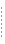

|
|
BEA Aqualogic Data Services Platform 用のデータ サービスを作成するにあたっての最初の手順は、アプリケーションに必要となるメタデータを、物理データから取得することです。
この章ではこのプロセスについて説明します。内容は以下のとおりです。
メタデータとは単に、データ ソースの構造に関する情報のことです。 たとえば、リレーショナル データベースにおけるテーブルおよびカラムのリストは、メタデータです。 Web サービスにおけるオペレーションのリストは、メタデータです。
AquaLogic Data Services Platform では、物理データはほぼ全体が、物理データ ソース内に対する参照に基づいています。
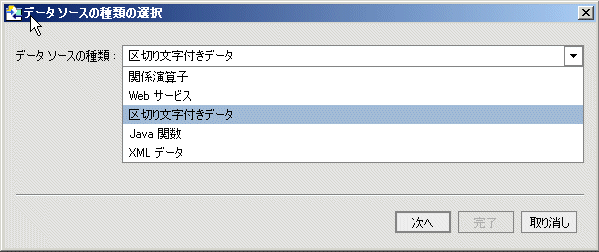
表 3-2 に、AquaLogic Data Services Platform がメタデータを作成できるソースの種類を示します。
メタデータ インポート ウィザードを使用して物理データに関する情報を作成すると、次の 2 つの処理が行われます。
アプリケーションで必要なデータ ソースのメタデータは、AquaLogic Data Services Platform のメタデータ インポート ウィザードを使用してインポートできます。 このウィザードは、使用可能なデータ ソース内を参照し、データ サービスおよび関数として表現できるデータ オブジェクトを識別します。 作成された物理データ サービスはクエリおよび論理データ サービスの構成要素となります。
データ ソース メタデータは、AquaLogic Data Services Platform の関数またはプロシージャとしてインポートできます。 たとえば、Web サービス オペレーションをインポートしたことによって、次のソースが得られたとします。
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com" kind="read" nativeName="getCustomerOrderByOrderID" nativeLevel1Container="ElecDBTest" nativeLevel2Container="ElecDBTestSoap" style="docu ment"/>::)
declare function f1:getCustomerOrderByOrderID($x1 as element(t1:getCustomerOrderByOrderID)) as schema-element(t1:getCustomerOrderByOrderIDResponse) external;
インポートされた Web サービスは、プラグマ内の「read」関数として記述されていることに留意してください。 「External」は、スキーマが別個のファイルであることを示しています。 ソース コードのアノテーションの詳細な説明は、『XQuery 開発者ガイド』の「Understanding AquaLogic Data Services Platform Annotations」を参照してください。
Web サービスなど、一部のデータ ソースの場合、インポートされたメタデータは、一般的に void を返す関数を表します (つまり、これらの関数は、データを返すのではなく操作を実行するものです)。 そのようなルーチンは、副作用関数、または正式には、AquaLogic Data Services Platform プロシージャとして分類されます。 また、ある特定のデータ ソースからインポートされたルーチンをプロシージャとしてマークすることもできます (「AquaLogic Data Services Platform のプロシージャの識別」を参照)。
Web サービス メタデータのインポートで、次のように副作用プロシージャとして識別されるオペレーションを含むソースが得られました。
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com" kind="hasSideEffects" nativeName="setCustomerOrder" style="document"/>::)
declare function f1:setCustomerOrder($x1 as element(t3:setCustomerOrder)) as schema-element(t3:setCustomerOrderResponse) external;
上のプラグマでは、関数は「hasSideEffects」として認識されます。
| 注意 : | AquaLogic Data Services Platform プロシージャは物理データ サービスとのみ関連付けられており、メタデータ インポート プロセスを通じてのみ作成可能です。 したがって、たとえばソース ビューを介して論理データ サービスへプロシージャを追加しようとすると、エラーが発生します。 |
Web サービス、リレーショナル ストアド プロシージャ、または Java 関数のソース メタデータをインポートする際には、副作用ルーチンを表すメタデータを識別する機会があります。 一般的な例としては、新規顧客レコードを作成する Web サービスが挙げられます。 データ サービス側から見ると、このようなルーチンはプロシージャです。
プロシージャは、スタンドアロンではありません。常に同じデータ ソースからのデータ サービスの一部です。
そのようなソースからデータをインポートする場合、メタデータ インポート ウィザードは void を返すルーチンを自動的にプロシージャとして分類します。 その理由は単純に、データを返さないルーチンは、他のデータ サービス関数と相互運用できないからです。
しかし、データを返すと共に、副作用もあるルーチンが存在します。これらのルーチンを、メタデータ インポート プロセス中に、プロシージャとして識別する必要があります。 そのようなプロシージャを識別することにより、アプリケーション開発者には、2 つの重要な利点がもたらされます。
表 3-4 に、共通の AquaLogic Data Services Platform における操作を示し、データ サービス プロシージャに使用できるものと使用できないものを特定します。
プロシージャを使用すると、invokeProcedure( ) API を指定することによって、非リレーショナルなバックエンドのデータ ソースを更新するプロセスが大幅に簡素化されます。 この API には、リレーショナル ストアド プロシージャ、Web サービス、または Java 関数を呼び出すのに必要なオペレーション論理がカプセル化されています。 このような場合には、更新論理をバックエンドのデータ ソース ルーチン内に構築でき、そのルーチンがデータを更新します。
非リレーショナルなソースの更新やその他の特別な場合に関する情報は、「データ サービスを介した更新の処理」を参照してください。
メタデータ インポート プロセス中に副作用プロシージャを識別する方法の例については、「Web サービスのメタデータのインポート」を参照してください。
BEA WebLogic Platform で使用可能なすべてのリレーショナル データ ソースについて、メタデータを取得することができます。 詳細については、BEA Platform のドキュメント「SQL Server や Oracle などのデータベースにデータベース コントロールを接続するには」を参照してください。
リレーショナル データ ソースからは、次の 5 種類のメタデータを取得できます。
| 注意 : | XA トランザクション ドライバを使用している場合、単一のデータベースによる読み取りと更新を正常に実行させるためには、LocalTransaction を許可するようにデータ ソースの接続プールをマークする必要があります。 |
| 注意 : | XA トランザクション アダプタ設定の詳細については、BEA WebLogic Integrationのドキュメントの『アダプタの開発』http://edocs.beasys.co.jp/e-docs/wli/docs81/devadapt/dbmssamp.html を参照してください。 |
リレーショナル テーブルおよびビューに関するメタデータを作成するには、次の手順に従います。
新しいデータ ソースの作成については、「新しいデータ ソースを作成する」を参照してください。
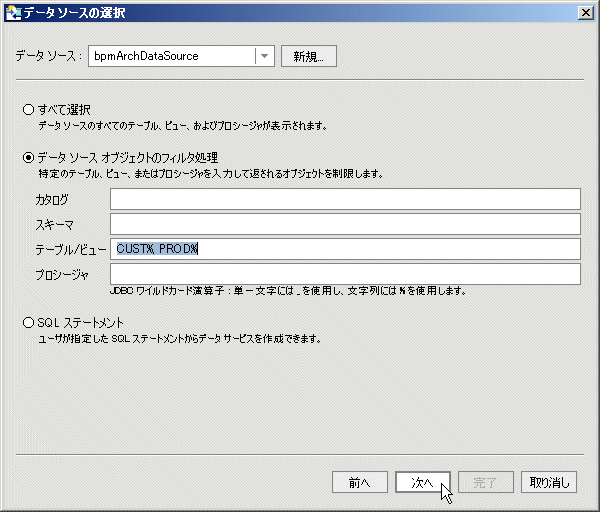
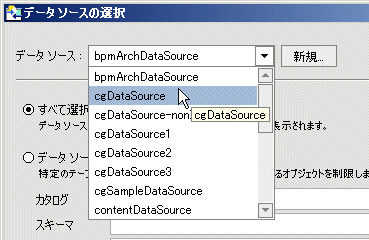
