

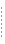

|
|
この章では、BEA AquaLogic Data Services Platform の概要について説明します。 この章の内容は以下のとおりです。
| 注意 : | BEA AquaLogic Data Services Platform の旧製品名は Liquid Data です。 製品、インストール パス、およびコンポーネントの一部のアーティファクトが、旧製品名のままになっている場合があります。 |
多くの場合、情報リソースは企業の最も重要な資産です。 正確な情報を適切なタイミングで入手できるかどうかは、日々の業務、製品やサービスのマーケティングと配送、戦略的な計画など、企業がその本質的な機能を果たせるかどうかを大きく左右します。
しかしながら、企業の成長に伴ってデータ リソースが徐々に断片化してしまうのは紛れもない事実です。 買収や合併、新しい技術の採用、IT 戦略の変更などが生じると、ひとまとまりの情報が物理的、技術的な境界によって隔離され、これがデータの断片化につながります。 通常、企業の情報は、データベースやファイル、アプリケーション内、または外部的に蓄積されているか、ビジネス パートナー、ベンダ、顧客などから Web サービスや XML ドキュメントとしてオンザフライで供給されます。図 1-1 に、このようにして断片化されたデータを図示します。
断片化された情報の統合には莫大な費用がかかるため、非常に重要度が高い場合を除き、必要であってもあきらめざるを得ないのが実情です。 また、重要度が高い場合であっても、開発者は非常に多様なデータ アクセス メカニズムや API と格闘しなければなりません。 その結果、開発されたアプリケーションはデータ管理ロジックの制約を受けることが多く、データ レイヤの変更に対応しにくいものになってしまいます。
アプリケーションのビジネス ロジックにデータ アクセス コードが埋め込まれているため、データ レイヤの変更が実際に発生した場合は、アプリケーションを修正してテストしなおす必要があります。 つまり、アプリケーションの開発の段階においても、情報が断片化されているために発生するコストは莫大なものになります。 さまざまな試算によれば、エンタープライズ アプリケーションの開発時間の最大 70% がデータ アクセス プログラミングに費やされています。
その他のコストとしては、莫大な費用がかかるデータ統合を躊躇して遅らせることによる損失が考えられます。これを定量化するのは困難ですが、かなり大きな影響があることは確かです。
データ サービスとは、アプリケーションの呼び出しによる異種データへのアクセスおよびその管理を容易にするためのクエリ ベースのアクセス レイヤです。
AquaLogic Data Services Platform は、統合されたデータ サービスを開発してデプロイするための AquaLogic コンポーネントです。 データ サービスは、分散された異種データにアクセスするための使いやすい統一的なモデルを提供します。
AquaLogic Data Services Platform を使用すると、再利用可能なデータ サービスを作成およびデプロイするための作業が大幅に簡略化できます。 AquaLogic Data Services Platform が提供するツールやフレームワークを使用して、既存のデータ サービスに基づく物理データ サービスをすばやく生成したり、論理データ サービスをグラフィカルに作成したりできます。
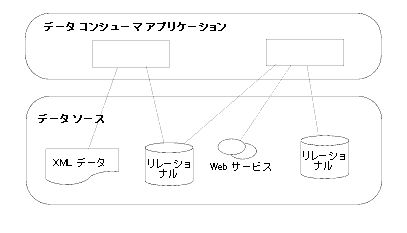
企業内のほとんどのデータは、クエリ可能データまたはアプリケーション データとして蓄積されています。 データ コンシューマから見た AquaLogic Data Services Platform は、それらの情報を取得および利用するための統一的なモデルを提供するプラットフォームです。 アプリケーションからは、データ サービスのパブリック API の 1 つを呼び出すだけで、データを取得したり更新したりできます。 バックエンド データの供給元としては、レガシー アプリケーション、リレーショナル データベース、Web サービスなどが考えられます。 したがって、データ サービスは、データ コンシューマとデータ ソースの間を統合するレイヤと捉えることができます (図 1-2 を参照)。
キャッシングの場合を除いて、AquaLogic Data Services Platform や WebLogic のコンポーネントがデータを保持することはありません。その意味では、AquaLogic Data Services Platform は仮想的なデータ レイヤです。 代わりに、データ サービスが物理データ ソースから動的にデータを取得します。 この動的なアクセスによって、アプリケーションが常に最新の情報 (リアルタイム情報) にアクセスできることを保証します。
データ サービスは、エンタープライズ データ モデル内の情報の単位を表します。 Web サービスと同様に、データ サービスも API パブリック インタフェースを 1 つまたは複数のアクセサ関数としてエクスポーズします。 データ サービスのアクセサ関数は、通常はデータ サービスの複雑データ型でデータを返します。 関数は、外部ソースからのデータを XQuery を使用して取得、変換、集約します。
返されたデータは、データ サービスの XML 型として定義された XML データ形式に格納されます。 個別のデータ サービスが表す情報の単位は比較的小さいため、応答時間が短いのが一般的です。 その他にもキャッシングやクエリの最適化を備えており、これらの機能を使用してデータ サービス レイヤのパフォーマンスを最適化できます。
