
|
|
AquaLogic Data Services Platform はリレーショナル データ ソースの更新を自動的に処理します。 Web サービスなどの非リレーショナル データ ソースも更新できます。
非リレーショナル ソースの場合、更新ロジックは常に、論理または物理データ サービスに関連付けられた更新オーバーライド クラスを通じて提供されます。 また、リレーショナル データ ソース用のカスタムの更新ロジックを提供することもできます。
この章では、データ サービスの更新オーバーライド クラス (更新動作を構成するクラス) を作成する方法について説明します。 この章の内容は以下のとおりです。
この章を読む際は、データ サービスを通じてエンタープライズ情報にアクセスおよび更新する機能をアプリケーション開発者に提供する、という全体的な目的を心に留めておくことが重要です。
アプリケーション開発者の観点からすると、サービス データ オブジェクト (SDO) Mediator API は、データ サービスを通じて情報を流すための手段です (同様に、AquaLogic Data Services Platform コントロールも同じ目的で使用できます)。 データ サービスに適用される SDO の詳細については、『クライアント アプリケーション開発者ガイド』の「データ プログラミング モデルと更新フレームワーク」を参照してください。
更新オーバーライド クラスは、以下のような更新フレームワーク アーティファクトにプログラム的にアクセスできます。
使用できる内容は、次のように、データ サービス コンテキストによって異なります。
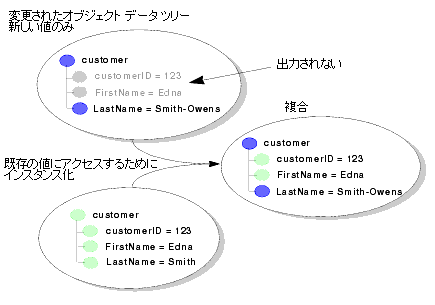
図 9-1 は、更新オーバーライド内のコンテキストの可視性を示したものです。
物理レベルのデータ サービスに対して更新オーバーライド クラスを実装する場合の考慮事項は以下のとおりです。
リレーショナル データ サービスの更新オーバーライドに関する追加の考慮事項は次のとおりです。
非リレーショナル物理データ サービスの場合、performChange( ) メソッドでは次のようにする必要があります。
更新オーバーライドは、デフォルトの更新プロセスをカスタマイズするか完全に置き換えるためのメカニズムを提供します。
データ サービスに関連付けられた更新オーバーライドを使用すると、以下のことを行えます。
更新オーバーライドのより概念的な説明については、AquaLogic Data Services Platform の『コンセプト ガイド』の「サービス データ オブジェクト (SDO) の使用」の「データの更新」を参照してください。
プログラミングの点から見ると、更新オーバーライドは、AquaLogic Data Services Platform API の 1 つである UpdateOverride インタフェース (<UpdateOverride>) を実装したコンパイル済みの Java ソース コード ファイルです。 この API は com.bea.ld.dsmediator.update パッケージにあります。 UpdateOverride インタフェースには performChange( ) という名前の空のメソッドが 1 つあります。
このメソッドがアプリケーション開発者にどのように使用されるのかを理解しておくことは重要です。 コード リスト 9-1 に示すように、performChange( ) メソッドは DataGraph オブジェクトを取ります (dsmediator.update パッケージまたはメディエータによって渡されます)。 更新オーバーライド クラスはこのメディエータ オブジェクトを処理します。 DataGraph にはデータ オブジェクト、オブジェクトに対する変更、およびメタデータなどの他のアーティファクトが格納されます (『クライアント アプリケーション開発者ガイド』の「データ プログラミング モデルと更新フレームワーク」を参照してください)。
package com.bea.ld.dsmediator.update;
import commonj.sdo.DataGraph;
import commonj.sdo.Property;
public interface UpdateOverride
{
public boolean performChange(DataGraph sdo)
{
}
}
コード リスト 9-1 の performChange( ) メソッド シグネチャからわかるように、メソッドはブール値を返します。 この値は次のように、メディエータに対するフラグの役目を果たします。
オーバーライドされるデータ サービスにバインドされているオブジェクトに対して送信が発行されると、performChange( ) メソッドが実行されます。
submit( ) で渡されるオブジェクトが DataService オブジェクトの配列である場合、配列はシングルトン DataService オブジェクトのリストに分解されます。 これらのオブジェクトは追加、削除、または変更されている可能性があるため、更新オーバーライドは複数回 (つまり、変更されたオブジェクトにつき 1 回ずつ) 実行される可能性があります。
アプリケーション開発者は、実行時に渡されるデータグラフのルート データ オブジェクトが、(更新オーバーライドがコンフィグレーションされている) データ サービスにバインドされたシングルトン データ オブジェクトのインスタンスであることを検証する必要があります。
アプリケーションがデータ サービス関数を実行して非リレーショナル データ ソースを更新する場合は、カスタム更新クラスを作成する必要があります。 Web サービス、XML ファイル、フラット ファイル、および AquaLogic Data Services Platform プロシージャでは、更新が必要な場合は、カスタム更新クラスが必要となります。
同様に、以下のような状況でも、カスタム更新クラスが必要になります。
たとえば、クライアント アプリケーションが部門と管理者の両方を追加する必要があるときに、管理者が部門の必須フィールドでもある場合、 管理者が存在する前に部門の管理者フィールドをどのように設定すればよいでしょうか。 次のように行います。
