
|
|
データ サービスを使用することで、企業内の情報の単位 (顧客、注文、製品、サービスなど) を構造化したビューにアクセスできるようになります。
複数のデータ サービスをまとめて構成することで、IT 環境内にデータ統合レイヤを構築できます。 データ サービスの詳細については、BEA AquaLogic Data Services Platform の『コンセプト ガイド』にある「データ サービスによる情報の統合」を参照してください。
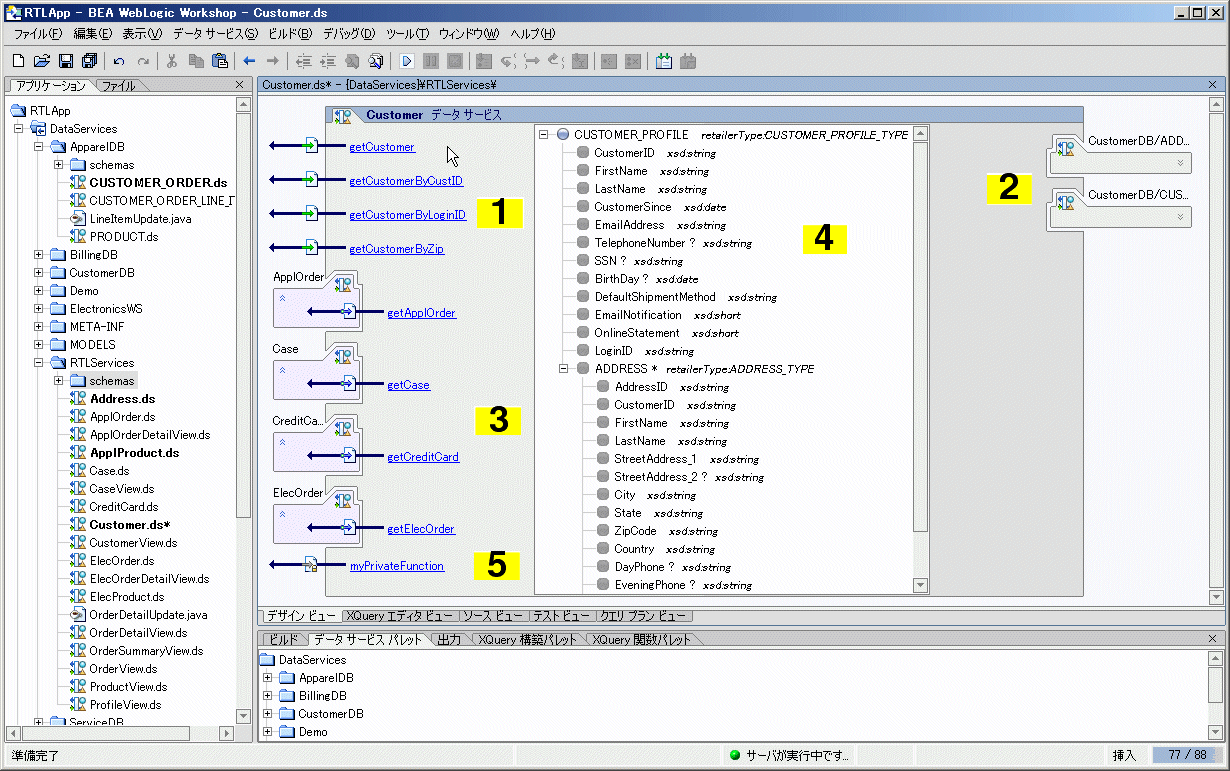
データ サービスは、デザイン ビューでは「集積回路」のように表されます。つまり、すべてのクエリ関数、基底のデータ ソース、ナビゲーション関係、および変換ロジックの配置図 (図 4-1) として表示されます。これらの配置されるアーティファクトは、返す結果を特定の形式 (戻り値型) でサポートしなければなりません。 詳細については、「AquaLogic Data Services Platform プロジェクトとプロジェクトのコンポーネント」を参照してください。
データ サービスは、AquaLogic Data Services Platform ベースのプロジェクト内に、クエリ関数およびメタデータのサポートを含んだ単一の XQuery ファイルとして存在します。 詳細については、「XQuery ソースの操作」および AquaLogic Data Services Platform の『XQuery 開発者ガイド』を参照してください。
関数および要素に対するセキュリティ ポリシーとキャッシング ポリシーの設定については、『管理ガイド』の「AquaLogic Data Services Platform リソースの保護」を参照してください。
現代の企業では、データは急速に 2 つの「世界」に分かれてきています。1 つはテーブル、カラム、ビュー、およびストアド プロシージャからなる従来のリレーショナルな世界であり、もう 1 つはデスクトップやさまざまな Web インタフェースを介してアクセスされる Web サービスおよびその他のデータ形式からなる世界です。
根本的に異なるアーキテクチャや目的に基づいた複数のシステムを通じてデータにアクセスしたりデータを更新したりするコストはますます膨大になり、サービス自体を設定するコストにも匹敵しかねません。
データ サービスは、以下の点で従来の Web サービスに似ています。
もちろん従来の Web サービスには、返すデータの形式操作を容易にするコア XML データ型はありません。 また、小さい相違点として、データ サービスは XQuery ライブラリ ファイル (.xfl ファイル) に含まれるプライベート関数にアクセスできます。
具体的に言うと、データ サービスは、データの取得、集約、および変換を実行するための XML Query (XQuery) 命令が格納されているファイルです。
データ サービスには、物理データ サービスと論理データ サービスの 2 種類があります。 物理データ サービスは、リレーショナル データとサービス データで構成されます。 論理データ サービスは、物理データ サービスまたは別の論理データ サービスのコンシューマです。 企業のデータ アクセス レイヤには、物理データ サービスと論理データ サービスの両方が含まれます。
この方法の大きな利点は、AquaLogic Data Services Platform などが提供する仮想データ アクセス レイヤの場合にはデータの転送も保管も発生しないことです (アプリケーションで指定されるキャッシングを除く)。 データ サービスは、データ ソースからデータを動的に取得する読み取り関数のインタフェース呼び出しをエクスポーズするだけです。 取得されたデータはその後、データ サービスの XML 型に基づいて配置されます。 更新ロジックは、各データ サービスに関連付けられます。 リレーショナル データの場合、更新ロジックは自動化されています。それ以外の場合は、カスタム更新関数を開発できます。 詳細については、「データ サービスを介した更新の処理」を参照してください。
| 注意 : | 論理データ サービスは、基底の物理的なデータ ソースを表す物理データ サービスに基づいて構築されます。 物理データ サービスは、物理的なソースのメタデータをインポートすることで作成され、同期を使用して更新されます。 このプロセスで生成されるスキーマ ファイル (XML 型) は、AquaLogic Data Services Platform でも外部でも変更してはいけません。 変更すると、データ サービスおよびそれに依存する論理データ サービスが無効になるおそれがあります (単一のソースに基づくデータ サービスを変更する場合は、その 1 つのソースに基づいて論理データ サービスを作成するのが簡単です)。 |
