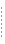

|
|
この章では、BEA Aqualogic Data Services Platform のサービス レイヤを作成するための一般的なガイドラインとパターンについて説明します。 この章の内容は以下のとおりです。
データ サービスのデプロイメントを計画している場合、データ サービス レイヤを組み立て工程との関連で考えると分かりやすくなります。 組み立て工程では、製品はその製造のある 1 局面を専門とする一連の機械または組み立て工によって段階的に処理されながら作り上げられていきます。
同様に、高度に設計されたデータ サービス レイヤでは、一連の小規模な変換を通じて段階的に、入力 (ソース データ) を出力 (構造化された情報) へ変換します。 このような設計により、データ サービスの開発と保守が容易になり、再利用の機会が増えます。
| 注意 : | ここで説明する複数レベルのデータ サービス実装モデルは、データ サービスがデプロイメントのためにコンパイルされる際に平坦化されることに留意してください。 つまり、概念的なレイヤを追加しても、DSP デプロイメントによるデータ統合作業にオーバーヘッドが追加されるわけではなく、したがって、パフォーマンスには影響がありません。 |
この設計によって、データ サービスのそれぞれ異なったサブセットが、変換レイヤ全体の中のサブレイヤを構成します。 データは、各レイヤを通過しつつ、比較的一般的な状態から、アプリケーションに特化した状態へと変換されていきます。
この設計についてさらに説明するため、以下のサブレイヤによるデプロイメントについて考えます。
このサブレイヤは、全体的なデータ サービス レイヤの統合作業と言えるものの大部分を行います。ここで、統合ロジックおよび述部とプライマリの関係が指定されます (小規模なプロジェクトでは、このレイヤは第 2 のサブレイヤと結合されることがあります。 つまり、データの正規化と、統合レイヤのためのデータ形式の定義の両方を行うデータ サービスがここに含まれることになります)。
非常に大きいデータベース ソースの場合は、単一のマスタ データ サービスを作成するのではなく、クライアント アプリケーションにとって必要なものを判断し、それに対応した最小限のデータ サービスをビルドすることが最も適切です。 考え方としては、適度な数のデータ ソースに問い合わせを行う、管理可能な数のビューから、クライアント固有のデータ サービスをビルドし、最も低いレベルおよび最も一般的な関係から抽象化を行いつつ、ビュー全体を適度に単純に保ちます。 AquaLogic Data Services Platform はまた、クライアント アプリケーションが実行時のデータ サービス間の関係を認識できるようにするメタデータ API を提供し、アプリケーションがマスタ データ サービスを必要とすることなくデータ サービス間を移動可能なようにしています。
この方法の最も重要な利点は、これによりデータ サービス レイヤ全体の中での再利用の機会が増えることです。 図 10-1 に示すように、一旦タスクに特化したデータ サービスでビジネス エンティティ (顧客など) の 1 つの形態を定義したら、データの正規化タスクと統合タスクを繰り返すことなく、その情報を複数のアプリケーション固有データ サービスで使用できます。 さらなる利点は、これによりデータ サービス レイヤ間で問題点がはっきりと切り分けされるため、保守がしやすくなるということです。
異種のデータ ソースを扱う場合、更新中にデータを正規化する必要が生じることがよくあります。 一般的な正規化には、単純な型キャスト、通貨、重量および寸法、複合キーの処理、テキストおよび数字のフォーマット定義などがあります。
変換関数は XQuery では容易に作成できますが、このような関数は基底のソースの処理能力を自動的に利用するわけではありません。 これは特に、大量のリレーショナル データが操作されている場合に顕著です。
論理データに対する高いパフォーマンスのデータ処理による利点を保持するためには、しばしば反転関数を使用できます。 加えて、反転関数を使用すると、Java 更新オーバーライドを作成する必要なしに、自動化された更新が可能になります (更新オーバーライドの詳細な説明については、「データ サービスを介した更新の処理」を参照)。
