| Oracle(c) Data Minerインストレーションおよび管理ガイド リリース4.1 E62043-01 |
|


 前 |
 次 |
SQLスクリプトの生成は、Oracle Data Miner 4.1で利用できる機能です。この章では、この機能の説明となる概要とユースケースを提供します。次のトピックがあります。
Oracle Data Miner 4.1には、SQLスクリプト生成機能が用意されています。この機能を使用して、ワークフロー内の1つまたはすべてのノード用にSQLスクリプトを生成できます。その後で、SQLスクリプトを別のアプリケーションに統合できます。このように、Oracle Data Minerは、データ・マイニングを別のエンド・ユーザー・アプリケーションと統合するためのスコープを提供します。ユースケースを援用しつつ、この機能について詳しく説明します。
SQLスクリプト生成機能について、サンプル・ワークフローcodegen_workflowとデモ・データベーステーブルINSUR_CUST_LTV_SAMPLEを使用するユースケースを援用しつつ説明します。このユースケースは次の操作の方法を示します。
ワークフローcodegen_workflowのインポート、実行およびデプロイ
ワークフローcodegen_workflowからのSQLスクリプトの生成
次を使用する、データベース上でのSQLスクリプトの実行のスケジューリング
Oracle SQL Developer
Oracle Enterprise Manager
生成されたSQLスクリプトの、ターゲットまたは本番データベース上へのデプロイ
ユースケース構築の前提は、次のとおりです。
データ・アナリストが、モデル構築とスコアリングのワークフローを定義します。
データ・アナリストは、新しいスクリプト生成機能を使用して、SQLスクリプト一式をデプロイメントのためにアプリケーション開発者に渡します。
アプリケーション開発者は、スクリプトをターゲットまたは本番データベースにデプロイし、そこで、定期的なスクリプトの実行をスケジュールすることができます。これにより、スクリプト実行のたびに、新しい顧客データを使用してモデルを作成できます。
デモ・データベース: このユースケースは、ユーザー・アカウントにインストールできるデモ・データベース表INSUR_CUST_LTV_SAMPLEを使用します。
事前定義済ワークフロー: このユースケースでは、事前定義済ワークフローcodegen_workflowを援用して手順を説明します。
事前定義済ワークフローを含むワークフロー・ファイルcodegen_workflow.xmlは、SQL Developerのインストール場所(<sqldeveloper>\dataminer\demos\workflows)から利用できます。
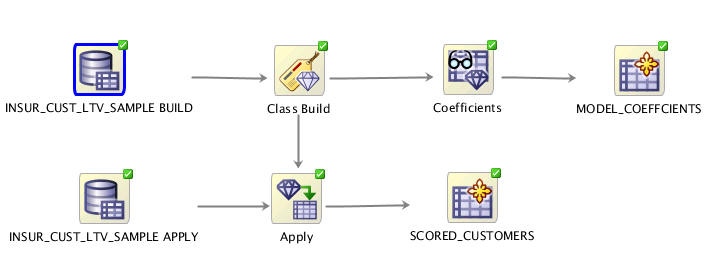
このユースケースcodegen_workflowのサンプル・ワークフローは、単一の系統に含まれる2つの異なったプロセス(図7-1に示すモデリング(上)とスコアリング(下))から構成されます。どちらの処理も、入力データ・ソースとしてデモ・データINSUR_CUST_LTV_SAMPLEを使用します。
モデリング: モデリング・プロセスにより、分類サポート・ベクター・マシン(SVM)モデルが構築されます。顧客が保険を買うかどうかを予測します。モデル係数は、表示のためにデータベース表に永続化されます。この表がアプリケーション統合の基盤になる場合があります。
スコアリング: スコアリング・プロセスは、モデリング系統によって作成されたサポート・ベクター・マシン(SVM)モデルを使用して顧客データを予測します。予測結果は、表示のためにデータベース・ビューに永続化されます。このビューは、次のものを提供します。