データ サービスは、データを取得および更新するための理解しやすい統一的なデータ アクセス レイヤをクライアント アプリケーションに提供するように設計されなければなりません。
データ サービスのインタフェースは、以下のような数種類の関数で構成されます。
.xfl ファイル) には、パブリック関数に加え、プライベート関数も含めることができます。 プライベート関数には、データ サービスまたは XFL 内の他の関数からのみアクセスできます。 通常、プライベート関数には共通の処理ロジック (データ サービス内の複数の関数で使用する処理) が格納されます。 複数のデータ サービスで共有されるように設計される関数については、「XQuery 関数ライブラリの作成および使用」を参照してください。
ソース ビューでは、プライベート関数は関数の上にあるプラグマ文で識別されます。
| 注意 : | 単一の submit() 関数は、ソース ビューに表示されます。 データ サービスのデザイン ビューには表示されません。 |
デザイン ビューでは、データ サービス全体を視覚的に表示することができます (図 4-1 を参照)。 各データ サービスは、省略可能なペインに囲まれた状態で WebLogic Workshop に表示されます。ペインには、アプリケーション コンポーネント、デザイン ビューで選択されたプロパティのプロパティなどが示されます。 AquaLogic Data Services Platform ベースのプロジェクトにおけるコンポーネントの詳細については、「AquaLogic Data Services Platform プロジェクトとプロジェクトのコンポーネント」を参照してください。
各データ サービスの中核となるのがその XML 型です。 XML 型は、データ サービスまたは関連するナビゲーション関数から読み取り関数が呼び出されたときに返されるドキュメントの形式を定義します。 詳細については、「XML 型と戻り値型」を参照してください。
表 4-2 に、図 4-1 で表示されているデータ サービスの機能コンポーネントの詳細を示します。
|
||||
| 注意 : | 複数のデータ サービスが単一の XML 型に依存する場合もあります。 このような状況は、複数のデータ サービスを、常に同じ XML 型を返す 1 つのグループとして設計する場合に便利です。 |
AquaLogic Data Services Platform ベースのプロジェクトの主要な生成物は、データ サービスのクエリ関数と戻り値型 (ターゲット スキーマとも呼ばれる) です。 XML スキーマは、物理データと論理データ、および AquaLogic Data Services Platform クエリから返されるドキュメントの形式を階層形式で表すために使用されます。
戻り値型は、データ サービスおよびデータ モデルの両方のバックボーンと考えることができます。 プログラム的には、戻り値型は for-let-where-return (flwr) クエリの「r」です。

データ サービスにおける XML 型の指定の詳細については、「XML 型を関連付ける」を参照してください。
AquaLogic Data Services Platform モデラー、データ サービス、XQuery エディタ、およびメタデータ ブラウザでは、以下のように XML 型表現が使用されます。
AquaLogic Data Services Platform で実装される XQuery および XML 仕様のバージョンについては、『XQuery 開発者ガイド』を参照してください。
| 注意 : | ADO.NET をサポートするデータ サービスには、さらに固有の XML 型要件があります。 詳細については、『クライアント アプリケーション開発者ガイド』の「ADO.NET クライアントのサポート」を参照してください。 |
戻り値型は、実行時にクエリによって生成されるデータの構造または形式を定義します。 戻り値型は、XML 型の 1 つのオブジェクトと考えることができます。
| 注意 : | アプリケーションで使用される AquaLogic Data Services Platform クエリの整合性を保持するためには、クエリの戻り値型が、クエリを含んでいるデータ サービスの XML 型と一致していることが重要です。 そのため、戻り値型を変更する場合は、XQuery エディタの [XML 型の保存および関連付け] コマンドを使用して、データ サービスの XML 型をクエリレベルの変更と一致させておく必要があります。 または、戻り値型に基づいて新しいデータ サービスを作成します。 詳細については、「単純なデータ サービス関数の作成」を参照してください。 |
データ サービスの作成には、以下のような数種類の方法があります。