更新オーバーライド クラスを構成する Java コードを記述してコンパイルしたら、そのクラスをデータ サービスに登録する必要があります。 更新オーバーライドは物理データ サービスまたは論理データ サービスに登録できます。 各データ サービスには [更新オーバーライド クラス] プロパティがあり、そのデータ サービス用の UpdateOverride の実装を構成する特定の Java クラス ファイルと関連付けることができます。
実際の関連付けは WebLogic Workshop のデザイン ビューまたはソース ビューから行えます。 2 つの方法の詳細は次のとおりです。
javaUpdateExit 要素タグの属性として、更新オーバーライド クラスの名前を追加する (クラス名のみで、.class 拡張子は付けない)。 次に例を示します。<javaUpdateExit className="SpecialOrderUpdate"/>
実行時に、データ サービスは、データサービスでプロパティ設定をもとに識別された UpdateOverride クラスを実行します。 AquaLogic Data Services Platform の『コンセプト ガイド』の「サービス データ オブジェクト (SDO) の使用」の「分解プロセス」を参照してください。
更新オーバーライド クラスの作成に関連する一般的な手順は次のとおりです。
import com.bea.ld.dsmediator.update.UpdateOverride;
import commonj.sdo.DataGraph;
public class SpecialOrders implements UpdateOverride
public boolean performChange(DataGraph graph)
package RTLServices;
import com.bea.ld.dsmediator.update.UpdateOverride;
import commonj.sdo.DataGraph;
import java.math.BigDecimal;
import java.math.BigInteger;
import retailer.ORDERDETAILDocument;
import retailerType.LINEITEMTYPE;
import retailerType.ORDERDETAILTYPE;
public class OrderDetailUpdate implements UpdateOverride
{
public boolean performChange(DataGraph graph){
ORDERDETAILDocument orderDocument =
(ORDERDETAILDocument) graph.getRootObject();
ORDERDETAILTYPE order =
orderDocument.getORDERDETAIL().getORDERDETAILArray(0);
BigDecimal total = new BigDecimal(0);
LINEITEMTYPE[] items = order.getLINEITEMArray();
for (int y=0; y < items.length; y++) {
BigDecimal quantity =
new BigDecimal(Integer.toString(items[y].getQuantity()));
total = total.add(quantity.multiply(items[y].getPrice()));
}
order.setSubTotal(total);
order.setSalesTax(
total.multiply(new BigDecimal(".06")).setScale(2,BigDecimal.ROUND_UP));
order.setHandlingCharge(new BigDecimal(15));
order.setTotalOrderAmount(
order.getSubTotal().add(
order.getSalesTax().add(order.getHandlingCharge())));
System.out.println(">>> OrderDetail.ds Exit completed");
return true;
}
}
コード リスト 9-2 のサンプル クラスでは、OrderDetailUpdate クラスが UpdateOverride クラスを実装しており、このインタフェースで求められているように、performChange( ) メソッドを定義しています。 コード リストでは、更新オーバーライドの一般的なコーディング パターンが例示されています。
ORDERDETAILDocument orderDocument =
(ORDERDETAILDocument) graph.getRootObject();
ORDERDETAILTYPE order =
orderDocument.getORDERDETAIL().getORDERDETAILArray(0)
「一般的な更新オーバーライドのプログラミング パターン」も参照してください。
表 9-3 に示すような場合では、更新オーバーライド ロジックがリレーショナル更新処理で必要になります。
ほとんどの RDBMS では、主キーが自動的に生成されます。つまり、リレーショナル データベースをバックエンドとするデータ サービスに新しいデータ オブジェクトを追加する際は、コード内で主キーを戻り値として処理しなければならない場合があるということになります。 たとえば、送信されたオブジェクト データ グラフに新しいデータ オブジェクト (たとえば新しい Customer オブジェクト) が含まれている場合は、必要となる主キーが AquaLogic Data Services Platform によって生成されます。
自動付番主キーのデータ挿入の場合は、新しい主キー値が生成されてクライアントに返されます。 返されるのは最上位レベルのデータ オブジェクト (マルチレベル データ サービスの最上位レベル) の主キーのみで、計算された主キーを持つネストされたデータ オブジェクトは返されません。
AquaLogic Data Services Platform では、挿入されたタプルの最上位レベルの主キーを返すことで、必要に応じて新しい主キーでタプルをフェッチしなおすことを可能にしています。