反転関数は、この節で説明するいくつかのタイプのよく発生する状況において、非常に有用です。 このトピックでは、以下の特性のある基底のデータ ソースを想定できます。
US_EMPLOYEE および UK_EMPLOYEE テーブルへは、論理データ サービスの 2 つの関数 US_EMPLOYEE() および UK_EMPLOYEE() を使ってアクセス可能です。
以下に、論理データに対してクエリを実行した結果、物理データそのものに対する処理と比較して著しくパフォーマンスが低下することが考えられる例をいくつか挙げます。
特定の日の後で入力された顧客の名前を収集する関数が正常に実行されても、その結果は最適化されないかもしれません。 言い換えると、関数によって要求される処理が、基底のデータベースの本来の処理能力を活用しない場合があります。 多数のレコードが関与していた場合、パフォーマンスへの影響はかなりのものとなることがあります。
反転関数を作成する際に留意しておくべきなのは、作成する関数が本当に反転可能でなければならないということです。
public static String dateToString(Calendar cal) {
SimpleDateFormat formatter;
formatter = new SimpleDateFormat("MM/dd/yyyy hh:mm:ss a");
return formatter.format(cal.getTime()) ;
}
しかし、ミリ秒の値が返された文字列値の中にありません。 データは返ってきますが、正確な要素が失われています。 デフォルトでは、予測されるすべての値が、オプティミスティックなロックのチェックに使用されるので、精度が失われることにより、データベースの元の値との間に不一致が生じ、そのために更新が失敗する場合があります。
上記のコードではむしろ、返された文字列値においてミリ秒の値を保持し、戻るデータが確実に元の値と同じになるようにすることが必要です。
以下に、反転関数によって、特に大量のデータが関与する場合に、パフォーマンスが向上する可能性があるその他のシナリオを示します。
declare function tns:getEmpWithFixedHireDate() as element(ns0:usemp)*{
for $e in ns1:USEMPLOYEES()
return
<emp>
<eid>{fn:data($e1/ID)}</eid>
<name>{mkName($e1/LNAME, $e1/FNAME)}</name>
<hiredate>{int2date($e1/HIRED)}</hiredate>
<salary>)fn:data($e1/SAL)}</salary>
</emp>
}
このような関数の場合、この関数に加えて hiredate に対してフィルタ クエリを発行した結果、実行の効率は悪くなります。なぜなら、すべてのレコードをバックエンドから取得し、その後、中間層において処理する必要があるからです。
「論理データに対してクエリを実行する場合の考慮事項」の最初の例では、大きなデータ セットに対して fullname( ) 関数を実行した場合、パフォーマンスに悪影響が及ぶことは明白です。
理想は、フルネームをインデックス化された構成要素に分解し、それらの構成要素を基底のデータベースに渡し、結果を取得して、返された結果を fullname( ) の要求に一致するように再構成する、1 つまたは複数の関数があることです。 実際、これが反転関数の基本です。
もちろん、連結された文字列を魔法のように分解する XQuery 関数は存在しません。 その代わりに、データ サービスの開発プロセスの一環として、エンジニアの fullname( ) を反転させるカスタム関数を定義する必要があります。
多くの場合、相補的な反転関数が必要です。 たとえば、FahrenheitToCentigrade() と centigradeToFahenheit() は、互いの反転形です。 相補的な反転関数はまた、fullname() のサポートにも必要です。
反転関数の作成に加えて、メタデータ インポート プロセスの一部として、反転関数を識別することも必要です。 インポート プロセスについては、「エンタープライズ メタデータの取得」で説明しています。 反転関数に関するこのプロセスの特定的な適用については、「手順 4: 反転関数をコンフィグレーションする」で説明しています。