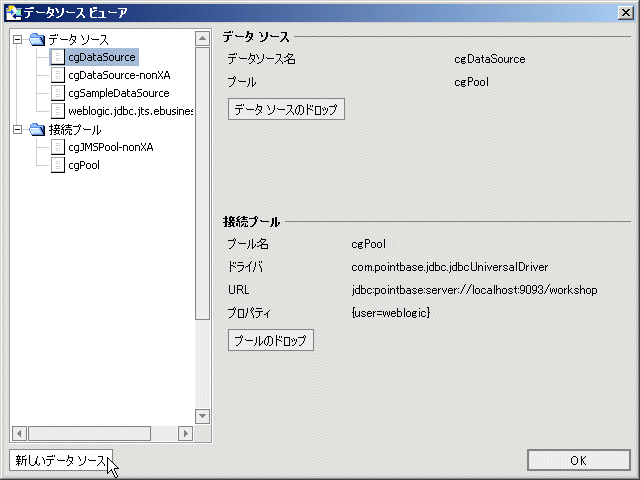
既存のデータ ソースから選択する場合は、いくつかのオプションが指定可能です (図 3-6)。
すべてを選択した場合は、カタログおよびスキーマによって整理された、データ ソース内のすべてのテーブル、ビュー、およびストアド プロシージャを含む表が表示されます。
場合によっては、データ ソース内のデータ サービスに変換するオブジェクトが正確に分かっていることがあります。 あるいは、データ ソースが大きすぎて、フィルタが必要な場合もあります。 また、特定の命名特性 (囲まれている文字列を含むすべてのオブジェクトを取得する、%audit2003% という文字列など) を持つオブジェクトを探している場合もあります。
そのような場合、標準的な JDBC のワイルドカードを使用して、データ サービスの候補とするリレーショナル ソースの部分を正確に識別できます。 アンダースコア (_) を付けると、単独の文字のためのワイルドカードになります。 パーセント記号 (%) は、文字列用のワイルドカードを示します。 入力内容の大文字/小文字は区別されます。
たとえば、CUST% と入力することで、CUST で開始されるすべてのテーブルを検索できます。 また、ELECTRONICS というリレーショナル スキーマがある場合は、[スキーマ] フィールドにその語を入力し、そのスキーマの一部であるすべてのテーブル、ビュー、およびストアド プロシージャを取得できます。
CUST%, PAY%
と [テーブル/ビュー] フィールドに入力することで、CUST または PAY で開始されるすべてのテーブルおよびビューが取得されます。
| 注意 : | 特定のフィールドについて、項目が何も入力されていなければ、一致するすべての項目が取得されます。 たとえば、[プロシージャ] フィールドにフィルタ処理用の入力がなかった場合、データ オブジェクト内のすべてのストアド プロシージャが取得されます。 |
リレーショナル テーブルおよびビューについては、[すべて選択] または [データ ソース オブジェクトのフィルタ処理] を選択する必要があります。
また、内部ストアド プロシージャに関するメタデータのインポートのサポートのために、ワイルドカードを使用することもできます。 たとえば、次の文字列をストアド プロシージャ フィルタとして入力します。
%TRIM%
これにより、以下のシステムのストアド プロシージャに関するメタデータが取得されます。
STANDARD.TRIM
このような状況では、同時に [テーブル/ビュー] フィールドに意味をなさない入力を行い、データベース内のすべてのテーブルおよびビューが取得されてしまうことを回避するとよいでしょう。
ストアド プロシージャの詳細については、「ストアド プロシージャベースのメタデータのインポート」を参照してください。
データ サービス作成の基盤として使用される SQL 文の入力を行えます。 詳細については、「SQL を使用したメタデータのインポート」を参照してください。
ほとんどの場合、作業は既存のデータ ソースで行います。 しかし、[新規...] を選択した場合は、WLS データソース ビューアが表示されます (図 3-7)。 データソース ビューアを使用すると、新しいデータ プールおよびソースを作成できます。
データソース ビューアの使い方の詳細については、WebLogic Workshop のドキュメントの「データ ソースをコンフィグレーションする」を参照してください。
AquaLogic Data Services Platform アプリケーションまたはプロジェクトで使用できるのは、BEA WebLogic Administration Console で設定したデータ ソースのみです。 AquaLogic Data Services Platform によって使用されている BEA WebLogic Server が、特定のリレーショナル データ ソースにアクセスするためには、JDBC 接続プールおよび JDBC データ ソースを設定することが必要です。
データ ソースを選択したら、メタデータの開発を、データベース内のすべてのオブジェクトを選択することによって行うのか、データベース オブジェクトをフィルタ処理して行うのか、それとも SQL 文を入力することによって行うのかを選択する必要があります (図 3-6 を参照)。
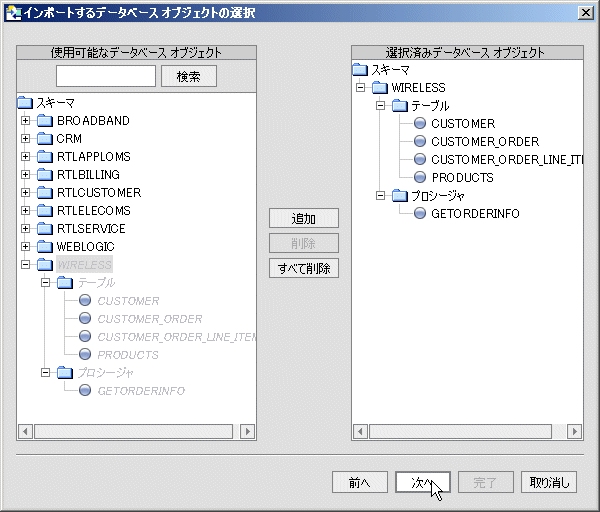
データ ソースおよび任意指定のフィルタを選択し終わると、使用可能なデータベース オブジェクトが表示されます。
標準のダイアログ コマンドを使って、1 つまたは複数のテーブルを、選択済みデータ オブジェクトのリストに追加できます。 テーブルの選択を解除するには、右側のカラムでそのテーブルを選択し、[削除] をクリックします。
[検索] フィールドを利用することもできます。 これは、多くのオブジェクトがあるデータ ソースには有用です。 検索文字列を入力して [検索] のクリックを繰り返し、リスト内を移動します。
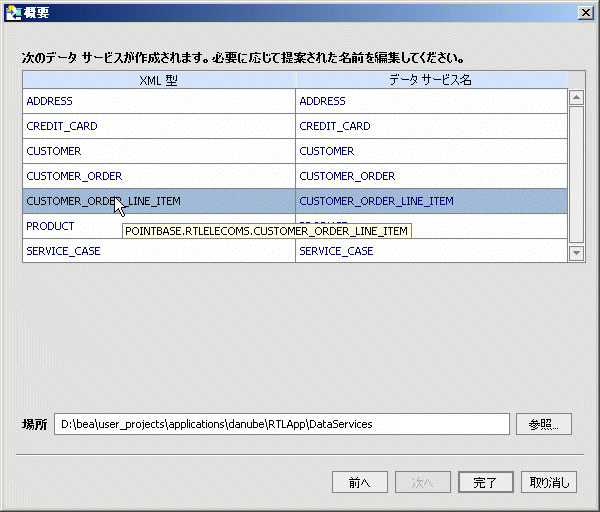
インポートされたデータの概要画面では、次のことが行われています。
データベースのベンダによる、データベース カタログおよびスキーマのサポート状況は、さまざまです。表 3-11 では、いくつかの大手ベンダの場合の、このサポートについて説明します。
XML の命名規約の範疇に収まらないソース名があった場合、デフォルトで生成された名前は、SQLX 標準に記載されているルールに従って変換されます。 一般的に、無効な XML 名の文字は、16 進値のエスケープ シーケンス (_xUUUU_ の形式) に置換されます。
詳細については、この標準の W3C 草案バージョンにおける節 9.1 を参照してください。
データ サービスを作成し終えたら、物理データに関する論理ビューの構築を開始できる準備が整った状態です。 「データ サービスの設計」および「データ サービスのモデル化」を参照してください。
多くの DBMS システムでは、クエリのパフォーマンス向上、データ操作の管理およびスケジューリング、セキュリティ強化などのために、ストアド プロシージャを利用しています。 特定的にサポートされているベンダの場合、ストアド プロシージャに基づくメタデータをインポートすることができます。 各ストアド プロシージャは、データ サービスとなります。
| 注意 : | 詳細については、AquaLogic Data Services Platform の『リリース ノート』の「サポート対象のコンフィグレーション」を参照してください。 ストアド プロシージャの作成と管理の詳細については、特定の DBMS のドキュメントを参照してください。 |
ストアド プロシージャとは本質的に、SQL のセットと、ネイティブ データベース プログラミング言語の文を論理的に 1 つのグループとし、特定のタスクを実行するものです。
表 3-12 では、いくつかの共通に使用される用語を、ストアド プロシージャに関するこの説明に当てはまるように定義しています。
インポートされたストアド プロシージャのメタデータは、リレーショナル テーブルおよびビューのインポートされたメタデータに、極めて似通っています。 ストアド プロシージャをインポートする手順の最初の 3 つは、任意のリレーショナル メタデータ (「リレーショナル テーブルおよびビューのメタデータのインポート」で説明) をインポートする際の手順と同じです。
| 注意 : | ストアド プロシージャの戻り値が 1 つしかなく、その値が、既存のスキーマにマッピングする単純型または行セットのいずれかである場合、スキーマ ファイルは作成されません。 |

データ ベース テーブル、ビュー、およびストアド プロシージャは、どのような組み合わせででも選択できます。 1 つまたは複数のストアド プロシージャを選択すると、メタデータ インポート ウィザードにより、ストアド プロシージャをデータ サービスに変換するために必要なさらなる手順が指示されます。 これらの手順は以下のとおりです。
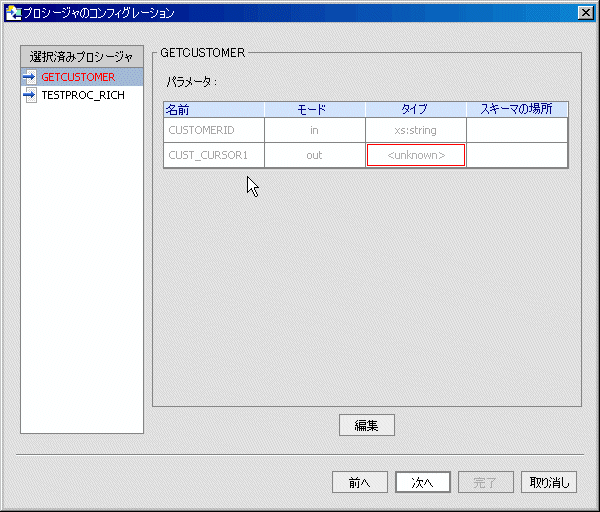
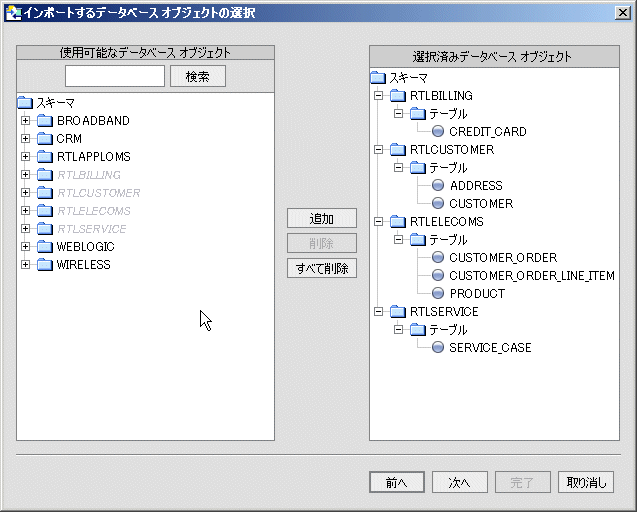
メタデータ インポート ウィザードで識別できないストアド プロシージャ内のデータ オブジェクトは、データ型なしで赤色表示されます。 そのような場合は、編集モードに入って ([編集] ボタンをクリック) データ型を特定する必要があります。
