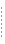

|
|
この章では、AquaLogic Data Services Platform のクライアントサイド アプリケーション プログラミング オブジェクト モデルであるサービス データ オブジェクト (SDO) について説明します。 この章の内容は以下のとおりです。
SDO は、データへのアクセスやデータの更新に使用する、Java ベースのデータ プログラミング モデルおよびアーキテクチャです。 SDO は、BEA と IBM が共同提案した仕様 (JSR 235) で定義されています。 SDO の目的は、基底のソースやデータの形式を気にすることなくアクセスおよび更新を行えるよう、統一的で使いやすいプログラミング モデルをアプリケーションに提供することです。
JDO や JDBC といった既存のデータ アクセス技術とは異なり、SDO にはデータにアクセスするための静的インタフェースと動的インタフェースの両方が指定されています。 静的な (厳密に型指定された) インタフェースは、値へのアクセスに使用できる更新可能な使いやすいモデルを提供します。 次に、静的インタフェースの関数の例を示します。
getCUSTOMERNAME()
この例の関数名から分かるように、静的インタフェースを使用する場合は、開発時点においてそのデータの型 (この場合であれば CUSTOMERNAME) が判明している必要があります。 開発時点で型が不明な場合は、動的な (緩やかに型指定された) インタフェースを使用できます。 次に、動的インタフェースの関数の例を示します。
cust.get("CUSTOMERNAME")
動的インタフェースは、データ型が不明な場合や開発時点でまだ定義されていない場合に使用できます。動的インタフェースが特に有用なのは、プログラミング ツールや、複数のデータ ソース型にまたがるフレームワークを作成する場合です。
SDO は、プログラミング インタフェースだけでなく、データ プログラミング アーキテクチャも定義します。 このアーキテクチャには、クライアントとデータ ソースの間のアダプタとして機能する「メディエータ」というコンポーネントが含まれています。 メディエータは、データ ソースとのデータのやり取りを専門に処理するコンポーネントで、 特定のソースからデータを取得し、変更内容をソースに返します。 データは、データ オブジェクトのグラフで構成される「データ グラフ」としてやり取りされます。
SDO 仕様に明記されているように、SDO 実装にはソース タイプ (データベースなど) ごとに専用のメディエータを定義するのが一般的です。 AquaLogic Data Services Platform は、SDO クライアントとデータ統合レイヤの間に常駐する「データ サービス メディエータ」を備えています。
SDO を使用すると、クライアントは本質的にステートレスかつ非接続な方法でデータを利用できます。 AquaLogic Data Services Platform では、データベースなどのソースからデータを取得する際に、データを取得するのに十分な長さの 1 つまたは複数のデータベース接続のみを取得します。 これらの接続は、データ取得後に解放されます。 クライアントは、データ ソースから切断された状態のデータのローカル コピーを使用して処理を行います。
ネットワークへのアクセスが再度発生するのは、クライアントがデータの変更をソースに適用する必要がある場合だけです。 データ アクセスを非接続にすることで、バックエンドのシステム リソースを長い時間拘束する必要がなくなり、スケーラブルで効率的なコンピューティング環境を構築できます。
また、更新の発生時にデータの整合性が保たれるよう、オプティミスティックな同時実行性ルールが採用されています。 オプティミスティックな同時実行性の場合、クライアントによる処理中もデータ ソースのデータはロックされません。 代わりに、データの更新時 (データがソースに伝播されるとき) に、潜在的な衝突がある (たとえば、そのクライアントがデータを取得した後に、他のクライアントによって同じデータが変更された) かどうかが検出されます。
サービス データ オブジェクトの詳細 (仕様、Javadoc など) については、次のドキュメントを参照してください。