データ サービスは常に、現在の AquaLogic Data Services Platform ベースのプロジェクト内に作成されます。 作成後は、[データ サービス] メニュー (または右クリック) を使用してデータ サービスを開発できます。表 4-5 に、使用可能な右クリック オプションとそれらの使い方を示します。
読み取り関数には、適切なセキュリティ資格を持つ呼び出し側のアプリケーションからアクセスできます。 データ サービスに読み取り関数を追加する場合は、デフォルトの関数名をそのまま使用することもできますし、デフォルト名を直接編集することもできます。 その後、新しい関数の名前をクリックすると、XQuery エディタに移動します。 「XQuery エディタの操作」を参照してください。
| 注意 : | アリティ (パラメータの数) が一致しない場合でも、所定のデータ サービス内の関数名はユニークであることが重要です。 これは、JDBC が同じ名前の関数を区別できないためです。 |
データ サービス プロシージャ (副作用関数とも呼ばれる) を使用して、必ずしもデータを返さない外部ルーチンを呼び出すことができます。 プロシージャを使用して、データを更新する Web サービスを呼び出すというのが、一般的なシナリオです。 プロシージャを使用して、データベース処理を実行するリレーショナル ストアド プロシージャを呼び出すという使い方もあります。 このような場合には、「success」メッセージだけが返される場合があります。「success」メッセージは、ストアド プロシージャがそのステータスをレポートするように設計され、さらに、呼び出し側のプロシージャが返されたデータを処理するように設定されている場合にのみ発生します。
プロシージャは、メタデータ インポート プロセスの一部として、物理データ サービスのみに追加されます。 詳細については、「AquaLogic Data Services Platform のプロシージャの識別」を参照してください。
プライベート関数は、読み取り関数と似ていますが、データ サービス内の他の関数からのみ使用できます。 プロパティ エディタを使用するか、またはソース ビューのプラグマを編集することで、プライベート関数を読み取り関数に変更できます。
関係を設定すると、データ サービスのインスタンスをパラメータとして使用して、別のデータ サービスを呼び出すことができます。 データは、関連するサービスの形式で返されます。 このようにして、データ サービスに一連の関数を設定できます。
1 つまたは複数の関係によって、2 つのデータ サービスを関連付けることができます。
たとえば、CUSTOMER と ORDER が、以下の 3 つのナビゲーション関数を含んだ CUSTOMER-ORDER 関係によって関連付けられているとします。
cst:getAllOrders(CUSTOMER)ORDER*
cst:getOpenOrders(CUSTOMER)ORDER*
ord:getCustomer(ORDER)CUSTOMER
最初の 2 つの関数は、CUSTOMER-ORDER 関係を顧客からその注文の全部または一部に移動する 2 種類の方法です。 3 番目の関数は、ORDER からそれに関連付けられた CUSTOMER に移動する方法です。
多くの一般的な関係では、2 つのナビゲーション関数 (関係を介して一方向に移動するための関数とその逆方向に移動するための関数) が使用されます。
あまり一般的でない一方向の関係には、ナビゲーション関数は 1 つしかありません。
データ サービスにおける読み取り関数とナビゲーション関数の機能的な相違点は、返されるデータの形式です。 以下に、簡単な例を示します。
以下の XML 型を持つ OpenOrders データ サービスがある場合、
<openOrders>
<custID>
<first_name>
<last_name>
<orderID>
..
</openOrders>
読み取り関数に 101 などの顧客 ID と、LRP-111 などの注文 ID を渡すと、クエリ結果は次のようになります。
<customerInfo>
<custID>101</custID>
<first_name>Jane</first_name>
<last_name>Smith</last_name>
<orderID>Smith</orderID>
..
</customerInfo>
しかし、データ サービスに TrackOrders テーブルに関連付けられたナビゲーション関数があると、クエリ パラメータは同じものが保持されますが、データは次のような TrackOrders 型の形式で返されます。
<TrackOrders>
<custID>
<first_name>
<last_name>
<orderID>
<ship_date>
<weight>
<delivery_date>
...