現在の入力データの予測。たとえば、入力表が新しいデータでリフレッシュされた場合、このビューは新しいデータの予測を自動的に取得します。
アプリケーション統合の基礎。
ワークフローをデプロイする前に、次のことを確実に行ってください。
システム上にOracle Data Miner 4.1をインストールします。
Oracle Data Minerユーザー・アカウントを作成します。
Data Miningユーザー・アカウントを作成するサンプル文の例を示します。この文は、権限のあるユーザーによって発行される必要があります。
grant create session, create table, create view,
create mining model, create procedure,
無制限の表領域
to <username>;
データベース表をロードします。
ワークフローをインポートして、実行します。
|
関連項目:
|
事前定義済のworkflow_codegen.xmlをインポートする手順:
SQL Developer 4.1で、「Data Miner」タブに移動し、接続を展開します。
接続を右クリックして、「新規プロジェクト」をクリックします。
作成したばかりのプロジェクトを右クリックして、「ワークフローのインポート」を選択します。
「ワークフローのインポート」ダイアログ・ボックスで、サンプル・ワークフロー・ファイルcodegen_workflow.xmlをダウンロードして保存した場所を参照します。codegen_workflow.xmlを選択し、「OK」をクリックします。図7-2に示すように、インポートしたワークフローcodegen_workflowが、Oracle Data MinerのUIに表示されるようになりました。
INSUR_CUST_LTV_SAMPLE_BUILDノードを右クリックし、「実行の強制」をクリックします。
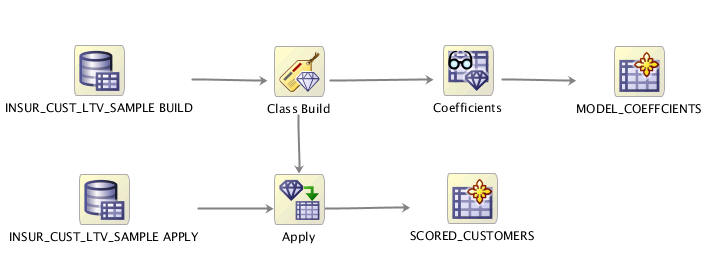
「実行の強制」サブメニューで、オプション「選択されたノードと子」を選択します。これにより、codegen_workflow内のすべてのノードが実行されます。ワークフローが正常に実行されると、図7-3に示すように、ワークフローのすべてのノードが、緑のチェック・マークで表されます。
これにより、ワークフローをインポートおよび実行するタスクが完了します。
SQLスクリプトを生成する前に、ワークフローを実行する必要があります。ワークフローからSQLスクリプト・ファイルを生成する手順:
任意のノードを右クリックして、「デプロイ」を選択します。このユースケースでは、INSUR_CUST_LTV_SAMPLE BUILDノードを右クリックし、「デプロイ」の下の、「選択したノードと接続ノード」オプションを選択します。
|
注意: このユースケースの場合、事前定義済ワークフローcodegen_workflowが使用されます。 |
スクリプト・デプロイメント・オプションは次のとおりです。
選択したノードと接続ノード: このオプションは、選択したノードとそのすべての親ノードのためのSQLスクリプトを生成します。たとえば、図7-3に示すように、適用ノードが選択された場合、次のノードのためのスクリプトが生成されます。
INSUR_CUST_LTV_SAMPLE BUILD
分類構築
INSUR_CUST_LTV_SAMPLE APPLY
適用
選択したノード、依存ノード、子ノード: このオプションは、選択したノードとそのすべての親および子ノードのためのスクリプトを生成します。たとえば、図7-3に示すように、適用ノードが選択された場合、次のノードのためのスクリプトが生成されます。
INSUR_CUST_LTV_SAMPLE BUILD
分類構築
INSUR_CUST_LTV_SAMPLE APPLY
適用
SCORED_CUSTOMERS
