| Oracle® Exadata Database Machineメンテナンス・ガイド 12cリリース1 (12.1) E56357-08 |
|


 前 |
 次 |
この章の内容は次のとおりです。
|
注意: 読みやすさを考慮して、Oracle Exadata Database MachineとOracle Exadata Storage拡張ラックの両方に言及する場合、「Oracle Exadataラック」という名前を使用します。 |
データベース・サーバー上で実行される管理サーバー(MS)は監視やアラートなどの管理機能を提供します。DBMCLIコマンドライン管理ツールも提供します。
物理ディスクを修理する際には、Oracle Exadata Database Machineのデータベース・サーバーをシャットダウンする必要はありません。ラックの停止時間は必要ありませんが、個別のサーバーが停止して、一時的にクラスタの外部で処理される場合があります。
この項の内容は次のとおりです。
各データベース・サーバーのディスク・ドライブは、LSI MegaRAID SAS 9261-8iまたは9361-8iディスク・コントローラによって管理されます。ディスクの構成はRAID-5構成です。Oracle Exadata Database Machine X6-2、Oracle Exadata Database Machine X5-2、Oracle Exadata Database Machine X4-2、Oracle Exadata Database Machine X3-2およびOracle Exadata Database Machine X2-2の各データベース・サーバーには4つのディスク・ドライブがあります。各Oracle Exadata Database Machine X4-8フル・ラック・データベース・サーバーには、7つのドライブがあります。デフォルトでは、1つのグローバル・ホット・スペア・ドライブを搭載した1つの6ディスクRAID-5として構成されます。Oracle Exadata Database Machine X5-8およびOracle Exadata Database Machine X3-8にはそれぞれ8つのディスク・ドライブがあります。RAIDセットには、仮想ドライブが1つ作成されています。データベース・サーバーRAIDデバイスのステータスを確認して、パフォーマンスへの影響がないか、または停止しないようにすることをお薦めします。RAIDデバイスの検証による影響は最小です。是正処置による影響は未対応の特定の問題によって異なり、単純な再構成から停止が必要になる場合があります。
次のコマンドを使用して、データベース・サーバーのディスク・コントローラ構成を確認します。
/opt/MegaRAID/MegaCli/MegaCli64 -AdpAllInfo -aALL | grep "Device Present" -A 8
次に、Oracle Exadata Database Machine X3-2またはOracle Exadata Database Machine X2-2の場合のコマンドの出力例を示します。
Device Present
================
Virtual Drives : 1
Degraded : 0
Offline : 0
Physical Devices : 5
Disks : 4
Critical Disks : 0
Failed Disks : 0
次に、Oracle Exadata Database Machine X4-8フル・ラックのコマンドの出力例を示します。
Device Present
================
Virtual Drives : 1
Degraded : 0
Offline : 0
Physical Devices : 8
Disks : 7
Critical Disks : 0
Failed Disks : 0
次に、Oracle Exadata Database Machine X5-8フル・ラックのコマンドの出力例を示します。
Device Present
================
Virtual Drives : 1
Degraded : 0
Offline : 0
Physical Devices : 9
Disks : 8
Critical Disks : 0
Failed Disks : 0
Oracle Exadata Database Machine X4-2、Oracle Exadata Database Machine X3-2およびOracle Exadata Database Machine X2-2の場合、予想される出力は仮想ドライブ1、パフォーマンス低下0、オフライン0、物理デバイス5 (1つのコントローラ + 4つのディスク)、ディスク4、クリティカル・ディスク0、障害が発生したディスク0です。
Oracle Exadata Database Machine X3-8フル・ラックおよびOracle Exadata Database Machine X2-8フル・ラックの場合、予想される出力は仮想ドライブ1、パフォーマンス低下0、オフライン0、物理デバイス11 (1つのコントローラ1 + 2つのSAS2拡張ポート + 8つのディスク)、ディスク8、クリティカル・ディスク0、障害が発生したディスク0です。
出力が異なる場合は、問題点を調査して修正します。パフォーマンスが低下した仮想ドライブは、通常は存在しない物理ディスクまたは障害が発生したディスクです。ノードで障害が発生したディスクの数が、システムの動作を維持するのに必要な数を超えた場合は、データ損失のリスクを回避するために、クリティカル・ディスクをすぐに交換してください。障害が発生したディスクもすぐに交換してください。
|
注意: その他の仮想ドライブまたはホット・スペアが存在する場合は、デプロイ時にディスク再利用手順が実行されなかったか、dualboot=no修飾子を使用せずにベア・メタル・リストア手順が実行された可能性があります。詳細は、『Oracle Exadata Database Machineインストレーションおよび構成ガイド』を参照してください。
ホット・スペアがあるデータベース・サーバーをOracle Exadata Storage Server Softwareリリース11.2.3.2.0以上にアップグレードする場合、ホット・スペアは削除され、アクティブ・ドライブとしてRAID構成に追加されます。データベース・サーバーはRAID 5冗長性の観点では同じ可用性で稼働し続け、ドライブが1つ失われても存続できます。ドライブで障害が発生した場合は、自動サービス・リクエストにより、そのドライブをできるだけ早く交換するように求める通知が送信されます。 |
仮想ドライブの構成を検証するには、次のコマンドを使用して、仮想ドライブの構成を検証します。
/opt/MegaRAID/MegaCli/MegaCli64 CfgDsply -aALL | grep "Virtual Drive:"; \ /opt/MegaRAID/MegaCli/MegaCli64 CfgDsply -aALL | grep "Number Of Drives"; \ /opt/MegaRAID/MegaCli/MegaCli64 CfgDsply -aALL | grep "^State"
次に、Oracle Exadata Database Machine X4-2、Oracle Exadata Database Machine X3-2およびOracle Exadata Database Machine X2-2の場合の出力例を示します。仮想デバイス0は4つのドライブを持ち、状態はOptimalです。
Virtual Drive : 0 (Target Id: 0) Number Of Drives : 4 State : Optimal
Oracle Exadata Database Machine X3-8フル・ラックおよびOracle Exadata Database Machine X2-8フル・ラックの場合は、仮想デバイスが8つのドライブを持ち、状態がOptimalであることを示す出力が表示されると予想されます。
|
注意: データベース・サーバーでdualboot=noオプションを使用しないでディスク交換がされた場合、データベース・サーバーには3つの仮想デバイスがある可能性があります。詳細または是正処置は、My Oracle Supportノート1323309.1を参照してください。 |
物理ドライブの構成を検証するには、次のコマンドを使用して、データベース・サーバーの物理ドライブの構成を検証します。
Linuxの場合は、次のコマンドを使用して、データベース・サーバーの物理ドライブの構成を検証します。
/opt/MegaRAID/MegaCli/MegaCli64 -PDList -aALL | grep "Firmware state"
次に、Oracle Exadata Database Machine X4-2、Oracle Exadata Database Machine X3-2およびOracle Exadata Database Machine X2-2の場合の出力例を示します。ドライブはOnline, Spun Upです。出力順序は重要ではありません。Oracle Exadata Database Machine X3-8フル・ラックまたはOracle Exadata Database Machine X2-8フル・ラックの場合は、Online, Spun Upの状態を示す出力が8行になります。
Firmware state: Online, Spun Up Firmware state: Online, Spun Up Firmware state: Online, Spun Up Firmware state: Online, Spun Up
出力が異なる場合は、問題点を調査して修正します。
パフォーマンスが低下した仮想ドライブは、通常は存在しない物理ディスクまたは障害が発生したディスクです。ノードで障害が発生したディスクの数が、システムの動作を維持するのに必要な数を超えた場合は、データ損失のリスクを回避するために、クリティカル・ディスクをすぐに交換してください。障害が発生したディスクもすぐに交換してください。
データベース・サーバーのRAIDセットのドライブを交換した場合は、RAIDセットの再構築の進捗状況を監視する必要があります。
ディスクを交換したデータベース・サーバーで次のコマンドを使用します。コマンドはrootユーザーとして実行します。
/opt/MegaRAID/MegaCli/MegaCli64 -pdrbld -showprog -physdrv \ [disk_enclosure:slot_number] -a0
前述のコマンドで、disk_enclosureおよびslot_numberは、MegaCli64 -PDListコマンドによって識別された交換ディスクを示します。次に、コマンドの出力例を示します。
Rebuild Progress on Device at Enclosure 252, Slot 2 Completed 41% in 13 Minutes.
Oracle Exadata Storage Server Softwareリリース12.1.2.1.0以上にアップグレードしたホット・スペア・ドライブがあるOracle Exadata Database Machinesは、reclaimdisks.shスクリプトを使用してドライブをリクレイムできません。手動でドライブをリクレイムする手順は、次のとおりです。
|
注意: この手順の実行中に、データベース・サーバーが2度再起動されます。この項の手順では、サーバーの再起動の後、Grid Infrastructureの再起動が無効であることを前提としています。ディスクが4つあるOracle Exadata Database Machine X2-2データベース・サーバーの出力例を、次に示します。エンクロージャ識別子、スロット番号などは、使用するシステムにより異なる場合があります。 |
次のコマンドを使用して、ホット・スペア・ドライブを識別します。
# /opt/MegaRAID/MegaCli/MegaCli64 -PDList -aALL
ホット・スペア・ドライブのコマンドの出力例を、次に示します。
... Enclosure Device ID: 252 Slot Number: 3 Enclosure position: N/A Device Id: 8 WWN: 5000CCA00A9FAA5F Sequence Number: 2 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Last Predictive Failure Event Seq Number: 0 PD Type: SASHotspare Information:Type: Global, with enclosure affinity, is revertibleRaw Size: 279.396 GB [0x22ecb25c Sectors] Non Coerced Size: 278.896 GB [0x22dcb25c Sectors] Coerced Size: 278.464 GB [0x22cee000 Sectors] Sector Size: 0 Logical Sector Size: 0 Physical Sector Size: 0Firmware state: Hotspare, Spun downDevice Firmware Level: A2A8 Shield Counter: 0 Successful diagnostics completion on : N/A ...
コマンドが、ホット・スペア・ドライブをエンクロージャ識別子252、スロット3で識別しました。
次のコマンドを使用して、仮想ドライブの情報を取得します。
# /opt/MegaRAID/MegaCli/MegaCli64 -LDInfo -Lall -Aall
次に、コマンドの出力例を示します。
Adapter 0 -- Virtual Drive Information:Virtual Drive: 0 (Target Id: 0)Name :DBSYS RAID Level : Primary-5, Secondary-0, RAID Level Qualifier-3 Size : 556.929 GB Sector Size : 512 Is VD emulated : No Parity Size : 278.464 GB State : Optimal Strip Size : 1.0 MB Number Of Drives : 3 Span Depth : 1 Default Cache Policy: WriteBack, ReadAheadNone, Direct, No Write Cache if Bad BBU Current Cache Policy: WriteBack, ReadAheadNone, Direct, No Write Cache if Bad BBU Default Access Policy: Read/Write Current Access Policy: Read/Write Disk Cache Policy : Disabled Encryption Type : None Is VD Cached: No
コマンドが、仮想ドライブ0のRAID 5構成をアダプタ0で識別しました。
次のコマンドを使用して、ホット・スペア・ドライブを削除します。
# /opt/MegaRAID/MegaCli/MegaCli64 -PDHSP -Rmv -PhysDrv[252:3] -a0
次のコマンドを使用して、ドライブをアクティブRAID 5ドライブとして追加します。
# /opt/MegaRAID/MegaCli/MegaCli64 -LDRecon -Start -r5 \ -Add -PhysDrv[252:3] -L0 -a0 Start Reconstruction of Virtual Drive Success. Exit Code: 0x00
|
注意: Failed to Start Reconstruction of Virtual Driveというメッセージが表示された場合、My Oracle Support note1505157.1, Failed to Start Reconstruction of Virtual Drive - Adding a hot-spare manuallyの手順に従ってください。 |
次のコマンドを使用して、RAID再構築の進捗状況を監視します。
# /opt/MegaRAID/MegaCli/MegaCli64 -LDRecon -ShowProg -L0 -a0 Reconstruction on VD #0 (target id #0) Completed 1% in 2 Minutes.
ホット・スペア・ドライブがRAID 5に追加され、再構築が終了した場合に表示されるコマンドの出力例を、次に示します。
Reconstruction on VD #0 is not in Progress.
次のコマンドを使用して、ドライブの数を確認します。
# /opt/MegaRAID/MegaCli/MegaCli64 -LDInfo -Lall -Aall
次に、コマンドの出力例を示します。
Adapter 0 -- Virtual Drive Information: Virtual Drive: 0 (Target Id: 0) Name :DBSYS RAID Level : Primary-5, Secondary-0, RAID Level Qualifier-3 Size : 835.394 GB Sector Size : 512 Is VD emulated : No Parity Size : 278.464 GB State : Optimal Strip Size : 1.0 MB Number Of Drives : 4 Span Depth : 1 Default Cache Policy: WriteBack, ReadAheadNone, Direct, No Write Cache if Bad BBU Current Cache Policy: WriteBack, ReadAheadNone, Direct, No Write Cache if Bad BBU Default Access Policy: Read/Write Current Access Policy: Read/Write Disk Cache Policy : Disabled Encryption Type : None Is VD Cached: No
次のコマンドを使用して、RAIDのサイズをチェックします。
# parted /dev/sda print
Model: LSI MR9261-8i (scsi)
Disk /dev/sda: 598GB
Sector size (logical/physical): 512B/4096B
Partition Table: msdos
Number Start End Size Type File system Flags
1 32.3kB 132MB 132MB primary ext3 boot
2 132MB 598GB 598GB primary lvm
変更を有効にするためにサーバーを再起動します。
次のコマンドを使用して、RAIDのサイズをチェックします。
# parted /dev/sda print
Model: LSI MR9261-8i (scsi)
Disk /dev/sda: 897GB
Sector size (logical/physical): 512B/4096B
Partition Table: msdos
Number Start End Size Type File system Flags
1 32.3kB 132MB 132MB primary ext3 boot
2 132MB 598GB 598GB primary lvm
RAIDのサイズが大きいと、ボリューム・グループを拡張できます。ボリューム・グループを拡張するには、ドライブにパーティションを更に追加する必要があります。
次のコマンドを使用して、セクター内に新しいサイズを取得します。
# parted /dev/sda GNU Parted 2.1 Using /dev/sda Welcome to GNU Parted! Type 'help' to view a list of commands.(parted) unit s(parted) printModel: LSI MR9261-8i (scsi) Disk /dev/sda:1751949312sSector size (logical/physical): 512B/4096B Partition Table: msdos Number Start End Size Type File system Flags 1 63s 257039s 256977s primary ext3 boot 2 257040s1167957629s1167700590s primary lvm
上記の例では、セクター1167957630で開始し、ディスクの末尾のセクター1751949311で終了する3番目のパーティションが作成されます。
次のコマンドを使用して、ドライブに追加のパーティションを作成します。
# parted /dev/sda GNU Parted 2.1 Using /dev/sda Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) unit s(parted) mkpartPartition type? primary/extended? primary File system type? [ext2]? ext2Start? 1167957630End? 1751949311Warning: The resulting partition is not properly aligned for best performance. Ignore/Cancel? Ignore Warning: WARNING: the kernel failed to re-read the partition table on /dev/sda (Device or resource busy). As a result, it may not reflect all of your changes until after reboot. (parted) (parted) print Model: LSI MR9261-8i (scsi) Disk /dev/sda: 1751949312s Sector size (logical/physical): 512B/4096B Partition Table: msdos Number Start End Size Type File system Flags 1 63s 257039s 256977s primary ext3 boot 2 257040s 1167957629s 1167700590s primary lvm 3 1167957630s 1751949311s 583991682s primary(parted) set 3 lvm onWarning: WARNING: the kernel failed to re-read the partition table on /dev/sda (Device or resource busy). As a result, it may not reflect all of your changes until after reboot. (parted) print Model: LSI MR9261-8i (scsi) Disk /dev/sda: 1751949312s Sector size (logical/physical): 512B/4096B Partition Table: msdos Number Start End Size Type File system Flags 1 63s 257039s 256977s primary ext3 boot 2 257040s 1167957629s 1167700590s primary lvm 3 1167957630s 1751949311s 583991682s primary lvm
データベース・サーバーを再起動します。
次のコマンドを使用して、物理ボリュームを作成します。
# pvcreate /dev/partition_name
次のコマンドを使用して、物理ボリュームを既存のボリューム・グループに追加します。
# vgextendvolume_group/dev/partition_nameVolume group "volume_name" successfully extended
「LVMパーティションのサイズ変更」の手順に従い、論理ボリュームおよびファイル・システムのサイズを変更します。
Management Server (MS)には、データベース・サーバー内の/ (root)ディレクトリからファイルを削除するポリシーがあり、ファイル・システムの使用率が高い場合にトリガーされます。ファイルの削除はファイル使用率が80パーセントの場合にトリガーされ、削除開始前にアラートが送信されます。アラートには、ディレクトリの名前と、サブディレクトリの領域の使用率が含まれます。削除ポリシーは次のとおりです。
次に示すディレクトリ内のファイルは、ファイル変更のタイム・スタンプに基づいたポリシーを使用して削除されます。
/opt/oracle/dbserver/log
/opt/oracle/dbserver/dbms/deploy/config/metrics
/opt/oracle/dbserver/dbms/deploy/log
metricHistoryDays属性によって設定された日数より古いファイルが最初に削除され、続けて古いファイルから変更タイムスタンプが10分以前のファイル、またはファイル・システムの使用率が75パーセントまでのファイルが削除されます。metricHistoryDays属性は/opt/oracle/dbserver/dbms/deploy/config/metrics内のファイルに適用されます。その他のログ・ファイルとトレース・ファイルには、diagHistoryDays属性を使用します。
12.1.2.2.0以上では、ms-odl.trcファイルとms-odl.logファイルの領域の最大容量は、trcファイル用が100MB (20個の5MBファイル)、logファイル用が100MB (20個の5MBファイル)です。以前は、trcファイルとlogファイルの両方とも、50MB (10個の5MBファイル)でした。
ms-odl生成ファイルは5MBに達すると名前が変更され、100MBの領域を使い切ると、最も古いファイルが削除されます。
データベース・サーバーにディスクを追加できます。ディスクの追加手順は、次のとおりです。
|
注意: ディスク拡張キットはOracle Exadata Database Machine X5-2およびX6-2システムでのみサポートされています。 |
プラスチック・フィルタをディスク拡張キットの4つのドライブに交換します。
ディスク拡張キットが検出され、既存のRAID5構成にそれらのドライブが自動的に追加されたこと、および対応する仮想ドライブの再構築を開始することを通知するアラートが生成されます。
仮想ドライブの再構築が完了したときに、再度アラートが生成されます。
/opt/oracle.SupportTools/reclaimdisks.sh -extend-vgexadbを実行し、VGExaDbボリューム・グループを/dev/sdaシステム・ディスクの残存領域まで拡張します。
|
注意: このコマンドは仮想ドライブの再構築が完了した後にのみ実行してください。完了前に実行した場合、次のメッセージが表示されます。[WARNING ] Reconstruction of the logical drive 0 is in progress: Completed: 14%. Left: 5 Hours 32 Minutes [WARNING ] Continue after reconstruction is complete この場合は、仮想ドライブの再構築が完了してから再度コマンドを実行します。 |
GPT (GUIDパーティション表)を修復するか、または現在の設定で続行するかを尋ねるプロンプトが表示された場合は、"F"を入力してGPTを修復します。
[root@dbnode01 ~]# /opt/oracle.SupportTools/reclaimdisks.sh -extend-vgexadb Model is ORACLE SERVER X6-2 Number of LSI controllers: 1 Physical disks found: 8 (252:0 252:1 252:2 252:3 252:4 252:5 252:6 252:7) Logical drives found: 1 Linux logical drive: 0 RAID Level for the Linux logical drive: 5 Physical disks in the Linux logical drive: 8 (252:0 252:1 252:2 252:3 252:4 252:5 252:6 252:7) Dedicated Hot Spares for the Linux logical drive: 0 Global Hot Spares: 0 Valid. Disks configuration: RAID5 from 8 disks with no global and dedicated hot spare disks. Valid. Booted: Linux. Layout: Linux + DOM0. [INFO ] Size of system block device /dev/sda: 4193GB [INFO ] Last partition on /dev/sda ends on: 1797GB [INFO ] Unused space detected on the system block device: /dev/sda [INFO ] Label of partition table on /dev/sda: gpt [INFO ] Adjust the partition table to use all of the space on /dev/sda [INFO ] Respond to the following prompt by typing 'F' Warning: Not all of the space available to /dev/sda appears to be used, you can fix the GPT to use all of the space (an extra 4679680000 blocks) or continue with the current setting? Fix/Ignore? F Model: LSI MR9361-8i (scsi) Disk /dev/sda: 4193GB Sector size (logical/physical): 512B/512B Partition Table: gpt Number Start End Size File system Name Flags 1 32.8kB 537MB 537MB ext4 primary boot 2 537MB 123GB 122GB primary lvm 3 123GB 1690GB 1567GB primary 4 1690GB 1797GB 107GB primary lvm [INFO ] Check for Linux with inactive DOM0 system disk [INFO ] Valid Linux with inactive DOM0 system disk is detected [INFO ] Number of partitions on the system device /dev/sda: 4 [INFO ] Higher partition number on the system device /dev/sda: 4 [INFO ] Last sector on the system device /dev/sda: 8189440000 [INFO ] End sector of the last partition on the system device /dev/sda: 3509759000 [INFO ] Unmount /u01 from /dev/mapper/VGExaDbOra-LVDbOra1 [INFO ] Remove inactive system logical volume /dev/VGExaDb/LVDbSys3 [INFO ] Remove xen files from /boot [INFO ] Remove logical volume /dev/VGExaDbOra/LVDbOra1 [INFO ] Remove volume group VGExaDbOra [INFO ] Remove physical volume /dev/sda4 [INFO ] Remove partition /dev/sda4 [INFO ] Remove device /dev/sda4 [INFO ] Remove partition /dev/sda3 [INFO ] Remove device /dev/sda3 [INFO ] Create primary partition 3 using 240132160 8189439966 [INFO ] Set lvm flag for the primary partition 3 on device /dev/sda [INFO ] Add device /dev/sda3 [INFO ] Primary LVM partition /dev/sda3 has size 7949307807 sectors [INFO ] Create physical volume on partition /dev/sda3 [INFO ] LVM Physical Volume /dev/sda3 has size 3654340511 sectors [INFO ] Size of LVM physical volume less than size of device /dev/sda3 [INFO ] Remove LVM physical volume /dev/sda3 [INFO ] Reboot is required to apply the changes in the partition table
必要であればノードを再起動し、パーティション表に変更を適用します。再起動が必要な場合は、前述のコマンドのメッセージの末尾にそのように表示されます。
[root@dbnode01 ~]# reboot
再起動が不要の場合は、手順7に進みます。
/opt/oracle.SupportTools/reclaimdisks.sh -extend-vgexadbを実行します。
このコマンドで次のようなエラーが表示されることがあります。このエラーは無視しても問題ありません。
[root@dbnode01 ~]# /opt/oracle.SupportTools/reclaimdisks.sh -extend-vgexadb
Model is ORACLE SERVER X6-2
Number of LSI controllers: 1
Physical disks found: 8 (252:0 252:1 252:2 252:3 252:4 252:5 252:6 252:7)
Logical drives found: 1
Linux logical drive: 0
RAID Level for the Linux logical drive: 5
Physical disks in the Linux logical drive: 8 (252:0 252:1 252:2 252:3 252:4 252:5 252:6 252:7)
Dedicated Hot Spares for the Linux logical drive: 0
Global Hot Spares: 0
Valid. Disks configuration: RAID5 from 8 disks with no global and dedicated hot spare disks.
Valid. Booted: Linux. Layout: Linux.
[INFO ] Check for Linux system disk
[INFO ] Number of partitions on the system device /dev/sda: 4
[INFO ] Higher partition number on the system device /dev/sda: 4
[INFO ] Last sector on the system device /dev/sda: 8189440000
[INFO ] End sector of the last partition on the system device /dev/sda: 8189439966
[INFO ] Next free available partition on the system device /dev/sda:
[INFO ] Primary LVM partition /dev/sda4 has size 4679680000 sectors
[INFO ] Create physical volume on partition /dev/sda4
[INFO ] LVM Physical Volume /dev/sda4 has size 4679680000 sectors
[INFO ] Size of LVM physical volume matches size of primary LVM partition /dev/sda4
[INFO ] Extend volume group VGExaDb with physical volume on /dev/sda4
[INFO ] Create 100Gb logical volume for DBORA partition in volume group VGExaDb
[WARNING ] Failed command at attempt: lvm lvcreate -L 100GB -n LVDbOra1 VGExaDb at 1/1
[ERROR ] Failed command: lvm lvcreate -L 100GB -n LVDbOra1 VGExaDb
[ERROR ] Unable to create logical volume LVDbOra1 in volume group VGExaDb
[ERROR ] Unable to reclaim all disk space
確認のため、/opt/oracle.SupportTools/reclaimdisks.shを実行します。
[root@dbnode01 ~]# /opt/oracle.SupportTools/reclaimdisks.sh
Model is ORACLE SERVER X6-2
Number of LSI controllers: 1
Physical disks found: 8 (252:0 252:1 252:2 252:3 252:4 252:5 252:6 252:7)
Logical drives found: 1
Linux logical drive: 0
RAID Level for the Linux logical drive: 5
Physical disks in the Linux logical drive: 8 (252:0 252:1 252:2 252:3 252:4 252:5 252:6 252:7)
Dedicated Hot Spares for the Linux logical drive: 0
Global Hot Spares: 0
Valid. Disks configuration: RAID5 from 8 disks with no global and dedicated hot spare disks.
Valid. Booted: Linux. Layout: Linux.
「LVMパーティションのサイズ変更」の手順に従い、論理ボリュームおよびファイル・システムのサイズを変更します。
データベース・サーバーにはメモリーを追加できます。メモリーの追加手順は、次のとおりです。
データベース・サーバーの電源を切ります。
『Sun Fire X4170 M2 Server Service Manual』に従って、プラスチック・フィルタを6つのDIMMに交換します。このガイドは次のWebサイトから入手できます。
データベース・サーバーの電源を投入します。
データベース・サーバーをクラスタに接続します。
Oracle Exadata Database Machine X4-2以降のシステムで実行されるデータベース・サーバー上のアクティブ・コア数を、インストール中に減らすことができます。追加の容量が必要な場合は、アクティブ・コア数を増やすことができます。これは、キャパシティ・オンデマンドと呼ばれます。
追加のコアは、Oracle Exadata Database Machine X4-2およびそれ以降のシステムでは2コア増分で、Oracle Exadata Database Machine X4-8フル・ラックおよびそれ以降のシステムでは8コア増分で増やします。表2-1に、キャパシティ・オンデマンドのコア・プロセッサの構成を示します。
表2-1 キャパシティ・オンデマンドのコア・プロセッサの構成
| Oracle Exadata Database Machine | 対象となるシステム | サーバー当たりの最小コア数 | サーバー当たりの最大コア数 | コアの増分 |
|---|---|---|---|---|
|
Oracle Exadata Database Machine X6-2 |
エイス・ラック以外の構成 |
14 |
44 |
14から44、2の倍数。 14, 16, 18, ..., 42, 44 |
|
Oracle Exadata Database Machine X6-2 |
エイス・ラック |
8 |
22 |
8から22、2の倍数。 8, 10, 12, ..., 20, 22 |
|
Oracle Exadata Database Machine X5-2 |
エイス・ラック以外の構成 |
14 |
36 |
14から36、2の倍数。 14, 16, 18, ..., 34, 36 |
|
Oracle Exadata Database Machine X5-2 |
エイス・ラック |
8 |
18 |
8から18、2の倍数。 8, 10, 12, ..., 16, 18 |
|
Oracle Exadata Database Machine X6-8およびX5-8 |
任意の構成 |
56 |
144 |
56から144、8の倍数。 56, 64, 72, ..., 136, 144 |
|
Oracle Exadata Database Machine X4-2 |
フル・ラック ハーフ・ラック クオータ・ラック |
12 |
24 |
12から24、2の倍数。 12, 14, 16, ..., 22, 24 |
|
Oracle Exadata Database Machine X4-8 |
フル・ラック |
48 |
120 |
48から120、8の倍数。 48, 56, 64, ..., 112, 120 |
|
注意: フェイルオーバーに備えて、各サーバーに同数のコアをライセンスすることをお薦めします。追加できるデータベース・サーバーは一度に1つずつで、キャパシティ・オンデマンドは個別のデータベース・サーバーに適用されます。このオプションはOracle Exadata Database Machine X5-2エイス・ラックでも使用できます。 |
|
関連項目: ライセンスおよび制限の詳細は、『Oracle Exadata Database Machineライセンス情報』を参照してください。 |
次の手順では、データベース・サーバーのアクティブ・コア数を増やす方法を説明します。
|
注意: 追加したコアを有効化してから、データベース・サーバーを再起動する必要があります。データベース・サーバーがクラスタの一部の場合、ローリング方式で有効化されます。 |
次のコマンドを使用して、アクティブな物理コアの数を確認します。
DBMCLI> LIST DBSERVER attributes coreCount
次のコマンドを使用して、アクティブ・コア数を増やします。
DBMCLI> ALTER DBSERVER pendingCoreCount = new_number_of_active_physical_cores
次のコマンドを使用して、承認待ちのアクティブ物理コア数を確認します。
DBMCLI> LIST DBSERVER attributes pendingCoreCount
サーバーを再起動します。
次のコマンドを使用して、アクティブ物理コア数を確認します。
DBMCLI> LIST DBSERVER attributes coreCount
ベア・メタルOracle RACクラスタからOVM RACクラスタへの移行は次の方法で実行できます。
既存のベア・メタルOracle RACクラスタを使用して、OVM RACクラスタを移行します。ダウンタイムは発生しません。
新しいOVM RACクラスタを作成して、OVM RACクラスタに移行します。多少のダウンタイムが発生します。
Oracle Data Guardを使用してOVM RACクラスタに移行します。多少のダウンタイムが発生します。
RMANバックアップとリストアを使用してOVM RACクラスタに移行します。ダウンタイムが発生します。
ベア・メタルOracle RACクラスタからOVM RACクラスタに変換することは、次のことを示唆します。
各データベース・サーバーがOracle Virtual Serverに変更されます。Oracle Virtual Serverには管理ドメインと、デプロイされるOracle RACクラスタの数に応じて1つ以上のユーザー・ドメインが作成されます。データベース・サーバー上の各ユーザー・ドメインは特定のOracle RACクラスタに所属します。
変換手順の一環として、ベア・メタルOracle RACクラスタが1つのOVM RACクラスタに変換されます。データベース・サーバーごとに1つのユーザー・ドメインがあります。
変換が終わった後のストレージ・セルのセル・ディスクとグリッド・ディスクの構成は、変換の開始時の構成と同じになります。
各データベース・サーバー上で管理ドメインによって使用されるシステム・リソースの量は同じになります。通常、管理ドメインでは8GBのメモリーと4つの仮想CPUが使用されます。この点を考慮してOVM RACクラスタで実行するデータベースのSGAのサイズを決定してください。
要件および詳細な手順については、My Oracle Supportノート2099488.1を参照してください。
Oracle Exadata Database Machine上のOracle VMユーザー・ドメインを管理するには、管理ドメイン(domain-0またはdom0)からxm(1)コマンドを実行します。xm helpを実行すると、すべてのOracle VM管理コマンドの一覧が表示されます。
|
注意: 次に示すxmサブコマンドは、Oracle Exadata Database Machineではサポートされていません。
mem-set mem-max migrate restore resume save suspend sched-* cpupool-* tmem-* |
この項の内容は次のとおりです。
|
注意: 特に明記された場合を除き、前述の手順で実行するすべてのコマンドはrootユーザーとして実行します。 |
次の手順では、実行中のドメインを表示する方法について説明します。
管理ドメイン、domain zeroまたはdom0に接続します。
xm listコマンドを実行します。次に、出力の例を示します。
Example # xm list Name ID Mem VCPUs State Time(s) Domain-0 0 8192 4 r----- 409812.7 dm01db01vm01 8 8192 2 -b---- 156610.6 dm01db01vm02 9 8192 2 -b---- 152169.8 dm01db01vm03 10 10240 4 -b---- 150225.9 dm01db01vm04 16 12288 8 -b---- 113519.3 dm01db01vm05 12 12288 8 -b---- 174101.6 dm01db01vm06 13 12288 8 -b---- 169115.9 dm01db01vm07 14 8192 4 -b---- 175573.0
次の手順では、ユーザー・ドメインを開始する方法について説明します。
次のコマンドを使用して、ユーザー・ドメインを起動します。
# xm create /EXAVMIMAGES/GuestImages/DomainName/vm.cfg
Using config file "/EXAVMIMAGES/GuestImages/dm01db01vm04/vm.cfg".
Started domain dm01db01vm04 (id=23)
前述のコマンドで、DomainNameはドメインの名前です。
|
注意: Oracle Linux起動メッセージをユーザー・ドメイン起動中に表示する場合は、起動中に-cオプションを使用してコンソールに接続します。起動が終了したら、CTRL+]を押してコンソールの接続を解除します。 |
次の手順では、管理ドメインが起動した場合に、ユーザー・ドメインが自動的に起動するのを無効にする方法について説明します。
管理ドメインに接続します。
次のコマンドを使用して、/etc/xen/autoディレクトリ内のユーザー・ドメイン構成ファイルへのシンボリック・リンクを削除します。
# rm /etc/xen/auto/DomainName.cfg
前述のコマンドで、DomainNameはドメインの名前です。
次の手順では、ユーザー・ドメイン内部でユーザー・ドメインをシャットダウンする方法について説明します。
rootユーザーとしてユーザー・ドメインに接続します。
次のコマンドを使用して、ドメインをシャットダウンします。
# shutdown -h now
次の手順では、管理ドメイン内部でユーザー・ドメインをシャットダウンする方法について説明します。
Oracle VMユーザー・ドメインでのOracle Databasesのバックアップおよびリストアは、物理ノードとの違いがありません。Exadataストレージを使用している場合、各OVM RACクラスタでは、それぞれのASMディスク・グループを"+RECO"などの高速リカバリ領域(FRA)として指定する必要があります。詳細は、ホワイト・ペーパー、『ExadataセルおよびOracle Exadata Database Machineを使用したバックアップおよびリカバリのパフォーマンスとベスト・プラクティス』 (Oracle Database 11.2.0.2以降)を参照してください。
ZFSストレージを使用している場合、ホワイト・ペーパー、『Oracle Exadata Database MachineでSun ZFSストレージ装置を使用したバックアップおよびリカバリのパフォーマンスとベスト・プラクティス』を参照してください。
OracleデータベースをOracle VMユーザー・ドメインでバックアップする場合、例外として、次の4つのパラメータをデータベース・ノード(ユーザー・ドメイン)の/etc/sysctl.confファイルに設定する必要があります。また、Exadataストレージを使用してバックアップを保持する場合、パラメータをExadataストレージ・セルの/etc/sysctl.confファイルに設定する必要があります。
net.core.rmem_default = 4194304
net.core.wmem_default = 4194304
net.core.rmem_max = 4194304
net.core.wmem_max = 4194304
次の手順では、ユーザー・ドメインに割り当てられたメモリーを変更する方法について説明します。
|
注意: ユーザー・ドメインに割り当てられるメモリーの量を減らす場合は、ユーザー・ドメインで実行中のデータベースのSGAサイズおよび対応するヒュージ・ページ・オペレーティング・システム構成を最初に確認して調整する必要があります。そうしない場合、Linuxオペレーティング・システムのブート中に、多すぎるメモリーがヒュージ・ページに予約されるため、ユーザー・ドメインを起動できなくなることがあります。詳細は、My Oracle Supportノート361468.1を参照してください。 |
|
注意: この手順では、ユーザー・ドメインを再起動する必要があります。メモリー割当てを変更する場合、xm mem-setコマンドはサポートされていません。 |
管理ドメインに接続します。
次のコマンドを使用して、割当てを増やす場合に使用できる空きメモリーの量を判別します。
# xm info | grep free_memory
|
注意: 空きメモリーをユーザー・ドメインに割り当てる場合、空きメモリーの約1から2パーセントがメタデータおよび制御構造で使用されます。つまり、増加可能なメモリーの量は、空メモリーの値の1から2パーセント未満です。 |
xm listコマンドで取得した名前を使用して、ユーザー・ドメインを正常にシャットダウンします。-wオプションを使用すると、ドメインがシャットダウンするまで待機してからxmコマンドが戻ります。
# xm shutdown DomainName -w
前述のコマンドで、DomainNameはドメインの名前です。
/EXAVMIMAGES/GuestImages/DomainName/vm.cfgファイルのバックアップ・コピーを作成します。
/EXAVMIMAGES/GuestImages/DomainName/vm.cfgファイルのmemory設定およびmaxmem設定を、テキスト・エディタを使用して編集します。memory設定およびmaxmem設定の値は、同一です。
次のコマンドを使用して、ユーザー・ドメインを起動します。
# xm create /EXAVMIMAGES/GuestImages/DomainName/vm.cfg
|
注意: Oracle Linux起動メッセージをユーザー・ドメイン起動中に表示する場合は、起動中に-cオプションを使用してコンソールに接続します。起動が終了したら、CTRL+]を押してコンソールの接続を解除します。 |
仮想CPU (vCPUs)の数を変更する場合、次の点に留意します。
ユーザー・ドメインに割り当てられた仮想CPU数を変更するためのすべてのアクションは、管理ドメインで実行されます。
ユーザー・ドメインに可能な仮想CPU数は、ユーザー・ドメインのvcpusパラメータで設定される値の範囲内で、動的に増減します。
仮想CPUをオーバーコミットすると、すべてのドメインに割り当てられた仮想CPUを、システム上の物理CPU数より多く割り当てることができます。ただし、CPUのオーバーコミットは、過剰に収容されたリソースへの競合するワークロードが十分理解され、同時に発生する要求が物理能力を超えない場合にのみ、実行する必要があります。
次の手順では、ユーザー・ドメインに割り当てられた仮想CPU数を変更する方法について説明します。
次の手順に従い、物理CPU数を判別します。
管理ドメインで、次のコマンドを実行します。
# xm info | grep -A3 nr_cpus nr_cpus : 24 nr_nodes : 2 cores_per_socket : 6 threads_per_core : 2
上記の例では、24の物理CPUが存在します(12のコア、各コアにスレッド2つ)。
次のコマンドを実行して、ユーザー・ドメインに構成されオンラインである仮想CPUの現在の設定を判別します。
# xm list DomainName -l | grep vcpus
(vcpus 4)
(online_vcpus 2)
前述のコマンドで、DomainNameはユーザー・ドメインの名前です。コマンドの出力例では、ユーザー・ドメインの仮想CPUの最大数は4で、現在のオンライン仮想CPUは2です。このユーザー・ドメインのオンラインの仮想CPUの数は、ユーザー・ドメインがオンラインの間に、vcpusパラメータよりも大きくない数に調整されます。オンラインの仮想CPUの数をvcpusパラメータよりも大きい値に増やすには、ユーザー・ドメインをオフラインにする必要があります。
次の手順に従い、仮想CPU数を小さくするまたは大きくします。
仮想CPU数を減らす手順は、次の通りです。
次のコマンドを使用して、ユーザー・ドメインに現在割り当てられている仮想CPUの数を判別します。
# xm list DomainName
次のコマンドを使用して、現在割り当てられている仮想CPU数を減らします。
# xm vcpu-setDomainNamevCPUs_preferred
前述のコマンドで、vCPUs_preferredは、推奨される仮想CPU数の値です
仮想CPU数を増やす手順は、次の通りです。
次のコマンドを使用して、vcpusパラメータの現在の設定を判別します。
# xm list DomainName -l | grep vcpus
(vcpus 4)
(online_vcpus 2)
推奨される仮想CPU数が、vcpusパラメータの値より小さいか等しい場合、次のコマンドを実行して、オンライン仮想CPU数を増やします。
# xm vcpu-set DomainName vCPUs_preferred
前述のコマンドで、vCPUs_preferredは、推奨される仮想CPU数の値です
推奨される仮想CPU数が、vcpusパラメータの値より大きい場合、オンラインの仮想CPUの数をvcpusパラメータよりも大きい値に増やすには、ユーザー・ドメインをオフラインする必要があります。次の手順を実行します。
i. ユーザー・ドメインをシャットダウンします。
ii./EXAVMIMAGES/GuestImages/DomainName/vm.cfgファイルのバックアップ・コピーを作成します。
iii./EXAVMIMAGES/GuestImages/DomainName/vm.cfgファイルを編集し、vcpusパラメータを推奨される仮想vCPUの数に設定します。
注意: デフォルトでは、ユーザー・ドメインは、vcpusパラメータで構成された仮想CPUの数をオンラインにします。一部の仮想CPUをオフラインにしてユーザー・ドメインを起動する場合は、maxvcpusパラメータをvm.cfgに追加し、ユーザー・ドメインでオンラインにできる仮想CPUの最大数に設定します。vcpusパラメータを仮想CPUの数に設定し、ユーザー・ドメインの起動時にオンラインにします。たとえば、2つの仮想CPUがオンラインのユーザー・ドメインを起動し、そのユーザー・ドメインがオンラインの間に、さらに6つの仮想CPUをユーザー・ドメインに追加する場合は、次の設定をvm.cfgに使用します。
maxvcpus=8 vcpus=2
iv.ユーザー・ドメインを開始します。
次の手順では、ユーザー・ドメインにおける論理ボリューム・マネージャ(LVM)、スワップ領域およびファイル・システムのサイズを増やす方法について説明します。この項の内容は次のとおりです。
次の手順では、新LVMディスクをユーザー・ドメインに追加して、ユーザー・ドメイン内で使用できるLVMディスク領域の量を増やす方法について説明します。この手順を実行すると、ファイル・システムまたはスワップLVMパーティションのサイズを増やすことができます。これはシステムがオンラインの場合に実行できます。
|
注意: この手順は、管理ドメイン(Domain-0)およびユーザー・ドメイン内で実行する必要があります。すべての手順を、 |
管理ドメインで、次のコマンドを使用して/EXAVMIMAGES内の空きディスク領域を確認します。
# df -h /EXAVMIMAGES
次に、コマンドの出力例を示します。
Filesystem Size Used Avail Use% Mounted on /dev/sda3 721G 111G 611G 16% /EXAVMIMAGES
管理ドメインで、新規ディスク・イメージの名前を選択し、ユーザー・ドメインで既に名前が使用されていないか確認します。
# ls -l /EXAVMIMAGES/GuestImages/DomainName/new_disk_image_namels: /EXAVMIMAGES/GuestImages/DomainName/new_disk_image_name: No such file or \ directory
上記のコマンドで、DomainNameはドメインの名前で、new_disk_image_nameは、新規ディスク・イメージの名前です。
# qemu-img create /EXAVMIMAGES/GuestImages/DomainName/new_disk_image_namesize
次のコマンドで、新規ディスク・イメージ名はpv2_vgexadb.img、イメージ・サイズは0 GBです。
# qemu-img create /EXAVMIMAGES/GuestImages/DomainName/pv2_vgexadb.img 10G
ユーザー・ドメインで、使用できるディスク名を判別します。次の例では、ディスク名xvdaからxvddを使用し、 ディスク名xvdeは使用しません。
# lsblk -id NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 13G 0 disk xvdb 202:16 0 20G 0 disk /u01/app/12.1.0.2/grid xvdc 202:32 0 20G 0 disk /u01/app/oracle/product/12.1.0.2/dbhome_1 xvdd 202:48 0 41G 0 disk
管理ドメインで、新規ディスク・イメージをユーザー・ドメインに読取り/書込みモードで割り当てます。次の例では、ユーザー・ドメイン内の新規ディスク・イメージは、デバイス/dev/xvdeとして表示されます。
# xm block-attachDomainName\ file:/EXAVMIMAGES/GuestImages/DomainName/new_disk_image_name/dev/xvde w
ユーザー・ドメインで、使用できるディスク・デバイスを確認します。次の例では、ディスク名xvdeがユーザー・ドメインで使用できます。
# lsblk -id NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 13G 0 disk xvdb 202:16 0 20G 0 disk /u01/app/12.1.0.2/grid xvdc 202:32 0 20G 0 disk /u01/app/oracle/product/12.1.0.2/dbhome_1 xvdd 202:48 0 41G 0 disk xvde 202:64 0 10G 0 disk
ユーザー・ドメインで、新規ディスク・デバイスにパーティションを作成します。次の例では、ディスク・デバイス/dev/xvdeにパーティションを作成します。
# parted /dev/xvde mklabel gpt # parted -s /dev/xvde mkpart primary 0 100% # parted -s /dev/xvde set 1 lvm on
parted mkpartコマンドが、次のメッセージを戻す場合があります。このメッセージは無視してかまいません。
Warning: The resulting partition is not properly aligned for best performance.
