベスト・プラクティス』を参照してください。
Oracle Enterprise Manager Cloud Controlでは、ビジネス・ユーザーが、様々なマルチテナント・アーキテクチャに対応するリソース・プール・モデルとともに、ITリソースをセルフ・サービスでデプロイできます。これらの機能は、Database as a Service (DBaaS)の実装に必要で、このパラダイムでは、エンド・ユーザー(データベース管理者、アプリケーション開発者、品質保証エンジニア、プロジェクト・リーダーなど)がデータベース・サービスをリクエストして、プロジェクトの存続期間に使用し、自動的にプロビジョニングが解除されてリソース・プールに戻されます。Cloud ControlのDatabase as a Service (DBaaS)では、次のものが提供されます。
データベース・サービスをプロビジョニングする共有の統合プラットフォーム
それらのリソースをプロビジョニングするセルフサービス・モデル
データベース・リソースをスケール・アウトおよびスケール・バックする柔軟性
データベースの使用状況に基づいたチャージバック
Oracle Engineered Systemsは、すべての層におけるデータベース統合とDBaaSの効率的なデプロイメント・オプションです。Oracle Database向けに事前に統合および最適化されたプラットフォームを標準とし、Oracleでサポートされているハードウェアとソフトウェアが使用されているため、Oracle Engineered Systemsを使用することで、ライフサイクル・コストが低減されます。Oracle Engineered Systemsには、次のものがあります。
Oracle Virtual Compute Applianceは、任意のLinux、Oracle SolarisまたはMicrosoft Windowsアプリケーション向けの仮想インフラストラクチャをインストール、デプロイおよび管理する方法を徹底的に簡略化します。
Oracle Database Applianceは、ソフトウェア、サーバー、ストレージ、ネットワーキングを簡素にすることを目的として設計された、完全で低コストなパッケージであり、データベースやアプリケーション・ワークロードのデプロイメント、メンテナンス、サポートが簡略化されているため、時間と費用を節約できます。Oracle Database Applianceでは、物理デプロイと仮想デプロイの両方がサポートされています。
Oracle Exadata Database Machineは、Oracle Databaseを実行するためのプラットフォームで、最高のパフォーマンスとスケーラビリティ、可用性を誇ります。Oracle Exadata Database Machineは、オンライン・トランザクション処理(OLTP)、データ・ウェアハウス(DW)および混合ワークロードの統合など、あらゆるタイプのデータベース・ワークロードを実行でき、データベース統合の理想的な基盤です。
Oracle SuperClusterエンジニアド・システムは、単一の汎用目的プラットフォーム上で、データベースやアプリケーション、プライベート・クラウド・デプロイメントおよびOracleソフトウェアを統合するのに最適です。Oracle SuperClusterには、SPARCアーキテクチャとExadataストレージを基盤として、世界最速のプロセッサが使用されています。
Oracle ZFS Storage Applianceでは、Network Attached Storage (NAS)を使用して、設置スペース、管理およびコストの面で直接のメリットを提供します。Oracle ZFSには、管理、監視、トラブルシューティング、スナップ、クローン、レプリケーション、およびどのOracle Engineered Systemsにも無理なく追加できる高度なデータ・サービスの豊富なソフトウェア・スイートが含まれています。
表7-1に、Bronze層のデータ保護機能をまとめます。表7-1の1列目は、物理破損および論理破損の検証がいつ実行されるかを示しています。
手動チェックは、管理者が開始するか、定期的なチェックを実行するスケジュール済ジョブによって一定の間隔で実行されます。
ランタイム・チェックは、データベースのオープン時に、バックグラウンド・プロセスによって継続的かつ自動的に実行されます。
バックグラウンド・チェックは、スケジュールされた定期的な間隔で実行されますが、リソースがアイドルの期間にかぎられます。
それぞれのチェックはOracle Database独自のもので、Oracleのデータ・ブロックやREDO構造に関する固有の知識が使用されています。
表7-1 Bronze層のデータ保護
| タイプ | 機能 | 物理ブロック破損 | 論理ブロック破損 |
|---|---|---|---|
|
手動 |
Dbverify、Analyze |
物理的ブロック・チェック |
ブロック内およびオブジェクト間の一貫性に関する論理チェック |
|
手動 |
RMAN |
バックアップおよびリストア中の物理的ブロック・チェック |
ブロック内論理チェック |
|
ランタイム |
データベース |
インメモリー・ブロックおよびREDOチェックサム |
インメモリーのブロック内論理チェック |
|
ランタイム |
ASM |
ローカル・エクステント・ペアを使用した自動破損検出および修復 |
|
|
ランタイム |
Exadata |
書込みに対するHARDチェック |
書込みに対するHARDチェック |
|
バックグラウンド |
Exadata |
自動ハード・ディスク修正および修復脚注1 |
脚注1 Exadata 11.2.3.3以降およびOracle Database 11gリリース2 (11.2.0.4)以降で使用可能。
HARD検証と、自動ハード・ディスク修正および修復(表2の最後の2行)は、Exadataストレージに固有であることに注意してください。HARD検証を行うと、Oracle Databaseにより、物理的に破損したブロックがディスクに書き込まれることはありません。アイドル・リソースがある場合、自動ハード・ディスク修正および修復により、破損または消耗しているディスク・セクター(ストレージのクラスタ)のあるハード・ディスクや、その他の物理的または論理的な不具合が定期的に検査および修復されます。別のミラー・コピーからデータを読み取ることにより、不良セクターの修復リクエストがExadataからASMに送信されます。デフォルトでは、ハード・ディスクの修正は2週間ごとに実行されます。