選択したノードと接続ノード: このオプションは、選択したノードと、選択したノードに接続されるすべてのノードのためのスクリプトを生成します。たとえば、図7-3に示すように、適用ノードが選択された場合、ワークフロー内の適用ノードに接続されたすべてのノードのためのスクリプトが生成されます。
|
注意: ワークフロー全体のためのスクリプトを生成するには、ワークフロー内のすべてのノードを選択して([Ctrl]キーを同時に押しながらすべてのノードをクリック)、前述の3つのデプロイメント・オプションのいずれかを選択します。 |
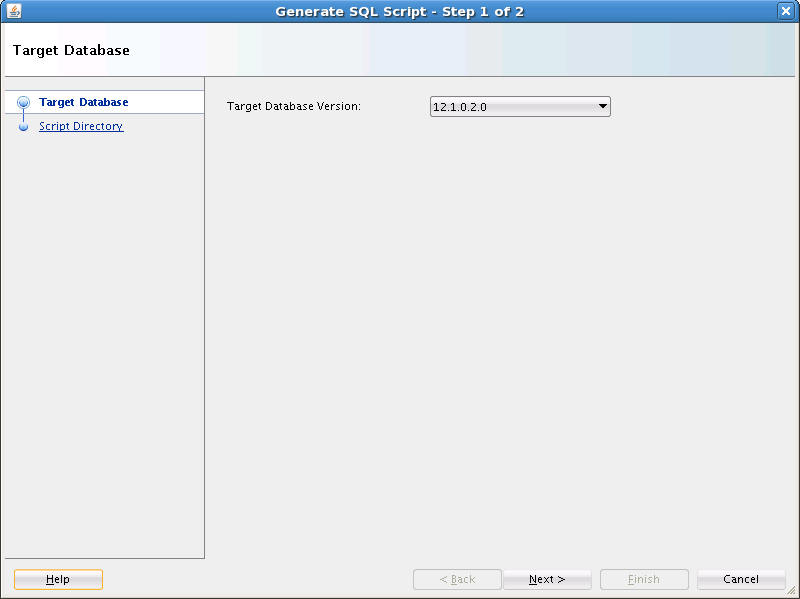
「デプロイ」オプションを選択した後、図7-4に示すように、SQLスクリプトの生成 - ステップ1/2ウィザードが開きます。
「ターゲット・データベースのバージョン」フィールドで、データベース・バージョンを選択します。生成されたスクリプトに、ここで選択したデータベースのバージョンとの互換性があることを確認します。これは、SQLスクリプトが実行されるデータベースです。
「次へ」をクリックします。図7-5に示すように、SQLスクリプトの生成 - ステップ2/2ウィンドウが開きます。
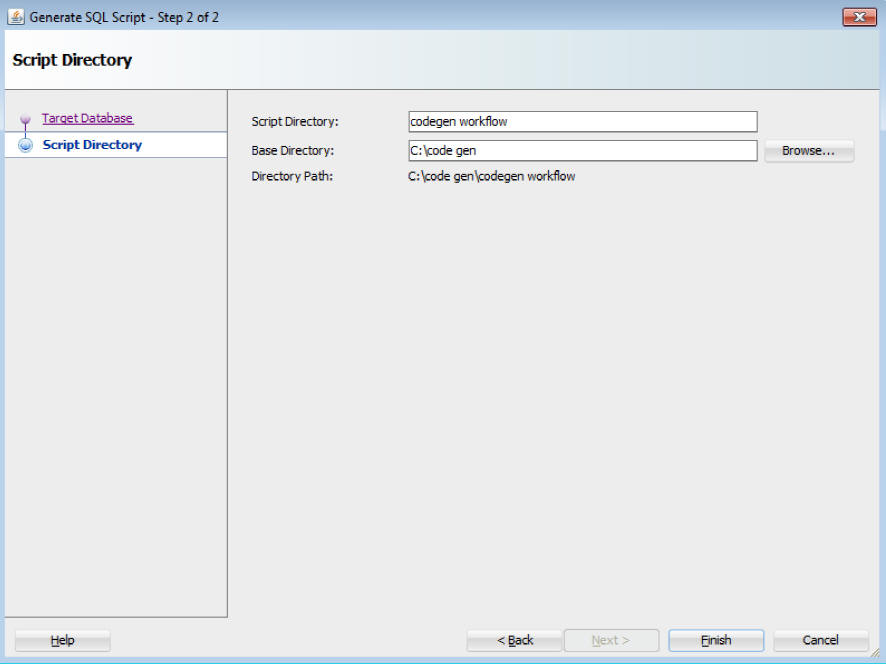
スクリプトの生成ウィザードのステップ2で、次の情報を入力します。
スクリプト・ディレクトリ: これは、生成されたスクリプトが格納されるディレクトリの名前です。
ベース・ディレクトリ: 「参照」をクリックして別の場所に移動して、スクリプトのディレクトリを作成します。
ディレクトリ・パス: スクリプト・ディレクトリのパスを表示します。
「終了」をクリックします。これは、スクリプト生成プロセスを起動します。スクリプトが正常に生成されると、図7-6に示すように、次のメッセージが表示されます。「OK」をクリックします。
ステップ5で定義したスクリプト・ディレクトリで、生成されたスクリプトのリストを確認できます。
表7-1に、codegen_workflowから生成されたSQLスクリプト・ファイルとその説明をリストします。
表7-1 生成されたスクリプト・ファイルとその説明
| スクリプト・ファイルのタイプ | スクリプト・ファイルの名前 | codegen_workflowから生成されたスクリプト・ファイルの例 | 説明 |
|---|---|---|---|
|
マスター・スクリプト |
|
|
必要なすべてのノード・レベル・スクリプトを正しい順序で起動します。それは次のタスクを実行します:
|
|
クリーンアップ・スクリプト |
|
|
マスター・スクリプトによって作成されたすべてのオブジェクトを削除します。次を削除します。
|
|
ワークフローのイメージ |
|
|
これは、スクリプト生成時におけるワークフローのイメージです。 |
|
ノード・スクリプト |
|
|
構築ノードのモデル作成など、ノード固有の操作を実行します。スクリプト生成に参加する各ノードにつき、1つのノード・スクリプトが生成されます。 |
ノードのために生成されたSQLスクリプトには、スクリプトによって作成されたパブリック・オブジェクトにオブジェクト名を提供する変数定義があります。マスター・スクリプトは、基礎となるノード・レベル・スクリプトをすべて、適切な順序で起動します。そのため、すべての変数定義は、マスター・スクリプトで定義される必要があります。
次の変数がサポートされます。
表またはビューおよびモデルなど、ノード・レベル・スクリプトに入力されるオブジェクトの名前の変更を可能にする変数。デフォルトでは、これらの名前は、表またはビュー名、およびモデルの元の名前です。
制御表の名前の変更を可能にする変数。デフォルトで、制御表の名前は、ワークフロー名です。