ユーザー・ドメインで、新規ディスク・パーティション上にLVM物理ボリュームを作成します。次の例では、LVM物理ボリュームをディスク・パーティション/dev/xvde1上に作成します。
# pvcreate /dev/xvde1
ユーザー・ドメインで、ボリューム・グループを拡張して、ボリューム・グループ内の追加領域を確認します。次の例では、ディスク名xvdeがユーザー・ドメインで使用できます。
# vgextend VGExaDb /dev/xvde1 # vgdisplay -s
管理ドメインで、ユーザー・ドメイン構成ファイルvm.cfgのバックアップを作成します。
# cp /EXAVMIMAGES/GuestImages/DomainName/vm.cfg \ /EXAVMIMAGES/GuestImages/DomainName/vm.cfg.backup
管理ドメインで、次のコマンドを使用して、ユーザー・ドメインのUUIDを取得します。
# grep ^uuid /EXAVMIMAGES/GuestImages/DomainName/vm.cfg
次の例では、ユーザー・ドメインUUIDは49ffddce4efe43f5910d0c61c87bba58です。
# grep ^uuid /EXAVMIMAGES/GuestImages/dm01db01vm01/vm.cfg uuid = '49ffddce4efe43f5910d0c61c87bba58'
管理ドメインで、次のコマンドを使用して、新規ディスク・イメージのUUIDを生成します。
# uuidgen | tr -d '-'
次の例では、新規ディスクUUIDは、0d56da6a5013428c97e73266f81c3404です。
# uuidgen | tr -d '-' 0d56da6a5013428c97e73266f81c3404
管理ドメインで、次のコマンドを使用して、/OVS/Repositoriesから新規ディスク・イメージへのシンボリック・リンクを作成します。
# ln -s /EXAVMIMAGES/GuestImages/DomainName/newDiskImage.img\ /OVS/Repositories/user_domain_uuid/VirtualDisks/new_disk_uuid.img
次の例では、新規ディスク・イメージ・ファイルpv2_vgexadb.imgへのシンボリック・リンクが、ユーザー・ドメインdm01db01vm01に作成されます。ユーザー・ドメインdm01db01vm01のUUIDは、i49ffddce4efe43f5910d0c61c87bba58です。新規ディスク・イメージのUUIDは、0d56da6a5013428c97e73266f81c3404です。
# ln -s /EXAVMIMAGES/GuestImages/dm01db01vm01/pv2_vgexadb.img \ /OVS/Repositories/49ffddce4efe43f5910d0c61c87bba58/VirtualDisks/ \ 0d56da6a5013428c97e73266f81c3404.img
管理ドメインで、新規ディスク用のエントリを、ユーザー・ドメイン構成ファイルvm.cfgのディスク・パラメータに付加します。これにより、次の起動時、新規ディスク・イメージが自動的にユーザー・ドメインへ割り当てられます。この新規エントリのフォーマットは次の通りです。
'file:/OVS/Repositories/user_domain_uuid/VirtualDisks/new_disk_uuid.img,disk_device,w'
次に、vm.cfgファイル内の元のディスク・パラメータ・エントリの例を示します。
disk=['file:/OVS/Repositories/49ffddce4efe43f5910d0c61c87bba58/VirtualDisks/ \ 76197586bc914d3d9fa9d4f092c95be2.img,xvda,w', \ 'file:/OVS/Repositories/49ffddce4efe43f591 0d0c61c87bba58/VirtualDisks/ \ 78470933af6b4253b9ce27814ceddbbd.img,xvdb,w', \ 'file:/OVS/Repositories/49ffddce4efe43f5910d0c61c87bba58/VirtualDisks/ \ 20d5528f5f9e4fd8a96f151a13d2006b.img,xvdc,w', \ 'file:/OVS/Repositories/49ffddce4efe43f5910d0c61c87bba58/VirtualDisks/ \ 058af368db2c4f27971bbe1f19286681.img,xvdd,w']
次の例では、ディスク・デバイス/dev/xvdeとしてユーザー・ドメイン内でアクセス可能な新規ディスク・イメージに対して、付加されたディスク・パラメータを示します。
disk=['file:/OVS/Repositories/49ffddce4efe43f5910d0c61c87bba58/VirtualDisks/ \ 76197586bc914d3d9fa9d4f092c95be2.img,xvda,w', \ 'file:/OVS/Repositories/49ffddce4efe43f591 0d0c61c87bba58/VirtualDisks/ \ 78470933af6b4253b9ce27814ceddbbd.img,xvdb,w', \ 'file:/OVS/Repositories/49ffddce4efe43f5910d0c61c87bba58/VirtualDisks/ \ 20d5528f5f9e4fd8a96f151a13d2006b.img,xvdc,w', \ 'file:/OVS/Repositories/49ffddce4efe43f5910d0c61c87bba58/VirtualDisks/ \ 058af368db2c4f27971bbe1f19286681.img,xvdd,w', \'file:/OVS/Repositories/49ffddce4efe43f5910d0c61c87bba58/VirtualDisks/\0d56da6a5013428c97e73266f81c3404.img,xvde,w']
次の手順では、システム・パーティションおよび/ (root)ファイル・システムのサイズを増やす方法について説明します。これはファイル・システムがオンラインの場合に実行できます。
|
注意: 2種類のシステム・パーティション、LVDbSys1およびLVDbSys2が使用できます。片方のパーティションがアクティブでマウントされます。もう一方のパーティションは非アクティブで、アップグレード中、バックアップする場所として使用します。この2つのシステム・パーティションは、サイズが等しい必要があります。
|
次のように、現在の環境に関する情報を収集します。
次のように、dfコマンドを使用して、rootパーティション(/)内の空き領域および使用済領域の容量を確認します。
# df -h /
次に、コマンドの出力例を示します。
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VGExaDb-LVDbSys1
12G 5.1G 6.2G 46% /
|
注意: アクティブなrootパーティションは、それ以前の保守アクティビティによりLVDbSys1またはLVDbSys2のいずれかに決定されます。 |
lvsコマンドを使用して、現在の論理ボリューム構成を表示します。
# lvs -o lv_name,lv_path,vg_name,lv_size
次に、コマンドの出力例を示します。
LV Path VG LSize LVDbOra1 /dev/VGExaDb/LVDbOra1 VGExaDb 10.00g LVDbSwap1 /dev/VGExaDb/LVDbSwap1 VGExaDb 8.00g LVDbSys1 /dev/VGExaDb/LVDbSys1 VGExaDb 12.00g LVDbSys2 /dev/VGExaDb/LVDbSys2 VGExaDb 12.00g
ボリューム・グループVGExaDbの使用可能な領域を確認するには、次のように、vgdisplayコマンドを使用します。
# vgdisplay VGExaDb -s
次に、コマンドの出力例を示します。
"VGExaDb" 53.49 GiB [42.00 GiB used / 11.49 GiB free]
ボリューム・グループは、二つのシステム・パーティションのサイズを増やすことができる空き領域を持ち、アップグレードの際にdbnodeupdate.shユーティリティで作成されるLVMスナップショットで使用するために、少なくとも1GBの空き領域を維持する必要があります。ボリューム・グループに十分な空き領域がない場合、新しいディスクをLVMに追加する必要があります。「新規LVMディスクのユーザー・ドメインへの追加」の項を参照してください。
LVDbSys1およびLVDbSys2論理ボリュームのサイズを変更するには、次のように、lvextendコマンドを使用します。
# lvextend -L +size/dev/VGExaDb/LVDbSys1 # lvextend -L +size/dev/VGExaDb/LVDbSys2
前述のコマンドで、sizeは論理ボリュームに追加する領域の容量です。いずれのシステム・パーティションにも、等しい容量の領域を追加します。
次の例では、拡大する論理ボリュームは10GBです。
# lvextend -L +10G /dev/VGExaDb/LVDbSys1 # lvextend -L +10G /dev/VGExaDb/LVDbSys2
論理ボリューム内のファイル・システムのサイズを変更するには、次のように、resize2fsコマンドを使用します。
# resize2fs /dev/VGExaDb/LVDbSys1 # resize2fs /dev/VGExaDb/LVDbSys2
dfコマンドを使用して、アクティブなシステム・パーティションで領域が拡大されたことを確認します。
# df -h /
次の手順では、/u01ファイル・システムのサイズを増やす方法について説明します。これはファイル・システムがオンラインの場合に実行できます。
|
注意: VGExaDbボリューム・グループ内に、少なくとも1GBの空き領域が必要です。空き領域は、ソフトウェア保守の際に、dbnodeupdate.shユーティリティで作成したLVMスナップショットで使用します。「Oracle Linuxデータベース・サーバーのスナップショット・ベースのバックアップの作成」の手順に従い、/ (root)および/u01ディレクトリのバックアップをスナップショット・ベースで作成する場合、 VGExaDbボリューム・グループに少なくとも6GBの空き領域が必要です。 |
次のように、現在の環境に関する情報を収集します。
dfコマンドを使用して、/u01パーティションの空き領域および使用済領域の容量を確認します。
# df -h /u01
次に、コマンドの出力例を示します。
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VGExaDb-LVDbOra1
9.9G 1.7G 7.8G 18% /u01
lvsコマンドを使用して、/u01ファイル・システムで使用される現在の論理ボリューム構成を表示します。
# lvs -o lv_name,lv_path,vg_name,lv_size /dev/VGExaDb/LVDbOra1
次に、コマンドの出力例を示します。
LV Path VG LSize LVDbOra1 /dev/VGExaDb/LVDbOra1 VGExaDb 10.00g
ボリューム・グループVGExaDbの使用可能な領域を確認するには、次のように、vgdisplayコマンドを使用します。
# vgdisplay VGExaDb -s
次に、コマンドの出力例を示します。
"VGExaDb" 53.49 GiB [42.00 GiB used / 11.49 GiB free]
コマンドの出力で空き領域が1GB未満と表示された場合は、論理ボリュームもファイル・システムも拡大できません。アップグレードの際にdbnodeupdate.shユーティリティで作成されるLVMスナップショットのために、VGExaDbボリューム・グループ内に、少なくとも1GBの空き領域が必要です。ボリューム・グループに十分な空き領域がない場合、新しいディスクをLVMに追加する必要があります。「新規LVMディスクのユーザー・ドメインへの追加」の項を参照してください。
論理ボリュームのサイズを変更するには、次のように、lvextendコマンドを使用します。
# lvextend -L +sizeG /dev/VGExaDb/LVDbOra1
前述のコマンドで、sizeは論理ボリュームに追加する領域の容量です。
次の例では、拡大する論理ボリュームは10GBです。
# lvextend -L +10G /dev/VGExaDb/LVDbOra1
論理ボリューム内のファイル・システムのサイズを変更するには、次のように、resize2fsコマンドを使用します。
# resize2fs /dev/VGExaDb/LVDbOra1
dfコマンドを使用して、領域が拡張されたことを確認します。
# df -h /u01
Oracle Grid InfrastructureホームおよびOracle Databaseソフトウェア・ホームのために、それぞれのディスク・イメージ・ファイルが管理ドメインに作成されます。ディスク・イメージ・ファイルの場所は、/EXAVMIMAGES/GuestImages/DomainName/ディレクトリです。ディスク・イメージ・ファイルは、仮想マシンの起動中に自動的にユーザー・ドメインに関連付けられ、別個にLVMではないファイル・システムとしてユーザー・ドメインにマウントされます。
次の手順では、ユーザー・ドメインにおけるデータベース・ホーム・ファイル・システムのサイズを増やす方法について説明します。グリッド・ホームのサイズを増やすには、同様の手順を使用します。
ユーザー・ドメインに接続し、ファイル・システム・サイズを確認するには、次のように、dfコマンドを使用します。
# df -h /u01/app/oracle/product/12.1.0.2/dbhome_1
次に、コマンドの出力例を示します。
Filesystem Size Used Avail Use% Mounted on /dev/xvdc 20G 6.5G 13G 35% /u01/app/oracle/product/12.1.0.2/dbhome_1
管理ドメインに接続し、ユーザー・ドメインをシャットダウンするには、次のように、xmコマンドを使用します。
# xm shutdown DomainName
上記のコマンドで、DomainNameはドメインの名前です。
OCFS reflinkを作成して、サイズを変更するディスク・イメージのバックアップとして使用するには、次のコマンドを使用します。
# cd /EXAVMIMAGES/GuestImages/DomainName
# reflink db12.1.0.2.1-3.img before_resize.db12.1.0.2.1-3.img
qemu-imgコマンドを使用して、空のディスク・イメージを作成し、データベース・ホーム・イメージに付加するには、次のようにします。空のディスク・イメージ・サイズは、拡張後のファイル・システムのサイズです。最後のコマンドにより、データベース・ホーム・ディスク・イメージに付加済の空のディスク・イメージが削除されます。
# qemu-img create emptyfile 10G # cat emptyfile >> db12.1.0.2.1-3.img # rm emptyfile
ファイル・システムを確認するには、次のように、e4fsckコマンドを使用します。
# e4fsck -f db12.1.0.2.1-3.img
ファイル・システムのサイズを変更するには、次のように、resize4fsコマンドを使用します。
# resize4fs db12.1.0.2.1-3.img
ユーザー・ドメインを起動するには、次のコマンドを使用します。
# xm create /EXAVMIMAGES/GuestImages/DomainName/vm.cfg
ユーザー・ドメインに接続し、ファイル・システム・サイズが増えていることを確認するには、次のコマンドを使用します。
# df -h /u01/app/oracle/product/12.1.0.2/dbhome_1
次に、コマンドの出力例を示します。
Filesystem Size Used Avail Use% Mounted on /dev/xvdc 30G 6.5G 22G 23% /u01/app/oracle/product/12.1.0.2/dbhome_1
管理ドメインに接続し、バックアップ・イメージを削除するには、次のコマンドまたは類似するコマンドを実行します。
# cd /EXAVMIMAGES/GuestImages/DomainName# rmback_up_image.img
上記のコマンドで、back_up_image.imgはバックアップ・イメージ・ファイルの名前です。
次の手順では、ユーザー・ドメインで構成されたスワップ領域の容量を増やす方法について説明します。
ボリューム・グループVGExaDbの使用可能な領域を確認するには、次のように、vgdisplayコマンドを使用します。
# vgdisplay VGExaDb -s
次に、コマンドの出力例を示します。
"VGExaDb" 53.49 GiB [42.00 GiB used / 11.49 GiB free]
コマンドの出力で空き領域が1GB未満と表示された場合は、論理ボリュームもファイル・システムも拡大できません。アップグレードの際にdbnodeupdate.shユーティリティで作成されるLVMスナップショットのために、VGExaDbボリューム・グループ内に、少なくとも1GBの空き領域が必要です。ボリューム・グループに十分な空き領域がない場合、新しいディスクをLVMに追加する必要があります。「新規LVMディスクのユーザー・ドメインへの追加」の項を参照してください。
論理ボリュームを作成してスワップ領域のサイズを大きくするには、次のように、lvcreateコマンドを使用します。次の例では、LVDbSwap2という名前の8GBの論理ボリュームが新たに作成されます。
# lvcreate -L 8G -n LVDbSwap2 VGExaDb
SWAP2のような一意のラベルのスワップ・デバイスとして論理ボリュームを新たに設定するには、次のように、mkswapコマンドを使用します。一意のラベルは、/etc/fstabファイルで現在使用されていないデバイスのLABELエントリです。
# mkswap -L SWAP2 /dev/VGExaDb/LVDbSwap2
新しいスワップ・デバイスを有効にするには、次のように、swaponコマンドを使用します。
# swapon -L SWAP2
新しいスワップ・デバイスが有効であることを確認するには、次のように、swaponコマンドを使用します。
# swapon -s
次に、コマンドの出力例を示します。
Filename Type Size Used Priority /dev/dm-3 partition 8388604 306108 -1 /dev/dm-4 partition 8388604 0 -2
/etc/fstabファイルを編集して、存在するスワップ・エントリをコピーして新しいスワップ・デバイスを追加し、新しいスワップ・デバイスの作成で使用したラベルへの新しいエントリのLABEL値を変更します。次の例では、新しいスワップ・デバイスが、i/etc/fstabファイルにLABEL=SWAP2として追加されます。
# cat /etc/fstab
LABEL=DBSYS / ext4 defaults 1 1
LABEL=BOOT /boot ext4 defaults,nodev 1 1
tmpfs /dev/shm tmpfs defaults,size=7998m 0
devpts /dev/pts devpts gid=5,mode=620 0 0
sysfs /sys sysfs defaults 0 0
proc /proc proc defaults 0 0
LABEL=SWAP swap swap defaults 0 0
LABEL=SWAP2 swap swap defaults 0 0
LABEL=DBORA /u01 ext4 defaults 1 1
/dev/xvdb /u01/app/12.1.0.2/grid ext4 defaults 1 1
/dev/xvdc /u01/app/oracle/product/12.1.0.2/dbhome_1 ext4 defaults 1 1
デプロイメント中、データベース・サーバー上の使用可能なディスク領域はすべてdom0に割り当てられ、その領域のほとんどがユーザー・ドメイン・ストレージ用の/EXAVMIMAGESに割り当てられます。データベース・サーバーにディスク拡張キットを追加するときには、適切な手順に従って、新しい領域を/EXAVMIMAGESファイル・システムに追加することが重要です。
次の例では、dm01db01がdom0管理ドメインの名前で、dm01db01vm01がゲスト・ユーザー・ドメインです。
reclaimdisks.shが実行されたことを確認します。これは、次の構文を使用して確認できます。
最後の行が"Layout: DOM0"になっています。reclaimdisks.shが実行されていない場合は、"Layout: DOM0 + Linux"のように表示されます。
[root@dm01db01 ~]# /opt/oracle.SupportTools/reclaimdisks.sh -check Model is ORACLE SERVER X5-2 Number of LSI controllers: 1 Physical disks found: 4 (252:0 252:1 252:2 252:3) Logical drives found: 1 Linux logical drive: 0 RAID Level for the Linux logical drive: 5 Physical disks in the Linux logical drive: 4 (252:0 252:1 252:2 252:3) Dedicated Hot Spares for the Linux logical drive: 0 Global Hot Spares: 0 Valid. Disks configuration: RAID5 from 4 disks with no global and dedicated hot spare disks. Valid. Booted: DOM0. Layout: DOM0.
ディスク拡張キットをデータベース・サーバーに追加します。キットには4台のハード・ドライブが含まれており、これを空いている4つのスロットに挿入します。フィラー・パネルを取り外し、ドライブを挿入します。ドライブは順不同で挿入できます。
alerthistoryの警告およびクリア・メッセージを参照し、RAIDの再構築が完了したことを確認します。完了までに数時間かかることもあります。次の例では約7時間かかっています。クリア・メッセージ(下のメッセージ1_2)がある場合は、再構築が完了しているため、次の手順を実行できます。
[root@dm01db01 ~]# dbmcli -e list alerthistory
1_1 2016-02-15T14:01:00-08:00 warning "A disk
expansion kit was installed. The additional physical drives were automatically
added to the existing RAID5 configuration, and reconstruction of the
corresponding virtual drive was automatically started."
1_2 2016-02-15T21:01:01-08:00 clear "Virtual drive
reconstruction due to disk expansion was completed."
次のように、現在の環境に関する情報を収集します。
[root@dm01db01 ~]# cat /proc/partitions |grep sda 8 0 4094720000 sda 8 1 524288 sda1 8 2 119541760 sda2 8 3 1634813903 sda3 [root@dm01db01 ~]# df -h /EXAVMIMAGES Filesystem Size Used Avail Use% Mounted on /dev/sda3 1.6T 44G 1.5T 3% /EXAVMIMAGES [root@dm01db01 ~]# xm list Name ID Mem VCPUs State Time(s) Domain-0 0 8192 4 r----- 94039.1 dm01db01vm01.us.oracle.com 4 16384 2 -b---- 3597.3
dom0から"xm shutdown –a –w"を実行し、すべてのユーザー・ドメイン・ゲストを停止します。すべてのユーザー・ドメインが停止すると、リストにDomain-0 (dom0)のみが表示されます。ユーザー・ドメインの停止の詳細は、「管理ドメイン内部のユーザー・ドメインのシャットダウン」を参照してください。
[root@dm01db01 ~]# xm shutdown –a -w Domain dm01db01vm01.us.oracle.com terminated All domains terminated [root@dm01db01 ~]# xm list Name ID Mem VCPUs State Time(s) Domain-0 0 8192 4 r----- 94073.4
partedを実行し、パーティション・サイズを確認します。不要なプロンプトを回避するには次の構文を使用します。
[root@dm01db01 ~]# parted -s /dev/sda print Model: LSI MR9361-8i (scsi) Disk /dev/sda: 4193GB Sector size (logical/physical): 512B/512B Partition Table: gpt Number Start End Size File system Name Flags 1 32.8kB 537MB 537MB ext3 primary boot 2 537MB 123GB 122GB primary lvm 3 123GB 1797GB 1674GB primary
前述のパーティション表に1674GBのパーティション3が表示されています。これが変更されるパーティションです。前述のパーティション表の出力の"Disk"行からわかるように、このパーティションは123GBで開始し、ディスク・サイズは4193GBです。これらの値は手順9で使用します。
パーティション3を削除します。
[root@dm01db01 ~]# parted /dev/sda (parted) rm 3 (parted) quit
このコマンドは出力を生成しません。
パーティションを再作成します。同じ開始位置を指定していることを確認します。次に、更新されたパーティション表を出力します。
[root@dm01db01 ~]# parted /dev/sda (parted) mkpart primary 123gb 4193gb (parted) print Model: LSI MR9361-8i (scsi) Disk /dev/sda: 4193GB Sector size (logical/physical): 512B/512B Partition Table: gpt Number Start End Size File system Name Flags 1 32.8kB 537MB 537MB ext3 primary boot 2 537MB 123GB 122GB primary lvm 3 123GB 4193GB 4070GB primary (parted) quit
/EXAVMIMAGESパーティションを再度マウントします。
[root@dm01db01 ~]# mount /EXAVMIMAGES [root@dm01db01 ~]# df -h /EXAVMIMAGES Filesystem Size Used Avail Use% Mounted on /dev/sda3 1.6T 44G 1.5T 3% /EXAVMIMAGES
ファイル・システムのサイズは、手順4の時点と同じで1.6TBです。
カーネルで確認されるパーティション表に、パーティション3の更新後のサイズが表示されることを確認します。sda3の出力が、手順4で確認した出力よりも大きくなっていることを確認します。
[root@dm01db01 ~]# cat /proc/partitions |grep sda 8 0 4094720000 sda 8 1 524288 sda1 8 2 119541760 sda2 8 3 3974653903 sda3
ファイル・システムを拡張します。ファイル・システムがマウント済で処理の実行中でも、この操作は実行できます。更新後のファイル・システムのサイズを、手順4の値と比較して確認します。tunefs.ocfs2コマンドは実行速度が速く、通常は出力が生成されません。
[root@dm01db01 ~]# tunefs.ocfs2 -S /dev/sda3 [root@dm01db01 ~]# df -h /EXAVMIMAGES Filesystem Size Used Avail Use% Mounted on /dev/sda3 3.8T 44G 3.7T 2% /EXAVMIMAGES
ユーザー・ドメインを再起動します。詳細は、「ユーザー・ドメインの開始」を参照してください。
次の手順では、Oracle Exadata Deployment Assistant構成ツールおよびデプロイメント・ツールを使用して、Oracle RAC VMクラスタを作成します。
Oracle RAC VMクラスタを追加する要件は、次の通りです。
システムが、1つ以上のOracle RAC VMクラスタにデプロイ済である。
メモリー、CPU、ローカル・ディスク領域およびExadata Storage Serverディスク領域などのリソースが、システムで使用可能である。
最初のシステム構成で使用したOracle Exadata Deployment Assistantデプロイメント・ファイルが、使用可能である。
次の手順では、Oracle RAC VMクラスタを作成する方法について説明します。
新しいユーザー・ドメインを管理ドメインに追加するのに十分なリソースが存在していることを確認します。Oracle RAC VMクラスタの作成後、新しいユーザー・ドメインを作成するすべての管理ドメインのリソースを確認します。
次のコマンドを使用して、Exadata Storage Serverのディスク領域を確認します。
# dcli -l celladmin -g cell_group "cellcli -e 'list celldisk attributes name, \ diskType, freeSpace where freeSpace>0'"
My Oracle Supportノート888828.1から、最新のOracle Exadata Deployment Assistantをダウンロードし、グラフィック・ベースのプログラムが実行可能なシステム上に置きます。デフォルトで、Oracle Exadata Database Machineのデータベース・サーバーにはOracle Databaseの実行に必要なパッケージのみが含まれ、データベース・サーバーではOracle Exadata Deployment Assistant構成ツールの実行はできません。
Oracle Exadata Deployment Assistantテンプレート・ファイルを取得して、システムをデプロイする際に使用します。
次のようにして、Oracle Exadata Deployment Assistantを実行します。
「Import」をクリックします。
XMLファイルを選択して開き、このファイルを使用して名前CustomerName-NamePrefix.xmlでシステムにデプロイします。
「次へ」をクリックして「クラスタ定義」ページを開き、IPアドレスおよびホスト名情報をページを移動しながら確認します。初回のデプロイの後、ネットワークに変更がない場合、変更する必要はありません。
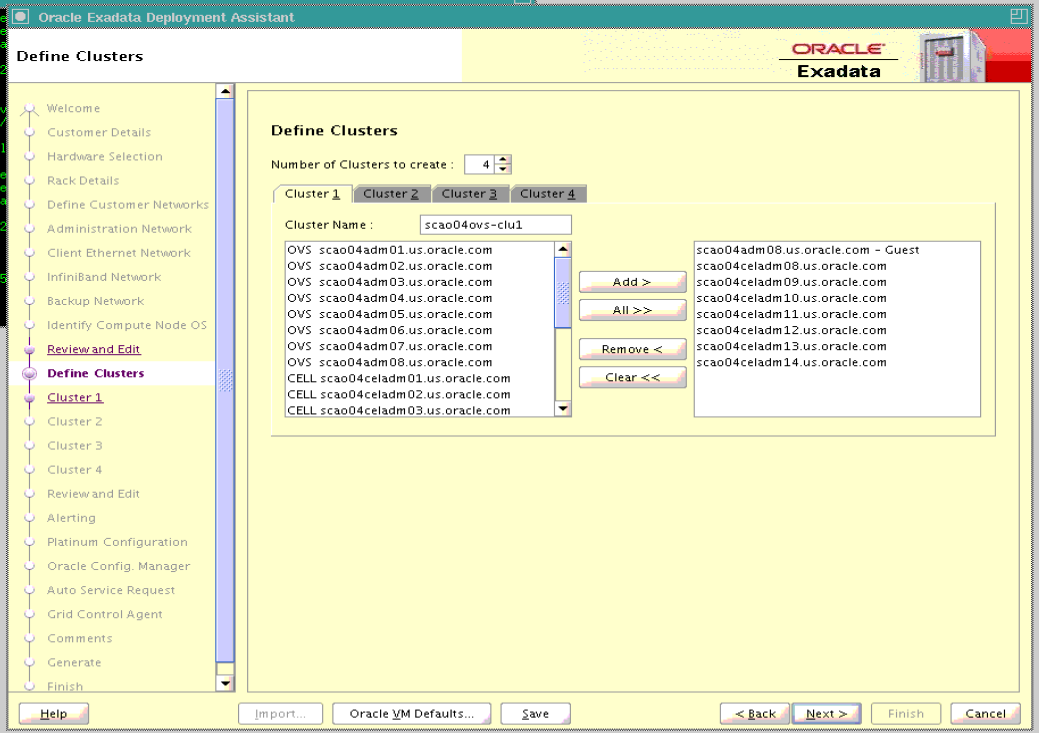
「クラスタ定義」ページで、クラスタ数をインクリメントして並び替えます。
新しいクラスタ・タブを選択し、クラスタ情報を編集します。それ以外のクラスタは変更しません。
クラスタに一意のクラスタ名を入力します。
OVSおよびCELLコンポーネントを新しいクラスタに選択し、「追加」をクリックします。
|
注意: 最良のパフォーマンスおよび管理の簡略化のために、すべてのセルを選択することをお勧めします。 |
必要に応じて「次へ」をクリックし、新しいクラスタのページへ進みます。それ以外のクラスタは変更しません。
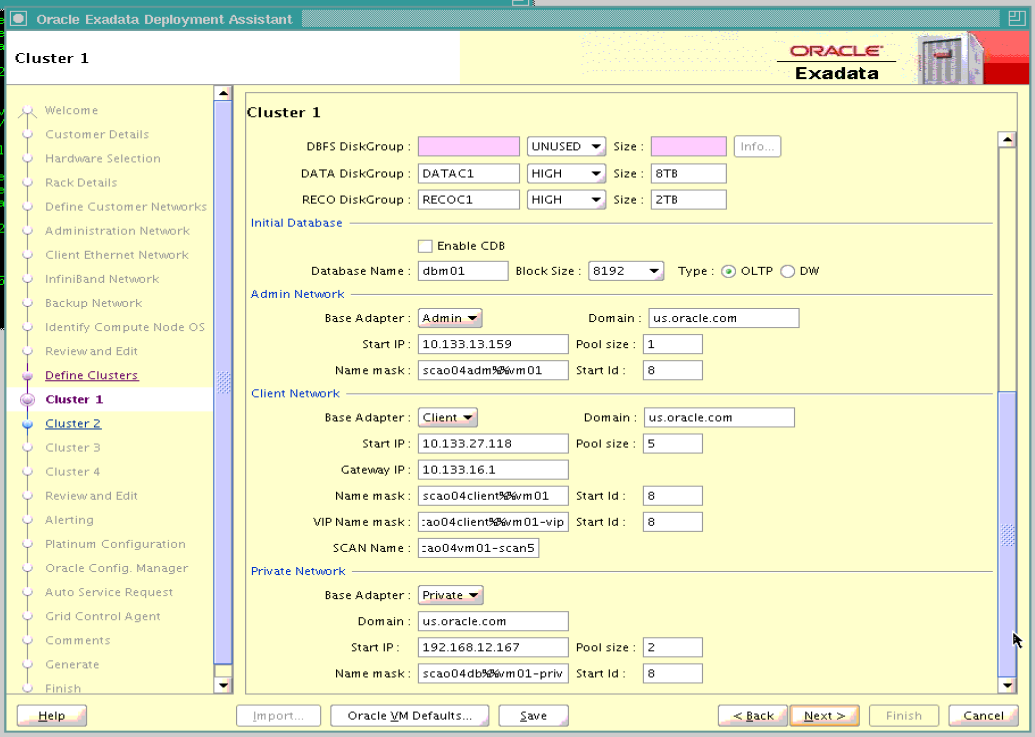
新しいクラスタに情報を入力します。情報には、仮想ゲスト・サイズ、ディスク・グループ詳細およびデータベース名が含まれます。データベース名は、同一のExadata Storage Serversを使用するすべてのデータベースに対して一意の名前です。
「次へ」をクリックして「確認と編集」ページを表示し、新しいクラスタの情報を確認します。
必要に応じて「次へ」をクリックし、「生成」ページへ進みます。
「次へ」をクリックして、新規構成ファイルを生成します。
構成ファイルの保存先ディレクトリを選択します。
「Save」をクリックします。
|
注意: Oracle VMのデフォルトをこのクラスタで変更した場合、既存クラスタの構成の詳細が、新しいテンプレート設定に一致するように書き換えられます。たとえば、vm01のSMALLをmemory=8GBにデプロイしていた場合、新しいVMのSMALLのテンプレートをmemory=10GBに変更します。vm01を変更していないにもかかわらず、Oracle Exadata Deployment Assistant XMLファイルには、vm01がmemory=10GBと表示されます。 |
「終了」ページの「インストール・テンプレート」をクリックして、新しいクラスタの詳細を確認します。
「終了」をクリックして構成ツールを終了します。
新しいクラスタがCustomerName-NamePrefix-ClusterName.xmlという名前で、保存場所フォルダに存在することをXMLファイルで確認します。
Grid Infrastructureおよび使用中のデータベース・リリースのデプロイメント・ファイルを取得し、それらをOracle Exadata Deployment Assistant WorkDirディレクトリに保存します。
Oracle Exadata Deployment Assistantデプロイメント・ツールを実行して、-cfオプションで新しいクラスタにXMLファイルを指定し、-lオプションで手順の一覧を表示するには、次のコマンドを実行します。
$ ./install.sh -cf \ ExadataConfigurations/CustomerName-NamePrefix-ClusterName.xml-l
手順「セル・アラートの構成」以外のすべての手順を、新しいクラスタのXMLファイルを使用して実行します。ほとんどのインストールでは、「セル・アラートの構成」は手順7です。たとえば、手順1を実行するには、次のコマンドを実行します。
$ ./install.sh -cf \ ExadataConfigurations/CustomerName-NamePrefix-ClusterName.xml -s 1
この項では、Oracle Exadata Deployment Assistantを使用してゲスト・ドメインを追加して、既存のOracle RAC VMクラスタを拡張する方法について説明します。
|
注意: この手順の実行中、既存のOracle RACクラスタ・ノードとそのデータベース・インスタンスでは、停止時間は発生しません。 |
この手順のユースケースは次のとおりです。
Exadataラックのデータベース・サーバーのサブセットのみを使用する既存のOracle RACクラスタがあり、現在クラスタによって使用されていないノードが使用候補になった場合。
新しいExadata OVSノードまたは個別のExadataラックと最近相互ラック接続された既存のOracle RACクラスタがある場合。
Oracle Exadata Deployment Assistantを使用して、新しいゲスト・ドメインをホストするdom0に追加する、新しいゲスト・ドメイン(VM)の情報を含む新しいXMLファイルを作成します。
生成されたXMLファイルを<unzipped_OEDA_location>/ExadataConfigurationsに保存します。
単一のゲスト・ドメインを追加している場合、XMLファイルは単一ノードRACクラスタを表します。
クラスタ定義画面の下のすべての画面のデータは、既存のクラスタのXMLファイルと同じです。
クラスタ定義画面で適切なOVSを選択します。次の図は、クラスタへの単一ノードの追加を示しています。
IPアドレスやプール・サイズなどのクラスタの詳細をクラスタの詳細画面に入力します。次の図は、クラスタへの単一ノードの追加を示しています。
手順1で作成したXMLファイルを使用して、OEDA (install.sh)を実行し、OEDAの手順2、3および4を実行します。
cd <unzipped OEDA location> ./install.sh -cf ./ExadataConfigurations/<xml file generated in step 1> -r 2-4
クラスタに追加するゲスト・ドメインをクリーン・アップし、後でaddnode.shによって使用されるように準備します。
新しく作成されたゲスト・ドメインにrootとしてログインし、次を実行します。
# cd / # chown -R oracle:oinstall /u01 # cd /u01/app/12.1.0.2/grid (cd to the GI home) # rm -rf * # cd /u01/app/oracle/product/12.1.0.2/dbhome_1 (cd to the rdbms_home) # rm -rf *
oraInventoryが/u01/app内に存在していないことを確認します。
/etc/oraInst.locが存在していないことを確認します。
新しく追加されたゲスト・ドメインからSSH等価のクラスタを他のすべてのノードに設定します。
新しく作成されたゲスト・ドメインを含むクラスタに属している各ゲスト・ドメインに、oracleとしてログインします。
新しく追加されたゲスト・ドメインを含むクラスタに属しているすべてのゲスト・ドメイン名が含まれている/home/oracleに、db_groupという名前のファイルを作成します。
新しく追加されたドメインを含むクラスタのすべてのゲスト・ドメインから、次のコマンドをoracleとして実行して、すべてのプロンプトに答えます。
dcli -g db_group -l oracle -k
クラスタのすべてのノードでSSH等価が正しく設定されていることを検証します。
クラスタのすべてのノードで、次のファイルの同期を取ります。
クラスタのすべてのノードで同じになるように、既存のクラスタからファイルを使用して、新しく追加されたノードに次のファイルの内容をコピーまたはマージします。
/etc/security/limits.conf
/etc/hosts
すべてのクラスタ・ノードのIPアドレスとセルのIPアドレスが含まれるように、/etc/hostsファイルを1つのノードで最初に変更してから、そのファイルをすべてのクラスタ・ノードにコピーする必要があります。
/etc/oracle/cell/network-config/cellip.ora
/etc/sysctl.conf
新しく追加されたすべてのノード(ゲスト・ドメイン)を再起動します。
新しく追加されたゲスト・ドメインの/etc/oracle/cell/network-config/cellip.oraの所有権を変更します。
# chown oracle:oinstall /etc/oracle/cell/network-config/cellip.ora
クラスタの既存のノードから次のコマンドを実行して、クラスタおよび新しいノードの完全性を確認します。このノードは、残りの手順で<init-node>と呼びます。
$ cluvfy stage -pre nodeadd -n <comma delimited new_node(s)> [-fixup] [-verbose]
Oracle Grid Infrastructureホームを新しいノードに拡張するには、<init-node>の$GRID_HOME/addnodeディレクトリに移動して、Oracle Clusterwareをインストールしたユーザーとしてaddnode.shスクリプトを実行します。
$ cd $GRID_HOME/addnode
$ ./addnode.sh -silent "CLUSTER_NEW_NODES={comma delimited new_node(s)}" "CLUSTER_NEW_VIRTUAL_HOSTNAMES={comma delimited new_node-vip(s)}"
プロンプトが表示されたら、新しく追加されたすべてのノードで、/opt/oracle/oraInventory/orainstRoot.shをrootとして順に実行します。
# /opt/oracle/oraInventory/orainstRoot.sh
新しく追加されたすべてのノードで、$GRID_HOME/root.shをrootとして順に実行します。
RDBMSホームを新しく追加されたノードに拡張します。<init-node>の$RDBMS_HOME/addnodeディレクトリに移動して、Oracle RACをインストールしたユーザーとしてaddnode.shを実行します。
$ cd $RDBMS_HOME/addnode
$ ./addnode.sh -silent "CLUSTER_NEW_NODES={comma delimited new_node(s)}"
プロンプトが表示されたら、新しく追加されたノードで$RDBMS_HOME/root.shをrootとして実行します。
dbcaを使用して、新しく追加されたノードにサイレント・モードまたはGUIを使用してデータベース・インスタンスを追加します。
サイレント・モードを使用している場合は、次のコマンドを実行します。
$ $RDBMS_HOME/bin/dbca -addInstance -gdbName <global database name>
-nodeName <node name for the new instance to add>
-instanceName <instance name for the new instance to add>
-sysDBAUserName SYS -sysDBAPassword <SYS Password> -silent
新しく追加されたASMインスタンスとRDBMSインスタンスにcluster_interconnectsパラメータを設定します。
新しく追加された各ノードから、そのノードの新しいASMインスタンスとRDBMSインスタンスに、次の手順を実行します。
SQL*Plusを起動して、ASMインスタンスに接続します。
次のコマンドを実行します。
alter system set cluster_interconnects='IP_address_of_private_interconnect(s)' scope=spfile sid='newly_added_ASM_instance';
SQL*Plusを起動して、RDBMSインスタンスに接続します。
次のコマンドを実行します。
alter system set cluster_interconnects='IP_address_of_private_interconnect(s)' scope=spfile sid='newly_added_RDBMS_instance';
新しく追加されたノードでGrid Infrastructureを再起動します。
ユーザー・ドメインは、システムにOracle Grid InfrastructureおよびOracle Databaseをインストールせずに作成することができます。新しいユーザー・ドメインの要素は、次の通りです。
オペレーティング・システム・イメージがOracle Linuxである。
管理ネットワーク、クライアント・ネットワークおよびInfiniBandネットワークへアクセスできる。
Oracle Grid InfrastructureおよびOracle Databaseがインストールされていない。
Oracle Grid InfrastructureおよびOracle Databaseの存在しないユーザー・ドメインを作成する手順は、次の通りです。
未使用の新規IPアドレスおよびホスト名を新しいユーザー・ドメインに割り当てます。IPアドレスおよびホスト名は、管理ネットワーク、クライアント(SCAN)ネットワークおよびプライベートInfiniBandネットワークで必要です。
|
注意: アドレスごとにpingコマンドを使用して、該当のInfiniBandネットワークのIPアドレスが使用されていないことを確認します。ibhostsコマンドには、ユーザー・ドメインのエントリが含まれていないため、このコマンドを使用して、すべてのInfiniBandネットワークのIPアドレスが使用されていることを確認することはできません。 |
必要に応じて、更新されたユーザー・ドメイン(domU)システム・イメージ・ファイルを取得します。
ユーザー・ドメインを作成するために、この手順の後で実行するexadata.img.domu_makerコマンドには、ユーザー・ドメイン(domU)システム・イメージ・ファイルSystem.first.boot.version.imgが/EXAVMIMAGESに必要です(versionは、管理ドメインのExadataソフトウェアのバージョンに一致し、管理ドメインで"imageinfo -ver"コマンドを実行することで確認できます)。
たとえば、exadata.img.domu_makerを実行して、新しいユーザー・ドメインを作成し、管理ドメインのExadataソフトウェアのバージョンが12.1.2.1.1.150316.2の場合、ユーザー・ドメイン(domU)システム・イメージ・ファイル/EXAVMIMAGES/System.first.boot.12.1.2.1.1.150316.2.imgが存在する必要があります。
# imageinfo -ver 12.1.2.1.1.150316.2 # ls -l /EXAVMIMAGES/System.first.boot.12.1.2.1.1.150316.2.img -rw-r--r-- 1 root root 13958643712 Mar 23 12:25 /EXAVMIMAGES/System.first.boot.12.1.2.1.1.150316.2.img
ユーザー・ドメイン(domU)システム・イメージ・ファイルが存在しない場合は、My Oracle Supportから取得し、管理ドメインの/EXAVMIMAGESに配置する必要があります。詳細は、My Oracle Supportノート888828.1を参照してください。
次のコマンドを使用して、管理ドメインで、既存のXML構成ファイルをデプロイ済ユーザー・ドメインからコピーして、新しい名前のファイルにコピーします。
# cp /EXAVMIMAGES/conf/existingDomainName-vm.xml /EXAVMIMAGES/conf/newDomainName-vm.xml
前述のコマンドで、existingDomainName-vm.xmlは、デプロイされたユーザー・ドメインのXML構成ファイルで、newDomainName-vm.xmlは新しいファイルの名前です。
次の例では、ユーザー・ドメイン"dm01db01vm01"の構成ファイルを、nondbdomain-vm.xmlにコピーします。
# cp /EXAVMIMAGES/conf/dm01db01vm01-vm.xml /EXAVMIMAGES/conf/nondbdomain-vm.xml
管理ドメインで、次のようにして、新しいXMLファイルを編集します。
すべての<Hostname>タグを変更して、対応するネットワークの新しいホスト名に一致させます。
すべての<IP_address>タグを変更して、対応するネットワークの新しいIPアドレスに一致させます。
<virtualMachine>タグを変更して、新しいホスト名を含めます。
<hostName>タグを変更して、新しいホスト名を含めます。
すべてのサブ要素を含む、<disk id="disk_2">および<disk id="disk_3">要素全体を削除します。開始<disk>タグから対応する終了</disk>の間のエントリ全体を削除する必要があります。
管理ドメインで、/opt/exadata_ovm/exadata.img.domu_makerコマンドを使用して、InfiniBandネットワークGUIDを新しいユーザー・ドメインに割り当てます。
# /opt/exadata_ovm/exadata.img.domu_maker allocate-guids \
/EXAVMIMAGES/conf/newDomainName-vm.xml \
/EXAVMIMAGES/conf/final-newDomainName-vm.xml
管理ドメインで、/opt/exadata_ovm/exadata.img.domu_makerコマンドを使用して、新しいユーザー・ドメインを作成します。
# /opt/exadata_ovm/exadata.img.domu_maker start-domain \
/EXAVMIMAGES/conf/final-newDomainName-vm.xml
ユーザー・ドメインを、別のデータベース・サーバーへ移動することができます。ターゲット・データベース・サーバーが、次の要件を満たしている必要があります。
ターゲット・データベース・サーバーに、同一リリースのOracle Exadata Storage Server SoftwareおよびOracle VMがインストールされている。
ターゲット・データベース・サーバーに、同一のネットワークが表示されている。
ターゲット・データベース・サーバーは、同一のExadata Storage Serversにアクセスできる。
ターゲット・データベース・サーバーで、ユーザー・ドメインの操作に必要な十分な空きリソース(メモリー、CPUおよびローカル・ディスク領域)が使用可能である。
仮想CPUをオーバーコミットすると、すべてのドメインに割り当てられた仮想CPUを、システム上の物理CPU数より多く割り当てることができます。CPUのオーバーコミットは、過剰に収容されたリソースへの競合するワークロードが十分理解され、同時に発生する要求が物理能力を超えない場合にのみ、実行する必要があります。
メモリーをオーバーコミットすることはできません。
ディスク・イメージをターゲット・データベース・サーバーにコピーすると、ディスク・イメージ・ファイルの領域の割当てが増加する場合があります。これは、コピーされたファイルは、OCFS2 reflinkを利用してディスク領域を省略できないためです。
ユーザー・ドメイン名は、ターゲット・データベース・サーバーで未使用の名前にする必要があります。
次の手順に従い、ユーザー・ドメインを同一のOracle Exadata Storage Server Software構成内の新しいデータベース・サーバーに移動します。すべての手順は、管理ドメインで実行してください。
次のコマンドを使用して、ユーザー・ドメインをシャットダウンします。
# xm shutdown DomainName -w
次のコマンドを使用して、ユーザー・ディスク・イメージおよび構成ファイルをターゲット・データベース・サーバーにコピーします。
# scp -r /EXAVMIMAGES/GuestImages/DomainName/ target:/EXAVMIMAGES/GuestImages
上記のコマンドで、DomainNameはドメインの名前です。
次のコマンドを使用して、ユーザー・ドメインのUUIDを取得します。
# grep ^uuid /EXAVMIMAGES/GuestImages/DomainName/vm.cfg
次の例では、ユーザー・ドメインUUIDは49ffddce4efe43f5910d0c61c87bba58です。
# grep ^uuid /EXAVMIMAGES/GuestImages/DomainName/vm.cfg
uuid = '49ffddce4efe43f5910d0c61c87bba58'
次のコマンドを実行して、ユーザー・ドメインのUUIDを使用し、ユーザー・ドメイン・シンボリック・リンクを/OVS/Repositoriesから、ターゲット・データベース・サーバーにコピーします。
# tar cpvf - /OVS/Repositories/UUID/ | ssh target "tar xpvf - -C /"
次のコマンドを使用して、ユーザー・ドメインをターゲット・データベース・サーバーで起動します。
# xm create /EXAVMIMAGES/GuestImages/DomainName/xm.cfg
次の手順では、クラスタ内で実行中のデータベースおよびこのデータベースで使用中のExadata Storage Serverで保存するすべてのデータを含む、VMクラスタのすべてのOracle RACノードを削除します。
VMクラスタの一部のユーザー・ドメインを削除する場合、次の項を参照してください。
VMクラスタを削除する手順は、主に2つあります。
ユーザー・ドメイン・ファイルを管理ドメインから削除する。
使用していないOracle Exadataグリッド・ディスクを削除する。
|
注意: Oracle Exadata Deployment Assistantxml構成ファイルを後で再び使用する場合、削除されたユーザー・ドメインの定義がOracle Exadata Deployment Assistantファイル内に残っているため、それらの構成ファイルは同期できません。 |
次の手順では、VMクラスタを削除する方法について説明します。
次のようなスクリプトを実行して、すべてのユーザー・ドメイン上のグリッド・ソフトウェア・オーナーを削除します。シェル・スクリプトの例では、2つのスクリプト、list_griddisk.shおよびdrop_griddisk.shが生成されます。これらは、後述する手順で実行します。指示があるまで、この生成されたスクリプトを実行しないでください。