メディエータは、主キーと外部キーの論理的な関係をキーペアとして保存します (Mediator API の KeyPair クラスを参照)。 KeyPair オブジェクトは、新しいデータ オブジェクトの作成プロセスの間に、外部キー フィールドを設定するために使用するプロパティ マップです。
プロパティがコンテナ内の自動付番主キー (つまり、自動付番された後のデータ ソース内の新しいレコード) である場合は、プロパティの値が親から子へ伝播されます。
KeyPair オブジェクトは、分解マップの隣接するレベル間で、対応するデータ要素を特定するために使用します。KeyPair オブジェクトを使用することで、親 (コンテナ) オブジェクト用に生成された主キー値を、子要素 (そのコンテナに含まれるオブジェクト) の外部キー フィールドに確実にマッピングできます。
例として、図 9-4 に Customers データ サービスの分解におけるプロパティ マッピングを示します。
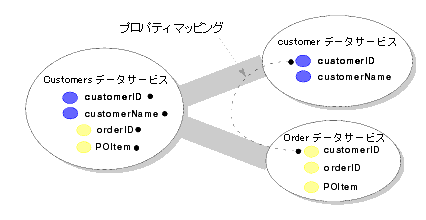
AquaLogic Data Services Platform は、データ サービス間の主キーと外部キーの関係を管理します。管理の方法は、以下に示すように、マルチレイヤ データ サービスのレイヤによって異なります。
Properties[] keys = ds.submit(doc);
タプルは、基本的にはレコードです。ただし、データ サービスのコンテキストでは、データ サービスの複数のレイヤにまたがるデータから 1 つのタプルが構成される場合もあります。
AquaLogic Data Services Platform では、変更の影響が主キーや外部キーに伝播されます。
たとえば、主キー フィールドが CustID の Customer オブジェクトの配列に、2 つの Customer を挿入したとします。ここで送信を実行すると、その Customer 型を基準とした CustID を名前とし、挿入された各 Customer の新しい主キー値を値として、2 つのプロパティの配列が返されます。
AquaLogic Data Services Platform は、更新プロセスの間の主キーの依存関係を管理します。 主キーを識別し、述語文内の外部キーを推量できます。 たとえば、データを結合するクエリでは、次のように値を比較します。
where customer/id = order/id
メディエータは、データ ソースの更新時に、推量されたキーと外部キーの関係に基づいてさまざまなサービスを実行します。
2 つの SDOToUpdate インスタンス (更新プラン内のデータ オブジェクト) の間に述語依存関係があり、コンテナ SDOToUpdate インスタンスが挿入または変更されて、コンテナに含まれる SDOToUpdate インスタンスが挿入または変更された場合、コンテナ SDO が更新のために送信された後に、コンテナ SDO のどの値をコンテナに含まれる SDO に移動すべきかを示すキーペア リストが特定されます。
このキーペア リストは、コンテナ SDO とコンテナに含まれる SDO のフィールドのセットに基づいています。これらは、現在の SDO が作成されたときには等しくなければならなかったものです。キーペア リストは、述語フィールドからこれらの主キーのみを特定します。
キーペアは、コンテナの主キーをコンテナに含まれるフィールドにのみマッピングします。 そうしないと、コンテナの完全な主キーがマップから特定できず、どのプロパティもマッピングされていないと判断されてしまうためです。
キーペア リストには、1 つまたは複数の項目が含まれており、これらによってコンテナ内のノード名や、マップされているコンテナ内のオブジェクトを特定します。
SDO の分解の送信によって計算が可能な場合、外部キーの値は親キーの値と一致するように設定されます。
メディエータに対する submit( ) は、トランザクションとして動作します。 submit() が成功したか失敗したかに応じて、次のどちらかを実施する必要があります。
送信では、常にデータ ソースの即時更新が実行されます。 ネストされたトランザクションのコンテキスト内でデータ オブジェクトの送信が発生した場合、ネスト内に含まれるトランザクションのコミットやロールバックは、送信されたデータ オブジェクトや更新サマリには影響しませんが、そのトランザクションに参加するすべてのデータ ソース更新には影響します。
コード リスト 9-3 では、データ サービス プロシージャを呼び出す更新オーバーライド クラスの例を示します。 UpdateOverride はローカルで (つまり、AquaLogic Data Services Platform サーバ内で) 呼び出されるため、このサンプルでは型指定された Mediator API を使用しています。 ここでは、setCustomerOrder Web サービスの setCustomerOrder( ) に基づくデータ サービスが作成されます。 このサービスには更新関数が含まれていて、同じ名前の副作用関数によってデータ サービスから参照されています。 最後に、更新オーバーライドを実装するクラスが示されています。
まず、Web サービスの更新が定義されます。 更新ロジックについては、RTLApp サンプルの ElecDBTest Web サービス (ElecDBTest.jws) を参照してください。 メソッドは次のとおりです。
setCustomerOrder(String doc);
データ サービス プロシージャ (副作用関数) は以下のデータ サービスで宣言されています。
ld:DataServices/ElectronicsWS/getCustomerOrderByOrderID
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com"
kind="hasSideEffects" nativeName="setCustomerOrder"
nativeLevel1Container="ElecDBTest"
nativeLevel2Container="ElecDBTestSoap"
style="document">
<nonCacheable/>
</f:function>::)
これで、更新ロジックを記述できるようになります。 コード リスト 9-3 に、更新ロジックをコメントとともに示します。
public boolean performChange(DataGraph datagraph){
