
|
|
BEA Aqualogic Data Services Platform に対応したプロジェクトは、2 通りの方法で WebLogic Workshop に追加できます。
WebLogic Workshop に関連した基本のメニュー、共通の動作、およびルック アンド フィールが AquaLogic Data Services Platform に適用されます。WebLogic Workshop の詳細については、以下を参照してください。
前述のように、AquaLogic Data Services Platform プロジェクトが自動的に含まれた WebLogic Workshop アプリケーションを作成できます。または、任意の BEA WebLogic アプリケーションに AquaLogic Data Services Platform プロジェクトを追加できます。
| 注意 : | 多くの場合、AquaLogic Data Services Platform クエリは、AquaLogic Data Services Platform の開発専用の WebLogic Workshop アプリケーションにまとめるのが適しています。その場合、他のアプリケーションは DSP Mediator API または AquaLogic Data Services Platform コントロールを通じてクエリにアクセスできます。クライアント アプリケーションから AquaLogic Data Services Platform の関数およびプロシージャにアクセスする方法の詳細については、『クライアント アプリケーション開発者ガイド』を参照してください。 |
AquaLogic Data Services Platform をアプリケーションで使用できるかどうか、または実行中のバージョンを確認するには、BEA WebLogic Server を起動して Administration Console にアクセスします。
例として、BEA WebLogic で提供しているサンプル ドメインの WebLogic Server Administration Console には、次の URL からアクセスできます。
http://localhost:7001/console[コンソール|バージョン] ページに移動して ([コンソール] は一番上のメニュー項目)、AquaLogic Data Services Platform のバージョン番号と作成日を見つけます。
AquaLogic Data Services Platform ベースのアプリケーションを作成するには、WebLogic Workshop メニューから [ファイル|新規作成|アプリケーション] を選択します。ダイアログが表示されたら、[Data Services Application] を選択します (図 2-1)。
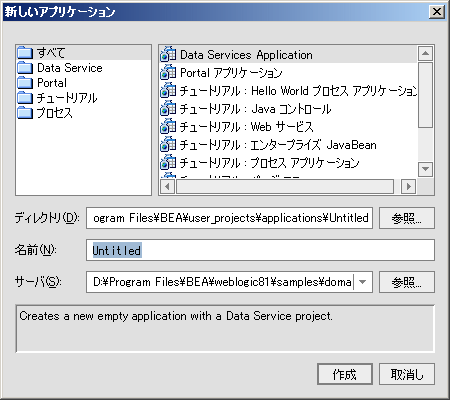
アプリケーションの名前は「Untitled」から別の名前に変更することができます。新しいアプリケーションには初期の AquaLogic Data Services Platform プロジェクトが自動的に含まれています。
[ファイル|保存]、[ファイル|名前をつけて保存]、または [ファイル|すべて保存] コマンドを使用して、アプリケーションをいつでも保存できます。[すべて保存] はアプリケーションで変更されたファイルをすべて保存します。
たとえば「myLD」という名前で WebLogic Workshop アプリケーションを最初に作成すると、アプリケーションのルート ディレクトリに myLD.work というファイルが作成されます。このファイルを使用して Workshop を呼び出すと、アプリケーションも開かれます。
アプリケーションには AquaLogic Data Services Platform や他のタイプの WebLogic Workshop プロジェクトをいくつでも含めることができます。
1 つまたは複数の AquaLogic Data Services Platform プロジェクトを任意の WebLogic Workshop アプリケーションに追加することもできます。
それには、[ファイル|新規作成|プロジェクト] を選択します。プロジェクト作成ダイアログが表示されたら、[Data Service Project] を選択します。
新しい AquaLogic Data Services Platform アプリケーションまたはプロジェクトを作成すると、AquaLogic Data Services Platform プロジェクト フォルダも作成されます。これがプロジェクトのルート ディレクトリになります (図 2-3 を参照)。ld-server-app.jar と mediator.jar の 2 つの Java アーカイブ (.jar) ファイルがアプリケーションのライブラリ フォルダに追加されます。後者のファイルは、サービス データ オブジェクト (SDO) の作成を管理します。詳細については、『クライアント アプリケーション開発者ガイド』を参照してください。
表 2-4 に、主な AquaLogic Data Services Platform のファイル タイプとその目的を示します。