表3に、様々な計画外停止や計画停止に対するBronze層のRTOおよびRPOをまとめます。
表7-2 Bronze層のリカバリ時間(RTO)およびデータ損失の可能性(RPO)
| タイプ | イベント | 停止時間 | データ損失の可能性 |
|---|---|---|---|
|
計画外 |
データベース・インスタンス障害 |
数分 |
ゼロ |
|
計画外 |
リカバリ可能なサーバー障害 |
数分から1時間 |
ゼロ |
|
計画外 |
データ破損、リカバリ不能なサーバー障害、データベース障害またはサイト障害 |
数時間から数日 |
最後のバックアップ以降 |
|
計画 |
オンライン・ファイル移動、オンライン再編成および再定義、オンライン・パッチ適用 |
ゼロ |
ゼロ |
|
計画 |
ハードウェアやオペレーティング・システムのメンテナンス、およびオンラインで適用できないデータベース・パッチ |
数分から数時間 |
ゼロ |
|
計画 |
データベースのアップグレード: パッチ・セットおよび完全なデータベース・リリース |
数分から数時間 |
ゼロ |
|
計画 |
プラットフォームの移行 |
数時間から1日 |
ゼロ |
|
計画 |
バックエンドのデータベース・オブジェクトを変更するアプリケーションのアップグレード |
数時間から数日 |
ゼロ |
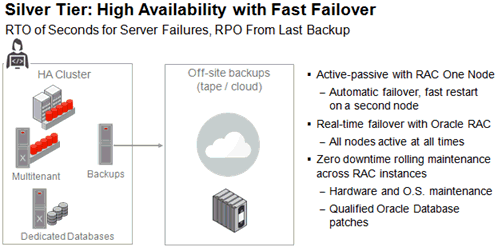
Silver層は、計画外停止と計画メンテナンスの両方の可用性を向上させるために、クラスタリング・テクノロジを組み込んで、Bronze上に構築されています。Silverでは、リカバリ不能なデータベース・インスタンスの停止やそれが実行されているサーバーで完全な障害が発生した場合に自動フェイルオーバーを可能にすることで、データ・センター内のHAにOracle RACまたはOracle RAC One Nodeを使用します。Oracle RACがもたらす利点も大きなもので、Oracle RACノード全体にローリング方式でメンテナンスを実行することにより、様々なタイプの計画停止時間をなくします。図7-3に、Silver層の概要を示します。
Silverには、次の各項で説明されているHAコンポーネントが含まれます。
データベース・インスタンスやそれが実行されているサーバーが停止した場合、Oracle RACが、データ・センター内のアプリケーションの可用性を向上します。Oracle RACを使用したサーバーのフェイルオーバーは一瞬です。機能しているインスタンスでサービスが再開される前に、非常に短い停止時間があり、停止したインスタンスのユーザーが再接続できます。Oracle RACノード全体にローリング方式で実行できる場合は、そうした計画メンテナンス・タスクの停止時間もなくなります。ユーザーは、メンテナンスが実行されるノードでの作業を完了し、セッションを終了します。再接続すると、別のノードですでに実行されているデータベース・インスタンスに移動されます。
Oracle RACがどのように機能するかを簡単に確認することで、その利点を理解できます。コンポーネントは、Oracle DatabaseインスタンスとOracle Database自体の2つです。
データベース・インスタンスは、サーバー・プロセスのセット、およびクライアントに対して特定のデータベースを使用可能にする単一ノード(またはサーバー)で実行中のメモリー構造として定義されます。
データベースは、永続記憶域に存在する特定の共有ファイルのセット(データ・ファイル、索引ファイル、制御ファイルおよび初期化ファイル)で、同時に開いて、データの読取りと書込みに使用できます。
Oracle RACにはアクティブ-アクティブ・アーキテクチャが使用されており、それぞれ別のノードで実行されている複数のデータベース・インスタンスが、同じデータベースに読取りと書込みを同時に実行できます。
Oracle RACのアクティブ-アクティブ・アーキテクチャには、多数の利点があります。
高可用性の向上: サーバーまたはデータベース・インスタンスが停止しても、機能しているインスタンスへの接続に影響はなく、停止したインスタンスへの接続は、クラスタ内の他のサーバーですでに実行され、オープンである機能しているインスタンスへすぐにフェイルオーバーされます。
スケーラビリティ: Oracle RACは、容量の動的な追加や、2つ以上のサーバー間における優先度の変更を必要とする大規模なアプリケーションや統合環境に最適です。個々のデータベースのインスタンスは、クラスタの1つ以上のノードで実行されます。同様に、データベース・サービスも、1つ以上のデータベース・インスタンスで使用可能です。追加のノード、データベース・インスタンスおよびデータベース・サービスを、オンラインでプロビジョニングできます。クラスタ間でワークロードを簡単に分散できるため、Oracle RACは、Oracle Multitenantに最適なコンポーネントです。
信頼性の高いパフォーマンス: Oracle Quality of Service (QoS)を優先度の高いデータベース・サービスへの容量の割当てに使用して、データベース統合環境で一貫して高いパフォーマンスを実現することができます。変化する要件に迅速に対応できるよう、容量は、ワークロード間で動的に移動できます。
計画メンテナンス中のHA: 高可用性は、Oracle RACノード全体にローリング方式で変更を実装することにより維持されます。これには、サーバーをオフラインにする必要がある、ハードウェア、OSまたはネットワークのメンテナンス、Oracle Grid Infrastructureまたはデータベースにパッチを適用するソフトウェア・メンテナンス、または容量を増加したり、ワークロードのバランスをとるために、データベース・インスタンスを別のサーバーに移動する必要がある場合が含まれます。
Oracle RACは、サーバーHAのMAAベスト・プラクティスです。
Oracle RAC One Nodeは、サーバーHAが要件ではあるが、スケーラビリティとインスタント・フェイルオーバーは不要な場合に、Silver層のOracle RACのオプションとなります。Oracle RAC One Nodeのライセンスは、Oracle RACのコストの半分であるため、サーバー障害を管理する際に、RTOが分単位でもかまわない場合には、よりコストのかからない選択肢です。
