
|
|
BEA Aqualogic Data Services Platform サービスは、利用可能なデータへのアクセスや変換に使用する関数を作成および管理するためのフレームワークを提供します。 これらの関数は、XQuery エディタを使用して作成できます。
有効なクエリ関数には、必ず戻り値の型が関連付けられています。 ソース ビューには、各関数の戻り値の型が記述されています。 通常、それらの戻り値の型は、データ サービスの形式を定義する XML 型 (スキーマ) と一致します。
作成したクエリ関数は、クライアント アプリケーションから呼び出すことができます。 AquaLogic Data Services Platform の関数を呼び出すさまざまな方法については、AquaLogic Data Services Platform の『クライアント アプリケーション開発者ガイド』を参照してください。
XQuery エディタを使用して、テスト ビューで実行できるスタンドアロンのクエリを作成することもできます (「クエリ関数のテストとクエリ プランの表示」を参照)。
XQuery エディタを使用すると、直感的なドラッグ アンド ドロップ操作でクエリ関数を作成できます。 関数の作成中は、エディタとソース ビューを簡単に切り替えることができます。
XQuery エディタでは、メタデータのデータ サービス関数を使用してさまざまなデータ型を表現します (メタデータのインポートの詳細については、「エンタープライズ メタデータの取得」を参照)。

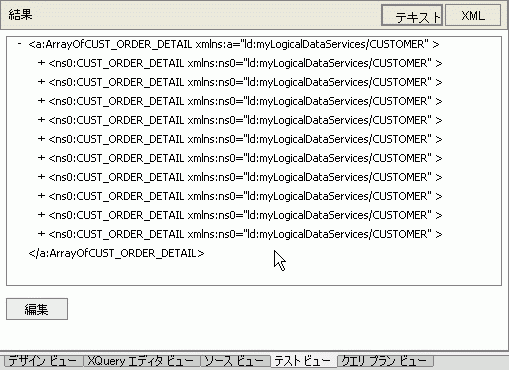
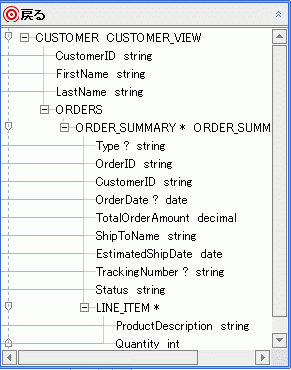
データ サービスは、物理データ ソースを表現する場合と、それ以前に作成された論理データ ソースを表現する場合があります。 データ サービス関数およびカスタム XQuery ライブラリ関数は、どちらもデータ サービス パレットから表現できます (図 6-2)。データ サービス パレットは、XQuery エディタ ビューがアクティブになっているときに使用できる WebLogic Workshop ペインです。
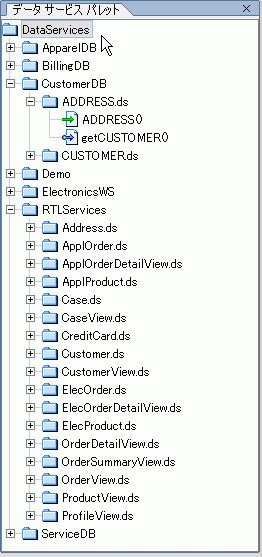
図 6-2 には、2 種類の関数表現が表示されています。緑色のまっすぐな矢印で示されている関数は「読み取り関数」です。一方、青色の変形した矢印で示されている関数は「ナビゲーション関数」です。
このようにグラフィカルにクエリ関数を作成すると、ソース ビューに XQuery が自動的に作成されます。
クエリ関数を作成したら、テスト ビューを使用して実行できます (「クエリ関数のテストとクエリ プランの表示」を参照)。 クエリ関数を実行すると、基底のデータ ソースへのアクセスが行われて結果が表示されます。 適切なパーミッションがある場合は、クエリの実行後にデータを直接更新することもできます。
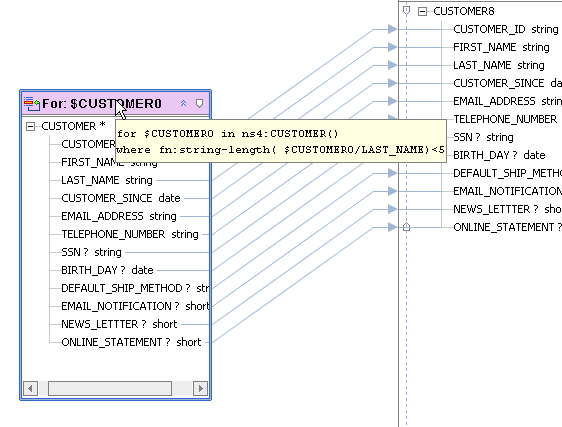
ソースのメタデータ表現は、データ サービス パレットから XQuery エディタにドラッグ アンド ドロップできます。 データ サービス パレットには、使用できるデータ サービスと、その読み取り関数および関係関数が一覧表示されます。 このような関数はすべて、XQuery エディタの作業領域にドラッグすると for 句に変換されます。
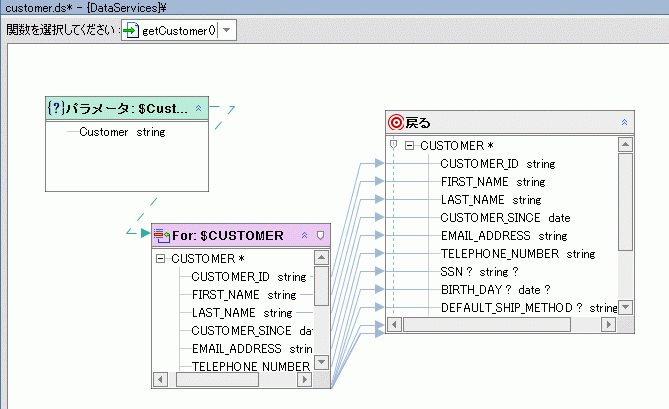
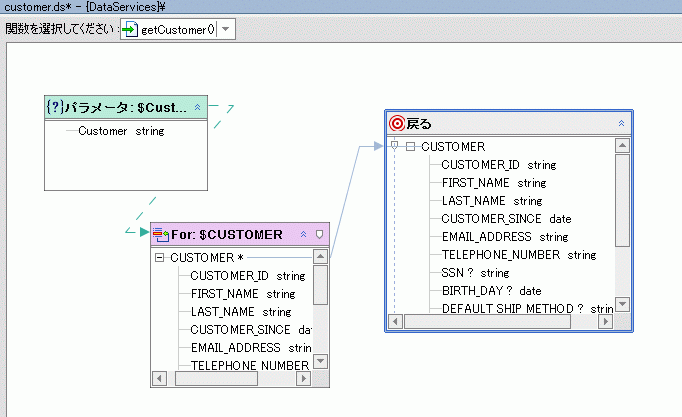
読み取り関数と Web サービスは、多くの場合入力パラメータを取ります。 たとえば、論理データ サービス Customer (customer.ds) は、XQuery エディタではその読み取り関数 getCustomer() および getPaymentList( ) で表現されます。 データ サービス パレットから XQuery エディタに getCustomer( ) 項目をドラッグすると、作業領域に図 6-3 のようなソース表現が表示されます。
必要に応じて、物理データ ソースや論理データ ソースの表現をクエリ内で複数回使用することもできます。
物理および論理データ サービスの作成については、「エンタープライズ メタデータの取得」および「データ サービスの設計」を参照してください。
データ サービスで新しい関数を作成して関数名をクリックすると、その関数が自動的に XQuery エディタに表示されます (図 6-1 を参照)。 別の方法として、[XQuery エディタ ビュー] タブをクリックし、ドロップダウン メニューから関数を選択することもできます。 初期状態の XQuery には戻り値の型しか定義されていませんが、これによりそのデータ サービスが XML 型に関連付けられているものと見なされます (「XML 型を関連付ける」を参照)。
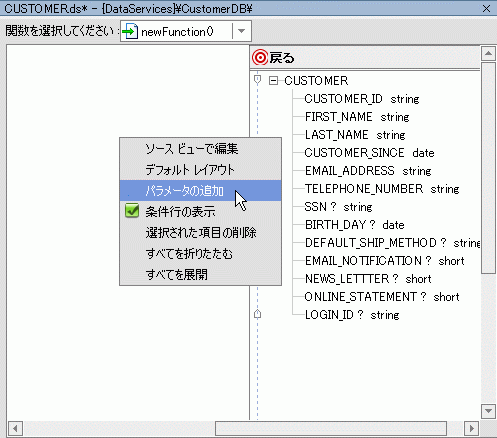
作業領域の空いている部分を右クリックすると、さまざまな右クリック メニュー オプションを使用できます。
この節では、データ サービスを作成する手順について説明します。データ サービスを作成することで、XQuery エディタの操作を体感でき、データ サービスのさまざまな側面を理解できます。
| ヒント : | XQuery エディタに加えた変更は、直ちにソース ビューに反映されます。 |
この演習の目的は、XQuery エディタを使用して、論理データ サービスとその XML 型をすばやく作成することです。 基本的な手順は次のとおりです。