String order = "ld:DataServices/ElectronicsWS/getCustomerOrderByOrderID";
System.out.println("INSIDE EXIT >>>> ");
ChangeSummary cs = datagraph.getChangeSummary();
if (cs.getChangedDataObjects().isEmpty()) {
System.out.println("WEB SERVICE EXIT COMPLETE!");
return false;
}
else {
GetCustomerOrderByOrderIDResponseDocument doc = (GetCustomerOrderByOrderIDResponseDocument) datagraph.getRootObject();
try {
Context cxt = getInitialContext();
// データ サービス プロシージャの更新関数を含むデータ サービスのハンドルを取得する
DataService creditDS =
DataServiceFactory.newDataService(cxt,
"RTLApp",
order);
// 副作用関数に渡される xmlbean オブジェクトを作成する
SetCustomerOrderDocument doc1 = SetCustomerOrderDocument.Factory.newInstance();
// xmlbean オブジェクトに SDO からの値を設定する
doc1.addNewSetCustomerOrder().setDoc(doc.getDataGraph().toString());
creditDS.invokeProcedure( "setCustomerOrder",
new Object[]{ doc1 } );
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("UPDATE ERROR: SQL ERROR: " + e.getMessage());Fine
System.out.println("WEB SERVICE EXIT COMPLETE!");
return false;
}
}
コード リスト 9-3 の例には、WebLogic Server インスタンス上でローカルに実行される Web サービスが含まれています。つまり、コンテキストと場所を取得するための設定コードは含まれていません。 Web サービスが WebLogic Server インスタンスのローカルでない場合、コードでは、InitialContext を取得して、適切な場所とセキュリティのプロパティを提供する必要があります。 『クライアント アプリケーション開発者ガイド』の「Java クライアントからのデータ サービスへのアクセス」の「AquaLogic Data Services Platform 用の WebLogic JNDI コンテキストの取得」を参照してください。
コード リスト 9-4 では、参照整合性を高めるために、製品情報をリストの中間から削除して末尾に追加することで更新プランを調整する、更新オーバーライドを示します。
// 項目と製品の間の参照整合性のために、注文、項目、製品を削除する
// 製品は項目の後で削除する必要がある
public boolean performChange(DataGraph graph)
{
DataServiceMediatorContext context = DataServiceMediatorContext.currentContext();
UpdatePlan up =context.getCurrentUpdatePlan( graph, false );
Collection dsCollection = up.getDataServiceList();
DataServiceToUpdate ds2u = null;
for (Iterator it=dsCollection.iterator();it.hasNext();)
{
ds2u = (DataServiceToUpdate)it.next();
if (ds2u.getDataServiceName().compareTo("ld:DataServices/PRODUCT.ds") == 0 ) {
// リストの中間から製品を削除して、末尾に追加する
up.removeContainedDataService( ds2u.getDataGraph() );
up.addDataService(ds2u.getDataGraph(), ds2u );
};
}
context.executeUpdatePlan( up );
return false;
}
}
変更が想定どおりに行われるように、データ サービスの更新は常にテストする必要があります。 テスト ビューを使用して送信をテストできます。 テスト ビューの詳細については、「テスト ビューの使用」を参照してください。
テスト ビューでは、作成したデータ サービス内の単純な更新を素早くテストできますが、より実質的なテストとトラブルシューティングを行うために、更新オーバーライド クラスを使用して、更新の分解マッピングと更新プランを検査することができます。
この節では、一般的な更新オーバーライドのプログラミング パターンを例示するコード サンプルを紹介し、説明します。 内容は以下のとおりです。
更新オーバーライド クラスには performChange( ) メソッドの実装を含める必要があります。プログラミング タスクで必要となるすべてのカスタム コードは、このメソッドの中に用意します。 performChange( ) メソッドは、メディエータによる処理を続行または中断させるブール値を返します。『クライアント アプリケーション開発者ガイド』の「データ プログラミング モデルと更新フレームワーク」の「How It Works: The Decomposition Process」を参照してください。
論理データ サービスが適切に更新されるようにするには (つまり、よく設計されたデータ サービスにするには)、どのデータ サービス関数がそのデータを提供しているかに関係なく、データ サービスからのデータの系統を同じにする必要があります。 たとえば、CustomerProfile データ サービスに以下の関数があるとします。