#!/bin/bash
# Run this script as the Grid Infrastructure software owner.
#
# This script identifies griddisks used by this cluster and the cells to
# which they belong, then creates two shell scripts - the list script to
# show the current status, and the drop script to drop the griddisks.
#
# In order for the drop script to succeed, the griddisks must not be in use,
# meaning databases and CRS are down, and the list script returns no output.
#
# The generated scripts are designed to run via dcli -x
ORACLE_SID=$(awk -F: '/^+ASM/{print $1}' /etc/oratab)
ORAENV_ASK=NO . oraenv >/dev/null
listGriddiskScript=list_griddisk.sh
dropGriddiskScript=drop_griddisk.sh
rm -f $listGriddiskScript $dropGriddiskScript
gridDiskList=$(asmcmd lsdsk --suppressheader | awk -F'/' '{print $NF}')
if [[ ${PIPESTATUS[0]} != 0 ]]; then echo "asmcmd failed - exiting"; exit 1; fi
cellList=$(echo "$gridDiskList" | awk -F_ '{print $NF}' | sort -u)
for cell in $cellList; do
myGriddisks=$(echo "$gridDiskList" | grep ${cell}$ | tr '\n' ',')
echo "[[ \$(hostname -s) == ${cell} ]] && cellcli -e 'LIST GRIDDISK \
${myGriddisks%,} attributes name, asmDiskGroupName, asmModeStatus \
where asmModeStatus != UNKNOWN'" >> $listGriddiskScript
echo >> $listGriddiskScript
done
chmod +x $listGriddiskScript
echo
echo "Run the following command to list griddisks in use by this cluster:"
echo
echo "# dcli -l celladmin -c ${cellList//$'\n'/,} -x $listGriddiskScript"
echo
for cell in $cellList; do
myGriddisks=$(echo "$gridDiskList" | grep ${cell}$ | tr '\n' ',')
echo "[[ \$(hostname -s) == ${cell} ]] && cellcli -e 'DROP GRIDDISK \
${myGriddisks%,}'" >> $dropGriddiskScript
echo >> $dropGriddiskScript
done
chmod +x $dropGriddiskScript
echo
echo "Stop CRS on all nodes in this cluster, then run the following"
echo "command to drop all griddisks used by this cluster:"
echo
echo "# dcli -l celladmin -c ${cellList//$'\n'/,} -x $dropGriddiskScript"
echo
exit
次のコマンドを実行して、削除対象のすべてのユーザー・ドメイン内のデータベースおよびOracle CRSを停止します。
# GI_HOME/bin/crsctl stop crs -f
削除対象のいずれかのユーザー・ドメインから、前述の手順で生成されたlist_griddisk.shスクリプトを実行します。そのコマンドの例を次に示します。
|
注意:
|
$ dcli -l celladmin -c dm01celadm01,dm01celadm02,dm01celadm03 \ -x list_griddisk.sh
list_griddisk.shスクリプトは、グリッド・ディスクを出力しません。list_griddisk.shスクリプトがグリッド・ディスクを戻す場合、そのグリッド・ディスクは使用中であるとみなされます。
|
注意: list_griddisk.shスクリプトが空の出力を戻し、使用中のグリッド・ディスクがないことを確認してから、次の手順に進みます。Grid Infrastructureおよびデータベースが、削除するすべてのユーザー・ドメインで停止していることを確認してください。 |
削除対象のいずれかのユーザー・ドメインから、前述の手順で生成されたdrop_griddisk.shスクリプトを実行します。
|
注意: dcliコマンドを使用してスクリプトを実行し、celladminユーザーとして構成内のすべてのExadata Storage Serversに接続します。 |
$ dcli -l celladmin -c dm01celadm01,dm01celadm02,dm01celadm03 \ -x drop_griddisk.sh
管理ドメインからexadata.img.domu_makerコマンドを実行して、すべてのユーザー・ドメインを削除します。このコマンドにより、ユーザー・ドメインが削除されます。
# /opt/exadata_ovm/exadata.img.domu_maker remove-domain DomainName
上記のコマンドで、DomainNameはドメインの名前です。
次の例では、コマンドを実行して、2ノードOracle RAC VMクラスタの2つのユーザー・ドメインを削除します。1つは、dom0 dm01db01上のユーザー・ドメインdm01db01vm04で、もう1つは、dom0 dm01db02上のユーザー・ドメインdm01db02vm04です。
[root@dm01db01 ~] # /opt/exadata_ovm/exadata.img.domu_maker \ remove-domain dm01db01vm04 [INFO] Start with command line: /opt/exadata_ovm/exadata.img.domu_maker \ remove-domain dm01db01vm04 [INFO] Shutting down DomU dm01db01vm04 [INFO] Autostart link for dm01db01vm04 deleted from /etc/xen/auto [INFO] Deleted OVM repository /OVS/Repositories/7bfd49d6bd5a4b2db2e46e8234788067 for DomU dm01db01vm04 [INFO] Deleted guest vm /EXAVMIMAGES/GuestImages/dm01db01vm04 for \ DomU dm01db01vm04 [root@dm01db02 ~]# /opt/exadata_ovm/exadata.img.domu_maker \ remove-domain dm01db02vm04 [INFO] Start with command line: /opt/exadata_ovm/exadata.img.domu_maker \ remove-domain dm01db02vm04 [INFO] Shutting down DomU dm01db02vm04 [INFO] Autostart link for dm01db02vm04 deleted from /etc/xen/auto [INFO] Deleted OVM repository /OVS/Repositories/1d29719ff26a4a17aca99b2f89fd8032 for DomU dm01db02vm04 [INFO] Deleted guest vm /EXAVMIMAGES/GuestImages/dm01db02vm04 \ for DomU dm01db02vm04
この項では、単一のOracle RACノードをVMクラスタから削除します。Oracle Exadataグリッド・ディスクは、クラスタ内に残っているノードで使用中のため、削除しないでください。
|
注意: Oracle Exadata Deployment Assistantxml構成ファイルを後で再び使用する場合、削除されたユーザー・ドメインの定義がOracle Exadata Deployment Assistantファイル内に残っているため、それらの構成ファイルは同期できません。 |
次の手順では、VMクラスタからユーザー・ドメインを削除する方法について説明します。
『Oracle Clusterware管理およびデプロイメント・ガイド』の説明に従って、クラスタ・ノードを削除します。
次のコマンドを使用して、ユーザー・ドメインをシャットダウンし、削除します。
# /opt/exadata_ovm/exadata.img.domu_maker remove-domain DomainName
上記のコマンドで、DomainNameはドメインの名前です。このコマンドは、ユーザー・ドメイン・ファイルを管理ドメインから削除します。
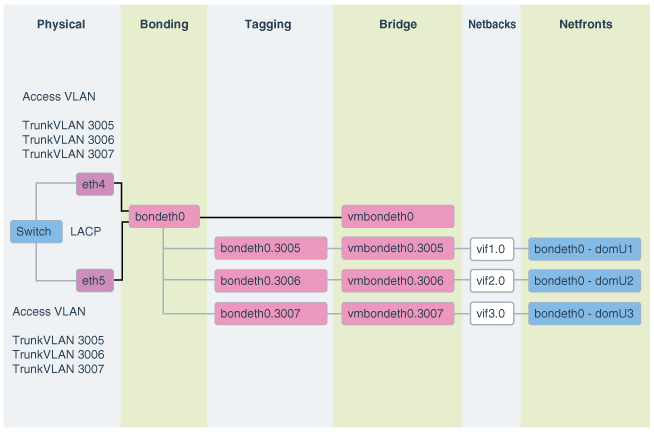
Oracle Exadata Database Machine上のOracle VMゲストで稼働しているOracleデータベースは、Oracle Exadata Deployment Assistant (OEDA)構成ツールで定義されたクライアントEthernetネットワークを介してアクセスされます。管理ドメイン(dom0)およびユーザー・ドメイン(domU's)の両方で、クライアント・ネットワーク構成は、初回のデプロイメント中にOEDAインストール・ツールが最初のユーザー・ドメインを作成すると、自動的に実行されます。
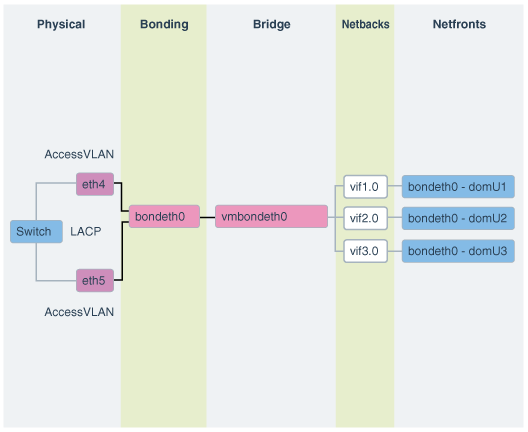
図2-3に、デフォルトの結合クライアント・ネットワーク構成を示します。
ネットワークは、次のように構成されます:
dom0では、OEDAで定義されて、domUクライアントへのアクセスが許可されているethスレーブ・インタフェース(たとえば、eth1とeth2またはeth4とeth5)が、検出、構成されて、起動しますが、IPは割り当てられません。
dom0では、bondeth0マスター・インタフェースが構成され、起動しますが、IPは割り当てられません。
dom0では、ブリッジ・インタフェースvmbondeth0が構成されますが、IPは割り当てられません。
dom0では、特定のdomU's bondeth0インタフェースにマッピングされる仮想バックエンド・インタフェース(vif)がdomUごとに1つずつ構成され、起動しますが、IPは割り当てられません。これらのvifsは、ブリッジ・インタフェースvmbondeth0の上に構成されます。dom0 vifインタフェースと、これに対応するユーザー・ドメイン・インタフェース、bondeth0の間のマッピングは、/EXAVMIMAGES/GuestImages/<user domain name>にあるvm.cfgと呼ばれるユーザー・ドメイン構成ファイルで定義されます。
デフォルトのインストールでは、単一のbondeth0と対応するvmbondeth0ブリッジ・インタフェースは、前述で説明するようにdom0内で構成されます。このbondeth0インタフェースは、デフォルトのAccess Virtual Local Area Network (Access VLAN)に基づいていて、これに対して、bondeth0を構築するスレーブ・インタフェースで使用されるスイッチ上のポートが構成されます。
VLANタグ付けの使用
Exadataの仮想デプロイメントで、ユーザー・ドメインをまたいでネットワーク分離を有効にするなど、クライアント・ネットワーク上の他のVLANにアクセスする必要がある場合、802.1QベースのVLANタグ付けにより解決できます。図2-4に、VLANタグ付けをしたクライアント・ネットワーク構成を示します。
図2-4 VLANタグ付けをしたOracle Virtual EnvironmentのNICレイアウト
このようなクライアント・ネットワーク上の追加のVLANタグ付けされたインタフェースの構成方法および使用方法の詳細は、My Oracle Supportノート2018550.1 「タグ付けされたVLANインタフェースのExadata上のOracle VM環境への実装」を参照してください。これらの手順の実行の前後に、Access VLANが継続して稼働および構成されていることが必須です。Access VLANが無効にされることはありません。
セキュリティの見地から、結合システムの重要な要件の1つは、結合システム内の複数の環境間のネットワーク分離です。Oracle Exadata上でOracle VM RACクラスタを使用した結合では、これは、1つのRACクラスタのネットワーク・トラフィックが別のRACクラスタにアクセスできないようにして、異なるOracle RACクラスタ同士の分離を意味します。Ethernetネットワークでは、これは、My Oracle Supportノート2018550.1で説明するように、VLANタグ付けを使用して完成します。InfiniBandネットワークでは、これは、カスタムInfiniBandパーティション、専用パーティション鍵およびパーティション化表を使用して完成します。
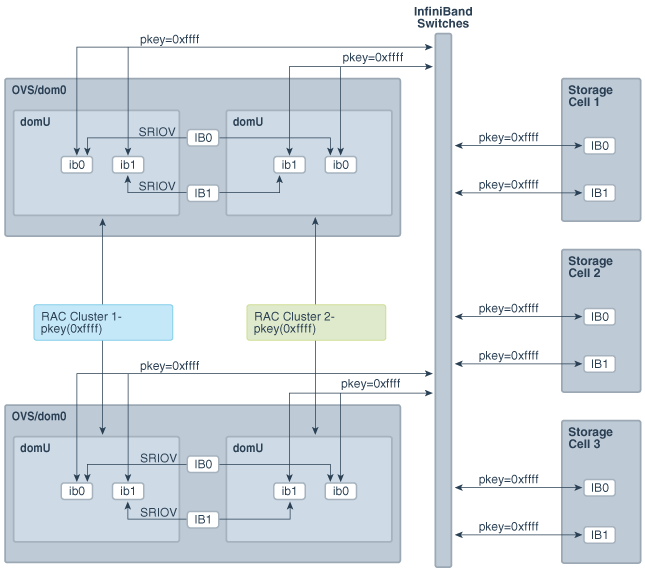
InfiniBandパーティションは、相互の通信を許可されるInfiniBandノードまたはメンバーのグループを定義します。InfiniBandパーティションでは、一意のパーティション鍵で識別されるパーティションが作成され、マスター・サブネット・マネージャで管理されます。メンバーは、これらのカスタム・パーティションに割り当てられます。パーティション内のメンバーは、メンバー自身同士でのみ通信できます(My Oracle Supportノート2018550.1の付録で説明するように、メンバーシップにより異なります)。1つのパーティションのマンバーは、別のパーティションのメンバーとは、メンバーシップにかかわらず、通信できません。これらのラインを継続して、特定の1つのクラスタのOVM RACノードが、クラスタウェア通信用の1つの専用パーティションに割り当てられ、ストレージ・セルとの通信用の1つのパーティションに割り当てられます。このようにして、1つのRACクラスタのノードは、異なるパーティションに属する別のRACクラスタのノードと通信できます。それぞれのRACクラスタのノードには、それらに割り当てられた異なるパーティション鍵があります。
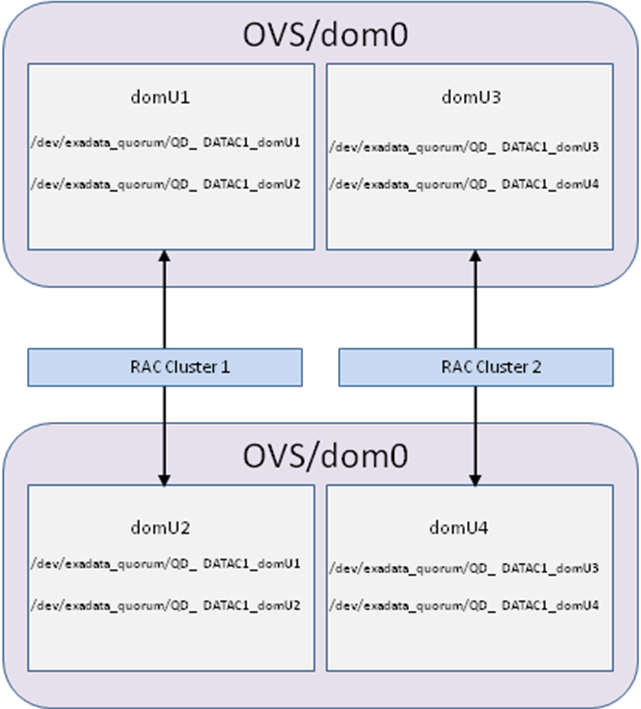
デフォルトで、InfiniBandサブネット・マネージャは、パーティション鍵0x7FFF (制限されたメンバーシップ)または0xFFFF (完全なメンバーシップ)により識別される単一パーティションを提供します。カスタムのInfiniBandパーティションを使用していないOracle Exadata上のOVMデプロイメントでは、すべてのユーザー・ドメイン間で、パーティション鍵0xFFFFが使用されます(図2-5)。
図2-5 クラスタ間でInfiniBandネットワーク分離がないOracle Exadata上のOVM RACクラスタ
OVM RACクラスタ間の分離の実装のかわりのデフォルトではないカスタム・パーティションを使用すると、構成は、図2-6に示すように変更されます。新しいインタフェースclib0、clib1 (クラスタpkey用)およびstib0、stib1 (ストレージpkey用)が、それぞれのユーザー・ドメイン(domU's)に存在します。
管理ドメイン(dom0)では、InfiniBandインタフェースの変更はありません。
図2-6 InfiniBandパーティションを使用してクラスタ間でInfiniBandネットワーク分離があるOracle Exadata上のOVM RACクラスタ
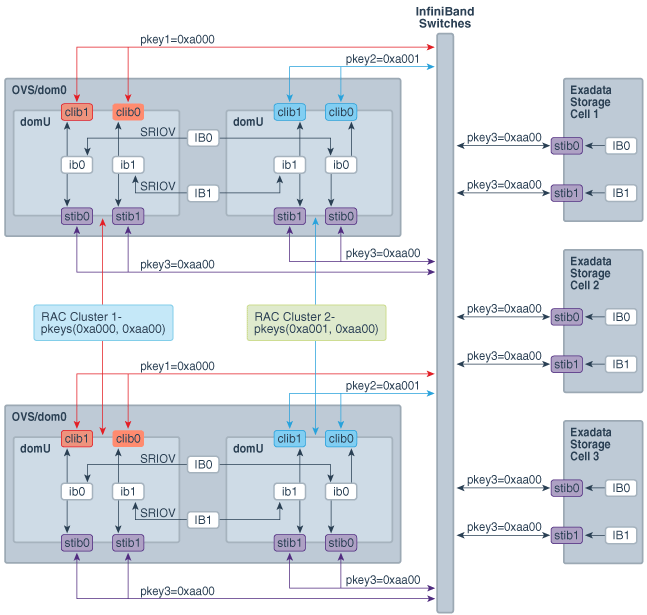
Oracle Exadata上のOVM RACクラスタ間でInfiniBandパーティションを実装する詳細は、My Oracle Supportノート2075398.1を参照してください。
Exadataでの仮想化は、exachkバージョン12.1.0.2.2以上でサポートされています。
Exadata OVM環境でexachk監査チェックの完全なセットを実行するには、exachkをインストールして、次のように複数の場所から実行する必要があります。
1つの管理ドメイン(dom0)から
RAC VMクラスタごとに1つのユーザー・ドメイン(domU)から
たとえば、4つのOracle RAC VMクラスタを含む2つのデータベース・サーバー(両方のデータベース・サーバーで合計8つのdomU、クラスタごとに2つのノード)を使用したOracle Exadata Database Machineクオータ・ラックでは、次のようにexachkを5回実行する必要があります。
クラスタ#1の最初のユーザー・ドメイン(domU)でexachkを実行します。
クラスタ#2の最初のユーザー・ドメイン(domU)でexachkを実行します。
クラスタ#3の最初のユーザー・ドメイン(domU)でexachkを実行します。
クラスタ#4の最初のユーザー・ドメイン(domU)でexachkを実行します。
最初の管理ドメイン(dom0)でexachkを実行します。
exachkによって実行される監査チェックは、次の表に指定されています。
表2-2 exachkによって実行される監査チェック
| exachkのインストールおよび実行先 | 実行される監査チェック |
|---|---|
|
管理ドメイン(dom0) |
ハードウェアおよびオペレーティング・システム・レベルのチェック対象:
|
|
ユーザー・ドメイン(domU) |
ユーザー・ドメインのオペレーティング・システム・レベル・チェックおよびOracle Grid InfrastructureおよびOracle Databaseのチェック |
exachkコマンドラインのオプション
exachkには、専用のコマンドライン・オプションが不要です。Exadata OVM環境で実行されていること、および管理ドメインまたはユーザー・ドメインで実行されているかどうかを自動的に検出し、適用可能な監査チェックを実行します。たとえば、最も簡単なケースとして、コマンドライン・オプションなしでexachkを実行できます。
./exachk
exachkが管理ドメインで実行されると、すべてのデータベース・サーバー、ストレージ・サーバー、およびInfiniBandネットワーク経由でアクセス可能なInfiniBandスイッチで監査チェックを実行します。
サーバーまたはスイッチのサブセットでexachkを実行するには、次のコマンドライン・オプションを使用します。
表2-3 exachkのコマンドライン・オプション
| オプション | 説明 |
|---|---|
|
|
データベース・サーバーのカンマ区切りリストを指定します。 |
|
|
ストレージ・サーバーのカンマ区切りリストを指定します。 |
|
|
InfiniBandスイッチのカンマ区切りリストを指定します。 |
たとえば、最初のクオータ・ラックのみが仮想化用に構成されているが、InfiniBandネットワーク経由ですべてのコンポーネントにアクセス可能なExadata Database Machineのフル・ラックの場合、データベース・サーバー"dm01adm01"から次のようなコマンドを実行できます。
./exachk -clusternodes dm01adm01,dm01adm02
-cells dm01celadm01,dm01celadm02,dm01celadm03
-ibswitches dm01swibs0,dm01sw-iba0,dm01sw-ibb0
詳細は、Exachkユーザー・ガイドの仮想化に関する考慮事項に関する項を参照してください。
この項では、データベース・サーバー内の論理ボリューム・マネージャ(LVM)パーティションについて説明します。LVMにはパーティションを再編成する柔軟性があります。
|
注意: ソフトウェア保守の際にdbnodeupdate.shユーティリティで作成されるLVMスナップショットのために、VGExaDbボリューム・グループ内に、少なくとも1GBの空き領域が必要です。「Oracle Linuxデータベース・サーバーのスナップショット・ベースのバックアップの作成」の手順に従い、/ (root)および/u01ディレクトリのバックアップをスナップショット・ベースで作成する場合、 VGExaDbボリューム・グループに少なくとも6GBの空き領域が必要です。 |
この項の内容は次のとおりです。
ルートLVMパーティションを拡張する手順は、Oracle Exadata Storage Server Softwareのリリースにより異なります。次の各項では、手順をリリースごとに説明します。
Oracle Exadata Storage Server Softwareリリース11.2.3.2.1以上を実行するシステムでの、ルートLVMパーティションの拡張
Oracle Exadata Storage Server Softwareリリース11.2.3.2.1より前のリリースを実行するシステムでの、ルートLVMパーティションの拡張
次の手順では、Oracle Exadata Storage Server Softwareリリース11.2.3.2.1以上を実行するシステム上で、ルート(/)パーティションのサイズを拡大する方法について説明します。
|
注意: この手順では、サーバーを停止する必要はありません。dom0システムの場合、アクティブのSys LVMと非アクティブのSys LVMは、LVDbSys1とLVDbSys2ではなく、LVDbSys2とLVDbSys3です。 LVDbSys1およびLVDbSys2のサイズが同じに設定されていることを確認します。 |
次のように、現在の環境に関する情報を収集します。
次のように、dfコマンドを使用して、rootパーティション(/)内の空き領域および使用済領域の容量を確認します。
# df -h /
次に、コマンドの出力例を示します。
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VGExaDb-LVDbSys1
30G 22G 6.2G 79% /
|
注意: アクティブなrootパーティションは、それ以前の保守アクティビティによりLVDbSys1またはLVDbSys2のいずれかに決定されます。 |
lvsコマンドを使用して、現在のボリューム構成を表示します。
# lvs -o lv_name,lv_path,vg_name,lv_size
次に、コマンドの出力例を示します。
LV Path VG LSize LVDbOra1 /dev/VGExaDb/LVDbOra1 VGExaDb 100.00g LVDbSwap1 /dev/VGExaDb/LVDbSwap1 VGExaDb 24.00g LVDbSys1 /dev/VGExaDb/LVDbSys1 VGExaDb 30.00g LVDbSys2 /dev/VGExaDb/LVDbSys2 VGExaDb 30.00g
tune2fsコマンドを使用して、オンラインのサイズ変更オプションを確認します。
tune2fs -l /dev/mapper/vg_name | grep resize_inode
resize_inodeオプションが、コマンド出力に表示されます。オプションが表示されない場合、パーティションのサイズ変更の操作をする以前に、ファイル・システムがアンマウントしています。「Oracle Exadata Storage Server Softwareリリース11.2.3.2.1より前のリリースを実行するシステムでの、ルートLVMパーティションの拡張」を参照して、パーティションのサイズを変更してください。
ボリューム・グループVGExaDbの使用可能な領域を確認するには、次のように、vgdisplayコマンドを使用します。
# vgdisplay -s
次に、コマンドの出力例を示します。
"VGExaDb" 834.89 GB [184.00 GB used / 650.89 GB free]
ボリューム・グループは、二つのシステム・パーティションのサイズを増やすことができる空き領域を持ち、アップグレードの際にdbnodeupdate.shユーティリティで作成されるLVMスナップショットで使用するために、少なくとも1GBの空き領域を維持する必要があります。
十分な空き領域がない場合、reclaimdisks.shユーティリティが実行中であるかどうか確認してください。ユーティリティが実行されていない場合、次のコマンドを実行して、ディスク領域をリクレイムします。
# /opt/oracle.SupportTools/reclaimdisks.sh -free -reclaim
ユーティリティが実行中で、十分な空き領域がない場合、LVMはサイズ変更できません。
|
注意: reclaimdisks.shは、RAID再構築(ディスクの置換えまたは拡張)と同時に実行できません。RAID再構築が完了するまで待機してから、reclaimdisks.shを実行してください。 |
LVDbSys1およびLVDbSys2論理ボリュームのサイズを変更するには、次のように、lvextendコマンドを使用します。
# lvextend -L +XG --verbose /dev/VGExaDb/LVDbSys1 # lvextend -L +XG --verbose /dev/VGExaDb/LVDbSys2
前述のコマンドのXGは、拡大される論理ボリュームの量(GB)です。いずれのシステム・パーティションにも、等しい容量の領域を追加します。
次の例では、拡大する論理ボリュームは10GBです。
# lvextend -L +10G /dev/VGExaDb/LVDbSys1 # lvextend -L +10G /dev/VGExaDb/LVDbSys2
論理ボリューム内のファイル・システムのサイズを変更するには、次のように、resize2fsコマンドを使用します。
# resize2fs /dev/VGExaDb/LVDbSys1 # resize2fs /dev/VGExaDb/LVDbSys2
dfコマンドを使用して、アクティブなシステム・パーティションで領域が拡大されたことを確認します。
# df -h /
次の手順では、Oracle Exadata Storage Server Softwareリリース11.2.3.2.1より前のリリースを実行するシステム上で、ルート(/)パーティションのサイズを拡大する方法について説明します。
|
注意: この手順では、システムをオフラインにしてから再起動する必要があります。ソフトウェア保守の際にdbnodeupdate.shユーティリティで作成されるLVMスナップショットのために、 dom0システムの場合、アクティブのSys LVMと非アクティブのSys LVMは、LVDbSys1とLVDbSys2ではなく、LVDbSys2とLVDbSys3です。 LVDbSys1およびLVDbSys2のサイズが同じに設定されていることを確認します。 |
次のように、現在の環境に関する情報を収集します。
dfコマンドを使用して、ルート・パーティション(/)およびルート以外のパーティション(/u01)のマウント・ポイント、およびそれぞれのLVMを確認します。次に、コマンドの出力例を示します。
# df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/VGExaDb-LVDbSys1 30963708 21867152 7523692 75% / /dev/sda1 126427 16355 103648 14% /boot /dev/mapper/VGExaDb-LVDbOra1 103212320 67404336 30565104 69% /u01 tmpfs 84132864 3294608 80838256 4% /dev/shm
dfコマンド出力のファイル・システム名は次のような形式になります。
/dev/mapper/VolumeGroup-LogicalVolune
前述の例のルート・ファイル・システムの完全論理ボリューム名は/dev/VGExaDb/LVDbSys1になります。
次のように、lvscanコマンドを使用して、論理ボリュームを表示します。
#lvm lvscan ACTIVE '/dev/VGExaDb/LVDbSys1' [30.00 GB] inherit ACTIVE '/dev/VGExaDb/LVDbSwap1' [24.00 GB] inherit ACTIVE '/dev/VGExaDb/LVDbOra1' [100.00 GB] inherit
lvdisplayコマンドを使用して、現在の論理ボリュームおよびボリューム・グループ構成を表示します。
#lvm lvdisplay /dev/VGExaDb/LVDbSys1 --- Logical volume --- LV Name /dev/VGExaDb/LVDbSys1 VG Name VGExaDb LV UUID GScpD7-lKa8-gLg9-oBo2-uWaM-ZZ4W-Keazih LV Write Access read/write LV Status available # open 1 LV Size 30.00 GB Current LE 7680 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 253:0
論理ボリュームを拡大できるように、ボリューム・グループVGExaDbに使用可能な領域があることを確認します。コマンドで空き領域がゼロと表示された場合は、論理ボリュームまたはファイル・システムは拡大できません。
# lvm vgdisplay VGExaDb -s "VGExaDb" 556.80 GB [154.00 GB used / 402.80 GB free]
次のように、システムを診断モードで再起動します。
ILOMインタフェースを使用して、/opt/oracle.SupportTools/diagnostics.isoファイルをマシンのディレクトリにコピーします。
ILOM Webインタフェースにログインします。
リモート制御タブを選択します。
リダイレクトタブを選択します。
リモート・コンソールの起動をクリックします。ILOMリモート・コンソールウィンドウが表示されます。
ILOMリモート・コンソールウィンドウで、「デバイス」メニューを選択します。
「CD-ROMイメージ」をクリックします。
ファイルのオープンダイアログ・ボックスで、ローカル・マシンのdiagnostics.isoファイルの場所に移動します。
diagnostics.isoファイルを選択します。
「開く」をクリックします。次のようなメッセージがコンソールに表示されます。

リモート制御タブからホスト制御を選択します。
次の起動デバイスとしてCDROMを値リストから選択します。
「Save」をクリックします。システムがブートすると、diagnostics.isoイメージが使用されます。システムは次の再起動後にデフォルトに戻ります。
ILOMリモート・コンソールウィンドウで、rootユーザーとしてログインします。
次のコマンドを使用して、サーバーを再起動します。
# shutdown -r now
システムはdiagnostics.isoイメージを使用し始めます。
次のように、eを入力して、診断シェルに入ります。
Choose from following by typing letter in '()': (e)nter interactive diagnostics shell. Must use credentials from Oracle support to login (reboot or power cycle to exit the shell), (r)estore system from NFS backup archive, Select:e
rootユーザーとしてシステムにログインします。パスワードを要求されます。
localhost login: root Password: ********* -sh-3.1#
次のコマンドを使用して、rootファイル・システムをアンマウントします。
# cd / # umount /mnt/cell
次のコマンドを使用して、論理ボリューム名を確認します。
# lvm lvscan ACTIVE '/dev/VGExaDb/LVDbSys1' [30.00 GB] inherit ACTIVE '/dev/VGExaDb/LVDbSwap1' [24.00 GB] inherit ACTIVE '/dev/VGExaDb/LVDbOra1' [100.00 GB] inherit
次のコマンドを使用して、現在のルート・ファイル・システムとバクアップ・ルート・ファイル・システムを保持するLVDbSys1とLVDbSys2のサイズを変更します。
# lvm lvextend -L+XG --verbose /dev/VGExaDb/LVDbSys1 # lvm lvextend -L+XG --verbose /dev/VGExaDb/LVDbSys2
前述のコマンドのXGは、拡大される論理ボリュームの量(GB)です。たとえば、論理ボリュームを5 GB拡大する場合、コマンドは次のようになります。
# lvm lvextend -L+5G --verbose /dev/VGExaDb/LVDbSys1 # lvm lvextend -L+5G --verbose /dev/VGExaDb/LVDbSys2
fsck.ext3またはfsck.ext4を使用して、ファイル・システムが有効であることを確認します。使用するコマンドはファイル・システムのタイプによって異なります。
# fsck.ext3 -f /dev/VGExaDb/LVDbSys1 # fsck.ext3 -f /dev/VGExaDb/LVDbSys2
または
# fsck.ext4 -f /dev/VGExaDb/LVDbSys1 # fsck.ext4 -f /dev/VGExaDb/LVDbSys2
次のコマンドを使用して、ファイル・システムのサイズを変更します。
# resize2fs -p /dev/VGExaDb/LVDbSys1 # resize2fs -p /dev/VGExaDb/LVDbSys2
システムを通常のモードで再起動します。
# reboot
システムにログインします。
ルート・ファイル・システム・マウントが新しいサイズで問題なくマウントされていることを確認します。
ルート以外のLVMパーティションのサイズを変更する手順は、Oracle Exadata Storage Server Softwareのリリースにより異なります。次の各項では、手順をリリースごとに説明します。
Oracle Exadata Storage Server Softwareリリース11.2.3.2.1以上を実行するシステムでの、非ルートLVMパーティションの拡張
Oracle Exadata Storage Server Softwareリリース11.2.3.2.1より前のリリースを実行するシステムでの、非ルートLVMパーティションの拡張
Oracle Exadata Storage Server Softwareリリース11.2.3.2.1以上を実行するシステムでの、非ルートLVMパーティションの縮小
次の手順では、Oracle Exadata Storage Server Softwareリリース11.2.3.2.1以上を実行するシステム上で、非ルート(/u01)パーティションのサイズを拡大する方法について説明します。
|
注意: この手順では、サーバーを停止する必要はありません。 |
次のように、現在の環境に関する情報を収集します。
dfコマンドを使用して、/u01パーティションの空き領域および使用済領域の容量を確認します。
# df -h /u01
次に、コマンドの出力例を示します。
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VGExaDb-LVDbOra1
99G 25G 70G 26% /u01
lvsコマンドを使用して、/u01ファイル・システムで使用される現在の論理ボリューム構成を表示します。
# lvs -o lv_name,lv_path,vg_name,lv_size
次に、コマンドの出力例を示します。
LV Path VG LSize LVDbOra1 /dev/VGExaDb/LVDbOra1 VGExaDb 100.00G LVDbSwap1 /dev/VGExaDb/LVDbSwap1 VGExaDb 24.00G LVDbSys1 /dev/VGExaDb/LVDbSys1 VGExaDb 30.00G LVDbSys2 /dev/VGExaDb/LVDbSys2 VGExaDb 30.00G
tune2fsコマンドを使用して、オンラインのサイズ変更オプションを確認します。
tune2fs -l /dev/mapper/vg_name | grep resize_inode
resize_inodeオプションが、コマンド出力に表示されます。オプションが表示されない場合、パーティションのサイズ変更の操作をする以前に、ファイル・システムがアンマウントしています。「Oracle Exadata Storage Server Softwareリリース11.2.3.2.1より前のリリースを実行するシステムでの、非ルートLVMパーティションの拡張」を参照して、パーティションのサイズを変更してください。
ボリューム・グループVGExaDbの使用可能な領域を確認するには、次のように、vgdisplayコマンドを使用します。
# vgdisplay -s
次に、コマンドの出力例を示します。
"VGExaDb" 834.89 GB [184.00 GB used / 650.89 GB free]
コマンドの出力で空き領域が1GB未満と表示された場合は、論理ボリュームもファイル・システムも拡大できません。アップグレードの際にdbnodeupdate.shユーティリティで作成されるLVMスナップショットのために、VGExaDbボリューム・グループ内に、少なくとも1GBの空き領域が必要です。
十分な空き領域がない場合、reclaimdisks.shユーティリティが実行中であるかどうか確認してください。ユーティリティが実行されていない場合、次のコマンドを実行して、ディスク領域をリクレイムします。
# /opt/oracle.SupportTools/reclaimdisks.sh -free -reclaim
ユーティリティが実行中で、十分な空き領域がない場合、LVMはサイズ変更できません。
|
注意: reclaimdisks.shは、RAID再構築(ディスクの置換えまたは拡張)と同時に実行できません。RAID再構築が完了するまで待機してから、reclaimdisks.shを実行してください。 |
論理ボリュームのサイズを変更するには、次のように、lvextendコマンドを使用します。
# lvextend -L +sizeG /dev/VGExaDb/LVDbOra1
前述のコマンドで、sizeは論理ボリュームに追加する領域の容量です。
次の例では、拡大する論理ボリュームは10GBです。
# lvextend -L +10G /dev/VGExaDb/LVDbOra1
論理ボリューム内のファイル・システムのサイズを変更するには、次のように、resize2fsコマンドを使用します。
# resize2fs /dev/VGExaDb/LVDbOra1
dfコマンドを使用して、領域が拡張されたことを確認します。
# df -h /u01
次の手順では、Oracle Exadata Storage Server Softwareリリース11.2.3.2.1より前のリリースを実行するシステム上で、非ルート(/u01)パーティションのサイズを拡大する方法について説明します。ここでは、/dev/VGExaDb/LVDbOra1が/u01でマウントされます。
|
注意: ソフトウェア保守の際にdbnodeupdate.shユーティリティで作成されるLVMスナップショットのために、VGExaDbボリューム・グループ内に、少なくとも1GBの空き領域が必要です。「Oracle Linuxデータベース・サーバーのスナップショット・ベースのバックアップの作成」の手順に従い、/ (root)および/u01ディレクトリのバックアップをスナップショット・ベースで作成する場合、 VGExaDbボリューム・グループに少なくとも6GBの空き領域が必要です。 |
次のように、現在の環境に関する情報を収集します。
dfコマンドを使用して、ルート・パーティション(/)およびルート以外のパーティション(/u01)のマウント・ポイント、およびそれぞれのLVMを確認します。
# df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/VGExaDb-LVDbSys1 30963708 21867152 7523692 75% / /dev/sda1 126427 16355 103648 14% /boot /dev/mapper/VGExaDb-LVDbOra1 103212320 67404336 30565104 69% /u01 tmpfs 84132864 3294608 80838256 4% /dev/shm
lvm lvscanコマンドを使用して、論理ボリュームを表示します。
ACTIVE '/dev/VGExaDb/LVDbSys1' [30.00 GB] inherit ACTIVE '/dev/VGExaDb/LVDbSwap1' [24.00 GB] inherit ACTIVE '/dev/VGExaDb/LVDbOra1' [100.00 GB] inherit
lvdisplayコマンドを使用して、現在のボリューム・グループ構成を表示します。