AquaLogic Data Services Platform では、SDO をクライアントサイド プログラミング モデルとして使用します。 つまり、Java クライアントがデータ サービスの読み取り関数を呼び出すと、戻り値が SDO データ オブジェクトとして返されます。この点は、AquaLogic Data Services Platform Mediator API を使用して呼び出した場合も、Workshop データ サービス コントロールを使用して呼び出した場合も同様です。 データ オブジェクトは、SDO プログラミング モデルの基本的なコンポーネントです。 データ オブジェクトは、構造化された情報の単位を表し、そのデータ値を取得および設定するための静的インタフェースと動的インタフェースから構成されます。
この節では、簡単なサンプル コードをもとに、SDO のプログラミングについて解説します。 このサンプルを見ると、SDO が単純で使いやすいクライアントサイド データ プログラミング モデルをどのように提供するかが分かります。
このサンプルは、図 5-1 に示すデータ サービス用に記述されたものです。
Customer データ サービスのデータ型は CUSTOMER です。 データ型とは、スキーマと呼ばれる構造化された XML ドキュメントです。 このサンプルでは、CUSTOMER データ型が顧客 ID、名前、注文といったプロパティから構成されています。 CUSTOMER インスタンスのデータは、他の 4 つのデータ サービス (CUSTOMERS、PO_CUSTOMERS、PO_ITEMS、および getCustomerCredit) から供給されます。 これらのデータ サービスは、物理的には拡張子 .ds の XQuery ドキュメントです (例 : PO_CUSTOMERS.ds)。
サンプルの Customer データ サービスには、データ型インスタンスを取得するためのメソッドがいくつか定義されています (getCustomer()、getCustomerById()、getPaymentList() など)。 関数 getPaymentList() はナビゲーション関数です。 この関数は、CUSTOMER ドキュメントを返すのではなく、論理的な関係が定義されているデータ サービスからのデータを返します。 getPaymentList() の場合は、関連するデータ サービス PAYMENTS から、指定された顧客の支払い履歴を返します。
ナビゲーション関数を使用すると、CUSTOMER ドキュメントを処理する際に必要となることの多い追加的な関連データを簡単に取得できます。 クライアント アプリケーションからは、顧客情報の取得に使用するのと同じデータ サービス ハンドルを使って、その顧客の支払い履歴の一覧を取得できることになります。
その結果として、コード リスト 5-1 に示すように、一貫性があって読みやすく、保守も容易なコードになります。
import java.util.Hashtable;
import javax.naming.Context;
import javax.naming.InitialContext;
import com.bea.dsp.dsmediator.client.*;
import org.openuri.temp.schemas.customer.CUSTOMERDocument;
public class myCust {
public static void main(String[] args) throws Exception {
Hashtable h = new Hashtable();
h.put(Context.INITIAL_CONTEXT_FACTORY,
"weblogic.jndi.WLInitialContextFactory");
h.put(Context.PROVIDER_URL,"t3://localhost:7001");
h.put(Context.SECURITY_PRINCIPAL,"weblogic");
h.put(Context.SECURITY_CREDENTIALS,"weblogic");
DataService ds =
com.bea.dsp.dsmediator.client.DataServiceFactory.newXmlService(
new InitialContext(h),
"Demo",
"ld:DataServices/Customer");
Object arg[]={new Integer("987655")};
CUSTOMERDocument myCustomer =