| ヒント : | XQuery エディタでの操作を元に戻したい場合は、[編集|元に戻す] コマンド (または〔Ctrl〕+〔Z〕) を使用するのが最も簡単な方法です。 アプリケーションを保存する前であれば、それまでの操作を無制限に元に戻すことができます。 ほとんどの場合、マッピング、ゾーン設定、条件などを描画し直すよりも、[元に戻す] コマンドを使用することをお勧めします。 |
以下の説明では、RTLApp サンプルとそのサーバがインストールおよび実行されていることを前提としています。
この節では、新しいデータ サービス対応プロジェクトを作成し、論理データ サービスで使用する予定のデータ ソースのメタデータをインポートします。
この節では、クライアント アプリケーションから顧客注文情報を取得するために使用する論理データ サービスを作成します。 基本的な手順は次のとおりです。
| 注意 : | この時点のデータ サービスには XML 型 (スキーマ) は定義されていません。 |
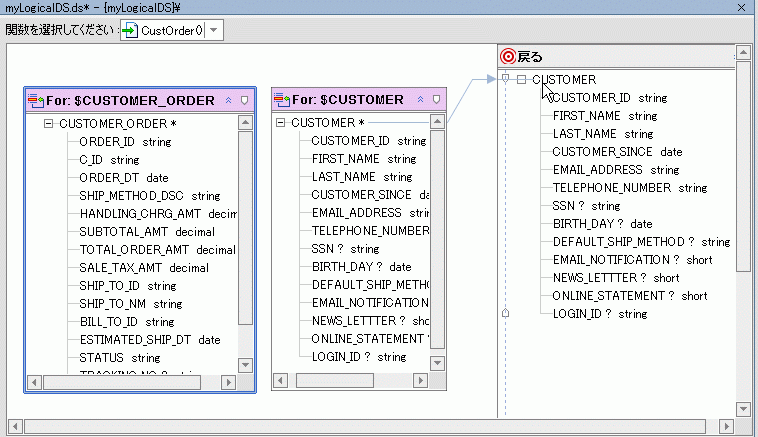
戻り値の型に空の要素が 2 つあることから、未完成の for 句が 2 つあることが分かります ($CUSTOMER および $CUSTOMER_ORDER)。
次に、関数の戻り値の型を設定する必要があります。 CUSTOMER_ORDER を CUSTOMER の子として設定することで、次のような形式で情報が返されるようにします。
Customer1
..
Order1
..
Order2
..
Customer2
..
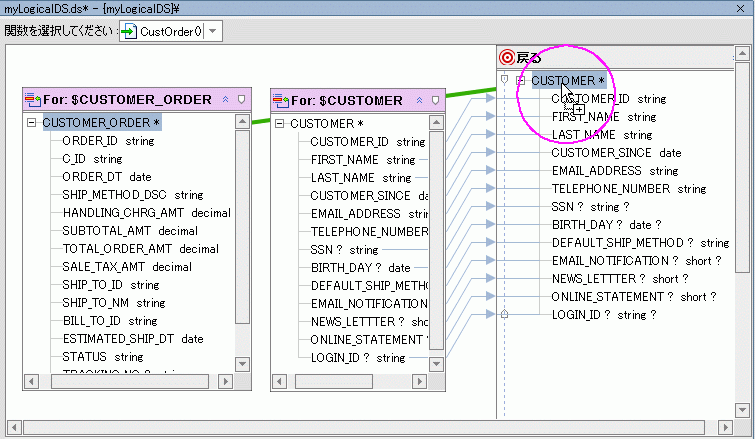
返されるドキュメントに、特定の顧客に関連付けられたすべての顧客注文が一覧表示されるようにするには、従属複合要素を作成する必要があります。 1 つの方法としては、次の手順に示すように、CUSTOMER_ORDER 型を CUSTOMER の従属要素として追加します。
CUSTOMER_ORDER 要素が、CUSTOMER の従属要素になります (図 6-9)。
ns0:customer
この時点で、新しいスキーマの名前とデータ サービスの名前が一致しました。デフォルトのネームスペースは、戻り値型のルート要素の「修飾名 (qname)」です。
ここまでの作業は、いくつかの別の手順でも実現できます。 重要な点は、クエリまたは戻り値型が完全に形成されていないために、アプリケーションを正常にビルドまたはデプロイできなくなるポイントがいくつかあることです。 したがって、各手順を順番どおりに実行することが重要です。
AquaLogic Data Services Platform では、以下を始めとするさまざまなデータ ソースがサポートされています。
これらのソースから AquaLogic Data Services Platform ベースのプロジェクトにデータ ソース メタデータをインポートする方法については、「エンタープライズ メタデータの取得」を参照してください。
XQuery エディタでは、XML スキーマ表現を以下として使用します。
詳細については、「XML 型と戻り値型」を参照してください。
XQuery エディタでは、グラフィカルに表現された以下のような句や関数を組み合わせることで、クエリ関数をグラフィカルに構築できます。
以下の節では、これらの XQuery 句について、XQuery エディタでの表示に基づいて説明します (AquaLogic Data Services Platform で使用する XQuery エンジンの詳細、およびソース ビューでの XQuery の使用方法については、AquaLogic Data Services Platform の『XQuery 開発者ガイド』を参照してください。 このマニュアルには、最新の XQuery W3C 仕様のリファレンスも含まれています)。
クエリ関数は、常に単一の戻り値型にマップします。 データ サービスを戻り値型に関連付けると、その型が [戻る] ノードに表示されます。
戻り値型は、以下をサポートするために拡張された XML 型と考えることができます。
戻り値型内の単純な要素をクリックすると、その要素のコンストラクタの式が表示されます。
for 句ノードは、名前付きの XQuery for 句コンストラクトを表します。 for 句ノードおよび let 句ノードは、必ずデータ サービス関数に基づいています。
デフォルトでは、データ サービスを XQuery エディタの作業領域に追加すると、そのデータ サービスが for ノードで表現されます。 通常、for ノードは、次のどちらかを使用してクエリ関数をループさせることを表します。
for ノードは、パラメータ化されたクエリ関数を表現し、入力と出力両方のセクションを提供します。 通例どおり、パラメータは入力要素にマップされ、出力要素は他のノードへの入力または戻り値型として機能します。
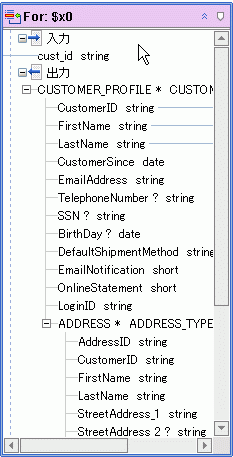
表 6-16 に、for ノードまたは let ノードのタイトルバーを右クリックすると表示されるオプションをまとめます。
for 句と let 句 (「let 文ノード」を参照) の多くの機能には互換性があります。
次のコードは、DataServices/RTLServices/Case/getCaseByCustID() 関数式の for 句です。
declare function ns1:getCaseByCustID($cust_id as xs:string) as element(ns0:CASE)* {