ストアド プロシージャと関連付けられた「<unknown>」条件 (図 3-14) を修正するにあたっての目的は、インポート ウィザードによって取得されたメタデータを、ストアド プロシージャの実際のメタデータに準拠させることです。 場合によっては、これは戻り値型の場所を修正することによって行われます。 それ以外の場合には、プロシージャの要素と関連付けられた型を調整するか、またはストアド プロシージャ内を最初に参照した際に見つからなかった要素を追加することが必要となります。
次の手順に進む前に、選択した各ストアド プロシージャについて情報の指定を完了させる必要があります。 特に、赤色で表示されているストアド プロシージャはすべて対処する必要があります。
ストアド プロシージャ内の各要素は、型と関連付けられています。 その項目が単純型である場合は、型のポップアップ リストから選択するだけで済みます。
複合型の場合は、適切なスキーマの指定が必要なことがあります。 スキーマの場所ボタンをクリックして、スキーマのパス名を入力するか、スキーマの場所を参照します。 このスキーマは、アプリケーション内に存在しているものでなければなりません。
スキーマ選択後は、スキーマ ファイルへのパスと、URI の両方が表示されます。 次に例を示します。
http://temp.openuri.org/schemas/Customer.xsd}CUSTOMER
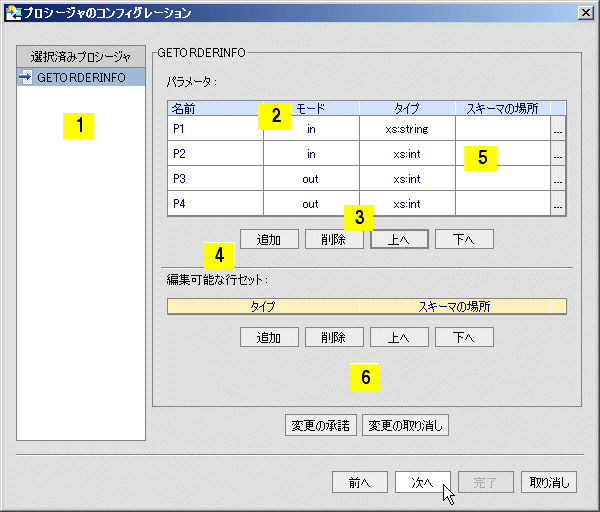
JDBC を介して機能するメタデータ インポート ウィザードは、ストアド プロシージャのパラメータもすべて識別します。 これには、名前、モード (入力 [in]、出力 [out]、または双方向 [inout]) およびデータ型が含まれます。 out モードは、スキーマの組み込みをサポートしています。
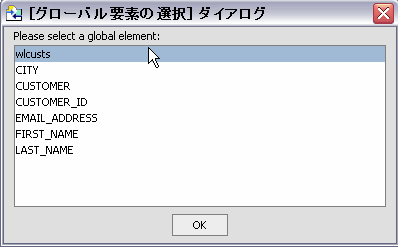
すべてのデータベースで行セットがサポートされているわけではありません。 加えて、JDBC は定義済みの行セットに関連付けられた情報を報告しません。 行セット情報を使用するストアド プロシージャからデータ サービスを作成するには、正しい順序 (一致する番号) とスキーマを指定します。 スキーマに複数のグローバル要素がある場合、[タイプ] 列から適切なものを選択できます。 選択しなかった場合、タイプはスキーマ ファイル内の最初のグローバル要素になります。
行セット情報の順序は重要です。この順序は、データ ソース内の順序に一致している必要があります。 [上へ] および [下へ] コマンドを使用して、行セットに割り当てられた順序番号を調整します。
[概要] 画面で項目を確認して受け入れることにより、プロシージャのインポートを完了させます (詳細については、「リレーショナル テーブルおよびビューのメタデータのインポート」の手順 4 を参照)。
| 注意 : | ストアド プロシージャから生成されたデータ サービスの XML 型では、ネイティブ型が表示されません。 しかし、ソース ビュー プラグマ (「XQuery ソースの操作」を参照) でネイティブ型を表示することができます。 |
行セットの型は、複合型です。 行セットの型の名前としては、以下のものがあります。
行セットの型には、行セットのフィールドを備えた繰り返し可能な要素 (たとえば、CUSTOMER という名前のもの) のシーケンスが入っています。
| 注意 : | すべての行セット型定義は、この構造に準拠している必要があります。 |
場合によっては、メタデータ インポート ウィザードで自動的に行セットの構造を検出して、要素構造を作成できます。 しかし、構造が不明な場合は、ウィザードを使ってそれを指定する必要があります。
独立したルーチンを、データ サービスを介してのエンタープライズ情報管理の一部として活用すると、役立つことがよくあります。 分かりやすい例としては、スタンドアロンの更新またはセキュリティ関数の、データ サービスを介した活用が挙げられます。 そのような関数は、noXML 型です。実際、通常は何も返しません (または、void を返します)。 その代わり、データ サービスではこれらの関数が副作用のあるものであり、プロシージャとして、同じデータ ソースのデータ サービスと関連付けられていることが認識されています。
ストアド プロシージャは、データに対して内部処理を行うため、データ サービス側から見ると、非常に多くの場合、副作用プロシージャです。 そのような場合は、メタデータ インポート プロセス中に、ストアド プロシージャをデータ サービス プロシージャとして識別するだけで済みます。
データ サービスまたは XML ファイル ライブラリ (XFL) に追加するストアド プロシージャを識別した後に、これらのうちどれをデータ サービス プロシージャとして識別するかを指定する機会も提供されます。
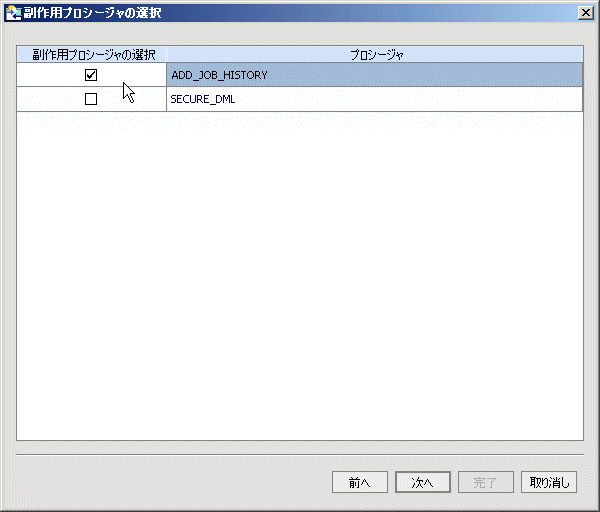
| 注意 : | 最小 (単純) 型の周辺を基盤とするデータ サービス プロシージャは、識別された XML 関数ライブラリ (XFL) ファイル内に収集されます。 その他のプロシージャは、AquaLogic Data Services Platform 対応のプロジェクトに対してローカルなデータ サービスと関連付けられる必要があります。 |
内部ストアド プロシージャのメタデータをインポートできます。 詳細については、「データ ソース オブジェクトをフィルタ処理する」を参照してください。
最新バージョンのストアド プロシージャのみが、AquaLogic Data Services Platform にインポート可能です。 このため、メタデータ インポート ウィザードでストアド プロシージャをインポートする際には、バージョン番号の識別はできません。 同様に、AquaLogic Data Services Platform ソースにバージョン番号を追加すると、クエリ例外が発生します。
ストアド プロシージャの入力パラメータが null 値を許す (null 値を受け入れることができる) ことが分かっている場合、ソース ビューで関数のシグネチャを変更して、パラメータの末尾に疑問符を付加することにより、そのようなパラメータを任意指定のものにすることができます。 次に例を示します (疑問符を太字で表示)。
function myProc($arg1 as xs:string) ...
function myProc($arg1 as xs:string?) ...
ソース ビューの詳細については、「XQuery ソースの操作」を参照してください。
ストアド プロシージャに対するアプローチは、データベース ベンダごとにさまざまです。 XQuery サポートの制限は、一般に、JDBC ドライバ上の制限に起因しています。
AquaLogic Data Services Platform では、行セットを入力パラメータとしてサポートしていません。
表 3-18 では、Oracle データベース プロシージャに対する AquaLogic Data Services Platform のサポートの概要を示しています。
|
|||
表 3-19 では、Sybase SQL Server データベース プロシージャに対する AquaLogic Data Services Platform のサポートの概要を示しています。
表 3-20 では、IBM DB2 データベース プロシージャに対する AquaLogic Data Services Platform のサポートの概要を示しています。
表 3-21 では、Microsoft SQL Server データベース プロシージャに対する AquaLogic Data Services Platform のサポートの概要を示しています。
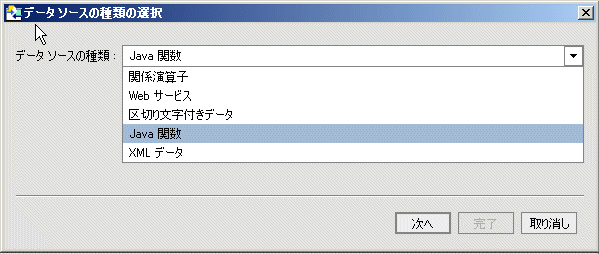
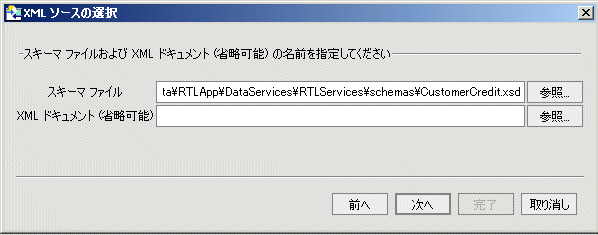
リレーショナル インポート メタデータ オプション (図 3-6 を参照) の 1 つは、SQL 文を使用して、データ ソース内への参照をカスタマイズすることです。 このオプションを選択すると、[SQL ステートメント] ダイアログが表示されます。
![[SQL ステートメント] ダイアログ ボックス](wwimages/sql_statement_db1.gif)
文のボックス (図 3-22) に SELECT 文の入力または貼り付けを行えます。その際、パラメータは、疑問符「?」で示します。 AquaLogic Data Services Platform データ サンプルの 1 つで、次の SELECT 文を使用できます。
SELECT * FROM RTLCUSTOMER.CUSTOMER WHERE CUSTOMER_ID = ?