|
|||
schemas プロジェクト内に置かれる。
|
|||
AquaLogic Data Services Platform プロジェクトで使用されるその他のファイルには、カスタム更新ロジックを含む Java ファイルや、sdo.xsdconfig のような SDO コンフィグレーション ファイル (XMLBean 技術で XMLBean ではなく SDO を作成できるようにする) などがあります。
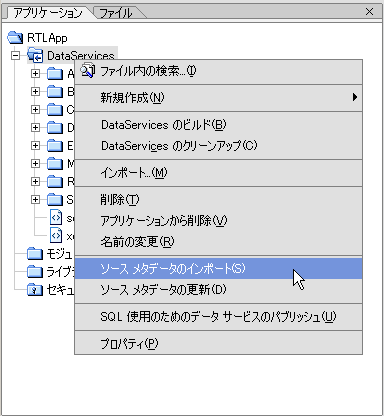
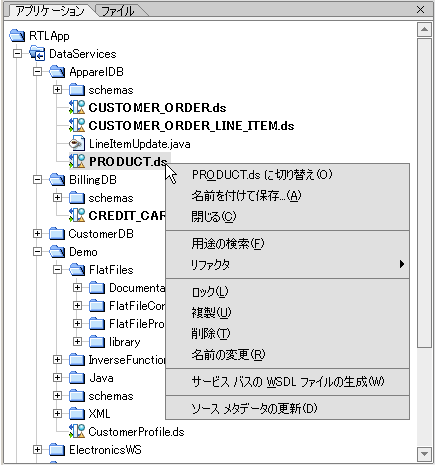
AquaLogic Data Services Platform では、標準の WebLogic Workshop プロジェクトの右クリック メニューにいくつかのオプションが追加されています (図 2-5)。
![新しい AquaLogic Data Services Platform アプリケーションの [アプリケーション] タブ](wwimages/proj_rt_click_menu_options1.gif)
次の表では、プロジェクトの右クリック メニューに追加された AquaLogic Data Services Platform の機能について説明します。
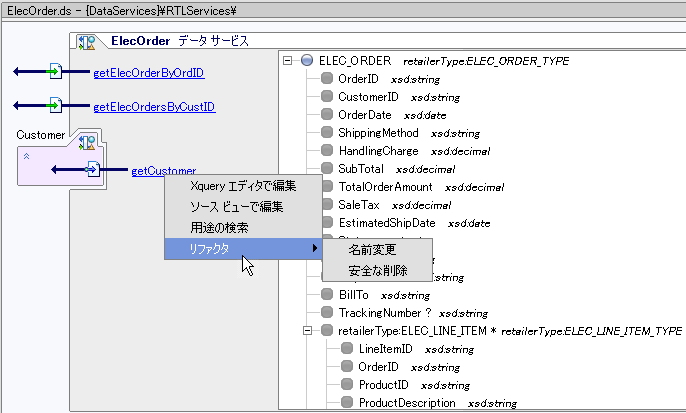
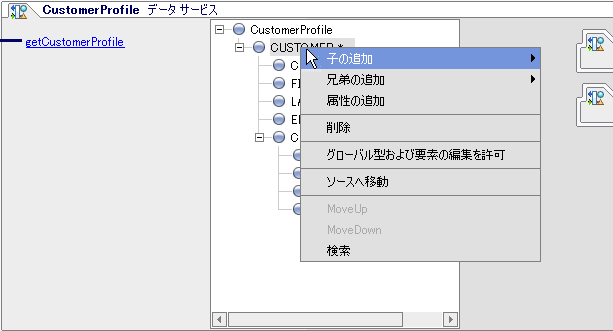
AquaLogic Data Services Platform では、データ サービスに関連付けられた右クリック メニューにいくつかのオプションが追加されています(図 2-7)。
次の表では、標準の右クリック メニュー オプションに追加された AquaLogic Data Services Platform の機能について説明します。
WebLogic Workshop はオンライン ドキュメントおよび印刷用ドキュメントで詳細に説明されています。最初に次のページを参照してください。
または、WebLogic Workshop には完全なオンライン ヘルプが用意されています。
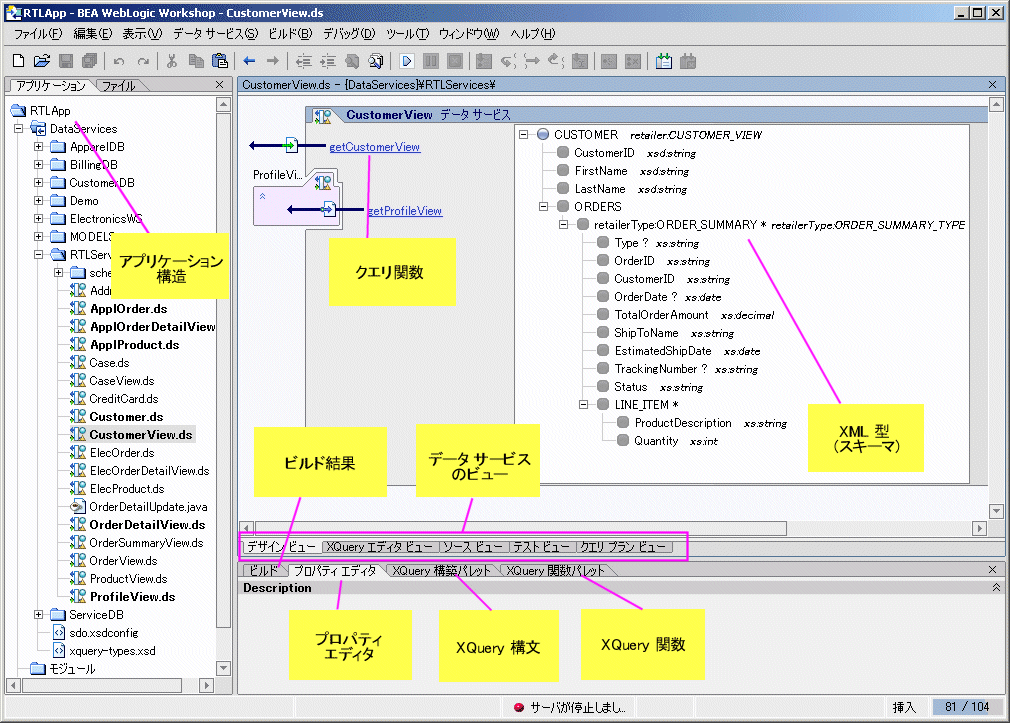
表 2-10 では、以下について簡単に説明します。
表 2-11 では、AquaLogic Data Services Platform プロジェクトでよく使用される WebLogic Workshop メニュー コマンドについて説明します。
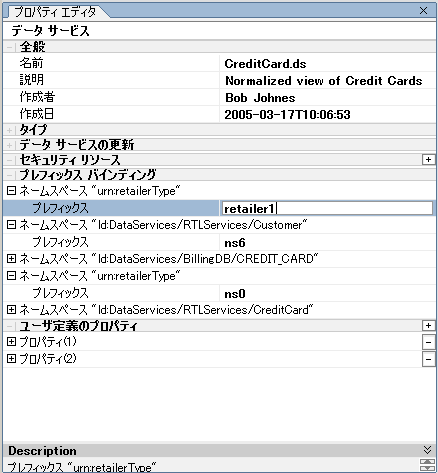
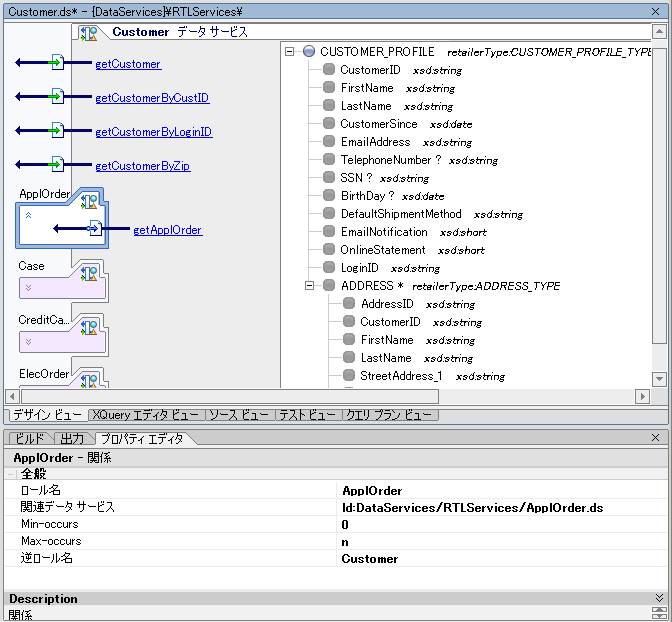
プロパティ エディタを使用して、WebLogic Workshop アーティファクトに関連する詳細を表示することができます (図 2-12 を参照)。たとえば、デザイン ビュー (「デザイン ビュー」) で一般的なデータ サービスをクリックすると、プロパティ エディタにはそのサービスの詳細が表示されます。データ サービス内の関係表現をクリックすると、その関係についてのプロパティの詳細が表示されます。ほとんどの場合、プロパティ設定は編集やコンフィグレーションが可能です。
WebLogic Workshop には、[編集] メニューから使用できる [ファイル内の検索] オプションによる包括的なファイル検索機能があります ([編集|ファイル内の検索])。
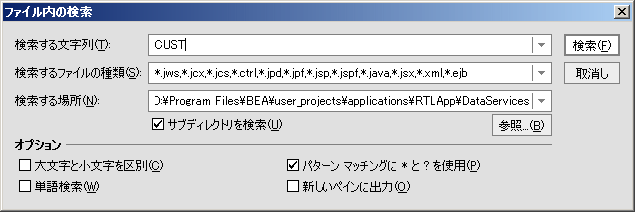
[ファイル内を検索] を使用すると、特定のデータ ソースや関数の使用など、任意の AquaLogic Data Services Platform アーティファクトの参照を検索することができます。
AquaLogic Data Services Platform プロジェクトでは、以下の機能をサポートするために、基本の WebLogic Workshop 環境にメニュー項目とビューが追加されています。
データ サービスは、AquaLogic Data Services Platform クエリで使用できるデータ モデルや物理および論理データ ビューの作成の中心となるものです。データ サービス作成の最初の手順は、対応する物理データ サービスを作成できるように、物理データ ソースからメタデータをインポートすることです。
AquaLogic Data Services Platform プロジェクトへのメタデータのインポートとメタデータの更新の詳細については、「エンタープライズ メタデータの取得」を参照してください。
データ モデル インタフェースを通じて、以下の操作を行うことができます。
データ モデルの開発と管理の詳細については、「データ サービスのモデル化」を参照してください。
各データ サービスには、デザイン ビュー、XQuery エディタ ビュー、ソース ビュー、テスト ビュー、クエリ プラン ビューがあります。各データ サービスは 1 つの XQuery ソース ファイルに基づいています。どのデータ サービスにも XML 型 (XDS ファイル) が関連付けられています。