for $x0 in ns1:getCase()
where $cust_id eq $x0/CustomerID
return $x0
};declare function ns1:getCaseByCustID($cust_id as xs:string) as element(ns0:CASE)* {
let $x0 := ns1:getCase()
where $cust_id eq $x0/CustomerID
return $x0
};
let 句は、ノード内でグラフィカルに表現されている要素のシーケンスを変数にバインドし、FLWR 式で使用できるようにします。
for 句で使用できるオプションは let 句でも使用できます。 「for ノードと let ノードのオプション」を参照してください。
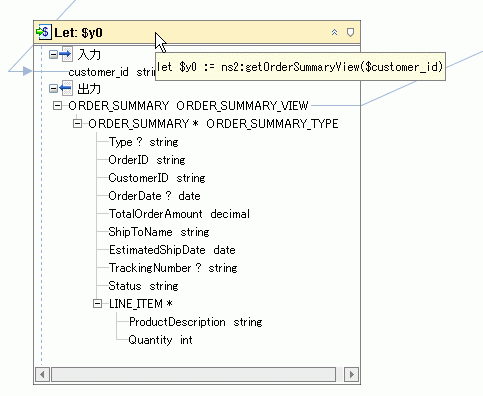
let 句を解釈するときには、代入文字列 (:=) を「バインド」と読み替えることができます。 たとえば、次の let 句を見てみます。
let $x := (1, 2, 3)
これは、「変数 x を項目 1、2、および 3 で構成されるシーケンスにバインドする」と解釈できます。
「for 句と let 句の間の変換」も参照してください。
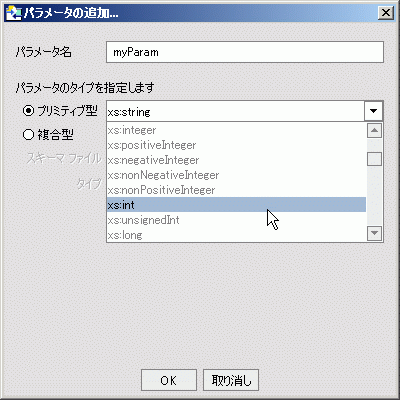
パラメータ ノードを使用すると、for 句や let 句にパラメータを関連付けることができます。 パラメータ ノードは、XQuery エディタの作業領域で作成します (図 6-4)。 右クリック オプションとしては、[名前変更]、[削除]、および [ソースの表示] を使用できます。
![XQuery エディタの [パラメータの追加] ダイアログ ボックス](wwimages/add_param1.gif)
単純なデータ要素から非常に複雑な要素まで、さまざまなパラメータを作成できます。
単純型のパラメータを作成するには、ドロップダウン リストから型を選択して [OK] をクリックします。
入力セクションのある for ノードや let ノードにパラメータを「マップ」するという動作によって、パラメータ化されたクエリを作成し、さらに where 条件を設定していることになります。 図 6-20 では、custID string パラメータを ADDRESS ノード内の要素にドラッグしています。その結果、where 句によってパラメータが関連付けられます。
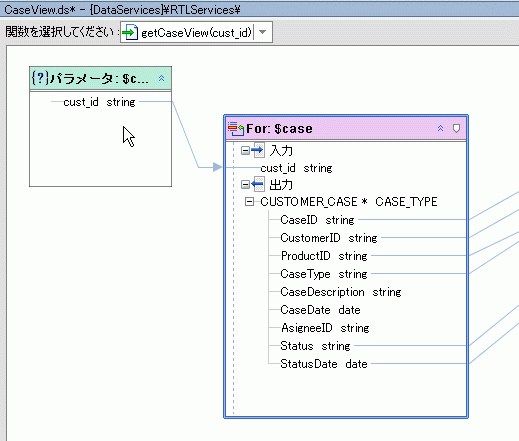
次に、これに対応するソース ビュー コードを示します。custID パラメータは太字で示されています。
declare function ns5:getCaseView($custID as xs:string) as element(ns6:CaseView) {
<ns6:CaseView>
{
<CASE_VIEW>
<CASES>{
for $Case in ns7:getCaseByCustID($custID)
return <CASE>
<CaseID> {fn:data($Case/CaseID)} </CaseID>
<CustomerID>{fn:data($Case/CustomerID)}</CustomerID>
<CaseType> {fn:data($Case/CaseType)} </CaseType>
<ProductID> {fn:data($Case/ProductID)} </ProductID>
<Status> {fn:data($Case/Status)} </Status>
<StatusDate> {fn:data($Case/StatusDate)} </StatusDate>
</CASE>
}
</CASES>
</CASE_VIEW>
}
</ns6:CaseView>
};
このような関数をアプリケーションから呼び出すとき (またはテスト ビューで実行するとき) には、そのパラメータの値を指定することになります。
複合パラメータは、スキーマ ファイルとグローバル要素を指定して作成します。 一部のスキーマには、グローバル要素を 1 つしか指定できません。
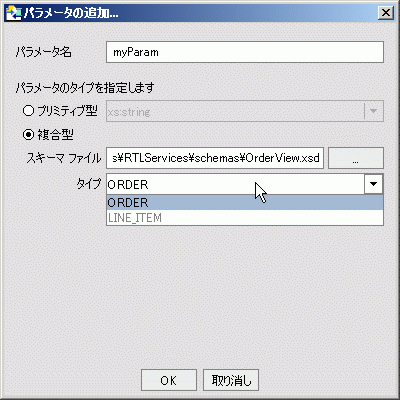
作成したパラメータは、どの for ノードまたは let ノードにも関連付けることができます。 「パラメータ化された入力」も参照してください。
パラメータ ダイアログを使用すると、単純型または複合型のパラメータを for 句または let 句内の要素にドラッグするだけで where 句条件を作成できます。 図 6-22 では、新たに作成したパラメータ productID を PRODUCT_ID にマップしています。$PRODUCT for ノードが選択されているため、where 句がスコープに含まれています。
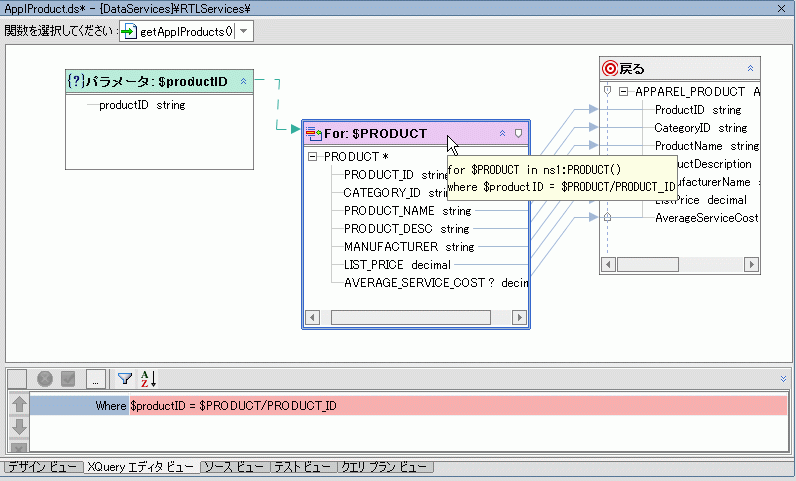
既存のデータ サービスに関係関数を追加する方法はいくつかありますが、 その中でも for ノードまたは let ノードの右クリック メニュー オプションを使用する方法をお勧めします。この方法だと、単純にデータ サービス パレットから作業領域に関係関数をドラッグする方法に比べ、より適切にネストされた句を作成できます。
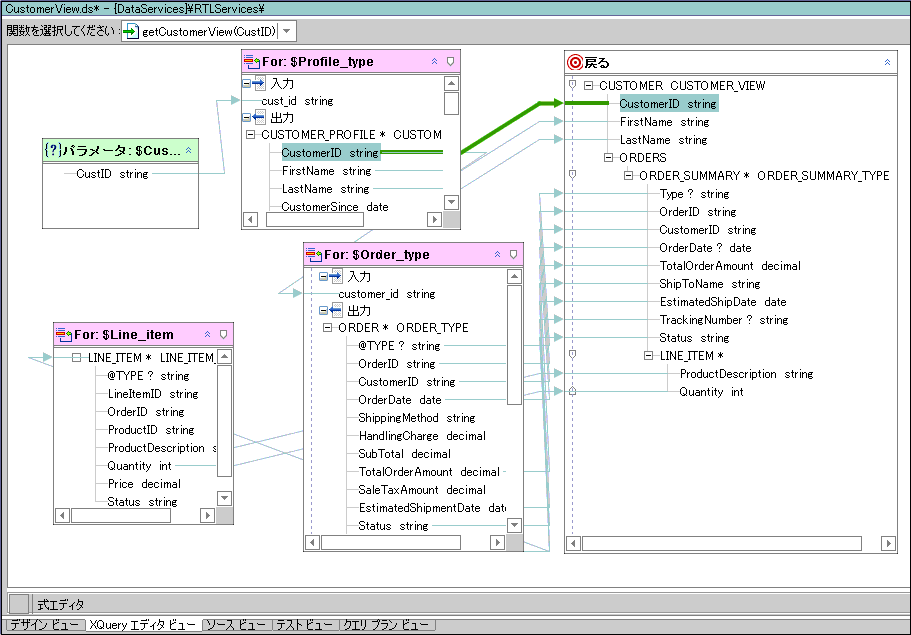
たとえば、顧客注文と注文明細を結合して論理データ サービスを作成する場合は、まず顧客注文を作成してから、それに関係する注文明細データを追加できます。