RTLCUSTOMER はデータ ソース内のスキーマ、CUSTOMER はこの場合テーブルです。
パラメータ フィールドについては、データ型を選択する必要があります。 この場合は、CHAR または VARCHAR です。
テスト ビューでクエリを実行する際には、そのクエリを正常に実行させるため、パラメータを指定する必要があります。
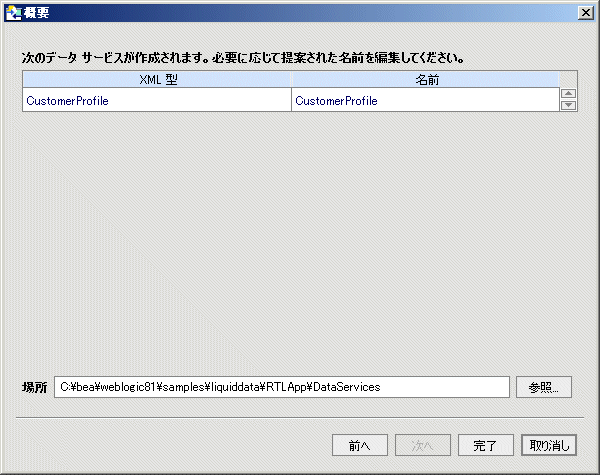
SQL 文および必要なすべてのパラメータを入力したら、[次へ] をクリックして、新しいデータ サービスの名前と場所を変更または確認します。
![[SQL ステートメント] ダイアログ ボックス](wwimages/datasrvc-03-1-16.gif)
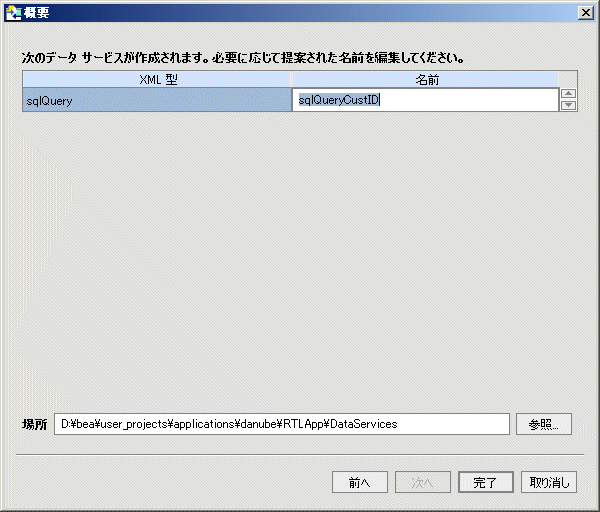
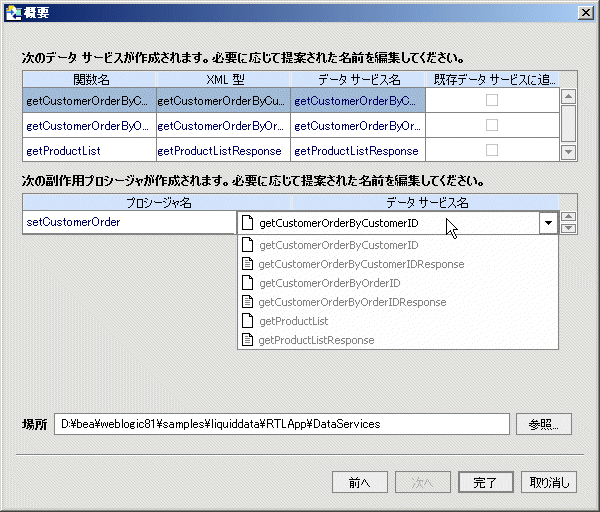
インポートされるデータの概要画面により、新しいデータ サービスについて提案される名前が識別されます。
最後の手順は、テーブルまたはビューからデータ サービスを作成した際のものと変わりありません。
次の表では、各種のリレーショナル データベースによって提供されるデータ型が、どのように XQuery データ型に変換されるのかを示します。 表 3-24 において、各型はアルファベット順に示されます。
リレーショナル ソースからメタデータをインポートする場合、ユーザのロールに応じて、さまざまなデータ ソースへユーザをマップする論理をアプリケーション内に指定できます。 これは、インターセプタを作成して、アプリケーション内の各データ サービスの RelationalDB アノテーションに属性を追加することによって実現します。
インターセプタとは、SourceBindingProvider インタフェースを実装する Java クラスです。 このクラスは、ユーザの現在の資格に応じて、論理データ ソース名 (1 つまたは複数) に、ユーザをマップするための論理を提供します。 これにより、論理データ ソース名に基づき、リレーショナル物理ソースへのアクセス レベルを制御できるようになります。
たとえば、WebLogic Server 上にデータ ソース名 cgDataSource1、cgDataSource2、および cgDataSource3 を定義し、管理者であるユーザは 3 つすべてのデータ ソースにアクセスできるが、通常のユーザはデータ ソース cgDataSource1 にしかアクセスできないように、クラス内の論理を定義できます。
| 注意 : | 同じリレーショナル データ ソースを参照する、すべてのリレーショナル、更新オーバーライド、ストアド プロシージャ データ サービス、またはストアド プロシージャ XFL ファイルは、ソース バインディング プロバイダも同じものを使用する必要があります。つまり、データ サービス (.ds) ファイルの少なくとも 1 つに対しソース バインディング プロバイダを指定したならば、その他のデータ サービス ファイルについてもそれを設定しなければなりません。 |
com.bea.ld.binds.SourceBindingsProvider を実装する Java クラス SQLInterceptor を記述し、クラス内に getBindings() パブリック メソッドを定義します。 このメソッドのシグネチャは、次のとおりです。public String getBinding(String genericLocator, boolean isUpdate)
genericLocator パラメータは、現在の論理データ ソース名を指定します。 isUpdate パラメータは、読み取りまたは更新が発生しているかどうかを示します。 true 値は、更新を示します。 false 値は、読み取りを示します。 返される文字列は、ユーザのマップ先となる論理データ ソース名です。コード リスト 3-1 に、SQLInterceptor クラスの例を示します。
sourceBindingProviderClassName 属性を追加することにより、DS または XFL ファイル (必要であれば両方) にデータ ソースのコンフィグレーション インターセプタを定義します。 属性は、有効な Java クラスの名前 (インターセプタ クラスの名前) に割り当てる必要があります。 次に例を示します (属性および Java クラスは太字)。<relationalDB dbVersion="4" dbType="pointbase" name="cgDataSource" sourceBindingProviderClassName="sql.SQLInterceptor"/>public class SqlProvider implements com.bea.ld.bindings.SourceBindingProvider{
public String getBinding(String dataSourceName, boolean isUpdate) {
weblogic.security.Security security = new weblogic.security.Security();
javax.security.auth.Subject subject = security.getCurrentSubject();
weblogic.security.SubjectUtils subUtils =
new weblogic.security.SubjectUtils();
System.out.println(" the user name is " + subUtils.getUsername(subject));
if (subUtils.getUsername(subject).equals("weblogic"))
dataSourceName = "cgDataSource1"; System.out.println("The data source is " + dataSourceName);
System.out.println("SDO " + (isUpdate ? " YES " : " NO ") );
return dataSourceName;
}
}
Web サービスとは、HTTP や SOAP など標準ベースのインターネット プロトコルだけでなく、アプリケーション アダプタを介してもアクセス可能な、完全に独立した、プラットフォームに依存しない、ビジネス論理単位です。
Web サービスにより、アプリケーション間の通信が著しく容易になります。 そのため、Web サービスはエンタープライズ データ リソースにおいて、ますます中心的なものとなってきています。 外部化された Web サービスのよく知られた例としては、Web アプリケーションに容易に統合できる更新頻度の高い天気ポートレットや株価ポートレットがあります。 同様に、Web サービスは、販売者から製造者への直送注文の追跡にも、効果的に利用できます。
| 注意 : | RPC モードの多次元配列はサポートされていません。 |
Web サービス定義 (スキーマ) に基づいたデータ サービスの作成は、リレーショナル データ ソース メタデータのインポートに類似しています (「リレーショナル テーブルおよびビューのメタデータのインポート」を参照)。
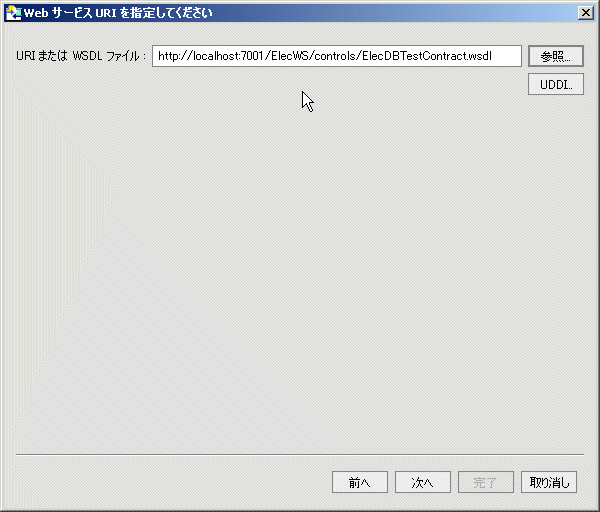
| 注意 : | Web サービス メタデータのインポート方法を示す目的で、以降の手順では RTLApp サンプルからの WSDL ファイルが使用されています。 この手順に従うならば、以下を URI フィールドに入力して、RTLApp に付属の WSDL にアクセスします。 |
| 注意 : | http://localhost:7001/ElecWS/controls/ElecDBTestContract.wsdl |
| 注意 : | インポートするオペレーションで void を返すものは、自動的に AquaLogic Data Services Platform プロシージャとしてインポートされます。 [副作用プロシージャの選択] ダイアログ (図 3-26) を使用し、他のオペレーションをプロシージャとして識別できます。 |
副作用オペレーションを、データ サービスを介してのエンタープライズ情報管理の一部として活用すると、役立つことがよくあります。 分かりやすい例としては、スタンドアロンの更新またはセキュリティ関数の、データ サービスを介した管理が挙げられます。 データ サービスは、該当するオペレーションを副作用のあるものとして登録します。
プロシージャは、スタンドアロンではありません。常に同じデータ ソースからのデータ サービスの一部です。
Web サービスは、実際にはデータを返す場合であっても、データ サービス側から見れば副作用のあるものです。 そのような場合、メタデータ インポート プロセス中に、Web サービス オペレーションをデータ サービスと関連付ける必要があります。
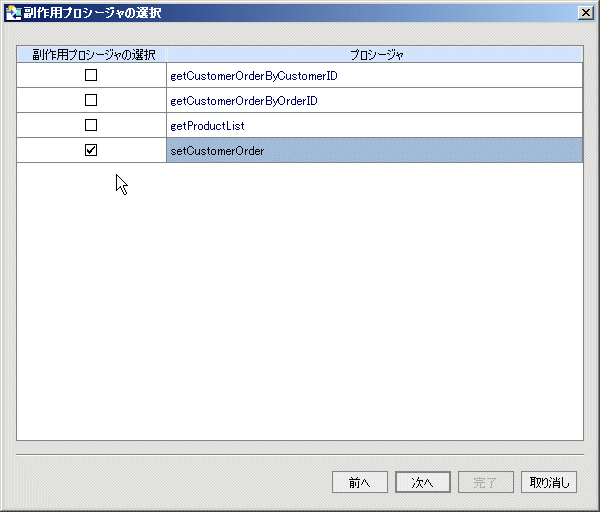
プロシージャは、AquaLogic Data Services Platform 対応のプロジェクトに対してローカルなデータ サービスと関連付けられる必要があります。
標準的なダイアログの編集コマンドを使用し、選択済みの Web サービス オペレーションのリストに追加する 1 つまたは複数のオペレーションを選択できます。 オペレーションの選択を解除するには、それをクリックしてから、[削除] をクリックします。 あるいは、[すべて削除] を選択して、初期状態に戻ります。
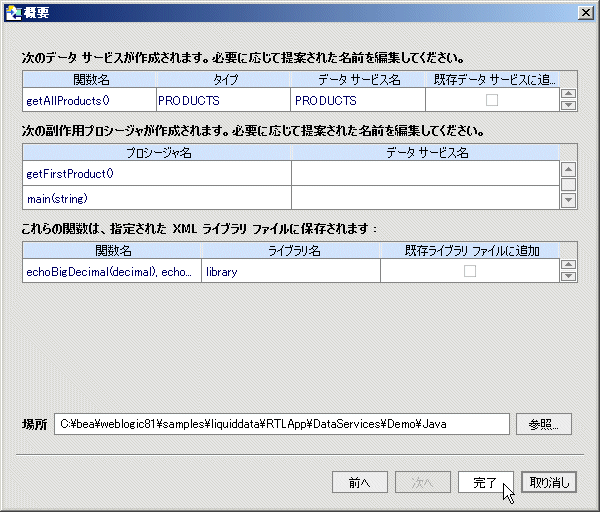
図 3-28 の概要画面では、次のことが行われています。
| 注意 : | 副作用プロシージャとして識別された Web サービス関数は、同じ WSDL に基づくデータ サービスと関連付けられている必要があります。 |
| 注意 : | それ自体に依存する (またはそれ自体を参照する) 1 つ以上のスキーマがある Web サービス オペレーションをインポートする場合、メタデータ インポート ウィザードは内部命名規約に従い、第 2 レベルのスキーマを作成します。 いくつかのオペレーションが同じ第 2 のスキーマを参照する場合、そのスキーマ用に生成された名前は、Web サービスを再インポートするか、または Web サービスと同期した場合には、変更されることがあります。 |
インターネット Web サービス URI でメタデータ インポート ウィザードをテストする場合、(本文書作成時点において) 下記のページでサンプル URI を提供しています。
http://www.strikeiron.com/BrowseMarketplace.aspx?c=14&m=1
単に、トピックを選択し、次のようなサンプル WSDL を示すページに移動します。
http://ws.strikeiron.com/SwanandMokashi/StockQuotes?WSDL
文字列を Web サービス URI フィールドにコピーし、[次へ] をクリックして、サンプル データ サービスまたはプロシージャに変換するオペレーションを選択します。
メタデータ インポートのテストに使用できるその他の外部 Web サービスは、下記の場所にあります。
http://www.whitemesa.net/wsdl/std/echoheadersvc.wsdl