データ サービスは読み取り関数およびナビゲーション関数とプロシージャで構成されています。読み取り関数はデータ サービスの XML 型を返す必要があります。ナビゲーション関数はネイティブ データ サービスの XML 型を返します。プロシージャは副次的な関数とも呼ばれ、何も返す必要はありません。
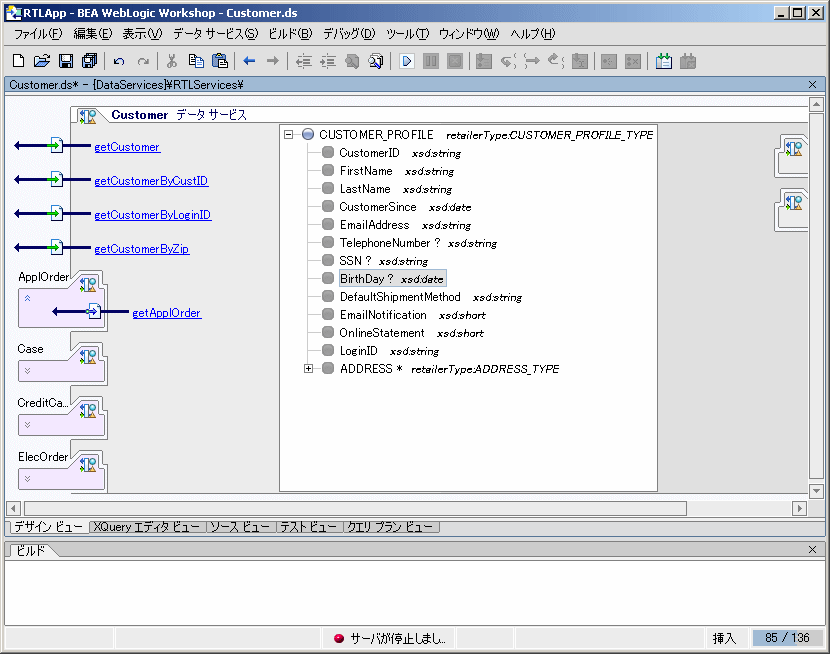
デザイン ビューはすべてのデータ サービスの中心的な参照基準となります。デザイン ビューから以下の操作を行うことができます。
データ サービスの開発と管理の詳細については、「データ サービスの設計」を参照してください。
XQuery エディタ ビューでは、変換と同様に、データ サービス関数の要素を関数の戻り値型に反映させることにより、クエリ関数を開発できます。
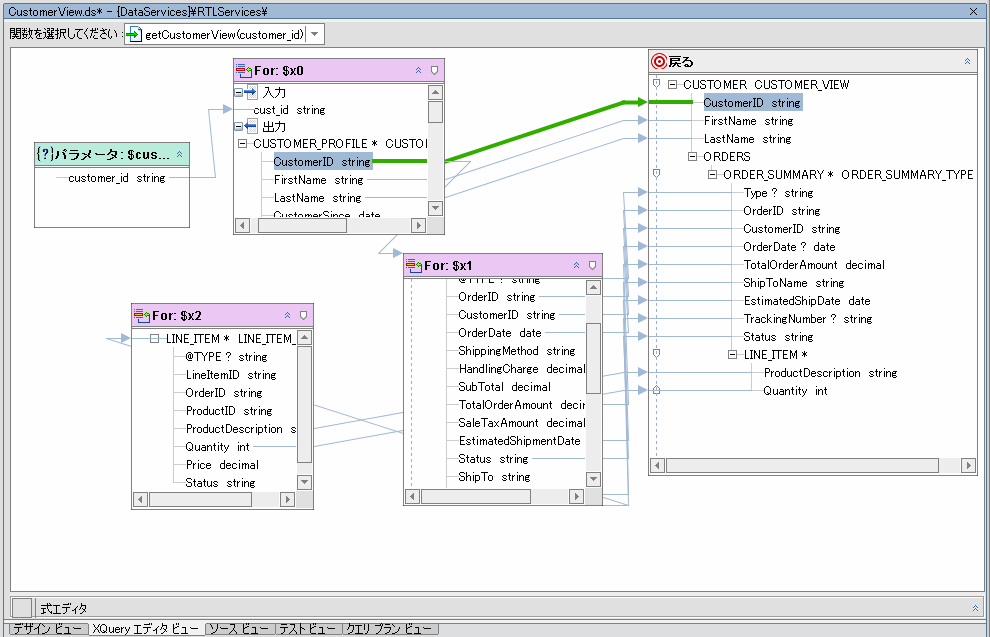
このグラフィカル エディタは、1.0 XQuery 標準の一般的な構文を直接サポートしています。ビジネス ロジックの開発と管理に役立つ複数のリソースが用意されています。これらのリソースは WebLogic Workshop の [表示|ウィンドウ] メニューから使用できます。
XQuery エディタ ビューを使用したクエリの開発の詳細については、「XQuery エディタの操作」を参照してください。
標準の XQuery 関数と BEA 固有の関数をサポートする XQuery 関数パレット (図 2-18) があります。この関数パレットも Workshop の [表示|ウィンドウ] メニューから使用できます。
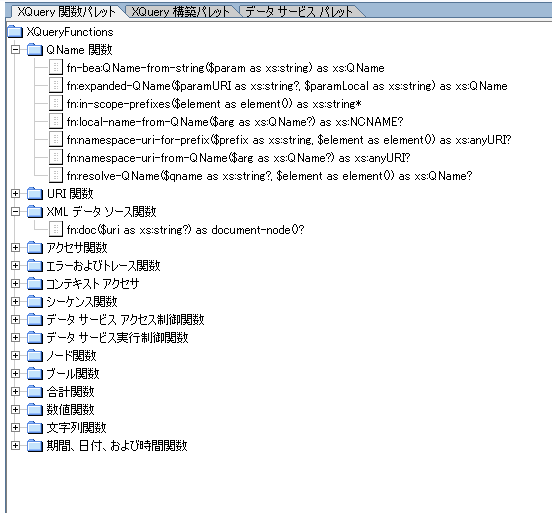
Workshop のすべてのペインと同様に、XQuery 関数パレットは WebLogic Workshop ウィンドウのどこにでも配置できます。このパレットから関数を XQuery エディタ ビューやソース ビューにドラッグできます。
AquaLogic Data Services Platform プロジェクトから XQuery 構築パレット (図 2-19) にアクセスできます。このパレットは、XQuery エディタ ビューまたはソース ビューでのさまざまな XQuery 文の作成をサポートします。FLWGR、FGWOR、FWGR などのさまざまな構文のプロトタイプは、最も一般的な XQuery 構文である FLWR (for-let-where-return) のバリエーションです。

たとえば、FLWGR は AquaLogic Data Services Platform の拡張である group by を追加したものです。このプロトタイプはソース ビューで次のように表示されます。
for $var in ()
let $var2:=()
where (true)
group by () as $var3 with partitions $var as $var4
return
()
group by や他の BEA XQuery 拡張の詳細については、『XQuery 開発者ガイド』を参照してください。
データ サービス パレット (図 2-20) は AquaLogic Data Services Platform プロジェクトでのみ使用できます。AquaLogic Data Services Platform の XQuery エディタに、データ サービスと XFL (XQuery 関数ライブラリ) ルーチンへのアクセスを提供します。
XQuery エディタの使用の詳細については、「XQuery エディタの操作」を参照してください。
モデル ダイアグラムとデータ サービスの XML 型、および XQuery エディタの戻り値型を変更するためのスキーマ エディタがあります。「論理データ サービスの XML 型の操作」を参照してください。ほとんどのエディタ オプションは右クリック メニューから使用できます。
戻り値型に関する右クリック メニュー コマンドは、XML 型エディタの場合と若干異なります。XQuery エディタでは、クエリ結果ドキュメントの形式をより正確に指定する手段として、if-then-else 構文、ゾーン、要素の複製などを作成できるためです。「戻り値型の変更」を参照してください。
クエリを開発したら、テスト ビューを使用してクエリを実行できます。詳細については、「クエリ関数のテストとクエリ プランの表示」を参照してください。
ソース ビューで作業すると、ビルド済みの XQuery 関数や構文のソースへの追加、データ サービスの編集変更などを簡単に行うことができます。詳細については、「XQuery ソースの操作」を参照してください。
生成された SQL を検証し、パフォーマンス改善の余地について検討するために、AquaLogic Data Services Platform で開発された特定の関数のクエリ プランを確認できます。「クエリ プラン ビューの使用」を参照してください。
クエリ プラン ビューア ユーティリティは、AquaLogic Data Services Platform 対応の WebLogic Workshop アプリケーションの [スタート] メニューから使用できます。
[スタート|すべてのプログラム|BEA WebLogic Platform 8.1|BEA AquaLogic Data Services Platform 2.5|Query Plan Viewer]