</TrackOrders>
データ サービスに関係を追加するプロセスは、以下の 3 つの手順で構成されます。
関係ウィザードを使用して、豊富な機能を備えたバイナリ ナビゲーション関数を開発できます。
ナビゲーション関数の価値は、関数の内部構造、結合条件などが分からなくても、クライアント アプリケーションで複合パラメータを使用してその関数を呼び出せることにあります。 データ サービス作成者から見ると、そのデータ サービス関数を呼び出すかどうかに関係なくアプリケーションに影響を与えずに、関数の内部を変更できます。
デザイン ビューまたはモデル ダイアグラムで関係を作成する場合には、関係ウィザードが表示されます。 ウィザードでは、ナビゲーション関数に対して以下の表記を設定できます。
また、パラメータを識別したり、where 句を指定したりすることもできます。
関係ウィザードの最初のダイアログでは、ロール名、方向、およびカーディナリティを設定できます。

表 4-8 に、図 4-7 で表示されている設定コンポーネントの詳細を示します。
|
||||
|
関係ウィザードの 2 番目のダイアログでは、ナビゲーション関数名およびその他の特性を設定できます。

表 4-10 に、図 4-9 で表示されている設定コンポーネントの詳細を示します。
この節では、簡単な例を取り上げ、関係ウィザードを使用して豊富な機能を備えたナビゲーション関数を作成する方法を示します。 この節の目的は、顧客 ID を指定することで特定の顧客の住所 (ファイルの最初にある使用可能な住所) を返すナビゲーション関数を作成することです。
次の手順では、AquaLogic Data Services Platform に付属の RTLApp が使用されています。
関係は双方向のままにしておきます。つまり、住所オブジェクトを指定することで顧客のプロファイル情報を取得でき、顧客のプロファイル オブジェクトを使用して住所情報を取得できます。 ただし、顧客は複数の注文を行うことができるので、Customer Profile  Address のカーディナリティの表記は 1 対 n になります。
Address のカーディナリティの表記は 1 対 n になります。
各ナビゲーション関数の次のステージでは、以下の作業を行います。
getCustomerProfile() ナビゲーション関数の場合の特徴は以下のとおりです。
衣料品の注文のデータ サービスには通常、複数の読み取り関数が含まれます。 getApparelOrdersByCustID() を選択すると、反対側のデータ サービスから要素 (cust_id) をマップできるようになります。
図 4-14 では、最初のナビゲーション関数に対して定義した where 句があらかじめ指定され、読み込み専用形式で表示されています。
テスト ビューでナビゲーション関数を実行するときには、複合パラメータの形式で入力を指定できます。複合パラメータは、たとえば顧客レコードを返すクエリの結果などになります。 または、テスト ビューのテンプレート オプションを使用して、適切なパラメータを指定できます。 「XML 型を使用して入力パラメータを指定する」を参照してください。
データ サービスのソース ビューでは、ナビゲーション関数はプラグマと関数の本文を使用して定義されます。 詳細については、AquaLogic Data Services Platform の『XQuery 開発者ガイド』を参照してください。
たとえば、Payment() という名前のナビゲーション関数に、読み取り関数 getPaymentList() があるとします。
declare function ns1:getCustomer($arg as element(ns0:APPL_ORDER)) as element(ns15:PROFILE)* {
for $b in ns16:getCustomerByCustID($arg/CustomerID)
return $b
};
この関数を理解するための重要な要素は、XML 型 PAYMENTList.xsd をモデル化するスキーマをインポートするネームスペース ns15 にあります。 ネームスペースは、次のように定義されます。
import schema namespace ns15="urn:retailerType" at
"ld:DataServices/RTLServices/schemas/Profile.xsd";
| 注意 : | データ サービスのプラグマにあるロール名を変更する場合、その関係がモデル ダイアグラムに存在しているときには、その関係を表示するすべてのモデル ダイヤグラムにあるロール名も同様に変更する必要があります。 変更しない場合、関係が無効になります。 |
データ サービスに関連付けられた読み取り関数は、データ サービスの XML 型の形式で情報を返します。
| 注意 : | 論理データ サービスは、基底の物理的なデータ ソースを表す物理データ サービスに基づいて構築されます。 物理データ サービスは、物理的なソースのメタデータをインポートすることで作成され、同期を使用して更新されます。 このプロセスで生成されるスキーマ ファイル (XML 型) は、AquaLogic Data Services Platform でも外部でも変更してはいけません。 変更すると、データ サービスおよびそれに依存する論理データ サービスが無効になるおそれがあります (単一のソースに基づくデータ サービスを変更する場合は、その 1 つのソースに基づいて論理データ サービスを作成するのが簡単です)。 |
ブラウザを使用して、データ サービスに関連付けられる XML 型を追加したり、置換したりできます。 型はアプリケーションのファイル構造内に存在しなければなりません。
選択するスキーマに複数のグローバル要素がある場合には、使用するグローバル要素を選択するためのダイアログが表示されます。

XML 型を編集することもできます。 XML 型の右クリック メニューからオプションを使用できます (表 4-17)。
| 警告 : | デザイン ビューで XML 型を編集すると、XML 型の基底のスキーマ ファイルが直接変更されます。 こうした変更は [元に戻す] コマンドで戻すことはできません。 このため、XML 型を変更する場合は、元のバージョンに戻さなければならない場合に備えて適切なバックアップを作成し、注意深く行う必要があります。 |
上記以外のオプションとして、特定の条件を満たしたリレーショナルベースの XML 型の要素に対しては [Enable Optimistic Locking] が使用できます。 「オプティミスティック ロックを有効または無効にする」を参照してください。
表 4-18 に、さまざまな XML 型要素に対して適用される右クリック オプションの一覧を示します。
スキーマに表示される複合型コンポーネントは、XML 型に表示されない場合があります。
| 注意 : | XML 型は、他のデータ サービスによって使用される可能性のあるスキーマに基づいています。 このため、XML 型を変更する場合は、元のバージョンに戻さなければならない場合に備えて適切なバックアップを作成し、注意深く行う必要があります。 同様に、データ サービス内のすべての関数は、データ サービスの XML 型を返すように記述されなければなりません。 |
表 4-18 に示した右クリック メニューだけでなく、[ソースへ移動] コマンドを使用して WebLogic Workshop のテキスト エディタでスキーマ ファイルを編集することもできます。
新しいデータ サービスに対して XML 型を作成できます。 データ サービスにすでに名前があるので、以下の項目のみを指定する必要があります。
デフォルトでは、スキーマ ファイル名、スキーマ、および対象ネームスペースは、データ サービスの名前と同じになります。