3 つの関数はすべて、同じ基底のデータ サービスから顧客データを取得する必要があります。 したがって、基底のソースに変更を戻して伝播する方法として適切なのは、ある時点で更新された顧客を取得するために 3 つのうちのどの関数を使用したか、ということに左右されない方法です。
可能な場合は、そのようなデータ サービスのデータ統合ロジックをすべて 1 つの関数 (getAllCustomers( ) など) にまとめて、残りのデータ サービス関数を定義するときにその関数を使用する、という方法をお勧めします。 次のような式があれば、
getAllCustomers( )[cid = $custId])
この目的が達成されて、データ マッピングや結合述語などのすべてをデータ サービスの関数ごとに複製する必要がなくなります。
データ サービスのデータを更新する場合、AquaLogic Data Services Platform は、影響を受けるすべてのデータ ソースに変更をどのように伝播するかを調べるために、データ系統を分析します。 このような系統分析を自動的に実行するために、指定されたデータ サービス関数が参照されます (「リバース エンジニアリング」されます)。 参照すべき関数が指定されていない場合は、データ サービス内の最上位の読み取り関数が使用されます。
データ サービス設計者は、データ サービスの指定された (またはデフォルトの) 分解関数が、同じデータ サービス内の読み取り関数に依存しないようにし、系統判別を正確に代行する関数となるように保証する必要があります。 上記の例の getAllCustomers( ) が選択すべき適切な関数となるには、データ サービス内の最初の読み取り関数であるか、プロパティ エディタで分解関数として明示的に指定される必要があります。
選択された分解関数を系統分析の目的に合ったものにすることは、データ サービス設計者の役割です。 この要件に反していると、オプティミスティック ロック エラーなどの予期しない、望ましくない実行時エラーが発生する可能性があります。
| 注意 : | データ サービスで指定された分解関数が同じデータ サービス内の他の読み取り関数を呼び出した場合、エラー状況が生じます。 特に、更新メディエータは実行時にエラーを検出し、内部データ サービス読み取り関数の誤った依存関係についてユーザに報告する例外を送出します。 |
分解および更新プロセス全体をカスタマイズするために、performChange( ) メソッドは以下のようなルーチンを実装できます。
performChange( ) メソッドで分解を行う場合は、メディエータが自動化された分解を実行しないようにするため、False を返すようにメソッドを設定する必要があります。
performChange( ) メソッドには、変更されたデータ オブジェクト値を検査して、エラーを伝える DataServiceException を生成し、場合によってはトランザクションをロールバックする、というコードを含めることができます。
True を返すと、メディエータは変更されたオブジェクトを使用して更新の伝播を続行します。
更新の変更プランと分解マップにアクセスするには、最初に、データ サービスのメディエータ コンテキストを取得する必要があります。 コンテキストを使用すると、分解マップの表示、更新プランの生成、更新プランの実行、現在処理されているデータ サービス オブジェクトのコンテナ データ サービス インスタンスへのアクセスなどを行うことができます。
DataServiceMediatorContext context =
DataServiceMediatorContext().getInstance();
コンテキストを取得したら、次のように分解マップにアクセスできます。
DecompositionMapDocument.DecompositionMap dm =
context.getCurrentDecompositionMap();
分解マップを取得したら、その toString( ) メソッドを使用して、XML マップの表示を文字列値として取得することができます。コード リスト 9-5 を参照してください (デフォルトの分解マップにアクセスすることはできますが、変更はできません)。
分解マップへのアクセスに加えて、オーバーライド クラスの更新プランにアクセスすることもできます。 ツリー内の値の変更、ノードの削除、ノードの再配置 (適用される順序の変更) などを行えます。 ただし、更新プランを変更した場合、その変更を保持するには、オーバーライド内でプランを実行する必要があります。 ツリー内の値の変更、ノードの削除または再配置を行うと、更新プランは変更リスト内で変更を自動的に追跡します。
<xml-fragment xmlns:upd="update.dsmediator.ld.bea.com">
<Binding>
<DSName>ld:DataServices/CUSTOMERS.ds</DSName>
<VarName>f1603</VarName>
</Binding>
<AttributeLineage>
<ViewProperty>CUSTOMERID</ViewProperty>
<SourceProperty>CUSTOMERID</SourceProperty>
<VarName>f1603</VarName>
</AttributeLineage>
<AttributeLineage>
<ViewProperty>CUSTOMERNAME</ViewProperty>
<SourceProperty>CUSTOMERNAME</SourceProperty>
<VarName>f1603</VarName>
</AttributeLineage>
<upd:DecompositionMap>
<Binding>
<DSName>ld:DataServices/getCustomerCreditRatingResponse.ds</DSName>
<VarName>getCustomerCreditRating</VarName>
</Binding>
<AttributeLineage>
<ViewProperty>CREDITSCORE</ViewProperty>
<SourceProperty>
getCustomerCreditRatingResult/TotalScore
</SourceProperty>
<VarName>getCustomerCreditRating</VarName>
</AttributeLineage>
...