このユーティリティはデータ サービスの開発中に使用できるものですが、主にクライアント アプリケーションの開発者によって使用されます。ユーティリティに関するドキュメントについては、『クライアント アプリケーション開発者ガイド』の「SQL を使用したデータ サービスへのアクセス」を参照してください。
AquaLogic Data Services Platform アーティファクトが他のどのアーティファクトで使用されているかを確認すると便利な場合があります。たとえば、XML 型で変更を行う前に、影響を受ける可能性のある他のデータ サービスを確認することは重要です。もちろん、AquaLogic Data Services Platform の『管理ガイド』の「メタデータの表示」で説明されているように、メタデータ ブラウザからでも確認できますが、WebLogic Workshop のナビゲーション ペインや AquaLogic Data Services Platform デザイン ビューのコンテキストで確認できると一層便利です。
たとえば、RTLApp でデータ サービスを右クリックすると、[用途の検索] を含むさまざまなオプションが表示されます (図 2-22)。
このオプションを選択すると、図 2-23 のように、アーティファクトの用途が表示されます。

以下の種類の AquaLogic Data Services Platform アーティファクトの用途を検索できます。
AquaLogic Data Services Platform アプリケーションを保存すると、その JAR ライブラリ ファイルがアプリケーションにバインドされます。それ以降に、AquaLogic Data Services Platform の新しいバージョンに移行する場合は、アプリケーションも最新のライブラリ ファイルにアップグレードする必要があります。詳細については、AquaLogic Data Services Platform の『インストール ガイド』を参照してください。
AquaLogic Data Services Platform は必要に応じてアプリケーションを再ビルドしようとします。ただし、ビルドを直接開始する必要がある場合もあります。
表 2-24 では、関連する [ビルド] メニュー オプションとその使用方法を説明します。
AquaLogic Data Services Platform ベースのプロジェクトからファイルを削除したときは、プロジェクトを再ビルドする必要があります。再ビルドはプロジェクト レベルでもアプリケーション レベルでも行うことができます。一般に、複数のプロジェクトを変更した場合でない限り、アプリケーション全体を再ビルドする必要はありません。
次の 2 つの手順でプロジェクト (アプリケーション) を再ビルドします。
| 注意 : | テスト ビューで関数を実行しようとして不意に失敗した場合は、クエリの実行を再試行する前に、アプリケーションをクリーンアップして再ビルドすると効果的な場合があります。 |
アプリケーションがすでにデプロイされている場合は、アプリケーションを再ビルドすると自動的に再デプロイされます。状況によっては、アプリケーションを最初にアンデプロイすることもできます。表 2-25 では、[アプリケーション] ペインでアプリケーション フォルダを右クリックしたときに使用できる、関連する [デプロイメント] メニュー オプションについて説明します。
WebLogic Workshop アプリケーションのデプロイの詳細については、以下を参照してください。
アプリケーションのクエリ関数を作成してテストしたら、クライアント アプリケーションで使用できるようにする必要があります。更新可能な関数へのアクセスを提供する主な手段として、SDO メディエータ API があります。
| 注意 : | SDO プログラミング、およびメディエータ API を通じた Java クライアントでのデータ アクセスの詳細については、『クライアント アプリケーション開発者ガイド』の「データ プログラミング モデルと更新フレームワーク」を参照してください。 |
SDO メディエータ クライアント Java アーカイブ (.jar) ファイルを作成する方法の 1 つは、右クリック メニュー オプションの [SDO メディエータ クライアントの構築] を使用する方法です。このメニュー オプションはアプリケーションのルート フォルダからのみ使用できます。
成功すると、アプリケーションのルート ディレクトリに SDO メディエータ クライアントが作成されます。ファイル名は次のようになります。
<name_of_your_application>-ld-client.jar
アプリケーションのライブラリ フォルダに、SDO メディエータ JAR ファイルも自動的に追加されます。
| 注意 : | SDO メディエータ JAR ファイルを作成する前に、プロジェクトのすべてを最新の状態にし、ビルドしておきます。「アプリケーションのビルド、デプロイ、および更新」も参照してください。 |
コマンドラインから ant スクリプトを使用して SDO メディエータ クライアント JAR ファイルを作成することもできます。