# lvdisplay /dev/VGExaDb/LVDbOra1 --- Logical volume --- LV Name /dev/VGExaDb/LVDbOra1 VG Name VGExaDb LV UUID vzoIE6-uZrX-10Du-UD78-314Y-WXmz-f7SXyY LV Write Access read/write LV Status available # open 1 LV Size 100.00 GB Current LE 25600 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 253:2
論理ドライブを拡大できるように、次のコマンドを使用して、ボリューム・グループVGExaDbに使用可能な領域があることを確認します。コマンドで空き領域がゼロと表示された場合は、論理ボリュームもファイル・システムも拡大できません。
# lvm vgdisplay VGExaDb -s "VGExaDb" 556.80 GB [154.00 GB used / 402.80 GB free]
/u01を使用するソフトウェアを停止します。次のソフトウェアは、通常/u01を使用します。
Oracle ClusterwareおよびOracle Database
# GI_HOME/bin/crsctl stop crs
トレース・ファイル・アナライザ
# GI_HOME/bin/tfactl stop
OS Watcher (リリース11.2.3.3.0より前のリリース)
# /opt/oracle.oswatcher/osw/stopOSW.sh
ExaWatcher (リリース11.2.3.3.0以上)
# /opt/oracle.ExaWatcher/ExaWatcher.sh --stop
Oracle Enterprise Managerエージェント
(oracle)$ agent_home/bin/emctl stop agent
次のコマンドを使用して、rootユーザーとしてパーティションをアンマウントします。
# umount /u01
|
注意: umountコマンドでファイル・システムがビジーとレポートされた場合、umountコマンドが成功するには、fuser(1)コマンドを使用して、停止する必要があるが、ファイル・システムにまだアクセスしているプロセスを特定します。
# umount /u01
umount: /u01: device is busy
umount: /u01: device is busy
# fuser -mv /u01
USER PID ACCESS COMMAND
/u01: root 6788 ..c.. ssh
root 8422 ..c.. bash
root 11444 ..c.. su
oracle 11445 ..c.. bash
oracle 11816 ....m mgr
root 16451 ..c.. bash
|
次のコマンドを使用して、ファイル・システムを確認します。
# e2fsck -f /dev/VGExaDb/LVDbOra1
次のようなコマンドを使用して、パーティションを拡張します。この例では、論理ボリュームが物理ボリュームのサイズの80%まで拡大されています。同時に、ファイル・システムがコマンドによってサイズ変更されます。
# lvextend -L+XG --verbose /dev/VGExaDb/LVDbOra1
前述のコマンドのXGは、拡大される論理ボリュームの量(GB)です。次は、論理ボリュームを200 GB追加して拡大する場合に使用するコマンドの例です。
# lvextend -L+200G --verbose /dev/VGExaDb/LVDbOra1
次のコマンドを使用して、/u01ファイル・システムを確認します。
# e2fsck -f /dev/VGExaDb/LVDbOra1
次のコマンドを使用して、/u01ファイル・システムのサイズを変更します。
# resize2fs -p /dev/VGExaDb/LVDbOra1
次のコマンドを使用して、パーティションをマウントします。
# mount -t ext3 /dev/VGExaDb/LVDbOra1 /u01
次のコマンドを使用して、領域が拡張されたことを確認します。
$ df -h /u01
次のように、手順2で停止したソフトウェアを再起動します。
Oracle ClusterwareおよびOracle Database
# GI_HOME/bin/crsctl start crs
トレース・ファイル・アナライザ
# GI_HOME/bin/tfactl start
OS Watcher (リリース11.2.3.3.0より前のリリース)
# /opt/oracle.cellos/vldrun -script oswatcher
ExaWatcher (リリース11.2.3.3.0以上)
# /opt/oracle.ExaWatcher/ExaWatcher.sh
Oracle Enterprise Managerエージェント
(oracle)$ agent_home/bin/emctl start agent
次の手順では、Oracle Exadata Storage Server Softwareリリース11.2.3.2.1以上を実行するシステム上で、非ルート(/u01)パーティションのサイズを縮小する方法について説明します。
|
注意: この手順では、サーバーを停止する必要はありません。手順を実行する前に、ファイル・システムをバックアップすることをお薦めします。 |
dfコマンドを使用して、/u01パーティションの空き領域および使用済領域の容量を確認します。
# df -h /u01
出力例:
Filesystem Size Used Avail Use% Mounted on /dev/mapper/VGExaDb-LVDbOra1 193G 25G 159G 14% /u01
lvmコマンドを使用して、/u01ファイル・システムで使用される現在の論理ボリューム構成を表示します。
# lvm vgdisplay VGExaDb -s "VGExaDb" 271.82 GB [250.04 GB used / 21.79 GB free] # lvm lvscan ACTIVE '/dev/VGExaDb/LVDbSys1' [30.00 GB] inherit ACTIVE '/dev/VGExaDb/LVDbSwap1' [24.00 GB] inherit ACTIVE '/dev/VGExaDb/LVDbOra1' [196.04 GB] inherit
この場合、LVDbSys2 (サイズは30.00 GB)をdbserver_backup.shスクリプトで作成できるように、LVDbOra1パーティションのサイズを縮小する必要があります。
/u01を使用するソフトウェアを停止します。次のソフトウェアは、通常/u01を使用します。
Oracle ClusterwareおよびOracle Database
# GI_HOME/bin/crsctl stop crs
トレース・ファイル・アナライザ
# GI_HOME/bin/tfactl stop
OS Watcher (11.2.3.3.0より前のリリース)
# /opt/oracle.oswatcher/osw/stopOSW.sh
ExaWatcher (リリース11.2.3.3.0以上)
# /opt/oracle.ExaWatcher/ExaWatcher.sh --stop
Oracle Enterprise Managerエージェント
(oracle)$ agent_home/bin/emctl stop agent
rootユーザーとしてパーティションをアンマウントします。
# umount /u01
|
注意: umountコマンドでファイル・システムがビジーとレポートされた場合、umountコマンドを正常に実行するには、fuser(1)コマンドを使用して、停止する必要があるファイル・システムにまだアクセスしているプロセスを特定します。
# umount /u01
umount: /u01: device is busy
umount: /u01: device is busy
# fuser -mv /u01
USER PID ACCESS COMMAND
/u01: root 6788 ..c.. ssh
root 8422 ..c.. bash
root 11444 ..c.. su
oracle 11445 ..c.. bash
oracle 11816 ....m mgr
root 16451 ..c.. bash
|
ファイル・システムを確認します。
# e2fsck -f /dev/VGExaDb/LVDbOra1 fsck 1.39 (29-May-2006) e2fsck 1.39 (29-May-2006) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information DBORA: 72831/25706496 files (2.1% non-contiguous), 7152946/51389440 blocks
必要なサイズ(次の例では120G)までファイル・システムのサイズを縮小します。
# resize2fs /dev/VGExaDb/LVDbOra1 120G resize2fs 1.39 (29-May-2006) Resizing the filesystem on /dev/VGExaDb/LVDbOra1 to 26214400 (4k) blocks. The filesystem on /dev/VGExaDb/LVDbOra1 is now 26214400 blocks long.
目的のサイズまでLVMのサイズを縮小します。
# lvm lvreduce -L 120G --verbose /dev/VGExaDb/LVDbOra1
Finding volume group VGExaDb
WARNING: Reducing active logical volume to 120.00 GB
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce LVDbOra1? [y/n]: y
Archiving volume group "VGExaDb" metadata (seqno 8).
Reducing logical volume LVDbOra1 to 120.00 GB
Found volume group "VGExaDb"
Found volume group "VGExaDb"
Loading VGExaDb-LVDbOra1 table (253:2)
Suspending VGExaDb-LVDbOra1 (253:2) with device flush
Found volume group "VGExaDb"
Resuming VGExaDb-LVDbOra1 (253:2)
Creating volume group backup "/etc/lvm/backup/VGExaDb" (seqno 9).
Logical volume LVDbOra1 successfully resized
次のコマンドを使用して、パーティションをマウントします。
# mount -t ext3 /dev/VGExaDb/LVDbOra1 /u01
次のコマンドを使用して、領域が縮小されていることを確認します。
# df -h /u01 Filesystem Size Used Avail Use% Mounted on /dev/mapper/VGExaDb-LVDbOra1 119G 25G 88G 22% /u01 # lvm vgdisplay -s "VGExaDb" 271.82 GB [174.00 GB used / 97.82 GB free]
次のように、手順3で停止したソフトウェアを再起動します。
Oracle ClusterwareおよびOracle Database
# GI_HOME/bin/crsctl start crs
トレース・ファイル・アナライザ
# GI_HOME/bin/tfactl start
OS Watcher (11.2.3.3.0より前のリリース)
# /opt/oracle.cellos/vldrun -script oswatcher
ExaWatcher (リリース11.2.3.3.0以上)
# /opt/oracle.cellos/vldrun -script oswatcher
Oracle Enterprise Managerエージェント
(oracle)$ agent_home/bin/emctl start agent
次の手順では、スワップ(/swap)パーティションのサイズを拡大する方法について説明します。
|
注意: この手順では、システムをオフラインにしてから再起動する必要があります。ソフトウェア保守の際にdbnodeupdate.shユーティリティで作成されるLVMスナップショットのために、 |
次のように、現在の環境に関する情報を収集します。
swaponコマンドを使用して、スワップ・パーティションを確認します。
# swapon -s Filename Type Size Used Priority /dev/mapper/VGExaDb-LVDbSwap1 parrtition 25165816 0 -1
lvm lvscanコマンドを使用して、論理ボリュームを表示します。
ACTIVE '/dev/VGExaDb/LVDbSys1' [30.00 GB] inherit ACTIVE '/dev/VGExaDb/LVDbSwap1' [24.00 GB] inherit ACTIVE '/dev/VGExaDb/LVDbOra1' [100.00 GB] inherit
vgdisplayコマンドを使用して、現在のボリューム・グループ構成を表示します。
# vgdisplay --- Volume group --- VG Name VGExaDb System ID Format lvm2 Metadata Areas 1 Metadata Sequence No 4 VG Access read/write VG Status resizable MAX LV 0 Cur LV 3 Open LV 3 Max PV 0 Cur PV 1 Act PV 1 VG Size 556.80 GB PE Size 4.00 MB Total PE 142541 Alloc PE / Size 39424 / 154.00 GB Free PE / Size 103117 / 402.80 GB VG UUID po3xVH-9prk-ftEI-vijh-giTy-5chm-Av0fBu
pvdisplayコマンドを使用して、LVMで作成され、オペレーティング・システムで使用される物理デバイスの名前を表示します。
# pvdisplay --- Physical volume --- PV Name /dev/sda2 VG Name VGExaDb PV Size 556.80 GB / not usable 2.30 MB Allocatable yes PE Size (KByte) 4096 Total PE 142541 Free PE 103117 Allocated PE 39424 PV UUID Eq0e7e-p1fS-FyGN-zrvj-0Oqd-oUSb-55x2TX
次のように、システムを診断モードで再起動します。
ILOMインタフェースを使用して、diagnostics.isoファイルをマシンのディレクトリにコピーします。
ILOM Webインタフェースにログインします。
リモート制御タブからリモート・コンソールを選択します。これにより、コンソールが起動します。
「デバイス」メニューを選択します。
CD-ROMイメージオプションを選択します。
diagnostics.isoファイルの場所に移動します。
diagnostics.isoファイルを開きます。
リモート制御タブからホスト制御を選択します。
次の起動デバイスとしてCDROMを値リストから選択します。
「Save」をクリックします。システムがブートすると、diagnostics.isoイメージが使用されます。
次のコマンドを使用して、ファイル・システムが有効であることを確認します。
#fsck -f /dev/VGExaDb/LVDbSwap1
次のようなコマンドを使用して、パーティションを拡張します。この例では、論理ボリュームが物理ボリュームのサイズの80%まで拡大されています。同時に、ファイル・システムがコマンドによってサイズ変更されます。
#lvextend -l+80%PVS --resizefs --verbose LogicalVolumePath PhysicalVolumePath
前述のコマンドで、LogicalVolumePathの値はlvm lvscanコマンドによって取得され、PhysicalVolumePathの値はpvdisplayコマンドによって取得されます。
システムを通常のモードで再起動します。
データベース・サーバーのソフトウェアの重要な変更の前後にバックアップを行う必要があります。たとえば、次の手順の前後にバックアップを作成する必要があります。
オペレーティング・システム・パッチの適用
Oracleパッチの適用
重要な操作パラメータの再構成
重要なOracle以外のソフトウェアのインストールまたは再構成
この項の内容は次のとおりです。
Oracle Linuxデータベース・サーバーのスナップショット・ベースのバックアップの作成 - パーティションをカスタマイズしていない場合
Oracle Linuxデータベース・サーバーのスナップショット・ベースのバックアップの作成 - パーティションをカスタマイズしている場合
元の出荷時の構成からデータベース・サーバー・パーティションをカスタマイズしていない場合、この項の手順を使用してバックアップを作成し、そのバックアップを使用してデータベース・サーバーをリストアします。
|
注意: リカバリ手順により、出荷時の名前およびサイズを含む正確なパーティションがリストアされます。パーティションを少しでも変更した場合、この手順は使用できません。変更には、サイズや名前の変更、パーティションの追加または削除が含まれます。パーティションを変更したシステムのリカバリ方法は、「Oracle Linuxデータベース・サーバーのスナップショット・ベースのバックアップの作成 - パーティションをカスタマイズしている場合」の手順を参照してください。 |
次の手順は、スナップショット・ベースのバックアップを取得する方法を示しています。手順で示す値は、例です。
|
注意: rootユーザーとして、すべての手順を実行する必要があります。 |
バックアップの保存先を準備します。書込み可能な大きいNFSの場所を指定できます。NFSの場所は、バックアップtarファイルを保存できるように十分大きい必要があります。カスタマイズされていないパーティションの場合は、145GBで十分です。
次のコマンドを使用して、NFS共有のマウント・ポイントを作成します。
mkdir -p /root/tar
次のコマンドを使用して、NFSの場所をマウントします。
mount -t nfs -o rw,intr,soft,proto=tcp,nolock ip_address:/nfs_location/ /root/tar
前述のコマンドで、ip_addressはNFSサーバーのIPアドレス、nfs_locationはNFSの場所です。
次に示すように、/(ルート)、/u01および/bootディレクトリのスナップショット・ベース・バックアップを取得します。
次のコマンドを使用して、ルート・ディレクトリにroot_snapという名前のスナップショットを作成します。
lvcreate -L1G -s -c 32K -n root_snap /dev/VGExaDb/LVDbSys1
次のコマンドを使用して、スナップショットにラベルを付けます。
e2label /dev/VGExaDb/root_snap DBSYS_SNAP
/ (ルート)および/u01ディレクトリのファイル・システム・タイプを確認します。
12.1.2.1.0以上を実行しているデータベース・サーバーの場合は、"ext4"ファイル・システム・タイプを使用し、古いシステムの場合は"ext3"を使用します。X5より前のシステムで、セルが12.1.2.1.0以上に更新されている場合も、"ext3"を使用します。
# mount -l
次のコマンドを使用して、スナップショットをマウントします。
前の手順で確認したように、次のmountコマンドでは、filesystem_type_of_/_directoryは、ファイル・システム・タイプのプレースホルダになります。
mkdir /root/mnt
mount /dev/VGExaDb/root_snap /root/mnt -t filesystem_type_of_/_directory
次のコマンドを使用して、/u01ディレクトリにu01_snapという名前のスナップショットを作成します。
lvcreate -L5G -s -c 32K -n u01_snap /dev/VGExaDb/LVDbOra1
次のコマンドを使用して、スナップショットにラベルを付けます。
e2label /dev/VGExaDb/u01_snap DBORA_SNAP
次のコマンドを使用して、スナップショットをマウントします。
前述の手順cで確認したように、次のmountコマンドでは、filesystem_type_of_/u01_directoryは、ファイル・システム・タイプのプレースホルダになります。
mkdir -p /root/mnt/u01
mount /dev/VGExaDb/u01_snap /root/mnt/u01 -t filesystem_type_of_/u01_directory
次のコマンドを使用して、バックアップのディレクトリに変更します。
cd /root/mnt
次のいずれかのコマンドを使用して、バックアップ・ファイルを作成します。
システムにNFSマウント・ポイントがない場合:
# tar -pjcvf /root/tar/mybackup.tar.bz2 * /boot --exclude \ tar/mybackup.tar.bz2 > /tmp/backup_tar.stdout 2> /tmp/backup_tar.stderr
システムにNFSマウント・ポイントがある場合:
# tar -pjcvf /root/tar/mybackup.tar.bz2 * /boot --exclude \
tar/mybackup.tar.bz2 --exclude nfs_mount_points > \
/tmp/backup_tar.stdout 2> /tmp/backup_tar.stderr
前述のコマンドのnfs_mount_pointsは、NFSマウント・ポイントです。マウント・ポイントを除外すると、大きいファイルと長いバックアップ時間が生成できなくなります。
/tmp/backup_tar.stderrファイルをチェックして、重大なエラーがないかを確認します。tarオープン・ソケットの障害に関するエラーおよび他の同様のエラーは無視できます。
次のコマンドを使用して、スナップショットをアンマウントし、ルートおよび/01ディレクトリのスナップショットを削除します。
cd / umount /root/mnt/u01 umount /root/mnt /bin/rm -rf /root/mnt lvremove /dev/VGExaDb/u01_snap lvremove /dev/VGExaDb/root_snap
次のコマンドを使用して、NFS共有をアンマウントします。
umount /root/tar
データベース・サーバー・パーティションをカスタマイズしている場合、バックアップ手順はパーティションをカスタマイズしていない場合の手順と同じですが、/u01のような追加パーティションをバックアップに追加する必要があります。また、パーティションの名前を変更した場合は、環境に定義した名前を使用してください。たとえば、/u01に/myown_u01という名前を使用している場合、コマンドに/myown_u01を使用します。
Oracle Virtual Serverデプロイメントで、管理ドメイン(dom0)とユーザー・ドメイン(domU)をバックアップする必要があります。
次の手順は、管理ドメインdom0のスナップショット・ベースのバックアップを取得する方法を示しています。次の手順で示す値は、例です。
rootユーザーとして、すべての手順を実行する必要があります。
バックアップの保存先を準備します。
バックアップ先は、書込み可能なNFSの場所など、ローカル・マシンの外部に存在するようにし、バックアップtarファイルを保持できる十分な大きさにする必要があります。カスタマイズされていないパーティションの場合、バックアップを保持するのに必要な領域は約60 GBです。
次のコマンドを使用してバックアップ先を準備できます。
# mkdir -p /remote_FS # mount -t nfs -o rw,intr,soft,proto=tcp,nolock ip_address:/nfs_location/ /remote_FS
ip_addressは、NFSサーバーのIPアドレスで、nfs_locationは、バックアップを保持するNFSの場所です。
/ (ルート)ディレクトリをホストするファイル・システムのスナップショット・ベースのバックアップを取得します。
/ (ルート)ディレクトリをホストするファイル・システムに、LVDbSys3_snapという名前のスナップショットを作成します。このコマンドでは、LVDbSys3がアクティブ・パーティションであることを前提とします。
# lvcreate -L1G -s -n LVDbSys3_snap /dev/VGExaDb/LVDbSys3
スナップショットにラベルを付けます。
# e4label /dev/VGExaDb/LVDbSys3_snap DBSYSOVS_SNAP
スナップショットをマウントします。
# mkdir /root/mnt # mount /dev/VGExaDb/LVDbSys3_snap /root/mnt -t ext4
バックアップのディレクトリに変更します。
# cd /root/mnt
バックアップ・ファイルを作成します。
# tar -pjcvf /remote_FS/mybackup.tar.bz2 * /boot > /tmp/backup_tar.stdout 2> /tmp/backup_tar.stderr
/tmp/backup_tar.stderrファイルをチェックして、重大なエラーがないかを確認します。tarオープン・ソケットの障害に関するエラーおよび他の同様のエラーは無視できます。
スナップショットをアンマウントして、ルート・ディレクトリのスナップショットを削除します。
# cd / # umount /root/mnt # /bin/rmdir /root/mnt # lvremove /dev/VGExaDb/LVDbSys3_snap
次のコマンドを使用して、NFS共有をアンマウントします。
# umount /remote_FS
ユーザー・ドメインのバックアップ方法は2つあります。
方法1: Oracle Cluster File System (OCFS) reflinkを使用して記憶域リポジトリをバックアップし、一貫性のあるバックアップを取得する
この方法では、/EXAVMIMAGES ocfs2ファイル・システムである記憶域リポジトリをバックアップします。
dom0によって管理されるすべてのユーザー・ドメインをバックアップする、/EXAVMIMAGES全体をバックアップしたり、バックアップするユーザー・ドメインを選択したりできます。ユーザー・ドメインは、/EXAVMIMAGES/GuestImages/userディレクトリにあります。
この方法では、方法2よりもより堅牢で包括的なバックアップが可能です。方法2は、特にロール別に分離された環境で、迅速で簡単なバックアップ方法が提供されます。
方法1は、dom0管理者がユーザー・ドメインのバックアップを担当している場合に最適です。
方法2: スナップショット・ベースのバックアップを使用してユーザー・ドメインをバックアップする
この方法では、ユーザー・ドメイン内部からスナップショット・ベースのバックアップを作成することで、単一のユーザー・ドメインをバックアップします。
方法2は、ユーザー・ドメイン管理者がユーザー・ドメインのバックアップを担当している場合に最適です。
次の手順は、/EXAVMIMAGES ocfs2ファイル・システムである記憶域リポジトリをバックアップする方法を示します。すべてのユーザー・ドメインがバックアップされます。
バックアップの保存先を準備します。
バックアップ先は、書込み可能なNFSの場所など、ローカル・マシンの外部に存在するようにし、バックアップを保持できる十分な大きさにする必要があります。バックアップの保持に必要な領域は、システムにデプロイされるVMの数に比例し、最大約1.6 TBです。
このガイドでは、管理ドメイン当たりのユーザー・ドメインが15未満であることを前提とします。
次のコマンドを使用してバックアップ先を準備できます。
# mkdir -p /remote_FS # mount -t nfs -o rw,intr,soft,proto=tcp,nolock ip_address:/nfs_location/ /remote_FS
ip_addressは、NFSサーバーのIPアドレスで、nfs_locationは、バックアップを保持するNFSの場所です。
|
注意: 次の手順2から4は、CSS misscount時間(デフォルトでは60秒に設定)内に完了する必要があります。ワークロードが高く、ユーザー・ドメインの一時停止とreflinkの作成に約45秒を超える時間がかかるような場合は、Oracle RACノードの削除を回避するために、reflinkを使用してスナップショットを取得する前に、VMをシャットダウンすることをお薦めします。これは、1つのOVS/dom0内のすべてのユーザー・ドメインを停止してバックアップし、その間Oracle RACクラスタ内のその他のユーザー・ドメインを起動しておくローリング方式で実行できます。CSS misscountの詳細は、My Oracle Supportノート294430.1を参照してください。 |
ユーザー・ドメインを一時停止します。
# xm pause domain_id
/EXAVMIMAGESのすべてのファイルにreflinkを作成します。
ユーザー・ドメインの一時停止を解除します。
# xm unpause domain_id
手順3で作成したreflinkファイルのスナップショットをtarファイルとしてバックアップします。
手順3で作成したreflinkを削除します。
次のサンプル・コマンドは、前述の手順2から5にリストされている操作の参照として使用できます。
## Create the Backup Directory
find /EXAVMIMAGES -type d|grep -v 'lost+found'|awk '{print "mkdir -p /EXAVMIMAGES/Backup"$1}'|sh
## Pause user domains
xm list|egrep -v '^Domain-0|^Name'|awk '{print "xm pause",$2}'|sh
## Create Reflinks for all the files to be backed up
find /EXAVMIMAGES/ -type f|awk '{print "reflink",$0,"/EXAVMIMAGES/Backup"$0}'|sh
## Unpause user domains
xm list|egrep -v '^Domain-0|^Name'|awk '{print "xm unpause",$2}'|sh;
## Backup from the reflinks
pushd /EXAVMIMAGES/Backup/EXAVMIMAGES
tar -Spcvf /remote_FS/exavmimages-sparse.tar * 1> /tmp/Backup.log 2> /tmp/Backup.err
popd
rm -rf /EXAVMIMAGES/Backup/*
次の手順は、ユーザー・ドメイン内からユーザー・ドメインのスナップショット・ベースのバックアップを取得する方法を示しています。
|
注意: LVMスナップショットを使用してユーザー・ドメイン内からユーザー・ドメインをバックアップする方法では、リカバリ時の使用に関して制限があります。このようなバックアップは、ユーザー・ドメインがまだブート可能で、rootユーザーとしてログインできる場合のリカバリ用にのみ使用できます。これは、一部のファイルに損失または損傷が発生したが、ユーザー・ドメインがブートされ、/ (ルート)パーティションがマウントされた後に、tarバックアップからリストアできるような損傷です。そのような状況ではなくユーザー・ドメインをブートできない損傷の場合は、上述の方法1で作成したバックアップを使用してユーザー・ドメインをリカバリする必要があります。この場合は次の手順を実行して、ユーザー・ドメイン・レベルでリカバリ手順を実行する必要があります。 |
すべての手順はユーザー・ドメイン内から実行します。
この手順では、次がバックアップされます。
LVDbSys1 lvm
LVDbOra1 lvm
/bootパーティション
グリッド・インフラストラクチャ・ホーム
RDBMSホーム
rootユーザーとして、すべての手順を実行する必要があります。
バックアップの保存先を準備します。
# mkdir -p /remote_FS # mount -t nfs -o rw,intr,soft,proto=tcp,nolock ip_address:/nfs_location/ /remote_FS
ip_addressは、NFSサーバーのIPアドレスで、nfs_locationは、バックアップを保持するNFSの場所です。
次のように、/ (ルート)および/u01ディレクトリを含むファイル・システムのスナップショット・ベースのバックアップを取得します。
ルート・ディレクトリを含むファイル・システムに、LVDbSys1_snapと言う名前のスナップショットを作成します。ボリューム・グループには、コマンドを正常に実行するのに少なくとも1 GBの空き領域が必要です。
# lvcreate -L1G -s -n LVDbSys1_snap /dev/VGExaDb/LVDbSys1
スナップショットにラベルを付けます。
# e2label /dev/VGExaDb/LVDbSys1_snap DBSYS_SNAP
スナップショットをマウントします。
# mkdir /root/mnt # mount /dev/VGExaDb/LVDbSys1_snap /root/mnt -t ext4
/u01ディレクトリにu01_snapという名前のスナップショットを作成します。
# lvcreate -L256M -s -n u01_snap /dev/VGExaDb/LVDbOra1
スナップショットにラベルを付けます。
# e2label /dev/VGExaDb/u01_snap DBORA_SNAP
スナップショットをマウントします。
# mkdir -p /root/mnt/u01 # mount /dev/VGExaDb/u01_snap /root/mnt/u01 -t ext4
バックアップのディレクトリに変更します。
# cd /root/mnt
バックアップ・ファイルを作成して、前述で取得した2つのスナップショット、/bootパーティション、RDBMSホームおよびグリッド・インフラストラクチャのホームをバックアップします。
# tar -pjcvf /remote_FS/mybackup.tar.bz2 * /boot /u01/app/12.1.0.2/grid /u01/app/oracle/product/12.1.0.2/dbhome_1 > /tmp/backup_tar.stdout 2> /tmp/backup_tar.stderr
/tmp/backup_tar.stderrファイルをチェックして、重大なエラーがないかを確認します。tarオープン・ソケットの障害に関するエラーおよび他の同様のエラーは無視できます。
ルート・ディレクトリを含むファイル・システムのスナップショットをアンマウントおよび削除します。
# cd / # umount /root/mnt/u01 # umount /root/mnt # /bin/rmdir /root/mnt # lvremove /dev/VGExaDb/u01_snap # lvremove /dev/VGExaDb/LVDbSys1_snap
NFS共有をアンマウントします。
# umount /remote_FS
この項では、データベース・サーバーで重大な障害が発生した後またはサーバー・ハードウェアを新しいハードウェアに交換する必要がある場合に、スナップショット・ベースのバックアップを使用して、Oracle Linuxを実行するデータベース・サーバー・ファイル・システムをリカバリする方法について説明します。たとえば、すべてのハード・ディスクを交換すると、システムの元のソフトウェアはトレースできません。これは、ソフトウェアの完全なシステムの交換と似ています。さらに、障害状態になる前にデータベース・サーバーが正常であったときに取得したLVMスナップショット・ベースのバックアップを使用するデータベース・サーバーの障害リカバリ方法を提供します。
リカバリ手順では、diagnostics.isoイメージを仮想CD-ROMとして使用し、ILOMを使用してレスキュー・モードでデータベース・サーバーを再起動します。一般的なワークフローには次の作業があります。
次のものを再作成します。
ブート・パーティション
物理ボリューム
ボリューム・グループ
論理ボリューム
ファイル・システム
スワップ・パーティション
スワップ・パーティションをアクティブ化します。
/bootパーティションがアクティブなブート・パーティションであることを確認します。
データをリストアします。
GRUBを再構成します。
サーバーを再起動します。
この項で説明するリカバリ手順には、Exadata Storage Serverまたはデータベース・データのバックアップまたはリカバリは含まれません。バックアップとリカバリ手順は定期的にテストすることをお薦めします。この項の内容は次のとおりです。
|
注意: テープからリストアする場合は、追加のドライブをロードする必要がありますが、この章では扱いません。ファイルはNFSの場所にバックアップし、既存のテープ・オプションを使用して、NFSホストとの間でバックアップとリカバリを行うことをお薦めします。 |
次の手順では、パーティションをカスタマイズしていない場合にスナップショット・ベースのバックアップを使用してOracle Linuxデータベース・サーバーをリカバリする方法について説明します。この手順は、パーティション、論理ボリューム、ファイル・システム、およびそれらのサイズの配置がデータベース・サーバーの最初のデプロイ時の配置と等しい場合に適用されます。
|
注意: ディスクの既存のすべてのデータは、この手順の実行中に失われます。 |
NFSサーバーを準備して、バックアップ・アーカイブmybackup.tar.bz2をホストします。IPアドレスを使用して、NFSサーバーにアクセスできる必要があります。たとえば、IPアドレスnfs_ipを使用するNFSサーバーで/exportディレクトリがNSFマウントからエクスポートされる場合は、/exportディレクトリにmybackup.tar.bz2ファイルを置きます。
正常なデータベース・サーバーにある/opt/oracle.SupportTools/diagnostics.isoファイルをリストア対象のデータベース・サーバーのILOMに仮想メディアとして接続します。
次に、ILOMインタフェースを使用した仮想CD-ROMの設定方法の例を示します。
ILOMインタフェースを使用して、diagnostics.isoファイルをマシンのディレクトリにコピーします。
ILOM Webインタフェースにログインします。
リモート制御タブからリモート・コンソールを選択します。これにより、コンソールが起動します。
「デバイス」メニューを選択します。
CD-ROMイメージオプションを選択します。
diagnostics.isoファイルの場所に移動します。
diagnostics.isoファイルを開きます。
リモート制御タブからホスト制御を選択します。
次の起動デバイスとしてCDROMを値リストから選択します。
「Save」をクリックします。システムがブートすると、diagnostics.isoイメージが使用されます。
起動中に、起動デバイスとしてCD-ROMを選択し、isoファイルからシステムを再起動します。次のコマンドを使用して、ブート中に手動で起動デバイスを選択するかわりに、リストア対象のデータベース・サーバーのILOMにアクセスできる他のマシンからipmitoolコマンドを使用して、起動デバイスを事前に設定することもできます。
ipmitool -H ILOM_ip_address_or_hostname \ -U root_user chassis bootdev cdrom ipmitool -H ILOM_ip_address_or_hostname \ -U root_user chassis power cycle
システムで要求された場合は、次のように入力します。レスポンスは太字で示されています。
Choose from following by typing letter in '()': (e)nter interactive diagnostics shell. Must use credentials from Oracle support to login (reboot or power cycle to exit the shell), (r)estore system from NFS backup archive, Select:rAre you sure (y/n) [n]:yThe backup file could be created either from LVM or non-LVM based compute node versions below 11.2.1.3.1 and 11.2.2.1.0 or higher do not support LVM based partitioning use LVM based scheme(y/n):yEnter path to the backup file on the NFS server in format:ip_address_of_the_NFS_share:/path/archive_fileFor example, 10.10.10.10:/export/operating_system.tar.bz2 NFS line:nfs_ip:/export/mybackup.tar.bz2IP Address of this host:IP address of the DB hostNetmask of this host:netmask for the above IP addressDefault gateway:Gateway for the above IP address. If there is no default gateway in your network, enter 0.0.0.0.
