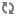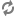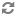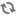Your pipeline functions as the script for the entire data transformation process that occurs when you run the Forge program. The pipeline specifies things like the format and location of the source data, any changes to be made to the source data (standardization), and the mapping method to use for each of the source data’s properties.
A pipeline is composed of a collection of components. Each component performs a specific function during the transformation of your source data into Guided Search records. Components are linked together by means of cross-references, giving the pipeline a sequential flow.
You add and edit pipeline components using the Pipeline Diagram editor in Developer Studio.
The pipeline diagram depicts the components in your pipeline and the relationship between them. It describes the flow of events that occur in the process of converting raw data to a format that the MDEX Engine can use, making it easy for you to trace the logic of your data model. The pipeline diagram is the best way to maneuver and maintain a high-level view of your pipeline as it grows in size and complexity.
For details on adding and editing pipeline components, see the Oracle Developer Studio Help.
You must give every component in your pipeline a unique name that identifies it to the other components. You use these names to specify cross-references between components, effectively creating a flow of data through the pipeline.
Example 8. Pipeline Example
For example, by tracing the data flow backwards in the following illustration and starting from the bottom, you can see that:
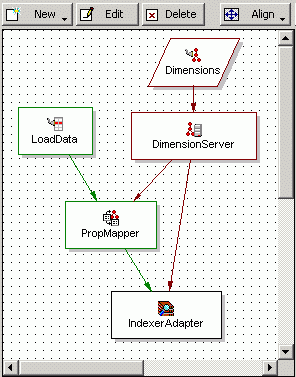
When you specify a data source within a component’s editor, you are indicating which of the other components will provide data to that component. Components can have multiple data sources, such as the PropMapper component above, which has both a record source, LoadData, and a dimension source, DimensionServer.
Example 9. Pipeline Example: Adding a Pipeline Component
Alternatively, you can connect pipeline components graphically in the Pipeline Diagram editor.
When you add and remove components, you must be careful to make any data source changes required to maintain the correct data flow. To illustrate this point, the example above is modified to include another component, RecordManipulator, that comes between LoadData and PropMapper in the data flow of the pipeline. Adding RecordManipulator in this location requires that:
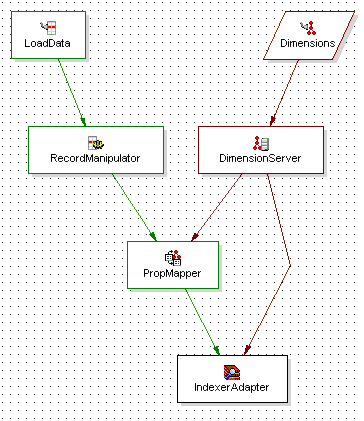
Similar care must be taken when removing a component from a pipeline.
Some of the components in the pipeline require URLs that point to external files, such as source data files. All of these URLs are relative to the location of the Pipeline.epx file.
This file contains the pipeline specifications that you have created in Developer Studio. Developer Studio automatically generates a Pipeline.epx file when you create a new project and saves it in the same directory as your .esp project file.
Note
As a rule, you should not move the Pipeline.epx file, or any other automatically generated files, from their location in the same directory as the .esp project file.