図 6-23 では、先に作成した RTLApp DataServices/ApparelDB/CUSTOMER_ORDER() 関数に、関係する getCUSTOMER_ORDER_LINE_ITEM() 関数を追加しています。
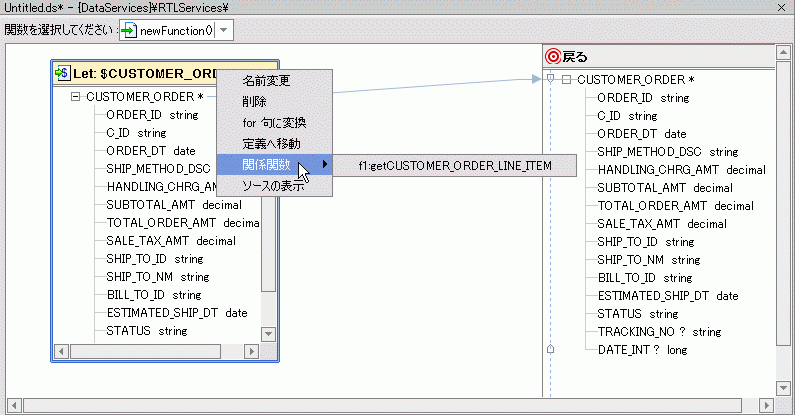
declare function tns:newFunction() as element(ns30:CUSTOMER_ORDER9)* {
for $CUSTOMER_ORDER in ns28:CUSTOMER_ORDER()
return $CUSTOMER_ORDER
};declare function tns:newFunction() as element(ns30:CUSTOMER_ORDER9)* {
for $CUSTOMER_ORDER in ns28:CUSTOMER_ORDER()
for $CUSTOMER_ORDER_LINE_ITEM in ns28:getCUSTOMER_ORDER_LINE_ITEM($CUSTOMER_ORDER)
return $CUSTOMER_ORDER
};
なお、この例を完了するには、関係するデータ サービスから戻り値型に要素を追加し、適切にマッピングおよび変換を行う必要があります。
group by ノードは、0 個以上のグループ化式で構成される単一の group by 句を表します。 group by ノードの最上部には、生成された group by 式で使用できる変数を定義します。 最下部には、グループ化式自体を定義します。
通常、group by 式は集約関数 (たとえば、売上金額別に顧客をグループ化する関数) で使用します。 for 句および let 句では、複数の group by 要素を使用できます。
group by ノードを生成するには、for 句または let 句のいずれかの要素を右クリックして [Group By の作成] を選択します。
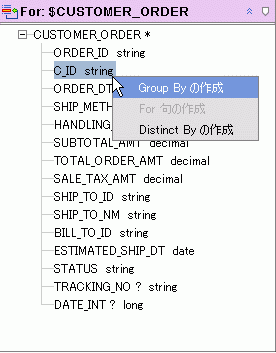
図 6-24 のようにすると、出力が C_ID (顧客 ID) 要素別にグループ化されます。 GroupBy ノードが作成されると、ターゲット オブジェクト (たとえば戻り値型) へのマッピングは新しいノード経由で行われます。
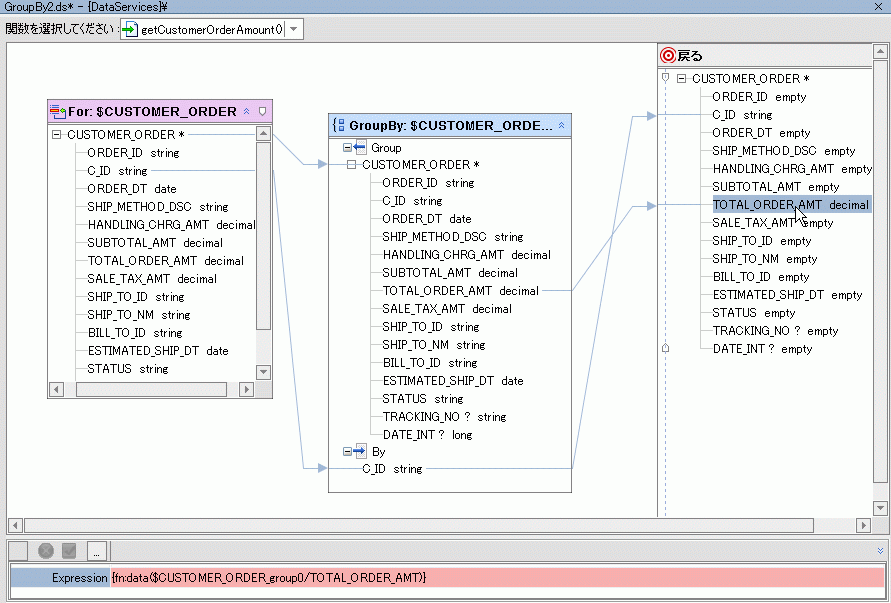
group by ノードのデフォルト名は、その for ノードまたは let ノードのローカル名に基づくユニークな名前です。 CUSTOMER_ORDER for 句は、CUSTOMER_ORDER_group0 の基盤になります。 group by ノードの名前を XQuery エディタから変更することはできません。
図 6-25 に示すように、すべてのノード マッピングは自動的に group by ノードに転送されます。
declare function tns:getCustomerOrderAmount() as element(ns5:CUSTOMER_ORDER)* {
for $CUSTOMER_ORDER in ns6:CUSTOMER_ORDER()
group $CUSTOMER_ORDER as $CUSTOMER_ORDER_group by $CUSTOMER_ORDER/C_ID as $C_ID_group
return
<ns5:CUSTOMER_ORDER>
<ORDER_ID></ORDER_ID>
<C_ID>{fn:data($C_ID_group)}</C_ID>
<ORDER_DT></ORDER_DT>
<SHIP_METHOD_DSC></SHIP_METHOD_DSC>
<HANDLING_CHRG_AMT></HANDLING_CHRG_AMT>
<SUBTOTAL_AMT></SUBTOTAL_AMT>
<TOTAL_ORDER_AMT>{fn:sum($CUSTOMER_ORDER_group/TOTAL_ORDER_AMT)}</TOTAL_ORDER_AMT>
<SALE_TAX_AMT></SALE_TAX_AMT>
<SHIP_TO_ID></SHIP_TO_ID>
<SHIP_TO_NM></SHIP_TO_NM>
<BILL_TO_ID></BILL_TO_ID>
<ESTIMATED_SHIP_DT></ESTIMATED_SHIP_DT>
<STATUS></STATUS>
<TRACKING_NO?></TRACKING_NO>
</ns5:CUSTOMER_ORDER>
};
group by ノードを削除した場合、親ノードからのマッピングはすべて描画しなおす必要があります。
この例に別のグループ化式を追加するには、新しい要素をドラッグして「By」セパレータの上にドロップします (図 6-26)。
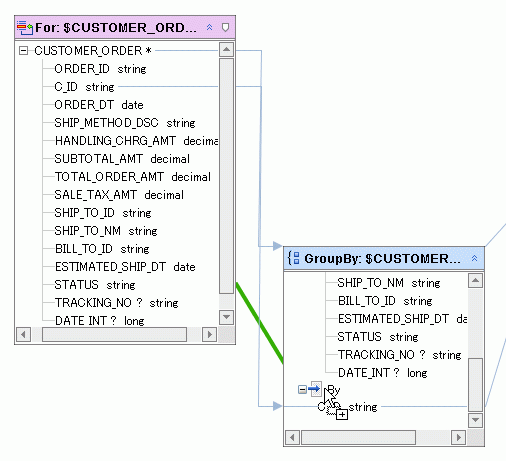
既存の group by 式に要素をドラッグするという動作によって、図 6-27 のように 2 つ目の group by 式が追加されます。
この例では、2 つ目の group by を追加したことで、顧客のステータス値別に注文総額がグループ化されるようになりました。
<ORDER_ID/>
<C_ID>CUSTOMER0</C_ID>
<TOTAL_ORDER_AMT>1173.2</TOTAL_ORDER_AMT>
<STATUS>CLOSED</STATUS>
</ns0:CUSTOMER_ORDER5>
<ns0:CUSTOMER_ORDER5 xmlns:ns0="ld:DataServices/ApparelDB/CUSTOMER_ORDER5">