名前付きオブジェクトを、スクリプトによって生成される前に、先に削除するべきかどうかを示す変数。
マスター・スクリプト<workflow name>_Run.sqlが実行されているとき、制御表名変数で指定された名前を使用して、制御表が先に作成されます。制御表は、次を実行します。
ビュー、モデル、テキスト仕様など、生成されたオブジェクトを登録します
ワークフロー内で入力オブジェクトが論理ノードによって参照されるのを可能にし、出力オブジェクトを登録します
クリーンアップ・スクリプトによって削除する必要があるオブジェクトを決定します
ワークフローを介してすぐにアクセスできないオブジェクトの内部名を提供します。たとえば、ユーザーは、制御表の表示によって、モデル・テスト結果表を見つけることができます。
異なる制御ファイル名と異なる出力変数名を使用すると、生成されたスクリプトを使用して、異なる結果を同時に生成、管理できます。これは、入力データ・ソースが、独立にマイニングするデータの異なるセットを継続する場合に、役に立つ場合があります。このユースケースでは、アプリケーションは、生成された結果の再実行または削除時に利用できるように、制御表の名前を保存する役割を果たします。
制御表の構造は、次のとおりです。
CREATE TABLE "&WORKFLOW_OUTPUT"
(
NODE_ID VARCHAR2(30) NOT NULL,
NODE_NAME VARCHAR2(30) NOT NULL,
NODE_TYPE VARCHAR2(30) NOT NULL,
MODEL_ID VARCHAR2(30),
MODEL_NAME VARCHAR2(65),
MODEL_TYPE VARCHAR2(35),
OUTPUT_NAME VARCHAR2(30) NOT NULL,
OUTPUT_TYPE VARCHAR2(30) NOT NULL,
ADDITIONAL_INFO VARCHAR2(65),
CREATION_TIME TIMESTAMP(6) NOT NULL,
COMMENTS VARCHAR2(4000 CHAR)
)
表7-2に、制御表の列と、その説明および例をリストします。
表7-2 制御表の列とその説明
| 列名 | 説明 | 例 |
|---|---|---|
|
NODE_ID |
これは、ワークフローの一部を構成するノードのIDです。ノードを一意に識別します。 |
10001, 10002 |
|
NODE_NAME |
これは、ワークフローの一部を構成するノードの名前です。 |
分類構築、MINING_DATA_BUILD_V |
|
NODE_TYPE |
これは、ノードのカテゴリです。 |
データソース・ノード、分類構築ノードなど。 |
|
MODEL_ID |
これは、ワークフロー・モデルのIDです。ワークフロー内で参照される各モデルを一意に識別します。 |
10101, 10102 |
|
MODEL_NAME |
これは、モデルの名前です。 |
CLAS_GLM_1_6 |
|
MODEL_TYPE |
モデル・タイプは、モデルが使用するアルゴリズム・タイプです。 |
一般化線形モデル、Support Vector Machineなど |
|
OUTPUT_NAME |
これは、出力の名前です。名前がユーザーの管理下にあるのでない限り、これは内部的に生成された名前です。 |
表/ビュー名、モデル名、テキスト・オブジェクト名。例: ODMR$15_37_21_839599RMAFRXI - 表名 "DMUSER"."CLAS_GLM_1_6" - 完全修飾モデル名 |
|
OUTPUT_TYPE |
出力オブジェクトのタイプを制限します。 |
表、ビュー、モデル |
|
ADDITIONAL_INFO |
これは、スクリプト実行に関するオブジェクトの目的を修飾する情報です。 |
テスト・リフト結果のためのターゲット・クラス |