Oracle RAC One Nodeは、アクティブ-パッシブ・フェイルオーバー・テクノロジです。Oracle RACと同じインフラストラクチャ上に構築されていますが、Oracle RAC One Nodeの場合、通常の操作中にオープンになるデータベース・インスタンスは一度に1つのみです。これにより、特に多数のデータベースを統合する場合に、メモリー要件が大幅に引き下げられます。オープン・インスタンスをホストしているサーバーが停止すると、Oracle RAC One Nodeにより、第2ノードに新しいデータベース・インスタンスが自動的に起動され、サービスが迅速に再開されます。
Oracle RAC One Nodeには、別のアクティブ-パッシブ・クラスタリング・テクノロジに勝る利点がいくつかあります。Oracle RAC One Node構成では、Oracle Database HAサービス、グリッド・インフラストラクチャおよびデータベース・リスナーが、常に第2ノードで実行されます。フェイルオーバーする際、起動する必要があるのはデータベース・インスタンスとデータベース・サービスのみであるため、サービスの再開に要する時間が短くなり、数分でサービスを再開できます。
また、Oracle RAC One Nodeの計画メンテナンスの利点は、Oracle RACと同じです。Oracle RAC One Nodeでは、計画メンテナンスの期間中は2つのデータベース・インスタンスをアクティブにできるため、停止時間なしで、1つのノードから別のノードにユーザーを正常に移行できます。メンテナンスは、ユーザーがいつでもデータベース・サービスを使用可能な状態で、ノード全体にローリング方式で実行されます。
データ保護のレベルは、Bronze層で提供されるものと比較して、異なる点はありません。Bronzeと比較してSilverで提供される改良点はすべて、サーバー停止のRTOや、頻繁に実行されるいくつかのタイプの計画メンテナンスに関連するものです。表7-3に、Silver層で有効になるRTOおよびRPOをまとめます。Bronzeと比較した場合に改良されている領域はカッコで囲んであります。
表7-3 Silver層のリカバリ時間(RTO)およびデータ損失の可能性(RPO)
| タイプ | イベント | 停止時間 | データ損失の可能性 |
|---|---|---|---|
|
計画外 |
データベース・インスタンス障害 |
Oracle RACの場合は数秒(Bronzeでは数分) |
ゼロ |
|
計画外 |
リカバリ可能なサーバー障害 |
Oracle RACの場合は数秒(Bronzeでは数分から1時間) Oracle RAC One Nodeの場合は数分(Bronzeでは数分から1時間) |
ゼロ ゼロ |
|
計画外 |
データ破損、リカバリ不能なサーバー障害、データベース障害またはサイト障害 |
数時間から数日 |
最後のバックアップ以降 |
|
計画 |
オンライン・ファイル移動、オンライン再編成および再定義、オンライン・パッチ適用 |
ゼロ |
ゼロ |
|
計画 |
ハードウェアやオペレーティング・システムのメンテナンス、およびオンラインでは適用できないが、Oracle RACローリング・インストールは可能なデータベース・パッチ |
ゼロ(Bronzeでは数分から数時間) |
ゼロ |
|
計画 |
データベースのアップグレード: パッチ・セットおよび完全なデータベース・リリース |
数分から数時間 |
ゼロ |
|
計画 |
プラットフォームの移行 |
数時間から1日 |
ゼロ |
|
計画 |
バックエンドのデータベース・オブジェクトを変更するアプリケーションのアップグレード |
数時間から数日 |
ゼロ |
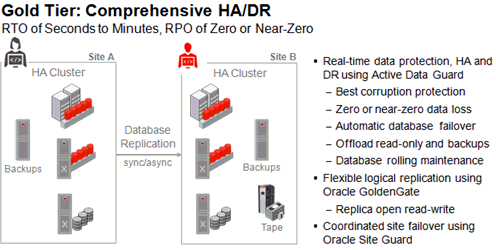
Gold層はデータベース・レプリケーション・テクノロジを使用してSilver上に構築されており、単一点障害をなくして、データ破損、データベース障害やサイト障害など、あらゆるタイプの計画外停止から、より高いレベルでデータを保護してHAを提供します。レプリケートされたコピーが存在することも、計画メンテナンス期間中の停止時間を短くする上で大きな利点になっています。図7-4に、Gold層の概要を示します。RTOは数秒または数分に短縮され、付随するRPOは構成に応じて、ゼロまたはほぼゼロです。
GoldではサーバーHAの標準として、Silverで使用可能な、オプションの少ないOracle RAC One Nodeのかわりに、Oracle RACが使用されることに注意してください。
Gold層には、高度なHAコンポーネントが追加されており、次の各項で説明されているサービス・レベルの向上が実現されています。
Oracle Active Data Guardでは、同期された物理レプリカ(スタンバイ・データベース)がリモートの場所に1つ以上維持され、本番データベース(プライマリ・データベース)の単一点障害をなくすために使用されます。Oracle Active Data Guardにより、Gold層に追加される機能は次のとおりです。
データ損失の可能性をゼロまたはほぼゼロのどちらにするか選択可能。Oracle Active Data Guardでは、プライマリからスタンバイ・データベースへ、変更内容がリアルタイムでレプリケートされます。変更がプライマリのログ・バッファから直接転送されるため、伝播の遅延やオーバーヘッドが最小化され、本番データベースのI/Oスタックで発生する可能性のある破損から、レプリケーションが完全に分離されます。
管理者は、データが損失しないことを保証する場合は、同期転送と最大可用性を選択できます。また、ほぼゼロのデータ損失の場合は、非同期転送と最大パフォーマンスを選択できます。ネットワーク帯域幅が転送量の処理に十分であれば、最大パフォーマンスの場合、データ損失の危険にさらされるのは1秒未満です。
Data Guardは、データ損失ゼロの保護を実現するOracleレプリケーション・テクノロジです。
プライマリ・データベースの可用性に影響するデータベースやサイトの停止が発生した場合、Oracle Active Data Guardのスタンバイ・データベースによって本番データベースが迅速に引き継がれ、サービスがリストアされます。Oracle Databaseは常に実行されており、プライマリ・ロールに遷移するために再起動する必要がなく、ロールの遷移は、負荷の高いシステムであっても60秒未満で完了します。