リカバリが完了すると、ログイン画面が表示されます。
rootユーザーとしてログインします。rootユーザーのパスワードがない場合は、Oracleサポート・サービスにお問い合せください。
diagnostics.isoファイルを切り離します。
rebootコマンドを使用して、システムを再起動します。リストア・プロセスが完了です。
データベース・サーバーにログインして、すべてのOracleソフトウェアが起動して動作していることを確認します。/usr/local/bin/imagehistoryコマンドは、データベース・サーバーが再構築されたことを示します。次に、出力の例を示します。
imagehistory Version : 11.2.2.1.0 Image activation date : 2010-10-13 13:42:58 -0700 Imaging mode : fresh Imaging status : success Version : 11.2.2.1.0 Image activation date : 2010-10-30 19:41:18 -0700 Imaging mode : restore from nfs backup Imaging status : success
リカバリをOracle Exadata Database Machineエイス・ラックで実行した場合は、「Oracle Exadata Database Machineエイス・ラックのOracle Linuxデータベース・サーバーのリカバリ後の構成」の手順を実行します。
次の手順では、パーティションをカスタマイズしている場合にスナップショット・ベースのバックアップを使用してOracle Linuxデータベース・サーバーをリカバリする方法について説明します。diagnostics.isoを使用してデータベース・サーバーを起動した後にenter interactive diagnostics shellおよびrestore system from NFS backup archiveオプションの選択を要求されるまで、カスタマイズされていないパーティションのリストア手順と同じです。
診断シェルの入力を選択して、rootユーザーとしてログインします。rootユーザーのパスワードがない場合は、Oracleサポート・サービスにお問い合せください。
必要に応じて、/opt/MegaRAID/MegaCli/MegaCli64を使用して、ディスク・コントローラを構成してディスクを設定します。
/bootにマウントする少なくとも128MBのプライマリ・ブート・パーティションが作成されていることを確認します。ブート領域にLVMパーティションは指定できません。
次のコマンドを使用して、ブート・パーティションを作成します。
umount /mnt/cell parted /dev/sda
インタラクティブ・シェルが表示されます。次の手順では、システム・プロンプトに応答する方法について説明します。
次のようにディスク・ラベルを割り当てます。
バージョン11.2.3.3.0以上を実行している場合は、mklabel gptを実行します。
11.2.3.3.0より前のバージョンを実行している場合は、mklabel msdosを実行します。
ユニット・サイズをセクターとして設定するには、「unit s」と入力します。
「print」と入力して既存のパーティションを表示して、パーティション表を確認します。
「rm <part#>」と入力して、再作成されるパーティションを削除します。
新しい最初のパーティションを作成するには、「mkpart primary 63 1048639」と入力します。
ブート・パーティションのブート可能フラグを設定するには、「set 1 boot on」と入力します。
次のように、2番目のプライマリ(lvm)・パーティションを作成します。
新しい2番目のパーティションを作成するには、「mkpart primary 1048640 -1」と入力します。
LVMを選択するには、「set 2 lvm on」と入力します。
ディスクに情報を書き込んだ後に終了するには、「quit」と入力します。
次のように、/sbin/lvmコマンドを使用して、カスタマイズされたLVMパーティションを再作成し、mkfsを使用してファイル・システムを作成します。
次のコマンドを使用して、物理ボリューム、ボリューム・グループおよび論理ボリュームを作成します。
lvm pvcreate /dev/sda2 lvm vgcreate VGExaDb /dev/sda2
次のコマンドを使用して、/(ルート)ディレクトリの論理ボリュームおよびファイル・システムを作成し、ラベルを付けます。
論理ボリュームを作成します。
lvm lvcreate -n LVDbSys1 -L40G VGExaDb
ファイル・システムを作成します。
ext4ファイル・システムがすでにある場合は、次のようにmkfs.ext4コマンドを使用します。
mkfs.ext4 /dev/VGExaDb/LVDbSys1
ext3ファイル・システムがすでにある場合は、次のようにmkfs.ext3コマンドを使用します。
mkfs.ext3 /dev/VGExaDb/LVDbSys1
ラベルを付けます。
e2label /dev/VGExaDb/LVDbSys1 DBSYS
次のコマンドを使用して、swapディレクトリの論理ボリュームを作成し、ラベルを付けます。
lvm lvcreate -n LVDbSwap1 -L24G VGExaDb mkswap -L SWAP /dev/VGExaDb/LVDbSwap1
次のコマンドを使用して、root/u01ディレクトリの論理ボリュームを作成し、ラベルを付けます。
論理ボリュームを作成します。
lvm lvcreate -n LVDbOra1 -L100G VGExaDb
ファイル・システムを作成します。
ext4ファイル・システムがすでにある場合は、次のようにmkfs.ext4コマンドを使用します。
mkfs.ext4 /dev/VGExaDb/LVDbOra1
ext3ファイル・システムがすでにある場合は、次のようにmkfs.ext3コマンドを使用します。
mkfs.ext3 /dev/VGExaDb/LVDbOra1
ラベルを付けます。
e2label /dev/VGExaDb/LVDbOra1 DBORA
次のコマンドを使用して、/bootパーティションにファイル・システムを作成し、ラベルを付けます。
ファイル・システムを作成します。
ext4ファイル・システムがすでにある場合は、次のようにmkfs.ext4コマンドを使用します。
mkfs.ext4 /dev/sda1
ext3ファイル・システムがすでにある場合は、次のようにmkfs.ext3コマンドを使用します。
mkfs.ext3 /dev/sda1
ラベルを付けます。
e2label /dev/sda1 BOOT
|
注意: カスタマイズされたファイル・システム配置の場合は、ここで追加の論理ボリュームを作成できます。カスタマイズされた配置では、異なるサイズが使用される場合があります。 |
すべてのパーティションのマウント・ポイントを作成して元のシステムをミラー化し、各パーティションをマウントします。たとえば、/mntがこの最上位ディレクトリとして使用されると、マウントされるパーティションのリストは次のようになります。
/dev/VGExaDb/LVDbSys1 on /mnt /dev/VGExaDb/LVDbOra1 on /mnt/u01 /dev/sda1 on /mnt/boot
次に、ルート・ファイル・システムのマウント方法および2つのマウント・ポイントの作成方法の例を示します。次のコマンドのfilesystem_type_of_/_directoryは、/ (ルート)ディレクトリのファイル・システム(ext3またはext4のいずれか)を指定します。
mount /dev/VGExaDb/LVDbSys1 /mnt -t filesystem_type_of_/_directory mkdir /mnt/u01 /mnt/boot mount /dev/VGExaDb/LVDbOra1 /mnt/u01 -t filesystem_type_of_/u01_directory mount /dev/sda1 /mnt/boot -t filesystem_type_of_/boot_directory
|
注意: カスタマイズされたファイル・システム配置で追加の論理ボリュームがある場合は、この手順で追加のマウント・ポイントを作成する必要があります。 |
次のように、ネットワークを起動し、バックアップが存在するNFSサーバーをマウントします。
次のコマンドを実行して、ネットワークを起動します。
オペレーティング・システムがOracle Linux 6以上の場合:
ip address add ip_address_for_eth0/netmask_for_eth0 dev eth0 ip link set up eth0 ip route add default via gateway_address dev eth0
オペレーティング・システムがOracle Linux 5の場合:
ifconfig eth0 ip_address_for_eth0 netmask netmask_for_eth0 up
NFSサーバーをIPアドレスnfs_ipでマウントし、次のコマンドを使用して/exportとしてバックアップする場所にエクスポートします。
mkdir -p /root/mnt mount -t nfs -o ro,intr,soft,proto=tcp,nolock nfs_ip:/export /root/mnt
次のコマンドを使用して、バックアップからリストアします。
tar -pjxvf /root/mnt/mybackup.tar.bz2 -C /mnt
次のコマンドを使用して、リストアしたファイル・システムをアンマウントし、/bootパーティションを再マウントします。
umount /mnt/u01
umount /mnt/boot
umount /mnt
mkdir /boot
mount /dev/sda1 /mnt/boot -t filesystem_type_of_/boot_directory
ブート・ローダーを設定します。次の場合、/dev/sda1が/boot領域です。
grub find /I_am_hd_boot (1) root (hdX,0) setup (hdX) quit
前述のコマンドの(1)により、(hd0,0)などのI_am_hd_bootファイルを含むハード・ディスクhdXが検索されます。
diagnostics.isoファイルを切り離します。
次のコマンドを使用して、/bootパーティションをアンマウントします。
umount /boot
システムを再起動します。これで、サーバーのリストア手順が完了です。
reboot
リカバリをOracle Exadata Database Machineエイス・ラックで実行した場合は、「Oracle Exadata Database Machineエイス・ラックのOracle Linuxデータベース・サーバーのリカバリ後の構成」の手順を実行します。
Oracle Exadata Database Machineエイス・ラックのOracle Linuxデータベース・サーバーを再イメージ化、リストアまたはレスキューした場合は、次の手順を実行する必要があります。
X3-2マシン
別のデータベース・サーバーにある/opt/oracle.SupportTools/resourcecontrolユーティリティを、リカバリしたサーバーの/opt/oracle.SupportTools/resourcecontrolディレクトリにコピーします。
次のコマンドを使用して、ユーティリティに対して適切な権限が設定されていることを確認します。
# chmod 740 /opt/oracle.SupportTools/resourcecontrol
次のコマンドを使用して、現在の構成を検証します。コマンドの出力が表示されます。
# /opt/oracle.SupportTools/resourcecontrol -show Validated hardware and OS. Proceed. Number of cores active: 8
エイス・ラック構成の場合、8個のコアが有効になっている必要があります。その値が表示された場合、構成の変更は不要です。その値が表示されなかった場合は、手順4に進みます。
|
注意: ユーティリティの実行後に次のようなエラーが発生した場合は、通常、サーバーを1回以上再起動すると、エラーが解消されます。Validated hardware and OS. Proceed. Cannot get ubisconfig export. Cannot Proceed. Exit. |
次のコマンドを使用して、構成を変更します。
# /opt/oracle.SupportTools/resourcecontrol -cores 8
次のコマンドを使用して、サーバーを再起動します。
# reboot
次のコマンドを使用して、構成の変更を検証します。
# /opt/oracle.SupportTools/resourcecontrol -show
コマンドを実行すると、データベース・サーバーについて次のような出力が表示されると予想されます。
This is a Linux database server. Validated hardware and OS. Proceed. Number of cores active per socket: 4
X4-2、X4-8、X5-2、X5-8およびX6-8マシン
リカバリしたサーバーで、resourcecontrolユーティリティが/opt/oracle.SupportToolsディレクトリに存在することを確認します。そうでない場合は、リカバリしたサーバーに別のデータベース・サーバーからコピーします。
次のコマンドを使用して、ユーティリティに対して適切な権限が設定されていることを確認します。
# chmod 740 /opt/oracle.SupportTools/resourcecontrol
次のコマンドを使用して、現在の構成を検証します。
# dbmcli -e list dbserver attributes coreCount
エイス・ラック構成の場合、X4-2で12個のコア、X5-2で18個のコアが有効になっている必要があります。正しい値が表示されている場合、構成の変更は不要です。その値が表示されなかった場合は、手順4に進みます。
次のコマンドを使用して、構成を変更します。
# dbmcli -e alter dbserver pendingCoreCount=new_core_count force
new_core_countは、X4-2では12個、X4-8では60個、X5-2では18個です。
次のコマンドを使用して、サーバーを再起動します。
# reboot
次のコマンドを使用して、構成の変更を検証します。
# dbmcli -e list dbserver attributes coreCount
次の手順では、重大な障害が発生してOVSが損傷を受けた場合、またはサーバー・ハードウェアを新しいハードウェアに交換する必要がある場合に、スナップショット・ベースのバックアップからOracle Virtual Server (OVS)をリカバリする方法について説明します。たとえば、すべてのハード・ディスクを交換すると、システムの元のソフトウェアはトレースできません。これは、ソフトウェアの完全なシステムの交換と似ています。さらに、障害状態になる前にデータベース・サーバーが正常であったときに取得したLVMスナップショット・ベースのバックアップを使用するデータベース・サーバーの障害リカバリ方法を提供します。
リカバリ手順では、diagnostics.isoイメージを仮想CD-ROMとして使用し、ILOMを使用してレスキュー・モードでOracle Virtual Serverを再起動します。この手順の概要は、次のようになります。
次のものを再作成します。
ブート・パーティション
物理ボリューム
ボリューム・グループ
論理ボリューム
ファイル・システム
スワップ・パーティション
スワップ・パーティションをアクティブ化します。
/bootパーティションがアクティブなブート・パーティションであることを確認します。
データをリストアします。
GRUBを再構成します。
サーバーを再起動します。
この項で説明するリカバリ手順には、Exadata Storage Serverまたはデータベース・データのバックアップまたはリカバリは含まれません。バックアップとリカバリ手順は定期的にテストすることをお薦めします。
|
注意: ディスクの既存のすべてのデータは、この手順の実行中に失われます。 |
NFSサーバーを準備して、バックアップ・アーカイブmybackup.tar.bz2をホストします。
IPアドレスを使用して、NFSサーバーにアクセスできる必要があります。たとえば、IPアドレスnfs_ipを使用するNFSサーバーで/exportディレクトリがNSFマウントからエクスポートされる場合は、/exportディレクトリにmybackup.tar.bz2ファイルを置きます。
正常なデータベース・サーバーにある/opt/oracle.SupportTools/diagnostics.isoファイルをリストア対象のOracle Virtual ServerのILOMに仮想メディアとして接続します。
次に、ILOMインタフェースを使用した仮想CD-ROMの設定方法の例を示します。
ILOMインタフェースを使用するマシンのディレクトリに、diagnostics.isoファイルをコピーします。
ILOM Webインタフェースにログインします。
Oracle ILOM Webインタフェースで、リモート制御→リダイレクトをクリックします。
ビデオのリダイレクトを使用するを選択します。
コンソールが起動したら、KVMSメニューのストレージをクリックします。
DVDイメージなどのストレージ・イメージを追加するには、ストレージ・デバイス・ダイアログ・ボックスで、「追加」をクリックします。
diagnostics.isoファイルを開きます。
図2-7 diagnostics.isoファイルを選択するための「ストレージ・デバイスの追加」ダイアログを表示するILOM Webインタフェース
ストレージ・デバイス・ダイアログ・ボックスからストレージ・メディアをリダイレクトするには、ストレージ・メディアを選択して、「接続」をクリックします。
デバイスとの接続が確立されると、ストレージ・デバイス・ダイアログ・ボックスの「接続」ボタンのラベルが「切断」に変わります。
「ホスト管理」タブからホスト制御を選択します。
次の起動デバイスとしてCDROMを値リストから選択します。
「保存」をクリックします。システムがブートすると、diagnostics.isoイメージが使用されます。
isoファイルからシステムを再起動します。
これは、次のいずれかの方法を使用して実行できます。
起動中に、CD-ROMを起動デバイスとして選択するか、または
リストア対象のOVSのILOMにアクセスできる他のマシンから、ipmitoolコマンドを実行して、起動デバイスを事前に設定します。
# ipmitool -H ILOM_ip_address_or_hostname -U root chassis bootdev cdrom # ipmitool -H ILOM_ip_address_or_hostname -U root chassis power cycle
システムに次が表示された場合:
Choose from following by typing letter in '()': (e)nter interactive diagnostics shell. Must use credentials from Oracle support to login (reboot or power cycle to exit the shell), (r)estore system from NFS backup archive,
"e"と入力して、診断シェルに入り、rootユーザーとしてログインします。rootユーザーのパスワードがない場合は、Oracleサポート・サービスに連絡してください。
必要に応じて、/opt/MegaRAID/MegaCli/MegaCli64を使用して、ディスク・コントローラを構成してディスクを設定します。
障害の発生後に論理ボリューム、ボリューム・グループおよび物理ボリュームが存在する場合は、それらを削除します。
# lvm vgremove VGExaDb # lvm pvremove /dev/sda2
既存のパーティションを削除し、ドライブをクリーン・アップします。
# parted GNU Parted 2.1 Using /dev/sda Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) rm 1 sda: sda2 sda3 (parted) rm 2 sda: sda3 (parted) rm 3 sda: (parted) q # dd if=/dev/zero of=/dev/sda bs=64M count=2
3つのパーティションを/dev/sdaに作成します。
ディスク/dev/sdaの終了セクタを取得し、変数に保存します。
# end_sector=$(parted -s /dev/sda unit s print|perl -ne '/^Disk\s+\S+:\s+(\d+)s/ and print $1')
次のコマンドの開始および終了セクタの値は、残りのdom0から取得されています。これらの値は時間とともに変更される場合があるため、次のコマンドを使用して、これらの値を残りのdom0から確認することをお薦めします。
# parted -s /dev/sda unit S print
/bootパーティション/dev/sda1を作成します。
# parted -s /dev/sda mklabel gpt mkpart primary 64s 1048639s set 1 boot on
LVMを保持するパーティション/dev/sda2を作成します。
# parted -s /dev/sda mkpart primary 1048640s 240132159s set 2 lvm on
ocfs2記憶域リポジトリ・パーティション/dev/sda3を作成します。
# parted -s /dev/sda mkpart primary 240132160s ${end_sector}s set 3
/sbin/lvmコマンドを使用して論理ボリュームを再作成し、mkfsを使用してファイル・システムを作成します。
物理ボリュームおよびボリューム・グループを作成します。
# lvm pvcreate /dev/sda2 # lvm vgcreate VGExaDb /dev/sda2
/ (ルート)ディレクトリを含むファイル・システムの論理ボリュームを作成して、ラベルを付けます。
# lvm lvcreate -n LVDbSys3 -L30G VGExaDb # mkfs.ext4 /dev/VGExaDb/LVDbSys3 # e2label /dev/VGExaDb/LVDbSys3 DBSYSOVS
スワップ・ディレクトリの論理ボリュームを作成して、ラベルを付けます。
# lvm lvcreate -n LVDbSwap1 -L24G VGExaDb # mkswap -L SWAP /dev/VGExaDb/LVDbSwap1
バックアップ・パーティションの論理ボリュームを作成して、その上部にファイル・システムを構築します。
# lvm lvcreate -n LVDbSys2 -L30G VGExaDb # mkfs.ext4 /dev/VGExaDb/LVDbSys2
予約パーティション用の論理ボリュームを作成します。
# lvm lvcreate -n LVDoNotRemoveOrUse –L1G VGExaDb
この論理ボリュームにファイル・システムは作成しません。
/dev/sda1パーティションにファイル・システムを作成し、ラベルを付けます。
次のmkfs.ext3コマンドで、inodeサイズを128に設定するには"-I 128"オプションが必要です。
# mkfs.ext3 -I 128 /dev/sda1 # tune2fs -c 0 -i 0 /dev/sda1 # e2label /dev/sda1 BOOT
すべてのパーティションのマウント・ポイントを作成して、各パーティションをマウントします。
たとえば、/mntが最上位ディレクトリとして使用されると、マウントされるパーティションのリストは次のようになります。
/dev/VGExaDb/LVDbSys3 on /mnt
/dev/sda1 on /mnt/boot
次の例では、ルート・ファイル・システムをマウントし、2つのマウント・ポイントを作成します。
# mount /dev/VGExaDb/LVDbSys3 /mnt -t ext4 # mkdir /mnt/boot # mount /dev/sda1 /mnt/boot -t ext3
eth0でネットワークを起動し、ホストのIPアドレス/ネットマスクを割り当てます。
# ifconfig eth0 ip_address_for_eth0 netmask netmask_for_eth0 up # route add -net 0.0.0.0 netmask 0.0.0.0 gw gateway_ip_address
バックアップを保持するNFSサーバーをマウントします。
# mkdir -p /root/mnt # mount -t nfs -o ro,intr,soft,proto=tcp,nolock nfs_ip:/location_of_backup /root/mnt
「スナップショット・ベースのバックアップを使用した管理ドメインdom0のバックアップ」で作成したバックアップ、/およびブート・ファイルシステムからリストアします。
# tar -pjxvf /root/mnt/backup-of-root-and-boot.tar -C /mnt
リストアした/dev/sda1パーティションをアンマウントし、/bootに再マウントします。
# umount /mnt/boot # mkdir /boot # mount /dev/sda1 /boot -t ext3
GRUBブート・ローダーを設定します。次の場合、/dev/sda1が/boot領域です。
# grub root (hd0,0) setup (hd0) quit
/bootパーティションをアンマウントします。
# umount /boot
diagnostics.isoファイルを切り離します。
これを行うには、手順2で「接続」をクリックしてDVD .isoイメージを割り当てたときに表示された、ILOM Webインタフェース・コンソールの「切断」をクリックします。
リストアした/etc/fstabファイルを確認し、/EXAVMIMAGESおよび/dev/sda3への参照を削除します。
# cd /mnt/etc
/EXAVMIMAGESまたは/dev/sda3を参照する行をすべてコメント・アウトします。
システムを再起動します。これで、OVS/dom0のリストア手順が完了です。
# reboot
必要であれば、エイス・ラックに変換します。
リカバリをOracle Exadata Database Machineエイス・ラックで実行する場合は、「Oracle Exadata Database Machineエイス・ラックのOracle Linuxデータベース・サーバーのリカバリ後の構成」の手順を実行します。
サーバーが再起動されたら、ocfs2ファイル・システムを/dev/sda3パーティションに構築します。
# mkfs -t ocfs2 -L ocfs2 -T vmstore --fs-features=local /dev/sda3 --force
ocfs2パーティション/dev/sda3を/EXAVMIMAGESにマウントします。
# mount -t ocfs2 /dev/sda3 /EXAVMIMAGES
/etc/fstabで、手順18でコメント・アウトした/EXAVMIMAGESおよび/dev/sda3への参照を非コメント化します。
記憶域リポジトリ(/EXAVMIMAGES)バックアップを保持するバックアップNFSサーバーをマウントし、すべてのユーザー・ドメイン・イメージを保持する/EXAVMIMAGESファイル・システムをリストアします。
# mkdir -p /root/mnt # mount -t nfs -o ro,intr,soft,proto=tcp,nolock nfs_ip:/location_of_backup /root/mnt
/EXAVMIMAGESファイル・システムをリストアします。
# tar -Spxvf /root/mnt/backup-of-exavmimages.tar -C /EXAVMIMAGES
各ユーザー・ドメインを起動します。
# xm create /EXAVMIMAGES/GuestImages/user_domain_hostname/vm.cfg
この時点で、すべてのユーザー・ドメインと、それらの中のGIおよびデータベース・インスタンスが起動し、残りの他のOVSノードによって形成されたOracle RACクラスタに参加します。
次の手順は、修復できないほどの損傷がOVS/dom0で発生し、バックアップがdom0に存在しないが、すべてのユーザー・ドメインを格納する記憶域リポジトリ(/EXAVMIMAGESファイル・システム)の中に利用可能なバックアップが存在する場合に使用できます。この手順では、dom0を再イメージ化し、すべてのユーザー・ドメインを再構築します。
「Oracle Linuxデータベース・サーバーの再イメージ化」の手順を使用して、ラック内のその他のOVS/dom0で使用されるイメージでOVSを再イメージ化します。
次のコマンドを実行します。
# /opt/oracle.SupportTools/switch_to_ovm.sh # /opt/oracle.SupportTools/reclaimdisks.sh –free –reclaim
リカバリをOracle Exadata Database Machineエイス・ラックで実行する場合は、「Oracle Exadata Database Machineエイス・ラックのOracle Linuxデータベース・サーバーのリカバリ後の構成」の手順を実行します。
ocfs2ファイル・システムを/dev/sda3パーティションに再構築します。
# umount /EXAVMIMAGES # mkfs -t ocfs2 -L ocfs2 -T vmstore --fs-features=local /dev/sda3 --force
ocfs2パーティション/dev/sda3を/EXAVMIMAGESにマウントします。
# mount -t ocfs2 /dev/sda3 /EXAVMIMAGES
バックアップNFSサーバーをマウントし、ユーザー・ドメイン・イメージを保持する/EXAVMIMAGESファイル・システムをリストアします。
# mkdir -p /remote_FS # mount -t nfs -o ro,intr,soft,proto=tcp,nolock nfs_ip:/location_of_backup /remote_FS
/EXAVMIMAGESファイル・システムをリストアします。
# tar -Spxvf /remote_FS/backup-of-exavmimages.tar -C /EXAVMIMAGES
|
注意: 記憶域リポジトリのリストア処理では、ユーザー・ドメイン固有のファイル(/EXAVMINAGES/GuestImages/<user_domain>/下のファイル)が通常のファイルとしてリストアされ、ユーザー・ドメインの作成時にこれらのファイルが記憶域リポジトリに最初に作成されたocfs2 reflinkとしてはリストアされません。したがって、/EXAVMINAGES内の領域の使用量は、バックアップ時の元の領域の使用量に比べて、リストア処理後に増加することがあります。 |
ネットワーク・ブリッジを手動で設定します。
ovmutils rpmのバージョンを確認します。
# rpm -qa|grep ovmutils
ovmutils rpmのバージョンが12.1.2.2.0より前の場合は、次の手順を実行します。
/opt/exadata_ovm/exadata.img.domu_makerをバックアップします。このバックアップ・コピーは後ほど必要になります。
# cp /opt/exadata_ovm/exadata.img.domu_maker /opt/exadata_ovm/exadata.img.domu_maker-orig
viなどのテキスト・エディタで/opt/exadata_ovm/exadata.img.domu_makerファイルを開き、"g_do_not_set_bridge=yes"を検索します。これは、CASE文オプション"network-discovery"の数行下にあります。
これを"g_do_not_set_bridge=no"に変更します。
/opt/exadata_ovm/exadata.img.domu_makerを保存して終了します。
/EXAVMIMAGES/confディレクトリのすべてのxmlファイルで/opt/exadata_ovm/exadata.img.domu_makerを手動で実行します。
# cd /EXAVMIMAGES/conf # ls -1|while read file; do /opt/exadata_ovm/exadata.img.domu_maker network-discovery $file /tmp/netdisc-$file; done
バックアップ・コピーから/opt/exadata_ovm/exadata.img.domu_makerをリストアします。
# cp /opt/exadata_ovm/exadata.img.domu_maker-orig /opt/exadata_ovm/exadata.img.domu_maker
ovmutils rpmのバージョンが12.1.2.2.0以降の場合、次のコマンドを実行します。
# /opt/exadata_ovm/exadata.img.domu_maker add-bonded-bridge-dom0 vmbondeth0 eth4 eth5
/EXAVMIMAGES/GuestImagesディレクトリ内のユーザー・ドメイン・ディレクトリごとに、次の手順を実行します。
ユーザー・ドメインのUUIDを取得します。
# grep ^uuid /EXAVMIMAGES/GuestImages/<user domain hostname>/vm.cfg|awk -F"=" '{print $2}'|sed s/"'"//g|sed s/" "//g
コマンドを実行すると、uuid値が返され、これは次のコマンドで使用されます。
# mkdir -p /OVS/Repositories/uuid
# ln -s /EXAVMIMAGES/GuestImages/user_domain_hostname/vm.cfg /OVS/Repositories/uuid/vm.cfg
# ln -s /OVS/Repositories/uuid/vm.cfg /etc/xen/auto/user_domain_hostname.cfg
# mkdir VirtualDisks
# cd VirtualDisks
vm.cfgファイ内にある4つのディスク・イメージ名を使用して、このディレクトリに4つのシンボリック・リンクを作成します(/EXAVMIMAGES/GuestImages/user_domain_hostnameディレクトリ内にある4つの".img"ファイルを指します)。
たとえば、/OVS/Repositories/uuidディレクトリのサンプルvm.cfgファイルのサンプル・ディスク・エントリを次に示します。
disk = ['file:/OVS/Repositories/6e7c7109c1bc4ebba279f84e595e0b27/VirtualDisks/dfd641a1c6a84bd69643da704ff98594.img,xvda,w','file:/OVS/Repositories/6e7c7109c1bc4ebba279f84e595e0b27/VirtualDisks/d349fd420a1e49459118e6a6fcdbc2a4.img,xvdb,w','file:/OVS/Repositories/6e7c7109c1bc4ebba279f84e595e0b27/VirtualDisks/8ac470eeb8704aab9a8b3adedf1c3b04.img,xvdc,w','file:/OVS/Repositories/6e7c7109c1bc4ebba279f84e595e0b27/VirtualDisks/333e7ed2850a441ca4d2461044dd0f7c.img,xvdd,w']
/EXAVMIMAGES/GuestImages/user_domain_hostnameディレクトリ内にある4つの".img"ファイルをリストできます。
ls /EXAVMIMAGES/GuestImages/user_domain_name/*.img
/EXAVMIMAGES/GuestImages/user_domain_name/System.img /EXAVMIMAGES/GuestImages/user_domain_name/grid12.1.0.2.2.img /EXAVMIMAGES/GuestImages/user_domain_name/db12.1.0.2.2-3.img /EXAVMIMAGES/GuestImages/user_domain_name/pv1_vgexadb.img
この場合、次のコマンドを使用して、4つのシンボリック・リンク(dbm01db08vm01はユーザー・ドメインのホスト名)を作成できます。
# ln -s /EXAVMIMAGES/GuestImages/dbm01db08vm01/System.img $(grep ^disk /EXAVMIMAGES/GuestImages/dbm01db08vm01/vm.cfg|awk -F":" '{print $2}'|awk -F"," '{print $1}'|awk -F"/" '{print $6}')
# ln -s /EXAVMIMAGES/GuestImages/dbm01db08vm01/grid12.1.0.2.2.img $(grep ^disk /EXAVMIMAGES/GuestImages/dbm01db08vm01/vm.cfg|awk -F":" '{print $3}'|awk -F"," '{print $1}'|awk -F"/" '{print $6}')
# ln -s /EXAVMIMAGES/GuestImages/dbm01db08vm01/db12.1.0.2.2-3.img $(grep ^disk /EXAVMIMAGES/GuestImages/dbm01db08vm01/vm.cfg|awk -F":" '{print $4}'|awk -F"," '{print $1}'|awk -F"/" '{print $6}')
# ln -s /EXAVMIMAGES/GuestImages/dbm01db08vm01/pv1_vgexadb.img $(grep ^disk /EXAVMIMAGES/GuestImages/dbm01db08vm01/vm.cfg|awk -F":" '{print $5}'|awk -F"," '{print $1}'|awk -F"/" '{print $6}')
各ユーザー・ドメインを起動します。
# xm create /EXAVMIMAGES/GuestImages/user_domain_hostname/vm.cfg
この時点で、すべてのユーザー・ドメインと、それらの中のグリッド・インフラストラクチャおよびデータベース・インスタンスが起動し、残りの他のOVSノードによって形成されたOracle RACクラスタに参加します。
失ったまたは損傷したユーザー・ドメイン内のファイルを、ユーザー・ドメイン内で作成したスナップショット・ベースのユーザー・ドメイン・バックアップを使用してリストアするには、次の手順を使用します。ユーザー・ドメイン・バックアップは「方法2: ユーザー・ドメイン内からユーザー・ドメインをバックアップする」の手順を使用して作成したものです。
rootユーザーとしてユーザー・ドメインにログインします。
バックアップNFSサーバーをマウントし、損傷または紛失が発生したファイルをリストアします。
# mkdir -p /root/mnt # mount -t nfs -o ro,intr,soft,proto=tcp,nolock nfs_ip:/location_of_backup /root/mnt
損傷または紛失が発生したファイルをバックアップからステージング領域に抽出します。
抽出されたファイルが保持されるように、ステージング領域を準備します。これには、バックアップLVM LVDbSys2を使用できます。
# mkdir /backup-LVM # mount /dev/mapper/VGExaDb-LVDbSys2 /backup-LVM # mkdir /backup-LVM/tmp_restore # tar -pjxvf /root/mnt/tar_file_name -C /backup-LVM/tmp_restore absolute_path_of_file_to_be_restored
必要に応じて、損傷または紛失が発生したファイルを一時ステージング領域からリストアします。
ユーザー・ドメインを再起動します。
Oracle Exadata Storage Server Software 11gリリース2 (11.2) 11.2.3.1.0以上では、データベース・サーバーの更新手順で、データベース・オペレーティング・システムおよびファームウェアの更新配信にUnbreakable Linuxネットワーク(ULN)を使用します。更新は、複数のrpmsで配信されます。dbnodeupdate.shユーティリティを使用して、更新を適用します。ユーティリティは、次のタスクを実行します。
データベース・サーバーがLogical Volume Manager (LVM)構成の場合、ビルトインdbserver_backup.shスクリプトを使用して、オペレーティング・システムをホストするファイル・システムのバックアップを実行します。
データベース、Grid Infrastructureスタック、Oracle Enterprise Manager Cloud Controlエージェントおよび潜在的なマウントされていないリモート・マウントの停止を含む、準備、更新および承認手順のすべてを自動化します。
既知の問題に対する最新のベスト・プラクティスおよび回避策を組み込みます。
更新の成功を確認してOracleバイナリを再リンクし、Oracleスタックを起動します。
Exadataリリース12.1.2.2.0以上では、patchmgrを実行して更新をオーケストレートできます。詳細は、「patchmgrによるデータベース・ノードの更新」を参照してください。
ULNを使用できない環境のために、Oracle Exadata Storage Server Softwareのリリースごとに、ISOリポジトリが用意されています。
dbnodeupdate.shユーティリティはMy Oracle Supportノート1553103.1から入手できます。ユーティリティは、すべての世代のハードウェア、Oracle Virtual Server (dom0)およびExadata Virtual Machines (domU)を実行するOracle Exadataデータベースをサポートしています。dbnodeupdate.shユーティリティは、Oracle Linux 5からOracle Linux 6の更新もサポートしています。Oracle Exadata Storage Server SoftwareパッチのREADMEファイルには、そのパッチが適用される世代のハードウェアが指定されています。常にサポート・ノートを確認して、最新リリースのユーティリティを更新に使用するようにしてください。
|
注意: ISOイメージ・メソッドは、ローカルULNミラーを完全に代替するものではありません。ISOイメージには、Oracle Exadataチャンネル・コンテンツのみが含まれます。他のULNチャンネルの別のコンテンツは、ISOイメージに含まれません。使用する環境が他のLinuxパッケージを使用し、更新にOracle Exadataチャンネルが含まれない場合、必要に応じてそのパッケージを、ULNチャンネルを使用して更新する必要があります。 |
この項の内容は次のとおりです。
リリース11.2.3.n.nまたは12.1.n.n.nにパッチ適用またはイメージ化を以前にしているデータベース・サーバーの更新
sudoによるdbnodeupdate.shおよびpatchmgr (およびdbnodeupdateオーケストレーション)の実行
|
注意: 個々のExadata以外のオペレーティング・システム・パッケージを更新する場合は、システム用のOracle Linuxの「最新の」チャネルのローカルyumミラーを設定し、yum update <packagename>を実行することができます。
他のパッケージも同様に引き込まれる可能性があることに常に注意してください。 多くの場合、最初にexadata-sun-computenode-exact rpmを削除する必要があります( パッケージ名を指定せずに 脆弱性に対処する方法についての説明は、My Oracle Supportノート1405320.1を参照してください。 |
Oracle Linux 5.5以上およびOracle Exadata Storage Server Softwareリリース11.2.2.4.2以上を実行しているデータベース・サーバーは、dbnodeupdate.shユーティリティを使用してデータベース・サーバーを更新します。Oracle Exadata Storage Server Softwareリリース11.2.2.4.2より前のリリースを実行しているOracle Linuxデータベース・サーバーは、dbnodeupdate.shユーティリティを使用して、最初にOracle Linux 5.5およびOracle Exadata Storage Server Software 11.2.2.4.2以上に更新する必要があります。
表2-4に、Oracle Exadata Storage Server SoftwareおよびOracle Linuxのリリース別の、データベース・サーバーの更新用のパスを示します。
表2-4 データベース・サーバーの更新パス
| 現在インストールされているOracle Exadata Storage Server Softwareリリース | 現在インストールされているOracle Linuxリリース脚注 1 | 推奨アクション |
|---|---|---|
|
リリース11.2.2.4.2以上 |
リリース5.5以上 |
「Oracle Linuxデータベース・サーバーの更新の概要」の説明に従い、ターゲット・リリースを更新します。 |
|
リリース11.2.2.4.2.より前 |
リリース5.5以上 |
|
|
リリース11.2.2.4.2.より前 |
リリース5.5より前 |
|
脚注 1 現在使用中のデータベース・サーバーのuname -rコマンドの出力に、リリース2.6.18-128.1.16.0.1以前のカーネル・リリースが表示される場合、データベース・サーバーはOracle Linux 5.3で実行しています。
|
注意:
|
この項の情報は、次の要件を満たしているデータベース・サーバーに適用されます。
Oracle Exadata Storage Server Software 11gリリース2 (11.2) 11.2.2.4.2以上がインストールされている。
Oracle Linux 5.5以上がインストールされている。Oracle Exadata Storage Server Software 11g2 (11.2) 11.2.3.1.0以上がインストールされている場合、この要件は満たされます。
データベース・サーバーがこれらの要件を満たしていない場合、表2-4「データベース・サーバーのパスの更新」を参照し、必須の手順を実行して要件を満たします。
次の手順では、Oracle Linuxデータベース・サーバーを新しいリリースの更新する方法について説明します。
「Oracle Exadataチャンネル・コンテンツでのyumリポジトリの準備と設定」で説明する手順に従い、ターゲット・リリースに対するOracle Exadataチャンネル・コンテンツで、yumリポジトリを準備および設定します。リリースで使用するULNチャンネル名の一覧は、パッチのそれぞれのREADMEファイルを参照してください。ULNチャンネルを使用しない場合、ISOイメージを使用できます。
Oracle Exadata Storage Server Softwareのリリース別に、前提条件チェック、更新およびパッチ適用後の手順を実行します。