|
CREATION_TIME |
これは、オブジェクト作成時刻です。 |
11-DEC-12 03.37.25.935193000 PM (形式はロケールにより決定) |
|
COMMENTS |
スクリプト実行に関するオブジェクトのロールを修飾するコメント。 |
出力データ(データソースのようなノードに表示される) データの使用方法(モデル構築に渡されるビューに表示される) 重みの設定(モデル構築に渡される重みの表に表示される) 構築設定(モデル構築に渡される構築設定表に表示される) モデル(モデル・オブジェクトに表示される) |
生成されたすべてのSQLスクリプト・ファイルは、データベース・インスタンスがアクセスできるターゲットまたは本番データベースにデプロイする必要があります。SQLスクリプト・ファイルは、同じディレクトリに一緒に格納する必要があります。
この項では、SQL DeveloperとOracle Enterprise Managerを使用して、マスター・スクリプトの実行をスケジュールする方法を説明します。
SQLスクリプト・ファイルをスケジュールする前提条件は、次のとおりです。
Oracle Database: 生成されたSQLスクリプト・ファイルをスケジュールするには、Oracle Databaseのインスタンスが必須です。
SQLスクリプト・ファイル: 生成されたすべてのSQLスクリプト・ファイルは、データベース・インスタンスがアクセスできるターゲットまたは本番データベース・ホストにデプロイする必要があります。すべてのスクリプト・ファイルを、同じディレクトリに一緒に格納する必要があります。
Oracle Data Minerリポジトリ: リポジトリが提供するサービスを一部のノード・スクリプトが実行時に使用するため、スクリプトを実行するにはData Minerリポジトリが必須です。リポジトリが提供するサービスの例には、Explorerノードのための統計計算、テキストの構築ノードのためのテキスト処理などがあります。
Oracle Data Minerユーザー・アカウント: リポジトリが提供するサービスに必要な権限をユーザー・アカウントが持っているため、スクリプト・ファイルの実行には必須です。
マスター・スクリプト・ファイル内の完全なディレクトリ・パス: マスター・スクリプト内の各ノード・スクリプトの起動への完全なディレクトリ・パスを追加します。これは、実行時にマスター・スクリプトが個々のノード・スクリプト・ファイルをコールするために必須です。
マスター・スクリプトに完全なディレクトリ・パスを追加する手順:
マスター・スクリプトcodegen_workflow_Run.sqlを開いて、次の行を見つけます。
-- Workflow run
@@"INSUR_CUST_LTV_SAMPLE BUILD.sql";
@@"INSUR_CUST_LTV_SAMPLE APPLY.sql";
@@"Class Build.sql"; @@"Coefficients.sql";
@@"MODEL_COEFFCIENTS.sql";
@@"Apply.sql";
@@"SCORED_CUSTOMERS.sql";
マスター・スクリプト・ファイルを編集して、スクリプトの格納先となるターゲットまたは本番データベースのホスト・コンピュータの完全なディレクトリ・パスを追加します。この例では、スクリプト・ファイルがhome/workspaceディレクトリにデプロイされると想定されています。次に例を示します。
-- Workflow run
@@"/home/workspace/INSUR_CUST_LTV_SAMPLE BUILD.sql";
@@"/home/workspace/INSUR_CUST_LTV_SAMPLE APPLY.sql";
@@"/home/workspace/Class Build.sql";