Goldでは、Data Guardのファスト・スタート・フェイルオーバーを使用して、データベースのフェイルオーバーを自動化します。これにより、管理者が通知を受けて停止に対応するまでに発生する遅延がなくなり、リカバリ時間が短縮されます。ファスト・スタート・フェイルオーバーでは、ロール固有のデータベース・サービスとOracleクライアント通知フレームワークを使用して、アプリケーションと停止したプライマリ・データベースとの接続がすぐに切断され、新しいプライマリに自動的に再接続されるようにしています。ロールの遷移は、コマンドライン・インタフェースまたはOracle Enterprise Managerを使用して、手動で実行することも可能です。
透過的なレプリケーション。Oracle Active Data Guardでは、Oracle Databaseの完全な一方向物理レプリケーションが実行されますが、パフォーマンスが高く、管理が簡単で、あらゆるデータ・タイプ、アプリケーションおよびワークロード(DML、DDL、OLTP、バッチ処理、データ・ウェアハウス、統合データベースなど)がサポートされるという特徴があります。Oracle Active Data Guardは、Oracle RAC、ASM、RMANおよびOracle Flashbackテクノロジと緊密に統合されています。
投資利益率(ROI)を高めるための本番オフロード。Oracle Active Data Guardのスタンバイ・データベースは、レプリケーションがアクティブな間は、読取り専用でオープンすることが可能で、本番データベースから非定型問合せやレポート作成ワークロードをオフロードするために使用できます。オフロードにより、アイドル状態であった容量が使用されるため、スタンバイ・システムのROIが高まり、すべてのワークロードのパフォーマンスが向上します。また、スタンバイ・システムが本番ワークロードをサポートする準備が整っているため、継続的なアプリケーションの検証にもなります。
バックアップのオフロード。プライマリ・システムとスタンバイ・システムは完全な物理レプリカであるため、プライマリからスタンバイ・データベースにバックアップをオフロードできます。スタンバイで取得されたバックアップは、プライマリとスタンバイ・データベースのどちらのリストアにも使用可能です。このため、管理者は、バックアップの実行によるオーバーヘッドで本番システムに負荷をかけることなく、柔軟にリカバリできます。
計画メンテナンスの停止時間の短縮。先にスタンバイでアップグレードを実装してから、本番を新しいバージョンに切り替えることにより、新しいOracleパッチセット(パッチ・リリース11.2.0.2から11.2.0.4など)、または新しいOracleリリース(リリース11.2から12.1など)へのローリング方式でのアップグレードに、スタンバイ・データベースを使用できます。合計停止時間は、メンテナンスが完了した後に、スタンバイ・データベースをプライマリ本番ロールに切り替えるために必要な時間のみです。
Oracle Active Data Guardのスタンバイでは、継続的にOracle検証が実行されるため、ソース・データベースから破損が伝播されることはありません。検出されるのは物理的および論理的なブロック間破損で、これはプライマリ・データベースでもスタンバイ・データベースでも、単独で発生する可能性があります。また、サイレント書込み欠落破損(I/Oサブシステムで成功と認識される書込み欠落または宛先違いの書込み)のランタイム検出を有効化する点も独特です。詳細は、My Oracle Supportのノート1302539.1「破損の検出、防止および自動修復のベスト・プラクティス」を参照してください。
自動ブロック修復。Oracle Active Data Guardでは、プライマリ・データベースでもスタンバイ・データベースでも、単独で発生する可能性がある断続的なランダムI/Oエラーが原因のブロックレベル破損が自動的に修復されます。これは、相手側のデータベースからブロックの正常なコピーを取得して実行されます。アプリケーションの変更は不要で、修復はユーザーに透過的です。
前述の内容は、リモート・ミラー化製品(SRDF、Hitachi社のTrueCopyなど)ではなく、Oracleレプリケーション・テクノロジをGold層に使用し、どのように同期コピーを維持しているかを説明しています。違いに関するより詳細な説明は、『Oracle Active Data Guardおよびストレージのリモート・ミラー化』を参照してください。
Oracle GoldenGateは、本番データベース(ソース・データベース)の同期コピー(ターゲット・データベース)を保持するための論理レプリケーションのオプションを提供します。論理レプリケーションは、物理レプリケーションよりも複雑なプロセスですが、様々なレプリケーション・シナリオや異種プラットフォームを処理する際の柔軟性を高めます。
論理レプリケーションは、データ分散の観点から、ソース・データベースのサブセットを効率的にレプリケートし、データを他のターゲット・データベースに分散できるよう設計されています。また、複数のソース・データベースから単一のターゲット・データベース(運用データ・ストアなど)にデータを統合する際にも使用できます。
高可用性の観点から、論理レプリケーションを使用してソース・データベースの完全なレプリカを保持し、ソース・データベースが使用不能になった場合の迅速なフェイルオーバーに備える障害保護や高可用性を実現できます。Oracle GoldenGateには、論理レプリケーション・プロセスが使用されています。変更はソース・データベースのディスクから読み取られ、そのデータがプラットフォームに依存しないファイル形式に変換されて、ターゲット・データベースに送信された後、ターゲット・データベースにネイティブなSQL (更新、挿入および削除)にデータが変換されます。ターゲット・データベースに含まれているデータは同じものですが、データベースはソースとは異なります(たとえば、バックアップの交換はできません)。
Oracle GoldenGateの論理レプリケーションを使用すると、Data Guardの物理レプリケーションでは不可能なローリング方式で、メンテナンスや移行を実行する際の柔軟性が高まります。たとえば、Oracle GoldenGateでは、ビッグエンディアン・プラットフォームで実行されているソースと、リトルエンディアン・プラットフォームで実行されているターゲットのレプリケーション(クロスエンディアン・レプリケーション)が可能です。これにより、カットオーバー後に、高速フォールバック用のレプリケーションを前のバージョンに戻すことができるという利点が加わった状態で、プラットフォームの移行を実行できるようになります。