AquaLogic Data Services Platform では、異種データ ソースの複雑さをデータ コンシューマ側で意識する必要はありません。 データ統合ロジックの詳細はカプセル化され、コンシューマにはデータにアクセスして更新するための一貫性のあるモデルが提供されます。 データ アクセス、ビジネス ロジック、プレゼンテーション ロジックの 3 つは完全に切り離されており、複雑なデータ アクセス コードが必要ないため、アプリケーションをより簡単に開発できます。
AquaLogic Data Services Platform では、データの読み取りの場合と同様に、データの更新においても統一的なインタフェースが提供されます。 クライアント アプリケーションは、分散された異種データ ソースを、あたかも単一のエンティティであるかのように変更したり更新したりできます。 異種データ ソースに変更を伝播するという複雑な作業は、AquaLogic Data Services Platform によって処理されます。
データ サービスの実装においても、更新可能なデータ サービスのライブラリを構築するという面倒な作業が、AquaLogic Data Services Platform の更新フレームワークによって大幅に軽減されます。 リレーショナル ソースの場合は、データ ソースへの変更が自動的に伝播されます。 その他のソースの場合や、リレーショナル更新をカスタマイズする場合は、AquaLogic Data Services Platform の更新フレームワーク アーティファクトと API を使用して、カスタマイズした更新可能サービスをすばやく実装できます。 どちらの場合も、データ コンシューマ側でデータ ソースの更新の詳細を意識する必要はありません。
サービス指向アーキテクチャ (SOA) は、IT 環境アーキテクチャの方式の 1 つです。 このアーキテクチャでは、ビジネス プロセスが疎結合サービスのセットとして提供されます。 SOA の実装を提供するのは Web サービスです。 Web サービスとは、プラットフォームに依存しない形で使用できるモジュール式の自己記述型コンポーネントです。
SOA の真価は、従来のアプリケーションが一体型のユニットとして構築されている点を考えると理解しやすくなります。 一体型のアプリケーションの場合、ユーザはプラットフォームに依存しなければならず、アプリケーションを新しいタイプの対話に適応させるのは容易ではありません。 Web サービスを使用することで、こうした一体型モデルに代えて、他の独立したコンポーネントやサービスと対話できる再利用可能な複数のコンポーネントとしてシステムを構築できます。 たとえば、1 つの財務アプリケーションを使用する代わりに、そのアプリケーションと同じビジネス処理を実行する 1 つまたは複数のサービスを、完全に独立したモジュール式の呼び出し可能プロセスとしてデプロイできます。 その結果、この財務システムのリソースを他のシステム (たとえば人事サービスまたはアプリケーション) から簡単に利用でき、将来的なニーズにも柔軟に対応することが可能になります。 このような点から、SOA は、アプリケーション間の障壁を取り除くもの、またはアプリケーションの必要性を完全になくしてしまうもの、と捉えることができます。
SOA を使用することで、仮想アプリケーションが組織全体に拡がっているかのような、有機的に統合された IT インフラストラクチャを構築できます。
SOA では、サービス プロバイダはインタフェースやコンシューマのビジネス処理を認識せず、サービス プロバイダへの明示的な参照がサービス呼び出しという形でコンシューマに含まれます。その意味で、SOA は疎結合 (完全には結合されていない) アーキテクチャとして捉えることができます。
疎結合の利点としては、簡略化されたデータ アクセス、再利用性、適応性などが挙げられます。 新しいサービスをエクスポーズして使用する際に、既存のアプリケーションを大幅に変更する必要はありません。 したがって、サービス レイヤの適応性が非常に高くなり、変更にも柔軟に対応できます。
データ ユーザと基底のデータ ソースの間にデータ抽象レイヤを設けることで、データ サービスが SOA に完全に適合します。 その結果、アプリケーション開発者は、明確に定義された統一的な SOA ベースのデータ アクセス インタフェースに依拠できます。 バックエンド データへの接続を確立するデータ アクセス スペシャリストの必要性は大幅に低下します。 アプリケーションからパブリック関数を呼び出すだけで済みます。
端的に表現するなら、AquaLogic Data Services Platform を利用することで、データを使用するアプリケーションからデータ プロバイダを解放できるということです。
その他にも、AquaLogic Data Services Platform を使用する利点として以下が挙げられます。
一般的なデータ モデルでは、ビジネス エンティティを表現する形でデータを編成します。 AquaLogic Data Services Platform では、ビジネス組織にとって合理的なデータ モデルを定義できます。 ビジネス エンティティとは、製品、注文、顧客など、ほとんどの組織に共通するエンティティです。 たとえば、Customer というデータ サービス オブジェクトには、デプロイする環境において顧客に関係するすべての属性 (連絡先、出荷方法、支払い情報など) を定義できます。 Customer オブジェクトを構成する要素の基底のデータ ソースは、そのデータの基底の構造や可用性が変更されたときにしか問題になりません。 データ サービスに、セキュリティやキャッシングなどのポリシーを設定することもできます。