すでに EAR ファイルがある場合は、次のスクリプトを使用できます。
ant -f $WL_HOME/liquiddata/bin/ld_clientapi.xml
-Darchive=</your_path/name_of_your_application>.ear>
この場合、JAR ファイルの名前は EAR ファイルの名前から取られます。
<name_of_your_application>-ld-client.jar
アプリケーション ディレクトリを指定するだけで、SDO メディエータ クライアント JAR ファイルを生成できます (EAR ファイルが必要ない場合)。
ant -f $WL_HOME/liquiddata/bin/ld_clientapi.xml
-Dapproot=</your_path/name_of_your_application>/root>
この方法では、アプリケーション ルートのディレクトリ名を使用して JAR ファイル名を計算します。上記の場合、名前は root-ld-client.jar になります。この動作を希望しない場合は、次のように指定して、
-Dsdojarname=<MyApp-ld-client.jar>
この動作をオーバーライドできます。いずれの方法でも、JAR ファイルはアプリケーション ルート ディレクトリに生成されます。
いずれの場合でも、次のような追加の ant パラメータを指定して、
-Doutdir=</path/to/dir>
特定のディレクトリの場所に JAR ファイルを生成できます。
-Dtmpdir=</path/to/tmp>
生成された .java コードなどの一時ファイル用に代替ディレクトリを指定できます。
デフォルトの一時ファイルの場所は Java システム プロパティで次のように指定されています。
java.io.tmpdir
いずれの方法でも、コマンドラインからビルドした場合は、SDO mediator.jar ファイルはアプリケーションのライブラリ フォルダ (図 2-2) に追加されません。
AquaLogic Data Services Platform プロジェクトのアーティファクトを移動、名前変更、または削除する必要がある場合があります。たとえば、許可のない個人に機密情報が公開されないようにするため、アプリケーションは最初にテスト データで開発されます。開発が済むと、アプリケーションは実際の保護されたデータ ソースと一緒にデプロイする準備が整います。リファクタリングを使用すると、AquaLogic Data Services Platform コンポーネントの名前の変更、削除、または移動が非常に簡単になります。
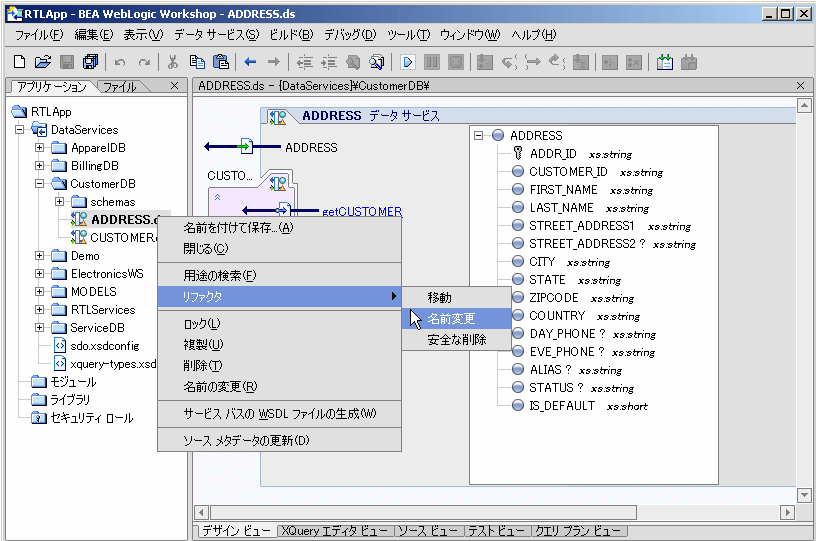
リファクタリングをしない場合、アーティファクト名を変更すると、すぐに無効な参照が生じる可能性があります。たとえば、データ サービス ファイルの名前を変更すると、そのファイルを参照している他のデータ サービスの関係関数が自動的に無効になります。リファクタリングの代わりとしては、特定のアーティファクトのすべての用途を手動で検索して、データ サービス ソースを手動で編集する方法があります。この方法は、特にプロジェクトが大きくなるほど、非常に手間がかかり、エラーが発生しやすくなります。
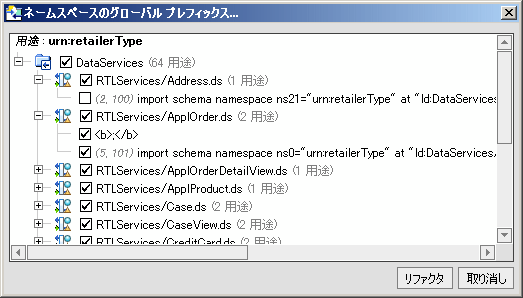
[リファクタ] オプションを使用すると、最初に、リファクタリングによる変更がアプリケーションのアーティファクトに与える影響が表示されます (図 2-27)。チェック ボックスを使用して、リファクタリング操作からアーティファクトを除外することができます。
| 注意 : | リファクタリングを推奨されている要素を選択解除するときは慎重に行ってください。基底のソースを手動で変更しないと、アプリケーションをビルドまたはデプロイできなくなる可能性があります。 |
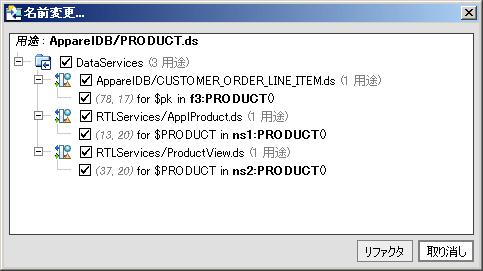
表 2-28 に、リファクタリングされるアーティファクトとそのオプションを示します。
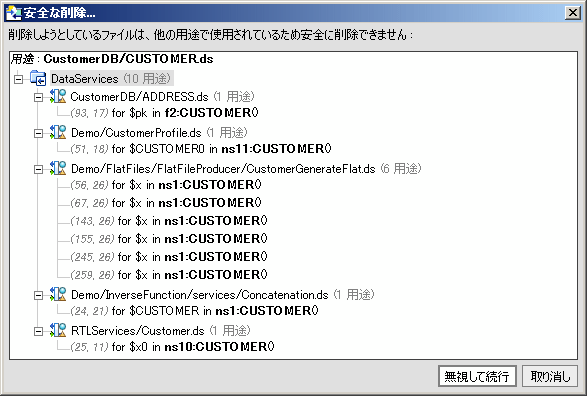
移動、名前変更、パラメータの追加/削除の各操作は、通常、悪影響を与えることはありません。しかし、削除操作は、プロジェクトに悪影響を与える可能性があります。このため、削除の対象として選択したアーティファクトの用途が表示されます (図 2-29 を参照)。この情報から、リファクタリング操作の自動化とその結果のトレードオフを簡単に確認することができます。自分で追加の手動操作を行う必要がある場合もあります。
リファクタ オプションにアクセスする方法はアーティファクトによって異なります。
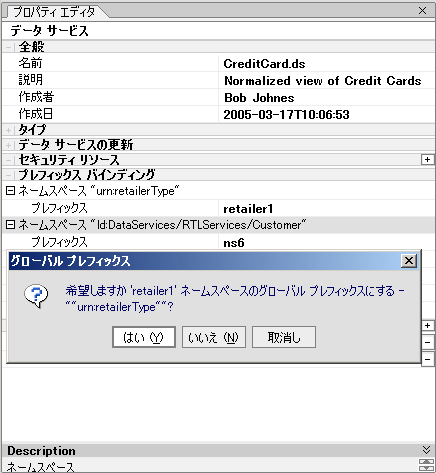
ネームスペースまたは外部スキーマ プレフィックスをリファクタするには、単に、プロパティ エディタでプレフィックス名 (バインディング) を変更します (図 2-30)。
プレフィックス バインディングを変更する場合は、変更をプロジェクト全体にわたって (グローバルに) 行うためのオプションも表示されます。