(CUSTOMERDocument) ds.invoke("getCustomer",arg);
myCustomer.getCUSTOMER().setCUSTOMERNAME("BigCo, Inc");
ds.submit(myCustomer,"ld:DataServices/Customer");
System.out.println(" Customer information: \n" + myCustomer);
}
}
適切なパッケージがインポートされ、サーバに対する初期コンテキストが確立されると、上に示したクライアント アプリケーションの 5 行のコードによって以下の処理が実行されます。
この手順全体の複雑さを、クライアント アプリケーションの開発者が意識する必要はありません。 この複雑な部分は、データ サービス レイヤと AquaLogic Data Services Platform フレームワークで処理されています。
SDO では、データの読み取りの場合と同様に、データの更新においても統一的なインタフェースが提供されます。 クライアント アプリケーションは、分散された異種データ ソースのデータを、あたかも単一のエンティティのデータであるかのように変更したり更新したりできます。 異種データ ソースに変更を伝播するという複雑な作業を、クライアントのプログラマが意識する必要はありません。
データ ソースの更新は、トランザクション的に安全な方法で行われます。つまり、複数のソースに影響する更新呼び出しが発生すると、その更新に関係するすべてのデータ ソースが正常に更新されるか、すべてのデータ ソースで更新が失敗するかのどちらかになります (必要に応じて、この動作をオーバーライドすることもできます)。
データ サービスの実装においても、更新可能なデータ サービスのライブラリを構築するという面倒な作業が、AquaLogic Data Services Platform の更新フレームワークによって大幅に軽減されます。 リレーショナル ソースの場合は、通常であればデータ ソースへの変更が自動的に伝播されます。 その他のソースの場合や、リレーショナル更新をカスタマイズする場合は、AquaLogic Data Services Platform の更新フレームワークとツールを使用してさまざまな更新可能サービスをすばやく実装できます。
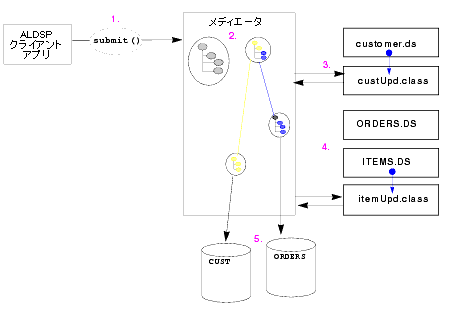
図 5-2 に示すように、更新のプロセスにおいては、まず要求された変更が分析されてデータの系統が判別されます。 次に、AquaLogic Data Services Platform メディエータが送信されたオブジェクトを構成要素に分解し、それぞれの変更を各データ ソースに伝播します。
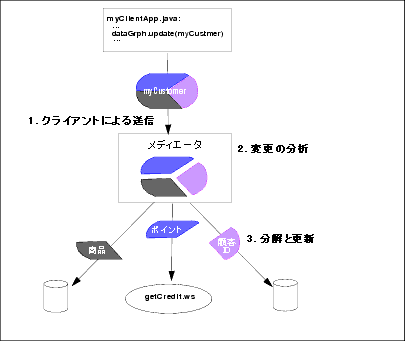
このプロセスのどの時点でも、独自のコードでプログラム的にプロセスに介入できます。たとえば、監査を目的として、更新の値を検証することもできます。
データ サービス メディエータは、AquaLogic Data Services Platform 更新フレームワークの中核的なメカニズムです。更新フレームワークは、以下に示すプログラミング アーティファクトから構成されています。
更新プランは、より細かなレベルで見ると、DataServiceToUpdate (変更されたデータ オブジェクトから構成されるデータ サービス) インスタンスのツリーで構成された Java オブジェクトです。 SDO Mediator API のクラスとしては、DataServiceToUpdate、KeyPair、UpdatePlan、および DataServiceMediatorContext が実装されています。パッケージ名は次のとおりです。
com.bea.ld.dsmediator.update パッケージ
『アプリケーション開発者ガイド』の「クライアント アプリケーション向けのデータ サービスについて」にあるトピック「Mediator API Javadoc」を参照してください。
SDO モデルの重要な性質の 1 つは、変更されたオブジェクトにバインドされているデータ サービスに対して submit( ) メソッドが呼び出されるまでは、そのオブジェクトに関連付けられているバックエンド データ ソースが変更されない点です。