</upd:DecompositionMap>
</upd:DecompositionMap>
<ViewName>ld:DataServices/Customer.ds</ViewName>
</xml-fragment>
送信されたデータ オブジェクト内の値を検証または変更した後で、現在のデータ オブジェクトを以下の関数に渡すことで、関数は更新プランを取得します。
DataServiceMediatorContext.getCurrentUpdatePlan()
更新プランを実行した後で、performChange( ) メソッドは、メディエータが更新プランを適用しないようにするため、False を返す必要があります。
更新プランを使用すると、更新される値をソースに対して変更できます。 また、更新順序を変更することもできます。
navigateUpdatePlan( ) のような独自のメソッドを使用して、更新プランの内容をプログラム的に表示することができます。 コード リスト 9-6 に示すように、navigateUpdatePlan( ) メソッドは Collection オブジェクトを取り、イテレータを使用してプランを反復的に走査します。
public boolean performChange(DataGraph datagraph){
UpdatePlan up = DataServiceMediatorContext.currentContext().
getCurrentUpdatePlan( datagraph );
navigateUpdatePlan( up.getDataServiceList() );
return true;
}
private void navigateUpdatePlan( Collection dsCollection ) {
DataServiceToUpdate ds2u = null;
for (Iterator it=dsCollection.iterator();it.hasNext();) {
ds2u = (DataServiceToUpdate)it.next();
// SDO の内容を出力する
System.out.println (ds2u.getDataGraph() );
// 格納されている SDO オブジェクトを走査する
navigateUpdatePlan (ds2u.getContainedDSToUpdateList() ); }
}
単純な更新プランの場合は次のように報告します。
UpdatePlan
SDOToUpdate
DSName: ... :PO_CUSTOMERS
DataGraph: ns3:PO_CUSTOMERS to be added
CUSOTMERID = 01
ORDERID = unset
PropertyMap = null
ここで、明細とその明細が含まれている注文を一緒に削除する例を検討してみましょう。 元のデータを示したコード リスト 9-7 では、品目 1001 が注文 100 から削除され、次にその注文が削除される更新プランを示しています。
UpdatePlan
SDOToUpdate
DSName:...:PO_CUSTOMERS
DataGraph: ns3:PO_CUSTOMERS to be deleted
CUSTOMERID = 01
ORDERID = 100
PropertyMap = null
SDOToUpdate
DSName:...:PO_ITEMS
DataGraph: ns4:PO_ITEMS to be deleted
ORDERID = 100
ITEMNUMBER = 1001
PropertyMap = null
この場合、更新プランは次のように実行されます。PO_CUSTOMERS を削除する前に、内包される SDOToUpdates ルーチンが処理されます。 その結果 PO_ITEMS が最初に削除され、次に PO_CUSTOMERS が削除されます。
更新プランの内容が変更された場合は、新しいプランが実行可能になります。 更新終了の時点で False を返して、それ以上の自動化が行われないことを知らせる必要があります。
更新プランを変更した後で、そのプランを実行することができます。 更新プランを実行すると、メディエータは指定されたデータ ソースに変更を伝播します。
up という名前の変更された更新プランがある場合、次のような文でプランを実行します。
context.executeUpdatePlan(up);
更新プランに対して処理されるデータ サービスがある場合は、その SDO コンテナを取得できます。 コンテナは分解されて、元の変更されたオブジェクト ツリー内に存在しているはずです。 コンテナが存在しない場合は null が返されます。 次の例を見てみましょう。
String containerDS = context.getContainerDataServiceName();
DataObject container = context.getContainerSDO();
この例では、Orders データ サービスの更新オーバーライド クラスに対してコンテナを要求すると、処理される Order インスタンスの Customer データ サービス オブジェクトが返されます。 その Customer インスタンスが更新プラン内にある場合は、その Customer インスタンスが返されます。 更新プラン内にない場合は、CustOrders から分解されて返されます。
更新プランは変更内容を示すだけです。 場合によっては、コンテナが更新プラン内に存在しないこともあります。 コードがコンテナを要求すると、存在する場合はコンテナは更新プランから返されます。更新プランに存在しない場合、コンテナはソース SDO から分解されます。
更新オーバーライドから他のデータ サービスにアクセスして更新することができます。 メディエータを使用すると、データ オブジェクトにアクセスして、データ オブジェクトの変更と送信を行えます。 または、変更されたデータ オブジェクトを更新プランに追加して、更新プランの実行時に更新することもできます。 データ オブジェクトを更新プランに追加した場合、そのデータ オブジェクトは現在のコンテキスト内で更新されます。データ オブジェクトのコンテナにはデータ サービスの更新オーバーライドの内部でアクセスできます。