AquaLogic Data Services Platform 用の Web サービスからメタデータをインポートする際、SOAP 要求および応答をインターセプトする SOAP ハンドラを作成できます。 ハンドラは、Web サービス メソッドが呼び出されたときに、呼び出されます。 コンフィグレーション ファイル内でシーケンスを定義することにより、特定のシーケンスにおいて次々と呼び出されるハンドラを連鎖させることができます。
ハンドラを作成して連鎖させるには、次の 2 つの手順に従います。
package WShandler;
import java.util.Iterator;
import javax.xml.rpc.handler.MessageContext;
import javax.xml.rpc.handler.soap.SOAPMessageContext;
import javax.xml.soap.SOAPElement;
import javax.xml.rpc.handler.HandlerInfo;
import javax.xml.rpc.handler.GenericHandler;
import javax.xml.namespace.QName;
/**
* Purpose: Log all messages to the Server console
*/
public class WShandler extends GenericHandler
{
HandlerInfo hinfo = null;
public void init (HandlerInfo hinfo) {
this.hinfo = hinfo;
System.out.println("*****************************");
System.out.println("ConsoleLoggingHandler r: init");
System.out.println(
"ConsoleLoggingHandler : init HandlerInfo" + hinfo.toString());
System.out.println("*****************************");
}
/**
* Handles incoming web service requests and outgoing callback requests
*/
public boolean handleRequest(MessageContext mc) {
logSoapMessage(mc, "handleRequest");
return true;
}
/**
* Handles outgoing web service responses and
* incoming callback responses
*/
public boolean handleResponse(MessageContext mc) {
this.logSoapMessage(mc, "handleResponse");
return true;
}
/**
* Handles SOAP Faults that may occur during message processing
*/
public boolean handleFault(MessageContext mc){
this.logSoapMessage(mc, "handleFault");
return true;
}
public QName[] getHeaders() {
QName [] qname = null;
return qname;
}
/**
* Log the message to the server console using System.out
*/
protected void logSoapMessage(MessageContext mc, String eventType){
try{
System.out.println("*****************************");
System.out.println("Event: "+eventType);
System.out.println("*****************************");
}
catch( Exception e ){
e.printStackTrace();
}
}
/**
* Get the method Name from a SOAP Payload.
*/
protected String getMethodName(MessageContext mc){
String operationName = null;
try{
SOAPMessageContext messageContext = (SOAPMessageContext) mc;
// オペレーション名が SOAP:Body 要素の後の最初の
// 要素であると仮定する
Iterator i = messageContext.
getMessage().getSOAPPart().getEnvelope().getBody().getChildElements();
while ( i.hasNext() )
{
Object obj = i.next();
if(obj instanceof SOAPElement)
{
SOAPElement e = (SOAPElement) obj;
operationName = e.getElementName().getLocalName();
break;
}
}
}
catch(Exception e){
e.printStackTrace();
}
return operationName;
}
}
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema targetNamespace="http://www.bea.com/2003/03/wlw/handler/config/" xmlns="http://www.bea.com/2003/03/wlw/handler/config/" xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" attributeFormDefault="unqualified">
<xs:element name="wlw-handler-config">
<xs:complexType>
<xs:sequence>
<xs:element name="handler-chain" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence minOccurs="0" maxOccurs="unbounded">
<xs:element name="handler">
<xs:complexType>
<xs:sequence>
<xs:element name="init-param"
minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="description"
type="xs:string" minOccurs="0"/>
<xs:element name="param-name" type="xs:string"/>
<xs:element name="param-value" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="soap-header"
type="xs:QName" minOccurs="0" maxOccurs="unbounded"/>
<xs:element name="soap-role"
type="xs:string" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="handler-name"
type="xs:string" use="optional"/>
<xs:attribute name="handler-class"
type="xs:string" use="required"/>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="name" type="xs:string" use="required"/>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
以下に、ハンドラ チェーン コンフィグレーションの例を示します。 このコンフィグレーションでは、2 つのチェーンがあります。 1 つは、LoggingHandler という名前です。 もう 1 つは、SampleHandler という名前です。 1 つ目のチェーンは、AuditHandler という名前の 1 つのハンドラを呼び出すのみです。 ハンドラ クラス属性により、ハンドラの完全修飾名が指定されます。
<?xml version="1.0"?>
<hc:wlw-handler-config name="sampleHandler" xmlns:hc="http://www.bea.com/2003/03/wlw/handler/config/">
<hc:handler-chain name="LoggingHandler">
<hc:handler
handler-name="handler1"handler-class="WShandler.AuditHandler"/>
</hc:handler-chain>
<hc:handler-chain name="SampleHandler">
<hc:handler
handler-name="TestHandler1" handler-class="WShandler.WShandler"/>
<hc:handler handler-name="TestHandler2"
handler-class="WShandler.WShandler"/>
</hc:handler-chain>
</hc:wlw-handler-config>
xquery version "1.0" encoding "WINDOWS-1252";
(::pragma xds <x:xds xmlns:x="urn:annotations.ld.bea.com"
targetType="t:echoStringArray_return"
xmlns:t="ld:SampleWS/echoStringArray_return">
<creationDate>2005-05-24T12:56:38</creationDate>
<webService targetNamespace=
"http://soapinterop.org/WSDLInteropTestRpcEnc"
wsdl="http://webservice.bea.com:7001/rpc/WSDLInteropTestRpcEncService?WSDL"/></x:xds>::)
declare namespace f1 = "ld:SampleWS/echoStringArray_return";
import schema namespace t1 = "ld:AnilExplainsWS/echoStringArray_return" at "ld:SampleWS/schemas/echoStringArray_param0.xsd";
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com" kind="read" nativeName="echoStringArray" nativeLevel1Container="WSDLInteropTestRpcEncService" nativeLevel2Container="WSDLInteropTestRpcEncPort" style="rpc">