Oracle Exadata Storage Server Softwareリリース11.2.3.1.0以上で実行するOracle Databaseの場合、「リリース11.2.3.n.nまたは12.1.n.n.nにパッチ適用またはイメージ化を以前にしているデータベース・サーバーの更新」を参照して、手順を実行してください。
Oracle Exadata Storage Server Softwareリリース11.2.2.4.2を実行するOracle Databaseの場合、「リリース11.2.2.4.2を実行中のデータベース・サーバーの更新」を参照して、手順を実行してください。
次のメソッドを使用して、Oracle Exadataチャンネル・コンテンツを含むyumリポジトリを作成し、使用します。dbnodeupdate.shユーティリティで、yumリポジトリを使用してOracle Exadata Database Machine内のデータベース・サーバーを更新します。次の各項で、それぞれの方法について詳しく説明します。
更新するデータベース・サーバーの数が多い。
すべてのデータベース・サーバーから、単一のリポジトリ・サーバーにアクセス可能である。
別のLinuxサーバーにULNミラーを構築するインフラストラクチャが存在する。
データベース・サーバーで、ほかのULNチャンネルからの更新が必要なカスタマイズされたソフトウェアを使用している。
ミラーは、別個のLinuxサーバーで、更新対象のULNからダウンロードしたチャンネル・データおよびOracle Exadataリリースを保持します。データベース・サーバーは、ローカル・ミラー(リポジトリ)に接続して更新を取得します。
|
注意: データベース・サーバーを、ローカルULNミラーとして使用することはできません。そのように使用すると、ULNがリポジトリ構築のために必要とするパッケージと、データベース・サーバーのインストールまたは更新のパッケージとの間に、依存性の競合が生じ、システム障害が発生する場合があります。別々のサーバーが使用できない場合、ISOイメージ・メソッドを使用してください。 |
ローカル・リポジトリの初回の設定の際に必要な追加のLinuxサブスクリプションは、リポジトリのホスト・サーバーで使用しているEnterprise LinuxまたはOracle Linuxのリリースによって異なります。サーバーは、次のような追加ULNチャンネルにサブスクライブして、リポジトリを構築する必要があります。
64-bit Enterprise Linux 4システムの場合:
el4_x86_64_latestおよびel4_x86_64_addons。
64-bit Enterprise Linux 5システムの場合:
el5_x86_64_latestおよびel5_x86_64_addons。
64-bit Oracle Linux 5システムの場合:
ol5_x86_64_latestおよびel5_x86_64_addons。
64-bit Oracle Linux 6システムの場合:
ol6_x86_64_latestおよびol6_x86_64_addons。
次の手順では、ローカルULNミラーをyumリポジトリとして作成および維持する方法について説明します。
次のURLを参照して、「ローカルUnbreakable Linux Networkミラーの作成方法」で説明される前提条件および手順を確認してください。
http://www.oracle.com/technetwork/articles/servers-storage-admin/yum-repo-setup-1659167.html
次のURLからULNにログインします。
「システム」タブをクリックします。
登録済のyumリポジトリ・サーバーに進みます。
サブスクリプションの管理をクリックします。
Oracle ExadataパッチのREADMEで名前を付けたチャンネルを追加します。たとえば、exadata_dbserver_12.1.1.1.0_x86_64_baseです。
|
注意: サブスクライブするOracle Exadataチャンネルは、更新するOracle Exadata Storage Server Softwareのリリースにより異なります。リリース別の詳細については、パッチのREADMEファイルを参照してください。 |
「Save」をクリックします。
前の項で説明したyumミラーを作成する手順では、ローカル・ミラーをyum mirror creation procedure described in the previous section provides a script that is used to populate the local mirror.スクリプトを実行すると、ULNからローカル・リポジトリへのrpmsダウンロードが開始します。
WebサーバーのDocument Rootディレクトリがディスク上のこの場所を指すように構成すると、HTTP Webサーバーを使用するOracle Exadata Linux Database Serversに対して、Oracle Exadataチャンネル・コンテンツが使用可能になります。
dbnodeupdate.shユーティリティに対するリポジトリの場所として指定されたURLは、次のグラフィックに示すように、repodataディレクトリと常に同じレベルです。
次のコマンドを使用して、rootユーザーとしてのリポジトリを確認します。
[root@dm01 ]# ./dbnodeupdate.sh -u -l http://yum-repo/yum/EngineeredSystems/exadata/dbserver/12.1.1.1.0/base/x86_64/ -v
|
注意: IPv6アドレスのみをリスニングしているyumリポジトリにアクセスするには、データベース・ノードでExadataリリース12.1.2.2.0以降が実行されている必要があります。 |
リリース11.2.3.1.0以上では、Oracle ExadataチャンネルのISOイメージを、My Oracle Supportからダウンロードするパッチとして入手できます。圧縮されたファイルの場所は、dbnodeupdate.shユーティリティへ、直接手渡されます。このメソッドは、次の条件が満たされた場合に推奨されます。
リポジトリ・サーバーとして使用可能な別のサーバーが存在しない。
追加ULNチャンネルからの更新を必要とするカスタマイズされたソフトウェアが、データベース・サーバーに存在しない。
簡略化されたメソッドが推奨される。
|
注意: ISOイメージ・メソッドは、ローカルULNミラーを完全に代替するものではありません。ISOイメージには、Oracle Exadataチャンネル・コンテンツのみが含まれます。他のULNチャンネルの別のコンテンツは、ISOイメージに含まれません。使用する環境が他のLinuxパッケージを使用し、更新にOracle Exadataチャンネルが含まれない場合、必要に応じてそのパッケージを、ULNチャンネルを使用して更新する必要があります。 |
次の手順では、ISOイメージをダウンロードおよび確認する方法について説明します。
更新対象のOracle ExadataリリースのISOイメージを、My Oracle Supportからダウンロードします。
圧縮されたファイル形式のISOイメージを、更新するすべてのデータベース・サーバーにコピーします。圧縮ファイルのパスは、dbnodeupdate.shユーティリティへの引数として使用します。ファイルを解凍しないでください。
次のコマンドを使用して、rootユーザーとしてのリポジトリを確認します。
[root@dm01 ]# ./dbnodeupdate.sh -u -l \ /u01/dbnodeupdate/p17997668_121110_Linux-x86-64.zip -v
リリース11.2.3.1.0以上では、Oracle ExadataチャンネルのISOイメージを、My Oracle Supportからダウンロードするパッチとして入手できます。これは、すべてのOracle Exadata Database Machineデータベース・サーバーにHTTP接続可能なWebサーバーにダウンロード、解凍および設定できます。リリース別のパッチ情報へのリンクは、My Oracle Supportノート888828.1を参照してください。このメソッドは、次の条件が満たされた場合に推奨されます。
更新するデータベース・サーバーの数が多い。
すべてのデータベース・サーバーから、単一のリポジトリ・サーバーにアクセス可能である。
追加ULNチャンネルからの更新を必要とするカスタマイズされたソフトウェアが、データベース・サーバーに存在しない。
次の手順では、Oracle Exadataチャンネル・コンテンツのISOイメージを、Apache HTTPサーバーを実行するLinuxベースのサーバーで使用する方法について説明します。それ以外のオペレーティング・システムも使用できますが、このドキュメントでは手順を説明しません。この手順では、ISOイメージは/u01/app/oracle/stageディレクトリにコピーされ、Webサーバー・ドキュメント内のDocument Rootエントリは/var/www/htmlです。
|
注意: 別のサーバーをWebサーバーとして使用することをお勧めします。Oracle Exadata Database Machine内のデータベース・サーバーを使用できますが、httpdパッケージはOracle Exadataパッケージの標準ではありません。データベース・サーバーを使用する場合、次の手順を実行する前に、Apache HTTPサーバーがサーバーにインストールされている必要があります。 |
更新対象のOracle Exadataリリースの圧縮ISOイメージを、My Oracle Supportからダウンロードします。この手順では、リリース12.1.1.1.0への更新を説明しますが、リリース11.2.3.1.0以上にも適用されます。
ISOイメージをWebサーバーへコピーします。
次のコマンドを使用して、ISOイメージ・マウント・ポイントをrootユーザーとして作成します。
[root@dm01 ]# mkdir -p /var/www/html/yum/unknown/EXADATA/dbserver/12.1.1.1.0/base
次のコマンドを使用して、ISOイメージをrootユーザーとして、解凍およびマウントします。
[root@dm01 ]# cd /u01/dbnodeupdate [root@dm01 ]# unzip p17997668_121110_Linux-x86-64.zip [root@dm01 ]# mount -o loop /u01/dbnodeupdate/121110_base_repo.iso /var/www/html/yum/unknown/EXADATA/dbserver/12.1.1.1.0/base
次の手順に従い、httpdサービスをrootユーザーとして起動します。
次のコマンドを使用して、httpdサーバーを追加し有効にします。
[root@dm01 ]# chkconfig --add httpd [root@dm01 ]# chkconfig httpd on
|
注意: httpdサービスの自動起動を有効にしておく必要はありません。 |
次のコマンドを使用してhttpdサービスを起動します。
[root@dm01 ]# service httpd start
次のコマンドを使用して、httpdサービスが有効であることを確認します。
[root@dm01 ]# chkconfig --list httpd
Webブラウザを使用して、接続したリポジトリURLを識別しテストします。リポジトリURLの例を、次に示します。
http://yum-repo/yum/unknown/EXADATA/dbserver/12.1.1.1.0/base/x86_64/
次のコマンドを使用して、rootユーザーとしてのリポジトリを確認します。
[root@dm01 ]# ./dbnodeupdate.sh -u -l \ http://yum-repo/yum/EngineeredSystems/exadata/dbserver/12.1.1.1.0/base/x86_64/ -v
更新を開始する前に、バックアップを作成し前提条件チェックを実行して、停止時間を短くします。実際の更新の際に、バックアップはスキップできます。バックアップは、リモートのネットワーク、NFSなどのマウントがアクティブではない場合に可能です。実際の更新の停止時間を開始する前日に、必ず前提条件チェックを実行する必要があります。
|
注意: LVMが有効なシステムを、Oracle Linux 5からOracle Linux 6に更新する場合、バックアップは実際の更新の一部として実行されます。バックアップをスキップすることはできません。 |
すべての警告および障害を、ダウンタイムの前に解決する必要があります。データベース・サーバーの更新の際、次の点に注意してください。
リリース11.2.3.n.nまたは12.1.n.n.nにパッチを適用する、またはイメージ化を以前にしているデータベース・サーバーを更新する場合:
Minimum依存性の障害のみが発生し、現在のイメージをOracle Linux 6への更新の前にバックアップしないと、更新が進行しません。Minimum依存性のチェックが失敗した場合、/var/log/cellosディレクトリのdbnodeupdate.logファイルを参照して、依存性の障害が発生した原因を確認してください。依存性チェックは、Oracle Linux 6へ更新する場合は実行しません。警告および障害を解決してから、前提条件チェックを再開します。
リリース11.2.2.4.2を実行中のデータベース・サーバーの更新
リリース11.2.2.4.2から更新する場合、依存性のチェックは実行されず、obsolete.lstおよびexclusion.lstリスト機能は有効ではありません。警告および障害を解決してから、前提条件チェックを再開します。
サーバーを更新する数日前に、データベース・サーバーをバックアップし、前提条件をチェックすることができます。次の手順では、アクティブ・システム・パーティションをバックアップして、前提条件を実行する方法について説明します。
次のコマンドを実行して、バックアップを作成します。
[root@dm01 ]# ./dbnodeupdate.sh -u -l repo -b
このコマンドで、repoはULNミラーのHTTPの場所または圧縮されたISOイメージの場所です。
|
注意: バックアップを事前に作成すると、実際の更新の際、dbnodeupdate.shユーティリティ内のバックアップ手順をスキップすることができます。次のコマンドを使用して、バックアップ作成をスキップします。
[root@dm01 ]# ./dbnodeupdate.sh -u -l
このコマンドで、repoはULNミラーのHTTPの場所または圧縮されたISOイメージの場所です。 LVMが有効なシステムを、Oracle Linux 5からOracle Linux 6に更新する場合、バックアップは実際の更新の一部として実行されます。 |
次のコマンドを使用して、前提条件チェックを実行します。
[root@dm01 ]# ./dbnodeupdate.sh -u -l repo -v
このコマンドで、repoはULNミラーのHTTPの場所または圧縮されたISOイメージの場所です。
dbnodeupdate.shユーティリティを使用して、リリース11.2.3.n.nおよびリリース12.1.n.n.nを実行するデータベース・サーバーを更新します。この項の手順では、データベース・サーバーがリリース11.2.2.4.2以上を実行し、更新がローカルULNミラーまたはローカルISOイメージとして使用可能であることを前提にしています。
この項の内容は次のとおりです。
|
注意: dbnodeupdate.shユーティリティを使用する場合、次の2つのコンポーネントが必要です。
|
システム管理者は、既存のOracle Exadataで供給されたパッケージに追加のパッケージをインストールして、より新しいリリースに更新することで、オペレーティング・システムをカスタマイズできます。この場合、カスタマイズにより、Oracle Exadata Storage Server Software機能を損なわないようにしてください。
|
注意: Oracle Support Servicesからの指示がないかぎり、カーネルおよびInfiniBandパッケージを更新または削除しないでください。 |
Oracle Exadata Storage Server Softwareリリース11.2.3.3.0以前に更新する場合、dbnodeupdate.shユーティリティを使用してyum更新を実行すると、MinimumおよびExact依存性が発生します。このような依存性は前提条件のチェックおよび更新で働くため、システムをカスタマイズする際に、管理者がExadataリリースを元の状態に忠実またはより近い状態を保つことを助けます。
依存性は、次のように、exadata-sun-computenode-exact rpmおよびexadata-sun-computenode-minimum rpmにより成立します。
exadata-sun-computenode-exact rpmは、Oracleが提供するパッケージの特定のリリースが更新の際に使用できるようにします。
exadata-sun-computenode-exact rpmは、Oracleが提供するパッケージの特定のリリースまたはそれより後のリリースが更新の際に使用できるようにします。
Exact依存性がexadata-sun-computenode-exact rpmで成立すると、Oracle Exadataパッケージが完全に同一のリリースであるため、あたかもシステムが新しいリリースに対してイメージが新たに作られたようになります。
exadata-sun-computenode-minimum rpmにより、Minimum依存性が成立し、すべてのパッケージがインストール済であると同時に、それより後のバージョンのパッケージも許容されます。
デフォルトで、dbnodeupdate.shユーティリティは、次のリリースに更新する際に、Exact依存性が成立するように更新します。Exact依存性が競合して成立できない場合、ユーティリティはexadata-sun-computenode-minimum rpmを適用し、Minimum依存性を成立させて更新します。Exact依存性の欠如または未更新は許容され、問題にはなりません。システムをExact依存性で更新する場合、すべての障害を解決する必要があります。dbnodeupdate.logファイルをチェックして、競合するパッケージを確認し、それらを丁寧に取り除いてからdbnodeupdate.shユーティリティを再び実行します。
次のコマンドを使用して、リリースで成立したExact依存性を確認します。
[root@dm01 ]# rpm -qR exadata-sun-computenode-exact | grep '=' | grep -v '('
コマンドの出力に、Exact依存性が表示されます。
たとえば、Oracle Exadata Storage Server Softwareリリース12.1.1.1.1の出力では、sendmailパッケージは8.13.8-8.1.el5_7と一致する必要があります。
次のコマンドを使用して、リリースで成立したMinimum依存性を確認します。
[root@dm01 ]# rpm -qR exadata-sun-computenode-minimum | grep '>=' | grep -v '('
コマンドの出力に、Minimum依存性が表示されます。
たとえば、Oracle Exadata Storage Server Softwareリリース12.1.1.1.1の出力では、minimumのsendmailパッケージはsendmail >= 8.13.8-8.1.el5_7です。つまり、Exact依存性が成立しない場合、後のリリースのsendmailを使用できます。
dbnodeupdate.shユーティリティの確認画面には、更新で成立する依存性が常に表示されます。Exact依存性およびMinimum依存性のいずれも適用できない場合、更新を続行することはできません。そのような場合、dbnodeupdate.logファイルを参照して、依存性の障害の原因を特定します。失敗した依存性を取り除いた後、dbnodeupdate.shユーティリティを再び実行して依存性を検証し、少なくともMinimum依存性が成立することを確認します。
予定されたメンテナンスの数日前に、-vフラグを使用してdbnodeupdate.shユーティリティを実行し、前提条件を確認することをお薦めします。dbnodeupdate.shユーティリティ・ログ・ファイルに、更新を実行して停止時間が発生する前に解決するべき依存性の問題が報告されます。前提条件チェック中または更新の開始前に、依存性エラーが発生した場合、次のようにして問題を解決します。
要件またはyumエラーを解析します。リリース11.2.3.1.0以上から更新する場合、画面に表示されるファイルを確認します。これには、/var/log/cellos/dbnodeupdate.logファイルが含まれます。リリース11.2.2.4.2から更新する場合、/var/log/exadata.computenode.post.logファイル、/var/log/exadata.computenode.post.logファイルおよび/var/log/cellos/bootstrap.uln.logファイルを確認してください。
内容によっては、依存問題または障害の原因となるrpmパッケージを、アンインストール、インストールまたは更新する必要があります。dbnodeupdate.logファイルを参照して、失敗した依存性を確認してください。
dbnodeupdate.shユーティリティを使用して、更新を実行してください。すでにバックアップが作成されている場合、-nフラグのみを使用して、バックアップをスキップします。デフォルトで、同一のイメージに対する既存のバックアップは上書きされます。
LVMが有効なシステムを、Oracle Linux 5からOracle Linux 6に更新する場合、バックアップは実際の更新の一部として実行されます。-nフラグは無視されます。
更新後にアンインストールしたカスタムrpmパッケージを、再びインストールします。
|
注意: セキュリティ要件により、使用するシステム上の個々のパッケージを手動で更新する場合があります。この時、exadata-sun-computenode-exactで成立した依存性が競合することがあります。これを解決するために、exadata-sun-computenode-exactパッケージをアンインストールして、新しいパッケージをインストールすることができます。これを行うには、次のコマンドを実行します。[root@dm01 ]# rpm -e exadata-sun-computenode-exact 後のOracle Exadata更新により新しいパッケージが含まれる場合、Exact依存性がdbnodeupdate.shユーティリティにより自動的に再インストールされます。 exadata-sun-computenode-minimumパッケージを削除することは、サポートされていません。Oracle Support Servicesからの指示がないかぎり、パッケージに対して強制的に |
dbnodeupdate.shユーティリティはMy Oracle Supportノート15553103.1から入手できます。次の手順では、サーバー上でユーティリティをダウンロードおよび準備する方法について説明します。
dbnodeupdateパッケージ・ファイルをMy Oracle Supportからダウンロードします。
zipファイルを、更新するデータベース・サーバーの/u01/dbnodeupdateディレクトリに置きます。
dbnodeupdateパッケージ、p16486998_12xxxx_Linux-x86-64.zipを、rootとして次のコマンドを使用して解凍します。
[root@dm01 ]# unzip p16486998_12xxxx_Linux-x86-64.zip
dbupdate-helpers.zipファイルを解凍しないでください。
|
注意: SUDO権限のあるユーザーは、SUDOを使用してdbnodeupdate.shユーティリティを実行できます。 |
リリース11.2.3.3.0以上に更新すると、データベース・サーバー上のパッケージの一部が廃止されて使用できません。データベース・サーバーの更新中、dbnodeupdate.shユーティリティにより、確認画面上に除外されたrpmリストおよび廃止されたrpmリストが表示されます。確認画面の例を、次に示します。この例では、除外リストはまだユーザーにより作成されていません。
Active Image version : 11.2.3.2.1.130302
Active Kernel version : 2.6.32-400.21.1.el5uek
Active LVM Name : /dev/mapper/VGExaDb-LVDbSys2
Inactive Image version : 11.2.3.2.1.130109
Inactive LVM Name : /dev/mapper/VGExaDb-LVDbSys1
Current user id : root
Action : upgrade
Upgrading to : 11.2.3.3.0.131014.1
Baseurl : http://mynode.us.example.com/yum/exadata_dbserver_11.2.3.3.0_x86_64_base/x86_64/ (http)
Create a backup : Yes
Shutdown stack : No (Currently stack is up)
RPM exclusion list : Not in use (add rpms to /etc/exadata/yum/exclusion.lst and restart dbnodeupdate.sh)
RPM obsolete list : /etc/exadata/yum/obsolete.lst (lists rpms to be removed by the update)
: RPM obsolete list is extracted from exadata-sun-computenode-11.2.3.3.0.131014.1-1.x86_64.rpm
Logfile : /var/log/cellos/dbnodeupdate.log (runid: 021213024645)
Diagfile : /var/log/cellos/dbnodeupdate.021213024645.diag
Server model : SUN FIRE X4170 M2 SERVER
Remote mounts exist : Yes (dbnodeupdate.sh will try unmounting)
dbnodeupdate.sh rel. : 2.20 (always check MOS 1553103.1 for the latest release)
Automatic checks incl. : Issue - Yum rolling update requires fix for 11768055 when Grid Infrastructure is below 11.2.0.2 BP12
Manual checks todo : Issue - Database Server upgrades to 11.2.2.3.0 or higher may hit network routing issues after the upgrade
Note : After upgrading and rebooting run './dbnodeupdate.sh -c' to finish post steps
Continue ? [Y/n]
廃止されるパッケージを確認するには、obsolete.lstファイルの内容を確認し、スクリプトに要求されたらNを入力します。obsolete.lstファイルの場所は確認画面に表示されます。obsolete.lstファイルには、更新中に何もアクションを実行しない限り、削除対象のパッケージのみが表示されます。このリストに手動で追加されたパッケージは無視されます。次はobsolete.lstファイルの例です。
[root@dm01 ]# cat /etc/exadata/yum/obsolete.lst # Generated by dbnodeupdate.sh runid: 021213024645 at.x86_64 java-*-openjdk rhino.noarch jline.noarch jpackage-utils.noarch giflib.x86_64 alsa-lib.x86_64 xorg-x11-fonts-Type1.noarch prelink.x86_64 biosconfig biosconfig_expat qlvnictools ibvexdmtools opensm.x86_64 ofed-scripts ibibverbs-devel-static infiniband-diags-debuginfo libibverbs-debuginfo librdmacm-debuginfo libibumad-debuginfo libibmad-debuginfo ibutils-debuginfo libmlx4-debuginfo libsdp-debuginfo mstflint-debuginfo perftest-debuginfo qperf-debuginfo libibcm-debuginfo compat-dapl-utils.x86_64 compat-dapl.x86_64 dapl-utils.x86_64 dapl.x86_64 libgfortran.x86_64 mdadm.x86_64 mpi-selector.noarch pygobject2.x86_64 specspo.noarch time.x86_64 tree.x86_64 unix2dos.x86_64 usbutils.x86_64 words.noarch
obsolete.lstファイルのリストに表示されたパッケージを削除しないようにするには、/etc/exadata/yum/exclusion.lstファイルを作成し、rpm名またはワイルドカードを入力して除外リストにrpmを含めます。
次の例は、除外リストに追加されたパッケージを示します。
[root@dm01 ]# cat /etc/exadata/yum/exclusion.lst java-*-openjdk
exclusion.lstファイルにエントリを追加し、dbnodeupdate.shユーティリティを再び実行すると、除外リストがユーティリティに検知されます。除外リスト上のrpmパッケージは、obsolete.lstファイルに表示されていますが、exclusion.lstファイル内にリストされたパッケージは更新の際に削除されません。次の確認画面の例では、エントリが追加された後、exclusion.lstファイルが使用中になります。
Active Image version : 11.2.3.2.1.130302
Active Kernel version : 2.6.32-400.21.1.el5uek
Active LVM Name : /dev/mapper/VGExaDb-LVDbSys2
Inactive Image version : 11.2.3.2.1.130109
Inactive LVM Name : /dev/mapper/VGExaDb-LVDbSys1
Current user id : root
Action : upgrade
Upgrading to : 11.2.3.3.0.131014.1
Baseurl : http://mynode.us.example.com/yum/exadata_dbserver_11.2.3.3.0_x86_64_base/x86_64/ (http)
Create a backup : Yes
Shutdown stack : No (Currently stack is up)
RPM exclusion list : In use (rpms listed in /etc/exadata/yum/exclusion.lst)
RPM obsolete list : /etc/exadata/yum/obsolete.lst (lists rpms to be removed by the update)
: RPM obsolete list is extracted from exadata-sun-computenode-11.2.3.3.0.131014.1-1.x86_64.rpm
Logfile : /var/log/cellos/dbnodeupdate.log (runid: 021213024900)
Diagfile : /var/log/cellos/dbnodeupdate.021213024900.diag
Server model : SUN FIRE X4170 M2 SERVER
Remote mounts exist : Yes (dbnodeupdate.sh will try unmounting)
dbnodeupdate.sh rel. : 2.20 (always check MOS 1553103.1 for the latest release)
Automatic checks incl. : Issue - Yum rolling update requires fix for 11768055 when Grid Infrastructure is below 11.2.0.2 BP12
Manual checks todo : Issue - Database Server upgrades to 11.2.2.3.0 or higher may hit network routing issues after the upgrade
Note : After upgrading and rebooting run './dbnodeupdate.sh -c' to finish post steps
Continue ? [Y/n]
|
注意: dbnodeupdate.shユーティリティまたはOracle Exadata Storage Server Software更新手順のいずれでも、obsolete.lstファイルにリストされていないrpmパッケージは削除されません。obsolete.lstファイル内にリストされたファイルのみが、exclusion.lstファイルに追加されます。カスタム・パッケージは削除されません。obsolete.lstおよびexclusion.lst機能は、リリース11.2.2.4.2から更新する場合、またはOracle Linux 6に更新する場合、使用できません。 |
次の手順では、更新モードでdbnodeupdate.shユーティリティを実行する方法を説明します。
リポジトリの場所に応じて、次のコマンドのいずれかを使用し、dbnodeupdate.shユーティリティを実行します。
ローカルULNミラーを使用する場合:
[root@dm01 ]# ./dbnodeupdate.sh -u -l http://my.repository.url/x86_64
圧縮されたISOイメージをデータベース・サーバー上で使用する場合:
[root@dm01 ]# ./dbnodeupdate.sh -u -l /u01/my_iso_file_zipped.zip
上記のコマンドで、my_iso_file_zippedは圧縮されたISOファイルの名前です。
|
注意: データベースおよびGrid Infrastructureスタックが有効な場合、データベース・サーバーを更新する前に停止する必要があります。-sフラグを更新コマンドに追加すると、dbnodeupdate.shユーティリティにより、更新の最中にスタックが停止します。次にコマンドを示します。
[root@dm01 ]# ./dbnodeupdate.sh -u -l |
次のコマンドを使用してサーバーの再起動が終了したら、完了後の手順を実行して更新を完了します。
[root@dm01 ]# ./dbnodeupdate.sh -c
ユーティリティは、次の完了後の手順に進みます。
|
注意: dbnodeupdate.sh -cコマンドの入力時に、更新の実行が継続中の場合があります。この時、ユーティリティはイメージ・ステータスを判別するまで待機します。保留中の更新が有効になるまでの待機中に、システムが再起動することがあります。このような場合、システムがオンラインに戻ってからdbnodeupdate.sh -cコマンドを再び入力します。 |
例2-1では、サーバーは、Oracle Exadata Storage Server Softwareリリース11.2.3.3.1を現在実行し(Active Image versionのエントリに表示されます)、カーネル2.6.39-400.128.17.el5uekを使用します(Active Kernel version)。現在のアクティブなシステム・パーティションはLVDbSys2です(Active LVM name)。システムは、圧縮ファイルで提供されたISOイメージを使用して(Iso file)、リリース12.1.1.1.1.140712に更新されます(Upgrading to)。
バックアップが作成され(Create a backup)、LVDbSys1に置かれます(Inactive LVM Name)。現在のシステムでは、データベース・スタックが実行されていますが(Shutdown Stack)、-sフラグが指定されています。バックアップおよび更新を継続する前に、スタックを停止します。
obsolete.lstファイル(RPM obsolete list)では、Oracleの更新の一部として削除されるrpmを指定します。exclusion.lstファイル(RPM exclusion list)は提供されません。
この例では、リリース12.1.1.1.1への更新は、exadata-computenode-minimum rpm依存性のみ可能で、Exact依存性チェックは失敗します。Minimum依存性制限へ更新する場合、競合はありません(Minimum dependencies)。MinimumおよびExact依存性の詳細は、「データベース・サーバー・パッケージのカスタマイズとMinimumおよびExact依存性の理解」を参照してください。
dbnodeupdate.shユーティリティ・プロセスのログは、dbnodeupdate.logファイル(Logfile)に添付されます。diagfileファイル(Diagfile)には、更新を開始する前の重要なシステム情報が記載されています。ユーティリティをどちらの方法で使用しても、diagfileファイルを生成します。これは必要な場合、トラブルシューティングでも使用されます。
NFSのようなアクティブ・リモート・ネットワーク・マウントが検知され(Remote mounts exist)、dbnodeupdate.shユーティリティが、マウントを解除しようとします。それが不可能な場合、ユーティリティは進行をブロックしているセッションを表示して、停止します。
dbnodeupdate.sh rel.エントリは、現在のdbnodeupdate.shリリースを指定します。常にMy Oracle Support note 1553103.1を参照し、最新リリースのdbnodeupdate.shユーティリティを確認してください。
ユーティリティがシステムをチェックし、dbnodeupdate.shユーティリティがOracle Exadataソースおよびターゲット・リリースで識別した既知の問題点が、スクリーン上のリストに表示されます。最初に、ユーティリティで自動的に解決される問題が表示され、次に、システム上で実行する必要がある手動チェックが表示されます。
例2-1 dbnodeupdate.shユーティリティの実行
[root@dm01 ]# ./dbnodeupdate.sh -u -l p18889969_121111_Linux-x86-64.zip -s
Active Image version : 11.2.3.3.1.140529.1
Active Kernel version : 2.6.39-400.128.17.el5uek
Active LVM Name : /dev/mapper/VGExaDb-LVDbSys2
Inactive Image version : 11.2.3.2.0.120713
Inactive LVM Name : /dev/mapper/VGExaDb-LVDbSys1
Current user id : root
Action : upgrade
Upgrading to : 12.1.1.1.1.140712 (to exadata-sun-computenode-minimum)
Baseurl : file:///var/www/html/yum/unknown/EXADATA/dbserver/121114021722/x86_64/ (iso)
Iso file : /u01/dbnodeupdate/iso.stage.121114021722/121111_base_repo_140712.iso
Create a backup : Yes
Shutdown stack : Yes (Currently stack is up)
RPM exclusion list : Not in use (add rpms to /etc/exadata/yum/exclusion.lst and restart dbnodeupdate.sh)
RPM obsolete list : /etc/exadata/yum/obsolete.lst (lists rpms to be removed by the update)
: RPM obsolete list is extracted from exadata-sun-computenode-12.1.1.1.1.140712-1.x86_64.rpm
Exact dependencies : Will fail on a next update. Update to 'exact' will be not possible. Falling back to 'minimum'
: See /var/log/exadatatmp/121114021722/exact_conflict_report.txt for more details
: Update target switched to 'minimum'
Minimum dependencies : No conflicts
Logfile : /var/log/cellos/dbnodeupdate.log (runid: 121114021722)
Diagfile : /var/log/cellos/dbnodeupdate.121114021722.diag
Server model : SUN FIRE X4170 SERVER
Remote mounts exist : Yes (dbnodeupdate.sh will try unmounting)
dbnodeupdate.sh rel. : 3.79b (always check MOS 1553103.1 for the latest release of dbnodeupdate.sh)
Note : After upgrading and rebooting run './dbnodeupdate.sh -c' to finish post steps.
The following known issues will be checked for and automatically corrected by dbnodeupdate.sh:
(*) - Issue - Adjust kernel.rcu_delay in /etc/sysctl.conf. See MOS 1916147.1
(*) - Issue - Fix for CVE-2014-6271 and CVE-2014-7169 (Shell-Shock)
The following known issues will be checked for but require manual follow-up:
(*) - Issue - Yum rolling update requires fix for 11768055 when Grid Infrastructure is below 11.2.0.2 BP12
Continue ? [y/n]
y
(*) 2014-11-12 02:21:19: Verifying GI and DB's are shutdown
(*) 2014-11-12 02:21:19: Shutting down GI and db
(*) 2014-11-12 02:23:17: Successfully unmounted network mount /mnt/rene
(*) 2014-11-12 02:23:17: Unmount of /boot successful
(*) 2014-11-12 02:23:17: Check for /dev/sda1 successful
(*) 2014-11-12 02:23:17: Mount of /boot successful
(*) 2014-11-12 02:23:17: Disabling stack from starting
(*) 2014-11-12 02:23:17: Performing filesystem backup to /dev/mapper/VGExaDb-LVDbSys1. Avg. 30
minutes (maximum 120) depends per environment........
(*) 2014-11-12 02:30:29: Backup successful
(*) 2014-11-12 02:30:36: ExaWatcher stopped successful
(*) 2014-11-12 02:30:36: Capturing service status and file attributes. This may take a while...
(*) 2014-11-12 02:30:42: Service status and file attribute report in: /etc/exadata/reports
(*) 2014-11-12 02:30:43: Validating the specified source location.
(*) 2014-11-12 02:30:44: Cleaning up the yum cache.
(*) 2014-11-12 02:30:47: Performing yum update. Node is expected to reboot when finished.
(*) 2014-11-12 02:31:03: Waiting for post rpm script to finish. Sleeping another 60 seconds (60 / 900)
Remote broadcast message (Wed Nov 12 02:31:08 2014):
Exadata post install steps started.
It may take up to 15 minutes.
Remote broadcast message (Wed Nov 12 02:31:53 2014):
Exadata post install steps completed.
(*) 2014-11-12 02:32:03: Waiting for post rpm script to finish. Sleeping another 60 seconds (120 / 900)
(*) 2014-11-12 02:33:03: All post steps are finished.
(*) 2014-11-12 02:33:03: System will reboot automatically for changes to take effect
(*) 2014-11-12 02:33:03: After reboot run "./dbnodeupdate.sh -c" to complete the upgrade
(*) 2014-11-12 02:33:05: Cleaning up iso and temp mount points
(*) 2014-11-12 02:33:05: Rebooting now...
Broadcast message from root (pts/0) (Wed Nov 12 02:33:05 2014):
The system is going down for reboot NOW!