DataService Mediator API を使用して更新を実行すると、クライアントから実行された場合と同様に、その送信用に新しい DataService コンテキストが確立されます。 この submit( ) はクライアント送信と同様に動作します。つまり、変更はデータ オブジェクト内に反映されません。 代わりに、この送信による変更を反映するために、オブジェクトを再フェッチする必要があります。
AquaLogic Data Services Platform はロギングに基底の WebLogic Server を使用します。 WebLogic ロギングは JDK 1.4 ロギング API (java.util.logging パッケージ) に基づいています。 (更新オーバーライドから) ログを開くには、次のように、DataServiceMediatorContext インスタンスを取得して、そのコンテキストの getLogger( ) メソッドを呼び出します。
DataServiceMediatorContext context =
DataServiceMediatorContext().getInstance();
Logger logger = context.getLogger()
適切なログ レベルの呼び出しを発行することで、ログへの書き込みが行えます。 WebLogic Server メッセージ カタログと NonCatalogLogger はメッセージを生成するときに、メッセージの重大度を weblogic.logging.WLLevel オブジェクトに変換します。 WLLevel オブジェクトでは、表 9-5 に影響の低い順から高い順に示された値を指定することができます。
| 注意 : | 開発時のロギングは以下の場所に書き込まれます。 |
<bea_home>\user_projects\domains\<domain_name>
ロギング レベルを指定されると、メディエータは 表 9-6 に示す情報をログに記録します。
コード リスト 9-8 では、サンプルのログ エントリを示します。
<Nov 4, 2004 11:50:10 AM PST> <Notice> <LiquidData> <000000> <Demo - begin client sumbitted DS: ld:DataServices/Customer.ds><Nov 4, 2004 11:50:10 AM PST> <Notice> <LiquidData> <000000> <Demo - ld:DataServices/Customer.ds number of execution: 1 total execution time:171>
<Nov 4, 2004 11:50:10 AM PST> <Info> <LiquidData> <000000> <Demo - ld:DataServices/CUSTOMERS.ds number of execution: 1 total execution time:0>
<Nov 4, 2004 11:50:10 AM PST> <Info> <LiquidData> <000000> <Demo - EXECUTING SQL: update WEBLOGIC.CUSTOMERS set CUSTOMERNAME=? where CUSTOMERID=? AND CUSTOMERNAME=? number of execution: 1 total execution time:0>
<Nov 4, 2004 11:50:10 AM PST> <Info> <LiquidData> <000000> <Demo - ld:DataServices/PO_ITEMS.ds number of execution: 3 total execution time:121>
<Nov 4, 2004 11:50:10 AM PST> <Info> <LiquidData> <000000> <Demo - EXECUTING SQL: update WEBLOGIC.PO_ITEMS set ORDERID=? , QUANTITY=? where ITEMNUMBER=? AND ORDERID=? AND QUANTITY=? AND KEY=? number of execution: 3 total execution time:91>
<Nov 4, 2004 11:50:10 AM PST> <Notice> <LiquidData> <000000> <Demo - end clientsumbitted ds: ld:DataServices/Customer.ds Overall execution time: 381>
ロック メカニズムは同時実行性制御を目的として各種のマルチユーザ システムで使用されています。 同時実行性制御は、システムに同時に関わるユーザの数に関係なく、複数のトランザクションにわたってデータの一貫性を保証するものです。 オプティミスティック ロック メカニズムは、一般に、データのデフォルトの状態をロックするのではなく、更新される (書き込まれる) 時点のデータのみをロックすることから、そのように呼ばれています (「オプティミスティック ロックを有効または無効にする」を参照してください)。
AquaLogic Data Services Platform はオプティミスティック ロック同時実行性制御ポリシーを採用しており、更新が試行された時点でのみデータをロックします。
AquaLogic Data Services Platform の WebLogic Server インスタンスは、送信されたデータ グラフを受け取ると、元のデータ オブジェクトのインスタンス化に使用されたデータの値をデータ グラフ内の元の値と比較して、データ オブジェクトがクライアント アプリケーションによって変更されている間に、そのデータが別のユーザ プロセスによって変更されていないことを確認します。
メディエータは元のフィールドとソースのフィールドを比較します。デフォルトでは、比較のポイントとして [PROJECTED] が使用されます (表 9-7 を参照)。
各テーブルの更新時に比較されるフィールドを指定できます。 主キー カラムは一致する必要があること、BLOB 型と浮動小数点型は比較されない場合があることに注意してください。表 9-7 では、オプティミスティック更新ポリシー オプションについて説明します。