Oracle GoldenGateの論理レプリケーションは、Data Guardの物理レプリケーションには適用されない数多くの前提条件がある複雑なプロセスです。そうした前提条件があるおかげで、Oracle GoldenGateには、アドバンスト・レプリケーションの要件に対応する独自の機能があります。それぞれのレプリケーション・テクノロジのトレードオフ、およびどちらか一方の使用または両方のテクノロジの補完的な使用が推奨される要件の詳細は、MAAベスト・プラクティス: Oracle Active Data GuardおよびOracle GoldenGateを参照してください。
Oracle Site Guardを使用すると、管理者は、本番サイトとリモートの障害時リカバリ・サイトの間で、Oracle環境、複数のデータベースおよびアプリケーションのスイッチオーバー(計画イベント)とフェイルオーバー(計画外停止への対応)を編成できます。Oracle Site Guardは、Oracle Enterprise Manager Life-Cycle Management Packに含まれています。
Oracle Site Guardには次のような利点があります。
サイト障害への対応が準備されているため、エラーが減少します。Oracle Site Guardは、障害時に人的エラーが起きる可能性を低減します。障害回復計画が作成およびテストされ、準備した対応の予行がアプリケーション内で行われます。管理者が障害時リカバリ向けのSite Guardの操作を開始した後は、人間が操作する必要はありません。
複数のアプリケーション、データベースおよび様々なレプリケーション・テクノロジの調整が行われます。サイトを起動または停止している間、Oracle Site Guardは自動的に、異なるターゲット間の依存性を処理します。Site GuardはOracle Active Data Guardと統合して、複数の同時データベース・フェイルオーバーを調整します。また、Site Guardには、ストレージのリモート・ミラー化製品と統合するために簡単なメカニズムが用意されています。操作ワークフロー内で、任意のユーザー定義のストレージ・ロール・リバーサル・スクリプトに対するコールアウトを使用して、スイッチオーバーまたはフェイルオーバーを実行するストレージ・アプライアンスと統合します。
リカバリ時間が短縮されます。Oracle Site Guardの自動化により、リカバリ・アクティビティの手動調整が最小限になります。これにより、手動作業がすべて正常に実行された場合と比べても、リカバリ時間が短くなります。Site Guardでは、時間がかかり、複雑な手順の手動実行を伴うことが多い、人的エラーの解決も回避できます。
表7-4に、Gold層で行われるデータ保護をまとめます。
表7-4 Gold層のデータ保護
| タイプ | 機能 | 物理ブロック破損 | 論理ブロック破損 |
|---|---|---|---|
|
手動 |
Dbverify、Analyze |
物理的ブロック・チェック |
ブロック内およびオブジェクト間の一貫性に関する論理チェック |
|
手動 |
RMAN |
バックアップおよびリストア中の物理的ブロック・チェック |
ブロック内論理チェック |
|
ランタイム |
Oracle Active Data Guard |
スタンバイにおける物理的ブロック・チェック プライマリとスタンバイを強力に分離することで単一点障害を排除 物理破損の自動修復 データベースの自動フェイルオーバー |
書込み欠落破損の検出、自動停止およびフェイルオーバー スタンバイにおけるブロック間論理チェック |
|
ランタイム |
データベース |
インメモリー・ブロックおよびREDOチェックサム |
インメモリーのブロック内論理チェック |
|
ランタイム |
ASM |
ローカル・エクステント・ペアを使用した自動破損検出および修復 |
|
|
ランタイム |
Exadata |
書込みに対するHARDチェック |
書込みに対するHARDチェック |
|
バックグラウンド |
Exadata |
ハード・ディスクの自動修正および修復 |
表7-5に、Gold層のRTOおよびRPOをまとめます。Gold層ではSilverと比較して、リカバリ時間およびデータ損失の可能性が大幅に減少します。Silver層と比較した場合に改良されている領域はカッコで囲んであります。
表7-5 Gold層のリカバリ時間(RTO)およびデータ損失の可能性(RPO)
| タイプ | イベント | 停止時間 | データ損失の可能性 |
|---|---|---|---|
|
計画外 |
データベース・インスタンス障害 |
数秒 |
ゼロ |
|
計画外 |
リカバリ可能なサーバー障害 |
数秒 |
ゼロ |
|
計画外 |
データ破損、リカバリ不能なサーバー障害、データベース障害またはサイト障害 |
ゼロから数分(Silverでは数時間から数日) |
ASYNCを使用している場合はほぼゼロ(Silverでは最後のバックアップ以降) Data Guardの同期転送を使用している場合はゼロ(Silverでは最後のバックアップ以降) |
|
計画 |
オンライン・ファイル移動、オンライン再編成および再定義、オンライン・パッチ適用 |
ゼロ |
ゼロ |
|
計画 |
ハードウェアやオペレーティング・システムのメンテナンス、およびオンラインで適用できないデータベース・パッチ |
ゼロ |
ゼロ |
|
計画 |
データベースのアップグレード: パッチ・セットおよび完全なデータベース・リリース |
数秒(Silverでは数分から数時間) |
ゼロ |
|
計画 |
プラットフォームの移行 |
数秒(Silverでは数時間から1日) |
ゼロ |
|
計画 |
バックエンドのデータベース・オブジェクトを変更するアプリケーションのアップグレード |
数時間から数日 |
ゼロ |
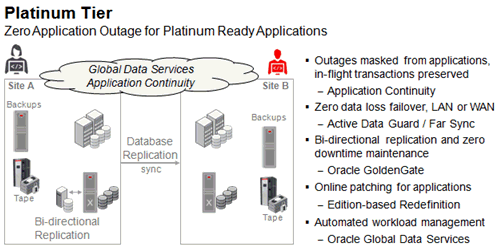