<ORDER_ID/>
<C_ID>CUSTOMER0</C_ID>
<TOTAL_ORDER_AMT>436.3</TOTAL_ORDER_AMT>
<STATUS>OPEN</STATUS>
</ns0:CUSTOMER_ORDER5>
<ns0:CUSTOMER_ORDER5 xmlns:ns0="ld:DataServices/ApparelDB/CUSTOMER_ORDER5">
<ORDER_ID/>
複数の group by 式を追加して、次のようなロジックを作成することもできます。
そのためには、別の for 句または let 句を作成し、このロジックをサポートするための親子構造を設定する必要があります。
第 2 レベルの group by を作成するには、次の手順に従います。
また、新しい子要素は、マウスでポイントすると強調表示されます。これは、その子要素自体がゾーンであることを示します。
テスト ビューを使用すると、以上の作業の結果を検証できます。
distinct by ノードは、単一の distinct by 句を表します。
for 句や let 句には、さまざまなタイプの条件をグラフィカルに適用できます。 条件を作成するには、XQuery エディタの作業領域の最下部に表示される多機能エディタを使用します (図 6-28)。
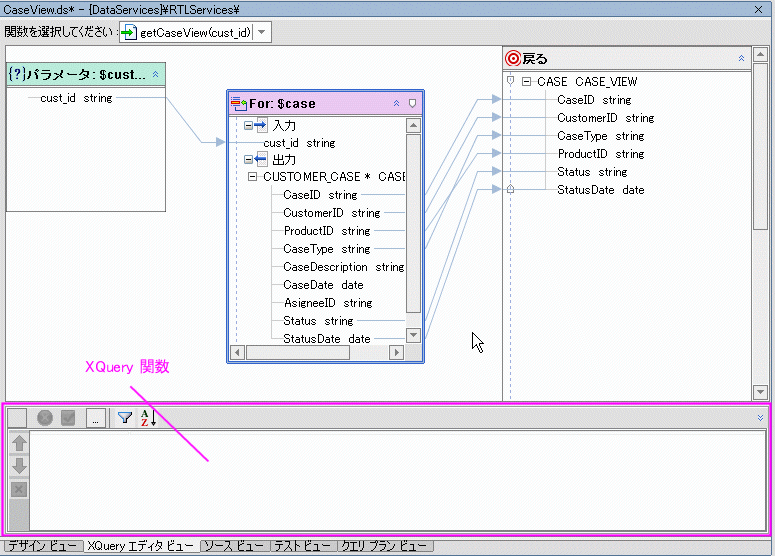
for ノードまたは let ノードに制約を追加したり、追加した制約を変更したりするには、そのノードを選択してから多機能エディタ内の任意の場所をクリックします。 選択した式以外のすべてのアーティファクトがグレー表示になります。これは、それらのアーティファクトが使用不可になったことを示します。
図 6-29 に、多機能エディタの詳細を示します。このエディタは、以下のような機能を備えています。
XQuery 関数パレットの関数は、多機能エディタにドラッグ アンド ドロップしてから編集できます。
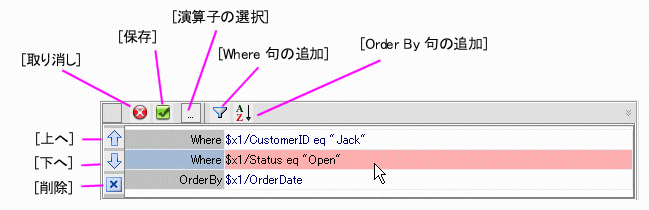
where 句を使用すると、for 句や let 句に条件を配置できます。 where 句は別の FLWR 式を含む任意のクエリ式です。 通常、where 句は FLWR ループでの一致数をフィルタ処理します。
where 句の一般的な用途の 1 つは、2 つのソース間の結合を指定することです。 たとえば、次のクエリを見てみます。
<results>
{
for $x in (1, 2, 3), $y in (2, 3, 4)
where $x eq $y
return
<matches>{$x}</matches>
}
</results>
このクエリの where 句は、for 句に指定された 2 つのシーケンスと一致する結果をフィルタ処理 (または結合あるいは制限) します。 この例では 2 と 3 が一致するので、クエリは次の結果を返します。
<results>
<matches>2</matches>
<matches>3</matches>
</results>
これを XQuery エディタで実現するには、where 条件を適用する for 句または let 句を選択し、 where 条件のフィールドに次のように入力します。
$x eq $y
要素の名前を直接入力しても、要素を作業領域のノードから多機能エディタにドラッグしても構いません。
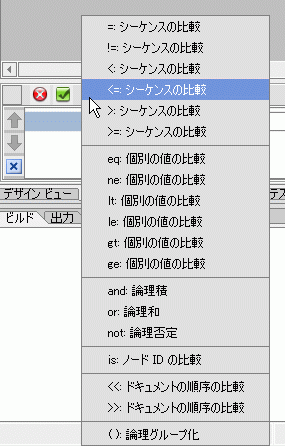
eq XQuery 演算子は、直接入力するか、条件演算子のポップアップ リストから選択できます (図 6-30).
次に、XQuery 関数を使用したより複雑な例を示します (「XQuery 関数の使用」を参照)。 この例では、名前が「Jack」の顧客をすべて検索します。
次の例では、多機能エディタで where 句を使用する方法を示します。
戻り値型をデータ サービスに関連付けることで、新しいデータ サービスの有効な XML 型 (スキーマ ファイル) を作成できます。 同じ物理データ サービスに基づく CUSTOMER という名前のスキーマがすでに存在するため、戻り値型のグローバル要素の名前、またはそのネームスペースに割り当てられているエリアス、あるいはその両方を変更する必要があります (保存と関連付けの詳細については、「単純なデータ サービス関数の作成」を参照)。
[名前] フィールドを CUSTOMER から CUSTOMER_WHERE に変更して [OK] をクリックすると、戻り値型内の複合要素の名前が変更されます。
$CUSTOMER/FIRST_NAME eq "Jack"
「パラメータ ダイアログを使用して where 句を作成する」も参照してください。
order by 句は、所定のデータ セットの出力順序を示します。
特に指定されていない場合、データは XML ツリーの順序で出力されます。 これを「ドキュメント順」と呼びます。 order by キーワードは、指定した要素の昇順でデータを並び替えることを示します。
XQuery キーワードとしては、descending などがサポートされます。 たとえば、姓の降順で顧客を並べ替えるための XQuery を記述できます。
for $customer in document('customers.xml')//顧客
order by last_name descending
return
<customer>
{$customer/first_name}
{$customer/last_name}
</customer>
...