データに関係するポリシーは、開発者が開発した個々のアプリケーションに実装しなくても、データに対して一貫して適用されます。
AquaLogic Data Services Platform では、分散された複雑な物理データの全体像を理解しやすいデータ モデルとして扱えるようにするため、データ サービスの開発方法として仮想的なモデル駆動型の手法がサポートされています。 モデリングでは、環境内のデータ リソースをグラフィカルに表現でき、大規模なシステムを俯瞰したり、大きな問題を複数の小さな問題に分割したりできます。
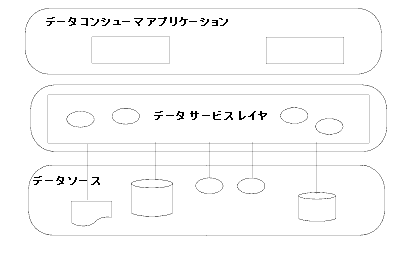
その結果、複数のアプリケーションやサービスで使用する情報にデータ サービス ポリシー (セキュリティ、キャッシングなど) を適用するための単一のポイントが提供される一方で、外部に永続化されているデータに論理データ モデルを介してリアルタイムにアクセスすることが可能になります (図 1-3 を参照)。
SOA では、サービスをプロセスという観点から捉えることが慣例になっています。 しかし、ほとんどの SOA イニシアチブは、実際にはデータから出発しています。 その性質上、データはビジネス プロセスよりも広義で、より汎用的な方法で使用するのが一般的です。 データ コンシューマは、同じデータをさまざまな方法で使用できます。 エンタープライズ データのデータ モデルをいったん開発すれば、データ サービスによってカプセル化されたデータ型をさまざまなデータ消費アプリケーションで再利用できます。
AquaLogic Data Services Platform のデプロイメントによって表現されたデータ モデルは、メタデータによって取り込まれます。 AquaLogic Data Services Platform では、メタデータを以下のようなさまざまな用途に使用します。
AquaLogic Data Services Platform Console のコンポーネントの 1 つであるメタデータ ブラウザは、メタデータによる検索や参照を行うための操作性の良いインタフェースを提供します。
データ サービスは、異種データを標準化、変換、および統合するためのロジックをカプセル化します。 クライアント アプリケーションやプロセスからデータ サービスを使用するには、データ サービスのいずれかのパブリック関数を呼び出します。 データ サービスに定義できるパブリック関数の数に制限はありません。各パブリック関数は、データ サービスに関連付けられた XML スキーマに記述されているデータ形式でデータを返します。
ロジックは、XML Query (XQuery) 言語で記述されたクエリとしてデータ サービスにカプセル化されます。 XQuery 1.0 (新しい W3C 標準仕様) は、SQL によく似た言語で、構造化された XML データを処理することを目的に設計されています。 宣言型言語である XQuery にはコンパイラ ベースの最適化手法が組み込まれており、最適化されたクエリ関数を記述するための特別なルールや手法を習得する必要はありません。
XQuery の多くの機能は SQL と共通であるため、SQL の知識があると XQuery を簡単に習得できます。 AquaLogic Data Services Platform には、操作しやすい IDE ツールを使用してグラフィカルに XQuery を作成するための XQuery エディタが用意されています。
AquaLogic Data Services Platform アプリケーションを WebLogic Server にデプロイすると、クライアントからアプリケーションを使用してリアルタイム データにアクセスできるようになります。 AquaLogic Data Services Platform では、以下のデータ クライアントがサポートされています。
どのクライアントの場合でも、Java インタフェース (AquaLogic Data Services Platform Mediator API および Workshop データ サービス コントロール) によるデータ アクセスか、またはデータ サービスのラッパーとして機能する Web サービスによるデータ アクセスがサポートされます。
その他のオプションとしては、AquaLogic Data Services Platform JDBC ドライバを使用して、SQL クライアント (レポート作成ツール、データベース ツールなど) や JDBC アプリケーションに、従来のデータベース指向のデータ レイヤを提供することも可能です。 JDBC ドライバのユーザから見ると、AquaLogic Data Services Platform によって供給されるデータのセットが、単一の仮想データベースとして供給されているイメージになります。 なお、SQL には特有の 2 次元ビュー データがありますが、SQL アクセスはフラット ビュー データを提供するデータ サービスでしかサポートされません。ご注意ください。
SOA 環境でデータ サービスを管理するための基本的な手順は次のとおりです。
SOA 環境では、開発者が多様なデータ ソースへの接続方法やその使用方法を理解している必要はありません。また、データを取得したときにどのビジネス ロジックやプレゼンテーション ロジックを実装する必要があるかについても理解している必要はありません。そのため、SOA 環境での開発タスクは、以下のように一般的な組織形態に合わせて分担できます。
この節では、BEA AquaLogic Data Services Platform に関係のある技術情報や製品情報へのリンクを示します。 これらのドキュメントは頻繁に改訂される可能性があり、以前のバージョンの製品に関する情報が含まれている場合もあります。
 
|