@@"/home/workspace/Coefficients.sql";
@@"/home/workspace/MODEL_COEFFCIENTS.sql";
@@"/home/workspace/Apply.sql";
@@"/home/workspace/SCORED_CUSTOMERS.sql";
マスター・スクリプト・ファイルを保存して閉じます。
資格証明はOracle Schedulerオブジェクトで、専用のデータベース・オブジェクトに格納されるユーザー名とパスワードのペアです。次のように、2つの資格証明を作成する必要があります。
ホスト資格証明: SQLPlusスクリプト・ジョブは、ホスト資格証明を使用して、SQLPlus実行可能ファイルを実行できるように、データベース・インスタンスまたはオペレーティング・システムに対して自己自身を認証します。
接続資格証明: この資格証明には、スクリプトを実行する前にSQLPlusをデータベースに接続するデータベース資格証明が含まれます。
資格証明を作成する手順:
「接続」タブで、ユーザー・アカウントが作成される接続を展開します。
その接続の下の「スケジューラ」を展開します。
「スケジューラ」の下で、「資格証明」を右クリックし、「新規資格証明」をクリックします。「資格証明の作成」ダイアログ・ボックスが開きます。
まず、ジョブが実行されているホストにログインするためのホスト資格証明を作成します。次の情報を指定します。
名前
「有効」を選択します。
説明
ユーザー名
パスワード
「適用」をクリックします。
これで、データベース・ホストと接続のための資格証明を作成するタスクは完了です。
Oracle SQL Developerには、Schedulerジョブを定義するためのグラフィカル・ユーザー・インタフェースがあります。SQL Developerを使用したSQLスクリプトのスケジューリングには、次が含まれます。
ジョブ・スケジュールを定義する手順:
SQL Developerの「接続」タブで、ユーザー・アカウントが作成される接続を展開します。
その接続の下の「スケジューラ」を展開します。
「スケジューラ」の下で、「ジョブ」を右クリックし、「新規ジョブ(ウィザード)」をクリックします。「ジョブの作成」ダイアログ・ボックスが開きます。
「ジョブ・ウィザードの作成 - ステップ1/6」ダイアログ・ボックスの「ジョブ詳細」に、次の情報を入力します。
ジョブ名:
「有効」を選択します。
説明:
ジョブ・クラス:
ジョブ・タイプ: 「スクリプト」を選択します。
スクリプト・タイプ: 「SQLPlus」を選択します。
ジョブの実行時期: 「繰返し間隔」を選択します。
「繰返し間隔」ダイアログ・ボックスで、繰り返し間隔、開始日、時刻を設定して、「OK」をクリックします。
「次へ」をクリックします。
「ジョブ・ウィザードの作成 - ステップ2/6」ダイアログ・ボックスで、次の項目を定義します。
ドロップダウン・リストからオプション「ローカル」を選択します。
資格証明の選択: ドロップダウン・リストから「データベース・ホストとデータベース用の資格証明の作成」で作成したホスト資格証明を選択します。
接続の資格証明名: ドロップダウン・リストから「データベース・ホストとデータベース用の資格証明の作成」で作成した接続資格証明を選択します。
「次へ」をクリックします。
「ジョブ・ウィザードの作成 - ステップ4/6」ダイアログ・ボックスで、ジョブ・ステータスに基づく電子メール通知を設定できます。
「イベントの選択」セクションで、電子メール通知を送信するジョブ・イベントを選択します。
「受信者」フィールドに、電子メール・アドレスを入力します。各メッセージについて、受信者の電子メール・アドレスと送信者(オプション)を指定できます。
「次へ」をクリックします。