Platinum層はGold上に構築され、停止やデータ損失が許されないアプリケーションで、最高レベルのHAとデータ保護を実現します。Platinum層には、Oracle Database 12cの複数の新機能と、以前から使用されていた製品で、最新リリースにおいて拡張されたものが導入されています。Platinumでは、アプリケーションやユーザーには停止の影響が伝わらず、リカバリ可能な障害の後には処理中のトランザクションも保存されます。メンテナンス、移行およびアプリケーションのアップグレードは停止時間なしで実行できます。サイト間の距離にかかわらず、いかなる理由でプライマリ・データベースに障害が発生した場合でも、データが損失することはありません。さらに、Platinumでは、データベース・サービスの可用性と、複数のサイトに存在するデータベース・レプリカ間でのワークロードのロード・バランシングが自動的に管理されます。図7-5に、Platinum層の概要を示します。
一部のアプリケーションでは、アプリケーションのゼロ停止を実現するために一定の変更を行う必要がありますが、これには、Platinum層で提供されている機能を使用します。Platinumが、Platinum対応アプリケーションにアプリケーションのゼロ停止を提供すると説明されるのは、このためです。データ損失ゼロの実現には、アプリケーションの変更は必要ありません。
Platinum層では、次の各項で説明されているHA機能が有効です。
アプリケーション・コンティニュイティは、インスタンス、サーバー、ストレージ、ネットワークまたはその他の関連コンポーネントを原因とするデータベース・セッション障害、さらには完全なデータベース障害からもアプリケーションを保護します。アプリケーション・コンティニュイティにより、影響を受けた処理中のリクエストが再生されるため、障害は実行のわずかな遅延としてしかアプリケーションに表れず、ユーザーは停止に気付きません。
Oracle RACクラスタ全体が停止し、データベースが使用不能になった場合は、Oracle Active Data Guardのフェイルオーバー後に、アプリケーション・コンティニュイティにより、トランザクションを含むセッションが再生されます。スタンバイ・データベースでアプリケーション・コンティニュイティを使用するには、Data Guardの最大可用性モード(データ損失なし)と、Data Guardのファスト・スタート・フェイルオーバー(自動データベース・フェイルオーバー)が必要です。
多くの場合、アプリケーション・コンティニュイティを使用するために、既存アプリケーションのコードを一部変更する必要がありますが、リカバリ可能な障害を透過的に処理できるようになるため、新しいアプリケーションの開発が簡単になります。
Oracle Active Data Guardは唯一のOracle対応レプリケーション・テクノロジで、データを損失させずにOracle Databaseをフェイルオーバーできます。データ損失ゼロは、Data Guardの最大可用性モードで同期転送を行うことにより実現されます。同期転送を使用すると、プライマリ・サイトとスタンバイ・サイトの間のネットワーク待機時間が、データベース・パフォーマンスに影響を与えます。サイト間の距離が離れるほど、待機時間が長くなり、データベース・パフォーマンスへの影響も大きくなります。プライマリとセカンダリのデータ・センターは遠く離れていることが多いため、データ損失のないフェイルオーバーを実装しても、多くのデータベースにとって実用的ではありません。
Oracle Database 12cでOracle Active Data Guardの遠隔同期を使用すれば、プライマリとスタンバイのデータベースがどれほど離れていても、プライマリ・データベースのパフォーマンスに影響を与えずにデータ損失ゼロのフェイルオーバーを実行できるため、前述の制限がなくなります。これを可能にしているのは軽量の転送メカニズムで、デプロイが簡単な上、Oracle Active Data Guardのフェイルオーバー操作やスイッチオーバー操作に対して透過的です。また、遠隔同期をOracle拡張圧縮オプションと組み合せて使用すると、オフホスト転送圧縮が可能になり、ネットワーク帯域幅を節約できます。
遠隔同期とData Guardのファスト・スタート・フェイルオーバー(自動データベース・フェイルオーバー)を組み合せると、プライマリ・サイトとスタンバイ・サイトの距離にかかわらず、アプリケーション・コンティニュイティにより、処理中のトランザクションが停止の影響を受けません。このため、任意のデータベースに対するデータ損失なしのフェイルオーバーと、サイト間の距離にかかわらず、アプリケーション・コンティニュイティを使用できるという、Platinum層で提供されている2つの重要な拡張を可能にしているのは、遠隔同期ということになります。遠隔同期を使用するために、アプリケーションを変更する必要はありません。
Platinum層では、Oracle GoldenGateのアドバンスト・レプリケーション機能を使用して、停止時間ゼロのメンテナンスと双方向レプリケーションを使用した移行が実装されています。このようなシナリオでは、次のことが行われます。
メンテナンスが、まずターゲット・データベースに実装されます。
Oracle GoldenGateの論理レプリケーションを使用して、ソースとターゲットがバージョンを超えて同期されます。これにより、クロスエンディアン・プラットフォーム移行が処理されます。また、バックエンド・オブジェクトを変更する複雑なアプリケーション・アップグレードも処理されますが、その場合は、レプリケーション・メカニズムで、新旧のバージョン間で相互にデータを変換できる必要があります。
新しいバージョンまたはプラットフォームが同期されて安定すると、ユーザーが旧バージョンでセッションを終了して再接続するに従って、双方向レプリケーションにより、ユーザーが新しいプラットフォームに徐々に移行され、停止時間が意識されることはありません。Oracle GoldenGateの双方向レプリケーションは、移行プロセス中に、新旧バージョンの同期を維持します。これは、ロードの追加時に、新しいバージョンで予期しない問題が発生した場合のクイック・フォール・バック・オプションにもなります。
アクティブ-アクティブの双方向レプリケーションは、同じデータの複数のコピーに対する継続した読取り/書込み接続が必要とされる可用性サービス・レベルの向上にも使用できます。