Oracle Exadata Storage Server Softwareリリース11.2.2.4.2を実行しているデータベース・サーバーの更新には、サーバーでyumを使用する準備のための更新が含まれます。サーバーは、dbnodeupdate.shユーティリティを使用して準備します。このため、Oracle Exadata release 11.2.2.4.2からの更新では、2つのdbnodeupdate.shユーティリティを別々の引数で実行する必要があります。どのコマンドをいつ実行するか、ユーティリティから指示があります。
データベース・サーバーの更新は、次の前提条件に基づいています。
Oracle Exadata Storage Server Softwareリリースが11.2.2.4.2である。
データベース・サーバーで、Oracle Linux 5.5以上を実行している。
データベース・サーバー更新が、ローカルULNミラーまたはローカルISOイメージとして使用可能である。
この項の内容は次のとおりです。
dbnodeupdate.shユーティリティはMy Oracle Supportノート15553103.1から入手できます。次の手順では、サーバー上でユーティリティをダウンロードおよび準備する方法について説明します。
dbnodeupdate.shユーティリティをMy Oracle Supportからダウンロードします。
データベース・サーバーにrootユーザーとしてログインします。
圧縮ファイルを、データベース・サーバーの/u01/dbnodeupdateディレクトリに置きます。このディレクトリがまだ存在しない場合は、ディレクトリを作成します。
/u01/dbnodeupdateディレクトリ内のp16486998_12xxxx_Linux-x86-64.zipパッケージ・ファイルを、次のコマンドを使用して解凍します。
[root@dm01 ]# unzip p16486998_12xxxx_Linux-x86-64.zip
|
注意:
|
次の手順では、dbnodeupdate.shユーティリティを、リリース11.2.2.4.2を実行するデータベース・サーバー上で使用する方法について説明します。
データベース・サーバーにrootユーザーとしてログインします。
次のコマンドを使用して、dbnodeupdate.shユーティリティを実行します。データベース・サーバーは自動的に再起動します。
[root@dm01 ]# ./dbnodeupdate.sh -u -l repo
このコマンドで、repoはULNミラーのHTTPの場所または圧縮されたISOイメージの場所です。
|
注意: データベース・サーバーは自動的に再起動します。再起動の直前に、次の手順の指示が画面に表示されます。 |
手順2で説明したように、再起動の後、次のコマンドを実行します。圧縮ISOイメージが使用された場合、ユーティリティはISOイメージを自動的に再マウントします。
[root@dm01 ]# ./dbnodeupdate.sh -u -p 2
次のコマンドを使用して、更新を終了します。
[root@dm01 ]# ./dbnodeupdate.sh -c
完了の手順では、ユーティリティが、更新後のチェック、ベスト・プラクティスの適用、Oracleホームの再リンクを実行した後、スタックを再起動します。
|
注意: dbnodeupdate.sh -cコマンドの入力時に、更新の実行が継続中の場合があります。この時、ユーティリティはイメージ・ステータスを判別するまで待機します。保留中の更新が有効になるまでの待機中に、システムが再起動することがあります。このような場合、システムがオンラインに戻ってからdbnodeupdate.sh -cコマンドを再び入力します。 |
データベース・サーバー更新は、Oracle Exadata Storage Server Software、Oracle Linuxシステム・ソフトウェアおよびファームウェアを変更します。更新は、Grid Infrastructureホーム、データベース・ホーム(dbnodeupdate.sh -c手順の再リンク以外)または顧客がインストールしたソフトウェアの変更は行いません。データベース・サーバー更新は、アクティブなシステム・ディスク・パーティションで実行されます。
アクティブなシステム・ディスク情報を表示するには、imageinfoコマンドを実行します。Logical Volume Manager (LVM)を使用するデータベース・サーバーには、少なくとも1つのシステム・パーティションがあります。imageinfoコマンドの出力例を次に示します。
Kernel version: 2.6.39-400.238.0.el6uek.x86_64 #1 SMP Fri Aug 15 14:27:21 PDT 2014 x86_64 Image version: 12.1.2.1.0.141022 Image activated: 2014-10-22 22:11:12 -0700 Image status: success System partition on device: /dev/mapper/VGExaDb-LVDbSys1
dbnodeupdate.shユーティリティが、ロールバックを実行すると、非アクティブなシステム・ディスク・パーティションがアクティブになり、アクティブなシステム・ディスク・パーティションが非アクティブになります。非アクティブなシステム・パーティションをアクティブ化することで以前のリリースにロールバックしても、ファームウェアはロールバックされません。Oracle Exadata Storage Server Softwareリリースでは、それ以降のファームウェア・リリースをサポートしています。
データベース・サーバー更新をロールバックするには、データベース・サーバーの更新の前にバックアップを作成する必要があります。dbnodeupdate.shユーティリティは、次の要件が満たされる場合、非アクティブなシステム・ディスク・パーティション上にバックアップを作成します。
システムでLVMを使用する。
非アクティブなパーティションとアクティブなパーティションのサイズが同じである。LVDbSys1パーティションのみが存在する場合、非アクティブなパーティションを作成するのに十分な空き領域がボリューム・グループにあります。
2つのシステム・ディスク・パーティション、LVDbSys1およびLVDbSys2が存在する場合、バックアップ中に一時的に作成されるスナップショットを格納するために、ボリューム・グループに少なくとも1GBの空き領域が必要。
前述の前提条件が満たされない場合、dbnodeupdate.shユーティリティにより通知され、処理の自動更新が無効になります。更新を継続する場合、更新をロールバックすることができません。
|
注意: Oracle Linux 6に更新したシステムでは、更新を継続する前にバックアップを実行する必要があります。LVMが有効なシステムをOracle Linux 5からOracle Linux 6へ更新する場合、バックアップが自動で実行されます。Oracle Virtual Server (dom0)として実行するデータベース・サーバーは、ロールバックの際にアクティブなシステム・パーティションとして、LVDbSys2とLVDbSys3との間をスイッチします。 Oracle Virtual Machine (domU)として実行するデータベース・サーバーでは、物理ハードウェア・デプロイメントよりも、LVDbSys1およびLVDbSys2のサイズは小型です。 |
バックアップがユーティリティで作成されることを確認するには、前提条件チェックまたは更新処理で表示されるdbnodeupdate.sh確認ダイアログをチェックします。作成される場合は、Create a backupエントリに、Yesと表示されます。
次のコマンドを使用すると、更新をロールバックします。
[root@dm01 ]# ./dbnodeupdate.sh -r -s
Oracle Linux 5からOracle Linux 6への更新の処理中、最初の再起動後にエラーが発生すると、LVMが有効なシステムに対して、自動的にロールバックが開始されます。
ロールバックの後、次のコマンドを使用して、パッチ処理後の手順を実行し、スタックを再リンクおよび起動する必要があります。
[root@dm01 ]# ./dbnodeupdate.sh -c
Exadataリリース12.1.2.2.0以上では、patchmgrを使用してOracle Exadataデータベース・ノード(11.2.2.4.2以上のリリースを実行)、Oracle Exadata仮想サーバー・ノード(dom0)およびOracle Exadata仮想マシン(domU)の更新、ロールバックおよびバックアップを行うことができます。スタンドアロン・モードでdbnodeupdate.shを実行することも可能ですが、patchmgrを実行して更新を行うと、単一のコマンドの実行によって同時に複数のノードを更新できます。各ノードで個別にdbnodeupdate.shを実行する必要はありません。patchmgrは、ローリングまたは非ローリング方式でノードを更新できます。
patchmgrでこのオーケストレーションを行うには、更新対象外のデータベース・ノードからpatchmgrを実行します。そのノードは、すでに更新されているノードからpatchmgrを実行するか、そのノード自体にスタンドアロンでdbnodeupdate.shを実行することにより、後で更新する必要があります。
セルの更新と同様に、更新するデータベース・ノード(domUおよびdom0を含む)のリストを指定するファイルを作成します。patchmgrは、ローリングまたは非ローリング方式で指定されたノードを更新します。デフォルトは、セルの更新と同様に非ローリングです。ロールバックは、ローリング方式で行われます。
dbnodeupdate.shをスタンドアロンで実行する場合は、patchmgrコンポーネントを使用せずにdbnodeupdate.shを実行するための標準手順に従います(詳細は、「Oracle Linuxデータベース・サーバーの更新」を参照してください)。My Oracle Supportノート1553103.1で、dbnodeupdate.shの最新リリースを常に確認してください。
リリース12.1.2.2.0以上では、patchmgrからdbnodeupdateを実行するための、新しいdbserver.patch.zipファイルが用意されています。zipファイルにはpatchmgrおよびdbnodeupdate.zipが含まれています。dbserver.patch.zipファイルを解凍し、そこからpatchmgrを実行します。dbnodeupdate.zipは解凍しないでください。My Oracle Supportノート1553103.1で、dbserver.patch.zipの最新リリースを常に確認してください。
圧縮ISO形式でローカルyumリポジトリを使用するユーザー向けに、通常のハードウェア/domUおよびdom0用に個別の圧縮ISOが用意されています。更新のためにISOファイルを使用する場合は、ISOファイルをdbnodeupdate.zipと同じディレクトリに置くことをお薦めします。
非ローリングのアップグレードの動作は次のとおりです。
ノードが事前チェックの段階で失敗した場合、プロセス全体が失敗します。
ノードがパッチまたはリブートの段階で失敗した場合、patchmgrは、それ以降のそのノードへのステップをスキップします。他のノードのアップグレード処理は続行されます。
事前チェックの段階は、シリアルで実行されます。
パッチ/再起動および完了の段階は、パラレルで実行されます。
通知アラートの順序は次のとおりです。
起動(すべてのノード、パラレル)
パッチ適用(すべてのノード、パラレル)
リブート(すべてのノード、パラレル)
完了ステップ(各ノード、シリアル)
成功(各ノード、シリアル)
Oracle Linux 5からOracle Linux 6への移行を伴うデータベース・ノードの更新を実行する場合:
patchmgrを使用して、前提条件チェックを実行します。
(オプション)バックアップを実行します。
必須のバックアップと更新を実行します。
Oracle Linux 5からOracle Linux 6への更新以外の更新を実行する場合:
前提条件チェックを実行します。
(オプション)バックアップを実行します。
オプションのバックアップと更新を実行します。
patchmgrを使用してデータベース・ノードを更新する場合、次のオプションがサポートされています。
表2-5 patchmgrのオプション
| オプション | 説明 |
|---|---|
|
|
データベース・ノードのリスト・ファイルの名前を指定します。ファイルには1行に1つのホスト名またはIPアドレスが記載されています。 |
|
|
リスト・ファイルに指定されたデータベース・ノードに対して更新前の検証チェックを実行します(実際の更新は行いません)。詳細は、「前提条件の確認」を参照してください。 |
|
|
リフト・ファイルに指定されているデータベース・ノードをアップグレードします。詳細は、「(データベース)ノードの更新」を参照してください。 |
|
|
リフト・ファイルに指定されているデータベース・ノードをバックアップします。 |
|
|
リフト・ファイルに指定されているデータベース・ノードをロールバックします。詳細は、「データベース・サーバー上のローリング・バック更新」を参照してください。 |
|
|
リポジトリの場所を指定します。これは、yumのhttpリポジトリへのURLまたは圧縮ISOファイルへのパスです。圧縮ISOファイルを使用する場合、dbnodeupdate.zipがあるディレクトリと同じ場所にそのファイルを配置することをお薦めします。 |
|
|
更新先の完全なリリース・バージョンを指定します。この情報は、パッチのREADMEファイルにあります。 |
|
|
patchmgr通知の送信元("from")の電子メール・アドレスを指定します。 |
|
|
patchmgr通知の送信先("to")の電子メール・アドレスを指定します。 |
|
|
「Return-Path:」メール・ヘッダーと同じ送信元("from")アドレスが使用されることを指定します。 |
|
|
終了する前に、データベース・ノードへのパスワードなしのSSHアクセスを削除します。 |
|
|
ローリング方式で更新を実行することを指定します。指定しない場合、更新は非ローリング方式で実行されます。 ロールバックは、このオプションを指定しない場合でも、常にローリング方式で実行されます。 |
|
|
アクティブのNFSまたはSMBマウントを使用してdbnodeupdateを実行することを許可します。 これは" |
|
|
Oracle Linux 5からOracle Linux 6へのデータベース・ノードの更新時にカスタムrpmを削除します。 これは" |
|
|
前提条件の確認時にrpmを変更しません。 これは" |
-dbnode_precheckオプションは更新をシミュレートし、実際の更新は行いません。これは、実際の更新前にエラーを捕捉して解決するためのものです。
使用方法:
# ./patchmgr -dbnode dbnode_list -dbnode_precheck -dbnode_loc patch_file_name -dbnode_version version
yumのhttpリポジトリの使用例:
# ./patchmgr -dbnode dbnode_list -dbnode_precheck -dbnode_loc http://yum-repo/yum/ol6/EXADATA/dbserver/12.1.2.2.0/base/x86_64/ -dbnode_version 12.1.2.2.0.date_stamp
date_stampは、バージョンのリリース日を指定します(例: 150731)。
yumの圧縮ISOリポジトリの使用例:
# ./patchmgr -dbnode dbnode_list -dbnode_precheck -dbnode_loc ./repo.zip -dbnode_version 12.1.2.2.0.date_stamp
-dbnode_upgradeオプションは、データベース・ノードの実際のアップグレードを実行します。システム内のすべてのデータベース・ノードを更新する必要がある場合は、駆動ノードからコマンドを実行する必要があります(駆動ノードは更新対象のデータベース・ノードに含めることはできません)。
使用方法:
# ./patchmgr -dbnode dbnode_list -dbnode_upgrade -dbnode_loc patch_file_name -dbnode_version version
yumのhttpリポジトリを使用したローリング更新の例:
# ./patchmgr -dbnode dbnode_list -dbnode_upgrade -dbnode_loc http://yum-repo/yum/ol6/EXADATA/dbserver/12.1.2.1.0/base/x86_64/ -dbnode_version 12.1.2.2.0.date_stamp -rolling
date_stampは、バージョンのリリース日を指定します(例: 150731)。
yumの圧縮ISOリポジトリを使用した非ローリング更新の例:
# ./patchmgr -dbnode dbnode_list -dbnode_upgrade -dbnode_loc ./repo.zip -dbnode_version 12.1.2.2.0.date_stamp
-dbnode_rollbackオプションは、LVMのアクティブ/非アクティブの切替え、/bootコンテンツのリストア、Grubの再インストールおよびデータベース・ノードの再起動を行って、アップグレードの影響を元に戻します。これを使用できるのは、LVMが有効なシステムに対してのみです。「データベース・サーバー上のローリング・バック更新」も参照してください。
|
注意: ロールバックは、-rollingを指定しない場合にも、ローリング方式でのみ実行されます。 |
使用方法:
# ./patchmgr -dbnode dbnode_list -dbnode_rollback
patchmgrを使用してデータベース・ノードを更新するための正しい構文は、「patchmgrのオプション」またはpatchmgrオンライン・ヘルプを参照してください。
patchmgrツールを使用したデータベース・ノードの更新は簡潔で、最小限の情報のみが画面に出力されます。追加情報が必要な場合は、patchmgrログと、patchmgrが失敗したノードからコピーしたdbnodeupdate.shログ(使用できる場合)を確認できます。
ストレージ・セルの更新のように、patchmgrではSSH等価を実行する必要があります。
いつものように、My Oracle Supportノート1553103.1から最新のdbserver.patch.zipをダウンロードしてください。詳細は、「dbserver.patch.zipの入手とインストール」を参照してください。
まれに、patchmgrで更新のステータス(更新の成否)を判断できないことがあります。このような場合は、更新が失敗したことを示すメッセージが表示されます。ただし、更新が正常に完了している可能性もあります。更新の実際のステータスを確認する手順:
(データベース)ノードのイメージ・ステータスをチェックします。これを行うには、imageinfoコマンドを実行します。「Image status」行にステータスが表示されます。
Exadataソフトウェアのバージョンをチェックします。これはimageinfoコマンドから確認することもできます。
イメージ・ステータスが成功(success)で、Exadataバージョンが予想される新しいバージョンの場合、更新は成功しているため、「update failed」(更新の失敗)メッセージは無視して構いません。その後、次の手順を実行します。
特定のノード上でdbnodeupdate.sh -cを手動で実行し、更新の完了手順を実行します。
完了したノードを(データベース)ノード・ファイルから削除します。
patchmgrを再実行し、残りのノードに対して更新を実行します。
patchmgrを使用したデータベース・ノードの更新は任意です。引き続きdbnodeupdate.shを手動で実行することもできます。クリティカル・システムの更新時にpatchmgrからブロック・エラーが返された場合、dbnodeupdate.shを手動で実行して更新することをお薦めします。
patchmgrオーケストレーションに失敗した理由を分析するには、Oracleサポートにサービス・リクエストを提出してください。
sudoを使用してdbnodeupdate.shを実行するために/etc/sudoersファイルを設定するには、次の手順を実行します。
rootとしてログインし、visudoを使用して/etc/sudoersを編集します。
# visudo
oracleユーザーなどのroot以外のユーザーが、dbnodeupdateをrootとして実行できるように、sudoersファイルの最後に、次のエントリを(すべてを1行で)追加します。
|
注意: 行の最初のフィールドは、dbnodeupdate.shコマンドのsudoアクセス権が付与される非rootユーザーを指定します。次の行では、oracleユーザーを例として使用しています。必要に応じて、異なるユーザーを指定できます。 |
oracle ALL=(ALL) NOPASSWD:SETENV: /u01/stage/patch/dbnodeupdate/dbnodeupdate.sh
rootとして、/u01/stage/patch/dbnodeupdateディレクトリを作成し、dbnodeupdate.zipを解凍します。
# mkdir -p /u01/stage/patch/dbnodeupdate # cp dbnodeupdate.zip /u01/stage/patch/dbnodeupdate # cd /u01/stage/patch/dbnodeupdate # unzip dbnodeupdate.zip
正しく設定されたかどうかを確認するために、oracleユーザーとして前提条件チェック・モードでdbnodeupdateを実行します。
[oracle]$ cd /u01/stage/patch/dbnodeupdate [oracle]$ sudo ./dbnodeupdate.sh -u -l http://my-yum-repo/yum/EngineeredSystems/exadata/dbserver/12.1.2.1.3/base/x86_64/ -v
dbnodeupdateは、root権限なしで実行された場合に終了します。
|
注意:
|
sudoを使用してpatchmgr (dbserver.patch.zipにパッケージされている)を実行することにより、セルのパッチ適用、InfiniBandスイッチのパッチ適用、dbnodeupdateの実行のオーケストレーションなど、patchmgrの任意の機能を実行できます。
sudoを使用してpatchmgrを実行するために/etc/sudoersファイルを設定するには、次の手順を実行します。
rootとしてログインし、visudoを使用して/etc/sudoersを編集します。
# visudo
oracleユーザーなどのroot以外のユーザーが、patchmgrをrootとして実行できるように、sudoersファイルの最後に、次のエントリを追加します。
|
注意: 行の最初のフィールドは、patchmgrコマンドのsudoアクセス権が付与される非rootユーザーを指定します。次の行では、oracleユーザーを例として使用しています。必要に応じて、異なるユーザーを指定できます。 |
oracle ALL=(ALL) NOPASSWD:SETENV: /u01/stage/patch/dbserverpatch/patchmgr
rootとして、/u01/stage/patch/dbserverpatchディレクトリを作成し、dbserver.patch.zipを解凍します。
# mkdir -p /u01/stage/patch/dbserverpatch/ # cp dbserver.patch.zip /u01/stage/patch/dbserverpatch/ # cd /u01/stage/patch/dbserverpatch/ # unzip dbserver.patch.zip
/u01/stage/patch/dbserverpatch/dbserver_patch_x.yymmddディレクトリ下のすべてを、/u01/stage/patch/dbserverpatch/に移動します。
# mv /u01/stage/patch/dbserverpatch/dbserver_patch_x.yymmdd/* /u01/stage/patch/dbserverpatch/
|
注意:
|
正しく設定されたかどうかを確認するために、oracleユーザーとして前提条件チェック・モードでpatchmgrを実行します。
[oracle]$ cd /u01/stage/patch/dbserverpatch/ [oracle]$ sudo ./patchmgr -dbnode dbgroup -dbnode_precheck \ -dbnode_loc http://my-yum-repo/yum/EngineeredSystems/exadata/dbserver/12.1.2.1.3/base/x86_64/ \ -dbnode_version 12.1.2.1.3.151021
Oracle Linuxデータベース・サーバーが修復できないほどダメージを受け、新しいデータベース・サーバーと交換した場合、または複数のディスク障害でローカル・ディスクのストレージに障害が発生し、データベース・サーバーがバックアップされなかった場合は、再イメージ化手順の実行が必要です。再イメージ化手順の実行中に、Oracle Exadata Database Machineの他のデータベース・サーバーを使用できます。クラスタに新しいサーバーを追加すると、ソフトウェアが既存のデータベース・サーバーから新しいサーバーにコピーされます。スクリプト、CRONジョブ、保守処置、Oracle以外のソフトウェアのリストアは顧客が行います。
|
注意: この項の手順は、データベースがOracle Databaseリリース12cリリース1 (12.1)またはリリース11gリリース2 (11.2)であることを前提としています。データベースがOracle Database 11gリリース1(11.1)の場合、クラスタのサーバーの追加および削除の詳細は、該当するリリースのドキュメントを参照してください。 |
Oracle Linuxデータベース・サーバーを再イメージ化する方法は、次のとおりです。
|
関連項目: 手動によるインスタンスの追加の詳細は、My Oracle Supportノート430909.1を参照してください。 |
Oracleサポート・サービスでOracleサポート・リクエストを開きます。サポート・エンジニアが障害が発生したサーバーを確認し、交換サーバーを送ります。サポート・エンジニアは、残存データベース・サーバーから実行したimagehistoryコマンドの出力結果を要求します。出力結果により、元のデータベース・サーバーのイメージ化に使用したcomputeImageMakerファイルへのリンクと、システムを同じレベルにリストアする手段が提供されます。
クラスタ検証ユーティリティ(cluvfy)の最新リリースは、My Oracle Supportで入手できます。ダウンロードの方法およびその他の情報は、My Oracle Supportノート316817.1を参照してください。
障害が発生したデータベース・サーバーをクラスタから削除する必要があります。この作業の手順は、クラスタで動作しているデータベース・サーバーを使用して実行されます。コマンドのworking_serverは動作しているデータベース・サーバー、replacement_serverは交換データベース・サーバーです。
|
関連項目: クラスタからのデータベース・サーバーの削除の詳細は、『Oracle Real Application Clusters管理およびデプロイメント・ガイド』を参照してください。 |
クラスタのデータベース・サーバーにoracleユーザーとしてログインします。
次のコマンドを使用して、障害が発生したサーバーで実行されるリスナーを無効化します。
$ srvctl disable listener -n failed_server $ srvctl stop listener -n failed_server
次のコマンドを使用して、OracleインベントリからOracleホームを削除します。
$ cd $ORACLE_HOME/oui/bin $ ./runInstaller -updateNodeList ORACLE_HOME= \ /u01/app/oracle/product/11.2.0/dbhome_1 "CLUSTER_NODES=list_of_working_servers"
前述のコマンドのlist_of_working_serversは、dm01db02やdm01db03などのクラスタで動作しているサーバーのリストです。
次のコマンドを使用して、障害が発生したサーバーの固定が解除されたことを確認します。
$ olsnodes -s -t
次に、コマンドの出力例を示します。
dm01db01 Inactive Unpinned dm01db02 Active Unpinned
次のコマンドを使用して、障害が発生したデータベース・サーバーのVIPリソースを停止および削除します。
# srvctl stop vip -i failed_server-vip PRCC-1016 : failed_server-vip.example.com was already stopped # srvctl remove vip -i failed_server-vip Please confirm that you intend to remove the VIPs failed_server-vip (y/[n]) y
次のコマンドを使用して、クラスタからサーバーを削除します。
# crsctl delete node -n failed_server
CRS-4661: Node dm01db01 successfully deleted.
次のようなエラー・メッセージを受領したら、投票ディスクを移動します。出力例の後に、投票ディスクの移動手順を示します。
CRS-4662: Error while trying to delete node dm01db01. CRS-4000: Command Delete failed, or completed with errors.
次のコマンドを使用して、投票ディスクの現在の場所を特定します。
# crsctl query css votedisk
次に、コマンドの出力例を示します。現在の場所はDBFS_DGです。
## STATE File Universal Id File Name Disk group -- ----- ----------------- --------- ---------- 1. ONLINE 123456789abab (o/192.168.73.102/DATA_CD_00_dm01cel07) [DBFS_DG] 2. ONLINE 123456789cdcd (o/192.168.73.103/DATA_CD_00_dm01cel08) [DBFS_DG] 3. ONLINE 123456789efef (o/192.168.73.100/DATA_CD_00_dm01cel05) [DBFS_DG] Located 3 voting disk(s).
次のコマンドを使用して、投票ディスクを別のディスク・グループに移動します。
# ./crsctl replace votedisk +DATA Successful addition of voting disk 2345667aabbdd. ... CRS-4266: Voting file(s) successfully replaced
次のコマンドを使用して、投票ディスクを元の場所に移動します。
# ./crsctl replace votedisk +DBFS_DG
クラスタからサーバーを削除します。
次のコマンドを使用して、Oracleインベントリを更新します。
$ cd $ORACLE_HOME/oui/bin $ ./runInstaller -updateNodeList ORACLE_HOME=/u01/app/11.2.0/grid \ "CLUSTER_NODES=list_of_working_servers" CRS=TRUE
次のコマンドを使用して、サーバーが正常に削除されたことを確認します。
$ cluvfy stage -post nodedel -n failed_server -verbose
次に、コマンドの出力例を示します。
Performing post-checks for node removal Checking CRS integrity... The Oracle clusterware is healthy on node "dm01db02" CRS integrity check passed Result: Node removal check passed Post-check for node removal was successful.
USBフラッシュ・ドライブを使用して、イメージを新しいデータベース・サーバーにリストアします。次の手順は、USBフラッシュ・ドライブを使用する準備方法を示しています。
|
注意: リリース12.1.2.1.0以降の場合、イメージの作成に使用されるシステムはOracle Linux 6を実行している必要があります。 |
空のUSBフラッシュ・ドライブをクラスタの動作しているデータベース・サーバーに挿入します。
rootユーザーとしてログインします。
次のコマンドを使用して、computeImageファイルを解凍します。
# unzip computeImageMaker_exadata_release_LINUX.X64_ \ release_date.platform.tar.zip # tar -xvf computeImageMaker_exadata_release_LINUX.X64_ \ release_date.platform.tar
前述のコマンドのexadata_releaseは11.2.1.2.0などのOracle Exadata Storage Server Softwareのリリース番号、release_dateは091102などのリリースの日付、platformはx86_64などのリリースのプラットフォームです。
次のコマンドを使用して、USBフラッシュ・ドライブにイメージをロードします。
# cd dl360 # ./makeImageMedia.sh -dualboot no
makeImageMedia.shスクリプトにより、情報を要求されます。
データベース・サーバーからUSBフラッシュ・ドライブを取り外します。
動作しているデータベース・サーバーから解凍したd1360ディレクトリおよびcomputeImageMakerファイルを削除します。このディレクトリおよびファイルには、約2GBの領域が必要です。
データベース・サーバーが交換された後、USBフラッシュ・ドライブを使用して、新しいデータベース・サーバーにイメージを配置します。次の手順は、新しいデータベース・サーバーにイメージをロードする方法を示しています。
交換データベース・サーバーのUSBポートにUSBフラッシュ・ドライブを挿入します。
サービス・プロセッサまたはKVMスイッチを使用してコンソールにログインし、進捗状況を監視します。
サービス・プロセッサ・インタフェースまたは電源ボタンを使用して、データベース・サーバーの電源を投入します。
BIOS中にF2キーを押してからBIOS設定を選択して起動順序を構成するか、またはF8キーを押してからワンタイム起動選択メニューを選択してUSBフラッシュ・ドライブを選択します。
マザーボードが交換されたら、BIOS起動順序を構成します。起動順序はUSBフラッシュ・ドライブ、次にRAIDコントローラの順です。
システムを起動できるようにします。システムが起動すると、CELLUSBINSTALLメディアが検出されます。イメージ化プロセスには、2つのフェーズがあります。次の手順に進む前に、各フェーズを完了します。
イメージ化プロセスの1つ目のフェーズでは、古いBIOSまたはファームウェアを識別し、イメージに対応するレベルにコンポーネントをアップグレードします。コンポーネントをアップグレードまたはダウングレードする必要がある場合は、システムが自動的に再起動します。
イメージ化プロセスの2つ目のフェーズでは、交換データベース・サーバーの工場出荷時のイメージをインストールします。
システムで要求された場合、USBフラッシュ・ドライブを取り外します。
USBフラッシュ・ドライブを取り外した後、[Enter]を押してサーバーの電源を切断します。
交換データベース・サーバーには、ホスト名、IPアドレス、DNSまたはNTP設定がありません。この作業の手順は、交換データベース・サーバーの構成方法を示しています。交換データベース・サーバーを構成する前に、次の情報が必要です。
ネーム・サーバー
南北アメリカ/シカゴなどのタイムゾーン
NTPサーバー
管理ネットワークのIPアドレス情報
クライアント・アクセス・ネットワークのIPアドレス情報
InfiniBandネットワークのIPアドレス情報
標準的なホスト名
デフォルトのゲートウェイ
Oracle Exadata Database Machineのすべてのデータベース・サーバーで情報を同じにする必要があります。IPアドレスは、DNSから取得できます。また、Oracle Exadata Database Machineがインストールされたときに、この情報を含むドキュメントが提供されています。
次の手順は、交換データベース・サーバーの構成方法を示しています。
交換データベース・サーバーの電源を投入します。システムがブートすると、自動的にOracle Exadataの構成ルーチンが実行され、情報の入力が要求されます。
要求された場合は情報を入力して、設定を確認します。起動プロセスが続行されます。
|
注意:
|
Oracle Exadata Database Machineの初期インストールの実行中、インストール・プロセスで特定のファイルが変更されました。次の手順は、初期インストールの実行中の変更が交換データベース・サーバーに行われることを確認する方法を示しています。
動作しているデータベース・サーバーのファイルを参照して、次のファイルの内容をコピーまたはマージします。
/etc/security/limits.confファイルの内容をコピーします。
/etc/hostsファイルの内容をマージします。
/etc/oracle/cell/network-config/cellinit.oraファイルをコピーします。
交換したデータベース・サーバーのBONDIB0インタフェースのIPアドレスでIPアドレスを更新します。
/etc/oracle/cell/network-config/cellip.oraファイルをコピーします。すべてのデータベース・サーバーでcellip.oraファイルの内容を同じにする必要があります。
10GbEなど、追加ネットワーク要件を構成します。
/etc/modprobe.confファイルをコピーします。すべてのデータベース・サーバーでファイルの内容を同じにする必要があります。
/etc/sysctl.confファイルをコピーします。すべてのデータベース・サーバーでファイルの内容を同じにする必要があります。
データベース・サーバーを再起動し、ネットワーク変更を有効にします。
Oracleソフトウェア所有者にグループを追加して、交換データベース・サーバーにoracleユーザーを設定します。通常、所有者はoracleです。グループ情報は、動作しているデータベース・サーバーで使用できます。
次のコマンドを使用して、動作しているデータベース・サーバーから現在のグループ情報を取得します。
# id oracle uid=1000(oracle) gid=1001(oinstall) groups=1001(oinstall),1002(dba),1003(oper),1004(asmdba)
次のようにgroupaddコマンドを使用して、グループ情報を交換データベース・サーバーに追加します。
# groupadd -g 1001 oinstall # groupadd -g 1002 dba # groupadd -g 1003 oper # groupadd -g 1004 asmdba
次のコマンドを使用して、動作しているデータベース・サーバーから現在のユーザー情報を取得します。
# id oracle uid=1000(oracle) gid=1001(oinstall) \ groups=1001(oinstall),1002(dba),1003(oper),1004(asmdba)
次のコマンドを使用して、ユーザー情報を交換データベース・サーバーに追加します。
# useradd -u 1000 -g 1001 -G 1001,1002,1003,1004 -m -d /home/oracle -s \ /bin/bash oracle
次のコマンドを使用して、/u01/app/oracleや/u01/app/11.2.0./gridなどのORACLE_BASEおよびグリッド・インフラストラクチャ・ディレクトリを作成します。
# mkdir -p /u01/app/oracle # mkdir -p /u01/app/11.2.0/grid # chown -R oracle:oinstall /u01/app
次のコマンドを使用して、cellip.oraおよびcellinit.oraファイルの所有権を変更します。通常、所有権はoracle:dbaです。
# chown -R oracle:dba /etc/oracle/cell/network-config
次のコマンドを使用して、リストアしたデータベース・サーバーをセキュリティで保護します。
$ chmod u+x /opt/oracle.SupportTools/harden_passwords_reset_root_ssh $ /opt/oracle.SupportTools/harden_passwords_reset_root_ssh
|
注意: データベース・サーバーが再起動されます。プロンプトが表示されたら、rootユーザーとしてログインします。新しいパスワードが要求されます。他のデータベース・サーバーのパスワードrootと一致するパスワードを設定します。 |
次のコマンドを使用して、Oracleソフトウェア所有者のパスワードを設定します。通常、所有者はoracleです。
# passwd oracle
次に示すように、oracleアカウントにSSHを設定します。
次のコマンドを使用して、交換データベース・サーバーのoracleアカウントにログインします。
# su - oracle
Oracleクラスタのサーバーをリストする交換データベース・サーバーのdcliグループ・ファイルを作成します。
次のコマンドを使用して、交換データベース・サーバーのsetssh-Linux.shスクリプトを実行します。次に示すコマンドによってスクリプトがインタラクティブ・モードで実行されます。
$ /opt/oracle.SupportTools/onecommand/setssh-Linux.sh -s
スクリプトによってサーバーのoracleパスワードが要求されます。-sオプションにより、スクリプトはサイレント・モードで実行されます。
次のコマンドを使用して、交換データベース・サーバーにoracleユーザーとしてログインします。
# su - oracle
次のコマンドを使用して、SSH等価を確認します。
$ dcli -g dbs_group -l oracle date
次のコマンドを使用して、動作しているデータベース・サーバーから交換データベース・サーバーにカスタム・ログイン・スクリプトを設定またはコピーします。
$ scp .bash* oracle@replacement_server:.
前述のコマンドのreplacement_serverは、dm01db01などの新しいサーバーの名前です。
Oracle Exadata Database MachineのOracle Exadata Storage Server Softwareパッチ・バンドルが定期的にリリースされています。computeImageMakerファイルのリリースよりも新しいパッチ・バンドルが動作しているデータベース・サーバーに適用された場合、パッチ・バンドルを交換データベース・サーバーに適用する必要があります。次に示すように、パッチ・バンドルが適用されているか確認します。
Oracle Exadata Storage Server Softwareリリース11.2.1.2.3以前のデータベース・サーバーは、バージョン履歴情報を保持していません。リリース番号を確認するには、Exadata Storage Serverにログインし、次のコマンドを実行します。
imageinfo -ver
computeImageMakerファイルで使用されるリリースと異なるリリースが表示された場合、Oracle Exadata Storage Server SoftwareパッチがOracle Exadata Database Machineに適用されているので、交換データベース・サーバーに適用する必要があります。
Oracle Exadata Storage Server Softwareリリース11.2.1.2.3以降、imagehistoryコマンドがデータベース・サーバーにあります。交換データベース・サーバーの情報を動作しているデータベース・サーバーの情報と比較します。動作しているデータベースのリリースが新しい場合、Exadata Storage Serverパッチ・バンドルを交換データベース・サーバーに適用します。
次の手順では、交換データベース・サーバーにGrid Infrastructureをクローニングする方法について説明します。コマンドのworking_serverは動作しているデータベース・サーバー、replacement_serverは交換データベース・サーバーです。手順中のコマンドは、動作しているデータベース・サーバーから実行します。
|
関連項目: クローニングの詳細は、Oracle Real Application Clusters管理およびデプロイメント・ガイドを参照してください。 |
次のようにクラスタ検証ユーティリティ(cluvfy)を使用して、ハードウェアおよびオペレーティング・システムのインストールを検証します。
$ cluvfy stage -post hwos -n replacement_server,working_server -verbose
レポートの最後にPost-check for hardware and operating system setup was successfulのフレーズが表示されます。
次のコマンドを使用して、ピア互換性を確認します。
$ cluvfy comp peer -refnode working_server -n replacement_server \ -orainv oinstall -osdba dba | grep -B 3 -A 2 mismatched
次に、出力の例を示します。
Compatibility check: Available memory [reference node: dm01db02] Node Name Status Ref. node status Comment ------------ ----------------------- ----------------------- ---------- dm01db01 31.02GB (3.2527572E7KB) 29.26GB (3.0681252E7KB) mismatched Available memory check failed Compatibility check: Free disk space for "/tmp" [reference node: dm01db02] Node Name Status Ref. node status Comment ------------ ----------------------- ---------------------- ---------- dm01db01 55.52GB (5.8217472E7KB) 51.82GB (5.4340608E7KB) mismatched Free disk space check failed
障害が発生したコンポーネントだけが物理メモリー、スワップ領域およびディスク領域に関連している場合は、手順を継続できます。
次のように、サーバーを追加するために必要な確認を行います。
GRID_HOME/network/admin/samplesディレクトリの権限が750に設定されていることを確認します。
次のコマンドを使用して、データベース・サーバーの追加を確認します。
$ cluvfy stage -pre nodeadd -n replacement_server -fixup -fixupdir \
/home/oracle/fixup.d
障害が発生したコンポーネントだけがスワップ領域に関連している場合は、手順を継続できます。
次のように、投票ディスクにエラーが発生する場合があります。
ERROR:
PRVF-5449 : Check of Voting Disk location "o/192.168.73.102/ \
DATA_CD_00_dm01cel07(o/192.168.73.102/DATA_CD_00_dm01cel07)" \
failed on the following nodes:
Check failed on nodes:
dm01db01
dm01db01:No such file or directory
…
PRVF-5431 : Oracle Cluster Voting Disk configuration check failed
このようなエラーが発生したら、環境変数を次のように設定します。
$ export IGNORE_PREADDNODE_CHECKS=Y
次のコマンドを使用して、交換データベース・サーバーをクラスタに追加します。
$ cd /u01/app/11.2.0/grid/oui/bin/
$ ./addNode.sh -silent "CLUSTER_NEW_NODES={replacement_server}" \
"CLUSTER_NEW_VIRTUAL_HOSTNAMES={replacement_server-vip}"
2つ目のコマンドを使用すると、Oracle Universal InstallerによってOracle Clusterwareソフトウェアが交換データベース・サーバーにコピーされます。次のようなメッセージが表示されます。
WARNING: A new inventory has been created on one or more nodes in this session. However, it has not yet been registered as the central inventory of this system. To register the new inventory please run the script at '/u01/app/oraInventory/orainstRoot.sh' with root privileges on nodes 'dm01db01'. If you do not register the inventory, you may not be able to update or patch the products you installed. The following configuration scripts need to be executed as the "root" user in each cluster node: /u01/app/oraInventory/orainstRoot.sh #On nodes dm01db01 /u01/app/11.2.0/grid/root.sh #On nodes dm01db01
次に示すように、端末のウィンドウの構成スクリプトを実行します。
端末のウィンドウを開きます。
rootユーザーとしてログインします。
各クラスタ・ノードのスクリプトを実行します。
スクリプトの実行後、次のメッセージが表示されます。
The Cluster Node Addition of /u01/app/11.2.0/grid was successful. Please check '/tmp/silentInstall.log' for more details.
次のコマンドを使用して、交換データベース・サーバーのorainstRoot.shおよびroot.shスクリプトを実行します。サンプルの出力が表示されます。
# /u01/app/oraInventory/orainstRoot.sh Creating the Oracle inventory pointer file (/etc/oraInst.loc) Changing permissions of /u01/app/oraInventory. Adding read,write permissions for group. Removing read,write,execute permissions for world. Changing groupname of /u01/app/oraInventory to oinstall. The execution of the script is complete. # /u01/app/11.2.0/grid/root.sh
|
注意: /u01/app/11.2.0/grid/install/ログ・ファイルで、root.shスクリプトの出力結果を確認します。スクリプトによって作成された出力ファイルで、交換したデータベース・サーバーのリスナー・リソースの起動が失敗したことが報告されます。これは予想された出力です。
/u01/app/11.2.0/grid/bin/srvctl start listener -n dm01db01 \ ...Failed /u01/app/11.2.0/grid/perl/bin/perl \ -I/u01/app/11.2.0/grid/perl/lib \ -I/u01/app/11.2.0/grid/crs/install \ /u01/app/11.2.0/grid/crs/install/rootcrs.pl execution failed |
次のコマンドを使用して、「作業3: クラスタの障害が発生したデータベース・サーバーの削除」で停止したリスナー・リソースを再有効化します。コマンドは、交換データベース・サーバーで実行されます。
# GRID_HOME/grid/bin/srvctl enable listener -l LISTENER \ -n replacement_server # GRID_HOME/grid/bin/srvctl start listener -l LISTENER \ -n replacement_server
次の手順は、交換サーバーへのOracle Databaseホームのクローニング方法を示しています。
|
関連項目: Oracle Real Application Clusters管理およびデプロイメント・ガイド |
次のコマンドを使用して、Oracle Database ORACLE_HOMEを交換データベース・サーバーに追加します。
$ cd /u01/app/oracle/product/11.2.0/dbhome_1/oui/bin/
$ ./addNode.sh -silent "CLUSTER_NEW_NODES={replacement_server}"
2つ目のコマンドを使用すると、Oracle Universal InstallerによってOracle Databaseソフトウェアが交換データベース・サーバーにコピーされます。
WARNING: The following configuration scripts need to be executed as the "root" user in each cluster node. /u01/app/oracle/product/11.2.0/dbhome_1/root.sh #On nodes dm01db01 To execute the configuration scripts: Open a terminal window. Log in as root. Run the scripts on each cluster node.
スクリプトの完了後、次のメッセージが表示されます。
The Cluster Node Addition of /u01/app/oracle/product/11.2.0/dbhome_1 was successful. Please check '/tmp/silentInstall.log' for more details.
交換データベース・サーバーで次のスクリプトを実行します。
# /u01/app/oracle/product/11.2.0/dbhome_1/root.sh
スクリプトの出力に/u01/app/oracle/product/11.2.0/dbhome_1/install/root_replacement_server.company.com_date.logファイルを確認します。
インスタンス・パラメータが交換したデータベース・インスタンスに設定されていることを確認します。次に、CLUSTER_INTERCONNECTSパラメータの例を示します。
SQL> SHOW PARAMETER cluster_interconnects NAME TYPE VALUE ------------------------------ -------- ------------------------- cluster_interconnects string SQL> ALTER SYSTEM SET cluster_interconnects='192.168.73.90' SCOPE=spfile SID='dbm1';
構成ファイルを次のように検証します。
ORACLE_HOME/dbs/initSID.oraファイルは、Oracle ASM共有記憶域のSPFILEを指します。
ORACLE_HOME/dbディレクトリにコピーされるパスワードは、orapwSIDに変更されています。
パラメータを設定したら、データベース・インスタンスを再起動します。
この手順をOracle Exadata Database Machineエイス・ラックで実行した場合は、「Oracle Exadata Database Machineエイス・ラックのOracle Linuxデータベース・サーバーのリカバリ後の構成」の手順を実行します。
この項では、既存のエラスティック構成に次の変更を行う方法について説明します。
ストレージ・セルを伴う変更については、「ストレージ・セルの既存のエラスティック構成の変更」を参照してください。
このシナリオでは、Exadata上の既存のOracle RACに新しいデータベース・サーバーを追加します。
新しいデータベース・サーバーを再イメージ化する必要があるかどうかを確認します。
新しいデータベース・サーバーを追加するクラスタ内のデータベース・サーバーのイメージ・ラベルをチェックします。クラスタ内の既存のデータベース・サーバーのイメージ・ラベルとの一致のためにデータベース・サーバーの再イメージ化が必要な場合は、「Oracle Linuxデータベース・サーバーの再イメージ化」の作業1、2、4、5および6に従ってデータベース・サーバーを再イメージ化します。
アップグレードが必要な場合は、dbnodeupdate.shを使用してアップグレードを実行できます。詳細は、My Oracle Supportノート1553103.1を参照してください。
クラスタにデータベース・サーバーを追加します。
これを実行するには、「Oracle Linuxデータベース・サーバーの再イメージ化」の作業7以降の作業を実行してください。
最新のexachkをダウンロードして実行し、結果の構成にOracle Exadataの最新のベスト・プラクティスが実装されたことを確認します。
このシナリオでは、既存のデータベース・サーバーを再利用し、同じExadataラック内の別のクラスタに移動します。
既存のクラスタからデータベース・サーバーを削除します。
データベース・サーバー上のグリッド・インフラストラクチャを停止します。
$GI_HOME/bin/crstl stop crs
「Oracle Linuxデータベース・サーバーの再イメージ化」の作業3を実行して、クラスタからデータベース・サーバーを削除します。
再利用するデータベース・サーバーの再イメージ化が必要かどうかを確認します。
再利用するデータベース・サーバーを追加するクラスタ内のデータベース・サーバーのイメージ・ラベルをチェックします。クラスタ内の既存のデータベース・サーバーのイメージ・ラベルとの一致のために再利用するデータベース・サーバーの再イメージ化が必要な場合は、「Oracle Linuxデータベース・サーバーの再イメージ化」の作業1、2、4、5および6に従ってデータベース・サーバーをイメージ化します。
アップグレードが必要な場合は、dbnodeupdate.shを使用してアップグレードを実行できます。詳細は、My Oracle Supportノート1553103.1を参照してください。
クラスタにデータベース・サーバーを追加します。
これを実行するには、「Oracle Linuxデータベース・サーバーの再イメージ化」の作業7以降の作業を実行してください。
最新のexachkをダウンロードして実行し、結果の構成にOracle Exadataの最新のベスト・プラクティスが実装されたことを確認します。
このシナリオでは、Oracle RACから、それに含まれているデータベース・サーバーを削除します。
削除するデータベース・サーバー上のグリッド・インフラストラクチャを停止します。
$GI_HOME/bin/crstl stop crs
「Oracle Linuxデータベース・サーバーの再イメージ化」の「作業3: クラスタの障害が発生したデータベース・サーバーの削除」を実行して、クラスタからデータベース・サーバーを削除します。
最新のexachkをダウンロードして実行し、結果の構成にOracle Exadataの最新のベスト・プラクティスが実装されたことを確認します。
この項には次のサブセクションが含まれます:
Quorumディスク管理ユーティリティはOracle Exadata release 12.1.2.3.0で導入されました。
このユーティリティを使用してiSCSI quorumディスクを2つのデータベース・ノード上に作成し、それら2つのquorumディスクに投票ファイルを格納できます。追加された2つの投票ファイルは、投票ファイル5つという高冗長性ディスク・グループの最小要件を満たすために使用されます。この機能は、次の要件を満たすExadataラックにのみ適用されます。
Exadataラック内のストレージ・サーバーの数が5台未満
Exadataラック内に少なくとも2つのデータベース・ノードがある
Exadataラックに少なくとも1つの高冗長性ディスク・グループがある
さらに2つの障害グループが存在することから、この機能では投票ファイルがExadataラック(ストレージ・サーバーが5台未満)上の高冗長性ディスク・グループに格納されます。
この機能を使用しない場合、投票ファイルはExadataラック(ストレージ・サーバーが5台未満)上の標準冗長性ディスク・グループに格納されます。これによりグリッド・インフラストラクチャは二重パートナ・ストレージ・サーバー障害に対して脆弱になり、投票ファイルquorumが喪失し、その結果クラスタおよびデータベースの完全停止を招くこともあります。このシナリオにおけるクラスタウェアおよびデータベースの再起動については、My Oracle Supportノート1339373.1を参照してください。
RDSの使用でib0とib1のIPアドレスの可用性が高くなるため、iSCSI quorumディスクの実装は高い可用性を実現します。将来的に内部ネットワークの構成の柔軟化または分離が行われても、このマルチパス機能によりiSCSI quorumディスク実装はシームレスに動作し続けます。
次の図内の各iSCSIデバイスは、iSCSIターゲットに向かう特定のパスに対応しています。各パスはデータベース・ノードのInfiniBandポートに対応しています。アクティブ–アクティブ・システム内のマルチパスquorumディスク・デバイスごとに、2つのiSCSIデバイス(ib0用とib1用)があります。
図2-8 アクティブ-アクティブ・システムにおいて、両方のiSCSIデバイスに接続するマルチパス・デバイス
この機能はベア・メタルOracle RACクラスタとOVM RACクラスタで使用できます。OVM RACクラスタの場合、quorumディスク・デバイスはOVMユーザー・ドメインであるRACクラスタ・ノード(次の図を参照)に配置されます。
pkeyが有効の環境では、ターゲットの発見に使用するインタフェースをOracle Clusterware通信で使用するpkeyインタフェースにする必要があります。これらのインタフェースは"$GRID_HOME/bin/oifcfg getif | grep cluster_interconnect | awk '{print $1}'"の出力に表示されます。
Quorumディスク管理ユーティリティ(quorumdiskmgr)は、iSCSI構成、iSCSIターゲット、iSCSI LUN、iSCSIデバイスなど、この機能の実装に必要なすべてのコンポーネントを作成および管理するために使用します。
Quorumディスク管理ユーティリティの詳細は、「quorumdiskmgrリファレンス」を参照してください。
この機能を使用するには、次のリリースが必要です。
Oracle Exadata softwareリリース12.1.2.3.0以上
すべてのデータベース・ホームにパッチ23200778を適用
Oracle Grid Infrastructure 12.1.0.2.160119(パッチ22722476および22682752を適用)またはOracle Grid Infrastructure 12.1.0.2.160419以上
新規のデプロイメントでは、OEDAによってパッチが自動的にインストールされます。
この項では、高冗長性ディスク・グループおよび5台未満のストレージ・ディスクを含むOracle Exadataラック上のデータベース・ノードに、quorumディスクを追加する方法を説明します。
この項の例では、2つのデータベース・ノード(db01およびdb02)のあるクオータ・ラックにquorumディスクを作成します。
これは、アクティブ-アクティブ・システムです。db01およびdb02の両方には、2つのInfiniBandポート、ib0およびib1があります。
iSCSIデバイスとの通信に使用するネットワーク・インタフェースは次のコマンドを使用して確認できます。
$ oifcfg getif | grep cluster_interconnect | awk '{print $1}'
各インタフェースのIPアドレスは次のコマンドを使用して確認できます。
ip addr show <interface_name>
この例のInfiniBand IPアドレスは次のとおりです。
db01の場合:
ネットワーク・インタフェース: ib0、IPアドレス: 192.168.10.45
ネットワーク・インタフェース: ib1、IPアドレス: 192.168.10.46
db02の場合:
ネットワーク・インタフェース: ib0、IPアドレス: 192.168.10.47
ネットワーク・インタフェース: ib1、IPアドレス: 192.168.10.48
quorumディスクが追加されるASMディスク・グループは、DATAC1です。ASM所有者はgrid,で、ユーザー・グループはoinstallです。
投票ファイルは当初、標準冗長性ディスク・グループRECOC1に配置されています。
$ $GRID_HOME/bin/crsctl query css votedisk ## STATE File Universal Id File Name Disk group -- ----- ----------------- --------- --------- 1. ONLINE 21f5507a28934f77bf3b7ecf88b26c47 (o/192.168.76.187;192.168.76.188/RECOC1_CD_00_celadm12) [RECOC1] 2. ONLINE 387f71ee81f14f38bfbdf0693451e328 (o/192.168.76.189;192.168.76.190/RECOC1_CD_00_celadm13) [RECOC1] 3. ONLINE 6f7fab62e6054fb8bf167108cdbd2f64 (o/192.168.76.191;192.168.76.192/RECOC1_CD_00_celadm14) [RECOC1] Located 3 voting disk(s).