「ジョブ・ウィザードの作成 - ステップ5/6」ダイアログ・ボックスで、「次」をクリックします。このユースケースでは、このステップはスキップされます。
「ジョブ・ウィザードの作成 - ステップ6/6」ダイアログ・ボックスで、「終了」をクリックします。これで、ジョブ・スケジュールの作成は完了です。
ジョブを作成したら、SQL Developerでそれを監視できます。
Oracle Enterprise Managerを使用すると、データベース管理者がジョブを定義できます。ジョブの定義は、完全なファイル・パスを使用して、スクリプト・ファイルとしてマスター・スクリプトの起動を定義します。ジョブをスケジュールに従って実行するか、オンデマンドにするかを決定できます。アプリケーションでジョブの実行を監視することもできます。
Oracle Enterprise Managerでジョブをスケジュールする手順:
Oracle Databaseアカウントを使用してOracle Enterprise Managerにログインします。
「ジョブ・アクティビティ」セクションで、「ジョブ」をクリックします。ジョブ作成ページが開きます。
「ジョブの作成」ドロップダウン・リストで「SQLスクリプト」を選択し、「実行」をクリックします。新しいジョブを定義できる「ジョブの作成」ページが開きます。
「一般」タブで、次の詳細を入力します。
名前
説明
ターゲット・データベース: ジョブが実行されるターゲット・データベースを入力します。
「パラメータ」タブの「SQLスクリプト」セクションに、クリーンアップ・スクリプトとマスター・スクリプトのフル・パス名を入力します。
「資格証明」タブで、次の資格証明を指定します。
データベース・ホスト資格証明
データベース資格証明
「スケジュール」タブで、ジョブのスケジュールを定義します。
「アクセス」タブで、ジョブ・ステータスに基づく電子メール通知を設定できます。
「発行」をクリックしてジョブを作成します。
SQLスクリプトのデプロイには、次のように、ベース・ディレクトリからのマスター・スクリプト・ファイルの実行が必要です。
> @" C: <base directory>\<workflow name>_Run.sql"
たとえば、SQLPlusで、ベース・ディレクトリから次のようにマスター・スクリプトcodegen_workflow_Run.sqlを実行します。
>@" C:\code gen\codegen workflow\codegen_workflow_Run.sql"
引き続きマスター・スクリプト・ファイルを実行する必要がある場合は、先にクリーンアップ・スクリプトcodegen_workflow_Drop.sqlを実行して以前に生成されたオブジェクトを削除し、その後で、次のようにマスター・スクリプトを実行します。
>@" C:\code gen\codegen workflow\codegen_workflow_Drop.sql"
>@" C:\code gen\codegen workflow\codegen_workflow_Run.sql"
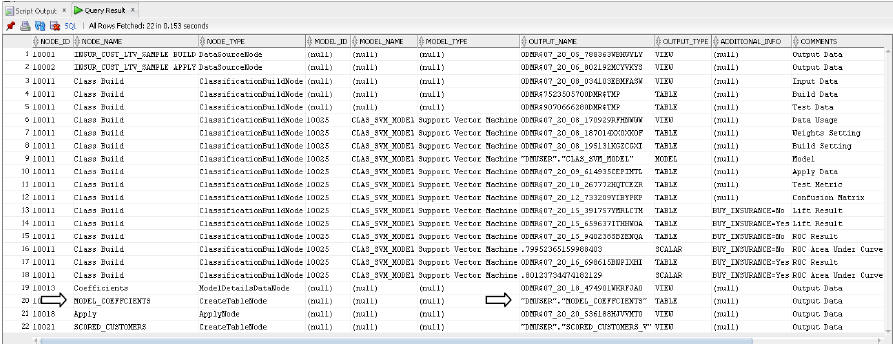
SQLスクリプトを実行した後で、生成されたオブジェクトを調べるために、制御表を問い合わせることができます。制御表を問い合わせるには、SQLPlusで次のコマンドを実行します。
>select * from <workflow_name>
たとえば、制御表でcodegen_workflowを問い合わせて、生成されたオブジェクトを次のように調べます。
>select * from "codegen_workflow"
この例では、表作成ノードMODEL_COEFFICIENTSにより、生成されたSVMモデルから抽出した係数データを永続化した出力表MODEL_COEFFCIENTSが作成されました。