これを XQuery エディタで実現するには、order by 条件を適用する for 句または let 句を選択し、order by フィールドに次のように入力します。
last_name descending
要素の名前を直接入力しても、要素を作業領域から多機能エディタ (図 6-29) にドラッグしても構いません。
結合条件は、where 句内で同等関係として表現します。 したがって、eq 関数を [条件] タブの行にドラッグ アンド ドロップし、2 つのソース要素/属性を同じ行にドラッグ アンド ドロップすることで同等関係を作成することもできます。
AquaLogic Data Services Platform には、あらゆる組み込み XQuery 関数が用意されています。 XQuery 関数パレットのほとんどの XQuery 関数は、W3C によってサポートされている標準の XQuery 関数です。 その他に、いくつかの BEA 固有の関数と、XQuery 言語の拡張も含まれています (1.0 XQuery エンジンの BEA 実装の詳細については、『XQuery 開発者ガイド』を参照してください。 標準の XQuery 関数の詳細については、W3C の XQuery 1.0 and XPath 2.0 Functions and Operators 仕様を参照してください)。
XQuery 関数パレットの関数は、for 句や let 句の周囲に条件を作成する際に便利です。 XQuery 関数は、以下のようなさまざまなコンテキストで使用できます。
クエリから返された顧客をフィルタ処理する where 句条件を作成するには、次の手順に従います。
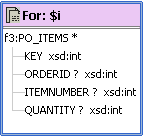
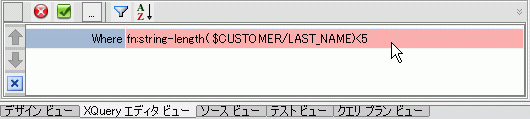
Where fn:string-length($CUSTOMER/LAST_NAME)<5」を追加します。文字列は次のようになります。Where fn:string-length($i/ORDERID)<5
for 句のタイトルバーをマウスでポイントすると、このフラグメントが条件に関連付けられたことを確認できます。 ソース ビューでもこの変更を確認できます。
通常、自動型キャストを使用すると、関数とマッピングで使用される入力パラメータを、それらが使用される関数に対応した型に変換できます。
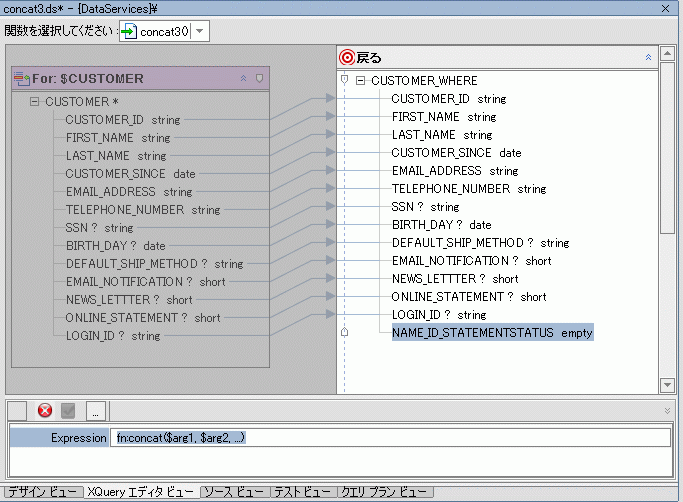
XQuery 変換関数も数多く用意されています。 次の例では、concat() 関数を使用して、関数によって返される要素を式に関連付ける機能を追加することで、物理データ サービスから多彩なデータをすばやく返せるようにします。
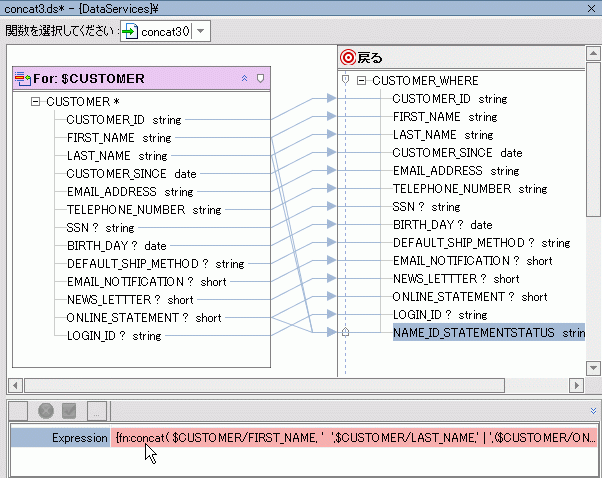
これらの編集が完了すると、XQuery 関数は次のようになります。
{fn:concat( $CUSTOMER/FIRST_NAME, ' ',$CUSTOMER/LAST_NAME,' | ',($CUSTOMER/ONLINE_STATEMENT cast as xs:string),' (online=1; printed=0)')}
また、新しい機能がソース/ターゲット マッピングにどのように反映されているかも確認してください (図 6-35 を参照)。
<NAME_ID_STATEMENTSTATUS>
Jack Black | 1 (online=1; printed=0)
</NAME_ID_STATEMENTSTATUS>
式エディタは、戻り値型の式を編集する際に最もよく使用するツールです。 たとえば、戻り値型に次のような要素が含まれているとします。
ORDERID xsd:int
式エディタを使用して、式のスコープを次のように単一の顧客に制限できます。
Expression>{fn:data($o/ORDERID)} eq "1001"
XQuery 関数パレットには関数のプロトタイプが用意されており、これらをエディタにドラッグ アンド ドロップして使用できます。また、組み込みのライン エディタを使用して、関数を直接入力することもできます。
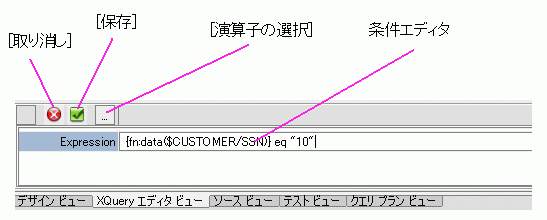
式エディタの操作は、多機能エディタの操作に似ています。 要素を選択すると、作業領域内の他のアーティファクトがグレー表示になります。 ただし、式エディタには、作業領域内のどのノードからでも要素をドラッグできます。
XQuery 演算子は、図 6-30 のようなドロップダウン リストから選択できます。もちろん、直接入力することも可能です。
選択したデータ要素を名詞 (作業の対象)、関数を動詞 (アクション) と考えた場合、データ要素間のマッピングによってクエリを表現する論理文が作成されます。
結果とクエリ パフォーマンスは、以下の方法によって大幅に変わります。
XQuery を記述してテスト ビューで実行することもできますが、一般的には次の手順でクエリを構築します。
| 注意 : | 一部の操作は確定的ではありません。 たとえば、ノード内の要素が戻り値型にマップされている場合に、そのマッピングを削除せずにノードを削除するとエラー状態になる可能性があります。 これを回避するには、[元に戻す] をクリックしてからマッピングを削除するか、ソース ビューで必要な変更を加えます。 |
要素間をマップすると、データ ソース要素と戻り値型 (または入力パラメータを必要とする中間ノード) との間に仮想的な関係が確立します。
スキーマ要素には、単純要素と複合要素の 2 種類があります。 複合要素には、複数の要素または属性が含まれます。

複合要素を展開するには、要素名の左にあるプラス記号 (+) をクリックします (名前自体をダブルクリックすると編集モードに切り替わります)。
「単純なデータ サービス関数の作成」で説明したように、XQuery エディタでは、戻り値型へのグラフィカルなマッピングに基づいてクエリが自動的に生成されます。
XQuery エディタは、「値マッピング」と「複合要素マッピング」の 2 種類のマッピングをサポートしています。 値マッピングでは、ソースの要素または属性の値のみを、そのターゲットの要素または属性の値にマップできます。 要素マッピングでは、ソース要素 (単純または複合) をターゲットにマップできます。
要素を戻り値型にマップするには、その要素をスコープに含める必要があります。 マップしようとしている要素がスコープに含まれていない場合は、そのマッピングが無効であることを示すメッセージが表示されます (図 6-38)。 無効なマッピングは、基底の for 文または let 文において、データ要素と戻り値型スキーマとの関連付けを正常に処理できない場合に発生します。