メディエータは、呼び出し側のクライアント アプリケーションからデータ オブジェクト (変更された SDO) を受信すると、物理データ サービスか論理データ サービスかに関係なく、必ず最初に更新オーバーライド クラスを検索します。 更新オーバーライド クラスが見つかると、それをインスタンス化して実行します。
メディエータは最初に、データ サービスの分解関数を使用して、データ オブジェクトの各構成要素を基底のデータ ソースまたはデータ サービスにマップし、それに基づいてデータ系統 (データの供給元) を判別します。 また、データ サービスに反転関数が指定されている場合は、それらを使用して完全な分解マップを定義します (反転関数については、『データ サービス開発者ガイド』の「ベスト プラクティスと高度なトピック」を参照してください)。
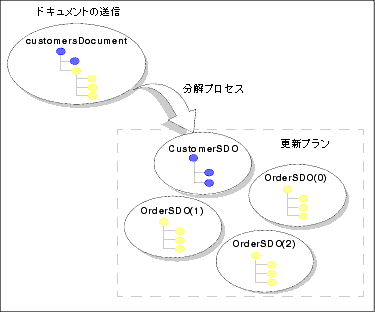
図 5-3 に示したように、更新された顧客情報 (Customer データ サービスからのデータ) と更新された注文 (Orders データ サービスからのデータ) から構成されている customersDocument オブジェクトは、4 つのオブジェクトに分解されます。
論理データ サービスの更新と物理データ サービスの更新には、次のような重要な違いがあります。
物理データ サービスの場合、データ サービスに更新オーバーライド クラスが関連付けられている場合を除き、データ サービスへの変更が即座に伝播されます。 分解マップや更新プランは必要ありません。
メディエータは、SDO を (submit( ) メソッド呼び出しから、または上位レベルのデータ サービスからの出力として) 受信すると、まずそのデータ サービスに UpdateOverride クラスが関連付けられているかどうかをチェックします。
1 つの論理データ サービスを構成するデータ サービス (論理または物理) の数に制限はありません。 最上位レベルのデータ サービス関数を実行する際は、それを構成する下位レベルの論理データ サービスが「混入」されるため、その関数が物理データ サービスに対して直接記述されているかのように見えます。 最上位レベルのデータ サービスから出力された情報のみが、次の下位レベルのデータ サービスに渡されます。
図 5-4 に、論理データ サービスの更新手順の概要を示します。
| 注意 : | 更新オーバーライド クラスは、マルチレイヤ データ サービスのレイヤごとに存在する可能性があります。 したがって、論理データ サービスが他の論理データ サービスの複数のレイヤで構成されている場合は、構成レイヤごとに更新オーバーライドをチェックする必要があります。 中間レイヤのデータ サービスに更新オーバーライドがない場合は、基底のデータ サービスの SDO オブジェクトが直接作成されるのではなく、SDO オブジェクトのインスタンス化がスキップされます。 更新フレームワークのこの動作は、更新オーバーライドが関連付けられている論理データ サービスや、物理データ サービスにも適用されます。 |
performChange( ) メソッドは、更新プランや分解マップにアクセスしてこれらを変更したり、他のカスタム処理を実行したりできます (処理全体を引き継ぐことも可能)。 このメソッドは、メディエータによる処理を続行するか中止するかを示す以下のブール値を返します。
ほとんどの RDBMS では、主キーが自動的に生成されます。つまり、リレーショナル データベースをバックエンドとするデータ サービスに新しいデータ オブジェクトを追加する際は、コード内で主キーを戻り値として処理しなければならない場合があるということになります。 たとえば、送信されたオブジェクト データ グラフに新しいデータ オブジェクト (たとえば新しい Customer オブジェクト) が含まれている場合は、必要となる主キーが AquaLogic Data Services Platform によって生成されます。
自動付番主キーのデータ挿入の場合は、新しい主キー値が生成されてクライアントに返されます。 返されるのは最上位レベルのデータ オブジェクト (マルチレベル データ サービスの最上位レベル) の主キーのみで、計算された主キーを持つネストされたデータ オブジェクトは返されません。
AquaLogic Data Services Platform では、挿入されたタプルの最上位レベルの主キーを返すことで、必要に応じて新しい主キーでタプルをフェッチしなおすことを可能にしています。