双方向レプリケーションは、アプリケーションに対して透過的ではありません。複数のデータベースで、同じレコードに同時に変更が行われた場合には、競合の検出と解決が必要です。また、様々な障害の状態やレプリケーション・ラグの影響についても、慎重に検討する必要があります。バックエンド・データベース・オブジェクトを変更するアプリケーションのアップグレードにGoldenGateの双方向レプリケーションを使用する場合、GoldenGateでバージョンを超えたレプリケートを可能にするには、新しいリリースで変更または追加されるデータベース・オブジェクトについて、開発者レベルの知識が必要になります。アプリケーションの新しいリリースごとに、バージョン間マッピングを実装する必要があります。
定義では、GoldenGateのレプリケーションは非同期プロセスであるため、データ損失ゼロの保護は実現できません。このため、プライマリ・データベースまたはプライマリ・サイトで計画外停止が発生したときに、リモートのレプリカでデータ損失ゼロの保護を実行する必要がある場合、Platinum層では、サイト間のレプリケーションにOracle GoldenGateを使用しません。Platinumでは、GoldenGateの双方向レプリケーションをOracle Active Data Guardと組み合せて使用することで、データ損失ゼロの要件に対応しています。ローカルのGoldenGateレプリカは、停止時間のない計画メンテナンスの実行に使用され、Oracle Active Data Guardのスタンバイは、メンテナンスの進行中に計画外停止が発生した場合に、データ損失ゼロのフェイルオーバー保護を継続して提供します。
エディションベース再定義(EBR)は、アプリケーションの可用性を損なわずに、バックエンド・データベース・オブジェクトを変更する、オンラインでのアプリケーションのアップグレードを可能にします。アップグレードのインストールが完了したら、アップグレード前のアプリケーションとアップグレード後のアプリケーションを同時に使用できます。既存のセッションでは、ユーザーがセッションを終了するまで、アップグレード前のアプリケーションを使用し続けることが可能で、新しいセッションはすべて、アップグレード後のアプリケーションを使用できます。アップグレード前のアプリケーションを使用するセッションがなくなったら、終了させることができます。この方法でEBRを使用すると、アップグレード前のバージョンからアップグレード後のバージョンへのホットロールオーバーが可能になります。
EBRを使用すると、オンラインでのアプリケーションのアップグレードが、次の方法で実行されます。
コード変更は、新しいエディションにより、暗黙的にインストールされます。
古いエディションでは表示されない新しい列または新しい表にのみ書き込むことで、データの変更が安全に行われます。エディショニング・ビューでは、表の異なる投影がそれぞれのエディションに公開されるため、各エディションにはそれ自身の列のみが表示されます。
クロスエディション・トリガーにより、古いエディションで行われたデータ変更が、新しいエディションの列に、あるいは(ホットロールオーバーで)相互に伝播されます。
Oracle GoldenGateの停止時間なしのアプリケーション・アップグレード同様、EBRを使用するには、アプリケーションに関する深い知識が必要で、開発者がEBRを組み込む際に手間がかかります。Oracle GoldenGateとは異なり、EBRを使用するには、一度作業が必要です。それ以降、後続の新しいリリースのアプリケーションでEBRを使用する際に必要な作業は、最小限になります。EBRは、非常に複雑なアプリケーションにも実装できることが証明されており、たとえばOracle E-Business Suite 12.2では、EBRを使用してオンライン・パッチ適用が実行されます。EBRは、費用のかからないオプションとしてOracle Databaseに含まれている機能で、アプリケーション開発者が適用することをお薦めします。
グローバル・データ・サービス(GDS)は、レプリケートされたデータベース向けに完全に自動化されたワークロード管理ソリューションで、Oracle Active Data GuardまたはOracle GoldenGateが使用されています。GDSを使用するとシステム使用率が高まり、レプリケートされたデータベースで実行されているアプリケーション・ワークロードのパフォーマンス、スケーラビリティおよび可用性が向上します。GDSには、レプリケートされたデータベースのセット向けに、次の機能が用意されています。
リージョンベースのワークロード・ルーティング
接続時ロード・バランシング
Oracle統合クライアント用のランタイム・ロード・バランシング・アドバイザ
内部データベース・サービス・フェイルオーバー
Oracle Active Data Guard用のレプリケーション・ラグに基づいたワークロード・ルーティング
Oracle Active Data Guard用のロールベースのグローバル・サービス
ワークロードの集中管理フレームワーク
Platinum層の破損保護は、Gold層と同一です。Platinum層とGold層の違いは、Platinum対応アプリケーションのリカバリ時間(RTO)とデータ損失の可能性(RPO)です。Platinum層のRTO/RPOを表7-6にまとめます。
表7-6 Platinum層のリカバリ時間(RTO)およびデータ損失の可能性(RPO)
| タイプ | イベント | 停止時間 | データ損失の可能性 |
|---|---|---|---|
|
計画外 |
データベース・インスタンス障害 |
アプリケーションの停止なし(Goldでは数秒) |
ゼロ |
|
計画外 |
リカバリ可能なサーバー障害 |
アプリケーションの停止なし(Goldでは数秒) |
ゼロ |
|
計画外 |
データ破損、リカバリ不能なサーバー障害、データベース障害またはサイト障害 |
アプリケーションの停止なし(Goldではゼロから数分) |
ゼロ(Goldではほぼゼロ) |
|
計画 |
オンライン・ファイル移動、オンライン再編成および再定義、オンライン・パッチ適用 |
ゼロ |
ゼロ |
|
計画 |
ハードウェアやオペレーティング・システムのメンテナンス、およびオンラインで適用できないデータベース・パッチ |
アプリケーションの停止なし |
ゼロ |
|
計画 |
データベースのアップグレード: パッチ・セットおよび完全なデータベース・リリース |
アプリケーションの停止なし(Goldでは数秒) |
ゼロ |
|
計画 |
プラットフォームの移行 |
アプリケーションの停止なし(Goldでは数秒) |
ゼロ |
|
計画 |
バックエンドのデータベース・オブジェクトを変更するアプリケーションのアップグレード |