![[新しいスキーマ ファイルの作成] ダイアログ ボックス](wwimages/newSchema.gif)
作成後は、データ サービスに組み込みのスキーマ エディタを使用してスキーマを作成できます。 または、XMLSpy などのプログラムでスキーマを作成できます。
データ サービスをクライアント アプリケーションで使用できるようにする前に、重要なデプロイメント前のタスクを行う必要があります。 データ サービスおよびその関数のプロパティの設定などを行います。

プロパティ エディタ ([表示|プロパティ エディタ]) を使用して、以下のようなデータ サービスの主要な機能を設定したり変更したりできます。
「主なデザイン ビューのプロパティ」を参照してください。
データ サービス関数をリファクタできます (名前の変更または安全な削除に限る)。 「AquaLogic Data Services Platform アーティファクトのリファクタリング」を参照してください。
ほとんどの AquaLogic Data Services Platform アーティファクトについては、右クリック メニュー オプションからその用途を即座に確認できます。 「データ サービス アーティファクトの用途」を参照してください。
各データ サービスには、その更新特性を指定するための一連のプロパティがあります。
| 注意 : | 分解関数、オーバーライド クラス、オプティミスティック ロック設定、およびその他の SDO 関連の情報については、「データ サービスを介した更新の処理」を参照してください。 |

プロパティ エディタの [更新の許可] オプションを使用して、呼び出し側のアプリケーションでデータ サービスに関連付けられた更新ロジックを実行できるかどうかを指定できます。 更新の許可はリレーショナルベースのデータ サービスでは特に重要になります。更新ロジックは無効にしない限り、自動的に使用可能になるからです。
更新を許可するには、このオプションを true に設定します。更新しないようにするには false に設定します。
データ サービスに関連付けられた非リレーショナル ソースを更新するには、更新オーバーライド クラスを作成する必要があります。 さらに、リレーショナル ソース用の組み込みの更新ロジックを上書きして、更新プロセスにカスタム ロジックを適用しなければならない場合もあります。
オーバーライド クラスを設定する前に、そのクラスを開発する必要があります。 必要な手順は次のとおりです。
オーバーライド クラスの開発については、「データ サービスを介した更新の処理」を参照してください。
| 注意 : | データ サービスごとに、更新オーバーライド クラスを 1 つだけ指定できます。 ただし、複数のデータ サービスで同じ更新オーバーライド クラスを共有できます。 |
リレーショナル データの SDO 更新メカニズムでは、変更の衝突を避けるためにオプティミスティック ロック ポリシーが使用されます。 オプティミスティック ロックの場合、SDO クライアントによるデータの取得後もデータ ソースはロックされません。 後に更新が必要になったときに、ソース内のデータが、取得されたときのデータのコピーと比較されます。 データの不一致があった場合、更新はコミットされません。
オプティミスティック ロック更新ポリシーは、データ サービスごとに設定されます。 次の表に、オプティミスティック ロック更新ポリシーのオプションを示します。
リレーショナルベースのデータ サービスの場合、オプティミスティック ロックのプロパティが [SELECTED FIELDS] に設定されると、XML 型の要素に対して [Enable/Disable Optimistic Locking] オプションが使用可能になります。 オプティミスティック ロック ポリシーは、プロパティ エディタで表示および設定されます (図 4-22)。 その他のプロパティについては、「主なデザイン ビューのプロパティ」を参照してください。
![更新が許可され、オプティミスティック ロックが [SELECTED FIELDS] に設定されたデータ サービス](wwimages/selected_fields2.gif)
アクティブなとき、[SELECTED FIELDS] オプションでは更新の前にオプティミスティック ロック ロジックを検証できます。 XML 型に関連付けられた右クリック メニューを使用して、任意の数のフィールドを選択できます。 複合要素が選択されると、マークされていなくても、そのすべての子が選択されます。
[SELECTED FIELDS] オプションが選択されると、右クリック メニューで [Enable/Disable Optimistic Locking] という切り替えオプションが使用可能になります。 複数の要素を選択できます。

図 4-23 では、2 つのフィールド PRODUCT_ID と QUANTITY が選択されています。
<optimisticLockingFields>
<field name="PRODUCT_ID"/>
<field name="QUANTITY"/>
</optimisticLockingFields>
オプティミスティック ロック ポリシーに基づく変更の衝突の処理については、「データ サービスを介した更新の処理」を参照してください。
セキュリティ リソース設定はデータ サービス レベルで作成され、AquaLogic Data Services Platform Console を使用してアクティブ化されます。 必要な手順は次のとおりです。
セキュリティ設定を理解する簡単な方法として、ここでは、RTLApp の DataServices/Demo/Java/Logical フォルダにある Shipping データ サービスを使用して例を作成します。
<目的> 目的は、EAST 出荷地域に対する XML 型の ShipRegion 文字列へのアクセスを Igor という名前の特定のトラフィック モニタに制限することです。
このアクションによって、ソース ビューのデータ サービス プラグマに新しいセキュリティ リソース (下の強調箇所) が追加されます。
(::pragma xds <x:xds targetType="ship:ShipSource" xmlns:ship="http://Logical/ShipSource" xmlns:x="urn:annotations.ld.bea.com">
<creationDate>2005-11-01T15:50:28</creationDate>
<userDefinedView/>
<secureResources>
<secureResource>shipregion</secureResource>
</secureResources>
</x:xds>
::)
この節では、XQuery エディタを使用して、新しく作成されたセキュリティ リソースを EAST グループの ShipRegion 要素にアタッチします。
| 注意 : | 組み込みの BEA 関数の詳細については、AquaLogic Data Services Platform の『XQuery 開発者ガイド』を参照してください。 式の編集の詳細については、「XQuery 関数を使用してデータを変換する」を参照してください。 |
ソース ビューでは、条件は XQuery if-else 文として表示されます。
if (fn:upper-case($SourceRegion) eq 'EAST') then
(
for $ShipSource1 in ns10:getShipSource1()/SHIPPING
where $ShipSource1/ShipSource eq $SourceState
and $ShipSource1/ShipDest eq $DestState
return
<SHIPPING DataLineage?="{'EAST Shipping Source'}">
...