たとえば、このオプションを選択した場合、プロジェクト内で URI (urn:retailerType) が表示される箇所があれば、プレフィックスは「retailer1」になります。
| 注意 : | リファクタ操作に含めるのが望ましくないアーティファクトを選択解除することはできますが、その場合は、そのアーティファクトと、そのアーティファクトに依存しているファイルが無効になります。このため、通常は、リファクタリングされるアーティファクトの選択解除は行わないでください。 |
| 注意 : | ネームスペース プレフィックスの場合、名前を変更するときは読みやすさや一貫性を考慮してください。ローカルな変更、またはグローバルな変更のいずれの場合も、コードに悪影響を与えることはありません。 |
リファクタ操作のさまざまな影響の可能性を理解しておくと便利です。表 2-34 では、リファクタリングの操作ごとに、関連するアーティファクトに与える影響の可能性について説明します。
XQuery 関数ライブラリ (XFL) には、アプリケーションでデータ サービスや他の XFL が使用できる関数が含まれています。ライブラリは次のものを提供します。
XFL ファイル内の関数はデータ サービス クライアントから直接呼び出すことはできません。代わりに、他のデータ サービスによって使用されます。XFL 関数は、実行可能なアーティファクトのセット内で共有できる、ユーザ定義のルーチンを提供します。
XQuery 関数ライブラリ (.xfl ファイル) は、共有可能な変換、セキュリティ、および他の種類の関数を作成するのに適しています。
最初の 3 タイプのファイルには、特定のタイプの物理ソース (リレーショナル、WSDL、またはクラス ファイル) のインスタンスにバインドされた関数が格納されます。ユーザ定義の XQuery 関数は、プロジェクト内のすべてのデータ サービスにわたって共通の関数を共有する機能を提供します。外部データベース関数は、アプリケーション プログラムに、ユーザ定義の SQL 関数または組み込みでベンダ固有の SQL 関数をデータ サービスから呼び出す機能を提供します。
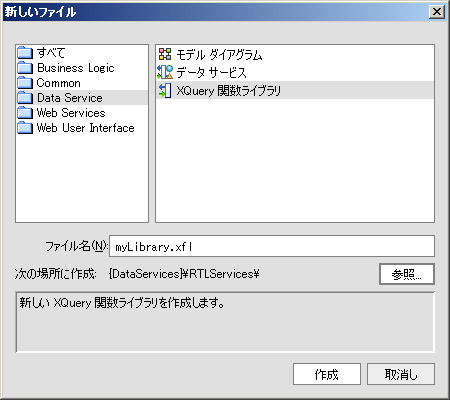
XQuery 関数ライブラリは 2 通りの方法で作成できます。
XQuery 関数ライブラリはデータ サービス パレットから使用できます。

XQuery 関数ライブラリ (XFL) には多数の関数を含めることができます。AquaLogic Data Services Platform 対応プロジェクトにおいて、XFL デザイン ビューはデータ サービスのデザイン ビュー (「サンプル データ サービス」を参照) と似ています。主な違いは次のとおりです。
データ サービスで使用できるタブ方式 (ソース ビュー、XQuery エディタ ビュー、テスト ビュー、クエリ プラン ビュー) は、XQuery 関数ライブラリでも使用できます。同様に、XFL 関数には関連付けられたプロパティがあり、プロパティ エディタで表示できます。
| 注意 : | XFL ファイルは反転関数の作成でも重要な役目を果たします。「ベスト プラクティスと高度なトピック」の「反転関数を使用したクエリ パフォーマンスの向上」を参照してください。 |
データ サービス内の関数を、XML 関数ライブラリとしてプロジェクト全体で使用できるようにするのは難しくありません。たとえば、以下の関数は RTLApp の DataServices/RTLServices/Credit Card データ サービスで使用できます (ソース ファイルの別のセクションからのネームスペース宣言も含まれています)。
declare namespace ns1="ld:DataServices/BillingDB/CREDIT_CARD";
import schema namespace ns0="urn:retailerType" at "ld:DataServices/RTLServices/schemas/CreditCard.xsd";
declare namespace tns="ld:DataServices/RTLServices/CreditCard";
(: ... :)
declare function tns:getCreditCard() as element(ns0:CREDIT_CARD)* {
for $CREDIT_CARD in ns1:CREDIT_CARD()
return <ns0:CREDIT_CARD>
<CreditCardID>{fn:data($CREDIT_CARD/CC_ID)}</CreditCardID>
<CustomerID>{fn:data($CREDIT_CARD/CUSTOMER_ID)}</CustomerID>
<CustomerName>{fn:data($CREDIT_CARD/CC_CUSTOMER_NAME)}</CustomerName>
<CreditCardType>{fn:data($CREDIT_CARD/CC_TYPE)}</CreditCardType>
<CreditCardBrand>{fn:data($CREDIT_CARD/CC_BRAND)}</CreditCardBrand>
<CreditCardNumber>{fn:data($CREDIT_CARD/CC_NUMBER)}</CreditCardNumber>