<params>
<param nativeType="null"/>
</params>
<interceptorConfiguration aliasName="LoggingHandler" fileName="ld:SampleWS/handlerConfiguration.xml" />
</f:function>::)
declare function f1:echoStringArray($x1 as element(t1:echoStringArray_param0)) as schema-element(t1:echoStringArray_return) external;
<interceptorConfiguration aliasName="LoggingHandler" fileName="ld:testHandlerWS/handlerConfiguration.xml">
ここでは、呼び出されるハンドラ チェーンの名前が aliasName 属性で指定され、コンフィグレーション ファイルの場所を fileName 属性が指定しています。
カスタム Java 関数に基づくメタデータを作成できます。 メタデータ インポート ウィザードを使用して .class ファイル内を参照すると、メタデータは複合型と単純型の双方の周辺に作成されています。 複合型はデータ サービスになりますが、単純型の Java ルーチンは XQuery に変換されて、XQuery 関数ライブラリ (XFL) 内に置かれます。 ソース ビュー (「XQuery ソースの操作」を参照) では、Java クラス、要素など複合型の関数シグネチャおよび関連のスキーマ型を定義するプラグマが作成されます。
RTLApp DataServices/Demo ディレクトリに、Java 関数メタデータのインポートの説明に使用できるサンプルがあります。
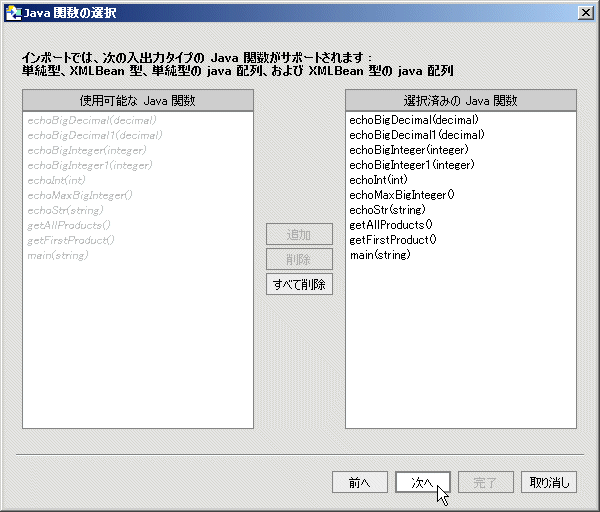
Java ファイルには、2 種類の関数を含めることができます。 これらについて、表 3-29 で説明します。
カスタム Java 関数に関するメタデータを作成する前に、スキーマおよび関数の情報を双方とも含む Java クラスを作成する必要があります。 詳細な例が、「Java 関数用の XMLBean サポートの作成」で説明されています。
Java 関数メタデータのインポートは、リレーショナル データ ソース メタデータのインポートに類似しています (「リレーショナル テーブルおよびビューのメタデータのインポート」を参照)。 Java 関数固有の必要な手順は、次のとおりです。
.java 関数から .class ファイルが作成され、アプリケーションのライブラリ内に置かれます。.class ファイルは、BEA WebLogic アプリケーション内に存在している必要があります。 ファイルの場所を参照するか、AquaLogic Data Services Platform ベースのプロジェクトのルート ディレクトリから始まる完全修飾されたパス名を入力できます。
独立したルーチンを、データ サービスを介してのエンタープライズ情報管理の一部として活用すると、役立つことがよくあります。 分かりやすい例としては、スタンドアロンの更新またはセキュリティ関数の、データ サービスを介した活用が挙げられます。 そのような関数は、noXML 型です。実際、通常は何も返しません (または、void を返します)。 その代わり、データ サービスではそのルーチンに副作用があることが分かっています。しかし、この副作用はサービスに対して透過的ではありません。 AquaLogic Data Services Platform プロシージャはまた、副作用関数として捉えることもできます。
Java 関数は、データに対して内部処理を行う場合、データ サービス側から見ると、「副作用」関数です。
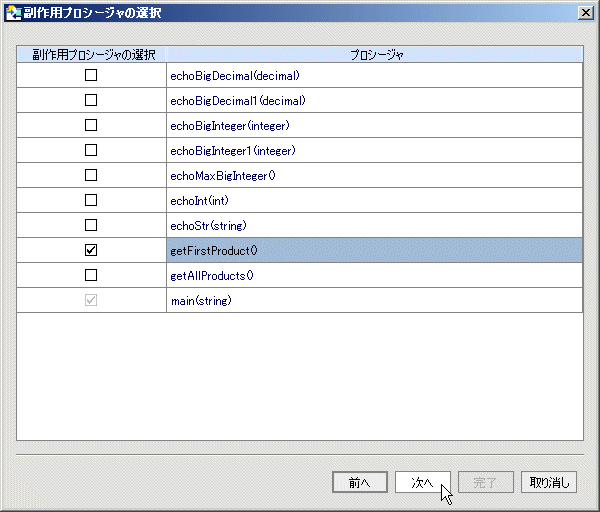
プロジェクトに追加する Java 関数を識別した後は、これらの中に AquaLogic Data Services Platform プロシージャとして処理するものがあれば、それを識別できます (図 3-33)。 main() の場合、メタデータ インポート ウィザードはこれが void を返すことを検出しているため、すでにプロシージャとしてマークされています。
| 注意 : | 副作用プロシージャは、同じデータ ソースからのデータ サービスと関連付けられている必要があります。 この場合、ソースは Java ファイルです。 つまり、Java 関数をプロシージャとして指定するには、複合要素を返す同じファイル内の関数を同時に作成する、またはこれがプロジェクト内にすでに存在している必要があります。 |
提案されたデータ サービス名は、明確化のために、あるいは既存のデータ サービスまたは予定されているデータ サービスとの衝突を回避するために、編集することができます。 複合データ型を返すすべての関数が、同じデータ サービス内に置かれます。 提案されたデータ サービス名をクリックして変更します。
プロシージャは、同じデータ ソース (Java ファイル) からデータを引き出すデータ サービスと関連付けられている必要があります。 図 3-34 に示すサンプルでは、唯一の使用可能なデータ サービスは PRODUCTS (または、任意に選択した名前) です。
プロジェクト内に既存の XFL ファイルがある場合は、そのライブラリに最小関数を追加するか、それらの関数のために新しいライブラリを作成するかの選択肢があります。 すべての Java ファイル最小関数は、同じライブラリ内に置かれます。
Java 関数メタデータをインポートできるようになるには、その前にグローバル要素および Java 関数のコンパイル済みバージョンに基づく XMLBean クラスが含まれた .class ファイルを作成する必要があります。 そのためには、まずデータのスキーマに基づく XMLBean クラスを作成します。 これを実現するには、いくつかの方法があります。 この節の例では、スキーマ型の WebLogic Workshop プロジェクトを作成します。
.xsd ファイル) のインポート。.class ファイルの作成 (AquaLogic Data Services Platform ベースのプロジェクトの場合)、または Java プロジェクトからアプリケーションのライブラリ フォルダへの JAR ファイルの追加。.class ファイルに基づくデータ サービスのメタデータの作成。
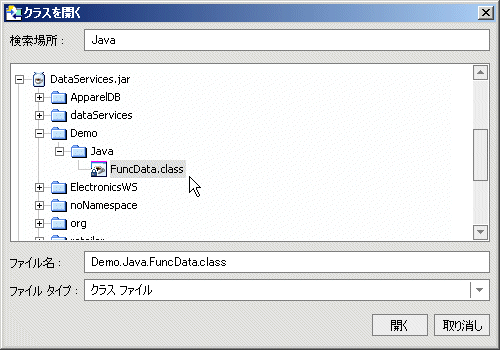
次の例では、FuncData.java という .java ファイルに、いくつかのカスタム関数があります。 RTLApp では、このファイルは下記の場所に置かれています。
ld:DataServices/Demo/Java/FuncData.java
このファイルの一部の関数はプリミティブ データ型を返し、その他の関数は複合要素を返します (表 3-35)。 参照されるデータを表す複合要素は、FuncData.xsd というスキーマ ファイル内にあります。
ld:DataServices/Demo/Java/schema/FuncData.xsd
このサンプルを簡素化するため、.java ファイル内に、小さいデータ セットが文字列として含まれています。
以下の手順により、FuncData.java 内の Java 関数からデータ サービスが作成されます。
FuncData.xsd を選択します。
スキーマ プロジェクトにスキーマ ファイルをインポートすると、プロジェクト ビルド プロセスが自動的に開始されます。
正常に完了すると、Java ファイル内の各関数に対して XMLBean クラスが作成され、JavaFunctSchema.jar という JAR ファイル内に入れられます。
JAR ファイルは、アプリケーションのライブラリ セクションにあります。
ld:DataServices/Demo/Java フォルダを参照して、インポート対象として FuncData.java を選択します。 [インポート] をクリックします。
AquaLogic Data Services Platform ベースのプロジェクト用に名前を付けられた JAR ファイルが、FuncData.class という名前の .class ファイルを含むように更新されます。メタデータ インポート ウィザードで参照できるのは、このファイルです。 このファイルは、アプリケーションのライブラリ セクション内の JavaFuncMetadata というフォルダにあります。
この例で使用される .java ファイルには、関数とデータの双方が含まれています。 さらに多くの場合、ルーチンは、データ インポート関数を介してデータにアクセスします。
コード リスト 3-4 の最初の関数は単に、PRODUCTS の配列内の最初の要素を取得するだけのものです。 2 番目の関数は、配列全体を返します。
public class JavaFunc {
...
public static noNamespace.PRODUCTSDocument.PRODUCTS getFirstProduct(){
noNamespace.PRODUCTSDocument.PRODUCTS products = null;
try{
noNamespace.DbDocument dbDoc = noNamespace.DbDocument.Factory.parse(testCustomer);
products = dbDoc.getDb().getPRODUCTSArray(1);
// products を返す
}catch(Exception e){
e.printStackTrace();
}
return products;
}
public static noNamespace.PRODUCTSDocument.PRODUCTS[] getAllProducts(){
noNamespace.PRODUCTSDocument.PRODUCTS[] products = null;
try{
noNamespace.DbDocument dbDoc = noNamespace.DbDocument.Factory.parse(testCustomer);
products = dbDoc.getDb().getPRODUCTSArray();
// products を返す
}catch(Exception e){
e.printStackTrace();
}
return products;
}
}
XMLBean の作成に使用されるスキーマを、コード リスト 3-5 に示します。 これは単に、複合要素の構造をモデル化するものです。最初にデータを直接参照することで得られていることもあります。
<xs:schema elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="db">
<xs:complexType>
<xs:sequence>
<xs:element ref="PRODUCTS" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="AVERAGE_SERVICE_COST" type="xs:decimal"/>
<xs:element name="LIST_PRICE" type="xs:decimal"/>