RTLApp には、反転関数のサンプルがいくつか格納されています。 fullname() 関数の場合、カスタム Java コードにより、基底の反転関数ロジックが提供されます。 以下のアクションは、このサンプルを作成する際に必要だったものです。
反転関数で必要とされる文字列操作ロジックは、RTLApp の以下の Java ファイルにあります。
DataServices/Demo/InverseFunction/functions/LastNameFirstName.java
このファイルでは、いくつかの簡単な文字列操作関数が定義されています。
package Demo.InverseFunction.functions;
public class LastNameFirstName
{
public static String mkname(String ln, String fn) { return ln + ", " + fn; }
public static String fname(String name) {
return name.substring( name.indexOf(',') + 2);
}
public static String lname(String name) {
int k = name.indexOf(',');
return name.substring( 0, k );
}
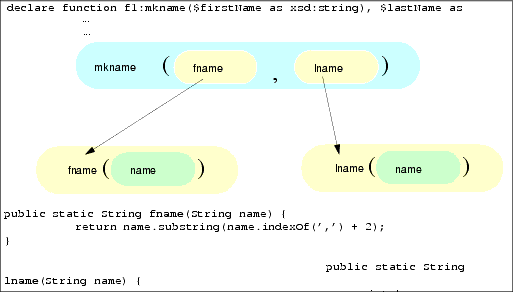
}
コード リスト 10-1 では、関数 mkname( ) は単純に、ファースト ネームとラスト ネームを連結しています。 fname( ) 関数と lname( ) 関数は、結果として得られたフル ネームを、ファースト ネームとラスト ネームの区切りを識別するマーカとして mkname 文字列内に必要とされるカンマを使用して、分解します。
Java 関数をコンパイル後は、そのクラス ファイル (この場合は LastNameFirstName.class) からメタデータをインポートできます。 得られた関数は、concatLibrary.xfl という XML ファイル ライブラリ (XFL) にインポートされます。図 10-4 は、その結果の XFL を、mkname() 関数について使用可能な右クリックオプションと共に示しています。
大抵の場合、いくつかの追加プログラミング ロジックが必要となります。 ここでは、concatLibrary XFL ファイルに、2 つの関数を追加することが必要です。
declare function f1:precedesName($x1 as xsd:string?, $x2 as xsd:string?) as xsd:boolean? {
f1:lname($x1) lt f1:lname($x2) or ( (f1:lname($x1) eq f1:lname($x2))
and (f1:fname($x1) lt f1:fname($x2)) )
};
この関数は、反転関数から順序付けされた名前のリストを取得するために必要です。
declare function f1:eqName($x1 as xsd:string?, $x2 as xsd:string?) as xsd:boolean? {
(f1:lname($x1) eq f1:lname($x2) and f1:fname($x1) eq f1:fname($x2))
};
反転関数は、入力および出力関数パラメータが最小型である場合のみ定義できます。
mkname() 関数に変更を加えることでコードの可読性を高めるには、次の作業を行います。 $x1 および $x2 変数を、それぞれ $lastName および firstName に置き換えます。 完了すると、関数は次のようになります。
declare function f1:mkname($lastName as xsd:string?, $firstName as xsd:string?) as xsd:string? external;
concatLibrary.xfl 内の関数はすべて、単純パラメータ型なので、各々について反転関数を作成できます。 この例では、反転関数が必要なのは、XQuery エンジンを有効化して mkname() 関数をその構成要素オペレーションに分解するためだけです。
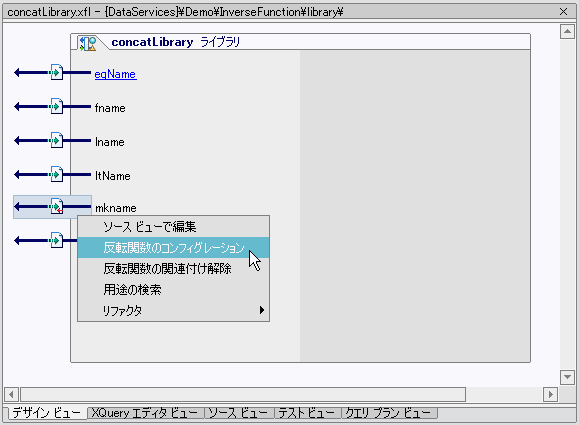
mkname() 関数内の各パラメータに対して、反転関数が識別されます。 オペレーションと関連コードを、図 10-5 に簡略化して示します。