メディエータは、主キーと外部キーの論理的な関係をキーペアとして保存します (Mediator API の KeyPair クラスを参照)。 KeyPair オブジェクトは、新しいデータ オブジェクトの作成プロセスの間に、外部キー フィールドを設定するために使用するプロパティ マップです。
プロパティがコンテナ内の自動付番主キー (つまり、自動付番された後のデータ ソース内の新しいレコード) である場合は、プロパティの値が親から子へ伝播されます。
KeyPair オブジェクトは、分解マップの隣接するレベル間で、対応するデータ要素を特定するために使用します。KeyPair オブジェクトを使用することで、親 (コンテナ) オブジェクト用に生成された主キー値を、子要素 (そのコンテナに含まれるオブジェクト) の外部キー フィールドに確実にマッピングできます。
例として、図 5-5 に Customers データ サービスの分解におけるプロパティ マッピングを示します。
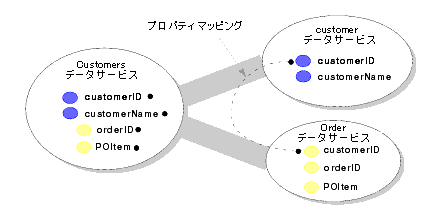
AquaLogic Data Services Platform は、データ サービス間の主キーと外部キーの関係を管理します。管理の方法は、以下に示すように、マルチレイヤ データ サービスのレイヤによって異なります。
Properties[] keys = ds.submit(doc);
タプルは、基本的にはレコードです。ただし、データ サービスのコンテキストでは、データ サービスの複数のレイヤにまたがるデータから 1 つのタプルが構成される場合もあります。
AquaLogic Data Services Platform では、変更の影響が主キーや外部キーに伝播されます。
たとえば、主キー フィールドが CustID の Customer オブジェクトの配列に、2 つの Customer を挿入したとします。ここで送信を実行すると、その Customer 型を基準とした CustID を名前とし、挿入された各 Customer の新しい主キー値を値として、2 つのプロパティの配列が返されます。
AquaLogic Data Services Platform は、更新プロセスの間の主キーの依存関係を管理します。 主キーを識別し、述語文内の外部キーを推量できます。 たとえば、データを結合するクエリでは、次のように値を比較します。
where customer/id = order/id
メディエータは、データ サービスの更新時に、推量されたキーと外部キーの関係に基づいてさまざまなサービスを実行します。
2 つの SDOToUpdate インスタンス (更新プラン内のデータ オブジェクト) の間に述語依存関係があり、コンテナ SDOToUpdate インスタンスが挿入または変更されて、コンテナに含まれる SDOToUpdate インスタンスが挿入または変更された場合、コンテナ SDO が更新のために送信された後に、コンテナ SDO のどの値をコンテナに含まれる SDO に移動すべきかを示すキーペア リストが特定されます。
このキーペア リストは、コンテナ SDO とコンテナに含まれる SDO のフィールドのセットに基づいています。これらは、現在の SDO が作成されたときには等しくなければならなかったものです。キーペア リストは、述語フィールドからこれらの主キーのみを特定します。
キーペアは、コンテナの主キーをコンテナに含まれるフィールドにのみマッピングします。 そうしないと、コンテナの完全な主キーがマップから特定できず、どのプロパティもマッピングされていないと判断されてしまうためです。
キーペア リストには、1 つまたは複数の項目が含まれており、これらによってコンテナ内のノード名や、マップされているコンテナ内のオブジェクトを特定します。
SDO の分解の送信によって計算が可能な場合、外部キーの値は親キーの値と一致するように設定されます。
メディエータに対する submit() は、トランザクションとして動作します。 submit() が成功したか失敗したかに応じて、次のどちらかを実施する必要があります。
送信では、常にデータ ソースの即時更新が実行されます。 ネストされたトランザクションのコンテキスト内でデータ オブジェクトの送信が発生した場合、ネスト内に含まれるトランザクションのコミットやロールバックは、送信されたデータ オブジェクトには影響しませんが、そのトランザクションに参加するすべてのデータ ソース更新には影響します。
 
|