アプリケーションの停止なし(Goldでは数時間から数日) |
ゼロ |
柔軟性のある自動高可用性ソリューションを使用することで、ビジネス目標の達成に必要な(Oracle WebLogic Serverにデプロイする)アプリケーションの可用性を確実に満たすことができます。このマニュアルで説明するソリューションの詳細は、『Oracle Fusion Middleware高可用性ガイド』を参照してください。
この項の内容は、次のとおりです。
|
関連項目:
|
Oracle WebLogic Serverには、あらゆる障害に対する最大の保護を目的とした高可用性および障害時リカバリ・ソリューションがあり、インストール、デプロイメントおよびセキュリティにおける柔軟性の高いオプションが用意されています。これらのソリューションは、ローカル高可用性ソリューションと障害時リカバリ・ソリューションに分類されます。ローカル高可用性ソリューションは、単一データ・センターのデプロイメントで高可用性を提供します。障害時リカバリ・ソリューションは、一般的に地理的に分散されたデプロイメントで、洪水や広範囲のネットワーク停止などの災害からアプリケーションを保護します。
高度なレベルで、Oracle WebLogic Serverのローカルの高可用性アーキテクチャには、アクティブ-アクティブおよびアクティブ-パッシブのアーキテクチャがあります。どちらのソリューションも高可用性を提供しますが、通常、アクティブ-アクティブ・ソリューションの方が、高いスケーラビリティと高速フェイルオーバーを提供します。ただし、費用が高額になる傾向があります。アクティブ-アクティブまたはアクティブ-パッシブのカテゴリでは、インストール、コスト、スケーラビリティおよびセキュリティの容易さが異なる複数のソリューションがあります。
Oracle WebLogic Serverでは、同じワークロードをサポートする複数のインスタンスをサポートすることにより、冗長性が得られます。このような冗長構成では、ワークロードの分散またはフェイルオーバーの設定のいずれか、またはその両方によって可用性が向上します。
Oracle WebLogic Serverシステムへのエントリ・ポイント(コンテンツのキャッシュ)からバック・エンド層(データ・ソース)まで、リクエストが通過するすべての層は、Oracle Application Serverを使用して冗長方式で構成できます。この構成は、Oracle WebLogic Server Clusterを使用したアクティブ-アクティブ構成、またはOracle WebLogic Server Cold Cluster Failoverを使用したアクティブ-パッシブ構成のいずれかになります。
『Oracle Fusion Middleware高可用性ガイド』では、次に示すOracle Fusion Middlewareの高可用性サービスを詳細に説明しています。
プロセス停止の検出と自動再起動
Oracle WebLogic Serverノード・マネージャは管理対象サーバーを監視します。管理対象サーバーが停止すると、ノード・マネージャは、構成された回数にわたって、管理対象サーバーの再起動を試行します。
クラスタリング
Oracle Fusion Middlewareでは、冗長性、フェイルオーバー、セッション状態レプリケーション、クラスタワイドのJNDIサービス、サーバー全体の移行、クラスタワイドの構成など、WebLogicが持つクラスタリング機能を使用します。
状態のレプリケーションとルーティング
Oracle WebLogic Serverは、ステートフル・アプリケーションの状態をレプリケートするように構成できます。
ロード・バランシングおよびフェイルオーバー
Oracle Fusion Middlewareには、Oracle RACデータベースの可用性およびスケーラビリティを活用するため、ロード・バランシングおよびフェイルオーバーの周囲に総合的な機能セットがあります。Oracle Fusion Middlewareのすべてのコンポーネントには、計画停止または計画外停止によってOracle RACインスタンスが使用できなくなったことが原因で発生した、サービス、データまたはトランザクションの消失に対する組込みの保護が用意されています。
サーバーの移行
Oracle Fusion Middlewareのコンポーネントは、WebLogic Serverの機能を活用して、フェイルオーバー時に別のクラスタ・メンバー上で自動的に再起動できます。
ローリング・パッチ適用
Oracle WebLogic Serverでは、ローリング・パッチを使用できます。ローリング・パッチでは、クラスタ全体を停止することなく、マイナーなメンテナンス・パッチをローリング形式で製品バイナリに適用できます。
構成管理
Oracle Fusion Middlewareコンポーネントのほとんどは、クラスタ・レベルで構成できます。Oracle Fusion Middlewareでは、データ・ソース、EJB、JMSなど、サーバーを構成するためのWebLogic Serverのクラスタワイドの構成機能、およびコンポーネントのアプリケーション・アーティファクト、ADFおよびWebCenterのカスタム・アプリケーションを使用します。
バックアップとリカバリ
Oracle Fusion Middlewareのバックアップとリカバリは、中間層コンポーネントのファイル・システム・コピーに基づく単純なソリューションです。
|
関連項目: Oracle Fusion Middleware高可用性ガイド |
可用性が高く、リジリエンスがあるアプリケーションでは、アプリケーションのすべてのコンポーネントで障害および変更が許容される必要があります。可用性の高いアプリケーションは、そのアプリケーションに影響を与えるすべてのコンポーネント(ネットワーク・トポロジ、アプリケーション・サーバー、アプリケーションのフローと設計、システム、およびデータベースの構成やアーキテクチャなど)を分析する必要があります。このマニュアルでは、主にデータベースの高可用性ソリューションに焦点を当てています。
Oracle Fusion Middleware、Oracle Fusion Applications、Oracle Enterprise ManagerおよびOracle Applications Unlimitedの高可用性ソリューションおよび推奨事項を次のMAA Webサイトで参照してください。
http://www.oracle.com/goto/maa