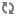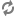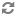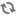Create a properties file named
columnHandler.properties.
Place this
file in the
ENDECA_ROOT\lib\java directory. The following table
lists the configuration options used in the
columnHandler.properties file:
|
|
The size (in bytes) of the incremental data chunk read and written while processing binary columns. This is a performance optimization setting; changing this value will not affect the values ultimately returned by the Advanced JDBC Column Handler. Default setting:
|
|
|
The size (in bytes) of the incremental data chunk read and written while processing character-data columns. This is a performance optimization setting; changing this value will not affect the values ultimately returned by the Advanced JDBC Column Handler. Default setting:
|
|
|
The directory to which data files will be written (see File System Output). Relative paths to an output directory will be relative to forge’s working directory. Default setting:
|
|
|
If this setting is true , character data will be written out to the file system (encoded
according to the value of the
Default setting:
|
|
|
Output encoding to use when writing character data to disk. A valid Java charset name must be specified. Some common encoding charsets are listed below:
This setting is only used if
Default setting:
|
Here is a sample
columnHandler.properties file:
binaryDataChunkSize=1024 charDataChunkSize=1024 outputDataDir=C:\\Endeca\\Apps\\Discover\\data\\forge_output charDataToDisk=true charDataOutputEnc=UTF-8
If Forge is triggered in standalone mode then this configuration file
can be placed in the same directory as the
adapter.jar file. The
outputDataDir in that case should point to the
current working directory.
During a baseline update using the JDBC Column Handler, if this file is
not present at
$ENDECA_ROOT\lib\java, there is a mismatch between
the output folders during execution and the output is not what is expected.