<ShipPrice>{fn:data($ShipSource1/ShipPrice)}</ShipPrice>
{
if (fn-bea:is-access-allowed("shipregion", "ld:DataServices/Demo/Java/Logical/Shipping")) then
<ShipRegion>{fn:data($ShipSource1/ShipRegion)}</ShipRegion>
else
<ShipRegion>{"N/A"}</ShipRegion>
}
<ShipTime>{fn:data($ShipSource1/ShipTime)}</ShipTime>
</SHIPPING>
次の手順では、AquaLogic Data Services Platform Console が必要になります。詳細については、AquaLogic Data Services Platform の『管理ガイド』にある「Data Services Platform リソースの保護」を参照してください。
| 注意 : | weblogic ユーザ、または weblogic ユーザがそのメンバーであるグループに対して、保護されたリソースが使用可能であるとマークされていない限り、リソースは使用できません。 |
セキュリティ ポリシーを設定したら、それをテストする必要があります。
Examples.txt ソース ファイルに示されています)。
データ サービス内の各関数に対して、[データ キャッシュの許可] オプションを true または false に設定できます。 false の場合、実行中のクエリ関数による結果はキャッシュされません。 true の場合、その関数のキャッシュが AquaLogic Data Services Platform Console で有効にされていれば、その関数の以前の呼び出しによる結果がキャッシュされます。 つまり、関数のキャッシングを行うには、データ サービス内で有効に ([データ キャッシュの許可] を true に設定) し、さらに AquaLogic Data Services Platform Console でも有効にしなければなりません。 関数のキャッシュの有効化とキャッシュの TTL (生存時間) の設定については、AquaLogic Data Services Platform の『管理ガイド』を参照してください。
特定の関数に対してキャッシングを有効にするかどうかを検討するときに注意すべき点を、以下に示します。
データ サービス内の特定の読み取り関数に対して許可されたキャッシング ポリシーを確認または設定するには、関数名の左にある矢印をクリックして、プロパティ エディタでキャッシング ポリシーを設定します。
キャッシング ポリシーの変更を有効にするには、アプリケーションをビルドする必要があります。
| 注意 : | 関数に対して [データ キャッシュの許可] のキャッシング ポリシーが false に設定されている場合に、AquaLogic Data Services Platform Console を使用してその設定をオーバーライドすることはできません。 |
次の表 4-31 に、AquaLogic Data Services Platform の主なデザイン ビューのプロパティを示します。
|
|||||
XQuery でモデル化されるデータ ソースは、以下の条件を満たした SQL クエリで使用できるリレーショナル データ ソースとしてエクスポーズできます。
このような関数は、リレーショナル対応 XQuery 関数と考えることができます。 こうした関数は、シグネチャに応じて、SQL テーブル、ストアド プロシージャ、またはデータベース関数として使用するためにパブリッシュできます。 関数と SQL オブジェクトの間の関連付けは、設計時に定義されます。
SQL アクセス用にパブリッシュ可能なアーティファクトのタイプは、以下のとおりです。