XFL デザイン ビューでは、入力型と出力型が最小である関数のパラメータを、反転関数と関連付けることができます。 これを行うには、関数を右クリックします。 適格な関数に対しては、オプション [反転関数のコンフィグレーション] (図 10-4 参照) が使用可能です。
図 10-6 は、パラメータと反転関数の関連付けを示します。
反転関数を正しいパラメータと関連付けた後は、関数とカスタム条件ロジックを関連付けることもできます。 これを行うには、そのような一般的な条件のカスタム関数を eq (等しい) および gt (より大きい) と置き換えます。表 10-7 では、そのような変換に使用できる条件オペレーションを示しています。
特定の条件文 (「より大きい」など) を変換関数と関連付けることにより、XQuery エンジンはそのようなカスタム ロジックを単純な条件文と置き換えられるようになります。
比較演算子を、変換関数と関連付けることができます。 AquaLogic Data Services Platform では常にそうですが、関数の元の基盤が何であるかは関係ありません。 データ サービス内にでも、XFL 内にでも、外部で Java またはその他のルーチン内にでも、作成できます。 この例では、変換関数 eqName( ) は、XFL ファイルです。
次の手順では、比較演算子を、等価な変換関数と一致させます。 比較オペレーションとの関連でプッシュダウン オペレーションをサポートするには、カスタム ロジックが必要です。 現在の実施例では、string-less-than (lt) オペレーションは XFL precedesName( ) 関数と関連付けられており、string-equal (eq) オペレーションは eqName( ) 関数と関連付けられています。 クエリ関数がこれらの演算子に遭遇すると、対応するカスタム ロジックが置換されます。
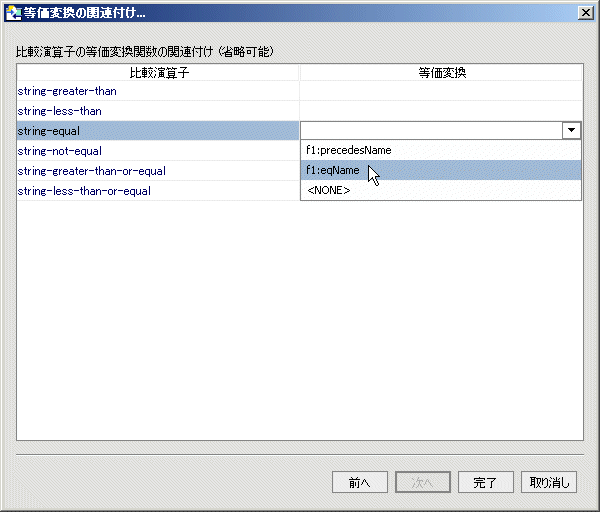
2 つの等価変換関数が、concatLibrary.xfl 内に作成されました。 1 つ目の関数 precedesName( ) は、名前をテストして、昇順になっていることを確認します。 2 つ目の関数 eqName( ) は、単に 2 つのファースト ネームと 2 つのラスト ネームを比較し、これらが同一であることを確認します。
これで、getCustomerByName() や getCustomerByNameLessThan() などの関数が格納されたデータ サービスを作成する準備が整いました。 使用可能な機能を確認すると、次のものがあります。
Concatenation というデータ サービスでは、LastNameFirstName.xsd スキーマと関連付けられた XML 型を使用しています。
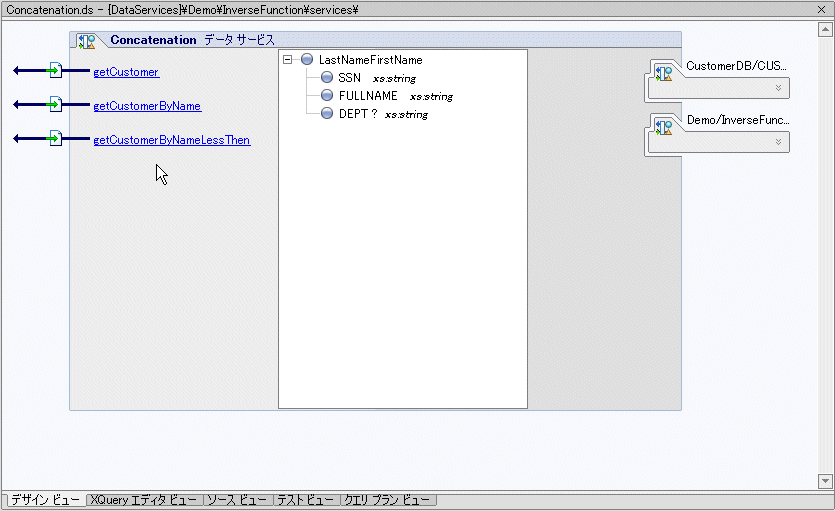
このスキーマは、XQuery エディタによってでも、AquaLogic Data Services Platform スキーマ エディタによってでも、サード パーティの編集ツールによってでも作成可能です (また、データ サービスの構成要素の 1 つは、concatLibrary XFL です)。
すでに知られている getCustomer() 関数が、このサンプルでは幾分、異なった動作をしています。
declare function tns:getCustomer() as element(ns0:LastNameFirstName)* {
for $CUSTOMER in ns1:CUSTOMER()
return
<ns0:LastNameFirstName>
<SSN>{fn:data($CUSTOMER/SSN)}</SSN>
<FULLNAME>{ns2:mkname(fn:data($CUSTOMER/LAST_NAME),fn:data($CUSTOMER/FIRST_NAME))}</FULLNAME>
<DEPT?></DEPT>
</ns0:LastNameFirstName>
};
米国社会保障番号を主キーとして使用しているこのルーチンは、Java ベースの mkName() 関数に依存して、データ ソースからファースト ネームとラスト ネームを取得し、その結果を「フルネーム」として連結しています。
