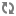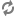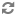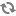This section discusses the performance implications of some aspects of Endeca record configuration.
The Select feature prevents the transfer of unneeded properties and dimension values when they are not used by the front-end Web application.
It therefore makes the application more efficient because the unneeded data does not take up network bandwidth and memory on the application server. This may be relevant if your logs are showing large result pages.
You set the selection list on the ENEQuery.setSelection() method (Java), or the ENEQuery.Selection property (.NET).
Aggregated records are not necessarily an expensive feature in the MDEX Engine. However, use them only when necessary, because they add organizational and implementation complexity to the application (particularly if the rollup key is different from the display information).
Using aggregated records slows down the performance of sorting and paging.
Note also that dynamic statistics on regular and aggregated records
(controlled with the
--stat-abins Dgraph flag) are expensive
computations for the MDEX Engine. See the topic in this section for more
details.
Some overhead is introduced to calculate derived properties on aggregated records. In most cases this should be negligible. However, large numbers of derived properties and, more importantly, aggregated records with many member records may degrade performance.
You can use the
Np parameter to specify the number of records to be
returned with an aggregated records. For example,
Np=1 means that a single representative record is
returned with each aggregate record, and
Np=2 brings back all records.
Utilizing
Np=2 may adversely affect your performance, as it
causes the MDEX Engine to serialize more records for each query. The degree to
which performance is affected is proportional to the number of base records for
each aggregate record that is returned.
In most cases, it is not recommended to bring back all records in each
query and aggregate all records with
Np=2 as this computation could be expensive for the
MDEX Engine to serialize the result. However,
Np=2 can be useful in some cases. The impact on
performance is proportional to the number of records that will be returned as
aggregates.
For example, if each aggregate record contains only 2 records, the
record serialization time is only twice the time as it is for
Np=1. If, however, each aggregated record has 100
records associated with it, it is 100 times more expensive to perform the
record serialization for Np=2 than for Np=1.
Record serialization time is typically only a large portion of the query processing time in very low latency applications or with very large numbers of returned records.
Note also that in many cases, a 100-fold increase in record
serialization time is barely noticeable. You can examine the
Prefetching horizontal records statistics in the
Hotspot Analysis section of the Stats page to
determine whether their performance issue is due to returning many records.
For example, if you have a very small data set with queries served
almost entirely from the cache, where most of the computation done by the
Dgraph for each query consists of assembling the records to be returned, the
negative effect on performance is reflected in the
Prefetching horizontal records statistics being very
large in this case which indicates that
Np=2 should not be used.