表 4-32 に、データ サービス アーティファクトと SQL オブジェクトの間の互換性一覧を示します。
| 注意 : | 読み取り関数、ナビゲーション関数、およびプロシージャの詳細については「データ サービス」を参照し、XFL 関数の詳細については「XQuery 関数ライブラリの作成および使用」を参照してください。 |
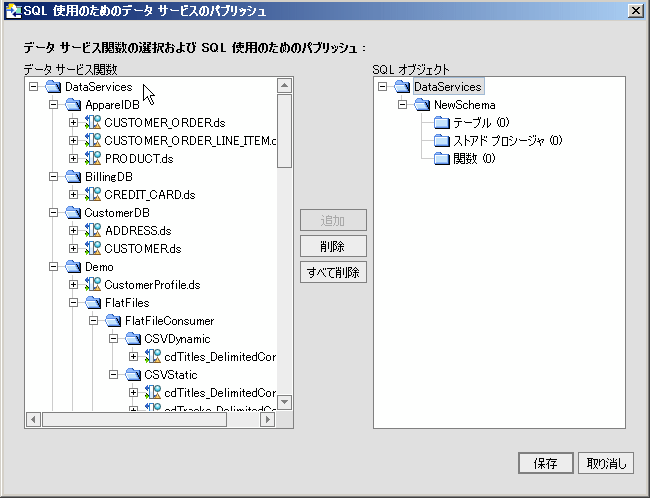
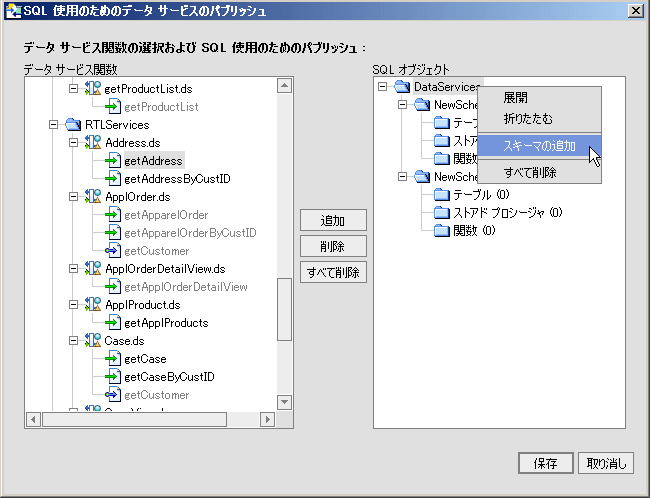
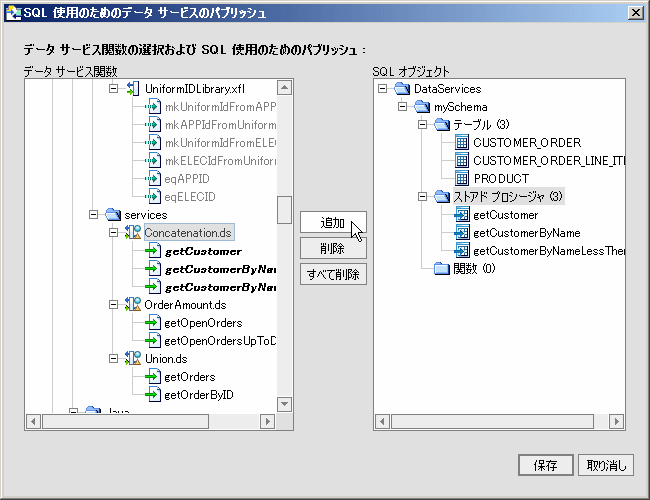
AquaLogic Data Services Platform 対応プロジェクトに関連付けられたウィザード (図 4-33) を使用して、データ サービス関数を SQL で使用可能にすることができます。 ウィザードの左側には、プロジェクト内のすべてのデータ サービス関数が表示されます。 パブリッシュできない関数はグレー表示されます。
ウィザードの右側には最初、SQL オブジェクトのタイプ名が含まれた、名前の変更が可能なスキーマのみが表示されます (図 4-33)。
SQL オブジェクトとしてパブリッシュできないと表示される関数は、以下のような規則に従って決められます。
| 注意 : | ウィザードでは、AquaLogic Data Services Platform プロジェクトと同じカタログ名で任意の数のスキーマを作成できます。 スキーマの名前変更、追加、または削除を行うには、右クリック メニューを使用します。 詳細については、「データ サービス関数のパブリッシュの例」を参照してください。 |
この節では、SQL で使用するためにデータ サービスをパブリッシュするために必要な手順について説明します。
| 注意 : | 選択しているプロジェクトで以前にデータ サービス アーティファクトと SQL オブジェクトの間のマッピングを作成した場合には、そのマッピングが表示されます。 それ以外の場合は、SQL オブジェクトへのマッピングのないウィザードが表示されます (図 4-33)。 |
| ヒント : | 関数またはフォルダを、選択された SQL オブジェクトのタイプにドラッグ アンド ドロップすることもできます。 |
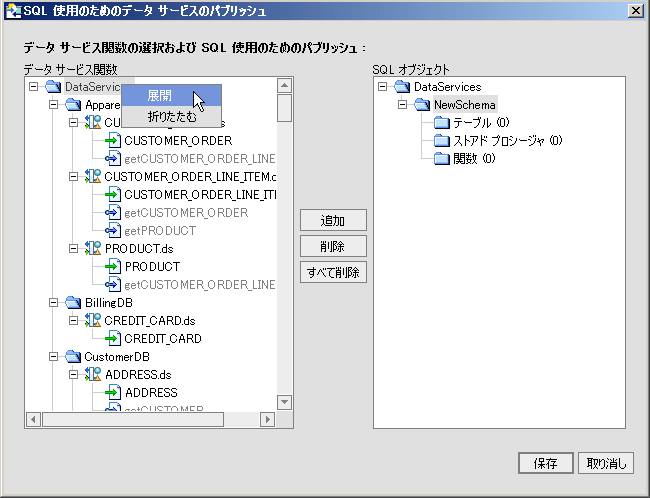
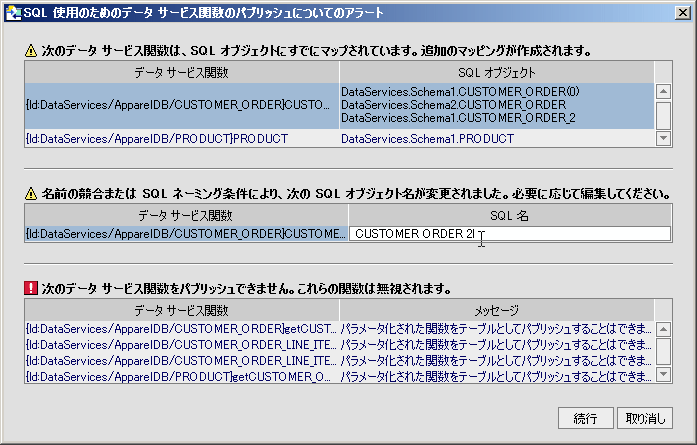
図 4-35 では、一部の関数がグレー表示され、SQL オブジェクトとしてのパブリッシュに使用できなくなっています。 そうした関数をマップしようとすると、その関数をマップできない理由を示すアラート ダイアログが表示されます。 関数をマップできない理由が複数ある場合でも、表示される理由はひとつだけです。
| 注意 : | パラメータを持たない関数をストアド プロシージャ オブジェクトとしてマップする理由は何でしょうか。 JDBC 側では、テーブル、ストアド プロシージャ、および関数に対して使用される API がそれぞれ異なります。 場合によっては、パラメータなしの関数をストアド プロシージャとして呼び出すほうが便利なこともあります。 |
| 注意 : | 同じデータ サービス関数を複数のスキーマにマップできます。 ただし、1 つの関数を複数の SQL オブジェクトのタイプにマップするときには、アラート ダイアログが表示されます。 |
| ヒント : | [SQL オブジェクト] 領域では、同じまたは異なるスキーマにあるテーブル、ストアド プロシージャ、および関数のフォルダ間で、パブリッシュされる関数をドラッグ アンド ドロップすることもできます。 この操作は、関数がパブリッシュの要件を満たしてさえいれば可能です。 詳細については、「データ サービス オブジェクトの SQL へのパブリッシュに関する制約」を参照してください。 |
関数を SQL オブジェクトにマップし、仮想データベース カタログを保存しようとすると、アラート ダイアログが表示されることがあります。 このダイアログには、マッピングに関連した警告やエラーがある場合に、それらの要約が包括的に示されます。