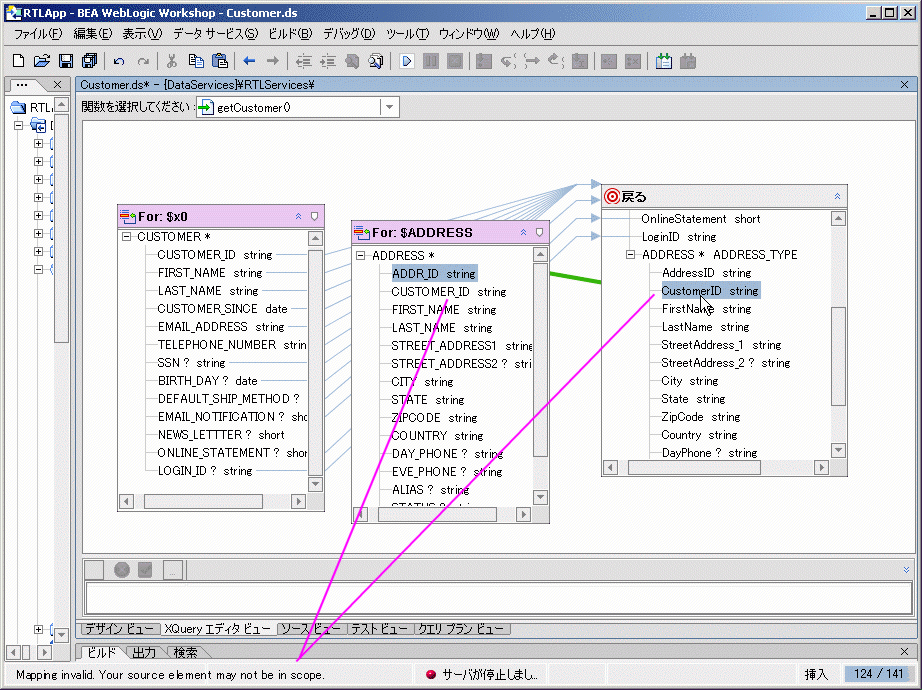
要素のスコープの詳細については、「XML 型と戻り値型」および「XML 型と戻り値型を編集する」を参照してください。
要素名の横に表示される疑問符 (?) は、それが省略可能な要素である (つまり、クエリにおいて必須ではない) ことを表します。 主キーを省略可能な要素にすることはできません。
複合要素を、ソースから戻り値型にすばやくマップできます。 これを誘導マッピングといい、戻り値型の全部または一部をソース表現に一致させる必要がある場合に便利です。
要素を型にマップすると便利な状況はたくさんあります。たとえば以下の場合です。
完全に一致しない場合は、複合要素から戻り値型へのマッピングが追加されます。
図 6-39 に、複合要素を戻り値型にマップした後の状態を示します。
| 注意 : | 複数の要素を、1 つのターゲット要素にマップすることはできません。 |
ソースを戻り値型にマップする方法としては、値マッピング、上書きマッピング、追加マッピングの 3 つがあります。
declare function tns:newFunction() as element(ns5:CREDIT_CARD)* {
for $CREDIT_CARD in tns:getCreditCard()
return
$CREDIT_CARD
通常、クエリ関数を作成する場合でも、それを実行する場合でも、誘導マッピングを作成しただけでは十分ではありません。 誘導マッピングはいつでも展開できます。展開するには、戻り値型内の要素を右クリックし、唯一選択可能なオプションである [複合マッピングの展開] を選択します。
複合マッピングを展開すると、それに応じてソースも次のように変更されます。
declare function tns:newFunction() as element(ns5:CREDIT_CARD)* {
for $CREDIT_CARD in tns:getCreditCard()
return
<ns5:CREDIT_CARD>
<CreditCardID>{fn:data($CREDIT_CARD/CreditCardID)}</CreditCardID>
<CustomerID>{fn:data($CREDIT_CARD/CustomerID)}</CustomerID>
<CustomerName>{fn:data($CREDIT_CARD/CustomerName)}</CustomerName>
<CreditCardType>{fn:data($CREDIT_CARD/CreditCardType)}</CreditCardType>
<CreditCardBrand>{fn:data($CREDIT_CARD/CreditCardBrand)}</CreditCardBrand>
<CreditCardNumber>{fn:data($CREDIT_CARD/CreditCardNumber)}</CreditCardNumber>
<LastDigits>{fn:data($CREDIT_CARD/LastDigits)}</LastDigits>
<ExpirationDate>{fn:data($CREDIT_CARD/ExpirationDate)}</ExpirationDate>
<Status?>{fn:data($CREDIT_CARD/Status)}</Status>
<Alias?>{fn:data($CREDIT_CARD/Alias)}</Alias>
<AddressID>{fn:data($CREDIT_CARD/AddressID)}</AddressID>
</ns5:CREDIT_CARD>
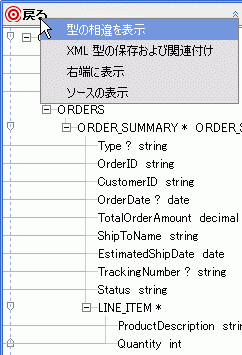
};| 注意 : | 戻り値型に変更を加えた場合は、それをデータ サービス XML 型に伝播する必要があります。そのためには、戻り値型のタイトルバーを右クリックし、[XML 型の保存および関連付け] オプションを選択します。 |
要素間のマッピングを削除するには、マッピング線 (リンク) を右クリックして [削除] を選択します。 マッピング線を選択した状態で、〔Delete〕を押して削除することもできます。
クエリから返される情報の形式は、その戻り値型によって決まります。 マッピングと戻り値型オプションを組み合わせることで、以下の操作が可能になります。
戻り値型を変更する必要があるのは、[XML 型の保存および関連付け] コマンドを使用してその変更をデータ サービスの XML 型に伝播する必要がある場合だけです。「単純なデータ サービス関数の作成」を参照してください。
いずれかの要素を右クリックすると、戻り値型を編集できます。 XQuery エディタで型を編集するためのオプションは、「XML 型を編集する」で説明したオプションとは多少異なります。 たとえば、戻り値型では、ゾーンを作成してクエリに for 句を自動的に追加できます。これにより、結果が「マスター/詳細」形式になります。
| 注意 : | 戻り値型を変更してそのままクエリを実行することは可能ですが、多くの場合、return 句とデータ サービスの XML 型が一致していない状態でアプリケーションからクエリを呼び出すと問題が発生します。 |
表 6-41 に、戻り値型の主な編集オプションをまとめます。
|
|
|
[複合マッピングの展開] は、誘導マッピングの場合にのみ選択可能になる特別なオプションです。 詳細については、「複合要素を戻り値型へマップする」を参照してください。
複合子要素を戻り値型に追加するには、スキーマを選択してグローバル要素 (型) を指定します。 複合子要素は、データ サービス スキーマ (.xsd ファイル) を戻り値型に組み込みます。
複合グローバル要素を戻り値型に追加するには、次の手順に従います。
| 注意 : | 複合子要素を追加する場合は、戻り値型内の同等の要素の末尾に配置する必要があります。 |
AquaLogic Data Services Platform では、戻り値型のゾーンによって、クエリの結果がどのように配置されるかが決まります。 XQuery エディタでゾーンを追加または変更するという動作は、ソース ビューで文の従属順序を追加または変更しているのと同じです (ゾーンを使用して論理データ サービスを構築し、マスター/詳細形式にネストされたデータを作成する詳細な例については、「単純なデータ サービス関数の作成」を参照してください)。
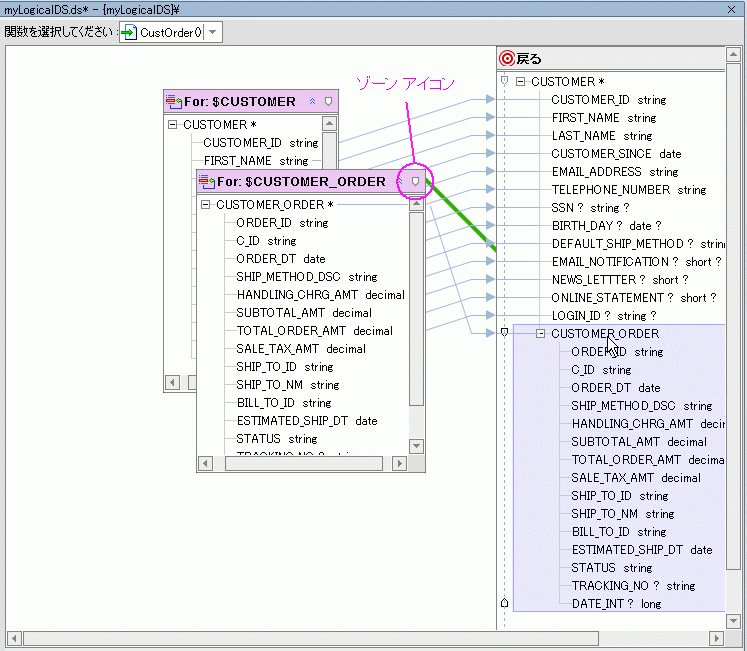
図 6-42 の例では、特定の顧客の CUSTOMER_ORDER 要素がその顧客の下にグループ化されます。
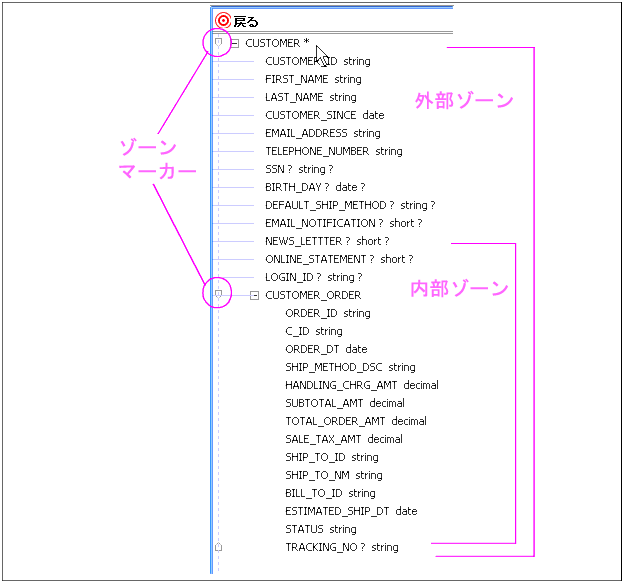