| 注意 : | AquaLogic Data Services Platform がデータベース テーブルからデータを読み取れない場合は、別のアプリケーションがテーブルをロックしているため、AquaLogic Data Services Platform が発行したクエリは、アプリケーションがロックを解放するまでキューに入れられます。 (WebLogic Server の JDBC 接続プールで) トランザクション アイソレーションを「read uncommitted」に設定することで、この問題を回避できます。 『管理ガイド』の「AquaLogic Data Services Platform アプリケーションのコンフィグレーション」の「トランザクション アイソレーション レベルの設定」を参照してください。 |
Java カスタム更新クラスを使用すると、さまざまなデータ サービスの更新を処理する JPD ワークフローを作成することができます。 また、JpdService インタフェースを使用して、同期または非同期の JPD を開始するサーバサイド Java コードを作成することができます。
AquaLogic Data Services Platform の他の種類のサーバサイド カスタム機能と同様に、更新オーバーライド インタフェースは実装を容易にするものです。
Java 更新オーバーライドを含むデータ サービスと JPD は、同じ WebLogic Server ドメインで実行することも、別々の WebLogic Server ドメインで実行することもできます。
次の例のように、JpdService は、JPD の名前、JPD の開始メソッド、サービス URI、および JPD のサーバの場所と資格を指定して呼び出されます。
JpdService jpd = JpdService.getInstance("CustOrderV1", "clientRequestwithReturn", env);
JPD はパブリック インタフェースを提供しています (JPD パブリック コントラクトまたはインタフェースのコンパイル済みクラス ファイルを格納した JAR ファイルとして提供されます)。 開発者にとって透過的に、JpdService オブジェクトは標準の Java リフレクション API を使用して、JPD パブリック コントラクトを実装する JPD クラスを見つけます。
サーバサイド更新は Java コードをオーバーライドしてから、メソッド呼び出しの引数として DataGraph を渡します。
Object jpd.invoke( DataGraph sdoDataGraph );
返されるオブジェクトは呼び出された JPD に依存しており、null の場合もあります。 たとえば、最上位の SDO が挿入されてその主キーが自動生成された場合、この SDO が JPD から返されるはずです (コード リスト 9-9 を参照)。
シリアライズされた UpdatePlan 内の最上位 DataObject のキーが、呼び出し側の関数に (バイト配列を構成する) Properties オブジェクトとして返されます。 したがって、次のように、ワークフローからの戻り値はシリアライズされたバイト配列である必要があります。
Properties [] jpd.invoke( byte[] serializedUpdatePlan );
返された配列は、シリアライズされてワークフローに返された UpdatePlan 内の最上位の DataObject のキーを表す、Properties オブジェクト配列です。
AquaLogic Data Services Platform による JPD のサポートは、UpdateOverride 実装から呼び出せる 2 つのサーバサイド API を通じて提供されます (表 9-8 を参照)。
コード リスト 9-9 に、UpdateOverride から JPD を呼び出す方法を示します。 このコード サンプルでは、ワークフローの一部としてコンフィグレーションされている一連のデータ サービスから成る JPD が存在すると仮定しています。
public boolean performChange( DataGraph ) {
ChangeSummary changeSum = dataGraph.getChangeSummary();
//サイズ 0 は変更がないため何も行われないことを意味する
if (changeSum.getChangedDataObjects().size()==0) {
return true;
}
Environment env = new Environment();
env.setProviderUrl( "t3://localhost:7001" );
env.setSecurityPrincipal( "weblogic" );
env.setSecurityCredentials( "weblogic" );
try {
JpdService jpd = JpdService.getInstance(
"CustOrderV1",
"clientRequestwithReturn",
env);
UpdatePlan updatePlan = DataServiceMediatorContext.
currentContext().getCurrentUpdatePlan( dataGraph );
byte[] bytePlan = UpdatePlan.getSerializedBytes( updatePlan );
Properties (Properties) returnProps = jpd.invoke( bytePlan );
}
catch( Exception e )
{
e.printStackTrace();
throw e;
}
return false;
}
}
AquaLogic Data Services Platform は同期および非同期の JPD 呼び出しをサポートしています。いずれの呼び出し方式も更新オーバーライド コードで同じように処理されます。 コード リスト 9-9 に例示したように、JPD を呼び出して、バイト配列として応答を受け取ります。
JPD に関する独自のエラー処理コードを記述する必要があります。 存在しない JPD を呼び出すと標準の Java 例外 ClassNotFoundException が発生します。
JPD でのコールバックの使用はサポートされていません。 クライアント コールバックを含むビジネス プロセスは実行時に失敗します。コールバックは JPD を開始した側のクライアントではなく、JPD プロキシに送信されるためです。
 
|