次のようにして、quorumディスクを作成します:
db01およびdb02に、ルートとしてログインします。
quorumdiskmgrコマンドを--create --configオプションを使用して実行し、quorumディスク構成をdb01およびdb02の両方に作成します。
# /opt/oracle.SupportTools/quorumdiskmgr --create --config --owner=grid --group=oinstall --network-iface-list="ib0, ib1"
quorumdiskmgrコマンドを--list --configオプションを使用して実行し、構成がdb01およびdb02の両方に正しく作成されたことを確認します。
# /opt/oracle.SupportTools/quorumdiskmgr --list --config
出力は次のようになります:
Owner: grid Group: oinstall ifaces: exadata_ib1 exadata_ib0
quorumdiskmgrコマンドを--create --targetオプションを使用して実行し、ASMディスク・グループDATAC1のターゲットをdb01およびdb02の両方に作成し、両方で表示されるようにします。
# /opt/oracle.SupportTools/quorumdiskmgr --create --target --asm-disk-group=datac1 --visible-to="192.168.10.45, 192.168.10.46, 192.168.10.47, 192.168.10.48"
quorumdiskmgrコマンドを--list --targetオプションを使用して実行し、ターゲットがdb01およびdb02の両方に正しく作成されたことを確認します。
# /opt/oracle.SupportTools/quorumdiskmgr --list --target
db01では、出力は次のようになります。
Name: iqn.2015-05.com.oracle:QD_DATAC1_DB01 Size: 128 MB Host name: DB01 ASM disk group name: DATAC1 Visible to: 192.168.10.45, 192.168.10.46, 192.168.10.47, 192.168.10.48 Discovered by:
db02では、出力は次のようになります。
Name: iqn.2015-05.com.oracle:QD_DATAC1_DB02 Size: 128 MB Host name: DB02 ASM disk group name: DATAC1 Visible to: 192.168.10.45, 192.168.10.46, 192.168.10.47, 192.168.10.48 Discovered by:
quorumdiskmgrコマンドを--create --deviceオプションを使用して実行し、db01およびdb02の両方のターゲットから、db01およびdb02の両方にデバイスを作成します。
# /opt/oracle.SupportTools/quorumdiskmgr --create --device --target-ip-list="192.168.10.45, 192.168.10.46, 192.168.10.47, 192.168.10.48"
quorumdiskmgrコマンドを--list --deviceオプションを使用して実行し、デバイスがdb01およびdb02の両方に正しく作成されたことを確認します。
# /opt/oracle.SupportTools/quorumdiskmgr --list --device
db01およびdb02の両方で、出力は次のようになります。
Device path: /dev/exadata_quorum/QD_DATAC1_DB01 Size: 128 MB Host name: DB01 ASM disk group name: DATAC1 Device path: /dev/exadata_quorum/QD_DATAC1_DB02 Size: 128 MB Host name: DB02 ASM disk group name: DATAC1
db01またはdb02のいずれかで、グリッド・ユーザーに切り替えます。
Oracle ASM環境を設定します。
asm_diskstring初期化パラメータを変更し、既存の文字列に/dev/exadata_quorum/*を追加します。
次に例を示します。
SQL> alter system set asm_diskstring='o/*/DATAC1_*','o/*/RECOC1_*','/dev/exadata_quorum/*' scope=both sid='*';
2つのquorumディスク・デバイスが、ASMにより自動的に検知されたことを確認します。
SQL> select inst_id, label, path, mode_status, header_status from gv$asm_disk where path like '/dev/exadata_quorum/%';
出力は次のようになります:
INST_ID LABEL PATH MODE_STATUS HEADER_STATUS ------- -------------- ---------------------------------- ------ --------- 1 QD_DATAC1_DB01 /dev/exadata_quorum/QD_DATAC1_DB01 ONLINE MEMBER 1 QD_DATAC1_DB02 /dev/exadata_quorum/QD_DATAC1_DB02 ONLINE MEMBER 2 QD_DATAC1_DB01 /dev/exadata_quorum/QD_DATAC1_DB01 ONLINE MEMBER 2 QD_DATAC1_DB02 /dev/exadata_quorum/QD_DATAC1_DB02 ONLINE MEMBER
2つのquorumディスク・デバイスを高冗長性ASMディスク・グループに追加します。
高冗長性ディスク・グループがない場合は、高冗長性ディスク・グループを作成して、この2つの新しいquorumディスクを含めます。次に例を示します。
SQL> create diskgroup DATAC1 high redundancy quorum failgroup db01 disk '/dev/exadata_quorum/QD_ DATAC1_DB01' quorum failgroup db02 disk '/dev/exadata_quorum/QD_ DATAC1_DB02' ...
高冗長性ディスク・グループがすでに存在する場合は、2つの新しいquorumディスクを追加します。次に例を示します。
SQL> alter diskgroup datac1 add quorum failgroup db01 disk '/dev/exadata_quorum/QD_DATAC1_DB02' quorum failgroup db02 disk '/dev/exadata_quorum/QD_DATAC1_DB01';
標準冗長性ディスク・グループの既存の投票ファイルを高冗長性ディスク・グループに移します。
$ $GRID_HOME/bin/crsctl replace votedisk +DATAC1
投票ディスクが高冗長性ディスク・グループに移動し、5つの投票ファイルが存在することを確認します。
crsctl query css votedisk
出力には、ストレージ・サーバーからの投票ディスク3つと、データベース・ノードからの投票ディスク2つが表示されます。
## STATE File Universal Id File Name Disk group -- ----- ----------------- --------- --------- 1. ONLINE ca2f1b57873f4ff4bf1dfb78824f2912 (o/192.168.10.42/DATAC1_CD_09_celadm12) [DATAC1] 2. ONLINE a8c3609a3dd44f53bf17c89429c6ebe6 (o/192.168.10.43/DATAC1_CD_09_celadm13) [DATAC1] 3. ONLINE cafb7e95a5be4f00bf10bc094469cad9 (o/192.168.10.44/DATAC1_CD_09_celadm14) [DATAC1] 4. ONLINE 4dca8fb7bd594f6ebf8321ac23e53434 (/dev/exadata_quorum/QD_ DATAC1_DB01) [DATAC1] 5. ONLINE 4948b73db0514f47bf94ee53b98fdb51 (/dev/exadata_quorum/QD_ DATAC1_DB02) [DATAC1] Located 5 voting disk(s).
ASMパスワード・ファイルとASM spfileを高冗長性ディスク・グループに移動します。
ASMパスワード・ファイルを移動します。
i) ソースのASMパスワード・ファイルの場所を取得します。
$ asmcmd pwget --asm
ii) ASMパスワード・ファイルを高冗長性ディスク・グループに移動します。
$ asmcmd pwmove --asm <full_path_of_source_file> <full_path_of_destination_file>
例:
asmcmd pwmove --asm +recoc1/ASM/PASSWORD/pwdasm.256.898960531 +datac1/asmpwdfile
ASM spfileを移動します。
i) 現在使用しているASM spfileを取得します。
$ asmcmd spget
ii) ASM spfileを高冗長性ディスク・グループにコピーします。
$ asmcmd spcopy <full_path_of_source_file> <full_path_of_destination_file>
iii) 次の再起動時に移動したspfileが使用されるように、グリッド・インフラストラクチャ構成を変更します。
$ asmcmd spset <full_path_of_destination_file>
このコマンドはいずれかのOVM RACクラスタ・ノードから実行する必要があります。
ダウンタイムが発生しても構わなければ、次のコマンドを使用してこの時点でグリッド・インフラストラクチャを再起動します。
# $GI_HOME/bin/crsctl stop crs # $GI_HOME/bin/crsctl start crs
ダウンタイムを許容できない場合は、グリッド・インフラストラクチャを再起動するまでの間は、ASM spfileの初期化パラメータの変更が必要になるたびに手順15.1を繰り返します。
MGMTDBを高冗長性ディスク・グループに移動します。
My Oracle Supportノート1589394.1を参照し、mgmtdb (実行している場合)を高冗長性ディスク・グループに移動します。
次の手順を使用し、hugepagesを使用しないようにmgmtdbを構成します。
export ORACLE_SID=-MGMTDB export ORACLE_HOME=$GRID_HOME sqlplus ”sys as sysdba” SQL> alter system set use_large_pages=false scope=spfile sid='*';
この手順はオプションです。
グリッド・インフラストラクチャを再起動します。
# $GI_HOME/bin/crsctl stop crs # $GI_HOME/bin/crsctl start crs
標準冗長性ディスク・グループを高冗長性ディスク・グループに変換します。
ディスク・グループの冗長性の変更方法の詳細は、My Oracle Supportノート438580.1を参照してください。
Oracle Exadataリリース12.1.2.3.0以上での新規デプロイメントでは、次の要件がすべて満たされる場合、OEDAによってデフォルトでこの機能が実装されます。
システムに少なくとも2つのデータベース・ノードと5台未満のストレージ・サーバーが含まれている
OEDAリリース2016年2月以降を実行している
「Quorumディスク管理のソフトウェア要件」に記載されているソフトウェア要件を満たしている
Oracle Databaseが11.2.0.4以上である
システム上に少なくとも1つの高冗長性ディスク・グループがある
システム上に3台のストレージ・サーバーがある場合、OEDAによって選択されたクラスタ内の最初の2つのデータベース・ノードに、2つのquorumディスクが作成されます。
システム上に4台のストレージ・サーバーがある場合、OEDAによって選択された最初のデータベース・ノードに、1つのquorumディスクが作成されます。
ターゲットのExadataシステム内に5台未満のストレージ・サーバー、少なくとも1つの高冗長性ディスク・グループおよび2つ以上のデータベース・ノードがある場合、quorumdiskmgrを使用して手動でこの機能を実装できます。詳細は、「Quorumディスクのデータベース・ノードへの追加」を参照してください。
既存のRACクラスタに2つ未満のデータベース・ノードと5台未満のストレージ・サーバーが含まれていて、投票ファイルが高冗長性ディスク・グループに配置されていない場合は、quorumディスクをデータベース・ノードに追加し、投票ファイルを高冗長性ディスク・グループに移動することをお薦めします。詳細は、「Quorumディスクのデータベース・ノードへの追加」を参照してください。「Quorumディスク管理のソフトウェア要件」を満たしている必要があります。
削除するデータベース・ノードがquorumディスクをホストしていない場合は、必要な処置はありません。
削除するデータベース・ノードが投票ファイルを含むquorumディスクをホストしていて、RACクラスタ内に5台以上のストレージ・サーバーがある場合、必要な処置はありません。投票ファイルをホストしているデータベース・ノードを削除すると、投票ファイルのリフレッシュ時に、投票ファイルがなかったストレージ・サーバー上に、削除された投票ファイルが自動的に再配置されます。
削除するデータベース・ノードが投票ファイルを含むquorumディスクをホストしていて、RACクラスタ内のストレージ・サーバーが5台未満の場合、データベース・ノードを削除する前に別のデータベース・ノードにquorumディスクを作成する必要があります。次の手順を実行します。
現在quorumディスクをホストしていないデータベース・ノードにquorumディスクを作成します。
db01およびdb02に、ルートとしてログインします。
quorumdiskmgrコマンドを--create --configオプションを使用して実行し、quorumディスク構成をdb01およびdb02の両方に作成します。
# /opt/oracle.SupportTools/quorumdiskmgr --create --config --owner=grid --group=oinstall --network-iface-list="ib0, ib1"
quorumdiskmgrコマンドを--list --configオプションを使用して実行し、構成がdb01およびdb02の両方に正しく作成されたことを確認します。
# /opt/oracle.SupportTools/quorumdiskmgr --list --config
出力は次のようになります:
Owner: grid Group: oinstall ifaces: exadata_ib1 exadata_ib0
quorumdiskmgrコマンドを--create --targetオプションを使用して実行し、ASMディスク・グループDATAC1のターゲットをdb01およびdb02の両方に作成し、両方で表示されるようにします。
# /opt/oracle.SupportTools/quorumdiskmgr --create --target --asm-disk-group=datac1 --visible-to="192.168.10.45, 192.168.10.46, 192.168.10.47, 192.168.10.48"
quorumdiskmgrコマンドを--list --targetオプションを使用して実行し、ターゲットがdb01およびdb02の両方に正しく作成されたことを確認します。
# /opt/oracle.SupportTools/quorumdiskmgr --list --target
db01では、出力は次のようになります。
Name: iqn.2015-05.com.oracle:QD_DATAC1_DB01 Size: 128 MB Host name: DB01 ASM disk group name: DATAC1 Visible to: 192.168.10.45, 192.168.10.46, 192.168.10.47, 192.168.10.48 Discovered by:
db02では、出力は次のようになります。
Name: iqn.2015-05.com.oracle:QD_DATAC1_DB02 Size: 128 MB Host name: DB02 ASM disk group name: DATAC1 Visible to: 192.168.10.45, 192.168.10.46, 192.168.10.47, 192.168.10.48 Discovered by:
quorumdiskmgrコマンドを--create --deviceオプションを使用して実行し、db01およびdb02の両方のターゲットから、db01およびdb02の両方にデバイスを作成します。
# /opt/oracle.SupportTools/quorumdiskmgr --create --device --target-ip-list="192.168.10.45, 192.168.10.46, 192.168.10.47, 192.168.10.48"
quorumdiskmgrコマンドを--list --deviceオプションを使用して実行し、デバイスがdb01およびdb02の両方に正しく作成されたことを確認します。
# /opt/oracle.SupportTools/quorumdiskmgr --list --device
db01およびdb02の両方で、出力は次のようになります。
Device path: /dev/exadata_quorum/QD_DATAC1_DB01 Size: 128 MB Host name: DB01 ASM disk group name: DATAC1 Device path: /dev/exadata_quorum/QD_DATAC1_DB02 Size: 128 MB Host name: DB02 ASM disk group name: DATAC1
2つのquorumディスク・デバイスを高冗長性ASMディスク・グループに追加します。
高冗長性ディスク・グループがない場合は、高冗長性ディスク・グループを作成して、この2つの新しいquorumディスクを含めます。次に例を示します。
SQL> create diskgroup DATAC1 high redundancy quorum failgroup db01 disk '/dev/exadata_quorum/QD_ DATAC1_DB01' quorum failgroup db02 disk '/dev/exadata_quorum/QD_ DATAC1_DB02' ...
高冗長性ディスク・グループがすでに存在する場合は、2つの新しいquorumディスクを追加します。次に例を示します。
SQL> alter diskgroup datac1 add quorum failgroup db01 disk '/dev/exadata_quorum/QD_DATAC1_DB02' quorum failgroup db02 disk '/dev/exadata_quorum/QD_DATAC1_DB01';
データベース・ノードを削除すると、投票ファイルが手順1で追加したquorumディスクに自動的に再配置されます。
quorumディスクを使用するストレージ・サーバーを追加する場合は、新しく追加するストレージ・サーバーにデータベース・ノード上の投票ファイルを再配置することをお薦めします。
Exadataストレージ・サーバーを追加します。詳細は、「セル・ノードの追加」を参照してください。
次の例では、追加される新しいストレージ・サーバーの名前は"celadm04"です。
ストレージ・サーバーの追加後、v$asm_disk内の新しい障害グループを確認します。
SQL> select distinct failgroup from v$asm_disk; FAILGROUP ------------------------------ ADM01 ADM02 CELADM01 CELADM02 CELADM03 CELADM04
少なくとも1つのデータベース・ノードに投票ファイルを含むquorumディスクが含まれていることを確認します。
$ crsctl query css votedisk ## STATE File Universal Id File Name Disk group -- ----- ----------------- --------- --------- 1. ONLINE 834ee5a8f5054f12bf47210c51ecb8f4 (o/192.168.12.125;192.168.12.126/DATAC5_CD_00_celadm01) [DATAC5] 2. ONLINE f4af2213d9964f0bbfa30b2ba711b475 (o/192.168.12.127;192.168.12.128/DATAC5_CD_00_celadm02) [DATAC5] 3. ONLINE ed61778df2964f37bf1d53ea03cd7173 (o/192.168.12.129;192.168.12.130/DATAC5_CD_00_celadm03) [DATAC5] 4. ONLINE bfe1c3aa91334f16bf78ee7d33ad77e0 (/dev/exadata_quorum/QD_DATAC5_ADM01) [DATAC5] 5. ONLINE a3a56e7145694f75bf21751520b226ef (/dev/exadata_quorum/QD_DATAC5_ADM02) [DATAC5] Located 5 voting disk(s).
この例では、2つのデータベース・ノード上に投票ファイルを含む2つのquorumディスクがあります。
いずれか1つのquorumディスクを削除します。
SQL> alter diskgroup datac5 drop quorum disk QD_DATAC5_ADM01;
削除したquorumディスク上の投票ファイルは、投票ファイルのリフレッシュ時にグリッド・インフラストラクチャによって、新しく追加したストレージ・サーバー上に自動的に再配置されます。これは次の方法で確認できます。
$ crsctl query css votedisk ## STATE File Universal Id File Name Disk group -- ----- ----------------- --------- --------- 1. ONLINE 834ee5a8f5054f12bf47210c51ecb8f4 (o/192.168.12.125;192.168.12.126/DATAC5_CD_00_celadm01) [DATAC5] 2. ONLINE f4af2213d9964f0bbfa30b2ba711b475 (o/192.168.12.127;192.168.12.128/DATAC5_CD_00_celadm02) [DATAC5] 3. ONLINE ed61778df2964f37bf1d53ea03cd7173 (o/192.168.12.129;192.168.12.130/DATAC5_CD_00_celadm03) [DATAC5] 4. ONLINE a3a56e7145694f75bf21751520b226ef (/dev/exadata_quorum/QD_DATAC5_ADM02) [DATAC5] 5. ONLINE ab5aefd60cf84fe9bff6541b16e33787 (o/192.168.12.131;192.168.12.132/DATAC5_CD_00_celadm04) [DATAC5]
ストレージ・サーバーを削除した結果、Oracle RACクラスタで使用されるストレージ・サーバーが5台未満になる場合で投票ファイルが高冗長性ディスク・グループ内にある場合は、データベース・ノードにquorumディスクを追加する(まだ存在しない場合)ことをお薦めします。「Quorumディスクのデータベース・ノードへの追加」を参照してください。
ストレージ・サーバーを削除する前にquorumディスクを追加しておき、ストレージ・サーバーの削除後すぐに5つの投票ファイルのコピーを使用できるようにしておきます。
quorumディスク管理ユーティリティ(quorumdiskmgr)を各データベース・サーバーで実行すると、iSCSI quorumディスクをデータベース・サーバー上に作成できます。quorumdiskmgrを使用して、iSCSI quorumディスクをデータベース・サーバーで作成、リスト、変更および削除できます。出荷時に、ユーティリティはデータベース・サーバーにインストールされます。
このリファレンスの項の内容は、次のとおりです。
quorumディスク管理ユーティリティは、コマンドライン・ツールです。構文は次のとおりです。
quorumdiskmgr --verb --object [--options]
verbは、オブジェクト上で実行されるアクションです。これは、alter、create、delete、listのいずれかです。
objectは、コマンドでアクションを実行するオブジェクトです。
optionsは、コマンドの追加パラメータを使用できるようにコマンドの組合せの使用範囲を拡大します。
quorumdiskmgrユーティリティを使用する場合は、次のルールが適用されます:
動詞、オブジェクトおよびオプションは、明示的に指定されている場合を除き、大/小文字が区別されます。
二重引用符文字を使用して、オプションの値をスペースおよび句読点を含めて囲みます。
| オブジェクト | 説明 |
|---|---|
config |
quorumディスク構成には、iSCSI quorumディスクを追加するASMインスタンスの所有者およびグループ、およびローカルおよびリモートiSCSI quorumディスクの発見で使用するネットワーク・インタフェースのリストが含まれます。 |
target |
ターゲットは、各データベース・サーバー上のエンドポイントで、iSCSIイニシエータがセッションを確立するまで待機し、必要なIOデータ転送を提供します。 |
device |
デバイスは、iSCSIデバイスで、ローカルまたはリモート・ターゲットへのログインで作成されます。 |
--create --configコマンドは、quorumディスク構成を作成します。構成は、ターゲットまたはデバイスが作成される前に作成する必要があります。
構文
quorumdiskmgr --create --config [--owner owner --group group] --network-iface-list network-iface-list
属性
次の表に、--create --configコマンドの属性の一覧を示します:
| 属性 | 説明 |
|---|---|
| owner | iSCSI quorumディスクを追加するASMインタフェースの所有者を指定します。これはオプションの属性です。デフォルト値は、gridです。 |
| group | iSCSI quorumディスクを追加するASMインタフェースのグループを指定します。これはオプションの属性です。デフォルト値は、oinstallです。 |
| network-iface-list | ローカルおよびリモート・ターゲットの発見で使用されるネットワーク・インタフェース名のリストを指定します。 |
例
quorumdiskmgr --create --config --owner=oracle --group=oinstall --network-iface-list="ib0, ib1"
--create --targetコマンドは、指定されたInfiniBand IPアドレスのリスト内のInfiniBand IPアドレスを使用してデータベース・サーバーによりアクセスされるターゲットを作成し、指定されたASMディスク・グループに追加されるデバイスを作成します。
ターゲットが作成されると、そのasm-disk-group、host-nameおよびsize属性は変更できません。
構文
quorumdiskmgr --create --target --asm-disk-group asm_disk_group --visible-to infiniband_ip_list [--host-name host_name] [--size size]
属性
| 属性 | 説明 |
|---|---|
| asm-disk-group | ターゲットから作成されるデバイスが追加されるASMディスク・グループを指定します。asm-disk-groupの値は大/小文字が区別されません。 |
| visible-to | InfiniBand IPアドレスのリストを指定します。リスト内のInfiniBand IPアドレスを持つデータベース・サーバーは、ターゲットへのアクセスがあります。 |
| host-name | quorumdiskmgrが稼働するデータベース・サーバーのホスト名を指定します。asm-disk-groupおよびhost-nameの合計の長さは、26文字を超えてはいけません。ホスト名が長すぎる場合、クオータ・ラックの各データベース・サーバーに別々のホスト名が指定されている場合にかぎり、短いホスト名を指定できます。
これはオプションの属性です。デフォルト値は、quorumdiskmgrが稼働するデータベース・サーバーのホスト名です。host-nameの値は大/小文字が区別されません。 |
| size | ターゲットのサイズを指定します。これはオプションの属性です。デフォルト値は128MBです。 |
例
quorumdiskmgr --create --target --size=128MB --asm-disk-group=datac1 --visible-to="192.168.10.45, 192.168.10.46" --host-name=db01
--create --deviceコマンドは、指定されたIPアドレスのリスト内のInfiniBand IPアドレスを使用してターゲットを発見およびログインし、デバイスを作成します。
作成されたデバイスは、構成の作成中に指定された所有者およびグループのあるASMインスタンスにより、自動的に発見されます。
構文
quorumdiskmgr --create --device --target-ip-list target_ip_list
属性
| 属性 | 説明 |
|---|---|
| target-ip-list | InfiniBand IPアドレスのリストを指定します。quorumdiskmgrは、InfiniBand IPアドレスを持つデータベース・サーバー上のターゲットを発見し、ターゲットにログインしてデバイスを作成します。 |
例
quorumdiskmgr --create --device --target-ip-list="192.168.10.45, 192.168.10.46"
--list --configコマンドは、quorumディスク構成をリストします。
構文
quorumdiskmgr --list --config
出力例
Owner: grid Group: oinstall ifaces: exadata_ib1 exadata_ib0
--list --targetコマンドは、ターゲット名、サイズ、ホスト名、ASMディスク・グループ名、ターゲットに対してアクセスを持つデータベース・サーバーを示すIPアドレスのリスト(visible-to IPアドレス・リスト)およびターゲットにログインしたデータベース・サーバーを示すIPアドレスのリスト(discovered-by IPアドレス・リスト)を含むターゲットの属性をリストします。
ASMディスク・グループが指定された場合、コマンドは、指定されたASMディスク・グループに作成されたすべてのローカル・ターゲットをリストします。それ以外の場合、コマンドは、quorumディスクに作成されたすべてのローカル・ターゲットをリストします。
構文
quorumdiskmgr --list --target [--asm-disk-group asm_disk_group]
属性
| 属性 | 説明 |
|---|---|
| asm-disk-group | ASMディスク・グループを指定します。quorumdiskmgrは、このASMディスク・グループのすべてのローカル・ターゲットを表示します。asm-disk-groupの値は大/小文字が区別されません。 |
出力例
Name: iqn.2015-05.com.oracle:QD_DATAC1_DB01 Size: 128 MB Host name: DB01 ASM disk group name: DATAC1 Visible to: 192.168.10.48, 192.168.10.49, 192.168.10.46, 192.168.10.47 Discovered by: 192.168.10.47, 192.168.10.46
--list --deviceコマンドは、デバイス・パス、サイズ、ホスト名およびASMディスク・グループを含むデバイスの属性をリストします。
ASMディスク・グループ名のみが指定された場合、コマンドは、ASMディスク・グループに追加されたすべてのデバイスをリストします。
ホスト名のみが指定された場合、コマンドは、ホスト上のターゲットから作成されたすべてのデバイスをリストします。
ASMディスク・グループ名およびホスト名の両方が指定された場合、ホスト上のターゲットから作成され、ASMディスク・グループに追加された単一のデバイスをリストします。
ASMディスク・グループ名およびホスト名のいずれも指定されない場合、コマンドは、すべてのquorumディスク・デバイスをリストします。
構文
quorumdiskmgr --list --device [--asm-disk-group asm_disk_group] [--host-name host_name]
属性
| 属性 | 説明 |
|---|---|
| asm-disk-group | デバイスが追加されたASMディスク・グループを指定します。asm-disk-groupの値は大/小文字が区別されません。 |
| host-name | ターゲット・デバイスが作成されたデータベース・サーバーのホスト名を指定します。host-nameの値は大/小文字が区別されません。 |
出力例
Device path: /dev/exadata_quorum/QD_DATAC1_DB01 Size: 128 MB Host name: DB01 ASM disk group name: DATAC1 Device path: /dev/exadata_quorum/QD_DATAC1_DB02 Size: 128 MB Host name: DB02 ASM disk group name: DATAC1
--delete --configコマンドは、quorumディスク構成を削除します。構成は、ターゲットまたはデバイスが存在しない場合にのみ削除できます。
構文
quorumdiskmgr --delete --config
--delete --targetコマンドは、データベース・サーバー上のquorumディスクに作成されたターゲットを削除します。
ASMディスク・グループが指定された場合、コマンドは、指定されたASMディスク・グループに作成されたすべてのローカル・ターゲットを削除します。それ以外の場合、コマンドは、quorumディスクに作成されたすべてのローカル・ターゲットを削除します。
構文
quorumdiskmgr --delete --target [--asm-disk-group asm_disk_group]
属性
| 属性 | 説明 |
|---|---|
| asm-disk-group | ASMディスク・グループを指定します。このディスク・グループに作成されたローカル・ターゲットが削除されます。asm-disk-groupの値は大/小文字が区別されません。 |
例
quorumdiskmgr --delete --target --asm-disk-group=datac1
--delete --deviceコマンドは、quorumディスク・デバイスを削除します。
ASMディスク・グループ名のみが指定された場合、コマンドは、ASMディスク・グループに追加されたすべてのデバイスを削除します。
ホスト名のみが指定された場合、コマンドは、ホスト上のターゲットから作成されたすべてのデバイスを削除します。
ASMディスク・グループ名およびホスト名の両方が指定された場合、ホスト上のターゲットから作成され、ASMディスク・グループに追加された単一のデバイスを削除します。
ASMディスク・グループ名およびホスト名のいずれも指定されない場合、コマンドは、すべてのquorumディスク・デバイスを削除します。
構文
quorumdiskmgr --delete --device [--asm-disk-group asm_disk_group] [--host-name host_name]
属性
| 属性 | 説明 |
|---|---|
| asm-disk-group | 削除する対象のデバイスのASMディスク・グループを指定します。asm-disk-groupの値は大/小文字が区別されません。 |
| host-name | データベース・サーバーのホスト名を指定します。このホスト上のターゲットから作成されたデバイスが削除されます。host-nameの値は大/小文字が区別されません。 |
例
quorumdiskmgr --delete --device --host-name=db01
--alter --configコマンドは、所有者およびグループ構成を変更します。
構文
quorumdiskmgr --alter --config --owner owner --group group
属性
| 属性 | 説明 |
|---|---|
| owner | iSCSI quorumディスクを追加するASMインタフェースの所有者を指定します。これはオプションの属性です。デフォルト値は、gridです。 |
| group | iSCSI quorumディスクを追加するASMインタフェースのグループを指定します。これはオプションの属性です。デフォルト値は、oinstallです。 |
例
quorumdiskmgr --alter --config --owner=grid --group=oinstall
--alter --targetコマンドは、指定されたASMディスク・グループに作成されたローカル・ターゲットへのアクセスを持つデータベース・サーバーのInfiniBand IPアドレスを変更します。
構文
quorumdiskmgr --alter --target --asm-disk-group asm_disk_group --visible-to infiniband_ip_list
属性
| 属性 | 説明 |
|---|---|
| asm-disk-group | ターゲットから作成されるデバイスが追加されるASMディスク・グループを指定します。asm-disk-groupの値は大/小文字が区別されません。 |
| visible-to | InfiniBand IPアドレスのリストを指定します。リスト内のInfiniBand IPアドレスを持つデータベース・サーバーは、ターゲットへのアクセスがあります。 |
例
quorumdiskmgr --alter --target --asm-disk-group=datac1 --visible-to="192.168.10.45, 192.168.10.47"
vmetricsパッケージを使用すると、vmetricsサービスで収集されたシステム統計を表示できます。dom0またはdomUから、システム統計にアクセスできます。vmetricsサービスはdom0上で稼働して、統計を収集し、それらをxenstoreへプッシュします。これにより、domU'sが統計にアクセスできます。
vmetricsサービスによって収集されたシステム統計を、サンプル値を使用して次に表示します:
com.sap.host.host.VirtualizationVendor=Oracle Corporation;
com.sap.host.host.VirtProductInfo=Oracle VM 3;
com.sap.host.host.PagedInMemory=0;
com.sap.host.host.PagedOutMemory=0;
com.sap.host.host.PageRates=0;
com.sap.vm.vm.uuid=2b80522b-060d-47ee-8209-2ab65778eb7e;
com.sap.host.host.HostName=scac10adm01.us.oracle.com;
com.sap.host.host.HostSystemInfo=scac10adm01;
com.sap.host.host.NumberOfPhysicalCPUs=24;
com.sap.host.host.NumCPUs=4;
com.sap.host.host.TotalPhyMem=98295;
com.sap.host.host.UsedVirtualMemory=2577;
com.sap.host.host.MemoryAllocatedToVirtualServers=2577;
com.sap.host.host.FreeVirtualMemory=29788;
com.sap.host.host.FreePhysicalMemory=5212;
com.sap.host.host.TotalCPUTime=242507.220000;
com.sap.host.host.Time=1453150151;
com.sap.vm.vm.PhysicalMemoryAllocatedToVirtualSystem=8192;
com.sap.vm.vm.ResourceMemoryLimit=8192;
com.sap.vm.vm.TotalCPUTime=10160.1831404;
com.sap.vm.vm.ResourceProcessorLimit=4;
vmetricsサービスをインストールするには、dom0上でrootユーザーとしてinstall.shスクリプトを実行します:
[root@scac10adm01]# cd /opt/oracle.SupportTools/vmetrics [root@scac10adm01]# ./install.sh
install.shスクリプトは、それがdom0で実行中であり、現在実行中のvmetricsサービスを停止、パッケージ・ファイルを/opt/oracle.vmetricsにコピーおよびvmetrics.svcを/etc/init.dにコピーすることを、確認します。
vmetricsサービスをdom0で開始するには、dom0上でrootユーザーとして次のコマンドを実行します:
[root@scac10adm01 vmetrics]# service vmetrics.svc start
統計を収集するコマンドは、30秒ごとに実行されます。
vmetricsパッケージには次のファイルが含まれます:
| ファイル | 説明 |
|---|---|
install.sh |
このファイルは、パッケージをインストールします。 |
vm-dump-metrics |
このスクリプトは、統計をxenstoreから読み取り、それらをXML形式で表示します。 |
vmetrics |
このPythonスクリプトは、システム・コマンドを実行し、それらをxenstoreにアップロードします。システム・コマンドは、vmetrics.confファイル内にリストされています。 |
vmetrics.conf |
このXMLファイルは、dom0がxenstoreへプッシュするべきメトリックおよび各メトリックで実行するシステム・コマンドを指定します。 |
vmetrics.svc |
vmetricsをLinuxサービスにするinit.dファイル。 |
統計がxenstoreにプッシュされた後、次のいずれかのコマンドを実行すると、dom0およびdomU上に統計を表示できます:
|
注意: domU's上に、xenstoreproviderおよびovmdパッケージがインストールされていることを確認してください。
次のコマンドを使用して、Oracle VM APIをサポートするためにOracle Linux 5および6で必要なパッケージをインストールします。 # yum install ovmd xenstoreprovider |
/usr/sbin/ovmd -g vmhostコマンドは、1つのライン上の統計を表示します。sedコマンドは、ラインを複数のラインに分割し、ラインごとに統計します。このコマンドは、rootユーザーとして実行する必要があります。
root@scac10db01vm04 ~]# /usr/sbin/ovmd -g vmhost |sed 's/; */;\n/g;s/:"/:"\n/g' com.sap.host.host.VirtualizationVendor=Oracle Corporation; com.sap.host.host.VirtProductInfo=Oracle VM 3; com.sap.host.host.PagedInMemory=0; com.sap.host.host.PagedOutMemory=0; com.sap.host.host.PageRates=0; com.sap.vm.vm.uuid=2b80522b-060d-47ee-8209-2ab65778eb7e; com.sap.host.host.HostName=scac10adm01.us.oracle.com; com.sap.host.host.HostSystemInfo=scac10adm01; com.sap.host.host.NumberOfPhysicalCPUs=24; com.sap.host.host.NumCPUs=4; ...
vm-dump-metricsコマンドは、XML形式でメトリックを表示します。
[root@scac10db01vm04 ~]# ./vm-dump-metrics <metrics> <metric type='real64' context='host'> <name>TotalCPUTime</name> <value>242773.600000</value> </metric> <metric type='uint64' context='host'> <name>PagedOutMemory</name> <value>0</value> </metric> ...
vm-dump-metricsコマンドを、コマンドを実行するdomU'sにコピーすることに注意してください。
独自のメトリックを追加して、vmetricsサービスで収集することができます。
/opt/oracle.SupportTools/vmetrics/vmetrics.confに、新しいメトリック、およびそのメトリックを取得および解析するためのシステム・コマンドを追加します。次に例を示します。
<metric type="uint32" context="host">
<name>NumCPUs</name>
<action>grep -c processor /proc/cpuinfo</action>
<action2>xm list | grep '^Domain-0' |awk '{print $4}'</action2>
</metric>
<name>要素に、新しいメトリックの名前を入力します。
<action>および<action2>要素に、新しいメトリックのシステム・コマンドを指定します。<action2>のみが必要ですが、<action2>がシステムで機能しない場合は、<action>をフォールバックとして使用できます。
vmの名前が必要なアクションはいずれもscas07client07vm01を使用する必要があることに留意してください。vmetricsが稼働すると、このダミー名を、dom0で稼働中の実際のdomU名とスワップします。
/opt/oracle.SupportTools/vmetrics/vmetricsで、リストgFieldsList内のメトリックを追加します。メトリックがホスト(dom0)に関する場合、メトリック名に接頭辞"host"を追加し、メトリックがvm (domU)に関する場合、"vm"を追加します。次に例を示します。
gFieldsListは、次のようになります:
gFieldsList = [ 'host.VirtualizationVendor',
'host.VirtProductInfo',
'host.PagedInMemory',
'vm.ResourceProcessorLimit' ]
"NumCPUs" (手順1の例で示すように)という名の新しいメトリックを追加して、このメトリックがdomUに対して、dom0がいくつの使用可能なCPUを持つか告げる場合、gFieldsListは、次のようになります:
gFieldsList = [ 'host.VirtualizationVendor',
'host.VirtProductInfo',
'host.PagedInMemory',
'vm.ResourceProcessorLimit',
'host.NumCPUs']
(オプション) /opt/oracle.SupportTools/vmetrics/vm-dump-metricsに、新しいメトリックをXML出力に含めたい場合、新しいメトリックを追加します。
この手順をスキップすると、ovmd -g vmhostコマンドを使用して新しいメトリックを表示できます。