データ サービス オブジェクトの SQL へのパブリッシュには、セマンティクスおよび構造に関する複数の制約があります。
セマンティクスに関する制約は、プライベート関数など、オブジェクトの一般的なタイプに対するものです。
表 4-32 に、パブリッシュ可能な AquaLogic Data Services Platform オブジェクトのタイプと、それらに対応する SQL オブジェクトのタイプの一覧が示されています。
データ サービス アーティファクトの SQL へのパブリッシュには、構造に関する制約もあります。 表 4-38 に、さまざまな一般的な制限事項を示します。
declare function f($p as xs:string*) as xs:int |
|
declare function f() as element() |
|
データ サービス関数の構造によって、その関数を SQL オブジェクトにマップできるかどうかが決まります。 たとえば、パラメータ化された関数は SQL テーブルとしてパブリッシュできません。定義上、SQL テーブルはパラメータを取らないからです。 構造に関する制約の中には、実質的に自明なものもあれば、分かりにくいものもあります。
| ヒント : | 特定の関数が特定のタイプの SQL オブジェクトにパブリッシュできるかどうかを簡単に判断するには、関数を SQL オブジェクトのテーブル、ストアド プロシージャ、または関数のフォルダにドラッグします。 関数がグレー表示されている (つまり、どのタイプの SQL オブジェクトにもパブリッシュできない) 場合でも、選択されたオブジェクトをパブリッシュできない理由を示すアラート ダイアログ (図 4-37) が表示されます。 |
たとえば、XML の出力構造は標準化された SQL テーブルにマップできないため、非テーブル形式の要素型を持つ関数はテーブルとしてもストアド プロシージャとしてもパブリッシュできません。
基底の各データ サービスは、XML 型 (スキーマ) です。 一部の XML 型は、SQL テーブルのように 2 次元であるため、JDBC で使用するために即座にマップできます。
<CUSTOMER>
<FIRST_NAME>
<LAST_NAME>
<CUSTOMER_ID>
</CUSTOMER>
SQL としてパブリッシュされると、テーブル構造は表 4-39 のように対応します。
オブジェクト マッパーが XML ドキュメントの構造を 1 ランクにまで引き下げることができれば、マッピングは可能になります。 次に例を示します。
<CUSTOMER>
<FIRST_NAME>
<LAST_NAME>
<CUSTOMER_NUMBER>
<CUSTOMER_ORDER>
<ORDER_ID>
<C_ID>
<ORDER_DT>
</CUSTOMER_ORDER>
</CUSTOMER>
上記の構造は、顧客に関連付けられた顧客注文が 1 つ以下である限り、次の形式でテーブルとしてパブリッシュできます。
ただし、CUSTOMER_ORDER 型がバインドされていない (つまり、1 人の顧客に関連付けられた複数の注文が表される可能性がある) 場合には、構造は整形式のリレーショナル テーブルに対応しなくなり、マッピングは許可されません。
| 注意 : | WebLogic Workshop では、バインドされない型は戻り値型のゾーンで作成され、ゾーン単位で識別されます。 「戻り値型にゾーンを設定する」を参照してください。 上記の例では、関数は、複数の注文が 1 人の顧客に関連付けられているため (リレーショナル用語の「マスター/詳細」)、最初はマップできません。 しかし、CUSTOMER_ORDER に関連付けられたゾーンが削除されると、関数はマップできるようになり、結果として生成されるテーブルは表 4-40 で示されているテーブルのようになります。 |
 
|