<LastDigits>{fn:data($CREDIT_CARD/LAST_DIGITS)}</LastDigits>
<ExpirationDate>{fn:data($CREDIT_CARD/EXP_DATE)}</ExpirationDate>
{fn-bea:rename($CREDIT_CARD/STATUS,<Status/>)}
{fn-bea:rename($CREDIT_CARD/ALIAS,<Alias/>)}
<AddressID>{fn:data($CREDIT_CARD/ADDR_ID)}</AddressID>
</ns0:CREDIT_CARD>
};
この関数を XQuery ライブラリ内に作成する手順は次のとおりです。
CREDIT_CARD 関数を含む XQuery ライブラリ ファイルのソースを以下に示します。簡単にするため、オブジェクトは個々にマップされた要素ではなく $x として返されています。
xquery version "1.0" encoding "WINDOWS-1252";
(::pragma xfl <x:xfl xmlns:x="urn:annotations.ld.bea.com"></x:xfl> ::)
declare namespace tns="lib:DataServices/myXQueryLibrary";
declare namespace ns1="ld:DataServices/BillingDB/CREDIT_CARD";
import schema namespace ns0="urn:retailerType" at "ld:DataServices/RTLServices/schemas/CreditCard.xsd";
declare function tns:getCreditCard() as element(ns1:CREDIT_CARD)* {
for $x in ns1:CREDIT_CARD()
return $x
};
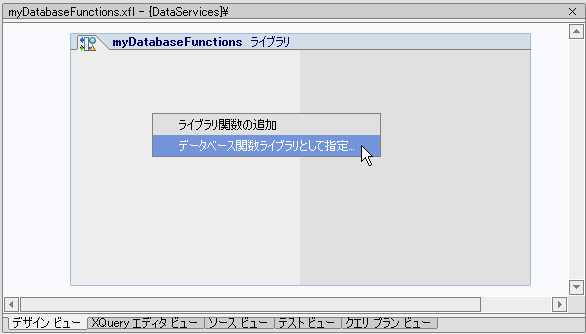
データベース関数ライブラリは、データベース関数の場所とシグネチャのみが含まれた XFL です。このライブラリにはデータベース関数のみを含めることができます。
データベース関数は、標準の JDBC 機能で提供される SQL サポートを拡張するために設計されています。次のような利点があります。
データベース関数ライブラリでは、さらに 2 つのタイプの SQL 関数にアクセスできます。
関数をライブラリに登録すると、XQuery を通じて、または SQL として、その関数を使用できるようになります。
| 注意 : | データベース関数ライブラリを作成したら、XFL プロパティ エディタ (図 2-40 を参照) からデータベース関数を追加することができます。 |
XFL データベース関数ライブラリはデータ サービス パレットから使用できます。
| 注意 : | XML と JDBC の型のマッピングについては、『クライアント アプリケーション開発者ガイド』の「SQL を使用したデータ サービスへのアクセス」を参照してください。 |
プロパティ エディタ (図 2-40) を使用して、カタログ、スキーマ、パッケージ、および XQuery 関数名の設定をいつでも調整できます。
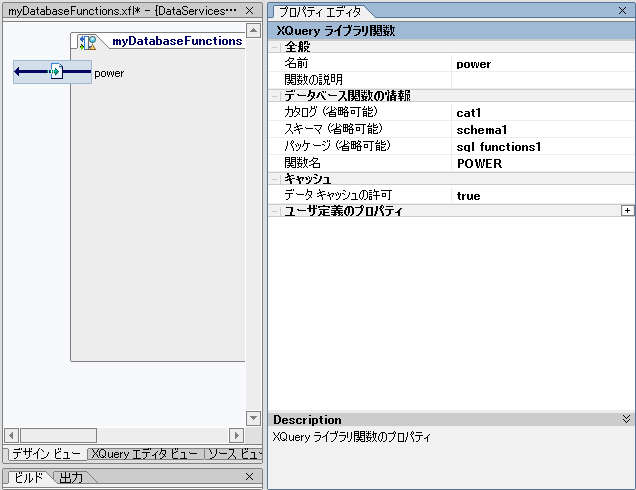
XFL データベース関数を SQL にパブリッシュして (「SQL で使用するためのデータ サービス関数のパブリッシュ」を参照)、AquaLogic Data Services Platform アプリケーションをデプロイすると、その関数は、JDBC などの標準のデータ サービス呼び出しや Mediator API を通じて、またはデータ サービス コントロールとして、クライアント アプリケーション開発者が使用できるようになります。
| 注意 : | レポート ツールを使用して SQL クエリをビルドする場合、生成される SQL では修飾されていない JDBC 関数名が使用されます。アプリケーション開発者が XFL データベース関数を呼び出す場合、JDBC 接続が作成されるときに、デフォルトのカタログとスキーマ名が定義されている必要があります。このため、JDBC 接続は、1 つのカタログ/スキーマ ペアの場所で用意されている関数を使用する必要があります。 |
| 注意 : | 以下は、JDBC 接続のデフォルトのカタログとスキーマを定義した URL の例です。 |
jdbc:dsp@localhost:7001/myApplication/myCatalog/mySchema
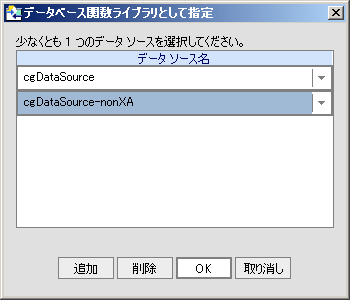
XFL プロパティ エディタを使用して DFL データ ソースを簡単に関連付けたり、関連付けを解除したりできます。図 2-41 では、サンプル XFL データベース関数ライブラリに関連付けられた 2 つのデータ ソース、cgDataSource と cgDataSource-nonXA が示されています。
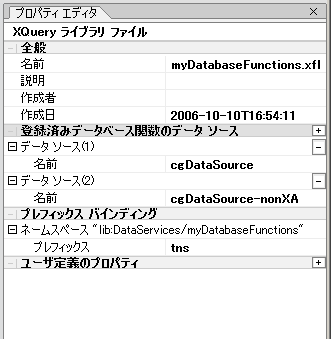