<xs:element name="MANUFACTURER" type="xs:string"/>
<xs:element name="PRODUCTS">
<xs:complexType>
<xs:sequence>
<xs:element ref="PRODUCT_NAME"/>
<xs:element ref="MANUFACTURER"/>
<xs:element ref="LIST_PRICE"/>
<xs:element ref="PRODUCT_DESCRIPTION"/>
<xs:element ref="AVERAGE_SERVICE_COST"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="PRODUCT_DESCRIPTION" type="xs:string"/>
<xs:element name="PRODUCT_NAME" type="xs:string"/>
</xs:schema>
Java 関数では、返された要素 (戻り値のシグネチャで指定されている) が、有効な XML ドキュメントから得られることを必要としています。 有効な XML ドキュメントには、0 または 1 以上の子を持つ単一のルート要素があり、そのコンテンツは、参照されるスキーマに一致しています。
public static noNamespace.PRODUCTSDocument.PRODUCTS getNextProduct(){
// dbDocument (ルート) を作成する
noNamespace.DbDocument dbDoc = noNamespace.DbDocument.Factory.newInstance();
// そこからの db 要素
noNamespace.DbDocument.Db db = dbDoc.addNewDb();
// PRODUCTS 要素を取得する
PRODUCTS product = db.addNewPRODUCTS();
//.. 子を作成する
product.setPRODUCTNAME("productName");
product.setMANUFACTURER("Manufacturer");
product.setLISTPRICE(BigDecimal.valueOf((long)12.22));
product.setPRODUCTDESCRIPTION("Product Description");
product.setAVERAGESERVICECOST(BigDecimal.valueOf((long)122.22));
// .. db の子を更新する
db.setPRODUCTSArray(0,product);
// .. db でドキュメントを更新する
dbDoc.setDb(db);
//.. これで dbDoc は db のある有効なドキュメントであり、かつ子である
// db の子である PRODUCTS が作業対象である
// したがって常に子を処理する前に有効なドキュメントを作成
すること
// 単に子要素を作成して返すだけでは、ドキュメントが
// 有効であるということにはならないため、不十分である
// 子は、グローバル要素のために作成された有効な
// ドキュメントから得られたものであることが必要である
return dbDoc.getDb().getPRODUCTSArray(0);
}
AquaLogic Data Services Platform では、ユーザ定義関数は通常、Java クラスです。 以下のものがサポートされます。
この機能をサポートするため、メタデータ インポート ウィザードでは、Java におけるトークン イテレータが XML に、また XML がトークン イテレータに変換されるよう、マーシャリングとマーシャリング解除をサポートしています。
作成する関数は、静的 Java 関数として定義される必要があります。 XQuery で使用される場合の Java メソッド名は、ネームスペースで修飾された XQuery 関数名となります。
表 3-37 に、単純 Java 型、スキーマ型、および XQuery 型に関するキャスト アルゴリズムを示します。
Java 関数はまた、XMLBean からスキーマを処理することによって生成される XMLBean 型の変数も消費します。 XMLBean によって生成されるクラスは、Java 関数ではパラメータまたは戻り値型として参照されます。
スキーマ内で参照される要素または型は、グローバル要素とする必要があります。これらだけが XMLBean の中で静的な解析メソッドを定義されている型であるためです。
次の節では、メタデータ インポート ウィザードが Java 関数をどのように使用してデータ サービスを作成するかを説明する、追加のコード サンプルを示します。
データ サービスまたは XQuery 関数ライブラリのメンバーを作成するには、まず Java 関数の定義から始めます。
たとえば、Java 関数 getListGivenMixed( ) は、次のように定義できます。
public static float[ ] getListGivenMixed(float[ ] fpList, int size) {
int listLen = ((fpList.length > size) ? size : fpList.length);
float fpListop = new float[listLen];
for (int i =0; i < listLen; i++)
fpListop[i]=fpList[i];
return fpListop;
}
関数がウィザードで処理された後は、次のメタデータ情報が作成されます。
xquery version "1.0" encoding "WINDOWS-1252";
(::pragma xfl <x:xfl xmlns:x="urn:annotations.ld.bea.com">
<creationDate>2005-06-01T14:25:50</creationDate>
<javaFunction class="DocTest"/>
</x:xfl>::)
declare namespace f1 = "lib:testdoc/library";
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com" nativeName="getListGivenMixed">
<params>
<param nativeType="[F"/>
<param nativeType="int"/>
</params>
</f:function>::)
declare function f1:getListGivenMixed($x1 as xsd:float*, $x2 as xsd:int) as xsd:float* external;
上記の関数を実行するための対応する XQuery は、次のとおりです。
declare namespace f1 = "ld:javaFunc/float";
let $y := (2.0, 4.0, 6.0, 8.0, 10.0)
let $x := f1:getListGivenMixed($y, 2)
return $x
以下に示すように、Customer というスキーマ (customer.xsd) があると考えます。
<?xml version="1.0" encoding="UTF-8" ?>
<xs:schema targetNamespace="ld:xml/cust:/BEA_BB10000" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="CUSTOMER">
<xs:complexType>
<xs:sequence>
<xs:element name="FIRST_NAME" type="xs:string" minOccurs="1"/>
<xs:element name="LAST_NAME" type="xs:string" minOccurs="1"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
CUSTOMER 要素に準拠するリストを生成する場合は、XMLBean 経由でスキーマを処理し、xml.cust.beaBB10000.CUSTOMERDocument.CUSTOMER を得られます。 これで、以下のように CUSTOMER 要素を使用できるようになりました。
public static xml.cust.beaBB10000.CUSTOMERDocument.CUSTOMER[]
getCustomerListGivenCustomerList(
xml.cust.beaBB10000.CUSTOMERDocument.CUSTOMER[] ipListOfCust)
throws XmlException {
xml.cust.beaBB10000.CUSTOMERDocument.CUSTOMER [] mylocalver =
ipListOfCust;
return mylocalver;
}
その後、ウィザードによって生成されるメタデータ情報は、以下のようになります。
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com" kind="datasource" access="public">
<params>
<param nativeType="[Lxml.cust.beaBB10000.CUSTOMERDocument$CUSTOMER;"/>
</params>
</f:function>::)
declare function f1:getCustomerListGivenCustomerList($x1 as element(t1:CUSTOMER)*) as element(t1:CUSTOMER)* external;
上記の関数を実行するための対応する XQuery は、次のとおりです。
declare namespace f1 = "ld:javaFunc/CUSTOMER";
let $z := (
validate(<n:CUSTOMER xmlns:n="ld:xml/cust:/BEA_BB10000"><FIRST_NAME>John2</FIRST_NAME><LAST_NAME>Smith2</LAST_NAME>
</n:CUSTOMER>),
validate(<n:CUSTOMER xmlns:n="ld:xml/cust:/BEA_BB10000"><FIRST_NAME>John2</FIRST_NAME><LAST_NAME>Smith2</LAST_NAME>
</n:CUSTOMER>),
validate(<n:CUSTOMER xmlns:n="ld:xml/cust:/BEA_BB10000"><FIRST_NAME>John2</FIRST_NAME><LAST_NAME>Smith2</LAST_NAME>
</n:CUSTOMER>),
validate(<n:CUSTOMER xmlns:n="ld:xml/cust:/BEA_BB10000"><FIRST_NAME>John2</FIRST_NAME><LAST_NAME>Smith2</LAST_NAME>
</n:CUSTOMER>))
for $zz in $z
return
f1:getCustomerListGivenCustomerList($z)
スプレッドシートは、情報 (特に迅速に変更する必要がある情報) を格納および操作するための非常に適応させやすい手段となります。 そのようなスプレッドシート データは、容易にデータ サービスにできます。