getCustomerByName( ) ルーチンは、フルネームを入力として受け取り、$LastNameFullName および関連付けられた社会保障番号を返します。
declare function tns:getCustomerByName($Name as xs:string) as element(ns0:LastNameFirstName)* {
for $LastNameFirstName in tns:getCustomer()
where $LastNameFirstName/FULLNAME eq $Name
return $LastNameFirstName
};
上記のコードでは、等価性 (eq) テストが、concatLibrary eqName() 関数の置換によって評価されます。
getCustomerByNameLessThan( ) ルーチンは、lt 演算子で使用可能な置換された条件ロジックを使用します。 まず、ルーチンは下記のとおりです。
declare function tns:getCustomerByNameLessThen($Name as xs:string) as element(ns0:LastNameFirstName)* {
for $LastNameFirstName in tns:getCustomer()
where $Name lt $LastNameFirstName/FULLNAME
return $LastNameFirstName
};
less-than 置換のロジックは、LastNameFirstName.java および concatLibrary の検証から得られます。 生の処理は、Java ファイルに格納されています。
public static boolean ltName(String name1, String name2) {
String ln1 = lname(name1);
String ln2 = lname(name2);
return (ln1.compareTo(ln2)<0) || (ln1.equals(ln2) && fname(name1).compareTo(fname(name2))<0);
}
XFL 関数 precedesName() は、下記のとおりです。
declare function f1:precedesName($x1 as xsd:string?, $x2 as xsd:string?) as xsd:boolean? {
f1:lname($x1) lt f1:lname($x2) or ( (f1:lname($x1) eq f1:lname($x2))
and (f1:fname($x1) lt f1:fname($x2)) )
};
論理データ サービスの一般的な設計パターンでは、フィルタ条件なしでデータ形式を定義する単一の読み取り関数を設定します。 この関数は、同じデータ サービス内の別の関数によってのみ呼び出し可能なように、プライベートなものとして宣言できます。 また、これは統合ロジックを含む唯一の関数です。 これを分解関数と呼びます。 デフォルトでは、分解関数は論理データ サービスのデザイン ビューに表示される最初の関数です。 ただし分解関数は、プロパティ エディタを使用して、データ サービス内の任意のパブリック関数またはプライベート関数として設定できます。 同じデータ サービス内のものであっても別のデータ サービス内のものであっても、追加された関数では、プライベート関数を使用してフィルタ条件を指定できます。図 10-10 に、このパターンを表示するデータ サービスのデザイン ビューを示します。
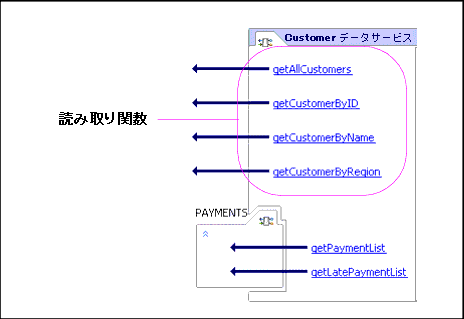
以下の XQuery サンプルでは、データ サービス再利用の背後の仕組みを示します。 この関数 getCustomerByName() は、顧客名に基づくインスタンスをフィルタ処理します。
declare function l1:getCustomerByName($c_name as xs:string)
as element(t1:CUSTOMER)*
{
for $c in l1:getAllCustomers()
where $c/CUSTOMERNAME eq $c_name
return $c
};
次に getAllCustomers() 関数が、返されたデータのデータ形式をアセンブルし、return 句に示されるように、結合ロジックと変換をもたらします。
...