デフォルトでは、戻り値型に設定されているゾーンは 1 つのみです。 しかし、ゾーン要素を追加しなくても、処理は自然な順序で繰り返されます。 図 6-42 に示した単純な例でいうと、ある顧客の注文が複数ある場合は、一致するすべての注文が処理されるまで、顧客情報と注文情報の両方が繰り返し処理されます。
次の少し簡略化された XML は、ゾーンを 1 つのみ使用した場合です。
<CUSTOMERID>987655</CUSTOMERID>
<CUSTOMERNAME>Supermart</CUSTOMERNAME>
<ORDER>
<ORDERID>632</ORDERID>
<CUSTOMERID>987655</CUSTOMERID>
<CUSTOMERID>987655</CUSTOMERID>
<CUSTOMERNAME>Supermart</CUSTOMERNAME>
<ORDER>
<ORDERID>888</ORDERID>
<CUSTOMERID>987655</CUSTOMERID>
..
この例では、CUSTOMERNAME と CUSTOMERID が繰り返し処理されています。
これに似た関数の XQuery ソースを見ると、どのように処理が繰り返されるかが分かります。
for $CUSTOMER in ns0:CUSTOMER()
for $CUSTOMER_ORDER in ns1:CUSTOMER_ORDER()
where $CUSTOMER/CUSTOMER_ID = $CUSTOMER_ORDER/C_ID
return <ns2:CUSTOMER7>
<CUSTOMER_ID>{fn:data($CUSTOMER/CUSTOMER_ID)}</CUSTOMER_ID>
<LAST_NAME>{fn:data($CUSTOMER/LAST_NAME)}</LAST_NAME>
<ns1:CUSTOMER_ORDER>
<ORDER_ID>{fn:data($CUSTOMER_ORDER/ORDER_ID)}</ORDER_ID>
<C_ID>{fn:data($CUSTOMER_ORDER/C_ID)}</C_ID>
<TOTAL_ORDER_AMT>{fn:data($CUSTOMER_ORDER/TOTAL_ORDER_AMT)}</TOTAL_ORDER_AMT>
</ns1:CUSTOMER_ORDER>
</ns2:CUSTOMER7>
一方、CUSTOMER_ORDER 要素の周囲に繰り返し可能なゾーンを作成すると、ソース ビューには従属する for 句が追加されます。
for $CUSTOMER in ns0:CUSTOMER()
return <ns2:CUSTOMER7>
<CUSTOMER_ID>{fn:data($CUSTOMER/CUSTOMER_ID)}</CUSTOMER_ID>
<LAST_NAME>{fn:data($CUSTOMER/LAST_NAME)}</LAST_NAME>{
for $CUSTOMER_ORDER in ns1:CUSTOMER_ORDER()
where $CUSTOMER/CUSTOMER_ID = $CUSTOMER_ORDER/ORDER_ID
return
<ns1:CUSTOMER_ORDER>
<ORDER_ID>{fn:data($CUSTOMER_ORDER/ORDER_ID)}</ORDER_ID>
<C_ID>{fn:data($CUSTOMER_ORDER/C_ID)}</C_ID>
<TOTAL_ORDER_AMT>{fn:data($CUSTOMER_ORDER/TOTAL_ORDER_AMT)}</TOTAL_ORDER_AMT>
</ns1:CUSTOMER_ORDER>
}
</ns2:CUSTOMER7>
2 番目のコードの where 句では、すべての注文を 1 つの顧客インスタンスにまとめています。
ゾーンを作成するには、要素を右クリックして [ゾーンとしてマーク] を選択します。 作成されたゾーンは、そのゾーンの制御領域内をマウスでポイントすると強調表示されます (図 6-42)。
XQuery では、for、let、および group by 句を別の for、let、または group by 句で囲むことができます。 同様に、ノードのタイトルバー上のゾーン作成アイコンを使用して、これらのコンストラクトを表すノードを戻り値型のゾーンに関連付けることができます (この章の冒頭の XQuery エディタの例で示した 図 6-10 を参照)。 このアイコンをドラッグして既存のゾーンにドロップすると、そのノードがゾーンに関連付けられます。
この操作が成功したかどうかを確認するには、マウスでゾーン アイコンをポイントします。 正常に関連付けられていると、適切なゾーンが強調表示されます (図 6-42 を参照)。 または、実際にソース ビューを見たり、テスト ビューでクエリを実行したりして確認することもできます。
| 注意 : | XQuery エディタでゾーンや XQuery の他の要素を作成する場合、どの順番で作成したかが重要になる場合があります。 たとえば、ゾーンは、where 句によって 2 つのノードを関連付ける前に作成する必要があります。 |
ゾーンを削除するには、ゾーンの親要素を右クリックして [ゾーンの削除] を選択します。
関数の戻り値型に変更を加え、データ サービスをその変更に合致させて最も適した状態にすることができます。
戻り値型を管理するため、以下の右クリック オプションが用意されています。
次に、2 つの新しい子要素を戻り値型に追加した例を示します。
戻り値型が XML 型と比較され、要素間の相違が検出されると赤や青で表示されます。 これらには、戻り値型から削除した要素や、戻り値型に追加した要素が含まれています。
戻り値型に DESCRIPTION を追加したとすると、図 6-45 のように青色で表示されます。
項目の左に表示されている矢印は、その変更が戻り値型で行われたか (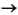 )、データ サービスの XML 型で行われたか () を示しています。
)、データ サービスの XML 型で行われたか () を示しています。
このコマンドを使用して戻り値型を保存する際には、そのスキーマ、スキーマの場所、ターゲット ネームスペース、またはルート名を、基底のデータ サービスで使用しているものから変更して保存することもできます。
データ サービス関数から戻り値型を構築した場合、[XML 型の保存および関連付け] コマンドを実行する前に、ネームスペースまたはルート名を変更しなければならない場合があります。 これは、戻り値型の当初の修飾名が、戻り値型の作成に使用した関数と同じ名前になってしまうためです。
 
|

![[XML 型の保存および関連付け] ダイアログ](wwimages/save_and_associate.gif)