スプレッドシート ドキュメントは、多くの場合、カンマ区切り値 (comma-separated values) を意味する CSV ファイルとして言及されています。 CSV はスプレッドシートとして一般的な本来の形式ではありませんが、スプレッドシートを CSV ファイルとして保存する機能は、ほぼ世界標準となっています。
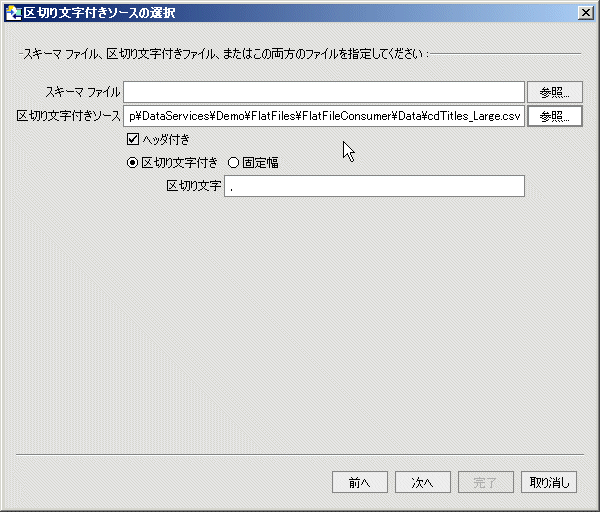
セパレータ フィールドは多くの場合、カンマですが、メタデータ インポート ウィザードでは固定長フィールドと共に、任意の ASCII 文字をセパレータとしてサポートしています。
| 注意 : | 1 つのサーバの文字区切り形式ファイルは、同一のエンコーディング形式を共有している必要があります。 このエンコーディングは、システム プロパティ ld.csv.encoding を使って指定し、JVM コマンドラインで直接、または startWebLogic.cmd (Windows) や startWebLogic.sh (UNIX) などのスクリプトを使って設定できます。 |
| 注意 : | このコマンドの形式は次のとおりです。 |
-Dld.csv.encoding=<encoding format>
ld.csv.encoding で形式が指定されていない場合は、file.encoding システム プロパティで指定された形式が使用されます。
RTLApp DataServices/Demo ディレクトリに、文字区切り形式ファイルのメタデータのインポートの説明に使用できるサンプルがあります。

文字区切り形式の情報に関するメタデータの作成には、必要に応じて、およびソースの性質に応じて、いくつかの方法があります。
| 注意 : | 生成されたスキーマには、ソース ファイルの名前が付きます。 |
XML ファイル情報のインポートは、リレーショナル データ ソース メタデータのインポートに類似しています (「リレーショナル テーブルおよびビューのメタデータのインポート」を参照)。 必要な手順は、次のとおりです。
file:///
たとえば、Windows システムの場合、以下の URI を使用して、ルート C: ディレクトリから Orders.xml などの XML ファイルにアクセスできます。
file:///<c:/home>/Orders.csv
UNIX システムの場合、以下の URI でそのようなファイルにアクセスします。
file:///<home>/Orders.csv
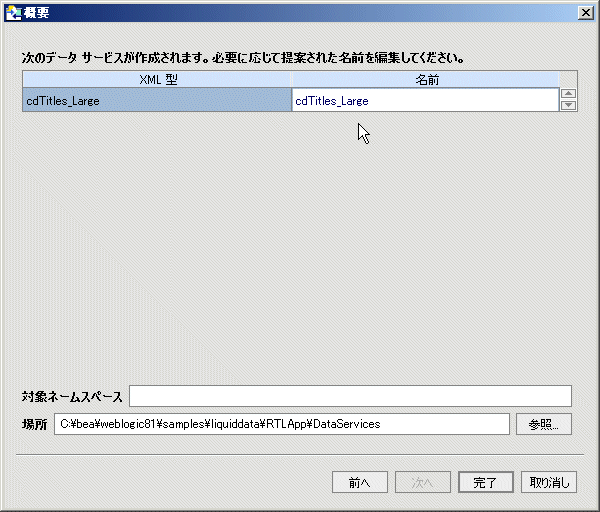
データ サービス名は、明確化のために、あるいは既存のデータ サービスまたは予定されているデータ サービスとの衝突を回避するために、編集することができます。 名前の衝突がある場合は、赤色で表示されています。 名前を変更するには、データ サービス名をダブルクリックして、ライン エディタをアクティブ化します。
.ds ファイル) が作成されます。 | 注意 : | CSV タイプのデータをインポートする際、いくつか留意すべき点があります。 |
XML ファイルは、階層的なデータを処理する便利な手段です。 XML ファイル、および関連のスキーマは、容易にデータ サービスにすることができます。
XML ファイル情報のインポートは、リレーショナル データ ソース メタデータのインポートに類似しています (「リレーショナル テーブルおよびビューのメタデータのインポート」を参照)。
メタデータ インポート ウィザードを使用すると、アプリケーション内の任意の場所にある XML ファイルを参照できます。 また、先頭に以下の文字列を付加した絶対パスを使用して、システム上の任意の XML ファイルからデータをインポートすることもできます。
file:///
たとえば、Windows システムの場合、以下の URI を使用して、ルート C: ディレクトリから Orders.xml などの XML ファイルにアクセスできます。
file:///c:/Orders.xml
UNIX システムの場合、以下の URI でそのようなファイルにアクセスします。
file:///home/Orders.xml
RTLApp DataServices/Demo ディレクトリに、XML ファイルのメタデータのインポートの説明に使用できるサンプルがあります。
データ サービス名は、明確化のために、あるいは既存のデータ サービスまたは予定されているデータ サービスとの衝突を回避するために、編集することができます。 衝突は、赤色で示されています。 単純にデータ サービス名をクリックして、名前を変更します。 [次へ] をクリックします。
XML データ ソースのメタデータを作成したが、データ ソース名を指定しなかった場合、データ サービスの読み取り関数を実行する際に、パラメータとしてデータ ソースの URI を識別する必要があります (データ サービス関数への各種アクセス方法の詳細については、『クライアント アプリケーション開発者ガイド』を参照)。
<uri>/path/filename.xml
ここで、uri はパスまたはパスのエリアスを表し、path はディレクトリを表し、filename.xml はファイル名を表します。 拡張子 .xml が必要です。
次の文字列を先頭に付加した絶対パスを使用して、ファイルにアクセスすることができます。
file:///
たとえば、Windows システムの場合、以下の URI を使用して、ルート C: ディレクトリから Orders.xml などの XML ファイルにアクセスできます。
file:///c:/Orders.xml
UNIX システムの場合、以下の URI でそのようなファイルにアクセスします。
file:///home/Orders.xml
図 3-45 では、XML ソース ファイルへの参照方法を示します。
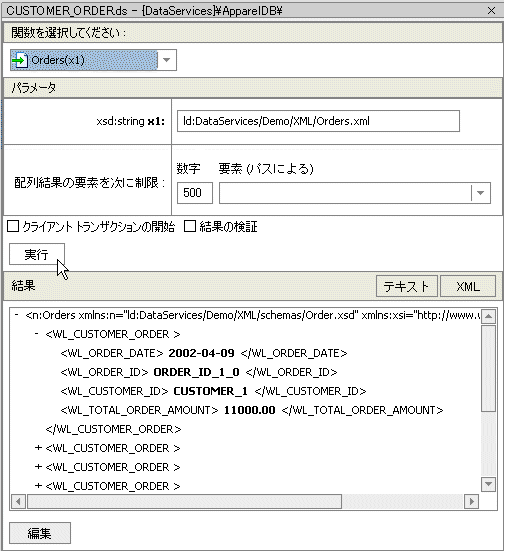
最初に物理データ サービスを作成するときには、その基底となるメタデータは定義上、そのデータ ソースと整合しています。 しかし時間の経過と共に、次のようないくつかの理由により、メタデータは「同期がずれて」しまう場合があります。
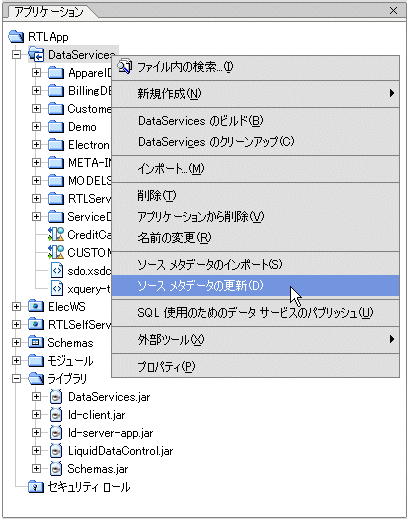
[ソース メタデータの更新] 右クリック メニュー オプションを使用して、ソース メタデータ ファイルとソース データ構造の間の、以下のような相違点を識別できます。
使用できないソースがある場合、この問題はおそらく、接続またはパーミッションに関連しています。 その他の種類の報告については、基底のデータ ソースに準拠するようデータ ソースのメタデータを更新すべきかどうかをユーザ側で判断できます。
メタデータと基底のソースの間に差がない場合、ソース メタデータ更新ウィザードは、テストされた各データ サービスについての最新情報を報告します。
ソース メタデータの更新には、注意が必要です。なぜなら、この操作には、直接的な影響と間接的な影響の双方が伴う場合があるからです。 たとえば、2 つの物理データ サービス間の関係を追加していた場合、ソース メタデータを更新すると、双方のデータ サービスからその関係を削除してしまうことになりかねません。 モデル ダイアグラム内にその関係が表示される場合、その関係の線は、現在はもうその関係がそれぞれのデータ サービスで記述されていないことを示す赤色で表示されます。
多くの場合、ソース メタデータ更新ウィザードは、ユーザによる変更を、更新されたメタデータと自動的に結合できます。 詳細については、「ソース メタデータ更新ウィザードの使用」を参照してください。
直接的な影響は、物理データ サービスに適用されます。 間接的な影響は、論理データ サービスに生じます。なぜなら、このようなサービスは、最終的にはそれ自体が (少なくとも部分的には) 物理データ サービスに基づいているからです。 たとえば、物理データ サービスと論理データ サービスの間に新しい関係を作成した場合、物理データ サービスを更新すると、その関係が無効になってしまうかもしれません。 物理データ サービスの場合は、関係の参照はありません。 論理データ サービスは、関係を記述したコードを保持しますが、対になる関係表記が存在しなくなっていれば、無効になります。
したがって、ソース メタデータの更新を行う際には、注意が必要です。 開発努力を無駄にせず、かつメタデータを最新のものに保ち続けられるようにしておくため、いくつかの予防手段が設けられています。 ソース更新の一環として、現在のメタデータがどのように保存されているかについては、「ソース メタデータのアーカイバル」を参照してください。
ソース メタデータ更新ウィザードを使用すると、ソース メタデータを更新できます。
| 注意 : | ソース メタデータの更新を試行する前に、ビルド プロジェクトにエラーがないことを確認する必要があります。 |
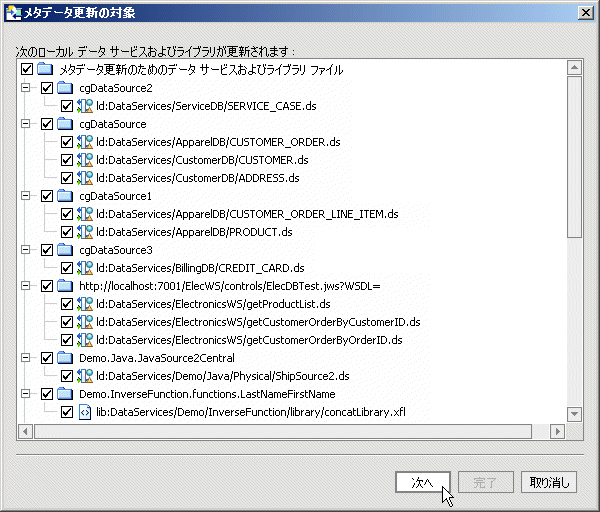
AquaLogic Data Services Platform ベースのプロジェクトの 1 つまたは複数の物理データ サービスに対し、メタデータの更新を実行することで、データ構造を確実に最新のものとすることができます。 たとえば、図 3-46 ではプロジェクト内のすべての物理データ サービスが更新されます。
対象を選択後、ウィザードは確認されるメタデータ、およびメタデータと基底のソースの間のすべての相違点を識別します。
ダイアログ内に表示されている任意のデータ サービスまたは XFL ファイルを、その名前の左にあるチェック ボックスを使用して、選択または選択解除できます (図 3-47)。
次に、ウィザードによってメタデータに対し、分析が行われます。 以下に示すタイプの同期化の不一致が識別されます。
これらの相違点の全般的な説明とフィールド レベルのデータに関する説明の双方を行う、更新プレビュー画面のレポート (図 3-48) が用意されています。
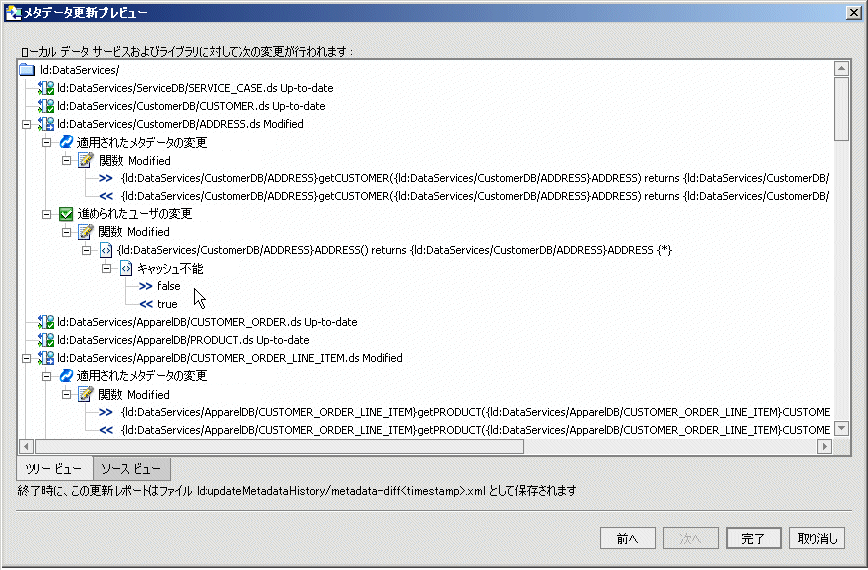
[メタデータ更新ブレビュー] 画面では、以下のものが識別されます。
アイコンにより、追加された要素、削除された要素、変更された要素が区別されています。表 3-49 で、ソース メタデータ更新メッセージの種類と色凡例について説明します。
状況によっては、ソース メタデータ更新ウィザードは、実際には変更が行われていない場合に、ローカルで変更されたものとしてデータ サービス アーティファクトにフラグを付けることがあります。
たとえば、Web サービス オペレーションのインポートの場合、別のスキーマによって依存される (または参照される) スキーマに、内部生成されたファイル名が割り当てられます。 プロジェクト内の 2 番目にインポートされた Web サービス オペレーションが同じ依存スキーマを参照する場合、ウィザードは同期化時に、インポートされる 2 次スキーマ ファイルの名前が変更されたことを指摘するかもしれません。 そのまま同期化を続行してください。古い第 2 レベルのスキーマは、自動的に削除されます。
ソース メタデータを更新する際には、2 つのファイルが作成されて、アプリケーション内の特別なディレクトリに格納されます。
メタデータ ソース更新操作により、生成されたファイルの双方に、同じタイムスタンプが割り当てられます。
特定の更新操作のレポートおよびソースによる作業をしていると、多くの場合、関係やその他のメタデータに対して加えられる変更を迅速に復元できる一方で、メタデータを確実に最新のものとしておけます。
 
|