データベース名をクリックして、ドロップダウン リストから別のデータベースを選択すると、データベース名の指定を変更できます。[登録済みデータベース関数のデータ ソース] プロパティの横にある [+] をクリックすると、新しいデータベースを追加できます。同様に、データ ソース名の横の [-] をクリックすると、登録されたデータベース関数のデータ ソースを削除できます。
XFL をデータベース関数ライブラリとして宣言すると、ソース ビューでは、データベース関数宣言用にその XFL を指定した基底のプラグマ文が生成されます。
コード リスト 2-1 では、関数宣言で使用できるデータベースの名前が customNativeFunctions 型の中に含まれています(カスタム ネイティブ関数は XFL データベース関数と同じです)。
(::pragma xfl <x:xfl xmlns:x="urn:annotations.ld.bea.com">
<creationDate>
2006-07-11T11:13:18
</creationDate>
<customNativeFunctions>
<relational>
<dataSource>cgDataSource-nonXA</dataSource>
<dataSource>bpmArchDataSource</dataSource>
</relational>
</customNativeFunctions>
</x:xfl> ::)
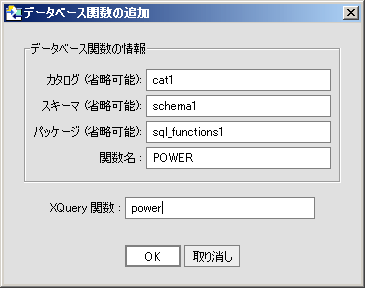
コード リスト 2-2 のサンプルは、XFL データベース関数宣言をライブラリに追加するときに自動的に作成されるコードを示しています。
(::pragma function
<f:function xmlns:f="urn:annotations.ld.bea.com" nativeLevel1Container="cat1"
nativeLevel2Container="schema1"
nativeLevel3Container="sql_functions1"
nativeName="POWER">
</f:function>::)
declare function tns:Power() as xdt:anyAtomicType? external;
関数はアプリケーションの外部として指定されていることに注目してください。
| 注意 : | 一連の dataSource 要素は、指定された関数が適用されるリレーショナル ソースの名前を示しています。各関数のネイティブの修飾名は次の値で取得されます。 |
"nativeLevelNContainer" (N = 1,2,3)
"nativeName"
たとえば、パッケージ STATISTICS の下で定義されているカスタム SQL 関数 MEDIAN の修飾名は、次のようなアノテーションで表現されます。
(::pragma function
<f:function xmlns:f="urn:annotations.ld.bea.com" nativeName="MEDIAN" nativeLevel3Container="STATISTICS"/> ::)
ネイティブ関数を表す XQuery 関数の修飾名 (qname) はユーザ定義です。
各関数のネイティブ シグネチャは、XQuery 関数宣言で指定されるシグネチャに反映されます。ユーザ定義の SQL 関数の場合、SQL 関数の入力パラメータまたは出力の SQL 型 (TIME など) が、関数シグネチャの対応する XQuery 型 (xs:time など) に反映されます。
| 注意 : | XML と SQL の間の型マッピングが正しいことが重要です。『クライアント アプリケーション開発者ガイド』の「SQL を使用したデータ サービスへのアクセス」の「XML および SQL 型のマッピング」を参照してください。 |
出力型がいずれかのパラメータの実際の型によって決定されるという、特定の多態性を示すネイティブ関数では、省略可能なアノテーション要素 isPolymorphic を使用することができます。要素 isPolymorphic では、必須の parameter 要素が内容として使用されます。表 2-42 のように、parameter 要素には index 属性が入ります。
以下の例では、isPolymorphic 要素の使用方法を示します。
declare namespace stat = "urn:sample";
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com" nativeName="MEDIAN" nativeLevel3Container="STATISTICS">
<isPolymorphic><parameter/></isPolymorphic>
</function>::)
declare function stat:median($x as xdt:anyAtomicType*) as xdt:anyAtomicType external;
 
|
![新しい AquaLogic Data Services Platform アプリケーションの [アプリケーション] タブ](wwimages/initialLDapp.gif)