return
<t1:CUSTOMER>
<CUSTOMERID>{fn:data($c/CUSTOMERID)}</CUSTOMERID>
<CUSTOMERNAME>{fn:data($c/CUSTOMERNAME)}</CUSTOMERNAME>
{
for $a in f2:ADDRESS()
where $c/CUSTOMERID eq $a/CUSTOMERID
return
<ADDRESS>
<STREET>{fn:data($a/RTL_STREET)}</STREET>
<CITY>{fn:data($a/RTL_CITY)}</CITY>
<STATE>{fn:data($a/RTL_STATE)}</STATE>
</ADDRESS>
}
</t1:CUSTOMER>
クライアント アプリケーション自体が、データ サービスの関数呼び出しに対してフィルタ条件を指定できることに留意してください。 したがって、データ サービス設計者は、大まかに定義されたデータ アクセス関数 (フィルタ条件なし) を設定してクライアント側で必要に応じてフィルタ処理の適用を行えるようにするのか、それとも API で条件を定義した綿密なデータ アクセス関数を設定するのかを選択できます。
| 注意 : | 本文が flwor (for-let-where-order-return) 文の何らかの変化形である関数はすべて、単数ではなく複数の結果を返すように宣言する必要があります。次に例を示します。 |
element(purchase_order)*| 注意 : | 以下の記述よりも上記のものが推奨されます。 |
element(purchase_order)| 注意 : | 読み取り関数およびナビゲーション関数の双方に適用されます。 |
| 注意 : | 戻り値が複数になるよう宣言する理由は、宣言された結果が確実に、実行時に実際に送られることを、XQuery コンパイラが要求するからです。 単数であると判断できないものがあった場合、コンパイラはクエリ評価プランに実行時型一致演算子を挿入します。 誤った結果が返ることはありませんが、この演算子のせいで、重要なプッシュダウン関係の最適化 (関数の展開) が無効化してしまいます。 |
データ サービスで独立した情報単位間の論理的な関係を実装するには、いくつかの方法があります。
データ形式において包含が実現されている場合、それはすなわち、データ サービスの XML データ型がネストされている、つまり、1 つの要素が別の要素の親になっているということです。 たとえば、以下のサンプルでは、顧客 (customer) 要素に注文 (order) が包含されています。
<customer>
<customerId>...</customerId>
<customerName>...</customerName>
<orders>
<order>...</order>
<orderId>...</orderId>
</orders>
</customer>

このタイプの包含においては、顧客と注文の間の親子階層構造は、データ形式の中にロックされています。 このネストは、大半のアプリケーション、特に顧客によって方向付けされるアプリケーションについては、道理にかなうものと言えるでしょう。 しかし、その他のアプリケーションでは、データを注文によって方向付けられた観点で捉えたほうが有利かもしれません。 たとえば、在庫アプリケーションでは、注文優先方式でデータを処理し、顧客を各注文の子要素としたほうがよい場合があります。

考え方としては、この場合注文は顧客の存在に依存していないとも言えるでしょう。 顧客レコードが削除されたとしても、必ずしもその顧客の注文も削除されるとは限りません。
また、これ以外の関係では、このタイプの階層構造上の柔軟性は必要ではありません。 ほとんどの場合、これはビジネス エンティティの存在が、親の存在に依存してはいないということを示唆しています。 たとえば、品目を包含する注文について考えます。
大半の論理データ モデルにおいては、品目を、それを包含する注文のコンテキスト外に置くことは理にかなわないことです。 注文を削除する際には、それを構成する注文品目も削除する必要があると考えて間違いないでしょう。
そのような包含のモデル化を、関係を通じて行うのか、データ形式のネストを通じて行うのかの選択は、これらを考慮することによって通知されます。 包含のモデル化を、データ形式のネストを通じて行うのか、関係を使用して行うのかを選択する際には、以下のことをお勧めします。
独立したエンティティを双方向関係でモデル化することにより、データ サービスのユーザおよび設計者は、ビジネス エンティティ間の論理階層構造を、容易にアプリケーションに最適な形に特化できます。
 
|